
1. Descripción general
En este codelab, compilarás Neighbor Loop, una app sustentable para compartir excedentes que trata la inteligencia como un ciudadano de primera clase de la capa de datos.
Con la integración de Gemini 3.0 Flash y AlloyDB AI, pasarás del almacenamiento básico al ámbito de la inteligencia en la base de datos. Aprenderás a realizar análisis de elementos multimodales y descubrimiento semántico directamente en SQL, lo que elimina el "impuesto de la IA" de la latencia y la sobrecarga arquitectónica.

Qué compilarás
Una aplicación web de alto rendimiento para compartir excedentes de la comunidad con la función "deslizar para encontrar coincidencias".
Qué aprenderás
- Aprovisionamiento con un solo clic: Cómo configurar un clúster y una instancia de AlloyDB diseñados para cargas de trabajo de IA
- Embeddings en la base de datos: Genera vectores de text-embedding-005 directamente en las instrucciones INSERT.
- Razonamiento multimodal: Uso de Gemini 3.0 Flash para "ver" elementos y generar biografías ingeniosas al estilo de las de citas automáticamente
- Descubrimiento semántico: Realiza "verificaciones de ambiente" basadas en la lógica dentro de las consultas en SQL con la función ai.if() para filtrar los resultados según el contexto, no solo las matemáticas.
La arquitectura
Neighbor Loop evita los cuellos de botella tradicionales de la capa de aplicación. En lugar de extraer datos para procesarlos, usamos lo siguiente:
- AlloyDB AI: Para generar y almacenar vectores en tiempo real
- Google Cloud Storage: Para almacenar imágenes
- Gemini 3.0 Flash: Para realizar razonamiento en menos de un segundo sobre datos de imágenes y texto directamente a través de SQL
- Cloud Run: Para alojar un backend de Flask liviano de un solo archivo
Requisitos
2. Antes de comenzar
Crea un proyecto
- En la página del selector de proyectos de la consola de Google Cloud, selecciona o crea un proyecto de Google Cloud.
- Asegúrate de que la facturación esté habilitada para tu proyecto de Cloud. Obtén información para verificar si la facturación está habilitada en un proyecto.
- Usarás Cloud Shell, un entorno de línea de comandos que se ejecuta en Google Cloud. Haz clic en Activar Cloud Shell en la parte superior de la consola de Google Cloud.

- Una vez que te conectes a Cloud Shell, verifica que ya te autenticaste y que el proyecto se configuró con tu ID del proyecto con el siguiente comando:
gcloud auth list
- En Cloud Shell, ejecuta el siguiente comando para confirmar que el comando gcloud conoce tu proyecto.
gcloud config list project
- Si tu proyecto no está configurado, usa el siguiente comando para hacerlo:
gcloud config set project <YOUR_PROJECT_ID>
- Habilita las APIs necesarias: Sigue el vínculo y habilita las APIs.
Como alternativa, puedes usar el comando de gcloud para esto. Consulta la documentación para ver los comandos y el uso de gcloud.
Problemas potenciales y solución de problemas
El "Proyecto Fantasma" : Síndrome | Ejecutaste |
La barricada de facturación | Habilitaste el proyecto, pero olvidaste la cuenta de facturación. AlloyDB es un motor de alto rendimiento que no se iniciará si el "tanque de combustible" (facturación) está vacío. |
Desfase de la propagación de la API | Hiciste clic en "Habilitar APIs", pero la línea de comandos aún dice |
Cuota de Quags | Si usas una cuenta de prueba nueva, es posible que alcances una cuota regional para las instancias de AlloyDB. Si falla |
Agente de servicio"oculto" | A veces, al agente de servicio de AlloyDB no se le otorga automáticamente el rol de |
3. Configuración de la base de datos
En este lab, usaremos AlloyDB como la base de datos para los datos de prueba. Utiliza clústeres para contener todos los recursos, como bases de datos y registros. Cada clúster tiene una instancia principal que proporciona un punto de acceso a los datos. Las tablas contendrán los datos reales.
Creemos un clúster, una instancia y una tabla de AlloyDB en los que se cargará el conjunto de datos de prueba.
- Haz clic en el botón o copia el siguiente vínculo en el navegador en el que accediste como usuario a la consola de Google Cloud.
- Una vez que se complete este paso, el repo se clonará en tu editor local de Cloud Shell y podrás ejecutar el siguiente comando desde la carpeta del proyecto (es importante que te asegures de estar en el directorio del proyecto):
sh run.sh
- Ahora usa la IU (haz clic en el vínculo de la terminal o en el vínculo "preview on web" de la terminal).
- Ingresa los detalles del ID del proyecto, el clúster y los nombres de las instancias para comenzar.
- Ve a tomar un café mientras se desplazan los registros. Aquí puedes leer cómo se hace esto en segundo plano.
Problemas potenciales y solución de problemas
El problema de la "paciencia" | Los clústeres de bases de datos son una infraestructura pesada. Si actualizas la página o finalizas la sesión de Cloud Shell porque "parece que se detuvo", es posible que termines con una instancia "fantasma" que se aprovisionó parcialmente y que es imposible borrar sin intervención manual. |
Región no coincidente | Si habilitaste tus APIs en |
Clústeres de zombis | Si antes usaste el mismo nombre para un clúster y no lo borraste, es posible que la secuencia de comandos indique que el nombre del clúster ya existe. Los nombres de los clústeres deben ser únicos dentro de un proyecto. |
Tiempo de espera de Cloud Shell | Si tu descanso para tomar café dura 30 minutos, es posible que Cloud Shell entre en modo de suspensión y desconecte el proceso |
4. Aprovisionamiento de esquemas
Una vez que tengas en funcionamiento tu clúster y tu instancia de AlloyDB, dirígete al editor de SQL de AlloyDB Studio para habilitar las extensiones de IA y aprovisionar el esquema.
Es posible que debas esperar a que termine de crearse la instancia. Una vez que lo hagas, accede a AlloyDB con las credenciales que creaste cuando creaste el clúster. Usa los siguientes datos para autenticarte en PostgreSQL:
- Nombre de usuario : "
postgres" - Base de datos : "
postgres" - Contraseña : "
alloydb" (o la que hayas configurado en el momento de la creación)
Una vez que te autentiques correctamente en AlloyDB Studio, ingresa los comandos SQL en el editor. Puedes agregar varias ventanas del editor con el signo más que se encuentra a la derecha de la última ventana.
Ingresarás comandos para AlloyDB en ventanas del editor, y usarás las opciones Ejecutar, Formatear y Borrar según sea necesario.
Habilitar extensiones
Para compilar esta app, usaremos las extensiones pgvector y google_ml_integration. La extensión pgvector te permite almacenar y buscar embeddings de vectores. La extensión google_ml_integration proporciona funciones que usas para acceder a los extremos de predicción de Vertex AI y obtener predicciones en SQL. Habilita estas extensiones ejecutando los siguientes DDL:
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
Crea una tabla
Puedes crear una tabla con la siguiente instrucción DDL en AlloyDB Studio:
-- Items Table (The "Profile" you swipe on)
CREATE TABLE items (
item_id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
owner_id UUID,
provider_name TEXT,
provider_phone TEXT,
title TEXT,
bio TEXT,
category TEXT,
image_url TEXT,
item_vector VECTOR(768),
status TEXT DEFAULT 'available',
created_at TIMESTAMP DEFAULT NOW()
);
-- Swipes Table (The Interaction)
CREATE TABLE swipes (
swipe_id SERIAL PRIMARY KEY,
swiper_id UUID,
item_id UUID REFERENCES items(item_id),
direction TEXT CHECK (direction IN ('left', 'right')),
is_match BOOLEAN DEFAULT FALSE,
created_at TIMESTAMP DEFAULT NOW()
);
La columna item_vector permitirá el almacenamiento de los valores vectoriales del texto.
Otorgar permiso
Ejecuta la siguiente instrucción para otorgar permiso de ejecución en la función "embedding":
GRANT EXECUTE ON FUNCTION embedding TO postgres;
Otorga el rol de usuario de Vertex AI a la cuenta de servicio de AlloyDB
En la consola de IAM de Google Cloud, otorga a la cuenta de servicio de AlloyDB (que se ve así: service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com) acceso al rol "Usuario de Vertex AI". PROJECT_NUMBER tendrá tu número de proyecto.
Como alternativa, puedes ejecutar el siguiente comando desde la terminal de Cloud Shell:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Registra el modelo Gemini 3 Flash en AlloyDB
Ejecuta la siguiente instrucción de SQL desde el editor de consultas de AlloyDB
CALL google_ml.create_model(
model_id => 'gemini-3-flash-preview',
model_request_url => 'https://aiplatform.googleapis.com/v1/projects/<<YOUR_PROJECT_ID>>/locations/global/publishers/google/models/gemini-3-flash-preview:generateContent',
model_qualified_name => 'gemini-3-flash-preview',
model_provider => 'google',
model_type => 'llm',
model_auth_type => 'alloydb_service_agent_iam'
);
--replace <<YOUR_PROJECT_ID>> with your project id.
Problemas potenciales y solución de problemas
El bucle de "amnesia de contraseña" | Si usaste la configuración "Con un clic" y no recuerdas tu contraseña, ve a la página de información básica de la instancia en la consola y haz clic en "Editar" para restablecer la contraseña de |
El error "No se encontró la extensión" | Si |
La brecha de propagación de IAM | Ejecutaste el comando de IAM |
Vector Dimension Mismatch | La tabla |
Error de escritura en el ID del proyecto | En la llamada |
5. Almacenamiento de imágenes (Google Cloud Storage)
Para almacenar las fotos de nuestros artículos excedentes, usamos un bucket de GCS. Para los fines de esta app de demostración, queremos que las imágenes sean de acceso público para que se rendericen al instante en nuestras tarjetas deslizables.
- Crea un bucket: Crea un bucket nuevo en tu proyecto de GCP (p.ej., neighborloop-images), de preferencia en la misma región que tu base de datos y tu aplicación.
- Configura el acceso público: * Navega a la pestaña Permisos del bucket.
- Agrega la entidad principal allUsers.
- Asigna el rol Visualizador de objetos de Storage (para que todos puedan ver las fotos) y el rol Creador de objetos de Storage (para fines de carga de demostración).
Alternativa (cuenta de servicio): Si prefieres no usar el acceso público, asegúrate de que la cuenta de servicio de tu aplicación tenga acceso completo a AlloyDB y los roles de Storage necesarios para administrar objetos de forma segura.
Problemas potenciales y solución de problemas
The Region Drag | Si tu base de datos está en |
Unicidad del nombre del bucket | Los nombres de los buckets son un espacio de nombres global. Si intentas nombrar tu bucket |
Confusión entre "Creador" y "Visualizador" | Confusión entre "Creador" y "Visualizador": Si solo agregas "Visualizador", tu app fallará cuando un usuario intente publicar un elemento nuevo porque no tiene permiso para escribir el archivo. Necesitas ambos para esta configuración de demostración específica. |
6. Creemos la aplicación
Clona este repo en tu proyecto y analicémoslo.
- Para clonar este proyecto, ejecuta el siguiente comando desde la terminal de Cloud Shell (en el directorio raíz o desde donde quieras crear este proyecto):
git clone https://github.com/AbiramiSukumaran/neighbor-loop
Esto debería crear el proyecto, y puedes verificarlo en el editor de Cloud Shell.

- Cómo obtener tu clave de API de Gemini
- Visita Google AI Studio: Ve a aistudio.google.com.
- Accede con la misma Cuenta de Google que usas para tu proyecto de Google Cloud.
- Crea la clave de API:
- En la barra lateral izquierda, haz clic en "Obtener clave de API".
- Haz clic en el botón "Crear clave de API en un proyecto nuevo".
- Copia la clave: Una vez que se genere la clave, haz clic en el ícono de copiar.
- Ahora, configura las variables de entorno en el archivo .env.
GEMINI_API_KEY=<<YOUR_GEMINI_API_KEY>>
DATABASE_URL=postgresql+pg8000://postgres:<<YOUR_PASSWORD>>@<<HOST_IP>>:<<PORT>>/postgres
GCS_BUCKET_NAME=<<YOUR_GCS_BUCKET>>
Reemplaza los valores de los marcadores de posición <<YOUR_GEMINI_API_KEY>>, <<YOUR_PASSWORD>, <<HOST_IP>>, <<PORT>> and <<YOUR_GCS_BUCKET>>..
Problemas potenciales y solución de problemas
Confusión entre varias cuentas | Si accediste a varias Cuentas de Google (personales y de trabajo), es posible que AI Studio use la cuenta incorrecta de forma predeterminada. Verifica el avatar en la esquina superior derecha para asegurarte de que coincida con la cuenta de tu proyecto de GCP. |
El límite de cuota del "nivel gratuito" | Si usas el nivel Free of Charge, existen límites de frecuencia (RPM: solicitudes por minuto). Si "deslizas" demasiado rápido en Neighbor Loop, es posible que recibas un error |
Seguridad de claves expuestas | Si accidentalmente |
El vacío del "Tiempo de espera de conexión" | Usaste la dirección IP privada en tu archivo .env, pero intentas conectarte desde fuera de la VPC (como tu máquina local). Solo se puede acceder a las IPs privadas desde la misma red de Google Cloud. Cambia a la IP pública. |
Suposición del puerto 5432 | Si bien 5432 es el puerto estándar de PostgreSQL, a veces AlloyDB requiere configuraciones de puertos específicos si usas un proxy de autenticación. Para este lab, asegúrate de usar :5432 al final de la cadena del host. |
El Gatekeeper de "Redes autorizadas" | Incluso si tienes la IP pública, AlloyDB "rechazará la conexión" a menos que hayas incluido en la lista de entidades permitidas la dirección IP de la máquina que ejecuta el código.Solución: En la configuración de la instancia de AlloyDB, agrega 0.0.0.0/0 (solo para pruebas temporales) o tu IP específica a las redes autorizadas. |
Error en el protocolo de enlace SSL/TLS | AlloyDB prefiere las conexiones seguras. Si tu DATABASE_URL no especifica el controlador correctamente (por ejemplo, si usas pg8000), es posible que la confirmación falle de forma silenciosa y que recibas un error genérico de "No se puede acceder a la base de datos". |
El intercambio de "principal vs. grupo de lectura" | Si copias por accidente la dirección IP del grupo de lectura en lugar de la instancia principal, tu app funcionará para buscar elementos, pero fallará con un error de "Solo lectura" cuando intentes publicar un elemento nuevo. Siempre usa la IP de la instancia principal para las escrituras. |
7. Verifiquemos el código
El "Perfil de citas" de tu contenido

Cuando un usuario sube una foto de un artículo, no debería tener que escribir una descripción larga. Uso Gemini 3 Flash para "ver" el artículo y escribir la ficha por ellos.
En el backend, el usuario solo proporciona un título y una foto. Gemini se encarga del resto:
prompt = """
You are a witty community manager for NeighborLoop.
Analyze this surplus item and return JSON:
{
"bio": "First-person witty dating-style profile bio for the product, not longer than 2 lines",
"category": "One-word category",
"tags": ["tag1", "tag2"]
}
"""
response = genai_client.models.generate_content(
model="gemini-3-flash-preview",
contents=[types.Part.from_bytes(data=image_bytes, mime_type="image/jpeg"), prompt],
config=types.GenerateContentConfig(response_mime_type="application/json")
)
Incorporaciones en la base de datos en tiempo real
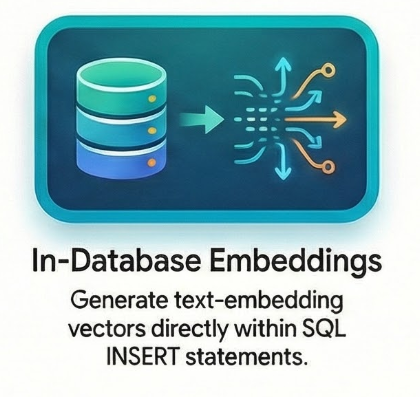
Una de las funciones más interesantes de AlloyDB es la capacidad de generar embeddings sin salir del contexto de SQL. En lugar de llamar a un modelo de incorporación en Python y enviar el vector de vuelta a la BD, lo hago todo en una sola sentencia INSERT con la función embedding():
INSERT INTO items (owner_id, provider_name, provider_phone, title, bio, category, image_url, status, item_vector)
VALUES (
:owner, :name, :phone, :title, :bio, :cat, :url, 'available',
embedding('text-embedding-005', :title || ' ' || :bio)::vector
)
Esto garantiza que cada elemento se pueda "buscar" por su significado en el momento en que se publica. Ten en cuenta que esta es la parte que abarca la función "publicar el producto" de la app de Neighbor Loop.
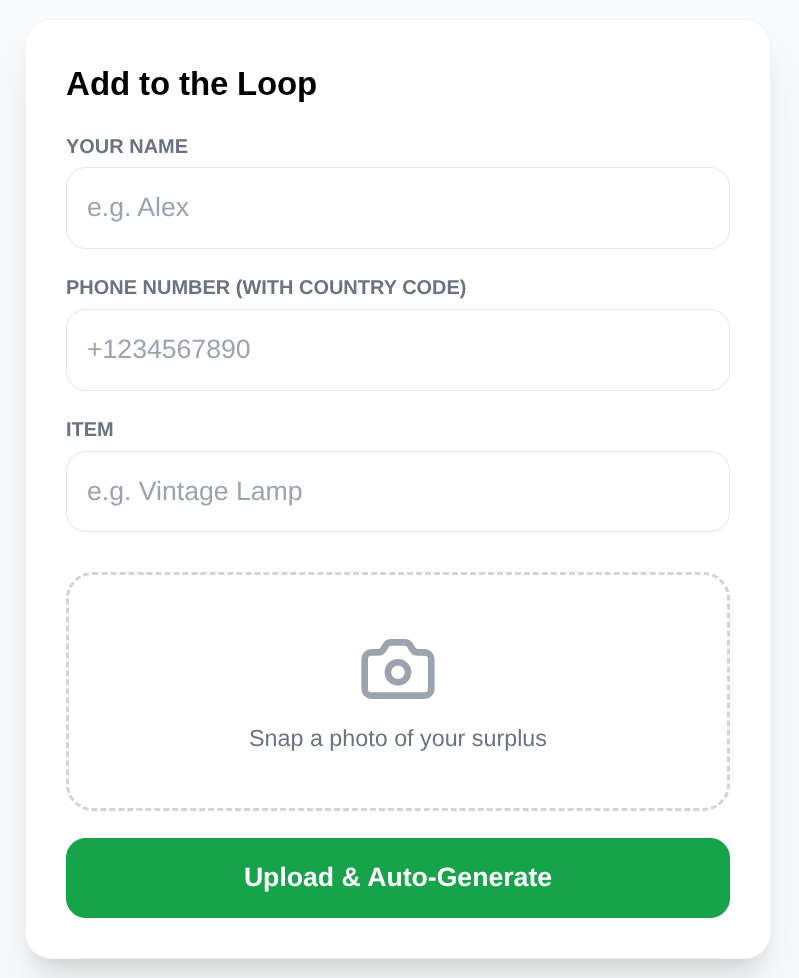
Búsqueda de vectores avanzada y filtrado inteligente con Gemini 3.0
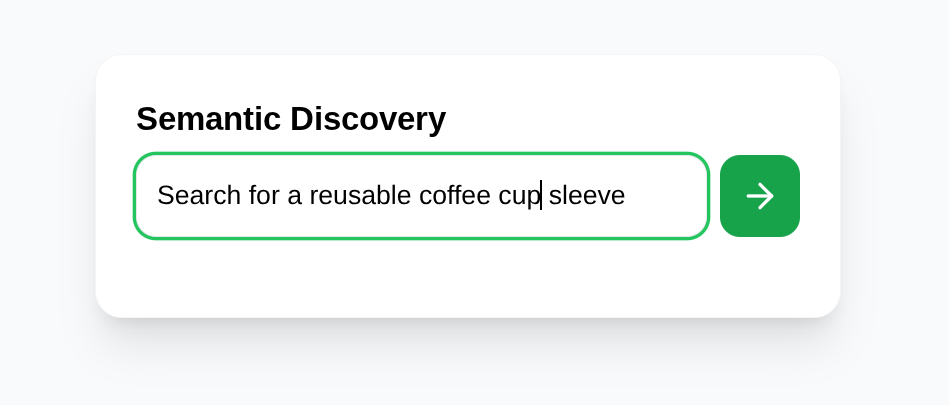
La búsqueda de palabras clave estándar es limitada. Si buscas "algo para arreglar mi silla", es posible que una base de datos tradicional no muestre ningún resultado si la palabra "silla" no aparece en un título. Neighbor Loop resuelve este problema con la búsqueda de vectores avanzada de AlloyDB AI.
Con la extensión pgvector y el almacenamiento optimizado de AlloyDB, podemos realizar búsquedas de similitud extremadamente rápidas. Pero la verdadera "magia" ocurre cuando combinamos la proximidad de vectores con la lógica basada en LLM.
AlloyDB AI nos permite llamar a modelos como Gemini directamente en nuestras consultas de SQL. Esto significa que podemos realizar un descubrimiento semántico que incluya una "verificación de cordura" basada en la lógica con la función ai.if():
SELECT item_id, title, bio, category, image_url,
1 - (item_vector <=> embedding('text-embedding-005', :query)::vector) as score
FROM items
WHERE status = 'available'
AND item_vector IS NOT NULL
AND ai.if(
prompt => 'Does this text: "' || bio ||'" match the user request: "' || :query || '", at least 60%? "',
model_id => 'gemini-3-flash-preview'
)
ORDER BY score DESC
LIMIT 5
Esta consulta representa un cambio arquitectónico importante: trasladamos la lógica a los datos. En lugar de extraer miles de resultados en el código de la aplicación para filtrarlos, Gemini 3 Flash realiza una "verificación de ambiente" dentro del motor de la base de datos. Esto reduce la latencia y los costos de salida, y garantiza que los resultados no solo sean similares desde el punto de vista matemático, sino también pertinentes según el contexto.
El bucle de “Deslizar para encontrar pareja”
La IU es un mazo de cartas clásico.
Deslizar hacia la izquierda: Descartar
Desliza el dedo hacia la derecha: ¡Hay coincidencia!
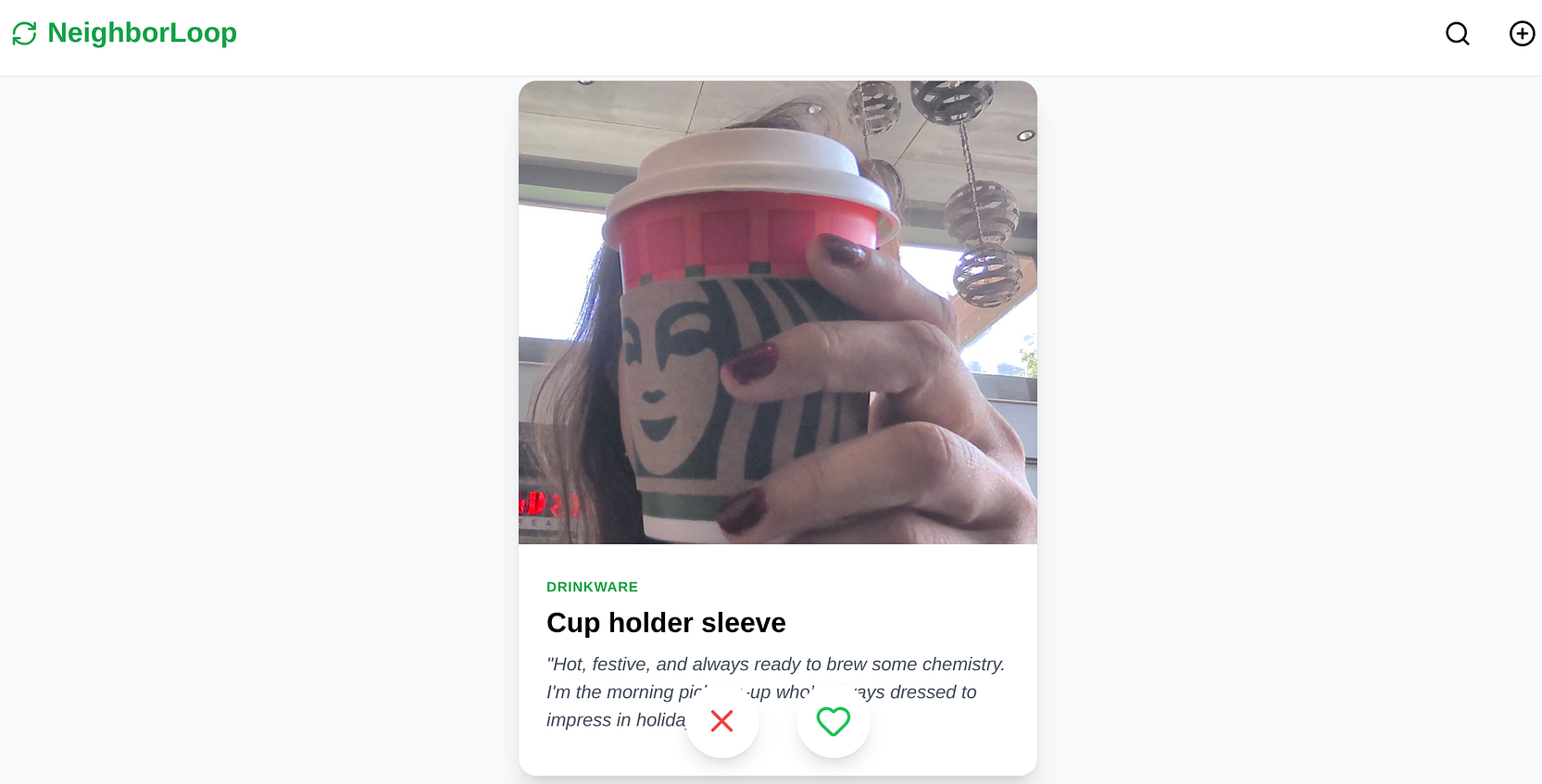
Cuando deslizas el dedo hacia la derecha, el backend registra la interacción en nuestra tabla de deslizamientos y marca el elemento como coincidente. El frontend activa al instante una ventana modal que muestra la información de contacto del proveedor para que puedas coordinar la recolección.
8. Implementémosla en Cloud Run
- Para implementarlo en Cloud Run, ejecuta el siguiente comando desde la terminal de Cloud Shell en la que se clonó el proyecto y asegúrate de estar dentro de la carpeta raíz del proyecto.
Ejecuta este comando en tu terminal de Cloud Shell:
gcloud beta run deploy neighbor-loop \
--source . \
--region=us-central1 \
--network=<<YOUR_NETWORK_NAME>> \
--subnet=<<YOUR_SUBNET_NAME>> \
--allow-unauthenticated \
--vpc-egress=all-traffic \
--set-env-vars GEMINI_API_KEY=<<YOUR_GEMINI_API_KEY>>,DATABASE_URL=postgresql+pg8000://postgres:<<YOUR_PASSWORD>>@<<PRIVATE_IP_HOST>>:<<PORT>>/postgres,GCS_BUCKET_NAME=<<YOUR_GCS_BUCKET>>
Reemplaza los valores de los marcadores de posición <<YOUR_GEMINI_API_KEY>>, <<YOUR_PASSWORD>, <<PRIVATE_IP_HOST>>, <<PORT>> and <<YOUR_GCS_BUCKET>>.
Una vez que finalice el comando, se mostrará una URL de servicio. Cópiala.
- Otorga el rol de cliente de AlloyDB a la cuenta de servicio de Cloud Run.Esto permite que tu aplicación sin servidores cree un túnel seguro hacia la base de datos.
Ejecuta este comando en tu terminal de Cloud Shell:
# 1. Get your Project ID and Project Number
PROJECT_ID=$(gcloud config get-value project)
PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
# 2. Grant the AlloyDB Client role
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$PROJECT_NUMBER-compute@developer.gserviceaccount.com" \
--role="roles/alloydb.client"
Ahora, usa la URL del servicio (el extremo de Cloud Run que copiaste antes) y prueba la app. Sube una foto de esa herramienta eléctrica antigua y deja que Gemini haga el resto.
Problemas potenciales y solución de problemas
El bucle de "Revisión fallida" | Si la implementación finaliza, pero la URL muestra un error |
El rol "sombra" de IAM | Incluso si tú tienes permiso para realizar la implementación, la cuenta de servicio de Cloud Run (por lo general, |
9. Solución de problemas de alto nivel
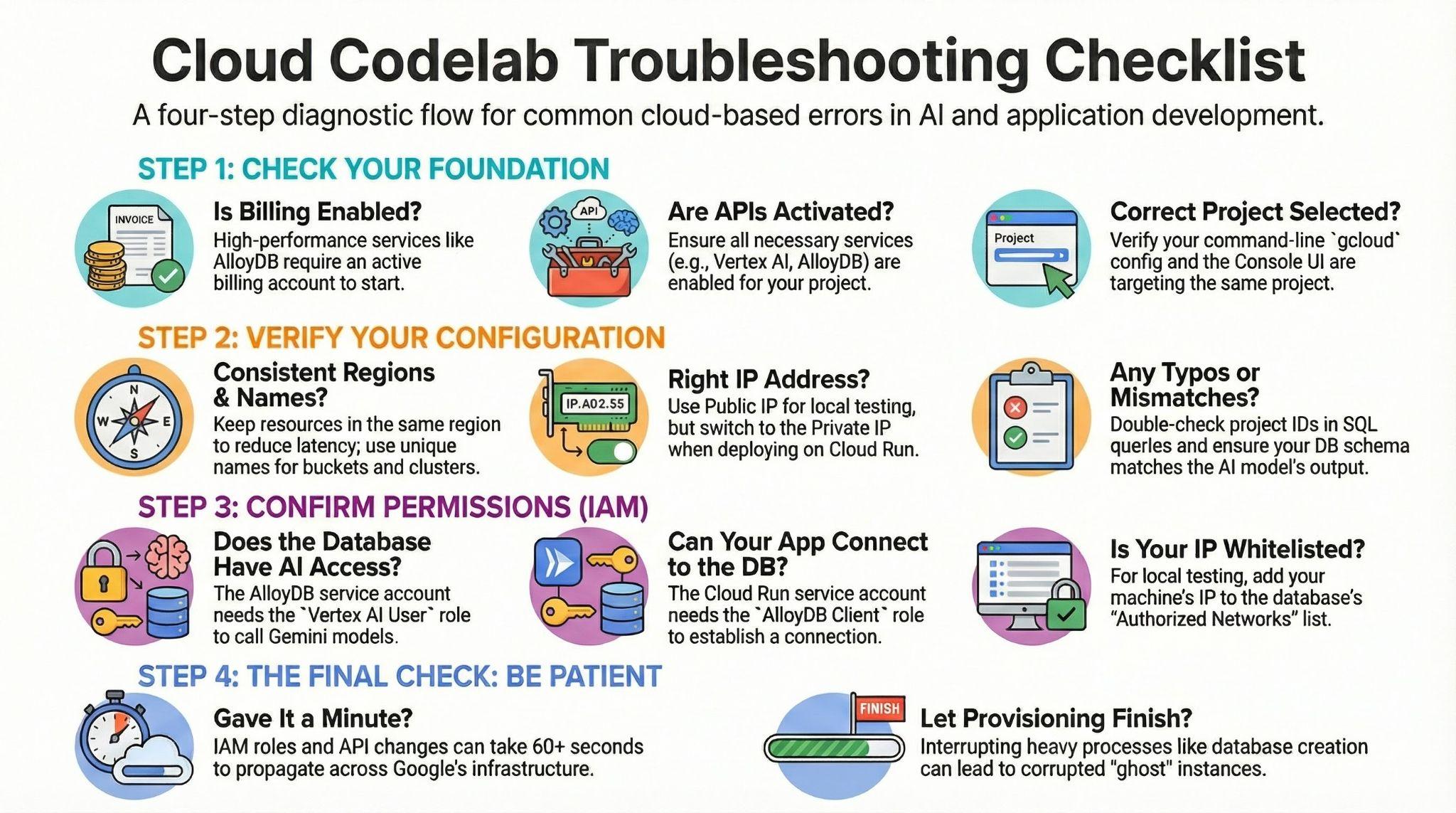
10. Demostración
Deberías poder usar tu extremo para las pruebas.
Sin embargo, para fines de demostración durante unos días, puedes probar lo siguiente:
11. Limpia
Cuando termines este lab, no olvides borrar el clúster y la instancia de AlloyDB.
Debería limpiar el clúster junto con sus instancias.
12. Felicitaciones
Compilaste correctamente la app de Neighbor Loop para comunidades sostenibles con Google Cloud. Al trasladar la lógica de la IA de Gemini 3 Flash y la incorporación a AlloyDB, la app es increíblemente rápida (sujeta a la configuración de implementación) y el código es notablemente limpio. No solo almacenamos datos, sino también intención.
La combinación de la velocidad de Gemini 3 Flash y el procesamiento de vectores optimizado de AlloyDB es realmente la próxima frontera para las plataformas impulsadas por la comunidad.