
1. Einführung
Google Antigravity ist eine agentische Entwicklungsplattform, die Ihnen bei der Entwicklung in dieser Ära von KI-Agenten helfen soll. Antigravity ist die zentrale Kommandozentrale für Ihre KI-Agenten und bietet eine einheitliche Plattform zum Starten, Überwachen und Orchestrieren ihrer Aktivitäten.
In diesem Codelab lernen wir zuerst Agenten-Skills kennen. Das ist ein einfaches, offenes Format, mit dem sich die Funktionen von KI-Agenten mit spezialisiertem Wissen und spezialisierten Workflows erweitern lassen. Sie erfahren, was Agent Skills sind, welche Vorteile sie bieten und wie sie aufgebaut sind. Anschließend entwickeln Sie mehrere Agent-Skills, darunter einen Git-Formatter, einen Vorlagengenerator und ein Tool-Code-Scaffolding, die alle in Antigravity verwendet werden können.
Voraussetzungen:
- Antigravity ist installiert und konfiguriert.
- Grundlegendes Wissen zu Google Antigravity Wir empfehlen, das Codelab Erste Schritte mit Google Antigravity durchzuarbeiten.
2. Warum Skills?
Moderne KI-Agenten haben sich von einfachen Zuhörern zu komplexen Vernunftwesen entwickelt, die sich über MCP-Server in lokale Dateisysteme und externe Tools einbinden lassen. Wenn Sie einen Agenten jedoch wahllos mit gesamten Codebases und Hunderten von Tools laden, führt das zu Context Saturation und „Tool Bloat“. Auch bei großen Kontextfenstern führt das Speichern von 40.000 bis 50.000 Tokens ungenutzter Tools im aktiven Speicher zu hoher Latenz, finanzieller Verschwendung und „Kontextverfall“, bei dem das Modell durch irrelevante Daten verwirrt wird.
Die Lösung: Agent Skills
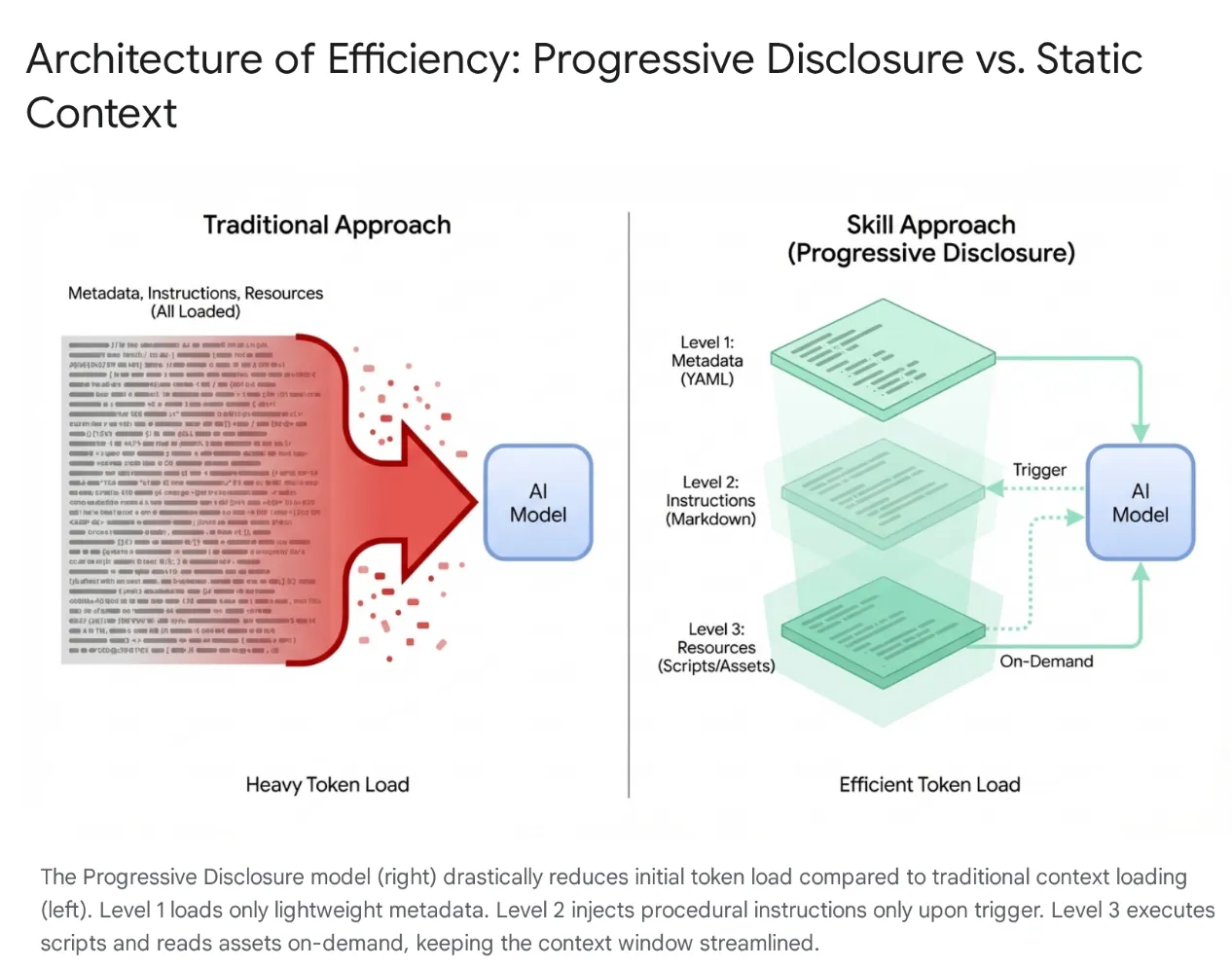
Um dieses Problem zu beheben, hat Anthropic Agent Skills eingeführt und die Architektur von monolithischem Kontextladen auf Progressive Disclosure umgestellt. Anstatt das Modell zu zwingen, sich zu Beginn einer Sitzung jeden spezifischen Workflow (z. B. Datenbankmigrationen oder Sicherheitsüberprüfungen) zu „merken“, werden diese Funktionen in modulare, auffindbare Einheiten verpackt.
Funktionsweise
Das Modell wird anfangs nur mit einem einfachen „Menü“ von Metadaten konfrontiert. Das umfangreiche prozedurale Wissen (Anleitungen und Skripts) wird nur geladen, wenn die Absicht des Nutzers genau mit einem Skill übereinstimmt. So wird dafür gesorgt, dass ein Entwickler, der die Refaktorierung der Authentifizierungs-Middleware anfordert, den Sicherheitskontext erhält, ohne dass nicht zugehörige CSS-Pipelines geladen werden. Der Kontext bleibt also schlank, schnell und kostengünstig.
3. Agent Skills und Antigravity
Im Antigravity-Ökosystem fungieren Skills als spezielle Trainingsmodule, die die Lücke zwischen den Generalistenmodellen und Ihrem spezifischen Kontext schließen. Sie ermöglichen es dem Agent, einen definierten Satz von Anweisungen und Protokollen, z. B. Datenbankmigrationsstandards oder Sicherheitsprüfungen, nur dann zu „aktivieren“, wenn eine entsprechende Aufgabe angefordert wird. Durch das dynamische Laden dieser Ausführungsprotokolle werden KI-Modelle durch Skills von einem generischen Programmierer in einen Spezialisten verwandelt, der sich strikt an die codifizierten Best Practices und Sicherheitsstandards einer Organisation hält.
Was ist ein Skill in Antigravity?
Im Kontext von Google Antigravity ist ein Skill ein verzeichnisbasiertes Paket, das eine Definitionsdatei (SKILL.md) und optionale unterstützende Assets (Skripts, Referenzen, Vorlagen) enthält.
Es handelt sich um einen Mechanismus zur On-Demand-Erweiterung von Funktionen.
- Bei Bedarf: Im Gegensatz zu einem System-Prompt, der immer geladen wird, wird ein Skill nur in den Kontext des Agents geladen, wenn der Agent feststellt, dass er für die aktuelle Anfrage des Nutzers relevant ist. Dadurch wird das Kontextfenster optimiert und der Agent wird nicht durch irrelevante Anweisungen abgelenkt. In großen Projekten mit Dutzenden von Tools ist dieses selektive Laden entscheidend für die Leistung und die Genauigkeit der Schlussfolgerungen.
- Capability Extension: Skills können mehr als nur Anweisungen geben; sie können auch Aktionen ausführen. Durch das Bündeln von Python- oder Bash-Skripts kann ein Skill dem Agenten die Möglichkeit geben, komplexe, mehrstufige Aktionen auf dem lokalen Computer oder in externen Netzwerken auszuführen, ohne dass der Nutzer Befehle manuell ausführen muss. Dadurch wird der Agent von einem Textgenerator zu einem Tool-Nutzer.
Fertigkeiten im Vergleich zum Ökosystem (Tools, Regeln und Workflows)
Das Model Context Protocol (MCP) fungiert als „Hände“ des Agenten und bietet leistungsstarke, dauerhafte Verbindungen zu externen Systemen wie GitHub oder PostgreSQL. Skills fungieren als „Gehirn“, das die Agenten steuert.
MCP verwaltet die zustandsorientierte Infrastruktur, während Skills einfache, kurzlebige Aufgabendefinitionen sind, die die Methodik für die Verwendung dieser Tools enthalten. Dieser serverlose Ansatz ermöglicht es Agents, Ad-hoc-Aufgaben wie das Generieren von Changelogs oder Migrationen auszuführen, ohne dass der operative Aufwand für die Ausführung persistenter Prozesse entsteht. Der Kontext wird nur geladen, wenn die Aufgabe aktiv ist, und sofort wieder freigegeben.
Skills werden durch den Agent ausgelöst: Das Modell erkennt automatisch die Absicht des Nutzers und stellt dynamisch das erforderliche Fachwissen bereit. Diese Architektur ermöglicht eine leistungsstarke Komposition. So kann beispielsweise mit einer globalen Regel die Verwendung eines „Safe-Migration“-Skills bei Datenbankänderungen erzwungen werden. Oder ein einzelner Workflow kann mehrere Skills orchestrieren, um eine robuste Bereitstellungspipeline zu erstellen.
4. Skills erstellen
Beim Erstellen eines Skills in Antigravity müssen Sie eine bestimmte Verzeichnisstruktur und ein bestimmtes Dateiformat einhalten. Durch diese Standardisierung sind Skills portierbar und der Agent kann sie zuverlässig parsen und ausführen. Das Design ist bewusst einfach gehalten und basiert auf weit verbreiteten Formaten wie Markdown und YAML. So wird die Einstiegshürde für Entwickler gesenkt, die die Funktionen ihrer IDE erweitern möchten.
Verzeichnisstruktur
Ein typisches Skill-Verzeichnis sieht so aus:
my-skill/
├── SKILL.md # The definition file
├── scripts/ # [Optional] Python, Bash, or Node scripts
├── run.py
└── util.sh
├── references/ # [Optional] Documentation or templates
└── api-docs.md
└── assets/ # [Optional] Static assets (images, logos)
Diese Struktur trennt die Anliegen effektiv. Die Logik (scripts) ist von der Anweisung (SKILL.md) und dem Wissen (references) getrennt, was den Standardverfahren der Softwareentwicklung entspricht.
Die SKILL.md-Definitionsdatei
Die Datei SKILL.md ist das Herzstück des Skills. Sie geben dem KI-Agenten vor, was der Skill ist, wann er verwendet werden soll und wie er ausgeführt wird.
Sie besteht aus zwei Teilen:
- YAML-Frontmatter
- Markdown-Body.
YAML-Frontmatter
Dies ist die Metadatenebene. Sie ist der einzige Teil des Skills, der vom High-Level-Router des Agents indexiert wird. Wenn ein Nutzer einen Prompt sendet, vergleicht der Agent den Prompt semantisch mit den Beschreibungsfeldern aller verfügbaren Skills.
---
name: database-inspector
description: Use this skill when the user asks to query the database, check table schemas, or inspect user data in the local PostgreSQL instance.
---
Wichtige Felder:
- name: Dies ist nicht obligatorisch. Muss innerhalb des Bereichs eindeutig sein. Kleinbuchstaben, Bindestriche sind zulässig (z.B.
postgres-query,pr-reviewer). Wenn kein Wert angegeben ist, wird standardmäßig der Verzeichnisname verwendet. - description: Dieses Feld ist obligatorisch und das wichtigste. Sie fungiert als „Auslösephrase“. Sie muss aussagekräftig genug sein, damit das LLM die semantische Relevanz erkennen kann. Eine vage Beschreibung wie „Datenbanktools“ reicht nicht aus. Eine genaue Beschreibung wie „Führt schreibgeschützte SQL-Abfragen für die lokale PostgreSQL-Datenbank aus, um Nutzer- oder Transaktionsdaten abzurufen. „Use this for debugging data states“ (Verwende dies zum Debuggen von Datenstatus) sorgt dafür, dass der Skill richtig erkannt wird.
Der Markdown-Text
Der Textkörper enthält die Anleitung. Dabei handelt es sich um „Prompt Engineering“, das in einer Datei gespeichert wird. Wenn der Skill aktiviert ist, werden diese Inhalte in das Kontextfenster des Agent eingefügt.
Der Body sollte Folgendes enthalten:
- Ziel: Eine klare Aussage dazu, was mit dem Skill erreicht werden soll.
- Anleitung: Schrittweise Logik.
- Beispiele: Beispiele für Eingaben und Ausgaben, die das Modell bei der Leistung unterstützen.
- Einschränkungen: „Nicht“-Regeln (z.B. „Keine DELETE-Abfragen ausführen“).
Beispiel für den Text der Datei SKILL.md:
Database Inspector
Goal
To safely query the local database and provide insights on the current data state.
Instructions
- Analyze the user's natural language request to understand the data need.
- Formulate a valid SQL query.
- CRITICAL: Only SELECT statements are allowed.
- Use the script scripts/query_runner.py to execute the SQL.
- Command: python scripts/query_runner.py "SELECT * FROM..."
- Present the results in a Markdown table.
Constraints
- Never output raw user passwords or API keys.
- If the query returns > 50 rows, summarize the data instead of listing it all.
Skriptintegration
Eine der leistungsstärksten Funktionen von Skills ist die Möglichkeit, die Ausführung an Skripts zu delegieren. So kann der Agent Aktionen ausführen, die für ein LLM direkt schwierig oder unmöglich sind, z. B. die Ausführung von Binärdateien, komplexe mathematische Berechnungen oder die Interaktion mit Legacy-Systemen.
Skripts werden im Unterverzeichnis scripts/ abgelegt. Im SKILL.md wird mit einem relativen Pfad auf sie verwiesen.
5. Authoring-Skills
In diesem Abschnitt geht es darum, Skills zu entwickeln, die in Antigravity integriert werden und nach und nach verschiedene Funktionen wie Ressourcen/Scripts usw. zeigen.
Sie können die Skills aus dem GitHub-Repository unter https://github.com/rominirani/antigravity-skills herunterladen.
Bevor wir uns ansehen, wie die einzelnen Skills entwickelt wurden, wollen wir uns ansehen, wie wir sie konfigurieren und in der Antigravity-Produktpalette verfügbar machen. Die unten aufgeführten Ordner sind zum Zeitpunkt der Veröffentlichung dieses Labs relevant.
Antigravity oder Antigravity CLI verwenden
Skills können in zwei Bereichen definiert werden, sodass sowohl projektspezifische als auch nutzerspezifische (globale) Skills möglich sind:
- Globaler Bereich (
~/.gemini/config/skills/): In allen Antigravity-Produkten (Antigravity, Antigravity IDE, Antigravity CLI) und -Projekten verfügbar. Diese Skills sind für alle Projekte auf dem Computer des Nutzers verfügbar. Dies eignet sich für allgemeine Dienstprogramme wie „JSON formatieren“, „UUIDs generieren“, „Code-Stil überprüfen“ oder die Integration in persönliche Produktivitätstools. - Projekt-/Arbeitsbereichsbereich (
<project-root>/.agents/skills/): Dadurch wird der Skill nur in einem bestimmten Projekt verfügbar. Das ist ideal für projektspezifische Skripts, z. B. für die Bereitstellung in einer bestimmten Umgebung, die Datenbankverwaltung für diese App oder das Generieren von Boilerplate-Code für ein proprietäres Framework.
Skills in Antigravity oder der Antigravity CLI installieren
Für diese Anleitung müssen wir nur die folgenden Schritte ausführen (Sie können auch anders vorgehen):
Schritt 1: Führe ein git clone von https://github.com/rominirani/antigravity-skills durch.
Schritt 2: Je nachdem, ob Sie Antigravity oder die Antigravity CLI verwenden, können Sie jetzt zum Ordner antigravity-skills/skills_tutorial wechseln.
Schritt 3: Sie finden eine Reihe von Skills, die in den entsprechenden Ordnern zusammengefasst sind. Kopieren Sie die folgenden vier Ordner:
git-commit-formatterlicense-header-adderdatabase-schema-validatorjson-to-pydantic
in den Zielordner für Skills für das Produkt (Projektbereich oder globaler Bereich).
Schritt 4:Wenn Sie Antigravity oder die Antigravity-Befehlszeile verwenden , kopieren Sie sie in den <project-root>/.agents/skills/-Bereich (Projektbereich).
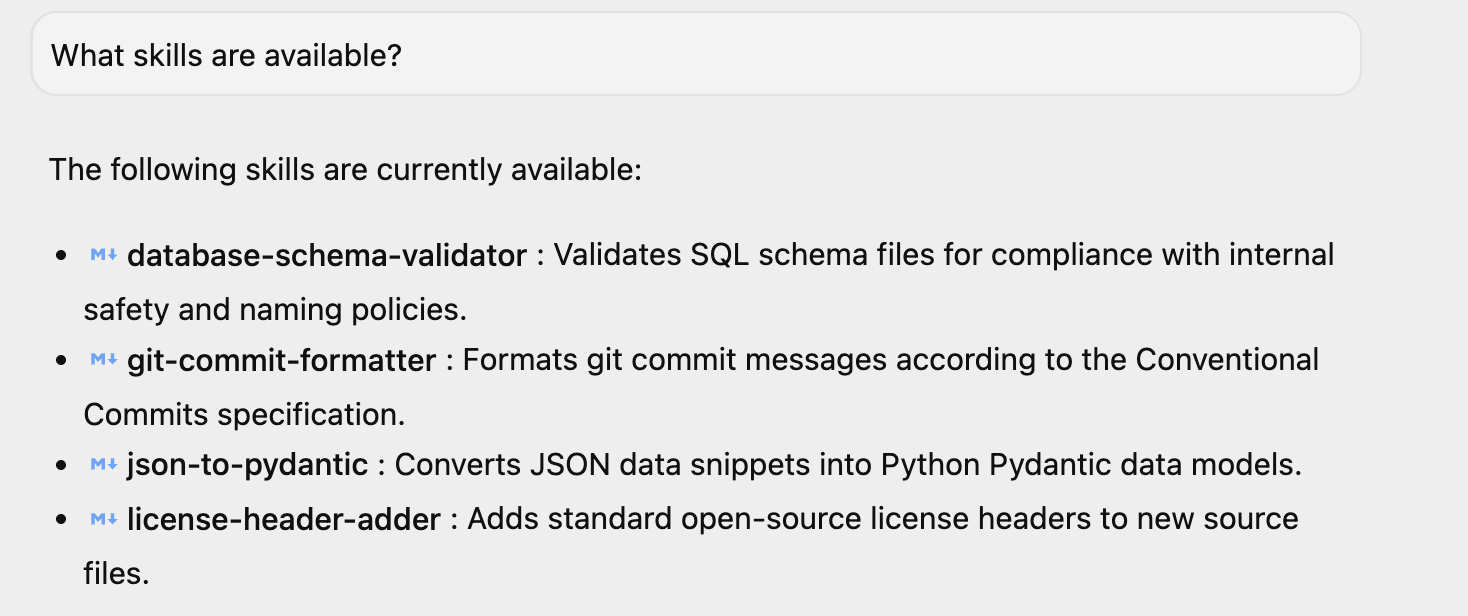
Wenn Sie Antigravity gestartet haben, können Sie eine einfache Frage wie Welche Skills sind verfügbar? stellen. Dort werden die vier Skills angezeigt. Möglicherweise haben Sie auch zusätzliche Skills installiert.
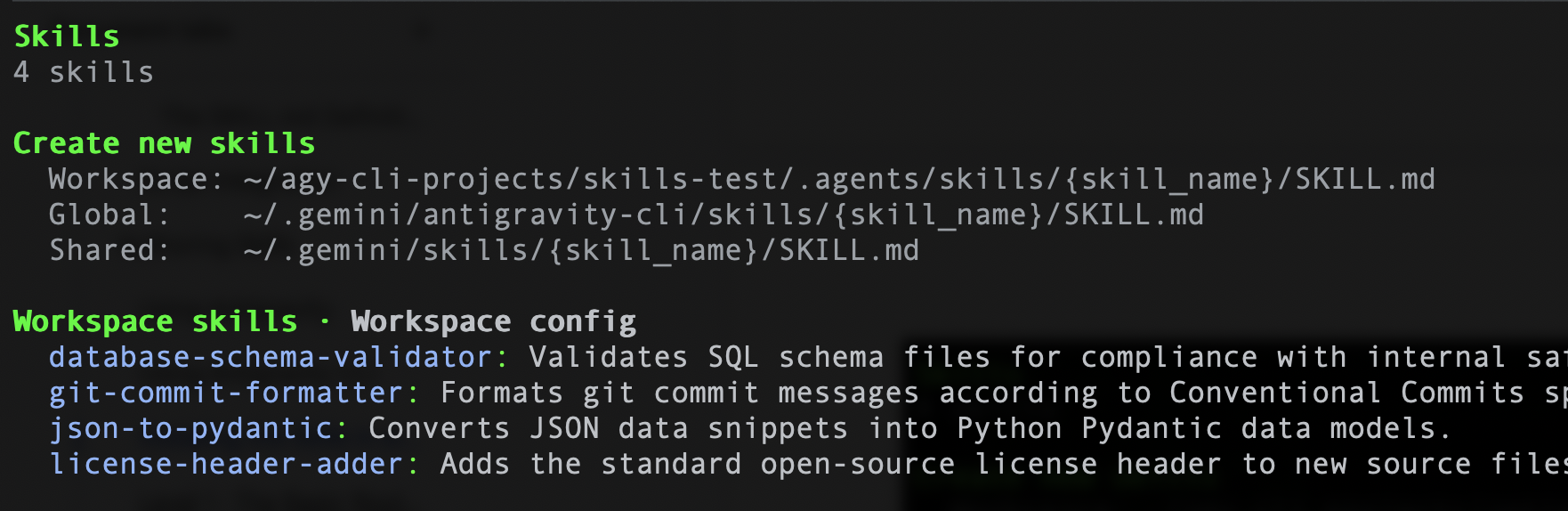
Wenn Sie die Antigravity CLI verwenden, können Sie den folgenden Befehl /skills eingeben. Daraufhin sollten die vier Skills aufgelistet werden. Im Folgenden finden Sie ein -Beispiel:
Nachdem wir nun wissen, wie die Skills eingerichtet werden, sehen wir uns die einzelnen Skills an und erfahren, wie sie erstellt wurden. Sie können diese Vorlagen auch verwenden, um eigene Skills zu erstellen.
Level 1 : Der einfache Router ( git-commit-formatter)
Das ist sozusagen das „Hallo Welt“ der Skills.
Entwickler schreiben oft unsaubere Commit-Nachrichten, z.B. „wip“, „fix bug“ oder „updates“. Die manuelle Durchsetzung von „Conventional Commits“ ist mühsam und wird oft vergessen. Wir implementieren eine Skill, die die Conventional Commits-Spezifikation erzwingt. Indem wir den Agenten einfach über die Regeln informieren, kann er diese auch durchsetzen.
git-commit-formatter/
└── SKILL.md (Instructions only)
Die SKILL.md-Datei wird unten angezeigt:
---
name: git-commit-formatter
description: Formats git commit messages according to Conventional Commits specification. Use this when the user asks to commit changes or write a commit message.
---
Git Commit Formatter Skill
When writing a git commit message, you MUST follow the Conventional Commits specification.
Format
`<type>[optional scope]: <description>`
Allowed Types
- **feat**: A new feature
- **fix**: A bug fix
- **docs**: Documentation only changes
- **style**: Changes that do not affect the meaning of the code (white-space, formatting, etc)
- **refactor**: A code change that neither fixes a bug nor adds a feature
- **perf**: A code change that improves performance
- **test**: Adding missing tests or correcting existing tests
- **chore**: Changes to the build process or auxiliary tools and libraries such as documentation generation
Instructions
1. Analyze the changes to determine the primary `type`.
2. Identify the `scope` if applicable (e.g., specific component or file).
3. Write a concise `description` in an imperative mood (e.g., "add feature" not "added feature").
4. If there are breaking changes, add a footer starting with `BREAKING CHANGE:`.
Example
`feat(auth): implement login with google`
Dieses Beispiel in Antigravity ausführen
Bei den folgenden Schritten wird davon ausgegangen, dass Git auf Ihrem lokalen Computer verfügbar und richtig eingerichtet ist.
Wenn Sie Antigravity oder die Antigravity CLI gestartet haben, führen Sie die folgenden Schritte aus:
Schritt 1: Git-Testrepository einrichten
Bitten Sie den Agent, ein sauberes, isoliertes Verzeichnis zum Testen von Git-Vorgängen einzurichten.
Ihr Prompt:
Create a folder named git_test in the workspace, initialize a git repository inside it, and create an initial file auth.py with def login(): pass. Stage this file and make an initial commit.
Der Agent erstellt das Verzeichnis, initialisiert das Repository, führt die Datei in die Staging-Area ein und committet sie mit einer Nachricht wie „initial commit“.
Schritt 2: Code ändern
Weisen Sie den Agent an, den Code so zu ändern, dass eine Änderung zum Committen vorhanden ist.
Ihr Prompt:
In the git_test folder, modify auth.py to add Google Login functionality.
Der Agent bearbeitet die Datei, um eine neue Funktion hinzuzufügen, und bereitet sie so für die Commit-Phase vor.
Schritt 3: Änderungen stagen und committen
Lösen Sie den git-commit-formatter-Skill aus, indem Sie den Agenten bitten, die Änderungen zu stagen und einen Commit zu erstellen.
Ihr Prompt:
Stage the changes in the git_test folder and commit them. Make sure to format the commit message using the Conventional Commits skill.
Der KI-Agent führt git add auth.py aus, analysiert den Diff, um festzustellen, dass dem Modul auth eine neue Funktion hinzugefügt wurde, und formuliert eine Nachricht für den konventionellen Commit wie feat(auth): implement google login, bevor er git commit ausführt.
Schritt 4: Git-Log überprüfen
Bitten Sie den Kundenservicemitarbeiter, den Git-Verlauf abzurufen, damit Sie bestätigen können, dass der formatierte Commit erfolgreich aufgezeichnet wurde.
Ihr Prompt:
Show me the git log in the git_test folder.
Der Agent führt git log -n 5 aus und gibt die Ausgabe mit der formatierten Commit-Nachricht zurück.
Level 2: Asset-Nutzung (license-header-adder)
Dies ist das Muster „Referenz“.
Für jede Quelldatei in einem Unternehmensprojekt ist möglicherweise ein bestimmter 20-zeiliger Apache 2.0-Lizenzheader erforderlich. Es ist ineffizient, diesen statischen Text direkt in den Prompt (oder SKILL.md) einzufügen. Bei jeder Indexierung des Skills werden Tokens verbraucht und das Modell kann Tippfehler in Rechtstexten „halluzinieren“. Es empfiehlt sich, den statischen Text in eine Nur-Text-Datei in einem resources/-Ordner auszulagern. Der Skill weist den Agenten an, diese Datei nur bei Bedarf zu lesen.
Sie finden die Dateien im Ordner license-header-adder im Verzeichnis skills.
license-header-adder/
├── SKILL.md
└── resources/
└── HEADER_TEMPLATE.txt (The heavy text)
Die SKILL.md-Datei wird unten angezeigt:
---
name: license-header-adder
description: Adds the standard open-source license header to new source files. Use involves creating new code files that require copyright attribution.
---
# License Header Adder Skill
This skill ensures that all new source files have the correct copyright header.
## Instructions
1. **Read the Template**:
First, read the content of the header template file located at `resources/HEADER_TEMPLATE.txt`.
2. **Prepend to File**:
When creating a new file (e.g., `.py`, `.java`, `.js`, `.ts`, `.go`), prepend the `target_file` content with the template content.
3. **Modify Comment Syntax**:
- For C-style languages (Java, JS, TS, C++), keep the `/* ... */` block as is.
- For Python, Shell, or YAML, convert the block to use `#` comments.
- For HTML/XML, use `<!-- ... -->`.
Dieses Beispiel in Antigravity ausführen
Wenn Sie Antigravity oder die Antigravity CLI gestartet haben, führen Sie die folgenden Schritte aus:
Schritt 1: Python-Datei mit Beispielcode erstellen
Ihr Prompt:
Create a new file my_script.py with the following python code:
def hello():
print("Hello, World!")
Was ist passiert (Erklärung): Der Agent hat ein Tool zum Schreiben von Dateien (write_to_file) aufgerufen, um eine neue Datei mit dem Namen „my_script.py“ direkt in Ihrem aktiven Arbeitsbereichverzeichnis zu erstellen und die grundlegende Python-Funktion hineinzuschreiben. Außerdem wurde durch den Prompt der Skill license-header-adder ausgelöst. Der Agent hat die Lizenzvorlagendatei (HEADER_TEMPLATE.txt) gefunden und gelesen, den Kommentarstil von C-Blockkommentaren (/* … */) zu Python-Kommentaren (#) geändert und sie mit dem Tool replace_file_content oben in die Datei eingefügt.
Schritt 2: Dateiinhalt überprüfen
Sehen Sie sich die Datei my_script.py an. Oben ist der Lizenzheader zu sehen.
Stufe 3: Lernen anhand von Beispielen (json-to-pydantic)
Das Muster „Few-Shot“.
Das Umwandeln von losen Daten (z. B. einer JSON API-Antwort) in strengen Code (z. B. Pydantic-Modelle) erfordert Dutzende von Entscheidungen. Wie sollen wir die Klassen benennen? Sollten wir Optional verwenden? snake_case oder camelCase? Es ist mühsam und fehleranfällig, diese 50 Regeln auf Englisch zu formulieren.
LLMs sind Engines für den Musterabgleich.
Es ist oft effektiver, Ihren Skill mit einem goldenen Beispiel (Input -> Output) zu erstellen, als ausführliche Anweisungen zu geben.
Wechseln Sie zum Ordner json-to-pydantic/, der die Skill-Dateien enthält, wie unten dargestellt:
json-to-pydantic/
├── SKILL.md
└── examples/
├── input_data.json (The Before State)
└── output_model.py (The After State)
Die SKILL.md-Datei wird unten angezeigt:
---
name: json-to-pydantic
description: Converts JSON data snippets into Python Pydantic data models.
---
# JSON to Pydantic Skill
This skill helps convert raw JSON data or API responses into structured, strongly-typed Python classes using Pydantic.
Instructions
1. **Analyze the Input**: Look at the JSON object provided by the user.
2. **Infer Types**:
- `string` -> `str`
- `number` -> `int` or `float`
- `boolean` -> `bool`
- `array` -> `List[Type]`
- `null` -> `Optional[Type]`
- Nested Objects -> Create a separate sub-class.
3. **Follow the Example**:
Review `examples/` to see how to structure the output code. notice how nested dictionaries like `preferences` are extracted into their own class.
- Input: `examples/input_data.json`
- Output: `examples/output_model.py`
Style Guidelines
- Use `PascalCase` for class names.
- Use type hints (`List`, `Optional`) from `typing` module.
- If a field can be missing or null, default it to `None`.
Im Ordner /examples befinden sich die JSON-Datei und die Ausgabedatei , d.h. die Python-Datei. Beide werden unten dargestellt:
input_data.json
{
"user_id": 12345,
"username": "jdoe_88",
"is_active": true,
"preferences": {
"theme": "dark",
"notifications": [
"email",
"push"
]
},
"last_login": "2024-03-15T10:30:00Z",
"meta_tags": null
}
output_model.py
from pydantic import BaseModel, Field
from typing import List, Optional
class Preferences(BaseModel):
theme: str
notifications: List[str]
class User(BaseModel):
user_id: int
username: str
is_active: bool
preferences: Preferences
last_login: Optional[str] = None
meta_tags: Optional[List[str]] = None
Dieses Beispiel in Antigravity ausführen
Wenn Sie Antigravity oder die Antigravity CLI gestartet haben, führen Sie die folgenden Schritte aus:
Schritt 1: JSON-Datei mit Beispieldaten erstellen
Bitten Sie den Agent, eine neue Datei product.json mit der rohen JSON-Nutzlast zu erstellen.
Ihr Prompt:
Create a new file product.json with the following JSON:
{
"product": "Widget",
"cost": 10.99,
"stock": null
}
Schritt 2: JSON in ein Pydantic-Modell konvertieren
Lösen Sie den json-to-pydantic-Skill aus, um die JSON-Daten in eine strukturierte Pydantic-Klasse zu konvertieren.
Ihr Prompt:
Convert the JSON in product.json to a Pydantic model and save it to product_model.py.
Schritt 3: Ausgabe überprüfen
Sehen Sie sich die Datei product_model.py an. Sie enthält das vollständige Pydantic-Modell.
Stufe 4: Prozedurale Logik (database-schema-validator)
Dies ist das Muster „Tool Use“ (Tool-Nutzung).
Wenn Sie ein LLM fragen: „Ist dieses Schema sicher?“, wird es möglicherweise antworten, dass alles in Ordnung ist, auch wenn ein wichtiger Primärschlüssel fehlt, einfach weil der SQL-Code korrekt aussieht.
Wir delegieren diese Prüfung an ein deterministisches Script. Mit unserem Skill database-schema-validator wird der Agent angewiesen, ein von uns geschriebenes Python-Script auszuführen. Das Skript liefert binäre (Wahr/Falsch) Ergebnisse.
database-schema-validator/
├── SKILL.md
└── scripts/
└── validate_schema.py (The Validator)
Die SKILL.md-Datei wird unten angezeigt:
---
name: database-schema-validator
description: Validates SQL schema files for compliance with internal safety and naming policies.
---
# Database Schema Validator Skill
This skill ensures that all SQL files provided by the user comply with our strict database standards.
Policies Enforced
1. **Safety**: No `DROP TABLE` statements.
2. **Naming**: All tables must use `snake_case`.
3. **Structure**: Every table must have an `id` column as PRIMARY KEY.
Instructions
1. **Do not read the file manually** to check for errors. The rules are complex and easily missed by eye.
2. **Run the Validation Script**:
Use the `run_command` tool to execute the python script provided in the `scripts/` folder against the user's file.
`python scripts/validate_schema.py <path_to_user_file>`
3. **Interpret Output**:
- If the script returns **exit code 0**: Tell the user the schema looks good.
- If the script returns **exit code 1**: Report the specific error messages printed by the script to the user and suggest fixes.
Die validate_schema.py-Datei wird unten angezeigt:
import sys
import re
def validate_schema(filename):
"""
Validates a SQL schema file against internal policy:
1. Table names must be snake_case.
2. Every table must have a primary key named 'id'.
3. No 'DROP TABLE' statements allowed (safety).
"""
try:
with open(filename, 'r') as f:
content = f.read()
lines = content.split('\n')
errors = []
# Check 1: No DROP TABLE
if re.search(r'DROP TABLE', content, re.IGNORECASE):
errors.append("ERROR: 'DROP TABLE' statements are forbidden.")
# Check 2 & 3: CREATE TABLE checks
table_defs = re.finditer(r'CREATE TABLE\s+(?P<name>\w+)\s*\((?P<body>.*?)\);', content, re.DOTALL | re.IGNORECASE)
for match in table_defs:
table_name = match.group('name')
body = match.group('body')
# Snake case check
if not re.match(r'^[a-z][a-z0-9_]*$', table_name):
errors.append(f"ERROR: Table '{table_name}' must be snake_case.")
# Primary key check
if not re.search(r'\bid\b.*PRIMARY KEY', body, re.IGNORECASE):
errors.append(f"ERROR: Table '{table_name}' is missing a primary key named 'id'.")
if errors:
for err in errors:
print(err)
sys.exit(1)
else:
print("Schema validation passed.")
sys.exit(0)
except FileNotFoundError:
print(f"Error: File '{filename}' not found.")
sys.exit(1)
if __name__ == "__main__":
if len(sys.argv) != 2:
print("Usage: python validate_schema.py <schema_file>")
sys.exit(1)
validate_schema(sys.argv[1])
Dieses Beispiel in Antigravity ausführen
Wenn Sie Antigravity oder die Antigravity CLI gestartet haben, führen Sie die folgenden Schritte aus:
Schritt 1: JSON-Datei mit Beispieldaten erstellen
Bitten Sie den Agent, eine neue Datei bad_schema.sql mit mehreren Richtlinienverstößen zu erstellen.
Ihr Prompt:
Create a new file bad_schema.sql with the following SQL:
DROP TABLE IF EXISTS legacy_users;
CREATE TABLE userProfile (
id INT PRIMARY KEY,
bio TEXT
);
CREATE TABLE posts (
title TEXT,
content TEXT,
created_at TIMESTAMP
);
CREATE TABLE comments (
id INT PRIMARY KEY,
post_id INT,
body TEXT
);
Die oben genannte Schemadatei verstößt gegen alle drei Richtlinien: Sie verwendet eine verbotene DROP TABLE-Anweisung, camelCase für den Tabellennamen userProfile und den Primärschlüssel id in der Tabelle posts.
Schritt 2: SQL-Schema validieren
Lösen Sie den database-schema-validator-Skill aus, um das Python-Validierungsskript für Ihre Datei auszuführen.
Ihr Prompt:
Validate bad_schema.sql using the database-schema-validator skill.
Schritt 3: Ausgabe überprüfen
Der Kundenservicemitarbeiter meldet den Fehler und zeigt die spezifischen Fehler, die vom Skript gefunden wurden, direkt im Chat an. Die Beispielausgabe ist unten dargestellt:
Suggested Fixes:
Remove the line DROP TABLE IF EXISTS legacy_users; as dropping tables is forbidden by safety policy.
Rename the table userProfile to use snake_case (e.g., user_profile).
Add a primary key column named id to the posts table definition.
6. Das Developer Toolkit (Agents CLI-Skills)
Das Muster „Aktion und Lebenszyklus“.
Die Entwicklung von KI-Agents umfasst sich wiederholende Aufgaben im Lebenszyklus: Scaffolding von Boilerplate-Dateien, Konfiguration lokaler Laufzeitumgebungen, Ausführung von Test-Prompts und Start interaktiver Playgrounds.
Anstatt Ihren Coding-Assistenten zu zwingen, Verzeichnisstrukturen zu erraten oder Boilerplate-Agentenkonfigurationen von Grund auf neu zu schreiben, werden diese Lifecycle-Kenntnisse in Agents CLI-Skills in spezifischen Agenten-Skills zusammengefasst.
Die Agent CLI-Skills (Command Line Interface) bieten eine optimierte, entwicklerorientierte Automatisierung direkt in Ihrem Terminal und schließen die Lücke zwischen rohem Code und autonomer Ausführung. Das Agent Development Kit (ADK) konzentriert sich auf das programmatische Framework und bietet Ihnen die SDKs, APIs und strukturellen Blaupausen zum Erstellen und Orchestrieren von KI-Agenten. Die Agent CLI-Skills bieten die operative Unterstützung. So können Entwickler Agents lokal erstellen, testen und bereitstellen und erhalten schnelles Feedback, ohne dass sie sich mit einer umfangreichen Benutzeroberfläche auseinandersetzen müssen.
Optional können Agent CLI-Skills, wenn sie Google Cloud zugeordnet sind, als direkte Pipeline zur Infrastruktur auf Unternehmensniveau fungieren. Anstatt sich durch Konsolen zu klicken, können Sie mit CLI-Befehlen Agent-Workflows sofort verpacken, Zugriffsberechtigungen verwalten und sie in Google Cloud-Ökosystemen wie Vertex AI oder Cloud Run bereitstellen. So werden komplexe Aufgaben der Cloud-Architektur in einfache, reproduzierbare Terminalbefehle umgewandelt, wodurch sich autonome Agents viel einfacher in bestehende CI/CD-Bereitstellungspipelines einbinden lassen.
Installation
Achten Sie darauf, dass Python 3.11+, Node.js und der uv-Paketmanager installiert sind. Führen Sie dann den Einrichtungsbefehl in Ihrem Terminal aus:
uvx google-agents-cli setup
Mit diesem Befehl wird die Binärdatei agents-cli installiert und die speziellen Skills für das Scaffolding und die Bewertung in der Umgebung Ihres Coding-Assistenten registriert.
Hinweis: Die Skills werden im Ordner ~/.agents/skills installiert, der für Antigravity sichtbar ist. Wenn Sie diese Skills in der Antigravity CLI sehen möchten, müssen Sie sie in den Ordner ~/.gemini/antigravity-cli/skills (globaler Bereich) verschieben.
Sie können prüfen, ob die Skills in Antigravity geladen wurden, indem Sie einfach fragen, welche Skills verfügbar sind. Unten sehen Sie eine Beispielantwort für die Agent CLI-Skills, die wir gerade installiert haben.

Schritt-für-Schritt-Anleitung
Sobald uvx google-agents-cli setup abgeschlossen ist, können Sie einen KI-Agenten vollständig auf Ihrem lokalen Computer hochfahren, mit ihm interagieren und ihn testen.
Schritt 1: Neues Projekt für KI-Agenten erstellen und initialisieren
Führen Sie den Erstellungsbefehl aus, um ein standardisiertes Layout zu erstellen. Nach der Erstellung müssen Sie die Projektabhängigkeiten installieren, bevor Sie Ausführungsaufgaben ausführen.
# 1. Create a lightweight prototype project structure
agents-cli create weather-assistant --prototype --yes
# 2. Move into the directory and install required ADK dependencies
cd weather-assistant
agents-cli install
Hinter den Kulissen wird ein sauberer Arbeitsbereich mit app/agent.py (Ihrem Hauptcode), pyproject.toml (Paketmetadaten) und agents-cli-manifest.yaml (Projekt-Tracker) erstellt.
Schritt 2: Lokale Testabfrage ausführen
Führen Sie einen schnellen, direkten Befehlszeilentest für Ihren Agenten aus. Achten Sie darauf, dass Sie GEMINI_API_KEY in Ihrem Terminal exportiert haben, wenn Sie nicht die Standardanmeldedaten für Anwendungen (Application Default Credentials, ADC) von Google Cloud verwenden. Hier können Sie einen Gemini API-Schlüssel erhalten. Sobald Sie den Schlüssel haben, exportieren Sie ihn in Ihrem Terminal mit dem folgenden Befehl:
export GEMINI_API_KEY="YOUR_GEMINI_API_KEY"
Geben Sie im Terminal den folgenden Befehl ein:
agents-cli run "How are you?"
Hinter den Kulissen: Die CLI initialisiert den ADK-Lebenszyklus (Agent Development Kit) vollständig im Arbeitsspeicher Ihres Terminals. Der Prompt wird sicher über Ihre lokalen Anmeldedaten weitergeleitet und die Livestreaming-Antwort wird direkt in Ihrer Befehlszeile protokolliert.
Schritt 3: Interactive Web Playground starten
Starten Sie den integrierten, lokalen webbasierten Playground, um visuell mit Ihrem Agenten zu interagieren.
agents-cli playground
Was passiert im Hintergrund: Über die Befehlszeile wird ein ADK-Web-UI-Server gestartet, der in der Regel unter http://localhost:8080 oder als Fallback unter http://127.0.0.1:8000 erreichbar ist. Hot-Reloading ist ebenfalls verfügbar. Wählen Sie in der Weboberfläche oben im Drop-down-Menü App auswählen die Option App aus und interagieren Sie mit dem Agenten über die Konversationsschnittstelle auf der rechten Seite der Webanwendung.
7. Agent-Skills mit „npx skills“ installieren
npx skills ist ein von Vercel Labs entwickeltes Befehlszeilentool, das als Paketmanager für KI-Agents (wie Antigravity, Claude Code, GitHub Copilot, Cursor und Cline) fungiert. Sie ist die CLI für das offene Ökosystem von Agent Skills.
Wenn Sie Agent Skills mit dem Paket npx skills herunterladen und installieren möchten, werden die Skills im Ordner ~/.agents/skills platziert. Es wird zwar erwähnt, dass Tools wie Antigravity die Skills aus diesem Ordner übernehmen, aber zum Zeitpunkt der Erstellung dieses Dokuments übernimmt Antigravity die Skills aus diesem Ordner, die Antigravity CLI jedoch nicht. Wie bereits erwähnt, müssen Sie diese im Ordner ~/.agents/skills installierten Skills in den Projekt- oder globalen Bereich für Skill-Ordner in der Antigravity CLI kopieren, d.h.
- Projektbereich: Befindet sich in
<project-root>/.agent/skills/. - Globaler Umfang: Befindet sich in
~/.gemini/antigravity-cli/skills/.
8. Glückwunsch
Glückwunsch! Sie haben Google Antigravity erfolgreich verwendet, um Ihren ersten Agent-Skill zu erstellen, zu konfigurieren und benutzerdefinierte Funktionen hinzuzufügen.
Sie haben außerdem eine Reihe von Agent-Skills sowohl auf Projekt- als auch auf globaler Ebene konfiguriert und so benutzerdefinierte Tools zum Leben erweckt.
Jetzt können Sie Antigravity die Arbeit in Ihren eigenen Projekten überlassen und Code auf Ihre Weise schreiben.
Kaggle-Auszeichnung „5-Day AI Agents“ erhalten
Haben Sie dieses Lab im Rahmen des 5-Day AI Agents: Intensive Vibe Coding Course with Google von Kaggle absolviert? Abzeichen für die erfolgreiche Teilnahme beantragen: Holen Sie sich das 5‑Day AI Agents Badge.
9. Referenzdokumente
- Codelab : Erste Schritte mit Google Antigravity
- Offizielle Website : https://antigravity.google/
- Dokumentation: https://antigravity.google/docs
- Download : https://antigravity.google/download
- Dokumentation zu Antigravity-Skills: https://antigravity.google/docs/skills