
1. Introduzione
Questo codelab mostra come utilizzare la ricerca file di Gemini per abilitare RAG nell'applicazione agentica. Utilizzerai la ricerca di file di Gemini per importare e indicizzare i tuoi documenti senza doverti preoccupare dei dettagli di suddivisione, incorporamento o database vettoriale.
Obiettivi didattici
- Le basi della RAG e perché è necessaria.
- Che cos'è Gemini File Search e quali vantaggi offre.
- Come creare un archivio di ricerca di file.
- Come caricare i tuoi file personalizzati nello Store di ricerca dei file.
- Come utilizzare lo strumento di ricerca file di Gemini per RAG.
- I vantaggi dell'utilizzo di Google Agent Development Kit (ADK).
- Come utilizzare lo strumento di ricerca file di Gemini in una soluzione agentica creata utilizzando l'ADK.
- Come utilizzare lo strumento di ricerca file di Gemini insieme agli strumenti "nativi" di Google come la Ricerca Google.
Attività previste
- Crea un progetto Google Cloud e configura l'ambiente di sviluppo.
- Crea un semplice agente basato su Gemini utilizzando SDK Google Gen AI (ma senza ADK) in grado di utilizzare la Ricerca Google, ma senza funzionalità RAG.
- Dimostrare la sua incapacità di fornire informazioni accurate e di alta qualità per informazioni personalizzate.
- Crea un notebook Jupyter (che puoi eseguire localmente o, ad esempio, su Google Colab) per creare e gestire un archivio di ricerca di file Gemini.
- Utilizza il notebook per caricare contenuti personalizzati nel File Search Store.
- Crea un agente a cui è collegato lo Store di ricerca file e dimostra che è in grado di produrre risposte migliori.
- Converti l'agente "di base" iniziale in un agente ADK, completo dello strumento Ricerca Google.
- Testa l'agente utilizzando l'interfaccia utente web dell'ADK.
- Incorpora l'archivio di ricerca file nell'agente ADK, utilizzando il pattern Agent-As-A-Tool per consentirci di utilizzare lo strumento di ricerca file insieme allo strumento di Ricerca Google.
2. Che cos'è la RAG e perché ne abbiamo bisogno
Così... Retrieval Augmented Generation.
Se sei qui, probabilmente sai di cosa si tratta, ma facciamo un breve riepilogo, per sicurezza. Gli LLM (come Gemini) sono brillanti, ma presentano alcuni problemi:
- Sono sempre obsoleti: conoscono solo ciò che hanno appreso durante l'addestramento.
- Non sanno tutto: certo, i modelli sono enormi, ma non sono onniscienti.
- Non conoscono le tue informazioni proprietarie: hanno una conoscenza generale, ma non hanno letto i tuoi documenti interni, i tuoi blog o i tuoi ticket Jira.
Quindi, quando chiedi a un modello qualcosa a cui non sa rispondere, in genere riceverai una risposta errata o addirittura inventata. Spesso, il modello fornirà questa risposta errata con sicurezza. Questo è ciò che chiamiamo allucinazione.
Una soluzione è quella di scaricare le nostre informazioni proprietarie direttamente nel contesto della conversazione. Questo va bene per una piccola quantità di informazioni, ma diventa rapidamente problematico quando ne hai molte. In particolare, porta a questi problemi:
- Latenza: risposte sempre più lente da parte del modello.
- Decadimento del segnale, noto anche come "lost-in-the-middle": il modello non è più in grado di ordinare i dati pertinenti da quelli inutili. Gran parte del contesto viene ignorato dal modello.
- Costo: perché i token costano.
- Esaurimento della finestra contestuale: a questo punto, Gemini non elaborerà le tue richieste.
Un modo molto più efficace per risolvere questa situazione è utilizzare RAG. Si tratta semplicemente del processo di ricerca di informazioni pertinenti dalle tue origini dati (utilizzando la corrispondenza semantica) e di inserimento di blocchi pertinenti di questi dati nel modello insieme alla tua domanda. Ancora il modello alla tua realtà.
Funziona importando dati esterni, suddividendoli in blocchi, convertendoli in vector embedding e poi memorizzandoli e indicizzandoli in un database vettoriale adatto.
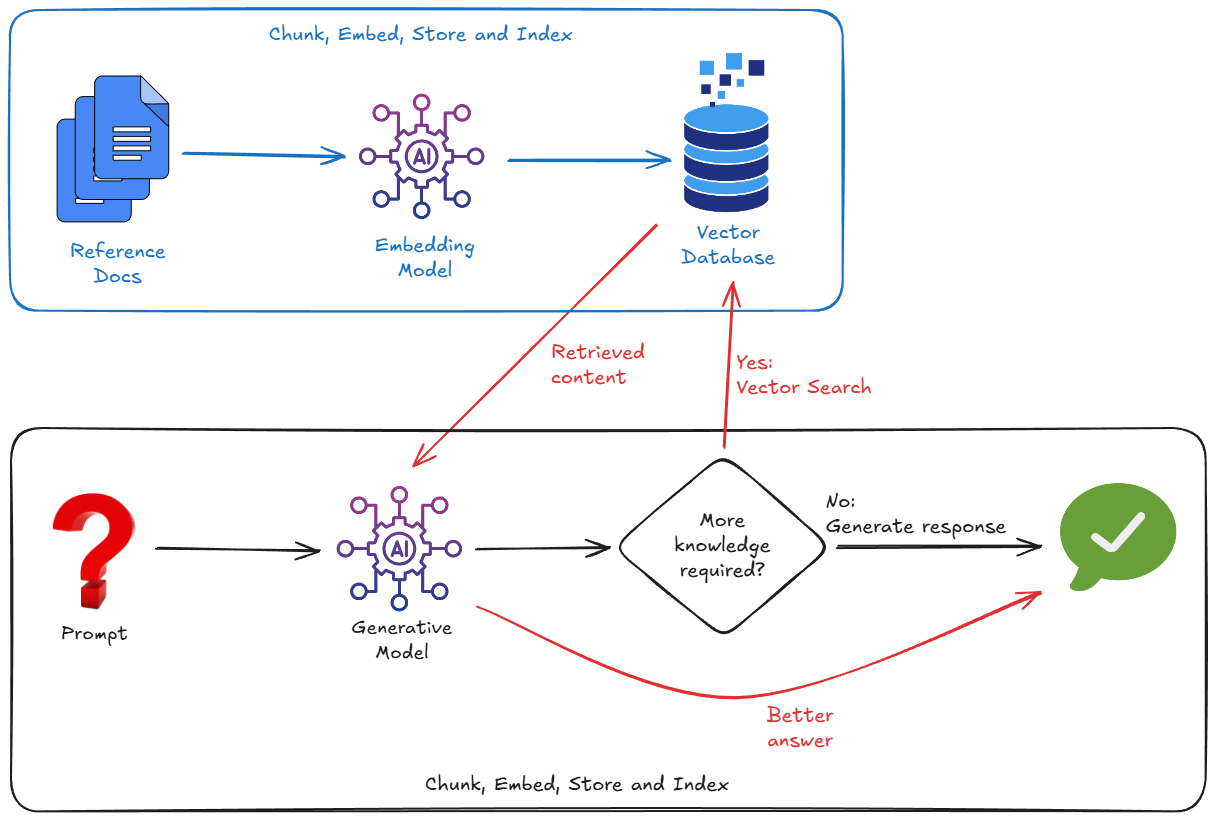
Pertanto, per implementare la RAG, in genere dobbiamo preoccuparci di:
- Creazione di un database vettoriale (Pinecone, Weaviate, Postgres con pgvector...).
- Scrivere uno script di chunking per dividere i documenti (ad es. PDF, markdown e così via).
- Generando embedding (vettori) per questi blocchi, utilizzando un modello di embedding.
- Archiviazione dei vettori nel database vettoriale.
Ma gli amici non lasciano che gli amici complichino troppo le cose. E se ti dicessi che c'è un modo più semplice?
3. Prerequisiti
Crea un progetto Google Cloud
Per eseguire questo codelab, devi avere un progetto Google Cloud. Puoi utilizzare un progetto esistente o crearne uno nuovo.
Assicurati che la fatturazione sia abilitata per il tuo progetto. Consulta questa guida per scoprire come controllare lo stato di fatturazione dei tuoi progetti.
Tieni presente che il completamento di questo codelab non dovrebbe comportare costi. Al massimo, pochi centesimi.
Prepara il tuo progetto. Aspetterò.
Clona il repository demo
Ho creato un repository con contenuti guidati per questo codelab. Ne avrai bisogno!
Esegui questi comandi dal terminale o dal terminale integrato nell'editor di Cloud Shell di Google. Cloud Shell e il relativo editor sono molto pratici, in quanto tutti i comandi necessari sono preinstallati e tutto funziona "out-of-the-box".
git clone https://github.com/derailed-dash/gemini-file-search-demo cd gemini-file-search-demo
Questo albero mostra le cartelle e i file chiave nel repository:
gemini-file-search-demo/ ├── app/ │ ├── basic_agent_adk/ # Agent with Google Search, using ADK framework │ │ └── agent.py │ ├── rag_agent_adk/ # Agent with Google Search and File Search, using ADK framework │ │ ├── agent.py │ │ └── tools_custom.py │ ├── sdk_agent.py # Agent using GenAI SDK (no ADK) with Google Search tool │ └── sdk_rag_agent.py # Agent using GenAI SDK (no ADK) with Gemini File Search tool ├── data/ │ └── story.md # Sample story with "bespoke content" to use with Gemini File Search Store ├── notebooks/ │ └── file_search_store.ipynb # Jupyter notebook for creating and managing Gemini File Search Store │ ├── .env.template # Template for environment variables - make a copy as .env ├── Makefile # Makefile for `make` commands ├── pyproject.toml # Project configuration and dependencies └── README.md # This file
Apri questa cartella nell'editor di Cloud Shell o nel tuo editor preferito. Hai già utilizzato Antigravity? In caso contrario, questo è il momento giusto per provare.)
Tieni presente che il repository contiene una storia di esempio, "The Wormhole Incursion", nel file data/story.md. L'ho scritta insieme a Gemini. Parla del comandante Dazbo e del suo squadrone di astronavi senzienti. (Ho tratto ispirazione dal gioco Elite Dangerous). Questa storia funge da "knowledge base personalizzata", contenente fatti specifici che Gemini non conosce e che non può cercare utilizzando la Ricerca Google.
Configura l'ambiente di sviluppo
Per comodità, ho fornito un Makefile per semplificare molti dei comandi che devi eseguire. Anziché memorizzare comandi specifici, puoi semplicemente eseguire un comando come make <target>. Tuttavia, make è disponibile solo negli ambienti Linux / macOS / WSL. Se utilizzi Windows (senza WSL), dovrai eseguire i comandi completi contenuti nei target make.
# Install dependencies with make make install # If you don't have make... uv sync --extra jupyter
Ecco come appare quando esegui make install nell'editor di Cloud Shell:
Crea una chiave API Gemini
Per utilizzare l'API Gemini Developer (necessaria per utilizzare lo strumento di ricerca file di Gemini), devi disporre di una chiave API Gemini. Il modo più semplice per ottenere una chiave API è utilizzare Google AI Studio, che fornisce un'interfaccia pratica per ottenere chiavi API per i tuoi progetti Google Cloud. Consulta questa guida per i passaggi specifici.
Una volta creata la chiave API, copiala e conservala in un luogo sicuro.
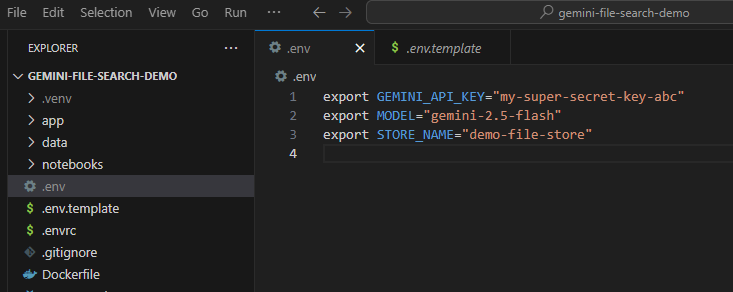
Ora devi impostare questa chiave API come variabile di ambiente. Possiamo farlo utilizzando un file .env. Copia il file .env.example incluso come nuovo file denominato .env. Il file sarà simile al seguente:
export GEMINI_API_KEY="your-api-key" export MODEL="gemini-2.5-flash" export STORE_NAME="demo-file-store"
Sostituisci your-api-key con la tua chiave API effettiva. Ora dovrebbe avere un aspetto simile a questo:
Ora assicurati che le variabili di ambiente siano caricate. Per farlo, esegui questo comando:
source .env
4. L'agente di base
Innanzitutto, stabiliamo una base di riferimento. Utilizzeremo l'SDK google-genai non elaborato per eseguire un semplice agente.
Il codice
Dai un'occhiata a app/sdk_agent.py. Si tratta di un'implementazione minima che:
- Crea un'istanza di
genai.Client. - Attiva lo strumento
google_search. - È tutto. Nessuna RAG.
Dai un'occhiata al codice e assicurati di capire cosa fa.
Running It
# With make make sdk-agent # Without make uv run python app/sdk_agent.py
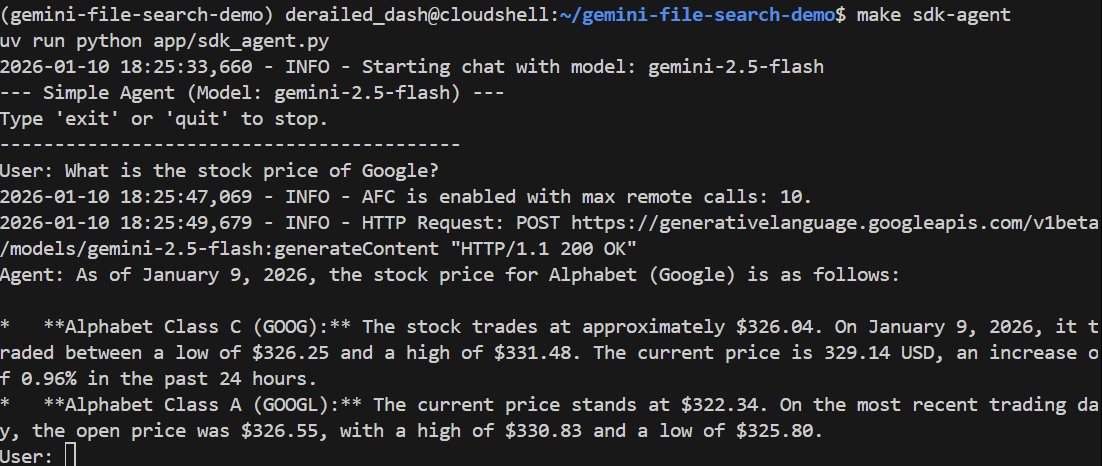
Poniamogli una domanda generale:
> What is the stock price of Google?
Dovrebbe rispondere correttamente utilizzando la Ricerca Google per trovare il prezzo attuale:
Ora, poniamo una domanda a cui non sa rispondere. Richiede che l'agente abbia letto la nostra storia.
> Who pilots the 'Too Many Pies' ship?
Dovrebbe non riuscire o addirittura avere allucinazioni. Vediamo:
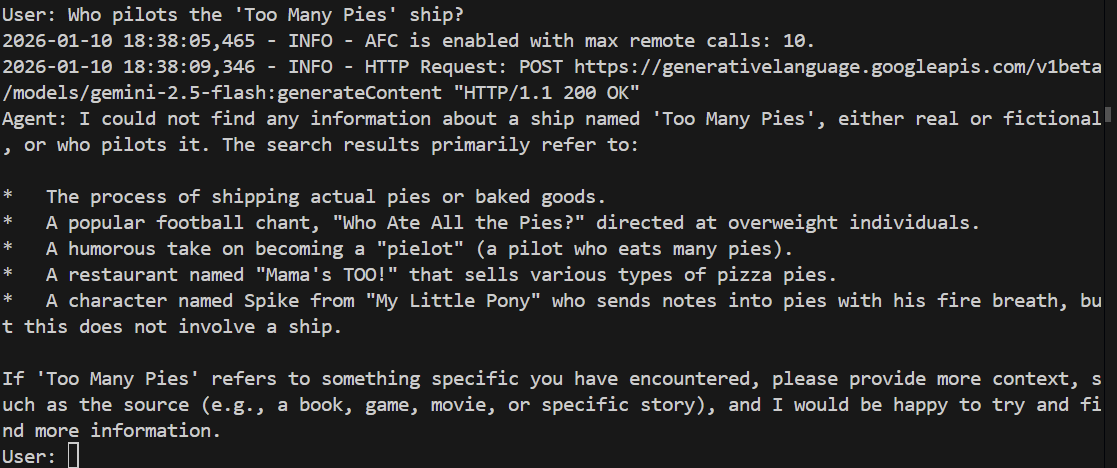
E infatti il modello non riesce a rispondere alla domanda. Non ha idea di cosa stiamo parlando.
Ora digita quit per uscire dall'agente.
5. Ricerca di file di Gemini: spiegazione
La ricerca file di Gemini è essenzialmente una combinazione di due elementi:
- Un sistema RAG completamente gestito: fornisci un insieme di file e Gemini File Search gestisce la suddivisione, l'incorporamento, l'archiviazione e l'indicizzazione vettoriale per te.
- Uno "strumento" nel senso agentico: puoi semplicemente aggiungere lo strumento di ricerca file di Gemini come strumento nella definizione dell'agente e indirizzarlo a un archivio di ricerca file.
Ma soprattutto: è integrato nell'API Gemini stessa. Ciò significa che non devi abilitare API aggiuntive o eseguire il deployment di prodotti separati per utilizzarlo. Quindi è davvero out-of-the-box.
Funzionalità di ricerca dei file di Gemini
Ecco alcune delle funzioni:
- I dettagli di suddivisione, incorporamento, archiviazione e indicizzazione sono astratti per te, lo sviluppatore. Ciò significa che non devi conoscere (o preoccuparti) del modello di embedding (che è Gemini Embeddings, tra l'altro) o di dove vengono archiviati i vettori risultanti. Non devi prendere alcuna decisione sul database vettoriale.
- Supporta un numero elevatissimo di tipi di documenti predefiniti. Inclusi, a titolo esemplificativo: PDF, DOCX, Excel, SQL, JSON, notebook Jupyter, HTML, Markdown, CSV e persino file zip. Puoi visualizzare l'elenco completo qui. Ad esempio, se vuoi basare il tuo agente su file PDF contenenti testo, immagini e tabelle, non devi eseguire alcuna pre-elaborazione di questi file PDF. Ti basta caricare i PDF grezzi e lasciare che Gemini si occupi del resto.
- Possiamo aggiungere metadati personalizzati a qualsiasi file caricato. Questo può essere molto utile per filtrare successivamente i file che vogliamo che lo strumento utilizzi in fase di runtime.
Dove risiedono i dati?
Carichi alcuni file. Lo strumento di ricerca file di Gemini ha preso questi file, ha creato i chunk, poi gli incorporamenti e li ha inseriti... da qualche parte. Ma dove?
La risposta è File Search Store. Si tratta di un contenitore completamente gestito per i tuoi incorporamenti. Non devi sapere (o preoccuparti) di come viene eseguita questa operazione. Tutto ciò che devi fare è crearne uno (a livello di programmazione) e poi caricare i file al suo interno.
È economico.
L'archiviazione e l'esecuzione di query sugli incorporamenti sono senza costi. In questo modo, puoi archiviare gli incorporamenti per tutto il tempo che vuoi e non paghi per questo spazio di archiviazione.
Infatti, l'unica cosa che paghi è la creazione degli incorporamenti al momento del caricamento/dell'indicizzazione. Al momento della stesura di questo documento, il costo è di 0,15 $per 1 milione di token. È piuttosto economico.
6. Come utilizziamo la ricerca di file di Gemini?
Sono previste due fasi:
- Crea e archivia gli embedding in un archivio di ricerca di file.
- Esegui una query nello store di ricerca file dall'agente.
Fase 1 - Blocco note Jupyter per creare e gestire un archivio di ricerca di file Gemini
Questa fase viene eseguita inizialmente e poi ogni volta che vuoi aggiornare il negozio. Ad esempio, quando hai nuovi documenti da aggiungere o quando i documenti di origine sono stati modificati.
Questa fase non è qualcosa che devi includere nel pacchetto della tua applicazione con agenti di deployment. Certo, se vuoi. Ad esempio, se vuoi creare una sorta di UI per gli utenti amministratori della tua applicazione con agenti. Tuttavia, spesso è perfettamente adeguato avere un po' di codice da eseguire su richiesta. Un ottimo modo per eseguire questo codice on demand? Un notebook Jupyter.
The Notebook
Apri il file notebooks/file_search_store.ipynb nell'editor. Se ti viene chiesto di installare estensioni Jupyter VS Code, procedi.
Se lo apriamo nell'editor di Cloud Shell, ha questo aspetto:
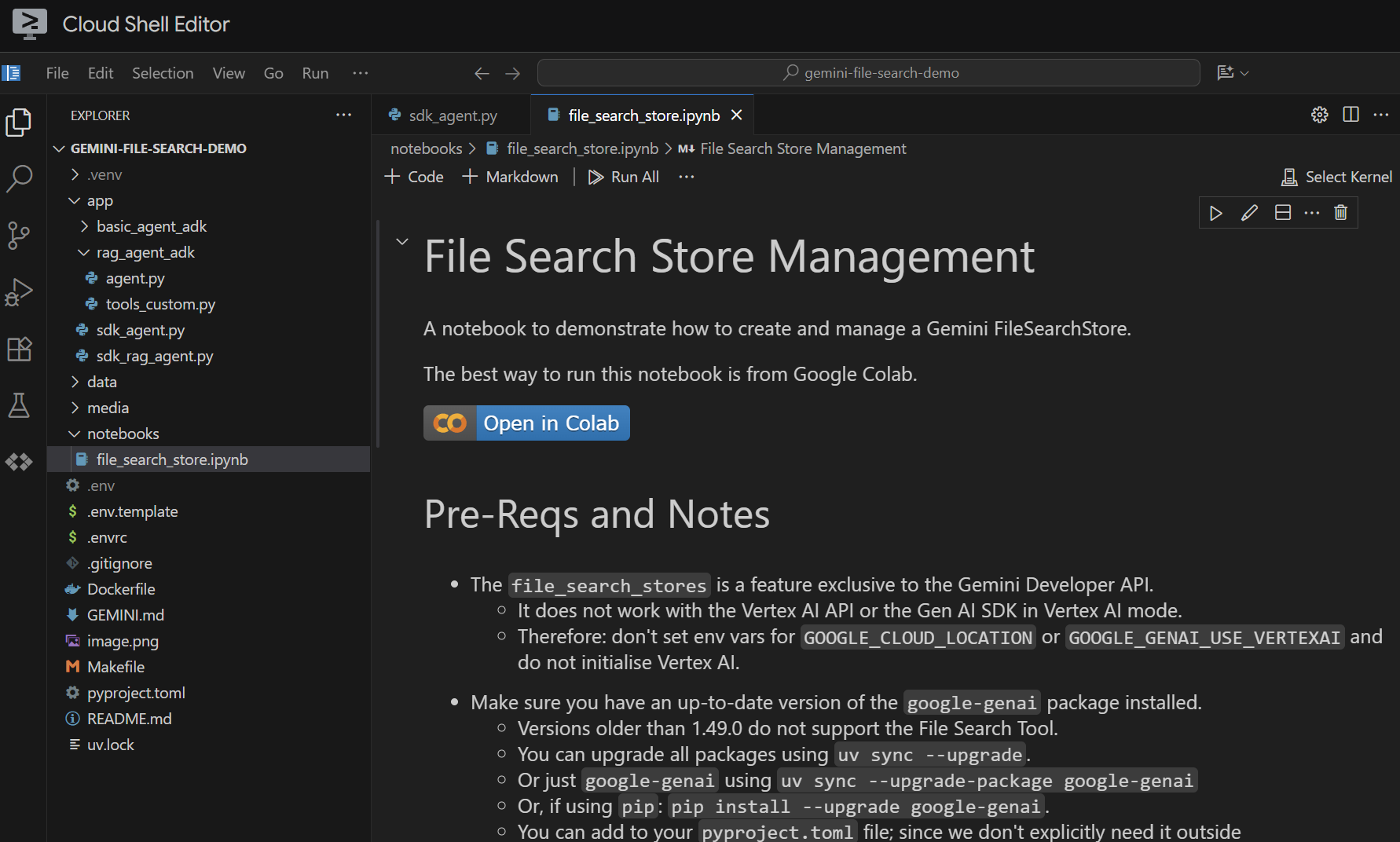
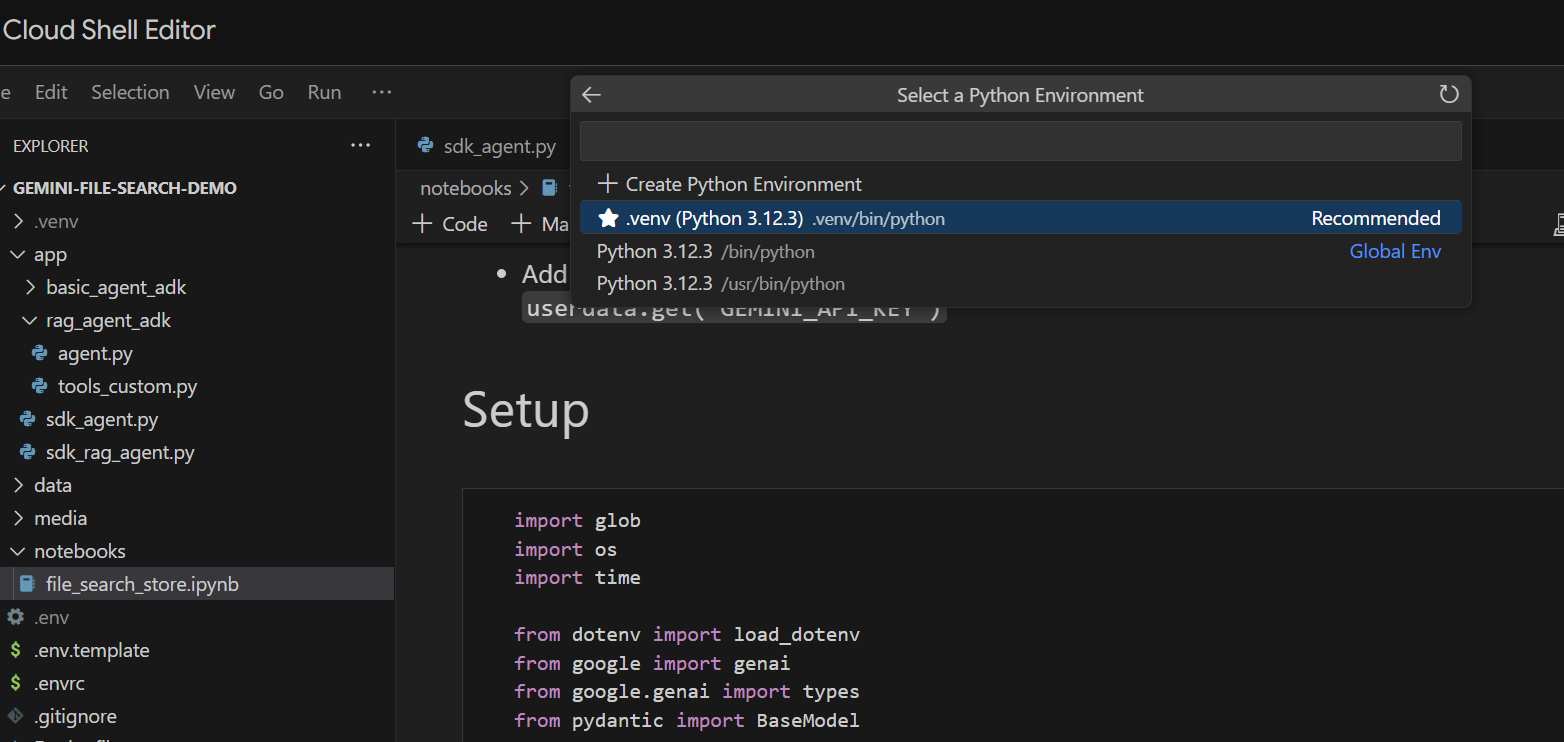
Eseguiamola cella per cella. Inizia eseguendo la cella Setup con le importazioni richieste. Se non hai mai eseguito un notebook, ti verrà chiesto di installare le estensioni richieste. Vai avanti e creale Ti verrà chiesto di selezionare un kernel. Seleziona "Python environments..." e poi il .venv locale che abbiamo installato quando abbiamo eseguito make install in precedenza:
Quindi:
- Esegui la cella "Solo locale" per importare le variabili di ambiente.
- Esegui la cella "Client Initialisation" per inizializzare il client Gemini Gen AI.
- Esegui la cella "Recupera lo Store" con la funzione helper per recuperare lo Store di Gemini File Search per nome.
Ora siamo pronti per creare lo store.
- Esegui la cella "Create the Store (One Time)" per creare lo store. Dovremo farlo solo una volta. Se il codice viene eseguito correttamente, dovresti visualizzare un messaggio che indica
"Created store: fileSearchStores/<someid>" - Esegui la cella "Visualizza lo Store" per vedere cosa contiene. A questo punto, dovresti vedere che contiene 0 documenti.
Bene. Ora abbiamo uno store Gemini File Search pronto all'uso.
Caricamento dei dati
Vogliamo caricare data/story.md sullo store. Segui questi passaggi:
- Esegui la cella che imposta il percorso di caricamento. che punta alla nostra cartella
data/. - Esegui la cella successiva, che crea funzioni di utilità per caricare i file nello store. Tieni presente che il codice in questa cella utilizza anche Gemini per estrarre i metadati da ogni file caricato. Prendiamo questi valori estratti e li memorizziamo come metadati personalizzati nello store. Non è obbligatorio, ma è una buona idea.
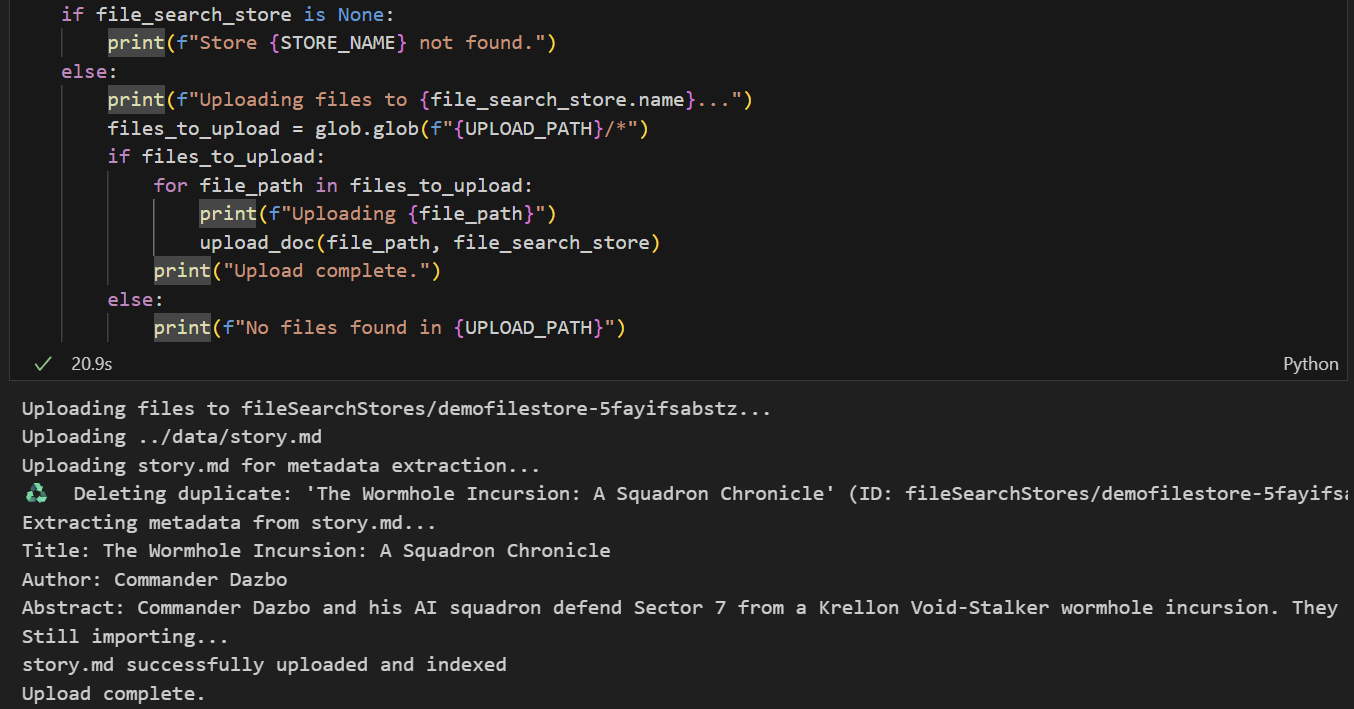
- Esegui la cella per caricare il file. Tieni presente che, se abbiamo già caricato un file con lo stesso nome, il notebook eliminerà prima la versione esistente prima di caricare quella nuova. Dovresti visualizzare un messaggio che indica che il file è stato caricato.
Fase 2: implementa RAG di ricerca file di Gemini nel nostro agente
Abbiamo creato un archivio di ricerca di file Gemini e caricato la nostra storia. Ora è il momento di utilizzare lo Store di ricerca file nel nostro agente. Creiamo un nuovo agente che utilizzi l'archivio di ricerca di file anziché la Ricerca Google. Dai un'occhiata a app/sdk_rag_agent.py.
La prima cosa da notare è che abbiamo implementato una funzione per recuperare il nostro negozio passando un nome del negozio:
def get_store(client: genai.Client, store_name: str) -> types.FileSearchStore | None:
"""Retrieve a store by display name"""
try:
for a_store in client.file_search_stores.list():
if a_store.display_name == store_name:
return a_store
except Exception as e:
logger.error(f"Error listing stores: {e}")
return None
Una volta creato lo store, utilizzarlo è semplice come allegarlo come strumento al nostro agente, in questo modo:
file_search_tool = types.Tool(file_search=types.FileSearch(file_search_store_names=[store.name]))
Esecuzione dell'agente RAG
Lo lanciamo così:
make sdk-rag-agent # Or, without make: uv run python app/sdk_rag_agent.py
Poniamo la domanda a cui l'agente precedente non è riuscito a rispondere:
> Who pilots the 'Too Many Pies' ship?
E la risposta?
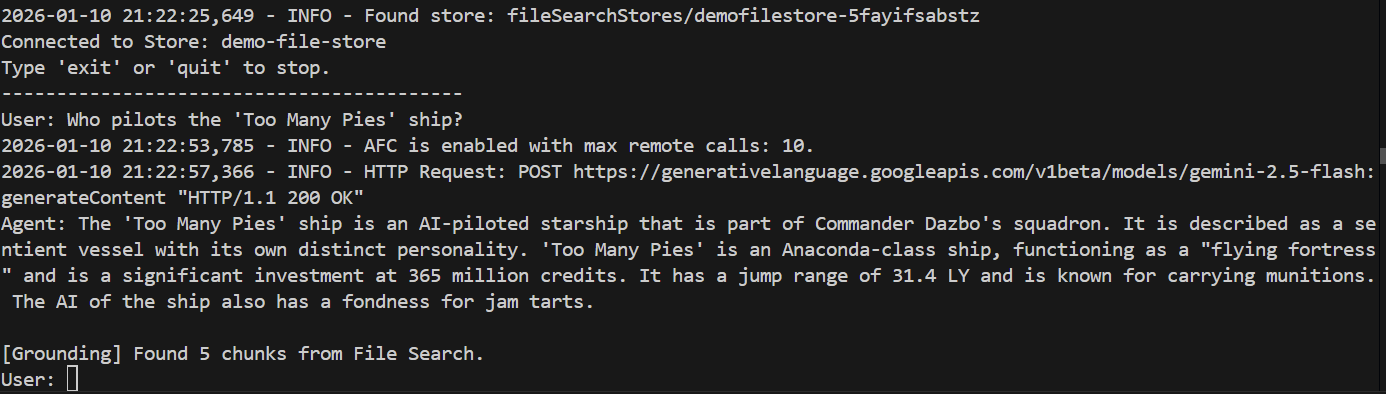
Operazione riuscita. Dalla risposta possiamo vedere che:
- Il nostro datastore è stato utilizzato per rispondere alla domanda.
- Sono stati trovati 5 segmenti pertinenti.
- La risposta è perfetta.
Digita quit per chiudere l'agente.
7. Conversione degli agenti per l'utilizzo di ADK
Google Agent Development Kit (ADK) è un framework modulare open source e un SDK che consente agli sviluppatori di creare agenti e sistemi agentici. Ci consente di creare e orchestrare facilmente sistemi multi-agente. Sebbene sia ottimizzato per Gemini e l'ecosistema Google, ADK è indipendente dal modello e dal deployment ed è progettato per la compatibilità con altri framework. Se non hai ancora utilizzato ADK, consulta la documentazione di ADK per saperne di più.
Agente ADK di base con la Ricerca Google
Dai un'occhiata a app/basic_agent_adk/agent.py. In questo codice campione puoi vedere che abbiamo implementato due agenti:
- Un
root_agentche gestisce l'interazione con l'utente e in cui abbiamo fornito l'istruzione principale del sistema. - Un
SearchAgentseparato che utilizzagoogle.adk.tools.google_searchcome strumento.
root_agent utilizza effettivamente SearchAgent come strumento, implementato utilizzando questa riga:
tools=[AgentTool(agent=search_agent)],
Il prompt di sistema dell'agente principale ha questo aspetto:
You are a helpful AI assistant designed to provide accurate and useful information.
If you don't know the answer, use the SearchAgent to perform a Google search.
Do not attempt to search more than ONCE.
If the search yields no relevant results or returns unrelated content, you MUST immediately respond with: "I could not find any information about that."
Do NOT retry the search with different terms. Do NOT ask for clarification. FAIL FAST.
Prova l'agente
L'ADK fornisce una serie di interfacce pronte all'uso per consentire agli sviluppatori di testare i propri agenti ADK. Una di queste interfacce è la UI web. In questo modo possiamo testare i nostri agenti in un browser, senza dover scrivere una riga di codice dell'interfaccia utente.
Possiamo avviare questa interfaccia eseguendo:
make adk-playground # Or, without make: uv run adk web app --port 8501 --reload_agents
Tieni presente che il comando indirizza lo strumento adk web alla cartella app, in cui rileva automaticamente tutti gli agenti ADK che implementano un root_agent. Proviamo:
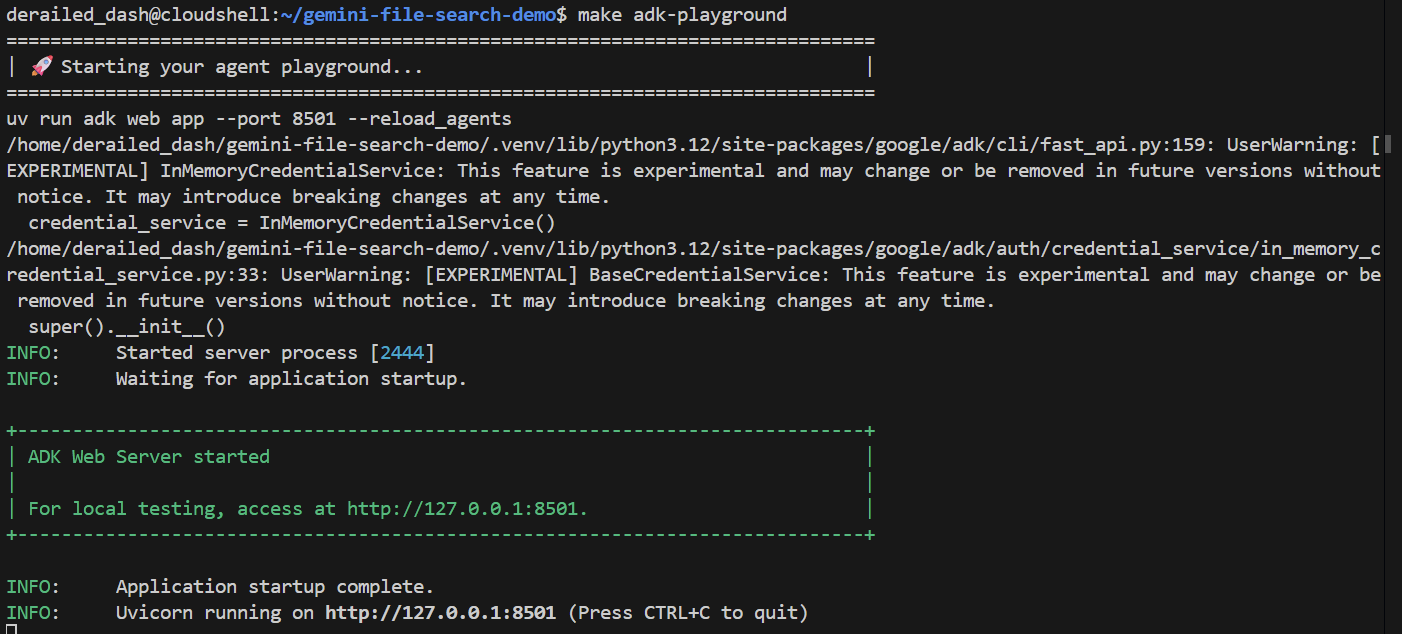
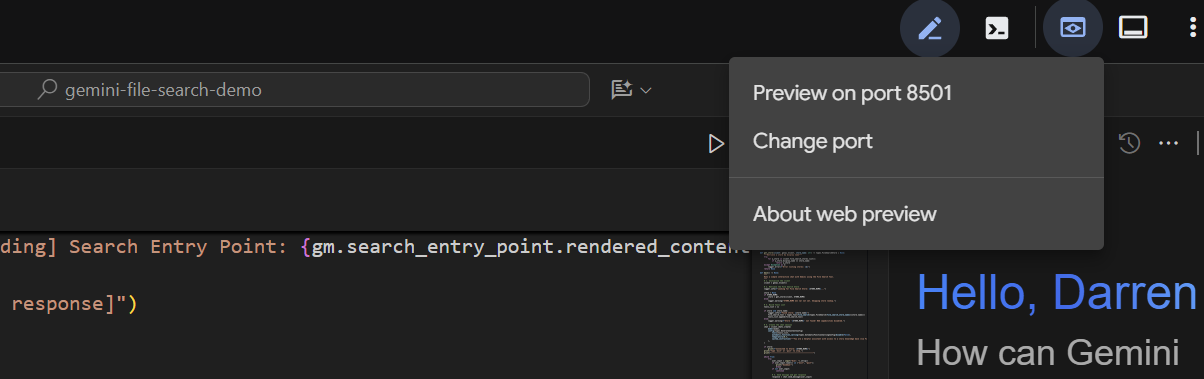
Dopo un paio di secondi, l'applicazione è pronta. Se esegui il codice localmente, indirizza il browser a http://127.0.0.1:8501. Se esegui l'applicazione nell'editor di Cloud Shell, fai clic su "Anteprima web" e modifica la porta in 8501:
Quando viene visualizzata l'interfaccia utente, seleziona basic_agent_adk dal menu a discesa e potrai porre domande:
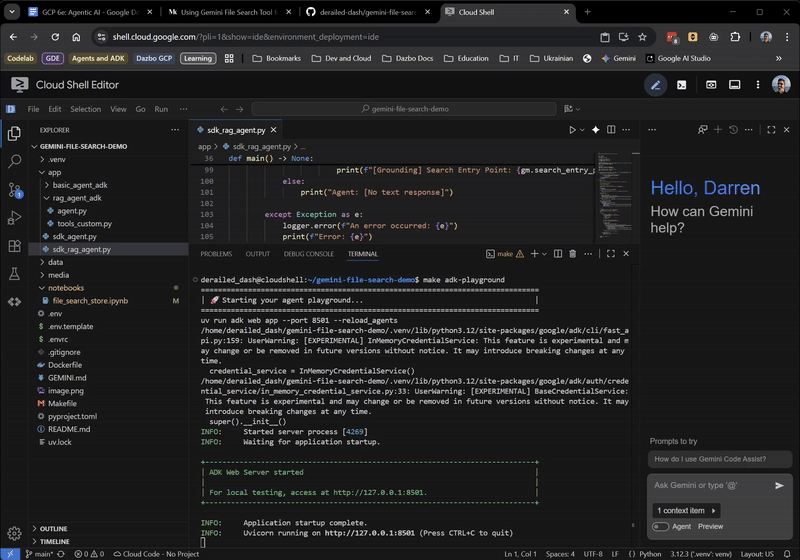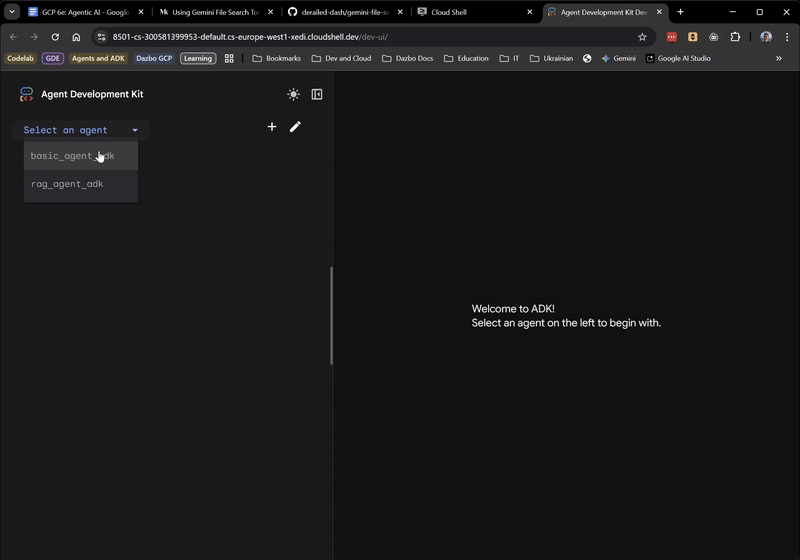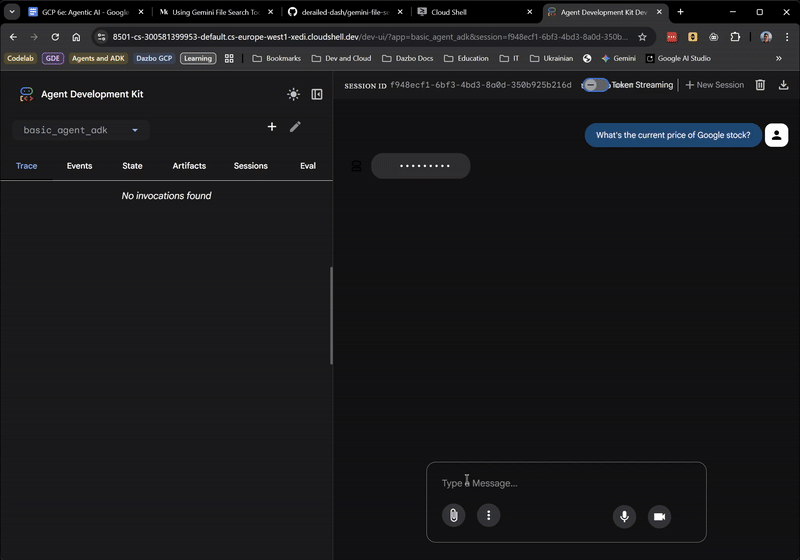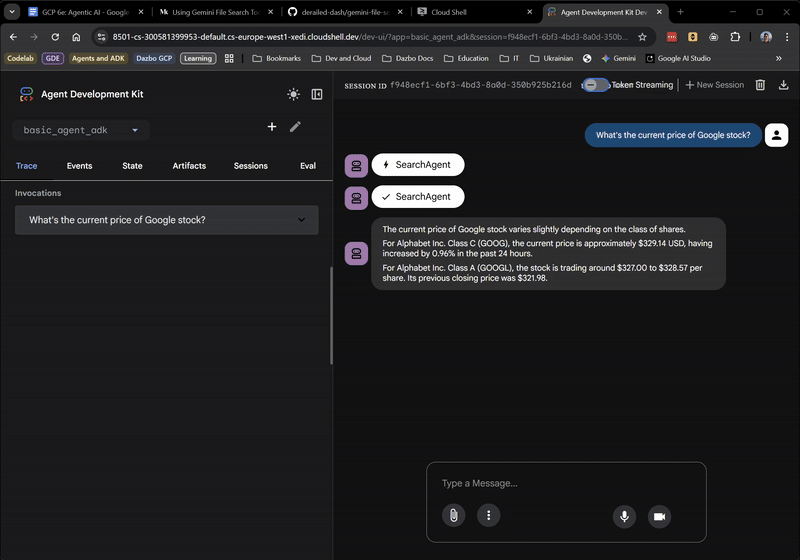
Finora stai andando bene. L'interfaccia utente web mostra anche quando l'agente principale delega l'SearchAgent. Si tratta di una funzionalità molto utile.
Ora poniamo la domanda che richiede la conoscenza della nostra storia:
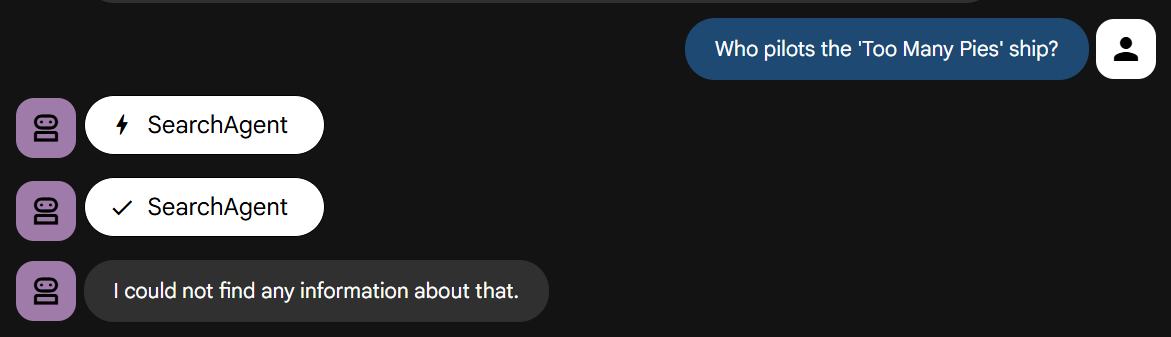
Fai una prova. Dovresti notare che il test non va a buon fine rapidamente, come indicato.
Incorporare File Search Store nell'agente ADK
Ora mettiamo tutto insieme. Eseguiremo un agente ADK in grado di utilizzare sia File Search Store sia la Ricerca Google. Dai un'occhiata al codice in app/rag_agent_adk/agent.py.
Il codice è simile all'esempio precedente, ma con alcune importanti differenze:
- Abbiamo un agente principale che coordina due agenti specializzati:
- RagAgent: l'esperto di conoscenza personalizzato che utilizza il nostro archivio di ricerca file di Gemini
- SearchAgent: l'esperto di conoscenze generali che utilizza la Ricerca Google
- Poiché ADK non dispone ancora di un wrapper integrato per
FileSearch, utilizziamo una classe wrapper personalizzataFileSearchToolper eseguire il wrapping dello strumento FileSearch, che inserisce la configurazionefile_search_store_namesnella richiesta del modello di basso livello. Questa operazione è stata implementata nello script separatoapp/rag_agent_adk/tools_custom.py.
Inoltre, c'è un aspetto da tenere presente. Al momento della stesura, non puoi utilizzare lo strumento nativo GoogleSearch e lo strumento FileSearch nella stessa richiesta allo stesso agente. Se provi, riceverai un errore come questo:
ERRORE - Si è verificato un errore: 400 INVALID_ARGUMENT. {‘error': {‘code': 400, ‘message': ‘Search as a tool and file search tool are not supported together', ‘status': ‘INVALID_ARGUMENT'}}
Errore: 400 INVALID_ARGUMENT. {‘error': {‘code': 400, ‘message': ‘Search as a tool and file search tool are not supported together', ‘status': ‘INVALID_ARGUMENT'}}
La soluzione consiste nell'implementare i due agenti specializzati come subagenti separati e passarli all'agente principale utilizzando il pattern Agente come strumento. Inoltre, l'istruzione di sistema dell'agente principale fornisce indicazioni molto chiare per utilizzare prima RagAgent:
Sei un assistente AI utile progettato per fornire informazioni accurate e utili.
Hai accesso a due agenti specializzati:
- RagAgent: per informazioni personalizzate dalla knowledge base interna.
- SearchAgent: per informazioni generali dalla Ricerca Google.
Prova sempre prima RagAgent. Se non riesci a ottenere una risposta utile, prova con SearchAgent.
Final Test
Esegui l'interfaccia utente web dell'ADK come prima:
make adk-playground # Or, without make: uv run adk web app --port 8501 --reload_agents
Questa volta, seleziona rag_agent_adk nella UI. Vediamo come funziona: 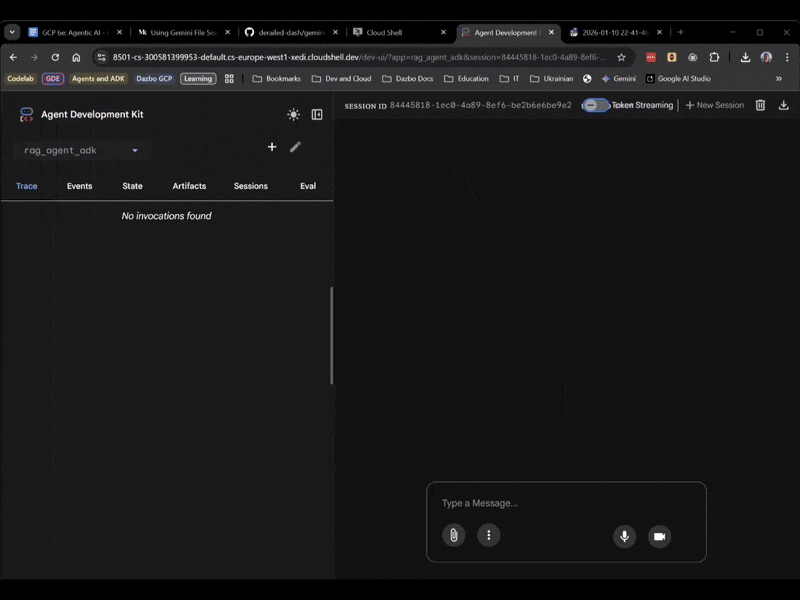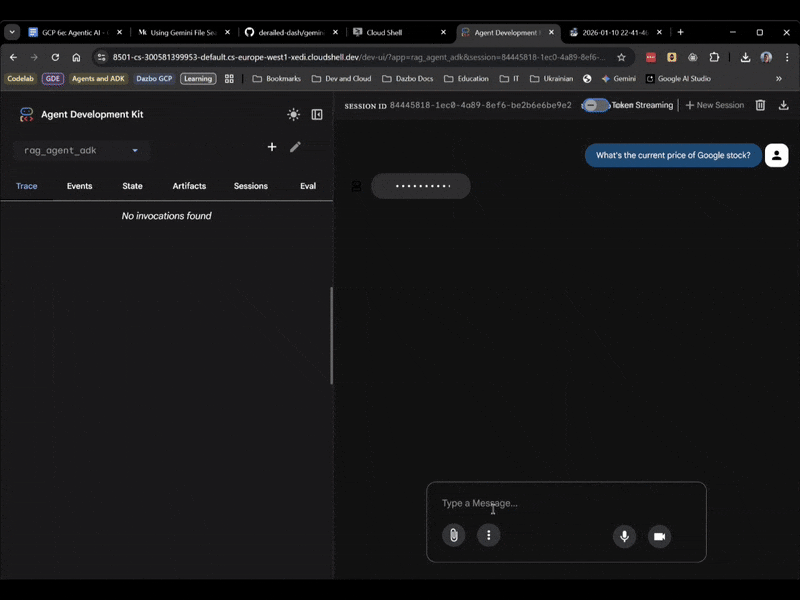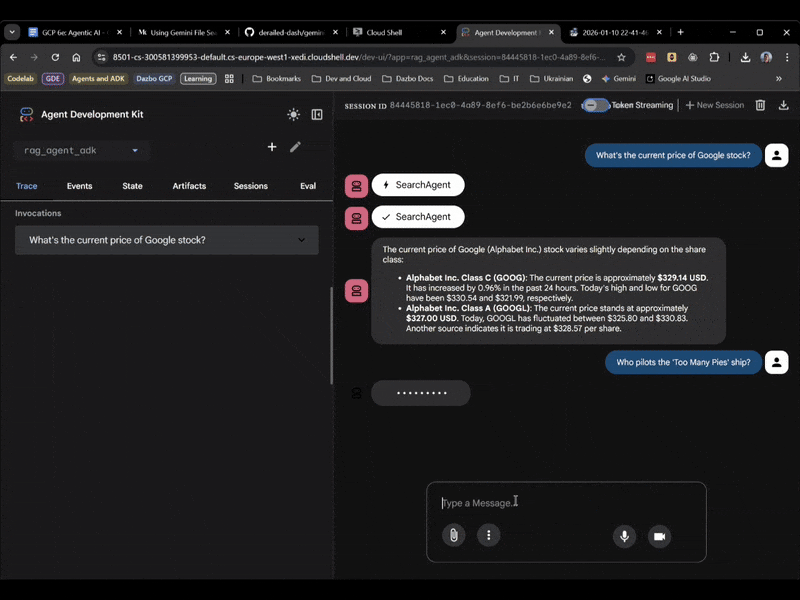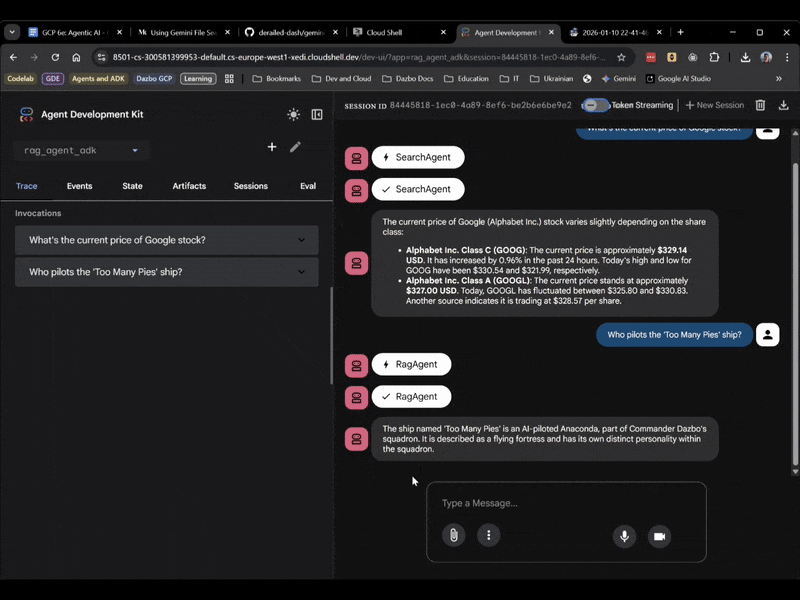
Possiamo vedere che sceglie il subagente appropriato in base alla domanda.
8. Conclusione
Congratulazioni per aver completato questo codelab.
Sei passato da un semplice script a un sistema multi-agente abilitato a RAG, il tutto senza una sola riga di codice di incorporamento e senza dover implementare un database vettoriale.
Abbiamo imparato che:
- Gemini File Search è una soluzione RAG gestita che fa risparmiare tempo e fatica.
- ADK ci fornisce la struttura necessaria per app multi-agente complesse e offre agli sviluppatori la comodità di interfacce come la UI web.
- Il pattern "Agent-as-a-Tool" risolve i problemi di compatibilità degli strumenti.
Spero che questo lab ti sia stato utile. A presto!