
1. Introduction
This codelab shows you how to use Gemini File Search to enable RAG in your Agentic Application. You'll use the Gemini File Search to ingest and index your documents without having to worry about the details of chunking, embedding or vector database.
What You'll Learn
- The basics of RAG and why we need it.
- What Gemini File Search is and its advantages.
- How to create a File Search Store.
- How to upload your own bespoke files to the File Search Store.
- How to use the Gemini File Search Tool for RAG.
- The benefits of using the Google Agent Development Kit (ADK).
- How to use the Gemini File Search Tool in an agentic solution built using the ADK.
- How to use the Gemini File Search Tool alongside Google "native" tools like Google Search.
What You'll Do
- Create a Google Cloud Project and set up your development environment.
- Create a simple Gemini-based agent using the Google Gen AI SDK (but without ADK) that has the ability to use Google search, but no RAG capability.
- Demonstrate its inability to provide accurate, high quality information for bespoke information.
- Create a Jupyter notebook (which you can run locally, or, say, on Google Colab) for creating and managing a Gemini File Search Store.
- Use the notebook to upload bespoke content to the File Search Store.
- Create an agent that has the File Search Store attached, and prove it is able to produce better responses.
- Convert our initial "basic" agent to an ADK agent, complete with Google Search tool.
- Test the agent using ADK Web UI.
- Incorporate the File Search Store into the ADK agent, using the Agent-As-A-Tool pattern to allow us to use the File Search Tool alongside the Google Search tool.
2. What is RAG and Why We Need It
So... Retrieval Augmented Generation.
If you're here, you probably know what it is, but let's do a quick recap, just in case. LLMs (like Gemini) are brilliant, but they suffer from a few issues:
- They are always out of date: They only know what they learned during training.
- They don't know everything: Sure, the models are huge, but they are not omniscient.
- They don't know your proprietary information: They have broad knowledge, but they haven't read your internal documents, your blogs, or your Jira tickets.
So when you ask a model something it doesn't know the answer to, you'll typically get an incorrect or even made-up answer. Often, the model will spew out this incorrect answer confidently. This is what we refer to as hallucination.
One solution is to just dump our proprietary information directly into our conversation context. This is fine for a small amount of information, but it rapidly becomes problematic when you have a lot of information. Specifically, it leads to these problems:
- Latency: slower and slower responses from the model.
- Signal rot, aka "lost-in-the-middle": where the model is no longer able to sort the relevant data from the junk. Much of the context gets ignored by the model.
- Cost: because tokens cost money.
- Context window exhaustion: At this point, Gemini will not action your requests.
A much more effective way to remedy this situation is to use RAG. It is simply the process of looking up relevant information from your data sources (using semantic matching) and feeding relevant chunks of this data to the model alongside your question. It grounds the model in your reality.
It works by importing external data, chopping the data into chunks, converting the data into vector embeddings, then storing and indexing those embeddings into a suitable vector database.
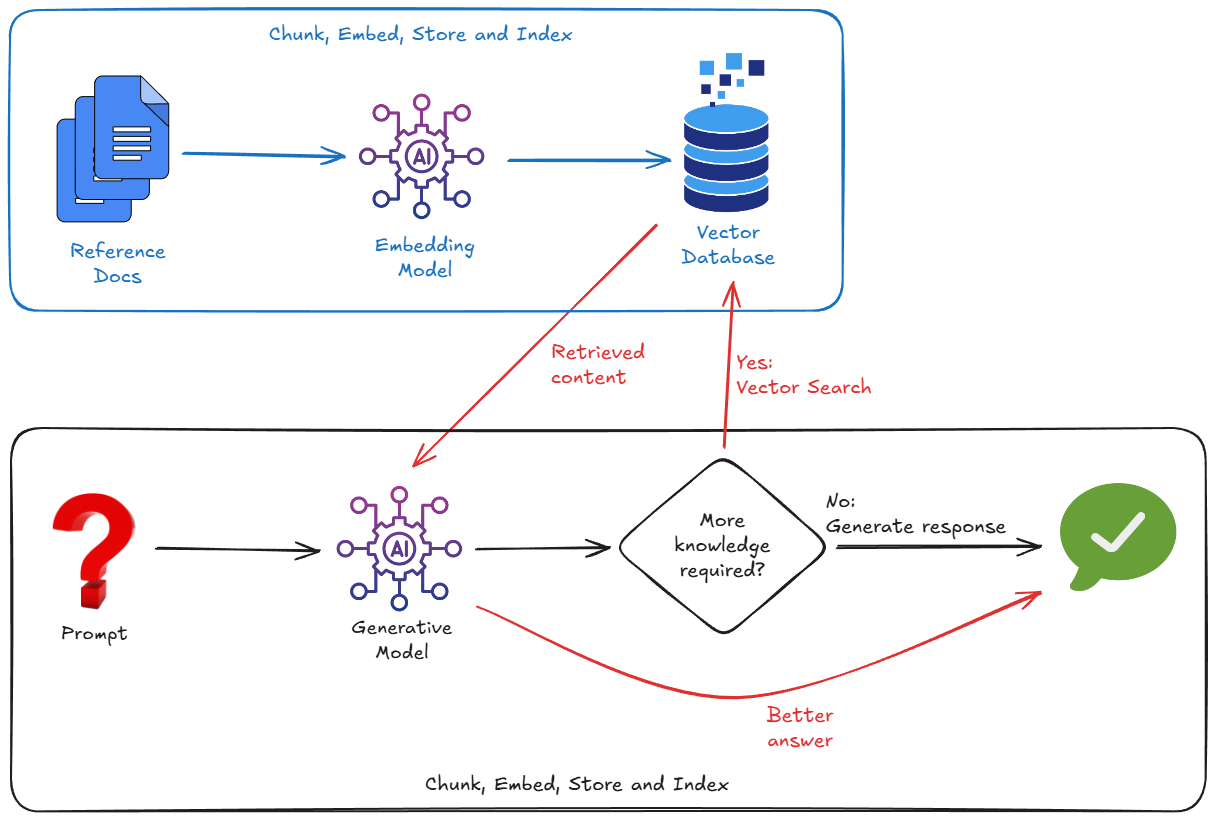
And so, to implement RAG, we typically have to worry about:
- Spinning up a Vector Database (Pinecone, Weaviate, Postgres with pgvector...).
- Writing a chunking script to slice up your documents (e.g. PDFs, markdown, whatever).
- Generating embeddings (vectors) for those chunks, using an embedding model.
- Storing the vectors in the Vector Database.
But friends don't let friends over-engineer things. What if I told you there's an easier way?
3. Prerequisites
Create a Google Cloud Project
You need a Google Cloud Project to run this codelab. You can use a project you already have, or create a new one.
Make sure billing is enabled on your project. See this guide to see how to check the billing status of your projects.
Note that completing this codelab is not expected to cost you anything. At most, a few pennies.
Go ahead and get your project ready. I'll wait.
Clone the Demo Repo
I have created a repo with guided content for this codelab. You're going to need it!
Run the following commands from your terminal, or from the terminal integrated into the Google Cloud Shell Editor. Cloud Shell and its editor are very convenient, as all the commands you need are pre-installed and everything just runs "out-of-the-box".
git clone https://github.com/derailed-dash/gemini-file-search-demo cd gemini-file-search-demo
This tree shows the key folders and files in the repo:
gemini-file-search-demo/ ├── app/ │ ├── basic_agent_adk/ # Agent with Google Search, using ADK framework │ │ └── agent.py │ ├── rag_agent_adk/ # Agent with Google Search and File Search, using ADK framework │ │ ├── agent.py │ │ └── tools_custom.py │ ├── sdk_agent.py # Agent using GenAI SDK (no ADK) with Google Search tool │ └── sdk_rag_agent.py # Agent using GenAI SDK (no ADK) with Gemini File Search tool ├── data/ │ └── story.md # Sample story with "bespoke content" to use with Gemini File Search Store ├── notebooks/ │ └── file_search_store.ipynb # Jupyter notebook for creating and managing Gemini File Search Store │ ├── .env.template # Template for environment variables - make a copy as .env ├── Makefile # Makefile for `make` commands ├── pyproject.toml # Project configuration and dependencies └── README.md # This file
Open this folder in Cloud Shell Editor, or your preferred editor. (Have you used Antigravity yet? If not, now would be a good time to try it out.)
Note that the repo contains a sample story - "The Wormhole Incursion" - in the file data/story.md. I co-wrote it with Gemini! It's about Commander Dazbo and his squadron of sentient starships. (I drew some inspiration from the game Elite Dangerous.) This story serves as our ‘bespoke knowledge base', containing specific facts that Gemini does not know, and furthermore, that it can't search for using a Google search.
Setup Your Development Environment
For convenience I've provided a Makefile to simplify many of the commands you need to run. Instead of remembering specific commands, you can just run something like make <target>. However, make is only available in Linux / MacOS / WSL environments. If you're using Windows (without WSL), you'll need to run the full commands that the make targets contain.
# Install dependencies with make make install # If you don't have make... uv sync --extra jupyter
This is what it looks like, when you run make install in the Cloud Shell Editor:
Create a Gemini API Key
To use the Gemini Developer API (which we need in order to use the Gemini File Search Tool), you need a Gemini API key. The easiest way to get an API key is to use Google AI Studio, which provides a convenient interface to obtain API keys for your Google Cloud project(s). See this guide for the specific steps.
Once your API key is created, copy it and keep it safe.
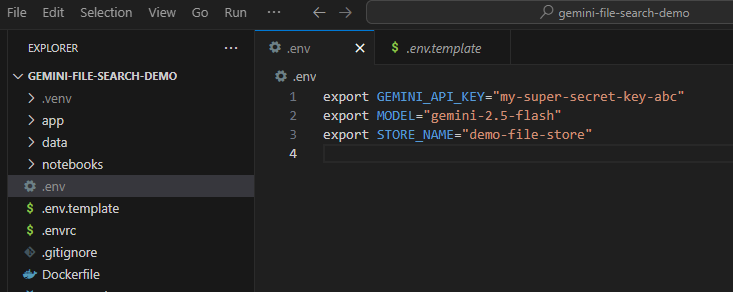
You now need to set this API key as an environment variable. We can do this using a .env file. Copy the included .env.example as a new file called .env. The file should look like this:
export GEMINI_API_KEY="your-api-key" export MODEL="gemini-2.5-flash" export STORE_NAME="demo-file-store"
Go ahead and replace your-api-key with your actual API key. Now it should look something like this:
Now make sure the environment variables are loaded. You can do this by running:
source .env
4. The Basic Agent
First, let's establish a baseline. We're going to use the raw google-genai SDK to run a simple agent.
The Code
Take a look at app/sdk_agent.py. It's a minimal implementation that:
- Instantiates a
genai.Client. - Enables the
google_searchtool. - That's it. No RAG.
Have a look through the code and make sure you understand what it does.
Running It
# With make make sdk-agent # Without make uv run python app/sdk_agent.py
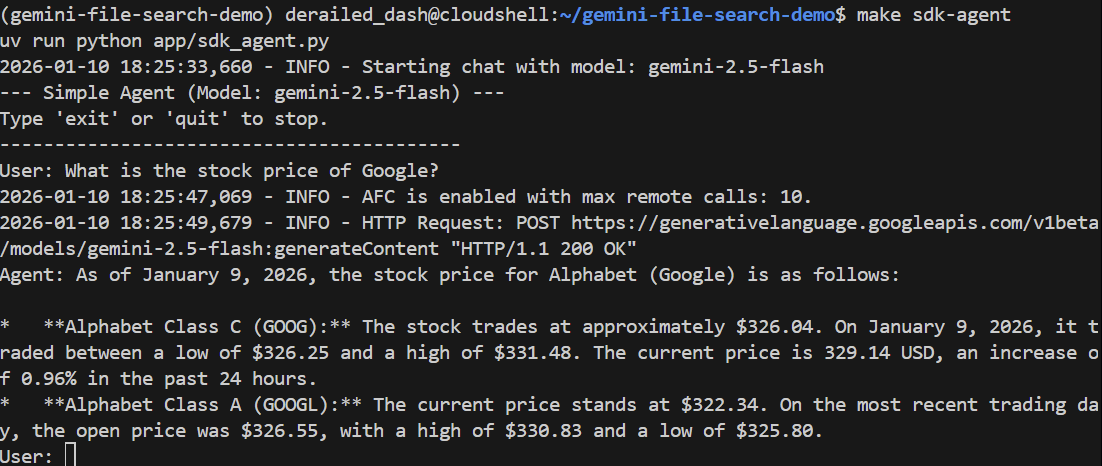
Let's ask it a general question:
> What is the stock price of Google?
It should answer correctly using Google Search to find the current price:
Now, let's ask a question it doesn't know how to answer. It requires the agent to have read our story.
> Who pilots the 'Too Many Pies' ship?
It should fail or even hallucinate. Let's see:
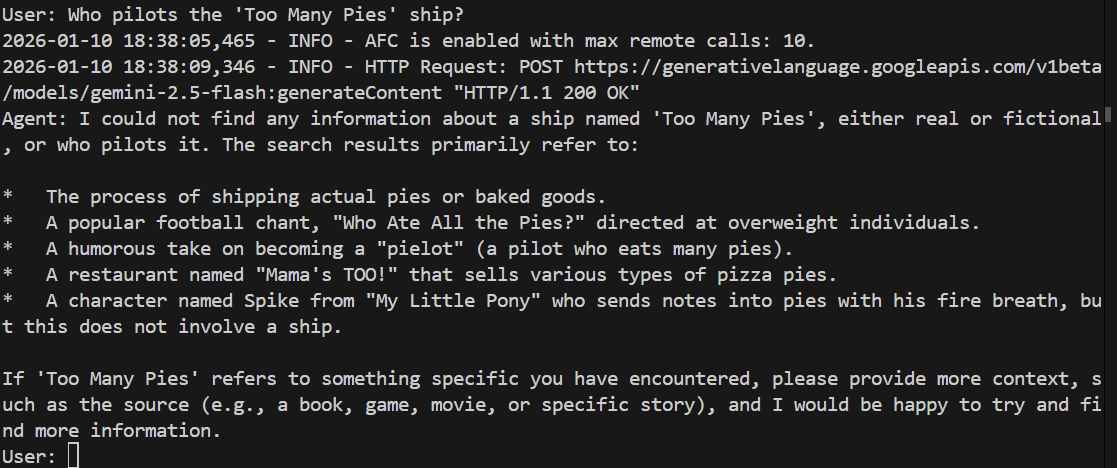
And sure enough, the model fails to answer the question. It has no idea what we're talking about!
Now type quit to exit the agent.
5. Gemini File Search: Explained
Gemini File Search is essentially a combination of two things:
- A fully-managed RAG system: you provide a bunch of files, and Gemini File Search handles the chunking, embedding, storing and vector indexing for you.
- A "tool" in the agentic sense: where you can simply add Gemini File Search Tool as a tool in your agent definition, and point the tool to a File Search Store.
But crucially: it's built into the Gemini API itself. That means you don't need to enable any additional APIs or deploy any separate products to use it. So it really is out-of-the-box.
Gemini File Search Features
Here are some of the features:
- The details of chunking, embedding, storing and indexing are abstracted from you, the developer. This means you do not need to know (or care) about the embedding model (which is Gemini Embeddings, by the way), or where the resulting vectors are stored. You do not have to make any vector database decisions.
- It supports a huge number of document types out-of-the-box. Including, but not limited to: PDF, DOCX, Excel, SQL, JSON, Jupyter notebooks, HTML, Markdown, CSV, and even zip files. You can see the full list here. So, for example, if you want to ground your agent with PDF files that contain text, pictures and tables, you don't need to do any pre-processing of these PDF files. Just upload the raw PDFs, and let Gemini handle the rest.
- We can add custom metadata to any uploaded file. This can be really useful for subsequently filtering which files we want the tool to use, at run time.
Where Does the Data Live?
You upload some files. Gemini File Search Tool has taken those files, created the chunks, then the embeddings, and put them... somewhere. But where?
The answer: a File Search Store. This is a fully-managed container for your embeddings. You don't need to know (or care) how this is done under-the-hood. All you need to do is create one (programmatically) and then upload your files to it.
It's Cheap!
The storing and querying of your embeddings is free. So you can store embeddings for as long as you like, and you don't pay for that storage!
In fact, the only thing you do pay for is the creation of the embeddings at upload/indexing time. At the time of writing, this costs $0.15 per 1 million tokens. That's pretty cheap.
6. How Do We Use Gemini File Search?
There are two phases:
- Create and store the embeddings, in a File Search Store.
- Query the File Search Store from your agent.
Phase 1 - Jupyter Notebook to Create and Manage a Gemini File Search Store
This phase is something you would do initially, and then whenever you want to update the store. For example, when you have new documents to add, or when the source documents have changed.
This phase is not something you need to package into your deployed agentic application. Sure, you could if you want to. For example, if you want to create some sort of UI for admin users of your agentic application. But it is often perfectly adequate to have a bit of code that you run on-demand. And one great way to run this code on-demand? A Jupyter notebook!
The Notebook
Open the file notebooks/file_search_store.ipynb in your editor. If you are prompted to install any Jupyter VS Code extensions, please go ahead and do that.
If we open it in the Cloud Shell Editor, it looks like this:
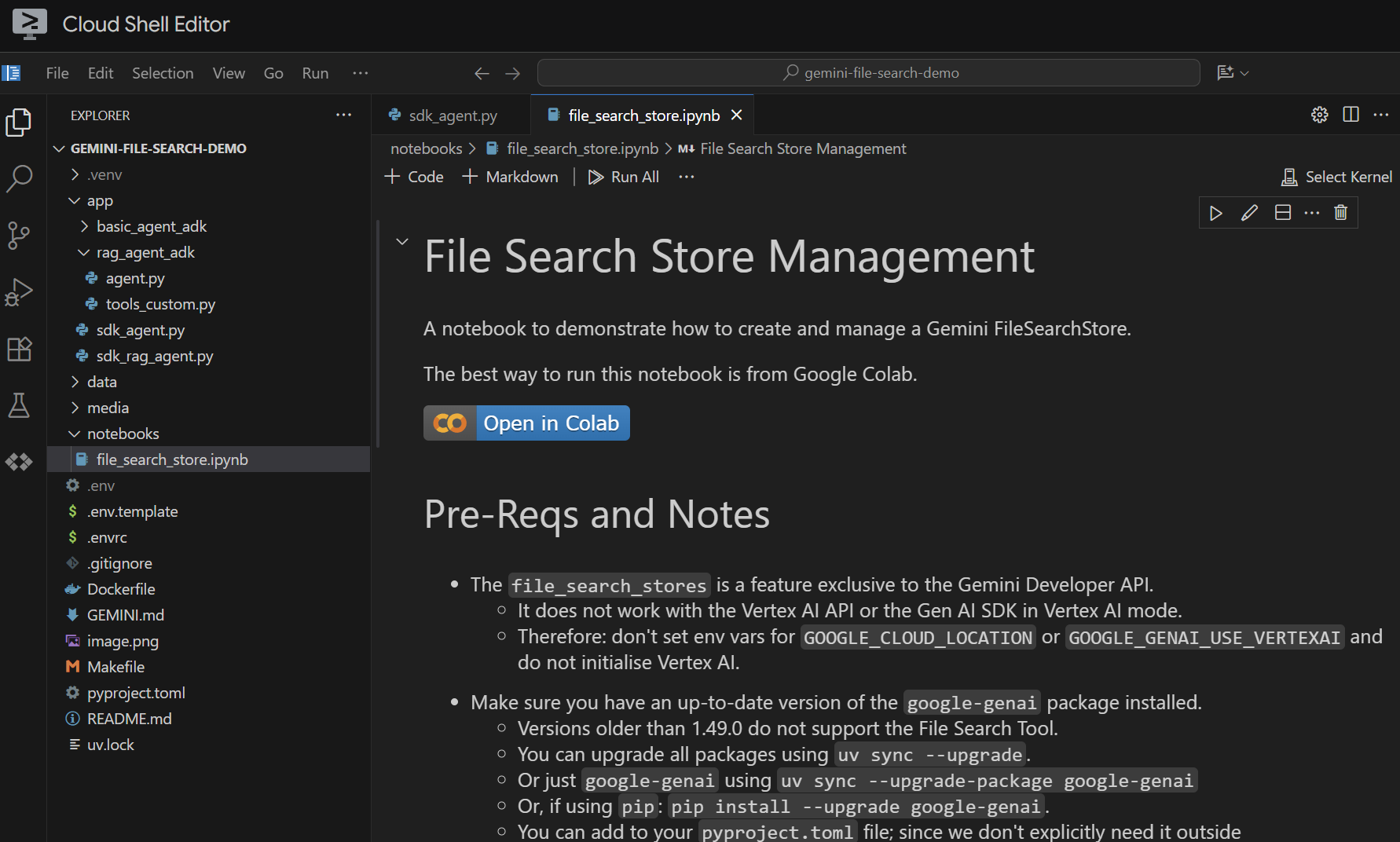
Let's run it cell by cell. Start by executing the Setup cell with the required imports. If you haven't previously run a notebook, you'll be asked to install the required extensions. Go ahead and do that. Then you'll be asked to select a kernel. Select "Python environments..." and then the local .venv that we installed when we ran make install earlier:
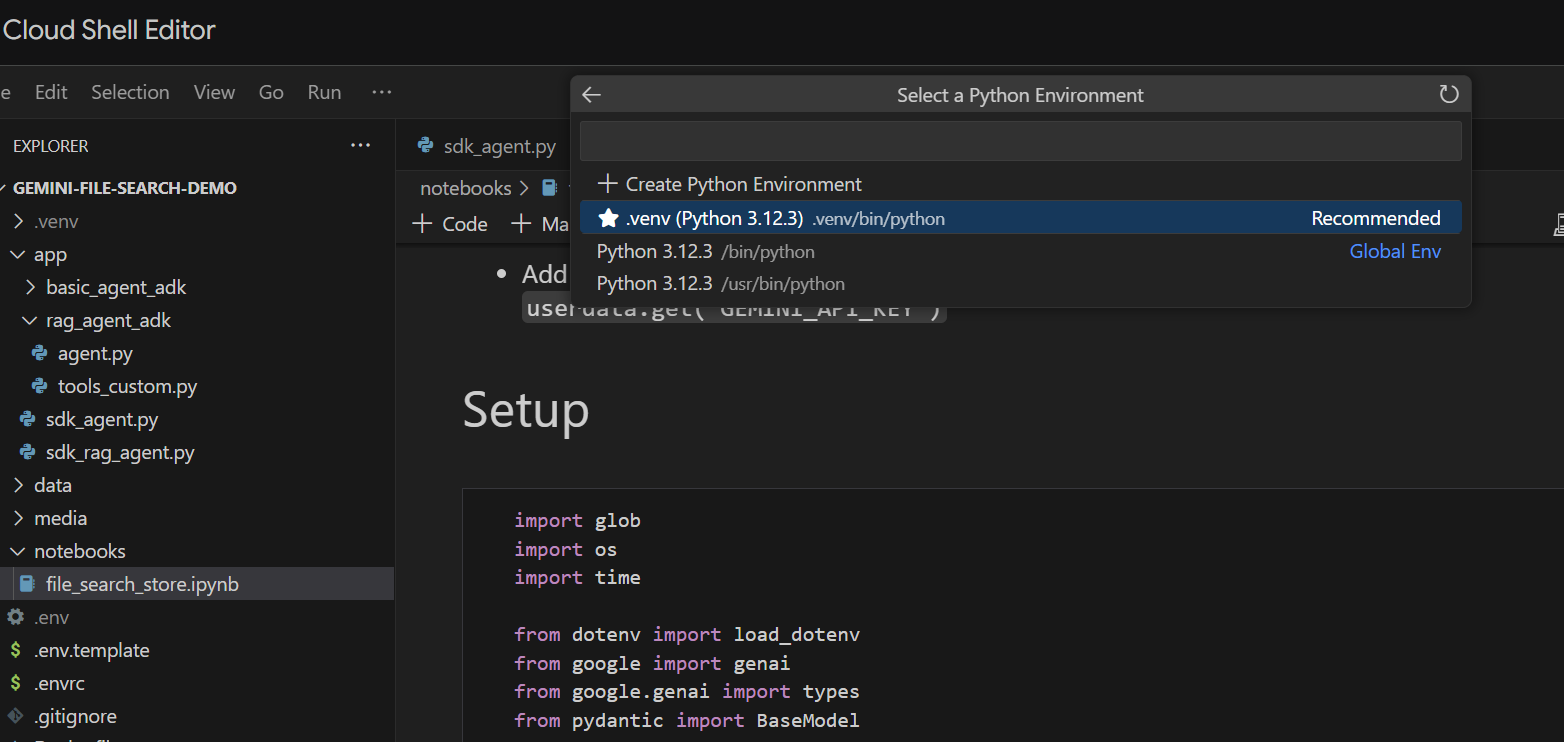
Then:
- Run the "Local Only" cell to pull in the environment variables.
- Run the "Client Initialisation" cell to initialise the Gemini Gen AI Client.
- Run the "Retrieve the Store" cell with the helper function for retrieving Gemini File Search Store by name.
Now we're ready to create the store.
- Run the "Create the Store (One Time)" cell to create the store. We only need to do this once. If the code runs successfully, you should see a message that says
"Created store: fileSearchStores/<someid>" - Run the "View the Store" cell to see what's in it. At this point, you should see that it contains 0 documents.
Great! We now have a Gemini File Search store ready to go.
Uploading the Data
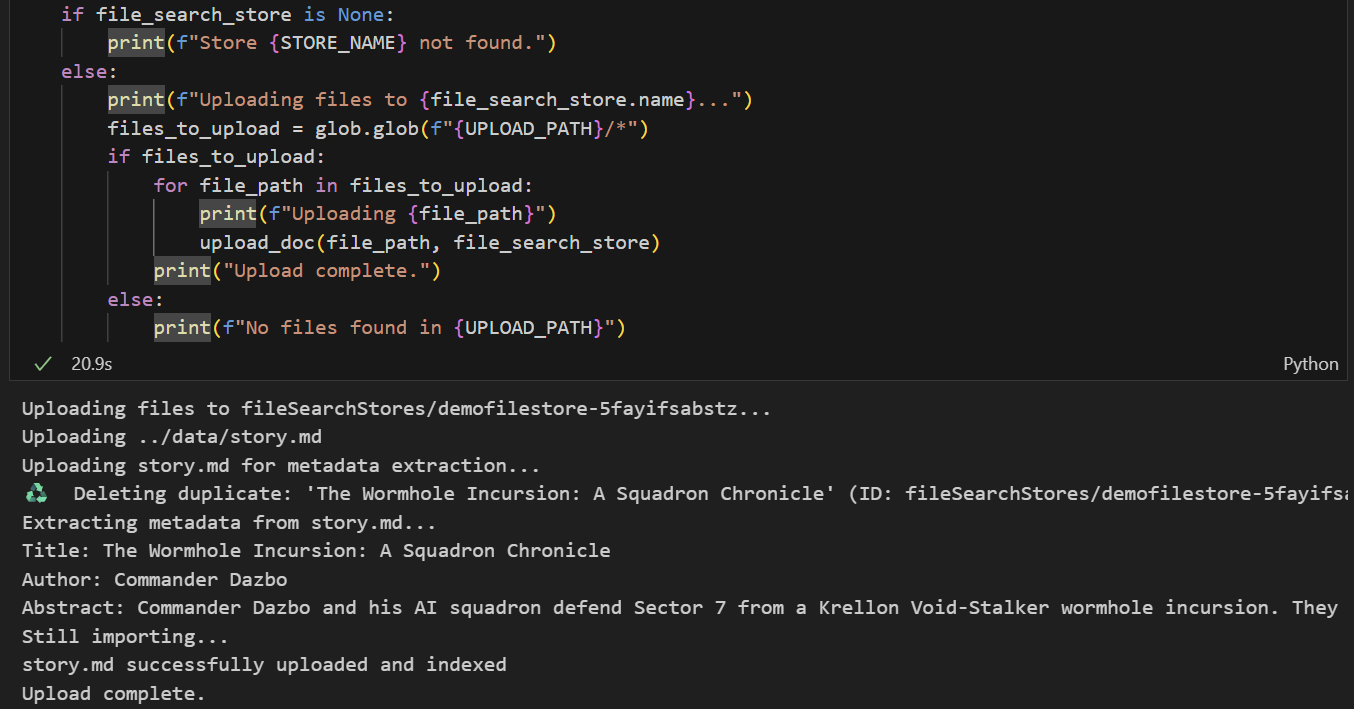
We want to upload data/story.md to the store. Do the following:
- Run the cell that sets the upload path. This points to our
data/folder. - Run the next cell, which creates utility functions for uploading files to the store. Note that the code in this cell also uses Gemini to extract metadata from each uploaded file. We take these extracted values and store them as custom metadata in the store. (You don't need to do this, but it's a useful thing to do.)
- Run the cell to upload the file. Note that if we've uploaded a file with the same name before, then the notebook will first delete the existing version before uploading the new one. You should see a message indicating that the file has been uploaded.
Phase 2 - Implement Gemini File Search RAG in our Agent
We've created a Gemini File Search Store and uploaded our story to it. Now it's time to use the File Search Store in our agent. Let's create a new agent that uses the File Search Store rather than Google Search. Take a look at app/sdk_rag_agent.py.
The first thing to note is that we've implemented a function to retrieve our store by passing in a store name:
def get_store(client: genai.Client, store_name: str) -> types.FileSearchStore | None:
"""Retrieve a store by display name"""
try:
for a_store in client.file_search_stores.list():
if a_store.display_name == store_name:
return a_store
except Exception as e:
logger.error(f"Error listing stores: {e}")
return None
Once we have our store, using it is as simple as attaching it as a tool to our agent, like this:
file_search_tool = types.Tool(file_search=types.FileSearch(file_search_store_names=[store.name]))
Running the RAG Agent
We launch it like this:
make sdk-rag-agent # Or, without make: uv run python app/sdk_rag_agent.py
Let's ask the question that the previous agent couldn't answer:
> Who pilots the 'Too Many Pies' ship?
And the response?
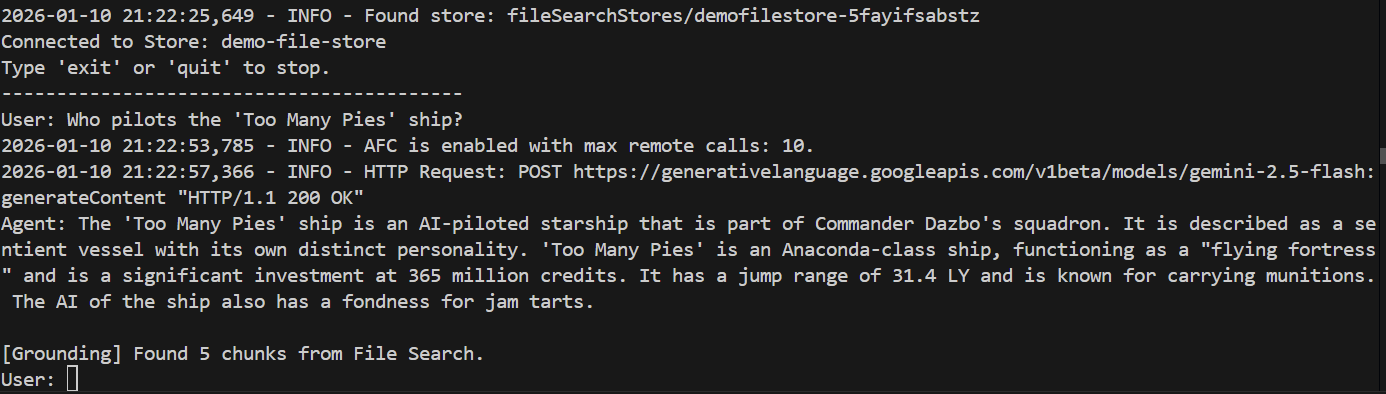
Success! We can see from the response that:
- Our file store was used to answer the question.
- 5 relevant chunks were found.
- The answer is spot on!
Type quit to close the agent.
7. Converting our Agents to use ADK
Google Agent Development Kit (ADK) is an open source modular framework and SDK for developers to build agents and agentic systems. It allows us to create and orchestrate multi-agent systems with ease. While optimized for Gemini and the Google ecosystem, ADK is model-agnostic, deployment-agnostic, and is built for compatibility with other frameworks. If you haven't used ADK yet, then head over to the ADK Docs to find out more.
The Basic ADK Agent with Google Search
Take a look at app/basic_agent_adk/agent.py. In this sample code you can see that we've actually implemented two agents:
- A
root_agentthat handles the interaction with the user, and where we've provided the main system instruction. - A separate
SearchAgentthat usesgoogle.adk.tools.google_searchas a tool.
The root_agent actually uses the SearchAgent as a tool, which is implemented using this line:
tools=[AgentTool(agent=search_agent)],
The root agent's system prompt looks like this:
You are a helpful AI assistant designed to provide accurate and useful information.
If you don't know the answer, use the SearchAgent to perform a Google search.
Do not attempt to search more than ONCE.
If the search yields no relevant results or returns unrelated content, you MUST immediately respond with: "I could not find any information about that."
Do NOT retry the search with different terms. Do NOT ask for clarification. FAIL FAST.
Trying the Agent
The ADK provides a number of out-of-the-box interfaces to allow developers to test their ADK agents. One of these interfaces is the Web UI. This allows us to test our agents in a browser, without having to write a line of user interface code!
We can launch this interface by running:
make adk-playground # Or, without make: uv run adk web app --port 8501 --reload_agents
Note that the command points the adk web tool to the app folder, where it will automatically discover any ADK agents that implement a root_agent. So let's try it out:
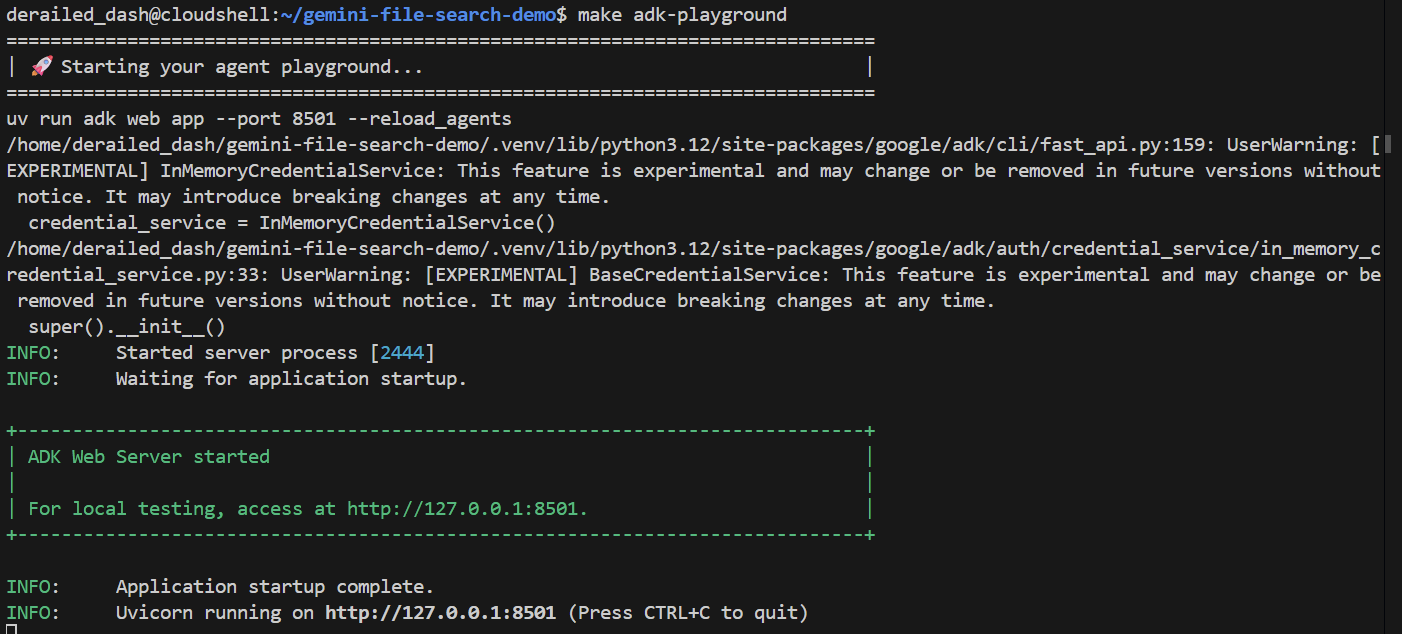
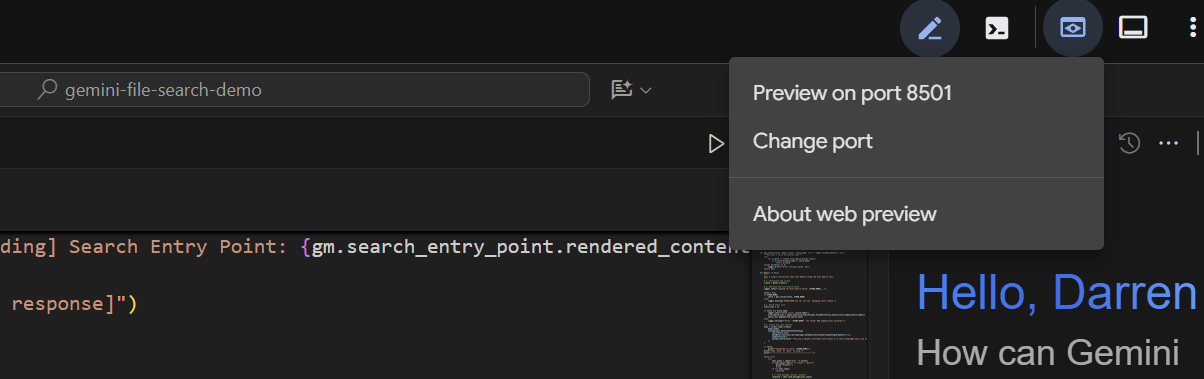
After a couple of seconds, the application is ready. If you're running the code locally, just point your browser to http://127.0.0.1:8501. If you're running in the Cloud Shell Editor, click on "Web preview", and change the port to 8501:
When the UI appears, select the basic_agent_adk from the dropdown, and then we can ask it questions:
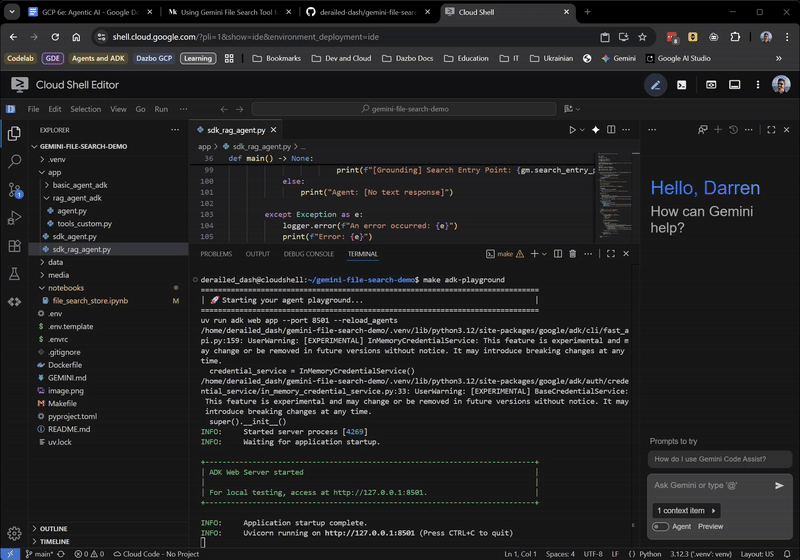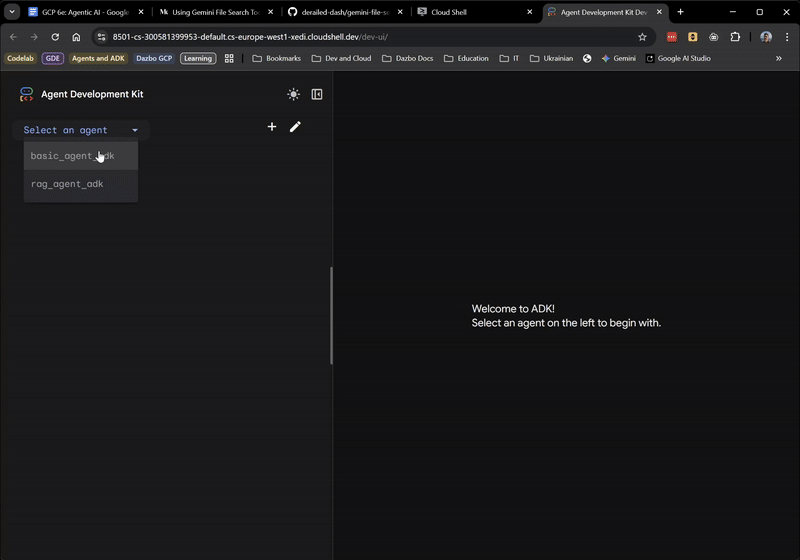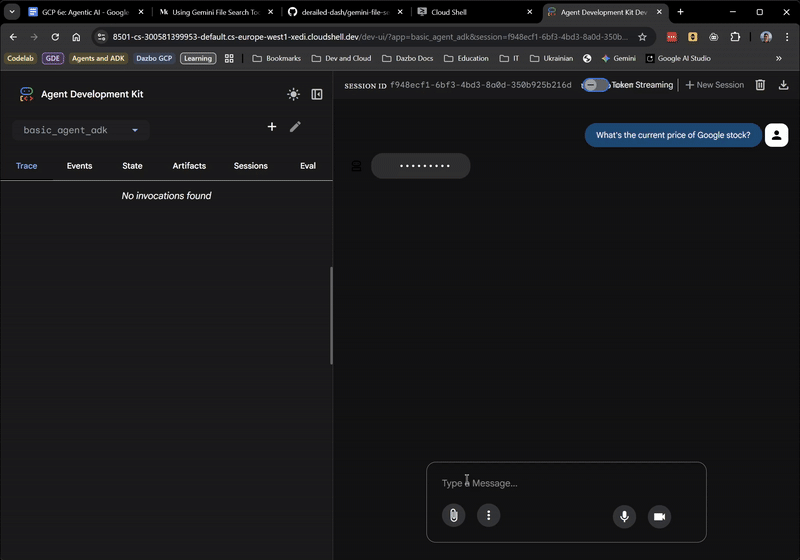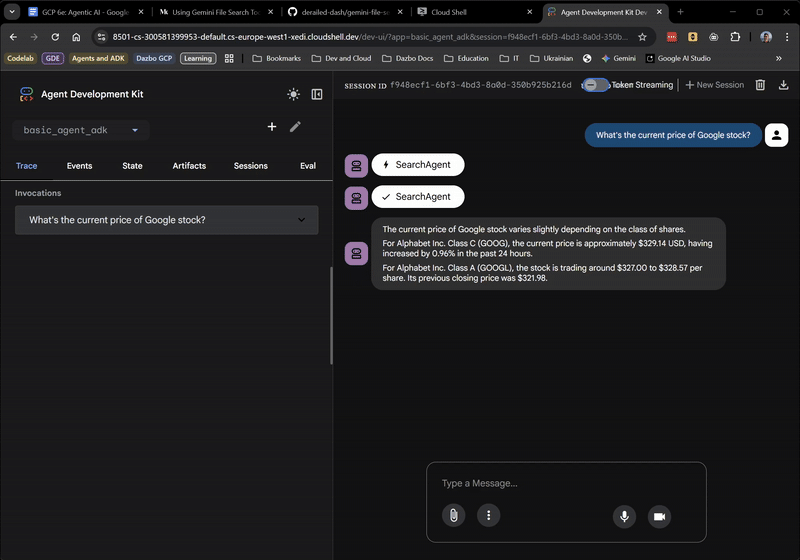
So far, so good! The web UI even shows you when the root agent is delegating to the SearchAgent. This is a very useful feature.
Now let's ask it our question that requires knowledge of our story:
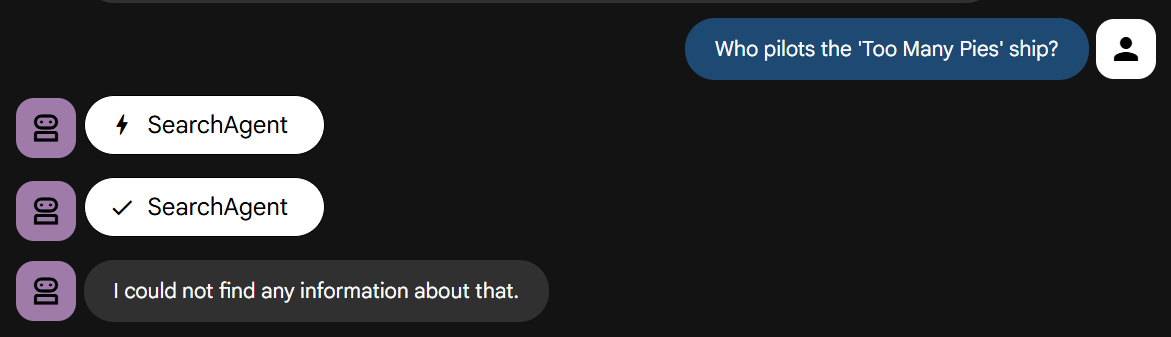
Try it yourself. You should find it fails fast, just as directed.
Incorporate the File Search Store into the ADK agent
Now we're going to bring it all together. We're going to run an ADK agent that is able to use both the File Search Store and Google Search. Take a look at the code in app/rag_agent_adk/agent.py.
The code is similar to the previous example, but with a few key differences:
- We have a root agent that orchestrates two specialist agents:
- RagAgent: The bespoke knowledge expert - using our Gemini File Search Store
- SearchAgent: The general knowledge expert - using Google Search
- Because ADK doesn't have a built-in wrapper for
FileSearchyet, we use a custom wrapper classFileSearchToolto wrap the FileSearch tool, which injects thefile_search_store_namesconfiguration into the low-level model request. This has been implemented into the separate scriptapp/rag_agent_adk/tools_custom.py.
Also, there's a "gotcha" to watch out for. At the time of writing, you cannot use the native GoogleSearch tool and the FileSearch tool in the same request to the same agent. If you try, you'll get an error like this:
ERROR - An error occurred: 400 INVALID_ARGUMENT. {‘error': {‘code': 400, ‘message': ‘Search as a tool and file search tool are not supported together', ‘status': ‘INVALID_ARGUMENT'}}
Error: 400 INVALID_ARGUMENT. {‘error': {‘code': 400, ‘message': ‘Search as a tool and file search tool are not supported together', ‘status': ‘INVALID_ARGUMENT'}}
The solution is to implement the two specialist agents as separate subagents, and pass them to the root agent using the Agent-as-a-Tool pattern. And crucially, the root agent's system instruction provides very clear guidance to use the RagAgent first:
You are a helpful AI assistant designed to provide accurate and useful information.
You have access to two specialist agents:
- RagAgent: For bespoke information from the internal knowledge base.
- SearchAgent: For general information from Google Search.
Always try the RagAgent first. If this fails to yield a useful answer, then try the SearchAgent.
Final Test
Run the ADK web UI as before:
make adk-playground # Or, without make: uv run adk web app --port 8501 --reload_agents
This time, select rag_agent_adk in the UI. Let's see it in action: 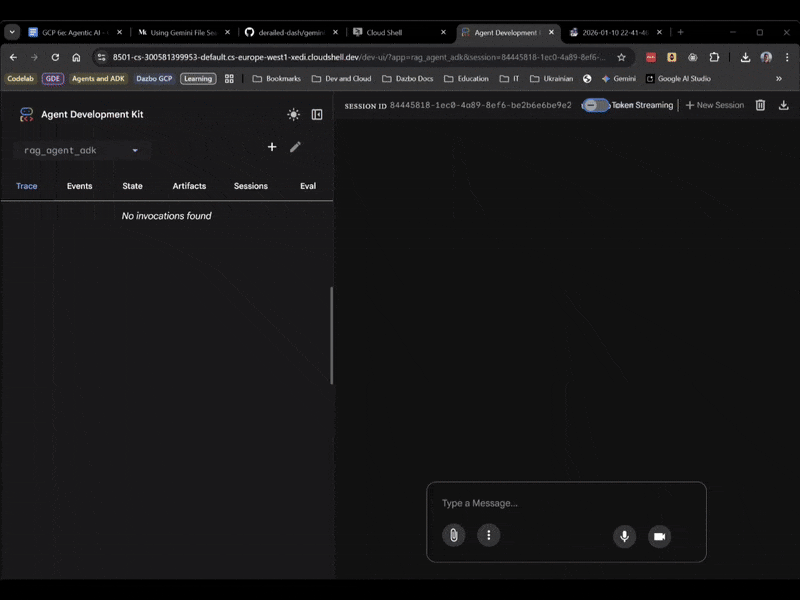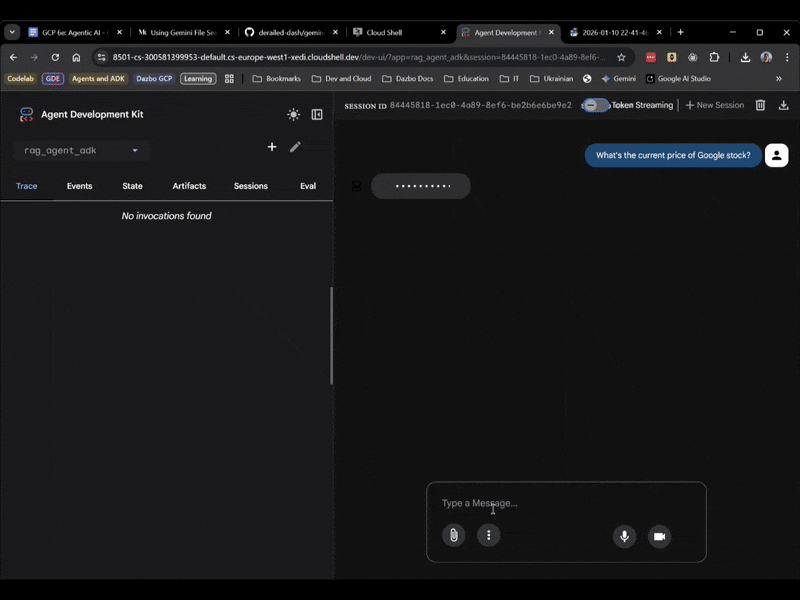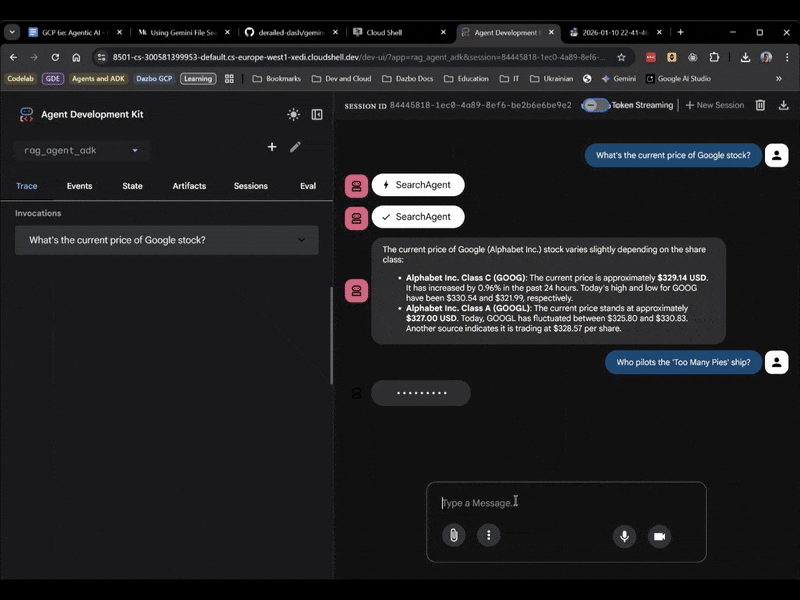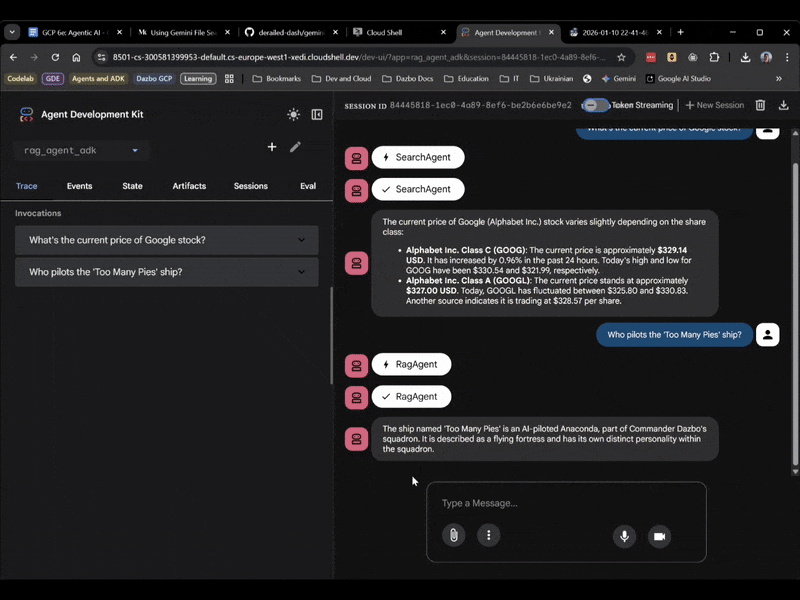
We can see it picks the appropriate subagent based on the question.
8. Conclusion
Congratulations on completing this codelab!
You've gone from a simple script to a multi-agent RAG-enabled system; all without a single line of embedding code, and without having to implement a vector database!
We learned:
- Gemini File Search is a managed RAG solution that saves time and sanity.
- ADK gives us the structure we need for complex multi-agent apps, and provides developer convenience through interfaces like the Web UI.
- The "Agent-as-a-Tool" pattern solves tool compatibility issues.
Hope you've found this lab useful. See you next time!