
1. Introduction
Google Antigravity est une plate-forme de développement agentique conçue pour vous aider à développer des applications à l'ère des agents. Antigravity sert de centre de commande central pour vos agents d'IA. Il fournit une plate-forme unifiée pour lancer, surveiller et orchestrer leurs activités.
Dans cet atelier de programmation, nous allons d'abord découvrir les compétences agentiques, un format ouvert et léger permettant d'étendre les capacités des agents IA avec des connaissances et des workflows spécialisés. Vous découvrirez ce que sont les compétences d'agent, leurs avantages et comment elles sont construites. Vous allez ensuite créer plusieurs compétences d'agent, allant d'un outil de mise en forme Git à un générateur de modèles, en passant par un échafaudage de code d'outil et plus encore, le tout utilisable dans Antigravity.
Prérequis :
- Antigravity est installé et configuré.
- Connaissances de base de Google Antigravity Nous vous recommandons de suivre l'atelier de programmation Premiers pas avec Google Antigravity.
2. Pourquoi les compétences ?
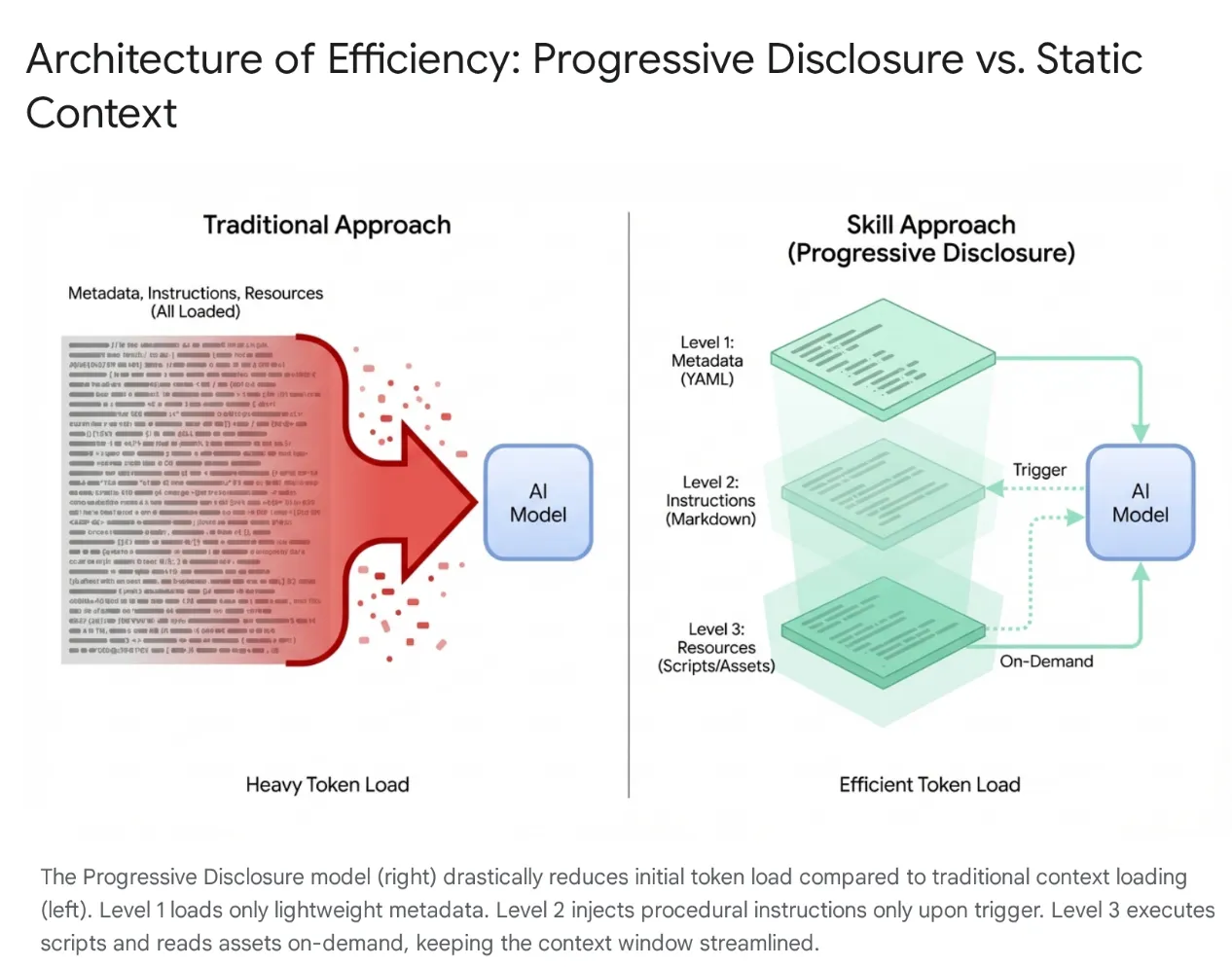
Les agents d'IA modernes sont passés de simples écouteurs à des raisonneurs complexes qui s'intègrent aux systèmes de fichiers locaux et aux outils externes (via les serveurs MCP). Toutefois, le chargement indiscriminé d'un agent avec des bases de code entières et des centaines d'outils entraîne une saturation du contexte et un "gonflement des outils". Même avec de grandes fenêtres de contexte, le fait de déverser 40 000 à 50 000 jetons d'outils inutilisés dans la mémoire active entraîne une latence élevée, un gaspillage financier et une "détérioration du contexte", où le modèle est perturbé par des données non pertinentes.
La solution : les compétences de l'agent
Pour résoudre ce problème, Anthropic a introduit les compétences des agents, en passant d'une architecture de chargement de contexte monolithique à une divulgation progressive. Au lieu de forcer le modèle à "mémoriser" chaque workflow spécifique (comme les migrations de bases de données ou les audits de sécurité) au début d'une session, ces capacités sont regroupées dans des unités modulaires et détectables.
Fonctionnement
Le modèle n'est initialement exposé qu'à un "menu" léger de métadonnées. Il charge les connaissances procédurales lourdes (instructions et scripts) uniquement lorsque l'intention de l'utilisateur correspond spécifiquement à une compétence. Cela garantit qu'un développeur qui demande à refactoriser le middleware d'authentification obtient un contexte de sécurité sans charger de pipelines CSS non liés, ce qui permet de maintenir le contexte léger, rapide et économique.
3. Compétences agentiques et Antigravity
Dans l'écosystème Antigravity, les compétences agissent comme des modules d'entraînement spécialisés qui comblent le fossé entre les modèles généralistes et votre contexte spécifique. Ils permettent à l'agent de "s'équiper" d'un ensemble défini d'instructions et de protocoles (normes de migration de base de données ou contrôles de sécurité, par exemple) uniquement lorsqu'une tâche pertinente est demandée. En chargeant dynamiquement ces protocoles d'exécution, les compétences transforment efficacement l'IA, qui passe d'un programmeur générique à un spécialiste qui respecte rigoureusement les bonnes pratiques et les normes de sécurité codifiées d'une organisation.
Qu'est-ce qu'une compétence dans Antigravity ?
Dans le contexte de Google Antigravity, une compétence est un package basé sur un répertoire contenant un fichier de définition (SKILL.md) et des ressources d'assistance facultatives (scripts, références, modèles).
Il s'agit d'un mécanisme d'extension des fonctionnalités à la demande.
- À la demande : contrairement à une invite système (qui est toujours chargée), une compétence n'est chargée dans le contexte de l'agent que lorsque celui-ci détermine qu'elle est pertinente pour la requête actuelle de l'utilisateur. Cela permet d'optimiser la fenêtre de contexte et d'éviter que l'agent soit distrait par des instructions non pertinentes. Dans les grands projets comportant des dizaines d'outils, ce chargement sélectif est essentiel pour les performances et la précision du raisonnement.
- Extension des capacités : les skills peuvent faire plus que donner des instructions, ils peuvent exécuter des tâches. En regroupant des scripts Python ou Bash, une compétence peut permettre à l'agent d'effectuer des actions complexes en plusieurs étapes sur la machine locale ou les réseaux externes sans que l'utilisateur ait besoin d'exécuter manuellement des commandes. L'agent passe alors du statut de générateur de texte à celui d'utilisateur d'outils.
Compétences vs écosystème (outils, règles et workflows)
Alors que le protocole MCP (Model Context Protocol) sert de "mains " à l'agent en fournissant des connexions persistantes et robustes à des systèmes externes tels que GitHub ou PostgreSQL, les compétences agissent comme le "cerveau" qui les dirige.
MCP gère l'infrastructure avec état, tandis que les compétences sont des définitions de tâches éphémères et légères qui regroupent la méthodologie d'utilisation de ces outils. Cette approche sans serveur permet aux agents d'exécuter des tâches ponctuelles (comme la génération de journaux de modifications ou de migrations) sans la surcharge opérationnelle liée à l'exécution de processus persistants, en chargeant le contexte uniquement lorsque la tâche est active et en le libérant immédiatement après.
Les compétences sont déclenchées par l'agent : le modèle détecte automatiquement l'intention de l'utilisateur et s'équipe dynamiquement de l'expertise spécifique requise. Cette architecture permet une composabilité puissante. Par exemple, une règle globale peut imposer l'utilisation d'une compétence "Migration sécurisée" lors des modifications de la base de données, ou un seul workflow peut orchestrer plusieurs compétences pour créer un pipeline de déploiement robuste.
4. Créer des compétences
La création d'une compétence dans Antigravity suit une structure de répertoire et un format de fichier spécifiques. Cette standardisation garantit la portabilité des compétences et permet à l'agent de les analyser et de les exécuter de manière fiable. La conception est intentionnellement simple et s'appuie sur des formats largement compris comme Markdown et YAML, ce qui réduit la barrière à l'entrée pour les développeurs qui souhaitent étendre les capacités de leur IDE.
Structure des répertoires
Voici à quoi ressemble un répertoire de skills type :
my-skill/
├── SKILL.md # The definition file
├── scripts/ # [Optional] Python, Bash, or Node scripts
├── run.py
└── util.sh
├── references/ # [Optional] Documentation or templates
└── api-docs.md
└── assets/ # [Optional] Static assets (images, logos)
Cette structure sépare efficacement les préoccupations. La logique (scripts) est séparée de l'instruction (SKILL.md) et des connaissances (references), ce qui reflète les pratiques standards de l'ingénierie logicielle.
Fichier de définition SKILL.md
Le fichier SKILL.md est le cerveau de la skill. Il indique à l'agent ce qu'est la compétence, quand l'utiliser et comment l'exécuter.
Il se compose de deux parties :
- Frontmatter YAML
- Corps Markdown.
Frontmatter YAML
Il s'agit de la couche de métadonnées. Il s'agit de la seule partie de la compétence indexée par le routeur de haut niveau de l'agent. Lorsqu'un utilisateur envoie une requête, l'agent effectue une correspondance sémantique entre la requête et les champs de description de toutes les compétences disponibles.
---
name: database-inspector
description: Use this skill when the user asks to query the database, check table schemas, or inspect user data in the local PostgreSQL instance.
---
Principaux champs :
- name : ce champ n'est pas obligatoire. Doit être unique dans le champ d'application. En minuscules, avec des tirets (par exemple,
postgres-query,pr-reviewer). Si aucune valeur n'est fournie, le nom du répertoire sera utilisé par défaut. - description : ce champ est obligatoire et le plus important. Elle sert de "phrase de déclenchement". Elle doit être suffisamment descriptive pour que le LLM puisse reconnaître la pertinence sémantique. Une description vague comme "Outils de base de données" est insuffisante. Une description précise, comme "Exécute des requêtes SQL en lecture seule sur la base de données PostgreSQL locale pour récupérer les données utilisateur ou de transaction. L'option "Utiliser pour déboguer les états de données" permet de s'assurer que la compétence est correctement sélectionnée.
Corps Markdown
Le corps contient les instructions. Il s'agit d'une "prompt engineering" persistante dans un fichier. Lorsque la compétence est activée, ce contenu est injecté dans la fenêtre de contexte de l'agent.
Le corps doit inclure les éléments suivants :
- Objectif : une description claire de ce que permet la compétence.
- Instructions : logique étape par étape.
- Exemples : exemples few-shot d'entrées et de sorties pour guider les performances du modèle.
- Contraintes : règles "Ne pas" (par exemple, "N'exécutez pas de requêtes DELETE").
Exemple de corps de fichier SKILL.md :
Database Inspector
Goal
To safely query the local database and provide insights on the current data state.
Instructions
- Analyze the user's natural language request to understand the data need.
- Formulate a valid SQL query.
- CRITICAL: Only SELECT statements are allowed.
- Use the script scripts/query_runner.py to execute the SQL.
- Command: python scripts/query_runner.py "SELECT * FROM..."
- Present the results in a Markdown table.
Constraints
- Never output raw user passwords or API keys.
- If the query returns > 50 rows, summarize the data instead of listing it all.
Intégration de script
L'une des fonctionnalités les plus puissantes des compétences est la possibilité de déléguer l'exécution à des scripts. Cela permet à l'agent d'effectuer des actions difficiles ou impossibles à réaliser directement par un LLM (comme l'exécution de fichiers binaires, des calculs mathématiques complexes ou l'interaction avec des systèmes existants).
Les scripts sont placés dans le sous-répertoire scripts/. Le SKILL.md les référence par chemin relatif.
5. Créer des compétences
L'objectif de cette section est de développer des compétences qui s'intègrent à Antigravity et d'afficher progressivement diverses fonctionnalités telles que des ressources, des scripts, etc.
Vous pouvez télécharger les compétences à partir du dépôt GitHub à l'adresse https://github.com/rominirani/antigravity-skills.
Avant de comprendre comment chacune de ces compétences a été développée, voyons comment les configurer et les rendre disponibles dans la suite de produits Antigravity. Les dossiers ci-dessous sont applicables au moment de la publication de cet atelier.
Utiliser Antigravity ou Antigravity CLI
Les compétences peuvent être définies à deux niveaux, ce qui permet d'avoir des compétences spécifiques à un projet et des compétences spécifiques à un utilisateur (c'est-à-dire des compétences globales) :
- Champ d'application global (
~/.gemini/config/skills/) : disponible dans tous les produits et projets Antigravity (Antigravity, Antigravity IDE, Antigravity CLI). Ces compétences sont disponibles dans tous les projets sur la machine de l'utilisateur. Cela convient aux utilitaires généraux tels que "Mettre en forme le JSON", "Générer des UUID", "Vérifier le style du code" ou l'intégration aux outils de productivité personnelle. - Champ d'application du projet/de l'espace de travail (
<project-root>/.agents/skills/) : la compétence ne serait disponible que dans un projet spécifique. C'est idéal pour les scripts spécifiques à un projet, tels que le déploiement dans un environnement spécifique, la gestion de bases de données pour cette application ou la génération de code récurrent pour un framework propriétaire.
Installer les compétences dans Antigravity ou la CLI Antigravity
Pour ce tutoriel, il vous suffit de suivre les étapes suivantes (vous pouvez également procéder à votre manière) :
Étape 1 : Effectuez un git clone de https://github.com/rominirani/antigravity-skills.
Étape 2 : Selon que vous utilisez Antigravity ou Antigravity CLI, vous pouvez accéder au dossier antigravity-skills/skills_tutorial.
Étape 3 : Vous trouverez un ensemble de compétences, regroupées dans leurs dossiers respectifs. Copiez les quatre dossiers suivants :
git-commit-formatterlicense-header-adderdatabase-schema-validatorjson-to-pydantic
dans le dossier de compétences cibles du produit (portée du projet ou portée globale).
Étape 4 : Si vous utilisez Antigravity ou Antigravity CLI , copiez-le dans <project-root>/.agents/skills/ (portée du projet).
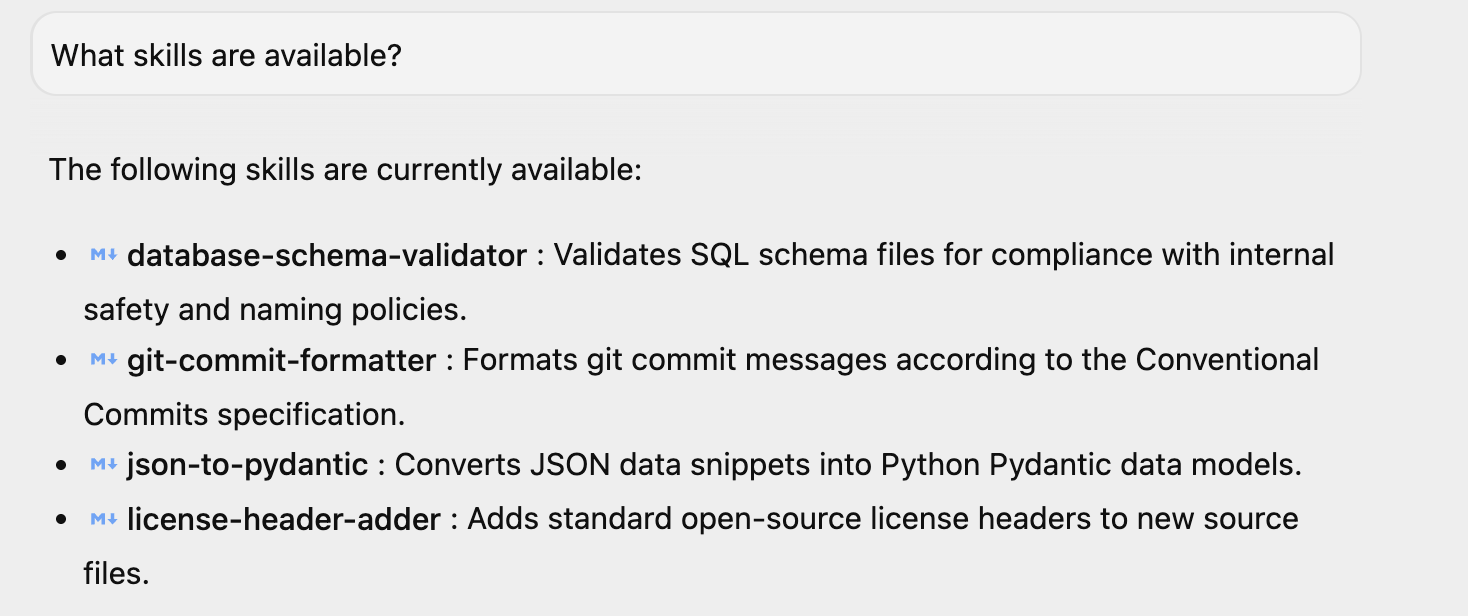
Si vous avez lancé Antigravity, vous pouvez poser une question simple comme Quelles sont les compétences disponibles ? et il vous répondra. Vous pouvez voir les quatre compétences listées. Vous pouvez également disposer de compétences supplémentaires si vous les avez installées dans votre environnement.
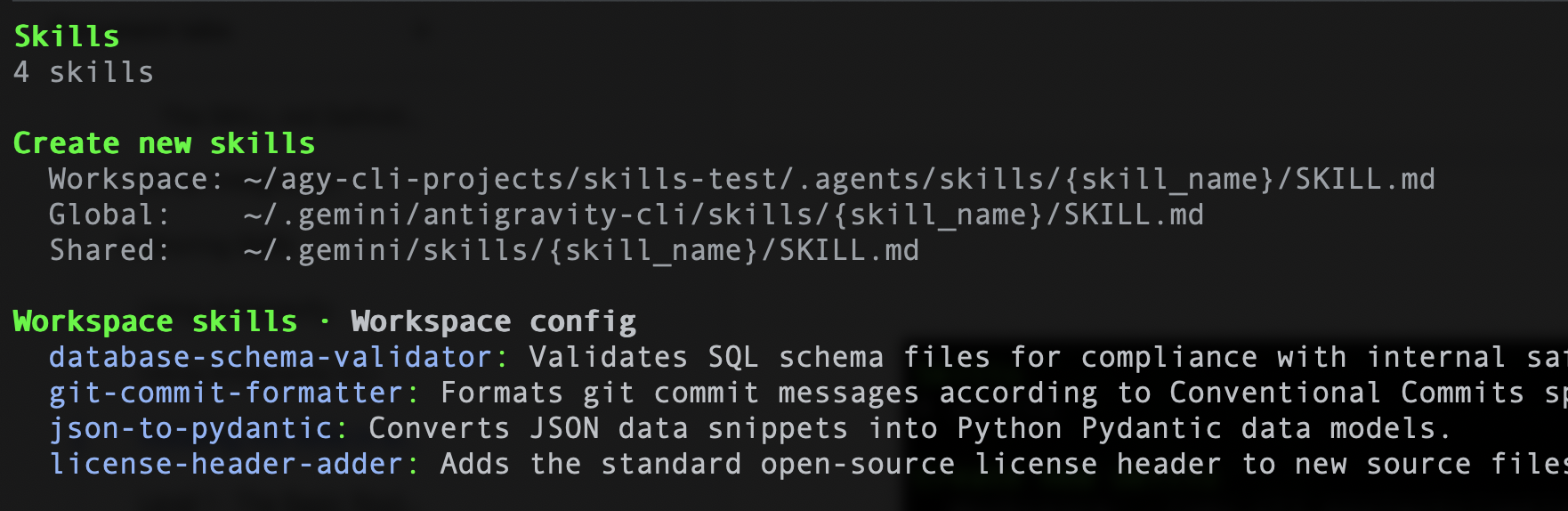
De même, si vous utilisez Antigravity CLI, vous pouvez exécuter la commande /skills, qui devrait lister les quatre compétences. Voici un exemple :
Maintenant que nous savons comment configurer les compétences, examinons chacune d'elles et comprenons comment elles ont été construites. Vous pouvez également utiliser ces modèles pour créer vos propres compétences.
Niveau 1 : le routeur de base ( git-commit-formatter)
Considérons cela comme le "Hello World" des skills.
Les développeurs écrivent souvent des messages de commit paresseux, par exemple "wip", "fix bug" ou "updates". L'application manuelle des "Conventional Commits" est fastidieuse et souvent oubliée. Implémentons une compétence qui applique la spécification Conventional Commits. En lui indiquant simplement les règles, nous lui permettons de les faire appliquer.
git-commit-formatter/
└── SKILL.md (Instructions only)
Le fichier SKILL.md est présenté ci-dessous :
---
name: git-commit-formatter
description: Formats git commit messages according to Conventional Commits specification. Use this when the user asks to commit changes or write a commit message.
---
Git Commit Formatter Skill
When writing a git commit message, you MUST follow the Conventional Commits specification.
Format
`<type>[optional scope]: <description>`
Allowed Types
- **feat**: A new feature
- **fix**: A bug fix
- **docs**: Documentation only changes
- **style**: Changes that do not affect the meaning of the code (white-space, formatting, etc)
- **refactor**: A code change that neither fixes a bug nor adds a feature
- **perf**: A code change that improves performance
- **test**: Adding missing tests or correcting existing tests
- **chore**: Changes to the build process or auxiliary tools and libraries such as documentation generation
Instructions
1. Analyze the changes to determine the primary `type`.
2. Identify the `scope` if applicable (e.g., specific component or file).
3. Write a concise `description` in an imperative mood (e.g., "add feature" not "added feature").
4. If there are breaking changes, add a footer starting with `BREAKING CHANGE:`.
Example
`feat(auth): implement login with google`
Exécuter cet exemple dans Antigravity
Les étapes ci-dessous supposent que Git est disponible sur votre machine locale et correctement configuré.
En supposant que vous ayez lancé Antigravity ou Antigravity CLI, procédez comme suit :
Étape 1 : Configurez un dépôt Git de test
Demandez à l'agent de configurer un répertoire propre et isolé pour tester les opérations Git.
Votre prompt :
Create a folder named git_test in the workspace, initialize a git repository inside it, and create an initial file auth.py with def login(): pass. Stage this file and make an initial commit.
L'agent crée le répertoire, initialise le dépôt, prépare le fichier et l'enregistre avec un message tel que "initial commit".
Étape 2 : Modifiez le code
Demandez à l'agent de modifier le code pour qu'il y ait un changement à valider.
Votre prompt :
In the git_test folder, modify auth.py to add Google Login functionality.
L'agent modifie le fichier pour ajouter une fonctionnalité, le préparant ainsi pour la phase de commit.
Étape 3 : Préparer et valider les modifications
Déclenchez la compétence git-commit-formatter en demandant à l'agent de préparer les modifications et de créer un commit.
Votre prompt :
Stage the changes in the git_test folder and commit them. Make sure to format the commit message using the Conventional Commits skill.
L'agent exécutera git add auth.py, analysera la différence pour déterminer qu'une nouvelle fonctionnalité a été ajoutée au module auth et formulera un message de commit conventionnel tel que feat(auth): implement google login avant d'exécuter git commit.
Étape 4 : Vérifiez le journal Git
Demandez à l'agent de récupérer l'historique Git pour que vous puissiez vérifier que le commit formaté a bien été enregistré.
Votre prompt :
Show me the git log in the git_test folder.
L'agent exécutera git log -n 5 et renverra le résultat affichant le message de commit mis en forme.
Niveau 2 : Utilisation des composants (license-header-adder)
Il s'agit du modèle "Référence".
Chaque fichier source d'un projet d'entreprise peut nécessiter un en-tête de licence Apache 2.0 spécifique de 20 lignes. Il est inutile de placer ce texte statique directement dans la requête (ou SKILL.md). Il consomme des jetons chaque fois que la skill est indexée, et le modèle peut "halluciner" des fautes de frappe dans le texte juridique. Il est recommandé de décharger le texte statique dans un fichier en texte brut dans un dossier resources/. La compétence indique à l'agent de lire ce fichier uniquement en cas de besoin.
Vous trouverez les fichiers dans le dossier license-header-adder du répertoire skills.
license-header-adder/
├── SKILL.md
└── resources/
└── HEADER_TEMPLATE.txt (The heavy text)
Le fichier SKILL.md est présenté ci-dessous :
---
name: license-header-adder
description: Adds the standard open-source license header to new source files. Use involves creating new code files that require copyright attribution.
---
# License Header Adder Skill
This skill ensures that all new source files have the correct copyright header.
## Instructions
1. **Read the Template**:
First, read the content of the header template file located at `resources/HEADER_TEMPLATE.txt`.
2. **Prepend to File**:
When creating a new file (e.g., `.py`, `.java`, `.js`, `.ts`, `.go`), prepend the `target_file` content with the template content.
3. **Modify Comment Syntax**:
- For C-style languages (Java, JS, TS, C++), keep the `/* ... */` block as is.
- For Python, Shell, or YAML, convert the block to use `#` comments.
- For HTML/XML, use `<!-- ... -->`.
Exécuter cet exemple dans Antigravity
En supposant que vous ayez lancé Antigravity ou Antigravity CLI, procédez comme suit :
Étape 1 : Créez le fichier Python avec l'exemple de code
Votre requête :
Create a new file my_script.py with the following python code:
def hello():
print("Hello, World!")
Explication : l'agent a invoqué un outil d'écriture de fichier (write_to_file) pour créer un fichier nommé my_script.py directement dans le répertoire de votre espace de travail actif et y a écrit la fonction Python de base. De plus, la requête a déclenché la compétence license-header-adder. L'agent a localisé et lu le fichier de modèle de licence (HEADER_TEMPLATE.txt), modifié le style de commentaire en passant des commentaires par blocs de style C (/* ... */) aux commentaires de style Python (#), et l'a ajouté en haut du fichier à l'aide de l'outil replace_file_content.
Étape 2 : Vérifiez le contenu du fichier
Examinez le fichier my_script.py. Il contiendra l'en-tête de licence en haut.
Niveau 3 : Apprentissage par l'exemple (json-to-pydantic)
Le modèle "Few-Shot".
La conversion de données non structurées (comme une réponse d'API JSON) en code strict (comme des modèles Pydantic) implique des dizaines de décisions. Comment devons-nous nommer les classes ? Faut-il utiliser Optional ? snake_case ou camelCase ? Écrire ces 50 règles en anglais est fastidieux et source d'erreurs.
Les LLM sont des moteurs de reconnaissance de formes.
Il est souvent plus efficace de créer votre skill à l'aide d'un exemple parfait (Input -> Output) que de donner des instructions détaillées.
Accédez au dossier json-to-pydantic/ contenant les fichiers de compétence, comme indiqué ci-dessous :
json-to-pydantic/
├── SKILL.md
└── examples/
├── input_data.json (The Before State)
└── output_model.py (The After State)
Le fichier SKILL.md est présenté ci-dessous :
---
name: json-to-pydantic
description: Converts JSON data snippets into Python Pydantic data models.
---
# JSON to Pydantic Skill
This skill helps convert raw JSON data or API responses into structured, strongly-typed Python classes using Pydantic.
Instructions
1. **Analyze the Input**: Look at the JSON object provided by the user.
2. **Infer Types**:
- `string` -> `str`
- `number` -> `int` or `float`
- `boolean` -> `bool`
- `array` -> `List[Type]`
- `null` -> `Optional[Type]`
- Nested Objects -> Create a separate sub-class.
3. **Follow the Example**:
Review `examples/` to see how to structure the output code. notice how nested dictionaries like `preferences` are extracted into their own class.
- Input: `examples/input_data.json`
- Output: `examples/output_model.py`
Style Guidelines
- Use `PascalCase` for class names.
- Use type hints (`List`, `Optional`) from `typing` module.
- If a field can be missing or null, default it to `None`.
Dans le dossier /examples, vous trouverez le fichier JSON et le fichier de sortie, c'est-à-dire le fichier Python. Les deux sont présentés ci-dessous :
input_data.json
{
"user_id": 12345,
"username": "jdoe_88",
"is_active": true,
"preferences": {
"theme": "dark",
"notifications": [
"email",
"push"
]
},
"last_login": "2024-03-15T10:30:00Z",
"meta_tags": null
}
output_model.py
from pydantic import BaseModel, Field
from typing import List, Optional
class Preferences(BaseModel):
theme: str
notifications: List[str]
class User(BaseModel):
user_id: int
username: str
is_active: bool
preferences: Preferences
last_login: Optional[str] = None
meta_tags: Optional[List[str]] = None
Exécuter cet exemple dans Antigravity
En supposant que vous ayez lancé Antigravity ou Antigravity CLI, procédez comme suit :
Étape 1 : Créez le fichier JSON avec des exemples de données
Demandez à l'agent de créer un fichier product.json contenant la charge utile JSON brute.
Votre requête :
Create a new file product.json with the following JSON:
{
"product": "Widget",
"cost": 10.99,
"stock": null
}
Étape 2 : Convertissez le JSON en modèle Pydantic
Déclenchez la compétence json-to-pydantic pour convertir les données JSON en classe Pydantic structurée.
Votre requête :
Convert the JSON in product.json to a Pydantic model and save it to product_model.py.
Étape 3 : Vérifiez le résultat
Examinez le fichier product_model.py. Il contiendra le modèle Pydantic terminé.
Niveau 4 : Logique procédurale (database-schema-validator)
Il s'agit du modèle "Utilisation d'outils".
Si vous demandez à un LLM "Ce schéma est-il sûr ?", il peut vous répondre que tout va bien, même s'il manque une clé primaire critique, simplement parce que le code SQL semble correct.
Déléguons cette vérification à un script déterministe. Notre compétence database-schema-validator redirigera l'agent pour exécuter un script Python que nous avons écrit. Le script fournit une vérité binaire (True/False).
database-schema-validator/
├── SKILL.md
└── scripts/
└── validate_schema.py (The Validator)
Le fichier SKILL.md est présenté ci-dessous :
---
name: database-schema-validator
description: Validates SQL schema files for compliance with internal safety and naming policies.
---
# Database Schema Validator Skill
This skill ensures that all SQL files provided by the user comply with our strict database standards.
Policies Enforced
1. **Safety**: No `DROP TABLE` statements.
2. **Naming**: All tables must use `snake_case`.
3. **Structure**: Every table must have an `id` column as PRIMARY KEY.
Instructions
1. **Do not read the file manually** to check for errors. The rules are complex and easily missed by eye.
2. **Run the Validation Script**:
Use the `run_command` tool to execute the python script provided in the `scripts/` folder against the user's file.
`python scripts/validate_schema.py <path_to_user_file>`
3. **Interpret Output**:
- If the script returns **exit code 0**: Tell the user the schema looks good.
- If the script returns **exit code 1**: Report the specific error messages printed by the script to the user and suggest fixes.
Le fichier validate_schema.py est présenté ci-dessous :
import sys
import re
def validate_schema(filename):
"""
Validates a SQL schema file against internal policy:
1. Table names must be snake_case.
2. Every table must have a primary key named 'id'.
3. No 'DROP TABLE' statements allowed (safety).
"""
try:
with open(filename, 'r') as f:
content = f.read()
lines = content.split('\n')
errors = []
# Check 1: No DROP TABLE
if re.search(r'DROP TABLE', content, re.IGNORECASE):
errors.append("ERROR: 'DROP TABLE' statements are forbidden.")
# Check 2 & 3: CREATE TABLE checks
table_defs = re.finditer(r'CREATE TABLE\s+(?P<name>\w+)\s*\((?P<body>.*?)\);', content, re.DOTALL | re.IGNORECASE)
for match in table_defs:
table_name = match.group('name')
body = match.group('body')
# Snake case check
if not re.match(r'^[a-z][a-z0-9_]*$', table_name):
errors.append(f"ERROR: Table '{table_name}' must be snake_case.")
# Primary key check
if not re.search(r'\bid\b.*PRIMARY KEY', body, re.IGNORECASE):
errors.append(f"ERROR: Table '{table_name}' is missing a primary key named 'id'.")
if errors:
for err in errors:
print(err)
sys.exit(1)
else:
print("Schema validation passed.")
sys.exit(0)
except FileNotFoundError:
print(f"Error: File '{filename}' not found.")
sys.exit(1)
if __name__ == "__main__":
if len(sys.argv) != 2:
print("Usage: python validate_schema.py <schema_file>")
sys.exit(1)
validate_schema(sys.argv[1])
Exécuter cet exemple dans Antigravity
En supposant que vous ayez lancé Antigravity ou Antigravity CLI, procédez comme suit :
Étape 1 : Créez le fichier JSON avec des exemples de données
Demandez à l'agent de créer un fichier bad_schema.sql contenant plusieurs cas de non-respect des règles.
Votre requête :
Create a new file bad_schema.sql with the following SQL:
DROP TABLE IF EXISTS legacy_users;
CREATE TABLE userProfile (
id INT PRIMARY KEY,
bio TEXT
);
CREATE TABLE posts (
title TEXT,
content TEXT,
created_at TIMESTAMP
);
CREATE TABLE comments (
id INT PRIMARY KEY,
post_id INT,
body TEXT
);
Le fichier de schéma ci-dessus ne respecte aucune des trois règles : il utilise une instruction DROP TABLE interdite, utilise camelCase pour le nom de la table userProfile et oublie la clé primaire id dans la table posts.
Étape 2 : Valider le schéma SQL
Déclenchez la compétence database-schema-validator pour exécuter le script de validation Python sur votre fichier.
Votre prompt :
Validate bad_schema.sql using the database-schema-validator skill.
Étape 3 : Vérifiez le résultat
L'agent signalera l'échec et affichera les erreurs spécifiques détectées par le script directement dans le chat. Voici un exemple de résultat :
Suggested Fixes:
Remove the line DROP TABLE IF EXISTS legacy_users; as dropping tables is forbidden by safety policy.
Rename the table userProfile to use snake_case (e.g., user_profile).
Add a primary key column named id to the posts table definition.
6. Boîte à outils pour les développeurs (compétences Agents CLI)
Modèle "Action & Lifecycle" (Action et cycle de vie).
Le développement d'agents d'IA implique des tâches répétitives liées au cycle de vie : échafaudage de fichiers de code standard, configuration d'environnements d'exécution locaux, exécution d'invites de test et démarrage d'ateliers interactifs.
Au lieu de forcer votre assistant de codage à deviner les structures de répertoire ou à écrire une configuration d'agent standard à partir de zéro, les compétences de l'interface de ligne de commande Agents regroupent cette expertise du cycle de vie dans des compétences d'agent spécifiques.
Les compétences de l'interface de ligne de commande (CLI) de l'agent permettent une automatisation simplifiée et axée sur les développeurs directement dans votre terminal, comblant ainsi le fossé entre le code brut et l'exécution autonome. Alors que l'Agent Development Kit (ADK) se concentre sur le framework programmatique, en vous fournissant les SDK, les API et les plans structurels pour créer et orchestrer des agents d'IA, les compétences de l'interface de ligne de commande Agent fournissent la puissance opérationnelle. Il permet aux développeurs de créer, de tester et de déployer des agents localement avec des boucles de rétroaction rapides, en contournant complètement la lourde charge de l'UI.
Si elles sont mappées à Google Cloud, les compétences de l'interface de ligne de commande de l'agent servent de canal direct vers une infrastructure de niveau entreprise. Au lieu de parcourir les consoles, vous pouvez utiliser des commandes CLI pour regrouper instantanément les workflows d'agent, gérer les autorisations d'accès et les déployer dans les écosystèmes Google Cloud (comme Vertex AI ou Cloud Run). Les tâches d'architecture cloud complexes sont ainsi transformées en commandes de terminal simples et reproductibles, ce qui facilite l'intégration d'agents autonomes dans les pipelines de déploiement CI/CD existants.
Installation
Assurez-vous que Python 3.11+, Node.js et le gestionnaire de packages uv sont installés. Exécutez ensuite la commande de configuration dans votre terminal :
uvx google-agents-cli setup
Cette commande installe le binaire agents-cli et enregistre ses compétences spécialisées pour l'échafaudage et l'évaluation dans l'environnement de votre assistant de codage.
Remarque : Les compétences seront installées dans le dossier ~/.agents/skills, qui est visible par Antigravity. Si vous souhaitez voir ces compétences dans l'interface de ligne de commande Antigravity, vous devrez les déplacer vers le dossier ~/.gemini/antigravity-cli/skills (portée globale).
Pour vérifier que les compétences ont été chargées dans Antigravity, il vous suffit de demander quelles compétences sont disponibles. Vous trouverez ci-dessous un exemple de réponse pour les compétences de l'interface de ligne de commande de l'agent que nous venons d'installer.

Tutoriel détaillé
Une fois uvx google-agents-cli setup terminé, vous pouvez lancer, tester et interagir avec un agent IA entièrement sur votre machine locale.
Étape 1 : Échafauder et initialiser un nouveau projet d'agent
Exécutez la commande de création pour générer une mise en page standardisée. Une fois créé, vous devez installer les dépendances de son projet avant d'exécuter des tâches.
# 1. Create a lightweight prototype project structure
agents-cli create weather-assistant --prototype --yes
# 2. Move into the directory and install required ADK dependencies
cd weather-assistant
agents-cli install
Ce qui se passe en arrière-plan : un espace de travail propre est créé, avec app/agent.py (votre code principal), pyproject.toml (métadonnées du package) et agents-cli-manifest.yaml (outil de suivi des projets).
Étape 2 : Exécutez une requête de test locale
Exécutez un test rapide et direct en ligne de commande sur votre agent. Assurez-vous d'avoir exporté votre GEMINI_API_KEY dans votre terminal si vous n'utilisez pas les identifiants par défaut de l'application (ADC) de Google Cloud. Vous pouvez obtenir une clé API Gemini ici. Une fois que vous avez la clé, exportez-la dans votre terminal à l'aide de la commande suivante :
export GEMINI_API_KEY="YOUR_GEMINI_API_KEY"
Exécutez la commande suivante dans votre terminal :
agents-cli run "How are you?"
Ce qui se passe en coulisses : la CLI initialise le cycle de vie de l'Agent Development Kit (ADK) entièrement en mémoire sur votre terminal. Il achemine la requête de manière sécurisée via vos identifiants locaux et enregistre la réponse de la diffusion en direct directement dans votre ligne de commande.
Étape 3 : Démarrer l'atelier Web interactif
Lancez le playground Web local intégré pour interagir visuellement avec votre agent.
agents-cli playground
Ce qui se passe en arrière-plan : la CLI lance un serveur d'interface utilisateur Web ADK, généralement accessible à l'adresse http://localhost:8080 ou à l'adresse de secours http://127.0.0.1:8000, avec rechargement à chaud. Dans l'interface Web, sélectionnez app dans le menu déroulant Sélectionner une application en haut de la page, puis interagissez avec l'agent dans l'interface conversationnelle à droite de l'application Web.
7. Installer des compétences d'agent à l'aide de npx skills
npx skills est un outil de ligne de commande développé par Vercel Labs qui sert de gestionnaire de packages pour les agents d'IA (comme Antigravity, Claude Code, GitHub Copilot, Cursor et Cline). Il s'agit de l'interface de ligne de commande pour l'écosystème de compétences d'agent ouvert.
Si vous souhaitez télécharger et installer les compétences d'agent à l'aide du package npx skills, notez qu'elles sont placées dans le dossier ~/.agents/skills. Bien qu'il mentionne que des outils comme Antigravity récupèrent les compétences de ce dossier, veuillez noter qu'au moment de la rédaction, Antigravity les récupère de ce dossier, mais pas Antigravity CLI. Comme mentionné précédemment, vous devrez copier ces compétences installées dans le dossier ~/.agents/skills, soit dans le champ du projet, soit dans le champ global pour les dossiers de compétences dans Antigravity CLI, c'est-à-dire :
- Champ d'application du projet : situé dans
<project-root>/.agent/skills/. - Champ d'application mondial : situé dans
~/.gemini/antigravity-cli/skills/.
8. Félicitations
Félicitations ! Vous avez réussi à utiliser Google Antigravity pour créer votre première compétence d'agent, à la configurer et à y ajouter des fonctionnalités personnalisées.
Vous avez également réussi à configurer un ensemble de compétences d'agent, à la fois au niveau du projet et au niveau mondial, pour donner vie à des outils personnalisés.
Vous êtes maintenant prêt à laisser Antigravity s'occuper des tâches les plus difficiles dans vos propres projets et à écrire du code à votre façon.
Gagner votre badge Kaggle "Agents IA en cinq jours"
Vous avez suivi cet atelier dans le cadre du cours intensif de cinq jours Agents IA : cours intensif de vibe coding avec Google de Kaggle ? Récupérez votre badge d'obtention : obtenez le badge "Agents d'IA en cinq jours".
9. Documents de référence
- Atelier de programmation : Premiers pas avec Google Antigravity
- Site officiel : https://antigravity.google/
- Documentation : https://antigravity.google/docs
- Télécharger : https://antigravity.google/download
- Documentation sur les compétences Antigravity : https://antigravity.google/docs/skills