
1. מבוא
ב-Codelab הזה נסביר איך משתמשים בחיפוש קבצים ב-Gemini כדי להפעיל RAG באפליקציית הסוכן. תשתמשו בחיפוש הקבצים ב-Gemini כדי להטמיע את המסמכים ולבצע להם אינדוקס, בלי שתצטרכו לדאוג לפרטים של חלוקה לחלקים, הטמעה או מסד נתונים וקטורי.
מה תלמדו
- הסבר על RAG ולמה אנחנו צריכים אותו.
- מה זה Gemini File Search והיתרונות שלו.
- איך יוצרים מאגר לחיפוש קבצים.
- איך מעלים קבצים בהתאמה אישית למאגר חיפוש הקבצים.
- איך משתמשים בכלי חיפוש הקבצים של Gemini ב-RAG.
- היתרונות של שימוש בערכת פיתוח הסוכנים (ADK) של Google.
- איך משתמשים בכלי חיפוש הקבצים של Gemini בפתרון מבוסס-סוכנים שנוצר באמצעות ה-ADK.
- איך משתמשים בכלי חיפוש הקבצים של Gemini לצד כלים 'מובנים' של Google כמו חיפוש Google.
הפעולות שתבצעו
- יוצרים פרויקט ב-Google Cloud ומגדירים את סביבת הפיתוח.
- ליצור סוכן פשוט מבוסס Gemini באמצעות Google Gen AI SDK (אבל בלי ADK) שיכול להשתמש בחיפוש Google, אבל אין לו יכולת RAG.
- להראות שהיא לא מסוגלת לספק מידע מדויק ואיכותי בהתאמה אישית.
- יוצרים מחברת Jupyter (שאפשר להריץ באופן מקומי או ב-Google Colab) כדי ליצור ולנהל מאגר של Gemini File Search.
- אפשר להשתמש ב-Notebook כדי להעלות תוכן בהתאמה אישית למאגר החיפוש של קבצים.
- תיצור סוכן עם חנות לחיפוש קבצים שמחוברת אליו, ותוכיח שהוא מסוגל לספק תשובות טובות יותר.
- המרת הסוכן ה "בסיסי" הראשוני לסוכן ADK, כולל כלי חיפוש Google.
- בודקים את הסוכן באמצעות ממשק המשתמש באינטרנט של ADK.
- משלבים את מאגר חיפוש הקבצים בסוכן ADK באמצעות התבנית Agent-As-A-Tool כדי לאפשר שימוש בכלי לחיפוש קבצים לצד הכלי לחיפוש Google.
2. מה זה RAG ולמה אנחנו צריכים את זה
אז... Retrieval Augmented Generation.
אם אתם קוראים את המאמר הזה, כנראה שאתם יודעים מה זה, אבל בכל זאת נסביר בקצרה. מודלים גדולים של שפה (LLM) (כמו Gemini) הם מבריקים, אבל יש להם כמה בעיות:
- הם תמיד לא מעודכנים: הם יודעים רק את מה שהם למדו במהלך האימון.
- הם לא יודעים הכול: נכון, המודלים עצומים, אבל הם לא יודעים הכול.
- הם לא יודעים את המידע הקנייני שלכם: יש להם ידע רחב, אבל הם לא קראו את המסמכים הפנימיים, הבלוגים או הכרטיסים שלכם ב-Jira.
לכן, כששואלים מודל שאלה שהוא לא יודע את התשובה אליה, בדרך כלל מקבלים תשובה שגויה או אפילו תשובה מומצאת. לרוב, המודל יציג את התשובה השגויה הזו בביטחון. מצב כזה נקרא הזיה.
אחת האפשרויות היא פשוט להעביר את המידע הקנייני שלנו ישירות להקשר של השיחה. השיטה הזו מתאימה לכמות קטנה של מידע, אבל היא הופכת לבעייתית מאוד כשמדובר בכמות גדולה של מידע. באופן ספציפי, היא גורמת לבעיות הבאות:
- זמן אחזור: תגובות איטיות יותר ויותר מהמודל.
- היחלשות האות, או 'אובדן באמצע': המודל כבר לא מצליח למיין את הנתונים הרלוונטיים מתוך הנתונים הלא רלוונטיים. המודל מתעלם מרוב ההקשר.
- עלות: כי טוקנים עולים כסף.
- מיצוי חלון ההקשר: בשלב הזה, Gemini לא יבצע את הבקשות שלכם.
דרך יעילה הרבה יותר לפתור את הבעיה הזו היא באמצעות RAG. זה פשוט תהליך של חיפוש מידע רלוונטי במקורות הנתונים שלכם (באמצעות התאמה סמנטית) והזנת נתחים רלוונטיים של הנתונים האלה למודל לצד השאלה שלכם. הוא מעגן את המודל במציאות שלכם.
הוא פועל על ידי ייבוא נתונים חיצוניים, חלוקת הנתונים למקטעים, המרת הנתונים להטמעות וקטוריות, ואז אחסון ההטמעות האלה ויצירת אינדקס שלהן במסד נתונים וקטורי מתאים.
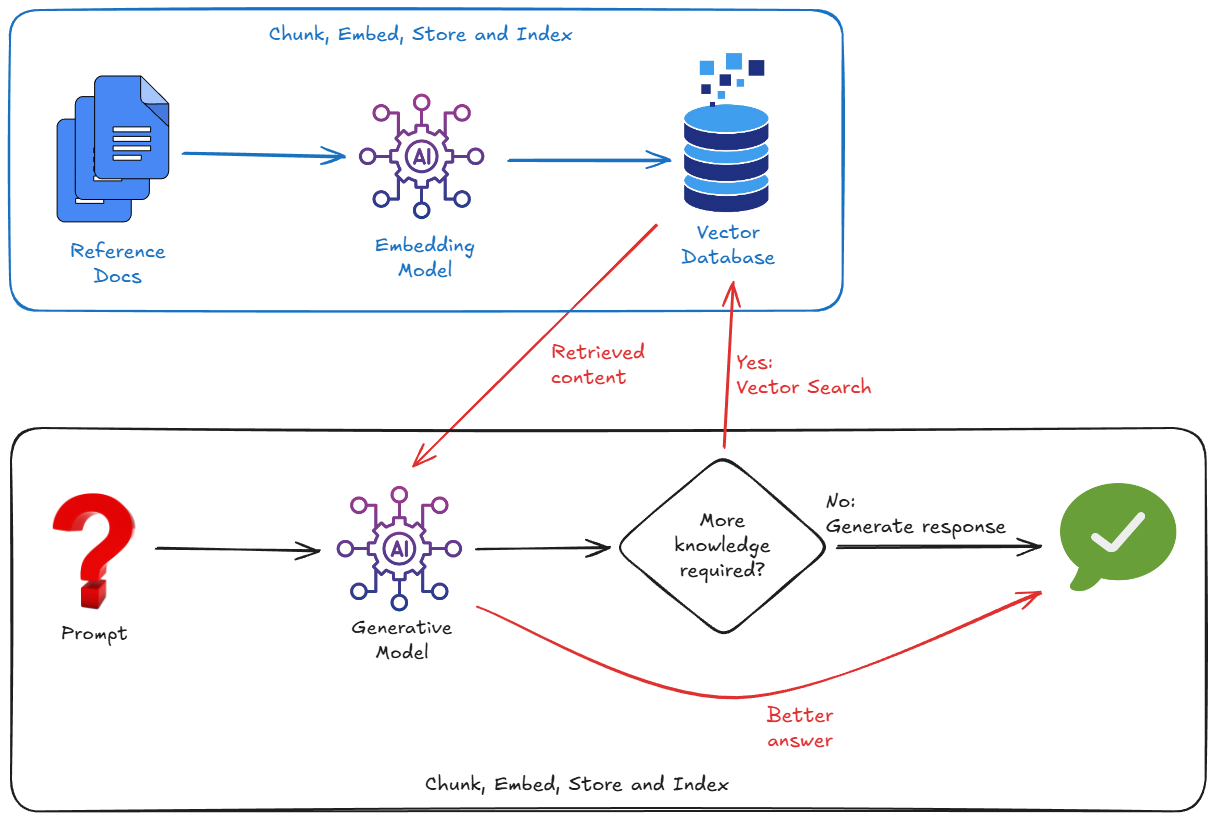
לכן, כדי להטמיע RAG, בדרך כלל צריך לדאוג לגבי:
- הפעלת מסד נתונים וקטורי (Pinecone, Weaviate, Postgres עם pgvector...).
- כתיבת סקריפט לחלוקת המסמכים (למשל, קובצי PDF, Markdown וכו').
- יצירת הטמעות (וקטורים) עבור החלקים האלה באמצעות מודל הטמעה.
- אחסון הווקטורים במסד הנתונים הווקטורי.
אבל חברים לא מאפשרים לחברים לתכנן דברים בצורה מוגזמת. מה אם אגיד לך שיש דרך קלה יותר?
3. דרישות מוקדמות
יצירת פרויקט ב-Google Cloud
כדי להפעיל את ה-codelab הזה, צריך פרויקט ב-Google Cloud. אתם יכולים להשתמש בפרויקט שכבר יש לכם או ליצור פרויקט חדש.
מוודאים שהחיוב מופעל בפרויקט. במדריך הזה מוסבר איך לבדוק את סטטוס החיוב של הפרויקטים.
הערה: לא צפוי שתצטרכו לשלם על השלמת ה-codelab הזה. לכל היותר, כמה אגורות.
אפשר להתחיל להכין את הפרויקט. אני אחכה.
שיבוט של מאגר ההדגמה
יצרתי מאגר עם תוכן מודרך ל-Codelab הזה. תצטרכו אותו!
מריצים את הפקודות הבאות מהטרמינל או מהטרמינל שמשולב ב-Cloud Shell Editor של Google. הנוחות של Cloud Shell והעורך שלו היא בכך שכל הפקודות שצריך מותקנות מראש, והכול פשוט פועל 'מהקופסה'.
git clone https://github.com/derailed-dash/gemini-file-search-demo cd gemini-file-search-demo
בעץ הזה מוצגים הקבצים והתיקיות העיקריים במאגר:
gemini-file-search-demo/ ├── app/ │ ├── basic_agent_adk/ # Agent with Google Search, using ADK framework │ │ └── agent.py │ ├── rag_agent_adk/ # Agent with Google Search and File Search, using ADK framework │ │ ├── agent.py │ │ └── tools_custom.py │ ├── sdk_agent.py # Agent using GenAI SDK (no ADK) with Google Search tool │ └── sdk_rag_agent.py # Agent using GenAI SDK (no ADK) with Gemini File Search tool ├── data/ │ └── story.md # Sample story with "bespoke content" to use with Gemini File Search Store ├── notebooks/ │ └── file_search_store.ipynb # Jupyter notebook for creating and managing Gemini File Search Store │ ├── .env.template # Template for environment variables - make a copy as .env ├── Makefile # Makefile for `make` commands ├── pyproject.toml # Project configuration and dependencies └── README.md # This file
פותחים את התיקייה הזו ב-Cloud Shell Editor או בעורך המועדף. (השתמשת כבר ב-Antigravity? אם לא, עכשיו זה זמן טוב לנסות.)
שימו לב שהמאגר מכיל סיפור לדוגמה – The Wormhole Incursion – בקובץ data/story.md. כתבתי את זה ביחד עם Gemini! הספר עוסק במפקד דזבו ובטייסת שלו של ספינות חלל בעלות תבונה. (קיבלתי השראה מהמשחק Elite Dangerous). הסיפור הזה משמש כ'מאגר ידע בהתאמה אישית' שלנו, שמכיל עובדות ספציפיות ש-Gemini לא יודע, וגם לא יכול לחפש באמצעות חיפוש Google.
הגדרת סביבת הפיתוח
לנוחיותך, צירפתי Makefile כדי לפשט רבות מהפקודות שצריך להריץ. במקום לזכור פקודות ספציפיות, אפשר פשוט להריץ פקודה כמו make <target>. עם זאת, make זמין רק בסביבות Linux / MacOS / WSL. אם אתם משתמשים ב-Windows (בלי WSL), תצטרכו להריץ את הפקודות המלאות שקובצי היעד של make מכילים.
# Install dependencies with make make install # If you don't have make... uv sync --extra jupyter
כך זה נראה כשמריצים את make install ב-Cloud Shell Editor:
יצירת מפתח Gemini API
כדי להשתמש ב-Gemini Developer API (שנדרש כדי להשתמש בכלי חיפוש הקבצים של Gemini), צריך מפתח Gemini API. הדרך הכי קלה לקבל מפתח API היא באמצעות Google AI Studio, שמספק ממשק נוח לקבלת מפתחות API לפרויקטים בענן שלכם ב-Google Cloud. השלבים הספציפיים מפורטים במדריך הזה.
אחרי שיוצרים את מפתח ה-API, מעתיקים אותו ושומרים אותו במקום בטוח.
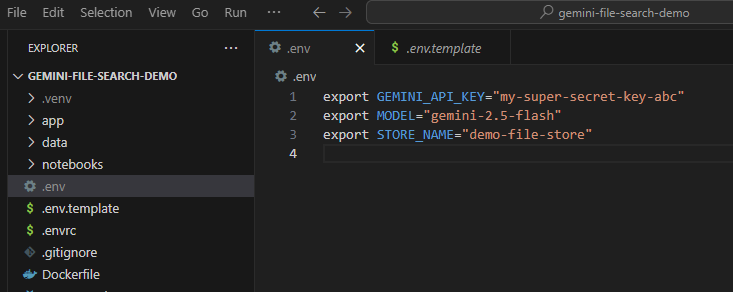
עכשיו צריך להגדיר את מפתח ה-API הזה כמשתנה סביבה. אפשר לעשות את זה באמצעות קובץ .env. מעתיקים את הקובץ .env.example שכלול בחבילה כקובץ חדש בשם .env. הקובץ צריך להיראות כך:
export GEMINI_API_KEY="your-api-key" export MODEL="gemini-2.5-flash" export STORE_NAME="demo-file-store"
מחליפים את הערך your-api-key במפתח ה-API שלכם. עכשיו הוא אמור להיראות בערך כך:
עכשיו מוודאים שמשתני הסביבה נטענו. כדי לעשות את זה, מריצים את הפקודה:
source .env
4. הנציג הבסיסי
קודם כל, נגדיר בסיס להשוואה. נשתמש ב-google-genai SDK הגולמי כדי להריץ סוכן פשוט.
הקוד
כדאי לעיין בapp/sdk_agent.py. זו הטמעה מינימלית שכוללת:
- יוצר מופע של
genai.Client. - הפעלה של הכלי
google_search. - זה הכול. אין RAG.
כדאי לעיין בקוד ולוודא שמבינים מה הוא עושה.
הפעלת התכונה
# With make make sdk-agent # Without make uv run python app/sdk_agent.py
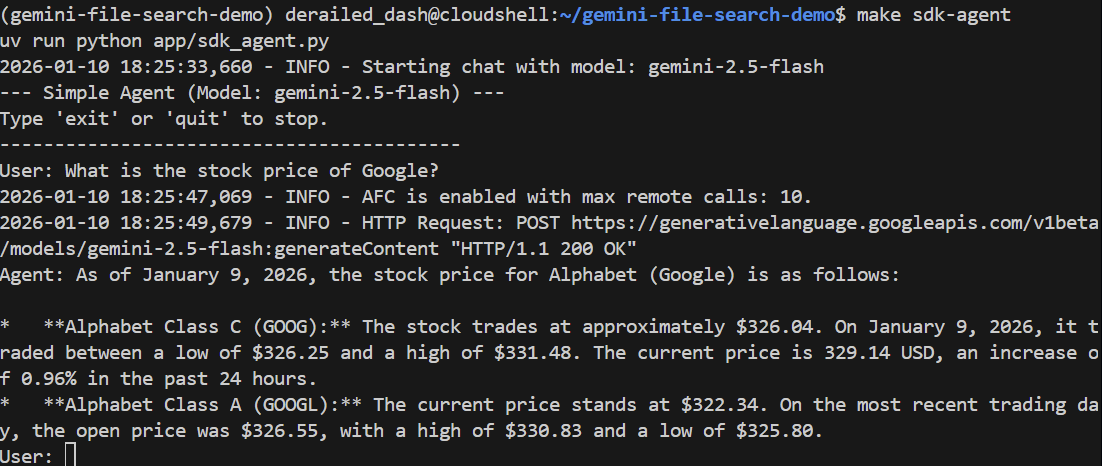
נשאל אותו שאלה כללית:
> What is the stock price of Google?
התשובה צריכה להיות נכונה, והיא צריכה להתבסס על חיפוש Google כדי למצוא את המחיר הנוכחי:
עכשיו נשאל שאלה שהוא לא יודע איך לענות עליה. היא מחייבת את הסוכן לקרוא את הסיפור שלנו.
> Who pilots the 'Too Many Pies' ship?
הוא עלול להיכשל או אפילו להמציא תשובות. בוא נראה:
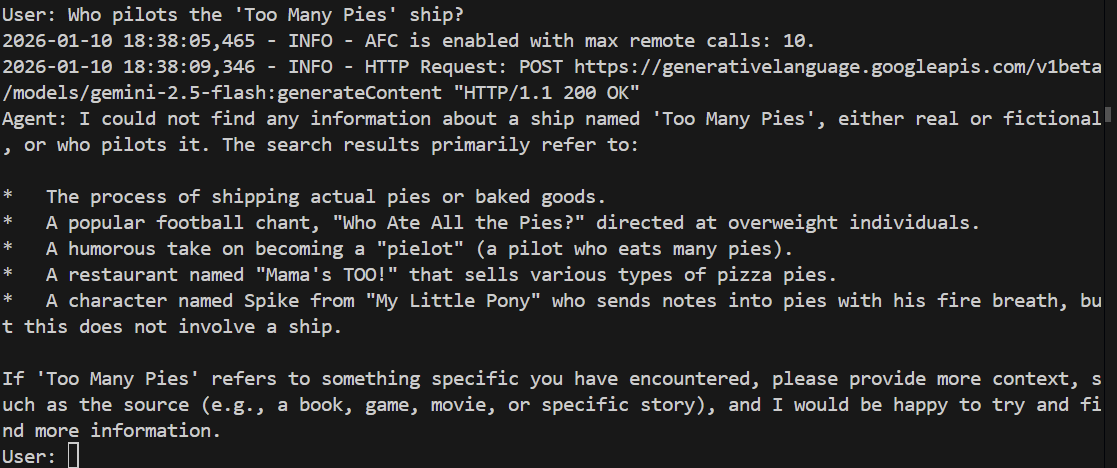
ואכן, המודל לא מצליח לענות על השאלה. אין לו מושג על מה אנחנו מדברים!
עכשיו מקלידים quit כדי לצאת מהסוכן.
5. חיפוש קבצים באמצעות Gemini: הסבר
חיפוש הקבצים ב-Gemini הוא בעצם שילוב של שני דברים:
- מערכת RAG מנוהלת באופן מלא: אתם מספקים קבוצה של קבצים, וכלי חיפוש הקבצים של Gemini מטפל בחלוקה לחלקים, בהטמעה, באחסון ובאינדוקס וקטורי בשבילכם.
- כלי במובן של סוכן: אפשר פשוט להוסיף את כלי חיפוש הקבצים של Gemini ככלי בהגדרת הסוכן, ולהפנות את הכלי אל מאגר חיפוש קבצים.
אבל מה שחשוב: הוא מובנה ב-Gemini API עצמו. כלומר, לא צריך להפעיל ממשקי API נוספים או לפרוס מוצרים נפרדים כדי להשתמש בו. אז זה באמת out-of-the-box.
התכונות של Gemini לחיפוש קבצים
אלה כמה מהתכונות:
- פרטי החלוקה לחלקים, ההטמעה, האחסון והאינדוקסציה מוסתרים מכם, המפתחים. זה אומר שלא צריך לדעת (או להתעניין) באיזה מודל הטמעה נעשה שימוש (אגב, זהו Gemini Embeddings), או איפה מאוחסנים הווקטורים שנוצרו. אין צורך לקבל החלטות לגבי מסד נתונים וקטורי.
- הוא תומך במספר עצום של סוגי מסמכים. כולל, בין היתר: PDF, DOCX, Excel, SQL, JSON, מחברות Jupyter, HTML, Markdown, CSV ואפילו קובצי zip. הרשימה המלאה מפורטת כאן. לדוגמה, אם רוצים לעגן את הסוכן לקובצי PDF שמכילים טקסט, תמונות וטבלאות, לא צריך לבצע עיבוד מוקדם של קובצי ה-PDF האלה. פשוט מעלים את קובצי ה-PDF הגולמיים, ו-Gemini כבר יעשה את כל השאר.
- אנחנו יכולים להוסיף מטא-נתונים מותאמים אישית לכל קובץ שמועלה. האפשרות הזו יכולה להיות שימושית מאוד לסינון קבצים שבהם רוצים שהכלי ישתמש, בזמן הריצה.
איפה הנתונים נמצאים?
אתם מעלים קבצים. כלי חיפוש הקבצים של Gemini לקח את הקבצים האלה, יצר את הנתחים ואת ההטמעות, והניח אותם… איפשהו. אבל איפה?
התשובה: מאגר חיפוש קבצים. זהו קונטיינר מנוהל לחלוטין להטמעות שלכם. אתם לא צריכים לדעת (או להתעניין) איך זה קורה מאחורי הקלעים. כל מה שצריך לעשות הוא ליצור תיקייה (באמצעות תוכנה) ואז להעלות אליה את הקבצים.
זה זול!
האחסון והשאילתות של ההטמעות הם בחינם. כך תוכלו לאחסן הטמעות כמה זמן שתרצו, ולא תצטרכו לשלם על האחסון הזה.
למעשה, הדבר היחיד שאתם משלמים עליו הוא יצירת ההטמעות בזמן ההעלאה או היצירה של האינדקס. בזמן כתיבת המאמר הזה, העלות היא 0.15 $למיליון טוקנים. זה די זול.
6. איך משתמשים בחיפוש קבצים ב-Gemini
יש שני שלבים:
- ליצור את ההטמעות ולאחסן אותן במאגר לחיפוש קבצים.
- שליחת שאילתה למאגר של חיפוש הקבצים מהסוכן.
שלב 1 – Jupyter Notebook ליצירה ולניהול של מאגר קבצים לחיפוש ב-Gemini
השלב הזה מתבצע בהתחלה, וגם בכל פעם שרוצים לעדכן את החנות. לדוגמה, כשרוצים להוסיף מסמכים חדשים או כשמסמכי המקור השתנו.
אתם לא צריכים לארוז את השלב הזה באפליקציה של הסוכן שפרסתם. בטח, אם רוצים. לדוגמה, אם רוצים ליצור ממשק משתמש כלשהו למשתמשי אדמין באפליקציה מבוססת-הסוכן. אבל לעיתים קרובות מספיק להשתמש בקטע קוד שמריצים לפי דרישה. מהי דרך מצוינת להריץ את הקוד הזה לפי דרישה? מחברת Jupyter!
המחברת
פותחים את הקובץ notebooks/file_search_store.ipynb בכלי העריכה. אם מוצגת בקשה להתקין תוספים של Jupyter VS Code, צריך להתקין אותם.
אם פותחים אותו ב-Cloud Shell Editor, הוא נראה כך:
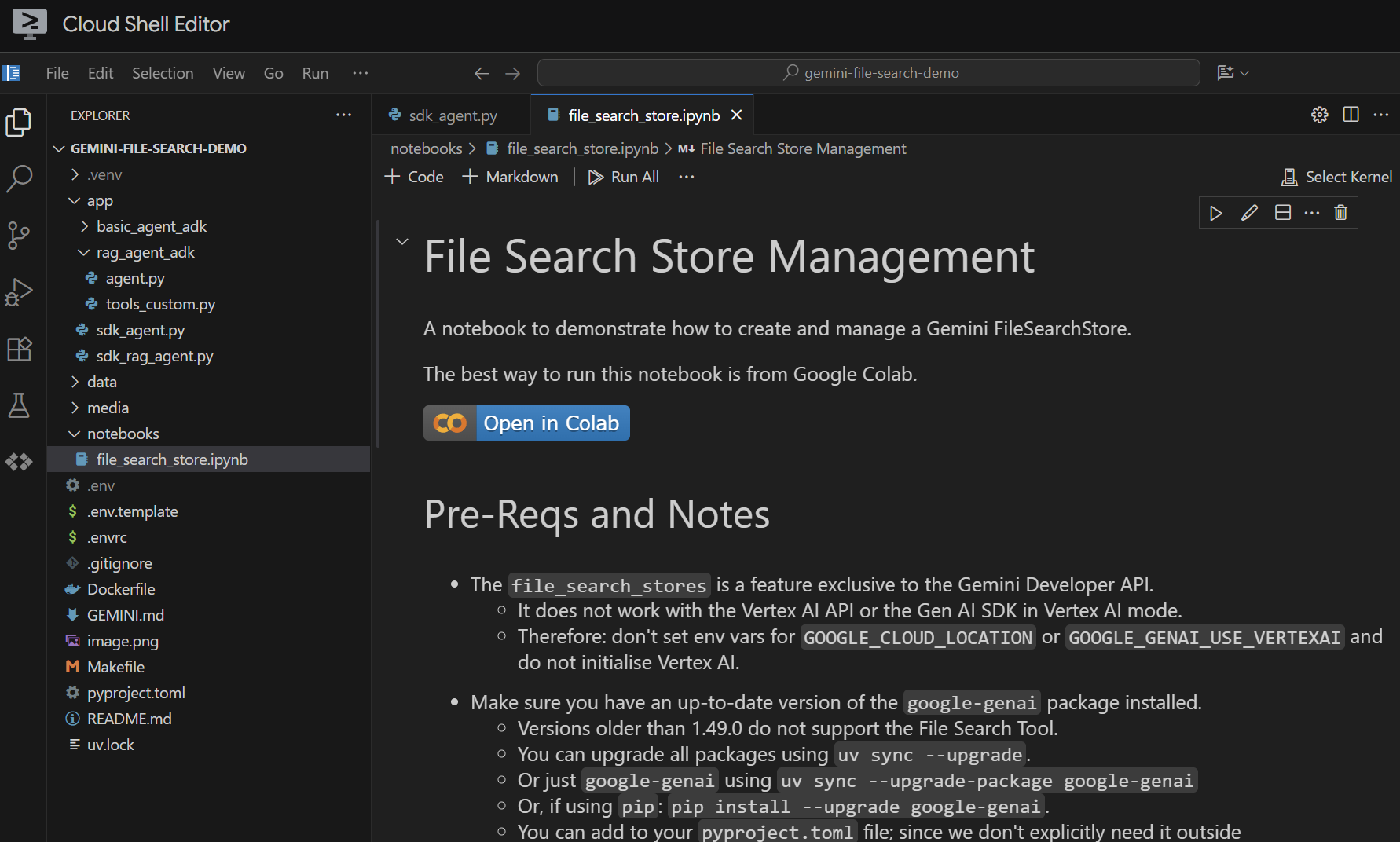
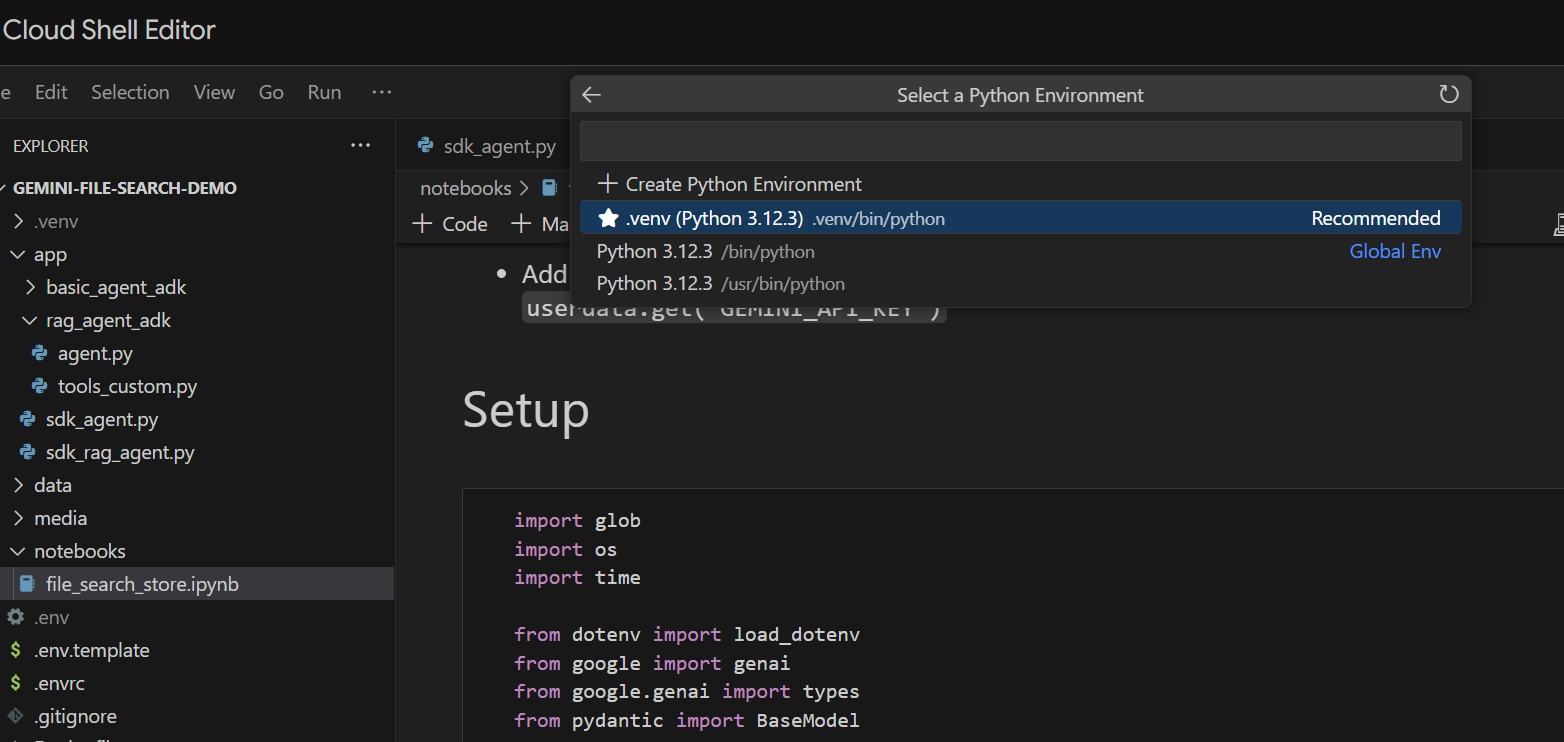
נריץ אותו תא אחרי תא. מתחילים בהרצת התא Setup עם הייבוא הנדרש. אם לא הפעלתם מחברת בעבר, תתבקשו להתקין את התוספים הנדרשים. אפשר לעשות את זה. לאחר מכן תתבקשו לבחור ליבה. בוחרים באפשרות Python environments... ואז ב-.venv המקומי שהתקנו כשביצענו את הפקודה make install קודם:
לאחר מכן:
- מריצים את התא Local Only כדי לאחזר את משתני הסביבה.
- מריצים את התא Client Initialisation כדי לאתחל את Gemini Gen AI Client.
- מריצים את התא Retrieve the Store (אחזור המאגר) עם פונקציית העזר לאחזור מאגר Gemini File Search לפי שם.
עכשיו אפשר ליצור את החנות.
- מריצים את התא Create the Store (One Time) כדי ליצור את החנות. צריך לעשות את זה רק פעם אחת. אם הקוד יפעל בהצלחה, תוצג ההודעה
"Created store: fileSearchStores/<someid>" - מריצים את התא View the Store כדי לראות מה יש בו. בשלב הזה, אמור להופיע שהמאגר מכיל 0 מסמכים.
מצוין! עכשיו יש לנו מאגר Gemini File Search שמוכן לשימוש.
העלאת הנתונים
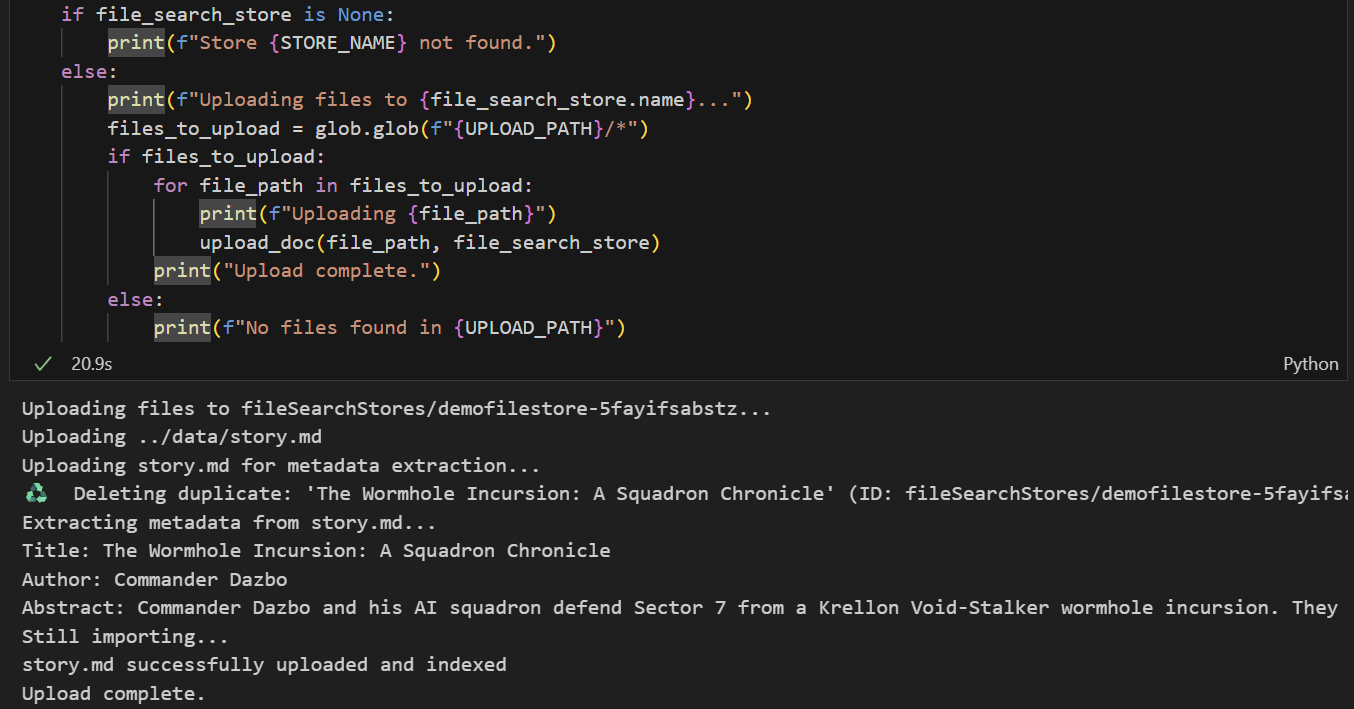
אנחנו רוצים להעלות את data/story.md לחנות. בצע את הפעולות הבאות:
- מריצים את התא שבו מוגדר נתיב ההעלאה. התיקייה הזו היא
data/. - מריצים את התא הבא, שיוצר פונקציות עזר להעלאת קבצים לחנות. שימו לב שהקוד בתא הזה משתמש גם ב-Gemini כדי לחלץ מטא-נתונים מכל קובץ שהועלה. אנחנו לוקחים את הערכים שחולצו ומאחסנים אותם כמטא-נתונים מותאמים אישית בחנות. (לא חייבים לעשות את זה, אבל זה מועיל).
- מריצים את התא כדי להעלות את הקובץ. שימו לב: אם העלינו בעבר קובץ עם אותו שם, המחברת תמחק קודם את הגרסה הקיימת לפני העלאת הגרסה החדשה. אמורה להופיע הודעה שהקובץ הועלה.
שלב 2 – הטמעה של RAG לחיפוש קבצים ב-Gemini בסוכן
יצרנו מאגר לחיפוש קבצים ב-Gemini והעלינו אליו את הסיפור שלנו. עכשיו הגיע הזמן להשתמש במאגר של כלי החיפוש של קבצים בסוכן שלנו. בואו ניצור סוכן חדש שמשתמש במאגר File Search Store במקום בחיפוש Google. כדאי לעיין בapp/sdk_rag_agent.py.
הדבר הראשון שחשוב לשים לב אליו הוא שהטמענו פונקציה לאחזור החנות שלנו על ידי העברת שם החנות:
def get_store(client: genai.Client, store_name: str) -> types.FileSearchStore | None:
"""Retrieve a store by display name"""
try:
for a_store in client.file_search_stores.list():
if a_store.display_name == store_name:
return a_store
except Exception as e:
logger.error(f"Error listing stores: {e}")
return None
אחרי שיצרנו את החנות, השימוש בה פשוט כמו צירוף שלה ככלי לסוכן, כך:
file_search_tool = types.Tool(file_search=types.FileSearch(file_search_store_names=[store.name]))
הרצת סוכן RAG
כך מפעילים אותו:
make sdk-rag-agent # Or, without make: uv run python app/sdk_rag_agent.py
אשאל את השאלה שהנציג הקודם לא הצליח לענות עליה:
> Who pilots the 'Too Many Pies' ship?
ומה התשובה?
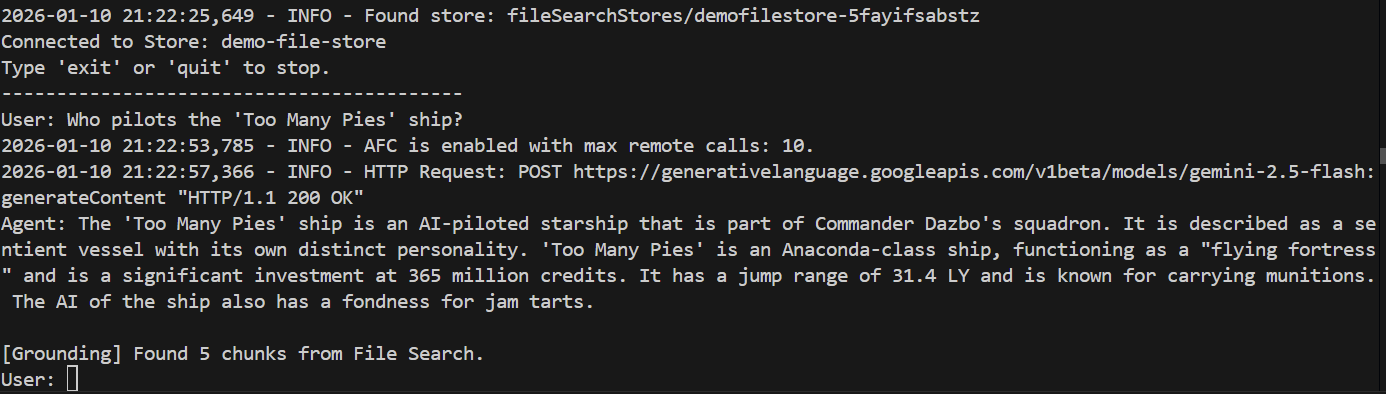
הצלחת! מהתשובה אפשר לראות ש:
- התשובה לשאלה מבוססת על מאגר הקבצים שלנו.
- נמצאו 5 קטעים רלוונטיים.
- התשובה מדויקת!
מקישים על quit כדי לסגור את הסוכן.
7. המרת הסוכנים שלנו לשימוש ב-ADK
הערכה לפיתוח סוכנים (ADK) של Google היא מסגרת מודולרית בקוד פתוח ו-SDK שמאפשרים למפתחים ליצור סוכנים ומערכות סוכניות. הוא מאפשר לנו ליצור ולתזמר בקלות מערכות מרובות סוכנים. ה-ADK מותאם ל-Gemini ולסביבת Google, אבל הוא לא תלוי במודל או בפריסה, והוא בנוי כך שיהיה תואם למסגרות אחרות. אם עוד לא השתמשתם ב-ADK, תוכלו לעבור אל מסמכי ADK כדי לקבל מידע נוסף.
סוכן ADK בסיסי עם חיפוש Google
כדאי לעיין בapp/basic_agent_adk/agent.py. בדוגמת הקוד הזו אפשר לראות שהטמענו שני סוכנים:
root_agentשמטפל באינטראקציה עם המשתמש, ושבו סיפקנו את ההוראה העיקרית למערכת.SearchAgentנפרד שמשתמש ב-google.adk.tools.google_searchככלי.
root_agent משתמש בפועל ב-SearchAgent ככלי, והוא מיושם באמצעות השורה הזו:
tools=[AgentTool(agent=search_agent)],
ההנחיה למערכת של סוכן הבסיס נראית כך:
You are a helpful AI assistant designed to provide accurate and useful information.
If you don't know the answer, use the SearchAgent to perform a Google search.
Do not attempt to search more than ONCE.
If the search yields no relevant results or returns unrelated content, you MUST immediately respond with: "I could not find any information about that."
Do NOT retry the search with different terms. Do NOT ask for clarification. FAIL FAST.
ניסיון להשתמש ב-Agent
ערכת ה-ADK מספקת מספר ממשקים מוכנים מראש כדי לאפשר למפתחים לבדוק את סוכני ה-ADK שלהם. אחד מהממשקים האלה הוא ממשק המשתמש האינטרנטי. כך אנחנו יכולים לבדוק את הסוכנים שלנו בדפדפן, בלי לכתוב שורה אחת של קוד ממשק משתמש!
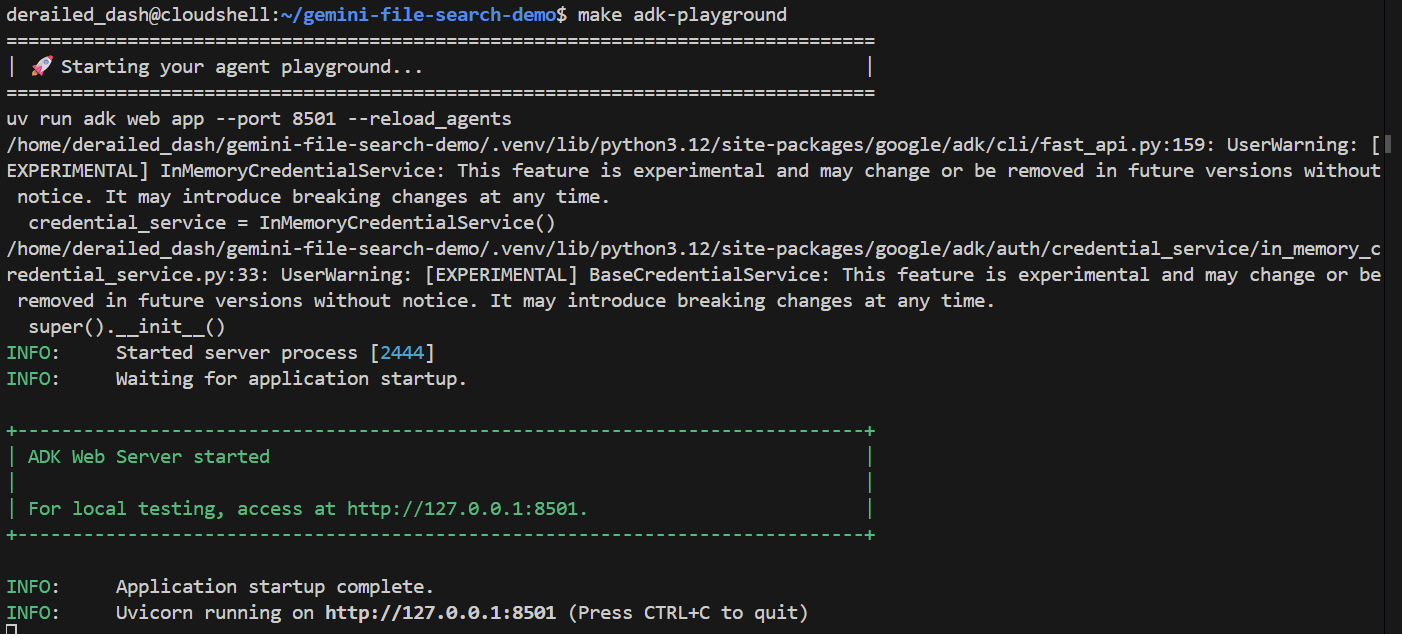
אפשר להפעיל את הממשק הזה באמצעות הפקודה:
make adk-playground # Or, without make: uv run adk web app --port 8501 --reload_agents
שימו לב שהפקודה מפנה את הכלי adk web לתיקייה app, שבה הוא יזהה באופן אוטומטי סוכני ADK שמטמיעים root_agent. אז בואו ננסה:
אחרי כמה שניות, האפליקציה מוכנה. אם מריצים את הקוד באופן מקומי, פשוט מפנים את הדפדפן אל http://127.0.0.1:8501. אם אתם מריצים את האפליקציה ב-Cloud Shell Editor, לוחצים על Web preview ומשנים את היציאה ל-8501:
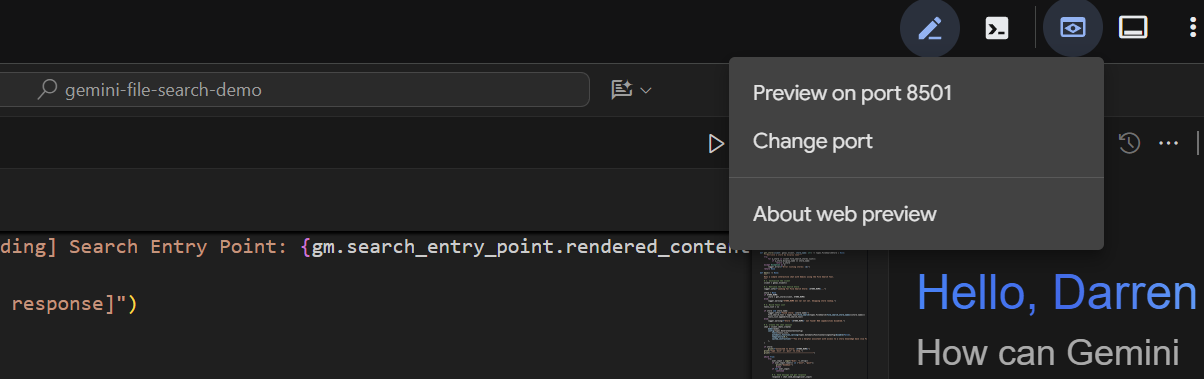
כשממשק המשתמש מופיע, בוחרים באפשרות basic_agent_adk מהתפריט הנפתח, ואז אפשר לשאול אותו שאלות:
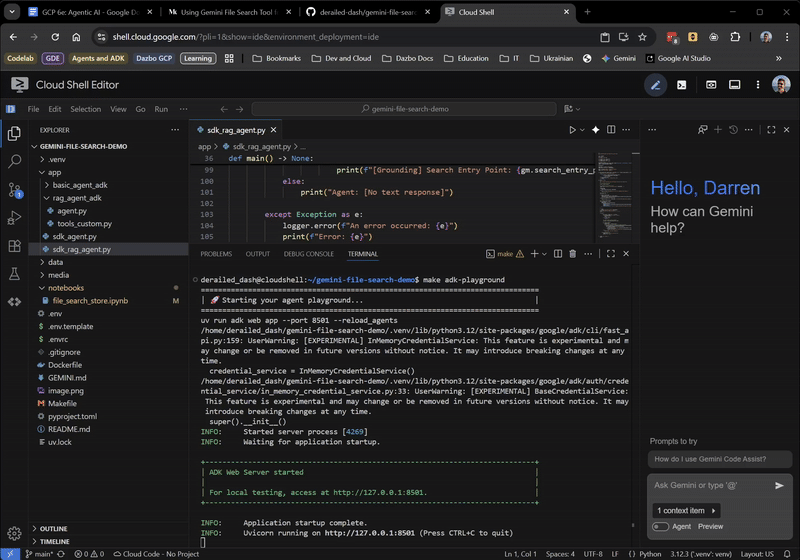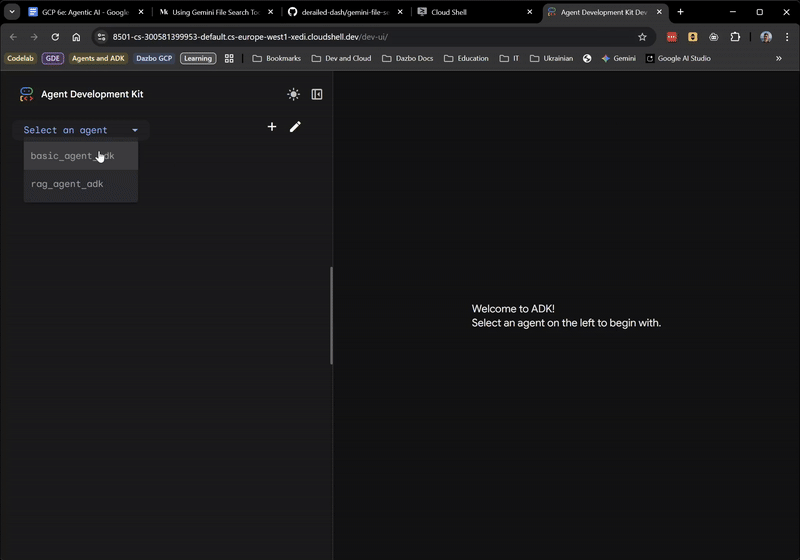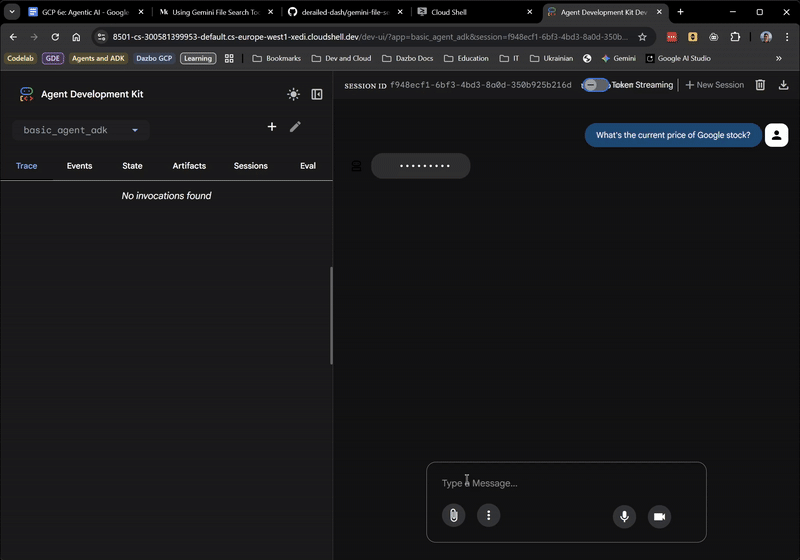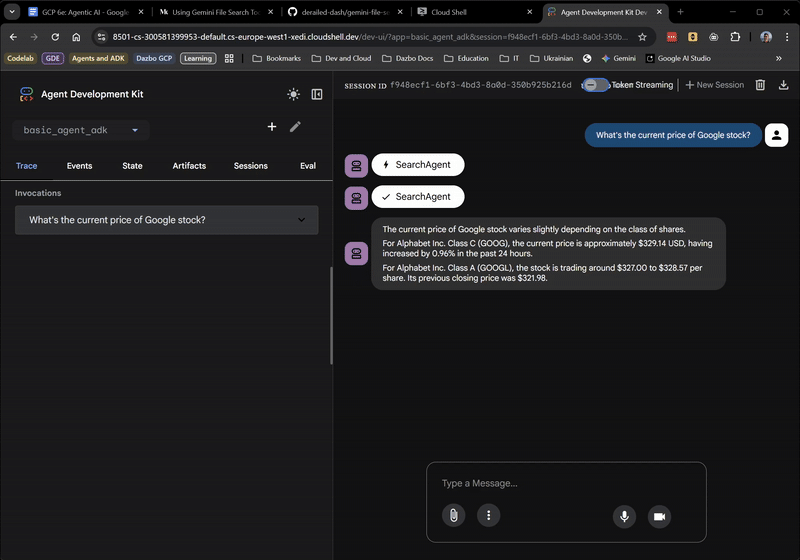
עד עכשיו, הכול טוב ויפה. בממשק המשתמש האינטרנטי אפשר לראות גם מתי סוכן הבסיס מעביר את הטיפול לסוכן SearchAgent. זו תכונה מאוד שימושית.
עכשיו נשאל אותו שאלה שדורשת ידע על הסיפור שלנו:
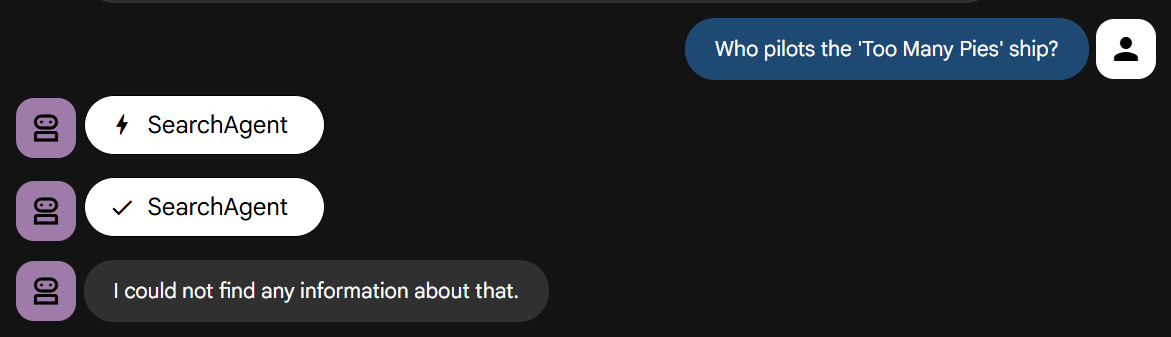
רוצים לנסות? הוא אמור להיכשל במהירות, בדיוק כמו שצוין.
שילוב מאגר לחיפוש קבצים בסוכן ADK
עכשיו נסכם את כל מה שלמדנו. אנחנו הולכים להפעיל סוכן ADK שיכול להשתמש גם במאגר לחיפוש קבצים וגם בחיפוש Google. בודקים את הקוד ב-app/rag_agent_adk/agent.py.
הקוד דומה לדוגמה הקודמת, אבל יש כמה הבדלים חשובים:
- יש לנו סוכן ראשי שמנהל שני סוכנים מומחים:
- RagAgent: מומחה ידע בהתאמה אישית – באמצעות מאגר חיפוש הקבצים של Gemini
- SearchAgent: מומחה לידע כללי – באמצעות חיפוש Google
- ל-ADK אין עדיין wrapper מובנה ל-
FileSearch, ולכן אנחנו משתמשים במחלקהFileSearchToolשל wrapper בהתאמה אישית כדי לעטוף את הכלי FileSearch, שמוסיף את ההגדרהfile_search_store_namesלבקשת המודל ברמה הנמוכה. ההגדרה הזו הוטמעה בסקריפט הנפרדapp/rag_agent_adk/tools_custom.py.
יש גם מלכודת שכדאי להיזהר ממנה. בזמן כתיבת המאמר הזה, אי אפשר להשתמש בכלי המקורי GoogleSearch ובכלי FileSearch באותה בקשה לאותו סוכן. אם תנסו, תקבלו הודעת שגיאה כזו:
שגיאה – אירעה שגיאה: 400 INVALID_ARGUMENT. {‘error': {‘code': 400, ‘message': ‘Search as a tool and file search tool are not supported together', ‘status': ‘INVALID_ARGUMENT'}}
שגיאה: 400 INVALID_ARGUMENT. {‘error': {‘code': 400, ‘message': ‘Search as a tool and file search tool are not supported together', ‘status': ‘INVALID_ARGUMENT'}}
הפתרון הוא להטמיע את שני הסוכנים המומחים כסוכני משנה נפרדים, ולהעביר אותם לסוכן הבסיסי באמצעות התבנית Agent-as-a-Tool. ובאופן מכריע, הוראות המערכת של סוכן הבסיס מספקות הנחיות ברורות מאוד לשימוש ב-RagAgent קודם:
אתה עוזר אישי מבוסס-AI שתפקידו לספק מידע מדויק ושימושי.
יש לך גישה לשני סוכנים מומחים:
- RagAgent: לקבלת מידע מותאם אישית ממאגר הידע הפנימי.
- SearchAgent: לקבלת מידע כללי מחיפוש Google.
תמיד כדאי לנסות קודם את RagAgent. אם לא מתקבלת תשובה מועילה, כדאי לנסות את SearchAgent.
מבחן סופי
מריצים את ממשק האינטרנט של ADK כמו קודם:
make adk-playground # Or, without make: uv run adk web app --port 8501 --reload_agents
הפעם, בוחרים באפשרות rag_agent_adk בממשק המשתמש. הנה דוגמה: 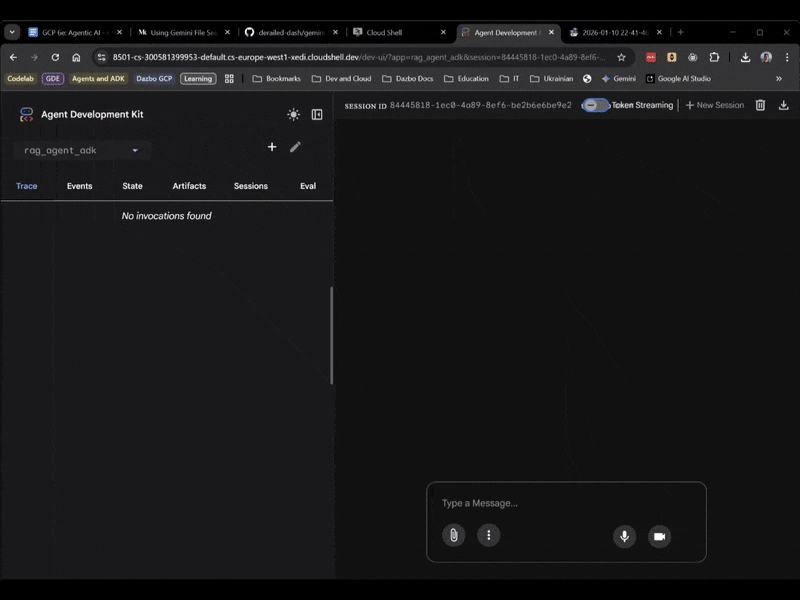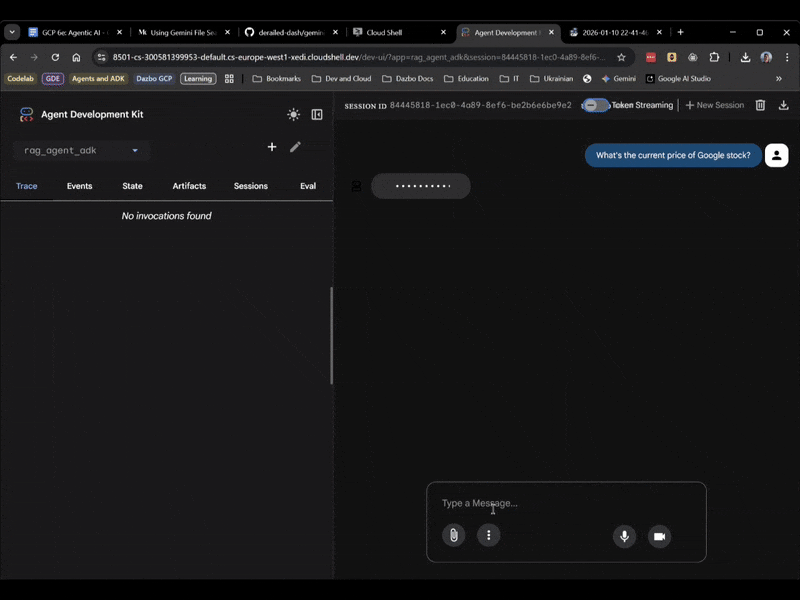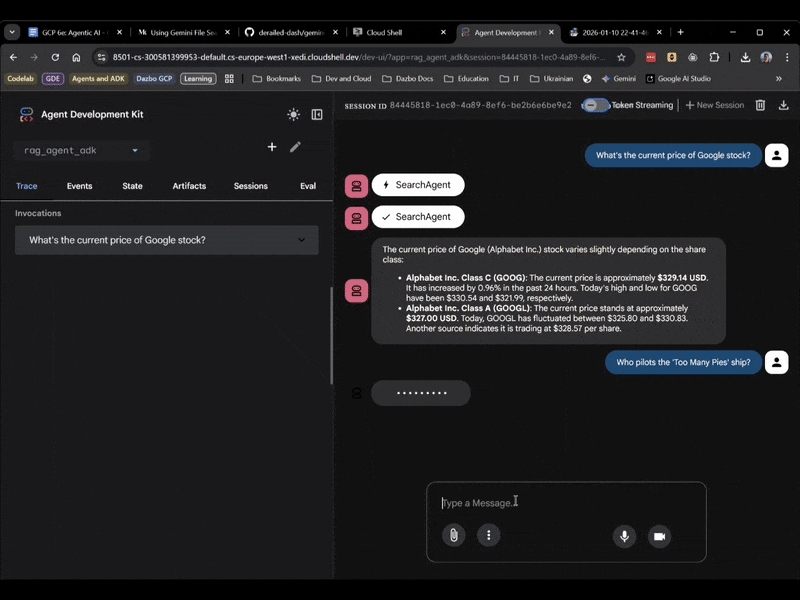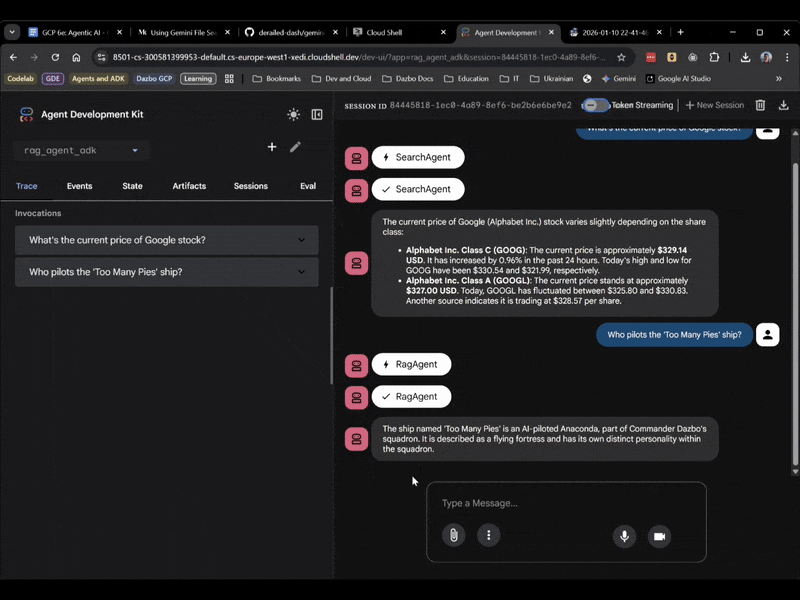
אפשר לראות שהמערכת בוחרת את הסוכן המשני המתאים על סמך השאלה.
8. סיכום
כל הכבוד, סיימתם את ה-Codelab הזה!
הפכתם סקריפט פשוט למערכת מרובת סוכנים עם RAG, בלי לכתוב שורת קוד אחת להטמעה ובלי להטמיע מסד נתונים וקטורי.
למדנו:
- Gemini File Search הוא פתרון RAG מנוהל שחוסך זמן ומאפשר לכם לשמור על שפיות.
- ADK מספק לנו את המבנה הדרוש לאפליקציות מורכבות עם כמה סוכנים, ומציע למפתחים נוחות באמצעות ממשקים כמו ממשק המשתמש באינטרנט.
- התבנית "Agent-as-a-Tool" פותרת בעיות תאימות של כלים.
מקווים שהתרגיל הזה היה מועיל. נתראה בפעם הבאה!