
1. 소개
Google Antigravity는 에이전트 시대에 개발할 수 있도록 설계된 에이전트형 개발 플랫폼입니다. Antigravity는 AI 에이전트의 중앙 지휘소 역할을 하며, 활동을 실행, 모니터링, 조정할 수 있는 통합 플랫폼을 제공합니다.
이 Codelab에서는 먼저 전문 지식과 워크플로를 통해 AI 에이전트 기능을 확장하는 경량의 개방형 형식인 에이전트 스킬에 대해 알아봅니다. 상담사 기술이 무엇인지, 어떤 이점이 있는지, 어떻게 구성되는지 알아볼 수 있습니다. 그런 다음 Antigravity 내에서 사용할 수 있는 Git 포맷터, 템플릿 생성기, 도구 코드 스캐폴딩 등 다양한 에이전트 스킬을 빌드합니다.
기본 요건:
- Antigravity가 설치되고 구성되었습니다.
- Google Antigravity에 대한 기본적인 이해 Google Antigravity 시작하기 Codelab을 완료하는 것이 좋습니다.
2. 스킬이 필요한 이유
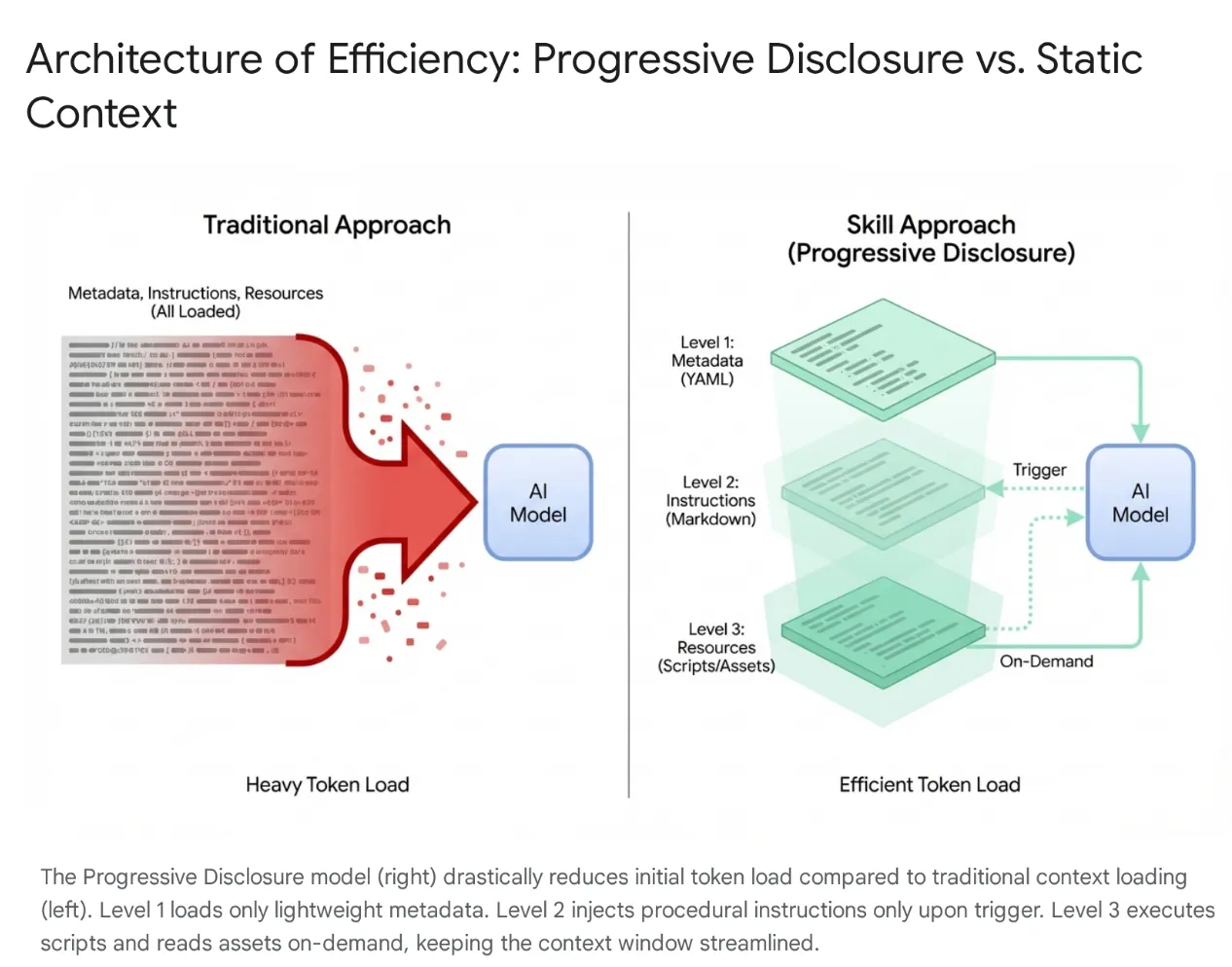
최신 AI 에이전트는 단순한 리스너에서 로컬 파일 시스템 및 외부 도구 (MCP 서버를 통해)와 통합되는 복잡한 추론자로 발전했습니다. 하지만 전체 코드베이스와 수백 개의 도구를 에이전트에 무분별하게 로드하면 컨텍스트 포화 및 '도구 블로트'가 발생합니다. 컨텍스트 윈도우가 크더라도 사용하지 않는 도구의 토큰 40, 000~50, 000개를 활성 메모리에 덤프하면 지연 시간이 길어지고, 재정적 낭비가 발생하며, 모델이 관련 없는 데이터로 인해 혼동을 겪는 '컨텍스트 손상'이 발생합니다.
해결책: 상담사 기술
이 문제를 해결하기 위해 Anthropic은 에이전트 스킬을 도입하여 아키텍처를 모놀리식 컨텍스트 로드에서 점진적 공개로 전환했습니다. 세션을 시작할 때 모델이 데이터베이스 마이그레이션이나 보안 감사와 같은 모든 특정 워크플로를 '기억'하도록 강제하는 대신 이러한 기능은 검색 가능한 모듈식 단위로 패키징됩니다.
작동 방식
모델은 처음에 경량 메타데이터 '메뉴'에만 노출됩니다. 사용자의 의도가 스킬과 구체적으로 일치하는 경우에만 무거운 절차적 지식 (안내 및 스크립트)을 로드합니다. 이렇게 하면 인증 미들웨어를 리팩터링하려는 개발자가 관련 없는 CSS 파이프라인을 로드하지 않고 보안 컨텍스트를 가져와 컨텍스트를 간결하고 빠르며 비용 효율적으로 유지할 수 있습니다.
3. 상담사 기술 및 Antigravity
Antigravity 생태계에서 스킬은 범용 모델과 특정 컨텍스트 간의 격차를 해소하는 전문 학습 모듈 역할을 합니다. 이를 통해 에이전트는 데이터베이스 이전 표준이나 보안 검사와 같은 정의된 일련의 요청 사항과 프로토콜을 관련 작업이 요청된 경우에만 '장착'할 수 있습니다. 이러한 실행 프로토콜을 동적으로 로드함으로써 스킬은 AI를 일반적인 프로그래머에서 조직의 성문화된 권장사항과 안전 표준을 엄격하게 준수하는 전문가로 효과적으로 변환합니다.
Antigravity의 스킬이란 무엇인가요?
Google Antigravity의 맥락에서 스킬은 정의 파일 (SKILL.md)과 선택적 지원 애셋 (스크립트, 참조, 템플릿)이 포함된 디렉터리 기반 패키지입니다.
주문형 기능 확장 메커니즘입니다.
- 주문형: 항상 로드되는 시스템 프롬프트와 달리 스킬은 에이전트가 사용자의 현재 요청과 관련이 있다고 판단할 때만 에이전트의 컨텍스트에 로드됩니다. 이렇게 하면 컨텍스트 윈도우가 최적화되고 에이전트가 관련 없는 요청 사항에 주의를 빼앗기지 않습니다. 수십 개의 도구가 있는 대규모 프로젝트에서는 이러한 선택적 로딩이 성능과 추론 정확도에 매우 중요합니다.
- 기능 확장: 스킬은 지시하는 것 외에도 실행할 수 있습니다. Python 또는 Bash 스크립트를 번들로 묶으면 사용자가 명령어를 수동으로 실행하지 않아도 스킬이 로컬 머신이나 외부 네트워크에서 복잡한 다단계 작업을 실행할 수 있습니다. 이렇게 하면 에이전트가 텍스트 생성기에서 도구 사용자로 변환됩니다.
기술과 생태계 (도구, 규칙, 워크플로)
모델 컨텍스트 프로토콜 (MCP)은 에이전트의 '손' 역할을 하여 GitHub 또는 PostgreSQL과 같은 외부 시스템에 강력하고 지속적인 연결을 제공하는 반면, 스킬은 이를 지시하는 '두뇌' 역할을 합니다.
MCP는 상태 저장 인프라를 처리하는 반면 스킬은 이러한 도구를 사용하는 방법론을 패키징하는 경량의 일시적인 작업 정의입니다. 이 서버리스 접근 방식을 사용하면 에이전트가 지속적인 프로세스를 실행하는 운영 오버헤드 없이 임시 작업을 실행할 수 있습니다 (예: 변경 로그 생성 또는 이전). 작업이 활성 상태일 때만 컨텍스트를 로드하고 작업이 완료되면 즉시 컨텍스트를 해제합니다.
스킬은 에이전트 트리거입니다. 모델이 사용자의 의도를 자동으로 감지하고 필요한 특정 전문 지식을 동적으로 갖춥니다. 이 아키텍처는 강력한 구성 가능성을 지원합니다. 예를 들어 전역 규칙은 데이터베이스 변경 중에 '안전한 이전' 스킬을 사용하도록 강제할 수 있으며, 단일 워크플로는 여러 스킬을 오케스트레이션하여 강력한 배포 파이프라인을 빌드할 수 있습니다.
4. 스킬 만들기
Antigravity에서 스킬을 만드는 것은 특정 디렉터리 구조와 파일 형식을 따릅니다. 이 표준화를 통해 스킬을 이동할 수 있으며 에이전트가 스킬을 안정적으로 파싱하고 실행할 수 있습니다. 이 설계는 의도적으로 간단하며 널리 이해되는 형식(예: 마크다운 및 YAML)을 사용하여 IDE의 기능을 확장하려는 개발자의 진입 장벽을 낮춥니다.
디렉터리 구조
일반적인 스킬 디렉터리는 다음과 같습니다.
my-skill/
├── SKILL.md # The definition file
├── scripts/ # [Optional] Python, Bash, or Node scripts
├── run.py
└── util.sh
├── references/ # [Optional] Documentation or templates
└── api-docs.md
└── assets/ # [Optional] Static assets (images, logos)
이 구조는 우려사항을 효과적으로 분리합니다. 논리 (scripts)는 명령어 (SKILL.md) 및 지식 (references)과 분리되어 표준 소프트웨어 엔지니어링 관행을 반영합니다.
SKILL.md 정의 파일
SKILL.md 파일은 스킬의 두뇌입니다. 이는 에이전트에게 스킬이 무엇인지, 언제 사용해야 하는지, 어떻게 실행해야 하는지 알려줍니다.
다음 두 부분으로 구성됩니다.
- YAML 프런트매터
- 마크다운 본문입니다.
YAML 프런트매터
메타데이터 레이어입니다. 이는 에이전트의 상위 라우터에 의해 색인이 생성되는 스킬의 유일한 부분입니다. 사용자가 프롬프트를 보내면 에이전트는 사용 가능한 모든 스킬의 설명 필드에 대해 프롬프트의 의미를 매칭합니다.
---
name: database-inspector
description: Use this skill when the user asks to query the database, check table schemas, or inspect user data in the local PostgreSQL instance.
---
주요 필드:
- name: 필수가 아닙니다. 범위 내에서 고유해야 합니다. 소문자, 하이픈 허용 (예:
postgres-query,pr-reviewer). 제공되지 않으면 기본적으로 디렉터리 이름이 사용됩니다. - description: 필수 항목이며 가장 중요한 필드입니다. '트리거 문구'로 작동합니다. LLM이 의미론적 관련성을 인식할 수 있을 만큼 설명이 충분해야 합니다. '데이터베이스 도구'와 같은 모호한 설명은 충분하지 않습니다. '로컬 PostgreSQL 데이터베이스에 대해 읽기 전용 SQL 쿼리를 실행하여 사용자 또는 트랜잭션 데이터를 가져옵니다. '데이터 상태 디버깅에 사용'을 사용하면 스킬이 올바르게 선택됩니다.
마크다운 본문
본문에는 명령어가 포함되어 있습니다. 이는 파일에 유지되는 '프롬프트 엔지니어링'입니다. 스킬이 활성화되면 이 콘텐츠가 에이전트의 컨텍스트 윈도우에 삽입됩니다.
본문에는 다음이 포함되어야 합니다.
- 목표: 스킬이 달성하는 바를 명확하게 설명합니다.
- 안내: 단계별 논리
- 예시: 모델의 성능을 안내하는 입력 및 출력의 퓨샷 예시입니다.
- 제약 조건: '하지 마세요' 규칙 (예: 'DELETE 쿼리를 실행하지 마세요')
SKILL.md 본문 예시:
Database Inspector
Goal
To safely query the local database and provide insights on the current data state.
Instructions
- Analyze the user's natural language request to understand the data need.
- Formulate a valid SQL query.
- CRITICAL: Only SELECT statements are allowed.
- Use the script scripts/query_runner.py to execute the SQL.
- Command: python scripts/query_runner.py "SELECT * FROM..."
- Present the results in a Markdown table.
Constraints
- Never output raw user passwords or API keys.
- If the query returns > 50 rows, summarize the data instead of listing it all.
스크립트 통합
스킬의 가장 강력한 기능 중 하나는 스크립트에 실행을 위임할 수 있다는 점입니다. 이를 통해 에이전트는 LLM이 직접 수행하기 어렵거나 불가능한 작업 (예: 바이너리 실행, 복잡한 수학 계산, 기존 시스템과의 상호작용)을 수행할 수 있습니다.
스크립트는 scripts/ 하위 디렉터리에 배치됩니다. SKILL.md는 상대 경로로 이를 참조합니다.
5. 스킬 제작
이 섹션의 목표는 Antigravity에 통합되고 리소스/스크립트 등 다양한 기능을 점진적으로 표시하는 스킬을 빌드하는 것입니다.
https://github.com/rominirani/antigravity-skills의 GitHub 저장소에서 스킬을 다운로드할 수 있습니다.
이러한 각 스킬이 어떻게 빌드되었는지 알아보기 전에 Antigravity 제품군 내에서 스킬을 구성하고 사용할 수 있도록 하는 방법을 살펴보겠습니다. 아래 폴더는 이 실습이 게시될 때 적용됩니다.
Antigravity 또는 Antigravity CLI 사용
기술은 두 가지 범위로 정의할 수 있으므로 프로젝트별 기술과 사용자별(즉, 전역) 기술을 모두 사용할 수 있습니다.
- 전역 범위 (
~/.gemini/config/skills/): 모든 Antigravity 제품 (Antigravity, Antigravity IDE, Antigravity CLI) 및 프로젝트에서 사용할 수 있습니다. 이러한 기술은 사용자 컴퓨터의 모든 프로젝트에서 사용할 수 있습니다. 'JSON 형식 지정', 'UUID 생성', '코드 스타일 검토' 또는 개인 생산성 도구와의 통합과 같은 일반 유틸리티에 적합합니다. - 프로젝트/워크스페이스 범위 (
<project-root>/.agents/skills/): 이렇게 하면 특정 프로젝트 내에서만 스킬을 사용할 수 있습니다. 이는 특정 환경에 배포, 해당 앱의 데이터베이스 관리, 독점 프레임워크용 상용구 코드 생성과 같은 프로젝트별 스크립트에 적합합니다.
Antigravity 또는 Antigravity CLI에 스킬 설치
이 튜토리얼에서는 다음 단계만 수행하면 됩니다 (원하는 방식으로 수행해도 됨).
1단계: https://github.com/rominirani/antigravity-skills의 git clone 실행
2단계: 이제 Antigravity 또는 Antigravity CLI 사용 여부에 따라 antigravity-skills/skills_tutorial 폴더로 이동할 수 있습니다.
3단계: 각각의 폴더에 패키지화된 스킬 세트가 표시됩니다. 다음 4개 폴더를 복사합니다.
git-commit-formatterlicense-header-adderdatabase-schema-validatorjson-to-pydantic
제품의 타겟팅된 기술 폴더 (프로젝트 범위 또는 전역 범위)에 복사합니다.
4단계: Antigravity 또는 Antigravity CLI를 사용하는 경우 <project-root>/.agents/skills/ (프로젝트 범위)에 복사합니다.
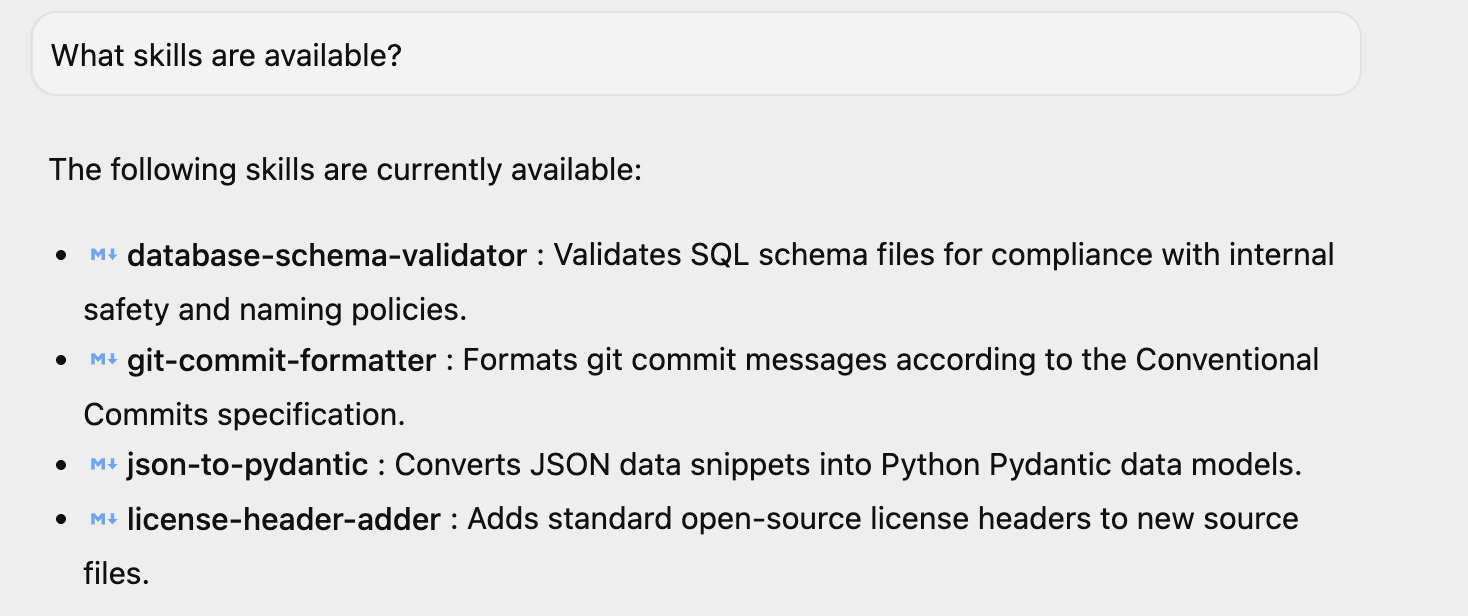
Antigravity를 실행한 경우 간단한 질문인 '사용 가능한 스킬은 무엇인가요?'을 물으면 동일한 내용으로 대답합니다. 나열된 4가지 스킬을 확인할 수 있습니다. 환경에 설치한 경우 추가 스킬이 있을 수도 있습니다.
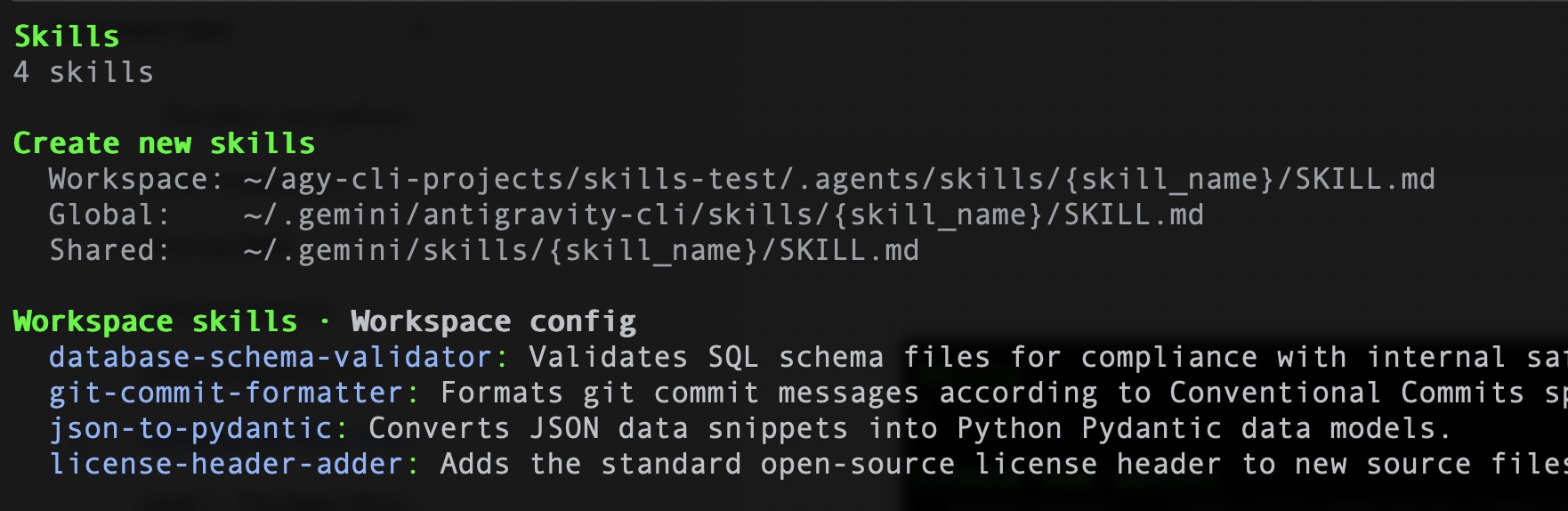
마찬가지로 Antigravity CLI를 사용하는 경우 다음 명령어 /skills를 입력하면 4가지 스킬이 나열됩니다. 샘플은 아래와 같습니다.
이제 스킬을 설정하는 방법을 알았으니 각 스킬로 이동하여 스킬이 어떻게 구성되었는지 알아보겠습니다. 이 템플릿을 사용하여 나만의 스킬을 만들 수도 있습니다.
레벨 1 : 기본 라우터 ( git-commit-formatter)
이를 스킬의 'Hello World'로 간주해 보겠습니다.
개발자는 'wip', '버그 수정', '업데이트'와 같이 대충 커밋 메시지를 작성하는 경우가 많습니다. 'Conventional Commits'를 수동으로 적용하는 것은 지루하고 잊히는 경우가 많습니다. 컨벤셔널 커밋 사양을 적용하는 스킬을 구현해 보겠습니다. 규칙에 대해 에이전트에게 간단히 지시함으로써 에이전트가 시행자 역할을 할 수 있습니다.
git-commit-formatter/
└── SKILL.md (Instructions only)
SKILL.md 파일은 아래와 같습니다.
---
name: git-commit-formatter
description: Formats git commit messages according to Conventional Commits specification. Use this when the user asks to commit changes or write a commit message.
---
Git Commit Formatter Skill
When writing a git commit message, you MUST follow the Conventional Commits specification.
Format
`<type>[optional scope]: <description>`
Allowed Types
- **feat**: A new feature
- **fix**: A bug fix
- **docs**: Documentation only changes
- **style**: Changes that do not affect the meaning of the code (white-space, formatting, etc)
- **refactor**: A code change that neither fixes a bug nor adds a feature
- **perf**: A code change that improves performance
- **test**: Adding missing tests or correcting existing tests
- **chore**: Changes to the build process or auxiliary tools and libraries such as documentation generation
Instructions
1. Analyze the changes to determine the primary `type`.
2. Identify the `scope` if applicable (e.g., specific component or file).
3. Write a concise `description` in an imperative mood (e.g., "add feature" not "added feature").
4. If there are breaking changes, add a footer starting with `BREAKING CHANGE:`.
Example
`feat(auth): implement login with google`
Antigravity에서 이 예시를 실행하는 방법
아래 단계에서는 로컬 머신에서 Git을 사용할 수 있고 올바르게 설정되어 있다고 가정합니다.
Antigravity 또는 Antigravity CLI를 실행했다고 가정하고 다음 단계를 따르세요.
1단계: 테스트 Git 저장소 설정하기
에이전트에게 Git 작업 테스트를 위한 깨끗하고 격리된 디렉터리를 설정해 달라고 요청합니다.
내 프롬프트:
Create a folder named git_test in the workspace, initialize a git repository inside it, and create an initial file auth.py with def login(): pass. Stage this file and make an initial commit.
에이전트는 디렉터리를 만들고, 저장소를 초기화하고, 파일을 스테이징하고, 'initial commit'과 같은 메시지로 커밋합니다.
2단계: 코드 변경하기
커밋할 변경사항이 있도록 코드를 수정하라고 에이전트에게 요청합니다.
내 프롬프트:
In the git_test folder, modify auth.py to add Google Login functionality.
에이전트가 파일을 수정하여 새 기능을 추가하고 커밋 단계를 준비합니다.
3단계: 변경사항 스테이징 및 커밋
에이전트에게 변경사항을 스테이징하고 커밋을 생성해 달라고 요청하여 git-commit-formatter 스킬을 트리거합니다.
내 프롬프트:
Stage the changes in the git_test folder and commit them. Make sure to format the commit message using the Conventional Commits skill.
에이전트는 git add auth.py를 실행하고, 차이점을 분석하여 auth 모듈에 새 기능이 추가되었음을 확인하고, git commit를 실행하기 전에 feat(auth): implement google login와 같은 기존 커밋 메시지를 작성합니다.
4단계: Git 로그 확인하기
형식이 지정된 커밋이 성공적으로 기록되었는지 확인할 수 있도록 담당자에게 git 기록을 가져오라고 요청합니다.
내 프롬프트:
Show me the git log in the git_test folder.
에이전트는 git log -n 5를 실행하고 형식이 지정된 커밋 메시지를 보여주는 출력을 반환합니다.
레벨 2: 애셋 활용 (license-header-adder)
'참조' 패턴입니다.
회사 프로젝트의 모든 소스 파일에는 특정 20줄 Apache 2.0 라이선스 헤더가 필요할 수 있습니다. 이 정적 텍스트를 프롬프트 (또는 SKILL.md)에 직접 넣는 것은 낭비입니다. 스킬이 색인화될 때마다 토큰이 사용되며 모델에서 법적 텍스트에 오타가 있다고 '환각'할 수 있습니다. 정적 텍스트를 resources/ 폴더의 일반 텍스트 파일로 오프로드하는 것이 좋습니다. 스킬은 필요한 경우에만 상담사에게 이 파일을 읽도록 안내합니다.
skills 디렉터리의 license-header-adder 폴더에서 파일을 찾을 수 있습니다.
license-header-adder/
├── SKILL.md
└── resources/
└── HEADER_TEMPLATE.txt (The heavy text)
SKILL.md 파일은 아래와 같습니다.
---
name: license-header-adder
description: Adds the standard open-source license header to new source files. Use involves creating new code files that require copyright attribution.
---
# License Header Adder Skill
This skill ensures that all new source files have the correct copyright header.
## Instructions
1. **Read the Template**:
First, read the content of the header template file located at `resources/HEADER_TEMPLATE.txt`.
2. **Prepend to File**:
When creating a new file (e.g., `.py`, `.java`, `.js`, `.ts`, `.go`), prepend the `target_file` content with the template content.
3. **Modify Comment Syntax**:
- For C-style languages (Java, JS, TS, C++), keep the `/* ... */` block as is.
- For Python, Shell, or YAML, convert the block to use `#` comments.
- For HTML/XML, use `<!-- ... -->`.
Antigravity에서 이 예시를 실행하는 방법
Antigravity 또는 Antigravity CLI를 실행했다고 가정하고 다음 단계를 따르세요.
1단계: 샘플 코드가 포함된 Python 파일 만들기
프롬프트:
Create a new file my_script.py with the following python code:
def hello():
print("Hello, World!")
발생한 상황 (설명): 에이전트가 파일 쓰기 도구 (write_to_file)를 호출하여 활성 작업공간 디렉터리에 my_script.py라는 새 파일을 직접 만들고 여기에 기본 Python 함수를 작성했습니다. 또한 프롬프트로 인해 license-header-adder 스킬이 트리거되었습니다. 에이전트가 라이선스 템플릿 파일 (HEADER_TEMPLATE.txt)을 찾아 읽고, 주석 스타일을 C 스타일 블록 주석 (/* ... */)에서 Python 스타일 주석 (#)으로 수정하고, replace_file_content 도구를 사용하여 파일 상단에 추가했습니다.
2단계: 파일 콘텐츠 확인하기
my_script.py 파일을 확인합니다. 상단에 라이선스 헤더가 포함됩니다.
3단계: 예시를 통한 학습 (json-to-pydantic)
'퓨샷' 패턴
JSON API 응답과 같은 느슨한 데이터를 Pydantic 모델과 같은 엄격한 코드로 변환하려면 수십 가지 결정을 내려야 합니다. 클래스 이름은 어떻게 지정해야 하나요? Optional을 사용해야 하나요? snake_case 또는 camelCase 중에 선택하세요. 이러한 50개의 규칙을 영어로 작성하는 것은 지루하고 오류가 발생하기 쉽습니다.
LLM은 패턴 매칭 엔진입니다.
골든 예시 (Input -> Output)를 사용하여 스킬을 작성하는 것이 장황한 안내보다 효과적인 경우가 많습니다.
아래와 같이 스킬 파일이 포함된 json-to-pydantic/ 폴더로 이동합니다.
json-to-pydantic/
├── SKILL.md
└── examples/
├── input_data.json (The Before State)
└── output_model.py (The After State)
SKILL.md 파일은 아래와 같습니다.
---
name: json-to-pydantic
description: Converts JSON data snippets into Python Pydantic data models.
---
# JSON to Pydantic Skill
This skill helps convert raw JSON data or API responses into structured, strongly-typed Python classes using Pydantic.
Instructions
1. **Analyze the Input**: Look at the JSON object provided by the user.
2. **Infer Types**:
- `string` -> `str`
- `number` -> `int` or `float`
- `boolean` -> `bool`
- `array` -> `List[Type]`
- `null` -> `Optional[Type]`
- Nested Objects -> Create a separate sub-class.
3. **Follow the Example**:
Review `examples/` to see how to structure the output code. notice how nested dictionaries like `preferences` are extracted into their own class.
- Input: `examples/input_data.json`
- Output: `examples/output_model.py`
Style Guidelines
- Use `PascalCase` for class names.
- Use type hints (`List`, `Optional`) from `typing` module.
- If a field can be missing or null, default it to `None`.
/examples 폴더에는 JSON 파일과 출력 파일(Python 파일)이 있습니다. 두 가지 모두 아래에 나와 있습니다.
input_data.json
{
"user_id": 12345,
"username": "jdoe_88",
"is_active": true,
"preferences": {
"theme": "dark",
"notifications": [
"email",
"push"
]
},
"last_login": "2024-03-15T10:30:00Z",
"meta_tags": null
}
output_model.py
from pydantic import BaseModel, Field
from typing import List, Optional
class Preferences(BaseModel):
theme: str
notifications: List[str]
class User(BaseModel):
user_id: int
username: str
is_active: bool
preferences: Preferences
last_login: Optional[str] = None
meta_tags: Optional[List[str]] = None
Antigravity에서 이 예시를 실행하는 방법
Antigravity 또는 Antigravity CLI를 실행했다고 가정하고 다음 단계를 따르세요.
1단계: 샘플 데이터로 JSON 파일 만들기
에이전트에게 원시 JSON 페이로드가 포함된 새 파일 product.json을 만들어 달라고 요청합니다.
프롬프트:
Create a new file product.json with the following JSON:
{
"product": "Widget",
"cost": 10.99,
"stock": null
}
2단계: JSON을 Pydantic 모델로 변환하기
json-to-pydantic 스킬을 트리거하여 JSON 데이터를 구조화된 Pydantic 클래스로 변환합니다.
프롬프트:
Convert the JSON in product.json to a Pydantic model and save it to product_model.py.
3단계: 출력 확인하기
product_model.py 파일을 확인합니다. 여기에는 완료된 Pydantic 모델이 포함됩니다.
4단계: 절차적 로직 (database-schema-validator)
'도구 사용' 패턴입니다.
LLM에 '이 스키마는 안전한가요?'라고 물으면 SQL이 올바르게 보이기 때문에 중요한 기본 키가 누락되어도 문제가 없다고 대답할 수 있습니다.
이 검사를 결정적인 스크립트에 위임해 보겠습니다. database-schema-validator 스킬은 에이전트가 작성된 Python 스크립트를 실행하도록 라우팅합니다. 스크립트는 이진 (참/거짓) 진실을 제공합니다.
database-schema-validator/
├── SKILL.md
└── scripts/
└── validate_schema.py (The Validator)
SKILL.md 파일은 아래와 같습니다.
---
name: database-schema-validator
description: Validates SQL schema files for compliance with internal safety and naming policies.
---
# Database Schema Validator Skill
This skill ensures that all SQL files provided by the user comply with our strict database standards.
Policies Enforced
1. **Safety**: No `DROP TABLE` statements.
2. **Naming**: All tables must use `snake_case`.
3. **Structure**: Every table must have an `id` column as PRIMARY KEY.
Instructions
1. **Do not read the file manually** to check for errors. The rules are complex and easily missed by eye.
2. **Run the Validation Script**:
Use the `run_command` tool to execute the python script provided in the `scripts/` folder against the user's file.
`python scripts/validate_schema.py <path_to_user_file>`
3. **Interpret Output**:
- If the script returns **exit code 0**: Tell the user the schema looks good.
- If the script returns **exit code 1**: Report the specific error messages printed by the script to the user and suggest fixes.
validate_schema.py 파일은 아래와 같습니다.
import sys
import re
def validate_schema(filename):
"""
Validates a SQL schema file against internal policy:
1. Table names must be snake_case.
2. Every table must have a primary key named 'id'.
3. No 'DROP TABLE' statements allowed (safety).
"""
try:
with open(filename, 'r') as f:
content = f.read()
lines = content.split('\n')
errors = []
# Check 1: No DROP TABLE
if re.search(r'DROP TABLE', content, re.IGNORECASE):
errors.append("ERROR: 'DROP TABLE' statements are forbidden.")
# Check 2 & 3: CREATE TABLE checks
table_defs = re.finditer(r'CREATE TABLE\s+(?P<name>\w+)\s*\((?P<body>.*?)\);', content, re.DOTALL | re.IGNORECASE)
for match in table_defs:
table_name = match.group('name')
body = match.group('body')
# Snake case check
if not re.match(r'^[a-z][a-z0-9_]*$', table_name):
errors.append(f"ERROR: Table '{table_name}' must be snake_case.")
# Primary key check
if not re.search(r'\bid\b.*PRIMARY KEY', body, re.IGNORECASE):
errors.append(f"ERROR: Table '{table_name}' is missing a primary key named 'id'.")
if errors:
for err in errors:
print(err)
sys.exit(1)
else:
print("Schema validation passed.")
sys.exit(0)
except FileNotFoundError:
print(f"Error: File '{filename}' not found.")
sys.exit(1)
if __name__ == "__main__":
if len(sys.argv) != 2:
print("Usage: python validate_schema.py <schema_file>")
sys.exit(1)
validate_schema(sys.argv[1])
Antigravity에서 이 예시를 실행하는 방법
Antigravity 또는 Antigravity CLI를 실행했다고 가정하고 다음 단계를 따르세요.
1단계: 샘플 데이터로 JSON 파일 만들기
에이전트에게 여러 정책 위반이 포함된 새 파일 bad_schema.sql를 만들어 달라고 요청합니다.
프롬프트:
Create a new file bad_schema.sql with the following SQL:
DROP TABLE IF EXISTS legacy_users;
CREATE TABLE userProfile (
id INT PRIMARY KEY,
bio TEXT
);
CREATE TABLE posts (
title TEXT,
content TEXT,
created_at TIMESTAMP
);
CREATE TABLE comments (
id INT PRIMARY KEY,
post_id INT,
body TEXT
);
위 스키마 파일은 금지된 DROP TABLE 문을 사용하고, userProfile 테이블 이름에 camelCase을 사용하고, posts 테이블에서 id 기본 키를 잊는 등 세 가지 정책을 모두 위반합니다.
2단계: SQL 스키마 유효성 검사하기
database-schema-validator 스킬을 트리거하여 파일에 대해 Python 검사기 스크립트를 실행합니다.
내 프롬프트:
Validate bad_schema.sql using the database-schema-validator skill.
3단계: 출력 확인하기
에이전트는 실패를 보고하고 스크립트에서 발견한 특정 오류를 채팅에 직접 표시합니다. 샘플 출력은 다음과 같습니다.
Suggested Fixes:
Remove the line DROP TABLE IF EXISTS legacy_users; as dropping tables is forbidden by safety policy.
Rename the table userProfile to use snake_case (e.g., user_profile).
Add a primary key column named id to the posts table definition.
6. 개발자 툴킷 (Agents CLI Skills)
'작업 및 수명 주기' 패턴
AI 에이전트 개발에는 반복적인 수명 주기 작업이 포함됩니다. 보일러플레이트 파일 스캐폴딩, 로컬 런타임 환경 구성, 테스트 프롬프트 실행, 대화형 Playground 시작 등이 있습니다.
코딩 어시스턴트가 디렉터리 구조를 추측하거나 처음부터 상용구 에이전트 구성을 작성하도록 강제하는 대신 Agents CLI 스킬은 이 수명 주기 전문 지식을 특정 에이전트 스킬로 패키징합니다.
에이전트 CLI (명령줄 인터페이스) 기술은 간소화된 개발자 중심 자동화를 터미널에 직접 제공하여 원시 코드와 자율 실행 간의 격차를 해소합니다. 에이전트 개발 키트 (ADK)는 프로그래매틱 프레임워크에 중점을 두어 AI 에이전트를 빌드하고 오케스트레이션할 수 있는 SDK, API, 구조적 청사진을 제공하는 반면, 에이전트 CLI 기술은 운영상의 근육을 제공합니다. 이를 통해 개발자는 무거운 UI 오버헤드를 완전히 우회하여 빠른 피드백 루프를 통해 로컬에서 에이전트를 스캐폴드, 테스트, 배포할 수 있습니다.
선택적으로 Google Cloud에 매핑되면 에이전트 CLI 기술이 엔터프라이즈급 인프라로 연결되는 직접 파이프라인 역할을 합니다. 콘솔을 클릭하는 대신 CLI 명령어를 사용하여 에이전트 워크플로를 즉시 패키징하고, 액세스 권한을 관리하고, Google Cloud 생태계 (예: Vertex AI 또는 Cloud Run)에 배포할 수 있습니다. 이를 통해 복잡한 클라우드 아키텍처 작업이 간단하고 재현 가능한 터미널 명령어로 바뀌어 자율 에이전트를 기존 CI/CD 배포 파이프라인에 훨씬 쉽게 통합할 수 있습니다.
설치 방법
Python 3.11+, Node.js, uv 패키지 관리자가 설치되어 있는지 확인합니다. 그런 다음 터미널에서 설정 명령어를 실행합니다.
uvx google-agents-cli setup
이 명령어는 agents-cli 바이너리를 설치하고 코딩 어시스턴트 환경 내에서 스캐폴딩 및 평가를 위한 전문 기술을 등록합니다.
참고: 스킬은 Antigravity에 표시되는 ~/.agents/skills 폴더에 설치됩니다. Antigravity CLI에서 이러한 스킬을 보려면 ~/.gemini/antigravity-cli/skills 폴더 (전역 범위)로 이동해야 합니다.
사용 가능한 스킬을 물어보면 Antigravity에 스킬이 로드되었는지 확인할 수 있습니다. 방금 설치한 에이전트 CLI 기술에 대한 샘플 응답은 아래와 같습니다.

단계별 안내
uvx google-agents-cli setup가 완료되면 로컬 머신에서 AI 에이전트를 완전히 가동하고, 상호작용하고, 테스트할 수 있습니다.
1단계: 새 에이전트 프로젝트 스캐폴딩 및 초기화
생성 명령어를 실행하여 표준화된 레이아웃을 스캐폴딩합니다. 생성한 후에는 실행 작업을 실행하기 전에 프로젝트 종속 항목을 설치해야 합니다.
# 1. Create a lightweight prototype project structure
agents-cli create weather-assistant --prototype --yes
# 2. Move into the directory and install required ADK dependencies
cd weather-assistant
agents-cli install
백그라운드에서 발생하는 작업: app/agent.py (핵심 코드), pyproject.toml (패키지 메타데이터), agents-cli-manifest.yaml (프로젝트 추적기)가 포함된 깨끗한 작업공간이 생성됩니다.
2단계: 로컬 테스트 쿼리 실행
에이전트에 대해 빠르고 직접적인 명령줄 테스트를 실행합니다. Google Cloud의 ADC (애플리케이션 기본 사용자 인증 정보)를 사용하지 않는 경우 터미널에서 GEMINI_API_KEY가 내보내져 있는지 확인합니다. 여기에서 Gemini API 키를 받을 수 있습니다. 키가 있으면 터미널에서 다음 명령어를 통해 내보냅니다.
export GEMINI_API_KEY="YOUR_GEMINI_API_KEY"
터미널에서 다음 명령어를 입력합니다.
agents-cli run "How are you?"
백그라운드에서 일어나는 일: CLI는 터미널의 메모리에서 에이전트 개발 키트 (ADK) 수명 주기를 완전히 초기화합니다. 로컬 사용자 인증 정보를 통해 프롬프트를 안전하게 라우팅하고 라이브 스트리밍 응답을 명령줄에 직접 로깅합니다.
3단계: 대화형 웹 Playground 시작
내장된 로컬 웹 기반 플레이그라운드를 실행하여 에이전트와 시각적으로 상호작용합니다.
agents-cli playground
백그라운드에서 발생하는 상황: CLI가 ADK 웹 UI 서버를 실행합니다. 이 서버는 일반적으로 http://localhost:8080 또는 대체 http://127.0.0.1:8000에서 액세스할 수 있으며 핫 리로드가 완료됩니다. 웹 인터페이스의 상단에 있는 앱 선택 드롭다운에서 앱을 선택하고 웹 애플리케이션의 오른쪽에 있는 대화형 인터페이스에서 에이전트와 상호작용합니다.
7. npx skills를 사용하여 에이전트 스킬 설치
npx skills는 Vercel Labs에서 개발한 명령줄 도구로, AI 에이전트 (예: Antigravity, Claude Code, GitHub Copilot, Cursor, Cline)의 패키지 관리자 역할을 합니다. 개방형 에이전트 스킬 생태계를 위한 CLI입니다.
npx skills 패키지를 사용하여 상담사 기술을 다운로드하고 설치하려는 경우 기술이 ~/.agents/skills 폴더에 배치됩니다. Antigravity와 같은 도구가 이 폴더에서 스킬을 가져온다고 언급되어 있지만, 작성 시점에는 Antigravity는 이 폴더에서 가져오지만 Antigravity CLI는 가져오지 않습니다. 앞서 언급한 것처럼 ~/.agents/skills 폴더에 설치된 이러한 스킬을 Antigravity CLI의 스킬 폴더용 프로젝트 또는 전역 범위에 복사해야 합니다.
- 프로젝트 범위:
<project-root>/.agent/skills/에 있습니다. - 전역 범위:
~/.gemini/antigravity-cli/skills/에 있습니다.
8. 축하합니다
축하합니다. Google Antigravity를 사용하여 첫 번째 에이전트 스킬을 빌드하고, 구성하고, 맞춤 기능을 추가했습니다.
또한 프로젝트 범위와 전역 범위 모두에서 에이전트 기술을 구성하여 맞춤설정된 도구를 구현했습니다.
이제 Antigravity를 사용하여 자체 프로젝트에서 힘든 작업을 처리하고 원하는 방식으로 코드를 작성할 수 있습니다.
Kaggle 5일 AI 에이전트 배지 획득
Kaggle의 5일간의 AI 에이전트: Google과 함께하는 집중 바이브 코딩 과정의 일환으로 이 실습을 완료하셨나요? 완료 배지 신청: 5일간의 AI 에이전트 배지를 획득하세요.
9. 참조 문서
- Codelab : Google Antigravity 시작하기
- 공식 사이트 : https://antigravity.google/
- 문서: https://antigravity.google/docs
- 다운로드 : https://antigravity.google/download
- Antigravity Skills 문서: https://antigravity.google/docs/skills