
1. 概要
MCP Toolbox for Databases は Google のオープンソース サーバーで、データベースを操作するための生成 AI ツールを簡単に構築できます。接続プーリングや認証などの複雑さを処理することで、ツールをより簡単、迅速、安全に開発できます。エージェントがデータベース内のデータにアクセスできるようにする生成 AI ツールの構築に役立ちます。ツールボックスには次のような機能があります。
開発の簡素化: 10 行未満のコードでエージェントにツールを統合し、複数のエージェントやフレームワーク間でツールを再利用できます。また、新しいバージョンのツールを簡単にデプロイできます。
パフォーマンスの向上: 接続プーリング、認証などのベスト プラクティス。
セキュリティの強化: 統合された認証により、データにより安全にアクセスできます。
エンドツーエンドのオブザーバビリティ: OpenTelemetry の組み込みサポートによる、すぐに使用できる指標とトレース。
Toolbox は、アプリケーションのオケストレーション フレームワークとデータベースの間にあり、ツールの変更、配布、呼び出しに使用されるコントロール プレーンを提供します。ツールの保存と更新を一元化できるため、ツールの管理が簡素化されます。エージェントとアプリケーション間でツールを共有し、アプリケーションを再デプロイしなくてもツールを更新できます。
作成するアプリの概要
このラボでは、ツールを使用してシンプルなデータベース(AlloyDB)クエリを実行するアプリケーションを構築し、そのクエリはエージェントまたは生成 AI アプリケーションから呼び出すことができます。そのためには、
- MCP Toolbox for Databases をインストールする
- Toolbox サーバーでツール(AlloyDB でタスクを実行するように設計)をセットアップする
- Cloud Run にデータベース用 MCP ツールボックスをデプロイする
- デプロイされた Cloud Run エンドポイントを使用してツールをテストする
- ツールボックスを呼び出す Cloud Run 関数を作成する
要件
2. 始める前に
プロジェクトを作成する
- Google Cloud コンソールのプロジェクト選択ページで、Google Cloud プロジェクトを選択または作成します。
- Cloud プロジェクトに対して課金が有効になっていることを確認します。詳しくは、プロジェクトで課金が有効になっているかどうかを確認する方法をご覧ください。
- ここでは、Google Cloud で動作するコマンドライン環境である Cloud Shell を使用します。Google Cloud コンソールの上部にある [Cloud Shell をアクティブにする] をクリックします。

- Cloud Shell に接続したら、次のコマンドを使用して、すでに認証されているかどうかと、プロジェクトが正しいプロジェクト ID に設定されているかどうかを確認します。
gcloud auth list
- Cloud Shell で次のコマンドを実行して、gcloud コマンドがプロジェクトを認識していることを確認します。
gcloud config list project
- プロジェクトが設定されていない場合は、次のコマンドを使用して設定します。
gcloud config set project <YOUR_PROJECT_ID>
- Cloud Shell ターミナルで次のコマンドを 1 つずつ実行して、必要な API を有効にします。
以下のコマンドを実行する 1 つのコマンドもありますが、トライアル アカウントのユーザーは、これらの機能を一括で有効にしようとすると、割り当ての問題が発生することがあります。1 行に 1 つずつコマンドが選ばれているのはそのためです。
gcloud services enable alloydb.googleapis.com
gcloud services enable compute.googleapis.com
gcloud services enable cloudresourcemanager.googleapis.com
gcloud services enable servicenetworking.googleapis.com
gcloud services enable run.googleapis.com
gcloud services enable cloudbuild.googleapis.com
gcloud services enable cloudfunctions.googleapis.com
gcloud services enable aiplatform.googleapis.com
gcloud コマンドの代わりに、プロダクトごとに検索するか、こちらのリンクを使用して、コンソールを使用することもできます。
いずれかの API が不足している場合は、実装中にいつでも有効にできます。
gcloud コマンドとその使用方法については、ドキュメントをご覧ください。
3. データベースの設定
このラボでは、小売データを保持するデータベースとして AlloyDB を使用します。クラスタを使用して、データベースやログなどのすべてのリソースを保持します。各クラスタには、データへのアクセス ポイントを提供するプライマリ インスタンスがあります。テーブルには実際のデータが格納されます。
e コマース データセットを読み込む AlloyDB クラスタ、インスタンス、テーブルを作成しましょう。
クラスタとインスタンスを作成する
- Cloud コンソールで AlloyDB ページに移動する。
Cloud コンソールのほとんどのページは、コンソールの検索バーで検索すると簡単に見つけることができます。
- そのページで [クラスタを作成] を選択します。

- 下のような画面が表示されます。次の値を使用してクラスタとインスタンスを作成します(リポジトリからアプリケーション コードのクローンを作成する場合は、値が一致していることを確認してください)。
- クラスタ ID: 「
vector-cluster」 - パスワード: 「
alloydb」 - PostgreSQL 15 対応
- 地域: 「
us-central1」 - ネットワーク: 「
default」
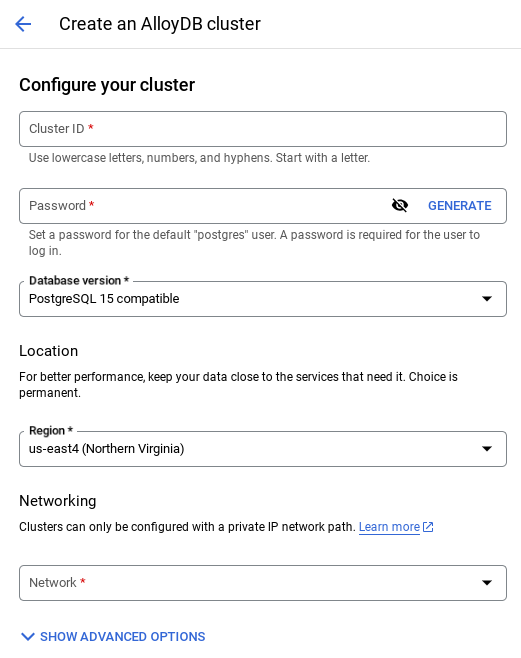
- デフォルト ネットワークを選択すると、次のような画面が表示されます。[接続を設定] を選択します。
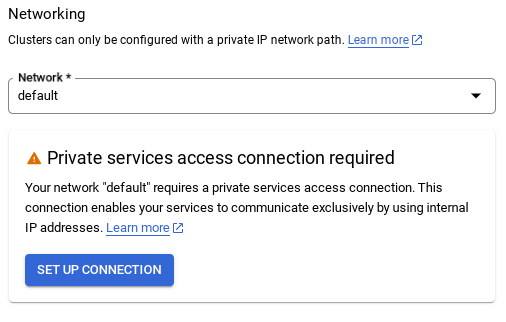
- そこから、[自動的に割り当てられた IP 範囲を使用する] を選択して [続行] を選択し、情報を確認したら、[接続を作成] を選択します。
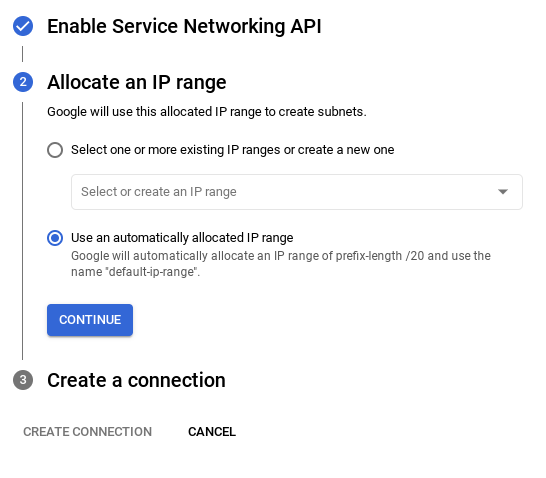
- ネットワークの設定が完了したら、クラスタの作成に進むことができます。[クラスタを作成] をクリックして、次に示すようにクラスタの設定を完了します。
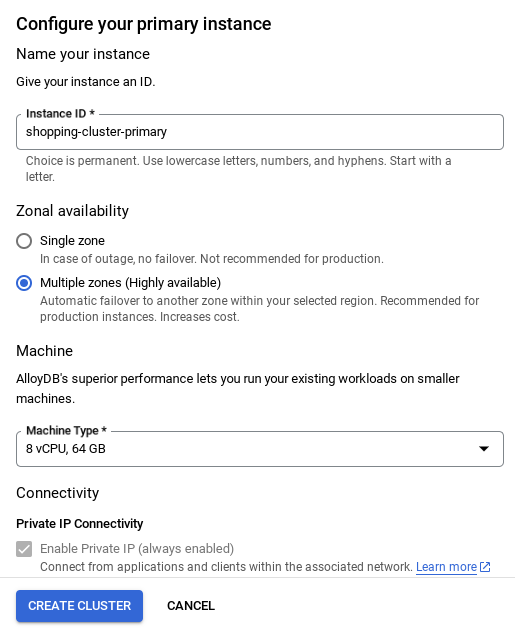
インスタンス ID を「
vector-instance"
クラスタの作成には 10 分ほどかかります。成功すると、先ほど作成したクラスタの概要を示す画面が表示されます。
4. データの取り込み
次に、店舗に関するデータを含むテーブルを追加します。AlloyDB に移動し、プライマリ クラスタを選択してから AlloyDB Studio を選択します。
インスタンスの作成が完了するまで待つ必要がある場合があります。完了したら、クラスタの作成時に作成した認証情報を使用して AlloyDB にログインします。PostgreSQL の認証には、次のデータを使用します。
- ユーザー名: 「
postgres」 - データベース: 「
postgres」 - パスワード: 「
alloydb」
認証が AlloyDB Studio に成功すると、エディタで SQL コマンドを入力できるようになります。最後のウィンドウの右側にあるプラス記号を使用すると、複数のエディタ ウィンドウを追加できます。
エディタ ウィンドウで AlloyDB のコマンドを入力し、必要に応じて [Run]、[Format]、[Clear] オプションを使用します。
拡張機能を有効にする
このアプリの作成では、拡張機能 pgvector と google_ml_integration を使用します。pgvector 拡張機能を使用すると、ベクトル エンベディングを保存および検索できます。google_ml_integration 拡張機能には、Vertex AI Prediction エンドポイントにアクセスして SQL で予測を取得するために使用する関数が用意されています。次の DDL を実行して、これらの拡張機能を有効にします。
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
データベースで有効になっている拡張機能を確認するには、次の SQL コマンドを実行します。
select extname, extversion from pg_extension;
テーブルを作成する
次の DDL ステートメントを使用してテーブルを作成します。
CREATE TABLE toys ( id VARCHAR(25), name VARCHAR(25), description VARCHAR(20000), quantity INT, price FLOAT, image_url VARCHAR(200), text_embeddings vector(768)) ;
上記のコマンドが正常に実行されると、データベース内のテーブルを表示できるはずです。
データを取り込む
このラボで使用するテストデータには、この SQL ファイル内に約 72 レコードが含まれています。これには id, name, description, quantity, price, image_url フィールドが含まれます。他のフィールドは、後ほどラボで入力します。
そこから行をコピーし、ステートメントを挿入し、それらの行を空白のエディタタブに貼り付けて、[実行] を選択します。
テーブルの内容を確認するには、Apparels という名前のテーブルが表示されるまで [エクスプローラ] セクションを展開します。トリコロン(⋮)を選択すると、テーブルにクエリを実行するオプションが表示されます。新しいエディタタブで SELECT ステートメントが開きます。
権限を付与
次のステートメントを実行して、embedding 関数の実行権限をユーザー postgres に付与します。
GRANT EXECUTE ON FUNCTION embedding TO postgres;
AlloyDB サービス アカウントに Vertex AI ユーザーロールを付与する
Cloud Shell ターミナルに移動し、次のコマンドを実行します。
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
5. コンテキストのエンベディングを作成する
コンピュータにとって、テキストを処理するよりも、数値を処理する方がはるかに簡単です。エンベディング システムは、テキストをベクトル エンベディングと呼ばれる一連の浮動小数点数に変換します。ベクトル エンベディングは、表現や使用する言語などに関係なく、テキストを表す必要があります。
たとえば、海辺の場所は「水上」、「ビーチフロント」、「部屋から海まで歩く」、「シュル・ラ・メール」、「ノア Берегу океана」などと呼ばれます。これらの用語はすべて異なるように見えますが、意味的な意味や ML 用語では、エンベディングは互いに非常に近い必要があります。
データとコンテキストの準備ができたので、SQL を実行して商品説明のエンベディングを embedding フィールドのテーブルに追加します。さまざまなエンベディング モデルを使用できます。Vertex AI の text-embedding-005 を使用しています。プロジェクト全体で必ず同じエンベディング モデルを使用してください。
注: 古い Google Cloud プロジェクトを使用している場合は、textembedding-gecko などの古いバージョンのテキスト エンベディング モデルを引き続き使用しなければならない場合があります。
[AlloyDB Studio] タブに戻り、次の DML を入力します。
UPDATE toys set text_embeddings = embedding( 'text-embedding-005', description);
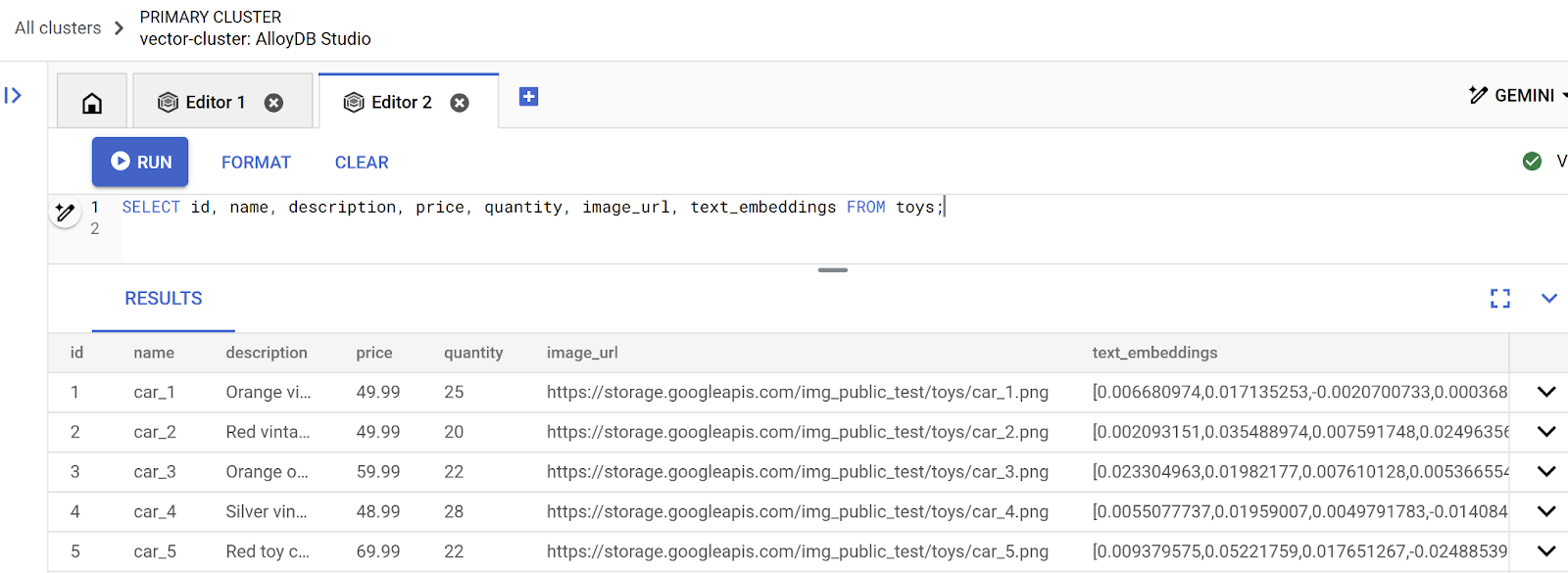
toys テーブルをもう一度見て、エンベディングを確認します。必ず SELECT ステートメントを再実行して、変更を確認してください。
SELECT id, name, description, price, quantity, image_url, text_embeddings FROM toys;
以下のように、おもちゃの説明に対して、浮動小数点数の配列のようなエンベディング ベクトルが返されます。
注: 無料枠で新しく作成された Google Cloud プロジェクトでは、エンベディング モデルに対して 1 秒あたりに許可されるエンベディング リクエストの数に関して、割り当ての問題が発生する可能性があります。ID にフィルタクエリを使用し、エンベディングを生成しながら 1 ~ 5 レコードなどを選択的に選択することをおすすめします。
6. ベクトル検索を実行する
テーブル、データ、エンベディングがすべて準備できたので、ユーザー検索テキストのリアルタイム ベクトル検索を実行しましょう。
お客様から次のような質問を受けたとします。
「I want a white plush teddy bear toy with a floral pattern」
以下のクエリを実行すると、これに一致するものを見つけることができます。
select * from toys
ORDER BY text_embeddings <=> CAST(embedding('text-embedding-005', 'I want a white plush teddy bear toy with a floral pattern') as vector(768))
LIMIT 5;
このクエリを詳しく見ていきましょう。
このクエリでは、
- ユーザーの検索テキストは「
I want a white plush teddy bear toy with a floral pattern.」です embedding()メソッドで、モデルtext-embedding-005を使用してエンベディングに変換します。このステップは、テーブル内のすべての項目にエンベディング関数を適用した最後のステップの後で見覚えがあるはずです。- 「
<=>」は、COSINE SIMILARITY 距離方式の使用を表します。利用可能なすべての類似度測定については、pgvector のドキュメントをご覧ください。 - エンベディング メソッドの結果をベクトル型に変換して、データベースに保存されているベクトルと互換性を持たせています。
- LIMIT 5 は、検索テキストから 5 つの最近傍を抽出することを表します。
結果は次のようになります。
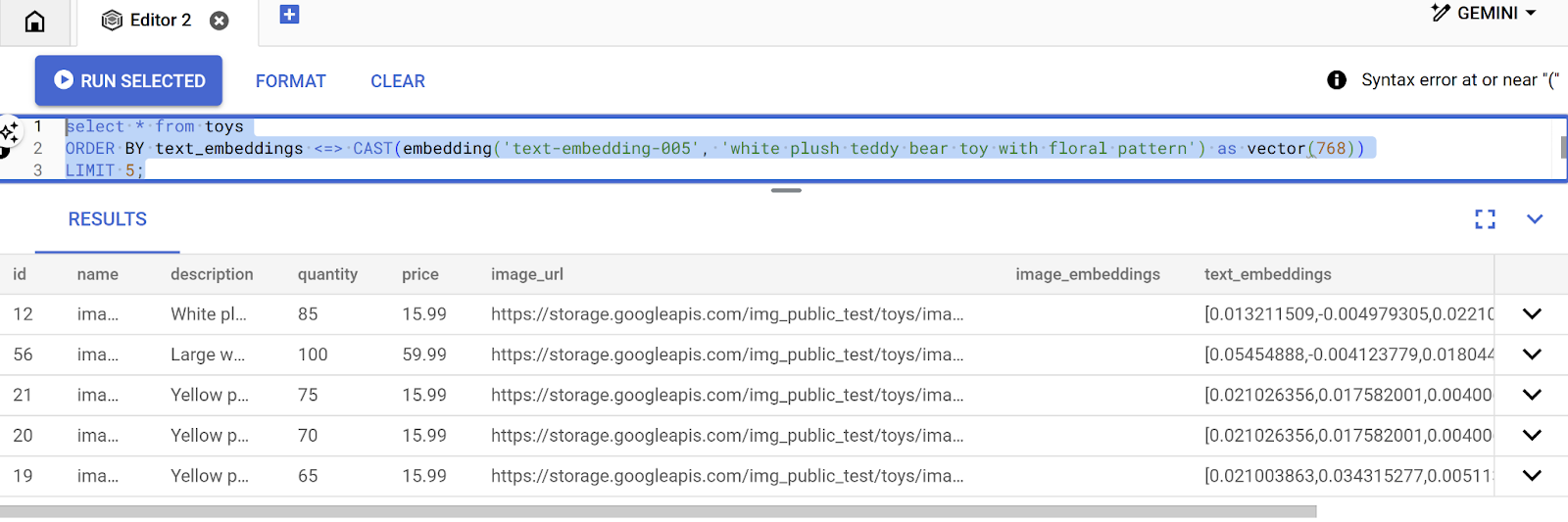
結果からわかるように、一致率は検索テキストにかなり近いものです。テキストを変更して、結果がどのように変わるか試してみましょう。
7. ツールボックス インタラクション用に AlloyDB を準備する
ツールボックスを設定する準備として、AlloyDB インスタンスでパブリック IP 接続を有効にして、新しいツールがデータベースにアクセスできるようにしましょう。
- AlloyDB インスタンスに移動し、[編集] をクリックして [プライマリ インスタンスの編集] ページに移動します。
- [パブリック IP 接続] セクションに移動し、[パブリック IP を有効にする] チェックボックスをオンにして、Cloud Shell マシンの IP アドレスを入力します。
- Cloud Shell マシンの IP を取得するには、Cloud Shell ターミナルに移動して「ifconfig」と入力します。結果から、eth0 inet アドレスを特定し、最後の 2 桁を 0.0 でマスクサイズ「/16」に置き換えます。たとえば、「XX.XX.0.0/16」のようになります。ここで、XX は数字です。
- この IP を、インスタンス編集ページの [承認済み外部ネットワーク] の [ネットワーク] テキストボックスに貼り付けます。
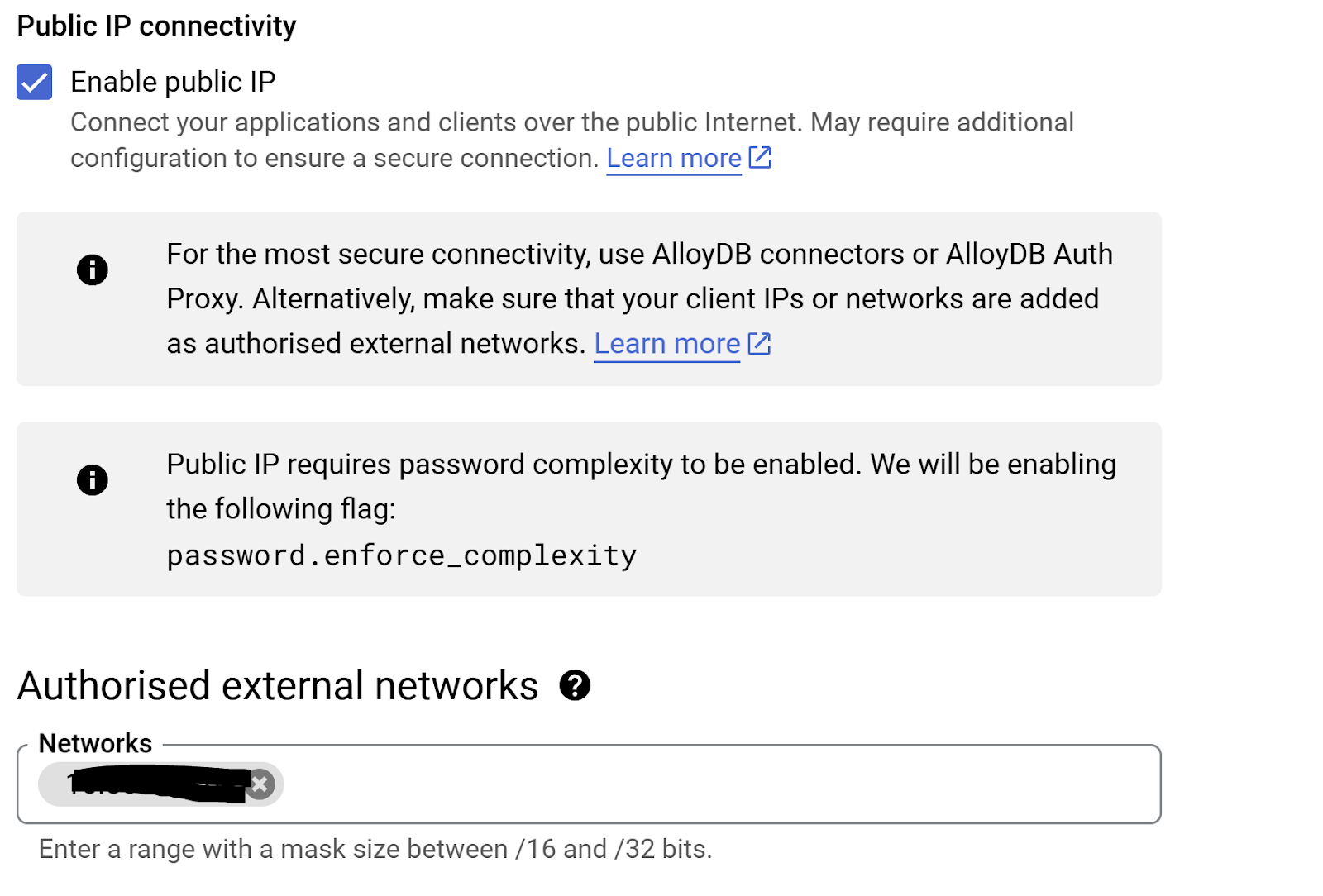
- 完了したら、[インスタンスを更新] をクリックします。
完了するまでに数分かかります。
8. MCP Toolbox for Databases Installation
- ツールの詳細を保存するためのプロジェクト フォルダを作成できます。今回は玩具店のデータを扱うため、「toystore」という名前のフォルダを作成してそのフォルダに移動します。Cloud Shell ターミナルに移動し、目的のプロジェクトが選択され、ターミナルのプロンプトに表示されていることを確認します。Cloud Shell ターミナルから次のコマンドを実行します。
mkdir toystore
cd toystore
- 次のコマンドを実行して、新しいフォルダにツールボックスをダウンロードしてインストールします。
# see releases page for other versions
export VERSION=0.1.0
curl -O https://storage.googleapis.com/genai-toolbox/v$VERSION/linux/amd64/toolbox
chmod +x toolbox
- Cloud Shell エディタに切り替えます。新しく作成した「toystore」フォルダを開き、「tools.yaml」という新しいファイルを作成します。以下の内容をコピーします。YOUR_PROJECT_ID を置き換えて、他のすべての接続の詳細が正しいかどうかを確認します。
sources:
alloydb-toys:
kind: "alloydb-postgres"
project: "YOUR_PROJECT_ID"
region: "us-central1"
cluster: "vector-cluster"
instance: "vector-instance"
database: "postgres"
user: "postgres"
password: "alloydb"
tools:
get-toy-price:
kind: postgres-sql
source: alloydb-toys
description: Get the price of a toy based on a description.
parameters:
- name: description
type: string
description: A description of the toy to search for.
statement: |
SELECT price FROM toys
ORDER BY text_embeddings <=> CAST(embedding('text-embedding-005', $1) AS vector(768))
LIMIT 1;
このツールでは、ユーザーの検索テキスト(カスタム玩具の説明)に最も近いテキストを見つけて、その価格を返します。これを修正して、最も近いおもちゃの上位 5 つの平均価格を求めることもできます。
select avg(price) from ( SELECT price FROM toys ORDER BY text_embeddings <=> CAST(embedding(‘text-embedding-005', $1) AS vector(768)) LIMIT 5 ) as price;
これでツールの定義は完了です。
tools.yaml の構成の詳細については、こちらのドキュメントをご覧ください。
- Cloud Shell ターミナルに切り替えて次のコマンドを入力し、ツールの構成でツールボックス サーバーを起動します。
./toolbox --tools_file "tools.yaml"
- これで、クラウド上でウェブ プレビュー モードでサーバーを開くと、
get-toy-price.という名前の新しいツールでツールボックス サーバーが稼働していることを確認できます。
9. Cloud Run での MCP Toolbox for Databases のデプロイ
このツールを実際に使用できるように、Cloud Run にデプロイしましょう。
- 「Cloud Run にデプロイする」セクションの 3 番目のポイントにある
gcloud run deploy toolboxコマンドに達するまで、このページの手順を 1 つずつ実行します。VPC ネットワーク方式を使用する場合、2 番目のオプションではなく、最初のオプションが必要です。 - デプロイに成功すると、ツールボックス サーバーの Cloud Run にデプロイされたエンドポイントが表示されます。CURL コマンドを使用してテストします。
ヒント:
ページに記載されている手順に沿って慎重に操作してください。
これで、新しくデプロイされたツールをエージェント アプリケーションで使用する準備が整いました。
10. MCP Toolbox for Databases でアプリを接続する
このパートでは、小規模なアプリケーションを作成し、ツールをテストして、アプリケーションのニーズに対応し、レスポンスを取得します。
- Google Colab に移動して、新しいノートブックを開きます。
- ノートブックで次のコマンドを実行します。
!pip install toolbox-core
from toolbox_core import ToolboxClient
# Replace with your Toolbox service's URL
toolbox = ToolboxClient("https://toolbox-*****-uc.a.run.app")
# This tool can be passed to your application!
tool = toolbox.load_tool("get-toy-price")
# If there are multiple tools
# These tools can be passed to your application!
# tools = await client.load_toolset("<<toolset_name>>")
# Invoke the tool with a search text to pass as the parameter
result = tool.invoke({"description": "white plush toy"})
# Print result
print(result)
- 結果は次のようになります。

ツールキットを使用する Python アプリケーションで明示的に呼び出されるツールです。toolbox-langchain.
- このツールを使用し、LangGraph 統合アプリケーション内のエージェントにバインドする場合は、
langgraphツールキットを使用して簡単に行うことができます。 - 詳しくは、コード スニペットをご覧ください。
11. Cloud に移行しましょう!
この Python コード スニペットを Cloud Run の関数でラップして、サーバーレスにしましょう。
- これを Cloud Functions に取り込むために、コード リポジトリ フォルダからソースをコピーします。
- Cloud Run Functions のコンソールに移動し、[関数を作成] をクリックします。
- デモ アプリケーション用には未認証のままにし、次のページで Python 3.11 ランタイムを選択します。
- ステップ 1 で共有したソース リポジトリから
main.pyファイルとrequirements.txtファイルをコピーして、それぞれのファイルに貼り付けます。 - main.py のサーバー URL を実際のサーバー URL に置き換えます。
- 関数をデプロイすると、toystore ウェブ アプリケーションで価格予測ツールにアクセスするための REST エンドポイントが手に入ります。
- エンドポイントは次のようになります。
https://us-central1-*****.cloudfunctions.net/toolbox-toys
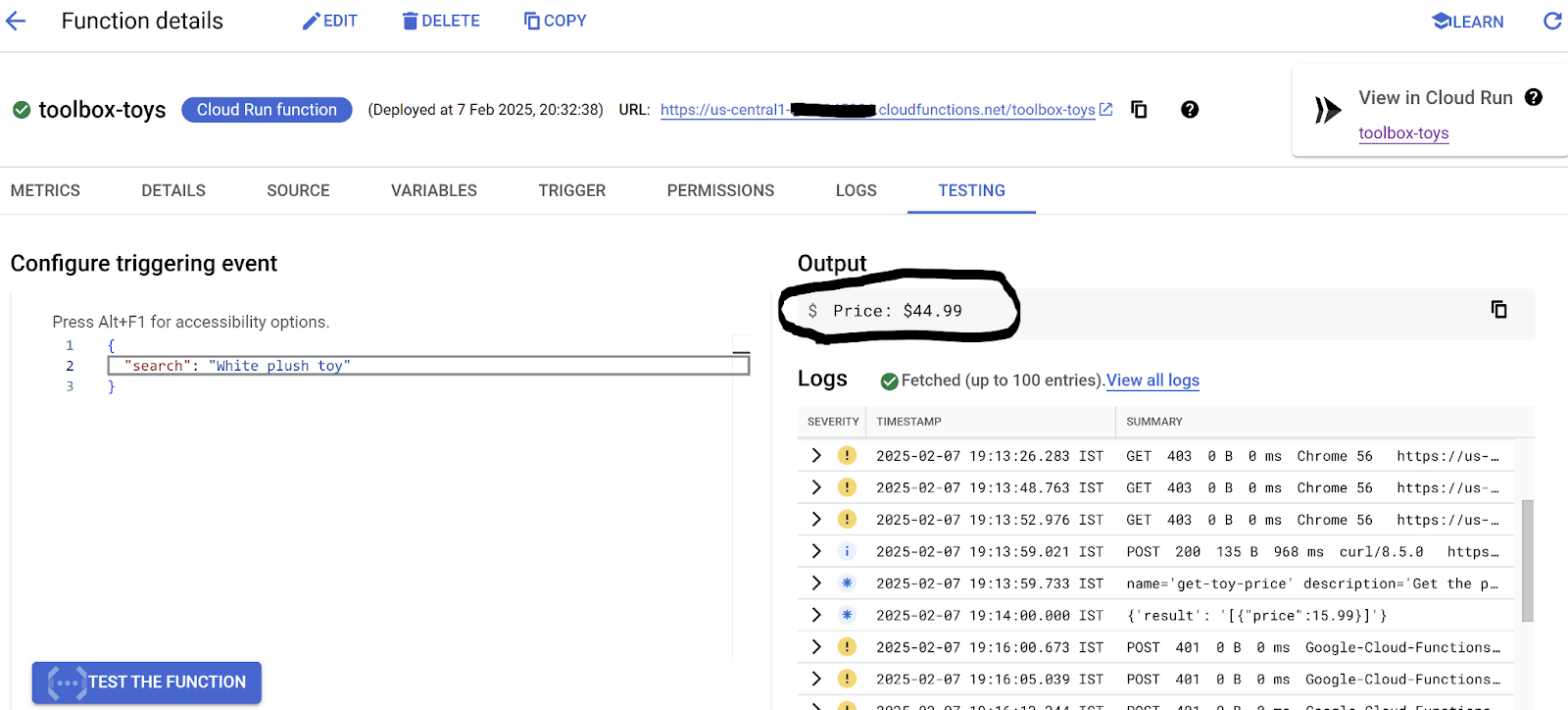
- Cloud Functions コンソールで [テスト] タブに移動し、リクエスト入力として次のように入力することで、直接テストできます。
{
"search": "White plush toy"
}
- [関数をテスト] をクリックするか、Cloud Shell ターミナルで何を選択しても実行します。右側の「Output」の下に結果が表示されます。
12. 完了
これで、データベース、プラットフォーム、生成 AI オーケストレーション フレームワークの間でやり取りできる、堅牢で真にモジュール化されたツールを作成できました。これにより、エージェント アプリケーションの作成を支援できます。