
1. Présentation
Dans cet atelier de programmation, vous allez créer Neighbor Loop, une application durable de partage des excédents qui traite l'intelligence comme un élément à part entière de la couche de données.
En intégrant Gemini 3.0 Flash et l'intégration du ML de Cloud SQL, vous passerez du stockage de base au domaine de l'intelligence intégrée à la base de données. Vous apprendrez à effectuer des analyses d'éléments multimodaux et des découvertes sémantiques directement dans SQL.

Ce que vous allez faire
Application Web "swipe-to-match" hautes performances pour le partage des surplus de la communauté.
Points abordés
- Provisionnement en un clic : découvrez comment configurer une instance Cloud SQL conçue pour les charges de travail d'IA.
- Embeddings dans la base de données : génération de vecteurs text-embedding-005 directement dans les instructions INSERT.
- Raisonnement multimodal : utiliser Gemini 3.0 Flash pour "voir" des éléments et générer automatiquement des bios amusantes de style "dating".
- Découverte sémantique : effectuez des "vérifications d'ambiance" basées sur la logique dans les requêtes SQL à l'aide de la fonction ai.if() pour filtrer les résultats en fonction du contexte, et pas seulement des mathématiques.
Architecture
Neighbor Loop contourne les goulots d'étranglement traditionnels de la couche application. Au lieu d'extraire les données pour les traiter, nous utilisons :
- Intégration Cloud SQL + ML : pour générer et stocker des vecteurs en temps réel.
- Google Cloud Storage : pour stocker les images
- Gemini 3.0 Flash : pour effectuer un raisonnement en moins d'une seconde sur des données d'image et de texte directement via SQL.
- Cloud Run : pour héberger un backend Flask léger et monofichier.
Conditions requises
2. Avant de commencer
Créer un projet
- Dans la console Google Cloud, sur la page du sélecteur de projet, sélectionnez ou créez un projet Google Cloud.
- Assurez-vous que la facturation est activée pour votre projet Cloud. Découvrez comment vérifier si la facturation est activée sur un projet.
- Vous allez utiliser Cloud Shell, un environnement de ligne de commande exécuté dans Google Cloud. Cliquez sur "Activer Cloud Shell" en haut de la console Google Cloud.

- Une fois connecté à Cloud Shell, vérifiez que vous êtes déjà authentifié et que le projet est défini sur votre ID de projet à l'aide de la commande suivante :
gcloud auth list
- Exécutez la commande suivante dans Cloud Shell pour vérifier que la commande gcloud connaît votre projet.
gcloud config list project
- Si votre projet n'est pas défini, utilisez la commande suivante pour le définir :
gcloud config set project <YOUR_PROJECT_ID>
- Activez les API requises : suivez ce lien et activez les API.
Vous pouvez également utiliser la commande gcloud. Consultez la documentation pour connaître les commandes gcloud ainsi que leur utilisation.
Problèmes et dépannage
Syndrome du projet fantôme | Vous avez exécuté |
Barricade de facturation | Vous avez activé le projet, mais oublié le compte de facturation. Cloud SQL ne démarrera pas si la facturation est vide. |
Décalage de la propagation de l'API | Vous avez cliqué sur "Activer les API", mais la ligne de commande indique toujours |
3. Configuration de la base de données
Dans cet atelier, nous utiliserons Cloud SQL pour PostgreSQL comme base de données pour les données de test.
Commençons par créer une instance Cloud SQL dans laquelle l'ensemble de données de test sera chargé.
- Cliquez sur le bouton ou copiez le lien ci-dessous dans le navigateur dans lequel l'utilisateur de la console Google Cloud est connecté.
- Une fois cette étape terminée, le dépôt sera cloné dans votre éditeur Cloud Shell local. Vous pourrez ensuite exécuter la commande ci-dessous à partir du dossier du projet (assurez-vous d'être dans le répertoire du projet) :
sh run.sh
- Utilisez maintenant l'UI (en cliquant sur le lien dans le terminal ou sur le lien "Prévisualiser sur le Web" dans le terminal).
- Saisissez les informations concernant l'ID du projet et le nom de l'instance pour commencer.
- Allez prendre un café pendant que les journaux défilent. Pour en savoir plus sur le fonctionnement en coulisses, cliquez ici.
Problèmes et dépannage
Région non concordante | Si vous avez activé vos API dans |
Délai d'inactivité de Cloud Shell | Si votre pause-café dure 30 minutes, Cloud Shell peut se mettre en veille et déconnecter le processus |
4. Provisionnement de schémas
Une fois votre instance Cloud SQL en cours d'exécution, accédez à l'éditeur SQL de Cloud SQL Studio pour activer les extensions d'IA et provisionner le schéma.
Vous devrez peut-être attendre que votre instance soit créée. Une fois l'instance créée, connectez-vous à Cloud SQL à l'aide des identifiants que vous avez créés. Utilisez les données suivantes pour vous authentifier auprès de PostgreSQL :
- Nom d'utilisateur : "
postgres" - Base de données : "
postgres" - Mot de passe : "
cloudsql" (ou celui que vous avez défini lors de la création)
Une fois l'authentification réussie dans Cloud SQL Studio, les commandes SQL sont saisies dans l'éditeur. Vous pouvez ajouter plusieurs fenêtres de l'éditeur en cliquant sur le signe plus à droite de la dernière fenêtre.
Vous saisirez des commandes pour Cloud SQL dans des fenêtres d'éditeur, en utilisant les options "Exécuter", "Mettre en forme" et "Effacer" selon les besoins.
Activer les extensions
Pour créer cette application, nous allons utiliser les extensions pgvector et google_ml_integration. L'extension pgvector vous permet de stocker et de rechercher des embeddings vectoriels. L'extension google_ml_integration fournit les fonctions que vous utilisez pour accéder aux points de terminaison de prédiction Vertex AI afin d'obtenir des prédictions en SQL. Activez ces extensions en exécutant les LDD suivants :
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
Créer une table
Vous pouvez créer une table à l'aide de l'instruction LDD ci-dessous dans Cloud SQL Studio :
-- Items Table (The "Profile" you swipe on)
CREATE TABLE items (
item_id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
owner_id UUID,
provider_name TEXT,
provider_phone TEXT,
title TEXT,
bio TEXT,
category TEXT,
image_url TEXT,
item_vector VECTOR(768),
status TEXT DEFAULT 'available',
created_at TIMESTAMP DEFAULT NOW()
);
-- Swipes Table (The Interaction)
CREATE TABLE swipes (
swipe_id SERIAL PRIMARY KEY,
swiper_id UUID,
item_id UUID REFERENCES items(item_id),
direction TEXT CHECK (direction IN ('left', 'right')),
is_match BOOLEAN DEFAULT FALSE,
created_at TIMESTAMP DEFAULT NOW()
);
La colonne item_vector permettra de stocker les valeurs vectorielles du texte.
Accorder l'autorisation
Exécutez l'instruction ci-dessous pour accorder l'exécution de la fonction "embedding" :
GRANT EXECUTE ON FUNCTION embedding TO postgres;
Activer l'intégration de ML
Pour exploiter les fonctionnalités de machine learning directement dans votre base de données, vous devez activer l'indicateur d'intégration ML.
Vous pouvez exécuter la commande ci-dessous à partir du terminal Cloud Shell :
INSTANCE_NAME="<<The name of your Cloud SQL Instance>>"
gcloud sql instances patch $INSTANCE_NAME --tier=db-custom-1-3840
gcloud sql instances patch $INSTANCE_NAME \
--database-flags=cloudsql.enable_google_ml_integration=on
gcloud sql instances patch $INSTANCE_NAME --enable-google-ml-integration
Attribuer le rôle Utilisateur Vertex AI au compte de service Cloud SQL
Dans la console Google Cloud IAM, accordez au compte de service Cloud SQL (qui ressemble à ceci : service-<<PROJECT_NUMBER>>@cp-sa-cloud-sql.iam.gserviceaccount.com) l'accès au rôle "Utilisateur Vertex AI". PROJECT_NUMBER correspondra au numéro de votre projet.
Vous pouvez également exécuter la commande ci-dessous à partir du terminal Cloud Shell :
INSTANCE_NAME="<<The name of your Cloud SQL Instance>>"
PROJECT_ID=$(gcloud config get-value project)
SA_EMAIL=$(gcloud sql instances describe $INSTANCE_NAME --format='value(serviceAccountEmailAddress)')
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SA_EMAIL" \
--role="roles/aiplatform.user"
Enregistrer le modèle Gemini 3 Flash dans Cloud SQL
Exécutez l'instruction SQL ci-dessous à partir de l'éditeur de requête Cloud SQL.
CALL google_ml.create_model(
model_id => 'gemini-3-flash-preview',
model_request_url => 'https://aiplatform.googleapis.com/v1/projects/<<YOUR_PROJECT_ID>>/locations/global/publishers/google/models/gemini-3-flash-preview:generateContent',
model_qualified_name => 'gemini-3-flash-preview',
model_provider => 'google',
model_type => 'generic',
model_auth_type => 'cloudsql_service_agent_iam'
);
--replace <<YOUR_PROJECT_ID>> with your project id.
Problèmes et dépannage
La boucle "Mot de passe oublié" | Si vous avez utilisé la configuration "En un clic" et que vous ne vous souvenez plus de votre mot de passe, accédez à la page "Informations de base sur l'instance" dans la console, puis cliquez sur "Modifier" pour réinitialiser le mot de passe |
Erreur "Extension introuvable" | Si |
Délai de propagation IAM | Vous avez exécuté la commande IAM |
Incompatibilité de la dimension du vecteur | La table |
Faute de frappe dans l'ID du projet | Dans l'appel |
L'intégration Vertex AI est désactivée | Exécutez |
5. Stockage d'images (Google Cloud Storage)
Pour stocker les photos de nos articles excédentaires, nous utilisons un bucket GCS. Pour cette application de démonstration, nous souhaitons que les images soient accessibles au public afin qu'elles s'affichent instantanément dans nos cartes à balayer.
- Créez un bucket : créez un bucket dans votre projet GCP (par exemple, neighborloop-images), de préférence dans la même région que votre base de données et votre application.
- Configurer l'accès public : accédez à l'onglet Autorisations du bucket.
- Ajoutez le compte principal allUsers.
- Attribuez le rôle Lecteur des objets Storage (pour que tout le monde puisse voir les photos) et le rôle Créateur des objets Storage (pour les besoins de l'importation de la démo).
Alternative (compte de service) : si vous préférez ne pas utiliser l'accès public, assurez-vous que le compte de service de votre application dispose d'un accès complet à Cloud SQL et des rôles Storage nécessaires pour gérer les objets de manière sécurisée.
Si vous souhaitez exécuter la commande et accorder un accès public. Exécutez les commandes ci-dessous dans le terminal Cloud Shell :
BUCKET_NAME="<<your-bucket-name>>"
gcloud storage buckets add-iam-policy-binding gs://$BUCKET_NAME \
--member="allUsers" \
--role="roles/storage.objectViewer"
Problèmes et dépannage
The Region Drag | Si votre base de données se trouve dans |
Unicité des noms de buckets | Les noms de buckets constituent un espace de noms global. Si vous essayez de nommer votre bucket |
Confusion entre "créateur" et "lecteur" | Confusion entre "Créateur" et "Lecteur" : si vous n'ajoutez que "Lecteur", votre application plantera lorsqu'un utilisateur tentera de lister un nouvel élément, car il n'aura pas l'autorisation d'écrire dans le fichier. Vous aurez besoin des deux pour cette configuration de démonstration spécifique. |
6. Créons l'application
Clonez ce dépôt dans votre projet et examinons-le.
- Pour cloner ce dépôt, exécutez les commandes suivantes une par une depuis le terminal Cloud Shell (dans le répertoire racine ou à l'emplacement où vous souhaitez créer ce projet) :
git clone https://github.com/flazer99/neighbor-loop-cloud-sql
cd neighbor-loop-cloud-sql/
Le projet devrait être créé. Vous pouvez le vérifier dans l'éditeur Cloud Shell.

- Obtenir votre clé API Gemini
- Accédez à Google AI Studio : rendez-vous sur aistudio.google.com.
- Connexion : utilisez le même compte Google que celui de votre projet Google Cloud.
- Créer une clé API :
- Dans la barre latérale de gauche, cliquez sur "Get API key" (Obtenir une clé API).
- Cliquez sur le bouton "Créer une clé API dans un nouveau projet".
- Copiez la clé : une fois la clé générée, cliquez sur l'icône de copie.
- Définissez maintenant les variables d'environnement dans le fichier .env.
GEMINI_API_KEY=<<YOUR_GEMINI_API_KEY>>
DATABASE_URL=postgresql+pg8000://postgres:<<YOUR_PASSWORD>>@<<HOST_IP>>:<<PORT>>/postgres
GCS_BUCKET_NAME=<<YOUR_GCS_BUCKET>>
Remplacez les valeurs des espaces réservés <<YOUR_GEMINI_API_KEY>>, <<YOUR_PASSWORD>, <<HOST_IP>>, <<PORT>> and <<YOUR_GCS_BUCKET>>..
Problèmes et dépannage
Confusion entre plusieurs comptes | Si vous êtes connecté à plusieurs comptes Google (personnel et professionnel), il est possible qu'AI Studio soit défini par défaut sur le mauvais compte. Vérifiez l'avatar en haut à droite pour vous assurer qu'il correspond à votre compte de projet GCP. |
Dépassement du quota du niveau sans frais | Si vous utilisez le niveau sans frais, des limites de fréquence (requêtes par minute) s'appliquent. Si vous balayez trop rapidement dans la boucle de quartier, vous pouvez obtenir une erreur |
Sécurité des clés exposées | Si vous avez accidentellement |
7. Vérifions le code
Le profil de rencontre de vos objets

Lorsqu'un utilisateur importe la photo d'un article, il ne devrait pas avoir à écrire une longue description. J'utilise Gemini 3 Flash pour "voir" l'article et rédiger la fiche à sa place.
Dans le backend, l'utilisateur fournit simplement un titre et une photo. Gemini s'occupe du reste :
prompt = """
You are a witty community manager for NeighborLoop.
Analyze this surplus item and return JSON:
{
"bio": "First-person witty dating-style profile bio for the product, not longer than 2 lines",
"category": "One-word category",
"tags": ["tag1", "tag2"]
}
"""
response = genai_client.models.generate_content(
model="gemini-3-flash-preview",
contents=[types.Part.from_bytes(data=image_bytes, mime_type="image/jpeg"), prompt],
config=types.GenerateContentConfig(response_mime_type="application/json")
)
Embeddings en temps réel dans la base de données
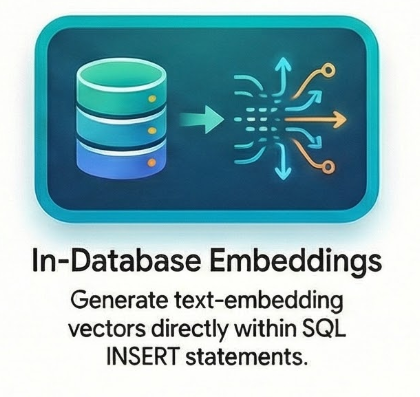
L'une des fonctionnalités les plus intéressantes de Cloud SQL est la possibilité de générer des embeddings sans quitter le contexte SQL. Au lieu d'appeler un modèle d'embedding en Python et de renvoyer le vecteur à la base de données, je fais tout en une seule instruction INSERT à l'aide de la fonction embedding() :
INSERT INTO items (owner_id, provider_name, provider_phone, title, bio, category, image_url, status, item_vector)
VALUES (
:owner, :name, :phone, :title, :bio, :cat, :url, 'available',
embedding('text-embedding-005', :title || ' ' || :bio)::vector
)
Cela permet de s'assurer que chaque élément est "recherchable" par sa signification dès qu'il est publié. Notez qu'il s'agit de la partie qui couvre la fonctionnalité "listing the product" (lister le produit) de l'application Neighbor Loop.
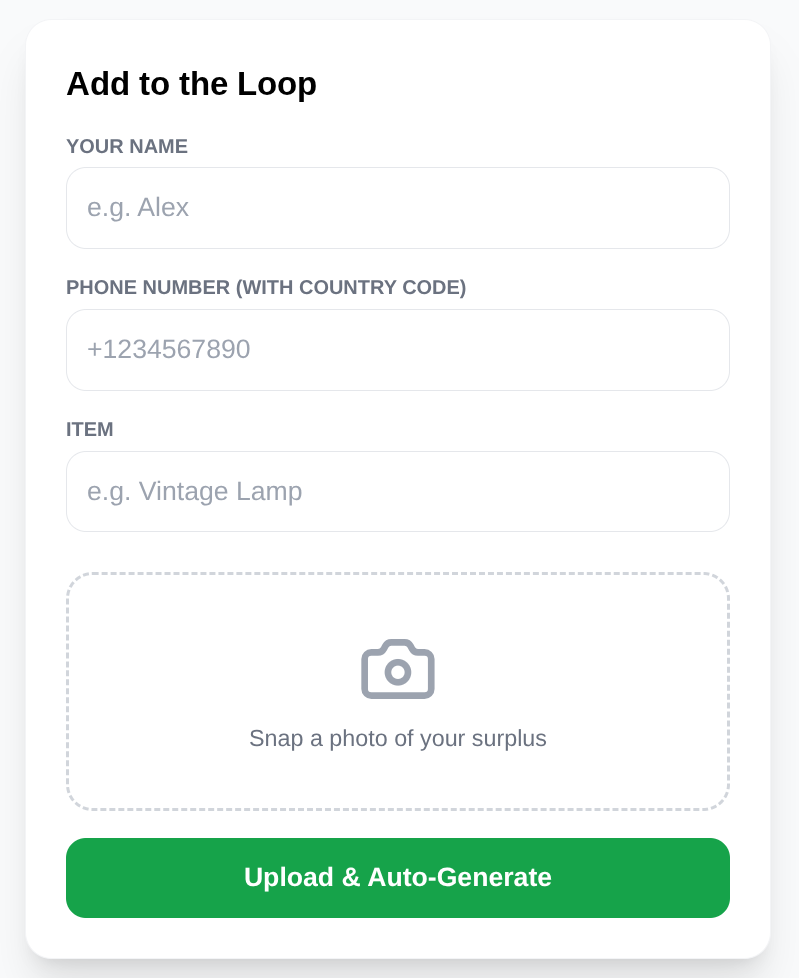
Recherche vectorielle avancée et filtrage intelligent avec Gemini 3.0
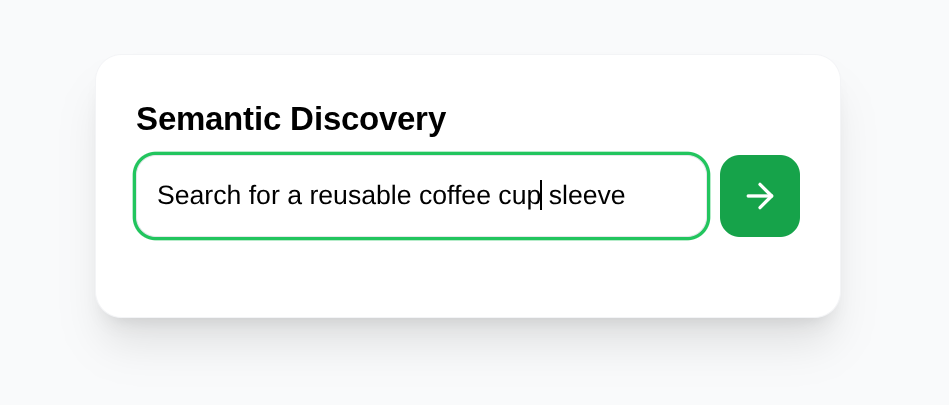
La recherche de mots clés standards est limitée. Si vous recherchez "quelque chose pour réparer ma chaise", une base de données traditionnelle peut ne renvoyer aucun résultat si le mot "chaise" ne figure pas dans un titre. Neighbor Loop résout ce problème grâce à la recherche vectorielle avancée de Cloud SQL AI.
En utilisant l'extension pgvector et le stockage optimisé de Cloud SQL, nous pouvons effectuer des recherches de similarité extrêmement rapides. Mais la vraie "magie" opère lorsque nous combinons la proximité vectorielle avec la logique basée sur les LLM.
SELECT item_id, title, bio, category, image_url,
1 - (item_vector <=> embedding('text-embedding-005', :query)::vector) as score
FROM items
WHERE status = 'available'
AND item_vector IS NOT NULL
ORDER BY score DESC
LIMIT 5
Cette requête représente un changement architectural majeur : nous déplaçons la logique vers les données. Au lieu d'extraire des milliers de résultats dans le code de l'application pour les filtrer, Gemini 3 Flash effectue une "vérification de l'ambiance" à l'intérieur du moteur de base de données. Cela réduit la latence et les coûts de sortie, et garantit que les résultats ne sont pas seulement similaires d'un point de vue mathématique, mais aussi pertinents d'un point de vue contextuel.
La boucle "Balayer pour trouver un partenaire"
L'UI est un jeu de cartes classique.
Balayez vers la gauche : supprimez.
Balayer vers la droite : c'est un match !
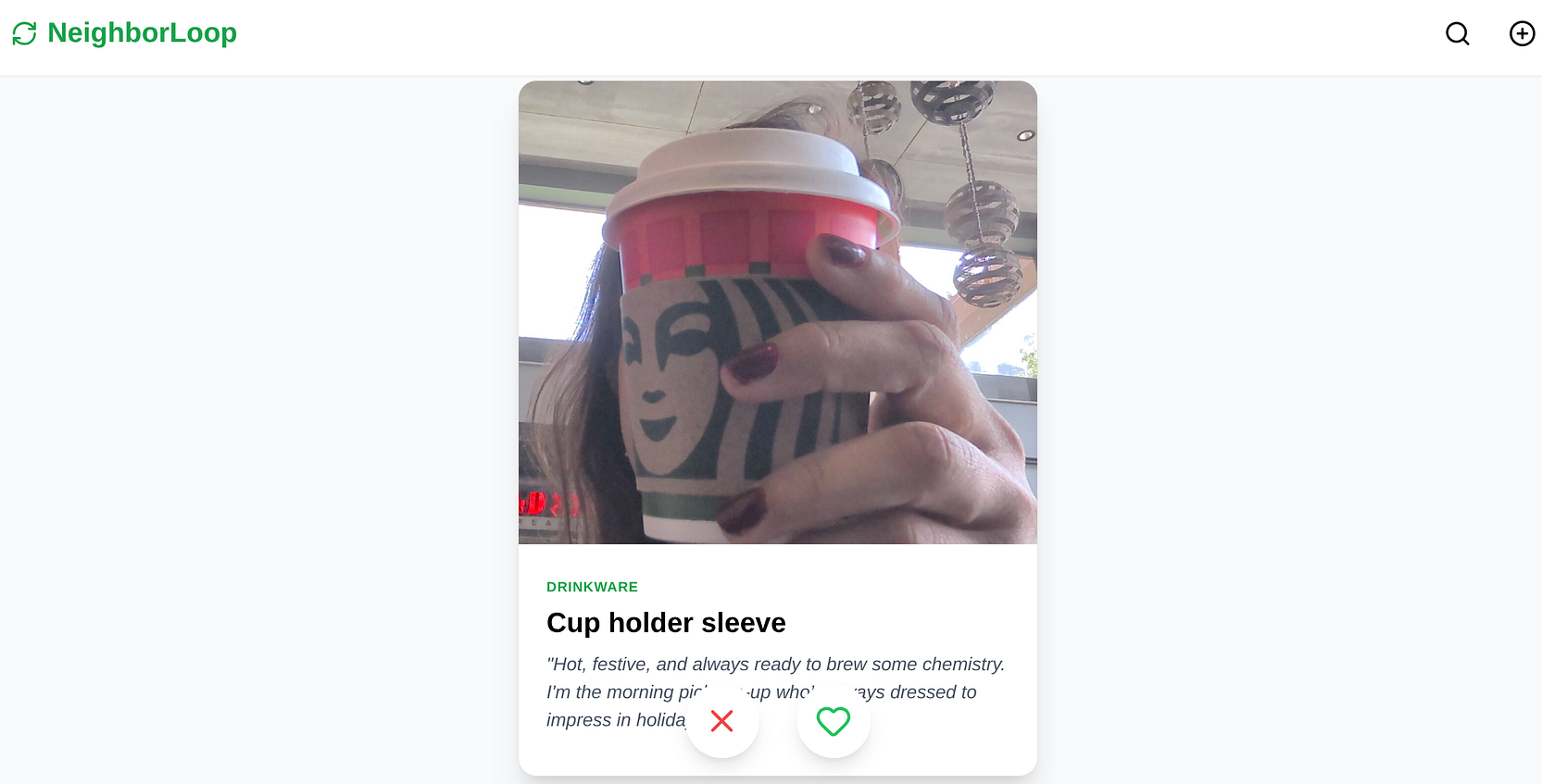
Lorsque vous balayez l'écran vers la droite, le backend enregistre l'interaction dans notre tableau des balayages et marque l'élément comme correspondant. L'interface utilisateur déclenche instantanément un pop-up affichant les coordonnées du fournisseur pour que vous puissiez organiser la collecte.
8. Déployons-la sur Cloud Run.
- Déployez-le sur Cloud Run en exécutant la commande suivante à partir du terminal Cloud Shell où le projet est cloné. Assurez-vous d'être dans le dossier racine du projet.
Exécutez la commande suivante dans votre terminal Cloud Shell :
gcloud run deploy neighbor-loop-cloud-sql \
--source . \
--region=us-central1 \
--allow-unauthenticated \
--network=easy-cloudsql-vpc \
--subnet=easy-cloudsql-subnet \
--vpc-egress=private-ranges-only \
--set-env-vars GEMINI_API_KEY=<<YOUR_GEMINI_API_KEY>>,DATABASE_URL=postgresql+pg8000://postgres:<<YOUR_PASSWORD>>@<<PRIVATE_IP_HOST>>:5432/postgres,GCS_BUCKET_NAME=<<YOUR_GCS_BUCKET>>
Remplacez les valeurs des espaces réservés <<YOUR_GEMINI_API_KEY>>, <<YOUR_PASSWORD>, <<PRIVATE_IP_HOST>>, <<PORT>> and <<YOUR_GCS_BUCKET>>.
Une fois la commande terminée, une URL de service est générée. Copiez-le.
Utilisez maintenant l'URL du service (point de terminaison Cloud Run que vous avez copié précédemment) et testez l'application. Importez une photo de cet ancien outil électrique et laissez Gemini faire le reste !
Problèmes et dépannage
La boucle "Échec de la révision" | Si le déploiement se termine, mais que l'URL renvoie un |
9. Dépannage de haut niveau
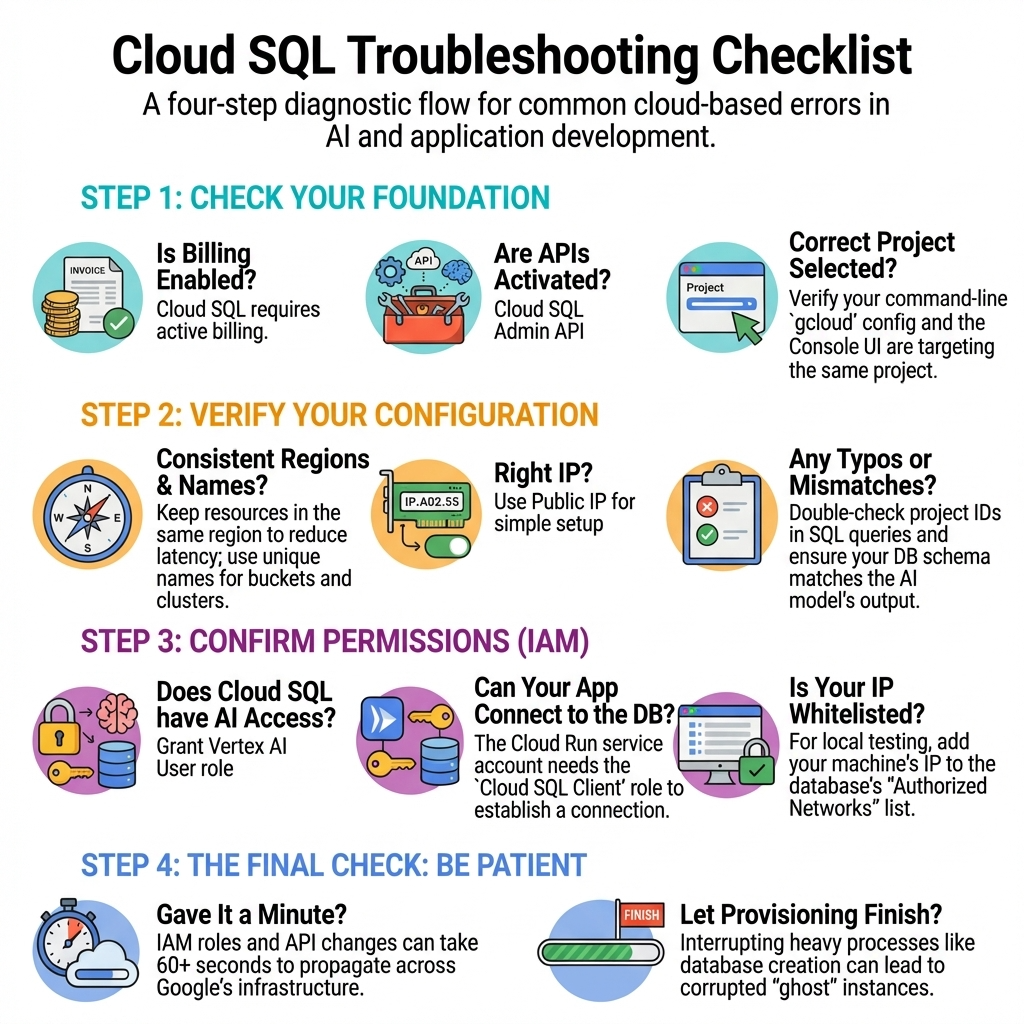
10. Démo
Vous devriez pouvoir utiliser votre point de terminaison pour les tests.
Toutefois, pour les besoins de la démonstration, vous pouvez utiliser cette méthode pendant quelques jours :
11. Effectuer un nettoyage
Une fois cet atelier terminé, n'oubliez pas de supprimer l'instance Cloud SQL.
12. Félicitations
Vous avez créé l'application Neighbor Loop pour des communautés durables avec Google Cloud. En déplaçant l'intégration et la logique d'IA Gemini 3 Flash dans Cloud SQL, l'application est incroyablement rapide (en fonction des paramètres de déploiement) et le code est remarquablement propre. Nous ne stockons pas seulement des données, mais aussi des intentions.
La combinaison de la vitesse de Gemini 3 Flash et du traitement vectoriel optimisé de Cloud SQL représente une véritable avancée pour les plates-formes axées sur la communauté.