
1. Giới thiệu
Lớp học lập trình này hướng dẫn bạn cách sử dụng Công cụ tìm kiếm tệp của Gemini để bật tính năng RAG trong Ứng dụng dựa trên tác nhân. Bạn sẽ sử dụng tính năng Tìm kiếm tệp của Gemini để nhập và lập chỉ mục tài liệu mà không cần lo lắng về các chi tiết của việc phân đoạn, nhúng hoặc cơ sở dữ liệu vectơ.
Kiến thức bạn sẽ học được
- Thông tin cơ bản về RAG và lý do chúng ta cần RAG.
- Gemini File Search là gì và những ưu điểm của công cụ này.
- Cách tạo Kho lưu trữ tìm kiếm tệp.
- Cách tải các tệp riêng của bạn lên Cửa hàng tìm kiếm tệp.
- Cách sử dụng Công cụ tìm kiếm tệp của Gemini cho RAG.
- Lợi ích khi sử dụng Bộ công cụ phát triển tác nhân (ADK) của Google.
- Cách sử dụng Công cụ tìm kiếm tệp của Gemini trong một giải pháp dựa trên tác nhân được xây dựng bằng ADK.
- Cách sử dụng Công cụ tìm kiếm tệp của Gemini cùng với các công cụ "gốc" của Google như Google Tìm kiếm.
Những việc bạn sẽ làm
- Tạo một dự án trên Google Cloud và thiết lập môi trường phát triển.
- Tạo một tác nhân đơn giản dựa trên Gemini bằng Google Gen AI SDK (nhưng không có ADK) có khả năng sử dụng Google Tìm kiếm nhưng không có khả năng RAG.
- Thể hiện khả năng không cung cấp thông tin chính xác, chất lượng cao cho thông tin theo yêu cầu.
- Tạo một sổ tay Jupyter (bạn có thể chạy cục bộ hoặc trên Google Colab) để tạo và quản lý Gemini File Search Store.
- Sử dụng sổ tay để tải nội dung riêng biệt lên Cửa hàng tìm kiếm tệp.
- Tạo một tác nhân có gắn Cửa hàng tìm kiếm tệp và chứng minh rằng tác nhân đó có thể đưa ra câu trả lời tốt hơn.
- Chuyển đổi tác nhân "cơ bản" ban đầu của chúng ta thành một tác nhân ADK, hoàn chỉnh với công cụ Google Tìm kiếm.
- Kiểm thử tác nhân bằng giao diện người dùng web ADK.
- Kết hợp Cửa hàng tìm kiếm tệp vào tác nhân ADK, sử dụng mẫu Tác nhân như một công cụ để cho phép chúng ta sử dụng Công cụ tìm kiếm tệp cùng với công cụ Google Tìm kiếm.
2. RAG là gì và tại sao chúng ta cần RAG
Vậy... Tạo sinh tăng cường dựa trên truy xuất.
Nếu đang ở đây, có lẽ bạn đã biết về tính năng này, nhưng chúng ta hãy cùng tóm tắt nhanh, phòng trường hợp bạn chưa biết. Các LLM (như Gemini) rất thông minh, nhưng chúng gặp phải một số vấn đề:
- Luôn lỗi thời: Các mô hình này chỉ biết những gì chúng đã học được trong quá trình huấn luyện.
- Chúng không biết mọi thứ: Chắc chắn rồi, các mô hình này rất lớn, nhưng chúng không phải là mô hình toàn tri.
- Họ không biết thông tin độc quyền của bạn: Họ có kiến thức rộng, nhưng họ chưa đọc các tài liệu nội bộ, blog hoặc phiếu yêu cầu hỗ trợ trên Jira của bạn.
Vì vậy, khi bạn hỏi một mô hình về điều mà mô hình không biết câu trả lời, bạn thường sẽ nhận được câu trả lời không chính xác hoặc thậm chí là câu trả lời bịa đặt. Thường thì mô hình sẽ đưa ra câu trả lời không chính xác này một cách tự tin. Đây là tình trạng mà chúng tôi gọi là ảo tưởng.
Một giải pháp là chỉ cần đổ thông tin thuộc quyền sở hữu riêng của chúng ta trực tiếp vào bối cảnh cuộc trò chuyện. Điều này không sao nếu bạn có ít thông tin, nhưng sẽ nhanh chóng trở thành vấn đề khi bạn có nhiều thông tin. Cụ thể, việc này dẫn đến những vấn đề sau:
- Độ trễ: phản hồi của mô hình ngày càng chậm.
- Tín hiệu bị hỏng, hay còn gọi là "mất dữ liệu ở giữa": trường hợp mô hình không còn khả năng sắp xếp dữ liệu liên quan từ dữ liệu rác. Mô hình sẽ bỏ qua phần lớn ngữ cảnh.
- Chi phí: vì mã thông báo có tính phí.
- Cửa sổ ngữ cảnh bị cạn kiệt: Tại thời điểm này, Gemini sẽ không xử lý yêu cầu của bạn.
Một cách hiệu quả hơn nhiều để khắc phục tình trạng này là sử dụng RAG. Đây chỉ đơn giản là quá trình tra cứu thông tin liên quan từ các nguồn dữ liệu của bạn (bằng cách sử dụng tính năng so khớp ngữ nghĩa) và cung cấp các phần dữ liệu liên quan cho mô hình cùng với câu hỏi của bạn. Việc này giúp mô hình phù hợp với thực tế của bạn.
Ứng dụng này hoạt động bằng cách nhập dữ liệu bên ngoài, chia dữ liệu thành các khối, chuyển đổi dữ liệu thành các vectơ nhúng, sau đó lưu trữ và lập chỉ mục các vectơ nhúng đó vào một cơ sở dữ liệu vectơ phù hợp.
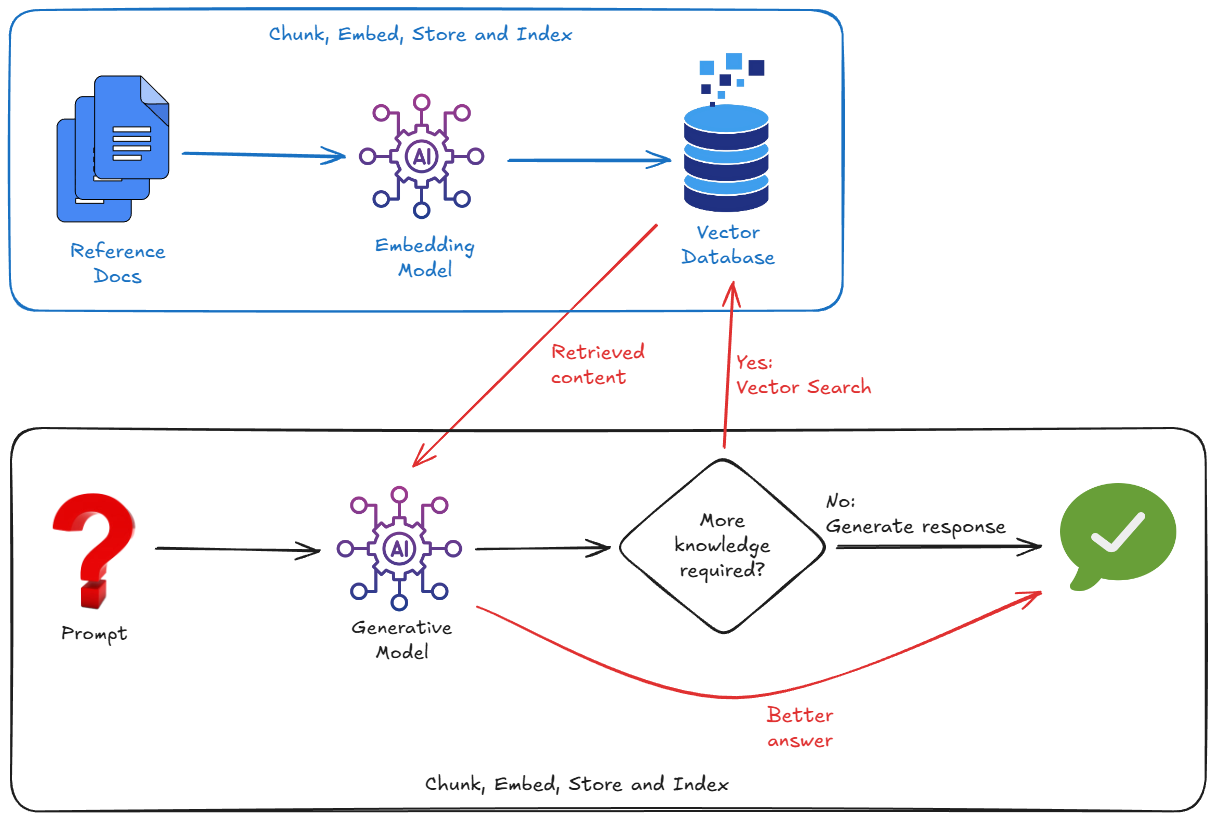
Do đó, để triển khai RAG, chúng ta thường phải lo lắng về:
- Tạo Cơ sở dữ liệu vectơ (Pinecone, Weaviate, Postgres với pgvector...).
- Viết một tập lệnh phân đoạn để chia nhỏ tài liệu (ví dụ: tệp PDF, markdown, v.v.).
- Tạo các vectơ nhúng cho những đoạn đó bằng cách sử dụng một mô hình nhúng.
- Lưu trữ các vectơ trong Cơ sở dữ liệu vectơ.
Nhưng bạn bè sẽ không để nhau thiết kế quá mức. Nếu tôi nói với bạn rằng có một cách dễ dàng hơn thì sao?
3. Điều kiện tiên quyết
Tạo một dự án trên Google Cloud
Bạn cần có một Dự án trên Google Cloud để chạy lớp học lập trình này. Bạn có thể sử dụng một dự án hiện có hoặc tạo một dự án mới.
Đảm bảo bạn đã bật tính năng thanh toán cho dự án của mình. Hãy xem hướng dẫn này để biết cách kiểm tra trạng thái thanh toán của các dự án.
Xin lưu ý rằng bạn không phải trả phí khi hoàn tất lớp học lập trình này. Nhiều nhất là vài xu.
Hãy tiếp tục và chuẩn bị sẵn sàng dự án của bạn. Tôi sẽ đợi.
Sao chép Kho lưu trữ bản minh hoạ
Tôi đã tạo một kho lưu trữ có nội dung hướng dẫn cho lớp học lập trình này. Bạn sẽ cần đến nó!
Chạy các lệnh sau từ cửa sổ dòng lệnh hoặc từ cửa sổ dòng lệnh được tích hợp vào Trình chỉnh sửa Cloud Shell của Google. Cloud Shell và trình chỉnh sửa của nó rất tiện lợi vì tất cả các lệnh bạn cần đều được cài đặt sẵn và mọi thứ đều chạy "ngay khi mở hộp".
git clone https://github.com/derailed-dash/gemini-file-search-demo cd gemini-file-search-demo
Cây này cho thấy các thư mục và tệp chính trong kho lưu trữ:
gemini-file-search-demo/ ├── app/ │ ├── basic_agent_adk/ # Agent with Google Search, using ADK framework │ │ └── agent.py │ ├── rag_agent_adk/ # Agent with Google Search and File Search, using ADK framework │ │ ├── agent.py │ │ └── tools_custom.py │ ├── sdk_agent.py # Agent using GenAI SDK (no ADK) with Google Search tool │ └── sdk_rag_agent.py # Agent using GenAI SDK (no ADK) with Gemini File Search tool ├── data/ │ └── story.md # Sample story with "bespoke content" to use with Gemini File Search Store ├── notebooks/ │ └── file_search_store.ipynb # Jupyter notebook for creating and managing Gemini File Search Store │ ├── .env.template # Template for environment variables - make a copy as .env ├── Makefile # Makefile for `make` commands ├── pyproject.toml # Project configuration and dependencies └── README.md # This file
Mở thư mục này trong Cloud Shell Editor hoặc trình chỉnh sửa mà bạn muốn. (Bạn đã dùng tính năng Antigravity chưa? Nếu chưa, thì đây là thời điểm thích hợp để bạn dùng thử.)
Xin lưu ý rằng kho lưu trữ này có chứa một câu chuyện mẫu ("The Wormhole Incursion") trong tệp data/story.md. Tôi đã cùng Gemini viết bài này! Nội dung xoay quanh chỉ huy Dazbo và phi đội tàu vũ trụ có tri giác của ông. (Tôi lấy cảm hứng từ trò chơi Elite Dangerous.) Câu chuyện này đóng vai trò là "cơ sở kiến thức riêng" của chúng tôi, chứa những thông tin cụ thể mà Gemini không biết và hơn nữa, Gemini không thể tìm kiếm bằng Google Tìm kiếm.
Thiết lập môi trường phát triển
Để thuận tiện, tôi đã cung cấp một Makefile để đơn giản hoá nhiều lệnh mà bạn cần chạy. Thay vì ghi nhớ các lệnh cụ thể, bạn chỉ cần chạy một lệnh như make <target>. Tuy nhiên, make chỉ có trong môi trường Linux / MacOS / WSL. Nếu đang sử dụng Windows (không có WSL), bạn sẽ cần chạy toàn bộ các lệnh mà mục tiêu make chứa.
# Install dependencies with make make install # If you don't have make... uv sync --extra jupyter
Đây là giao diện khi bạn chạy make install trong Cloud Shell Editor:
Tạo khoá Gemini API
Để sử dụng Gemini Developer API (cần thiết để sử dụng Công cụ tìm kiếm tệp của Gemini), bạn cần có khoá Gemini API. Cách dễ nhất để lấy khoá API là sử dụng Google AI Studio. Nền tảng này cung cấp một giao diện thuận tiện để lấy khoá API cho(các) dự án trên đám mây của bạn. Hãy xem hướng dẫn này để biết các bước cụ thể.
Sau khi tạo khoá API, hãy sao chép và lưu trữ khoá đó một cách an toàn.
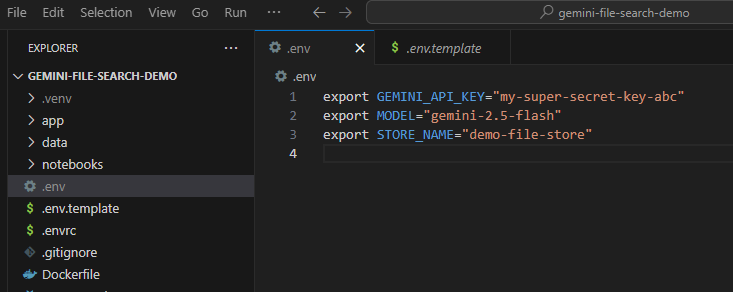
Giờ đây, bạn cần đặt khoá API này làm biến môi trường. Chúng ta có thể thực hiện việc này bằng cách sử dụng tệp .env. Sao chép .env.example đi kèm dưới dạng một tệp mới có tên .env. Tệp này sẽ có dạng như sau:
export GEMINI_API_KEY="your-api-key" export MODEL="gemini-2.5-flash" export STORE_NAME="demo-file-store"
Hãy thay thế your-api-key bằng khoá API thực tế của bạn. Giờ đây, mã sẽ có dạng như sau:
Bây giờ, hãy đảm bảo rằng các biến môi trường đã được tải. Bạn có thể thực hiện việc này bằng cách chạy:
source .env
4. The Basic Agent
Trước tiên, hãy thiết lập một đường cơ sở. Chúng ta sẽ sử dụng SDK google-genai thô để chạy một tác nhân đơn giản.
Mã
Hãy xem tệp app/sdk_agent.py. Đây là một phương thức triển khai tối giản:
- Tạo thực thể cho
genai.Client. - Bật công cụ
google_search. - Vậy là xong. Không có RAG.
Xem qua mã và đảm bảo bạn hiểu rõ chức năng của mã.
Chạy ứng dụng
# With make make sdk-agent # Without make uv run python app/sdk_agent.py
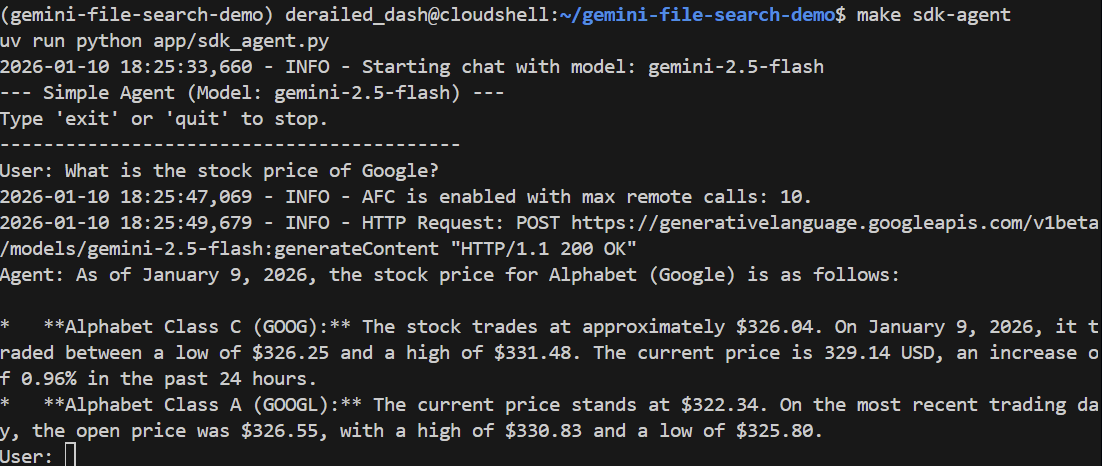
Hãy đặt cho Gemini một câu hỏi chung:
> What is the stock price of Google?
Bạn phải trả lời chính xác bằng cách sử dụng Google Tìm kiếm để tìm giá hiện tại:
Bây giờ, hãy đặt một câu hỏi mà mô hình này không biết cách trả lời. Điều này đòi hỏi nhân viên hỗ trợ phải đọc câu chuyện của chúng tôi.
> Who pilots the 'Too Many Pies' ship?
Có lẽ không thành công hoặc thậm chí là ảo tưởng. Hãy xem:
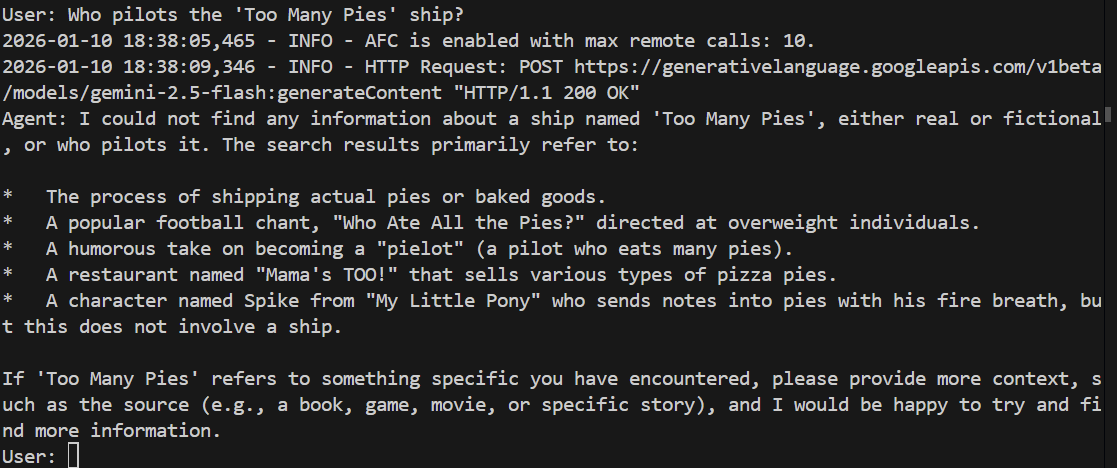
Và chắc chắn là mô hình không trả lời được câu hỏi. Nó không biết chúng ta đang nói về điều gì!
Giờ đây, hãy nhập quit để thoát khỏi tác nhân.
5. Tìm kiếm tệp bằng Gemini: Thông tin giải thích
Về cơ bản, tính năng Tìm kiếm tệp của Gemini là sự kết hợp của hai yếu tố:
- Hệ thống RAG được quản lý toàn diện: bạn cung cấp một loạt tệp và Công cụ tìm kiếm tệp của Gemini sẽ xử lý việc phân đoạn, nhúng, lưu trữ và lập chỉ mục vectơ cho bạn.
- "Công cụ" theo nghĩa của tác nhân: bạn chỉ cần thêm Công cụ tìm kiếm tệp của Gemini làm công cụ trong định nghĩa tác nhân và trỏ công cụ đến một Cửa hàng tìm kiếm tệp.
Nhưng điều quan trọng là: tính năng này được tích hợp vào chính Gemini API. Điều này có nghĩa là bạn không cần bật thêm API nào hoặc triển khai bất kỳ sản phẩm riêng biệt nào để sử dụng tính năng này. Vì vậy, nó thực sự là một out-of-the-box.
Các tính năng tìm kiếm tệp của Gemini
Sau đây là một số tính năng:
- Thông tin chi tiết về việc phân đoạn, nhúng, lưu trữ và lập chỉ mục sẽ được trừu tượng hoá đối với bạn (nhà phát triển). Điều này có nghĩa là bạn không cần biết (hoặc quan tâm) đến mô hình nhúng (là Gemini Embeddings), hoặc nơi lưu trữ các vectơ kết quả. Bạn không cần phải đưa ra bất kỳ quyết định nào về cơ sở dữ liệu vectơ.
- Thư viện này hỗ trợ rất nhiều loại tài liệu ngay khi bạn cài đặt. Bao gồm nhưng không giới hạn ở: PDF, DOCX, Excel, SQL, JSON, sổ tay Jupyter, HTML, Markdown, CSV và thậm chí cả tệp zip. Bạn có thể xem danh sách đầy đủ tại đây. Ví dụ: nếu muốn liên kết thực tế cho tác nhân của mình bằng các tệp PDF chứa văn bản, hình ảnh và bảng, bạn không cần phải xử lý trước các tệp PDF này. Bạn chỉ cần tải tệp PDF thô lên, còn lại cứ để Gemini lo.
- Chúng tôi có thể thêm siêu dữ liệu tuỳ chỉnh vào mọi tệp được tải lên. Điều này có thể thực sự hữu ích cho việc lọc những tệp mà chúng ta muốn công cụ sử dụng, tại thời gian chạy.
Dữ liệu được lưu trữ ở đâu?
Bạn tải một số tệp lên. Công cụ tìm kiếm tệp của Gemini đã lấy những tệp đó, tạo các đoạn, sau đó tạo các vectơ nhúng và đặt chúng ở một nơi nào đó. Nhưng ở đâu?
Câu trả lời: Cửa hàng tìm kiếm tệp. Đây là một vùng chứa được quản lý hoàn toàn cho các mục nhúng của bạn. Bạn không cần biết (hoặc quan tâm) đến cách thực hiện việc này. Bạn chỉ cần tạo một thư mục (theo cách lập trình) rồi tải tệp lên thư mục đó.
Giá rẻ!
Bạn không phải trả phí khi lưu trữ và truy vấn các vectơ nhúng. Vì vậy, bạn có thể lưu trữ các vectơ nhúng bao lâu tuỳ thích mà không phải trả phí cho bộ nhớ đó!
Trên thực tế, bạn chỉ phải trả phí cho việc tạo các vectơ nhúng tại thời điểm tải lên/lập chỉ mục. Tại thời điểm viết bài, chi phí này là 0,15 USD cho mỗi 1 triệu mã thông báo. Giá đó khá rẻ.
6. Cách sử dụng tính năng Tìm kiếm tệp của Gemini
Có 2 giai đoạn:
- Tạo và lưu trữ các vectơ nhúng trong một Kho lưu trữ tìm kiếm tệp.
- Truy vấn Cửa hàng tìm kiếm tệp từ tác nhân của bạn.
Giai đoạn 1 – Jupyter Notebook để tạo và quản lý kho lưu trữ tìm kiếm tệp Gemini
Đây là giai đoạn mà bạn sẽ thực hiện ban đầu, sau đó là bất cứ khi nào bạn muốn cập nhật cửa hàng. Ví dụ: khi bạn có tài liệu mới cần thêm hoặc khi tài liệu nguồn đã thay đổi.
Bạn không cần đóng gói giai đoạn này vào ứng dụng dựa trên tác nhân đã triển khai. Chắc chắn rồi, bạn có thể làm vậy nếu muốn. Ví dụ: nếu bạn muốn tạo một loại giao diện người dùng nào đó cho người dùng quản trị của ứng dụng dựa trên tác nhân. Tuy nhiên, bạn chỉ cần một đoạn mã để chạy theo yêu cầu. Và một cách tuyệt vời để chạy mã này theo yêu cầu? Sổ tay Jupyter!
The Notebook
Mở tệp notebooks/file_search_store.ipynb trong trình chỉnh sửa. Nếu bạn được nhắc cài đặt bất kỳ tiện ích nào của Jupyter VS Code, vui lòng tiếp tục và cài đặt.
Nếu chúng ta mở tệp này trong Cloud Shell Editor, tệp sẽ có dạng như sau:
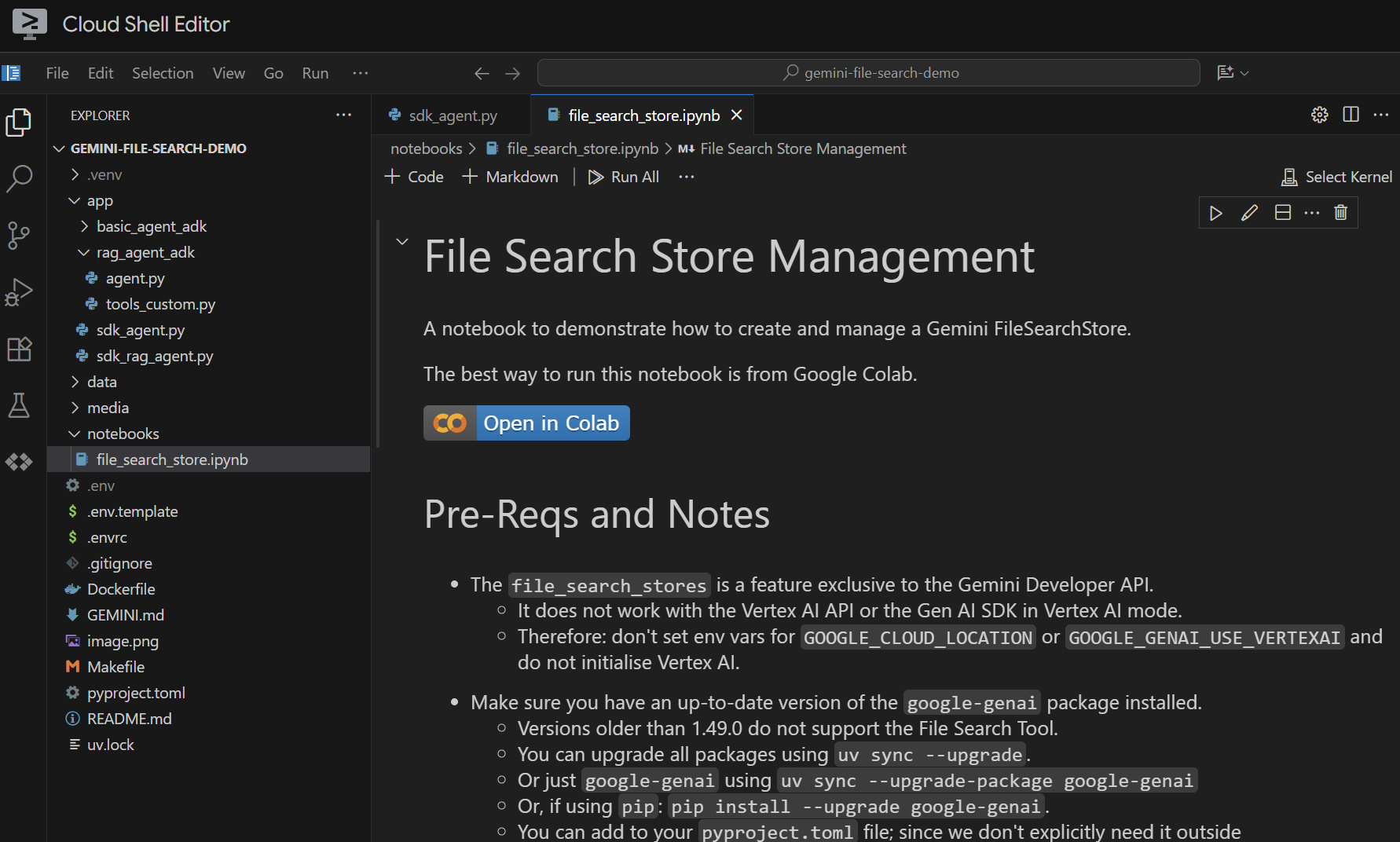
Hãy chạy từng ô. Bắt đầu bằng cách thực thi ô Setup với các nội dung nhập bắt buộc. Nếu chưa chạy sổ tay trước đây, bạn sẽ được yêu cầu cài đặt các tiện ích bắt buộc. Hãy tiếp tục và làm việc đó. Sau đó, bạn sẽ được yêu cầu chọn một nhân. Chọn "Python environments...", sau đó chọn .venv cục bộ mà chúng ta đã cài đặt khi chạy make install trước đó:
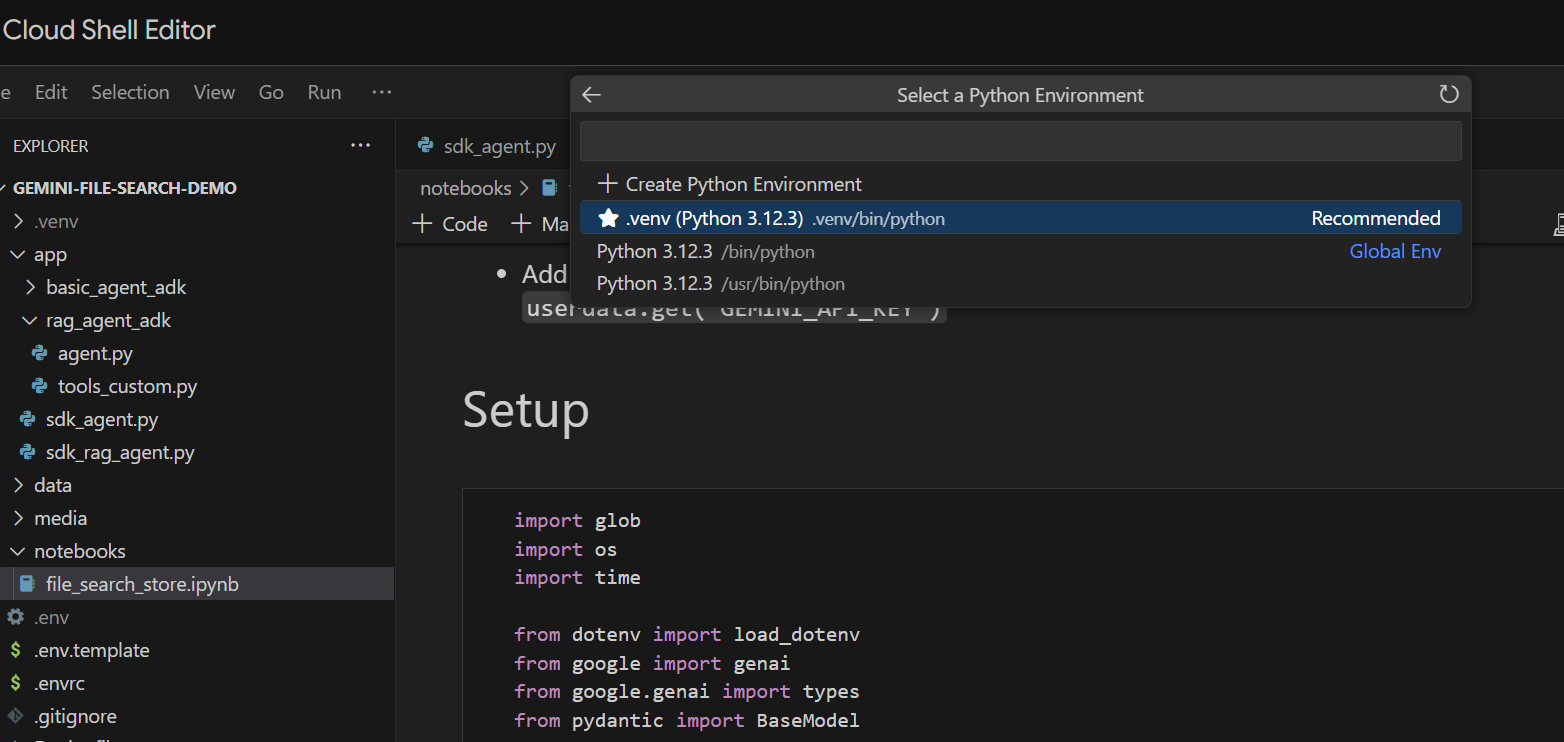
Sau đó:
- Chạy ô "Local Only" để kéo các biến môi trường vào.
- Chạy ô "Khởi tạo ứng dụng" để khởi tạo Gemini Gen AI Client.
- Chạy ô "Retrieve the Store" (Truy xuất Cửa hàng) bằng hàm trợ giúp để truy xuất Cửa hàng Tìm kiếm tệp của Gemini theo tên.
Giờ thì chúng ta đã sẵn sàng tạo cửa hàng.
- Chạy ô "Create the Store (One Time)" (Tạo cửa hàng (Một lần)) để tạo cửa hàng. Chúng ta chỉ cần thực hiện việc này một lần. Nếu mã chạy thành công, bạn sẽ thấy thông báo
"Created store: fileSearchStores/<someid>" - Chạy ô "View the Store" (Xem cửa hàng) để xem nội dung trong đó. Tại thời điểm này, bạn sẽ thấy rằng nó chứa 0 tài liệu.
Tuyệt vời! Chúng tôi hiện đã có một cửa hàng Gemini File Search sẵn sàng hoạt động.
Tải dữ liệu lên
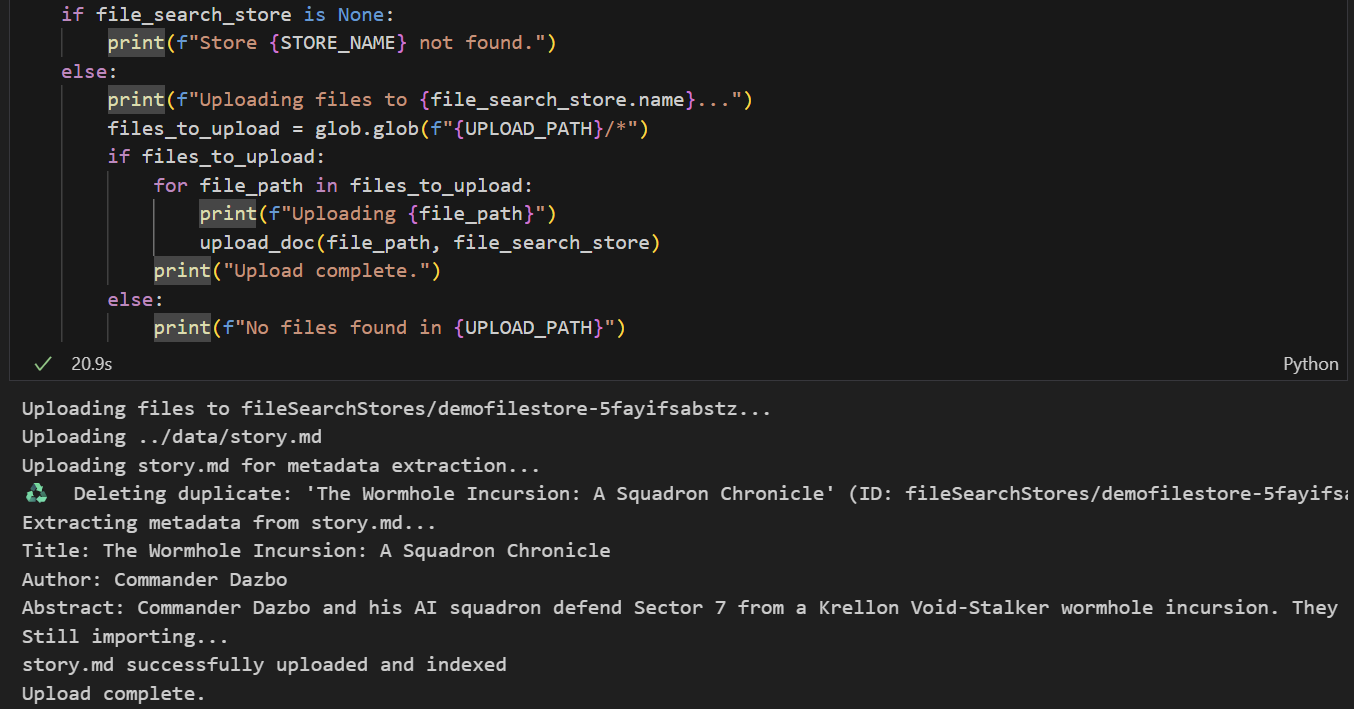
Chúng tôi muốn tải data/story.md lên cửa hàng. Hãy thực hiện như sau:
- Chạy ô thiết lập đường dẫn tải lên. Thư mục này trỏ đến thư mục
data/của chúng ta. - Chạy ô tiếp theo để tạo các hàm tiện ích nhằm tải tệp lên cửa hàng. Xin lưu ý rằng mã trong ô này cũng sử dụng Gemini để trích xuất siêu dữ liệu từ mỗi tệp được tải lên. Chúng tôi lấy những giá trị được trích xuất này và lưu trữ chúng dưới dạng siêu dữ liệu tuỳ chỉnh trong cửa hàng. (Bạn không cần phải làm việc này, nhưng đây là một việc hữu ích nên làm.)
- Chạy ô để tải tệp lên. Xin lưu ý rằng nếu trước đây chúng ta đã tải một tệp có cùng tên lên, thì sổ tay sẽ xoá phiên bản hiện có trước khi tải phiên bản mới lên. Bạn sẽ thấy một thông báo cho biết tệp đã được tải lên.
Giai đoạn 2 – Triển khai RAG Tìm kiếm tệp của Gemini trong Tác nhân của chúng tôi
Chúng tôi đã tạo một Cửa hàng Tìm kiếm tệp trên Gemini và tải câu chuyện của mình lên đó. Giờ là lúc sử dụng File Search Store trong tác nhân của chúng ta. Hãy tạo một tác nhân mới sử dụng File Search Store thay vì Google Tìm kiếm. Hãy xem tệp app/sdk_rag_agent.py.
Điều đầu tiên cần lưu ý là chúng ta đã triển khai một hàm để truy xuất cửa hàng bằng cách truyền vào tên cửa hàng:
def get_store(client: genai.Client, store_name: str) -> types.FileSearchStore | None:
"""Retrieve a store by display name"""
try:
for a_store in client.file_search_stores.list():
if a_store.display_name == store_name:
return a_store
except Exception as e:
logger.error(f"Error listing stores: {e}")
return None
Sau khi có kho lưu trữ, việc sử dụng kho lưu trữ cũng đơn giản như đính kèm kho lưu trữ dưới dạng một công cụ vào tác nhân của chúng ta, như sau:
file_search_tool = types.Tool(file_search=types.FileSearch(file_search_store_names=[store.name]))
Chạy tác nhân RAG
Chúng tôi ra mắt tính năng này như sau:
make sdk-rag-agent # Or, without make: uv run python app/sdk_rag_agent.py
Hãy đặt câu hỏi mà nhân viên hỗ trợ trước đó không trả lời được:
> Who pilots the 'Too Many Pies' ship?
Và câu trả lời là?
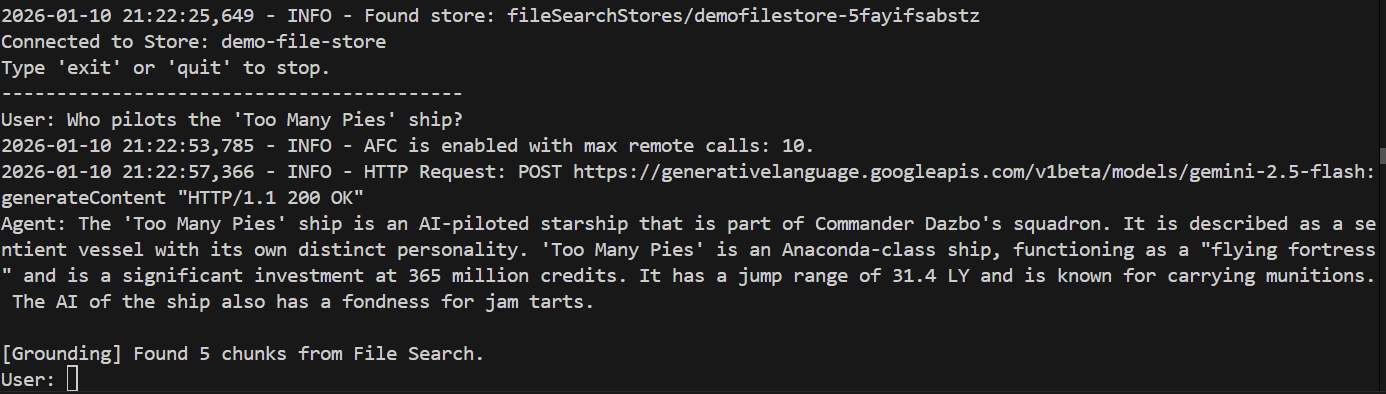
Thành công! Chúng ta có thể thấy từ phản hồi rằng:
- Chúng tôi đã sử dụng kho lưu trữ tệp để trả lời câu hỏi.
- Đã tìm thấy 5 đoạn có liên quan.
- Câu trả lời rất chính xác!
Nhập quit để đóng nhân viên hỗ trợ.
7. Chuyển đổi các tác nhân để sử dụng ADK
Agent Development Kit (ADK) của Google là một khung mô-đun và SDK nguồn mở dành cho nhà phát triển để xây dựng các tác nhân và hệ thống tác nhân. Nhờ đó, chúng ta có thể dễ dàng tạo và điều phối các hệ thống đa tác nhân. Mặc dù được tối ưu hoá cho Gemini và hệ sinh thái của Google, nhưng ADK không phụ thuộc vào mô hình, không phụ thuộc vào việc triển khai và được xây dựng để tương thích với các khung khác. Nếu bạn chưa sử dụng ADK, hãy truy cập vào Tài liệu về ADK để tìm hiểu thêm.
Tác nhân ADK cơ bản có Google Tìm kiếm
Hãy xem tệp app/basic_agent_adk/agent.py. Trong mã mẫu này, bạn có thể thấy rằng chúng tôi đã triển khai 2 tác nhân:
- Một
root_agentxử lý hoạt động tương tác với người dùng và nơi chúng tôi đã cung cấp hướng dẫn chính của hệ thống. - Một
SearchAgentriêng biệt sử dụnggoogle.adk.tools.google_searchlàm công cụ.
root_agent thực sự sử dụng SearchAgent làm công cụ, được triển khai bằng dòng này:
tools=[AgentTool(agent=search_agent)],
Câu lệnh hệ thống của tác nhân gốc sẽ có dạng như sau:
You are a helpful AI assistant designed to provide accurate and useful information.
If you don't know the answer, use the SearchAgent to perform a Google search.
Do not attempt to search more than ONCE.
If the search yields no relevant results or returns unrelated content, you MUST immediately respond with: "I could not find any information about that."
Do NOT retry the search with different terms. Do NOT ask for clarification. FAIL FAST.
Dùng thử Tác nhân
ADK cung cấp một số giao diện có sẵn để cho phép nhà phát triển kiểm thử các tác nhân ADK của họ. Một trong những giao diện này là giao diện người dùng trên web. Điều này cho phép chúng ta kiểm thử các tác nhân trong trình duyệt mà không cần viết một dòng mã giao diện người dùng nào!
Chúng ta có thể chạy giao diện này bằng cách chạy:
make adk-playground # Or, without make: uv run adk web app --port 8501 --reload_agents
Xin lưu ý rằng lệnh này sẽ trỏ công cụ adk web đến thư mục app, nơi công cụ này sẽ tự động phát hiện mọi tác nhân ADK triển khai root_agent. Vậy hãy thử xem sao:
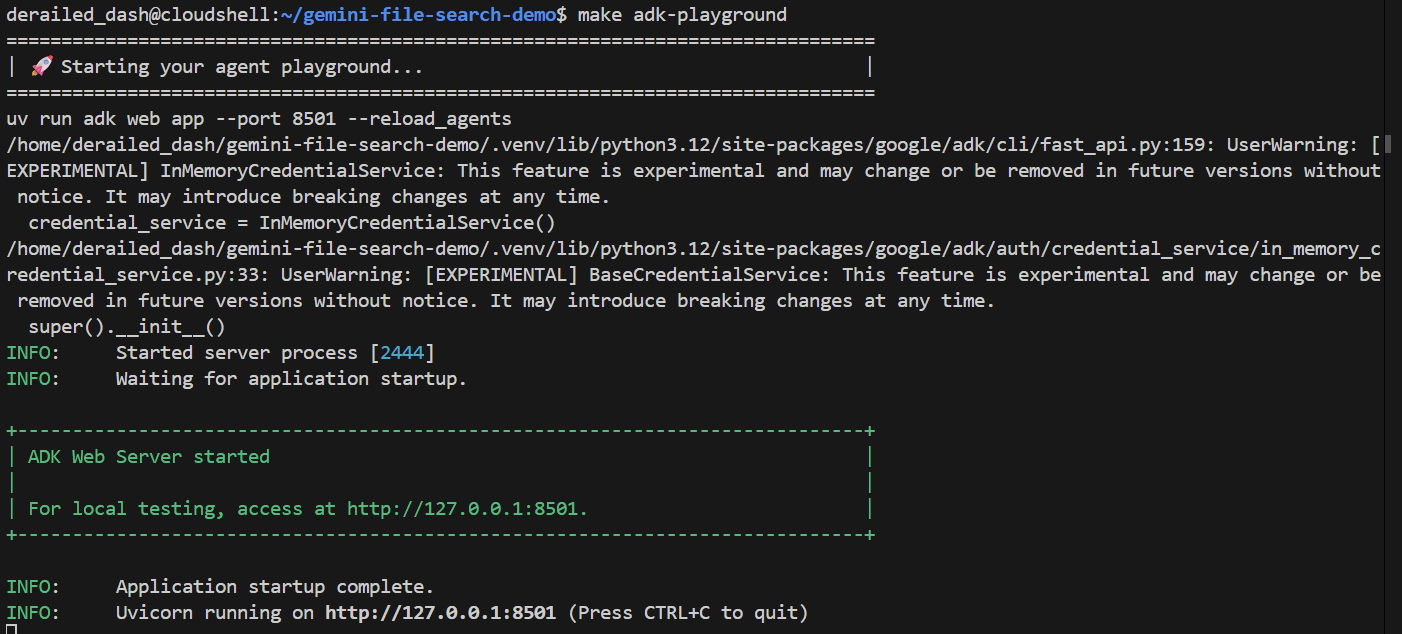
Sau vài giây, ứng dụng sẽ sẵn sàng. Nếu bạn đang chạy mã cục bộ, chỉ cần trỏ trình duyệt đến http://127.0.0.1:8501. Nếu bạn đang chạy trong Cloud Shell Editor, hãy nhấp vào "Xem trước trên web" rồi thay đổi cổng thành 8501:
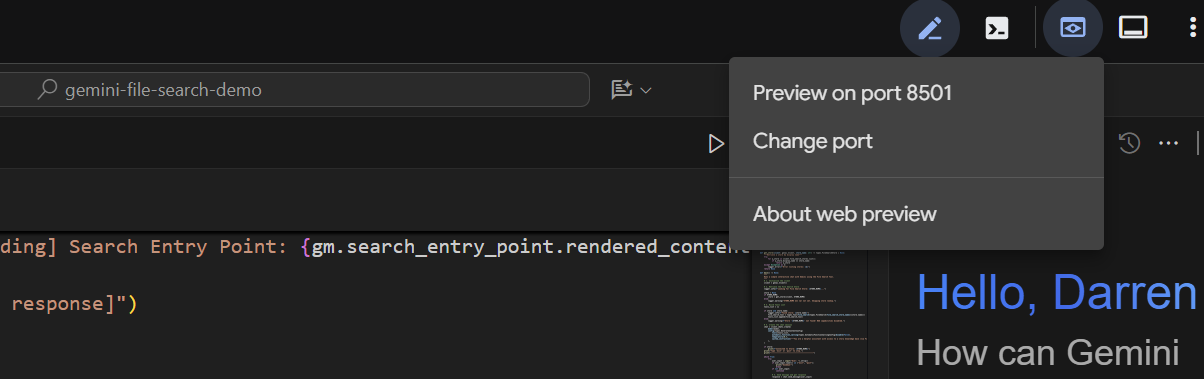
Khi giao diện người dùng xuất hiện, hãy chọn basic_agent_adk trong trình đơn thả xuống, sau đó chúng ta có thể đặt câu hỏi cho công cụ này:
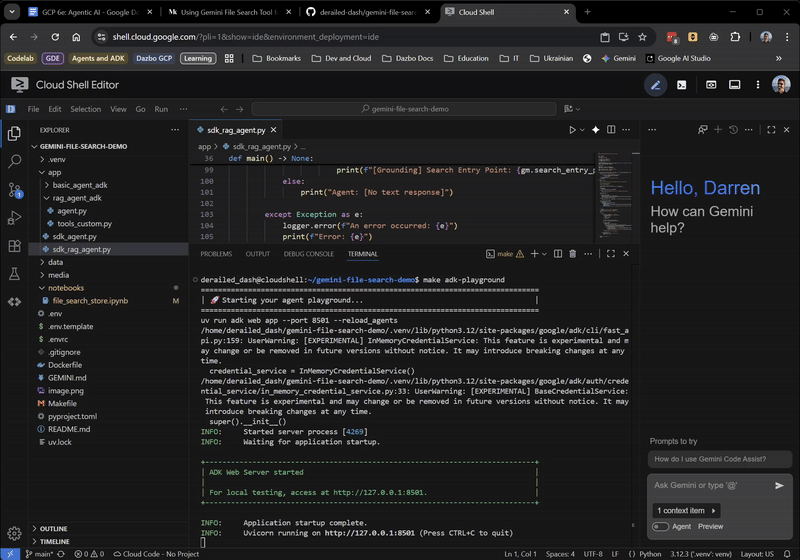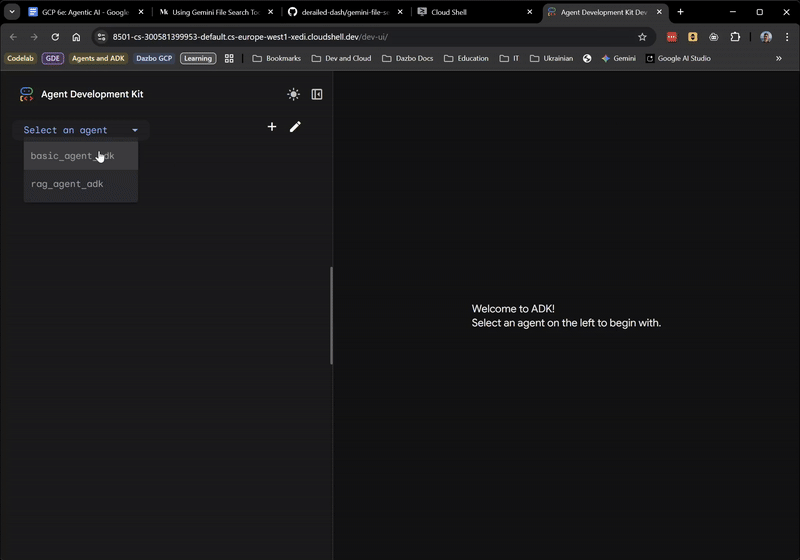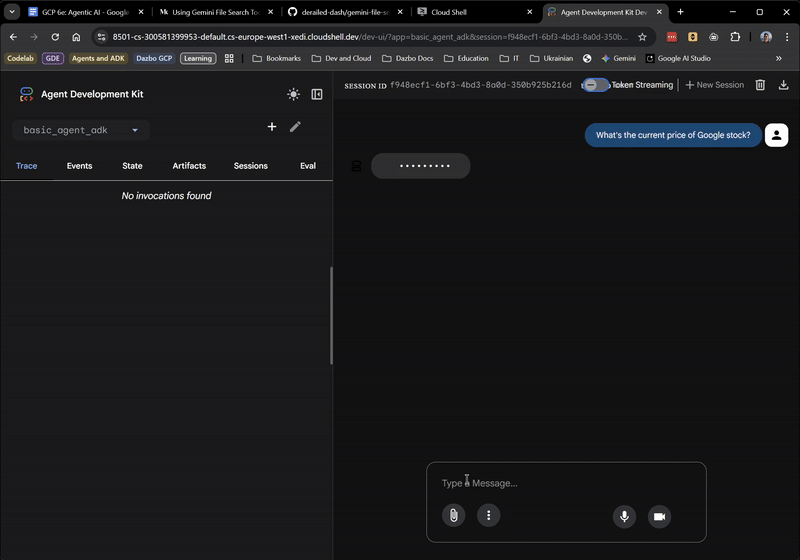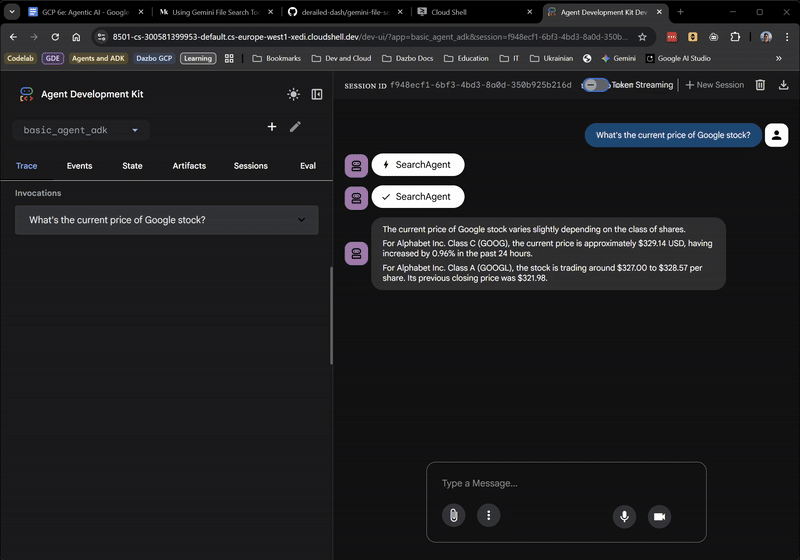
Cho đến giờ mọi thứ đều ổn! Giao diện người dùng trên web thậm chí còn cho bạn biết thời điểm tác nhân gốc uỷ quyền cho SearchAgent. Đây là một tính năng rất hữu ích.
Bây giờ, hãy đặt cho nó câu hỏi đòi hỏi kiến thức về câu chuyện của chúng ta:
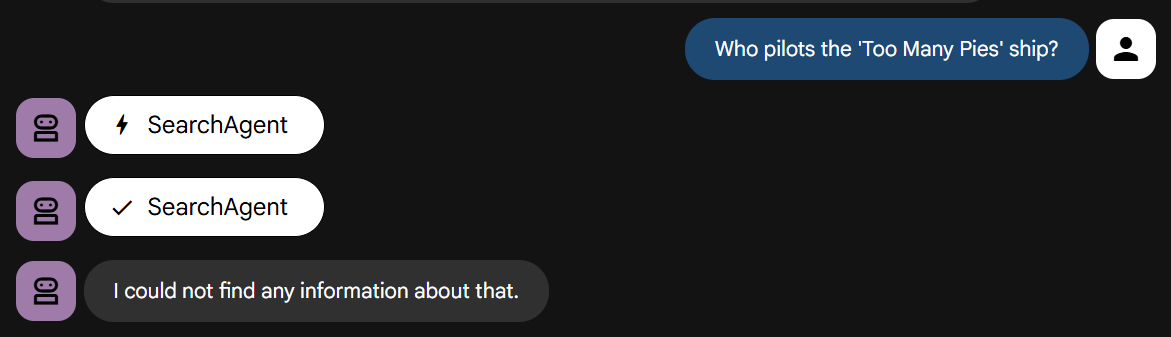
Hãy tự mình trải nghiệm. Bạn sẽ thấy nó nhanh chóng thất bại, đúng như hướng dẫn.
Kết hợp Cửa hàng tìm kiếm tệp vào tác nhân ADK
Bây giờ, chúng ta sẽ tổng hợp tất cả lại. Chúng ta sẽ chạy một tác nhân ADK có thể sử dụng cả Cửa hàng tìm kiếm tệp và Google Tìm kiếm. Hãy xem mã trong app/rag_agent_adk/agent.py.
Mã này tương tự như ví dụ trước, nhưng có một số điểm khác biệt chính:
- Chúng tôi có một tác nhân gốc điều phối 2 tác nhân chuyên biệt:
- RagAgent: Chuyên gia kiến thức chuyên biệt – sử dụng Gemini File Search Store của chúng tôi
- SearchAgent: Chuyên gia về kiến thức chung – sử dụng Google Tìm kiếm
- Vì ADK chưa có trình bao bọc tích hợp cho
FileSearch, nên chúng ta sẽ dùng một lớp trình bao bọc tuỳ chỉnhFileSearchToolđể bao bọc công cụ FileSearch, công cụ này sẽ chèn cấu hìnhfile_search_store_namesvào yêu cầu mô hình cấp thấp. Việc này đã được triển khai vào tập lệnh riêngapp/rag_agent_adk/tools_custom.py.
Ngoài ra, bạn cần lưu ý một điểm "bẫy". Tại thời điểm viết bài này, bạn không thể sử dụng công cụ GoogleSearch gốc và công cụ FileSearch trong cùng một yêu cầu đối với cùng một tác nhân. Nếu cố gắng, bạn sẽ gặp phải lỗi như sau:
LỖI – Đã xảy ra lỗi: 400 INVALID_ARGUMENT. {‘error': {‘code': 400, ‘message': ‘Không được hỗ trợ dùng đồng thời công cụ tìm kiếm và công cụ tìm kiếm tệp', ‘status': ‘INVALID_ARGUMENT'}}
Lỗi: 400 INVALID_ARGUMENT. {‘error': {‘code': 400, ‘message': ‘Không được hỗ trợ dùng đồng thời công cụ tìm kiếm và công cụ tìm kiếm tệp', ‘status': ‘INVALID_ARGUMENT'}}
Giải pháp là triển khai hai tác nhân chuyên gia này dưới dạng các tác nhân phụ riêng biệt và truyền chúng đến tác nhân gốc bằng cách sử dụng mẫu Tác nhân dưới dạng công cụ. Điều quan trọng là chỉ dẫn hệ thống của tác nhân gốc đưa ra hướng dẫn rất rõ ràng để sử dụng RagAgent trước:
Bạn là một trợ lý AI hữu ích, được thiết kế để cung cấp thông tin chính xác và hữu ích.
Bạn có thể liên hệ với 2 chuyên viên hỗ trợ:
- RagAgent: Để biết thông tin cụ thể từ cơ sở kiến thức nội bộ.
- SearchAgent: Để biết thông tin chung từ Google Tìm kiếm.
Luôn thử RagAgent trước. Nếu không nhận được câu trả lời hữu ích, hãy thử dùng SearchAgent.
Bài kiểm tra cuối cùng
Chạy giao diện người dùng web ADK như trước:
make adk-playground # Or, without make: uv run adk web app --port 8501 --reload_agents
Lần này, hãy chọn rag_agent_adk trong giao diện người dùng. Hãy xem ví dụ thực tế: 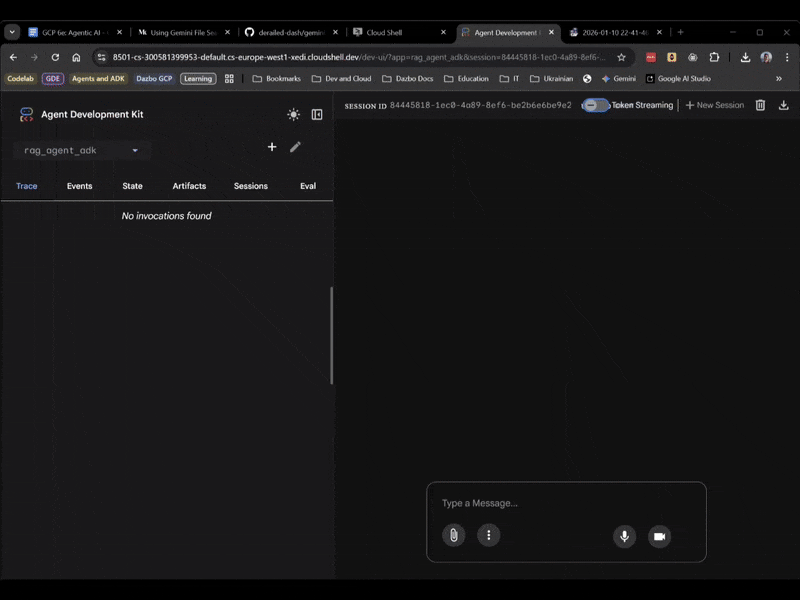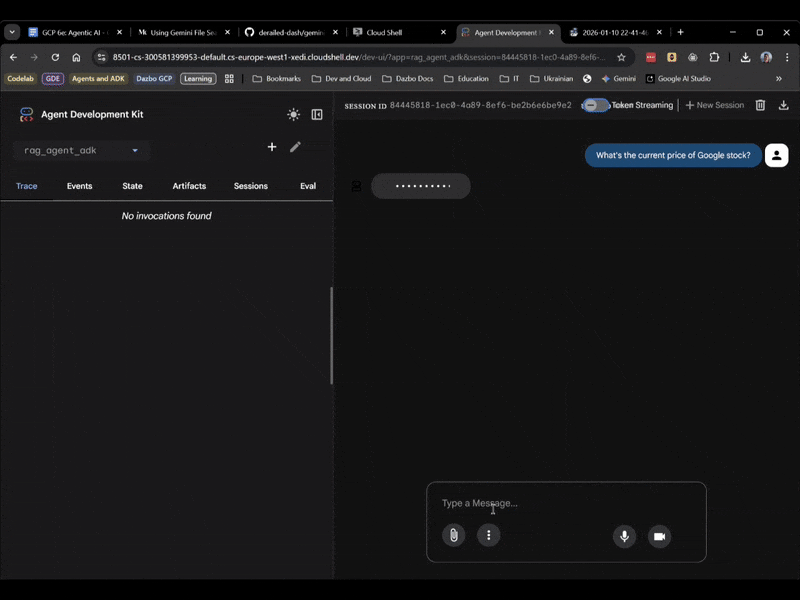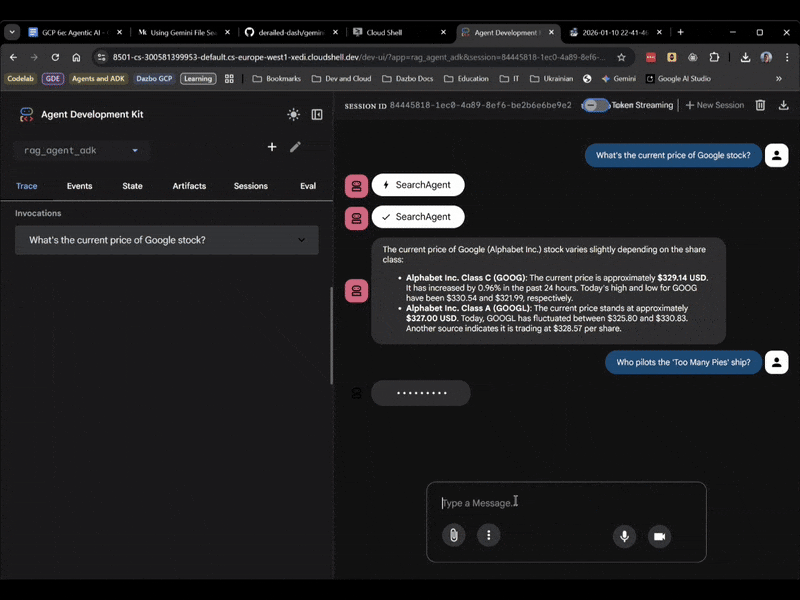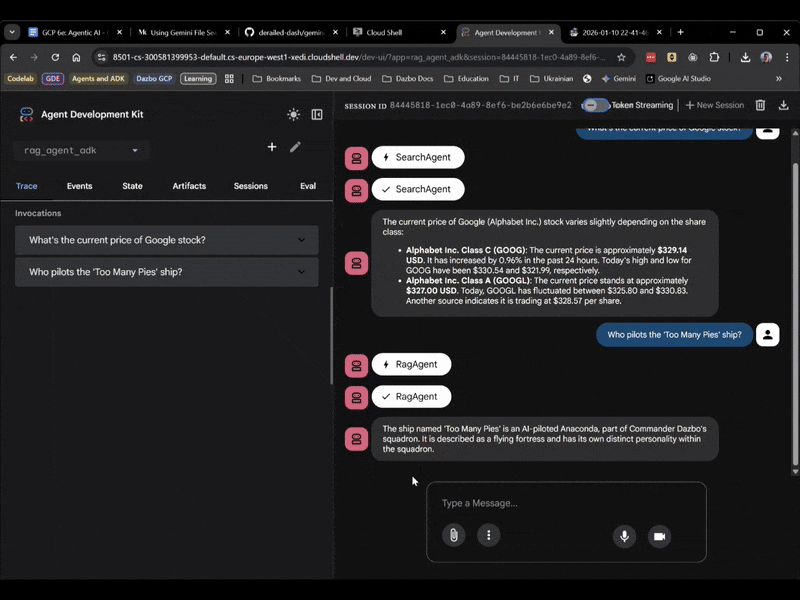
Chúng ta có thể thấy rằng mô hình này chọn trợ lý ảo phù hợp dựa trên câu hỏi.
8. Kết luận
Chúc mừng bạn đã hoàn thành lớp học lập trình này!
Bạn đã chuyển từ một tập lệnh đơn giản sang một hệ thống đa tác nhân có hỗ trợ RAG; tất cả đều không cần một dòng mã nhúng và không cần triển khai cơ sở dữ liệu vectơ!
Chúng tôi nhận thấy:
- Gemini File Search là một giải pháp RAG được quản lý giúp tiết kiệm thời gian và công sức.
- ADK cung cấp cho chúng ta cấu trúc cần thiết cho các ứng dụng phức tạp có nhiều tác nhân và mang lại sự thuận tiện cho nhà phát triển thông qua các giao diện như Giao diện người dùng web.
- Mẫu "Agent-as-a-Tool" (Tác nhân dưới dạng công cụ) giải quyết các vấn đề về khả năng tương thích của công cụ.
Hy vọng bạn thấy phòng thí nghiệm này hữu ích. Hẹn gặp bạn lần sau!