
1. Wprowadzenie
W tym ćwiczeniu pokazujemy, jak używać wyszukiwania plików Gemini, aby włączyć RAG w aplikacji agentowej. Użyjesz wyszukiwarki plików Gemini do pozyskiwania i indeksowania dokumentów bez konieczności martwienia się o szczegóły dzielenia na fragmenty, wektorów dystrybucyjnych czy bazy danych wektorowych.
Czego się nauczysz
- Podstawy RAG i dlaczego jest potrzebna.
- Czym jest wyszukiwanie plików w Gemini i jakie ma zalety.
- Jak utworzyć magazyn wyszukiwania plików.
- Instrukcje: jak przesyłać własne pliki do magazynu wyszukiwarki plików.
- Jak używać narzędzia wyszukiwania plików Gemini na potrzeby RAG.
- korzyści z używania pakietu Google Agent Development Kit (ADK),
- Jak używać narzędzia wyszukiwania plików Gemini w rozwiązaniu agentowym utworzonym za pomocą pakietu ADK.
- Jak używać narzędzia wyszukiwania plików Gemini razem z „natywnymi” narzędziami Google, takimi jak wyszukiwarka Google.
Co zrobisz
- Utwórz projekt Google Cloud i skonfiguruj środowisko programistyczne.
- Utwórz prostego agenta opartego na Gemini za pomocą pakietu Google Gen AI SDK (ale bez ADK), który może korzystać z wyszukiwarki Google, ale nie ma funkcji RAG.
- wykazać, że nie jest w stanie dostarczać dokładnych informacji wysokiej jakości w przypadku informacji dostosowanych do potrzeb użytkownika.
- Utwórz notatnik Jupyter (który możesz uruchomić lokalnie lub np. w Google Colab), aby utworzyć sklep Gemini File Search Store i nim zarządzać.
- Użyj notatnika, aby przesłać niestandardowe treści do magazynu wyszukiwarki plików.
- Utwórz agenta z dołączonym magazynem wyszukiwania plików i udowodnij, że potrafi on generować lepsze odpowiedzi.
- Przekształć naszego początkowego „podstawowego” agenta w agenta ADK z narzędziem wyszukiwarki Google.
- Przetestuj agenta za pomocą interfejsu internetowego ADK.
- Włącz magazyn File Search Store do agenta ADK, używając wzorca „Agent jako narzędzie”, aby umożliwić korzystanie z narzędzia File Search Tool razem z narzędziem wyszukiwarki Google.
2. Czym jest RAG i dlaczego jest potrzebny
A więc... Generowanie wspomagane wyszukiwaniem
Jeśli tu jesteś, prawdopodobnie wiesz, czym jest ta usługa, ale na wszelki wypadek zróbmy krótkie podsumowanie. LLM (takie jak Gemini) są świetne, ale mają kilka problemów:
- Zawsze są nieaktualne: znają tylko to, czego nauczyły się podczas szkolenia.
- Nie wiedzą wszystkiego: modele są ogromne, ale nie są wszechwiedzące.
- Nie znają Twoich informacji zastrzeżonych: mają szeroką wiedzę, ale nie czytały Twoich dokumentów wewnętrznych, blogów ani zgłoszeń w Jirze.
Dlatego gdy zapytasz model o coś, na co nie zna odpowiedzi, zwykle otrzymasz nieprawidłową lub nawet zmyśloną odpowiedź. Często model z pewnością podaje nieprawidłową odpowiedź. Nazywamy to halucynacjami.
Jednym z rozwiązań jest po prostu zrzucenie naszych zastrzeżonych informacji bezpośrednio do kontekstu rozmowy. W przypadku niewielkiej ilości informacji jest to w porządku, ale gdy informacji jest dużo, szybko staje się to problematyczne. Prowadzi to w szczególności do tych problemów:
- Opóźnienie: coraz wolniejsze odpowiedzi modelu.
- Degradacja sygnału, czyli „zagubienie w środku”: model nie jest już w stanie odróżnić istotnych danych od nieistotnych. Model ignoruje większość kontekstu.
- Koszt: tokeny kosztują.
- Wykorzystanie okna kontekstu: w tym momencie Gemini nie będzie realizować Twoich próśb.
Znacznie skuteczniejszym sposobem na rozwiązanie tego problemu jest użycie RAG. Jest to po prostu proces wyszukiwania odpowiednich informacji ze swoich źródeł danych (za pomocą dopasowywania semantycznego) i przekazywania odpowiednich fragmentów tych danych do modelu wraz z pytaniem. Osadza model w Twojej rzeczywistości.
Działa on w ten sposób, że importuje dane zewnętrzne, dzieli je na części, przekształca je w wektory dystrybucyjne, a następnie przechowuje i indeksuje te wektory w odpowiedniej bazie danych wektorów.
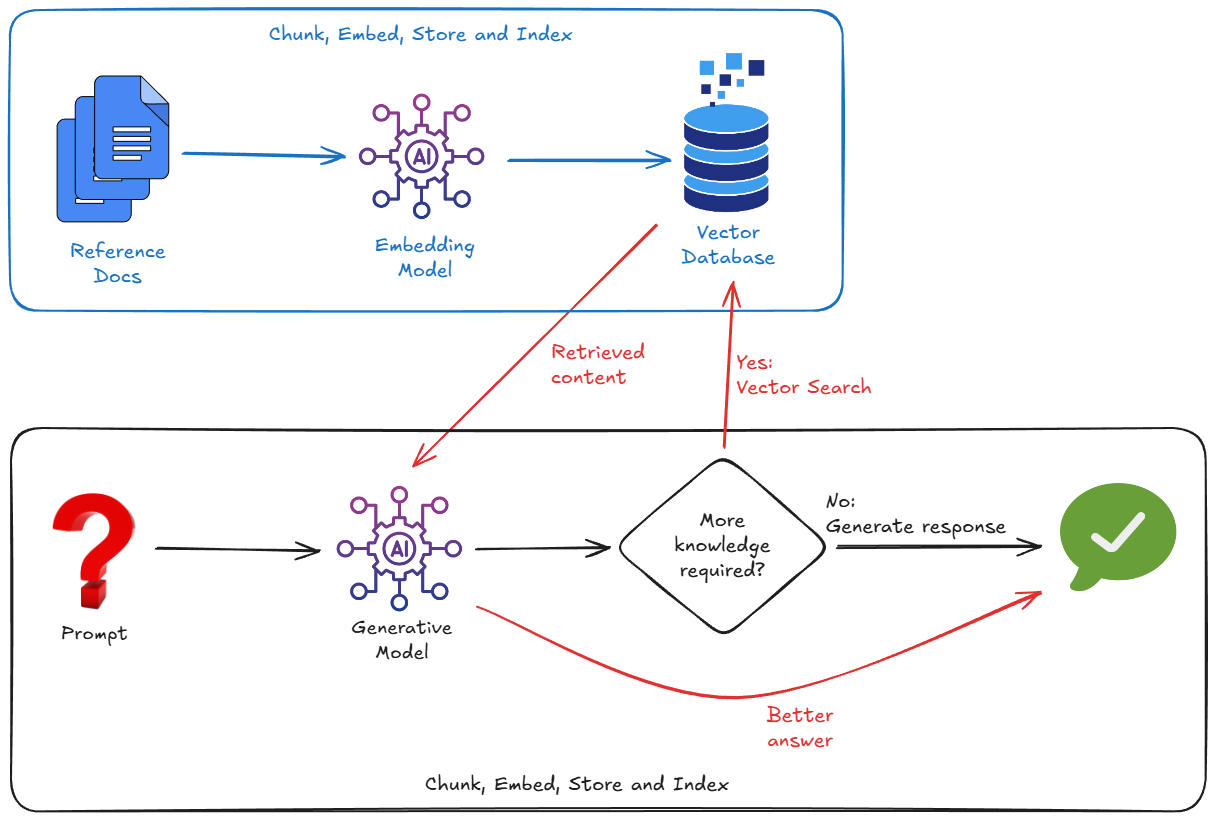
Aby wdrożyć RAG, musimy zwykle zadbać o te kwestie:
- Uruchomienie wektorowej bazy danych (Pinecone, Weaviate, Postgres z pgvector...).
- Napisz skrypt dzielący dokumenty (np.pliki PDF, Markdown itp.) na mniejsze części.
- Generowanie wektorów dystrybucyjnych dla tych fragmentów za pomocą modelu wektorów dystrybucyjnych.
- przechowywanie wektorów w bazie danych wektorów,
Ale przyjaciele nie pozwalają sobie na zbytnie komplikowanie spraw. A gdybym Ci powiedział, że jest łatwiejszy sposób?
3. Wymagania wstępne
Tworzenie projektu Google Cloud
Aby wykonać to ćwiczenie, musisz mieć projekt Google Cloud. Możesz użyć istniejącego projektu lub utworzyć nowy.
Sprawdź, czy w projekcie włączone są płatności. Więcej informacji o sprawdzaniu stanu rozliczeń projektów znajdziesz w tym przewodniku.
Pamiętaj, że ukończenie tego laboratorium nie powinno wiązać się z żadnymi kosztami. Maksymalnie kilka groszy.
Przygotuj projekt. Poczekam.
Klonowanie repozytorium demonstracyjnego
Utworzyłem repozytorium z treściami pomocniczymi do tego ćwiczenia. Będzie Ci potrzebny.
Uruchom te polecenia w terminalu lub w terminalu zintegrowanym z Edytorem Cloud Shell Google. Cloud Shell i jego edytor są bardzo wygodne, ponieważ wszystkie potrzebne polecenia są już zainstalowane i wszystko działa od razu.
git clone https://github.com/derailed-dash/gemini-file-search-demo cd gemini-file-search-demo
To drzewo pokazuje najważniejsze foldery i pliki w repozytorium:
gemini-file-search-demo/ ├── app/ │ ├── basic_agent_adk/ # Agent with Google Search, using ADK framework │ │ └── agent.py │ ├── rag_agent_adk/ # Agent with Google Search and File Search, using ADK framework │ │ ├── agent.py │ │ └── tools_custom.py │ ├── sdk_agent.py # Agent using GenAI SDK (no ADK) with Google Search tool │ └── sdk_rag_agent.py # Agent using GenAI SDK (no ADK) with Gemini File Search tool ├── data/ │ └── story.md # Sample story with "bespoke content" to use with Gemini File Search Store ├── notebooks/ │ └── file_search_store.ipynb # Jupyter notebook for creating and managing Gemini File Search Store │ ├── .env.template # Template for environment variables - make a copy as .env ├── Makefile # Makefile for `make` commands ├── pyproject.toml # Project configuration and dependencies └── README.md # This file
Otwórz ten folder w edytorze Cloud Shell lub w wybranym edytorze. (Czy korzystasz już z Antigravity? Jeśli nie, to dobry moment, aby wypróbować tę funkcję).
Zwróć uwagę, że repozytorium zawiera przykładowe opowiadanie „The Wormhole Incursion” w pliku data/story.md. Napisałem(-am) go wspólnie z Gemini. Opowiada o dowódcy Dazbo i jego eskadrze inteligentnych statków kosmicznych. (Zainspirowałem się grą Elite Dangerous). Ta historia służy jako nasza „baza wiedzy na zamówienie”, zawierająca konkretne fakty, których Gemini nie zna i których nie może wyszukać za pomocą wyszukiwarki Google.
Konfigurowanie środowiska programistycznego
Aby uprościć wiele poleceń, które musisz uruchomić, udostępniliśmy Makefile. Zamiast zapamiętywać konkretne polecenia, możesz po prostu uruchomić coś takiego jak make <target>. Funkcja make jest jednak dostępna tylko w środowiskach Linux, macOS i WSL. Jeśli używasz systemu Windows (bez WSL), musisz uruchomić pełne polecenia, które zawierają make.
# Install dependencies with make make install # If you don't have make... uv sync --extra jupyter
Tak wygląda wynik działania polecenia make install w edytorze Cloud Shell:
Tworzenie klucza interfejsu Gemini API
Aby korzystać z interfejsu Gemini Developer API (którego potrzebujemy do używania narzędzia wyszukiwania plików Gemini), musisz mieć klucz interfejsu Gemini API. Najłatwiejszym sposobem uzyskania klucza interfejsu API jest użycie Google AI Studio, które zapewnia wygodny interfejs do uzyskiwania kluczy interfejsu API dla projektów w chmurze Google. Szczegółowe instrukcje znajdziesz w tym przewodniku.
Po utworzeniu klucza interfejsu API skopiuj go i zadbaj o jego bezpieczeństwo.
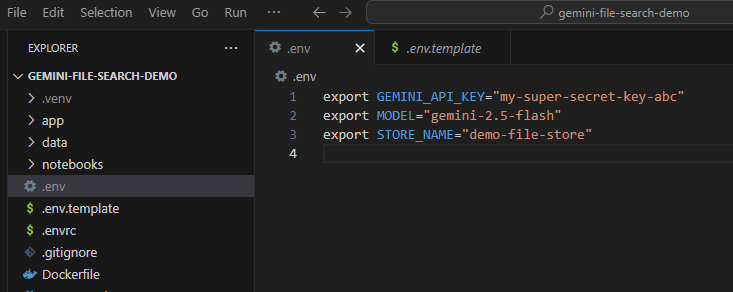
Teraz musisz ustawić ten klucz interfejsu API jako zmienną środowiskową. Możemy to zrobić za pomocą .envpliku. Skopiuj dołączony plik .env.example jako nowy plik o nazwie .env. Plik powinien wyglądać tak:
export GEMINI_API_KEY="your-api-key" export MODEL="gemini-2.5-flash" export STORE_NAME="demo-file-store"
Zastąp your-api-key rzeczywistym kluczem interfejsu API. Powinien on teraz wyglądać mniej więcej tak:
Teraz sprawdź, czy zmienne środowiskowe zostały wczytane. Aby to zrobić, uruchom:
source .env
4. Agent podstawowy
Najpierw ustalmy wartość bazową. Użyjemy podstawowego pakietu google-genai SDK, aby uruchomić prostego agenta.
Kodeks
Sprawdź app/sdk_agent.py. Jest to minimalna implementacja, która:
- Tworzy instancję klasy
genai.Client. - Włącza narzędzie
google_search. - To wszystko. Brak RAG.
Sprawdź kod i upewnij się, że rozumiesz, co robi.
Running It
# With make make sdk-agent # Without make uv run python app/sdk_agent.py
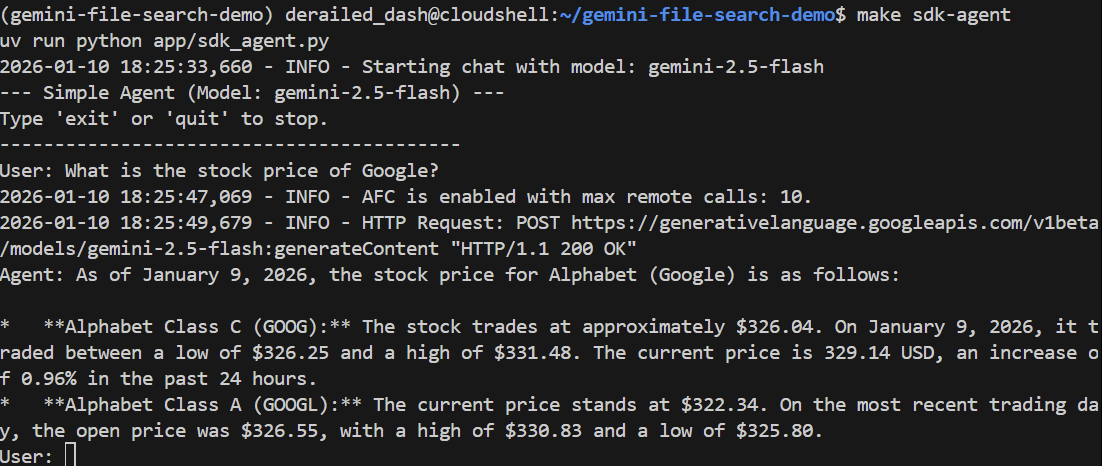
Zadajmy mu ogólne pytanie:
> What is the stock price of Google?
Powinna poprawnie odpowiedzieć, korzystając z wyszukiwarki Google, aby znaleźć aktualną cenę:
Teraz zadajmy pytanie, na które nie zna odpowiedzi. Wymaga to od agenta przeczytania naszej historii.
> Who pilots the 'Too Many Pies' ship?
Powinien się pomylić lub nawet wygenerować halucynacje. Sprawdźmy:
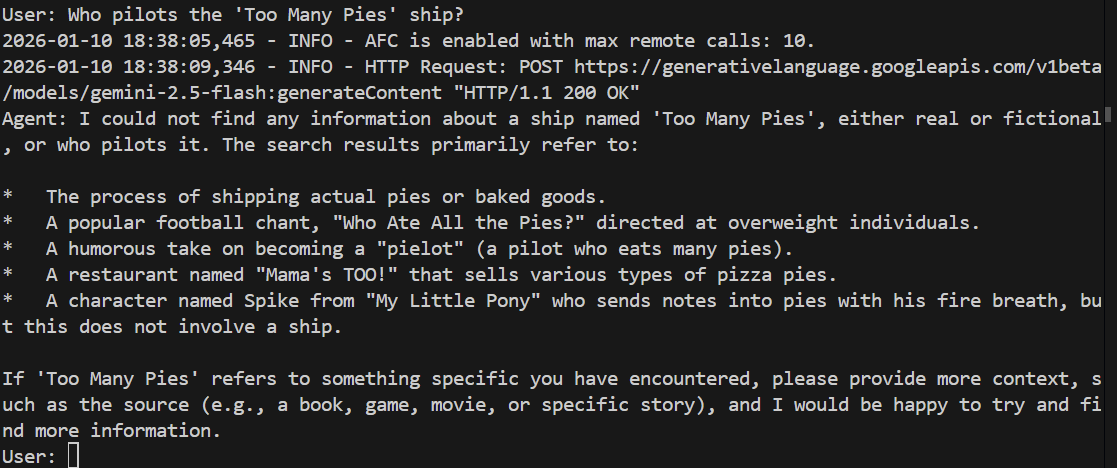
I rzeczywiście, model nie potrafi odpowiedzieć na to pytanie. Nie ma pojęcia, o czym mówimy.
Teraz wpisz quit, aby zamknąć agenta.
5. Wyszukiwanie plików w Gemini: wyjaśnienie
Wyszukiwanie plików w Gemini to połączenie dwóch elementów:
- Usługa RAG w pełni zarządzana: przesyłasz wiele plików, a wyszukiwanie plików Gemini zajmuje się dzieleniem na fragmenty, tworzeniem wektorów dystrybucyjnych, przechowywaniem i indeksowaniem wektorowym.
- „Narzędzie” w kontekście agentów: możesz po prostu dodać narzędzie wyszukiwania plików Gemini do definicji agenta i skierować je do magazynu wyszukiwania plików.
Co ważne, jest on wbudowany w sam interfejs Gemini API. Oznacza to, że aby z niej korzystać, nie musisz włączać żadnych dodatkowych interfejsów API ani wdrażać żadnych osobnych usług. Jest to więc rozwiązanie out-of-the-box.
Funkcje wyszukiwania plików w Gemini
Oto kilka funkcji:
- Szczegóły dotyczące dzielenia na części, wektorów dystrybucyjnych, przechowywania i indeksowania są ukryte przed deweloperem. Oznacza to, że nie musisz znać (ani się tym przejmować) modelu wektorów dystrybucyjnych (którym jest Gemini Embeddings) ani tego, gdzie są przechowywane wynikowe wektory. Nie musisz podejmować żadnych decyzji dotyczących bazy danych wektorów.
- Obsługuje on wiele typów dokumentów od razu po wyjęciu z pudełka. Obejmuje to między innymi pliki PDF, DOCX, Excel, SQL, JSON, notatniki Jupyter, HTML, Markdown, CSV, a nawet pliki ZIP. Pełną listę znajdziesz tutaj. Jeśli na przykład chcesz, aby Twój agent korzystał z plików PDF zawierających tekst, obrazy i tabele, nie musisz ich wstępnie przetwarzać. Wystarczy, że prześlesz pliki PDF w formacie RAW, a Gemini zajmie się resztą.
- Możemy dodać niestandardowe metadane do dowolnego przesłanego pliku. Może to być bardzo przydatne do późniejszego filtrowania plików, których narzędzie ma używać w czasie działania.
Gdzie są przechowywane dane?
Przesyłasz niektóre pliki. Narzędzie wyszukiwania plików Gemini pobrało te pliki, utworzyło z nich fragmenty, a następnie wektory osadzeń i umieściło je w określonym miejscu. Ale gdzie?
Odpowiedź: File Search Store. Jest to usługa w pełni zarządzana kontenera na Twoje wektory. Nie musisz wiedzieć (ani się tym przejmować), jak to działa. Wystarczy, że utworzysz go (programowo), a potem prześlesz do niego pliki.
Jest tanio!
Przechowywanie i wysyłanie zapytań dotyczących wektorów osadzania jest bezpłatne. Możesz przechowywać osadzenia tak długo, jak chcesz, i nie płacisz za to miejsca na dane.
Płacisz tylko za utworzenie wektorów w momencie przesyłania lub indeksowania. W momencie pisania tego artykułu kosztuje to 0, 15 USD za 1 milion tokenów. To całkiem tanio.
6. Jak korzystamy z wyszukiwania plików w Gemini?
Są 2 fazy:
- Utwórz i zapisz wektory w magazynie wyszukiwania plików.
- Wysyłaj zapytania do File Search Store z poziomu agenta.
Etap 1. Notatnik Jupyter do tworzenia i zarządzania magazynem wyszukiwania plików Gemini
Ten etap wykonujesz na początku, a potem zawsze, gdy chcesz zaktualizować sklep. Na przykład gdy masz nowe dokumenty do dodania lub gdy dokumenty źródłowe uległy zmianie.
Ten etap nie musi być częścią wdrożonej aplikacji opartej na agentach. Oczywiście, jeśli chcesz. Na przykład jeśli chcesz utworzyć interfejs użytkownika dla administratorów aplikacji opartej na agentach. Często jednak wystarczy mieć fragment kodu, który można uruchamiać na żądanie. A jaki jest świetny sposób na uruchamianie tego kodu na żądanie? Notatnik Jupyter.
Pamiętnik
Otwórz plik notebooks/file_search_store.ipynb w edytorze. Jeśli pojawi się prośba o zainstalowanie rozszerzeń Jupyter VS Code, zrób to.
Jeśli otworzymy go w edytorze Cloud Shell, będzie wyglądać tak:
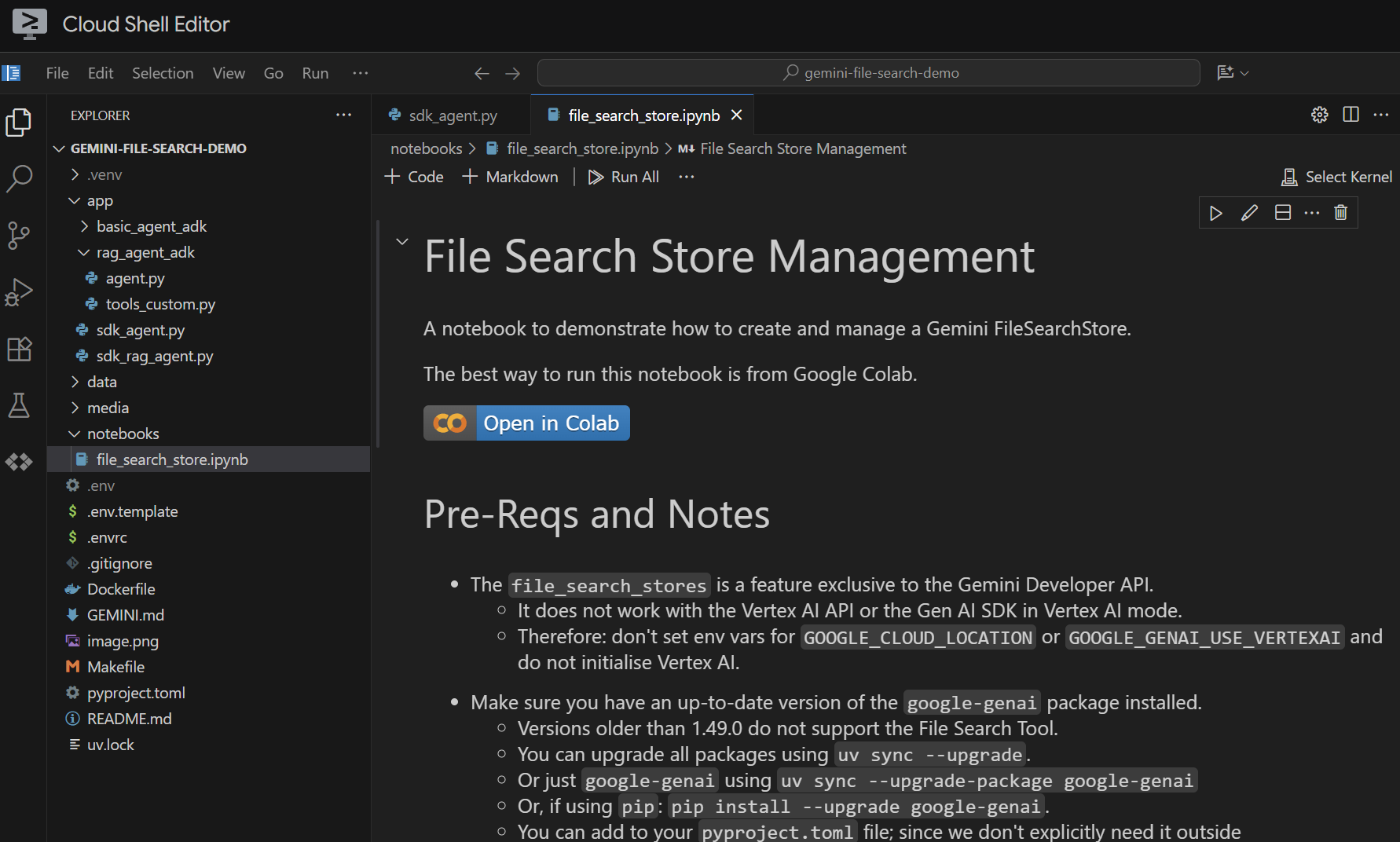
Uruchommy go komórka po komórce. Zacznij od wykonania komórki Setup z wymaganymi importami. Jeśli nie masz jeszcze uruchomionego notatnika, pojawi się prośba o zainstalowanie wymaganych rozszerzeń. Zrób to. Następnie pojawi się prośba o wybranie jądra. Kliknij „Python environments...”, a potem lokalny pakiet .venv, który został zainstalowany podczas wcześniejszego uruchomienia polecenia make install:
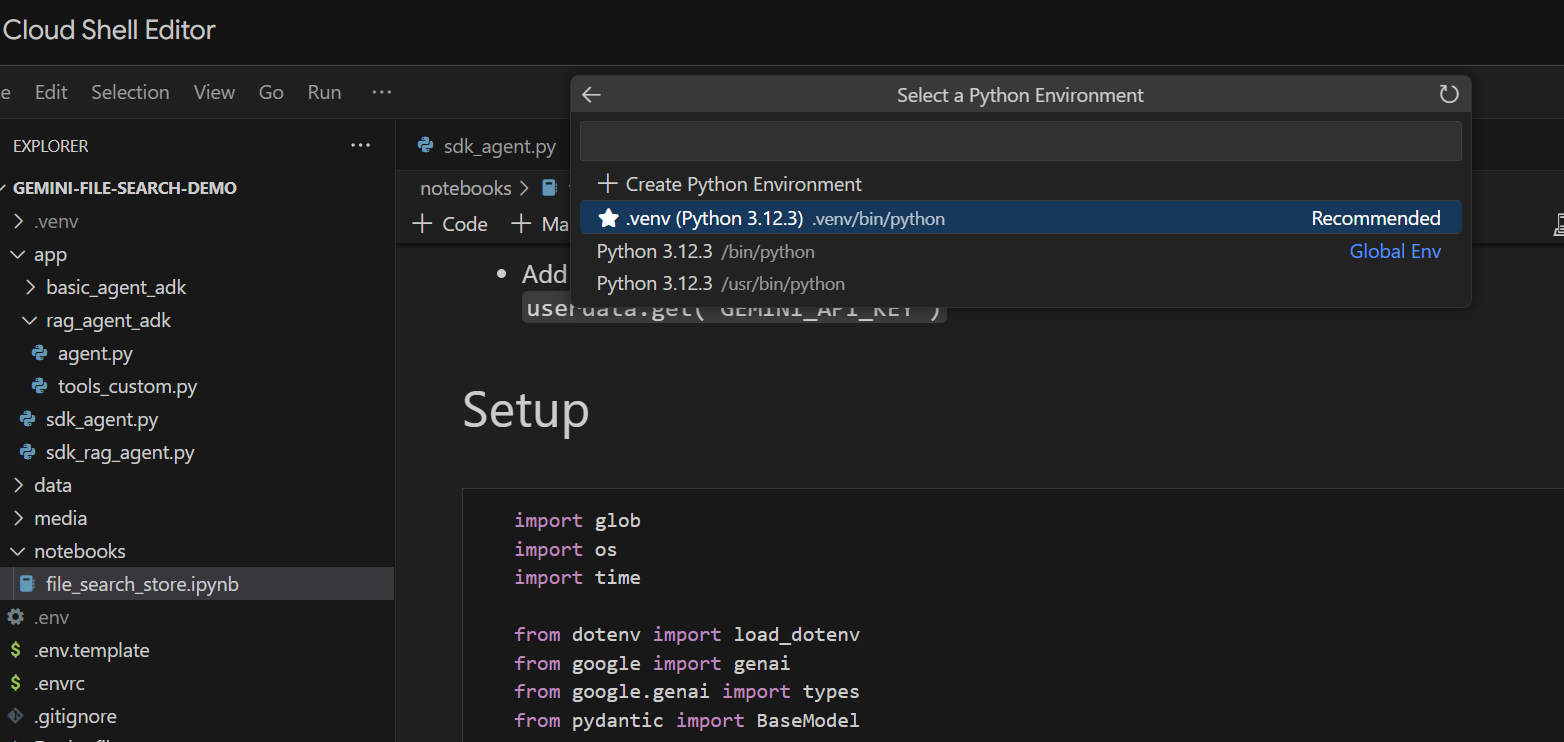
Następnie:
- Uruchom komórkę „Tylko lokalnie”, aby pobrać zmienne środowiskowe.
- Uruchom komórkę „Client Initialisation”, aby zainicjować klienta Gemini Gen AI.
- Uruchom komórkę „Retrieve the Store” (Pobierz sklep) z funkcją pomocniczą do pobierania sklepu Gemini File Search Store według nazwy.
Teraz możemy utworzyć sklep.
- Uruchom komórkę „Create the Store (One Time)” (Utwórz sklep (jednorazowo)), aby utworzyć sklep. Wystarczy to zrobić tylko raz. Jeśli kod zostanie uruchomiony prawidłowo, powinien wyświetlić się komunikat
"Created store: fileSearchStores/<someid>" - Uruchom komórkę View the Store, aby zobaczyć jej zawartość. W tym momencie powinna zawierać 0 dokumentów.
Świetnie. Mamy już gotowy magazyn Gemini File Search.
Przesyłanie danych
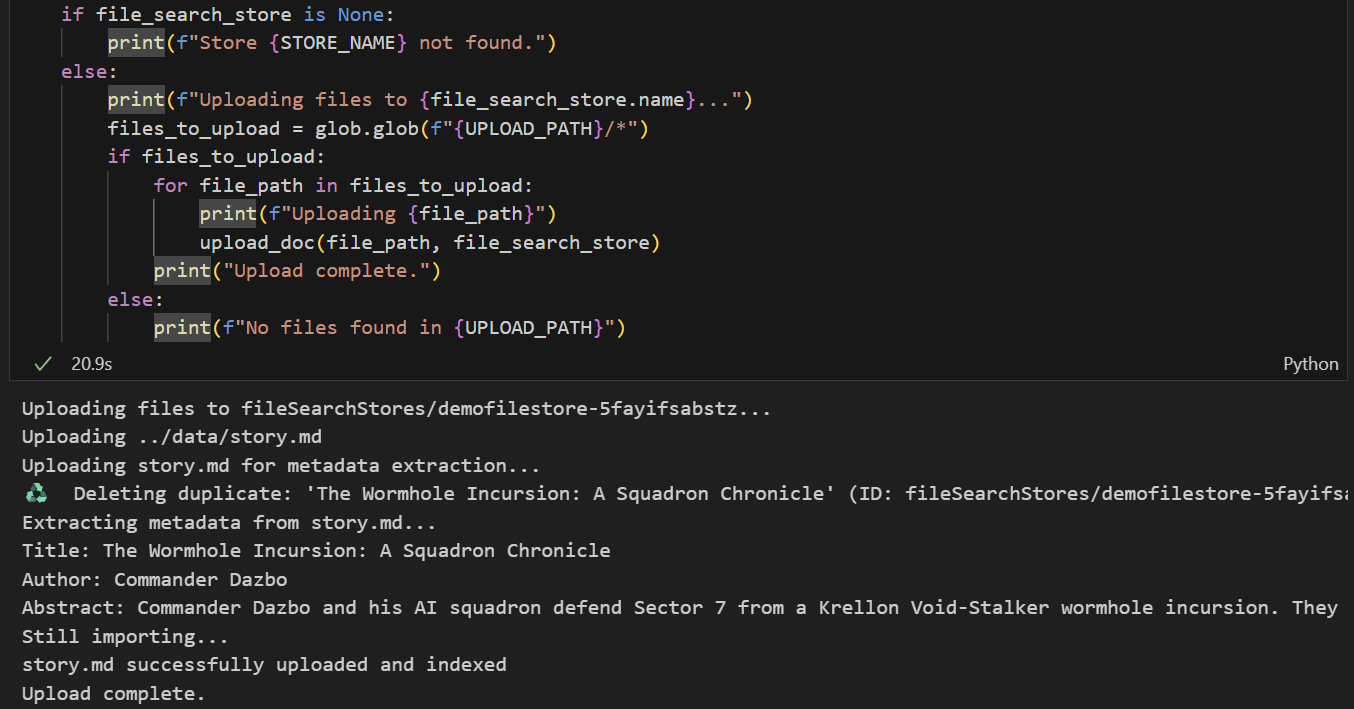
Chcemy przesłać data/story.md do sklepu. Wykonaj te czynności:
- Uruchom komórkę, która ustawia ścieżkę przesyłania. Wskazuje to na nasz folder
data/. - Uruchom następną komórkę, która tworzy funkcje użytkowe do przesyłania plików do magazynu. Pamiętaj, że kod w tej komórce również używa Gemini do wyodrębniania metadanych z każdego przesłanego pliku. Wyodrębnione wartości są przechowywane w sklepie jako niestandardowe metadane. (Nie musisz tego robić, ale warto).
- Uruchom komórkę, aby przesłać plik. Pamiętaj, że jeśli wcześniej przesłaliśmy plik o tej samej nazwie, najpierw usuniemy istniejącą wersję, a potem prześlemy nową. Powinien pojawić się komunikat informujący o przesłaniu pliku.
Faza 2. Wdrażanie RAG wyszukiwania plików Gemini w naszym agencie
Utworzyliśmy magazyn wyszukiwania plików Gemini i przesłaliśmy do niego nasz materiał. Teraz czas użyć w naszym agencie narzędzia File Search Store. Utwórzmy nowego agenta, który zamiast wyszukiwarki Google będzie korzystać z pamięci wyszukiwania plików. Sprawdź app/sdk_rag_agent.py.
Pierwsza rzecz, na którą warto zwrócić uwagę, to funkcja pobierania sklepu na podstawie jego nazwy:
def get_store(client: genai.Client, store_name: str) -> types.FileSearchStore | None:
"""Retrieve a store by display name"""
try:
for a_store in client.file_search_stores.list():
if a_store.display_name == store_name:
return a_store
except Exception as e:
logger.error(f"Error listing stores: {e}")
return None
Gdy mamy już sklep, korzystanie z niego jest tak proste, jak dołączenie go do agenta jako narzędzia:
file_search_tool = types.Tool(file_search=types.FileSearch(file_search_store_names=[store.name]))
Uruchamianie agenta RAG
Uruchamiamy go w ten sposób:
make sdk-rag-agent # Or, without make: uv run python app/sdk_rag_agent.py
Zadajmy pytanie, na które poprzedni pracownik nie potrafił odpowiedzieć:
> Who pilots the 'Too Many Pies' ship?
A odpowiedź?
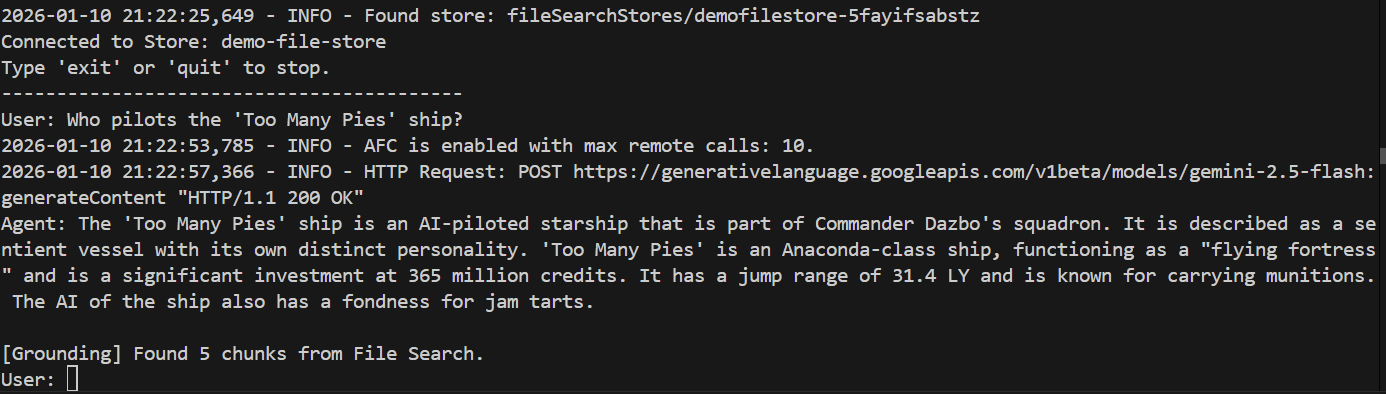
Gotowe! Z odpowiedzi wynika, że:
- Do udzielenia odpowiedzi na pytanie wykorzystano nasz magazyn plików.
- Znaleziono 5 odpowiednich fragmentów.
- Odpowiedź jest trafna.
Aby zamknąć agenta, wpisz quit.
7. Przekształcanie agentów w celu korzystania z pakietu ADK
Pakiet Agent Development Kit (ADK) od Google to modułowa platforma typu open source i pakiet SDK, które umożliwiają deweloperom tworzenie agentów i systemów agentowych. Umożliwia łatwe tworzenie systemów wieloagentowych i zarządzanie nimi. Pakiet ADK jest zoptymalizowany pod kątem Gemini i ekosystemu Google, ale jest niezależny od modelu i wdrożenia oraz został stworzony z myślą o kompatybilności z innymi platformami. Jeśli nie korzystasz jeszcze z ADK, odwiedź dokumentację ADK, aby dowiedzieć się więcej.
Podstawowy agent ADK z wyszukiwarką Google
Sprawdź app/basic_agent_adk/agent.py. W tym przykładowym kodzie widać, że zaimplementowaliśmy 2 agenty:
root_agent, który obsługuje interakcję z użytkownikiem i w którym podaliśmy główną instrukcję systemową.- Osobny
SearchAgent, który korzysta zgoogle.adk.tools.google_searchjako narzędzia.
Funkcja root_agent używa funkcji SearchAgent jako narzędzia, co jest realizowane za pomocą tego wiersza:
tools=[AgentTool(agent=search_agent)],
Prompt systemowy agenta głównego wygląda tak:
You are a helpful AI assistant designed to provide accurate and useful information.
If you don't know the answer, use the SearchAgent to perform a Google search.
Do not attempt to search more than ONCE.
If the search yields no relevant results or returns unrelated content, you MUST immediately respond with: "I could not find any information about that."
Do NOT retry the search with different terms. Do NOT ask for clarification. FAIL FAST.
Wypróbowanie agenta
ADK udostępnia szereg gotowych interfejsów, które umożliwiają deweloperom testowanie agentów ADK. Jednym z nich jest interfejs internetowy. Dzięki temu możemy testować nasze agenty w przeglądarce bez konieczności pisania kodu interfejsu użytkownika.
Aby uruchomić ten interfejs, wpisz:
make adk-playground # Or, without make: uv run adk web app --port 8501 --reload_agents
Pamiętaj, że polecenie kieruje narzędzie adk web do folderu app, w którym automatycznie wykryje wszystkie agenty pakietu ADK implementujące root_agent. Spróbujmy:
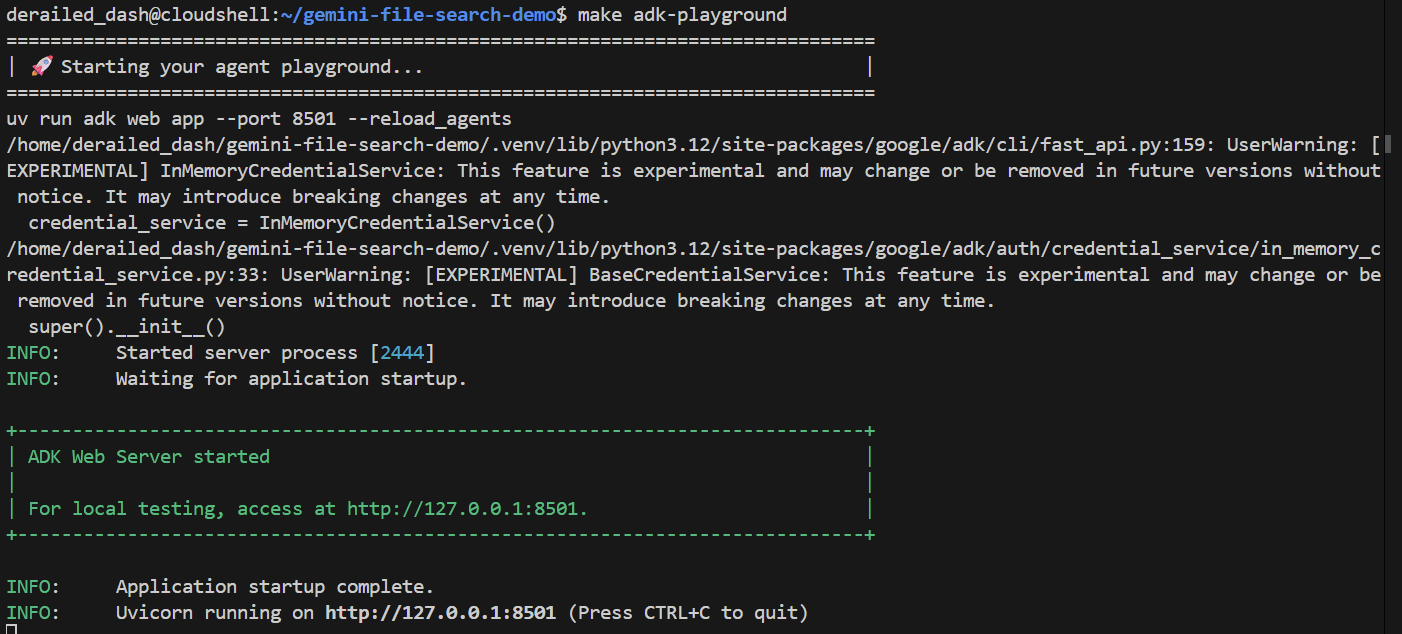
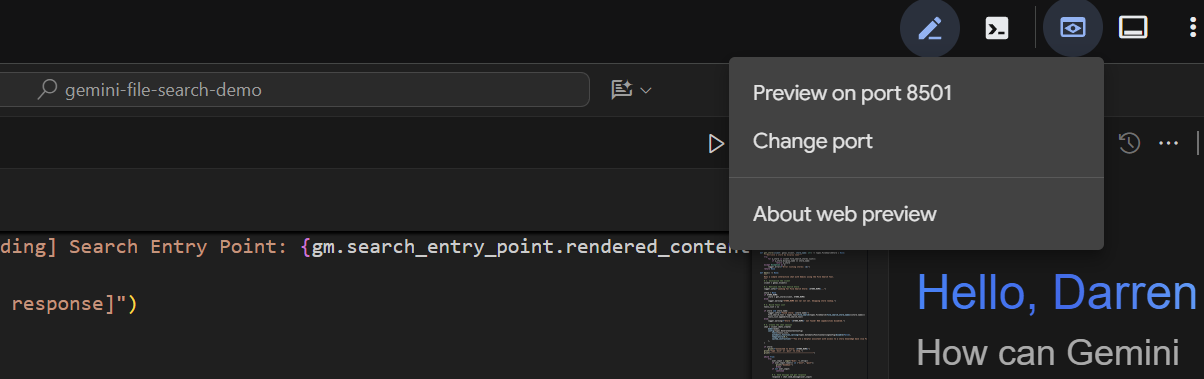
Po kilku sekundach aplikacja będzie gotowa. Jeśli kod jest uruchamiany lokalnie, otwórz w przeglądarce stronę http://127.0.0.1:8501. Jeśli korzystasz z edytora Cloud Shell, kliknij „Podgląd w przeglądarce” i zmień port na 8501:
Gdy pojawi się interfejs, wybierz basic_agent_adk z menu, a potem zadaj pytanie:
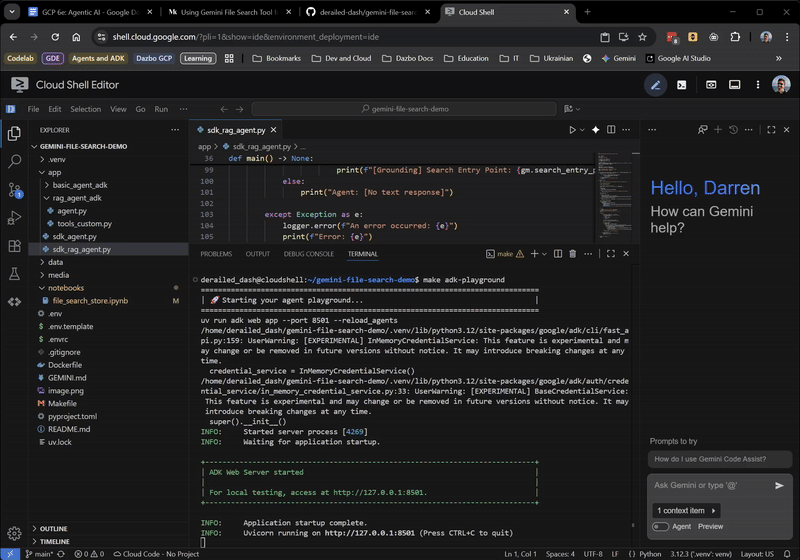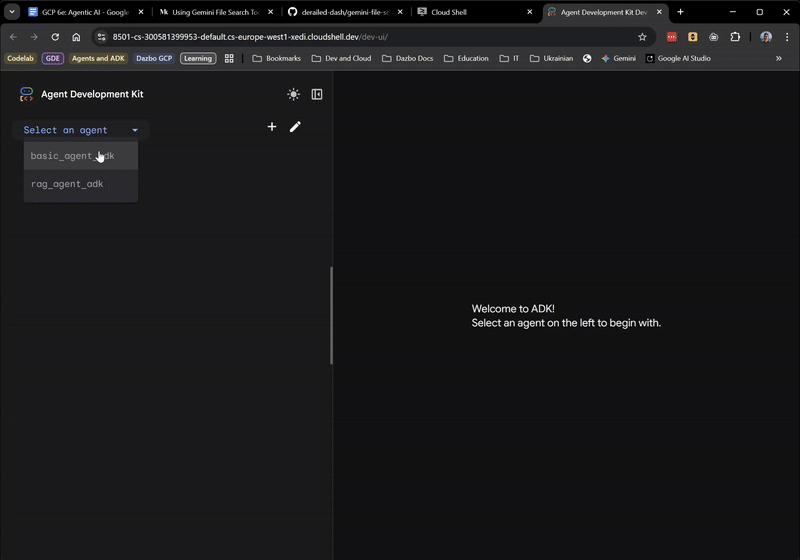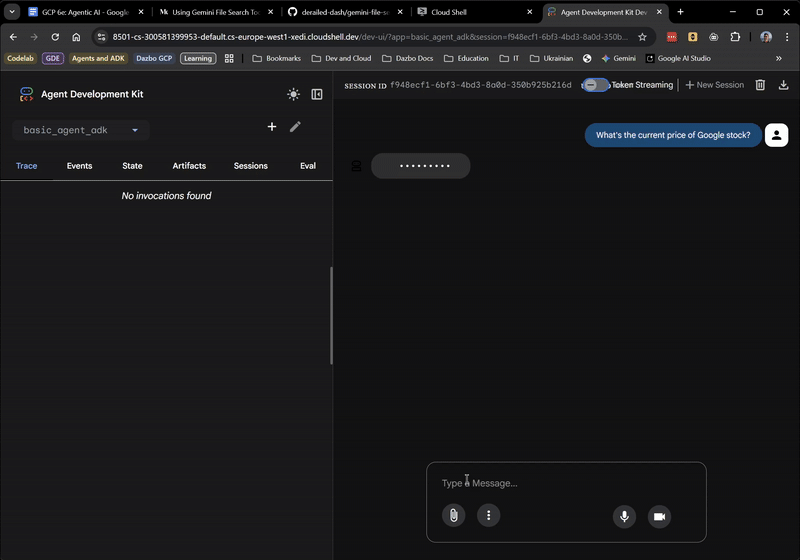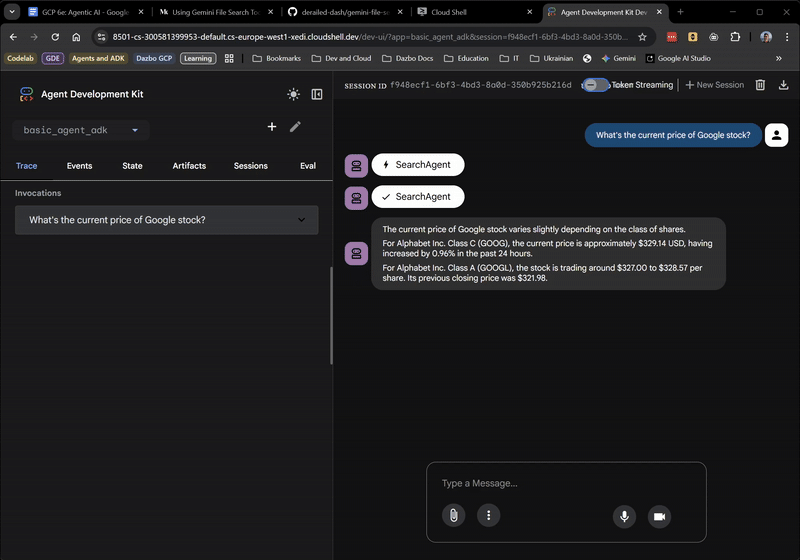
Póki co idzie jej dobrze. Interfejs internetowy pokazuje nawet, kiedy agent główny przekazuje zadanie do SearchAgent. To bardzo przydatna funkcja.
Teraz zadajmy mu pytanie, które wymaga znajomości naszej historii:
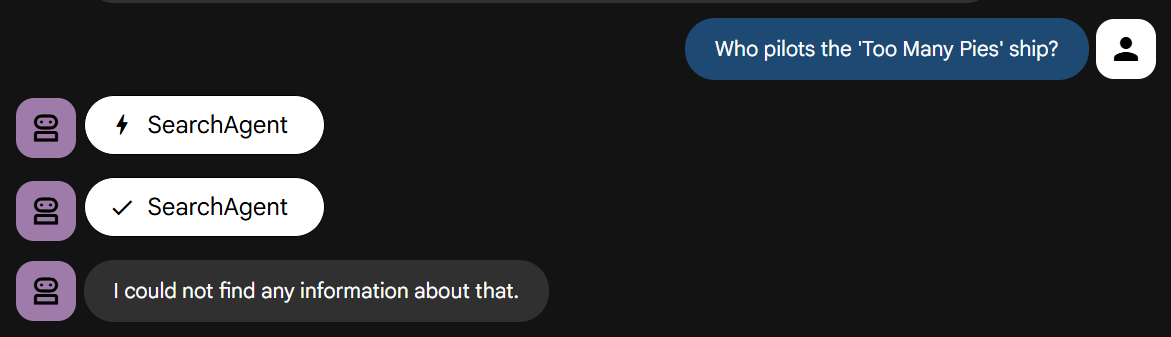
Sprawdź to. Powinien szybko zakończyć się niepowodzeniem, zgodnie z instrukcjami.
Włączanie magazynu File Search Store do agenta ADK
Teraz połączymy to wszystko. Uruchomimy agenta ADK, który może korzystać zarówno z magazynu wyszukiwania plików, jak i z wyszukiwarki Google. Zapoznaj się z kodem w app/rag_agent_adk/agent.py.
Kod jest podobny do tego z poprzedniego przykładu, ale różni się od niego w kilku kluczowych kwestiach:
- Mamy agenta głównego, który koordynuje pracę 2 agentów specjalistów:
- RagAgent specjalista od wiedzy – korzysta z naszego sklepu z narzędziem wyszukiwania plików Gemini.
- SearchAgent: ekspert w zakresie wiedzy ogólnej – korzysta z wyszukiwarki Google.
- Ponieważ pakiet ADK nie ma jeszcze wbudowanej otoki dla
FileSearch, używamy niestandardowej klasy otokiFileSearchTool, aby opakować narzędzie FileSearch, które wstrzykuje konfiguracjęfile_search_store_namesdo żądania modelu niskiego poziomu. Zostało to zaimplementowane w osobnym skrypcieapp/rag_agent_adk/tools_custom.py.
Jest też pewien haczyk, na który trzeba uważać. W momencie pisania tego artykułu nie można używać narzędzia natywnego GoogleSearch i narzędzia FileSearch w tym samym żądaniu do tego samego agenta. Jeśli spróbujesz to zrobić, pojawi się taki błąd:
BŁĄD – wystąpił błąd: 400 INVALID_ARGUMENT. {‘error': {‘code': 400, ‘message': ‘Wyszukiwanie jako narzędzie i narzędzie wyszukiwania plików nie są obsługiwane razem', ‘status': ‘INVALID_ARGUMENT'}}
Błąd: 400 INVALID_ARGUMENT. {‘error': {‘code': 400, ‘message': ‘Wyszukiwanie jako narzędzie i narzędzie wyszukiwania plików nie są obsługiwane razem', ‘status': ‘INVALID_ARGUMENT'}}
Rozwiązaniem jest wdrożenie 2 specjalistycznych agentów jako osobnych subagentów i przekazanie ich do agenta głównego za pomocą wzorca „Agent jako narzędzie”. Co najważniejsze, instrukcja systemowa agenta głównego zawiera bardzo jasne wytyczne, aby najpierw użyć RagAgent:
Jesteś pomocnym asystentem AI, który ma za zadanie dostarczać dokładne i przydatne informacje.
Masz dostęp do 2 specjalistów:
- RagAgent: do uzyskiwania spersonalizowanych informacji z wewnętrznej bazy wiedzy.
- SearchAgent: do uzyskiwania ogólnych informacji z wyszukiwarki Google.
Zawsze najpierw wypróbuj RagAgent. Jeśli nie uda się uzyskać przydatnej odpowiedzi, spróbuj użyć SearchAgent.
Final Test
Uruchom interfejs internetowy ADK jak poprzednio:
make adk-playground # Or, without make: uv run adk web app --port 8501 --reload_agents
Tym razem wybierz rag_agent_adk w interfejsie. Zobaczmy, jak to działa: 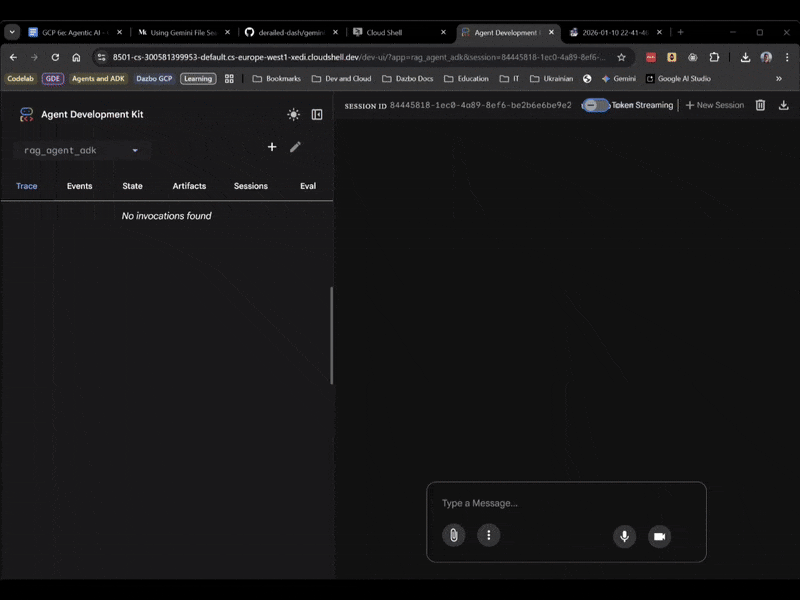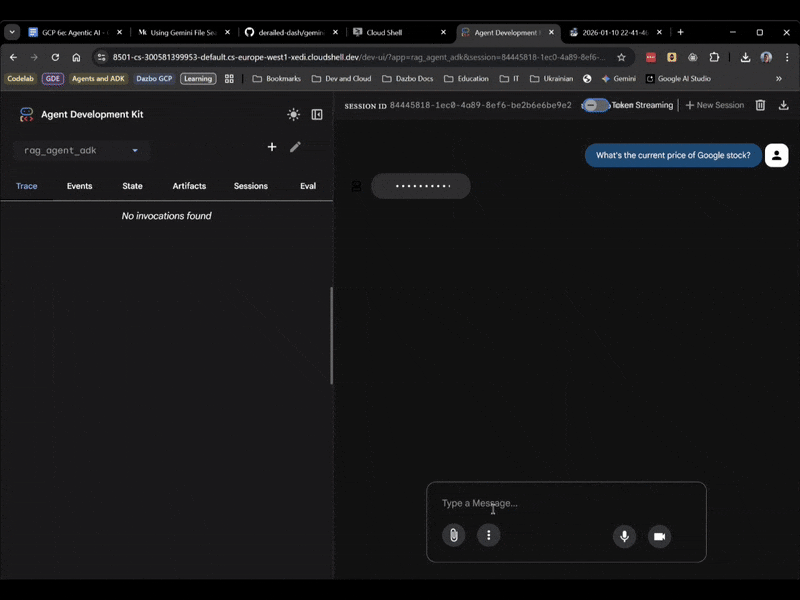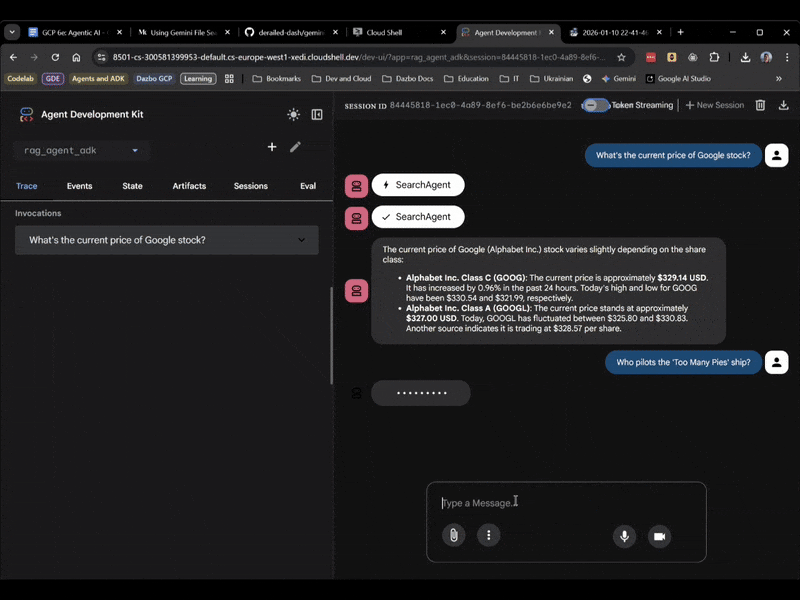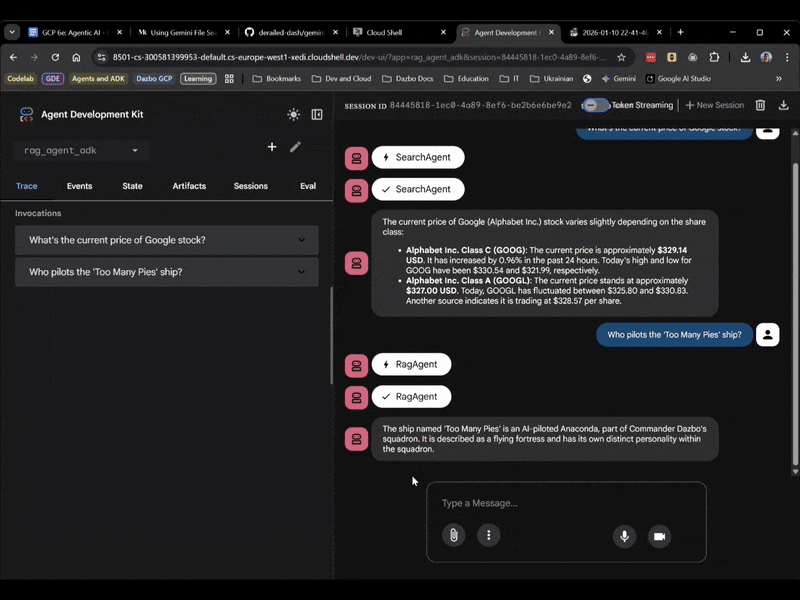
Widać, że wybiera on odpowiedniego subagenta na podstawie pytania.
8. Podsumowanie
Gratulujemy ukończenia tego ćwiczenia!
Z prostego skryptu powstał system RAG z wieloma agentami. Wszystko to bez jednej linijki kodu osadzania i bez konieczności wdrażania bazy danych wektorów.
Dowiedzieliśmy się, że:
- Gemini File Search to zarządzane rozwiązanie RAG, które pozwala oszczędzać czas i nerwy.
- ADK zapewnia nam strukturę potrzebną do tworzenia złożonych aplikacji z wieloma agentami i ułatwia pracę deweloperom dzięki interfejsom takim jak interfejs internetowy.
- Wzorzec "Agent-as-a-Tool" rozwiązuje problemy ze zgodnością narzędzi.
Mamy nadzieję, że to laboratorium okazało się przydatne. Do zobaczenia!