
1. Introduction
Cet atelier de programmation vous explique comment utiliser la recherche de fichiers Gemini pour activer la RAG dans votre application agentique. Vous utiliserez la recherche de fichiers Gemini pour ingérer et indexer vos documents sans avoir à vous soucier des détails concernant le découpage, l'embedding ou la base de données vectorielle.
Au programme
- Principes de base du RAG et pourquoi nous en avons besoin.
- Découvrez la recherche de fichiers Gemini et ses avantages.
- Découvrez comment créer un File Search Store.
- Découvrez comment importer vos propres fichiers personnalisés dans la boutique de recherche de fichiers.
- Utiliser l'outil de recherche de fichiers Gemini pour le RAG
- Avantages de l'utilisation de Google Agent Development Kit (ADK)
- Comment utiliser l'outil de recherche de fichiers Gemini dans une solution agentique créée à l'aide de l'ADK.
- Découvrez comment utiliser l'outil de recherche de fichiers Gemini avec les outils "natifs" de Google, comme la recherche Google.
Objectifs de l'atelier
- Créez un projet Google Cloud et configurez votre environnement de développement.
- Créez un agent simple basé sur Gemini à l'aide du SDK Google Gen AI (mais sans ADK) qui peut utiliser la recherche Google, mais sans capacité RAG.
- démontrer son incapacité à fournir des informations précises et de haute qualité pour des informations personnalisées ;
- Créez un notebook Jupyter (que vous pouvez exécuter localement ou, par exemple, sur Google Colab) pour créer et gérer un Gemini File Search Store.
- Utilisez le notebook pour importer du contenu personnalisé dans le File Search Store.
- Créez un agent auquel le File Search Store est associé et prouvez qu'il est capable de générer de meilleures réponses.
- Convertir notre agent "de base" initial en agent ADK, avec l'outil de recherche Google
- Testez l'agent à l'aide de l'UI Web d'ADK.
- Intégrez le File Search Store à l'agent ADK, en utilisant le modèle Agent-As-A-Tool pour nous permettre d'utiliser l'outil de recherche de fichiers en même temps que l'outil de recherche Google.
2. Qu'est-ce que le RAG et pourquoi en avons-nous besoin ?
Donc bon... Génération augmentée par récupération.
Si vous êtes ici, vous savez probablement ce que c'est, mais faisons un petit récapitulatif, au cas où. Les LLM (comme Gemini) sont brillants, mais ils présentent quelques problèmes :
- Elles sont toujours obsolètes : elles ne connaissent que ce qu'elles ont appris lors de l'entraînement.
- Ils ne savent pas tout : les modèles sont certes énormes, mais ils ne sont pas omniscients.
- Elles ne connaissent pas vos informations propriétaires : elles disposent de connaissances générales, mais n'ont pas lu vos documents internes, vos blogs ni vos tickets Jira.
Ainsi, lorsque vous posez une question à un modèle dont il ne connaît pas la réponse, vous obtenez généralement une réponse incorrecte, voire inventée. Souvent, le modèle fournira cette réponse incorrecte avec assurance. C'est ce que l'on appelle une hallucination.
Une solution consiste à simplement déverser nos informations propriétaires directement dans le contexte de la conversation. Cette méthode convient pour une petite quantité d'informations, mais devient rapidement problématique lorsque vous en avez beaucoup. Plus précisément, cela entraîne les problèmes suivants :
- Latence : le modèle fournit des réponses de plus en plus lentes.
- La détérioration du signal, également appelée "perte d'informations en milieu de séquence", se produit lorsque le modèle n'est plus en mesure de trier les données pertinentes des données inutiles. Le modèle ignore une grande partie du contexte.
- Coût : les jetons ont un coût.
- Fenêtre de contexte épuisée : à ce stade, Gemini ne traitera pas vos demandes.
Une façon beaucoup plus efficace de remédier à cette situation consiste à utiliser le RAG. Il s'agit simplement de rechercher des informations pertinentes dans vos sources de données (à l'aide de la correspondance sémantique) et de fournir des blocs pertinents de ces données au modèle en même temps que votre question. Elle ancre le modèle dans votre réalité.
Pour ce faire, il importe des données externes, les découpe en blocs, les convertit en représentations vectorielles continues, puis stocke et indexe ces représentations dans une base de données vectorielle appropriée.
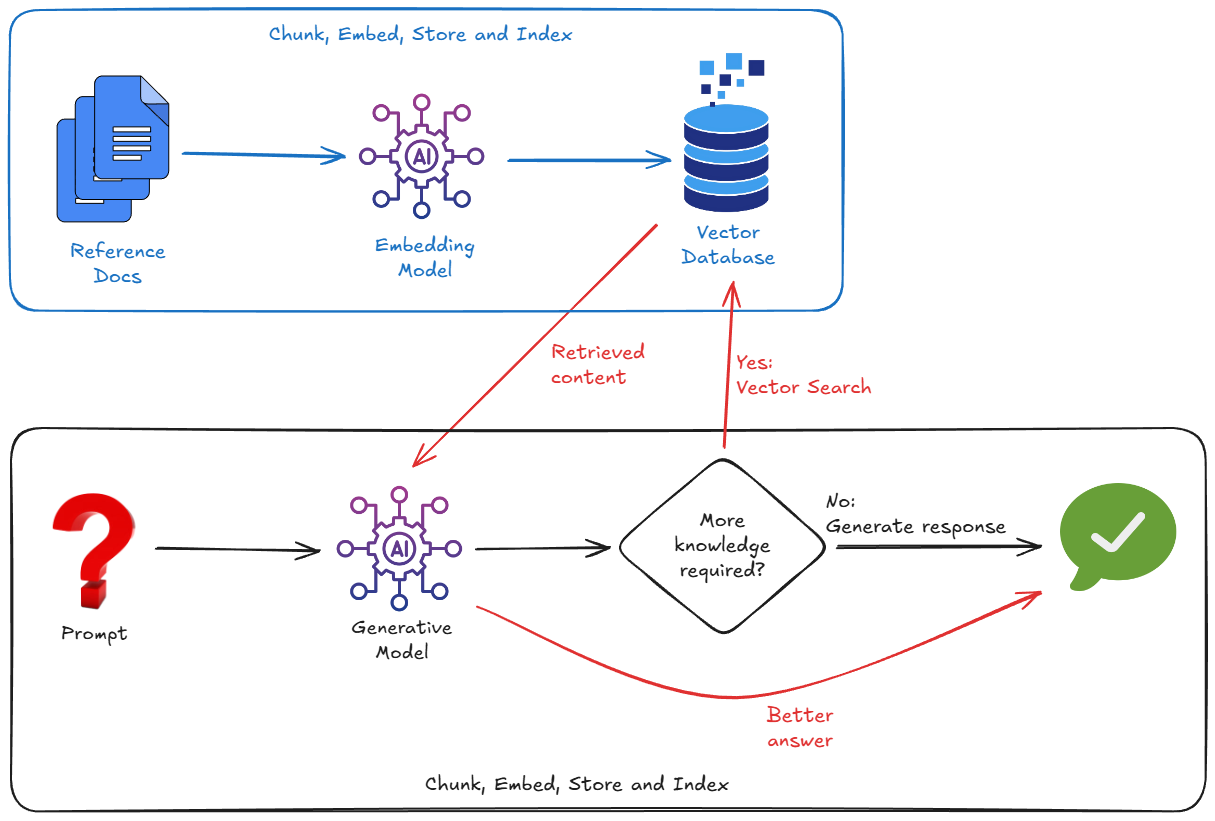
Pour implémenter le RAG, nous devons généralement nous soucier des éléments suivants :
- Création d'une base de données vectorielle (Pinecone, Weaviate, Postgres avec pgvector, etc.).
- Écrire un script de segmentation pour découper vos documents (PDF, Markdown, etc.).
- Générer des embeddings (vecteurs) pour ces blocs à l'aide d'un modèle d'embedding
- Stockage des vecteurs dans la base de données vectorielle.
Mais les amis ne laissent pas les amis sur-concevoir les choses. Et si je vous disais qu'il existe un moyen plus simple ?
3. Prérequis
Créer un projet Google Cloud
Pour suivre cet atelier de programmation, vous avez besoin d'un projet Google Cloud. Vous pouvez utiliser un projet existant ou en créer un.
Assurez-vous que la facturation est activée pour votre projet. Consultez ce guide pour savoir comment vérifier l'état de facturation de vos projets.
Notez que cet atelier de programmation ne devrait rien vous coûter. Au maximum, quelques centimes.
Préparez votre projet. Je vais attendre.
Cloner le dépôt de démonstration
J'ai créé un dépôt avec du contenu guidé pour cet atelier de programmation. Vous en aurez besoin !
Exécutez les commandes suivantes à partir de votre terminal ou de celui intégré à l'éditeur Cloud Shell de Google. Cloud Shell et son éditeur sont très pratiques, car toutes les commandes dont vous avez besoin sont préinstallées et tout fonctionne "prêt à l'emploi".
git clone https://github.com/derailed-dash/gemini-file-search-demo cd gemini-file-search-demo
Cet arbre montre les dossiers et fichiers clés du dépôt :
gemini-file-search-demo/ ├── app/ │ ├── basic_agent_adk/ # Agent with Google Search, using ADK framework │ │ └── agent.py │ ├── rag_agent_adk/ # Agent with Google Search and File Search, using ADK framework │ │ ├── agent.py │ │ └── tools_custom.py │ ├── sdk_agent.py # Agent using GenAI SDK (no ADK) with Google Search tool │ └── sdk_rag_agent.py # Agent using GenAI SDK (no ADK) with Gemini File Search tool ├── data/ │ └── story.md # Sample story with "bespoke content" to use with Gemini File Search Store ├── notebooks/ │ └── file_search_store.ipynb # Jupyter notebook for creating and managing Gemini File Search Store │ ├── .env.template # Template for environment variables - make a copy as .env ├── Makefile # Makefile for `make` commands ├── pyproject.toml # Project configuration and dependencies └── README.md # This file
Ouvrez ce dossier dans l'éditeur Cloud Shell ou dans l'éditeur de votre choix. (Avez-vous déjà utilisé Antigravity ? Si ce n'est pas le cas, c'est le moment de l'essayer.)
Notez que le dépôt contient un exemple d'histoire ("The Wormhole Incursion") dans le fichier data/story.md. Je l'ai coécrit avec Gemini ! Il s'agit du commandant Dazbo et de son escadron de vaisseaux spatiaux intelligents. (Je me suis inspiré du jeu Elite Dangerous.) Cette histoire sert de "base de connaissances personnalisée". Elle contient des faits spécifiques que Gemini ne connaît pas et qu'il ne peut pas rechercher à l'aide de la recherche Google.
Configurer votre environnement de développement
Pour plus de commodité, j'ai fourni un Makefile afin de simplifier de nombreuses commandes que vous devez exécuter. Au lieu de mémoriser des commandes spécifiques, vous pouvez simplement exécuter une commande comme make <target>. Toutefois, make n'est disponible que dans les environnements Linux / macOS / WSL. Si vous utilisez Windows (sans WSL), vous devrez exécuter les commandes complètes contenues dans les cibles make.
# Install dependencies with make make install # If you don't have make... uv sync --extra jupyter
Voici ce que vous obtenez lorsque vous exécutez make install dans l'éditeur Cloud Shell :
Créer une clé API Gemini
Pour utiliser l'API Gemini Developer (dont nous avons besoin pour utiliser l'outil de recherche de fichiers Gemini), vous avez besoin d'une clé API Gemini. Le moyen le plus simple d'obtenir une clé API consiste à utiliser Google AI Studio, qui fournit une interface pratique pour obtenir des clés API pour vos projets Google Cloud. Pour connaître la procédure à suivre, consultez ce guide.
Une fois votre clé API créée, copiez-la et conservez-la en lieu sûr.
Vous devez maintenant définir cette clé API comme variable d'environnement. Pour ce faire, nous pouvons utiliser un fichier .env. Copiez le fichier .env.example inclus et enregistrez-le sous le nom .env. Le fichier doit se présenter comme suit :
export GEMINI_API_KEY="your-api-key" export MODEL="gemini-2.5-flash" export STORE_NAME="demo-file-store"
Remplacez your-api-key par votre véritable clé API. Le résultat devrait se présenter comme suit :
Assurez-vous maintenant que les variables d'environnement sont chargées. Pour ce faire, exécutez la commande suivante :
source .env
4. L'agent de base
Commençons par établir une référence. Nous allons utiliser le SDK google-genai brut pour exécuter un agent simple.
Le code
Regardez le fichier app/sdk_agent.py. Il s'agit d'une implémentation minimale qui :
- Elle instancie un
genai.Client. - Active l'outil
google_search. - Et voilà ! Pas de RAG.
Examinez le code et assurez-vous de comprendre ce qu'il fait.
Exécuter l'application
# With make make sdk-agent # Without make uv run python app/sdk_agent.py
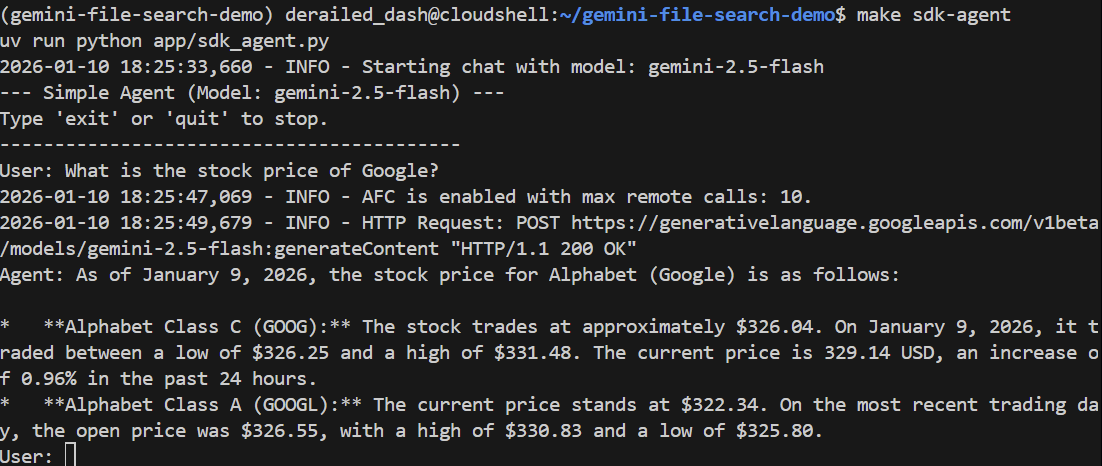
Posons-lui une question générale :
> What is the stock price of Google?
Il doit répondre correctement en utilisant la recherche Google pour trouver le prix actuel :
Maintenant, posons-lui une question à laquelle il ne sait pas répondre. L'agent doit avoir lu notre histoire.
> Who pilots the 'Too Many Pies' ship?
Il devrait échouer ou même halluciner. Voyons voir :
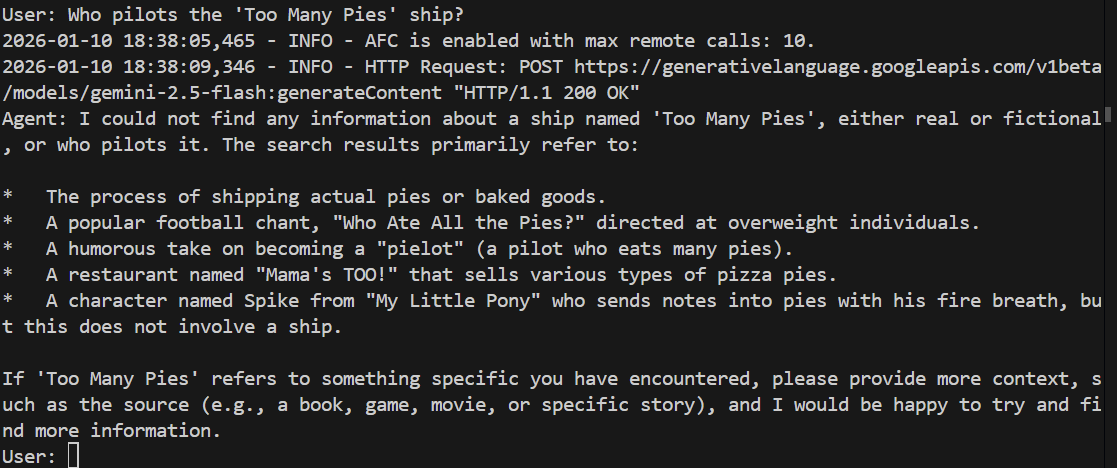
Et effectivement, le modèle ne parvient pas à répondre à la question. Il n'a aucune idée de ce dont nous parlons !
Saisissez maintenant quit pour quitter l'agent.
5. Présentation de la recherche de fichiers Gemini
La recherche de fichiers Gemini est essentiellement une combinaison de deux éléments :
- Un système RAG entièrement géré : vous fournissez un ensemble de fichiers, et Gemini Recherche de fichiers s'occupe du découpage, de l'intégration, du stockage et de l'indexation vectorielle pour vous.
- Un "outil" au sens agentique : vous pouvez simplement ajouter l'outil de recherche de fichiers Gemini en tant qu'outil dans la définition de votre agent et le rediriger vers un File Search Store.
Mais surtout, il est intégré à l'API Gemini elle-même. Cela signifie que vous n'avez pas besoin d'activer d'API supplémentaires ni de déployer de produits distincts pour l'utiliser. Il est donc out-of-the-box.
Fonctionnalités de recherche de fichiers Gemini
Découvrez ici quelques-unes de ses fonctionnalités.
- Les détails du découpage, de l'intégration, du stockage et de l'indexation sont abstraits pour vous, le développeur. Cela signifie que vous n'avez pas besoin de connaître (ni de vous soucier) du modèle d'embedding (qui est Gemini Embeddings, au passage) ni de l'emplacement de stockage des vecteurs résultants. Vous n'avez pas besoin de prendre de décision concernant la base de données vectorielles.
- Il est compatible avec un grand nombre de types de documents prêts à l'emploi. y compris, mais sans s'y limiter, les fichiers PDF, DOCX, Excel, SQL, JSON, les notebooks Jupyter, les fichiers HTML, Markdown, CSV et même les fichiers ZIP. Vous pouvez consulter la liste complète ici. Par exemple, si vous souhaitez ancrer votre agent avec des fichiers PDF contenant du texte, des images et des tableaux, vous n'avez pas besoin de prétraiter ces fichiers PDF. Il vous suffit d'importer les PDF bruts et de laisser Gemini s'occuper du reste.
- Vous pouvez ajouter des métadonnées personnalisées à n'importe quel fichier importé. Cela peut être très utile pour filtrer ensuite les fichiers que nous voulons que l'outil utilise, au moment de l'exécution.
Où sont stockées les données ?
Vous importez des fichiers. L'outil de recherche de fichiers Gemini a pris ces fichiers, créé les blocs, puis les embeddings, et les a placés quelque part. Mais où ?
La réponse : un File Search Store. Il s'agit d'un conteneur entièrement géré pour vos embeddings. Vous n'avez pas besoin de savoir (ni de vous soucier) comment cela se fait en interne. Il vous suffit d'en créer un (par programmation), puis d'y importer vos fichiers.
C'est bon marché !
Le stockage et l'interrogation de vos embeddings sont sans frais. Vous pouvez donc stocker des embeddings aussi longtemps que vous le souhaitez, sans frais.
En fait, la seule chose que vous payez est la création des embeddings au moment de l'importation/de l'indexation. Au moment de la rédaction de cet article, cela coûte 0,15 $par million de jetons. C'est plutôt bon marché.
6. Comment utilisons-nous la recherche de fichiers Gemini ?
Il existe deux phases :
- Créez et stockez les embeddings dans un File Search Store.
- Interrogez le File Search Store depuis votre agent.
Étape 1 : Notebook Jupyter pour créer et gérer un Gemini File Search Store
Cette phase doit être effectuée initialement, puis chaque fois que vous souhaitez mettre à jour le magasin. Par exemple, lorsque vous avez de nouveaux documents à ajouter ou lorsque les documents sources ont été modifiés.
Cette phase n'est pas quelque chose que vous devez inclure dans votre application agentique déployée. Oui, vous pouvez le faire si vous le souhaitez. Par exemple, si vous souhaitez créer une interface utilisateur pour les administrateurs de votre application agentique. Toutefois, il est souvent tout à fait suffisant d'avoir un peu de code que vous exécutez à la demande. Et quel est le meilleur moyen d'exécuter ce code à la demande ? Un notebook Jupyter !
The Notebook
Ouvrez le fichier notebooks/file_search_store.ipynb dans votre éditeur. Si vous êtes invité à installer des extensions Jupyter VS Code, faites-le.
Si nous l'ouvrons dans l'éditeur Cloud Shell, il se présente comme suit :
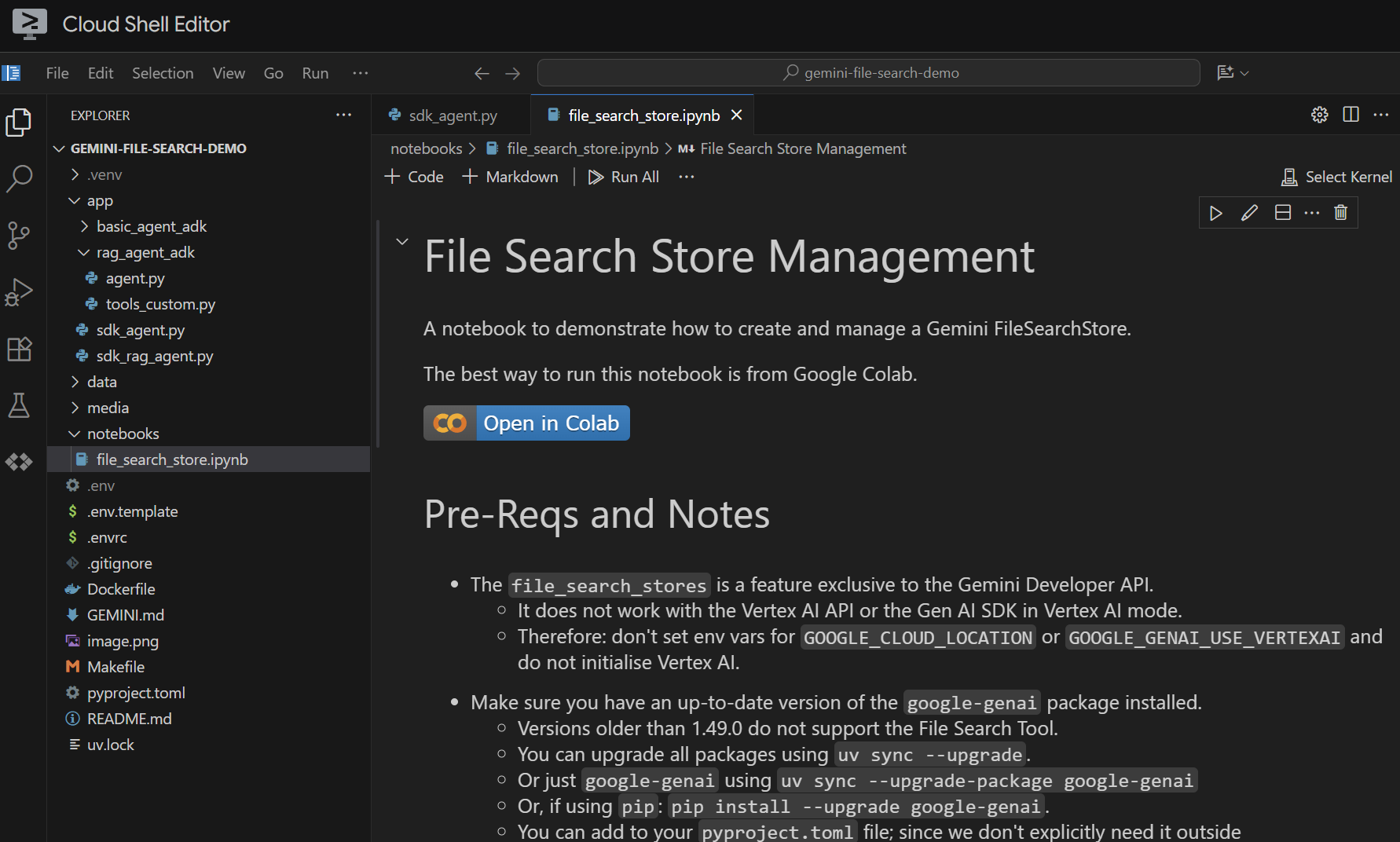
Exécutons-le cellule par cellule. Commencez par exécuter la cellule Setup avec les importations requises. Si vous n'avez jamais exécuté de notebook, vous serez invité à installer les extensions requises. Faites-le. Vous serez ensuite invité à sélectionner un kernel. Sélectionnez "Python environments...", puis le .venv local que nous avons installé lorsque nous avons exécuté make install précédemment :
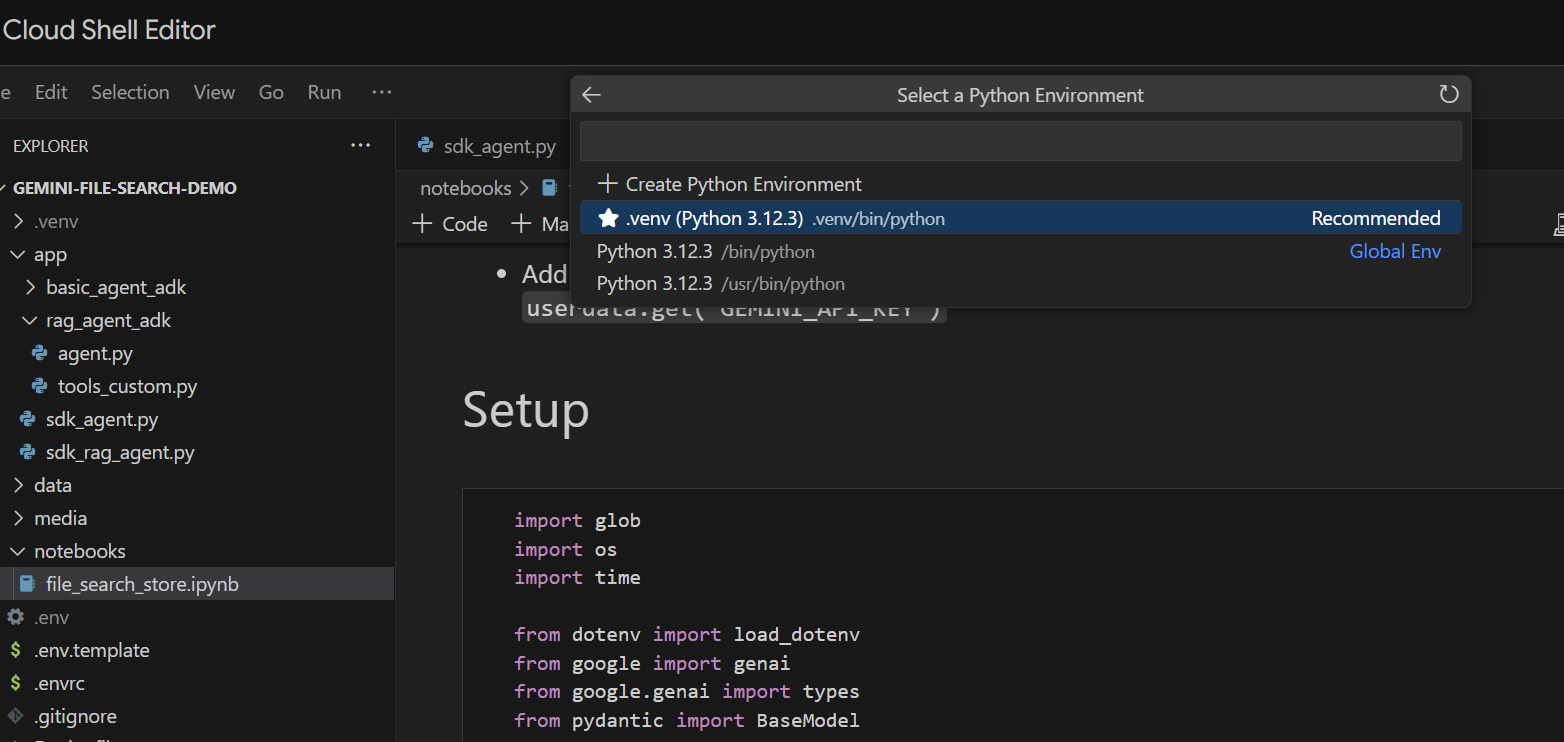
Ensuite :
- Exécutez la cellule Local Only (Local uniquement) pour extraire les variables d'environnement.
- Exécutez la cellule Client Initialisation (Initialisation du client) pour initialiser le client Gemini Gen AI.
- Exécutez la cellule Retrieve the Store (Récupérer le Store) avec la fonction d'assistance permettant de récupérer le Gemini File Search Store par nom.
Nous sommes maintenant prêts à créer le magasin.
- Exécutez la cellule Create the Store (One Time) pour créer le magasin. Nous n'avons besoin de le faire qu'une seule fois. Si le code s'exécute correctement, le message
"Created store: fileSearchStores/<someid>"s'affiche. - Exécutez la cellule Afficher le magasin pour voir son contenu. À ce stade, vous devriez constater qu'il contient zéro document.
Parfait ! Nous disposons maintenant d'un Gemini File Search Store prêt à l'emploi.
Importer les données
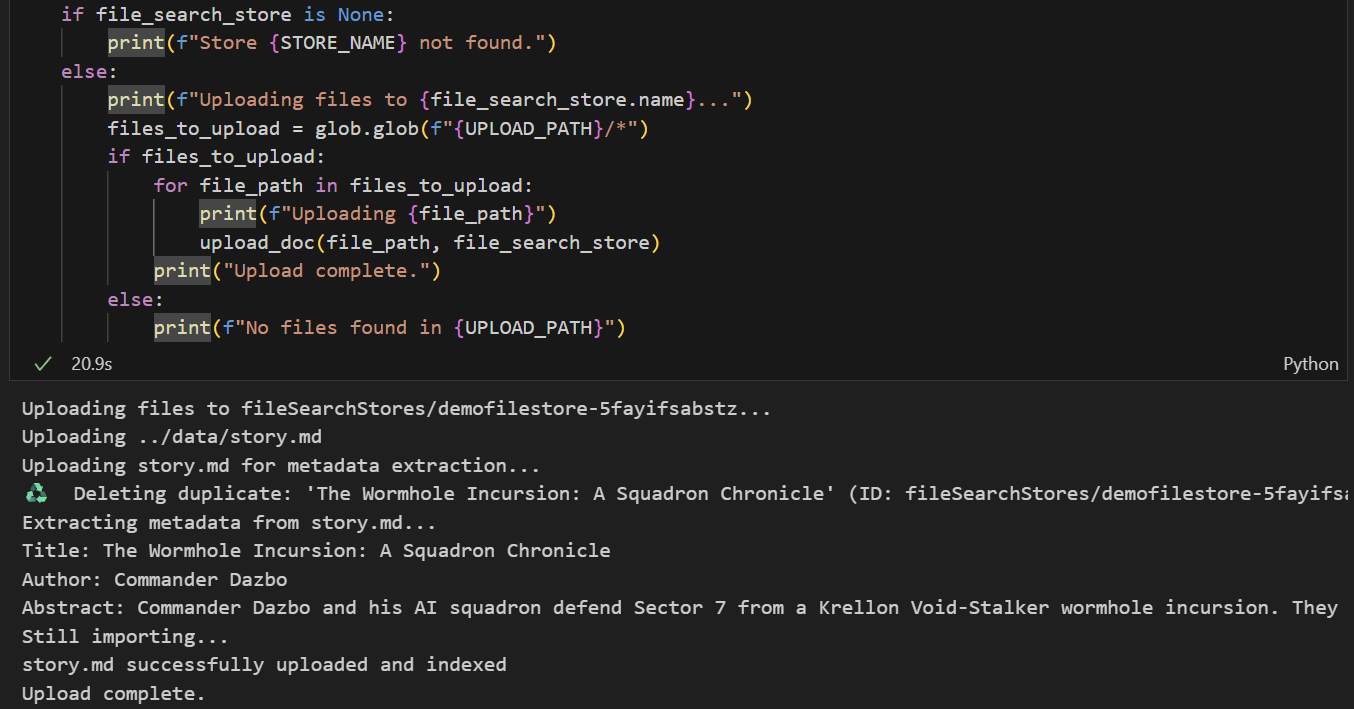
Nous voulons importer data/story.md dans le magasin. Procédez comme suit :
- Exécutez la cellule qui définit le chemin d'accès à l'importation. Il pointe vers notre dossier
data/. - Exécutez la cellule suivante, qui crée des fonctions utilitaires pour importer des fichiers dans le magasin. Notez que le code de cette cellule utilise également Gemini pour extraire les métadonnées de chaque fichier importé. Nous extrayons ces valeurs et les stockons en tant que métadonnées personnalisées dans le magasin. (Vous n'êtes pas obligé de le faire, mais c'est une bonne pratique.)
- Exécutez la cellule pour importer le fichier. Notez que si nous avons déjà importé un fichier portant le même nom, le notebook supprimera d'abord la version existante avant d'importer la nouvelle. Un message indiquant que le fichier a été importé doit s'afficher.
Phase 2 : Implémenter le RAG de recherche de fichiers Gemini dans notre agent
Nous avons créé un Gemini File Search Store et y avons importé notre histoire. Il est maintenant temps d'utiliser le File Search Store dans notre agent. Nous allons créer un agent qui utilise le File Search Store au lieu de la recherche Google. Regardez le fichier app/sdk_rag_agent.py.
La première chose à noter est que nous avons implémenté une fonction pour récupérer notre magasin en transmettant un nom de magasin :
def get_store(client: genai.Client, store_name: str) -> types.FileSearchStore | None:
"""Retrieve a store by display name"""
try:
for a_store in client.file_search_stores.list():
if a_store.display_name == store_name:
return a_store
except Exception as e:
logger.error(f"Error listing stores: {e}")
return None
Une fois que nous avons notre magasin, l'utiliser est aussi simple que de l'associer en tant qu'outil à notre agent, comme ceci :
file_search_tool = types.Tool(file_search=types.FileSearch(file_search_store_names=[store.name]))
Exécuter l'agent RAG
Pour le lancer, procédez comme suit :
make sdk-rag-agent # Or, without make: uv run python app/sdk_rag_agent.py
Posons la question à laquelle l'agent précédent n'a pas pu répondre :
> Who pilots the 'Too Many Pies' ship?
Et la réponse ?
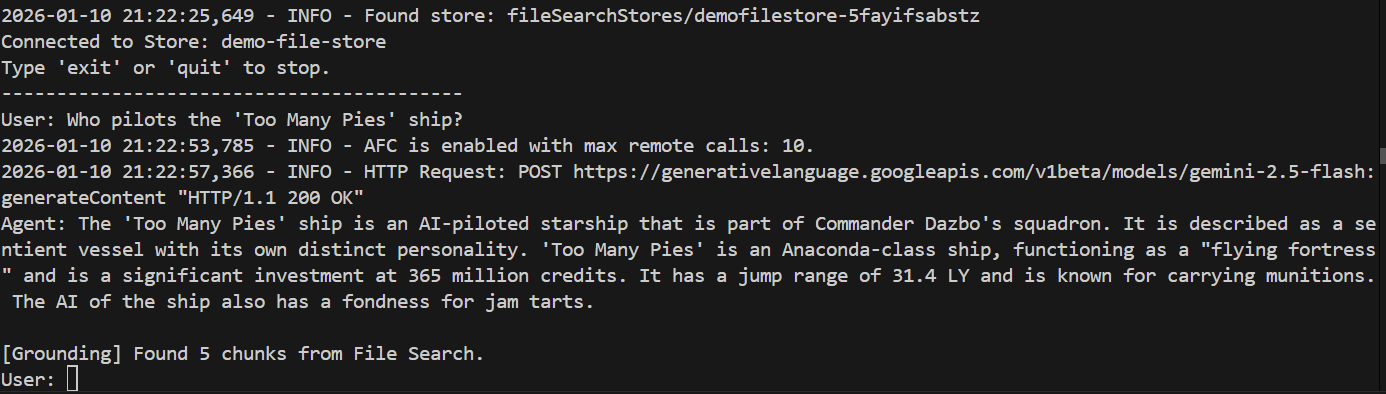
Opération réussie ! La réponse indique que :
- Notre dépôt de fichiers a été utilisé pour répondre à la question.
- 5 blocs pertinents ont été trouvés.
- La réponse est parfaite !
Saisissez quit pour fermer l'agent.
7. Convertir nos agents pour qu'ils utilisent ADK
Google Agent Development Kit (ADK) est un framework et un SDK modulaires Open Source permettant aux développeurs de créer des agents et des systèmes agentiques. Il nous permet de créer et d'orchestrer facilement des systèmes multi-agents. Bien qu'il soit optimisé pour Gemini et l'écosystème Google, l'ADK est indépendant des modèles et des déploiements, et est conçu pour être compatible avec d'autres frameworks. Si vous n'avez pas encore utilisé l'ADK, consultez la documentation de l'ADK pour en savoir plus.
Agent ADK de base avec la recherche Google
Regardez le fichier app/basic_agent_adk/agent.py. Dans cet exemple de code, vous pouvez voir que nous avons implémenté deux agents :
- Un
root_agentqui gère l'interaction avec l'utilisateur et où nous avons fourni l'instruction système principale. - Un
SearchAgentdistinct qui utilisegoogle.adk.tools.google_searchcomme outil.
root_agent utilise en fait SearchAgent comme outil, qui est implémenté à l'aide de cette ligne :
tools=[AgentTool(agent=search_agent)],
La requête système de l'agent racine se présente comme suit :
You are a helpful AI assistant designed to provide accurate and useful information.
If you don't know the answer, use the SearchAgent to perform a Google search.
Do not attempt to search more than ONCE.
If the search yields no relevant results or returns unrelated content, you MUST immediately respond with: "I could not find any information about that."
Do NOT retry the search with different terms. Do NOT ask for clarification. FAIL FAST.
Essayer l'agent
L'ADK fournit plusieurs interfaces prêtes à l'emploi pour permettre aux développeurs de tester leurs agents ADK. L'une de ces interfaces est l'interface utilisateur Web. Cela nous permet de tester nos agents dans un navigateur, sans avoir à écrire une ligne de code d'interface utilisateur.
Nous pouvons lancer cette interface en exécutant la commande suivante :
make adk-playground # Or, without make: uv run adk web app --port 8501 --reload_agents
Notez que la commande pointe l'outil adk web vers le dossier app, où il détectera automatiquement tous les agents ADK qui implémentent un root_agent. Faisons un essai :
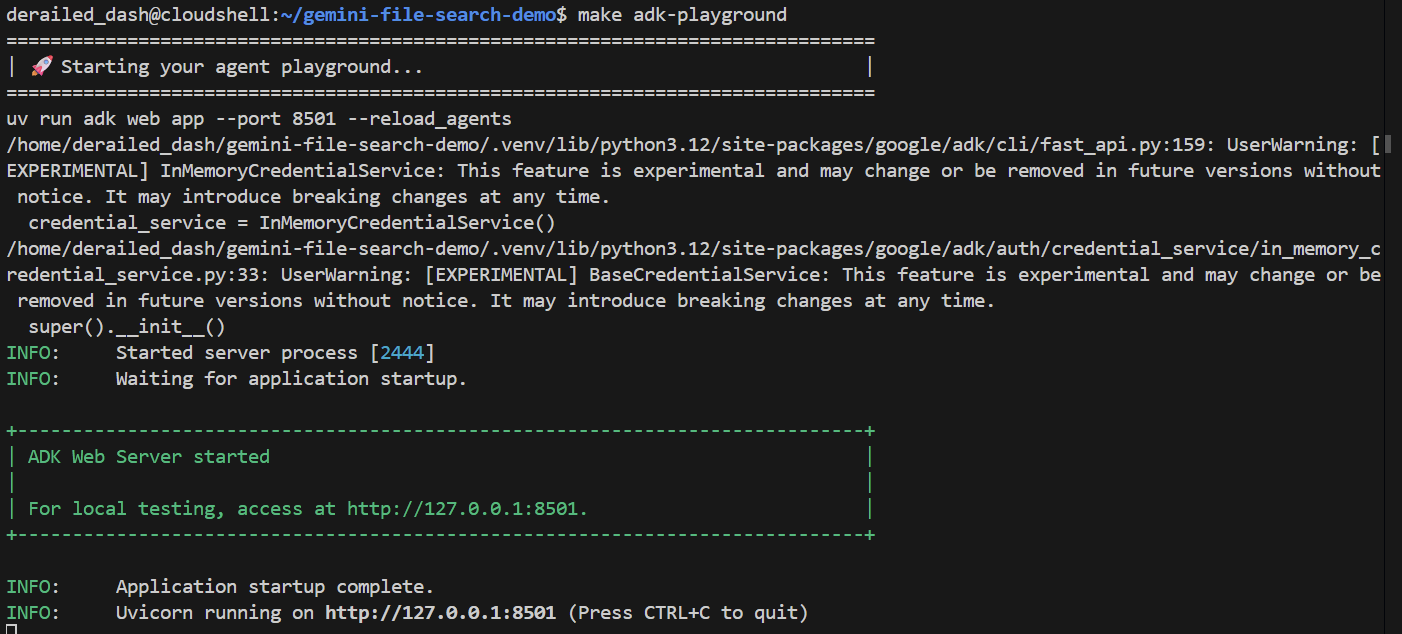
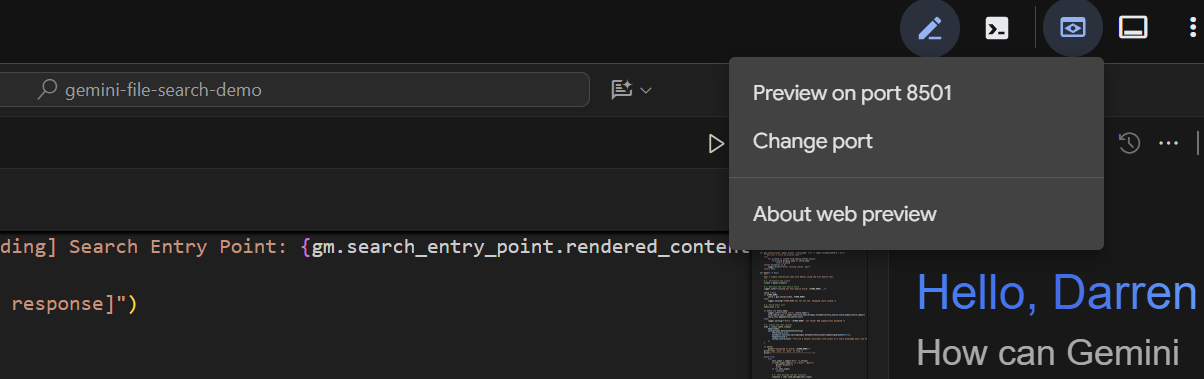
Après quelques secondes, l'application est prête. Si vous exécutez le code en local, il vous suffit de diriger votre navigateur vers http://127.0.0.1:8501. Si vous exécutez le code dans l'éditeur Cloud Shell, cliquez sur Aperçu Web, puis remplacez le port par 8501 :
Lorsque l'UI s'affiche, sélectionnez basic_agent_adk dans le menu déroulant, puis posez-lui des questions :
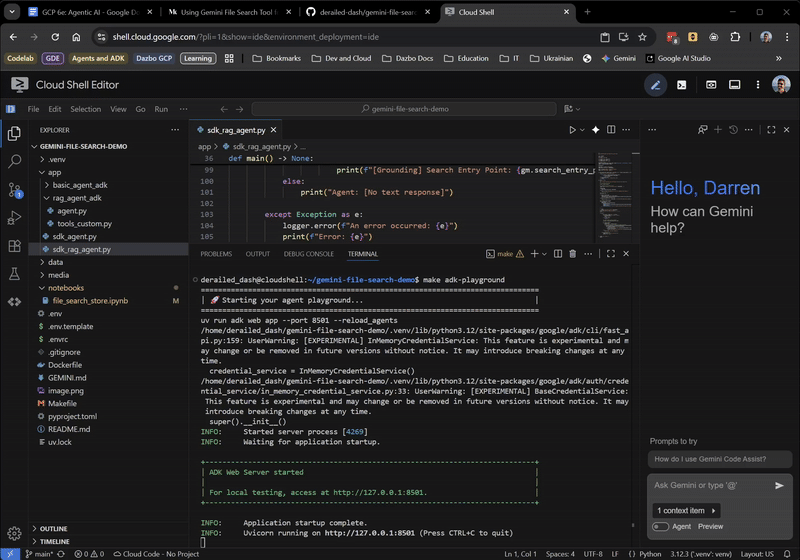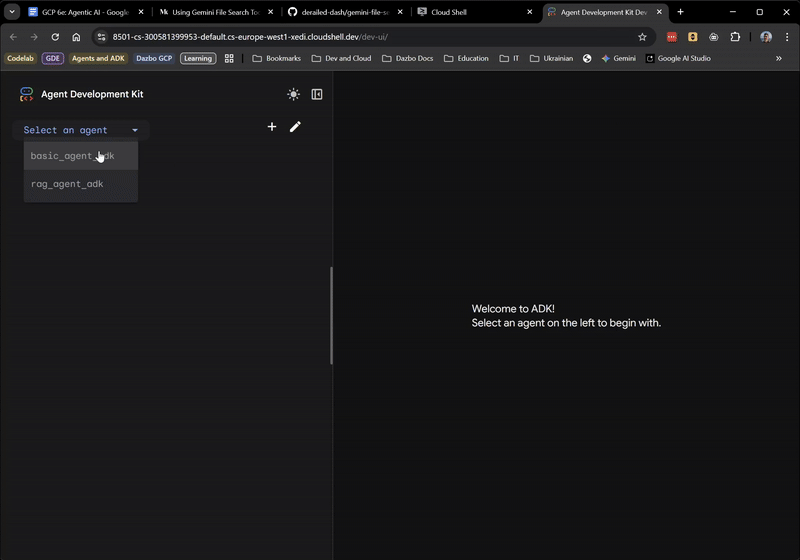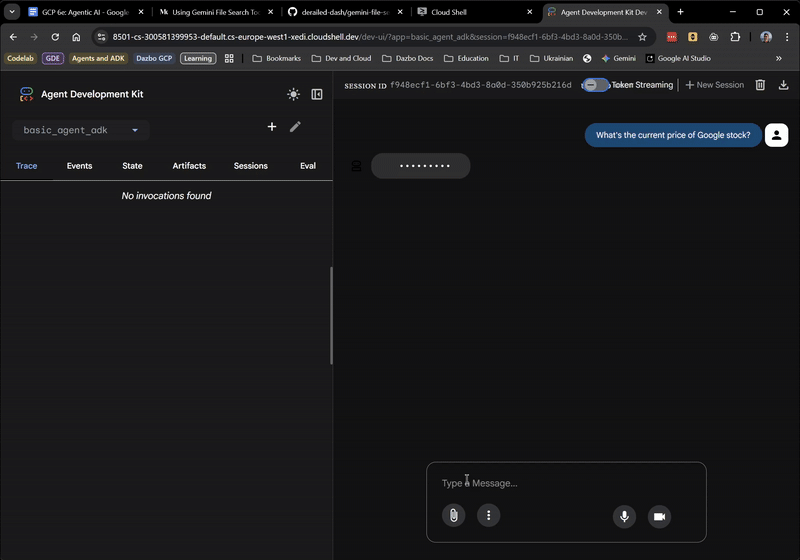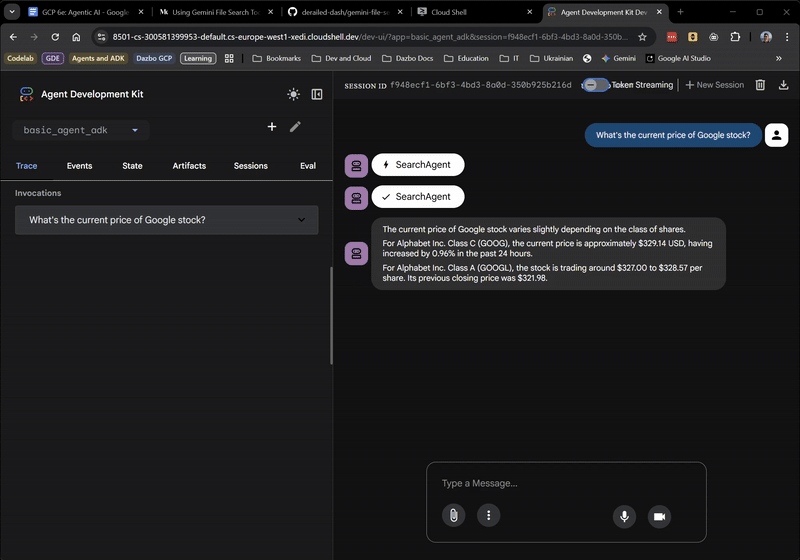
Aucun problème pour le moment ! L'UI Web vous indique même quand l'agent racine délègue à SearchAgent. Il s'agit d'une fonctionnalité très utile.
Posons-lui maintenant notre question qui nécessite une connaissance de notre histoire :
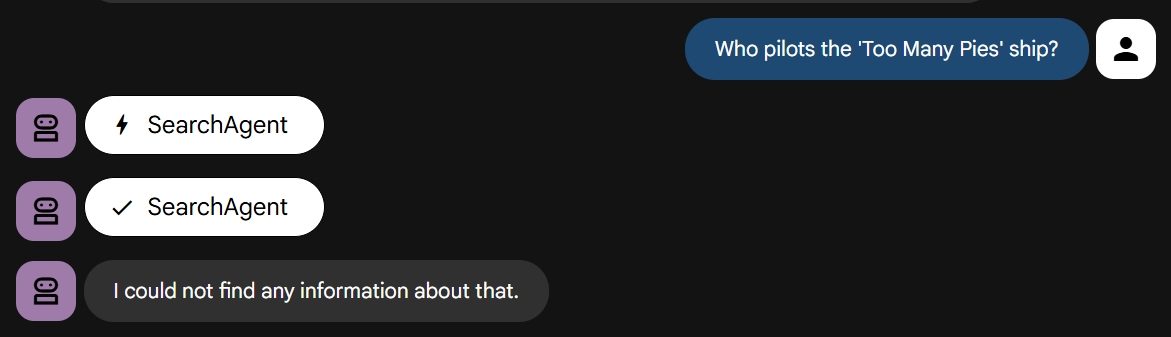
À votre tour ! Vous devriez constater qu'il échoue rapidement, comme indiqué.
Intégrer le File Search Store à l'agent ADK
Nous allons maintenant rassembler tous ces éléments. Nous allons exécuter un agent ADK capable d'utiliser à la fois le store de recherche de fichiers et la recherche Google. Examinez le code dans app/rag_agent_adk/agent.py.
Le code est semblable à l'exemple précédent, mais présente quelques différences importantes :
- Nous avons un agent racine qui orchestre deux agents spécialisés :
- RagAgent : l'expert en connaissances sur mesure qui utilise notre Gemini File Search Store
- SearchAgent : expert en connaissances générales utilisant la recherche Google
- Comme ADK ne dispose pas encore d'un wrapper intégré pour
FileSearch, nous utilisons une classe de wrapper personnaliséeFileSearchToolpour encapsuler l'outil FileSearch, qui injecte la configurationfile_search_store_namesdans la requête de modèle de bas niveau. Cette fonctionnalité a été implémentée dans le script distinctapp/rag_agent_adk/tools_custom.py.
Il y a également un piège à éviter. Au moment de la rédaction de cet article, vous ne pouvez pas utiliser l'outil GoogleSearch natif et l'outil FileSearch dans la même requête adressée au même agent. Si vous essayez, un message d'erreur semblable à celui-ci s'affiche :
ERREUR : Une erreur s'est produite : 400 INVALID_ARGUMENT. {‘error': {‘code': 400, ‘message': ‘Search as a tool and file search tool are not supported together', ‘status': ‘INVALID_ARGUMENT'}}
Erreur : 400 INVALID_ARGUMENT. {‘error': {‘code': 400, ‘message': ‘Search as a tool and file search tool are not supported together', ‘status': ‘INVALID_ARGUMENT'}}
La solution consiste à implémenter les deux agents spécialisés en tant que sous-agents distincts et à les transmettre à l'agent racine à l'aide du modèle Agent-as-a-Tool. Et surtout, l'instruction système de l'agent racine indique très clairement d'utiliser RagAgent en premier :
Tu es un assistant IA utile conçu pour fournir des informations précises et utiles.
Vous avez accès à deux agents spécialisés :
- RagAgent : pour obtenir des informations personnalisées à partir de la base de connaissances interne.
- SearchAgent : pour obtenir des informations générales issues de la recherche Google.
Essayez toujours RagAgent en premier. Si cela ne donne pas de réponse utile, essayez SearchAgent.
Test final
Exécutez l'UI Web ADK comme précédemment :
make adk-playground # Or, without make: uv run adk web app --port 8501 --reload_agents
Cette fois, sélectionnez rag_agent_adk dans l'UI. Voyons cela en action : 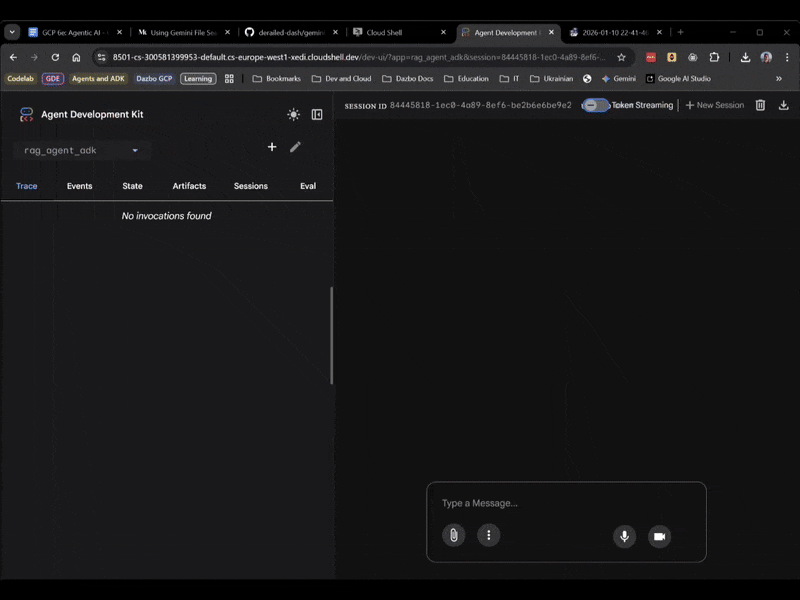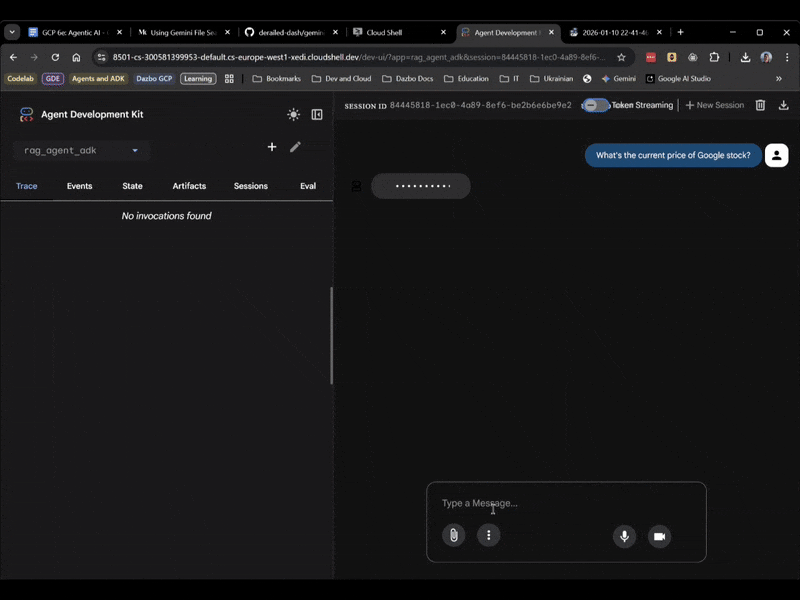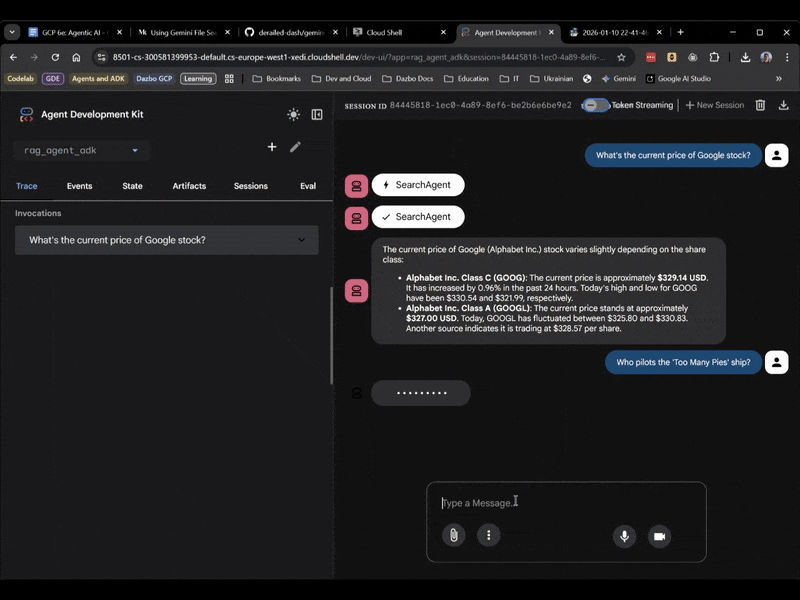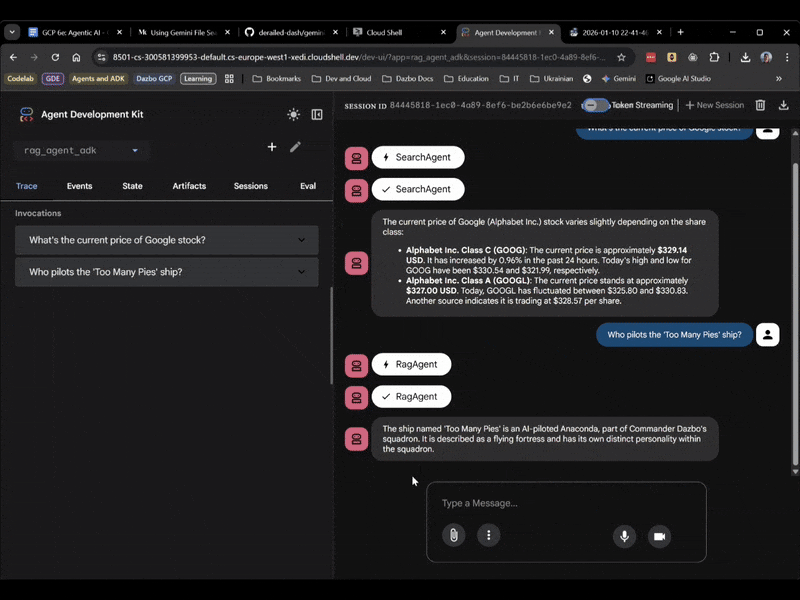
On voit qu'il choisit le sous-agent approprié en fonction de la question.
8. Conclusion
Félicitations, vous avez terminé cet atelier de programmation !
Vous êtes passé d'un simple script à un système RAG multi-agents, sans écrire une seule ligne de code d'intégration ni avoir à implémenter une base de données vectorielle.
Nous avons appris :
- La recherche de fichiers Gemini est une solution RAG gérée qui vous fait gagner du temps et vous évite de vous arracher les cheveux.
- ADK nous fournit la structure dont nous avons besoin pour les applications multi-agents complexes et offre aux développeurs une expérience pratique grâce à des interfaces telles que l'interface utilisateur Web.
- Le modèle "Agent-as-a-Tool" résout les problèmes de compatibilité des outils.
Nous espérons que cet atelier vous a été utile. À bientôt !