
1. Einführung
In diesem Codelab erfahren Sie, wie Sie Gemini File Search verwenden, um RAG in Ihrer Agentic Application zu aktivieren. Mit der Gemini-Dateisuche können Sie Ihre Dokumente aufnehmen und indexieren, ohne sich um die Details der Aufteilung in Chunks, der Einbettung oder der Vektordatenbank kümmern zu müssen.
Lerninhalte
- Die Grundlagen von RAG und warum wir es brauchen.
- Was ist Gemini File Search und welche Vorteile bietet es?
- So erstellen Sie einen File Search Store.
- So laden Sie Ihre eigenen Dateien in den File Search Store hoch.
- So verwenden Sie das Gemini File Search Tool für RAG.
- Die Vorteile der Verwendung des Google Agent Development Kit (ADK).
- Verwendung des Gemini File Search Tool in einer agentischen Lösung, die mit dem ADK erstellt wurde
- So verwenden Sie das Gemini File Search Tool zusammen mit „nativen“ Google-Tools wie der Google Suche.
Aufgaben
- Erstellen Sie ein Google Cloud-Projekt und richten Sie Ihre Entwicklungsumgebung ein.
- Erstellen Sie mit dem Google Gen AI SDK (aber ohne ADK) einen einfachen auf Gemini basierenden KI-Agenten, der die Google Suche nutzen kann, aber keine RAG-Funktion hat.
- Demonstriere, dass es nicht in der Lage ist, genaue, hochwertige Informationen für maßgeschneiderte Informationen bereitzustellen.
- Erstellen Sie ein Jupyter-Notebook, das Sie lokal oder z. B. in Google Colab ausführen können, um einen Gemini File Search Store zu erstellen und zu verwalten.
- Mit dem Notebook können Sie benutzerdefinierte Inhalte in den File Search Store hochladen.
- Erstellen Sie einen KI-Agenten, dem der File Search Store angehängt ist, und beweisen Sie, dass er bessere Antworten liefern kann.
- Wir wandeln unseren ursprünglichen „einfachen“ Agenten in einen ADK-Agenten um, der das Google-Suchtool enthält.
- Agenten über die ADK-Web-UI testen
- Binden Sie den File Search Store in den ADK-Agenten ein. Verwenden Sie dazu das Muster „Agent-as-a-Tool“, damit das File Search Tool zusammen mit dem Google Search Tool verwendet werden kann.
2. Was ist RAG und warum brauchen wir es?
Also... Retrieval Augmented Generation
Wenn Sie diese Seite aufgerufen haben, wissen Sie wahrscheinlich, was das ist. Zur Sicherheit fassen wir es aber noch einmal kurz zusammen. LLMs (wie Gemini) sind zwar leistungsstark, haben aber einige Probleme:
- Sie sind immer veraltet: Sie wissen nur, was sie während des Trainings gelernt haben.
- Sie wissen nicht alles: Die Modelle sind zwar riesig, aber nicht allwissend.
- Sie kennen Ihre vertraulichen Informationen nicht: Sie haben ein breites Wissen, aber sie haben Ihre internen Dokumente, Ihre Blogs oder Ihre Jira-Tickets nicht gelesen.
Wenn Sie ein Modell also nach etwas fragen, worauf es keine Antwort weiß, erhalten Sie in der Regel eine falsche oder sogar erfundene Antwort. Oft gibt das Modell diese falsche Antwort selbstbewusst aus. Das bezeichnen wir als Halluzination.
Eine Lösung besteht darin, unsere proprietären Informationen einfach direkt in den Konversationskontext zu übertragen. Bei einer kleinen Menge an Informationen ist das kein Problem, aber bei einer großen Menge wird es schnell problematisch. Konkret führt dies zu folgenden Problemen:
- Latenz: Das Modell reagiert immer langsamer.
- Signalverfall (auch „Lost in the Middle“): Das Modell kann die relevanten Daten nicht mehr von den irrelevanten Daten trennen. Ein Großteil des Kontexts wird vom Modell ignoriert.
- Kosten: Tokens kosten Geld.
- Erschöpfung des Kontextfensters: An diesem Punkt werden Ihre Anfragen von Gemini nicht mehr bearbeitet.
Eine viel effektivere Methode, um dieses Problem zu beheben, ist die Verwendung von RAG. Es geht lediglich darum, relevante Informationen aus Ihren Datenquellen (mithilfe von semantischem Abgleich) zu suchen und relevante Teile dieser Daten zusammen mit Ihrer Frage an das Modell zu übergeben. Dadurch wird das Modell in Ihre Realität eingebunden.
Dazu werden externe Daten importiert, in Chunks zerlegt, in Vektoreinbettungen konvertiert und dann in einer geeigneten Vektordatenbank gespeichert und indexiert.
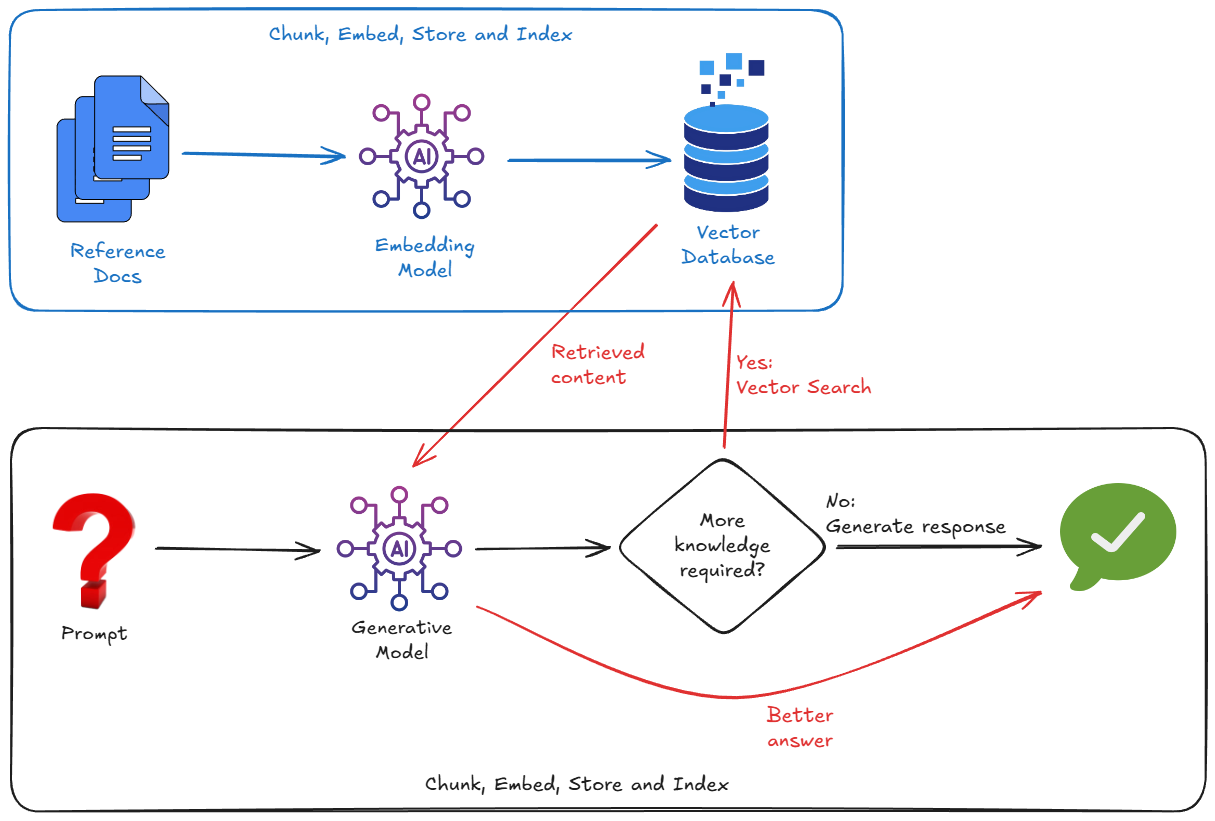
Für die Implementierung von RAG müssen wir uns in der Regel mit folgenden Aspekten befassen:
- Eine Vektordatenbank einrichten (Pinecone, Weaviate, Postgres mit pgvector usw.).
- Ein Chunking-Skript schreiben, um Ihre Dokumente (z. B. PDFs, Markdown usw.) aufzuteilen.
- Einbettungen (Vektoren) für diese Chunks mit einem Einbettungsmodell generieren.
- Speichern der Vektoren in der Vektordatenbank.
Aber Freunde lassen Freunde nicht übertreiben. Was, wenn ich dir sage, dass es eine einfachere Möglichkeit gibt?
3. Vorbereitung
Google Cloud-Projekt erstellen
Für dieses Codelab benötigen Sie ein Google Cloud-Projekt. Sie können ein vorhandenes Projekt verwenden oder ein neues erstellen.
Achten Sie darauf, dass die Abrechnung für Ihr Projekt aktiviert ist. In diesem Leitfaden erfahren Sie, wie Sie den Abrechnungsstatus Ihrer Projekte prüfen.
Das Durcharbeiten dieses Codelabs sollte Sie nichts kosten. Höchstens ein paar Cent.
Bereiten Sie Ihr Projekt vor. Ich warte.
Demo-Repository klonen
Ich habe ein Repository mit Anleitungen für dieses Codelab erstellt. Du wirst es brauchen!
Führen Sie die folgenden Befehle über Ihr Terminal oder über das im Cloud Shell-Editor integrierte Terminal aus. Cloud Shell und der zugehörige Editor sind sehr praktisch, da alle benötigten Befehle vorinstalliert sind und alles sofort einsatzbereit ist.
git clone https://github.com/derailed-dash/gemini-file-search-demo cd gemini-file-search-demo
In dieser Baumstruktur werden die wichtigsten Ordner und Dateien im Repository angezeigt:
gemini-file-search-demo/ ├── app/ │ ├── basic_agent_adk/ # Agent with Google Search, using ADK framework │ │ └── agent.py │ ├── rag_agent_adk/ # Agent with Google Search and File Search, using ADK framework │ │ ├── agent.py │ │ └── tools_custom.py │ ├── sdk_agent.py # Agent using GenAI SDK (no ADK) with Google Search tool │ └── sdk_rag_agent.py # Agent using GenAI SDK (no ADK) with Gemini File Search tool ├── data/ │ └── story.md # Sample story with "bespoke content" to use with Gemini File Search Store ├── notebooks/ │ └── file_search_store.ipynb # Jupyter notebook for creating and managing Gemini File Search Store │ ├── .env.template # Template for environment variables - make a copy as .env ├── Makefile # Makefile for `make` commands ├── pyproject.toml # Project configuration and dependencies └── README.md # This file
Öffnen Sie diesen Ordner im Cloud Shell-Editor oder in Ihrem bevorzugten Editor. (Haben Sie Antigravity schon verwendet? Wenn nicht, ist jetzt ein guter Zeitpunkt, es auszuprobieren.
Das Repository enthält eine Beispielgeschichte („The Wormhole Incursion“) in der Datei data/story.md. Ich habe es gemeinsam mit Gemini geschrieben. Es geht um Commander Dazbo und seine Staffel von intelligenten Raumschiffen. (Ich habe mich vom Spiel Elite Dangerous inspirieren lassen.) Dieser Artikel dient als unsere „maßgeschneiderte Wissensdatenbank“ mit spezifischen Fakten, die Gemini nicht kennt und nach denen Gemini auch nicht über die Google Suche suchen kann.
Entwicklungsumgebung einrichten
Zur Vereinfachung habe ich ein Makefile bereitgestellt, das viele der Befehle, die Sie ausführen müssen, vereinfacht. Anstatt sich bestimmte Befehle zu merken, können Sie einfach make <target> eingeben. make ist jedoch nur in Linux-, MacOS- und WSL-Umgebungen verfügbar. Wenn Sie Windows ohne WSL verwenden, müssen Sie die vollständigen Befehle ausführen, die die make-Ziele enthalten.
# Install dependencies with make make install # If you don't have make... uv sync --extra jupyter
So sieht es aus, wenn Sie make install im Cloud Shell-Editor ausführen:
Gemini API-Schlüssel erstellen
Wenn Sie die Gemini Developer API verwenden möchten (die wir für die Verwendung des Gemini File Search Tool benötigen), benötigen Sie einen Gemini API-Schlüssel. Am einfachsten erhalten Sie einen API-Schlüssel über Google AI Studio. Dort steht Ihnen eine praktische Benutzeroberfläche zum Abrufen von API-Schlüsseln für Ihre Google Cloud-Projekte zur Verfügung. Hier finden Sie eine detaillierte Anleitung.
Kopieren Sie den API-Schlüssel, sobald er erstellt wurde, und bewahren Sie ihn sicher auf.
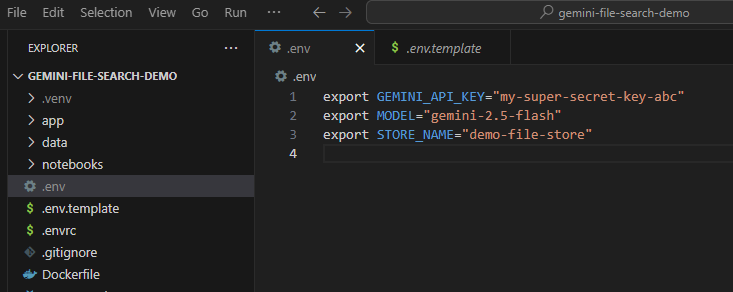
Sie müssen diesen API-Schlüssel nun als Umgebungsvariable festlegen. Dazu können wir eine .env-Datei verwenden. Kopieren Sie die enthaltene Datei .env.example als neue Datei mit dem Namen .env. Die Datei sollte so aussehen:
export GEMINI_API_KEY="your-api-key" export MODEL="gemini-2.5-flash" export STORE_NAME="demo-file-store"
Ersetzen Sie your-api-key durch Ihren tatsächlichen API-Schlüssel. Das sollte jetzt so aussehen:
Prüfen Sie, ob die Umgebungsvariablen geladen wurden. Führen Sie dazu folgenden Befehl aus:
source .env
4. Der Basis-Agent
Zuerst müssen wir eine Baseline festlegen. Wir verwenden das google-genai SDK, um einen einfachen Agenten auszuführen.
Der Code
app/sdk_agent.py Es handelt sich um eine minimale Implementierung, die:
- Instanziiert ein
genai.Client. - Aktiviert das
google_search-Tool. - Das war's. Kein RAG.
Sehen Sie sich den Code an und vergewissern Sie sich, dass Sie seine Funktion verstehen.
Running It
# With make make sdk-agent # Without make uv run python app/sdk_agent.py
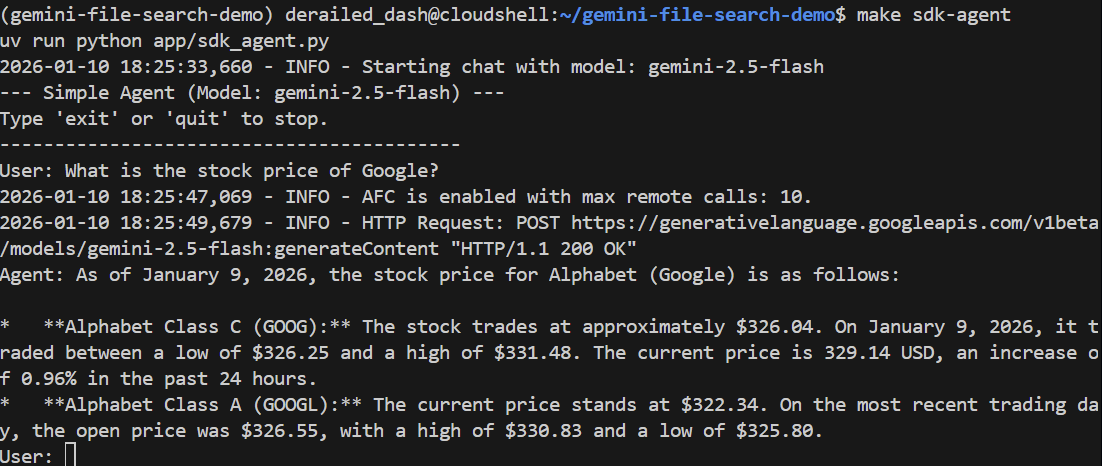
Stellen wir ihm eine allgemeine Frage:
> What is the stock price of Google?
Es sollte mithilfe der Google Suche den aktuellen Preis ermitteln und korrekt antworten:
Stellen wir nun eine Frage, die es nicht beantworten kann. Dazu muss der KI-Agent unsere Geschichte gelesen haben.
> Who pilots the 'Too Many Pies' ship?
Es sollte fehlschlagen oder sogar halluzinieren. Sehen wir uns das an:
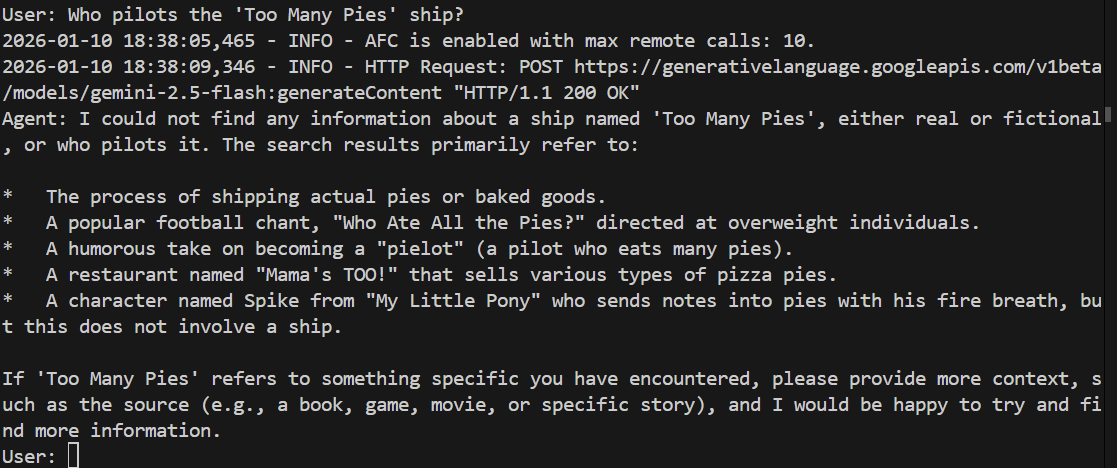
Und tatsächlich kann das Modell die Frage nicht beantworten. Es hat keine Ahnung, wovon wir reden!
Geben Sie jetzt quit ein, um den KI-Agenten zu beenden.
5. Gemini File Search: Erläuterungen
Gemini File Search ist im Grunde eine Kombination aus zwei Dingen:
- Vollständig verwaltetes RAG-System: Sie stellen eine Reihe von Dateien bereit und Gemini File Search übernimmt das Chunking, Einbetten, Speichern und Vektorindexieren für Sie.
- Ein „Tool“ im agentischen Sinne: Sie können einfach das Gemini File Search Tool als Tool in Ihrer Agentendefinition hinzufügen und das Tool auf einen File Search Store verweisen.
Wichtig ist jedoch, dass sie in die Gemini API selbst integriert ist. Sie müssen also keine zusätzlichen APIs aktivieren oder separate Produkte bereitstellen, um sie zu verwenden. Es ist also wirklich out-of-the-box.
Gemini-Funktionen für die Dateisuche
Hier sehen Sie einige der Funktionen:
- Die Details zum Aufteilen in Chunks, zum Einbetten, Speichern und Indexieren werden für Sie als Entwickler abstrahiert. Das bedeutet, dass Sie das Einbettungsmodell (Gemini Embeddings) oder den Speicherort der resultierenden Vektoren nicht kennen müssen. Sie müssen keine Entscheidungen zur Vektordatenbank treffen.
- Es unterstützt eine Vielzahl von Dokumenttypen. Dazu gehören unter anderem: PDF, DOCX, Excel, SQL, JSON, Jupyter-Notebooks, HTML, Markdown, CSV und sogar ZIP-Dateien. Eine vollständige Liste finden Sie hier. Wenn Sie Ihren Agenten beispielsweise mit PDF-Dateien mit Text, Bildern und Tabellen abstützen möchten, müssen Sie diese PDF-Dateien nicht vorab verarbeiten. Laden Sie einfach die Roh-PDFs hoch und lassen Sie Gemini den Rest erledigen.
- Wir können jeder hochgeladenen Datei benutzerdefinierte Metadaten hinzufügen. Das kann sehr nützlich sein, um später zu filtern, welche Dateien das Tool zur Laufzeit verwenden soll.
Wo werden die Daten gespeichert?
Sie laden einige Dateien hoch. Das Gemini File Search Tool hat diese Dateien verwendet, die Chunks und dann die Einbettungen erstellt und sie irgendwo gespeichert. Aber wo?
Die Antwort: ein File Search Store. Dies ist ein vollständig verwalteter Container für Ihre Einbettungen. Sie müssen nicht wissen (oder sich darum kümmern), wie das im Hintergrund funktioniert. Sie müssen nur einen Ordner programmatisch erstellen und dann Ihre Dateien hochladen.
Es ist günstig!
Das Speichern und Abfragen Ihrer Einbettungen ist kostenlos. Sie können Embeddings also so lange speichern, wie Sie möchten, und zahlen nicht für diesen Speicherplatz.
Tatsächlich zahlen Sie nur für die Erstellung der Einbettungen beim Hochladen/Indexieren. Zum Zeitpunkt der Erstellung dieses Artikels kostet das 0, 15 $pro 1 Million Tokens. Das ist ziemlich günstig.
6. Wie verwenden wir die Gemini-Dateisuche?
Es gibt zwei Phasen:
- Erstellen und speichern Sie die Einbettungen in einem File Search Store.
- Fragen Sie den File Search Store über Ihren KI‑Agenten ab.
Phase 1: Jupyter-Notebook zum Erstellen und Verwalten eines Gemini File Search-Speichers
Diese Phase wird anfangs und dann immer dann durchlaufen, wenn Sie den Store aktualisieren möchten. Das kann beispielsweise der Fall sein, wenn Sie neue Dokumente hinzufügen möchten oder sich die Quelldokumente geändert haben.
Diese Phase muss nicht in Ihre bereitgestellte agentenbasierte Anwendung aufgenommen werden. Ja, das ist möglich. Das ist z. B. nützlich, wenn Sie eine Benutzeroberfläche für Administratoren Ihrer agentenbasierten Anwendung erstellen möchten. Oft reicht es aber vollkommen aus, wenn Sie ein bisschen Code haben, den Sie bei Bedarf ausführen. Eine gute Möglichkeit, diesen Code bei Bedarf auszuführen, ist Ein Jupyter-Notebook!
Wie ein einziger Tag
Öffnen Sie die Datei notebooks/file_search_store.ipynb in einem Editor. Wenn Sie aufgefordert werden, Jupyter VS Code-Erweiterungen zu installieren, tun Sie das bitte.
Wenn wir sie im Cloud Shell-Editor öffnen, sieht sie so aus:
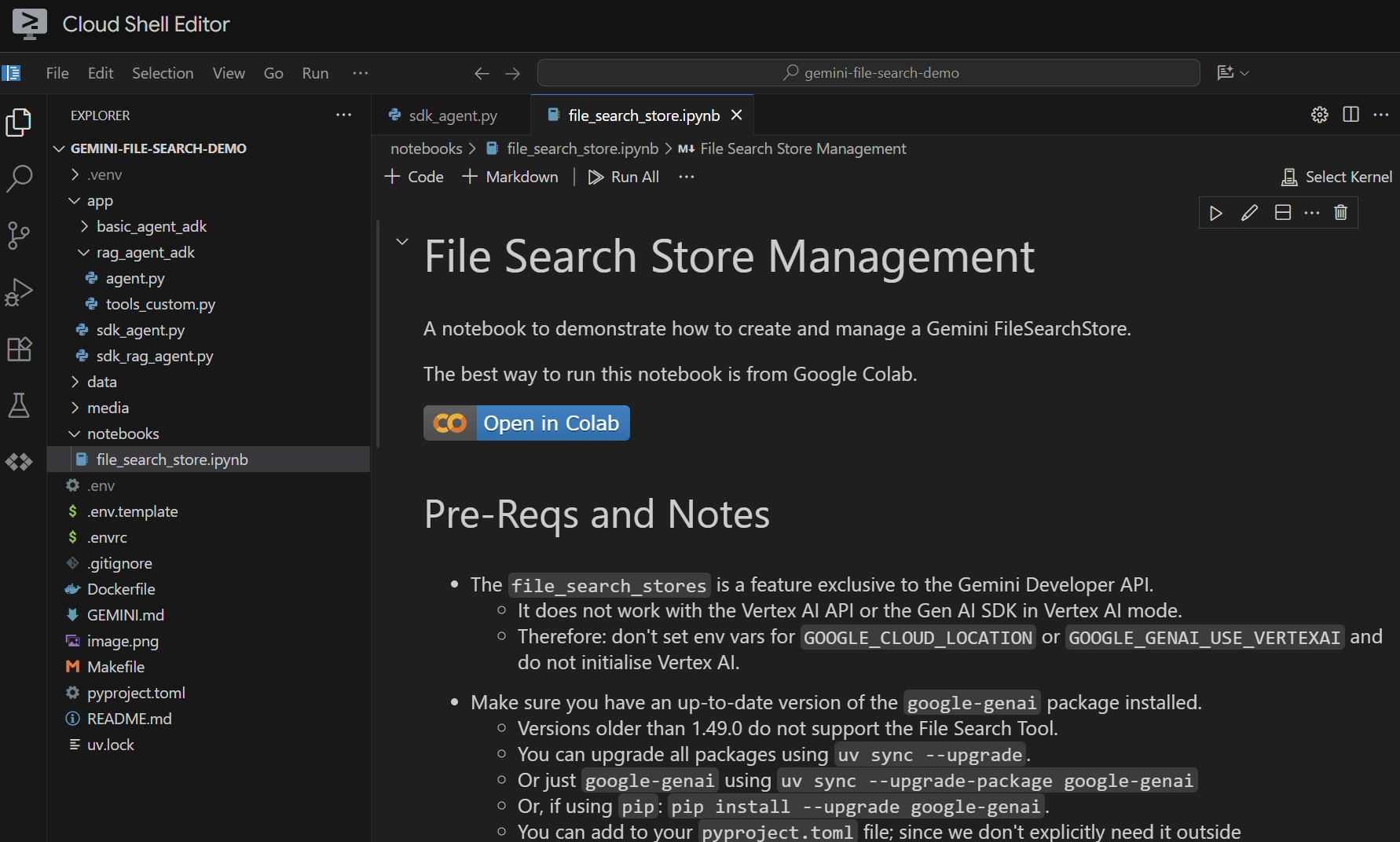
Führen wir ihn Zelle für Zelle aus. Führen Sie zuerst die Setup-Zelle mit den erforderlichen Importen aus. Wenn Sie noch kein Notebook ausgeführt haben, werden Sie aufgefordert, die erforderlichen Erweiterungen zu installieren. Tun Sie das. Anschließend werden Sie aufgefordert, einen Kernel auszuwählen. Wählen Sie „Python environments...“ und dann die lokale .venv aus, die wir beim Ausführen von make install installiert haben:
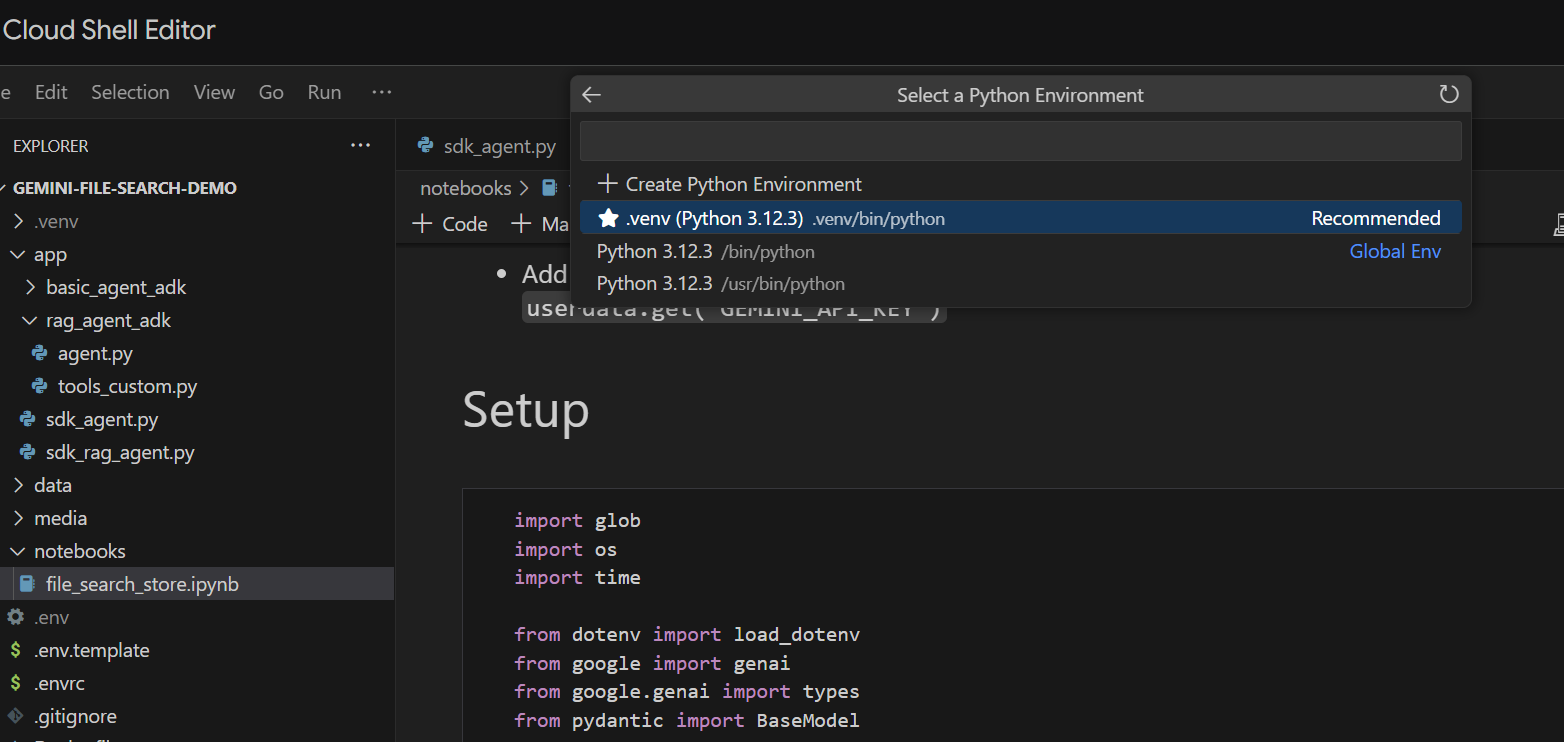
Dann:
- Führen Sie die Zelle Nur lokal aus, um die Umgebungsvariablen abzurufen.
- Führen Sie die Zelle Client Initialisation aus, um den Gemini Gen AI-Client zu initialisieren.
- Führen Sie die Zelle Store abrufen mit der Hilfsfunktion zum Abrufen des Gemini File Search-Stores nach Namen aus.
Jetzt können wir den Shop erstellen.
- Führen Sie die Zelle „Create the Store (One Time)“ aus, um den Store zu erstellen. Das ist nur einmal erforderlich. Wenn der Code erfolgreich ausgeführt wird, sollte die Meldung
"Created store: fileSearchStores/<someid>"angezeigt werden. - Führen Sie die Zelle View the Store aus, um sich den Inhalt anzusehen. An diesem Punkt sollte angezeigt werden, dass sie 0 Dokumente enthält.
Sehr gut! Wir haben jetzt einen Gemini File Search-Speicher, der einsatzbereit ist.
Daten hochladen
Wir möchten data/story.md im Store hochladen. Gehen Sie dazu so vor:
- Führen Sie die Zelle aus, in der der Uploadpfad festgelegt wird. Dies verweist auf unseren Ordner
data/. - Führen Sie die nächste Zelle aus, um Hilfsfunktionen zum Hochladen von Dateien in den Store zu erstellen. Beachten Sie, dass im Code in dieser Zelle auch Gemini verwendet wird, um Metadaten aus jeder hochgeladenen Datei zu extrahieren. Wir nehmen diese extrahierten Werte und speichern sie als benutzerdefinierte Metadaten im Store. (Das ist nicht erforderlich, aber sinnvoll.)
- Führen Sie die Zelle aus, um die Datei hochzuladen. Wenn wir zuvor eine Datei mit demselben Namen hochgeladen haben, wird die vorhandene Version zuerst gelöscht, bevor die neue Version hochgeladen wird. Sie sollten eine Meldung sehen, dass die Datei hochgeladen wurde.
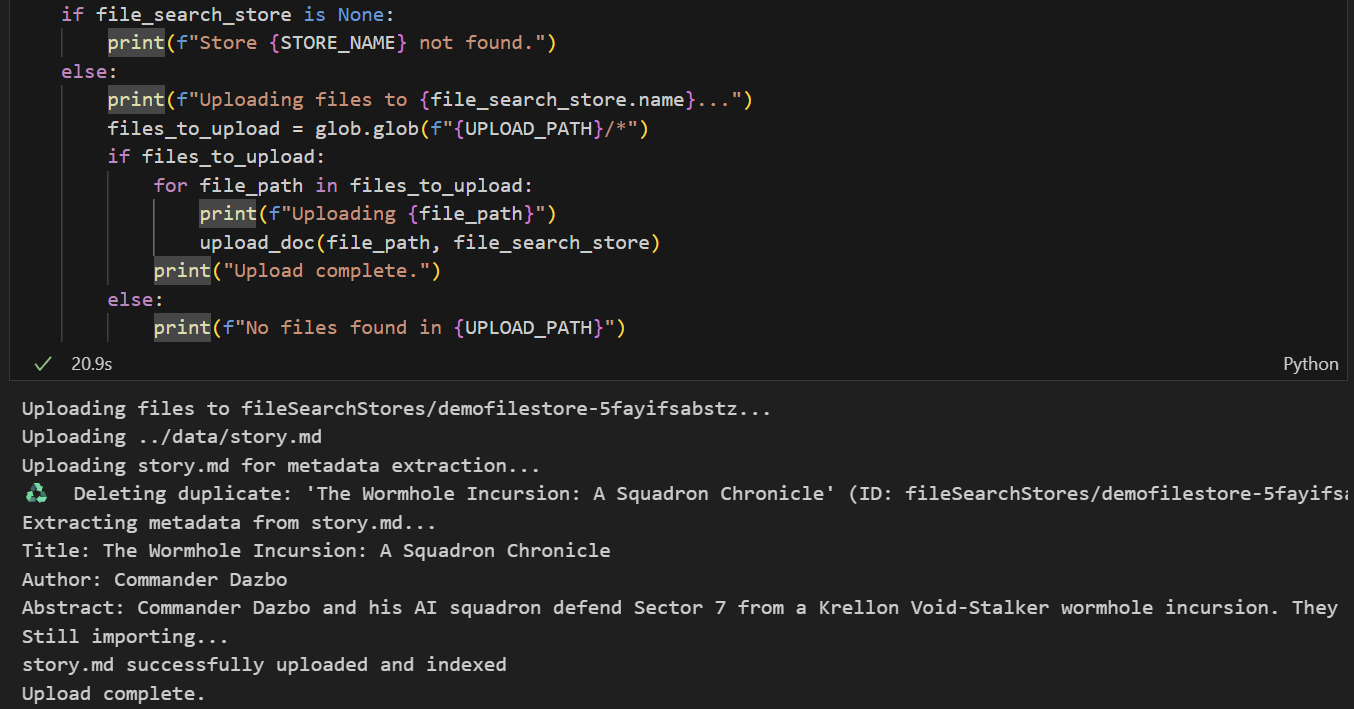
Phase 2: Gemini File Search RAG in unseren Agenten implementieren
Wir haben einen Gemini File Search Store erstellt und unsere Geschichte darin hochgeladen. Jetzt ist es an der Zeit, den File Search Store in unserem Agenten zu verwenden. Erstellen wir einen neuen Agent, der den File Search Store anstelle der Google Suche verwendet. app/sdk_rag_agent.py
Zuerst haben wir eine Funktion zum Abrufen unseres Geschäfts implementiert, indem wir einen Geschäftsnamen übergeben:
def get_store(client: genai.Client, store_name: str) -> types.FileSearchStore | None:
"""Retrieve a store by display name"""
try:
for a_store in client.file_search_stores.list():
if a_store.display_name == store_name:
return a_store
except Exception as e:
logger.error(f"Error listing stores: {e}")
return None
Sobald wir unseren Store haben, können wir ihn ganz einfach als Tool an unseren Agenten anhängen:
file_search_tool = types.Tool(file_search=types.FileSearch(file_search_store_names=[store.name]))
RAG-Agent ausführen
So starten wir es:
make sdk-rag-agent # Or, without make: uv run python app/sdk_rag_agent.py
Stellen wir die Frage, die der vorherige Kundenservicemitarbeiter nicht beantworten konnte:
> Who pilots the 'Too Many Pies' ship?
Und die Reaktion?
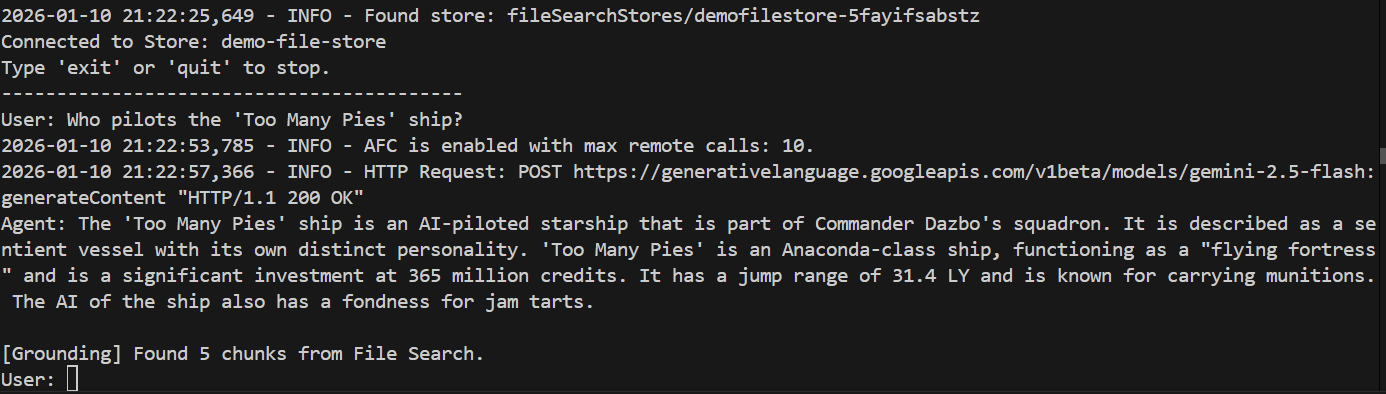
Fertig! Aus der Antwort geht Folgendes hervor:
- Unser Dateispeicher wurde verwendet, um die Frage zu beantworten.
- Es wurden 5 relevante Abschnitte gefunden.
- Die Antwort ist genau richtig.
Geben Sie quit ein, um den KI-Agenten zu schließen.
7. Umstellung unserer Agenten auf ADK
Das Agent Development Kit (ADK) von Google ist ein modulares Open-Source-Framework und SDK für Entwickler zum Erstellen von Agenten und Agentensystemen. So können wir Multi-Agent-Systeme ganz einfach erstellen und orchestrieren. Das ADK ist zwar für Gemini und das Google-Ökosystem optimiert, ist aber modell- und bereitstellungsunabhängig und für die Kompatibilität mit anderen Frameworks konzipiert. Wenn Sie das ADK noch nicht verwendet haben, finden Sie weitere Informationen in der ADK-Dokumentation.
Der Basic ADK Agent mit Google Suche
app/basic_agent_adk/agent.py In diesem Beispielcode sehen Sie, dass wir zwei Agenten implementiert haben:
- Ein
root_agent, das die Interaktion mit dem Nutzer übernimmt und in dem wir die Hauptsystemanweisung angegeben haben. - Ein separates
SearchAgent, dasgoogle.adk.tools.google_searchals Tool verwendet.
Das root_agent verwendet das SearchAgent als Tool, das mit dieser Zeile implementiert wird:
tools=[AgentTool(agent=search_agent)],
Der Systemprompt des Stamm-Agents sieht so aus:
You are a helpful AI assistant designed to provide accurate and useful information.
If you don't know the answer, use the SearchAgent to perform a Google search.
Do not attempt to search more than ONCE.
If the search yields no relevant results or returns unrelated content, you MUST immediately respond with: "I could not find any information about that."
Do NOT retry the search with different terms. Do NOT ask for clarification. FAIL FAST.
Agent ausprobieren
Das ADK bietet eine Reihe von sofort einsatzbereiten Schnittstellen, mit denen Entwickler ihre ADK-Agents testen können. Eine dieser Schnittstellen ist die Web-UI. So können wir unsere Agents in einem Browser testen, ohne eine Zeile Code für die Benutzeroberfläche schreiben zu müssen.
Wir können diese Schnittstelle mit folgendem Befehl starten:
make adk-playground # Or, without make: uv run adk web app --port 8501 --reload_agents
Mit dem Befehl wird das adk web-Tool auf den Ordner app verwiesen, in dem automatisch alle ADK-Agents erkannt werden, die eine root_agent implementieren. Probieren wir es aus:
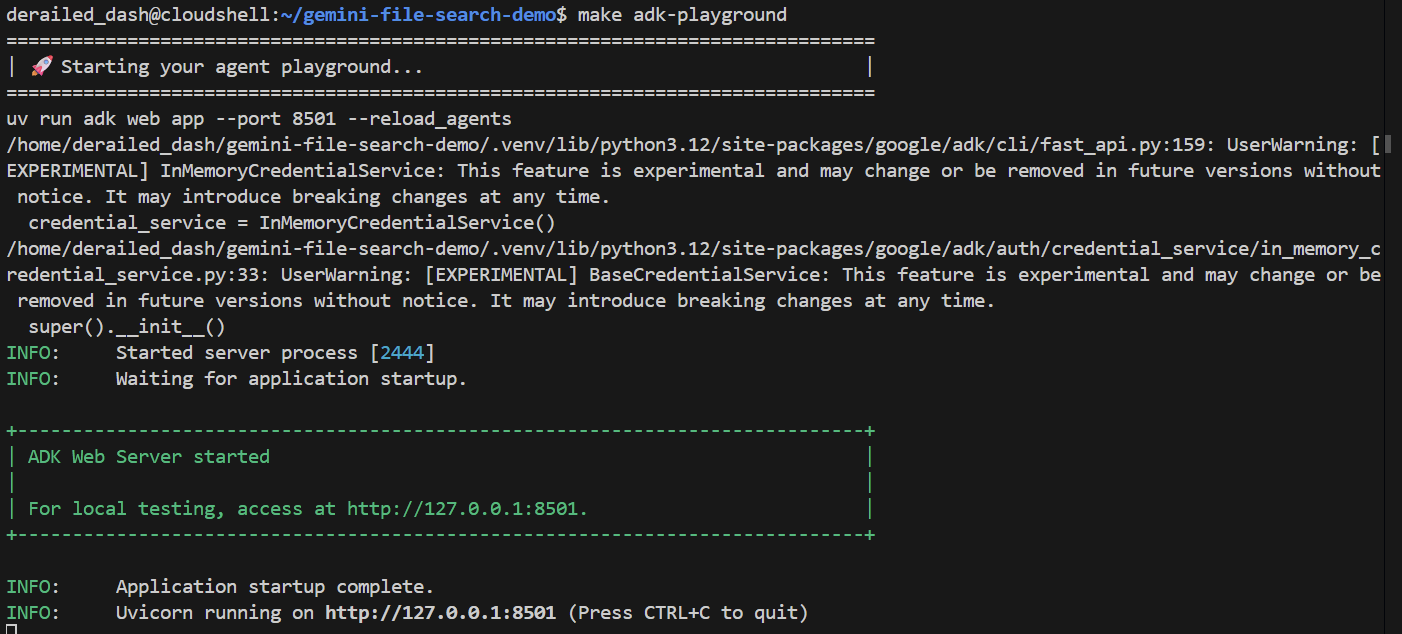
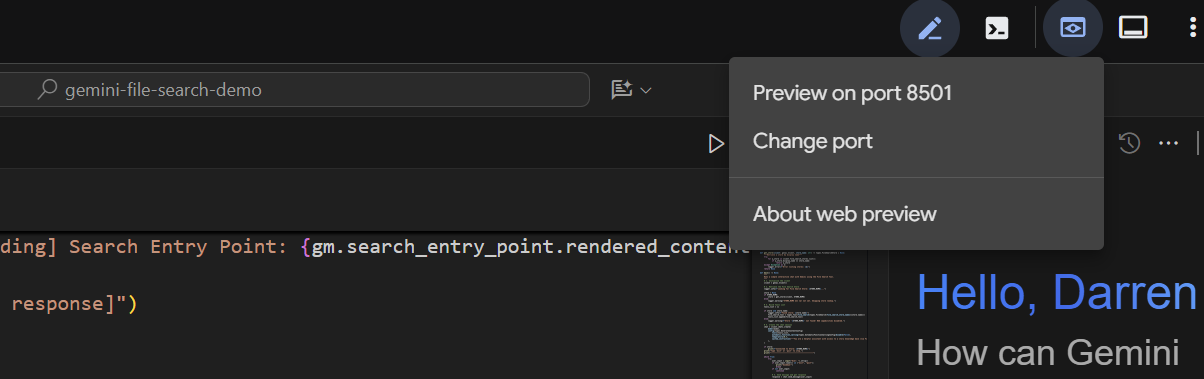
Nach einigen Sekunden ist die Anwendung bereit. Wenn Sie den Code lokal ausführen, rufen Sie einfach http://127.0.0.1:8501 in Ihrem Browser auf. Wenn Sie den Cloud Shell Editor verwenden, klicken Sie auf Webvorschau und ändern Sie den Port in 8501:
Wenn die Benutzeroberfläche angezeigt wird, wählen Sie basic_agent_adk aus dem Drop-down-Menü aus. Anschließend können Sie Fragen stellen:
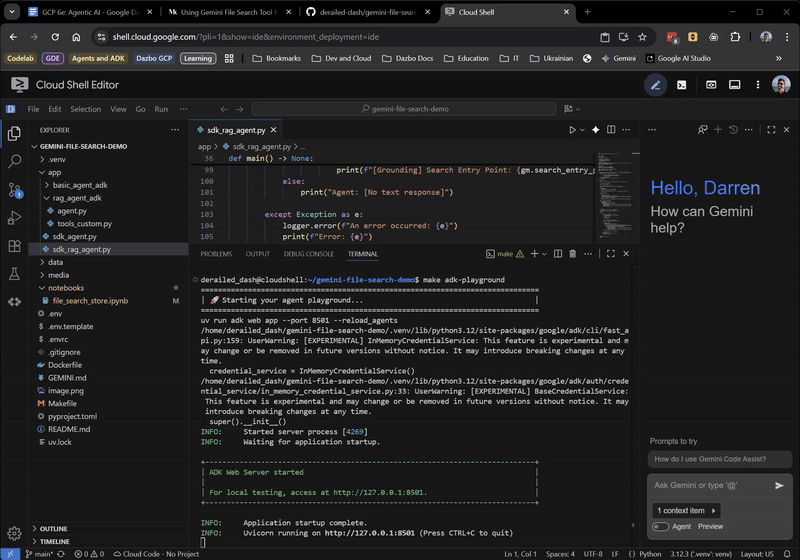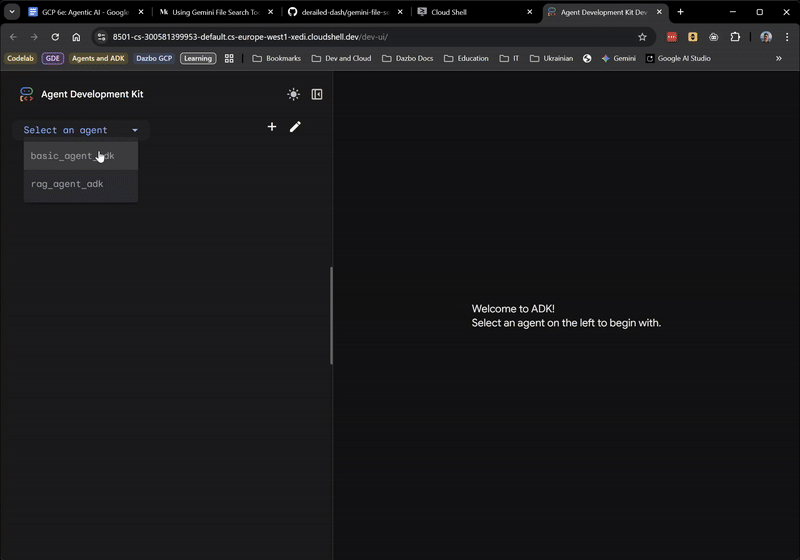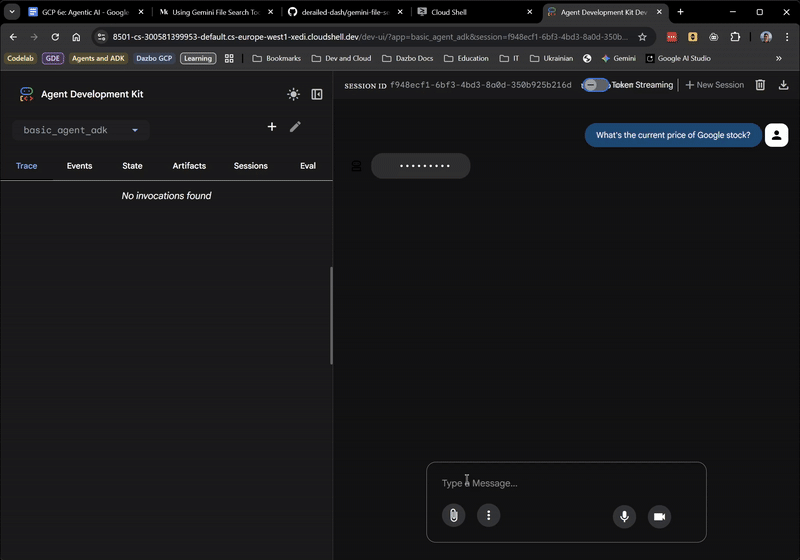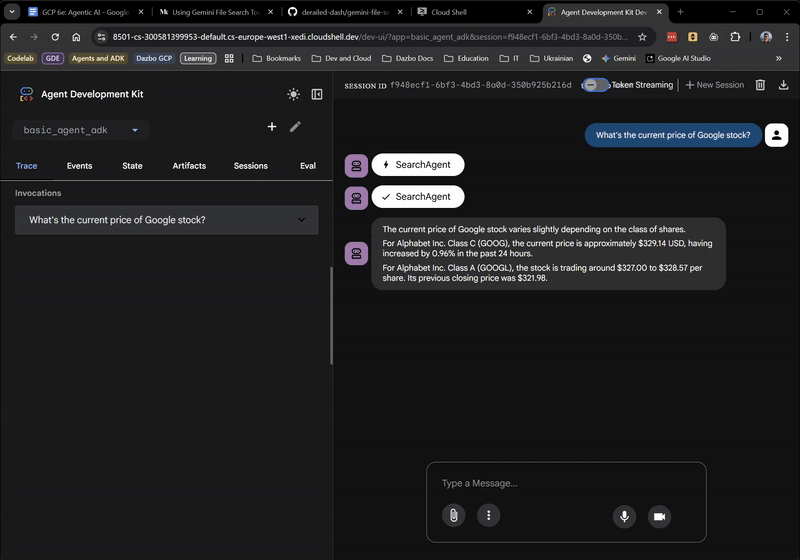
So weit, so gut! In der Web-UI wird sogar angezeigt, wenn der Stamm-KI‑Agent an SearchAgent delegiert. Das ist eine sehr nützliche Funktion.
Stellen wir nun unsere Frage, für die Wissen über unsere Geschichte erforderlich ist:
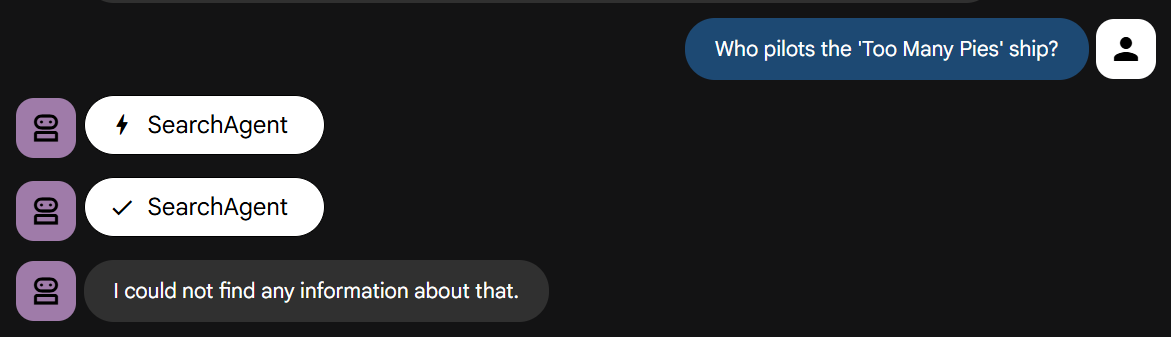
Sie können es selbst ausprobieren. Sie sollten feststellen, dass der Test wie vorgesehen schnell fehlschlägt.
File Search Store in den ADK-Agenten einbinden
Jetzt fassen wir alles zusammen. Wir werden einen ADK-Agenten ausführen, der sowohl den File Search Store als auch die Google Suche verwenden kann. Sehen Sie sich den Code in app/rag_agent_adk/agent.py an.
Der Code ähnelt dem vorherigen Beispiel, weist aber einige wichtige Unterschiede auf:
- Wir haben einen Stamm-KI-Agenten, der zwei Spezial-KI-Agenten orchestriert:
- RagAgent: Der maßgeschneiderte Wissensexperte – mit unserem Gemini File Search Store
- SearchAgent: Der Experte für Allgemeinwissen – nutzt die Google Suche
- Da das ADK noch keinen integrierten Wrapper für
FileSearchhat, verwenden wir eine benutzerdefinierte Wrapper-KlasseFileSearchTool, um das Tool „FileSearch“ zu umschließen. Dadurch wird diefile_search_store_names-Konfiguration in die Low-Level-Modellanfrage eingefügt. Dies wurde im separaten Skriptapp/rag_agent_adk/tools_custom.pyimplementiert.
Außerdem gibt es einen Haken, den Sie beachten sollten. Zum Zeitpunkt der Erstellung dieses Dokuments können Sie das native GoogleSearch-Tool und das FileSearch-Tool nicht in derselben Anfrage an denselben Agenten verwenden. Wenn Sie es versuchen, erhalten Sie eine Fehlermeldung wie diese:
FEHLER: Es ist ein Fehler aufgetreten: 400 INVALID_ARGUMENT. {‘error': {‘code': 400, ‘message': ‘Search as a tool and file search tool are not supported together', ‘status': ‘INVALID_ARGUMENT'}}
Fehler: 400 INVALID_ARGUMENT. {‘error': {‘code': 400, ‘message': ‘Search as a tool and file search tool are not supported together', ‘status': ‘INVALID_ARGUMENT'}}
Die Lösung besteht darin, die beiden spezialisierten Agenten als separate Sub-Agents zu implementieren und sie mithilfe des Agent-as-a-Tool-Musters an den Root-Agent zu übergeben. Die Systemanweisung des Stamm-Agents enthält eine sehr klare Anleitung, zuerst RagAgent zu verwenden:
Du bist ein hilfreicher KI-Assistent, der genaue und nützliche Informationen bereitstellt.
Sie haben Zugriff auf zwei Kundenservicemitarbeiter:
- RagAgent: Für maßgeschneiderte Informationen aus der internen Wissensdatenbank.
- SearchAgent: Für allgemeine Informationen aus der Google Suche.
Versuchen Sie es immer zuerst mit dem RagAgent. Wenn dies keine nützliche Antwort liefert, versuchen Sie es mit dem SearchAgent.
Abschlusstest
Führen Sie die ADK-Web-UI wie zuvor aus:
make adk-playground # Or, without make: uv run adk web app --port 8501 --reload_agents
Wählen Sie dieses Mal rag_agent_adk in der Benutzeroberfläche aus. Hier ein Beispiel: 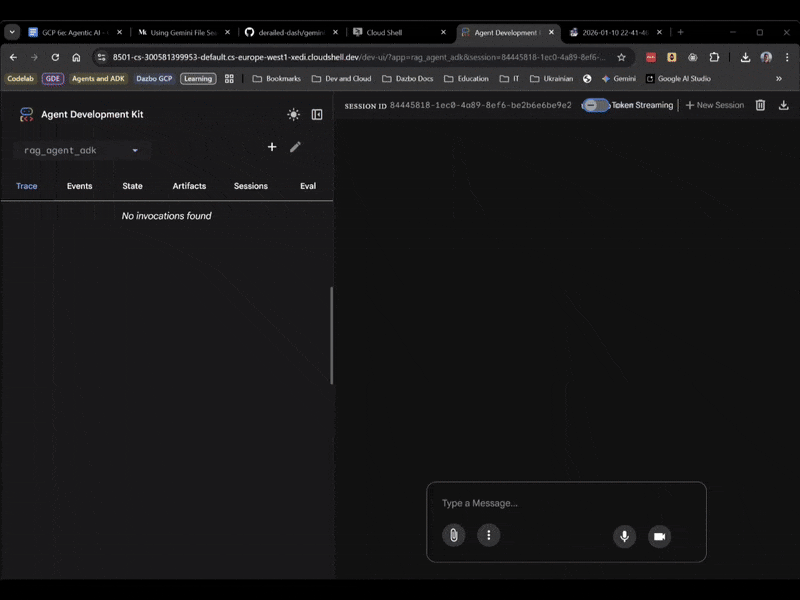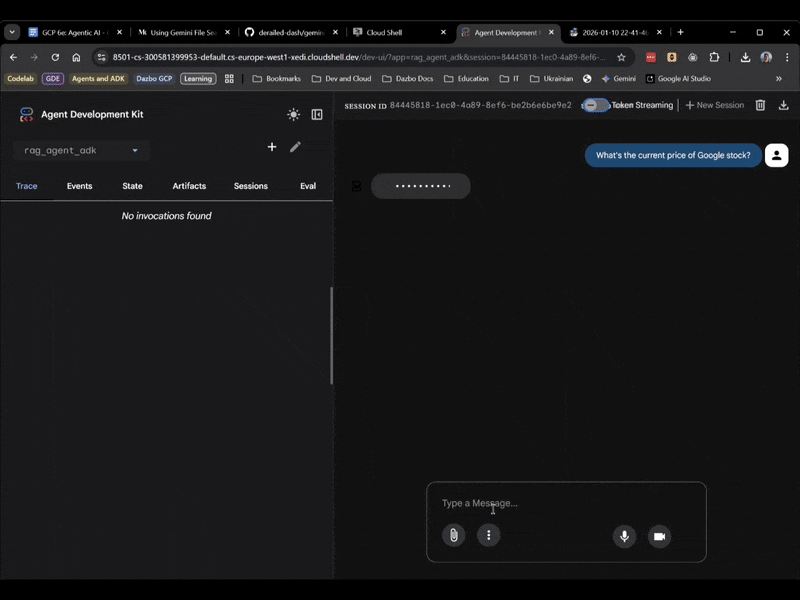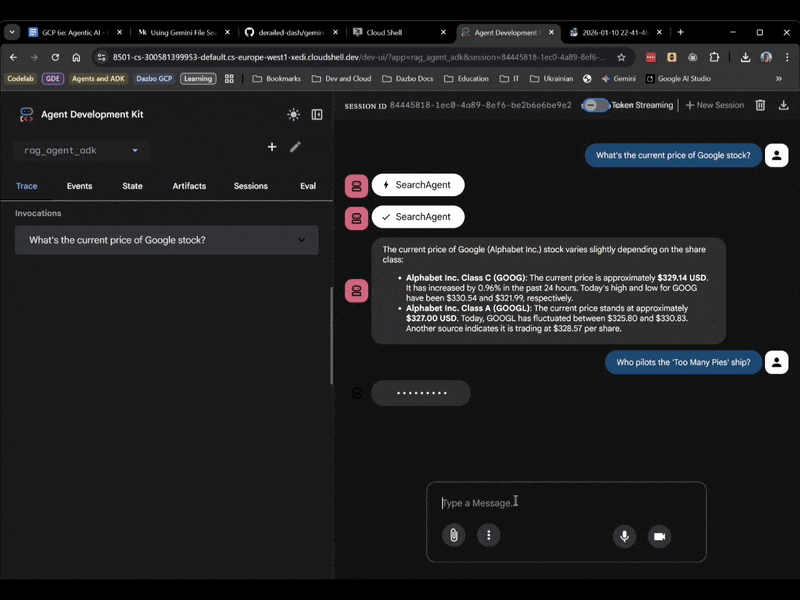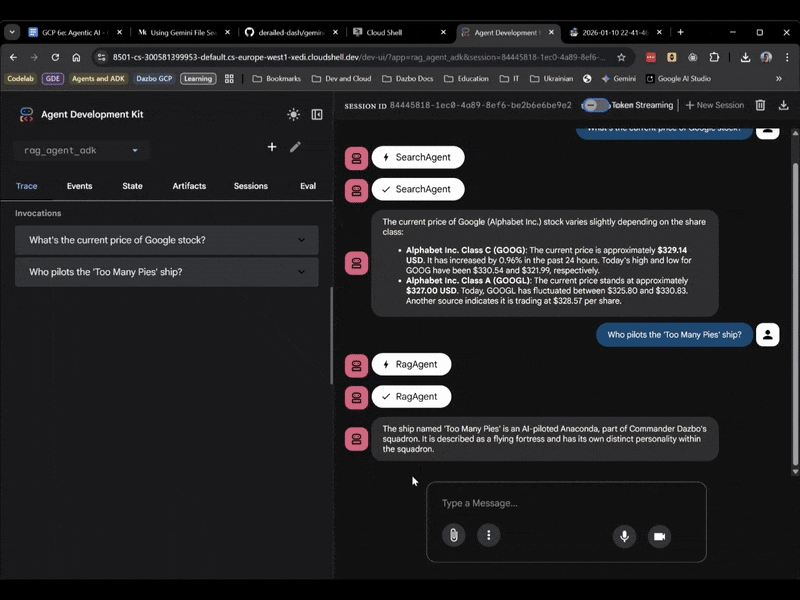
Wir sehen, dass der richtige untergeordnete Agent basierend auf der Frage ausgewählt wird.
8. Fazit
Sie haben dieses Codelab abgeschlossen.
Sie haben ein einfaches Skript in ein RAG-fähiges Multi-Agenten-System umgewandelt – ohne eine einzige Zeile Einbettungscode und ohne eine Vektordatenbank implementieren zu müssen.
Wir haben Folgendes gelernt:
- Gemini File Search ist eine verwaltete RAG-Lösung, mit der Sie Zeit und Nerven sparen.
- Das ADK bietet uns die Struktur, die wir für komplexe Multi-Agenten-Apps benötigen, und bietet Entwicklern Komfort durch Schnittstellen wie die Web-UI.
- Das "Agent-as-a-Tool" löst Probleme mit der Tool-Kompatibilität.
Wir hoffen, dass dieses Lab für Sie hilfreich war. Bis zum nächsten Mal!