
1. परिचय
Google Antigravity, एजेंटिक डेवलपमेंट प्लैटफ़ॉर्म है. इसे एजेंट के इस दौर में, आपको डेवलप करने में मदद करने के लिए डिज़ाइन किया गया है. Antigravity, आपके एआई एजेंट के लिए एक सेंट्रल कमांड सेंटर की तरह काम करता है. यह एक यूनिफ़ाइड प्लैटफ़ॉर्म उपलब्ध कराता है, ताकि एआई एजेंट की गतिविधियों को लॉन्च, मॉनिटर, और व्यवस्थित किया जा सके.
इस कोडलैब में, हम सबसे पहले Agent Skills के बारे में जानेंगे. यह एक लाइटवेट और ओपन फ़ॉर्मैट है. इसकी मदद से, खास जानकारी और वर्कफ़्लो की मदद से, एआई एजेंट की क्षमताओं को बढ़ाया जा सकता है. आपको Agent Skills के बारे में जानकारी मिलेगी. साथ ही, उनके फ़ायदों और उन्हें बनाने के तरीके के बारे में भी पता चलेगा. इसके बाद, आपको कई Agent Skills बनानी होंगी. जैसे, Git फ़ॉर्मेटर, टेंप्लेट जनरेटर, टूल कोड स्कैफ़ोल्डिंग वगैरह. इन सभी का इस्तेमाल Antigravity में किया जा सकता है.
ज़रूरी शर्तें:
- Antigravity इंस्टॉल और कॉन्फ़िगर किया गया हो.
- Google Antigravity की बुनियादी जानकारी. हमारा सुझाव है कि आप यह कोडलैब पूरा करें: Google Antigravity का इस्तेमाल शुरू करना.
2. स्किल क्यों
आधुनिक एआई एजेंट, सिर्फ़ सुनने वाले एजेंट से बदलकर, जटिल तर्क देने वाले एजेंट बन गए हैं. ये एजेंट, लोकल फ़ाइल सिस्टम और बाहरी टूल के साथ इंटिग्रेट होते हैं. ऐसा एमसीपी सर्वर के ज़रिए होता है. हालांकि, किसी एजेंट को पूरे कोडबेस और सैकड़ों टूल के साथ लोड करने से, कॉन्टेक्स्ट सैचुरेशन और "टूल ब्लोट" की समस्या होती है. कॉन्टेक्स्ट विंडो बड़ी होने पर भी, इस्तेमाल न किए गए टूल के 40 से 50 हज़ार टोकन को ऐक्टिव मेमोरी में डालने से, ज़्यादा इंतज़ार करना पड़ता है, पैसे की बर्बादी होती है, और "कॉन्टेक्स्ट रॉट" की समस्या होती है. इसमें मॉडल, काम के न होने वाले डेटा की वजह से भ्रमित हो जाता है.
समाधान: एजेंट की क्षमताएं
इस समस्या को हल करने के लिए, Anthropic ने Agent Skills को लॉन्च किया. इससे आर्किटेक्चर को मोनोलिथिक कॉन्टेक्स्ट लोडिंग से प्रोग्रेसिव डिसक्लोज़र में बदल दिया गया. सेशन की शुरुआत में, मॉडल को हर वर्कफ़्लो (जैसे, डेटाबेस माइग्रेशन या सुरक्षा ऑडिट) को "याद रखने" के लिए मजबूर करने के बजाय, इन क्षमताओं को मॉड्यूलर, खोजने योग्य इकाइयों में पैकेज किया जाता है.
यह कैसे काम करता है
शुरुआत में, मॉडल को सिर्फ़ मेटाडेटा के "मेन्यू" के बारे में बताया जाता है. यह भारी-भरकम प्रोसेस से जुड़ी जानकारी (निर्देश और स्क्रिप्ट) सिर्फ़ तब लोड करता है, जब उपयोगकर्ता का मकसद किसी स्किल से मैच करता हो. इससे यह पक्का होता है कि पुष्टि करने वाले मिडलवेयर को फिर से फ़ैक्टर करने का अनुरोध करने वाले डेवलपर को सुरक्षा कॉन्टेक्स्ट मिलता है. साथ ही, इससे मिलती-जुलती सीएसएस पाइपलाइन लोड नहीं होती हैं. इससे कॉन्टेक्स्ट को कम, तेज़, और किफ़ायती रखा जा सकता है.

3. एजेंट की स्किल और Antigravity
Antigravity के ईकोसिस्टम में, Skills खास ट्रेनिंग मॉड्यूल के तौर पर काम करती हैं. ये मॉड्यूल, सामान्य मॉडल और आपके खास संदर्भ के बीच के अंतर को कम करते हैं. ये एजेंट को निर्देशों और प्रोटोकॉल का तय किया गया सेट "इस्तेमाल" करने की अनुमति देते हैं. जैसे, डेटाबेस माइग्रेशन के स्टैंडर्ड या सुरक्षा जांच. ऐसा सिर्फ़ तब किया जाता है, जब कोई काम का अनुरोध किया जाता है. इन एक्ज़ीक्यूशन प्रोटोकॉल को डाइनैमिक तरीके से लोड करके, Skills एआई को एक सामान्य प्रोग्रामर से एक विशेषज्ञ में बदल देती हैं. यह विशेषज्ञ, किसी संगठन के कोड में शामिल सबसे सही तरीकों और सुरक्षा मानकों का सख्ती से पालन करता है.
Antigravity में स्किल क्या होती है?
Google Antigravity के हिसाब से, स्किल एक डायरेक्ट्री-आधारित पैकेज होता है. इसमें एक डेफ़िनिशन फ़ाइल (SKILL.md) और कुछ अन्य ऐसेट (स्क्रिप्ट, रेफ़रंस, टेंप्लेट) शामिल होती हैं जो स्किल के साथ काम करती हैं.
यह मांग पर उपलब्ध सुविधा एक्सटेंशन के लिए एक तरीका है.
- ऑन-डिमांड: सिस्टम प्रॉम्प्ट हमेशा लोड होता है. हालांकि, स्किल को एजेंट के कॉन्टेक्स्ट में सिर्फ़ तब लोड किया जाता है, जब एजेंट को लगता है कि यह उपयोगकर्ता के मौजूदा अनुरोध के लिए काम की है. इससे कॉन्टेक्स्ट विंडो को ऑप्टिमाइज़ किया जाता है. साथ ही, एजेंट को काम के न होने वाले निर्देशों से ध्यान भटकने से रोका जाता है. कई टूल वाले बड़े प्रोजेक्ट में, परफ़ॉर्मेंस और गहराई से विश्लेषण की सटीकता के लिए, चुनिंदा टूल लोड करना ज़रूरी होता है.
- क्षमता बढ़ाना: स्किल सिर्फ़ निर्देश देने के अलावा, उन्हें पूरा भी कर सकती हैं. Python या Bash स्क्रिप्ट को बंडल करके, कोई स्किल एजेंट को लोकल मशीन या बाहरी नेटवर्क पर मुश्किल और कई चरणों वाली कार्रवाइयां करने की सुविधा दे सकती है. इसके लिए, उपयोगकर्ता को मैन्युअल तरीके से कमांड चलाने की ज़रूरत नहीं होती. इससे एजेंट, टेक्स्ट जनरेट करने वाले एजेंट से टूल का इस्तेमाल करने वाले एजेंट में बदल जाता है.
स्किल बनाम इकोसिस्टम (टूल, नियम, और वर्कफ़्लो)
Model Context Protocol (MCP), एजेंट के "हाथों" की तरह काम करता है. यह GitHub या PostgreSQL जैसे बाहरी सिस्टम से लगातार और मज़बूत कनेक्शन उपलब्ध कराता है. वहीं, स्किल, "दिमाग" की तरह काम करती हैं और एजेंट को निर्देश देती हैं.
MCP, स्टेटफ़ुल इन्फ़्रास्ट्रक्चर को मैनेज करता है. वहीं, Skills, हल्के-फुल्के और कुछ समय के लिए उपलब्ध रहने वाले टास्क की परिभाषाएं होती हैं. इनमें उन टूल को इस्तेमाल करने का तरीका शामिल होता है. सर्वरलेस अप्रोच की मदद से एजेंट, बिना किसी रुकावट के विज्ञापन से जुड़े टास्क (जैसे, बदलावों का लॉग जनरेट करना या माइग्रेशन करना) पूरे कर सकते हैं. साथ ही, एजेंट को लगातार प्रोसेस चलाने की ज़रूरत नहीं होती. इससे, टास्क के चालू होने पर ही कॉन्टेक्स्ट लोड होता है और टास्क पूरा होने के तुरंत बाद कॉन्टेक्स्ट हट जाता है.
स्किल एजेंट के ट्रिगर किए जाने पर काम करती हैं: मॉडल, उपयोगकर्ता के इंटेंट का अपने-आप पता लगाता है और ज़रूरत के हिसाब से, खास जानकारी उपलब्ध कराता है. इस आर्किटेक्चर की मदद से, कई तरह के काम किए जा सकते हैं. उदाहरण के लिए, डेटाबेस में बदलाव करते समय, ग्लोबल नियम "सुरक्षित माइग्रेशन" स्किल का इस्तेमाल करने के लिए लागू किया जा सकता है. इसके अलावा, एक वर्कफ़्लो कई स्किल को व्यवस्थित करके, मज़बूत डिप्लॉयमेंट पाइपलाइन बना सकता है.
4. स्किल बनाना
Antigravity में कोई स्किल बनाने के लिए, डायरेक्ट्री के स्ट्रक्चर और फ़ाइल फ़ॉर्मैट का पालन करना ज़रूरी है. मानक तय करने से यह पक्का होता है कि स्किल को एक जगह से दूसरी जगह ले जाया जा सकता है. साथ ही, एजेंट उन्हें भरोसेमंद तरीके से पार्स और लागू कर सकता है. इस डिज़ाइन को जान-बूझकर आसान बनाया गया है. इसमें Markdown और YAML जैसे फ़ॉर्मैट का इस्तेमाल किया गया है, जिन्हें आसानी से समझा जा सकता है. इससे उन डेवलपर के लिए एंट्री बैरियर कम हो जाता है जो अपने IDE की क्षमताओं को बढ़ाना चाहते हैं.
डायरेक्ट्री स्ट्रक्चर
आम तौर पर, कौशल की डायरेक्ट्री ऐसी दिखती है:
my-skill/
├── SKILL.md # The definition file
├── scripts/ # [Optional] Python, Bash, or Node scripts
├── run.py
└── util.sh
├── references/ # [Optional] Documentation or templates
└── api-docs.md
└── assets/ # [Optional] Static assets (images, logos)
इस स्ट्रक्चर में, समस्याओं को अलग-अलग करके दिखाया जाता है. लॉजिक (scripts) को निर्देश (SKILL.md) और जानकारी (references) से अलग किया जाता है. यह स्टैंडर्ड सॉफ़्टवेयर इंजीनियरिंग के तरीकों के जैसा होता है.
SKILL.md डेफ़िनिशन फ़ाइल
SKILL.md फ़ाइल, स्किल का मुख्य हिस्सा होती है. इससे एजेंट को पता चलता है कि स्किल क्या है, इसका इस्तेमाल कब करना है, और इसे कैसे लागू करना है.
इसके दो हिस्से होते हैं:
- YAML फ़्रंटमैटर
- मार्कडाउन फ़ॉर्मैट में मुख्य हिस्सा.
YAML Frontmatter
यह मेटाडेटा लेयर है. यह स्किल का सिर्फ़ वह हिस्सा है जिसे एजेंट के हाई-लेवल राऊटर से इंडेक्स किया जाता है. जब कोई उपयोगकर्ता प्रॉम्प्ट भेजता है, तो एजेंट सभी उपलब्ध स्किल के ब्यौरे वाले फ़ील्ड के साथ प्रॉम्प्ट का सिमैंटिक मिलान करता है.
---
name: database-inspector
description: Use this skill when the user asks to query the database, check table schemas, or inspect user data in the local PostgreSQL instance.
---
मुख्य फ़ील्ड:
- name: यह ज़रूरी नहीं है. स्कोप में यूनीक होना चाहिए. छोटे अक्षरों और हाइफ़न का इस्तेमाल किया जा सकता है. उदाहरण के लिए,
postgres-query,pr-reviewer. अगर यह वैल्यू नहीं दी जाती है, तो डायरेक्ट्री के नाम का इस्तेमाल डिफ़ॉल्ट रूप से किया जाएगा. - description: यह ज़रूरी और सबसे अहम फ़ील्ड है. यह "ट्रिगर फ़्रेज़" के तौर पर काम करता है. यह इतना जानकारी देने वाला होना चाहिए कि एलएलएम, सिमैंटिक तौर पर मिलते-जुलते शब्दों को पहचान सके. "डेटाबेस टूल" जैसी अधूरी जानकारी काफ़ी नहीं है. सटीक जानकारी, जैसे कि "यह कुकी, उपयोगकर्ता या लेन-देन का डेटा वापस पाने के लिए, स्थानीय PostgreSQL डेटाबेस के ख़िलाफ़ सिर्फ़ पढ़ने के लिए SQL क्वेरी को एक्ज़ीक्यूट करती है. "Use this for debugging data states" का इस्तेमाल करने से, यह पक्का होता है कि स्किल को सही तरीके से चुना गया है.
मार्कडाउन बॉडी
मुख्य हिस्से में निर्देश शामिल होते हैं. यह "प्रॉम्प्ट इंजीनियरिंग" है, जिसे किसी फ़ाइल में सेव किया गया है. स्किल चालू होने पर, इस कॉन्टेंट को एजेंट की कॉन्टेक्स्ट विंडो में डाला जाता है.
ईमेल के मुख्य हिस्से में यह जानकारी शामिल होनी चाहिए:
- लक्ष्य: साफ़ तौर पर यह बताना कि स्किल से क्या हासिल किया जा सकता है.
- निर्देश: चरण-दर-चरण लॉजिक.
- उदाहरण: मॉडल की परफ़ॉर्मेंस को बेहतर बनाने के लिए, इनपुट और आउटपुट के कुछ उदाहरण.
- पाबंदियां: "ऐसा न करें" वाले नियम (जैसे, "DELETE क्वेरी न चलाएं").
SKILL.md फ़ाइल के मुख्य हिस्से का उदाहरण:
Database Inspector
Goal
To safely query the local database and provide insights on the current data state.
Instructions
- Analyze the user's natural language request to understand the data need.
- Formulate a valid SQL query.
- CRITICAL: Only SELECT statements are allowed.
- Use the script scripts/query_runner.py to execute the SQL.
- Command: python scripts/query_runner.py "SELECT * FROM..."
- Present the results in a Markdown table.
Constraints
- Never output raw user passwords or API keys.
- If the query returns > 50 rows, summarize the data instead of listing it all.
स्क्रिप्ट इंटिग्रेशन
स्किल की सबसे बेहतरीन सुविधाओं में से एक है, स्क्रिप्ट को टास्क पूरा करने की अनुमति देना. इससे एजेंट को ऐसी कार्रवाइयां करने में मदद मिलती है जिन्हें एलएलएम सीधे तौर पर नहीं कर सकता. जैसे, बाइनरी एक्ज़ीक्यूशन, जटिल गणितीय गणना या लेगसी सिस्टम के साथ इंटरैक्ट करना.
स्क्रिप्ट, scripts/ सबडायरेक्ट्री में रखी जाती हैं. SKILL.md, रिलेटिव पाथ के हिसाब से उनका रेफ़रंस देता है.
5. स्किल तैयार करना
इस सेक्शन का मकसद, ऐसी स्किल बनाना है जो Antigravity में इंटिग्रेट हो सकें. साथ ही, धीरे-धीरे अलग-अलग सुविधाएं दिखा सकें. जैसे, संसाधन / स्क्रिप्ट / वगैरह.
Github repo से Skills को यहां डाउनलोड किया जा सकता है: https://github.com/rominirani/antigravity-skills.
इन सभी स्किल को बनाने के तरीके के बारे में जानने से पहले, आइए देखते हैं कि हम इन्हें कैसे कॉन्फ़िगर करते हैं और Antigravity के प्रॉडक्ट के सुइट में उपलब्ध कराते हैं. इस लैब को पब्लिश करते समय, नीचे दिए गए फ़ोल्डर लागू होते हैं.
Antigravity या Antigravity CLI का इस्तेमाल करना
स्किल्स को दो स्कोप में तय किया जा सकता है. इससे प्रोजेक्ट के हिसाब से और उपयोगकर्ता के हिसाब से, यानी ग्लोबल स्किल्स तय की जा सकती हैं.:
- ग्लोबल स्कोप (
~/.gemini/config/skills/): यह Antigravity के सभी प्रॉडक्ट (Antigravity, Antigravity IDE, Antigravity CLI) और प्रोजेक्ट में उपलब्ध है. ये स्किल, उपयोगकर्ता के मशीन पर मौजूद सभी प्रोजेक्ट के लिए उपलब्ध होती हैं. यह "JSON फ़ॉर्मैट करो", "यूयूआईडी जनरेट करो", "कोड स्टाइल की समीक्षा करो" या निजी प्रॉडक्टिविटी टूल के साथ इंटिग्रेट करने जैसे सामान्य कामों के लिए सही है. - प्रोजेक्ट/Workspace का स्कोप (
<project-root>/.agents/skills/): इससे यह स्किल सिर्फ़ किसी खास प्रोजेक्ट में उपलब्ध होगी. यह प्रोजेक्ट से जुड़ी स्क्रिप्ट के लिए सबसे सही है. जैसे, किसी खास एनवायरमेंट में डिप्लॉयमेंट, उस ऐप्लिकेशन के लिए डेटाबेस मैनेजमेंट या मालिकाना हक वाले फ़्रेमवर्क के लिए बॉयलरप्लेट कोड जनरेट करना.
Antigravity या Antigravity CLI में Skills इंस्टॉल करना
इस ट्यूटोरियल के लिए, हमें सिर्फ़ यह तरीका अपनाना होगा. हालांकि, आपके पास इसे अपने हिसाब से करने का विकल्प भी है:
पहला चरण: https://github.com/rominirani/antigravity-skills का git clone करें
दूसरा चरण: अब अगर Antigravity या Antigravity CLI का इस्तेमाल किया जा रहा है, तो antigravity-skills/skills_tutorial फ़ोल्डर में जाएं.
तीसरा चरण: आपको अलग-अलग फ़ोल्डर में, कई तरह की स्किल दिखेंगी. इन चार फ़ोल्डर को कॉपी करें:
git-commit-formatterlicense-header-adderdatabase-schema-validatorjson-to-pydantic
प्रॉडक्ट के लिए टारगेट किए गए कौशल फ़ोल्डर में (प्रोजेक्ट स्कोप या ग्लोबल स्कोप).
चौथा चरण: अगर Antigravity या Antigravity CLI का इस्तेमाल किया जा रहा है , तो इसे <project-root>/.agents/skills/ (प्रोजेक्ट स्कोप) में कॉपी करें.
अगर आपने Antigravity लॉन्च किया है, तो "कौनसी सुविधाएं उपलब्ध हैं?" जैसा कोई सामान्य सवाल पूछें. इसके जवाब में, आपको इसकी जानकारी मिल जाएगी. आपको वहां चार स्किल दिखेंगी. अगर आपने अपने एनवायरमेंट में अन्य स्किल इंस्टॉल की हैं, तो आपके पास अतिरिक्त स्किल भी हो सकती हैं.
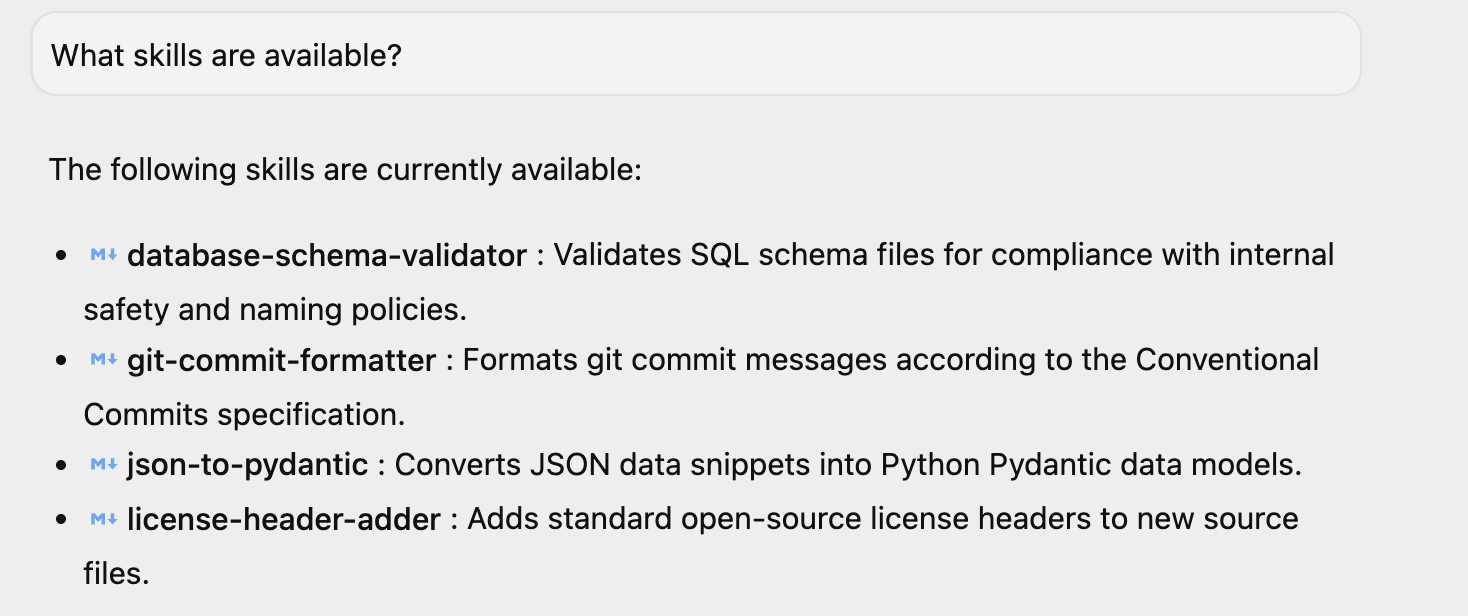
इसी तरह, अगर Antigravity CLI का इस्तेमाल किया जा रहा है, तो /skills कमांड दी जा सकती है. इससे चार स्किल की सूची दिखनी चाहिए. यहां एक सैंपल दिखाया गया है:
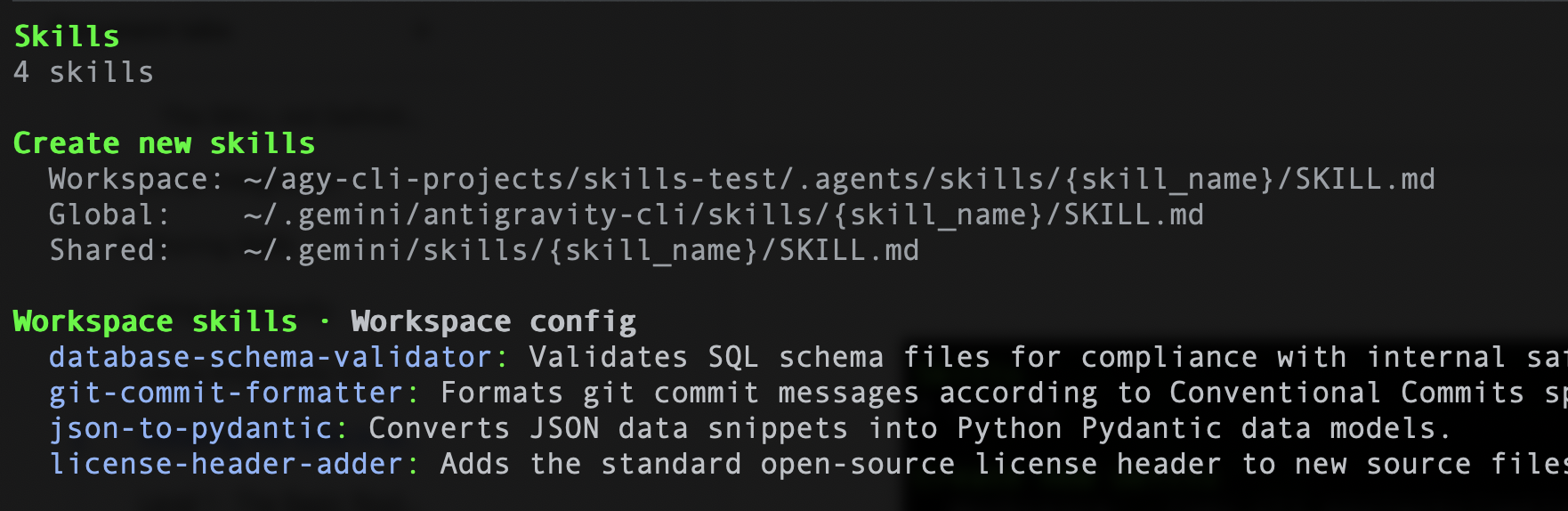
अब जब हमें Skills को सेट अप करने का तरीका पता चल गया है, तो आइए हर Skill के बारे में जानते हैं और समझते हैं कि उन्हें कैसे बनाया गया था. इन टेंप्लेट का इस्तेमाल करके, अपनी खुद की स्किल भी बनाई जा सकती हैं.
लेवल 1 : बुनियादी राऊटर ( git-commit-formatter )
इसे कौशल का "नमस्ते दुनिया" माना जा सकता है.
डेवलपर अक्सर कम शब्दों में कमिट मैसेज लिखते हैं. जैसे, "wip", "fix bug", "updates". "कन्वेंशनल कमिट" को मैन्युअल तरीके से लागू करना मुश्किल होता है. साथ ही, अक्सर इसे लागू करना भूल जाते हैं. चलिए, एक ऐसी स्किल लागू करते हैं जो कन्वेंशनल कमिट स्पेसिफ़िकेशन को लागू करती है. एजेंट को नियमों के बारे में निर्देश देकर, हम उसे नियमों को लागू करने की अनुमति देते हैं.
git-commit-formatter/
└── SKILL.md (Instructions only)
SKILL.md फ़ाइल यहां दिखाई गई है:
---
name: git-commit-formatter
description: Formats git commit messages according to Conventional Commits specification. Use this when the user asks to commit changes or write a commit message.
---
Git Commit Formatter Skill
When writing a git commit message, you MUST follow the Conventional Commits specification.
Format
`<type>[optional scope]: <description>`
Allowed Types
- **feat**: A new feature
- **fix**: A bug fix
- **docs**: Documentation only changes
- **style**: Changes that do not affect the meaning of the code (white-space, formatting, etc)
- **refactor**: A code change that neither fixes a bug nor adds a feature
- **perf**: A code change that improves performance
- **test**: Adding missing tests or correcting existing tests
- **chore**: Changes to the build process or auxiliary tools and libraries such as documentation generation
Instructions
1. Analyze the changes to determine the primary `type`.
2. Identify the `scope` if applicable (e.g., specific component or file).
3. Write a concise `description` in an imperative mood (e.g., "add feature" not "added feature").
4. If there are breaking changes, add a footer starting with `BREAKING CHANGE:`.
Example
`feat(auth): implement login with google`
Antigravity में इस उदाहरण को कैसे चलाएं
यहां दिया गया तरीका इस आधार पर है कि आपकी लोकल मशीन पर Git उपलब्ध है और उसे सही तरीके से सेटअप किया गया है.
मान लें कि आपने Antigravity या Antigravity CLI लॉन्च कर दिया है. इसके बाद, यह तरीका अपनाएं:
पहला चरण: टेस्ट के लिए Git रिपॉज़िटरी सेट अप करना
एजेंट से, Git के ऑपरेशन की जांच करने के लिए, एक साफ़ और अलग डायरेक्ट्री सेट अप करने के लिए कहें.
आपका प्रॉम्प्ट:
Create a folder named git_test in the workspace, initialize a git repository inside it, and create an initial file auth.py with def login(): pass. Stage this file and make an initial commit.
एजेंट, डायरेक्ट्री बनाएगा, रिपॉज़िटरी को शुरू करेगा, फ़ाइल को स्टेज करेगा, और "initial commit" जैसे मैसेज के साथ उसे कमिट करेगा.
दूसरा चरण: कोड में बदलाव करना
एजेंट को कोड में बदलाव करने के लिए कहें, ताकि बदलाव को सेव किया जा सके.
आपका प्रॉम्प्ट:
In the git_test folder, modify auth.py to add Google Login functionality.
एजेंट, फ़ाइल में बदलाव करके नई सुविधा जोड़ेगा. इससे फ़ाइल को कमिट फ़ेज़ के लिए तैयार किया जा सकेगा.
तीसरा चरण: बदलावों को स्टेज करना और कमिट करना
बदलावों को स्टेज करने और कमिट बनाने के लिए, एजेंट से कहकर git-commit-formatter स्किल को ट्रिगर करें.
आपका प्रॉम्प्ट:
Stage the changes in the git_test folder and commit them. Make sure to format the commit message using the Conventional Commits skill.
एजेंट git add auth.py चलाएगा. इसके बाद, अंतर का विश्लेषण करके यह पता लगाएगा कि auth मॉड्यूल में कोई नई सुविधा जोड़ी गई है. इसके बाद, git commit चलाने से पहले, feat(auth): implement google login जैसा कोई सामान्य कमिट मैसेज बनाएगा.
चौथा चरण: Git लॉग की पुष्टि करना
एजेंट से git का इतिहास वापस लाने के लिए कहें, ताकि यह पुष्टि की जा सके कि फ़ॉर्मैट किया गया कमिट सही तरीके से रिकॉर्ड किया गया है.
आपका प्रॉम्प्ट:
Show me the git log in the git_test folder.
एजेंट, git log -n 5 को चलाएगा और फ़ॉर्मैट किए गए कमिट मैसेज को आउटपुट के तौर पर दिखाएगा.
दूसरा लेवल: ऐसेट का इस्तेमाल (license-header-adder)
यह "रेफ़रंस" पैटर्न है.
किसी कॉर्पोरेट प्रोजेक्ट की हर सोर्स फ़ाइल के लिए, Apache 2.0 लाइसेंस का 20 लाइन वाला हेडर ज़रूरी हो सकता है. इस स्टैटिक टेक्स्ट को सीधे तौर पर प्रॉम्प्ट (या SKILL.md) में डालने से कोई फ़ायदा नहीं होता. हर बार स्किल को इंडेक्स करने पर, यह टोकन का इस्तेमाल करता है. साथ ही, मॉडल कानूनी टेक्स्ट में टाइपिंग की गलतियां "हैलुसिनेट" कर सकता है. स्टैटिक टेक्स्ट को resources/ फ़ोल्डर में मौजूद सामान्य टेक्स्ट फ़ाइल में ऑफ़लोड करना एक अच्छा तरीका है. स्किल, एजेंट को इस फ़ाइल को सिर्फ़ तब पढ़ने का निर्देश देती है, जब इसकी ज़रूरत होती है.
आपको ये फ़ाइलें, skills डायरेक्ट्री के license-header-adder फ़ोल्डर में मिलेंगी.
license-header-adder/
├── SKILL.md
└── resources/
└── HEADER_TEMPLATE.txt (The heavy text)
SKILL.md फ़ाइल यहां दिखाई गई है:
---
name: license-header-adder
description: Adds the standard open-source license header to new source files. Use involves creating new code files that require copyright attribution.
---
# License Header Adder Skill
This skill ensures that all new source files have the correct copyright header.
## Instructions
1. **Read the Template**:
First, read the content of the header template file located at `resources/HEADER_TEMPLATE.txt`.
2. **Prepend to File**:
When creating a new file (e.g., `.py`, `.java`, `.js`, `.ts`, `.go`), prepend the `target_file` content with the template content.
3. **Modify Comment Syntax**:
- For C-style languages (Java, JS, TS, C++), keep the `/* ... */` block as is.
- For Python, Shell, or YAML, convert the block to use `#` comments.
- For HTML/XML, use `<!-- ... -->`.
Antigravity में इस उदाहरण को कैसे चलाएं
मान लें कि आपने Antigravity या Antigravity CLI लॉन्च कर दिया है. इसके बाद, यह तरीका अपनाएं:
पहला चरण: सैंपल कोड के साथ Python फ़ाइल बनाना
आपका प्रॉम्प्ट:
Create a new file my_script.py with the following python code:
def hello():
print("Hello, World!")
क्या हुआ (जानकारी): एजेंट ने फ़ाइल लिखने वाले टूल (write_to_file) का इस्तेमाल करके, आपकी मौजूदा वर्कस्पेस डायरेक्ट्री में सीधे तौर पर my_script.py नाम की एक नई फ़ाइल बनाई. साथ ही, इसमें बुनियादी Python फ़ंक्शन लिखा. इसके अलावा, प्रॉम्प्ट ने license-header-adder स्किल को ट्रिगर किया. एजेंट ने लाइसेंस टेंप्लेट फ़ाइल (HEADER_TEMPLATE.txt) का पता लगाया और उसे पढ़ा. इसके बाद, टिप्पणी की स्टाइल को C-स्टाइल ब्लॉक टिप्पणियों (/* ... */) से बदलकर Python-स्टाइल टिप्पणियां (#) कर दिया. साथ ही, replace_file_content टूल का इस्तेमाल करके, इसे फ़ाइल के सबसे ऊपर जोड़ दिया.
दूसरा चरण: फ़ाइल के कॉन्टेंट की पुष्टि करना
my_script.py फ़ाइल देखें. इसमें सबसे ऊपर लाइसेंस का हेडर होगा.
लेवल 3: उदाहरण से सीखना (json-to-pydantic)
"कुछ उदाहरणों के साथ जवाब देना" पैटर्न.
लूज़ डेटा (जैसे, JSON API रिस्पॉन्स) को स्ट्रिक्ट कोड (जैसे, Pydantic मॉडल) में बदलने के लिए, कई फ़ैसले लेने पड़ते हैं. हमें क्लास के नाम कैसे रखने चाहिए? क्या हमें Optional का इस्तेमाल करना चाहिए? snake_case या camelCase? इन 50 नियमों को अंग्रेज़ी में लिखना मुश्किल है और इसमें गलतियां हो सकती हैं.
एलएलएम, पैटर्न मैच करने वाले इंजन होते हैं.
अपनी स्किल को किसी बेहतरीन उदाहरण (Input -> Output) के साथ तैयार करना, अक्सर लंबे-चौड़े निर्देशों से ज़्यादा असरदार होता है.
json-to-pydantic/फ़ोल्डर में जाएं. इसमें स्किल की फ़ाइलें होती हैं. इसे नीचे दिखाया गया है:
json-to-pydantic/
├── SKILL.md
└── examples/
├── input_data.json (The Before State)
└── output_model.py (The After State)
SKILL.md फ़ाइल यहां दिखाई गई है:
---
name: json-to-pydantic
description: Converts JSON data snippets into Python Pydantic data models.
---
# JSON to Pydantic Skill
This skill helps convert raw JSON data or API responses into structured, strongly-typed Python classes using Pydantic.
Instructions
1. **Analyze the Input**: Look at the JSON object provided by the user.
2. **Infer Types**:
- `string` -> `str`
- `number` -> `int` or `float`
- `boolean` -> `bool`
- `array` -> `List[Type]`
- `null` -> `Optional[Type]`
- Nested Objects -> Create a separate sub-class.
3. **Follow the Example**:
Review `examples/` to see how to structure the output code. notice how nested dictionaries like `preferences` are extracted into their own class.
- Input: `examples/input_data.json`
- Output: `examples/output_model.py`
Style Guidelines
- Use `PascalCase` for class names.
- Use type hints (`List`, `Optional`) from `typing` module.
- If a field can be missing or null, default it to `None`.
/examples फ़ोल्डर में , JSON फ़ाइल और आउटपुट फ़ाइल यानी Python फ़ाइल मौजूद है. इन दोनों को यहां दिखाया गया है:
input_data.json
{
"user_id": 12345,
"username": "jdoe_88",
"is_active": true,
"preferences": {
"theme": "dark",
"notifications": [
"email",
"push"
]
},
"last_login": "2024-03-15T10:30:00Z",
"meta_tags": null
}
output_model.py
from pydantic import BaseModel, Field
from typing import List, Optional
class Preferences(BaseModel):
theme: str
notifications: List[str]
class User(BaseModel):
user_id: int
username: str
is_active: bool
preferences: Preferences
last_login: Optional[str] = None
meta_tags: Optional[List[str]] = None
Antigravity में इस उदाहरण को कैसे चलाएं
मान लें कि आपने Antigravity या Antigravity CLI लॉन्च कर दिया है. इसके बाद, यह तरीका अपनाएं:
पहला चरण: सैंपल डेटा के साथ JSON फ़ाइल बनाना
एजेंट से, रॉ JSON पेलोड वाली नई फ़ाइल product.json बनाने के लिए कहें.
आपका प्रॉम्प्ट:
Create a new file product.json with the following JSON:
{
"product": "Widget",
"cost": 10.99,
"stock": null
}
दूसरा चरण: JSON को Pydantic मॉडल में बदलना
JSON डेटा को स्ट्रक्चर्ड Pydantic क्लास में बदलने के लिए, json-to-pydantic स्किल को ट्रिगर करें.
आपका प्रॉम्प्ट:
Convert the JSON in product.json to a Pydantic model and save it to product_model.py.
तीसरा चरण: आउटपुट की पुष्टि करना
product_model.py फ़ाइल देखें. इसमें पूरा किया गया Pydantic मॉडल शामिल होगा.
लेवल 4: प्रोसीजरल लॉजिक (database-schema-validator)
यह "टूल का इस्तेमाल" पैटर्न है.
अगर एलएलएम से पूछा जाए कि "क्या यह स्कीमा सुरक्षित है?", तो हो सकता है कि वह कहे कि सब ठीक है. भले ही, कोई अहम प्राइमरी कुंजी मौजूद न हो. ऐसा इसलिए, क्योंकि एसक्यूएल सही दिखता है.
आइए, इस जांच को डिटरमिनिस्टिक स्क्रिप्ट को सौंपते हैं. हमारी database-schema-validator स्किल, एजेंट को Python स्क्रिप्ट चलाने के लिए रूट करेगी. यह स्क्रिप्ट हमने लिखी है. स्क्रिप्ट, बाइनरी (सही/गलत) जवाब देती है.
database-schema-validator/
├── SKILL.md
└── scripts/
└── validate_schema.py (The Validator)
SKILL.md फ़ाइल यहां दिखाई गई है:
---
name: database-schema-validator
description: Validates SQL schema files for compliance with internal safety and naming policies.
---
# Database Schema Validator Skill
This skill ensures that all SQL files provided by the user comply with our strict database standards.
Policies Enforced
1. **Safety**: No `DROP TABLE` statements.
2. **Naming**: All tables must use `snake_case`.
3. **Structure**: Every table must have an `id` column as PRIMARY KEY.
Instructions
1. **Do not read the file manually** to check for errors. The rules are complex and easily missed by eye.
2. **Run the Validation Script**:
Use the `run_command` tool to execute the python script provided in the `scripts/` folder against the user's file.
`python scripts/validate_schema.py <path_to_user_file>`
3. **Interpret Output**:
- If the script returns **exit code 0**: Tell the user the schema looks good.
- If the script returns **exit code 1**: Report the specific error messages printed by the script to the user and suggest fixes.
validate_schema.py फ़ाइल यहां दिखाई गई है:
import sys
import re
def validate_schema(filename):
"""
Validates a SQL schema file against internal policy:
1. Table names must be snake_case.
2. Every table must have a primary key named 'id'.
3. No 'DROP TABLE' statements allowed (safety).
"""
try:
with open(filename, 'r') as f:
content = f.read()
lines = content.split('\n')
errors = []
# Check 1: No DROP TABLE
if re.search(r'DROP TABLE', content, re.IGNORECASE):
errors.append("ERROR: 'DROP TABLE' statements are forbidden.")
# Check 2 & 3: CREATE TABLE checks
table_defs = re.finditer(r'CREATE TABLE\s+(?P<name>\w+)\s*\((?P<body>.*?)\);', content, re.DOTALL | re.IGNORECASE)
for match in table_defs:
table_name = match.group('name')
body = match.group('body')
# Snake case check
if not re.match(r'^[a-z][a-z0-9_]*$', table_name):
errors.append(f"ERROR: Table '{table_name}' must be snake_case.")
# Primary key check
if not re.search(r'\bid\b.*PRIMARY KEY', body, re.IGNORECASE):
errors.append(f"ERROR: Table '{table_name}' is missing a primary key named 'id'.")
if errors:
for err in errors:
print(err)
sys.exit(1)
else:
print("Schema validation passed.")
sys.exit(0)
except FileNotFoundError:
print(f"Error: File '{filename}' not found.")
sys.exit(1)
if __name__ == "__main__":
if len(sys.argv) != 2:
print("Usage: python validate_schema.py <schema_file>")
sys.exit(1)
validate_schema(sys.argv[1])
Antigravity में इस उदाहरण को कैसे चलाएं
मान लें कि आपने Antigravity या Antigravity CLI लॉन्च कर दिया है. इसके बाद, यह तरीका अपनाएं:
पहला चरण: सैंपल डेटा के साथ JSON फ़ाइल बनाना
एजेंट से ऐसी नई फ़ाइल bad_schema.sql बनाने के लिए कहें जिसमें नीति के उल्लंघन से जुड़ी कई समस्याएं शामिल हों.
आपका प्रॉम्प्ट:
Create a new file bad_schema.sql with the following SQL:
DROP TABLE IF EXISTS legacy_users;
CREATE TABLE userProfile (
id INT PRIMARY KEY,
bio TEXT
);
CREATE TABLE posts (
title TEXT,
content TEXT,
created_at TIMESTAMP
);
CREATE TABLE comments (
id INT PRIMARY KEY,
post_id INT,
body TEXT
);
ऊपर दी गई स्कीमा फ़ाइल, तीनों नीतियों का उल्लंघन करती है: इसमें पाबंदी वाला DROP TABLE स्टेटमेंट इस्तेमाल किया गया है, userProfile टेबल के नाम के लिए camelCase का इस्तेमाल किया गया है, और posts टेबल में id प्राइमरी कुंजी को शामिल नहीं किया गया है.
दूसरा चरण: एसक्यूएल स्कीमा की पुष्टि करना
अपनी फ़ाइल के लिए Python पुष्टि करने वाले प्रोग्राम स्क्रिप्ट चलाने के लिए database-schema-validator स्किल को ट्रिगर करें.
आपका प्रॉम्प्ट:
Validate bad_schema.sql using the database-schema-validator skill.
तीसरा चरण: आउटपुट की पुष्टि करना
एजेंट, फ़ंक्शन के काम न करने की सूचना देगा. साथ ही, स्क्रिप्ट में मिली गड़बड़ियों को सीधे तौर पर चैट में दिखाएगा. यहां सैंपल आउटपुट दिखाया गया है:
Suggested Fixes:
Remove the line DROP TABLE IF EXISTS legacy_users; as dropping tables is forbidden by safety policy.
Rename the table userProfile to use snake_case (e.g., user_profile).
Add a primary key column named id to the posts table definition.
6. डेवलपर टूलकिट (एजेंट के लिए सीएलआई स्किल)
"ऐक्शन और लाइफ़साइकल" पैटर्न.
एआई एजेंट डेवलप करने में, लाइफ़साइकल के ये टास्क बार-बार करने पड़ते हैं: बॉयलरप्लेट फ़ाइलों को स्कैफ़ोल्ड करना, लोकल रनटाइम एनवायरमेंट कॉन्फ़िगर करना, टेस्ट प्रॉम्प्ट चलाना, और इंटरैक्टिव प्लेग्राउंड शुरू करना.
कोडिंग असिस्टेंट को डायरेक्ट्री स्ट्रक्चर का अनुमान लगाने या स्क्रैच से बॉयलरप्लेट एजेंट कॉन्फ़िगरेशन लिखने के लिए मजबूर करने के बजाय, Agents CLI Skills इस लाइफ़साइकल की विशेषज्ञता को एजेंट की खास क्षमताओं में पैकेज करता है.
Agent CLI (कमांड लाइन इंटरफ़ेस) की मदद से, डेवलपर के लिए ऑटोमेशन की सुविधा सीधे आपके टर्मिनल में मिलती है. इससे, रॉ कोड और अपने-आप होने वाले एक्ज़ीक्यूशन के बीच के अंतर को कम किया जा सकता है. एजेंट डेवलपमेंट किट (एडीके), प्रोग्रामैटिक फ़्रेमवर्क पर फ़ोकस करती है. यह आपको एसडीके, एपीआई, और स्ट्रक्चरल ब्लूप्रिंट देती है, ताकि एआई एजेंट बनाए जा सकें और उन्हें व्यवस्थित किया जा सके. वहीं, एजेंट सीएलआई की मदद से, ऑपरेशनल काम किए जा सकते हैं. इससे डेवलपर, एजेंट को स्थानीय तौर पर तैयार कर सकते हैं, उनकी जांच कर सकते हैं, और उन्हें डिप्लॉय कर सकते हैं. साथ ही, उन्हें तुरंत फ़ीडबैक मिल सकता है. इसमें यूज़र इंटरफ़ेस (यूआई) से जुड़ी ज़्यादा मेहनत करने की ज़रूरत नहीं होती.
अगर एजेंट की सीएलआई स्किल को Google Cloud से मैप किया जाता है, तो ये स्किल एंटरप्राइज़-ग्रेड के इंफ़्रास्ट्रक्चर के लिए डायरेक्ट पाइपलाइन के तौर पर काम करती हैं. हालांकि, ऐसा करना ज़रूरी नहीं है. कंसोल पर क्लिक करने के बजाय, सीएलआई कमांड का इस्तेमाल करके एजेंट वर्कफ़्लो को तुरंत पैकेज किया जा सकता है. साथ ही, ऐक्सेस करने की अनुमतियों को मैनेज किया जा सकता है और उन्हें Google Cloud के इकोसिस्टम (जैसे, Vertex AI या Cloud Run) में डिप्लॉय किया जा सकता है. इससे, क्लाउड आर्किटेक्चर से जुड़े मुश्किल टास्क को आसान, दोहराई जा सकने वाली टर्मिनल कमांड में बदल दिया जाता है. इससे, अपने-आप काम करने वाले एजेंट को मौजूदा सीआई/सीडी डिप्लॉयमेंट पाइपलाइन में इंटिग्रेट करना बहुत आसान हो जाता है.
इंस्टॉल करने का तरीका
पक्का करें कि आपने Python 3.11+, Node.js, और uv पैकेज मैनेजर इंस्टॉल कर लिया हो. इसके बाद, अपने टर्मिनल में सेटअप कमांड चलाएं:
uvx google-agents-cli setup
इस कमांड से, agents-cli बाइनरी इंस्टॉल हो जाती है. साथ ही, यह आपके कोडिंग असिस्टेंट के एनवायरमेंट में, स्केफ़ोल्डिंग और आकलन के लिए अपनी खास सुविधाएं रजिस्टर कर लेती है.
ध्यान दें: ये स्किल, ~/.agents/skills फ़ोल्डर में इंस्टॉल होंगी. यह फ़ोल्डर, Antigravity को दिखता है. अगर आपको इन स्किल को Antigravity CLI में देखना है, तो आपको इन्हें ~/.gemini/antigravity-cli/skills फ़ोल्डर (ग्लोबल स्कोप) में ले जाना होगा.
यह देखने के लिए कि Antigravity में Skills लोड की गई हैं या नहीं, बस यह पूछें कि कौनसी Skills उपलब्ध हैं. यहां एजेंट सीएलआई की उन स्किल के लिए जवाब का एक उदाहरण दिया गया है जिन्हें हमने अभी इंस्टॉल किया है.

कदम-दर-कदम निर्देश
uvx google-agents-cli setup पूरा होने के बाद, एआई एजेंट को अपनी लोकल मशीन पर स्पिन अप किया जा सकता है. साथ ही, उससे इंटरैक्ट किया जा सकता है और उसे टेस्ट किया जा सकता है.
पहला चरण: नया एजेंट प्रोजेक्ट तैयार करना और उसे शुरू करना
स्टैंडर्ड लेआउट बनाने के लिए, क्रिएशन कमांड चलाएं. इसे बनाने के बाद, आपको कोई भी टास्क चलाने से पहले, इसके प्रोजेक्ट की डिपेंडेंसी इंस्टॉल करनी होंगी.
# 1. Create a lightweight prototype project structure
agents-cli create weather-assistant --prototype --yes
# 2. Move into the directory and install required ADK dependencies
cd weather-assistant
agents-cli install
बैकग्राउंड में क्या होता है: इससे एक साफ़-सुथरा वर्कस्पेस बनता है. इसमें app/agent.py (आपका मुख्य कोड), pyproject.toml (पैकेज मेटाडेटा), और agents-cli-manifest.yaml (प्रोजेक्ट ट्रैकर) शामिल होता है.
दूसरा चरण: लोकल टेस्ट क्वेरी चलाना
अपने एजेंट के ख़िलाफ़, कमांड-लाइन टेस्ट को तुरंत और सीधे तौर पर लागू करें. अगर Google Cloud के एडीसी (ऐप्लिकेशन के लिए डिफ़ॉल्ट क्रेडेंशियल) का इस्तेमाल नहीं किया जा रहा है, तो पक्का करें कि आपने अपने टर्मिनल में GEMINI_API_KEY एक्सपोर्ट किया हो. Gemini API पासकोड पाने के लिए, यहां जाएं. कुंजी मिलने के बाद, इसे अपने टर्मिनल में यहां दिए गए निर्देश की मदद से एक्सपोर्ट करें:
export GEMINI_API_KEY="YOUR_GEMINI_API_KEY"
अपने टर्मिनल में यह कमांड डालें:
agents-cli run "How are you?"
पर्दे के पीछे क्या होता है: सीएलआई, एजेंट डेवलपमेंट किट (एडीके) के लाइफ़साइकल को पूरी तरह से आपके टर्मिनल की मेमोरी में शुरू करता है. यह आपके लोकल क्रेडेंशियल के ज़रिए प्रॉम्प्ट को सुरक्षित तरीके से रूट करता है. साथ ही, लाइव स्ट्रीमिंग के जवाब को सीधे तौर पर आपकी कमांड लाइन में लॉग करता है.
तीसरा चरण: इंटरैक्टिव वेब प्लेग्राउंड शुरू करना
अपने एजेंट के साथ विज़ुअल तरीके से इंटरैक्ट करने के लिए, वेब पर आधारित लोकल प्लेग्राउंड लॉन्च करें.
agents-cli playground
पर्दे के पीछे क्या होता है: सीएलआई, ADK वेब यूज़र इंटरफ़ेस (यूआई) सर्वर को शुरू करता है. आम तौर पर, इसे http://localhost:8080 या फ़ॉलबैक http://127.0.0.1:8000 पर ऐक्सेस किया जा सकता है. इसमें हॉट-रीलोडिंग की सुविधा भी होती है. वेब इंटरफ़ेस में सबसे ऊपर मौजूद, कोई ऐप्लिकेशन चुनें ड्रॉपडाउन में जाकर ऐप्लिकेशन चुनें. इसके बाद, वेब ऐप्लिकेशन की दाईं ओर मौजूद बातचीत वाले इंटरफ़ेस में जाकर एजेंट से बातचीत करें.
7. npx skills का इस्तेमाल करके एजेंट की क्षमताएं इंस्टॉल करना
npx skills, Vercel Labs ने बनाया है. यह एक कमांड-लाइन टूल है. यह एआई एजेंट (जैसे, Antigravity, Claude Code, GitHub Copilot, Cursor, और Cline) के लिए पैकेज मैनेजर के तौर पर काम करता है. यह ओपन एजेंट स्किल्स के इकोसिस्टम के लिए सीएलआई है.
अगर आपको npx skills पैकेज का इस्तेमाल करके, एजेंट की क्षमताओं को डाउनलोड और इंस्टॉल करना है, तो ध्यान दें कि इससे क्षमताओं को ~/.agents/skills फ़ोल्डर में रखा जाता है. इसमें बताया गया है कि Antigravity जैसे टूल, इस फ़ोल्डर से स्किल चुनेंगे. हालांकि, कृपया ध्यान दें कि इस लेख को लिखते समय, Antigravity इस फ़ोल्डर से स्किल चुनता है, लेकिन Antigravity सीएलआई ऐसा नहीं करता. जैसा कि पहले बताया गया है, आपको ~/.agents/skills फ़ोल्डर में इंस्टॉल की गई इन स्किल को Antigravity CLI में स्किल फ़ोल्डर के प्रोजेक्ट या ग्लोबल स्कोप में कॉपी करना होगा. जैसे,
- प्रोजेक्ट का स्कोप:
<project-root>/.agent/skills/में मौजूद है. - ग्लोबल स्कोप:
~/.gemini/antigravity-cli/skills/में मौजूद है.
8. बधाई हो
बधाई हो! आपने Google Antigravity का इस्तेमाल करके, एजेंट की पहली स्किल बना ली है. साथ ही, उसे कॉन्फ़िगर कर लिया है और उसमें कस्टम सुविधाएं जोड़ ली हैं.
आपने प्रोजेक्ट और ग्लोबल स्कोप, दोनों के लिए एजेंट स्किल का एक सेट भी कॉन्फ़िगर किया है. इससे, ज़रूरत के मुताबिक टूल इस्तेमाल किए जा सकेंगे!
अब आप अपने प्रोजेक्ट के लिए, Antigravity को काम करने की अनुमति दे सकते हैं. साथ ही, अपनी पसंद के मुताबिक कोड लिख सकते हैं.
Kaggle पर, पांच दिनों में एआई एजेंट से जुड़ा बैज पाना
क्या आपने इस लैब को Kaggle के पांच दिनों के एआई एजेंट: Google के साथ इंटेंसिव वाइब कोडिंग कोर्स के हिस्से के तौर पर पूरा किया है? कोर्स पूरा करने पर अपना बैज हासिल करें: पांच दिनों में एआई एजेंट बनाने का बैज पाएं.
9. रेफ़रंस के लिए दस्तावेज़
- कोडलैब : Google Antigravity का इस्तेमाल शुरू करना
- आधिकारिक साइट : https://antigravity.google/
- दस्तावेज़: https://antigravity.google/docs
- डाउनलोड करें : https://antigravity.google/download
- Antigravity Skills के बारे में दस्तावेज़: https://antigravity.google/docs/skills