
۱. مقدمه
این آزمایشگاه کد به شما نشان میدهد که چگونه از جستجوی فایل Gemini برای فعال کردن RAG در برنامه Agentic خود استفاده کنید. شما از جستجوی فایل Gemini برای دریافت و فهرستبندی اسناد خود بدون نگرانی در مورد جزئیات قطعهبندی، جاسازی یا پایگاه داده برداری استفاده خواهید کرد.
آنچه یاد خواهید گرفت
- اصول اولیه RAG و دلیل نیاز به آن
- جستجوی فایل Gemini چیست و مزایای آن چیست؟
- نحوه ایجاد فروشگاه جستجوی فایل.
- چگونه فایلهای سفارشی خود را در فروشگاه جستجوی فایل آپلود کنید.
- نحوه استفاده از ابزار جستجوی فایل Gemini برای RAG.
- مزایای استفاده از کیت توسعه عامل گوگل (ADK)
- نحوه استفاده از ابزار جستجوی فایل Gemini در یک راهکار عاملمحور ساخته شده با استفاده از ADK.
- نحوه استفاده از ابزار جستجوی فایل Gemini در کنار ابزارهای "بومی" گوگل مانند جستجوی گوگل.
کاری که انجام خواهید داد
- یک پروژه گوگل کلود ایجاد کنید و محیط توسعه خود را تنظیم کنید.
- با استفاده از Google Gen AI SDK (اما بدون ADK) یک عامل ساده مبتنی بر Gemini ایجاد کنید که قابلیت استفاده از جستجوی گوگل را داشته باشد، اما قابلیت RAG نداشته باشد.
- ناتوانی خود را در ارائه اطلاعات دقیق و با کیفیت بالا برای اطلاعات سفارشی نشان دهد.
- برای ایجاد و مدیریت فروشگاه جستجوی فایل Gemini، یک دفترچه یادداشت Jupyter (که میتوانید آن را به صورت محلی یا مثلاً در Google Colab اجرا کنید) ایجاد کنید.
- از دفترچه یادداشت برای آپلود محتوای سفارشی در فروشگاه جستجوی فایل استفاده کنید.
- عاملی ایجاد کنید که فروشگاه جستجوی فایل به آن متصل باشد و ثابت کنید که قادر به تولید پاسخهای بهتری است.
- عامل «پایه» اولیه ما را به یک عامل ADK تبدیل کنید، که با ابزار جستجوی گوگل تکمیل میشود.
- با استفاده از رابط کاربری وب ADK، عامل را آزمایش کنید.
- با استفاده از الگوی Agent-As-A-Tool، فروشگاه جستجوی فایل را در عامل ADK ادغام کنید تا بتوانیم از ابزار جستجوی فایل در کنار ابزار جستجوی گوگل استفاده کنیم.
۲. RAG چیست و چرا به آن نیاز داریم؟
بنابراین... بازیابی نسل افزوده .
اگر اینجا هستید، احتمالاً میدانید چیست، اما بیایید برای احتیاط، یک مرور سریع انجام دهیم. LLM ها (مانند Gemini) عالی هستند، اما از چند مشکل رنج میبرند:
- آنها همیشه از رده خارج هستند : آنها فقط چیزهایی را که در طول آموزش یاد گرفتهاند، میدانند.
- آنها همه چیز را نمیدانند : بله، مدلها بسیار بزرگ هستند، اما دانای کل نیستند.
- آنها اطلاعات اختصاصی شما را نمیدانند : آنها دانش گستردهای دارند، اما اسناد داخلی، وبلاگهای شما یا تیکتهای Jira شما را نخواندهاند.
بنابراین وقتی از یک مدل چیزی میپرسید که جوابش را نمیداند، معمولاً یک جواب نادرست یا حتی ساختگی دریافت خواهید کرد. اغلب، مدل این جواب نادرست را با اطمینان بیان میکند. این چیزی است که ما به آن توهم میگوییم.
یک راه حل این است که اطلاعات اختصاصی خود را مستقیماً در متن مکالمه خود قرار دهیم . این برای مقدار کمی اطلاعات خوب است، اما وقتی اطلاعات زیادی دارید، به سرعت مشکل ساز می شود. به طور خاص، منجر به این مشکلات می شود:
- تأخیر : پاسخهای کندتر و کندتر از مدل.
- خرابی سیگنال ، که به آن «گم شدن در میانه» هم میگویند: جایی که مدل دیگر قادر به مرتبسازی دادههای مرتبط از دادههای بیارزش نیست. بخش زیادی از زمینه توسط مدل نادیده گرفته میشود.
- هزینه : زیرا توکنها هزینه دارند.
- اتمام پنجره متن : در این مرحله، جمینی درخواستهای شما را انجام نمیدهد.
یک راه بسیار مؤثرتر برای اصلاح این وضعیت، استفاده از RAG است. این روش به سادگی فرآیند جستجوی اطلاعات مرتبط از منابع داده شما (با استفاده از تطبیق معنایی) و ارائه بخشهای مرتبط از این دادهها به مدل در کنار سوال شما است. این روش، مدل را بر اساس واقعیت شما بنا میکند .
این روش با وارد کردن دادههای خارجی، خرد کردن دادهها به قطعات کوچک، تبدیل دادهها به جاسازیهای برداری و سپس ذخیره و فهرستبندی آن جاسازیها در یک پایگاه داده برداری مناسب کار میکند.
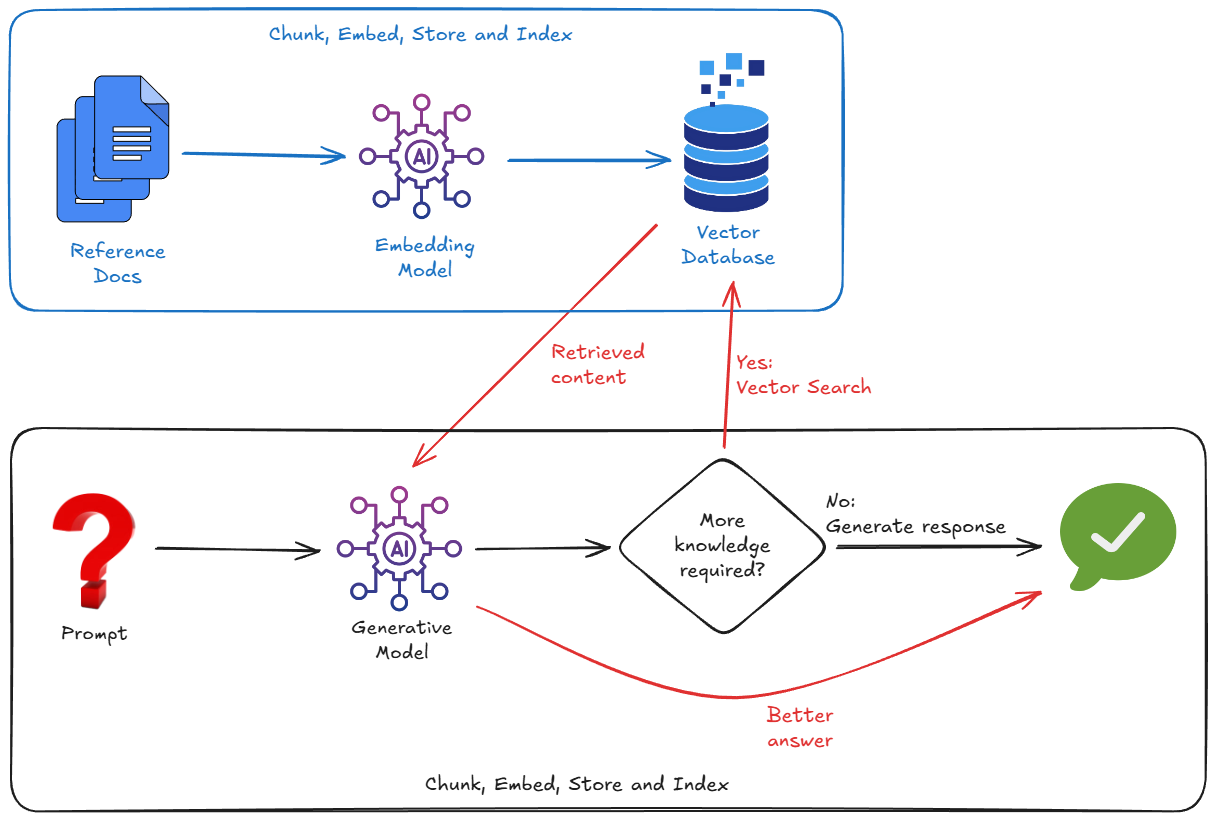
و بنابراین، برای پیادهسازی RAG، معمولاً باید نگران موارد زیر باشیم:
- راهاندازی یک پایگاه داده برداری (Pinecone، Weaviate، Postgres با pgvector...).
- نوشتن یک اسکریپت قطعهبندی برای قطعه قطعه کردن اسنادتان (مثلاً PDF، markdown، هر چیز دیگری).
- تولید جاسازیها (بردارها) برای آن تکهها، با استفاده از یک مدل جاسازی.
- ذخیره بردارها در پایگاه داده بردار.
اما دوستان اجازه نمیدهند که دوستانشان چیزها را بیش از حد مهندسی کنند. اگر به شما بگویم راه سادهتری هم وجود دارد، چه؟
۳. پیشنیازها
ایجاد یک پروژه ابری گوگل
برای اجرای این آزمایشگاه کد به یک پروژه ابری گوگل نیاز دارید. میتوانید از پروژهای که از قبل دارید استفاده کنید یا یک پروژه جدید ایجاد کنید .
مطمئن شوید که صورتحساب در پروژه شما فعال است. برای مشاهده نحوه بررسی وضعیت صورتحساب پروژههای خود، به این راهنما مراجعه کنید.
توجه داشته باشید که تکمیل این آزمایشگاه کد هیچ هزینهای برای شما نخواهد داشت. حداکثر، چند پنی.
برو و پروژهات را آماده کن. من منتظر میمانم.
مخزن نسخه آزمایشی را کلون کنید
من یک مخزن (repo) با محتوای راهنما برای این آزمایشگاه کد ایجاد کردهام. به آن نیاز خواهید داشت!
دستورات زیر را از ترمینال خود یا از ترمینالی که در ویرایشگر Google Cloud Shell ادغام شده است، اجرا کنید. Cloud Shell و ویرایشگر آن بسیار راحت هستند، زیرا تمام دستورات مورد نیاز شما از قبل نصب شدهاند و همه چیز به صورت "خارج از جعبه" اجرا میشود.
git clone https://github.com/derailed-dash/gemini-file-search-demo cd gemini-file-search-demo
این نمودار درختی، پوشهها و فایلهای کلیدی موجود در مخزن را نشان میدهد:
gemini-file-search-demo/ ├── app/ │ ├── basic_agent_adk/ # Agent with Google Search, using ADK framework │ │ └── agent.py │ ├── rag_agent_adk/ # Agent with Google Search and File Search, using ADK framework │ │ ├── agent.py │ │ └── tools_custom.py │ ├── sdk_agent.py # Agent using GenAI SDK (no ADK) with Google Search tool │ └── sdk_rag_agent.py # Agent using GenAI SDK (no ADK) with Gemini File Search tool ├── data/ │ └── story.md # Sample story with "bespoke content" to use with Gemini File Search Store ├── notebooks/ │ └── file_search_store.ipynb # Jupyter notebook for creating and managing Gemini File Search Store │ ├── .env.template # Template for environment variables - make a copy as .env ├── Makefile # Makefile for `make` commands ├── pyproject.toml # Project configuration and dependencies └── README.md # This file
این پوشه را در ویرایشگر Cloud Shell یا ویرایشگر مورد نظر خود باز کنید. (آیا تا به حال از Antigravity استفاده کردهاید؟ اگر نه، اکنون زمان مناسبی برای امتحان کردن آن است.)
توجه داشته باشید که این مخزن شامل یک داستان نمونه - "تهاجم کرمچاله" - در فایل data/story.md است. من آن را با همکاری Gemini نوشتم! این داستان درباره فرمانده دازبو و اسکادران سفینههای فضایی هوشمند اوست. (من از بازی Elite Dangerous الهام گرفتم.) این داستان به عنوان "پایگاه دانش سفارشی" ما عمل میکند و شامل حقایق خاصی است که Gemini نمیداند و علاوه بر این، نمیتواند با استفاده از جستجوی گوگل آنها را جستجو کند.
محیط توسعه خود را راهاندازی کنید
برای راحتی کار، من یک Makefile ارائه دادهام تا بسیاری از دستوراتی که باید اجرا کنید را سادهتر کند. به جای به خاطر سپردن دستورات خاص، میتوانید چیزی شبیه make <target> را اجرا کنید. با این حال، make فقط در محیطهای لینوکس / مک او اس / WSL در دسترس است. اگر از ویندوز (بدون WSL) استفاده میکنید، باید دستورات کاملی را که make targets شامل میشوند، اجرا کنید.
# Install dependencies with make make install # If you don't have make... uv sync --extra jupyter
وقتی make install در ویرایشگر Cloud Shell اجرا میکنید، این شکلی میشود:
یک کلید API جمینی ایجاد کنید
برای استفاده از رابط برنامهنویسی توسعهدهنده Gemini (که برای استفاده از ابزار جستجوی فایل Gemini به آن نیاز داریم)، به یک کلید API Gemini نیاز دارید. سادهترین راه برای دریافت کلید API، استفاده از Google AI Studio است که رابط کاربری مناسبی برای دریافت کلیدهای API برای پروژه(های) Google Cloud شما فراهم میکند. برای مراحل خاص، به این راهنما مراجعه کنید.
پس از ایجاد کلید API، آن را کپی کرده و در جای امنی نگه دارید.
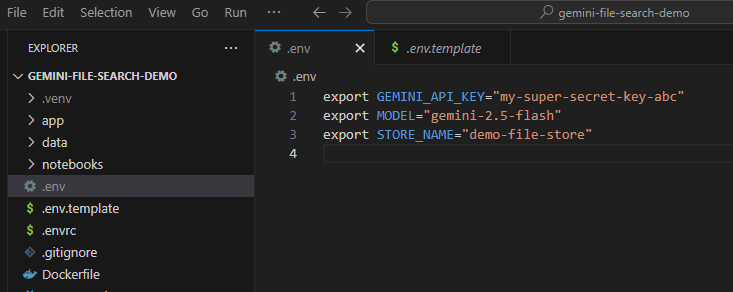
اکنون باید این کلید API را به عنوان یک متغیر محیطی تنظیم کنید. میتوانیم این کار را با استفاده از یک فایل .env انجام دهیم. فایل .env.example را به عنوان یک فایل جدید با نام .env کپی کنید. فایل باید به شکل زیر باشد:
export GEMINI_API_KEY="your-api-key" export MODEL="gemini-2.5-flash" export STORE_NAME="demo-file-store"
حالا به جای your-api-key ، کلید API واقعی خودتان را قرار دهید. حالا باید چیزی شبیه به این باشد:
حالا مطمئن شوید که متغیرهای محیطی بارگذاری شدهاند. میتوانید این کار را با اجرای دستور زیر انجام دهید:
source .env
۴. عامل پایه
اول، بیایید یک پایه ایجاد کنیم. ما قصد داریم از SDK خام google-genai برای اجرای یک عامل ساده استفاده کنیم.
کد
به app/sdk_agent.py نگاهی بیندازید. این یک پیادهسازی مینیمال است که:
- یک نمونه از
genai.Clientایجاد میکند. - ابزار
google_searchرا فعال میکند. - همین. بدون RAG.
نگاهی به کد بیندازید و مطمئن شوید که متوجه شدهاید چه کاری انجام میدهد.
اجرای آن
# With make make sdk-agent # Without make uv run python app/sdk_agent.py
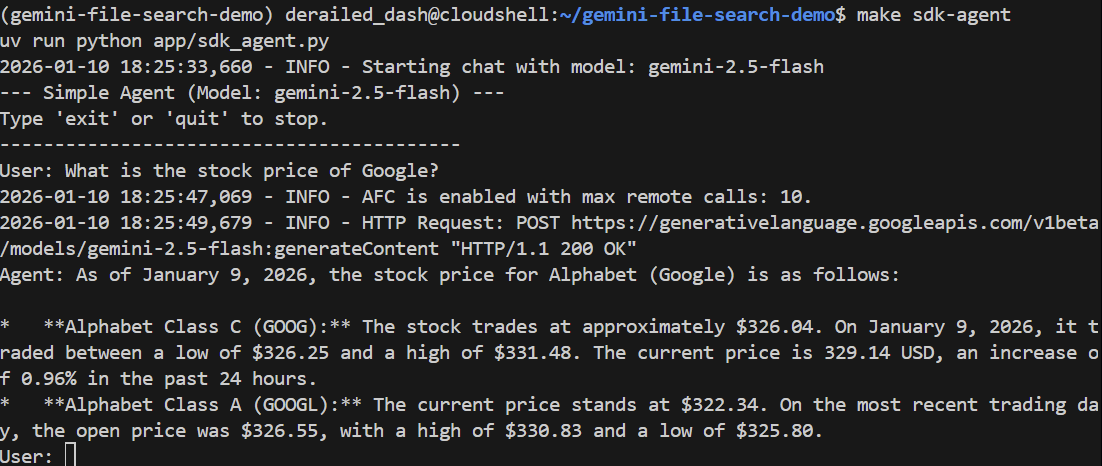
بیایید یک سوال کلی بپرسیم:
> What is the stock price of Google?
باید با استفاده از جستجوی گوگل برای یافتن قیمت فعلی، به درستی پاسخ دهد:
حالا، بیایید سوالی بپرسیم که نمیداند چگونه به آن پاسخ دهد. این سوال مستلزم آن است که عامل، داستان ما را خوانده باشد.
> Who pilots the 'Too Many Pies' ship?
باید از کار بیفتد یا حتی دچار توهم شود. بیایید ببینیم:
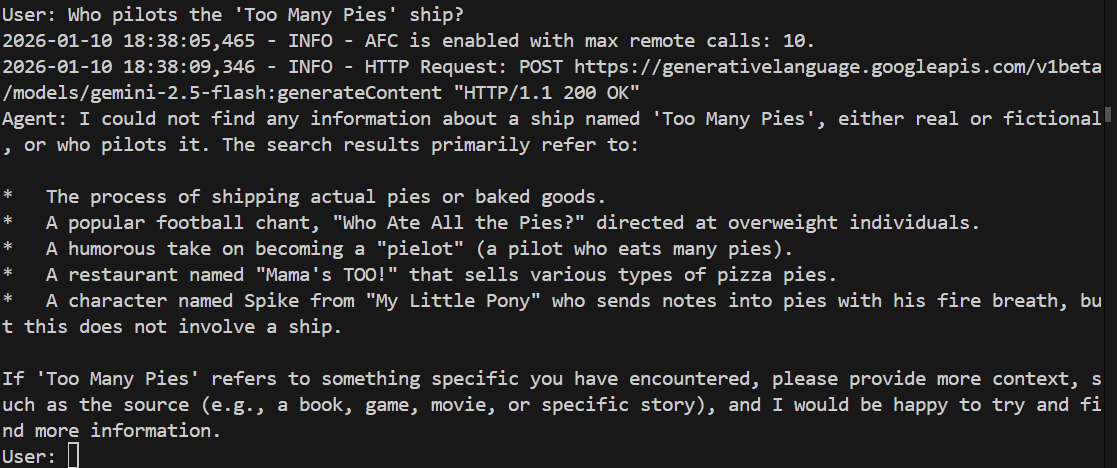
و مطمئناً، مدل در پاسخ به این سوال شکست میخورد. اصلاً نمیداند که ما در مورد چه چیزی صحبت میکنیم!
حالا برای خروج از عامل، quit را تایپ کنید.
۵. جستجوی فایل Gemini: توضیح داده شده
جستجوی فایل Gemini اساساً ترکیبی از دو چیز است:
- یک سیستم RAG کاملاً مدیریتشده : شما تعدادی فایل ارائه میدهید و جستجوی فایل Gemini عملیات تکهتکه کردن، جاسازی، ذخیرهسازی و نمایهسازی برداری را برای شما انجام میدهد.
- یک «ابزار» به معنای عامل : که در آن میتوانید به سادگی ابزار جستجوی فایل Gemini را به عنوان ابزاری در تعریف عامل خود اضافه کنید و ابزار را به یک فروشگاه جستجوی فایل هدایت کنید.
اما نکتهی مهم این است که این قابلیت در خودِ رابط برنامهنویسی نرمافزار Gemini تعبیه شده است . این یعنی برای استفاده از آن نیازی به فعال کردن هیچ رابط برنامهنویسی کاربردی (API) اضافی یا پیادهسازی هیچ محصول جداگانهای ندارید. بنابراین واقعاً آماده و بدون نیاز به نصب است.
ویژگیهای جستجوی فایل Gemini
در اینجا برخی از ویژگیها آورده شده است:
- جزئیات قطعهبندی، جاسازی، ذخیرهسازی و نمایهسازی از شما، به عنوان توسعهدهنده، انتزاعی است. این بدان معناست که شما نیازی به دانستن (یا اهمیت دادن) در مورد مدل جاسازی (که اتفاقاً Gemini Embeddings است) یا محل ذخیره بردارهای حاصل ندارید. شما مجبور نیستید هیچ تصمیمی در مورد پایگاه داده برداری بگیرید.
- این برنامه از تعداد زیادی از انواع سند به صورت پیشفرض پشتیبانی میکند. از جمله، اما نه محدود به: PDF، DOCX، Excel، SQL، JSON، Jupyter notebooks، HTML، Markdown، CSV و حتی فایلهای زیپ. میتوانید لیست کامل را اینجا مشاهده کنید. بنابراین، برای مثال، اگر میخواهید عامل خود را با فایلهای PDF حاوی متن، تصاویر و جداول راهاندازی کنید، نیازی به انجام پیشپردازش این فایلهای PDF ندارید. فقط PDFهای خام را آپلود کنید و بگذارید Gemini بقیه کار را انجام دهد.
- ما میتوانیم متادیتای سفارشی را به هر فایل آپلود شده اضافه کنیم. این میتواند برای فیلتر کردن فایلهایی که میخواهیم ابزار در زمان اجرا استفاده کند، بسیار مفید باشد.
دادهها کجا ذخیره میشوند؟
شما چند فایل آپلود میکنید. ابزار جستجوی فایل Gemini آن فایلها را گرفته، تکهها و سپس جاسازیها را ایجاد کرده و آنها را... در جایی قرار داده است. اما کجا؟
پاسخ: یک فروشگاه جستجوی فایل . این یک محفظه کاملاً مدیریتشده برای جاسازیهای شماست. لازم نیست بدانید (یا اهمیتی بدهید) که این کار چگونه در پشت صحنه انجام میشود. تنها کاری که باید انجام دهید این است که یکی (به صورت برنامهنویسی) ایجاد کنید و سپس فایلهای خود را در آن آپلود کنید.
ارزان است!
ذخیره و بررسی جاسازیهای شما رایگان است . بنابراین میتوانید جاسازیها را تا هر زمان که دوست دارید ذخیره کنید و برای این ذخیرهسازی هزینهای پرداخت نمیکنید!
در واقع، تنها چیزی که شما برای آن هزینه میکنید، ایجاد جاسازیها در زمان آپلود/ایندکس کردن است. در زمان نگارش این مطلب، هزینه آن برای هر ۱ میلیون توکن ۰.۱۵ دلار است. این مبلغ بسیار ارزان است.
۶. چگونه از جستجوی فایل Gemini استفاده کنیم؟
دو مرحله وجود دارد:
- جاسازیها را در یک فروشگاه جستجوی فایل ایجاد و ذخیره کنید.
- از نماینده خود، از فروشگاه جستجوی فایل، پرس و جو کنید.
مرحله ۱ - Jupyter Notebook برای ایجاد و مدیریت یک فروشگاه جستجوی فایل Gemini
این مرحله کاری است که شما در ابتدا انجام میدهید و سپس هر زمان که بخواهید فروشگاه را بهروزرسانی کنید، آن را انجام میدهید. به عنوان مثال، وقتی اسناد جدیدی برای اضافه کردن دارید یا وقتی اسناد منبع تغییر کردهاند.
این مرحله چیزی نیست که لازم باشد در برنامه عامل مستقر شده خود بگنجانید. مطمئناً، اگر بخواهید میتوانید این کار را انجام دهید. به عنوان مثال، اگر میخواهید نوعی رابط کاربری برای کاربران مدیر برنامه عامل خود ایجاد کنید. اما اغلب داشتن کمی کد که در صورت تقاضا اجرا کنید کاملاً کافی است. و یک راه عالی برای اجرای این کد در صورت تقاضا؟ یک نوت بوک Jupyter!
دفترچه یادداشت
فایل notebooks/file_search_store.ipynb در ویرایشگر خود باز کنید. اگر از شما خواسته شد افزونههای Jupyter VS Code را نصب کنید، لطفاً این کار را انجام دهید.
اگر آن را در ویرایشگر Cloud Shell باز کنیم، به این شکل خواهد بود:
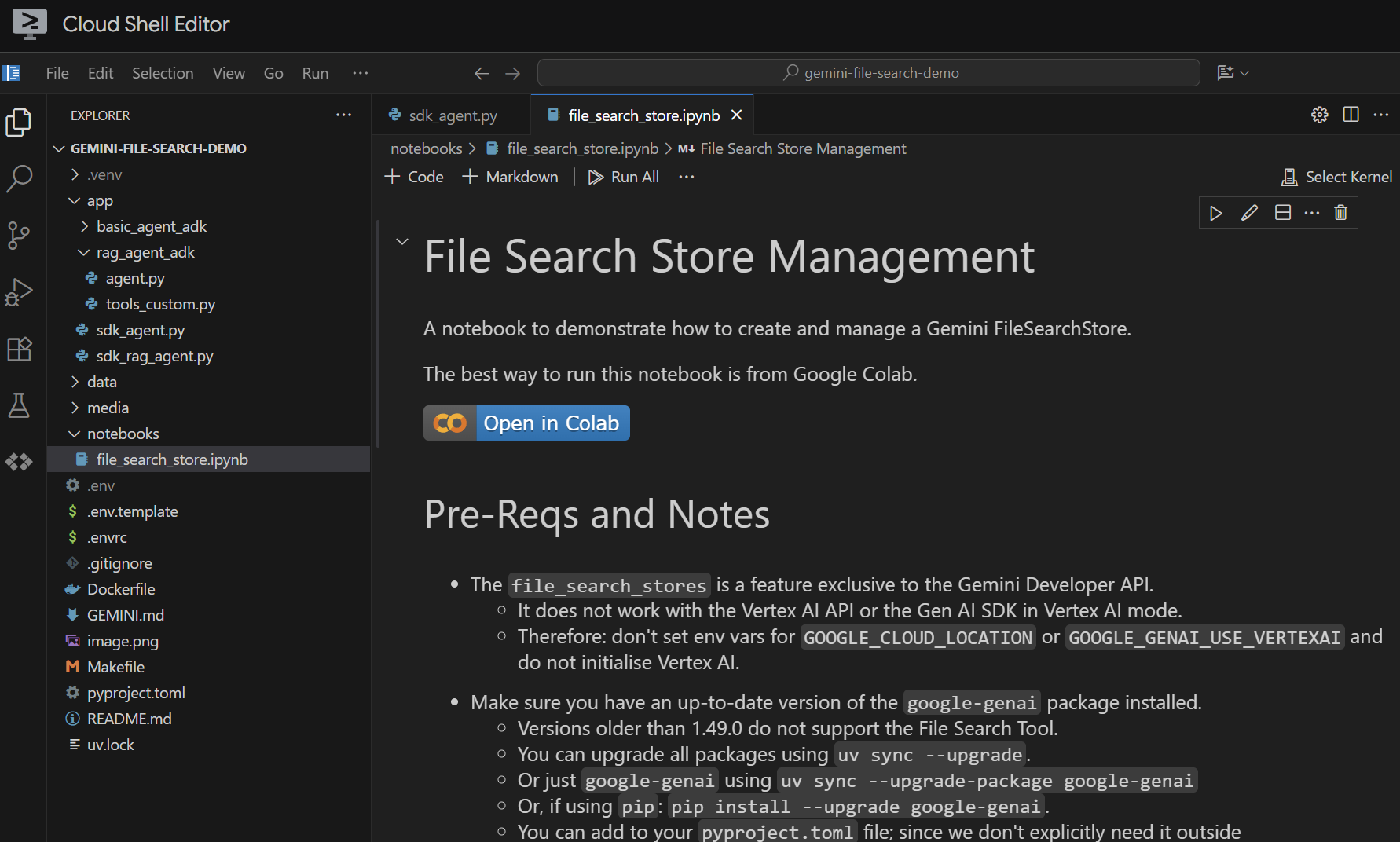
بیایید آن را سلول به سلول اجرا کنیم. با اجرای سلول Setup با وارد کردنهای مورد نیاز شروع کنید. اگر قبلاً نوتبوک را اجرا نکردهاید، از شما خواسته میشود افزونههای مورد نیاز را نصب کنید. این کار را انجام دهید. سپس از شما خواسته میشود یک هسته انتخاب کنید. " Python environments... " و سپس فایل .venv محلی را که هنگام اجرای make install قبلاً نصب کردیم، انتخاب کنید:
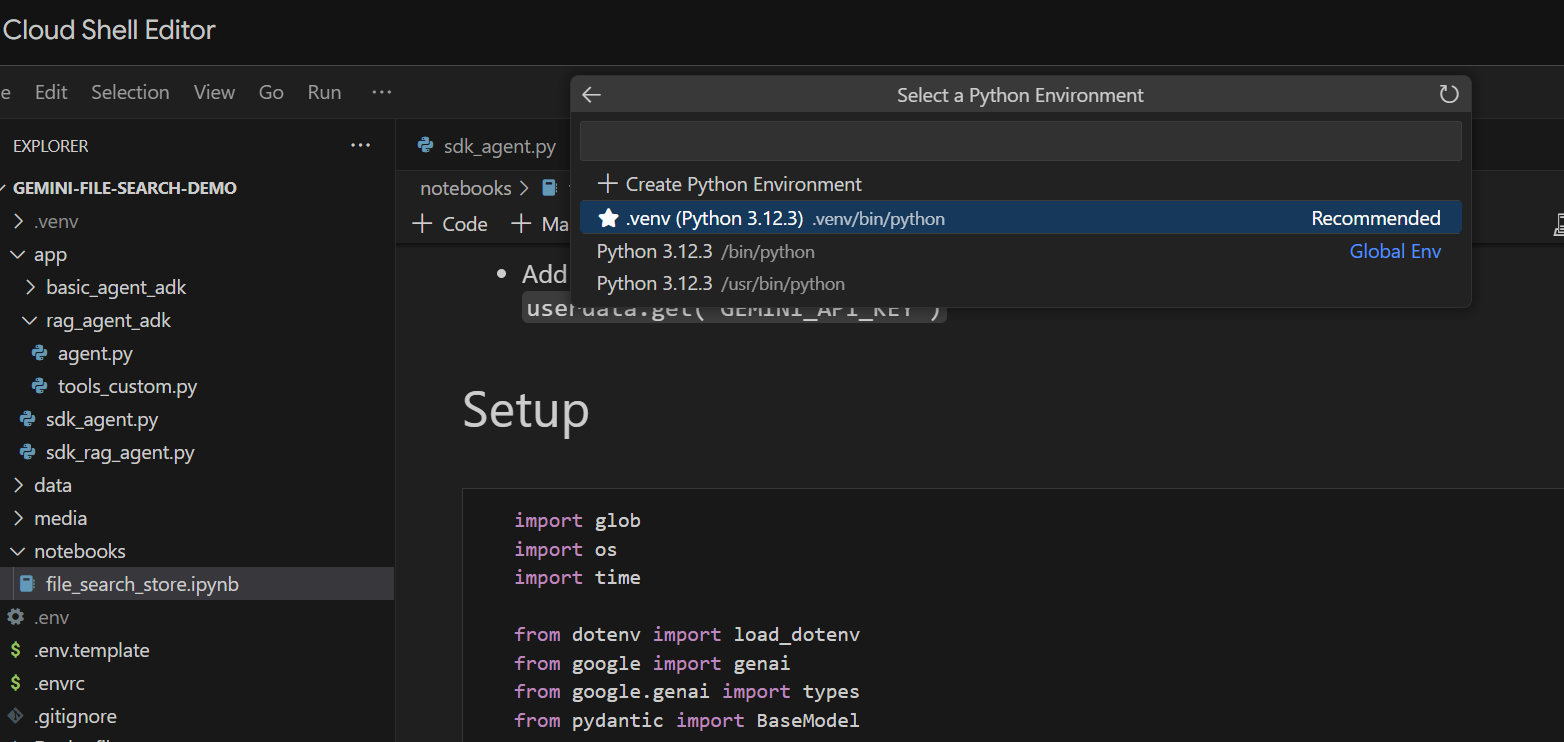
سپس:
- سلول « فقط محلی » را اجرا کنید تا متغیرهای محیطی را دریافت کنید.
- سلول "Client Initialisation" را برای مقداردهی اولیه Gemini Gen AI Client اجرا کنید.
- سلول "بازیابی فروشگاه" را با تابع کمکی برای بازیابی فروشگاه جستجوی فایل Gemini بر اساس نام اجرا کنید.
حالا آمادهایم تا فروشگاه را ایجاد کنیم.
- برای ایجاد فروشگاه، سلول «ایجاد فروشگاه (یک بار)» را اجرا کنید. ما فقط باید یک بار این کار را انجام دهیم. اگر کد با موفقیت اجرا شود، باید پیامی با عنوان
"Created store: fileSearchStores/<someid>"را ببینید. - سلول « مشاهده فروشگاه» را اجرا کنید تا ببینید چه چیزی در آن وجود دارد. در این مرحله، باید ببینید که حاوی 0 سند است.
عالیه! حالا ما یک فروشگاه جستجوی فایل Gemini آماده داریم.
بارگذاری دادهها
ما میخواهیم data/story.md را در فروشگاه آپلود کنیم. مراحل زیر را انجام دهید:
- سلولی که مسیر آپلود را تعیین میکند، اجرا کنید. این به پوشهی
data/ما اشاره دارد. - سلول بعدی را اجرا کنید که توابع کاربردی برای آپلود فایلها به فروشگاه را ایجاد میکند. توجه داشته باشید که کد موجود در این سلول همچنین از Gemini برای استخراج فراداده از هر فایل آپلود شده استفاده میکند. ما این مقادیر استخراج شده را گرفته و آنها را به عنوان فراداده سفارشی در فروشگاه ذخیره میکنیم. (نیازی به انجام این کار نیست، اما انجام آن مفید است.)
- سلول را برای آپلود فایل اجرا کنید. توجه داشته باشید که اگر قبلاً فایلی با همین نام آپلود کرده باشیم، نوتبوک ابتدا نسخه موجود را قبل از آپلود نسخه جدید حذف میکند. باید پیامی مبنی بر آپلود فایل مشاهده کنید.
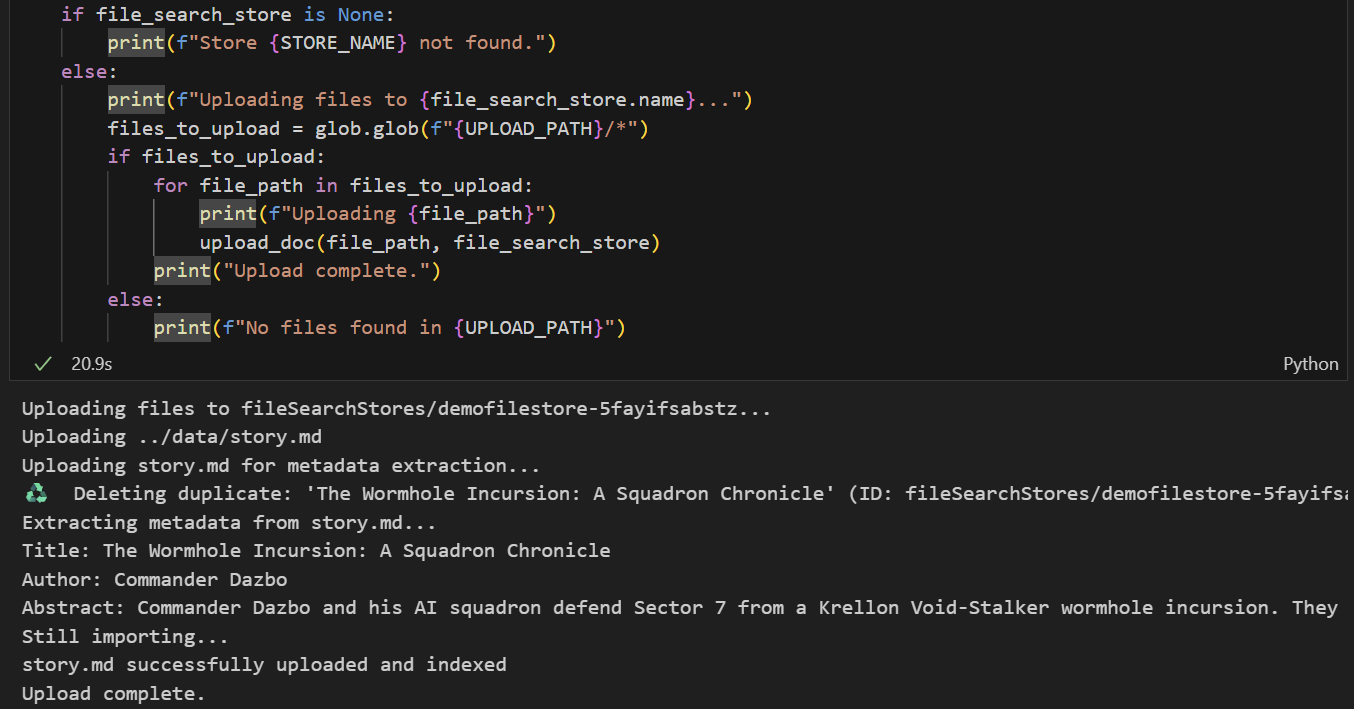
مرحله ۲ - پیادهسازی RAG جستجوی فایل Gemini در Agent ما
ما یک فروشگاه جستجوی فایل Gemini ایجاد کردهایم و داستان خود را در آن آپلود کردهایم. اکنون زمان آن رسیده است که از فروشگاه جستجوی فایل در عامل خود استفاده کنیم. بیایید یک عامل جدید ایجاد کنیم که به جای جستجوی گوگل از فروشگاه جستجوی فایل استفاده میکند. نگاهی به app/sdk_rag_agent.py بیندازید.
اولین نکتهای که باید به آن توجه کنید این است که ما یک تابع برای بازیابی فروشگاه خود با ارسال نام فروشگاه پیادهسازی کردهایم:
def get_store(client: genai.Client, store_name: str) -> types.FileSearchStore | None:
"""Retrieve a store by display name"""
try:
for a_store in client.file_search_stores.list():
if a_store.display_name == store_name:
return a_store
except Exception as e:
logger.error(f"Error listing stores: {e}")
return None
وقتی فروشگاه خود را داشتیم، استفاده از آن به سادگی اتصال آن به عنوان ابزاری به عامل ما است، مانند این:
file_search_tool = types.Tool(file_search=types.FileSearch(file_search_store_names=[store.name]))
اجرای عامل RAG
ما آن را به این صورت راه اندازی می کنیم:
make sdk-rag-agent # Or, without make: uv run python app/sdk_rag_agent.py
بیایید سوالی را بپرسیم که نماینده قبلی نتوانست به آن پاسخ دهد:
> Who pilots the 'Too Many Pies' ship?
و پاسخ؟
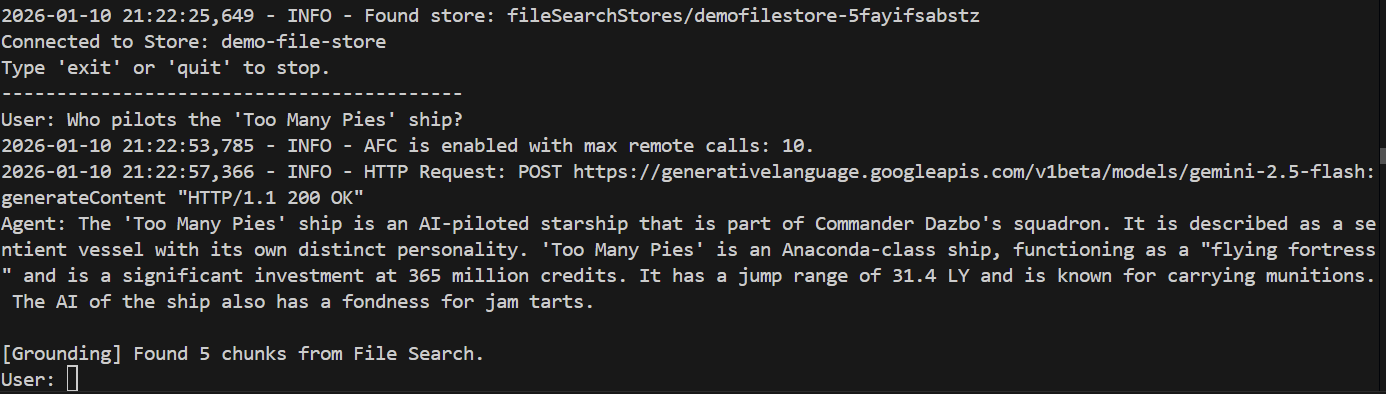
موفقیت! از پاسخ میتوانیم ببینیم که:
- از فروشگاه فایل ما برای پاسخ به این سوال استفاده شد.
- ۵ قطعه مرتبط پیدا شد.
- جواب کاملاً واضح است!
برای بستن عامل، quit را تایپ کنید.
۷. تبدیل نمایندگان ما به استفاده از ADK
کیت توسعه عامل گوگل (ADK) یک چارچوب ماژولار متنباز و SDK برای توسعهدهندگان است تا عاملها و سیستمهای عاملمحور را بسازند. این کیت به ما امکان میدهد سیستمهای چندعامله را به راحتی ایجاد و هماهنگ کنیم. ADK در حالی که برای Gemini و اکوسیستم گوگل بهینه شده است، مستقل از مدل و مستقل از استقرار است و برای سازگاری با سایر چارچوبها ساخته شده است. اگر هنوز از ADK استفاده نکردهاید، برای کسب اطلاعات بیشتر به مستندات ADK مراجعه کنید.
عامل ADK پایه با جستجوی گوگل
به app/basic_agent_adk/agent.py نگاهی بیندازید. در این کد نمونه میتوانید ببینید که ما در واقع دو عامل را پیادهسازی کردهایم:
- یک
root_agentکه تعامل با کاربر را مدیریت میکند، و جایی است که ما دستورالعمل اصلی سیستم را ارائه دادهایم. - یک
SearchAgentجداگانه کهgoogle.adk.tools.google_searchبه عنوان ابزار استفاده میکند.
root_agent در واقع از SearchAgent به عنوان ابزاری استفاده میکند که با استفاده از این خط پیادهسازی شده است:
tools=[AgentTool(agent=search_agent)],
اعلان سیستم عامل ریشه به این شکل است:
You are a helpful AI assistant designed to provide accurate and useful information.
If you don't know the answer, use the SearchAgent to perform a Google search.
Do not attempt to search more than ONCE.
If the search yields no relevant results or returns unrelated content, you MUST immediately respond with: "I could not find any information about that."
Do NOT retry the search with different terms. Do NOT ask for clarification. FAIL FAST.
امتحان کردن عامل
ADK تعدادی رابط کاربری آماده ارائه میدهد تا توسعهدهندگان بتوانند عاملهای ADK خود را آزمایش کنند. یکی از این رابطها، رابط کاربری وب است. این به ما امکان میدهد عاملهای خود را در یک مرورگر آزمایش کنیم، بدون اینکه مجبور باشیم حتی یک خط کد رابط کاربری بنویسیم!
میتوانیم این رابط را با اجرای دستور زیر راهاندازی کنیم:
make adk-playground # Or, without make: uv run adk web app --port 8501 --reload_agents
توجه داشته باشید که این دستور، ابزار adk web را به پوشه app هدایت میکند، جایی که به طور خودکار هر ADK agent که root_agent پیادهسازی میکند، پیدا میکند. پس بیایید آن را امتحان کنیم:
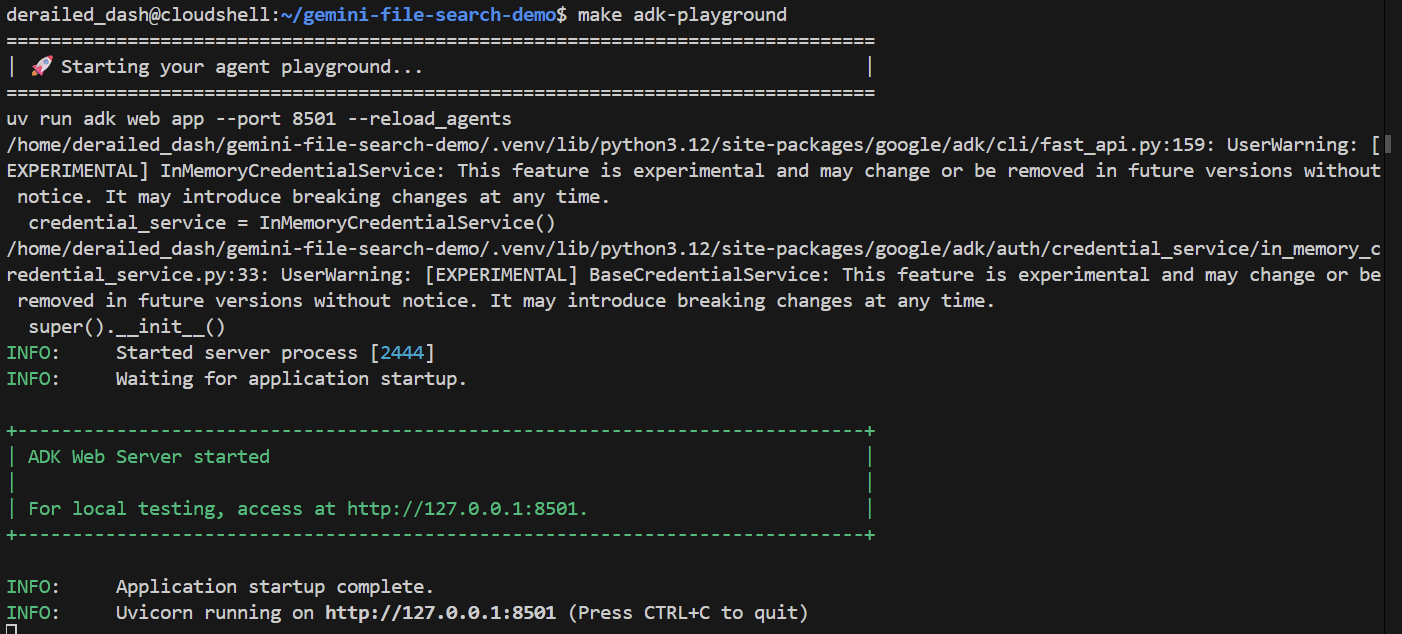
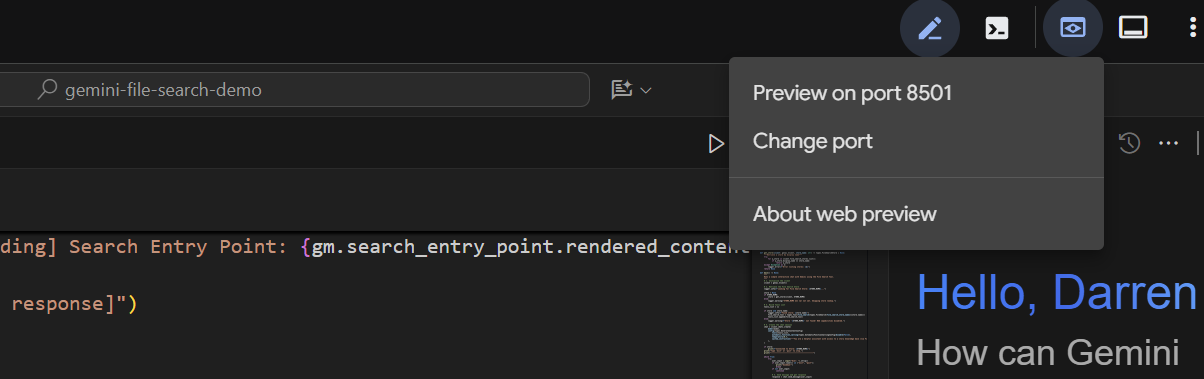
بعد از چند ثانیه، برنامه آماده است. اگر کد را به صورت محلی اجرا میکنید، کافیست در مرورگر خود به http://127.0.0.1:8501 بروید. اگر در ویرایشگر Cloud Shell اجرا میکنید، روی « پیشنمایش وب » کلیک کنید و پورت را به 8501 تغییر دهید:
وقتی رابط کاربری ظاهر شد، از منوی کشویی basic_agent_adk را انتخاب کنید، و سپس میتوانیم از آن سوالاتی بپرسیم:
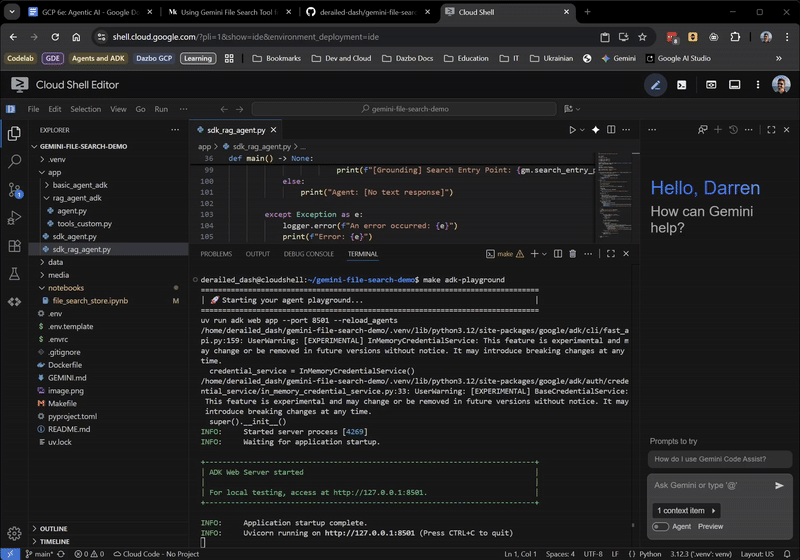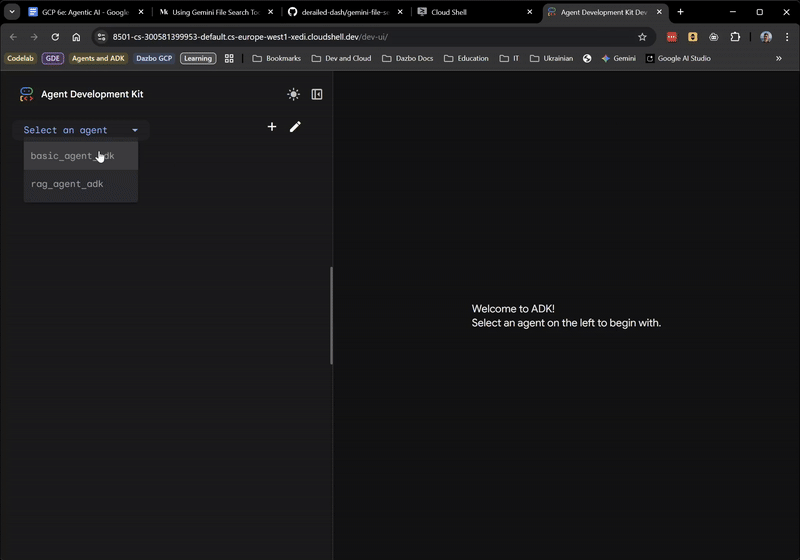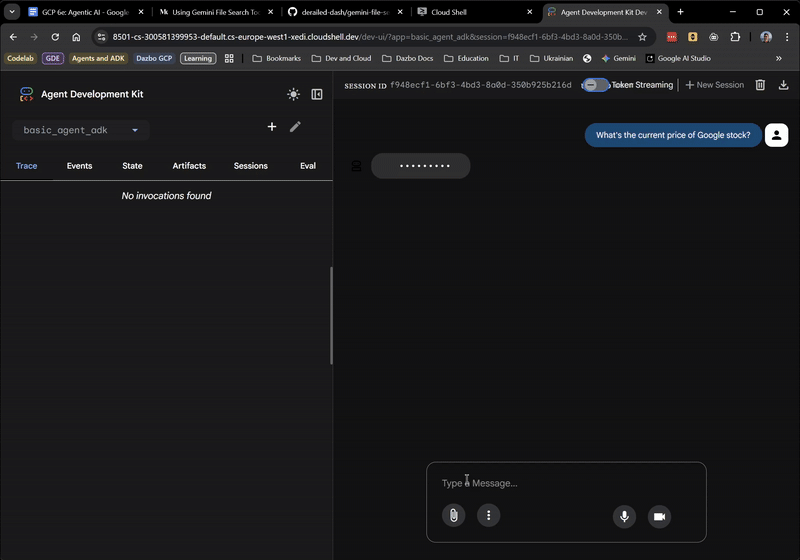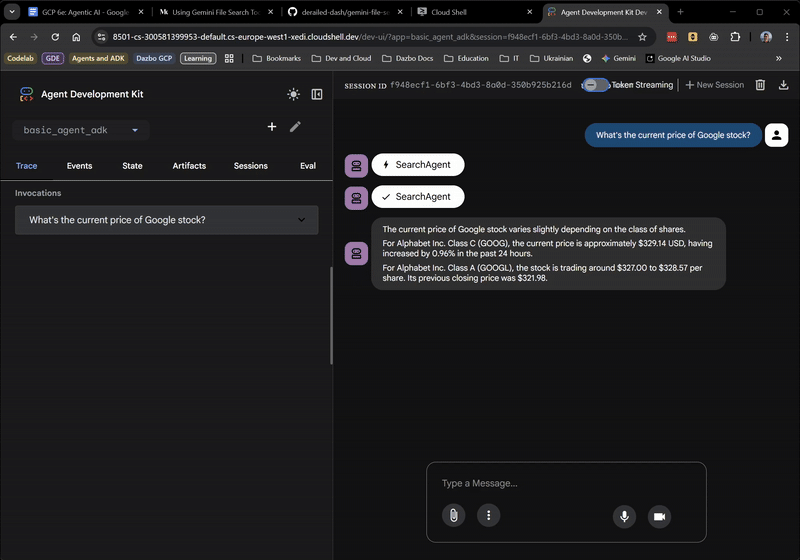
تا اینجا که خوب بوده! رابط کاربری تحت وب حتی به شما نشان میدهد که چه زمانی عامل ریشه در حال واگذاری وظایف به SearchAgent است. این یک ویژگی بسیار مفید است.
حالا بیایید سوال خودمان را که نیاز به دانستن داستان ما دارد، بپرسیم:
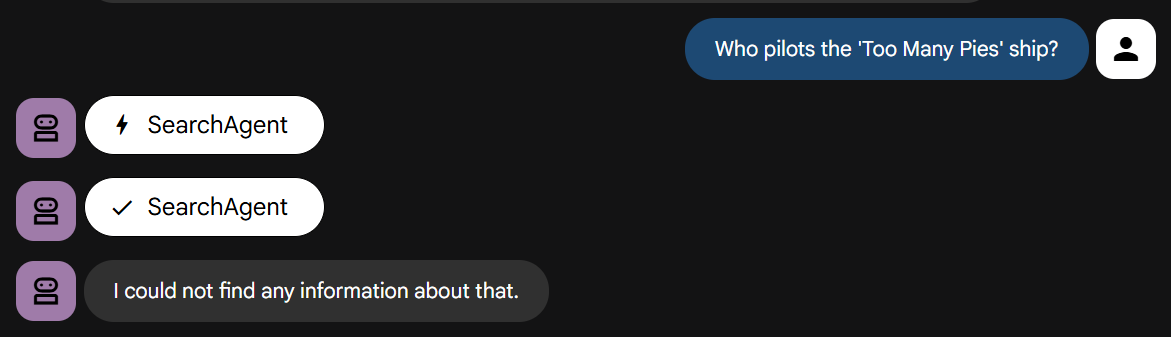
خودتان امتحان کنید. همانطور که گفته شد، باید متوجه شوید که به سرعت از کار میافتد.
گنجاندن فروشگاه جستجوی فایل در عامل ADK
حالا میخواهیم همه چیز را کنار هم بگذاریم. قرار است یک ADK agent اجرا کنیم که بتواند هم از File Search Store و هم از Google Search استفاده کند. به کد موجود در app/rag_agent_adk/agent.py نگاهی بیندازید.
کد مشابه مثال قبلی است، اما با چند تفاوت کلیدی:
- ما یک نماینده ریشه داریم که دو نماینده متخصص را هماهنگ میکند:
- RagAgent : متخصص دانش سفارشی - با استفاده از فروشگاه جستجوی فایل Gemini ما
- SearchAgent : متخصص دانش عمومی - با استفاده از جستجوی گوگل
- از آنجا که ADK هنوز یک wrapper داخلی برای
FileSearchندارد، ما از یک کلاس wrapper سفارشیFileSearchToolبرای wrap کردن ابزار FileSearch استفاده میکنیم که پیکربندیfile_search_store_namesرا به درخواست مدل سطح پایین تزریق میکند. این پیکربندی در اسکریپت جداگانهapp/rag_agent_adk/tools_custom.pyپیادهسازی شده است.
همچنین، یک نکته وجود دارد که باید مراقب آن باشید. در زمان نگارش این مطلب، شما نمیتوانید از ابزار بومی GoogleSearch و ابزار FileSearch در یک درخواست به یک عامل استفاده کنید. اگر این کار را امتحان کنید، با خطایی مانند این مواجه خواهید شد:
خطا - خطایی رخ داده است: ۴۰۰ INVALID_ARGUMENT. {'error': {'code': 400, 'message': 'جستجو به عنوان یک ابزار و ابزار جستجوی فایل با هم پشتیبانی نمیشوند', 'status': 'INVALID_ARGUMENT'}}
خطا: ۴۰۰ INVALID_ARGUMENT. {'error': {'code': 400, 'message': 'جستجو به عنوان یک ابزار و ابزار جستجوی فایل با هم پشتیبانی نمیشوند', 'status': 'INVALID_ARGUMENT'}}
راه حل این است که دو عامل متخصص را به عنوان زیرعاملهای جداگانه پیادهسازی کنیم و آنها را با استفاده از الگوی عامل به عنوان ابزار به عامل ریشه منتقل کنیم. و نکته مهم این است که دستورالعمل سیستم عامل ریشه، راهنمایی بسیار روشنی برای استفاده از RagAgent در ابتدا ارائه میدهد:
شما یک دستیار هوش مصنوعی مفید هستید که برای ارائه اطلاعات دقیق و مفید طراحی شدهاید.
شما به دو نماینده متخصص دسترسی دارید:
- RagAgent: برای اطلاعات سفارشی از پایگاه دانش داخلی.
- SearchAgent: برای اطلاعات کلی از جستجوی گوگل.
همیشه ابتدا RagAgent را امتحان کنید. اگر این هم جواب مفیدی نداد، SearchAgent را امتحان کنید.
آزمون نهایی
رابط کاربری وب ADK را مانند قبل اجرا کنید:
make adk-playground # Or, without make: uv run adk web app --port 8501 --reload_agents
این بار، rag_agent_adk را در رابط کاربری انتخاب کنید. بیایید آن را در عمل ببینیم: 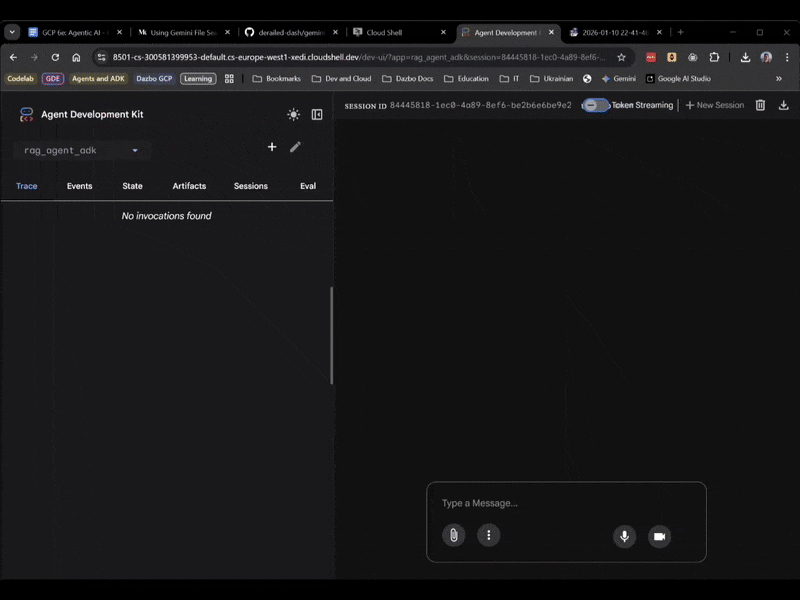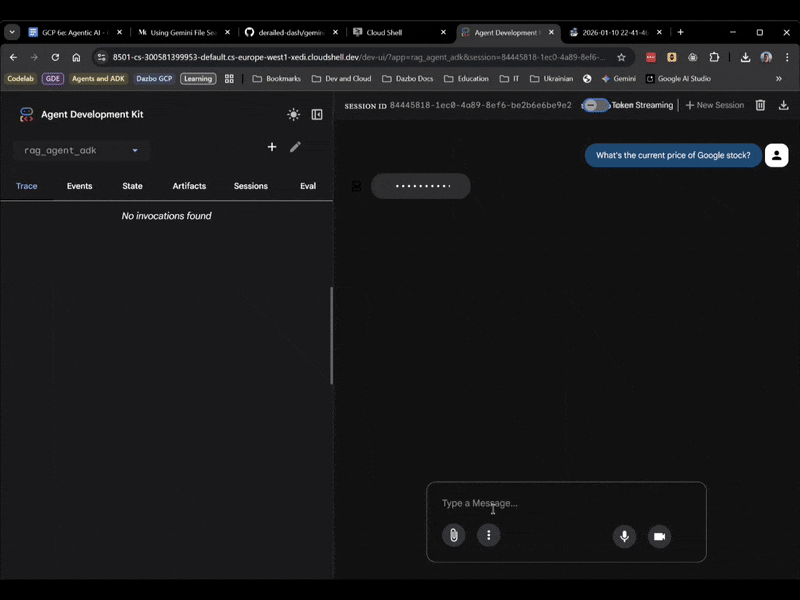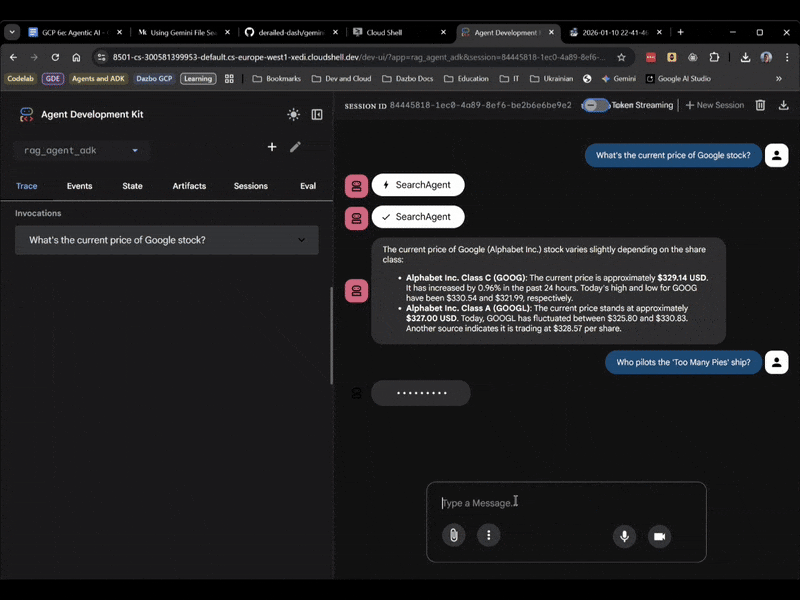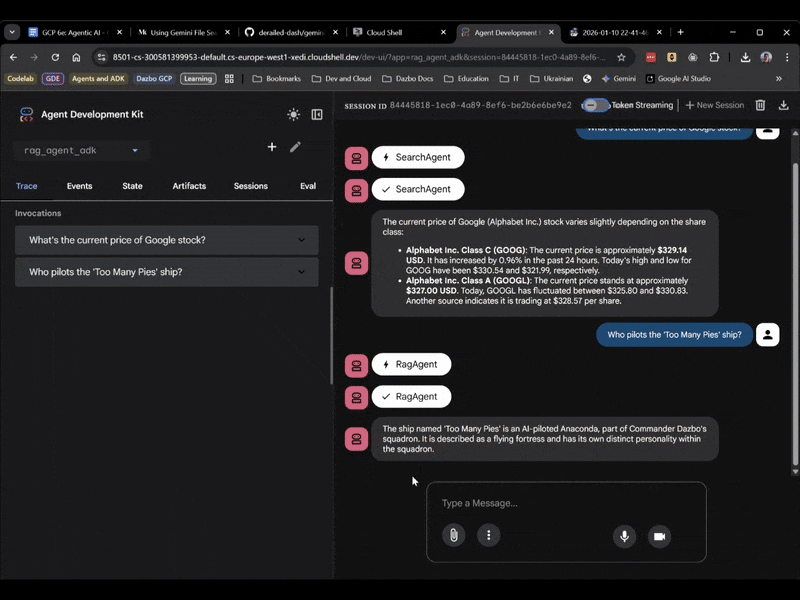
میتوانیم ببینیم که بر اساس سوال، زیرعامل مناسب را انتخاب میکند.
۸. نتیجهگیری
تبریک میگویم که این آزمایشگاه کد را به پایان رساندید!
شما از یک اسکریپت ساده به یک سیستم چندعاملی با قابلیت RAG رسیدهاید؛ همه اینها بدون حتی یک خط کد جاسازی و بدون نیاز به پیادهسازی یک پایگاه داده برداری!
ما یاد گرفتیم:
- جستجوی فایل Gemini یک راهکار مدیریتشدهی RAG است که باعث صرفهجویی در زمان و صرفهجویی در هزینه میشود.
- ADK ساختار مورد نیاز برای برنامههای پیچیده چندعاملی را در اختیار ما قرار میدهد و از طریق رابطهایی مانند رابط کاربری وب، راحتی را برای توسعهدهندگان فراهم میکند.
- الگوی «عامل به عنوان ابزار» مشکلات سازگاری ابزار را حل میکند.
امیدوارم این آزمایشگاه برای شما مفید بوده باشد. دفعه بعد میبینمت!