
1. Introducción
En este codelab, se muestra cómo usar la Búsqueda de archivos de Gemini para habilitar la RAG en tu aplicación de agente. Usarás la Búsqueda de archivos con Gemini para incorporar y, luego, indexar tus documentos sin tener que preocuparte por los detalles de la fragmentación, la incorporación ni la base de datos de vectores.
Qué aprenderá
- Los conceptos básicos de RAG y por qué lo necesitamos
- Qué es la Búsqueda de archivos con Gemini y cuáles son sus ventajas
- Cómo crear un almacén de búsqueda de archivos
- Cómo subir tus propios archivos personalizados a la Tienda de búsqueda de archivos
- Cómo usar la herramienta de búsqueda de archivos de Gemini para RAG
- Los beneficios de usar el Kit de desarrollo de agentes (ADK) de Google
- Cómo usar la herramienta de búsqueda de archivos de Gemini en una solución de agentes creada con el ADK
- Cómo usar la herramienta de búsqueda de archivos de Gemini junto con las herramientas "nativas" de Google, como la Búsqueda de Google
Actividades
- Crea un proyecto de Google Cloud y configura tu entorno de desarrollo.
- Crea un agente simple basado en Gemini con el SDK de IA generativa de Google (pero sin el ADK) que pueda usar la Búsqueda de Google, pero que no tenga capacidad de RAG.
- Demostrar que no puede proporcionar información precisa y de alta calidad para la información personalizada
- Crea un notebook de Jupyter (que puedes ejecutar de forma local o, por ejemplo, en Google Colab) para crear y administrar un almacén de Gemini File Search.
- Usa el notebook para subir contenido personalizado al almacén de búsqueda de archivos.
- Crea un agente que tenga adjunto el almacén de búsqueda de archivos y demuestra que puede producir mejores respuestas.
- Convertir nuestro agente "básico" inicial en un agente del ADK, con la herramienta de la Búsqueda de Google
- Prueba el agente con la IU web del ADK.
- Incorpora el almacén de búsqueda de archivos en el agente del ADK con el patrón Agent-As-A-Tool para permitirnos usar la herramienta de búsqueda de archivos junto con la herramienta de Búsqueda de Google.
2. Qué es la RAG y por qué la necesitamos
Entonces… Generación mejorada por recuperación.
Si estás aquí, probablemente sepas qué es, pero hagamos un repaso rápido por si acaso. Los LLMs (como Gemini) son brillantes, pero tienen algunos problemas:
- Siempre están desactualizados: Solo saben lo que aprendieron durante el entrenamiento.
- No lo saben todo: Claro, los modelos son enormes, pero no son omniscientes.
- No conocen tu información patentada: Tienen un amplio conocimiento, pero no leyeron tus documentos internos, tus blogs ni tus tickets de Jira.
Por lo tanto, cuando le preguntas algo a un modelo cuya respuesta desconoce, es probable que obtengas una respuesta incorrecta o incluso inventada. A menudo, el modelo dará esta respuesta incorrecta con confianza. A esto nos referimos como alucinación.
Una solución es simplemente volcar nuestra información patentada directamente en el contexto de la conversación. Esto funciona bien para una pequeña cantidad de información, pero rápidamente se vuelve problemático cuando tienes mucha información. Específicamente, genera los siguientes problemas:
- Latencia: El modelo genera respuestas cada vez más lentas.
- Pérdida de señal, también conocida como "perdido en el medio": El modelo ya no puede ordenar los datos relevantes de la basura. El modelo ignora gran parte del contexto.
- Costo: Porque los tokens cuestan dinero.
- Agotamiento de la ventana de contexto: En este punto, Gemini no realizará ninguna acción en respuesta a tus solicitudes.
Una forma mucho más eficaz de remediar esta situación es usar RAG. Es simplemente el proceso de buscar información pertinente en tus fuentes de datos (con la correlación semántica) y proporcionar fragmentos pertinentes de estos datos al modelo junto con tu pregunta. Fundamenta el modelo en tu realidad.
Funciona importando datos externos, dividiéndolos en fragmentos, convirtiéndolos en embeddings de vectores y, luego, almacenando e indexando esos embeddings en una base de datos de vectores adecuada.
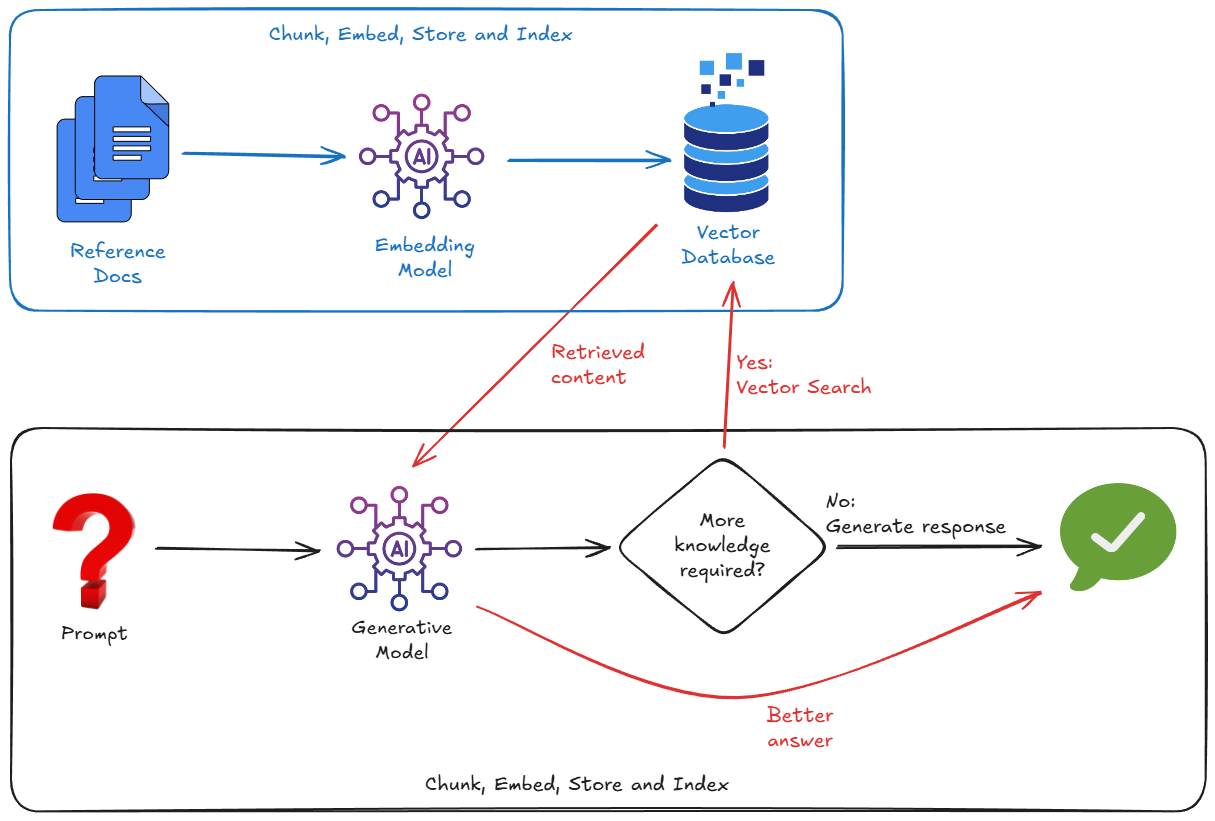
Por lo tanto, para implementar la RAG, normalmente debemos preocuparnos por lo siguiente:
- Iniciar una base de datos de vectores (Pinecone, Weaviate, Postgres con pgvector…).
- Escribir una secuencia de comandos de fragmentación para dividir tus documentos (p.ej., PDFs, Markdown, etc.)
- Generar embeddings (vectores) para esos fragmentos con un modelo de embedding
- Almacenar los vectores en la base de datos de vectores
Pero los amigos no dejan que sus amigos compliquen demasiado las cosas. ¿Y si te dijera que hay una forma más fácil?
3. Requisitos previos
Crea un proyecto de Google Cloud
Necesitas un proyecto de Google Cloud para ejecutar este codelab. Puedes usar un proyecto que ya tengas o crear uno nuevo.
Asegúrate de que la facturación esté habilitada en tu proyecto. Consulta esta guía para saber cómo verificar el estado de facturación de tus proyectos.
Ten en cuenta que no se espera que completar este codelab te genere ningún costo. A lo sumo, unos centavos.
Prepara tu proyecto. Esperaré.
Clona el repositorio de demostración
Creé un repo con contenido guiado para este codelab. ¡Lo vas a necesitar!
Ejecuta los siguientes comandos desde tu terminal o desde la terminal integrada en el Editor de Cloud Shell de Google. Cloud Shell y su editor son muy convenientes, ya que todos los comandos que necesitas están preinstalados y todo se ejecuta "de inmediato".
git clone https://github.com/derailed-dash/gemini-file-search-demo cd gemini-file-search-demo
Este árbol muestra las carpetas y los archivos clave del repo:
gemini-file-search-demo/ ├── app/ │ ├── basic_agent_adk/ # Agent with Google Search, using ADK framework │ │ └── agent.py │ ├── rag_agent_adk/ # Agent with Google Search and File Search, using ADK framework │ │ ├── agent.py │ │ └── tools_custom.py │ ├── sdk_agent.py # Agent using GenAI SDK (no ADK) with Google Search tool │ └── sdk_rag_agent.py # Agent using GenAI SDK (no ADK) with Gemini File Search tool ├── data/ │ └── story.md # Sample story with "bespoke content" to use with Gemini File Search Store ├── notebooks/ │ └── file_search_store.ipynb # Jupyter notebook for creating and managing Gemini File Search Store │ ├── .env.template # Template for environment variables - make a copy as .env ├── Makefile # Makefile for `make` commands ├── pyproject.toml # Project configuration and dependencies └── README.md # This file
Abre esta carpeta en el Editor de Cloud Shell o en tu editor preferido. (¿Ya usaste Antigravity? Si no es así, este es un buen momento para probarlo.
Ten en cuenta que el repo contiene un ejemplo de historia, "The Wormhole Incursion", en el archivo data/story.md. La escribí junto con Gemini. Se trata del comandante Dazbo y su escuadrón de naves espaciales inteligentes. (Me inspiré en el juego Elite Dangerous). Esta historia sirve como nuestra "base de conocimiento personalizada", ya que contiene hechos específicos que Gemini no conoce y que, además, no puede buscar con la Búsqueda de Google.
Configura tu entorno de desarrollo
Para tu comodidad, proporcioné un Makefile para simplificar muchos de los comandos que necesitas ejecutar. En lugar de recordar comandos específicos, puedes ejecutar algo como make <target>. Sin embargo, make solo está disponible en entornos de Linux, macOS y WSL. Si usas Windows (sin WSL), deberás ejecutar los comandos completos que contienen los destinos de make.
# Install dependencies with make make install # If you don't have make... uv sync --extra jupyter
Así se ve cuando ejecutas make install en el editor de Cloud Shell:
Crea una clave de la API de Gemini
Para usar la API para desarrolladores de Gemini (que necesitamos para usar la herramienta de búsqueda de archivos de Gemini), necesitas una clave de API de Gemini. La forma más sencilla de obtener una clave de API es usar Google AI Studio, que proporciona una interfaz conveniente para obtener claves de API para tus proyectos de Google Cloud. Consulta esta guía para conocer los pasos específicos.
Una vez que se cree tu clave de API, cópiala y guárdala en un lugar seguro.
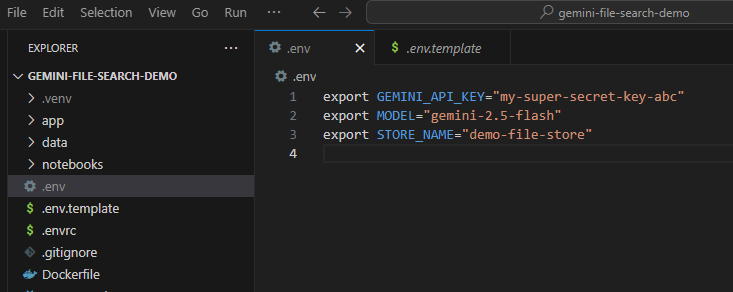
Ahora debes establecer esta clave de API como una variable de entorno. Podemos hacerlo con un archivo .env. Copia el archivo .env.example incluido como un archivo nuevo llamado .env. El archivo debería verse de la siguiente manera:
export GEMINI_API_KEY="your-api-key" export MODEL="gemini-2.5-flash" export STORE_NAME="demo-file-store"
Reemplaza your-api-key por tu clave de API real. Ahora, debería verse de la siguiente manera:
Ahora, asegúrate de que se carguen las variables de entorno. Para ello, puedes ejecutar el siguiente comando:
source .env
4. El agente básico
Primero, establezcamos un valor de referencia. Usaremos el SDK de google-genai sin procesar para ejecutar un agente simple.
El código
Echa un vistazo a app/sdk_agent.py. Es una implementación mínima que hace lo siguiente:
- Crea una instancia de
genai.Client. - Habilita la herramienta
google_search. - Eso es todo. No hay RAG.
Revisa el código y asegúrate de comprender lo que hace.
Ejecución
# With make make sdk-agent # Without make uv run python app/sdk_agent.py
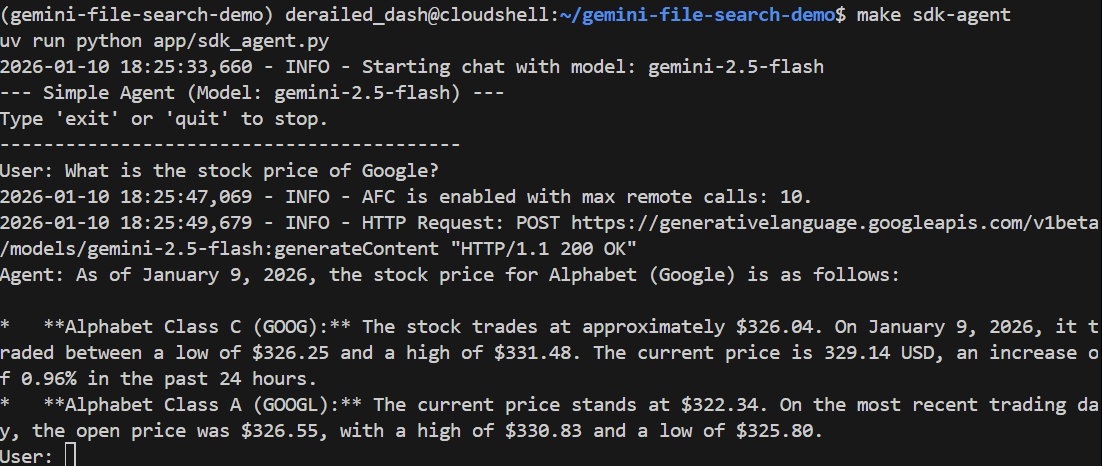
Hagámosle una pregunta general:
> What is the stock price of Google?
Debe responder correctamente usando la Búsqueda de Google para encontrar el precio actual:
Ahora, hagámosle una pregunta que no sabe responder. Requiere que el agente haya leído nuestro cuento.
> Who pilots the 'Too Many Pies' ship?
Debe fallar o incluso alucinar. Veamos:
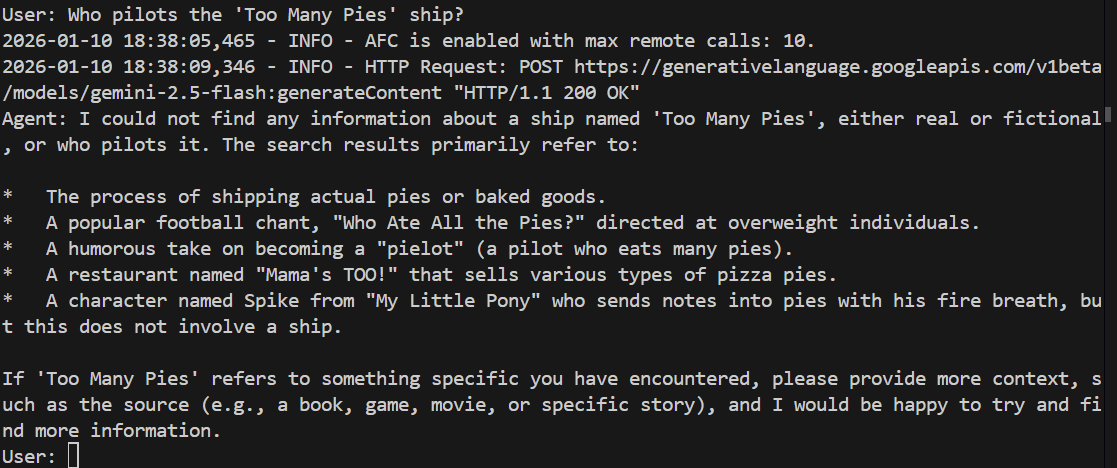
Y, efectivamente, el modelo no responde la pregunta. No tiene idea de lo que estamos hablando.
Ahora, escribe quit para salir del agente.
5. Búsqueda de archivos con Gemini: Explicación
Básicamente, la Búsqueda de archivos con Gemini es una combinación de dos elementos:
- Un sistema de RAG completamente administrado: Proporcionas una gran cantidad de archivos, y la Búsqueda de archivos con Gemini se encarga de la fragmentación, la incorporación, el almacenamiento y la indexación de vectores por ti.
- Una "herramienta" en el sentido de agente: En la que puedes agregar simplemente la herramienta de búsqueda de archivos de Gemini como una herramienta en la definición de tu agente y dirigir la herramienta a un almacén de búsqueda de archivos.
Pero, lo más importante, es que está integrada en la API de Gemini. Esto significa que no necesitas habilitar ninguna API adicional ni implementar ningún producto separado para usarla. Por lo tanto, es out-of-the-box.
Funciones de búsqueda de archivos de Gemini
Estas son algunas de las funciones:
- Los detalles de la fragmentación, la incorporación, el almacenamiento y la indexación se abstraen de ti, el desarrollador. Esto significa que no necesitas saber (ni preocuparte) por el modelo de incorporación (que, por cierto, es Gemini Embeddings) ni por dónde se almacenan los vectores resultantes. No tienes que tomar ninguna decisión sobre la base de datos de vectores.
- Admite una gran cantidad de tipos de documentos listos para usar. Incluidos, sin limitaciones, los siguientes: PDF, DOCX, Excel, SQL, JSON, notebooks de Jupyter, HTML, Markdown, CSV y hasta archivos ZIP. Puedes ver la lista completa aquí. Por ejemplo, si quieres fundamentar tu agente con archivos PDF que contengan texto, imágenes y tablas, no necesitas realizar ningún procesamiento previo de estos archivos. Solo sube los archivos PDF sin procesar y deja que Gemini se encargue del resto.
- Podemos agregar metadatos personalizados a cualquier archivo subido. Esto puede ser muy útil para filtrar posteriormente qué archivos queremos que use la herramienta en el tiempo de ejecución.
¿Dónde se encuentran los datos?
Subes algunos archivos. La herramienta de Búsqueda de archivos con Gemini tomó esos archivos, creó los fragmentos y, luego, las incorporaciones, y los colocó… en algún lugar. Pero ¿dónde?
La respuesta es un almacén de búsqueda de archivos. Este es un contenedor completamente administrado para tus incorporaciones. No necesitas saber (ni preocuparte) cómo se hace esto de forma interna. Lo único que debes hacer es crear uno (de forma programática) y, luego, subir tus archivos a él.
¡Es económico!
El almacenamiento y la consulta de tus embeddings son gratuitos. Por lo tanto, puedes almacenar incorporaciones durante el tiempo que quieras y no pagarás por ese almacenamiento.
De hecho, lo único que pagas es la creación de las incorporaciones en el momento de la carga o la indexación. Al momento de escribir este artículo, el costo es de USD 0.15 por cada millón de tokens. Es bastante económico.
6. ¿Cómo usamos la Búsqueda de archivos con Gemini?
Existen dos fases:
- Crea y almacena las incorporaciones en un almacén de búsqueda de archivos.
- Consulta la tienda de búsqueda de archivos desde tu agente.
Fase 1: Notebook de Jupyter para crear y administrar un almacén de Gemini File Search
Esta fase es algo que harías inicialmente y, luego, cada vez que quieras actualizar la tienda. Por ejemplo, cuando tienes documentos nuevos para agregar o cuando cambiaron los documentos fuente.
Esta fase no es algo que debas empaquetar en tu aplicación agentiva implementada. Claro, puedes hacerlo si quieres. Por ejemplo, si deseas crear algún tipo de IU para los usuarios administradores de tu aplicación basada en agentes. Sin embargo, a menudo es perfectamente adecuado tener un poco de código que ejecutes a pedido. ¿Y cuál es una excelente manera de ejecutar este código a pedido? Un notebook de Jupyter
Diario de una pasión
Abre el archivo notebooks/file_search_store.ipynb en tu editor. Si se te solicita que instales alguna extensión de Jupyter para VS Code, hazlo.
Si lo abrimos en el editor de Cloud Shell, se verá de la siguiente manera:
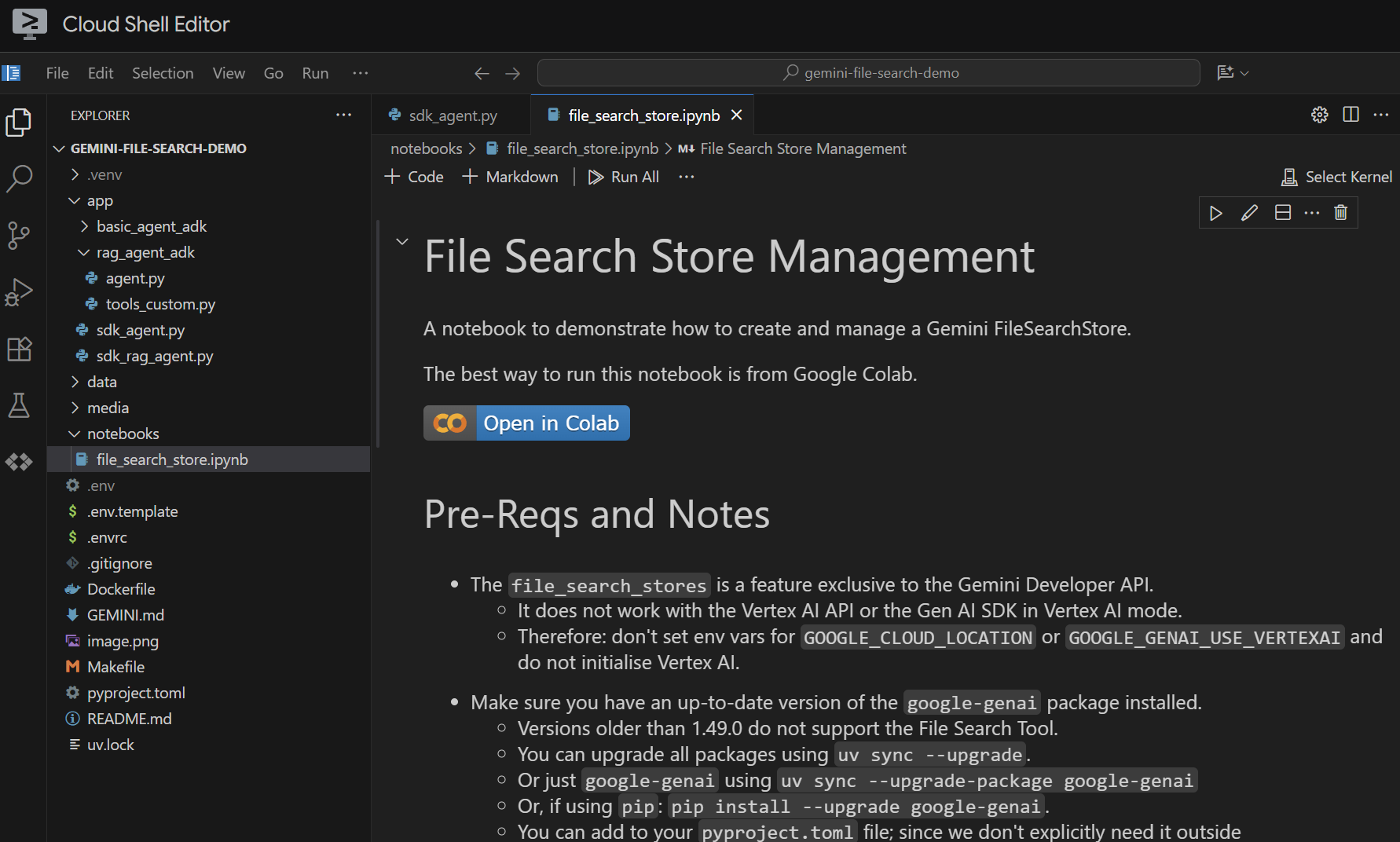
Ejecutémoslo celda por celda. Comienza por ejecutar la celda Setup con las importaciones requeridas. Si no ejecutaste un notebook antes, se te pedirá que instales las extensiones necesarias. Adelante, hazlo. Luego, se te pedirá que selecciones un kernel. Selecciona "Python environments..." y, luego, el .venv local que instalamos cuando ejecutamos make install anteriormente:
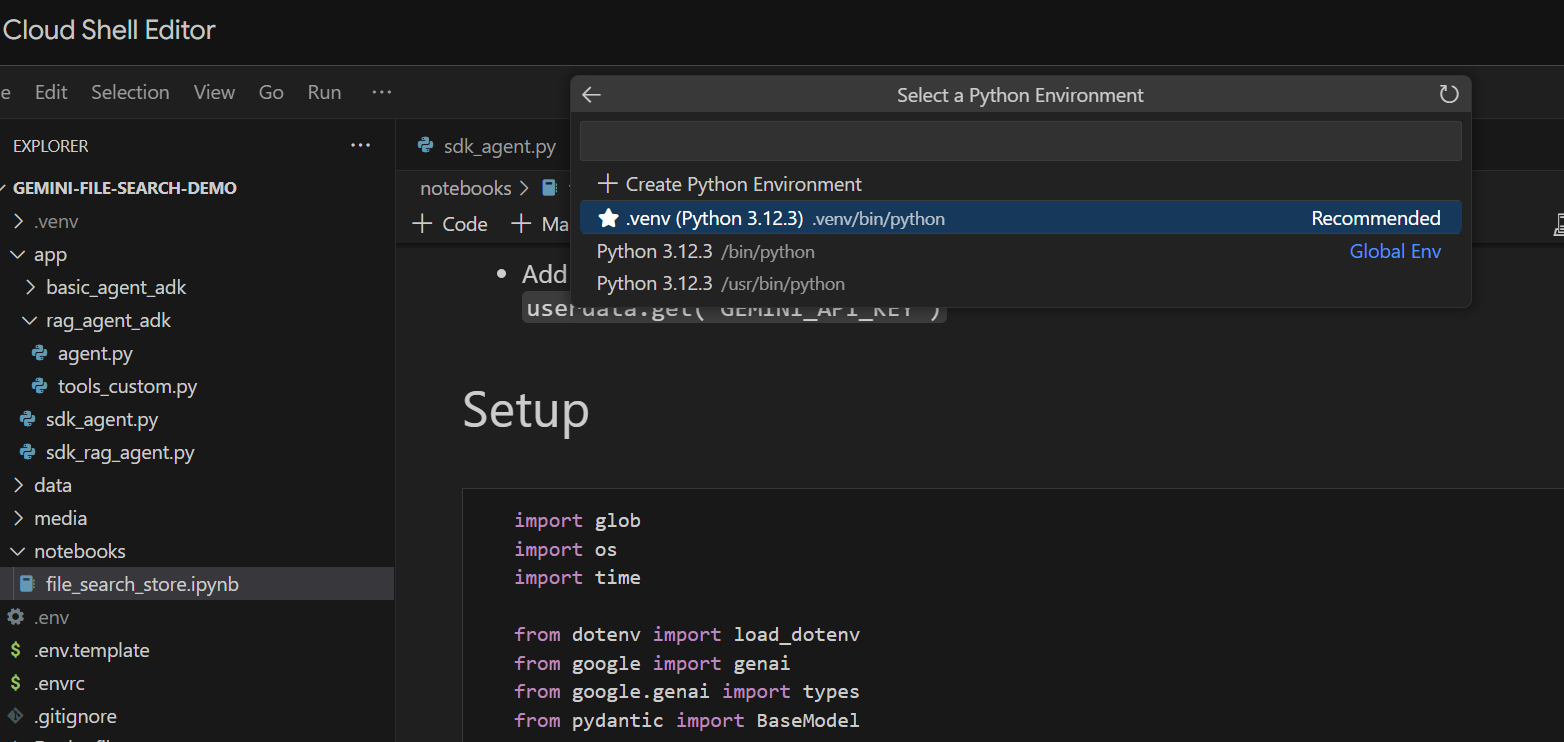
Luego:
- Ejecuta la celda "Local Only" para extraer las variables de entorno.
- Ejecuta la celda "Client Initialisation" para inicializar el cliente de IA generativa de Gemini.
- Ejecuta la celda "Retrieve the Store" con la función de ayuda para recuperar Gemini File Search Store por nombre.
Ahora sí podemos crear la tienda.
- Ejecuta la celda "Create the Store (One Time)" para crear el almacén. Solo necesitamos hacerlo una vez. Si el código se ejecuta correctamente, deberías ver un mensaje que diga
"Created store: fileSearchStores/<someid>" - Ejecuta la celda "View the Store" para ver su contenido. En este punto, deberías ver que contiene 0 documentos.
¡Genial! Ahora tenemos una tienda de Gemini File Search lista para usar.
Cómo subir los datos
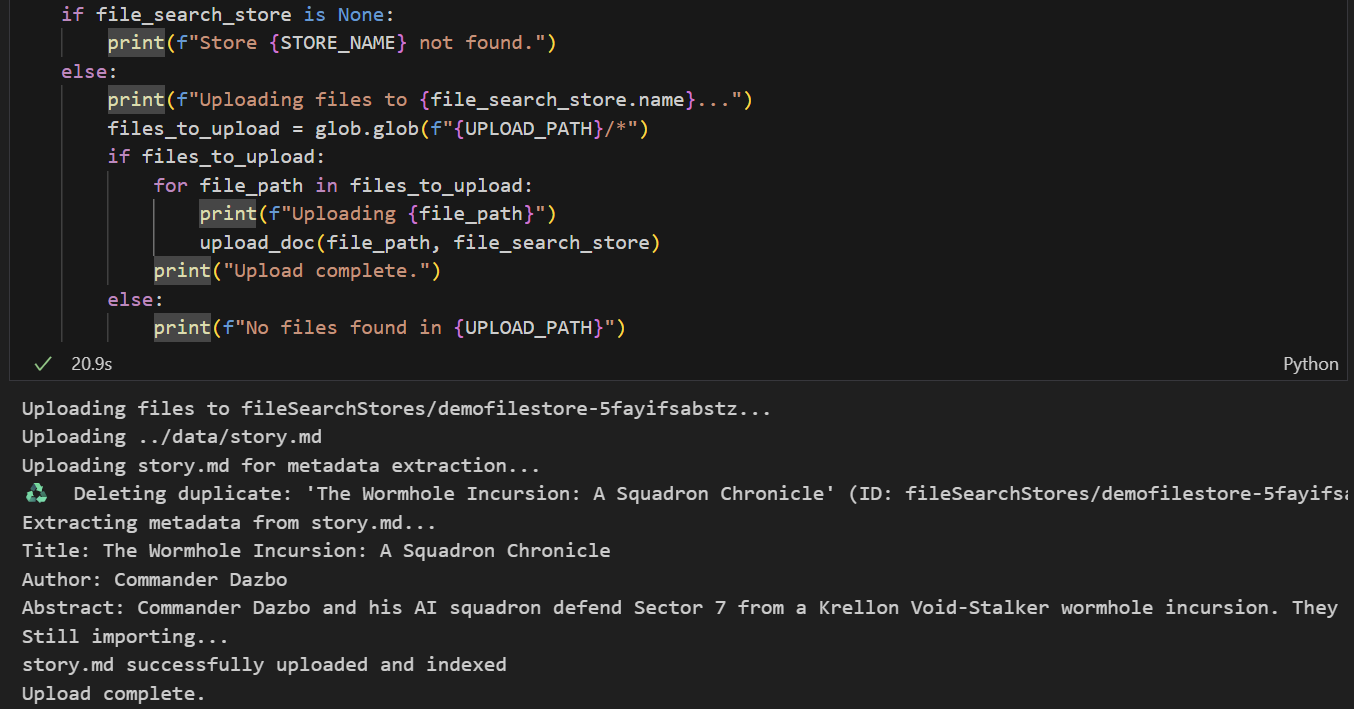
Queremos subir data/story.md a la tienda. Puedes hacer lo siguiente:
- Ejecuta la celda que establece la ruta de carga. Esto apunta a nuestra carpeta
data/. - Ejecuta la siguiente celda, que crea funciones de utilidad para subir archivos a la tienda. Ten en cuenta que el código de esta celda también usa Gemini para extraer metadatos de cada archivo subido. Tomamos estos valores extraídos y los almacenamos como metadatos personalizados en la tienda. (No es necesario que lo hagas, pero es útil).
- Ejecuta la celda para subir el archivo. Ten en cuenta que, si ya subimos un archivo con el mismo nombre, el notebook primero borrará la versión existente antes de subir la nueva. Deberías ver un mensaje que indica que se subió el archivo.
Fase 2: Implementa la RAG de la Búsqueda de archivos de Gemini en nuestro agente
Creamos un almacén de Gemini File Search y subimos nuestra historia a él. Ahora es momento de usar File Search Store en nuestro agente. Creemos un nuevo agente que use el almacén de búsqueda de archivos en lugar de la Búsqueda de Google. Echa un vistazo a app/sdk_rag_agent.py.
Lo primero que debes tener en cuenta es que implementamos una función para recuperar nuestro almacén pasando un nombre de almacén:
def get_store(client: genai.Client, store_name: str) -> types.FileSearchStore | None:
"""Retrieve a store by display name"""
try:
for a_store in client.file_search_stores.list():
if a_store.display_name == store_name:
return a_store
except Exception as e:
logger.error(f"Error listing stores: {e}")
return None
Una vez que tenemos nuestro almacén, usarlo es tan simple como adjuntarlo como herramienta a nuestro agente, de la siguiente manera:
file_search_tool = types.Tool(file_search=types.FileSearch(file_search_store_names=[store.name]))
Cómo ejecutar el agente de RAG
Lo lanzamos de la siguiente manera:
make sdk-rag-agent # Or, without make: uv run python app/sdk_rag_agent.py
Hagamos la pregunta que el agente anterior no pudo responder:
> Who pilots the 'Too Many Pies' ship?
¿Y la respuesta?
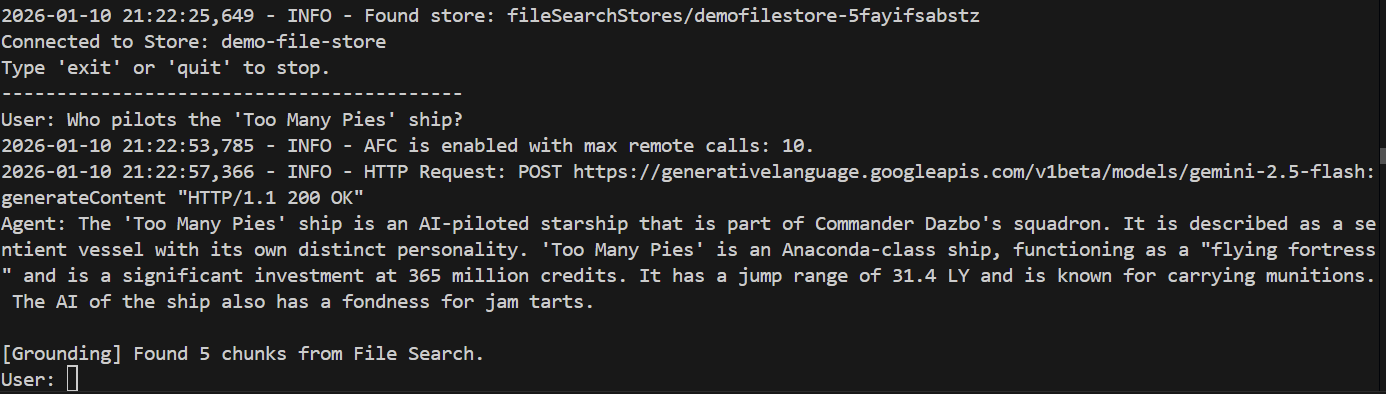
¡Listo! Según la respuesta, podemos ver lo siguiente:
- Se usó nuestro almacén de archivos para responder la pregunta.
- Se encontraron 5 fragmentos pertinentes.
- La respuesta es correcta.
Escribe quit para cerrar el agente.
7. Cómo convertir nuestros agentes para que usen el ADK
El Kit de desarrollo de agentes (ADK) de Google es un framework modular de código abierto y un SDK para que los desarrolladores creen agentes y sistemas basados en agentes. Nos permite crear y organizar sistemas multiagente con facilidad. Si bien está optimizado para Gemini y el ecosistema de Google, el ADK es independiente del modelo y de la implementación, y se creó para ser compatible con otros frameworks. Si aún no usaste el ADK, consulta la documentación del ADK para obtener más información.
El agente básico del ADK con la Búsqueda de Google
Echa un vistazo a app/basic_agent_adk/agent.py. En este código de muestra, puedes ver que, en realidad, implementamos dos agentes:
- Un
root_agentque controla la interacción con el usuario y en el que proporcionamos la instrucción principal del sistema. - Un
SearchAgentindependiente que usagoogle.adk.tools.google_searchcomo herramienta.
En realidad, el root_agent usa el SearchAgent como herramienta, que se implementa con esta línea:
tools=[AgentTool(agent=search_agent)],
La instrucción del sistema del agente raíz se ve de la siguiente manera:
You are a helpful AI assistant designed to provide accurate and useful information.
If you don't know the answer, use the SearchAgent to perform a Google search.
Do not attempt to search more than ONCE.
If the search yields no relevant results or returns unrelated content, you MUST immediately respond with: "I could not find any information about that."
Do NOT retry the search with different terms. Do NOT ask for clarification. FAIL FAST.
Cómo probar el agente
El ADK proporciona varias interfaces listas para usar que permiten a los desarrolladores probar sus agentes del ADK. Una de estas interfaces es la IU web. Esto nos permite probar nuestros agentes en un navegador sin tener que escribir una sola línea de código de la interfaz de usuario.
Para iniciar esta interfaz, ejecuta el siguiente comando:
make adk-playground # Or, without make: uv run adk web app --port 8501 --reload_agents
Ten en cuenta que el comando dirige la herramienta adk web a la carpeta app, en la que descubrirá automáticamente cualquier agente del ADK que implemente un root_agent. Probémoslo:
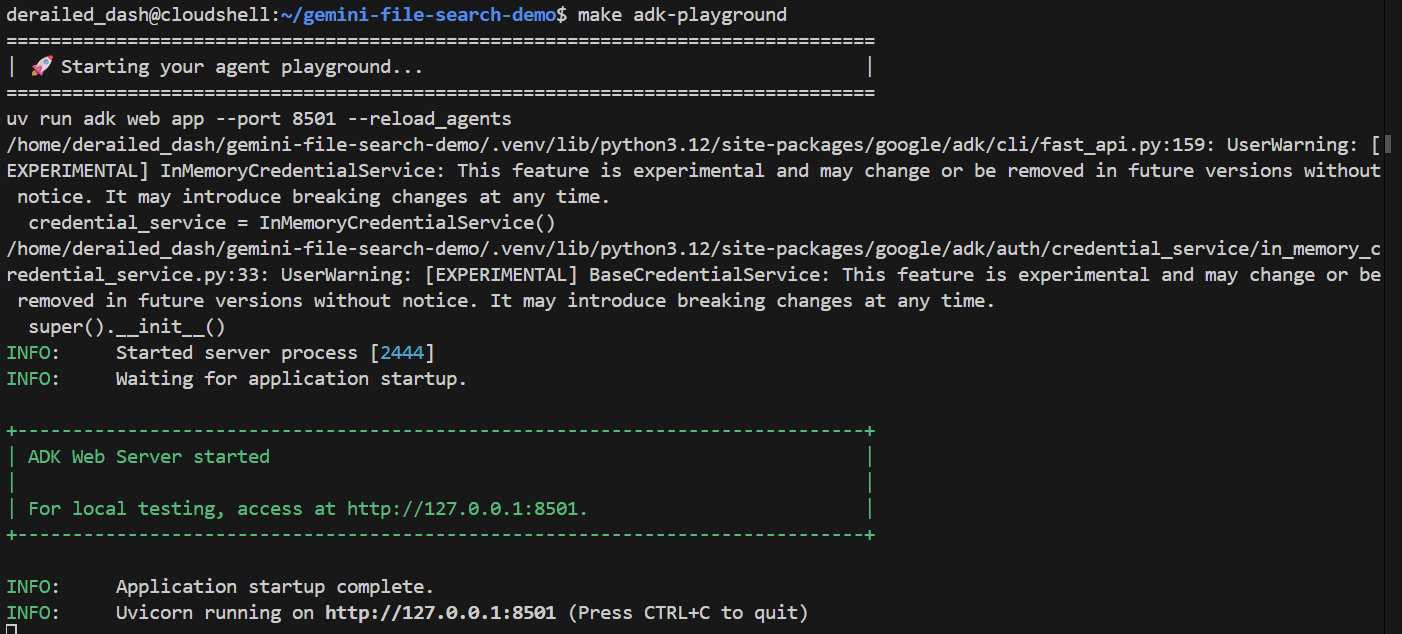
Después de unos segundos, la aplicación estará lista. Si ejecutas el código de forma local, solo dirige tu navegador a http://127.0.0.1:8501. Si ejecutas el editor de Cloud Shell, haz clic en "Vista previa en la Web" y cambia el puerto a 8501:
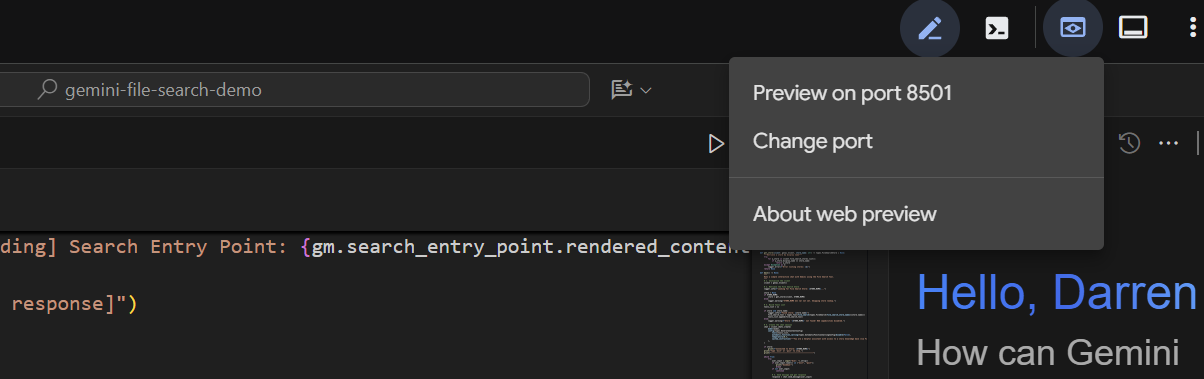
Cuando aparezca la IU, selecciona basic_agent_adk en el menú desplegable y, luego, podremos hacerle preguntas:
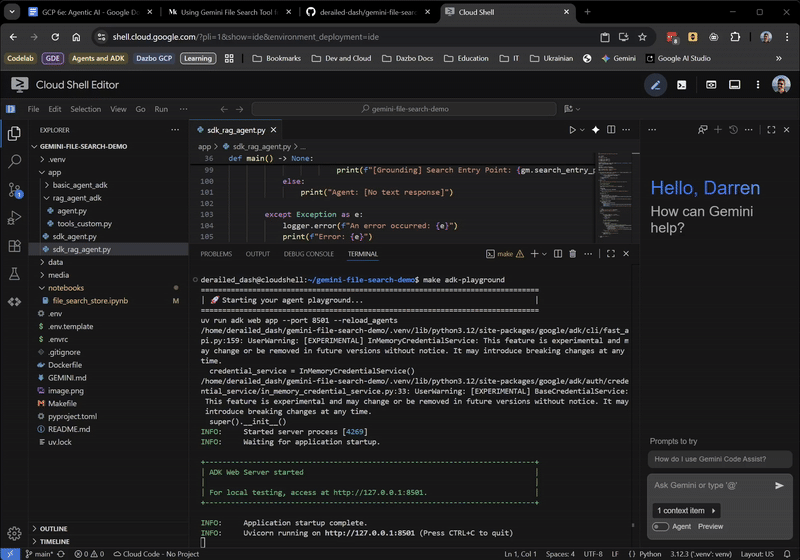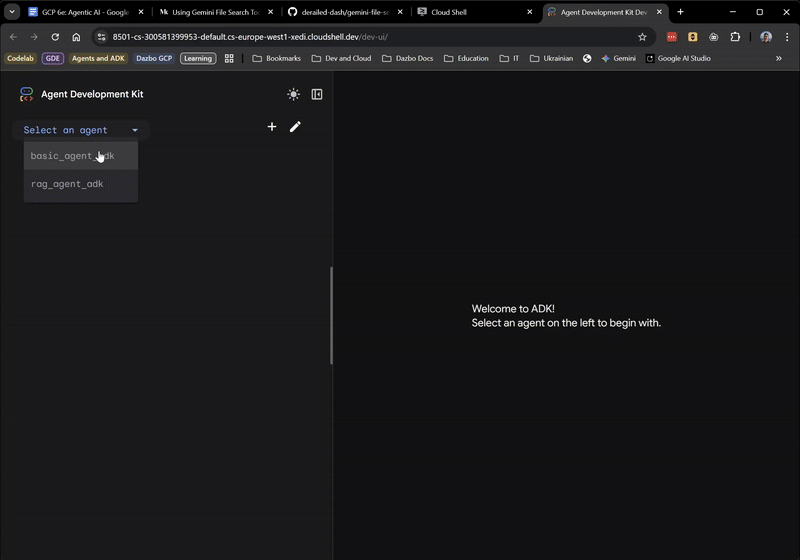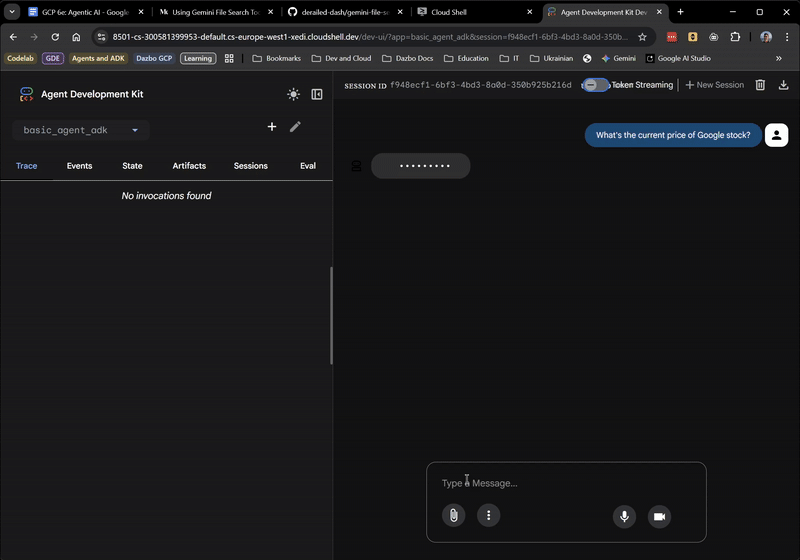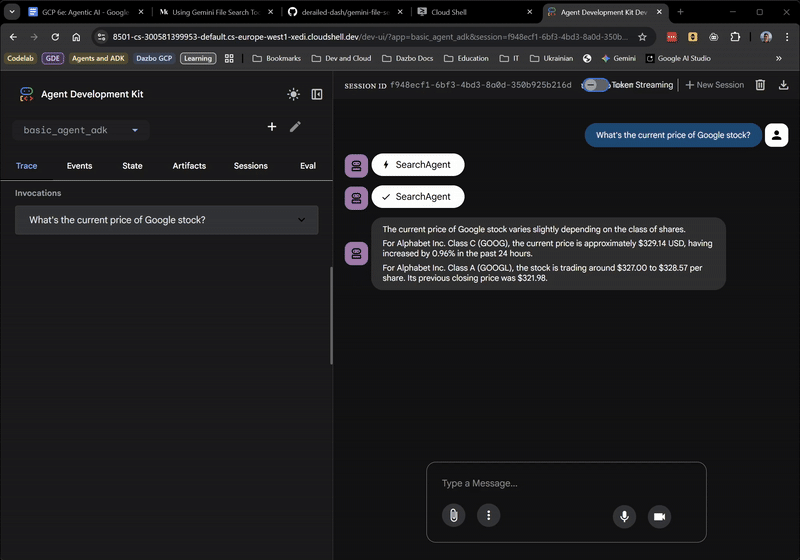
Hasta aquí, todo bien. La IU web incluso te muestra cuando el agente raíz delega en SearchAgent. Esta es una función muy útil.
Ahora, hagámosle la pregunta que requiere conocimiento de nuestra historia:
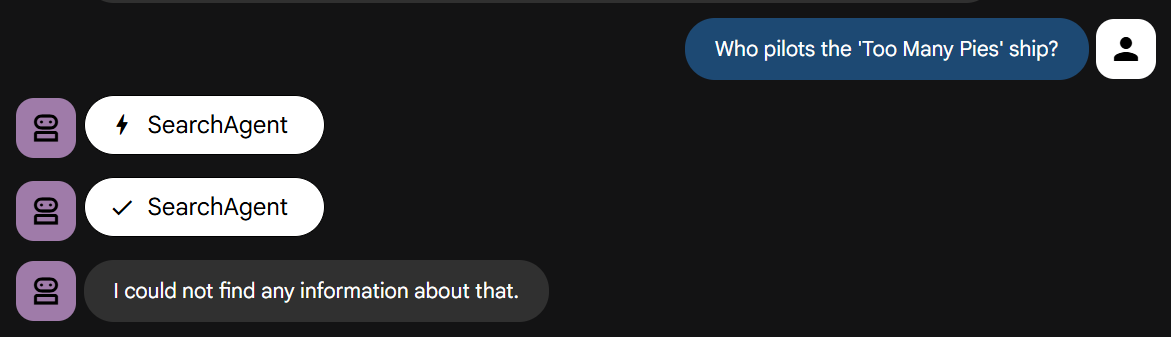
Compruébalo. Deberías ver que falla rápidamente, tal como se indica.
Incorpora el almacén de búsqueda de archivos en el agente del ADK
Ahora vamos a unir todo. Ejecutaremos un agente del ADK que pueda usar tanto el almacén de búsqueda de archivos como la Búsqueda de Google. Echa un vistazo al código en app/rag_agent_adk/agent.py.
El código es similar al ejemplo anterior, pero con algunas diferencias clave:
- Tenemos un agente raíz que organiza dos agentes especialistas:
- RagAgent: El experto en conocimiento personalizado que usa nuestra tienda de búsqueda de archivos de Gemini
- SearchAgent: El experto en conocimiento general que usa la Búsqueda de Google
- Como el ADK aún no tiene un wrapper integrado para
FileSearch, usamos una clase de wrapper personalizadaFileSearchToolpara unir la herramienta FileSearch, que inyecta la configuración defile_search_store_namesen la solicitud del modelo de bajo nivel. Esto se implementó en la secuencia de comandos independienteapp/rag_agent_adk/tools_custom.py.
También hay una trampa que debes evitar. En el momento de escribir este documento, no puedes usar la herramienta GoogleSearch nativa y la herramienta FileSearch en la misma solicitud al mismo agente. Si lo intentas, recibirás un error como el siguiente:
ERROR: Se produjo un error: 400 INVALID_ARGUMENT. {"error": {"code": 400, "message": "Search as a tool and file search tool are not supported together", "status": "INVALID_ARGUMENT"}}
Error: 400 INVALID_ARGUMENT. {"error": {"code": 400, "message": "Search as a tool and file search tool are not supported together", "status": "INVALID_ARGUMENT"}}
La solución es implementar los dos agentes especialistas como subagentes separados y pasarlos al agente raíz con el patrón de agente como herramienta. Y, lo que es fundamental, la instrucción del sistema del agente raíz proporciona una guía muy clara para usar RagAgent primero:
Eres un asistente de IA útil diseñado para proporcionar información precisa y útil.
Tienes acceso a dos agentes especialistas:
- RagAgent: Para obtener información personalizada de la base de conocimiento interna.
- SearchAgent: Para obtener información general de la Búsqueda de Google
Siempre prueba primero el RagAgent. Si no se obtiene una respuesta útil, prueba con SearchAgent.
Prueba final
Ejecuta la IU web del ADK como antes:
make adk-playground # Or, without make: uv run adk web app --port 8501 --reload_agents
Esta vez, selecciona rag_agent_adk en la IU. Veamos cómo funciona: 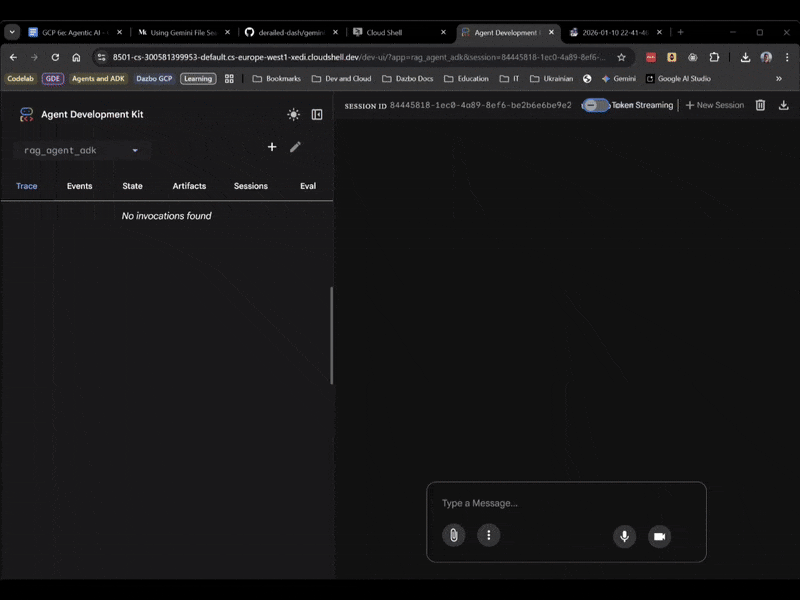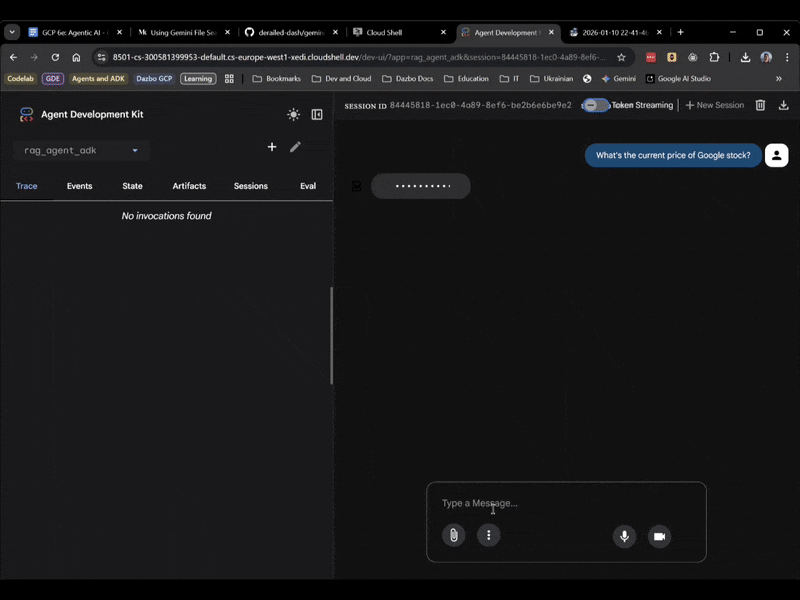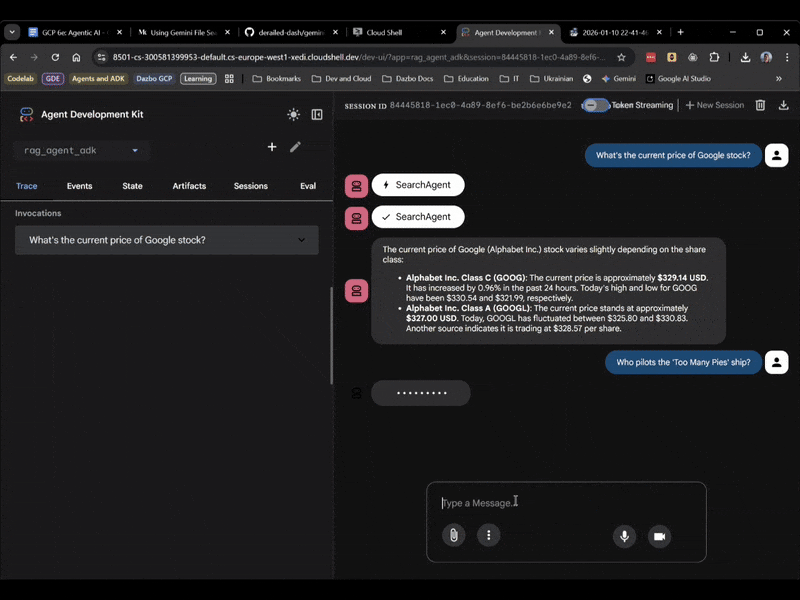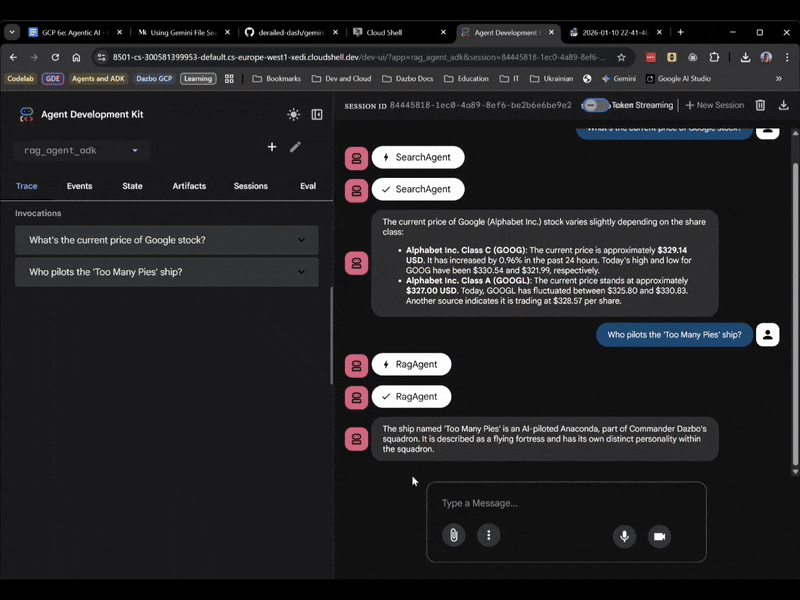
Podemos ver que elige el subagente adecuado según la pregunta.
8. Conclusión
¡Felicitaciones por completar este codelab!
Pasaste de un script simple a un sistema multiagente habilitado para RAG, todo sin una sola línea de código de incorporación y sin tener que implementar una base de datos de vectores.
Aprendimos lo siguiente:
- La Búsqueda de archivos con Gemini es una solución RAG administrada que ahorra tiempo y cordura.
- El ADK nos brinda la estructura que necesitamos para las apps complejas de agentes múltiples y ofrece comodidad a los desarrolladores a través de interfaces como la IU web.
- El patrón "Agent-as-a-Tool" resuelve los problemas de compatibilidad de herramientas.
Esperamos que este lab te haya resultado útil. Hasta la próxima.