
1. บทนำ
Google Antigravity เป็นแพลตฟอร์มการพัฒนาด้าน Agentic AI ที่ออกแบบมาเพื่อช่วยคุณพัฒนาในยุคของ Agent Antigravity ทำหน้าที่เป็นศูนย์บัญชาการกลางของ AI Agent โดยมีแพลตฟอร์มแบบรวมเพื่อเปิดตัว ตรวจสอบ และประสานงานกิจกรรมของ AI Agent
ใน Codelab นี้ เราจะมาเรียนรู้เกี่ยวกับทักษะของ Agent ซึ่งเป็นรูปแบบเปิดที่มีน้ำหนักเบาสำหรับการขยายความสามารถของ AI Agent ด้วยความรู้และเวิร์กโฟลว์เฉพาะทาง คุณจะได้เรียนรู้ว่าทักษะ Agent คืออะไร ประโยชน์ของทักษะ และวิธีสร้างทักษะ จากนั้นคุณจะสร้าง Agent Skill หลายอย่าง ตั้งแต่ตัวจัดรูปแบบ Git, เครื่องมือสร้างเทมเพลต, การจัดโครงสร้างโค้ดเครื่องมือ และอื่นๆ ซึ่งทั้งหมดนี้ใช้ได้ภายใน Antigravity
ข้อกำหนดเบื้องต้น
- ติดตั้งและกำหนดค่า Antigravity แล้ว
- ความเข้าใจพื้นฐานเกี่ยวกับ Google Antigravity เราขอแนะนำให้ทำ Codelab เริ่มต้นใช้งาน Google Antigravity ให้เสร็จสมบูรณ์
2. เหตุผลที่ต้องมีทักษะ
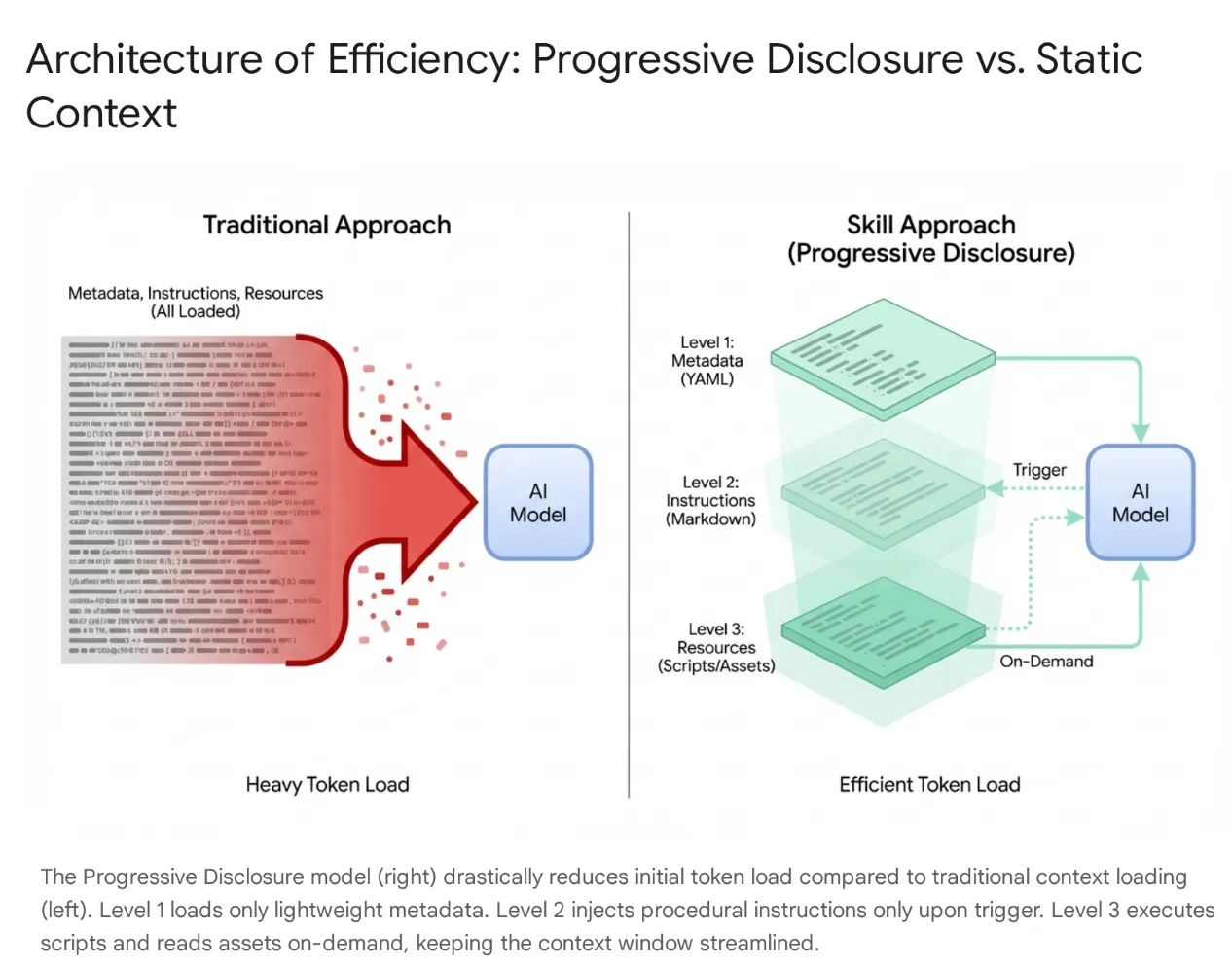
Agent AI สมัยใหม่พัฒนาจากการเป็นเพียงผู้ฟังไปสู่ผู้ให้เหตุผลที่ซับซ้อนซึ่งผสานรวมกับระบบไฟล์ในเครื่องและเครื่องมือภายนอก (ผ่านเซิร์ฟเวอร์ MCP) อย่างไรก็ตาม การโหลด Agent ด้วยโค้ดเบสทั้งหมดและเครื่องมือนับร้อยโดยไม่เลือกจะทำให้เกิดบริบทอิ่มตัวและ "เครื่องมือมากเกินไป" แม้จะมีหน้าต่างบริบทขนาดใหญ่ การทิ้งโทเค็น 40,000-50,000 รายการของเครื่องมือที่ไม่ได้ใช้ลงในหน่วยความจำที่ใช้งานอยู่จะทำให้เกิดเวลาในการตอบสนองสูง การสิ้นเปลืองทางการเงิน และ "บริบทเสื่อม" ซึ่งโมเดลจะสับสนกับข้อมูลที่ไม่เกี่ยวข้อง
วิธีแก้ปัญหา: ทักษะของ Agent
Anthropic จึงเปิดตัวทักษะของ Agent เพื่อแก้ปัญหานี้ โดยเปลี่ยนสถาปัตยกรรมจากการโหลดบริบทแบบ Monolithic ไปเป็นการเปิดเผยแบบค่อยเป็นค่อยไป ความสามารถเหล่านี้จะรวมอยู่ในหน่วยแบบแยกส่วนที่ค้นพบได้ แทนที่จะบังคับให้โมเดล "จดจำ" เวิร์กโฟลว์ที่เฉพาะเจาะจงทุกรายการ (เช่น การย้ายข้อมูลฐานข้อมูลหรือการตรวจสอบความปลอดภัย) เมื่อเริ่มเซสชัน
วิธีการทำงาน
โดยในตอนแรก โมเดลจะแสดงเฉพาะ "เมนู" ข้อมูลเมตาแบบเบา โดยจะโหลดความรู้เชิงกระบวนการที่ซับซ้อน (คำสั่งและสคริปต์) ก็ต่อเมื่อความตั้งใจของผู้ใช้ตรงกับทักษะอย่างเจาะจงเท่านั้น วิธีนี้ช่วยให้มั่นใจได้ว่านักพัฒนาแอปที่ขอรีแฟกเตอร์มิดเดิลแวร์การตรวจสอบสิทธิ์จะได้รับบริบทความปลอดภัยโดยไม่ต้องโหลดไปป์ไลน์ CSS ที่ไม่เกี่ยวข้อง ซึ่งจะช่วยให้บริบทมีขนาดเล็ก รวดเร็ว และประหยัดค่าใช้จ่าย
3. ทักษะของเอเจนต์และ Antigravity
ในระบบนิเวศของ Antigravity Skills จะทำหน้าที่เป็นโมดูลการฝึกเฉพาะทางที่เชื่อมช่องว่างระหว่างโมเดลทั่วไปกับบริบทเฉพาะของคุณ ซึ่งจะช่วยให้เอเจนต์ "ติดตั้ง" ชุดคำสั่งและโปรโตคอลที่กำหนดไว้ เช่น มาตรฐานการย้ายข้อมูลฐานข้อมูลหรือการตรวจสอบความปลอดภัย ได้เฉพาะเมื่อมีการขอให้ทำงานที่เกี่ยวข้องเท่านั้น การโหลดโปรโตคอลการดำเนินการเหล่านี้แบบไดนามิกจะช่วยให้ทักษะเปลี่ยน AI จากโปรแกรมเมอร์ทั่วไปให้กลายเป็นผู้เชี่ยวชาญที่ยึดมั่นในแนวทางปฏิบัติแนะนำและมาตรฐานด้านความปลอดภัยที่กำหนดไว้ขององค์กรอย่างเคร่งครัด
ทักษะใน Antigravity คืออะไร
ในบริบทของ Google Antigravity ทักษะคือแพ็กเกจที่อิงตามไดเรกทอรีซึ่งมีไฟล์คำจำกัดความ (SKILL.md) และเนื้อหาเสริมที่ไม่บังคับ (สคริปต์ การอ้างอิง เทมเพลต)
ซึ่งเป็นกลไกสำหรับการขยายความสามารถตามความต้องการ
- ตามต้องการ: ต่างจากพรอมต์ระบบ (ซึ่งจะโหลดเสมอ) ทักษะจะโหลดลงในบริบทของเอเจนต์ก็ต่อเมื่อเอเจนต์พิจารณาแล้วว่าเกี่ยวข้องกับคำขอปัจจุบันของผู้ใช้ ซึ่งจะช่วยเพิ่มประสิทธิภาพหน้าต่างบริบทและป้องกันไม่ให้เอเจนต์เสียสมาธิกับคำสั่งที่ไม่เกี่ยวข้อง ในโปรเจ็กต์ขนาดใหญ่ที่มีเครื่องมือหลายสิบรายการ การโหลดแบบเลือกนี้มีความสําคัญอย่างยิ่งต่อประสิทธิภาพและความแม่นยําในการให้เหตุผล
- การขยายความสามารถ: สกิลทำได้มากกว่าแค่สั่งการ แต่ยังสามารถดำเนินการได้ด้วย การรวมสคริปต์ Python หรือ Bash ทำให้ทักษะสามารถให้ความสามารถแก่เอเจนต์ในการดำเนินการที่ซับซ้อนและมีหลายขั้นตอนในเครื่องภายในหรือเครือข่ายภายนอกได้โดยที่ผู้ใช้ไม่ต้องเรียกใช้คำสั่งด้วยตนเอง ซึ่งจะเปลี่ยน Agent จากเครื่องมือสร้างข้อความเป็นผู้ใช้เครื่องมือ
ทักษะเทียบกับระบบนิเวศ (เครื่องมือ กฎ และเวิร์กโฟลว์)
ในขณะที่ Model Context Protocol (MCP) ทำหน้าที่เป็น "มือ" ของ Agent ซึ่งให้การเชื่อมต่อที่ใช้งานหนักและต่อเนื่องกับระบบภายนอก เช่น GitHub หรือ PostgreSQL ทักษะจะทำหน้าที่เป็น "สมอง" ที่สั่งการ
MCP จัดการโครงสร้างพื้นฐานแบบมีสถานะ ในขณะที่ทักษะเป็นคำจำกัดความของงานแบบชั่วคราวที่มีน้ำหนักเบาซึ่งรวมวิธีการใช้เครื่องมือเหล่านั้น แนวทางแบบ Serverless นี้ช่วยให้ตัวแทนสามารถทำงานเฉพาะกิจ (เช่น การสร้างบันทึกการเปลี่ยนแปลงหรือการย้ายข้อมูล) โดยไม่ต้องมีค่าใช้จ่ายด้านการดำเนินงานในการเรียกใช้กระบวนการที่ต่อเนื่อง โหลดบริบทเฉพาะเมื่องานทำงานอยู่ และปล่อยบริบททันทีหลังจากนั้น
ทักษะจะทริกเกอร์โดยเอเจนต์: โมเดลจะตรวจหาความตั้งใจของผู้ใช้โดยอัตโนมัติและติดตั้งความเชี่ยวชาญเฉพาะที่จำเป็นแบบไดนามิก สถาปัตยกรรมนี้ช่วยให้สามารถประกอบกันได้อย่างมีประสิทธิภาพ เช่น กฎส่วนกลางสามารถบังคับใช้ทักษะ "การย้ายข้อมูลอย่างปลอดภัย" ในระหว่างการเปลี่ยนแปลงฐานข้อมูล หรือเวิร์กโฟลว์เดียวสามารถประสานงานทักษะหลายอย่างเพื่อสร้างไปป์ไลน์การติดตั้งใช้งานที่แข็งแกร่ง
4. การสร้างทักษะ
การสร้างทักษะใน Antigravity จะต้องเป็นไปตามโครงสร้างไดเรกทอรีและรูปแบบไฟล์ที่เฉพาะเจาะจง การกำหนดมาตรฐานนี้ช่วยให้มั่นใจได้ว่าทักษะจะสามารถนำไปใช้ได้ และเอเจนต์จะสามารถแยกวิเคราะห์และดำเนินการได้อย่างน่าเชื่อถือ การออกแบบตั้งใจให้เรียบง่าย โดยอาศัยรูปแบบที่เข้าใจกันอย่างกว้างขวาง เช่น Markdown และ YAML ซึ่งจะช่วยลดอุปสรรคในการเริ่มต้นใช้งานสำหรับนักพัฒนาซอฟต์แวร์ที่ต้องการขยายความสามารถของ IDE
โครงสร้างไดเรกทอรี
ไดเรกทอรีทักษะทั่วไปจะมีลักษณะดังนี้
my-skill/
├── SKILL.md # The definition file
├── scripts/ # [Optional] Python, Bash, or Node scripts
├── run.py
└── util.sh
├── references/ # [Optional] Documentation or templates
└── api-docs.md
└── assets/ # [Optional] Static assets (images, logos)
โครงสร้างนี้แยกความกังวลได้อย่างมีประสิทธิภาพ ตรรกะ (scripts) จะแยกออกจากคำสั่ง (SKILL.md) และความรู้ (references) ซึ่งสะท้อนถึงแนวทางปฏิบัติในการพัฒนาซอฟต์แวร์มาตรฐาน
ไฟล์คำจำกัดความ SKILL.md
ไฟล์ SKILL.md คือหัวใจของทักษะ โดยจะบอก Agent ว่าทักษะคืออะไร เมื่อใดที่ควรใช้ และวิธีใช้ทักษะ
โดยประกอบด้วย 2 ส่วน ดังนี้
- YAML Frontmatter
- เนื้อความมาร์กดาวน์
Frontmatter ของ YAML
นี่คือเลเยอร์ข้อมูลเมตา ซึ่งเป็นส่วนเดียวของทักษะที่จัดทำดัชนีโดยเราเตอร์ระดับสูงของตัวแทน เมื่อผู้ใช้ส่งพรอมต์ เอเจนต์จะจับคู่ความหมายของพรอมต์กับช่องคำอธิบายของทักษะที่มีอยู่ทั้งหมด
---
name: database-inspector
description: Use this skill when the user asks to query the database, check table schemas, or inspect user data in the local PostgreSQL instance.
---
ฟิลด์คีย์:
- ชื่อ: ไม่บังคับ ต้องไม่ซ้ำกันภายในขอบเขต อนุญาตให้ใช้ตัวพิมพ์เล็กและขีดกลาง (เช่น
postgres-query,pr-reviewer) หากไม่ได้ระบุ ระบบจะใช้ชื่อไดเรกทอรีเป็นค่าเริ่มต้น - คำอธิบาย: เป็นฟิลด์ที่ต้องระบุและสำคัญที่สุด โดยจะทำหน้าที่เป็น "วลีทริกเกอร์" โดยต้องสื่อความหมายมากพอเพื่อให้ LLM รู้จักความเกี่ยวข้องเชิงความหมาย คำอธิบายที่คลุมเครือ เช่น "เครื่องมือฐานข้อมูล" ไม่เพียงพอ คำอธิบายที่ชัดเจน เช่น "เรียกใช้คำค้นหา SQL แบบอ่านอย่างเดียวกับฐานข้อมูล PostgreSQL ในเครื่องเพื่อดึงข้อมูลผู้ใช้หรือธุรกรรม "ใช้สำหรับแก้ไขข้อบกพร่องของสถานะข้อมูล" ช่วยให้มั่นใจได้ว่าระบบจะเลือกทักษะได้อย่างถูกต้อง
เนื้อหาในรูปแบบมาร์กดาวน์
เนื้อความมีวิธีการ นี่คือ "วิศวกรรมพรอมต์" ที่บันทึกลงในไฟล์ เมื่อเปิดใช้งานทักษะ ระบบจะแทรกเนื้อหานี้ลงในหน้าต่างบริบทของเอเจนต์
เนื้อหาของอีเมลควรมีข้อมูลต่อไปนี้
- เป้าหมาย: ข้อความที่ชัดเจนเกี่ยวกับสิ่งที่ทักษะทำได้
- วิธีการ: ตรรกะทีละขั้นตอน
- ตัวอย่าง: ตัวอย่างอินพุตและเอาต์พุตแบบไม่กี่ช็อตเพื่อเป็นแนวทางในการทำงานของโมเดล
- ข้อจำกัด: กฎ "ห้าม" (เช่น "ห้ามเรียกใช้การค้นหา DELETE")
ตัวอย่างเนื้อหา SKILL.md:
Database Inspector
Goal
To safely query the local database and provide insights on the current data state.
Instructions
- Analyze the user's natural language request to understand the data need.
- Formulate a valid SQL query.
- CRITICAL: Only SELECT statements are allowed.
- Use the script scripts/query_runner.py to execute the SQL.
- Command: python scripts/query_runner.py "SELECT * FROM..."
- Present the results in a Markdown table.
Constraints
- Never output raw user passwords or API keys.
- If the query returns > 50 rows, summarize the data instead of listing it all.
การผสานรวมสคริปต์
ฟีเจอร์ที่มีประสิทธิภาพมากที่สุดอย่างหนึ่งของทักษะคือความสามารถในการมอบหมายการดำเนินการให้กับสคริปต์ ซึ่งช่วยให้เอเจนต์ดำเนินการที่ LLM ทำได้ยากหรือทำไม่ได้โดยตรง (เช่น การดำเนินการแบบไบนารี การคำนวณทางคณิตศาสตร์ที่ซับซ้อน หรือการโต้ตอบกับระบบเดิม)
สคริปต์จะอยู่ในไดเรกทอรีย่อย scripts/ SKILL.md จะอ้างอิงถึงไฟล์เหล่านั้นตามเส้นทางสัมพัทธ์
5. ทักษะการเขียน
เป้าหมายของส่วนนี้คือการสร้างทักษะที่ผสานรวมเข้ากับ Antigravity และค่อยๆ แสดงฟีเจอร์ต่างๆ เช่น แหล่งข้อมูล / สคริปต์ / ฯลฯ
คุณดาวน์โหลดทักษะจากที่เก็บ Github ได้ที่ https://github.com/rominirani/antigravity-skills
ก่อนที่จะทำความเข้าใจวิธีสร้างทักษะแต่ละอย่างเหล่านี้ เรามาดูวิธีกำหนดค่าและทำให้ทักษะเหล่านี้พร้อมใช้งานภายในชุดผลิตภัณฑ์ Antigravity กัน โฟลเดอร์ด้านล่างนี้ใช้ได้ในขณะที่เผยแพร่แล็บนี้
การใช้ Antigravity หรือ Antigravity CLI
คุณกำหนดทักษะได้ 2 ขอบเขต ซึ่งจะช่วยให้มีทั้งทักษะเฉพาะโปรเจ็กต์และทักษะเฉพาะผู้ใช้ หรือก็คือทักษะส่วนกลาง
- ขอบเขตส่วนกลาง (
~/.gemini/config/skills/): ใช้ได้ในผลิตภัณฑ์และโปรเจ็กต์ Antigravity ทั้งหมด (Antigravity, Antigravity IDE, Antigravity CLI) ทักษะเหล่านี้พร้อมใช้งานในทุกโปรเจ็กต์ในเครื่องของผู้ใช้ เหมาะสำหรับยูทิลิตีทั่วไป เช่น "จัดรูปแบบ JSON" "สร้าง UUID" "ตรวจสอบรูปแบบโค้ด" หรือการผสานรวมกับเครื่องมือเพิ่มประสิทธิภาพส่วนบุคคล - ขอบเขตโปรเจ็กต์/พื้นที่ทำงาน (
<project-root>/.agents/skills/): การดำเนินการนี้จะทำให้ทักษะพร้อมใช้งานภายในโปรเจ็กต์ที่เฉพาะเจาะจงเท่านั้น ซึ่งเหมาะสำหรับสคริปต์เฉพาะโปรเจ็กต์ เช่น การติดตั้งใช้งานในสภาพแวดล้อมที่เฉพาะเจาะจง การจัดการฐานข้อมูลสำหรับแอปนั้น หรือการสร้างโค้ด Boilerplate สำหรับเฟรมเวิร์กที่เป็นกรรมสิทธิ์
การติดตั้งทักษะใน Antigravity หรือ Antigravity CLI
สำหรับบทแนะนำนี้ สิ่งที่เราต้องทำคือขั้นตอนต่อไปนี้ (คุณจะทำตามวิธีของคุณเองก็ได้)
ขั้นตอนที่ 1: ทำ git clone ของ https://github.com/rominirani/antigravity-skills
ขั้นตอนที่ 2: ตอนนี้คุณสามารถไปที่โฟลเดอร์ antigravity-skills/skills_tutorial ได้โดยขึ้นอยู่กับว่าคุณใช้ Antigravity หรือ Antigravity CLI
ขั้นตอนที่ 3: คุณจะเห็นชุดทักษะที่จัดอยู่ในโฟลเดอร์ที่เกี่ยวข้อง คัดลอกโฟลเดอร์ 4 โฟลเดอร์ต่อไปนี้
git-commit-formatterlicense-header-adderdatabase-schema-validatorjson-to-pydantic
ลงในโฟลเดอร์ทักษะเป้าหมายสำหรับผลิตภัณฑ์ (ขอบเขตของโปรเจ็กต์หรือขอบเขตทั่วโลก)
ขั้นตอนที่ 4: หากคุณใช้ Antigravity หรือ Antigravity CLI ให้คัดลอกไปยัง <project-root>/.agents/skills/ (ขอบเขตโปรเจ็กต์)
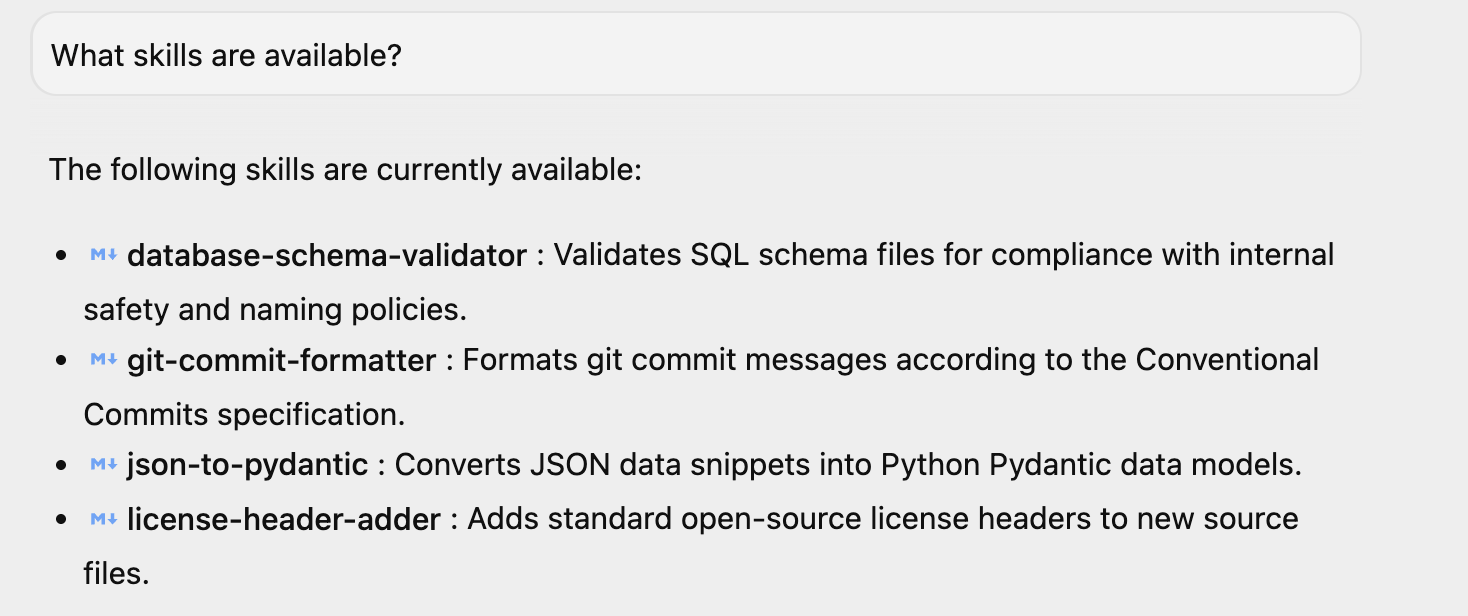
หากเปิดใช้ Antigravity แล้ว คุณสามารถถามคำถามง่ายๆ ว่า "มีทักษะอะไรบ้าง" แล้วแอปจะตอบกลับด้วยทักษะเหล่านั้น คุณจะเห็นทักษะ 4 อย่างที่แสดงอยู่ นอกจากนี้ คุณอาจมีทักษะเพิ่มเติมด้วย หากได้ติดตั้งทักษะเหล่านั้นในสภาพแวดล้อมของคุณ
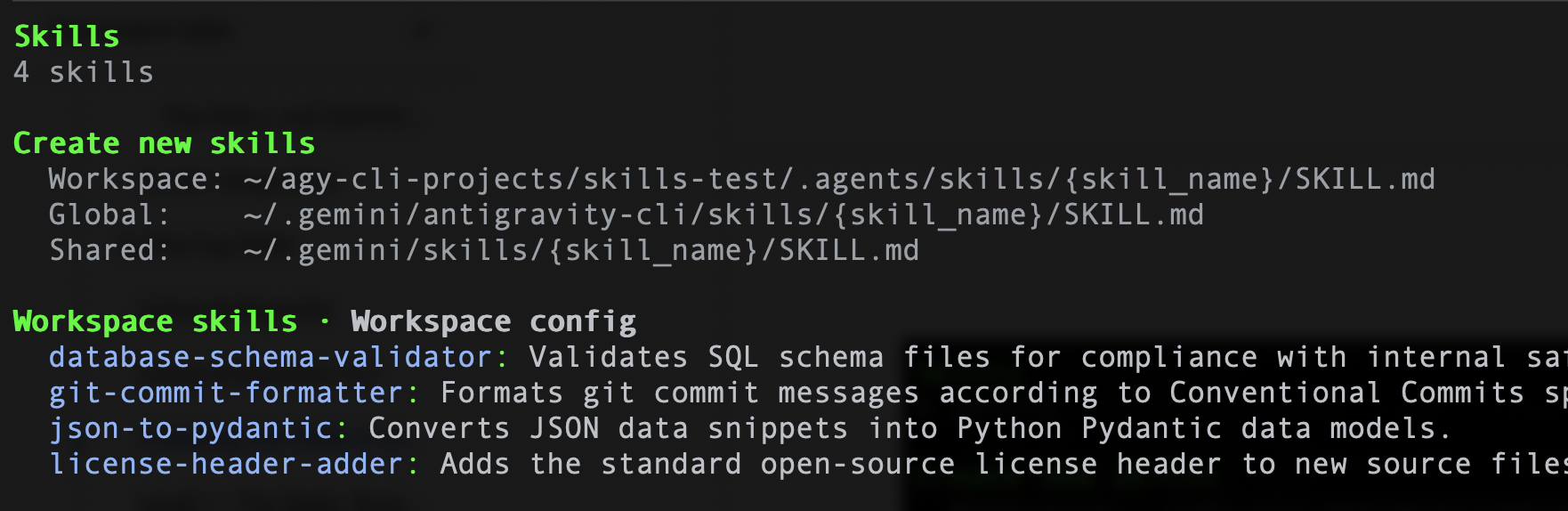
ในทำนองเดียวกัน หากคุณใช้ Antigravity CLI คุณสามารถใช้คำสั่งต่อไปนี้ /skills และควรแสดงทักษะทั้ง 4 รายการ ตัวอย่างแสดงอยู่ด้านล่าง
เมื่อทราบวิธีตั้งค่าทักษะแล้ว เรามาดูทักษะแต่ละอย่างและทำความเข้าใจวิธีสร้างทักษะเหล่านั้นกัน คุณสามารถใช้เทมเพลตเหล่านี้เพื่อสร้างทักษะของคุณเองได้เช่นกัน
ระดับ 1 : เราเตอร์พื้นฐาน ( git-commit-formatter)
มาพิจารณาว่านี่คือ "Hello World" ของทักษะกัน
นักพัฒนาซอฟต์แวร์มักเขียนข้อความคอมมิตแบบขี้เกียจ เช่น "wip" "แก้ไขข้อบกพร่อง" "อัปเดต" การบังคับใช้ "Conventional Commits" ด้วยตนเองนั้นน่าเบื่อและมักถูกลืม มาใช้ทักษะที่บังคับใช้ข้อกำหนด Conventional Commits กัน เพียงแค่สั่งให้เอเจนต์ทำตามกฎ เราก็อนุญาตให้เอเจนต์ทำหน้าที่บังคับใช้กฎได้
git-commit-formatter/
└── SKILL.md (Instructions only)
ไฟล์ SKILL.md แสดงอยู่ด้านล่าง
---
name: git-commit-formatter
description: Formats git commit messages according to Conventional Commits specification. Use this when the user asks to commit changes or write a commit message.
---
Git Commit Formatter Skill
When writing a git commit message, you MUST follow the Conventional Commits specification.
Format
`<type>[optional scope]: <description>`
Allowed Types
- **feat**: A new feature
- **fix**: A bug fix
- **docs**: Documentation only changes
- **style**: Changes that do not affect the meaning of the code (white-space, formatting, etc)
- **refactor**: A code change that neither fixes a bug nor adds a feature
- **perf**: A code change that improves performance
- **test**: Adding missing tests or correcting existing tests
- **chore**: Changes to the build process or auxiliary tools and libraries such as documentation generation
Instructions
1. Analyze the changes to determine the primary `type`.
2. Identify the `scope` if applicable (e.g., specific component or file).
3. Write a concise `description` in an imperative mood (e.g., "add feature" not "added feature").
4. If there are breaking changes, add a footer starting with `BREAKING CHANGE:`.
Example
`feat(auth): implement login with google`
วิธีเรียกใช้ตัวอย่างนี้ใน Antigravity
ขั้นตอนด้านล่างนี้ถือว่าคุณมี Git ในเครื่องและตั้งค่าอย่างถูกต้องแล้ว
หากคุณเปิดใช้ Antigravity หรือ Antigravity CLI แล้ว ให้ทำตามขั้นตอนต่อไปนี้
ขั้นตอนที่ 1: ตั้งค่าที่เก็บ Git สำหรับทดสอบ
ขอให้ตัวแทนตั้งค่าไดเรกทอรีที่สะอาดและแยกต่างหากสำหรับการทดสอบการดำเนินการ Git
พรอมต์ของคุณ:
Create a folder named git_test in the workspace, initialize a git repository inside it, and create an initial file auth.py with def login(): pass. Stage this file and make an initial commit.
เอเจนต์จะสร้างไดเรกทอรี เริ่มต้นที่เก็บ จัดเตรียมไฟล์ และคอมมิตไฟล์พร้อมข้อความ เช่น "initial commit"
ขั้นตอนที่ 2: ทำการเปลี่ยนแปลงโค้ด
บอกให้ตัวแทนแก้ไขโค้ดเพื่อให้มีการเปลี่ยนแปลงที่จะคอมมิต
พรอมต์ของคุณ:
In the git_test folder, modify auth.py to add Google Login functionality.
เอเจนต์จะแก้ไขไฟล์เพื่อเพิ่มฟีเจอร์ใหม่ ซึ่งเป็นการเตรียมไฟล์สำหรับระยะการคอมมิต
ขั้นตอนที่ 3: จัดเตรียมและคอมมิตการเปลี่ยนแปลง
เรียกใช้ทักษะ git-commit-formatter โดยขอให้ Agent จัดเตรียมการเปลี่ยนแปลงและสร้างคอมมิต
พรอมต์ของคุณ:
Stage the changes in the git_test folder and commit them. Make sure to format the commit message using the Conventional Commits skill.
Agent จะเรียกใช้ git add auth.py วิเคราะห์ความแตกต่างเพื่อพิจารณาว่ามีการเพิ่มฟีเจอร์ใหม่ลงในโมดูล auth และสร้างข้อความ Conventional Commit เช่น feat(auth): implement google login ก่อนที่จะเรียกใช้ git commit
ขั้นตอนที่ 4: ยืนยันบันทึก Git
ขอให้ตัวแทนดึงประวัติ Git เพื่อให้คุณยืนยันได้ว่าบันทึกการเปลี่ยนแปลงที่จัดรูปแบบแล้วบันทึกสำเร็จ
พรอมต์ของคุณ:
Show me the git log in the git_test folder.
เอเจนต์จะเรียกใช้ git log -n 5 และแสดงผลลัพธ์ที่แสดงข้อความคอมมิตที่จัดรูปแบบแล้ว
ระดับที่ 2: การใช้ประโยชน์จากเนื้อหา (license-header-adder)
นี่คือรูปแบบ "อ้างอิง"
ไฟล์แหล่งที่มาทุกไฟล์ในโปรเจ็กต์ขององค์กรอาจต้องมีส่วนหัวของใบอนุญาต Apache 2.0 แบบ 20 บรรทัดที่เฉพาะเจาะจง การใส่ข้อความแบบคงที่นี้ลงในพรอมต์โดยตรง (หรือ SKILL.md) เป็นการสิ้นเปลือง โดยจะใช้โทเค็นทุกครั้งที่จัดทำดัชนีทักษะ และโมเดลอาจ "หลอน" การสะกดคำผิดในข้อความทางกฎหมาย แนวทางปฏิบัติที่ดีคือการนำข้อความคงที่ไปไว้ในไฟล์ข้อความธรรมดาในโฟลเดอร์ resources/ โดยทักษะจะสั่งให้ตัวแทนอ่านไฟล์นี้เมื่อจำเป็นเท่านั้น
คุณจะเห็นไฟล์ในโฟลเดอร์ license-header-adder ในไดเรกทอรี skills
license-header-adder/
├── SKILL.md
└── resources/
└── HEADER_TEMPLATE.txt (The heavy text)
ไฟล์ SKILL.md แสดงอยู่ด้านล่าง
---
name: license-header-adder
description: Adds the standard open-source license header to new source files. Use involves creating new code files that require copyright attribution.
---
# License Header Adder Skill
This skill ensures that all new source files have the correct copyright header.
## Instructions
1. **Read the Template**:
First, read the content of the header template file located at `resources/HEADER_TEMPLATE.txt`.
2. **Prepend to File**:
When creating a new file (e.g., `.py`, `.java`, `.js`, `.ts`, `.go`), prepend the `target_file` content with the template content.
3. **Modify Comment Syntax**:
- For C-style languages (Java, JS, TS, C++), keep the `/* ... */` block as is.
- For Python, Shell, or YAML, convert the block to use `#` comments.
- For HTML/XML, use `<!-- ... -->`.
วิธีเรียกใช้ตัวอย่างนี้ใน Antigravity
หากคุณเปิดใช้ Antigravity หรือ Antigravity CLI แล้ว ให้ทำตามขั้นตอนต่อไปนี้
ขั้นตอนที่ 1: สร้างไฟล์ Python ด้วยโค้ดตัวอย่าง
พรอมต์ของคุณ:
Create a new file my_script.py with the following python code:
def hello():
print("Hello, World!")
สิ่งที่เกิดขึ้น (คำอธิบาย): เอเจนต์เรียกใช้เครื่องมือเขียนไฟล์ (write_to_file) เพื่อสร้างไฟล์ใหม่ชื่อ my_script.py ในไดเรกทอรีพื้นที่ทำงานที่ใช้งานอยู่โดยตรง และเขียนฟังก์ชัน Python พื้นฐานลงในไฟล์นั้น นอกจากนี้ พรอมต์ยังทริกเกอร์ทักษะ license-header-adder ด้วย เอเจนต์ค้นหาและอ่านไฟล์เทมเพลตใบอนุญาต (HEADER_TEMPLATE.txt) แก้ไขรูปแบบความคิดเห็นจากความคิดเห็นแบบบล็อกสไตล์ C (/* ... */) เป็นความคิดเห็นสไตล์ Python (#) และเพิ่มไว้ที่ด้านบนของไฟล์โดยใช้เครื่องมือ replace_file_content
ขั้นตอนที่ 2: ตรวจสอบเนื้อหาของไฟล์
ดูmy_script.pyไฟล์ โดยจะมีส่วนหัวของใบอนุญาตที่ด้านบน
ระดับ 3: การเรียนรู้จากตัวอย่าง (json-to-pydantic)
รูปแบบ "Few-Shot"
การแปลงข้อมูลที่ไม่เข้มงวด (เช่น การตอบกลับของ JSON API) เป็นโค้ดที่เข้มงวด (เช่น โมเดล Pydantic) ต้องมีการตัดสินใจหลายสิบครั้ง เราควรตั้งชื่อชั้นเรียนอย่างไร เราควรใช้ Optional ไหม snake_case หรือ camelCase การเขียนกฎ 50 ข้อนี้เป็นภาษาอังกฤษเป็นเรื่องที่น่าเบื่อและมีโอกาสเกิดข้อผิดพลาดได้ง่าย
LLM เป็นเครื่องมือจับคู่รูปแบบ
การเขียนทักษะด้วยตัวอย่างที่ยอดเยี่ยม (Input -> Output) มักจะมีประสิทธิภาพมากกว่าคำสั่งที่ยาว
ไปที่โฟลเดอร์ json-to-pydantic/ ที่มีไฟล์ทักษะ ดังที่แสดงด้านล่าง
json-to-pydantic/
├── SKILL.md
└── examples/
├── input_data.json (The Before State)
└── output_model.py (The After State)
ไฟล์ SKILL.md แสดงอยู่ด้านล่าง
---
name: json-to-pydantic
description: Converts JSON data snippets into Python Pydantic data models.
---
# JSON to Pydantic Skill
This skill helps convert raw JSON data or API responses into structured, strongly-typed Python classes using Pydantic.
Instructions
1. **Analyze the Input**: Look at the JSON object provided by the user.
2. **Infer Types**:
- `string` -> `str`
- `number` -> `int` or `float`
- `boolean` -> `bool`
- `array` -> `List[Type]`
- `null` -> `Optional[Type]`
- Nested Objects -> Create a separate sub-class.
3. **Follow the Example**:
Review `examples/` to see how to structure the output code. notice how nested dictionaries like `preferences` are extracted into their own class.
- Input: `examples/input_data.json`
- Output: `examples/output_model.py`
Style Guidelines
- Use `PascalCase` for class names.
- Use type hints (`List`, `Optional`) from `typing` module.
- If a field can be missing or null, default it to `None`.
ในโฟลเดอร์ /examples จะมีไฟล์ JSON และไฟล์เอาต์พุต เช่น ไฟล์ Python โดยทั้ง 2 อย่างแสดงอยู่ด้านล่าง
input_data.json
{
"user_id": 12345,
"username": "jdoe_88",
"is_active": true,
"preferences": {
"theme": "dark",
"notifications": [
"email",
"push"
]
},
"last_login": "2024-03-15T10:30:00Z",
"meta_tags": null
}
output_model.py
from pydantic import BaseModel, Field
from typing import List, Optional
class Preferences(BaseModel):
theme: str
notifications: List[str]
class User(BaseModel):
user_id: int
username: str
is_active: bool
preferences: Preferences
last_login: Optional[str] = None
meta_tags: Optional[List[str]] = None
วิธีเรียกใช้ตัวอย่างนี้ใน Antigravity
หากคุณเปิดใช้ Antigravity หรือ Antigravity CLI แล้ว ให้ทำตามขั้นตอนต่อไปนี้
ขั้นตอนที่ 1: สร้างไฟล์ JSON ด้วยข้อมูลตัวอย่าง
ขอให้ตัวแทนสร้างไฟล์ใหม่ product.json ที่มีเพย์โหลด JSON ดิบ
พรอมต์ของคุณ:
Create a new file product.json with the following JSON:
{
"product": "Widget",
"cost": 10.99,
"stock": null
}
ขั้นตอนที่ 2: แปลง JSON เป็นโมเดล Pydantic
เรียกใช้ทักษะ json-to-pydantic เพื่อแปลงข้อมูล JSON เป็นคลาส Pydantic ที่มีโครงสร้าง
พรอมต์ของคุณ:
Convert the JSON in product.json to a Pydantic model and save it to product_model.py.
ขั้นตอนที่ 3: ตรวจสอบเอาต์พุต
ดูproduct_model.pyไฟล์ ซึ่งจะมีโมเดล Pydantic ที่เสร็จสมบูรณ์
ระดับ 4: ตรรกะเชิงกระบวนการ (database-schema-validator)
นี่คือรูปแบบ "การใช้เครื่องมือ"
หากคุณถาม LLM ว่า "สคีมานี้ปลอดภัยไหม" LLM อาจตอบว่าปลอดภัยดี แม้ว่าจะไม่มีคีย์หลักที่สำคัญก็ตาม เพียงเพราะ SQL ดูถูกต้อง
มามอบหมายการตรวจสอบนี้ให้กับสคริปต์ที่อ้างอิงจากข้อมูลที่แม่นยำและเฉพาะเจาะจงกัน database-schema-validatorทักษะของเราจะกำหนดเส้นทางให้ตัวแทนเรียกใช้สคริปต์ Python ที่เราเขียนขึ้น สคริปต์จะให้ค่าความจริงแบบไบนารี (จริง/เท็จ)
database-schema-validator/
├── SKILL.md
└── scripts/
└── validate_schema.py (The Validator)
ไฟล์ SKILL.md แสดงอยู่ด้านล่าง
---
name: database-schema-validator
description: Validates SQL schema files for compliance with internal safety and naming policies.
---
# Database Schema Validator Skill
This skill ensures that all SQL files provided by the user comply with our strict database standards.
Policies Enforced
1. **Safety**: No `DROP TABLE` statements.
2. **Naming**: All tables must use `snake_case`.
3. **Structure**: Every table must have an `id` column as PRIMARY KEY.
Instructions
1. **Do not read the file manually** to check for errors. The rules are complex and easily missed by eye.
2. **Run the Validation Script**:
Use the `run_command` tool to execute the python script provided in the `scripts/` folder against the user's file.
`python scripts/validate_schema.py <path_to_user_file>`
3. **Interpret Output**:
- If the script returns **exit code 0**: Tell the user the schema looks good.
- If the script returns **exit code 1**: Report the specific error messages printed by the script to the user and suggest fixes.
ไฟล์ validate_schema.py แสดงอยู่ด้านล่าง
import sys
import re
def validate_schema(filename):
"""
Validates a SQL schema file against internal policy:
1. Table names must be snake_case.
2. Every table must have a primary key named 'id'.
3. No 'DROP TABLE' statements allowed (safety).
"""
try:
with open(filename, 'r') as f:
content = f.read()
lines = content.split('\n')
errors = []
# Check 1: No DROP TABLE
if re.search(r'DROP TABLE', content, re.IGNORECASE):
errors.append("ERROR: 'DROP TABLE' statements are forbidden.")
# Check 2 & 3: CREATE TABLE checks
table_defs = re.finditer(r'CREATE TABLE\s+(?P<name>\w+)\s*\((?P<body>.*?)\);', content, re.DOTALL | re.IGNORECASE)
for match in table_defs:
table_name = match.group('name')
body = match.group('body')
# Snake case check
if not re.match(r'^[a-z][a-z0-9_]*$', table_name):
errors.append(f"ERROR: Table '{table_name}' must be snake_case.")
# Primary key check
if not re.search(r'\bid\b.*PRIMARY KEY', body, re.IGNORECASE):
errors.append(f"ERROR: Table '{table_name}' is missing a primary key named 'id'.")
if errors:
for err in errors:
print(err)
sys.exit(1)
else:
print("Schema validation passed.")
sys.exit(0)
except FileNotFoundError:
print(f"Error: File '{filename}' not found.")
sys.exit(1)
if __name__ == "__main__":
if len(sys.argv) != 2:
print("Usage: python validate_schema.py <schema_file>")
sys.exit(1)
validate_schema(sys.argv[1])
วิธีเรียกใช้ตัวอย่างนี้ใน Antigravity
หากคุณเปิดใช้ Antigravity หรือ Antigravity CLI แล้ว ให้ทำตามขั้นตอนต่อไปนี้
ขั้นตอนที่ 1: สร้างไฟล์ JSON ด้วยข้อมูลตัวอย่าง
ขอให้ Agent สร้างไฟล์ใหม่bad_schema.sqlที่มีการละเมิดนโยบายหลายรายการ
พรอมต์ของคุณ:
Create a new file bad_schema.sql with the following SQL:
DROP TABLE IF EXISTS legacy_users;
CREATE TABLE userProfile (
id INT PRIMARY KEY,
bio TEXT
);
CREATE TABLE posts (
title TEXT,
content TEXT,
created_at TIMESTAMP
);
CREATE TABLE comments (
id INT PRIMARY KEY,
post_id INT,
body TEXT
);
ไฟล์สคีมาข้างต้นละเมิดนโยบายทั้ง 3 ข้อ โดยใช้คำสั่ง DROP TABLE ที่ไม่อนุญาต ใช้ camelCase สำหรับชื่อตาราง userProfile และลืมคีย์หลัก id ในตาราง posts
ขั้นตอนที่ 2: ตรวจสอบความถูกต้องของสคีมา SQL
เรียกใช้database-schema-validatorทักษะเพื่อเรียกใช้สคริปต์โปรแกรมตรวจสอบ Python กับไฟล์
พรอมต์ของคุณ:
Validate bad_schema.sql using the database-schema-validator skill.
ขั้นตอนที่ 3: ตรวจสอบเอาต์พุต
เอเจนต์จะรายงานความล้มเหลวและแสดงข้อผิดพลาดที่สคริปต์พบในแชทโดยตรง เอาต์พุตตัวอย่างแสดงอยู่ด้านล่าง
Suggested Fixes:
Remove the line DROP TABLE IF EXISTS legacy_users; as dropping tables is forbidden by safety policy.
Rename the table userProfile to use snake_case (e.g., user_profile).
Add a primary key column named id to the posts table definition.
6. ชุดเครื่องมือสำหรับนักพัฒนาซอฟต์แวร์ (ทักษะ CLI ของเอเจนต์)
รูปแบบ "การดำเนินการและวงจร"
การพัฒนา AI Agent เกี่ยวข้องกับงานวงจรการจัดการที่ต้องทำซ้ำๆ ได้แก่ การสร้างไฟล์บอยเลอร์เพลต การกำหนดค่าสภาพแวดล้อมรันไทม์ในเครื่อง การเรียกใช้พรอมต์ทดสอบ และการเริ่มต้นพื้นที่ทดสอบแบบอินเทอร์แอกทีฟ
ทักษะ CLI ของ Agent จะรวมความเชี่ยวชาญด้านวงจรนี้ไว้ในทักษะของ Agent ที่เฉพาะเจาะจงแทนที่จะบังคับให้ผู้ช่วยเขียนโค้ดของคุณคาดเดาโครงสร้างไดเรกทอรีหรือเขียนการกำหนดค่า Agent แบบ Boilerplate ตั้งแต่ต้น
ทักษะ Agent CLI (อินเทอร์เฟซบรรทัดคำสั่ง) ช่วยให้การทำงานอัตโนมัติที่เน้นนักพัฒนาซอฟต์แวร์เป็นหลักมีประสิทธิภาพมากขึ้นในเทอร์มินัลของคุณโดยตรง ซึ่งช่วยลดช่องว่างระหว่างโค้ดดิบกับการดำเนินการแบบอัตโนมัติ แม้ว่า Agent Development Kit (ADK) จะมุ่งเน้นที่เฟรมเวิร์กแบบเป็นโปรแกรม โดยให้ SDK, API และพิมพ์เขียวโครงสร้างแก่คุณเพื่อสร้างและประสานงาน AI Agent แต่ทักษะ Agent CLI จะช่วยให้คุณดำเนินการได้ ซึ่งช่วยให้นักพัฒนาซอฟต์แวร์สามารถสร้างโครงสร้าง ทดสอบ และติดตั้งใช้งานเอเจนต์ในเครื่องด้วยวงจรความคิดเห็นที่รวดเร็ว โดยไม่ต้องใช้ UI ที่ซับซ้อน
ไม่บังคับ เมื่อแมปกับ Google Cloud ทักษะ CLI ของ Agent จะทำหน้าที่เป็นไปป์ไลน์โดยตรงไปยังโครงสร้างพื้นฐานระดับองค์กร คุณสามารถใช้คำสั่ง CLI เพื่อจัดแพ็กเกจเวิร์กโฟลว์ของเอเจนต์ จัดการสิทธิ์เข้าถึง และนำไปใช้งานในระบบนิเวศของ Google Cloud (เช่น Vertex AI หรือ Cloud Run) ได้ทันทีแทนการคลิกผ่านคอนโซล ซึ่งจะเปลี่ยนงานสถาปัตยกรรมระบบคลาวด์ที่ซับซ้อนในอดีตให้เป็นคำสั่งเทอร์มินัลที่เรียบง่ายและทำซ้ำได้ ทำให้การผสานรวม Agent แบบอัตโนมัติเข้ากับไปป์ไลน์การติดตั้งใช้งาน CI/CD ที่มีอยู่เป็นเรื่องง่ายขึ้นมาก
วิธีการติดตั้ง
ตรวจสอบว่าคุณได้ติดตั้ง Python 3.11+, Node.js และเครื่องมือจัดการแพ็กเกจ uv แล้ว จากนั้นเรียกใช้คำสั่งการตั้งค่าในเทอร์มินัล
uvx google-agents-cli setup
คำสั่งนี้จะติดตั้งไบนารี agents-cli และลงทะเบียนทักษะเฉพาะทางสำหรับการจัดโครงสร้างและการประเมินภายในสภาพแวดล้อมของผู้ช่วยการเขียนโค้ด
หมายเหตุ: ระบบจะติดตั้งทักษะในโฟลเดอร์ ~/.agents/skills ซึ่ง Antigravity มองเห็นได้ หากต้องการดูทักษะเหล่านี้ใน Antigravity CLI คุณจะต้องย้ายทักษะไปยังโฟลเดอร์ ~/.gemini/antigravity-cli/skills (ขอบเขตส่วนกลาง)
คุณตรวจสอบว่าโหลดทักษะใน Antigravity แล้วได้โดยเพียงแค่ถามว่ามีทักษะใดบ้างที่พร้อมใช้งาน ตัวอย่างการตอบกลับจะแสดงด้านล่างสำหรับทักษะ CLI ของตัวแทนที่เราเพิ่งติดตั้ง

คำแนะนำแบบทีละขั้นอย่างละเอียด
เมื่อ uvx google-agents-cli setup เสร็จสมบูรณ์แล้ว คุณจะสามารถเปิดใช้งาน โต้ตอบ และทดสอบ AI Agent ในเครื่องของคุณได้ทั้งหมด
ขั้นตอนที่ 1: จัดโครงสร้างและเริ่มต้นโปรเจ็กต์ Agent ใหม่
เรียกใช้คำสั่งสร้างเพื่อจัดโครงร่างเลย์เอาต์ที่ได้มาตรฐาน เมื่อสร้างแล้ว คุณต้องติดตั้งการอ้างอิงของโปรเจ็กต์ก่อนที่จะเรียกใช้การดำเนินการใดๆ
# 1. Create a lightweight prototype project structure
agents-cli create weather-assistant --prototype --yes
# 2. Move into the directory and install required ADK dependencies
cd weather-assistant
agents-cli install
สิ่งที่เกิดขึ้นเบื้องหลัง: การดำเนินการนี้จะสร้างพื้นที่ทํางานที่สะอาดซึ่งมี app/agent.py (โค้ดหลักของคุณ), pyproject.toml (ข้อมูลเมตาของแพ็กเกจ) และ agents-cli-manifest.yaml (เครื่องมือติดตามโปรเจ็กต์)
ขั้นตอนที่ 2: เรียกใช้การค้นหาทดสอบในเครื่อง
ทำการทดสอบบรรทัดคำสั่งอย่างรวดเร็วและโดยตรงกับ Agent ตรวจสอบว่าคุณได้GEMINI_API_KEYส่งออกในเทอร์มินัลแล้ว หากไม่ได้ใช้ ADC (ข้อมูลรับรองเริ่มต้นของแอปพลิเคชัน) ของ Google Cloud คุณสามารถรับคีย์ Gemini API ได้จากที่นี่ เมื่อได้คีย์แล้ว ให้ส่งออกคีย์ในเทอร์มินัลโดยใช้คำสั่งต่อไปนี้
export GEMINI_API_KEY="YOUR_GEMINI_API_KEY"
ป้อนคำสั่งต่อไปนี้ในเทอร์มินัล
agents-cli run "How are you?"
สิ่งที่เกิดขึ้นเบื้องหลัง: CLI จะเริ่มต้นวงจรการใช้งานชุดพัฒนาเอเจนต์ (ADK) ทั้งหมดในหน่วยความจำบนเทอร์มินัล โดยจะกำหนดเส้นทางพรอมต์อย่างปลอดภัยผ่านข้อมูลเข้าสู่ระบบในเครื่องของคุณ และบันทึกการตอบกลับการสตรีมแบบสดกลับไปยังบรรทัดคำสั่งโดยตรง
ขั้นตอนที่ 3: เริ่มใช้ Interactive Web Playground
เปิดใช้งาน Playground บนเว็บในเครื่องที่มาพร้อมกับเครื่องมือเพื่อโต้ตอบกับเอเจนต์ด้วยภาพ
agents-cli playground
สิ่งที่เกิดขึ้นเบื้องหลัง: CLI จะเปิดเซิร์ฟเวอร์ UI เว็บของ ADK ซึ่งโดยปกติจะเข้าถึงได้ที่ http://localhost:8080 หรือ http://127.0.0.1:8000 (หากเข้าถึงไม่ได้) พร้อมด้วยการโหลดซ้ำแบบด่วน จากอินเทอร์เฟซเว็บ ให้เลือกแอปในเมนูแบบเลื่อนลงเลือกแอปที่ด้านบน แล้วโต้ตอบกับตัวแทนในอินเทอร์เฟซการสนทนาทางด้านขวาของเว็บแอปพลิเคชัน
7. การติดตั้งทักษะของ Agent โดยใช้ npx skills
npx skills เป็นเครื่องมือบรรทัดคำสั่งที่พัฒนาโดย Vercel Labs ซึ่งทำหน้าที่เป็นตัวจัดการแพ็กเกจสำหรับเอเจนต์ AI (เช่น Antigravity, Claude Code, GitHub Copilot, Cursor และ Cline) ซึ่งเป็น CLI สำหรับระบบนิเวศของทักษะเอเจนต์แบบเปิด
หากต้องการดาวน์โหลดและติดตั้งทักษะของตัวแทนโดยใช้แพ็กเกจ npx skills โปรดทราบว่าระบบจะวางทักษะไว้ในโฟลเดอร์ ~/.agents/skills แม้ว่าจะมีข้อความระบุว่าเครื่องมืออย่าง Antigravity จะดึงทักษะจากโฟลเดอร์นี้ แต่โปรดทราบว่าในขณะที่เขียนอยู่นี้ Antigravity จะดึงทักษะจากโฟลเดอร์นี้ แต่ Antigravity CLI จะไม่ดึง ดังที่ได้กล่าวไปก่อนหน้านี้ คุณจะต้องคัดลอกทักษะเหล่านี้ที่ติดตั้งไว้ในโฟลเดอร์ ~/.agents/skills ไปยังขอบเขตโปรเจ็กต์หรือขอบเขตส่วนกลางสำหรับโฟลเดอร์ทักษะใน Antigravity CLI กล่าวคือ
- ขอบเขตของโปรเจ็กต์: ตั้งอยู่ใน
<project-root>/.agent/skills/ - ขอบเขตทั่วโลก: ตั้งอยู่ใน
~/.gemini/antigravity-cli/skills/
8. ขอแสดงความยินดี
ยินดีด้วย คุณใช้ Google Antigravity เพื่อสร้างทักษะ Agent แรก กำหนดค่า และเพิ่มความสามารถที่กำหนดเองลงในทักษะนั้นเรียบร้อยแล้ว
นอกจากนี้ คุณยังกำหนดค่าชุดทักษะของเอเจนต์ได้ทั้งในขอบเขตของโปรเจ็กต์และขอบเขตส่วนกลาง ซึ่งจะช่วยให้เครื่องมือที่ปรับแต่งเองใช้งานได้จริง
ตอนนี้คุณพร้อมที่จะให้ Antigravity จัดการงานหนักในโปรเจ็กต์ของคุณเองและเขียนโค้ดในแบบของคุณแล้ว
รับป้าย AI Agent 5 วันของ Kaggle
คุณทำแล็บนี้เสร็จแล้วในฐานะส่วนหนึ่งของ 5-Day AI Agents: Intensive Vibe Coding Course with Google ของ Kaggle ใช่ไหม รับป้ายสำเร็จหลักสูตร: รับป้ายเอเจนต์ AI 5 วัน
9. เอกสารอ้างอิง
- Codelab : การเริ่มต้นใช้งาน Google Antigravity
- เว็บไซต์อย่างเป็นทางการ : https://antigravity.google/
- เอกสารประกอบ: https://antigravity.google/docs
- ดาวน์โหลด : https://antigravity.google/download
- เอกสารประกอบเกี่ยวกับทักษะ Antigravity: https://antigravity.google/docs/skills