
1. Introdução
Este codelab mostra como usar a Pesquisa de arquivos do Gemini para ativar a RAG no seu aplicativo agentivo. Você vai usar a Pesquisa de arquivos do Gemini para ingerir e indexar seus documentos sem se preocupar com os detalhes de divisão, incorporação ou banco de dados vetorial.
O que você aprenderá
- Os conceitos básicos do RAG e por que precisamos dele.
- O que é a Pesquisa de arquivos do Gemini e quais são as vantagens dela.
- Como criar um repositório de pesquisa de arquivos.
- Como fazer upload dos seus próprios arquivos personalizados para o repositório de pesquisa de arquivos.
- Como usar a ferramenta de pesquisa de arquivos do Gemini para RAG.
- Os benefícios de usar o Kit de Desenvolvimento de Agente (ADK) do Google.
- Como usar a ferramenta de pesquisa de arquivos do Gemini em uma solução agentiva criada com o ADK.
- Como usar a ferramenta de pesquisa de arquivos do Gemini com ferramentas "nativas" do Google, como a Pesquisa Google.
O que você vai fazer
- Crie um projeto do Google Cloud e configure seu ambiente de desenvolvimento.
- Crie um agente simples baseado no Gemini usando o SDK de IA Generativa do Google (mas sem o ADK) que possa usar a Pesquisa Google, mas não tenha capacidade de RAG.
- Demonstrar a incapacidade de fornecer informações precisas e de alta qualidade para informações personalizadas.
- Crie um notebook Jupyter (que pode ser executado localmente ou, por exemplo, no Google Colab) para criar e gerenciar um repositório de pesquisa de arquivos do Gemini.
- Use o notebook para fazer upload de conteúdo personalizado no File Search Store.
- Crie um agente com o repositório de pesquisa de arquivos anexado e prove que ele é capaz de produzir respostas melhores.
- Converter nosso agente "básico" inicial em um agente do ADK, com a ferramenta de Pesquisa Google.
- Teste o agente usando a interface da Web do ADK.
- Incorpore o repositório de pesquisa de arquivos ao agente do ADK usando o padrão Agente como Ferramenta para usar a ferramenta de pesquisa de arquivos com a Pesquisa Google.
2. O que é RAG e por que precisamos dela
Então... Geração aumentada de recuperação.
Se você está aqui, provavelmente sabe o que é, mas vamos fazer uma recapitulação rápida, só por precaução. Os LLMs (como o Gemini) são incríveis, mas têm alguns problemas:
- Eles estão sempre desatualizados: só sabem o que aprenderam durante o treinamento.
- Eles não sabem tudo: é claro que os modelos são enormes, mas não são oniscientes.
- Eles não conhecem suas informações exclusivas: têm um conhecimento amplo, mas não leram seus documentos internos, blogs ou tíquetes do Jira.
Por isso, quando você pergunta algo a um modelo que ele não sabe, geralmente recebe uma resposta incorreta ou até inventada. Muitas vezes, o modelo vai dar essa resposta incorreta com confiança. Isso é o que chamamos de alucinação.
Uma solução é simplesmente despejar nossas informações proprietárias diretamente no contexto da conversa. Isso funciona bem para uma pequena quantidade de informações, mas rapidamente se torna problemático quando há muitas informações. Especificamente, isso causa os seguintes problemas:
- Latência: respostas cada vez mais lentas do modelo.
- Decadência de sinal, também conhecida como "perdido no meio": quando o modelo não consegue mais separar os dados relevantes dos inúteis. Grande parte do contexto é ignorada pelo modelo.
- Custo: porque os tokens custam dinheiro.
- Esgotamento da janela de contexto: neste ponto, o Gemini não vai atender aos seus pedidos.
Uma maneira muito mais eficaz de remediar essa situação é usar o RAG. É simplesmente o processo de pesquisar informações relevantes nas suas fontes de dados (usando correspondência semântica) e fornecer partes relevantes desses dados ao modelo junto com sua pergunta. Ele baseia o modelo na sua realidade.
Ele importa dados externos, divide os dados em partes, converte os dados em embeddings de vetor e armazena e indexa esses embeddings em um banco de dados de vetores adequado.
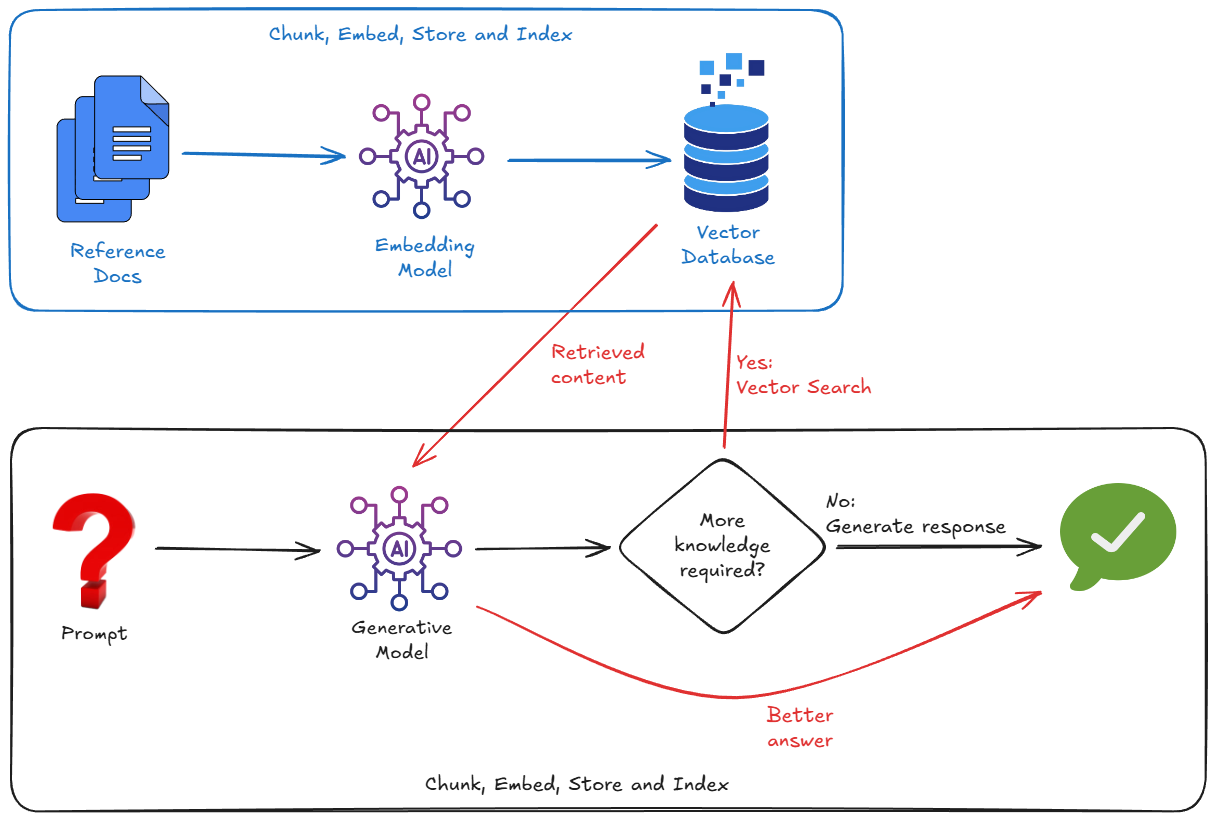
Para implementar a RAG, normalmente precisamos nos preocupar com:
- Criar um banco de dados de vetores (Pinecone, Weaviate, Postgres com pgvector etc.).
- Escrever um script de divisão para segmentar seus documentos (por exemplo, PDFs, markdown, etc.).
- Gerar embeddings (vetores) para esses trechos usando um modelo de embedding.
- Armazenar os vetores no banco de dados de vetores.
Mas amigos não deixam amigos complicarem demais as coisas. E se eu disser que há uma maneira mais fácil?
3. Pré-requisitos
Criar um projeto do Google Cloud
Você precisa de um projeto do Google Cloud para executar este codelab. Você pode usar um projeto que já tem ou criar um novo.
Verifique se o faturamento está ativado no projeto. Consulte este guia para saber como verificar o status de faturamento dos seus projetos.
A conclusão deste codelab não deve gerar custos. No máximo, alguns centavos.
Prepare seu projeto. Vou esperar.
Clonar o repositório de demonstração
Criei um repositório com conteúdo guiado para este codelab. Você vai precisar dele!
Execute os comandos a seguir no terminal ou no terminal integrado ao Editor do Cloud Shell do Google. O Cloud Shell e o editor dele são muito convenientes, já que todos os comandos necessários estão pré-instalados e tudo funciona "pronto para uso".
git clone https://github.com/derailed-dash/gemini-file-search-demo cd gemini-file-search-demo
Essa árvore mostra as principais pastas e arquivos no repositório:
gemini-file-search-demo/ ├── app/ │ ├── basic_agent_adk/ # Agent with Google Search, using ADK framework │ │ └── agent.py │ ├── rag_agent_adk/ # Agent with Google Search and File Search, using ADK framework │ │ ├── agent.py │ │ └── tools_custom.py │ ├── sdk_agent.py # Agent using GenAI SDK (no ADK) with Google Search tool │ └── sdk_rag_agent.py # Agent using GenAI SDK (no ADK) with Gemini File Search tool ├── data/ │ └── story.md # Sample story with "bespoke content" to use with Gemini File Search Store ├── notebooks/ │ └── file_search_store.ipynb # Jupyter notebook for creating and managing Gemini File Search Store │ ├── .env.template # Template for environment variables - make a copy as .env ├── Makefile # Makefile for `make` commands ├── pyproject.toml # Project configuration and dependencies └── README.md # This file
Abra essa pasta no editor do Cloud Shell ou no editor de sua preferência. Você já usou o Antigravity? Se não, agora é um bom momento para testar.)
Observe que o repo contém uma história de exemplo - "The Wormhole Incursion" - no arquivo data/story.md. Eu escrevi com a ajuda do Gemini! É sobre o Comandante Dazbo e seu esquadrão de naves espaciais sencientes. (Me inspirei no jogo Elite Dangerous.) Essa história serve como nossa "base de conhecimento personalizada", contendo fatos específicos que o Gemini não conhece e que não podem ser pesquisados usando a Pesquisa Google.
Configurar o ambiente de desenvolvimento
Para sua conveniência, forneci um Makefile para simplificar muitos dos comandos que você precisa executar. Em vez de lembrar comandos específicos, basta executar algo como make <target>. No entanto, make está disponível apenas em ambientes Linux / MacOS / WSL. Se você estiver usando o Windows (sem WSL), execute os comandos completos que os destinos make contêm.
# Install dependencies with make make install # If you don't have make... uv sync --extra jupyter
Esta é a aparência quando você executa make install no editor do Cloud Shell:
Criar uma chave da API Gemini
Para usar a API Gemini Developer (necessária para usar a ferramenta de pesquisa de arquivos do Gemini), você precisa de uma chave de API Gemini. A maneira mais fácil de conseguir uma chave de API é usar o Google AI Studio, que oferece uma interface conveniente para obter chaves de API para seus projetos na nuvem do Google Cloud. Consulte este guia para conferir as etapas específicas.
Depois que a chave de API for criada, copie e guarde com segurança.
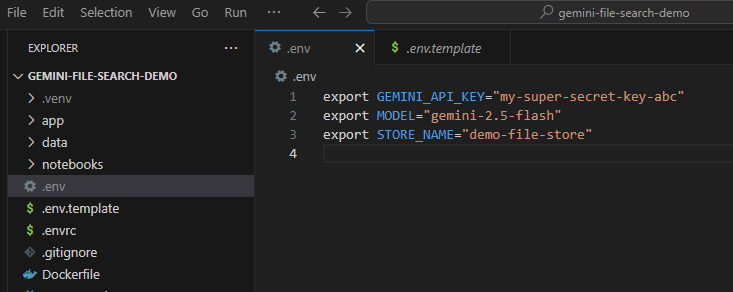
Agora, defina essa chave de API como uma variável de ambiente. Podemos fazer isso usando um arquivo .env. Copie o .env.example incluído como um novo arquivo chamado .env. O arquivo deve ficar assim:
export GEMINI_API_KEY="your-api-key" export MODEL="gemini-2.5-flash" export STORE_NAME="demo-file-store"
Substitua your-api-key pela sua chave de API. Agora ele vai ficar assim:
Agora verifique se as variáveis de ambiente foram carregadas. Para isso, execute:
source .env
4. O agente básico
Primeiro, vamos estabelecer um valor de referência. Vamos usar o SDK google-genai bruto para executar um agente simples.
O código
Dê uma olhada no arquivo app/sdk_agent.py. É uma implementação mínima que:
- Instancia um
genai.Client. - Ativa a ferramenta
google_search. - É isso. Sem RAG.
Analise o código e confira se você entendeu o que ele faz.
Running It
# With make make sdk-agent # Without make uv run python app/sdk_agent.py
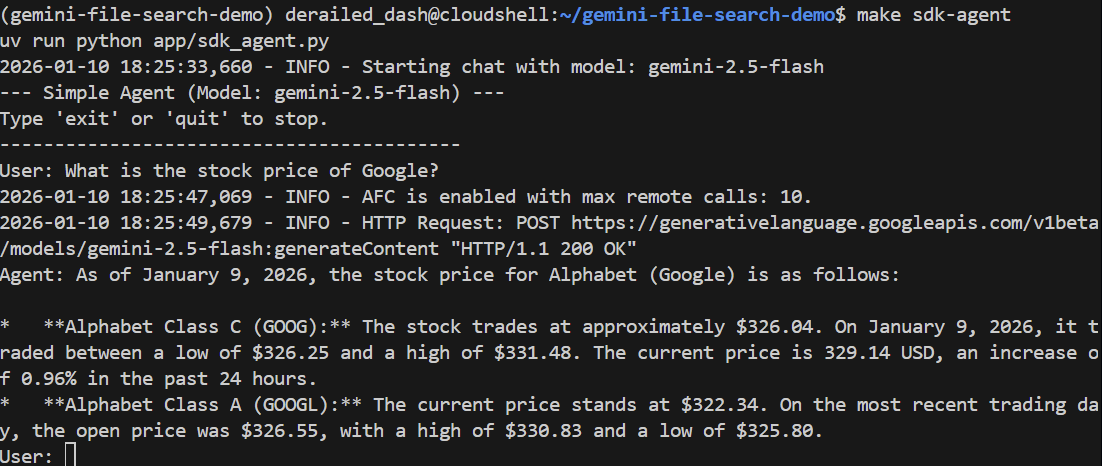
Vamos fazer uma pergunta geral:
> What is the stock price of Google?
Ele precisa responder corretamente usando a Pesquisa Google para encontrar o preço atual:
Agora, vamos fazer uma pergunta que ele não sabe responder. Ele exige que o agente tenha lido nossa história.
> Who pilots the 'Too Many Pies' ship?
Ela vai falhar ou até mesmo alucinar. Vamos conferir:
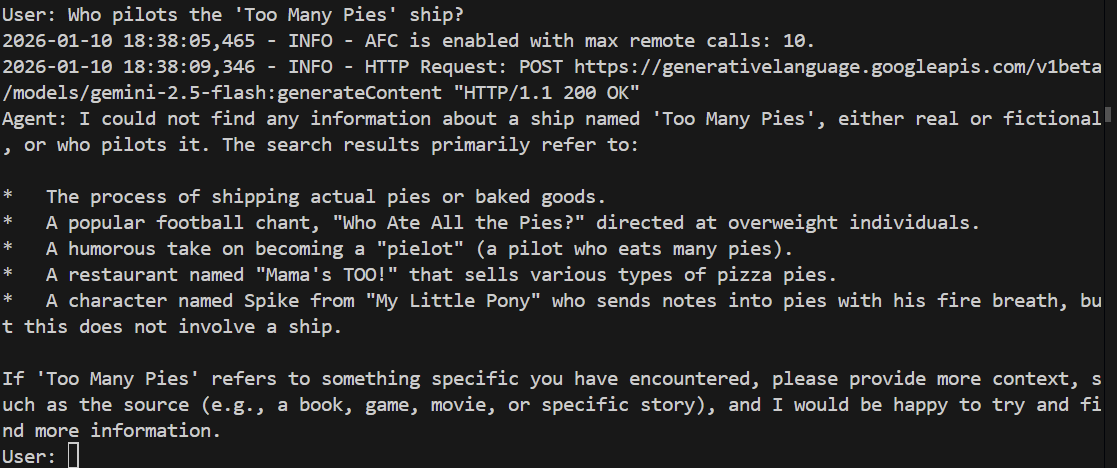
E, de fato, o modelo não consegue responder à pergunta. Ela não tem ideia do que estamos falando!
Agora digite quit para sair do agente.
5. Pesquisa de arquivos do Gemini: explicação
A Pesquisa de arquivos do Gemini é essencialmente uma combinação de duas coisas:
- Um sistema RAG totalmente gerenciado: você fornece vários arquivos, e a Pesquisa de arquivos do Gemini cuida da divisão, incorporação, armazenamento e indexação de vetores para você.
- Uma "ferramenta" no sentido agentivo: basta adicionar a ferramenta de pesquisa de arquivos do Gemini como uma ferramenta na definição do agente e direcioná-la para um repositório de pesquisa de arquivos.
Mas, principalmente, ele é integrado à própria API Gemini. Isso significa que não é necessário ativar outras APIs nem implantar produtos separados para usar o recurso. Então, ele é realmente out-of-the-box.
Recursos de pesquisa de arquivos do Gemini
Aqui estão alguns dos recursos:
- Os detalhes de divisão em partes, incorporação, armazenamento e indexação são abstraídos de você, o desenvolvedor. Isso significa que você não precisa saber (ou se importar) com o modelo de embedding (que é o Gemini Embeddings, aliás) ou onde os vetores resultantes são armazenados. Você não precisa tomar decisões sobre o banco de dados de vetores.
- Ele oferece suporte a um grande número de tipos de documentos prontos para uso. Incluindo, mas não se limitando a: PDF, DOCX, Excel, SQL, JSON, notebooks Jupyter, HTML, Markdown, CSV e até arquivos ZIP. Confira a lista completa aqui. Por exemplo, se você quiser embasar seu agente com arquivos PDF que contenham texto, imagens e tabelas, não será necessário pré-processar esses arquivos. Basta fazer upload dos PDFs brutos e deixar o Gemini cuidar do resto.
- É possível adicionar metadados personalizados a qualquer arquivo enviado. Isso pode ser muito útil para filtrar posteriormente quais arquivos queremos que a ferramenta use durante a execução.
Onde os dados estão?
Você faz upload de alguns arquivos. A ferramenta de pesquisa de arquivos do Gemini pegou esses arquivos, criou os blocos e os embeddings e os colocou... em algum lugar. Mas onde?
A resposta: um repositório de pesquisa de arquivos. É um contêiner totalmente gerenciado para seus embeddings. Você não precisa saber (ou se importar) como isso é feito nos bastidores. Basta criar um (de maneira programática) e fazer upload dos arquivos nele.
É barato!
O armazenamento e a consulta dos seus embeddings são sem custo financeiro. Assim, você pode armazenar embeddings pelo tempo que quiser sem pagar por isso.
Na verdade, a única coisa que você paga é a criação dos embeddings no momento do upload/indexação. No momento da redação, isso custa US $0,15 por 1 milhão de tokens. Isso é bem barato.
6. Como usamos a Pesquisa de arquivos do Gemini?
Há duas fases:
- Crie e armazene os embeddings em um repositório de pesquisa de arquivos.
- Consulte o repositório de pesquisa de arquivos do seu agente.
Fase 1: notebook Jupyter para criar e gerenciar um repositório de pesquisa de arquivos do Gemini
Essa fase é algo que você faria inicialmente e sempre que quisesse atualizar a loja. Por exemplo, quando você tem novos documentos para adicionar ou quando os documentos de origem mudaram.
Essa fase não precisa ser incluída no pacote do aplicativo generativo implantado. Claro, se quiser. Por exemplo, se você quiser criar algum tipo de interface para usuários administradores do seu aplicativo com tecnologia de agente. Mas muitas vezes é perfeitamente adequado ter um pouco de código que você executa sob demanda. E uma ótima maneira de executar esse código sob demanda? Um notebook do Jupyter!
Diário de uma Paixão
Abra o arquivo notebooks/file_search_store.ipynb no editor. Se você receber uma solicitação para instalar extensões do Jupyter VS Code, faça isso.
Se abrirmos no editor do Cloud Shell, ele vai aparecer assim:
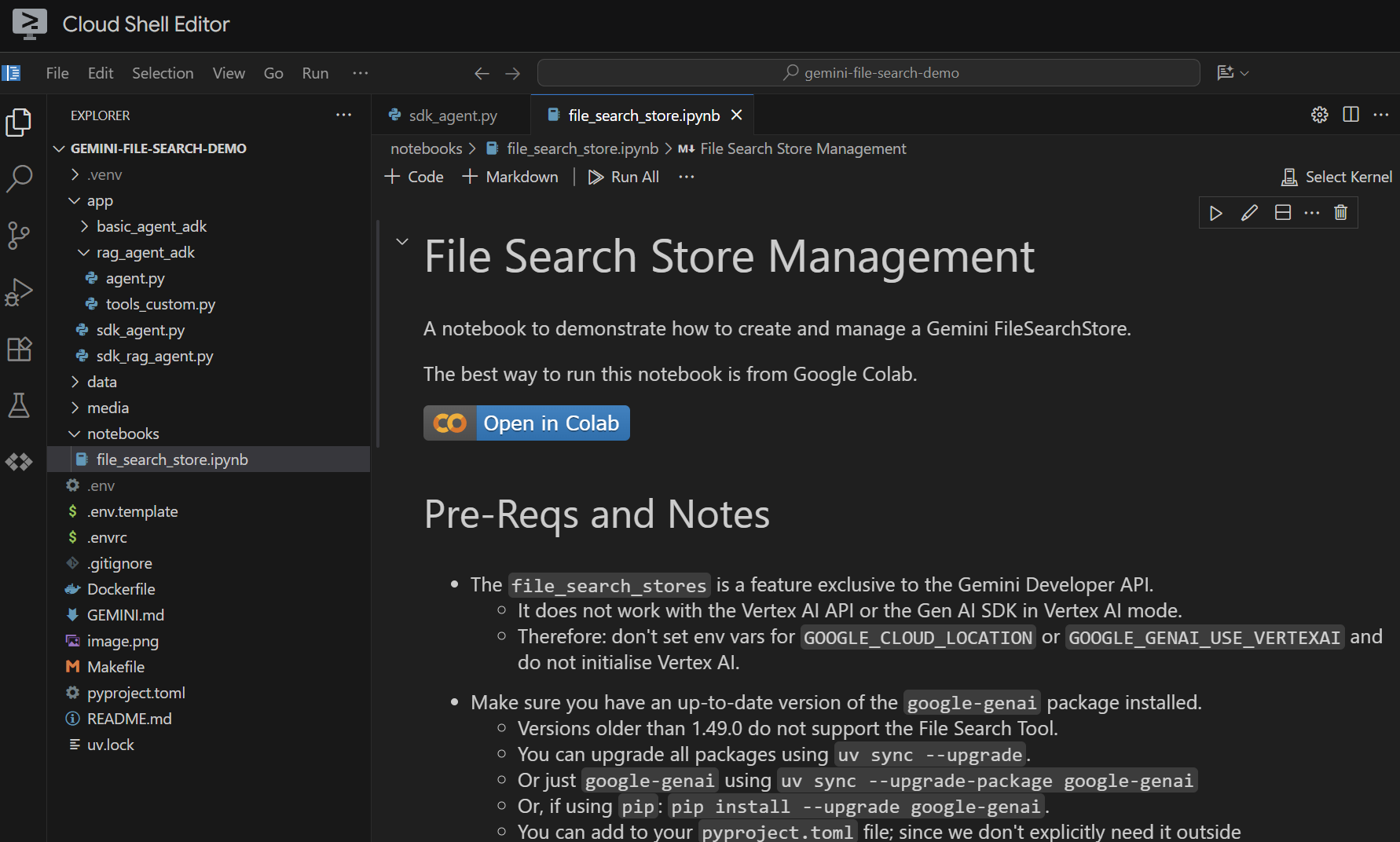
Vamos executar célula por célula. Comece executando a célula Setup com as importações necessárias. Se você nunca executou um notebook, será necessário instalar as extensões necessárias. Vá em frente e crie as chaves. Em seguida, selecione um kernel. Selecione "Python environments..." e o .venv local que instalamos quando executamos make install antes:
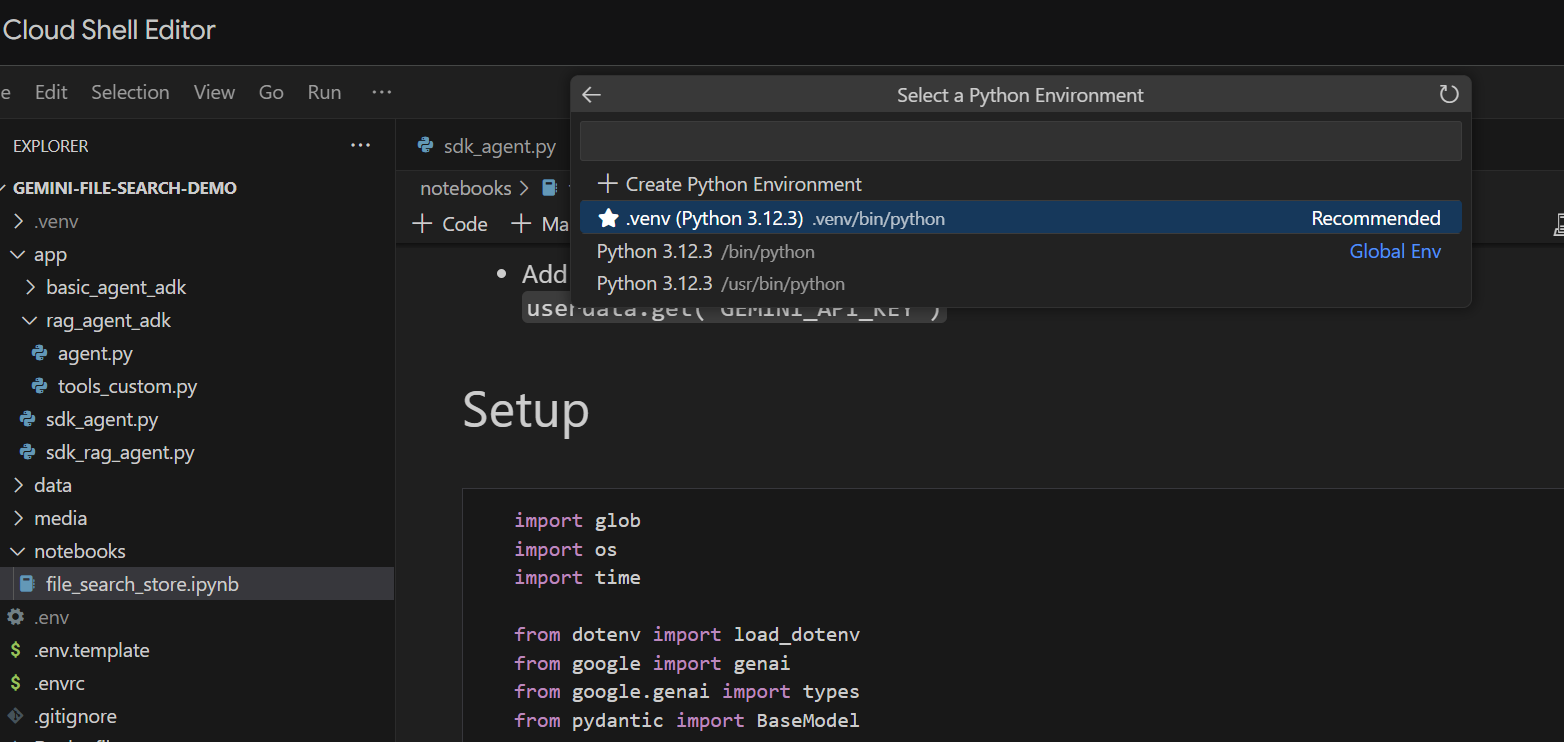
Em seguida:
- Execute a célula Local Only para extrair as variáveis de ambiente.
- Execute a célula "Inicialização do cliente" para inicializar o cliente de IA generativa do Gemini.
- Execute a célula "Recuperar o repositório" com a função auxiliar para recuperar o repositório de pesquisa de arquivos do Gemini por nome.
Agora já podemos criar a loja.
- Execute a célula "Create the Store (One Time)" para criar a loja. Só precisamos fazer isso uma vez. Se o código for executado com sucesso, você vai ver uma mensagem dizendo
"Created store: fileSearchStores/<someid>" - Execute a célula View the Store para ver o que há nela. Neste ponto, você vai notar que ele contém zero documentos.
Ótimo! Agora temos um repositório de pesquisa de arquivos do Gemini pronto para uso.
Como fazer o upload dos dados
Queremos fazer upload de data/story.md para a loja. Faça o seguinte:
- Execute a célula que define o caminho de upload. Isso aponta para nossa pasta
data/. - Execute a próxima célula, que cria funções utilitárias para fazer upload de arquivos para o repositório. Observe que o código nesta célula também usa o Gemini para extrair metadados de cada arquivo enviado. Esses valores extraídos são armazenados como metadados personalizados no repositório. Não é necessário fazer isso, mas é útil.
- Execute a célula para fazer upload do arquivo. Se já tivermos enviado um arquivo com o mesmo nome antes, o bloco vai excluir a versão atual antes de enviar a nova. Uma mensagem vai aparecer indicando que o arquivo foi enviado.
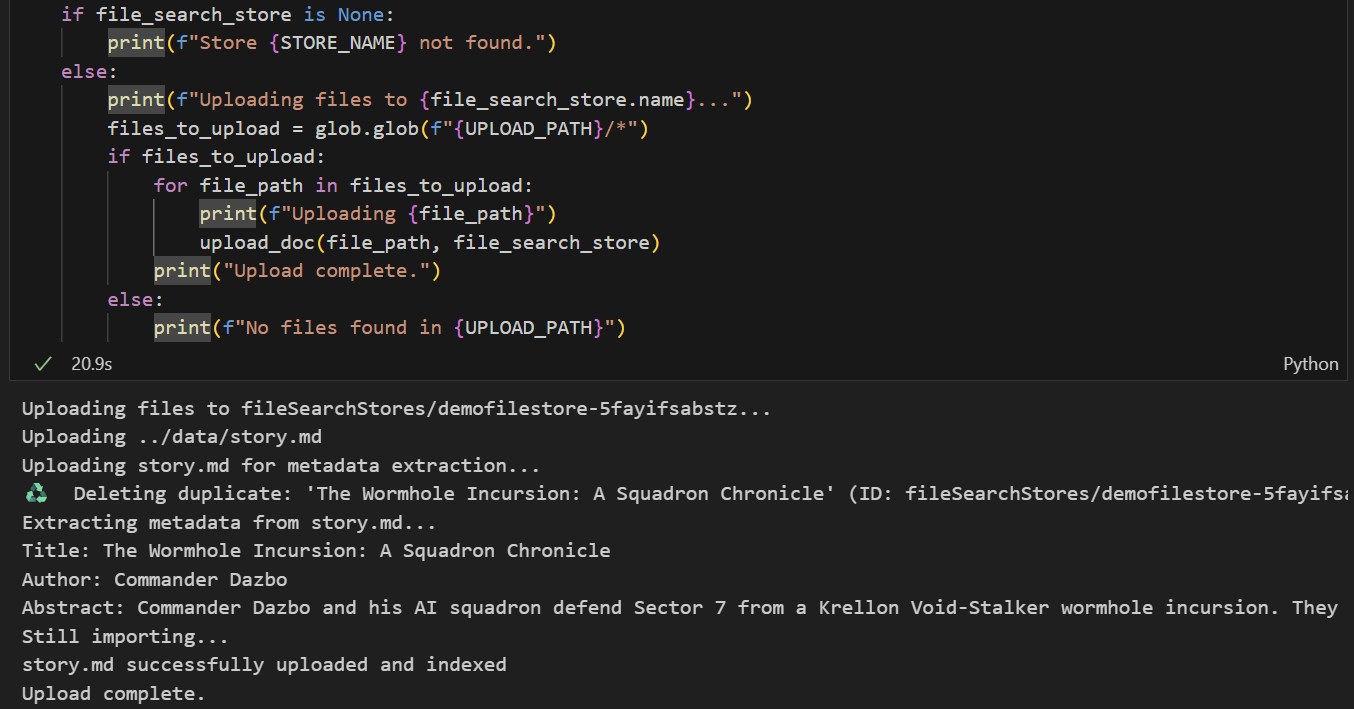
Fase 2: implementar a RAG da pesquisa de arquivos do Gemini no nosso agente
Criamos um repositório de pesquisa de arquivos do Gemini e fizemos upload da nossa história nele. Agora é hora de usar a File Search Store no nosso agente. Vamos criar um novo agente que usa o repositório de pesquisa de arquivos em vez da Pesquisa Google. Dê uma olhada no arquivo app/sdk_rag_agent.py.
A primeira coisa a observar é que implementamos uma função para recuperar nosso repositório transmitindo um nome de loja:
def get_store(client: genai.Client, store_name: str) -> types.FileSearchStore | None:
"""Retrieve a store by display name"""
try:
for a_store in client.file_search_stores.list():
if a_store.display_name == store_name:
return a_store
except Exception as e:
logger.error(f"Error listing stores: {e}")
return None
Depois de criar a loja, basta anexá-la como uma ferramenta ao agente, assim:
file_search_tool = types.Tool(file_search=types.FileSearch(file_search_store_names=[store.name]))
Executar o agente de RAG
Vamos lançar assim:
make sdk-rag-agent # Or, without make: uv run python app/sdk_rag_agent.py
Vamos fazer a pergunta que o agente anterior não conseguiu responder:
> Who pilots the 'Too Many Pies' ship?
E a resposta?
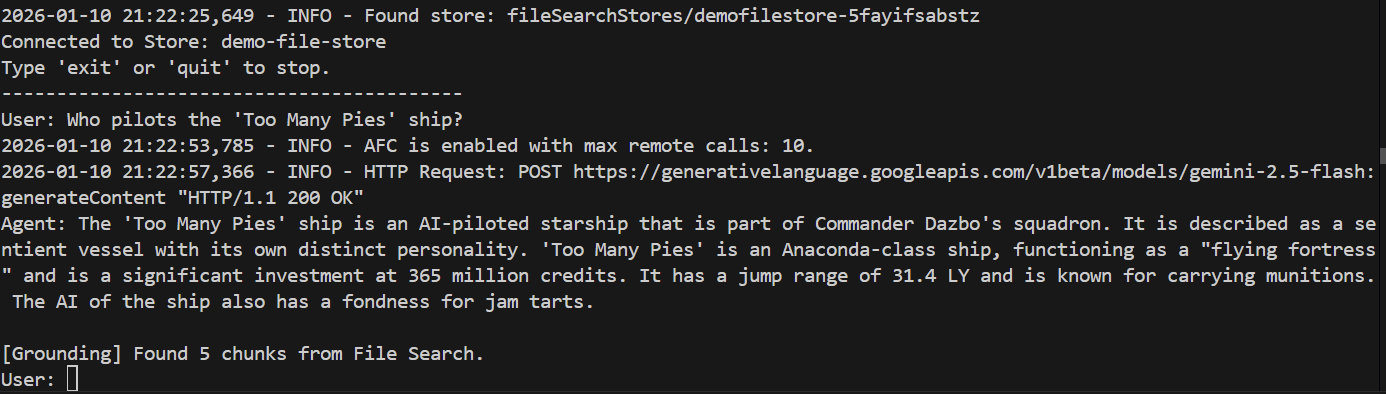
Pronto! Pela resposta, podemos ver que:
- Nosso repositório de arquivos foi usado para responder à pergunta.
- Foram encontrados cinco trechos relevantes.
- A resposta está certa!
Digite quit para fechar o agente.
7. Converter nossos agentes para usar o ADK
O Kit de Desenvolvimento de Agente (ADK) do Google é um framework modular de código aberto e um SDK para desenvolvedores criarem agentes e sistemas de agentes. Ele permite criar e orquestrar sistemas multiagentes com facilidade. Embora otimizado para o Gemini e o ecossistema do Google, o ADK é independente de modelo e implantação e foi criado para ser compatível com outros frameworks. Se você ainda não usou o ADK, acesse a documentação do ADK para saber mais.
O agente básico do ADK com a Pesquisa Google
Dê uma olhada no arquivo app/basic_agent_adk/agent.py. Neste exemplo de código, você pode ver que implementamos dois agentes:
- Um
root_agentque processa a interação com o usuário e onde fornecemos a principal instrução do sistema. - Um
SearchAgentseparado que usa ogoogle.adk.tools.google_searchcomo ferramenta.
O root_agent usa o SearchAgent como uma ferramenta, que é implementada usando esta linha:
tools=[AgentTool(agent=search_agent)],
O comando do sistema do agente raiz é semelhante a este:
You are a helpful AI assistant designed to provide accurate and useful information.
If you don't know the answer, use the SearchAgent to perform a Google search.
Do not attempt to search more than ONCE.
If the search yields no relevant results or returns unrelated content, you MUST immediately respond with: "I could not find any information about that."
Do NOT retry the search with different terms. Do NOT ask for clarification. FAIL FAST.
Como testar o agente
O ADK oferece várias interfaces prontas para uso que permitem aos desenvolvedores testar os agentes do ADK. Uma dessas interfaces é a interface da Web. Isso permite testar nossos agentes em um navegador sem precisar escrever uma linha de código de interface do usuário.
Podemos iniciar essa interface executando:
make adk-playground # Or, without make: uv run adk web app --port 8501 --reload_agents
O comando aponta a ferramenta adk web para a pasta app, onde ela vai descobrir automaticamente os agentes do ADK que implementam um root_agent. Vamos testar:
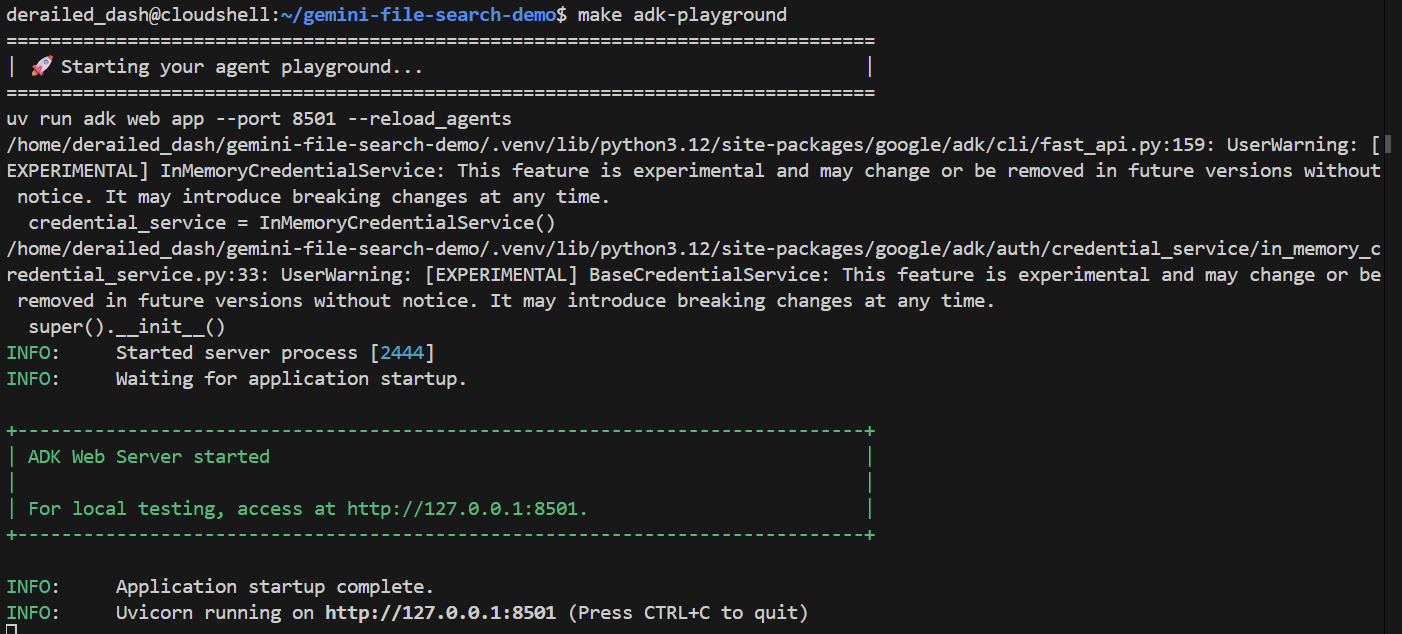
Depois de alguns segundos, o aplicativo estará pronto. Se você estiver executando o código localmente, basta direcionar o navegador para http://127.0.0.1:8501. Se você estiver executando no editor do Cloud Shell, clique em Visualização na Web e mude a porta para 8501:
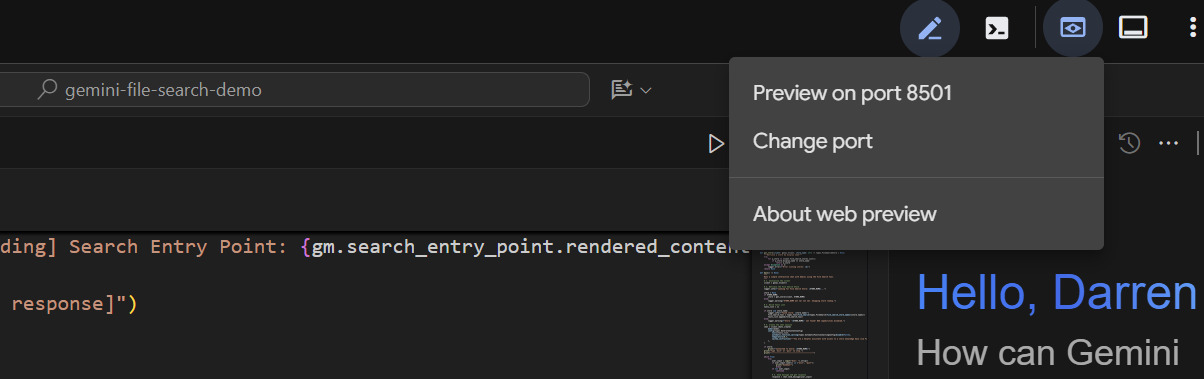
Quando a interface aparecer, selecione o basic_agent_adk no menu suspenso e faça perguntas:
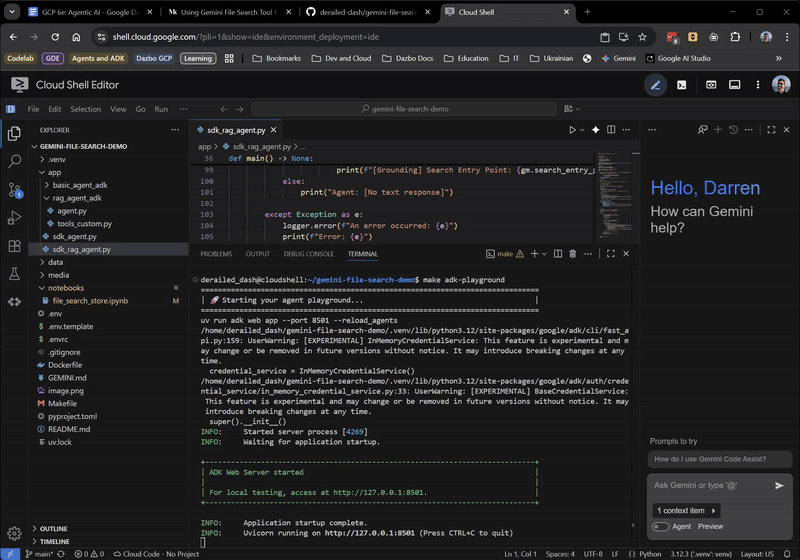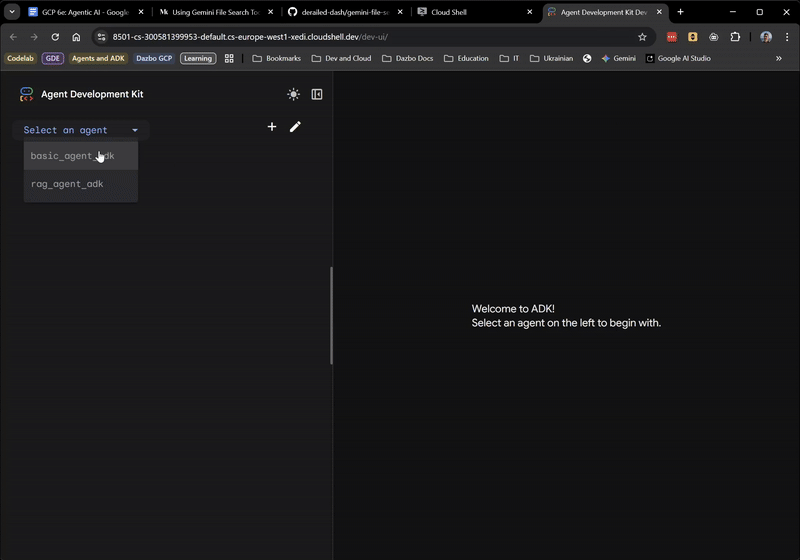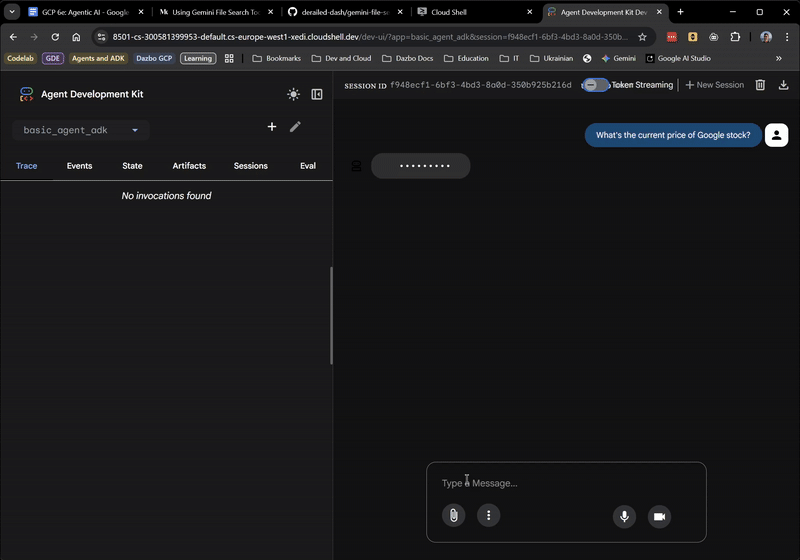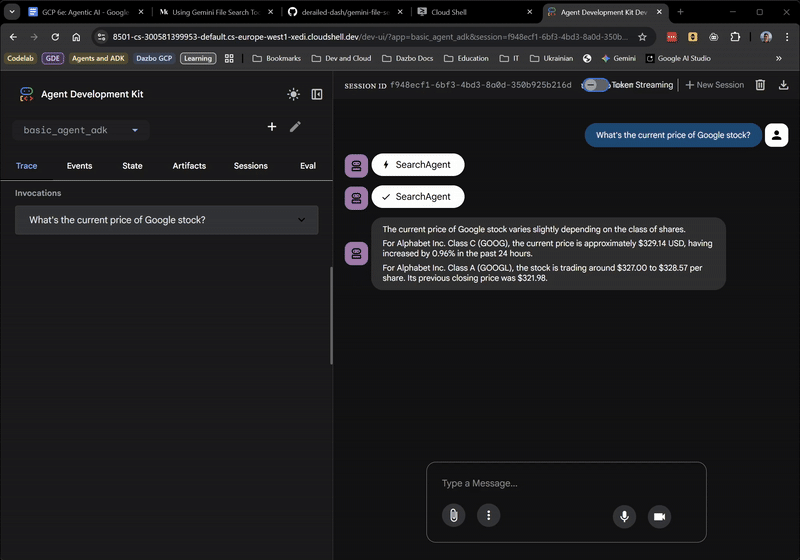
Até aqui, tudo bem! A interface da Web mostra até mesmo quando o agente raiz está delegando ao SearchAgent. Esse é um recurso muito útil.
Agora vamos fazer a pergunta que exige conhecimento da nossa história:
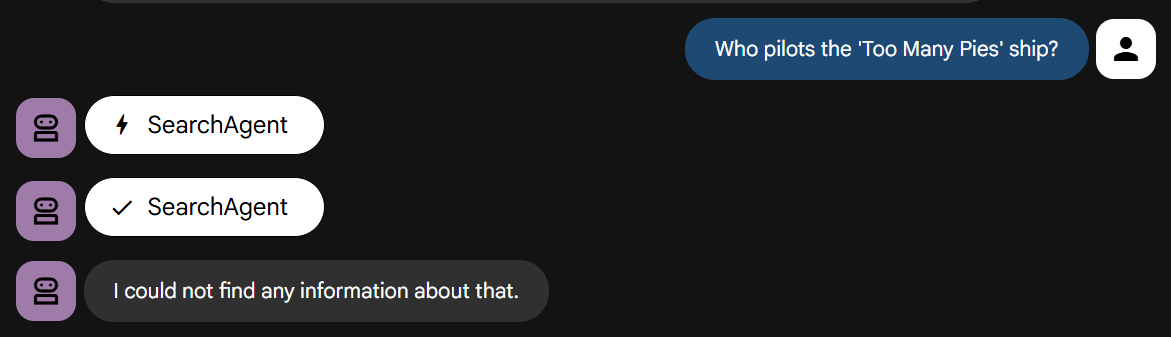
Teste por conta própria. Ele vai falhar rapidamente, conforme indicado.
Incorporar o repositório de pesquisa de arquivos ao agente do ADK
Agora vamos juntar tudo. Vamos executar um agente do ADK que pode usar o repositório de pesquisa de arquivos e a Pesquisa Google. Confira o código em app/rag_agent_adk/agent.py.
O código é semelhante ao exemplo anterior, mas com algumas diferenças importantes:
- Temos um agente raiz que coordena dois agentes especializados:
- RagAgent: o especialista em conhecimento personalizado que usa nosso repositório de pesquisa de arquivos do Gemini
- SearchAgent: o especialista em conhecimento geral que usa a Pesquisa Google.
- Como o ADK ainda não tem um wrapper integrado para
FileSearch, usamos uma classe wrapper personalizadaFileSearchToolpara encapsular a ferramenta FileSearch, que injeta a configuraçãofile_search_store_namesna solicitação de modelo de baixo nível. Isso foi implementado no script separadoapp/rag_agent_adk/tools_custom.py.
Além disso, há um "problema" a ser evitado. No momento da redação deste artigo, não é possível usar a ferramenta nativa GoogleSearch e a ferramenta FileSearch na mesma solicitação para o mesmo agente. Se você tentar, vai receber um erro como este:
ERRO: ocorreu um erro: 400 INVALID_ARGUMENT. {"error": {"code": 400, "message": "A pesquisa como ferramenta e a ferramenta de pesquisa de arquivos não são compatíveis juntas", "status": "INVALID_ARGUMENT"}}
Erro: 400 INVALID_ARGUMENT. {"error": {"code": 400, "message": "A pesquisa como ferramenta e a ferramenta de pesquisa de arquivos não são compatíveis juntas", "status": "INVALID_ARGUMENT"}}
A solução é implementar os dois agentes especializados como subagentes separados e transmiti-los ao agente raiz usando o padrão "Agente como ferramenta". E, principalmente, a instrução do sistema do agente raiz fornece orientações muito claras para usar o RagAgent primeiro:
Você é um assistente de IA útil criado para fornecer informações precisas e úteis.
Você tem acesso a dois representantes especializados:
- RagAgent: para informações personalizadas da base de conhecimento interna.
- SearchAgent: para informações gerais da Pesquisa Google.
Sempre tente usar o RagAgent primeiro. Se isso não gerar uma resposta útil, tente o SearchAgent.
Teste final
Execute a interface da Web do ADK como antes:
make adk-playground # Or, without make: uv run adk web app --port 8501 --reload_agents
Desta vez, selecione rag_agent_adk na interface. Vamos conferir como funciona: 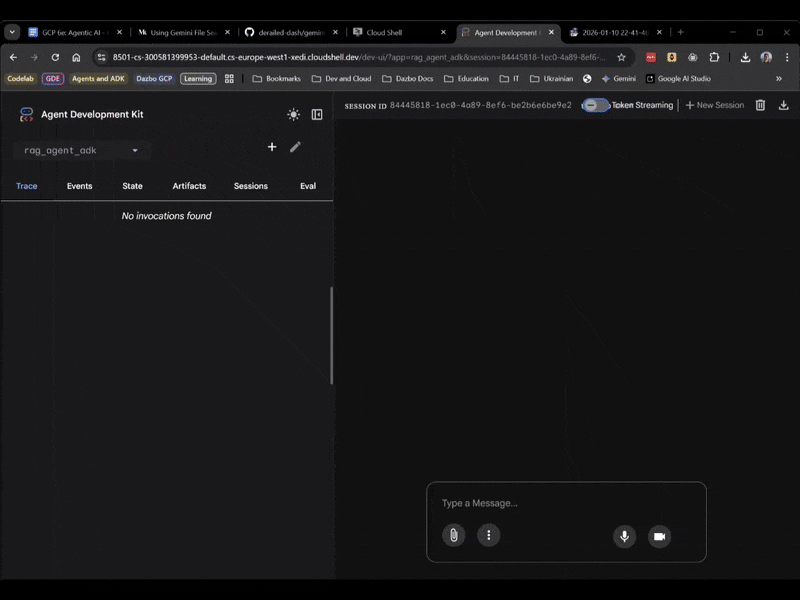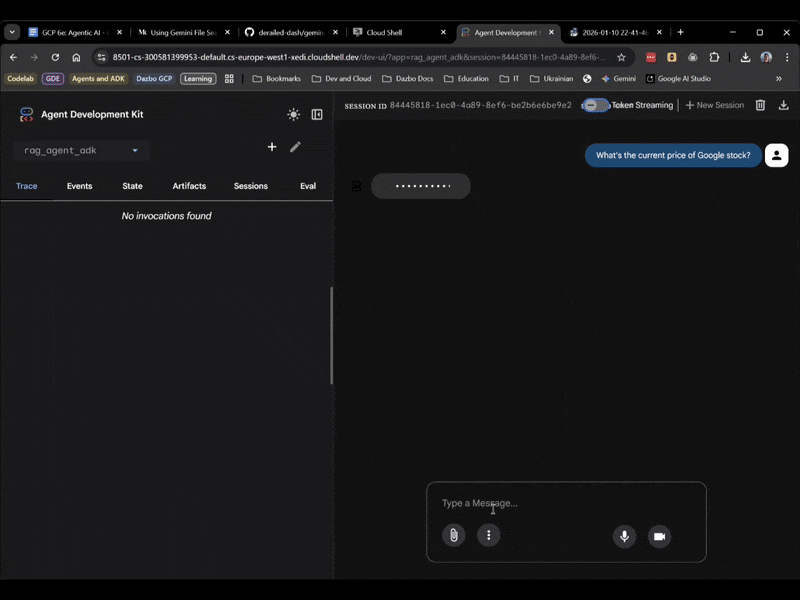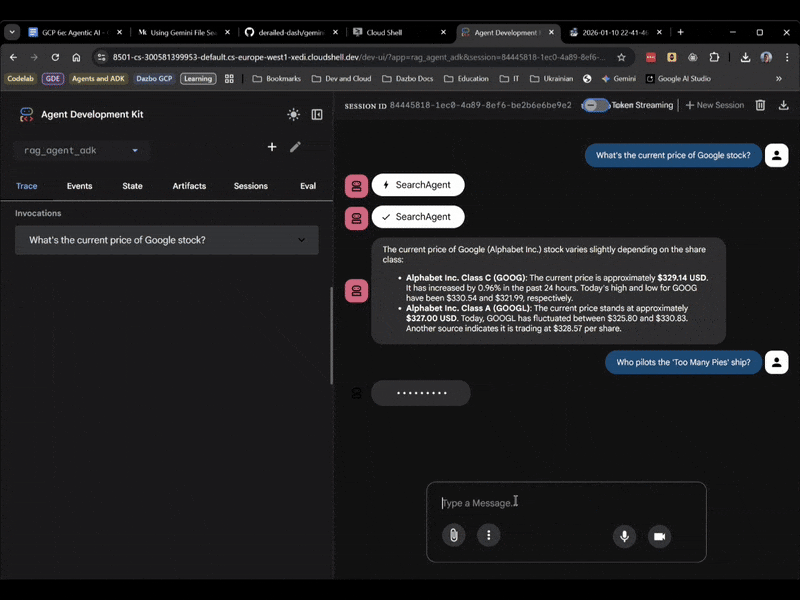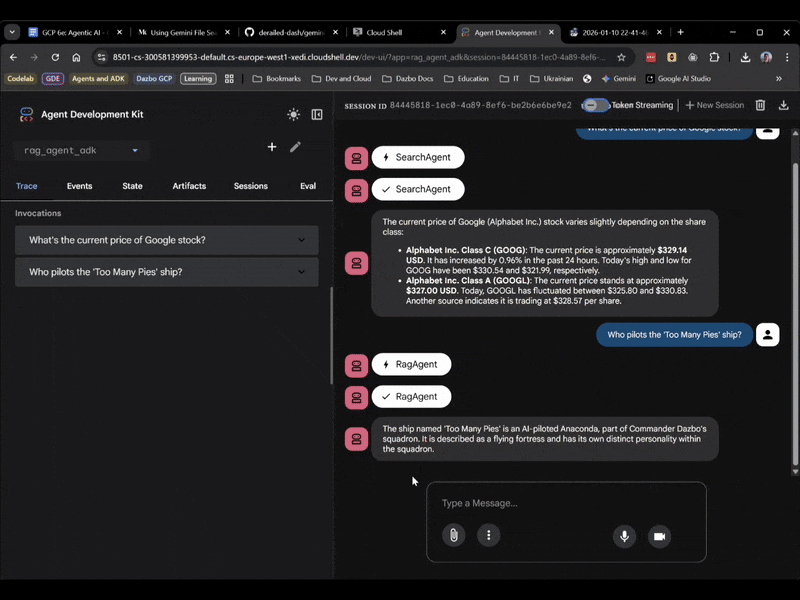
Ele escolhe o subagente adequado com base na pergunta.
8. Conclusão
Parabéns por concluir este codelab!
Você passou de um script simples para um sistema multiagente com RAG, tudo sem uma única linha de código de embedding e sem precisar implementar um banco de dados vetorial.
Aprendemos que:
- A Pesquisa de arquivos do Gemini é uma solução de RAG gerenciada que economiza tempo e sanidade.
- O ADK oferece a estrutura necessária para apps multiagentes complexos e conveniência para desenvolvedores com interfaces como a interface da Web.
- O padrão "Agent-as-a-Tool" resolve problemas de compatibilidade de ferramentas.
Esperamos que este laboratório tenha sido útil. Até a próxima!