
1. はじめに
この Codelab では、Gemini ファイル検索を使用してエージェント アプリケーションで RAG を有効にする方法について説明します。Gemini ファイル検索を使用して、チャンク、エンベディング、ベクトル データベースの詳細を気にすることなく、ドキュメントを取り込んでインデックス登録します。
ラボの内容
- RAG の基本と、RAG が必要な理由。
- Gemini ファイル検索の概要とメリット。
- ファイル検索ストアを作成する方法。
- 独自のカスタムファイルをファイル検索ストアにアップロードする方法。
- RAG に Gemini ファイル検索ツールを使用する方法。
- Google Agent Development Kit(ADK)を使用するメリット。
- ADK を使用して構築されたエージェント ソリューションで Gemini ファイル検索ツールを使用する方法。
- Google 検索などの Google の「ネイティブ」ツールと Gemini ファイル検索ツールを併用する方法。
演習内容
- Google Cloud プロジェクトを作成し、開発環境を設定します。
- Google 検索を使用できるが RAG 機能のない、Google Gen AI SDK(ADK なし)を使用してシンプルな Gemini ベースのエージェントを作成します。
- カスタマイズされた情報に対して正確で質の高い情報を提供できないことを示す。
- Gemini ファイル検索ストアの作成と管理を行うための Jupyter ノートブック(ローカルまたは Google Colab などで実行可能)を作成します。
- ノートブックを使用して、カスタマイズされたコンテンツをファイル検索ストアにアップロードします。
- ファイル検索ストアが接続されたエージェントを作成し、より適切な回答を生成できることを証明します。
- 最初の「基本」エージェントを Google 検索ツールを備えた ADK エージェントに変換します。
- ADK ウェブ UI を使用してエージェントをテストします。
- 「ツールとしてのエージェント」パターンを使用して、ファイル検索ストアを ADK エージェントに組み込み、ファイル検索ツールと Google 検索ツールを並行して使用できるようにします。
2. RAG とは?RAG が必要な理由
では、検索拡張生成。
このページをご覧になっている方は、おそらくご存知だと思いますが、念のため簡単に説明します。LLM(Gemini など)は優れていますが、いくつかの問題があります。
- 常に最新ではない: トレーニング中に学習したことしか認識できません。
- すべてを知っているわけではない: モデルは巨大ですが、全知全能ではありません。
- 独自の情報を知らない: 幅広い知識を持っていますが、社内ドキュメント、ブログ、Jira チケットは読んでいません。
そのため、モデルが答えを知らないことを質問すると、通常は間違った答えやでっち上げの答えが返ってきます。多くの場合、モデルはこの誤った回答を自信を持って出力します。これをハルシネーションと呼びます。
解決策の 1 つは、独自の情報を会話コンテキストに直接ダンプすることです。情報量が少ない場合は問題ありませんが、情報量が多い場合はすぐに問題が発生します。具体的には、次のような問題が発生します。
- レイテンシ: モデルからのレスポンスが遅くなる。
- シグナル ロット(「lost-in-the-middle」とも呼ばれます): モデルが関連データをジャンクから分類できなくなる状態。コンテキストの多くがモデルによって無視される。
- 費用: トークンには費用がかかるため。
- コンテキスト ウィンドウの枯渇: この時点で、Gemini はリクエストを処理しません。
この状況を改善するはるかに効果的な方法は、RAG を使用することです。これは、自分のデータソースから関連情報を検索し(セマンティック マッチングを使用)、質問とともにこのデータの関連するチャンクをモデルにフィードするプロセスです。モデルを現実世界に根ざした形で構築します。
外部データをインポートし、データをチャンクに分割し、データをベクトル エンベディングに変換してから、これらのエンベディングを適切なベクトル データベースに保存してインデックス登録します。
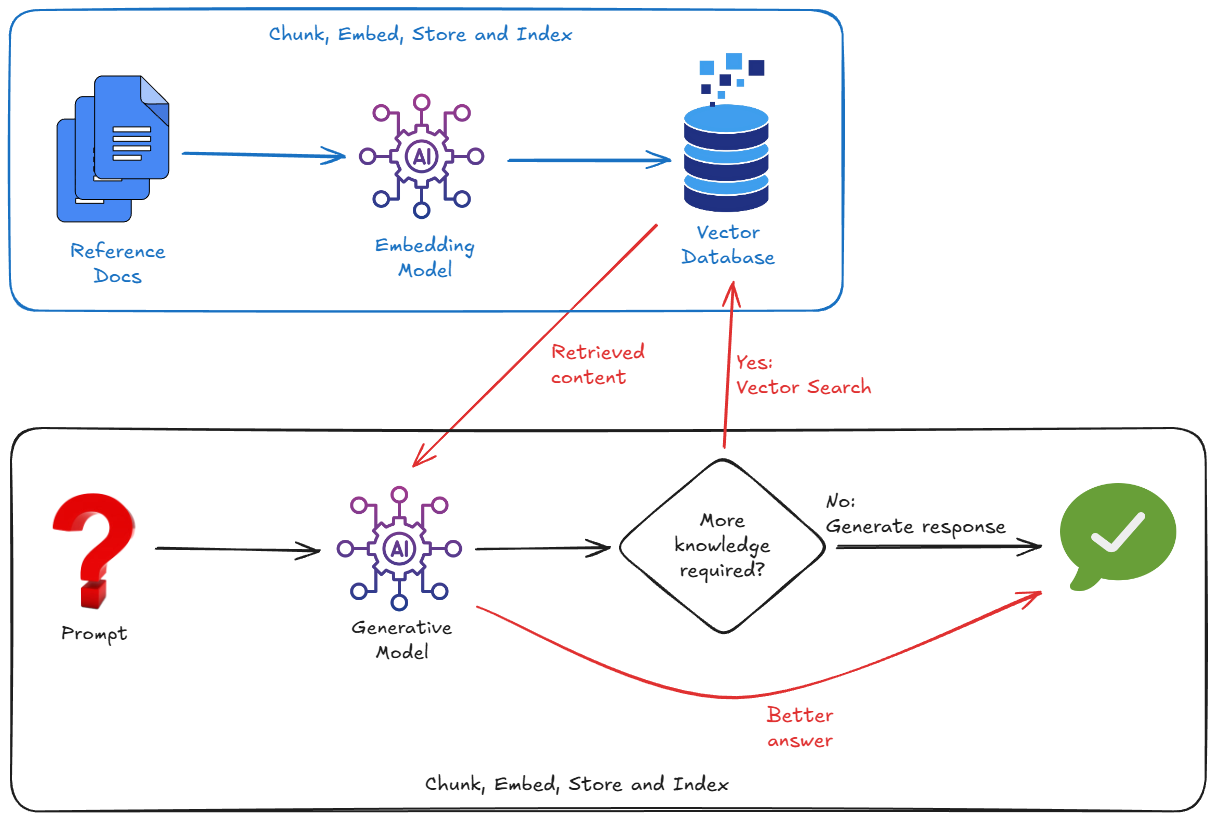
RAG を実装するには、通常、次のことを考慮する必要があります。
- ベクトル データベース(Pinecone、Weaviate、pgvector を使用した Postgres など)を起動します。
- ドキュメント(PDF、マークダウンなど)を分割するチャンク スクリプトを作成する。
- エンベディング モデルを使用して、これらのチャンクのエンベディング(ベクトル)を生成する。
- ベクトルをベクトル データベースに保存する。
しかし、友人は友人が過剰な設計をすることを許しません。もっと簡単な方法があるとしたらどうでしょう。
3. 前提条件
Google Cloud プロジェクトの作成
この Codelab を実行するには、Google Cloud プロジェクトが必要です。既存のプロジェクトを使用することも、新しいプロジェクトを作成することもできます。
プロジェクトで課金が有効になっていることを確認します。プロジェクトの課金ステータスを確認する方法については、こちらのガイドをご覧ください。
この Codelab の完了に費用はかかりません。
プロジェクトの準備を始めましょう。お待ちしております。
デモリポジトリのクローンを作成する
この Codelab のガイド付きコンテンツを含むリポジトリを作成しました。きっと必要になるはずです。
ターミナルまたは Google Cloud Shell エディタに統合されたターミナルから、次のコマンドを実行します。Cloud Shell とそのエディタは非常に便利です。必要なコマンドがすべてプリインストールされており、すべてがすぐに実行できます。
git clone https://github.com/derailed-dash/gemini-file-search-demo cd gemini-file-search-demo
このツリーには、リポジトリ内の主なフォルダとファイルが表示されます。
gemini-file-search-demo/ ├── app/ │ ├── basic_agent_adk/ # Agent with Google Search, using ADK framework │ │ └── agent.py │ ├── rag_agent_adk/ # Agent with Google Search and File Search, using ADK framework │ │ ├── agent.py │ │ └── tools_custom.py │ ├── sdk_agent.py # Agent using GenAI SDK (no ADK) with Google Search tool │ └── sdk_rag_agent.py # Agent using GenAI SDK (no ADK) with Gemini File Search tool ├── data/ │ └── story.md # Sample story with "bespoke content" to use with Gemini File Search Store ├── notebooks/ │ └── file_search_store.ipynb # Jupyter notebook for creating and managing Gemini File Search Store │ ├── .env.template # Template for environment variables - make a copy as .env ├── Makefile # Makefile for `make` commands ├── pyproject.toml # Project configuration and dependencies └── README.md # This file
このフォルダを Cloud Shell エディタまたは任意のエディタで開きます。(反重力はもうお使いになりましたか?(まだお試しでない場合は、この機会にぜひお試しください)。
リポジトリには、data/story.md ファイルに「The Wormhole Incursion」というサンプル ストーリーが含まれています。Gemini と共同で作成しました。ダズボ司令官と彼の知覚力のある宇宙船の飛行隊についての物語です。(ゲームの Elite Dangerous からインスピレーションを得ました)。このストーリーは、Gemini が知らない、さらに Google 検索でも検索できない特定の事実を含む「カスタム ナレッジベース」として機能します。
開発環境を設定する
便宜上、実行する必要がある多くのコマンドを簡素化する Makefile を用意しました。特定のコマンドを覚えておく代わりに、make <target> のようなコマンドを実行するだけで済みます。ただし、make は Linux、macOS、WSL 環境でのみ使用できます。Windows(WSL なし)を使用している場合は、make ターゲットに含まれる完全なコマンドを実行する必要があります。
# Install dependencies with make make install # If you don't have make... uv sync --extra jupyter
Cloud Shell エディタで make install を実行すると、次のようになります。
Gemini API キーを作成する
Gemini Developer API(Gemini ファイル検索ツールを使用するために必要)を使用するには、Gemini API キーが必要です。API キーを取得する最も簡単な方法は、Google AI Studio を使用することです。このツールは、Google Cloud プロジェクトの API キーを取得するための便利なインターフェースを提供します。具体的な手順については、こちらのガイドをご覧ください。
API キーが作成されたら、コピーして安全に保管します。
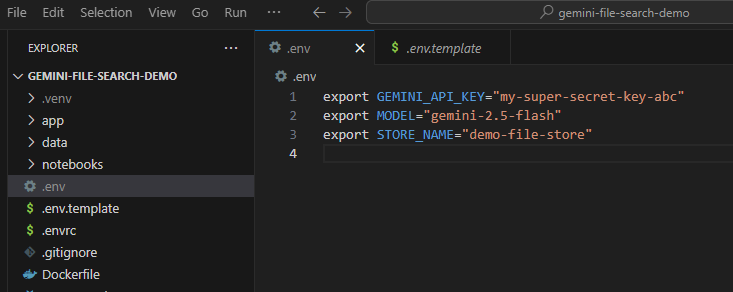
この API キーを環境変数として設定する必要があります。これは .env ファイルを使用して行うことができます。含まれている .env.example を .env という名前の新しいファイルとしてコピーします。ファイルの内容は次のようになります。
export GEMINI_API_KEY="your-api-key" export MODEL="gemini-2.5-flash" export STORE_NAME="demo-file-store"
your-api-key を実際の API キーに置き換えます。次のようになります。
環境変数が読み込まれていることを確認します。これを行うには、以下を実行します。
source .env
4. 基本的なエージェント
まず、ベースラインを確立しましょう。生の google-genai SDK を使用して、シンプルなエージェントを実行します。
コード
app/sdk_agent.py をご覧ください。これは、次の最小限の実装です。
genai.Clientをインスタンス化します。google_searchツールを有効にします。- 以上です。RAG なし。
コードを確認して、その内容を理解してください。
Running It
# With make make sdk-agent # Without make uv run python app/sdk_agent.py
一般的な質問をしてみましょう。
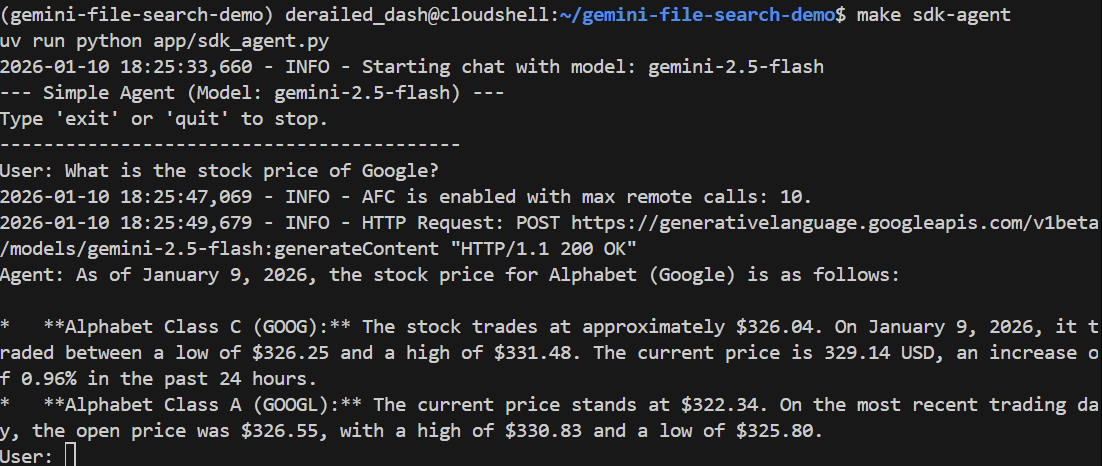
> What is the stock price of Google?
Google 検索を使用して現在の価格を調べ、正しく回答する必要があります。
次に、回答できない質問をしてみましょう。エージェントがストーリーを読んでいることが前提となります。
> Who pilots the 'Too Many Pies' ship?
失敗するか、ハルシネーションが発生する可能性があります。手順は次のとおりです。
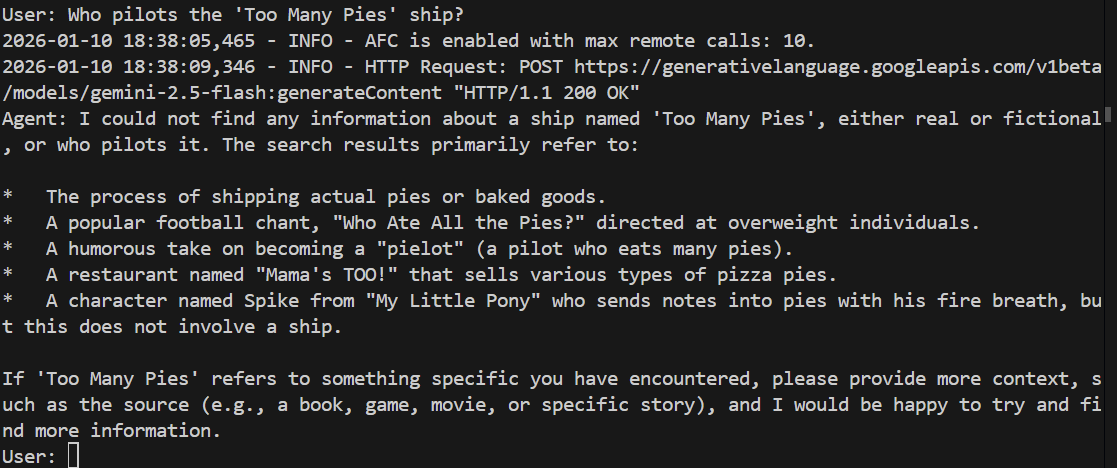
案の定、モデルは質問に答えられません。何の話をしているのか、まったくわかっていないようです。
「quit」と入力してエージェントを終了します。
5. Gemini ファイル検索: 説明
Gemini ファイル検索は、基本的に次の 2 つの組み合わせです。
- フルマネージド RAG システム: 複数のファイルを提供すると、Gemini ファイル検索がチャンク化、エンベディング、保存、ベクトル インデックス登録を処理します。
- エージェントの「ツール」: エージェント定義で Gemini ファイル検索ツールをツールとして追加し、ツールをファイル検索ストアに指定するだけです。
重要なのは、Gemini API 自体に組み込まれていることです。つまり、この機能を使用するために追加の API を有効にしたり、個別のプロダクトをデプロイしたりする必要はありません。まさにout-of-the-box状態です。
Gemini ファイル検索機能
ここでは、主な機能についてご紹介します:
- チャンク化、エンベディング、保存、インデックス登録の詳細は、デベロッパーから抽象化されます。つまり、エンベディング モデル(ちなみに Gemini Embeddings)や、結果のベクトルがどこに保存されるかを把握する必要はありません。ベクトル データベースの選択を行う必要はありません。
- このツールは、すぐに使用できるドキュメント タイプを多数サポートしています。PDF、DOCX、Excel、SQL、JSON、Jupyter ノートブック、HTML、マークダウン、CSV、zip ファイルなど、以下を含みます(ただしこれらに限定されません)。完全なリストはこちらで確認できます。たとえば、テキスト、画像、表を含む PDF ファイルでエージェントをグラウンディングする場合、これらの PDF ファイルを前処理する必要はありません。PDF をアップロードするだけで、残りの処理は Gemini が行います。
- アップロードされたファイルにカスタム メタデータを追加できます。これは、実行時にツールで使用するファイルをフィルタリングする際に非常に便利です。
データはどこに保存されますか?
ファイルをアップロードします。Gemini ファイル検索ツールは、これらのファイルを取得してチャンクを作成し、エンベディングを作成して、どこかに配置しました。しかし、どこに?
答えは、ファイル検索ストアです。これは、エンベディング用のフルマネージド コンテナです。この処理がどのように行われるかを把握する必要はありません。必要なのは、1 つのバケットを(プログラムで)作成し、そこにファイルをアップロードすることだけです。
It's Cheap!
エンベディングの保存とクエリは無料です。そのため、エンベディングを必要なだけ保存でき、そのストレージの料金は発生しません。
実際には、アップロード時またはインデックス登録時のエンベディングの作成に対してのみ料金が発生します。このドキュメントの作成時点では、100 万トークンあたり $0.15 です。かなり安いですね。
6. Gemini ファイル検索の仕組み
次の 2 つのフェーズがあります。
- エンベディングを作成して、ファイル検索ストアに保存します。
- エージェントからファイル検索ストアにクエリを実行します。
フェーズ 1 - Gemini ファイル検索ストアを作成して管理する Jupyter ノートブック
このフェーズは、最初に行うもので、その後はストアを更新するたびに行います。たとえば、追加する新しいドキュメントがある場合や、ソース ドキュメントが変更された場合などです。
このフェーズは、デプロイされたエージェント アプリケーションにパッケージ化する必要はありません。はい、必要に応じて変更できます。たとえば、エージェント アプリケーションの管理者ユーザー向けの UI を作成する場合などです。しかし、オンデマンドで実行するコードを少し用意するだけで十分な場合もよくあります。このコードをオンデマンドで実行する最適な方法の 1 つは、Jupyter ノートブックです。
きみと歩く道
エディタで notebooks/file_search_store.ipynb ファイルを開きます。Jupyter VS Code 拡張機能をインストールするよう求められた場合は、インストールしてください。
Cloud Shell エディタで開くと、次のようになります。
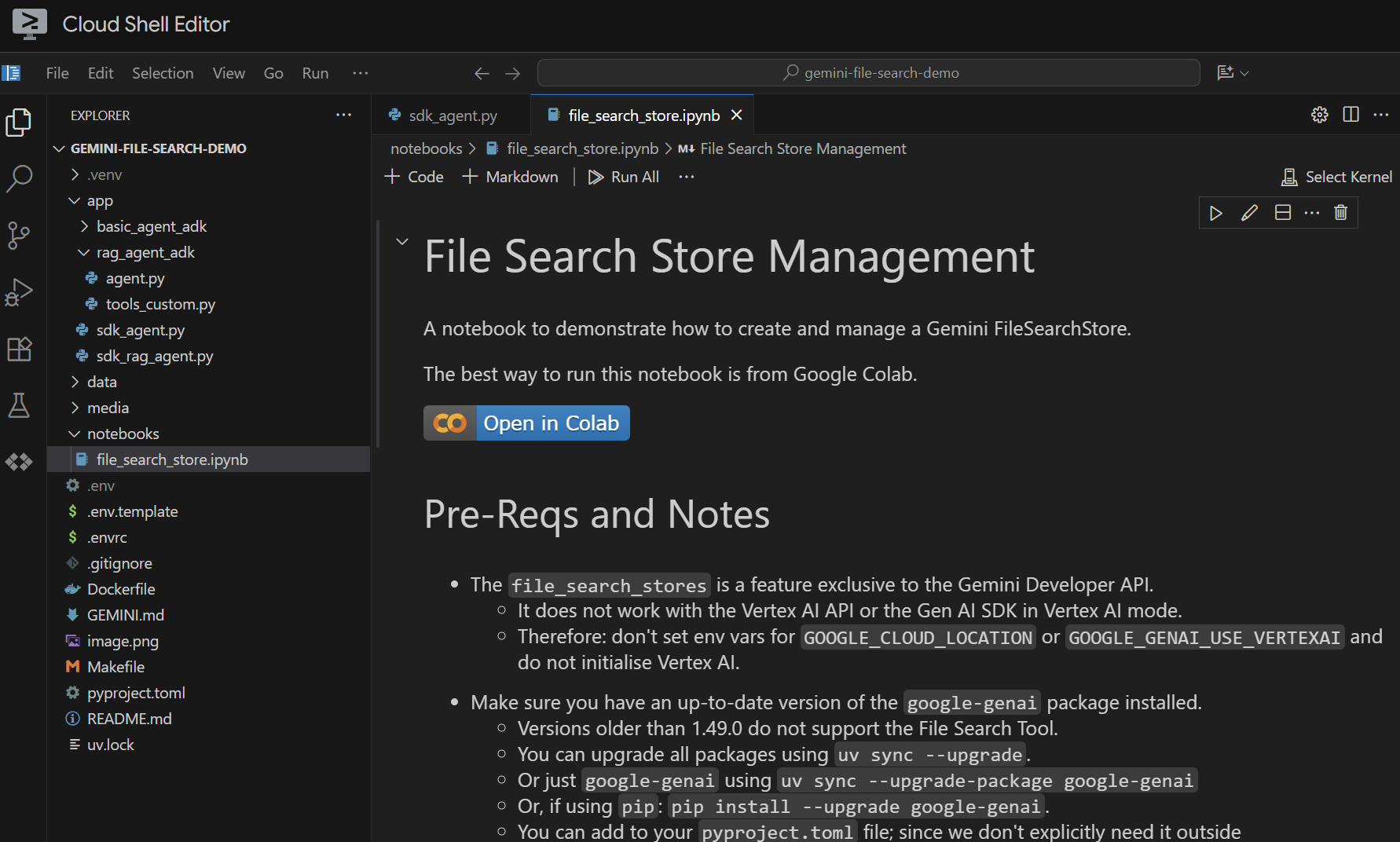
セルごとに実行してみましょう。まず、必要なインポートを含む Setup セルを実行します。ノートブックをまだ実行していない場合は、必要な拡張機能をインストールするように求められます。それでは、実際にやってみましょう。カーネルを選択するよう求められます。[Python environments...] を選択し、先ほど make install を実行したときにインストールしたローカル .venv を選択します。
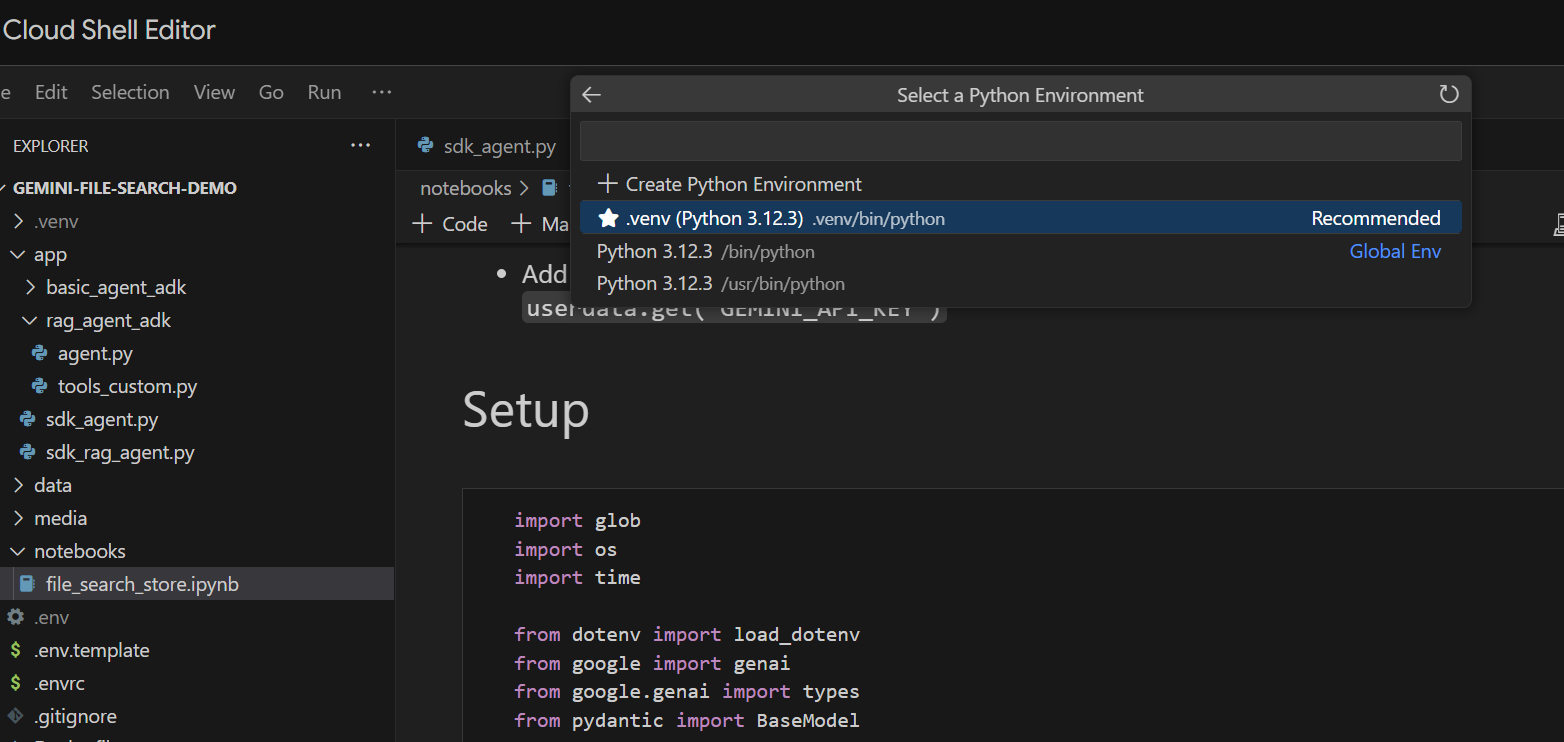
以下の手順を行います。
- [Local Only] セルを実行して、環境変数を取得します。
- 「クライアントの初期化」セルを実行して、Gemini Gen AI クライアントを初期化します。
- 名前で Gemini ファイル検索ストアを取得するヘルパー関数を使用して、「ストアを取得」セルを実行します。
これで、ストアを作成する準備が整いました。
- 「Create the Store (One Time)」セルを実行して、ストアを作成します。この操作は 1 回だけ行う必要があります。コードが正常に実行されると、「
"Created store: fileSearchStores/<someid>"」というメッセージが表示されます。 - 「View the Store」セルを実行して、内容を確認します。この時点で、ドキュメントが 0 個含まれていることが確認できます。
これで、これで、Gemini ファイル検索ストアを使用できるようになりました。
データのアップロード
data/story.md をストアにアップロードします。手順は次のとおりです。
- アップロード パスを設定するセルを実行します。これは
data/フォルダを指します。 - 次のセルを実行します。これにより、ファイルをストアにアップロードするためのユーティリティ関数が作成されます。このセルのコードでは、Gemini を使用して、アップロードされた各ファイルからメタデータを抽出します。抽出されたこれらの値は、ストアにカスタム メタデータとして保存されます。(これは必須ではありませんが、やっておくと便利です)。
- セルを実行してファイルをアップロードします。同じ名前のファイルを以前にアップロードしたことがある場合、ノートブックは新しいファイルをアップロードする前に、既存のバージョンを削除します。ファイルがアップロードされたことを示すメッセージが表示されます。
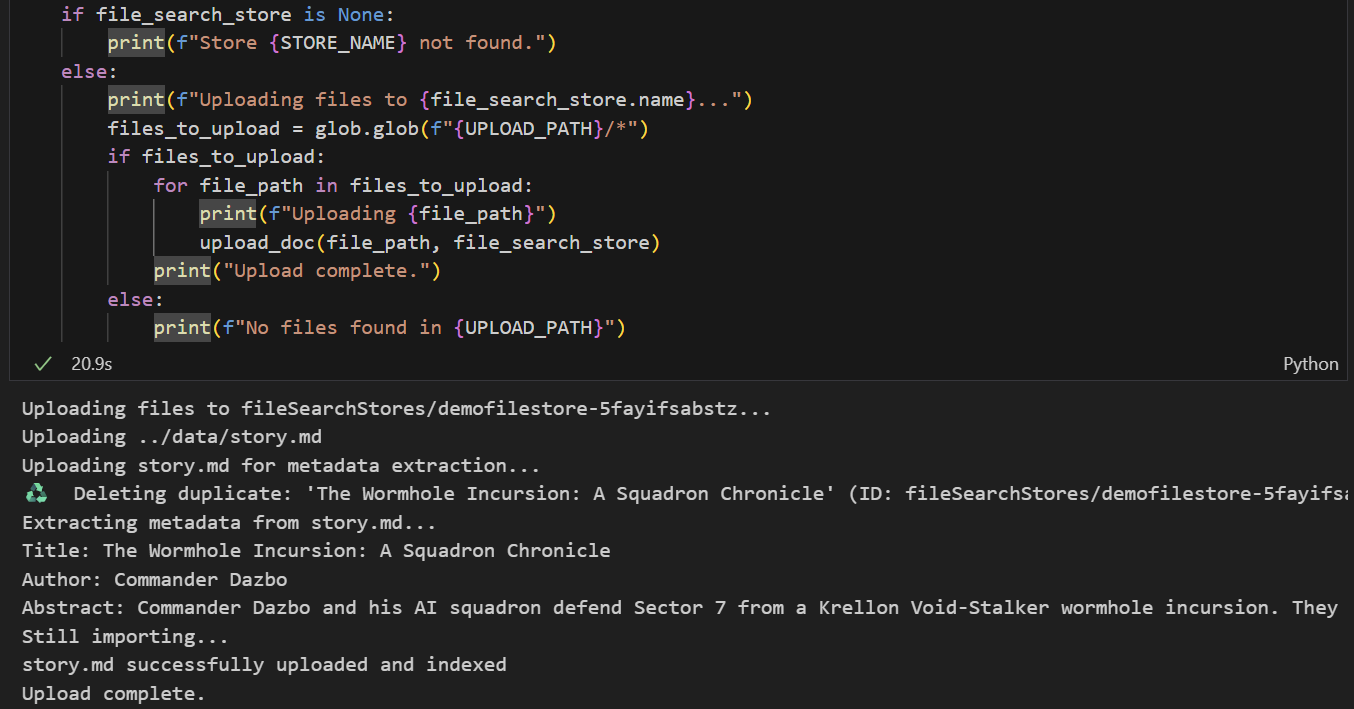
フェーズ 2 - エージェントに Gemini ファイル検索 RAG を実装する
Gemini ファイル検索ストアを作成し、ストーリーをアップロードしました。次に、エージェントでファイル検索ストアを使用します。Google 検索ではなくファイル検索ストアを使用する新しいエージェントを作成しましょう。app/sdk_rag_agent.py をご覧ください。
まず、ショップ名を受け取ってストアを取得する関数を実装しました。
def get_store(client: genai.Client, store_name: str) -> types.FileSearchStore | None:
"""Retrieve a store by display name"""
try:
for a_store in client.file_search_stores.list():
if a_store.display_name == store_name:
return a_store
except Exception as e:
logger.error(f"Error listing stores: {e}")
return None
ストアを作成したら、次のようにエージェントにツールとしてアタッチするだけで使用できます。
file_search_tool = types.Tool(file_search=types.FileSearch(file_search_store_names=[store.name]))
RAG エージェントの実行
起動方法は次のとおりです。
make sdk-rag-agent # Or, without make: uv run python app/sdk_rag_agent.py
前のエージェントが回答できなかった質問をしてみましょう。
> Who pilots the 'Too Many Pies' ship?
そして、その回答は?
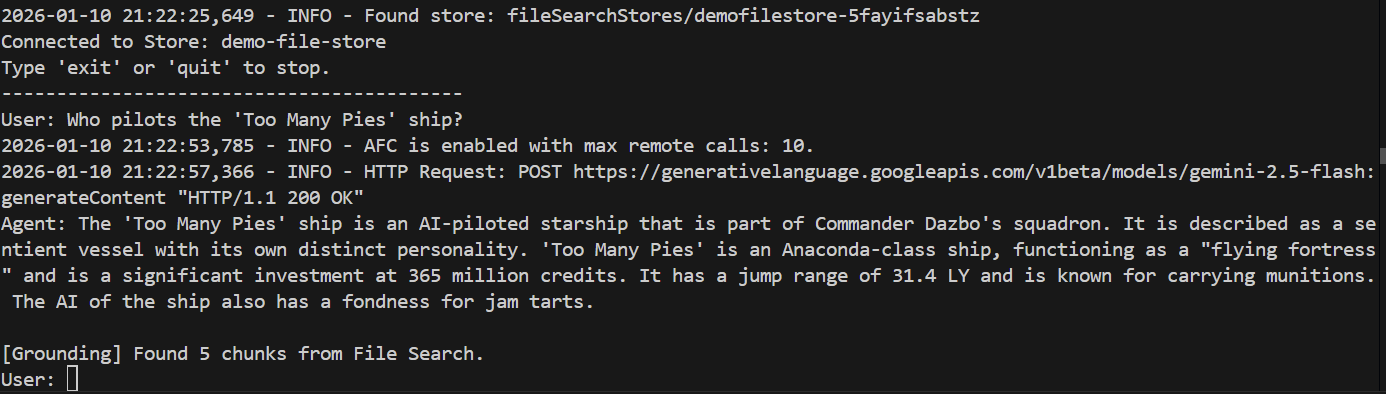
完了しました。レスポンスから次のことがわかります。
- 質問への回答にファイル ストアが使用されました。
- 関連するチャンクが 5 つ見つかりました。
- 答えはぴったりです。
「quit」と入力してエージェントを閉じます。
7. ADK を使用するようにエージェントを変換する
Google Agent Development Kit(ADK)は、デベロッパーがエージェントとエージェント システムを構築するためのオープンソースのモジュラー フレームワークと SDK です。これにより、マルチエージェント システムを簡単に作成してオーケストレートできます。Gemini と Google エコシステム向けに最適化されていますが、モデルやデプロイに依存せず、他のフレームワークとの互換性を保つよう構築されています。ADK をまだ使用していない場合は、ADK のドキュメントで詳細をご確認ください。
Google 検索を備えた基本的な ADK エージェント
app/basic_agent_adk/agent.py をご覧ください。このサンプルコードでは、実際に 2 つのエージェントを実装していることがわかります。
- ユーザーとのやり取りを処理し、メインのシステム指示が提供されている
root_agent。 google.adk.tools.google_searchをツールとして使用する別のSearchAgent。
root_agent は実際には SearchAgent をツールとして使用します。これは次の行を使用して実装されます。
tools=[AgentTool(agent=search_agent)],
ルート エージェントのシステム プロンプトは次のようになります。
You are a helpful AI assistant designed to provide accurate and useful information.
If you don't know the answer, use the SearchAgent to perform a Google search.
Do not attempt to search more than ONCE.
If the search yields no relevant results or returns unrelated content, you MUST immediately respond with: "I could not find any information about that."
Do NOT retry the search with different terms. Do NOT ask for clarification. FAIL FAST.
エージェントを試す
ADK には、デベロッパーが ADK エージェントをテストするためのさまざまなインターフェースが用意されています。これらのインターフェースの 1 つがウェブ UI です。これにより、ユーザー インターフェースのコードを 1 行も記述することなく、ブラウザでエージェントをテストできます。
このインターフェースは、次のコマンドを実行して起動できます。
make adk-playground # Or, without make: uv run adk web app --port 8501 --reload_agents
このコマンドは adk web ツールを app フォルダに指定します。このフォルダでは、root_agent を実装する ADK エージェントが自動的に検出されます。試してみましょう。
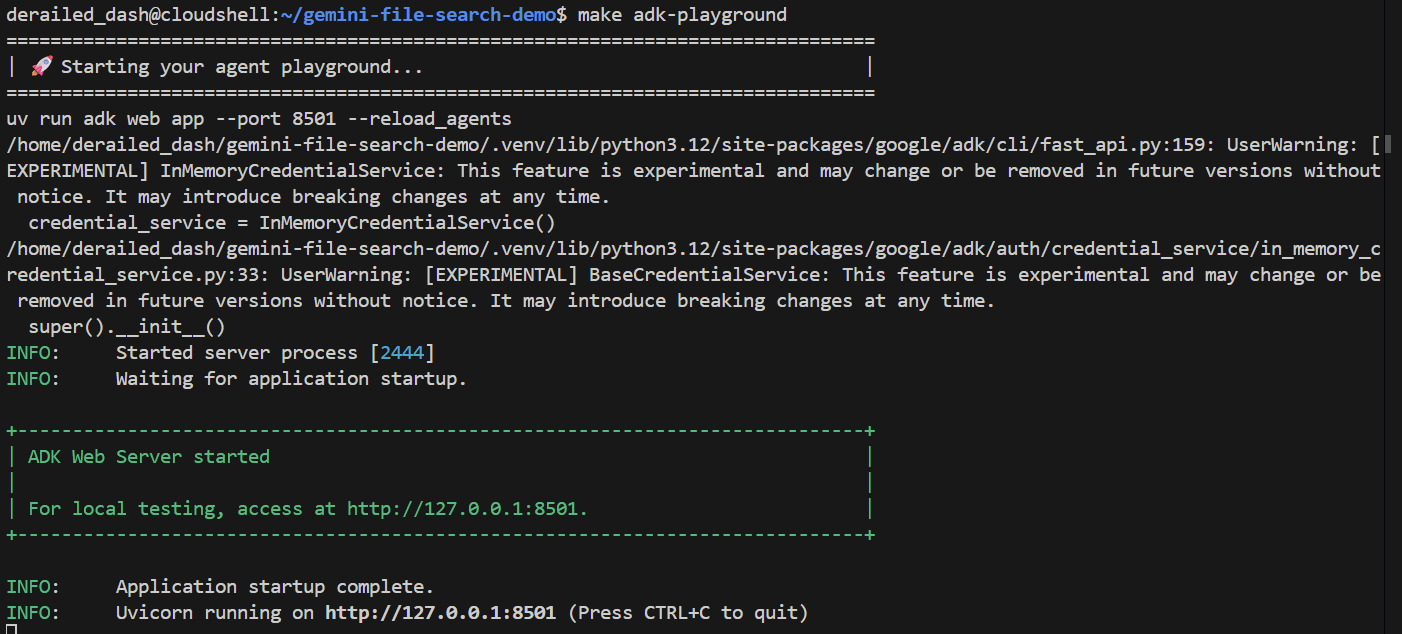
数秒後にアプリケーションの準備が整います。コードをローカルで実行している場合は、ブラウザで http://127.0.0.1:8501 を指定します。Cloud Shell エディタで実行している場合は、[ウェブでプレビュー] をクリックして、ポートを 8501 に変更します。
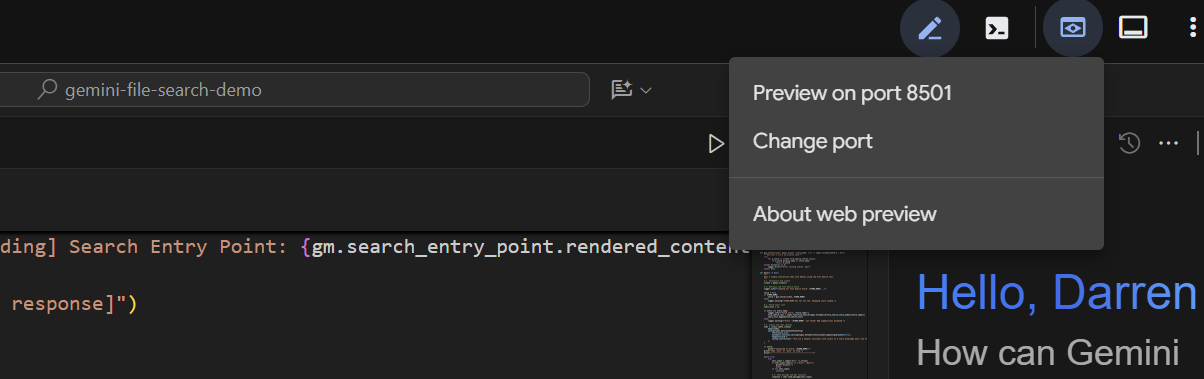
UI が表示されたら、プルダウンから basic_agent_adk を選択します。これで、質問をすることができます。
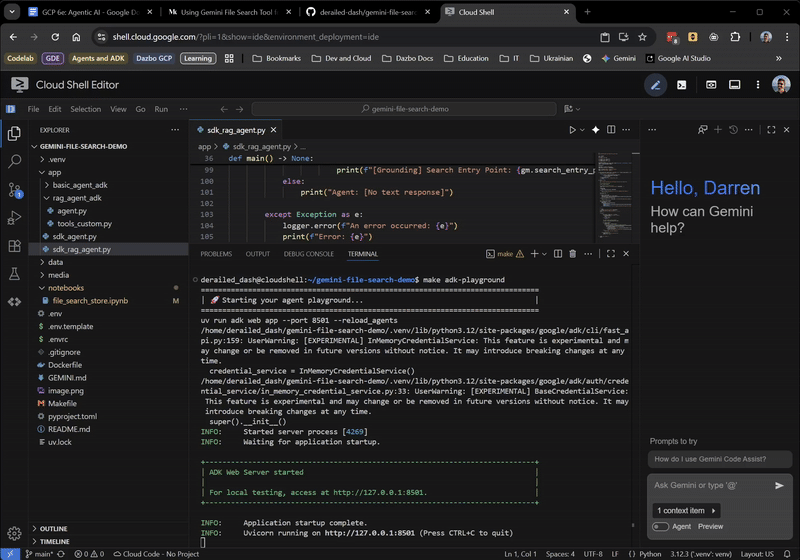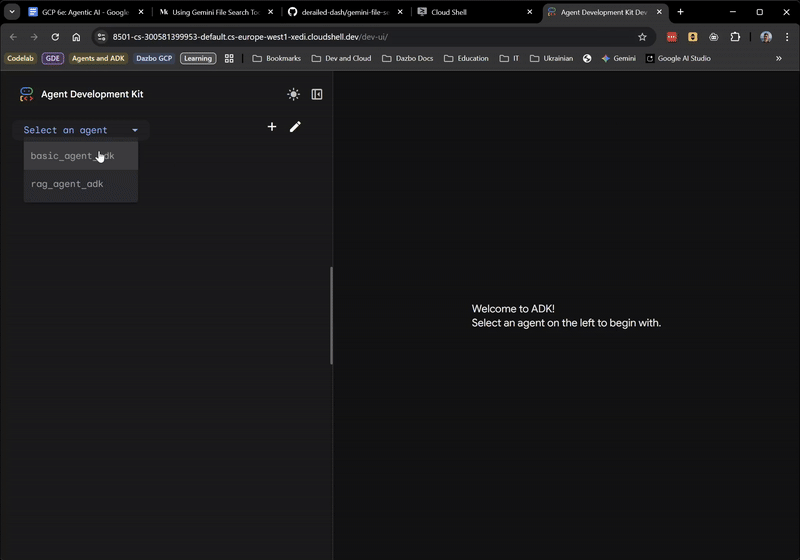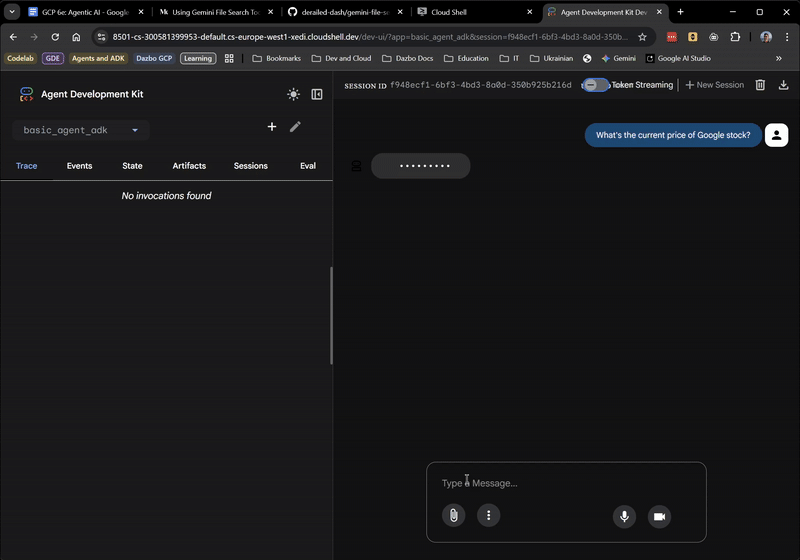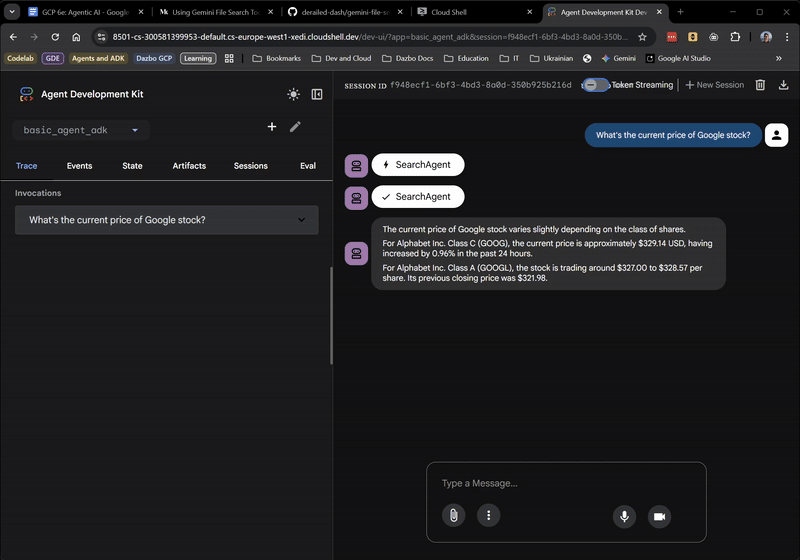
ここまでは順調です。ウェブ UI には、ルート エージェントが SearchAgent に委任しているタイミングも表示されます。これは非常に便利な機能です。
それでは、ストーリーに関する知識が必要な質問をしてみましょう。
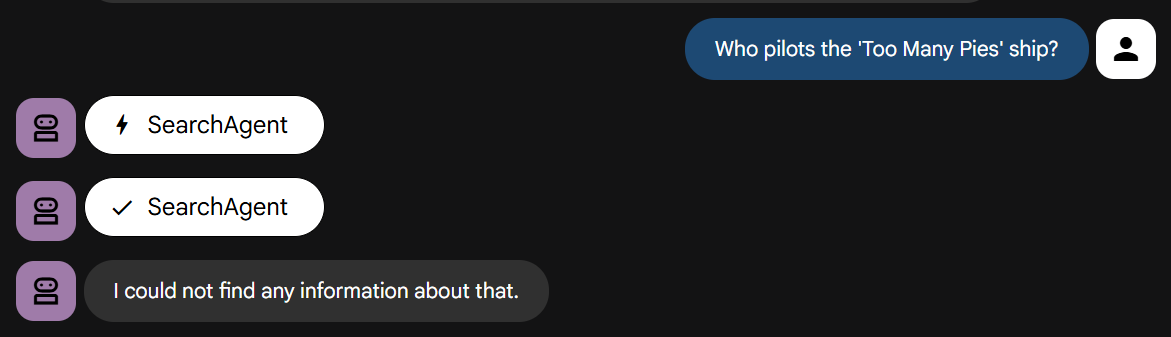
実際に試してみましょう。指示どおりに、すぐに失敗することがわかります。
ファイル検索ストアを ADK エージェントに組み込む
では、これらをまとめてみましょう。ファイル検索ストアと Google 検索の両方を使用できる ADK エージェントを実行します。app/rag_agent_adk/agent.py のコードを見てみましょう。
このコードは前の例と似ていますが、いくつかの重要な違いがあります。
- 2 つの専門エージェントをオーケストレートするルート エージェントがあります。
- RagAgent: カスタム ナレッジ エキスパート - Gemini ファイル検索ストアを使用
- SearchAgent: 一般知識のエキスパート - Google 検索を使用
- ADK には
FileSearchの組み込みラッパーがまだないため、カスタム ラッパー クラスFileSearchToolを使用して FileSearch ツールをラップし、file_search_store_names構成を低レベルのモデル リクエストに挿入します。これは、別のスクリプトapp/rag_agent_adk/tools_custom.pyに実装されています。
また、注意すべき点もあります。執筆時点では、同じリクエストで同じエージェントに対してネイティブの GoogleSearch ツールと FileSearch ツールを使用することはできません。試すと、次のようなエラーが表示されます。
ERROR - エラーが発生しました: 400 INVALID_ARGUMENT。{‘error': {‘code': 400, ‘message': ‘Search as a tool and file search tool are not supported together', ‘status': ‘INVALID_ARGUMENT'}}
エラー: 400 INVALID_ARGUMENT。{‘error': {‘code': 400, ‘message': ‘Search as a tool and file search tool are not supported together', ‘status': ‘INVALID_ARGUMENT'}}
このソリューションでは、2 つの専門エージェントを個別のサブエージェントとして実装し、Agent-as-a-Tool パターンを使用してルート エージェントに渡します。重要なのは、ルート エージェントのシステム指示で、最初に RagAgent を使用するよう明確なガイダンスが提供されていることです。
あなたは、正確で有用な情報を提供するように設計された、便利な AI アシスタントです。
次の 2 つのスペシャリスト エージェントをご利用いただけます。
- RagAgent: 内部ナレッジベースからのカスタム情報。
- SearchAgent: Google 検索からの一般的な情報。
常に RagAgent を最初に試してください。この方法で有用な回答が得られない場合は、SearchAgent を試してください。
最終テスト
ADK ウェブ UI を以前と同様に実行します。
make adk-playground # Or, without make: uv run adk web app --port 8501 --reload_agents
今回は、UI で rag_agent_adk を選択します。実際に動作を見ていきましょう。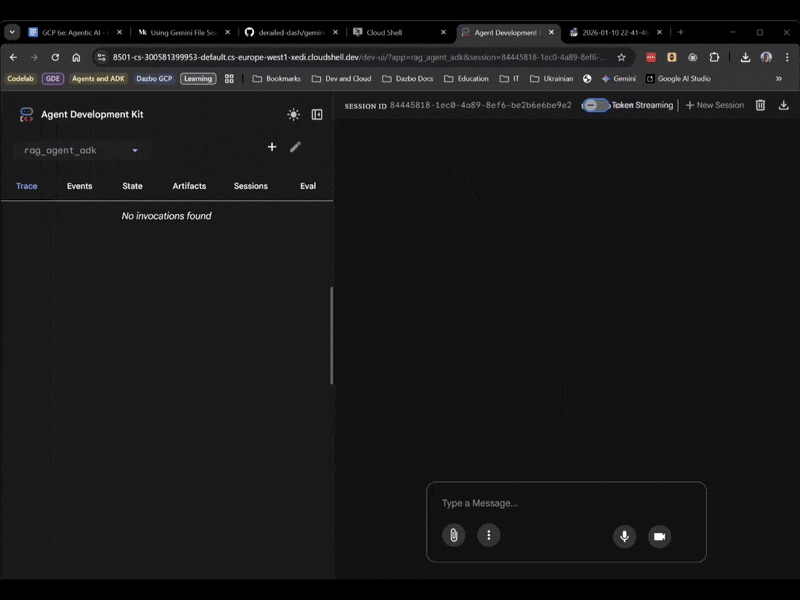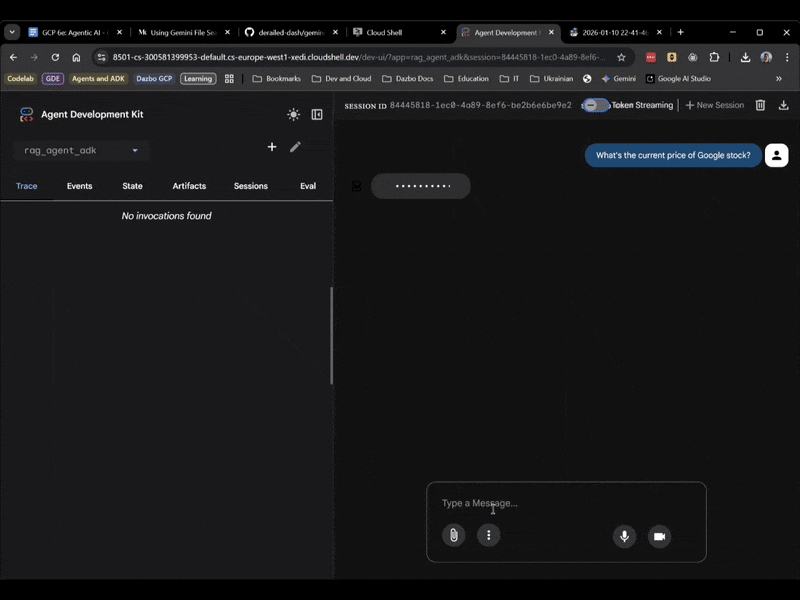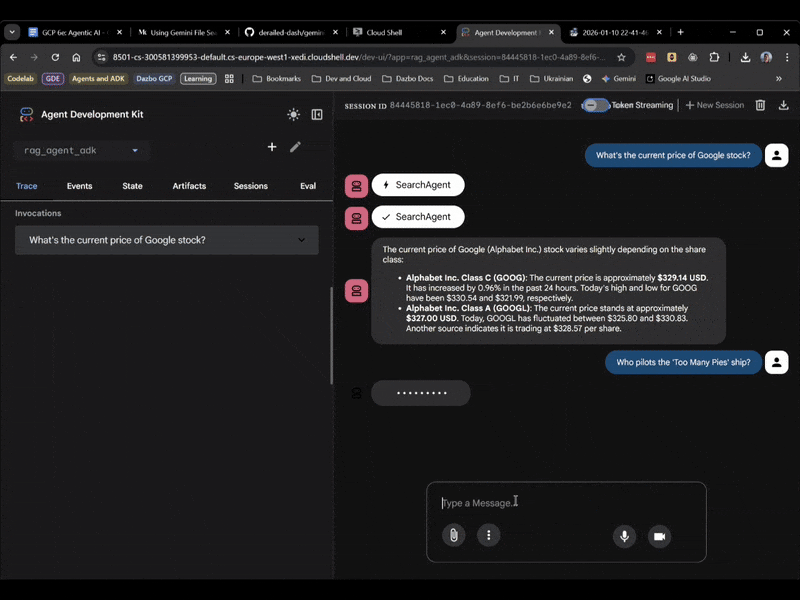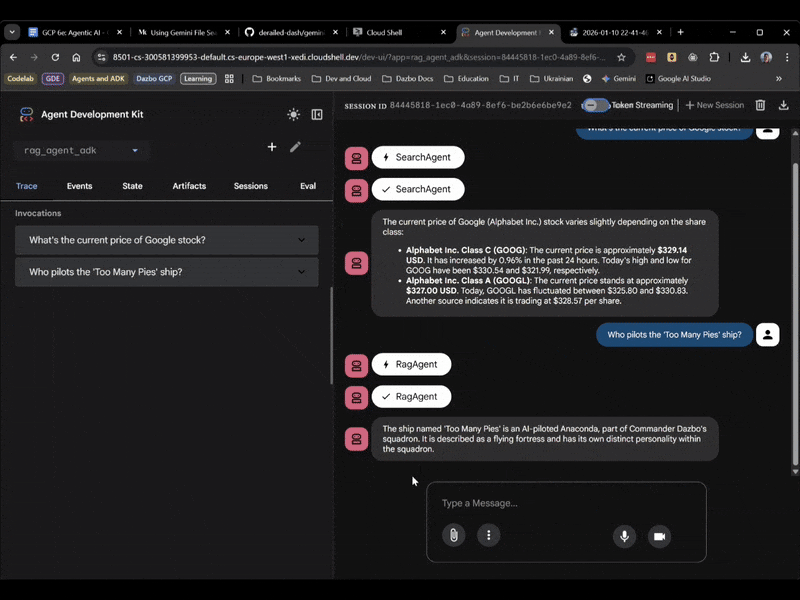
質問に基づいて適切なサブエージェントが選択されていることがわかります。
8. まとめ
これでこの Codelab は完了です。
シンプルなスクリプトからマルチエージェント RAG 対応システムに移行しました。埋め込みコードを 1 行も記述せず、ベクトル データベースを実装する必要もありません。
学習内容:
- Gemini ファイル検索は、時間と正気を節約するマネージド RAG ソリューションです。
- ADK は、複雑なマルチエージェント アプリに必要な構造を提供し、ウェブ UI などのインターフェースを通じてデベロッパーの利便性を高めます。
- "Agent-as-a-Tool"パターンは、ツールの互換性の問題を解決します。
このラボがお役に立てば幸いです。それではまた、お会いしましょう。