
1. Введение
В этом практическом занятии показано, как использовать Gemini File Search для включения RAG в вашем приложении Agentic. Вы будете использовать Gemini File Search для загрузки и индексирования документов, не беспокоясь о деталях разбиения на фрагменты, встраивания или векторных баз данных.
Что вы узнаете
- Основы RAG и почему он нам нужен.
- Что такое Gemini File Search и каковы его преимущества.
- Как создать хранилище для поиска файлов.
- Как загрузить собственные файлы в хранилище поиска файлов.
- Как использовать инструмент поиска файлов Gemini для RAG.
- Преимущества использования Google Agent Development Kit (ADK).
- Как использовать инструмент поиска файлов Gemini в агентском решении, созданном с использованием ADK.
- Как использовать инструмент поиска файлов Gemini вместе с «собственными» инструментами Google, такими как поиск Google.
Что вы будете делать
- Создайте проект в Google Cloud и настройте среду разработки.
- Создайте простого агента на основе Gemini, используя Google Gen AI SDK (но без ADK), который может использовать поиск Google, но не имеет возможностей RAG.
- Продемонстрировать свою неспособность предоставлять точную и высококачественную информацию по индивидуальным запросам.
- Создайте блокнот Jupyter (который можно запустить локально или, например, в Google Colab) для создания и управления хранилищем файлов Gemini File Search Store.
- Используйте блокнот для загрузки пользовательского контента в хранилище поиска файлов.
- Создайте агента, к которому подключено хранилище результатов поиска файлов, и докажите, что он способен выдавать более качественные ответы.
- Преобразуйте наш базовый агент в агент ADK, дополненный инструментом поиска Google.
- Протестируйте агента с помощью веб-интерфейса ADK.
- Интегрируйте хранилище результатов поиска файлов в агент ADK, используя шаблон «Агент как инструмент», чтобы мы могли использовать инструмент поиска файлов вместе с инструментом поиска Google.
2. Что такое RAG и почему он нам нужен?
Итак... Расширенная генерация поиска .
Если вы здесь, вы, вероятно, знаете, о чём идёт речь, но давайте на всякий случай кратко вспомним. Магистратура (например, по программе «Близнецы») — это блестящее дело, но у неё есть несколько недостатков:
- Они всегда устаревают : они знают только то, чему их научили во время обучения.
- Они не всё знают : конечно, модели огромны, но они не всеведущи.
- Они не знают вашей конфиденциальной информации : у них есть обширные знания, но они не читали ваши внутренние документы, ваши блоги или ваши задачи в Jira.
Поэтому, когда вы задаете модели вопрос, на который она не знает ответа, вы, как правило, получите неверный или даже выдуманный ответ. Часто модель уверенно выдает этот неверный ответ. Это то, что мы называем галлюцинацией .
Одно из решений — просто вставлять нашу конфиденциальную информацию непосредственно в контекст разговора. Это подходит для небольшого объема информации, но быстро становится проблематичным, когда информации много. В частности, это приводит к следующим проблемам:
- Задержка : всё более медленная реакция модели.
- «Потеря сигнала» , или «потеря в середине»: ситуация, когда модель больше не может отделить релевантные данные от ненужных. Большая часть контекста игнорируется моделью.
- Стоимость : потому что жетоны стоят денег.
- Исчерпание контекстного окна : на данном этапе Gemini не будет обрабатывать ваши запросы.
Гораздо более эффективным способом решения этой проблемы является использование RAG . Это просто процесс поиска релевантной информации в ваших источниках данных (с использованием семантического сопоставления) и передачи соответствующих фрагментов этих данных в модель вместе с вашим вопросом. Это позволяет модели ориентироваться в вашей реальности .
Принцип работы заключается в импорте внешних данных, их разделении на фрагменты, преобразовании в векторные представления, а затем сохранении и индексировании этих представлений в подходящей векторной базе данных.
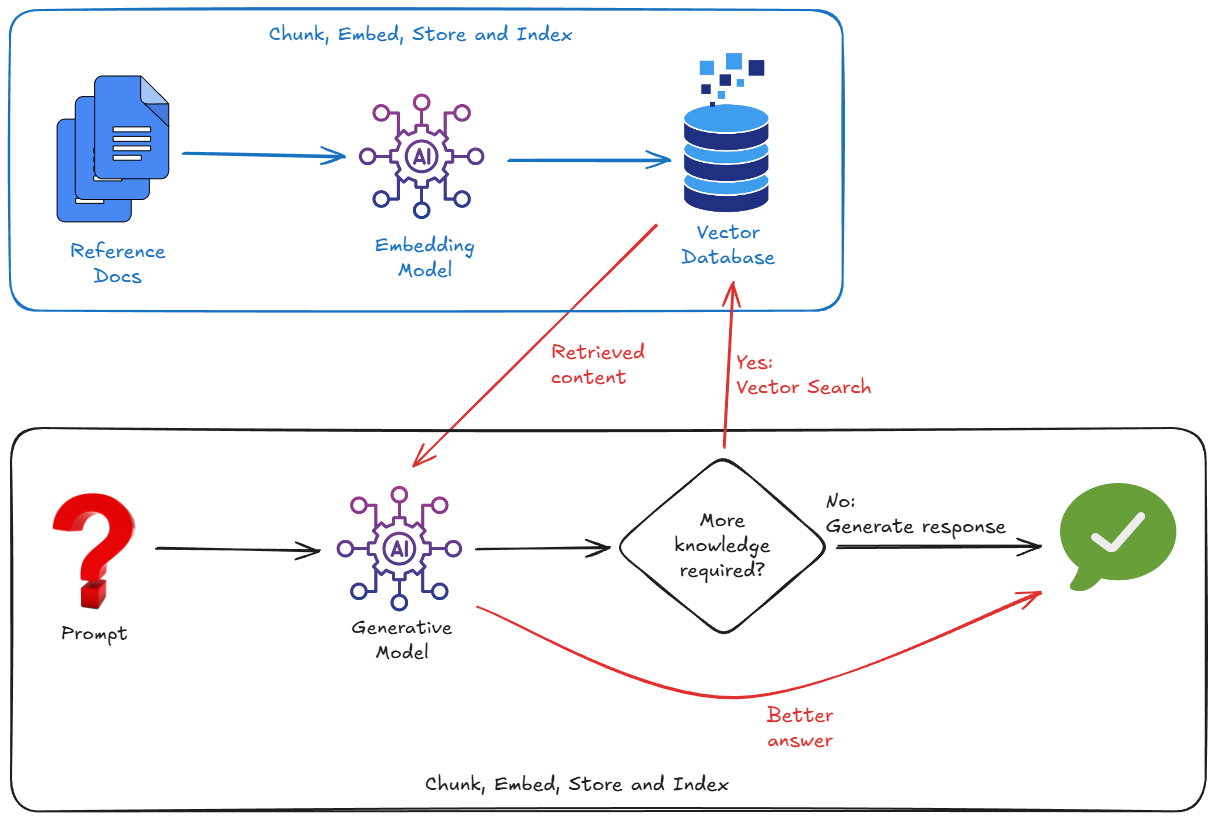
Таким образом, для внедрения RAG нам, как правило, приходится учитывать следующие факторы:
- Создание векторной базы данных (Pinecone, Weaviate, Postgres с pgvector...).
- Написание скрипта для разбивки документов на части (например, PDF-файлов, файлов Markdown и т.д.).
- Генерация эмбеддингов (векторов) для этих фрагментов с использованием модели эмбеддингов.
- Хранение векторов в базе данных векторов.
Но друзья не позволяют друзьям чрезмерно усложнять вещи. А что, если я скажу вам, что есть более простой способ?
3. Предварительные требования
Создайте проект в Google Cloud.
Для выполнения этого практического задания вам потребуется проект Google Cloud. Вы можете использовать уже имеющийся у вас проект или создать новый .
Убедитесь, что в вашем проекте включена функция выставления счетов . Инструкции по проверке статуса выставления счетов для ваших проектов вы найдете в этом руководстве .
Обратите внимание, что выполнение этого практического задания не потребует от вас никаких затрат. Максимум — несколько центов.
Давайте, подготовьте свой проект. Я подожду.
Клонируйте демо-репозиторий
Я создал репозиторий с пошаговыми инструкциями для этого практического занятия. Он вам понадобится!
Выполните следующие команды в терминале или в терминале, встроенном в редактор Google Cloud Shell . Cloud Shell и его редактор очень удобны, поскольку все необходимые команды предустановлены, и все работает "из коробки".
git clone https://github.com/derailed-dash/gemini-file-search-demo cd gemini-file-search-demo
Эта структура отображает ключевые папки и файлы в репозитории:
gemini-file-search-demo/ ├── app/ │ ├── basic_agent_adk/ # Agent with Google Search, using ADK framework │ │ └── agent.py │ ├── rag_agent_adk/ # Agent with Google Search and File Search, using ADK framework │ │ ├── agent.py │ │ └── tools_custom.py │ ├── sdk_agent.py # Agent using GenAI SDK (no ADK) with Google Search tool │ └── sdk_rag_agent.py # Agent using GenAI SDK (no ADK) with Gemini File Search tool ├── data/ │ └── story.md # Sample story with "bespoke content" to use with Gemini File Search Store ├── notebooks/ │ └── file_search_store.ipynb # Jupyter notebook for creating and managing Gemini File Search Store │ ├── .env.template # Template for environment variables - make a copy as .env ├── Makefile # Makefile for `make` commands ├── pyproject.toml # Project configuration and dependencies └── README.md # This file
Откройте эту папку в Cloud Shell Editor или в любом другом удобном для вас редакторе. (Вы уже пользовались Antigravity? Если нет, сейчас самое время попробовать .)
Обратите внимание, что в репозитории находится пример рассказа — «Вторжение в червоточину» — в файле data/story.md . Я написал его в соавторстве с Gemini! Он рассказывает о командире Дазбо и его эскадрилье разумных звездолетов. (Я черпал вдохновение из игры Elite Dangerous .) Этот рассказ служит нашей «специальной базой знаний», содержащей конкретные факты, которые Gemini не знает и, более того, которые он не может найти с помощью поиска Google.
Настройте среду разработки.
Для удобства я предоставил Makefile , чтобы упростить выполнение многих необходимых команд. Вместо того чтобы запоминать конкретные команды, вы можете просто запустить что-то вроде make <target> . Однако make доступен только в средах Linux / MacOS / WSL. Если вы используете Windows (без WSL), вам потребуется выполнить все команды, содержащиеся в целях make .
# Install dependencies with make make install # If you don't have make... uv sync --extra jupyter
Вот как это выглядит при выполнении команды make install в редакторе Cloud Shell:
Создайте ключ API Gemini
Для использования API разработчика Gemini (который необходим для работы с инструментом поиска файлов Gemini) вам потребуется ключ API Gemini. Самый простой способ получить ключ API — использовать Google AI Studio , который предоставляет удобный интерфейс для получения ключей API для ваших проектов Google Cloud. Подробные инструкции см. в этом руководстве .
После создания API-ключа скопируйте его и сохраните в безопасном месте.
Теперь вам нужно установить этот ключ API в качестве переменной окружения. Мы можем сделать это с помощью файла .env . Скопируйте прилагаемый файл .env.example в новый файл с именем .env . Файл должен выглядеть примерно так:
export GEMINI_API_KEY="your-api-key" export MODEL="gemini-2.5-flash" export STORE_NAME="demo-file-store"
Замените your-api-key на свой фактический API-ключ. Теперь должно получиться примерно так:
Теперь убедитесь, что переменные среды загружены. Это можно сделать, выполнив команду:
source .env
4. Базовый агент
Для начала давайте определим базовый уровень. Мы будем использовать исходный SDK google-genai для запуска простого агента.
Кодекс
Взгляните на app/sdk_agent.py . Это минимальная реализация, которая:
- Создает экземпляр
genai.Client. - Включает инструмент
google_search. - Вот и всё. Никакой ржавки.
Внимательно изучите код и убедитесь, что вы понимаете, что он делает.
Запуск
# With make make sdk-agent # Without make uv run python app/sdk_agent.py
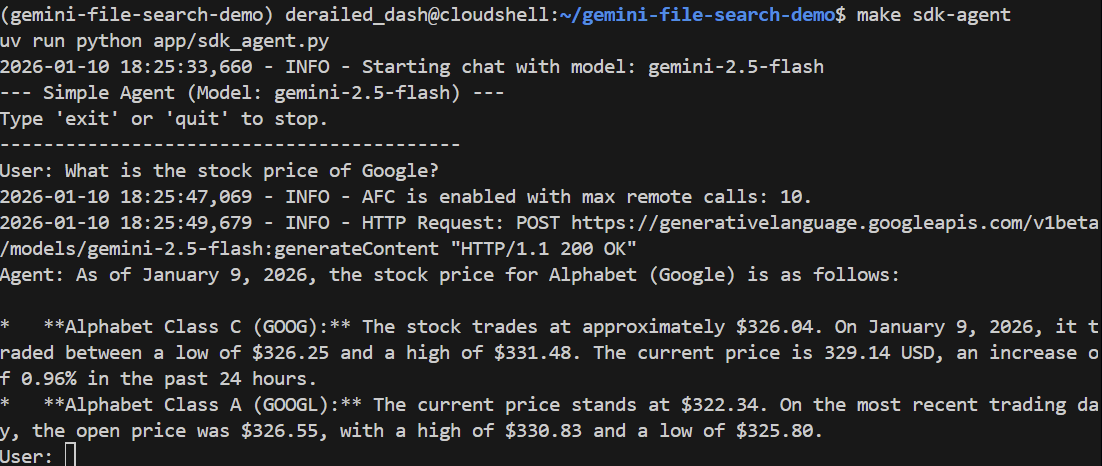
Давайте зададим общий вопрос:
> What is the stock price of Google?
Поиск в Google должен дать правильный ответ, указав актуальную цену:
Теперь давайте зададим вопрос, на который он не знает ответа. Для этого агенту необходимо прочитать нашу историю.
> Who pilots the 'Too Many Pies' ship?
Оно должно провалиться или даже выдать галлюцинацию. Посмотрим:
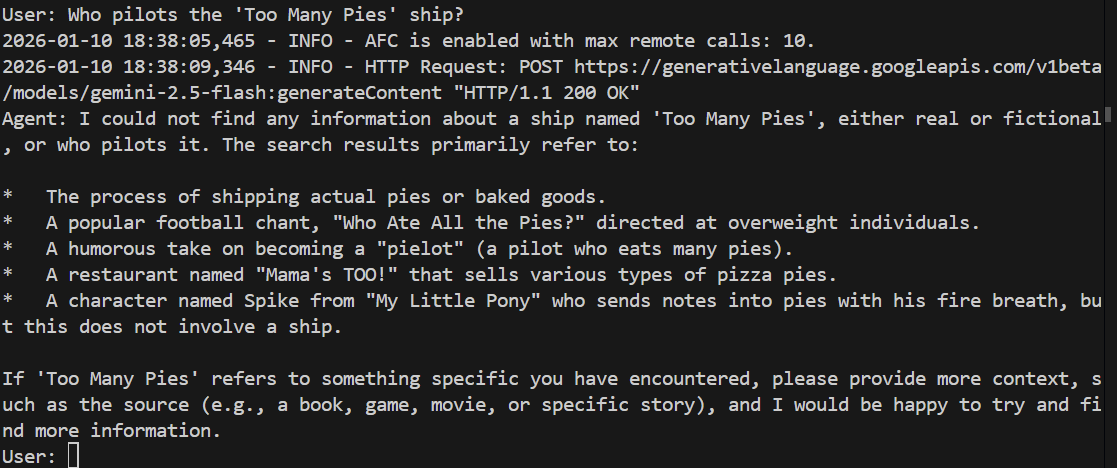
И, как и следовало ожидать, модель не может ответить на вопрос. Она понятия не имеет, о чём мы говорим!
Теперь введите команду quit , чтобы выйти из агента.
5. Поиск файлов Gemini: объяснение
Поиск файлов Gemini по сути представляет собой сочетание двух вещей:
- Полностью управляемая система RAG : вы предоставляете набор файлов, а Gemini File Search берет на себя разбиение на фрагменты, встраивание, хранение и векторное индексирование.
- «Инструмент» в агентском смысле : вы можете просто добавить Gemini File Search Tool в качестве инструмента в определение вашего агента и указать инструменту хранилище результатов поиска файлов.
Но самое главное: это встроено в сам API Gemini . Это значит, что вам не нужно включать какие-либо дополнительные API или развертывать отдельные продукты, чтобы его использовать. Так что это действительно готовое решение .
Функции поиска файлов Gemini
Вот некоторые из особенностей:
- Детали разбиения на блоки, встраивания, хранения и индексирования абстрагированы от вас, разработчика. Это означает, что вам не нужно знать (или интересоваться) моделью встраивания (которая, кстати, представляет собой Gemini Embeddings) или местом хранения результирующих векторов. Вам не нужно принимать никаких решений относительно базы данных векторов.
- Он поддерживает огромное количество типов документов «из коробки». Включая, помимо прочего: PDF, DOCX, Excel, SQL, JSON, блокноты Jupyter, HTML, Markdown, CSV и даже ZIP-файлы. Полный список можно посмотреть здесь. Так, например, если вы хотите закрепить своего агента с помощью PDF-файлов, содержащих текст, изображения и таблицы, вам не нужно выполнять никакой предварительной обработки этих PDF-файлов. Просто загрузите исходные PDF-файлы, и Gemini позаботится обо всем остальном.
- Мы можем добавить пользовательские метаданные к любому загруженному файлу. Это может быть очень полезно для последующей фильтрации файлов, которые инструмент должен использовать во время выполнения.
Где хранятся данные?
Вы загружаете файлы. Инструмент поиска файлов Gemini берет эти файлы, создает фрагменты, затем векторные представления и помещает их... куда-то. Но куда?
Ответ: хранилище поиска файлов . Это полностью управляемый контейнер для ваших встраиваемых файлов. Вам не нужно знать (или интересоваться), как это работает изнутри. Все, что вам нужно сделать, это создать его (программно), а затем загрузить в него свои файлы.
Это дёшево!
Хранение и запрос ваших эмбеддингов бесплатны . Таким образом, вы можете хранить эмбеддинги сколько угодно долго, и вам не нужно платить за это хранение!
Фактически, вы платите только за создание встраиваний во время загрузки/индексирования. На момент написания статьи это стоит 0,15 доллара за 1 миллион токенов. Это довольно дешево.
6. Как использовать поиск файлов Gemini?
Существует два этапа:
- Создайте и сохраните векторные представления в хранилище результатов поиска файлов.
- Запрос к хранилищу файловых поисковых запросов можно отправить через вашего агента.
Этап 1 — Использование Jupyter Notebook для создания и управления хранилищем файлов Gemini File Search Store
Этот этап следует выполнять на начальном этапе, а затем по мере необходимости для обновления хранилища. Например, при добавлении новых документов или при изменении исходных документов.
Этот этап не обязательно включать в развернутое агентское приложение. Конечно, можно, если хотите. Например, если вы хотите создать какой-либо пользовательский интерфейс для администраторов вашего агентского приложения. Но часто вполне достаточно иметь небольшой фрагмент кода, который запускается по запросу. И один из отличных способов запустить этот код по запросу? Блокнот Jupyter!
Дневник
Откройте файл notebooks/file_search_store.ipynb в вашем редакторе. Если появится запрос на установку каких-либо расширений Jupyter VS Code, пожалуйста, сделайте это.
Если открыть его в редакторе Cloud Shell, он будет выглядеть так:
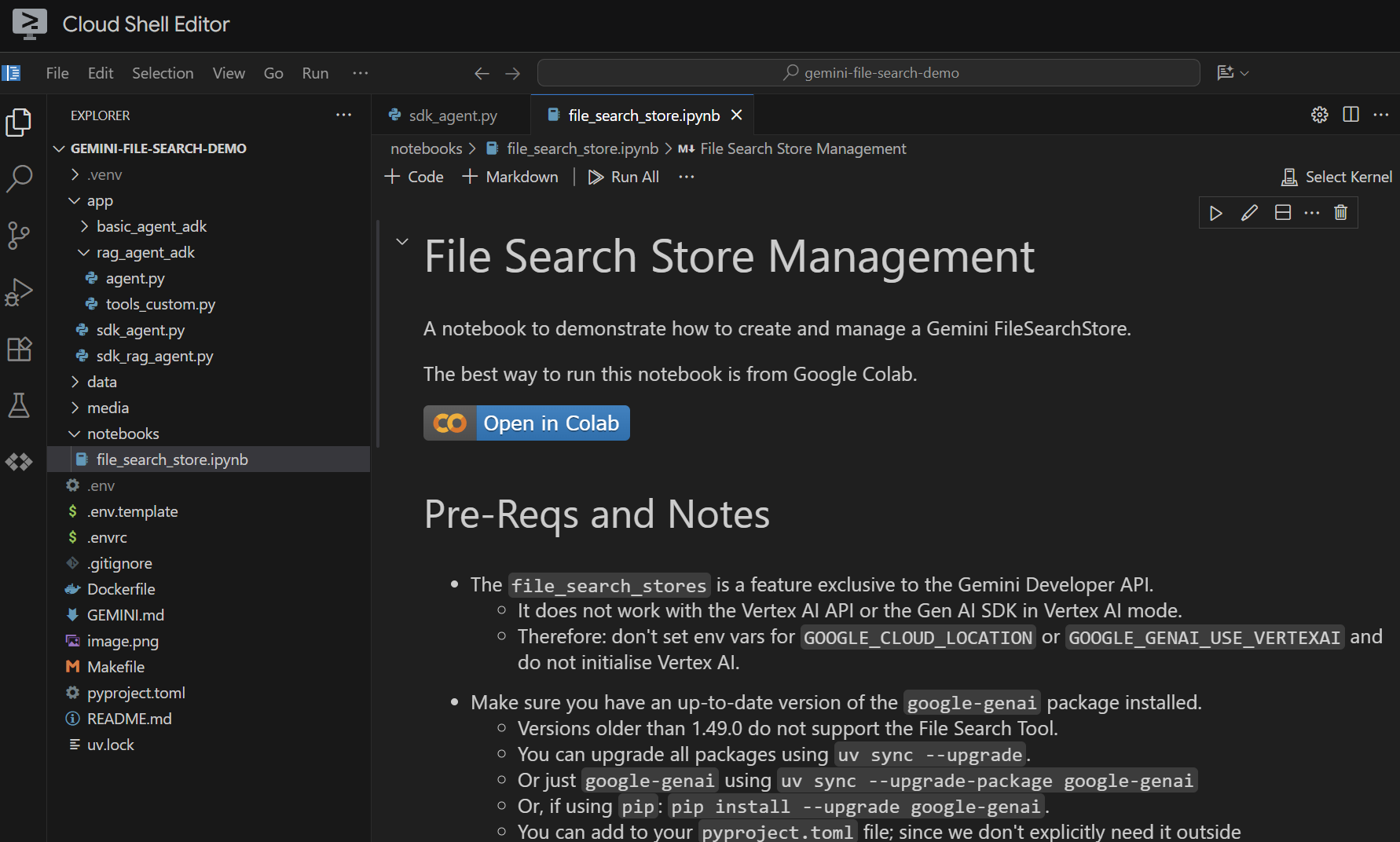
Давайте разберем это по ячейкам. Начнем с выполнения ячейки Setup с необходимыми импортами. Если вы раньше не запускали ноутбук, вам будет предложено установить необходимые расширения. Сделайте это. Затем вам будет предложено выбрать ядро. Выберите " Python environments... ", а затем локальный .venv , который мы установили при выполнении команды make install ранее:
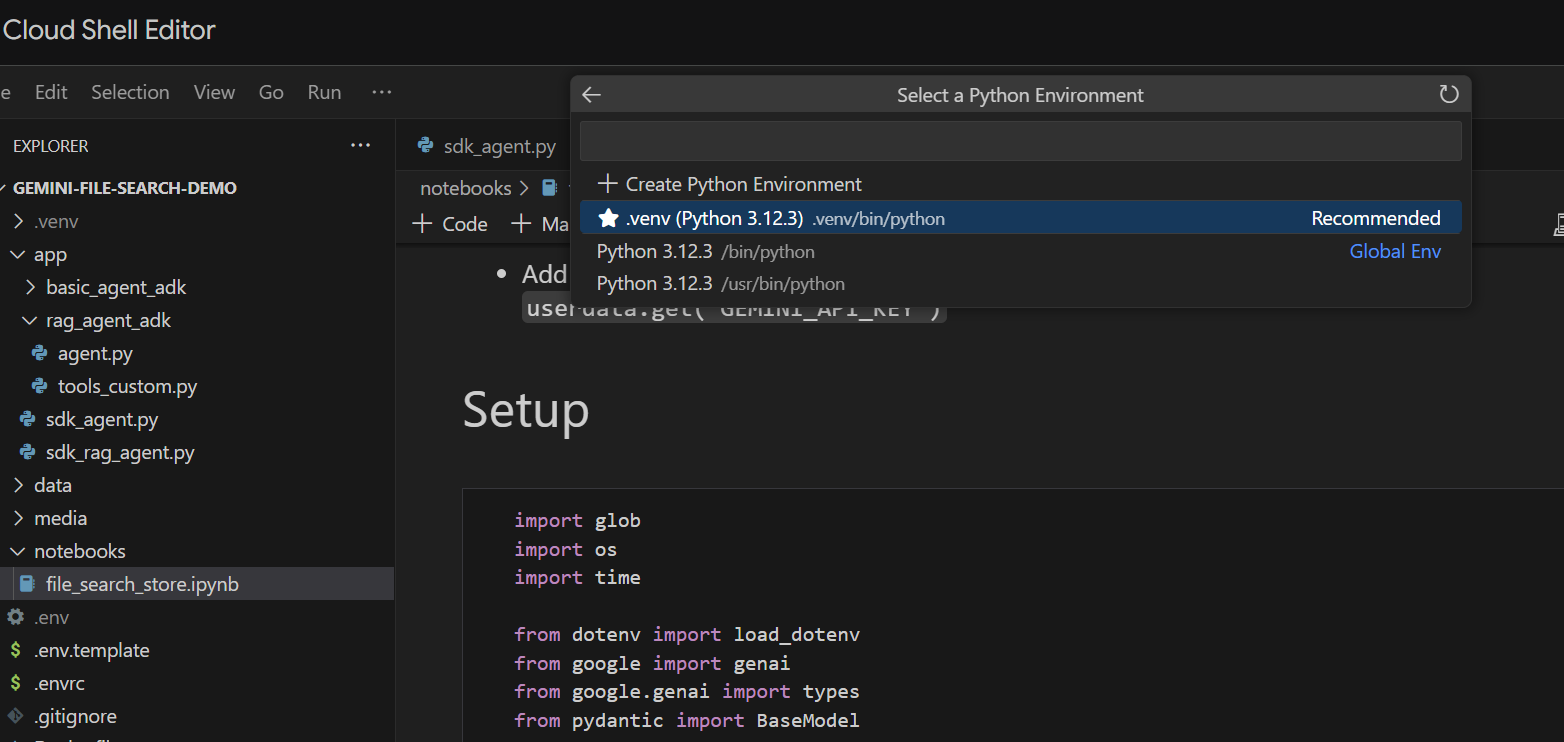
Затем:
- Запустите ячейку " Только локальные переменные ", чтобы подтянуть переменные среды.
- Запустите ячейку «Инициализация клиента» , чтобы инициализировать клиент Gemini Gen AI.
- Запустите ячейку "Получить хранилище" с помощью вспомогательной функции для получения хранилища файлов Gemini File Search Store по имени.
Теперь мы готовы создать магазин.
- Для создания магазина выполните команду в ячейке "Создать магазин (один раз)" . Это нужно сделать только один раз. Если код выполнится успешно, вы увидите сообщение
"Created store: fileSearchStores/<someid>" - Откройте ячейку « Просмотреть магазин», чтобы увидеть, что в ней находится. На этом этапе вы должны увидеть, что она содержит 0 документов.
Отлично! Теперь у нас есть готовый к использованию магазин Gemini File Search.
Загрузка данных
Мы хотим загрузить data/story.md в хранилище. Сделайте следующее:
- Запустите ячейку, которая задает путь для загрузки. Она указывает на нашу папку
data/. - Запустите следующую ячейку, которая создает вспомогательные функции для загрузки файлов в хранилище. Обратите внимание, что код в этой ячейке также использует Gemini для извлечения метаданных из каждого загруженного файла. Мы берем эти извлеченные значения и сохраняем их в качестве пользовательских метаданных в хранилище. (Это необязательно, но полезно.)
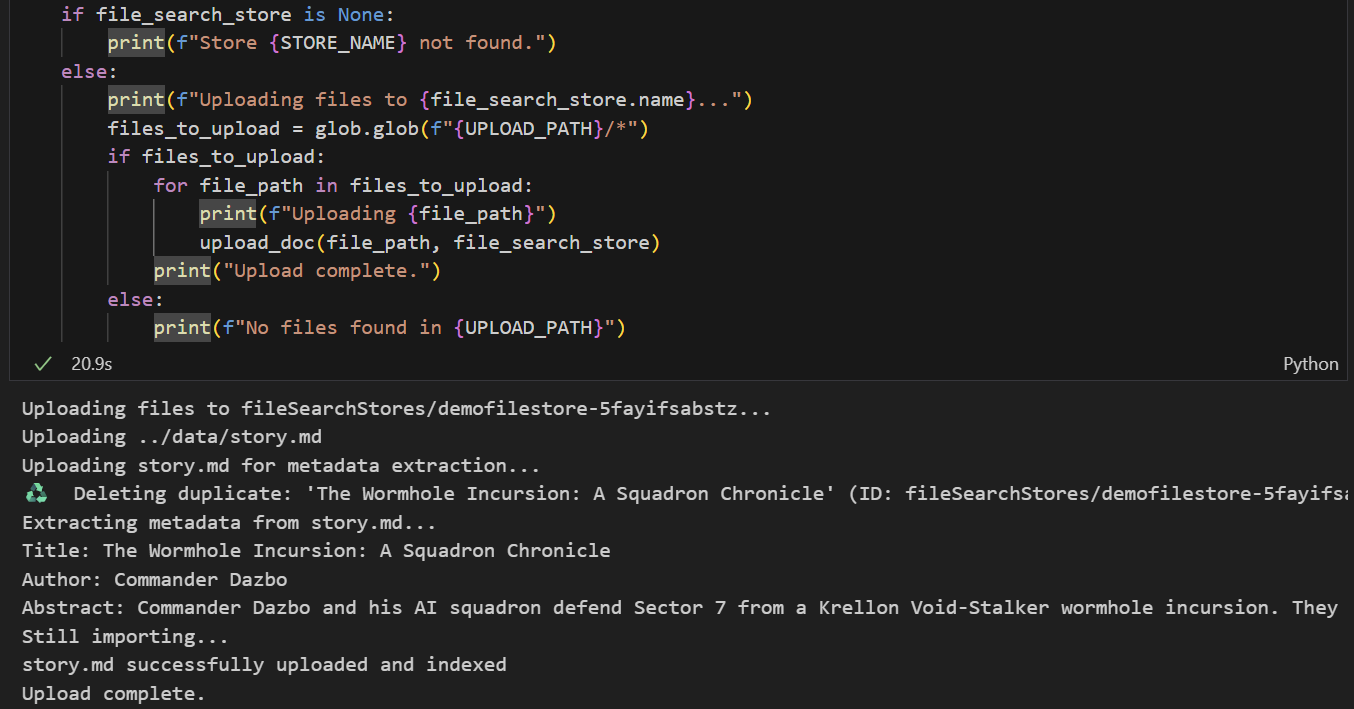
- Запустите ячейку для загрузки файла. Обратите внимание, что если файл с таким же именем уже загружался ранее, то блокнот сначала удалит существующую версию, прежде чем загрузить новую. Вы должны увидеть сообщение о том, что файл загружен.
Этап 2 — Внедрение функции поиска файлов Gemini RAG в наш агент.
Мы создали хранилище файлов Gemini File Search Store и загрузили в него наш рассказ. Теперь пришло время использовать хранилище файлов File Search Store в нашем агенте. Давайте создадим нового агента, который будет использовать хранилище файлов File Search Store вместо поиска Google. Взгляните на app/sdk_rag_agent.py .
Первое, что следует отметить, это то, что мы реализовали функцию для получения информации о нашем магазине по запросу, указав в качестве параметра название магазина:
def get_store(client: genai.Client, store_name: str) -> types.FileSearchStore | None:
"""Retrieve a store by display name"""
try:
for a_store in client.file_search_stores.list():
if a_store.display_name == store_name:
return a_store
except Exception as e:
logger.error(f"Error listing stores: {e}")
return None
После того, как мы создали свой магазин, использовать его очень просто: достаточно прикрепить его в качестве инструмента к нашему агенту, вот так:
file_search_tool = types.Tool(file_search=types.FileSearch(file_search_store_names=[store.name]))
Запуск агента RAG
Мы запускаем его следующим образом:
make sdk-rag-agent # Or, without make: uv run python app/sdk_rag_agent.py
Давайте зададим вопрос, на который предыдущий агент не смог ответить:
> Who pilots the 'Too Many Pies' ship?
А каков был ответ?
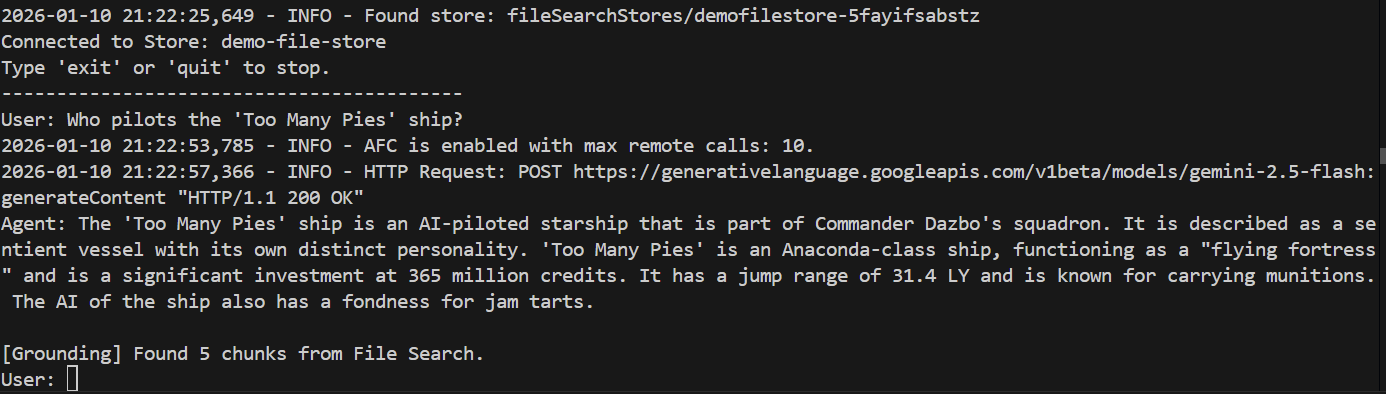
Успех! Из полученных откликов видно, что:
- Для ответа на этот вопрос мы использовали наше хранилище файлов.
- Было найдено 5 релевантных фрагментов.
- Ответ абсолютно верный!
Введите команду quit , чтобы закрыть агент.
7. Перевод наших агентов на использование ADK.
Google Agent Development Kit (ADK) — это модульная платформа с открытым исходным кодом и SDK для разработчиков, позволяющая создавать агентов и агентные системы. Она позволяет с легкостью создавать и управлять многоагентными системами. Оптимизированный для Gemini и экосистемы Google, ADK не зависит от модели, способа развертывания и совместимости с другими платформами. Если вы еще не использовали ADK, перейдите в документацию ADK, чтобы узнать больше.
Базовый агент ADK с поиском Google.
Взгляните на app/basic_agent_adk/agent.py . В этом примере кода вы можете увидеть, что мы фактически реализовали два агента:
-
root_agentэто объект, обрабатывающий взаимодействие с пользователем, в котором мы предоставили основную системную инструкцию. - Отдельный
SearchAgent, использующийgoogle.adk.tools.google_searchв качестве инструмента.
На самом деле root_agent использует SearchAgent в качестве инструмента, что реализовано с помощью следующей строки кода:
tools=[AgentTool(agent=search_agent)],
Системная подсказка корневого агента выглядит следующим образом:
You are a helpful AI assistant designed to provide accurate and useful information.
If you don't know the answer, use the SearchAgent to perform a Google search.
Do not attempt to search more than ONCE.
If the search yields no relevant results or returns unrelated content, you MUST immediately respond with: "I could not find any information about that."
Do NOT retry the search with different terms. Do NOT ask for clarification. FAIL FAST.
Проверка агента
ADK предоставляет ряд готовых интерфейсов, позволяющих разработчикам тестировать свои агенты ADK. Один из таких интерфейсов — веб-интерфейс. Это позволяет тестировать агентов в браузере, не написав ни строчки кода пользовательского интерфейса!
Запустить этот интерфейс можно, выполнив следующую команду:
make adk-playground # Or, without make: uv run adk web app --port 8501 --reload_agents
Обратите внимание, что эта команда указывает adk web на папку app , где он автоматически обнаружит все агенты ADK, реализующие root_agent . Давайте попробуем:
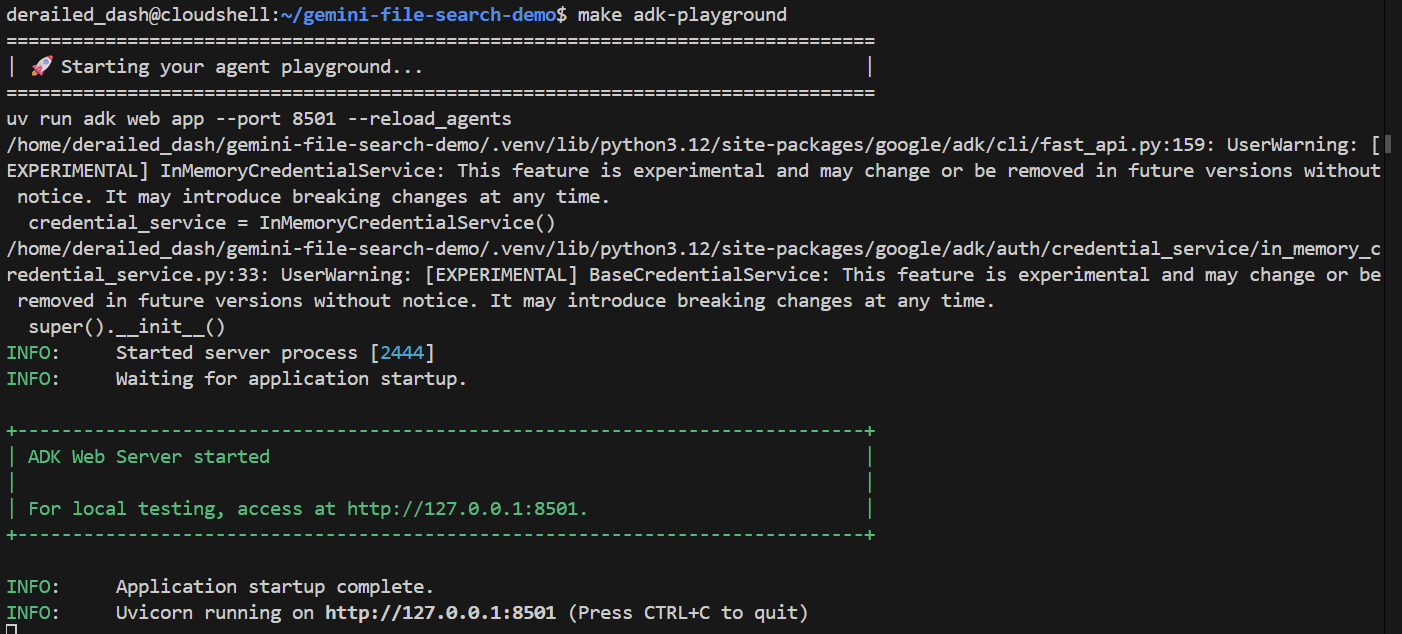
Через пару секунд приложение будет готово. Если вы запускаете код локально, просто откройте в браузере адрес http://127.0.0.1:8501 . Если вы работаете в редакторе Cloud Shell, нажмите « Предварительный просмотр веб-страницы » и измените порт на 8501 .
Когда появится пользовательский интерфейс, выберите basic_agent_adk из выпадающего списка, после чего мы сможем задавать ему вопросы:
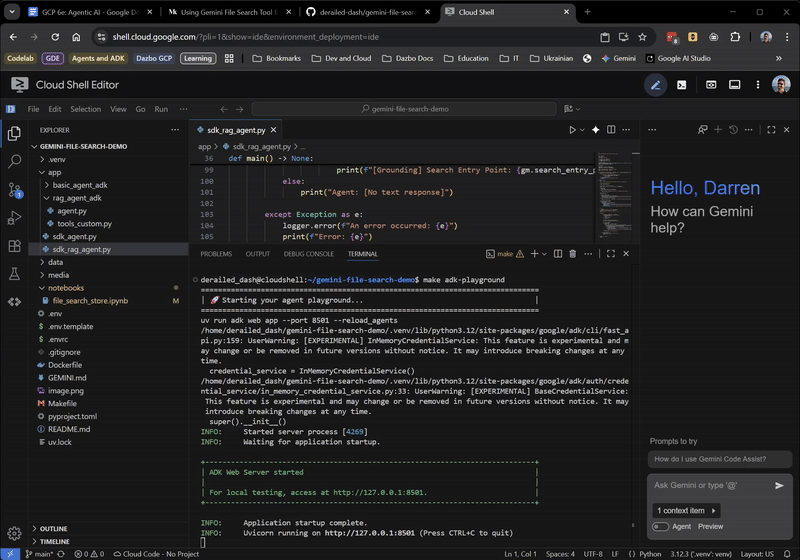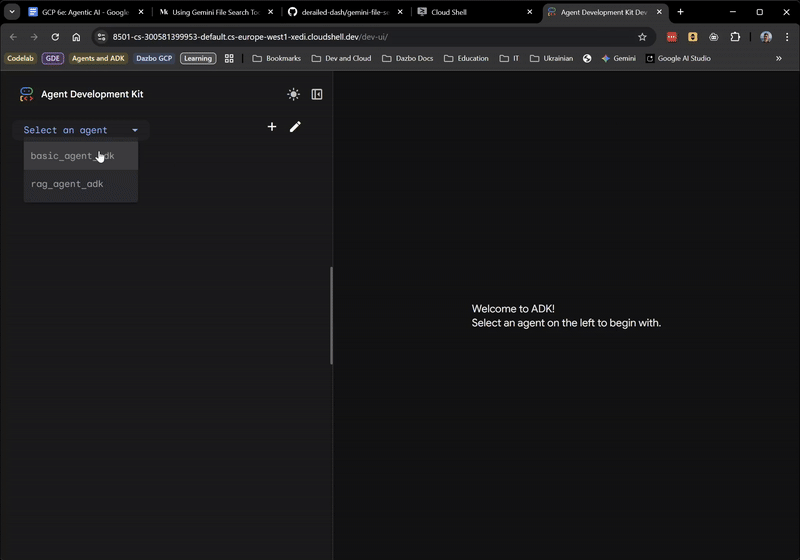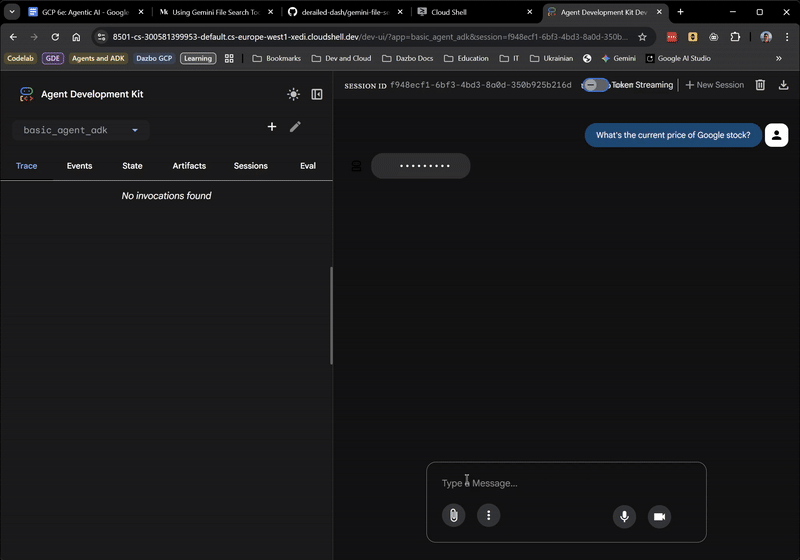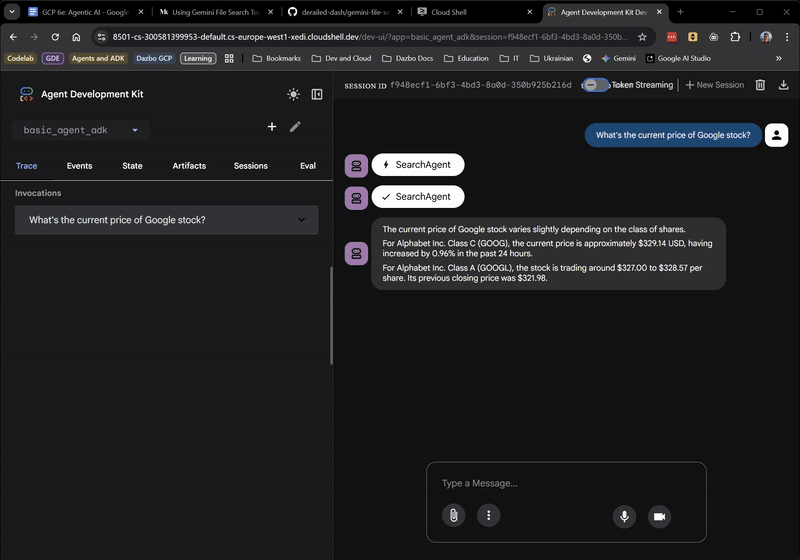
Пока все отлично! Веб-интерфейс даже показывает, когда корневой агент делегирует задачи SearchAgent . Это очень полезная функция.
Теперь давайте зададим ему наш вопрос, для ответа на который необходимо знать нашу историю:
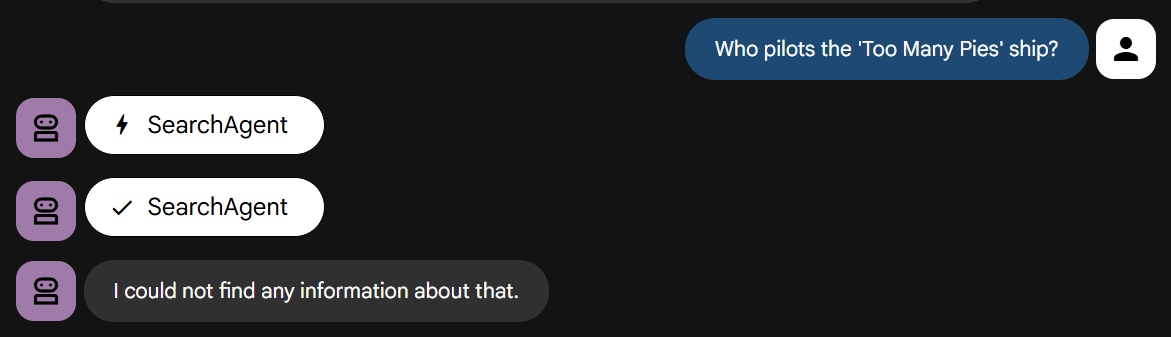
Попробуйте сами. Вы быстро убедитесь, что это не сработает, как и указано в инструкции.
Интегрируйте хранилище результатов поиска файлов в агент ADK.
Теперь мы объединим все это. Мы запустим агент ADK, который сможет использовать как File Search Store, так и Google Search. Взгляните на код в app/rag_agent_adk/agent.py .
Код похож на предыдущий пример, но с несколькими ключевыми отличиями:
- У нас есть корневой агент, который координирует работу двух специализированных агентов:
- RagAgent : Эксперт по специализированным знаниям — используйте наше хранилище файлов Gemini File Search Store.
- SearchAgent : Эксперт по общим знаниям — использование поиска Google.
- Поскольку в ADK пока нет встроенной обертки для
FileSearch, мы используем собственный класс-оберткуFileSearchToolдля обертывания инструмента FileSearch, который внедряет конфигурациюfile_search_store_namesв низкоуровневый запрос модели. Это реализовано в отдельном скриптеapp/rag_agent_adk/tools_custom.py.
Кроме того, есть один нюанс, на который следует обратить внимание. На момент написания этой статьи вы не можете использовать встроенный инструмент GoogleSearch и инструмент FileSearch в одном запросе к одному и тому же агенту. Если вы попытаетесь это сделать, вы получите ошибку примерно такого вида:
ОШИБКА - Произошла ошибка: 400 INVALID_ARGUMENT. {'error': {'code': 400, 'message': 'Поиск как инструмент и инструмент поиска файлов не поддерживаются одновременно', 'status': 'INVALID_ARGUMENT'}}
Ошибка: 400 INVALID_ARGUMENT. {'error': {'code': 400, 'message': 'Поиск как инструмент и поиск файлов не поддерживаются одновременно', 'status': 'INVALID_ARGUMENT'}}
Решение состоит в том, чтобы реализовать двух специализированных агентов как отдельных субагентов и передать их корневому агенту, используя шаблон «Агент как инструмент». И что особенно важно, системная инструкция корневого агента содержит очень четкие указания использовать RagAgent в первую очередь:
Вы — полезный ИИ-помощник, созданный для предоставления точной и полезной информации.
Вам доступны услуги двух специализированных агентов:
- RagAgent: Для получения персонализированной информации из внутренней базы знаний.
- SearchAgent: Общая информация от Google Поиска.
Всегда сначала пробуйте RagAgent. Если это не даст полезного результата, тогда попробуйте SearchAgent.
Итоговый тест
Запустите веб-интерфейс ADK, как и раньше:
make adk-playground # Or, without make: uv run adk web app --port 8501 --reload_agents
На этот раз выберите rag_agent_adk в пользовательском интерфейсе. Давайте посмотрим, как это работает: 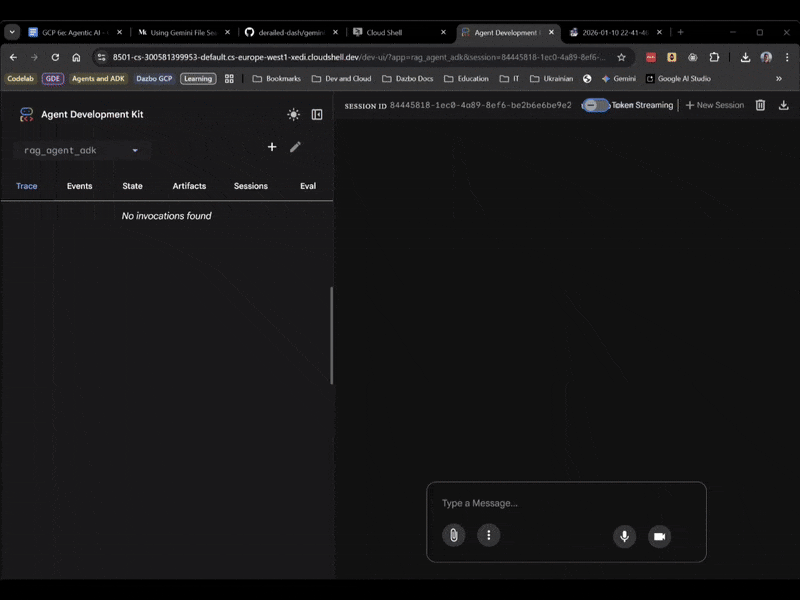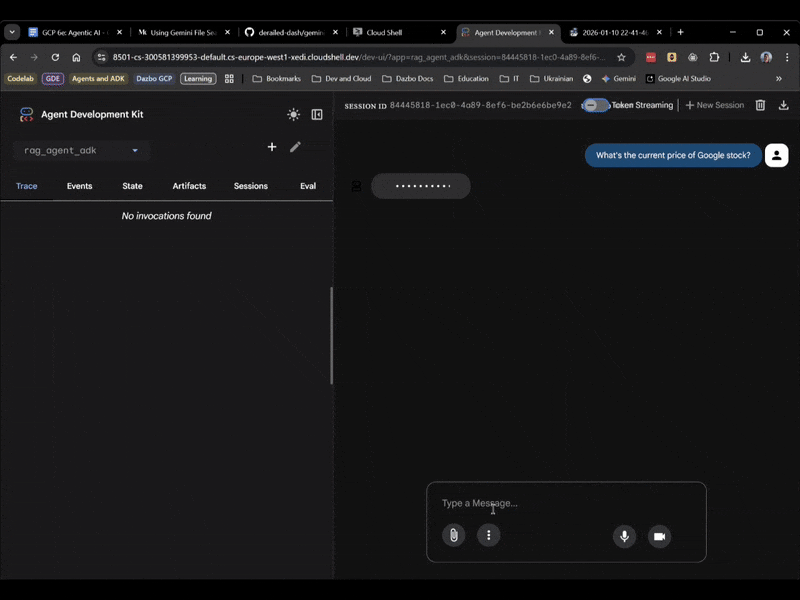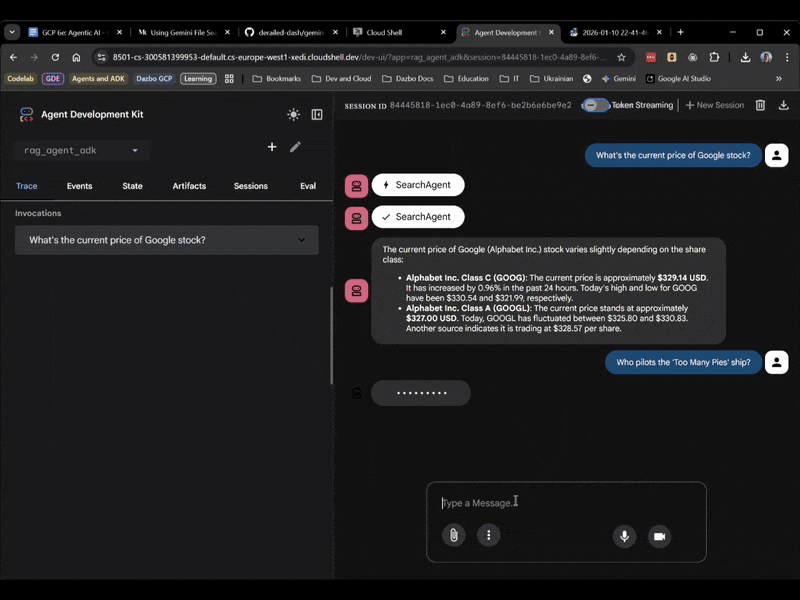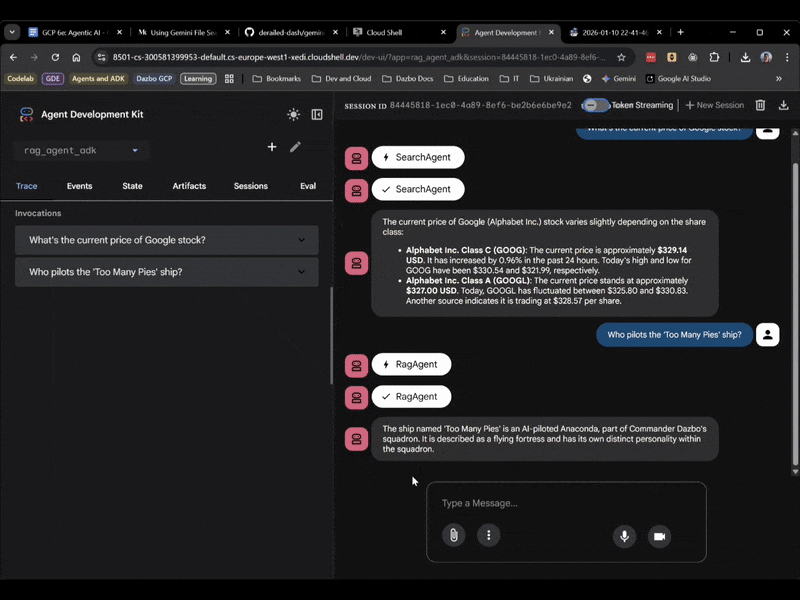
Как мы видим, система выбирает подходящего субагента в зависимости от заданного вопроса.
8. Заключение
Поздравляем с завершением этого практического занятия!
Вы перешли от простого скрипта к многоагентной системе с поддержкой RAG; и всё это без единой строчки кода встраивания и без необходимости реализации векторной базы данных!
Мы узнали:
- Gemini File Search — это управляемое решение RAG, которое экономит время и нервы.
- ADK предоставляет нам необходимую структуру для сложных многоагентных приложений и обеспечивает удобство для разработчиков благодаря таким интерфейсам, как веб-интерфейс.
- Паттерн «Агент как инструмент» решает проблемы совместимости инструментов.
Надеюсь, эта лабораторная работа оказалась для вас полезной. До встречи в следующий раз!