
1. Introduzione
Google Antigravity è una piattaforma di sviluppo agentica progettata per aiutarti a sviluppare in questa era di agenti. Antigravity funge da centro di comando centrale degli agenti AI, fornendo una piattaforma unificata per avviare, monitorare e orchestrare le loro attività.
In questo codelab, inizieremo a scoprire le competenze degli agenti, un formato aperto e leggero per estendere le funzionalità degli agenti AI con conoscenze e workflow specializzati. Potrai scoprire cosa sono le competenze degli agenti, i loro vantaggi e come vengono create. Quindi, creerai più competenze dell'agente, che vanno da un formattatore Git a un generatore di modelli, a uno scaffolding di codice di strumenti e altro ancora, tutto utilizzabile in Antigravity.
Prerequisiti:
- Antigravity installato e configurato.
- Conoscenza di base di Google Antigravity. Ti consigliamo di completare il codelab Introduzione a Google Antigravity.
2. Perché le skill
Gli agenti AI moderni si sono evoluti da semplici ascoltatori a complessi ragionatori che si integrano con i file system locali e gli strumenti esterni (tramite i server MCP). Tuttavia, caricare indiscriminatamente un agente con intere codebase e centinaia di strumenti porta alla saturazione del contesto e all'"eccesso di strumenti". Anche con finestre contestuali di grandi dimensioni, il dumping di 40-50.000 token di strumenti inutilizzati nella memoria attiva causa latenza elevata, spreco finanziario e "context rot", in cui il modello viene confuso da dati irrilevanti.
La soluzione: skill dell'agente
Per risolvere questo problema, Anthropic ha introdotto Agent Skills, spostando l'architettura dal caricamento del contesto monolitico alla divulgazione progressiva. Anziché forzare il modello a "memorizzare" ogni flusso di lavoro specifico (come le migrazioni di database o i controlli di sicurezza) all'inizio di una sessione, queste funzionalità sono raggruppate in unità modulari e rilevabili.
Come funziona
Inizialmente, il modello viene esposto solo a un "menu" leggero di metadati. Carica le conoscenze procedurali pesanti (istruzioni e script) solo quando l'intent dell'utente corrisponde in modo specifico a un'abilità. In questo modo, uno sviluppatore che chiede di eseguire il refactoring del middleware di autenticazione ottiene il contesto di sicurezza senza caricare pipeline CSS non correlate, mantenendo il contesto snello, veloce ed economico.
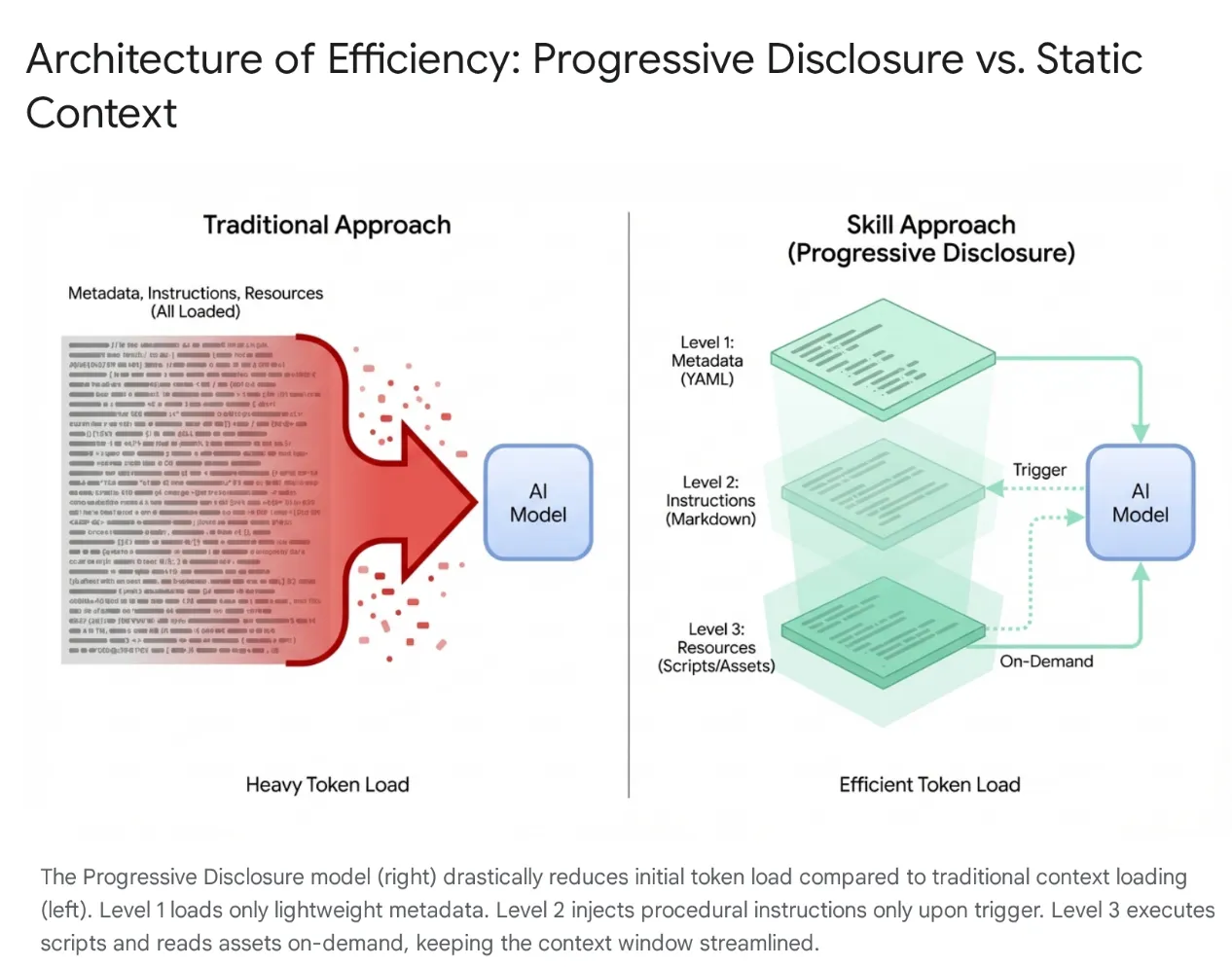
3. Skill dell'agente e Antigravity
Nell'ecosistema Antigravity, le Competenze fungono da moduli di addestramento specializzati che colmano il divario tra i modelli generalisti e il tuo contesto specifico. Consentono all'agente di "dotarsi" di un insieme definito di istruzioni e protocolli, come standard di migrazione del database o controlli di sicurezza, solo quando viene richiesta un'attività pertinente. Caricando dinamicamente questi protocolli di esecuzione, le competenze trasformano efficacemente l'AI da programmatore generico in uno specialista che aderisce rigorosamente alle best practice e agli standard di sicurezza codificati di un'organizzazione.
Che cos'è una competenza in Antigravity?
Nel contesto di Google Antigravity, una skill è un pacchetto basato su directory contenente un file di definizione (SKILL.md) e risorse di supporto facoltative (script, riferimenti, modelli).
È un meccanismo per l'estensione delle funzionalità on demand.
- On-demand: a differenza di un prompt di sistema (che viene sempre caricato), una competenza viene caricata nel contesto dell'agente solo quando l'agente determina che è pertinente alla richiesta corrente dell'utente. In questo modo, la finestra contestuale viene ottimizzata e l'agente non viene distratto da istruzioni non pertinenti. Nei progetti di grandi dimensioni con decine di strumenti, questo caricamento selettivo è fondamentale per le prestazioni e l'accuratezza del ragionamento.
- Estensione delle funzionalità: le skill possono fare molto di più che dare istruzioni, possono eseguire azioni. Raggruppando script Python o Bash, una skill può dare all'agente la possibilità di eseguire azioni complesse in più passaggi sulla macchina locale o su reti esterne senza che l'utente debba eseguire manualmente i comandi. In questo modo, l'agente si trasforma da generatore di testo in utente di strumenti.
Competenze e ecosistema (strumenti, regole e flussi di lavoro)
Mentre il Model Context Protocol (MCP) funge da "mani " dell'agente, fornendo connessioni persistenti e resistenti a sistemi esterni come GitHub o PostgreSQL, le competenze fungono da "cervello" che le dirige.
MCP gestisce l'infrastruttura stateful, mentre le competenze sono definizioni di attività leggere ed effimere che raggruppano la metodologia per l'utilizzo di questi strumenti. Questo approccio serverless consente agli agenti di eseguire attività ad hoc (come la generazione di changelog o migrazioni) senza l'overhead operativo dell'esecuzione di processi persistenti, caricando il contesto solo quando l'attività è attiva e rilasciandolo immediatamente dopo.
Le competenze sono attivate dall'agente: il modello rileva automaticamente l'intenzione dell'utente e fornisce dinamicamente le competenze specifiche richieste. Questa architettura consente una composizione potente. Ad esempio, una regola globale può imporre l'utilizzo di una competenza "Safe-Migration" durante le modifiche al database oppure un singolo flusso di lavoro può orchestrare più competenze per creare una pipeline di deployment solida.
4. Creazione di skill
La creazione di una skill in Antigravity segue una struttura di directory e un formato di file specifici. Questa standardizzazione garantisce che le skill siano portabili e che l'agente possa analizzarle ed eseguirle in modo affidabile. Il design è intenzionalmente semplice e si basa su formati ampiamente compresi come Markdown e YAML, riducendo la barriera all'ingresso per gli sviluppatori che desiderano estendere le funzionalità del proprio IDE.
Struttura delle directory
Una tipica directory delle skill ha questo aspetto:
my-skill/
├── SKILL.md # The definition file
├── scripts/ # [Optional] Python, Bash, or Node scripts
├── run.py
└── util.sh
├── references/ # [Optional] Documentation or templates
└── api-docs.md
└── assets/ # [Optional] Static assets (images, logos)
Questa struttura separa efficacemente le problematiche. La logica (scripts) è separata dall'istruzione (SKILL.md) e dalla conoscenza (references), rispecchiando le pratiche standard di ingegneria del software.
Il file di definizione SKILL.md
Il file SKILL.md è il cervello della skill. Indica all'agente cos'è la skill, quando utilizzarla e come eseguirla.
È composto da due parti:
- Frontmatter YAML
- Corpo Markdown.
YAML Frontmatter
Questo è il livello dei metadati. È l'unica parte dell'intent che viene indicizzata dal router di alto livello dell'agente. Quando un utente invia un prompt, l'agente esegue la corrispondenza semantica del prompt con i campi di descrizione di tutte le skill disponibili.
---
name: database-inspector
description: Use this skill when the user asks to query the database, check table schemas, or inspect user data in the local PostgreSQL instance.
---
Campi chiave:
- name: questo campo non è obbligatorio. Deve essere univoco nell'ambito. Lettere minuscole, trattini consentiti (ad es.
postgres-query,pr-reviewer). Se non viene fornito, il valore predefinito sarà il nome della directory. - description: questo campo è obbligatorio ed è il più importante. Funziona come "frase di attivazione". Deve essere sufficientemente descrittivo per consentire all'LLM di riconoscere la pertinenza semantica. Una descrizione vaga come "Strumenti di database" non è sufficiente. Una descrizione precisa come "Esegue query SQL di sola lettura sul database PostgreSQL locale per recuperare dati di utenti o transazioni. Utilizza questa opzione per il debug degli stati dei dati" garantisce che la skill venga rilevata correttamente.
The Markdown Body
Il corpo contiene le istruzioni. Si tratta di "prompt engineering" salvato in un file. Quando la skill viene attivata, questi contenuti vengono inseriti nella finestra contestuale dell'agente.
Il corpo deve includere:
- Obiettivo: una dichiarazione chiara di ciò che la skill ottiene.
- Istruzioni: logica passo passo.
- Esempi: esempi few-shot di input e output per guidare le prestazioni del modello.
- Vincoli: regole "Non" (ad es. "Non eseguire query DELETE").
Esempio di corpo del file SKILL.md:
Database Inspector
Goal
To safely query the local database and provide insights on the current data state.
Instructions
- Analyze the user's natural language request to understand the data need.
- Formulate a valid SQL query.
- CRITICAL: Only SELECT statements are allowed.
- Use the script scripts/query_runner.py to execute the SQL.
- Command: python scripts/query_runner.py "SELECT * FROM..."
- Present the results in a Markdown table.
Constraints
- Never output raw user passwords or API keys.
- If the query returns > 50 rows, summarize the data instead of listing it all.
Integrazione di script
Una delle funzionalità più potenti delle skill è la possibilità di delegare l'esecuzione agli script. Ciò consente all'agente di eseguire azioni difficili o impossibili da eseguire direttamente per un LLM (come l'esecuzione binaria, calcoli matematici complessi o l'interazione con sistemi legacy).
Gli script vengono inseriti nella sottodirectory scripts/. SKILL.md fa riferimento a questi file tramite il percorso relativo.
5. Creazione di competenze
Lo scopo di questa sezione è creare competenze che si integrino in Antigravity e mostrino progressivamente varie funzionalità come risorse, script e così via.
Puoi scaricare le skill dal repository GitHub qui: https://github.com/rominirani/antigravity-skills.
Prima di capire come sono state create queste competenze, vediamo come le configuriamo e le rendiamo disponibili all'interno della suite di prodotti Antigravity. Le cartelle riportate di seguito sono applicabili al momento della pubblicazione di questo lab.
Utilizzo di Antigravity o Antigravity CLI
Le competenze possono essere definite in due ambiti, consentendo competenze specifiche del progetto e competenze specifiche dell'utente, ovvero competenze globali:
- Ambito globale (
~/.gemini/config/skills/): disponibile in tutti i prodotti Antigravity (Antigravity, Antigravity IDE, Antigravity CLI) e progetti. Queste competenze sono disponibili in tutti i progetti sul computer dell'utente. È adatto a utilità generali come "Formatta JSON", "Genera UUID", "Rivedi stile codice" o all'integrazione con strumenti di produttività personale. - Ambito progetto/workspace (
<project-root>/.agents/skills/): in questo modo, la skill sarà disponibile solo all'interno di un progetto specifico. Questa opzione è ideale per gli script specifici del progetto, ad esempio il deployment in un ambiente specifico, la gestione del database per l'app o la generazione di codice boilerplate per un framework proprietario.
Installazione delle skill in Antigravity o in Antigravity CLI
Per questo tutorial, tutto ciò che dobbiamo fare è seguire i seguenti passaggi (puoi farlo anche a modo tuo):
Passaggio 1: esegui un git clone di https://github.com/rominirani/antigravity-skills
Passaggio 2: ora, a seconda che tu stia utilizzando Antigravity o Antigravity CLI, puoi passare alla cartella antigravity-skills/skills_tutorial.
Passaggio 3: troverai un insieme di competenze raggruppate nelle rispettive cartelle. Copia le seguenti 4 cartelle:
git-commit-formatterlicense-header-adderdatabase-schema-validatorjson-to-pydantic
nella cartella delle competenze mirate per il prodotto (ambito del progetto o ambito globale).
Passaggio 4: se utilizzi Antigravity o Antigravity CLI , copialo in <project-root>/.agents/skills/ (ambito del progetto).
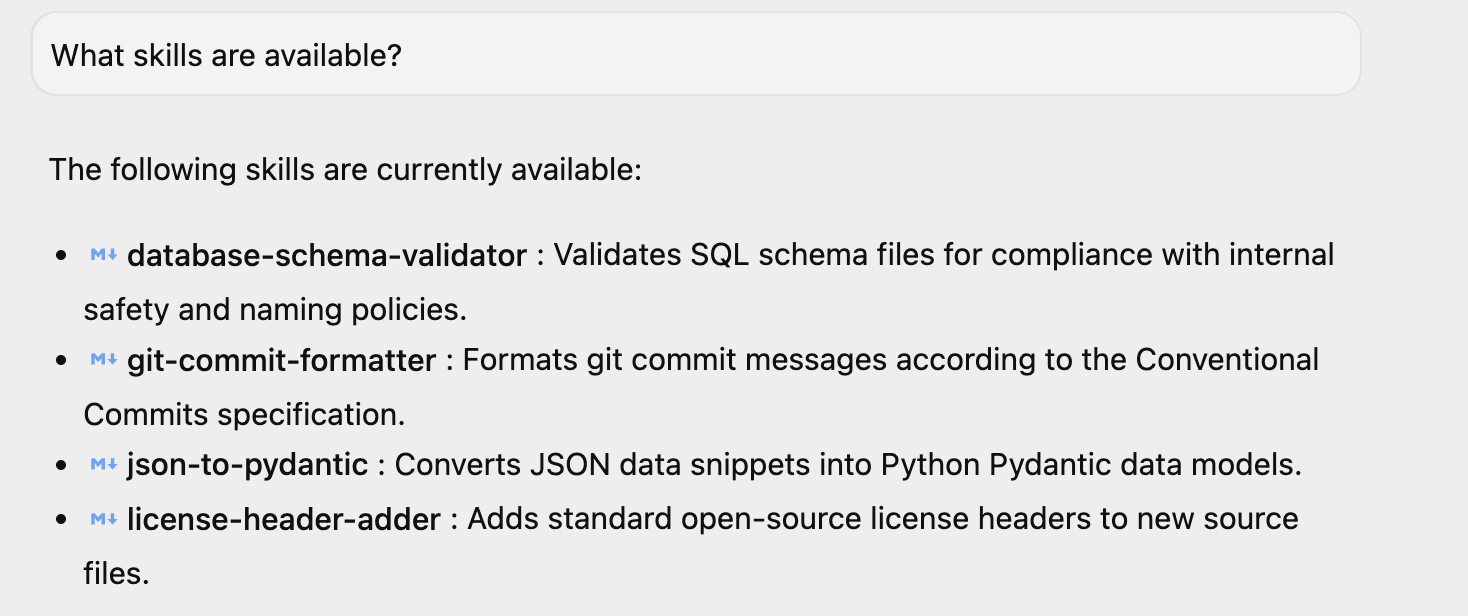
Se hai avviato Antigravity, puoi porre una semplice domanda "Quali competenze sono disponibili?" e la risposta sarà la stessa. Puoi vedere le quattro skill elencate. Potresti avere anche altre skill, se le hai installate nel tuo ambiente.
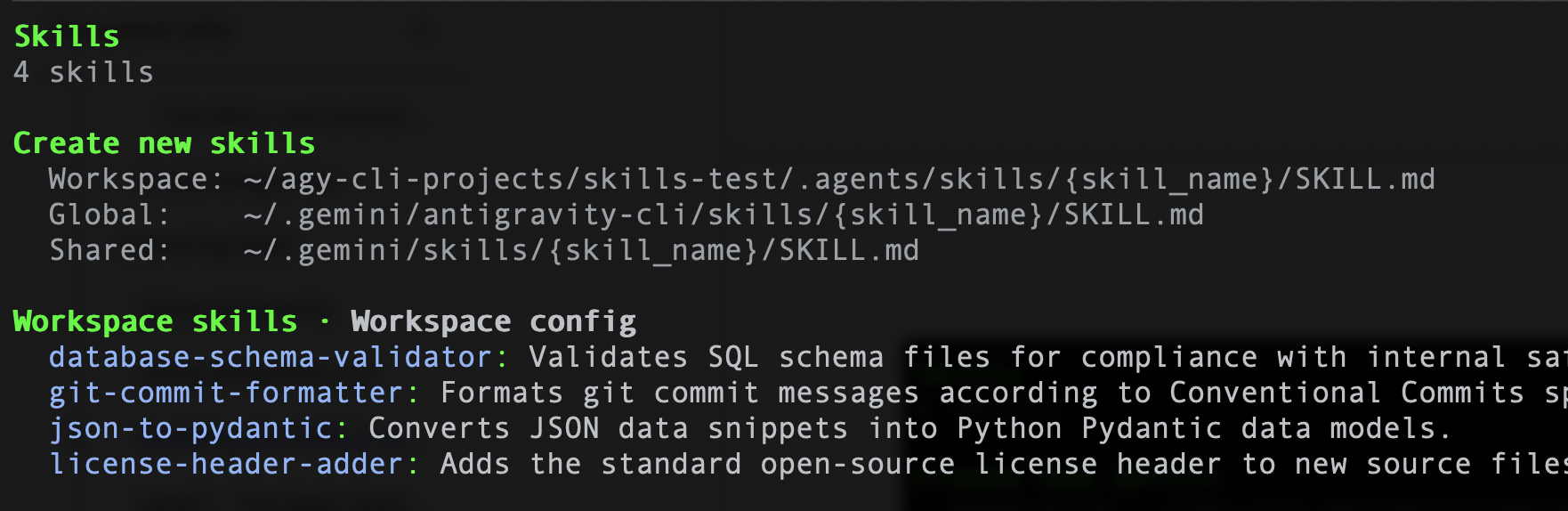
Allo stesso modo, se utilizzi Antigravity CLI, puoi eseguire il seguente comando /skills e dovresti visualizzare le 4 competenze. Di seguito è riportato un esempio:
Ora che sappiamo come configurare le competenze, analizziamo ciascuna di esse e capiamo come sono state create. Puoi utilizzare questi modelli anche per creare le tue competenze.
Livello 1 : il router di base ( git-commit-formatter)
Consideriamolo come l'equivalente di "Hello World" per le skill.
Gli sviluppatori spesso scrivono messaggi di commit pigri, ad esempio "wip", "fix bug", "updates". L'applicazione manuale di "Conventional Commits" è noiosa e spesso dimenticata. Implementiamo una competenza che applichi la specifica Conventional Commits. Basta istruire l'agente sulle regole per consentirgli di agire come responsabile dell'applicazione.
git-commit-formatter/
└── SKILL.md (Instructions only)
Il file SKILL.md è mostrato di seguito:
---
name: git-commit-formatter
description: Formats git commit messages according to Conventional Commits specification. Use this when the user asks to commit changes or write a commit message.
---
Git Commit Formatter Skill
When writing a git commit message, you MUST follow the Conventional Commits specification.
Format
`<type>[optional scope]: <description>`
Allowed Types
- **feat**: A new feature
- **fix**: A bug fix
- **docs**: Documentation only changes
- **style**: Changes that do not affect the meaning of the code (white-space, formatting, etc)
- **refactor**: A code change that neither fixes a bug nor adds a feature
- **perf**: A code change that improves performance
- **test**: Adding missing tests or correcting existing tests
- **chore**: Changes to the build process or auxiliary tools and libraries such as documentation generation
Instructions
1. Analyze the changes to determine the primary `type`.
2. Identify the `scope` if applicable (e.g., specific component or file).
3. Write a concise `description` in an imperative mood (e.g., "add feature" not "added feature").
4. If there are breaking changes, add a footer starting with `BREAKING CHANGE:`.
Example
`feat(auth): implement login with google`
Come eseguire questo esempio in Antigravity
I passaggi riportati di seguito presuppongono che Git sia disponibile sulla tua macchina locale e configurato correttamente.
Supponendo che tu abbia avviato Antigravity o Antigravity CLI, segui questi passaggi:
Passaggio 1: configura un repository Git di test
Chiedi all'agente di configurare una directory pulita e isolata per testare le operazioni Git.
Il tuo prompt:
Create a folder named git_test in the workspace, initialize a git repository inside it, and create an initial file auth.py with def login(): pass. Stage this file and make an initial commit.
L'agente creerà la directory, inizializzerà il repository, preparerà il file e lo eseguirà con un messaggio come "initial commit".
Passaggio 2: esegui una modifica del codice
Chiedi all'agente di modificare il codice in modo che ci sia una modifica da eseguire.
Il tuo prompt:
In the git_test folder, modify auth.py to add Google Login functionality.
L'agente modificherà il file per aggiungere una nuova funzionalità, preparandolo per la fase di commit.
Passaggio 3: esegui lo staging e il commit delle modifiche
Attiva la skill git-commit-formatter chiedendo all'agente di preparare le modifiche e creare un commit.
Il tuo prompt:
Stage the changes in the git_test folder and commit them. Make sure to format the commit message using the Conventional Commits skill.
L'agente eseguirà git add auth.py, analizzerà la differenza per determinare che è stata aggiunta una nuova funzionalità al modulo auth e formulerà un messaggio di commit convenzionale come feat(auth): implement google login prima di eseguire git commit.
Passaggio 4: verifica il log Git
Chiedi all'agente di recuperare la cronologia Git per verificare che il commit formattato sia stato registrato correttamente.
Il tuo prompt:
Show me the git log in the git_test folder.
L'agente eseguirà git log -n 5 e restituirà l'output che mostra il messaggio di commit formattato.
Livello 2: utilizzo degli asset (license-header-adder)
Questo è il pattern "Riferimento".
Ogni file sorgente di un progetto aziendale potrebbe richiedere un'intestazione di licenza Apache 2.0 specifica di 20 righe. Inserire questo testo statico direttamente nel prompt (o in SKILL.md) è uno spreco. Consuma token ogni volta che la skill viene indicizzata e il modello potrebbe "allucinare" errori di battitura nel testo legale. È consigliabile scaricare il testo statico in un file di testo normale in una cartella resources/. La competenza indica all'agente di leggere questo file solo quando necessario.
Troverai i file nella cartella license-header-adder della directory skills.
license-header-adder/
├── SKILL.md
└── resources/
└── HEADER_TEMPLATE.txt (The heavy text)
Il file SKILL.md è mostrato di seguito:
---
name: license-header-adder
description: Adds the standard open-source license header to new source files. Use involves creating new code files that require copyright attribution.
---
# License Header Adder Skill
This skill ensures that all new source files have the correct copyright header.
## Instructions
1. **Read the Template**:
First, read the content of the header template file located at `resources/HEADER_TEMPLATE.txt`.
2. **Prepend to File**:
When creating a new file (e.g., `.py`, `.java`, `.js`, `.ts`, `.go`), prepend the `target_file` content with the template content.
3. **Modify Comment Syntax**:
- For C-style languages (Java, JS, TS, C++), keep the `/* ... */` block as is.
- For Python, Shell, or YAML, convert the block to use `#` comments.
- For HTML/XML, use `<!-- ... -->`.
Come eseguire questo esempio in Antigravity
Supponendo che tu abbia avviato Antigravity o Antigravity CLI, segui questi passaggi:
Passaggio 1: crea il file Python con il codice di esempio
Il tuo prompt:
Create a new file my_script.py with the following python code:
def hello():
print("Hello, World!")
Cosa è successo (spiegazione): l'agente ha richiamato uno strumento di scrittura di file (write_to_file) per creare un nuovo file denominato my_script.py direttamente nella directory dello spazio di lavoro attivo e ha scritto la funzione Python di base. Inoltre, il prompt ha attivato la competenza license-header-adder. L'agente ha individuato e letto il file del modello di licenza (HEADER_TEMPLATE.txt), ha modificato lo stile dei commenti da commenti a blocchi in stile C (/* ... */) a commenti in stile Python (#) e lo ha aggiunto all'inizio del file utilizzando lo strumento replace_file_content.
Passaggio 2: verifica i contenuti del file
Dai un'occhiata al file my_script.py. Contiene l'intestazione della licenza nella parte superiore.
Livello 3: apprendimento tramite esempi (json-to-pydantic)
Il pattern "Few-Shot".
La conversione di dati non strutturati (come una risposta API JSON) in codice rigoroso (come i modelli Pydantic) comporta decine di decisioni. Come dobbiamo chiamare i corsi? Dobbiamo usare Optional? snake_case o camelCase? Scrivere queste 50 regole in inglese è noioso e soggetto a errori.
Gli LLM sono motori di corrispondenza di pattern.
Creare la tua skill con un esempio pratico (Input -> Output) è spesso più efficace di istruzioni dettagliate.
Vai alla cartella json-to-pydantic/ che contiene i file di skill, come mostrato di seguito:
json-to-pydantic/
├── SKILL.md
└── examples/
├── input_data.json (The Before State)
└── output_model.py (The After State)
Il file SKILL.md è mostrato di seguito:
---
name: json-to-pydantic
description: Converts JSON data snippets into Python Pydantic data models.
---
# JSON to Pydantic Skill
This skill helps convert raw JSON data or API responses into structured, strongly-typed Python classes using Pydantic.
Instructions
1. **Analyze the Input**: Look at the JSON object provided by the user.
2. **Infer Types**:
- `string` -> `str`
- `number` -> `int` or `float`
- `boolean` -> `bool`
- `array` -> `List[Type]`
- `null` -> `Optional[Type]`
- Nested Objects -> Create a separate sub-class.
3. **Follow the Example**:
Review `examples/` to see how to structure the output code. notice how nested dictionaries like `preferences` are extracted into their own class.
- Input: `examples/input_data.json`
- Output: `examples/output_model.py`
Style Guidelines
- Use `PascalCase` for class names.
- Use type hints (`List`, `Optional`) from `typing` module.
- If a field can be missing or null, default it to `None`.
Nella cartella /examples sono presenti il file JSON e il file di output , ovvero il file Python. Entrambi sono mostrati di seguito:
input_data.json
{
"user_id": 12345,
"username": "jdoe_88",
"is_active": true,
"preferences": {
"theme": "dark",
"notifications": [
"email",
"push"
]
},
"last_login": "2024-03-15T10:30:00Z",
"meta_tags": null
}
output_model.py
from pydantic import BaseModel, Field
from typing import List, Optional
class Preferences(BaseModel):
theme: str
notifications: List[str]
class User(BaseModel):
user_id: int
username: str
is_active: bool
preferences: Preferences
last_login: Optional[str] = None
meta_tags: Optional[List[str]] = None
Come eseguire questo esempio in Antigravity
Supponendo che tu abbia avviato Antigravity o Antigravity CLI, segui questi passaggi:
Passaggio 1: crea il file JSON con dati di esempio
Chiedi all'agente di creare un nuovo file product.json contenente il payload JSON non elaborato.
Il tuo prompt:
Create a new file product.json with the following JSON:
{
"product": "Widget",
"cost": 10.99,
"stock": null
}
Passaggio 2: converti il JSON in un modello Pydantic
Attiva la skill json-to-pydantic per convertire i dati JSON in una classe Pydantic strutturata.
Il tuo prompt:
Convert the JSON in product.json to a Pydantic model and save it to product_model.py.
Passaggio 3: verifica l'output
Dai un'occhiata al file product_model.py. Conterrà il modello Pydantic completato.
Livello 4: logica procedurale (database-schema-validator)
Questo è il pattern "Utilizzo degli strumenti".
Se chiedi a un LLM "Questo schema è sicuro?", potrebbe rispondere che va tutto bene, anche se manca una chiave primaria critica, semplicemente perché l'SQL sembra corretto.
Deleghiamo questo controllo a uno script deterministico. La nostra skill database-schema-validator indirizzerà l'agente all'esecuzione di uno script Python che abbiamo scritto. Lo script fornisce un valore di verità binario (vero/falso).
database-schema-validator/
├── SKILL.md
└── scripts/
└── validate_schema.py (The Validator)
Il file SKILL.md è mostrato di seguito:
---
name: database-schema-validator
description: Validates SQL schema files for compliance with internal safety and naming policies.
---
# Database Schema Validator Skill
This skill ensures that all SQL files provided by the user comply with our strict database standards.
Policies Enforced
1. **Safety**: No `DROP TABLE` statements.
2. **Naming**: All tables must use `snake_case`.
3. **Structure**: Every table must have an `id` column as PRIMARY KEY.
Instructions
1. **Do not read the file manually** to check for errors. The rules are complex and easily missed by eye.
2. **Run the Validation Script**:
Use the `run_command` tool to execute the python script provided in the `scripts/` folder against the user's file.
`python scripts/validate_schema.py <path_to_user_file>`
3. **Interpret Output**:
- If the script returns **exit code 0**: Tell the user the schema looks good.
- If the script returns **exit code 1**: Report the specific error messages printed by the script to the user and suggest fixes.
Il file validate_schema.py è mostrato di seguito:
import sys
import re
def validate_schema(filename):
"""
Validates a SQL schema file against internal policy:
1. Table names must be snake_case.
2. Every table must have a primary key named 'id'.
3. No 'DROP TABLE' statements allowed (safety).
"""
try:
with open(filename, 'r') as f:
content = f.read()
lines = content.split('\n')
errors = []
# Check 1: No DROP TABLE
if re.search(r'DROP TABLE', content, re.IGNORECASE):
errors.append("ERROR: 'DROP TABLE' statements are forbidden.")
# Check 2 & 3: CREATE TABLE checks
table_defs = re.finditer(r'CREATE TABLE\s+(?P<name>\w+)\s*\((?P<body>.*?)\);', content, re.DOTALL | re.IGNORECASE)
for match in table_defs:
table_name = match.group('name')
body = match.group('body')
# Snake case check
if not re.match(r'^[a-z][a-z0-9_]*$', table_name):
errors.append(f"ERROR: Table '{table_name}' must be snake_case.")
# Primary key check
if not re.search(r'\bid\b.*PRIMARY KEY', body, re.IGNORECASE):
errors.append(f"ERROR: Table '{table_name}' is missing a primary key named 'id'.")
if errors:
for err in errors:
print(err)
sys.exit(1)
else:
print("Schema validation passed.")
sys.exit(0)
except FileNotFoundError:
print(f"Error: File '{filename}' not found.")
sys.exit(1)
if __name__ == "__main__":
if len(sys.argv) != 2:
print("Usage: python validate_schema.py <schema_file>")
sys.exit(1)
validate_schema(sys.argv[1])
Come eseguire questo esempio in Antigravity
Supponendo che tu abbia avviato Antigravity o Antigravity CLI, segui questi passaggi:
Passaggio 1: crea il file JSON con dati di esempio
Chiedi all'agente di creare un nuovo file bad_schema.sql contenente più violazioni delle norme.
Il tuo prompt:
Create a new file bad_schema.sql with the following SQL:
DROP TABLE IF EXISTS legacy_users;
CREATE TABLE userProfile (
id INT PRIMARY KEY,
bio TEXT
);
CREATE TABLE posts (
title TEXT,
content TEXT,
created_at TIMESTAMP
);
CREATE TABLE comments (
id INT PRIMARY KEY,
post_id INT,
body TEXT
);
Il file dello schema precedente viola tutte e tre le norme: utilizza un'istruzione DROP TABLE vietata, utilizza camelCase per il nome della tabella userProfile e dimentica la chiave primaria id nella tabella posts.
Passaggio 2: convalida lo schema SQL
Attiva la skill database-schema-validator per eseguire lo script di convalida Python sul file.
Il tuo prompt:
Validate bad_schema.sql using the database-schema-validator skill.
Passaggio 3: verifica l'output
L'agente segnalerà l'errore e mostrerà gli errori specifici rilevati dallo script direttamente nella chat. Di seguito è riportato l'output di esempio:
Suggested Fixes:
Remove the line DROP TABLE IF EXISTS legacy_users; as dropping tables is forbidden by safety policy.
Rename the table userProfile to use snake_case (e.g., user_profile).
Add a primary key column named id to the posts table definition.
6. Developer Toolkit (competenze CLI di Agents)
Il pattern "Azione e ciclo di vita".
Lo sviluppo di agenti AI comporta attività ripetitive del ciclo di vita: creazione di file boilerplate, configurazione di ambienti di runtime locali, esecuzione di prompt di test e avvio di playground interattivi.
Anziché costringere l'assistente alla programmazione a indovinare le strutture delle directory o a scrivere da zero la configurazione dell'agente boilerplate, Agents CLI Skills raggruppa questa esperienza del ciclo di vita in competenze specifiche dell'agente.
Le competenze dell'interfaccia a riga di comando (CLI) dell'agente portano l'automazione semplificata e incentrata sugli sviluppatori direttamente nel tuo terminale, colmando il divario tra il codice non elaborato e l'esecuzione autonoma. Mentre l'Agent Development Kit (ADK) si concentra sul framework programmatico, fornendo SDK, API e progetti strutturali per creare e orchestrare agenti AI, le competenze della CLI dell'agente forniscono la forza operativa. Consente agli sviluppatori di creare, testare ed eseguire il deployment degli agenti localmente con cicli di feedback rapidi, bypassando completamente il sovraccarico dell'interfaccia utente.
Se mappate a Google Cloud, le competenze dell'interfaccia a riga di comando dell'agente fungono da pipeline diretta all'infrastruttura di livello aziendale. Anziché fare clic sulle console, puoi utilizzare i comandi CLI per creare pacchetti istantaneamente dei flussi di lavoro degli agenti, gestire le autorizzazioni di accesso ed eseguirli nel deployment negli ecosistemi Google Cloud (come Vertex AI o Cloud Run). In questo modo, quelle che prima erano complesse attività di architettura cloud si trasformano in comandi del terminale semplici e riproducibili, semplificando notevolmente l'integrazione di agenti autonomi nelle pipeline di deployment CI/CD esistenti.
Come installare
Assicurati di aver installato Python 3.11+, Node.js e il gestore di pacchetti uv. Poi, esegui il comando di configurazione nel terminale:
uvx google-agents-cli setup
Questo comando installa il binario agents-cli e registra le sue competenze specializzate per la generazione di impalcature e la valutazione nell'ambiente dell'assistente alla codifica.
Nota: le skill verranno installate nella cartella ~/.agents/skills, visibile ad Antigravity. Se vuoi visualizzare queste competenze in Antigravity CLI, devi spostarle nella cartella ~/.gemini/antigravity-cli/skills (ambito globale).
Puoi verificare che le competenze siano state caricate in Antigravity semplicemente chiedendo quali sono disponibili. Di seguito è riportato un esempio di risposta per le competenze della CLI dell'agente che abbiamo appena installato.

Procedura dettagliata
Una volta completato uvx google-agents-cli setup, puoi creare, interagire e testare un agente AI interamente sulla tua macchina locale.
Passaggio 1: crea e inizializza un nuovo progetto di agente
Esegui il comando di creazione per creare uno scaffolding di un layout standardizzato. Una volta creato, devi installare le dipendenze del progetto prima di eseguire qualsiasi attività di esecuzione.
# 1. Create a lightweight prototype project structure
agents-cli create weather-assistant --prototype --yes
# 2. Move into the directory and install required ADK dependencies
cd weather-assistant
agents-cli install
Cosa succede dietro le quinte: viene creato uno spazio di lavoro pulito con app/agent.py (il codice principale), pyproject.toml (i metadati del pacchetto) e agents-cli-manifest.yaml (il tracker del progetto).
Passaggio 2: esegui una query di test locale
Esegui un test rapido e diretto della riga di comando sull'agente. Se non utilizzi le credenziali predefinite dell'applicazione (ADC) di Google Cloud, assicurati di aver esportato GEMINI_API_KEY nel terminale. Puoi ottenere una chiave API Gemini qui. Una volta ottenuta la chiave, esportala nel terminale tramite il seguente comando:
export GEMINI_API_KEY="YOUR_GEMINI_API_KEY"
Esegui questo comando nel terminale:
agents-cli run "How are you?"
Cosa succede dietro le quinte: la CLI inizializza il ciclo di vita dell'Agent Development Kit (ADK) interamente in memoria sul terminale. Instrada in modo sicuro il prompt tramite le tue credenziali locali e registra la risposta dello streaming live direttamente nella riga di comando.
Passaggio 3: avvia l'Interactive Web Playground
Avvia il playground web locale integrato per interagire visivamente con l'agente.
agents-cli playground
Cosa succede dietro le quinte: la CLI avvia un server dell'interfaccia utente web dell'ADK, in genere accessibile all'indirizzo http://localhost:8080 o di fallback http://127.0.0.1:8000, completo di ricaricamento rapido. Dall'interfaccia web, seleziona app nel menu a discesa Seleziona un'app in alto e interagisci con l'agente nell'interfaccia conversazionale sul lato destro dell'applicazione web.
7. Installare le skill dell'agente utilizzando npx skills
npx skills è uno strumento a riga di comando sviluppato da Vercel Labs che funge da gestore di pacchetti per gli agenti di AI (come Antigravity, Claude Code, GitHub Copilot, Cursor e Cline). È l'interfaccia a riga di comando per l'ecosistema aperto delle competenze degli agenti.
Se vuoi scaricare e installare le competenze dell'agente utilizzando il pacchetto npx skills, tieni presente che le competenze vengono inserite nella cartella ~/.agents/skills. Sebbene venga indicato che strumenti come Antigravity prelevano le competenze da questa cartella, tieni presente che al momento della stesura, Antigravity le preleva da questa cartella, ma Antigravity CLI no. Come accennato in precedenza, dovrai copiare queste competenze installate nella cartella ~/.agents/skills nell'ambito globale o del progetto per le cartelle delle competenze nell'interfaccia a riga di comando Antigravity, ad esempio:
- Ambito del progetto: si trova in
<project-root>/.agent/skills/. - Ambito globale: si trova in
~/.gemini/antigravity-cli/skills/.
8. Complimenti
Complimenti! Hai utilizzato correttamente Google Antigravity per creare la tua prima skill dell'agente, l'hai configurata e hai aggiunto funzionalità personalizzate.
Sei anche riuscito a configurare un insieme di competenze dell'agente, sia a livello di progetto che globale, dando vita a strumenti personalizzati.
Ora puoi lasciare che Antigravity si occupi del lavoro più pesante nei tuoi progetti e scrivere codice a modo tuo.
Ottieni il badge Agenti AI di Kaggle in 5 giorni
Hai completato questo lab nell'ambito del corso intensivo di programmazione 5-Day AI Agents: Intensive Vibe Coding Course with Google di Kaggle? Richiedi il badge di completamento: ottieni il badge Agenti AI di 5 giorni.
9. Documenti di riferimento
- Codelab : Guida introduttiva a Google Antigravity
- Sito ufficiale : https://antigravity.google/
- Documentazione: https://antigravity.google/docs
- Download : https://antigravity.google/download
- Documentazione di Antigravity Skills: https://antigravity.google/docs/skills