
1. مقدمة
في هذا الدرس العملي، ستنشئ مسارًا موزعًا لاكتساب المعرفة في "Petverse". ستعالج أصول الوسائط المتعدّدة غير المنظَّمة (الصوت والفيديو والصور والنصوص/ملفات CSV) من حزمة Cloud Storage، وتستخرج المعلومات الأساسية حول الحيوانات الأليفة (الطعام المفضّل والهوايات)، وتنشئ رسمًا بيانيًا معرفيًا. ستوسّع نطاق معالجة ملف الوسائط المتعددة باستخدام ميزة المعالجة المتعددة الوسائط في Gemini على Google Kubernetes Engine (GKE). أخيرًا، ستخزِّن هذه البيانات في BigQuery وتستخدم ميزة "الرسم البياني للمواقع" الجديدة في BigQuery لتحليل العلاقات.
سنستخدم إمكانات Google Kubernetes Engine لتوضيح كيفية معالجة كميات كبيرة من البيانات بالتوازي.
لماذا الرسوم البيانية المعرفية؟
تُعدّ الرسومات البيانية المعرفية أكثر ملاءمة من قواعد البيانات الارتباطية التقليدية لتمثيل العلاقات المعقّدة بين الكيانات وتحليلها.
سنستخدم Gemini 2.5 Flash لتحليل الصور والملفات الصوتية وملفات الفيديو وتحديد معلومات عن الحيوانات الأليفة المختلفة.
الإجراءات التي ستنفذّها
- إنشاء مهمة معالجة بيانات موزّعة ونشرها على GKE
- استخدام Gemini لاستخراج الكيانات والعلاقات من ملفات الوسائط المتعددة
- تخزين بيانات الرسم البياني المعرفي في BigQuery
- إنشاء رسم بياني للعلاقات والاستعلام عنه في BigQuery باستخدام "لغة طلبات البحث في الرسوم البيانية" (GQL)
المتطلبات
- متصفّح ويب، مثل Chrome
- مشروع Google Cloud تم تفعيل الفوترة فيه
- أذونات في المشروع لإنشاء موارد وتعديل سياسات "إدارة الهوية وإمكانية الوصول"
هذا الدرس التطبيقي حول الترميز مخصّص للمطوّرين من جميع المستويات، بما في ذلك المبتدئين.
المدة المقدَّرة: 45 دقيقة
التكلفة: يجب أن تكون تكلفة الموارد التي تم إنشاؤها في هذا الدرس التطبيقي حول الترميز أقل من 5 دولارات أمريكية.
2. قبل البدء
إنشاء مشروع على Google Cloud
- انتقِل إلى Google Cloud Console: https://console.cloud.google.com، ثم اختَر مشروعًا على السحابة الإلكترونية أو أنشِئ مشروعًا على السحابة الإلكترونية.
- ⚠️ دوِّن رقم تعريف المشروع. ستستخدمه مع عدة أوامر في هذا الدرس التطبيقي.
بدء Cloud Shell
- افتح Cloud Shell في علامة تبويب جديدة: https://shell.cloud.google.com/.
- انقر على تفويض إذا طُلب منك ذلك.
- استبدِل
PROJECT_IDوالصِق الأمر التالي في الوحدة الطرفية:
export PROJECT_ID="YOUR_PROJECT_ID"
gcloud config set project $PROJECT_ID
📝 ملاحظة سيظهر مشروعك باللون الأصفر في سطر الأوامر. إذا تمت إعادة تشغيل جلستك، تأكَّد من إعادة تنفيذ الأمر أعلاه لضبط رقم تعريف المشروع.
تفعيل واجهات برمجة التطبيقات
نفِّذ الأمر التالي لتفعيل جميع واجهات برمجة التطبيقات المطلوبة:
gcloud services enable \
aiplatform.googleapis.com \
bigquery.googleapis.com \
artifactregistry.googleapis.com \
container.googleapis.com \
cloudbuild.googleapis.com \
pubsub.googleapis.com
استنساخ المستودع
نفِّذ الأوامر التالية لاستنساخ المستودع.
cd ~/
git clone --filter=blob:none --no-checkout https://github.com/GoogleCloudPlatform/devrel-demos.git
cd ~/devrel-demos
git sparse-checkout init --cone
git sparse-checkout set codelabs/gke-knowledge-graph
git checkout main
cd codelabs/gke-knowledge-graph/
تشغيل نص التهيئة البرمجي
يعمل هذا النص البرمجي على إعداد الخلفية تلقائيًا من خلال:
- إنشاء صورة حاوية ومستودع Artifact Registry
- إنشاء مجموعة بيانات في BigQuery
- إنشاء اتصال BigQuery لتنفيذ وظائف الذكاء الاصطناعي من Gemini من SQL
نفِّذ الأمر التالي في الوحدة الطرفية:
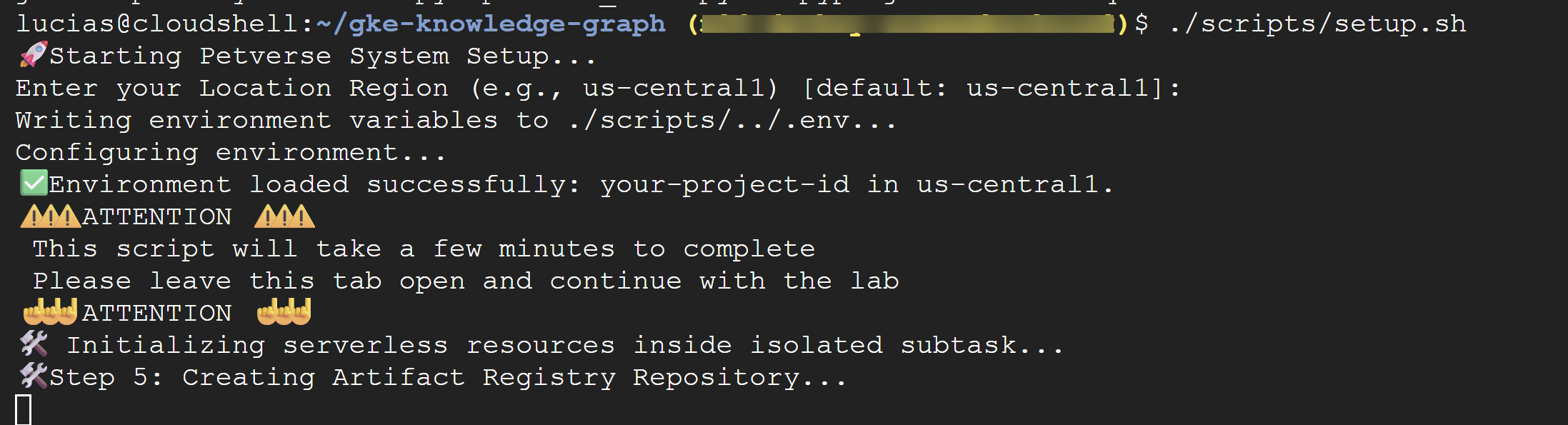
./scripts/setup.sh
إذا طلب منك النص البرمجي تقديم تفاصيل الإعداد، استخدِم القيم التالية:
- رقم تعريف المشروع: استخدِم رقم التعريف الذي أنشأته في الخطوة السابقة.
- المنطقة:
us-central1
⚠️ ملاحظة مهمة سيستغرق إكمال النص البرمجي بضع دقائق. يُرجى إبقاء نافذة المحطة الطرفية هذه مفتوحة لإنهاء العملية في الخلفية. للمتابعة إلى الخطوة التالية، افتح علامة تبويب أو نافذة وحدة طرفية جديدة لتنفيذ الأوامر التالية.
3- إعداد "مجموعة أدوات وكيل البيانات"
- فعِّل Cloud Shell Editor باستخدام رمز القلم الرصاص في أعلى يسار الصفحة.
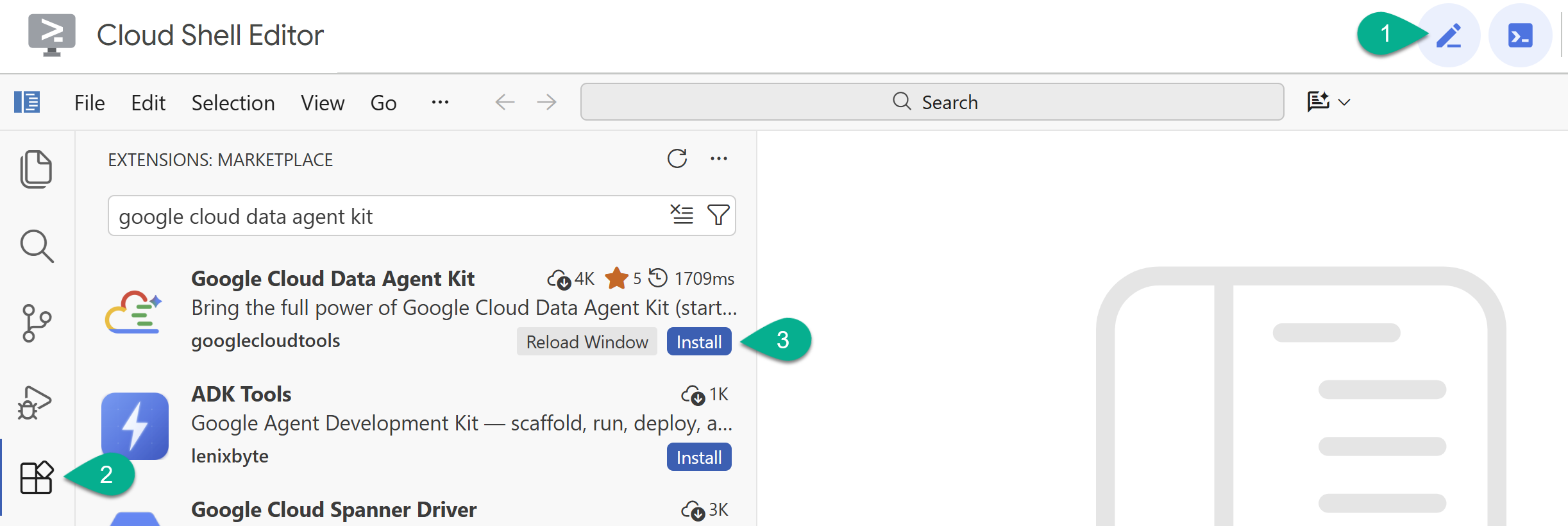
- في "أداة تعديل Cloud Shell"، انقر على رمز الإضافات في الشريط الجانبي الأيمن.
- ابحث عن Google Cloud Data Agent Kit وانقر على تثبيت إذا لم يكن مثبّتًا من قبل.
- سجِّل الدخول إلى حسابك على Google باستخدام الإضافة.
- في "ملخّص الإعداد"، أدخِل رقم تعريف مشروعك و
us-central1كمنطقة.
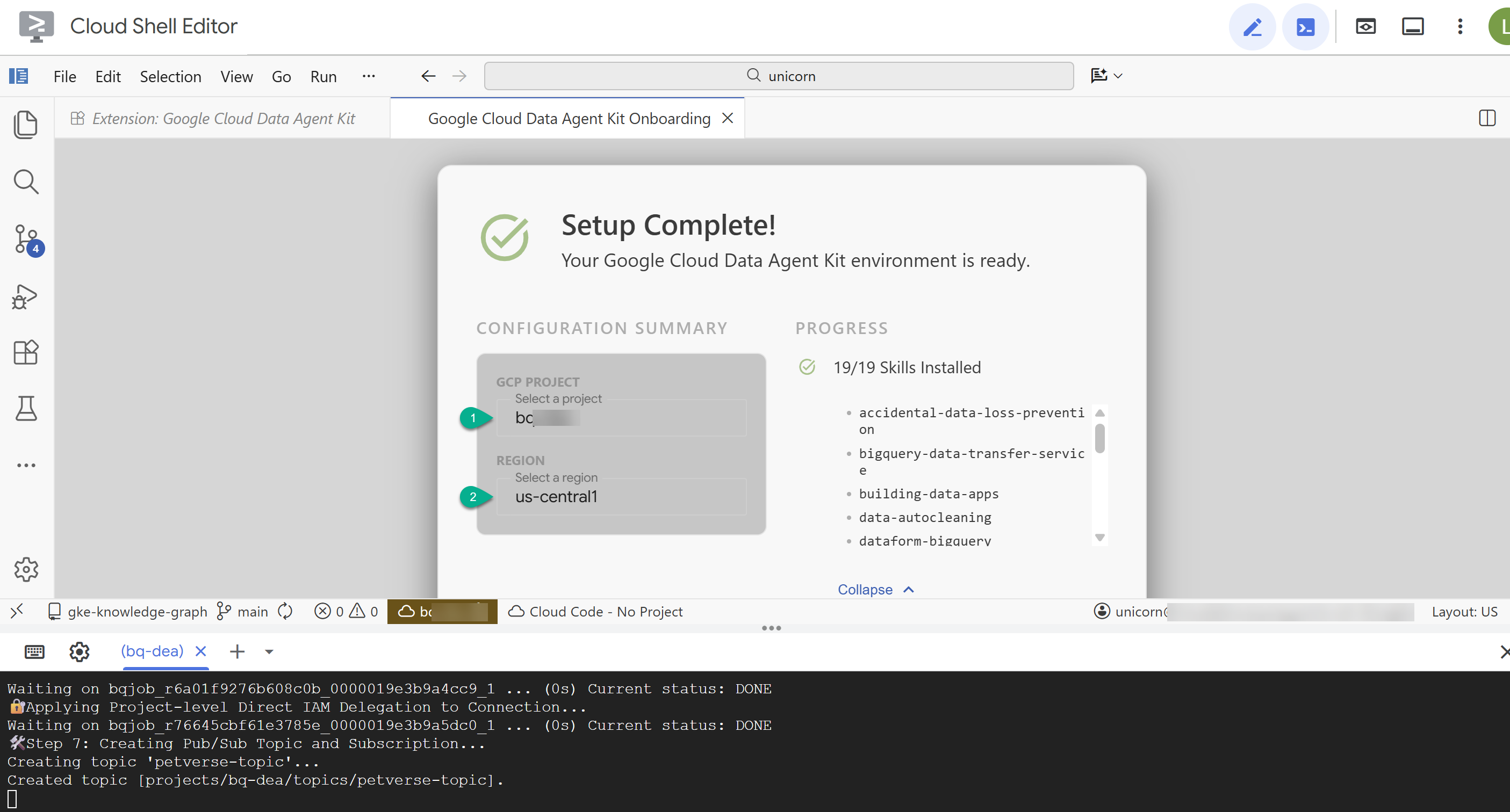
- انقر على ضبط خوادم MCP. ليس عليك إجراء أي تغييرات على هذه النافذة، ما عليك سوى النقر على بدء.
- أعِد تحميل النافذة إذا طُلب منك ذلك. يمكنك إغلاق علامة التبويب "دليل البدء السريع" في الوقت الحالي.
إعداد الجداول في BigQuery
- في الشريط الجانبي، ارجع إلى "المستكشف". إذا لم يكن مجلدك الرئيسي (مثل
/home/your_user_name/) مفتوحًا، انقر على فتح المجلد واختَره.
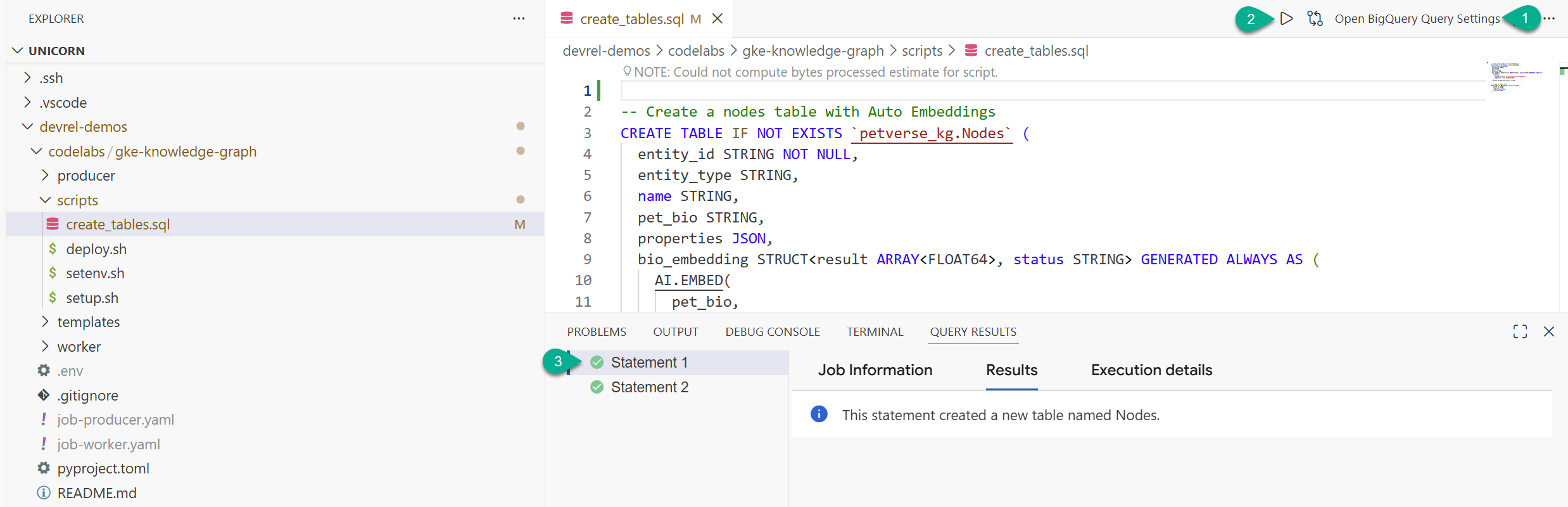
- في نافذة "المستكشف"، ابحث عن المجلد الذي نسخته من المستودع (
devrel-demos). ضمنcodelabs/gke-knowledge-graph/scripts، ستجدcreate_tables.sql. افتح هذا الملف. - في أعلى يسار الصفحة، انقر على فتح إعدادات طلب البحث.
- اختَر BigQuery. حفظ وإغلاق
- انقر على تشغيل.
من المفترض أن تظهر لك عبارتان تم تنفيذهما بنجاح. لقد أنشأت الآن الجداول لتخزين العُقد والحواف في الرسم البياني المعرفي.
يمكنك إغلاق علامة التبويب create_tables.sql ووحدة تحكّم النتائج.
4. إعداد مجموعة GKE
سنستخدم وضع Autopilot في GKE لتشغيل مهمة معالجة البيانات. يُعدّ Autopilot أفضل الممارسات المقترَحة لأنّه يدير البنية الأساسية للمجموعة نيابةً عنك.
من المفترض أن يكون قد تم الانتهاء من نص التهيئة البرمجي الآن. من المفترض أن تظهر لك رسالة تفيد بنجاح العملية: 🎉🦄 Setup successfully finished! 🎉🦄.
الصِق هذا الأمر في الوحدة الطرفية لإنشاء المجموعة:
source scripts/setenv.sh
gcloud container clusters create-auto petverse-cluster \
--region=$REGION
🕓 سيستغرق ذلك حوالي 5 دقائق.
احصل على بيانات الاعتماد للتفاعل مع المجموعة:
source scripts/setenv.sh
gcloud container clusters get-credentials petverse-cluster --region $REGION
من المفترض أن تظهر لك النتيجة التالية:
Fetching cluster endpoint and auth data. kubeconfig entry generated for petverse-cluster.
5- ضبط Workload Identity
تتيح ميزة Workload Identity Federation for GKE (باستخدام ميزة الوصول المباشر إلى الموارد) لأحمال عمل GKE الوصول بشكل آمن إلى خدمات Google Cloud بدون الحاجة إلى إدارة مفاتيح حساب الخدمة.
تنفيذ deploy.sh على:
- إنشاء حساب خدمة Kubernetes
- منح أدوار "إدارة الهوية وإمكانية الوصول" (IAM) اللازمة مباشرةً إلى مدير حساب الخدمة في Kubernetes
- ربط حساب خدمة إدارة الهوية وإمكانية الوصول بحساب خدمة Kubernetes
- إضافة تعليق توضيحي إلى حساب خدمة Kubernetes لإكمال عملية الربط
source scripts/setenv.sh
./scripts/deploy.sh
6. نشر مهام المعالجة المنفصلة
في هذه الخطوة، ستنفّذ عملية نشر لبرنامج إضافة المهام إلى قائمة الانتظار (المنتج) ومحركات المعالجة (العاملون) على GKE.
تستخدم بنيتنا الجديدة المنفصلة Google Cloud Pub/Sub لمعالجة مواد العرض بشكل غير متزامن:
- يفحص المنتج خدمة GCS ويضيف جميع مسارات الملفات إلى قائمة انتظار Pub/Sub.
- يتم توسيع نطاق مجموعة من العاملين في GKE، ما يؤدي إلى سحب المهام بشكل ديناميكي بالتوازي ومعالجتها من خلال Gemini والكتابة إلى BigQuery.
لقد أنشأ النص البرمجي setup.sh بالفعل صور حاويات كلّ من Producer وWorker، وأضاف مواضيع Pub/Sub إلى قائمة الانتظار، وأنشأ بشكل ديناميكي بيانات نشر GKE: job-producer.yaml وjob-worker.yaml.
- طبِّق مهمة Producer لمسح حزمة التخزين ووضع جميع مواد العرض في قائمة الانتظار:
kubectl apply -f job-producer.yaml
يتم تشغيل هذه المهمة وإكمالها بسرعة لأنّها لا تضع سوى البيانات الوصفية في قائمة الانتظار.
- نفِّذ مهمة Worker Job التي تم ضبطها لتشغيل 6 مهام متوازية لإفراغ قائمة الانتظار:
kubectl apply -f job-worker.yaml
سيرصد وضع Autopilot في GKE تلقائيًا وحدات pod المعلقة، وسيزيد حجم عُقد الحوسبة بشكل ديناميكي، وسيشغّل العاملين بالتوازي لمعالجة المقاطع الصوتية والفيديوهات والصور وملفات CSV التي تمت إضافتها إلى قائمة الانتظار.
7. التحقّق من النتائج
- الاطّلاع على حالة مهامك:
kubectl get jobs
انتظِر إلى أن تظهر علامة اكتمال ناجح لكل من petverse-producer-job وpetverse-worker-job.
🕓 سيستغرق ذلك حوالي 10 دقائق. يمكنك الاطّلاع على مستوى التقدّم باستخدام الأوامر أدناه.
- تحقَّق من سجلّات Producer للتأكّد من أنّه أضاف الملفات إلى قائمة الانتظار بنجاح:
cd ~/devrel-demos/codelabs/gke-knowledge-graph
source scripts/setenv.sh
kubectl logs -l app=petverse-producer --tail=50
- شاهِد العاملين المتوازيين وهم يعالجون الملفات من قائمة الانتظار:
kubectl logs -l app=petverse-worker --tail=50
(تتضمّن ميزة المنفِّذين مهلة عدم نشاط مدتها 60 ثانية، وسيتم إيقافها وتنظيفها تلقائيًا عندما يكون صف Pub/Sub فارغًا).
تحقَّق من البيانات في BigQuery.
- انتقِل إلى BigQuery Studio. سيظهر لك جدولان تم إنشاؤهما: petverse_kg.Nodes وpetverse_kg.Edges.
- للاطّلاع على محتوى الجداول، انقر مرّتين على أسمائها ثم انقر على معاينة.
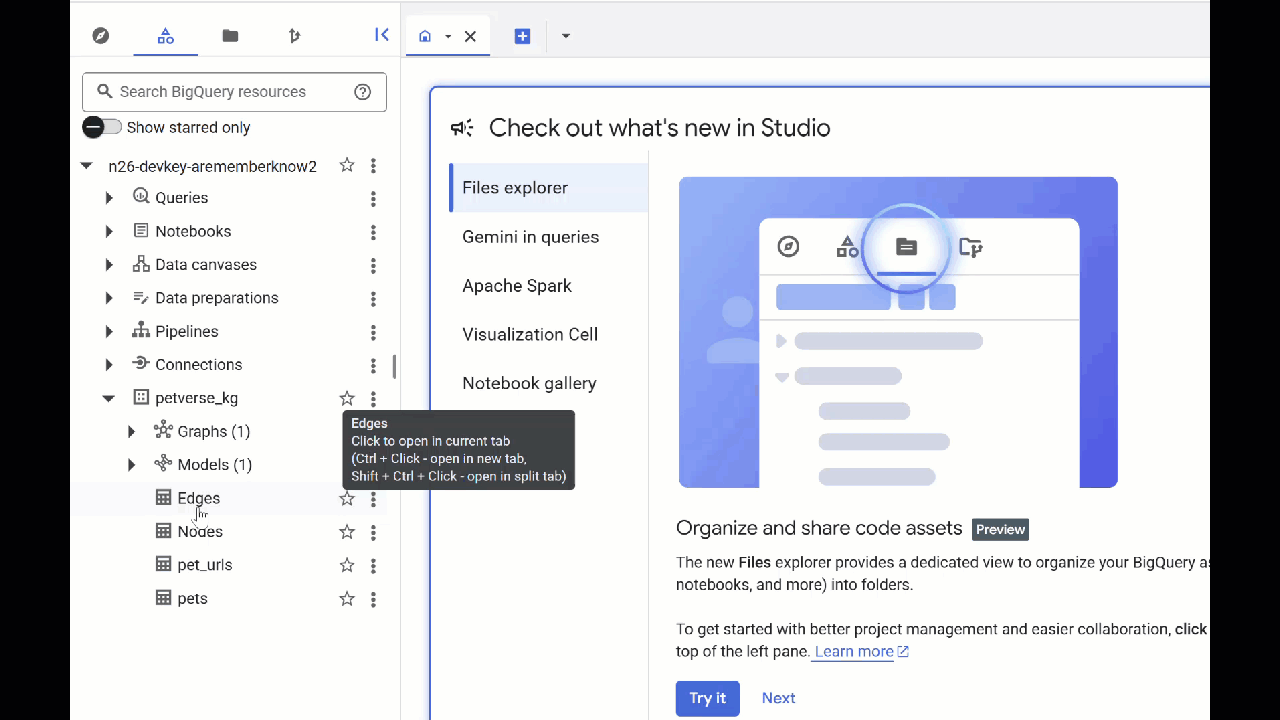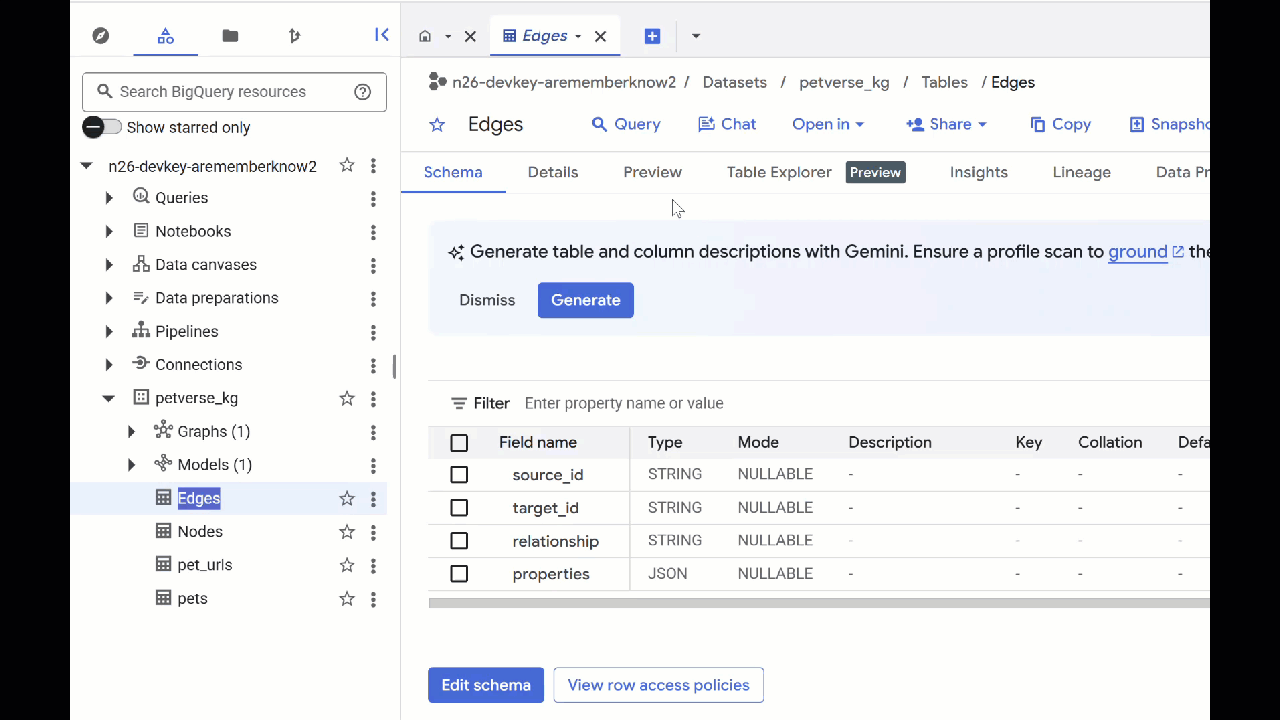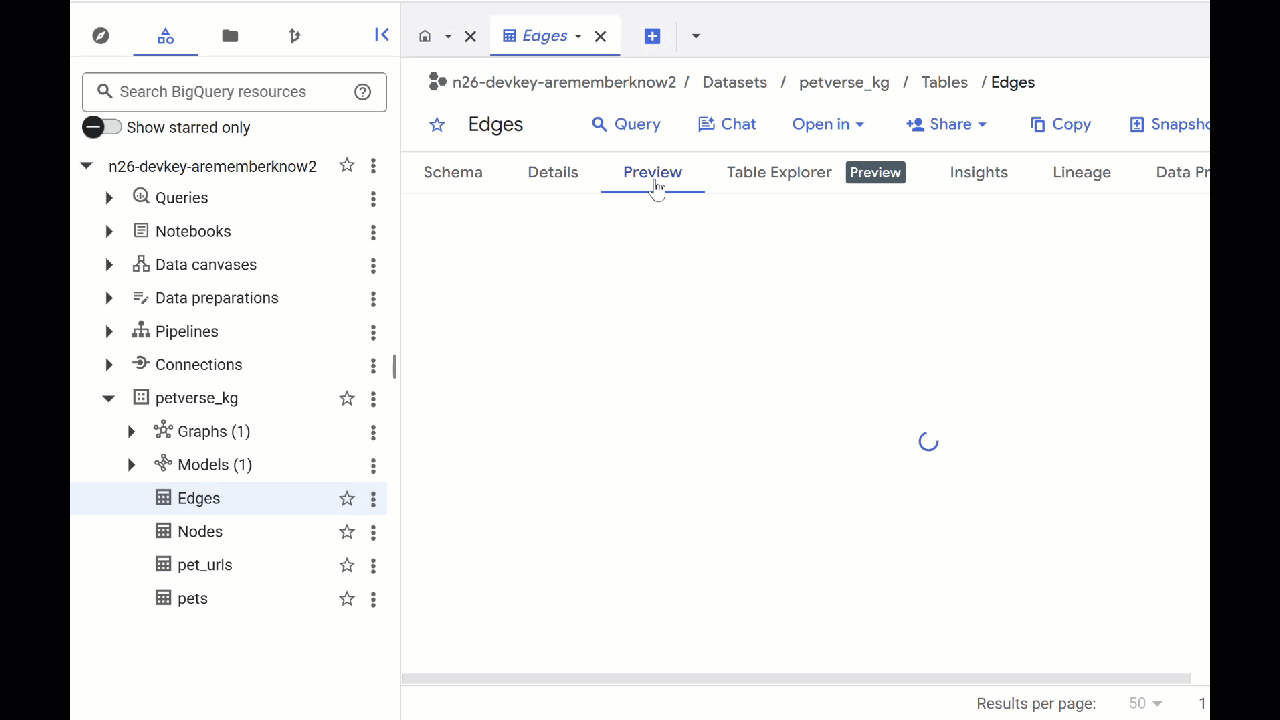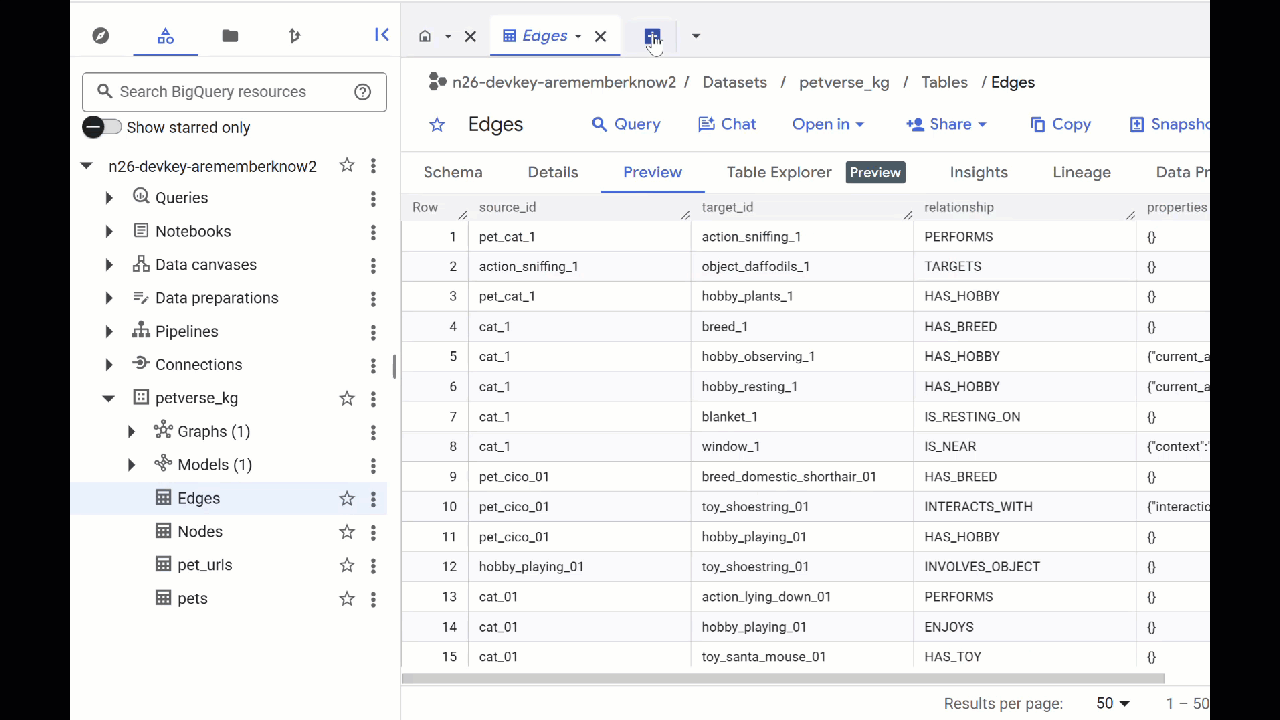
ستلاحظ أنّ جدول "العُقد" يتضمّن معلومات حول الكيانات التي رصدتها Gemini في المقاطع الصوتية والفيديوهات والصور. يحتوي جدول "الحواف" على العلاقات بينها. على سبيل المثال، إذا استمعت إلى مقطع صوتي عن قط اسمه SQL، ستعرف أنّه يحب اللعب بأربطة الأحذية ويستمتع بتناول السمك المجفف.
- استخدِم الزر + لإنشاء طلب بحث جديد. ألصِق العبارة التالية وانقر على تنفيذ:
SELECT n.name, n.entity_id, e.relationship, e.target_id
FROM
`petverse_kg.Nodes` n
JOIN
`petverse_kg.Edges` e
ON n.entity_id = e.source_id
WHERE n.name = 'SQL'
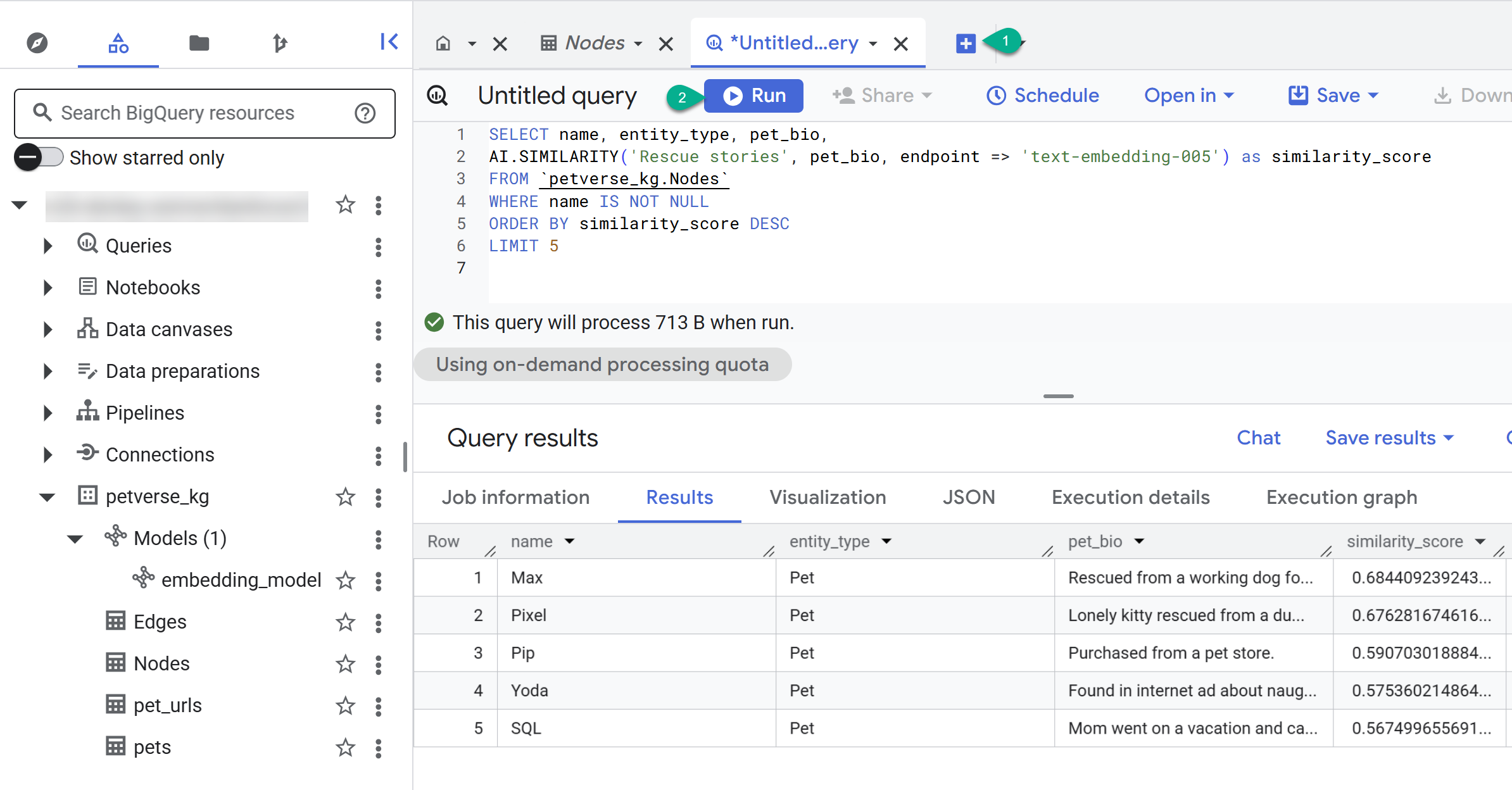
- استخدِم الزر + لإنشاء طلب بحث جديد. ألصِق العبارة التالية وانقر على تنفيذ:
SELECT name, entity_type, pet_bio,
AI.SIMILARITY('Pets who like to relax', pet_bio, endpoint => 'text-embedding-005') as similarity_score
FROM `petverse_kg.Nodes`
WHERE name IS NOT NULL
ORDER BY similarity_score DESC
LIMIT 5
من المفترض أن تظهر لك عُقد الحيوانات الأليفة التي تحب الاسترخاء. نفّذ طلب البحث هذا بحثًا دلاليًا باستخدام دالة الذكاء الاصطناعي AI.SIMILARITY للعثور على حيوانات أليفة تتشابه سيرها الذاتية مع نص طلب البحث.
إنشاء الرسم البياني للعلاقات
بعد أن أصبح لدينا عُقد وحواف في BigQuery، يمكننا إنشاء "رسم بياني للعلاقات" للاستعلام عن العلاقات بسهولة.
إنشاء الرسم البياني
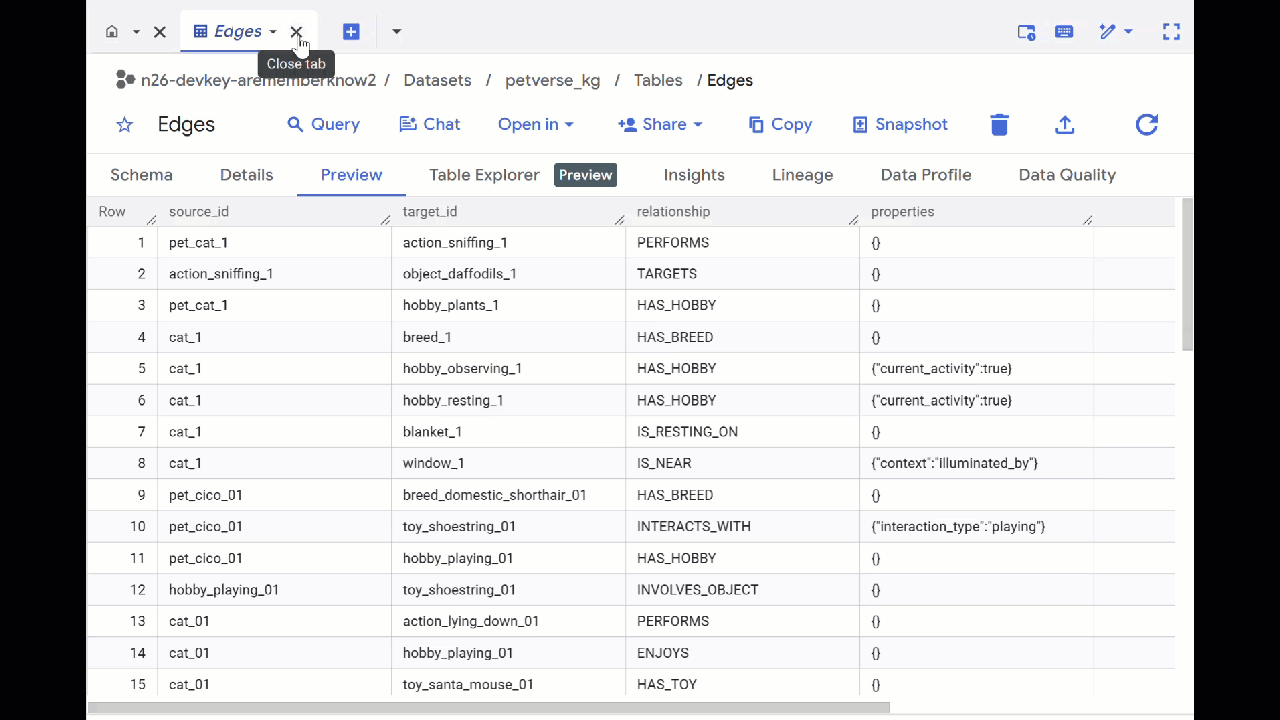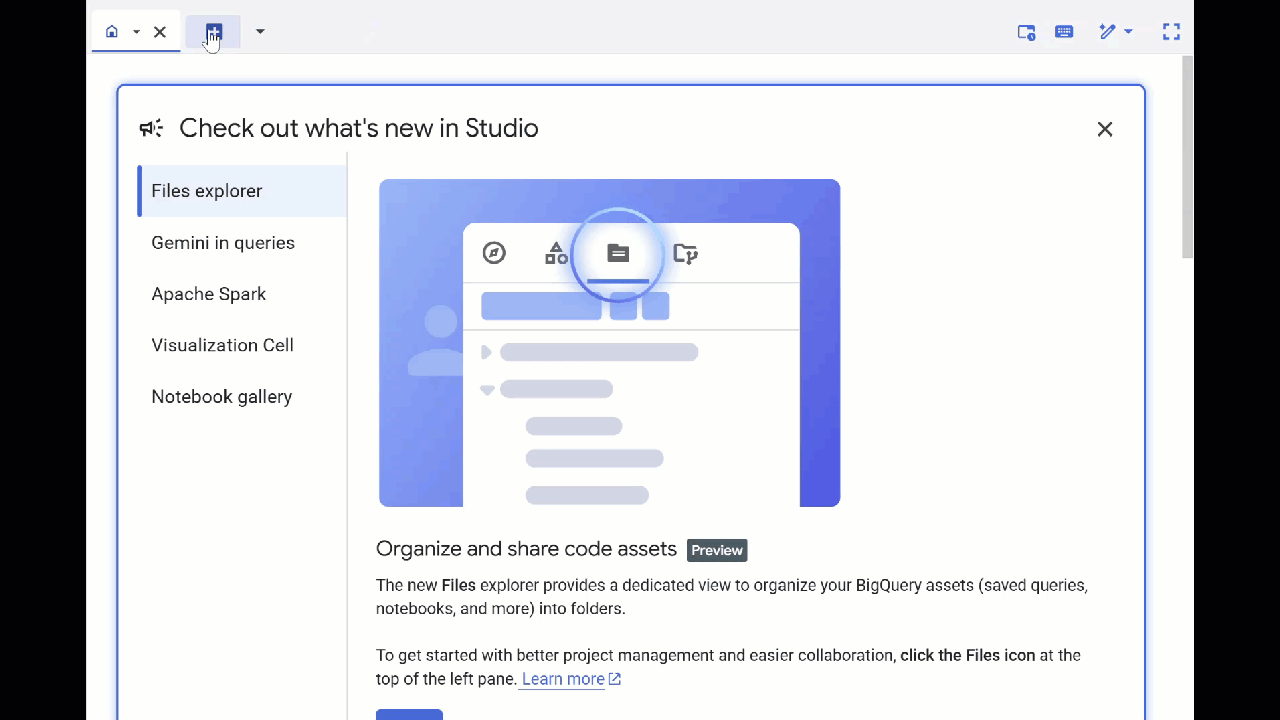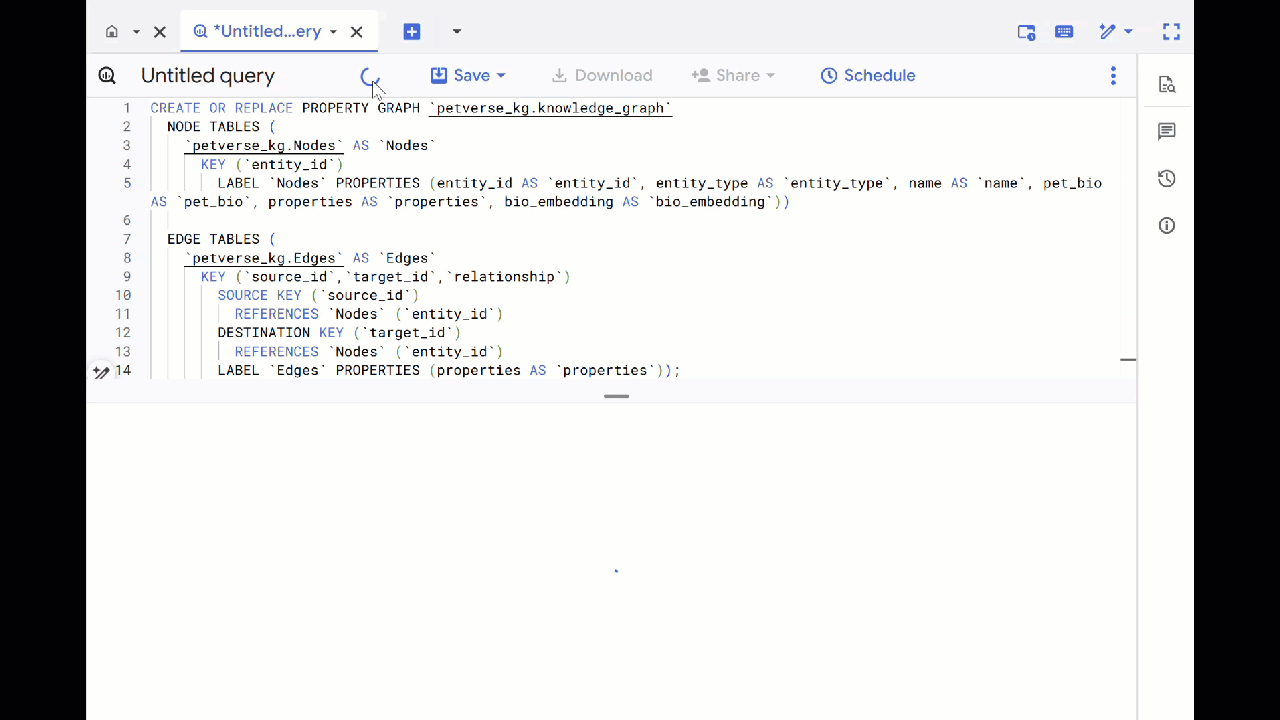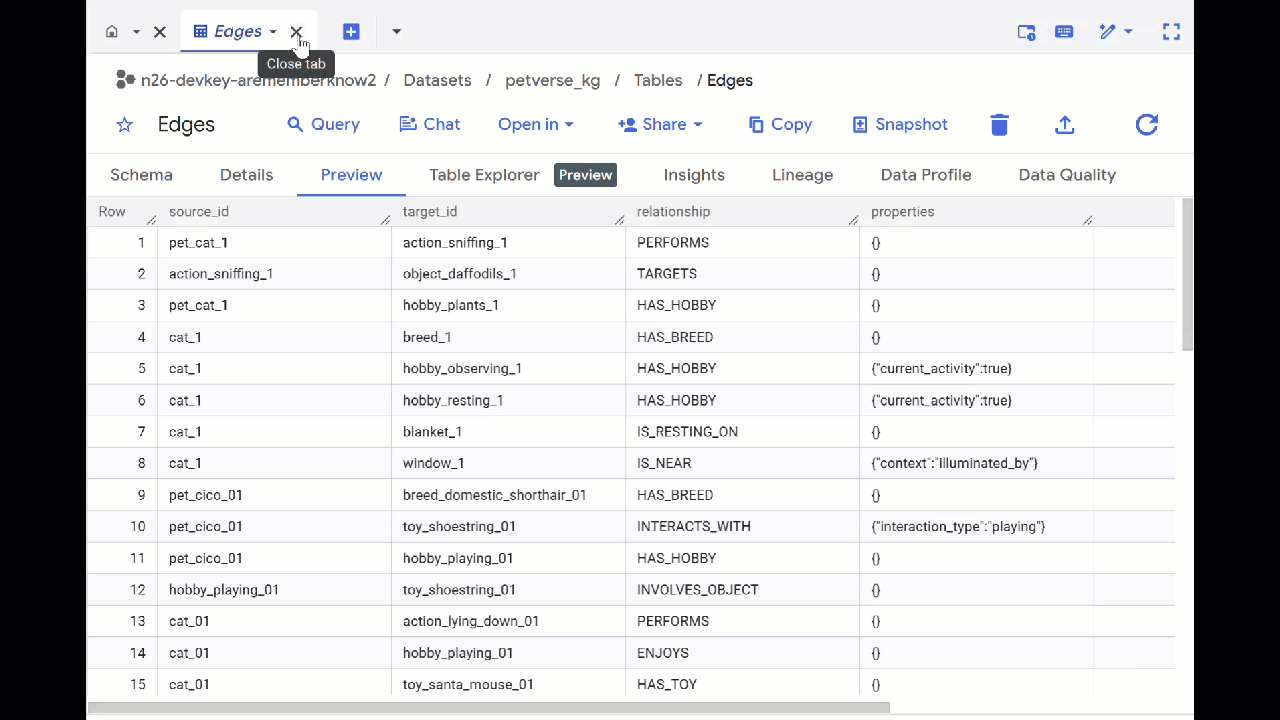
- استبدِل الاستعلام السابق ونفِّذ DDL التالي لإنشاء الرسم البياني للمواقع:
CREATE OR REPLACE PROPERTY GRAPH `petverse_kg.knowledge_graph`
NODE TABLES (
`petverse_kg.Nodes` AS `Nodes`
KEY (`entity_id`)
LABEL `Nodes` PROPERTIES (entity_id AS `entity_id`, entity_type AS `entity_type`, name AS `name`, pet_bio AS `pet_bio`, properties AS `properties`, bio_embedding AS `bio_embedding`))
EDGE TABLES (
`petverse_kg.Edges` AS `Edges`
KEY (`source_id`,`target_id`,`relationship`)
SOURCE KEY (`source_id`)
REFERENCES `Nodes` (`entity_id`)
DESTINATION KEY (`target_id`)
REFERENCES `Nodes` (`entity_id`)
LABEL `Edges` PROPERTIES (properties AS `properties`));
- انقر على الانتقال إلى الرسم البياني. سيظهر لك تصور الرسم البياني مع عقدة لها حافة خاصة بها. هذا مُتوقع.
طلب البحث في الرسم البياني
- يمكنك إغلاق جميع طلبات البحث السابقة وفتح طلب بحث جديد فارغ باستخدام الزر +.
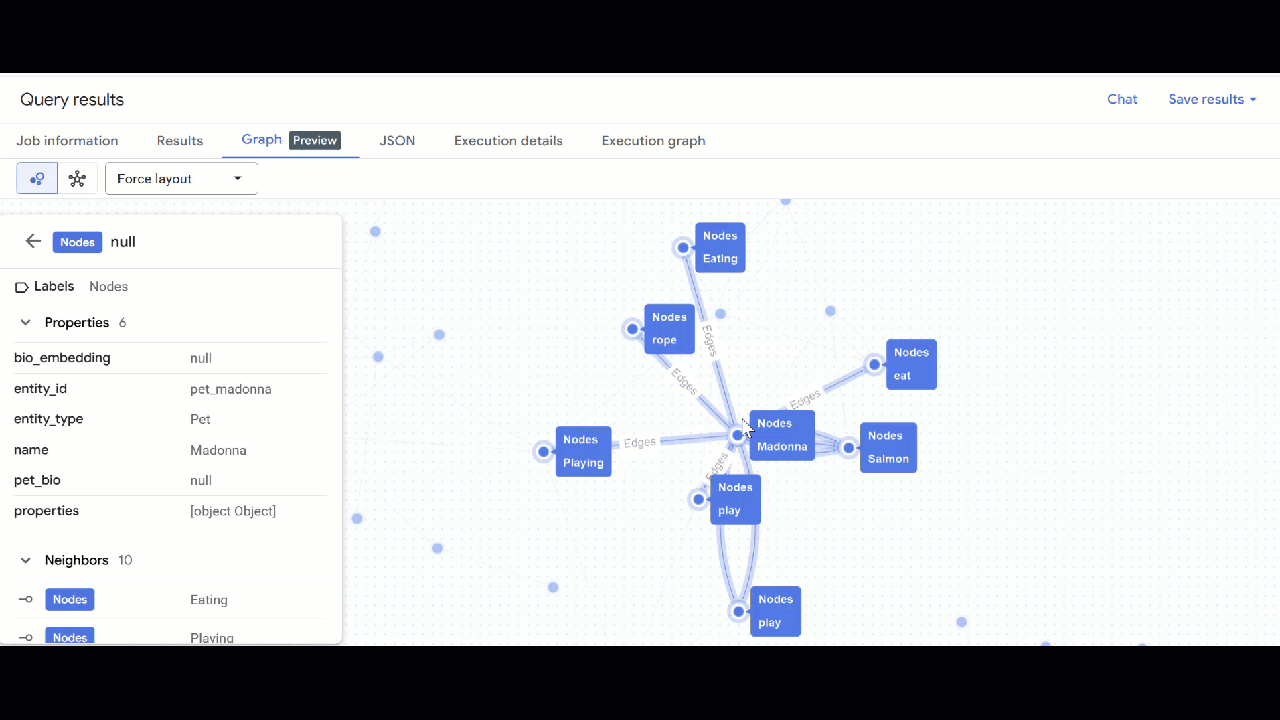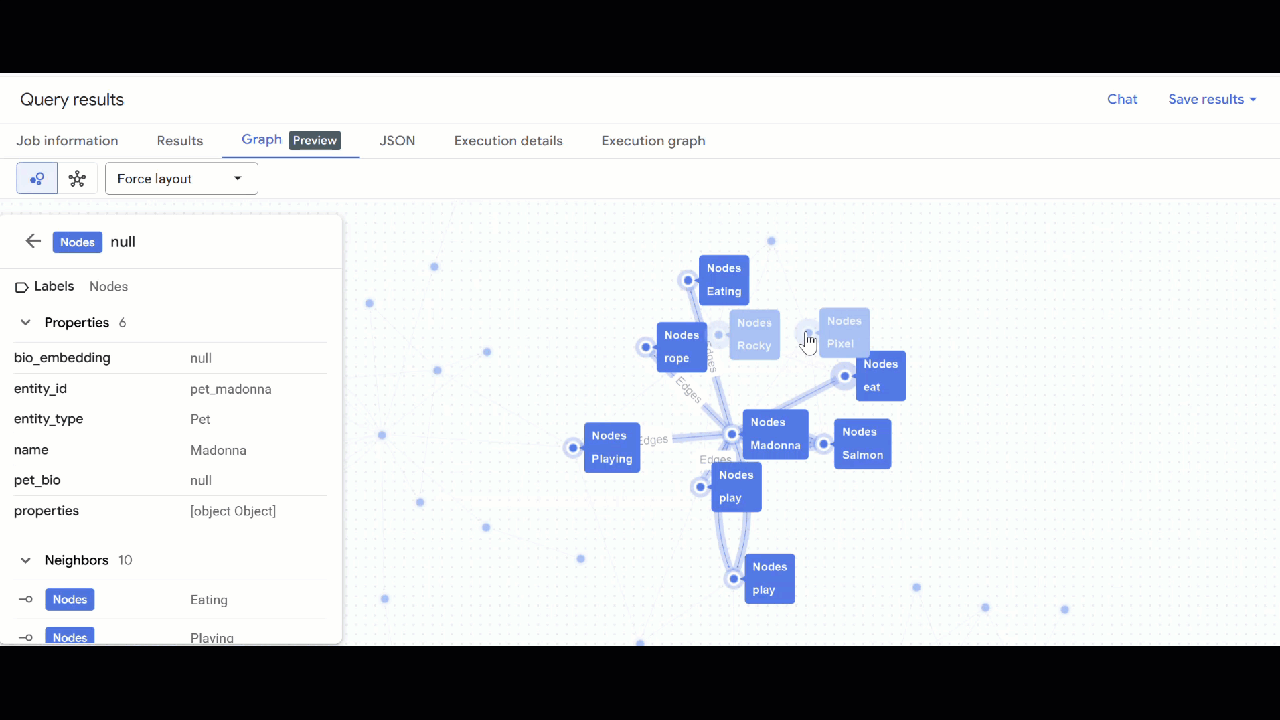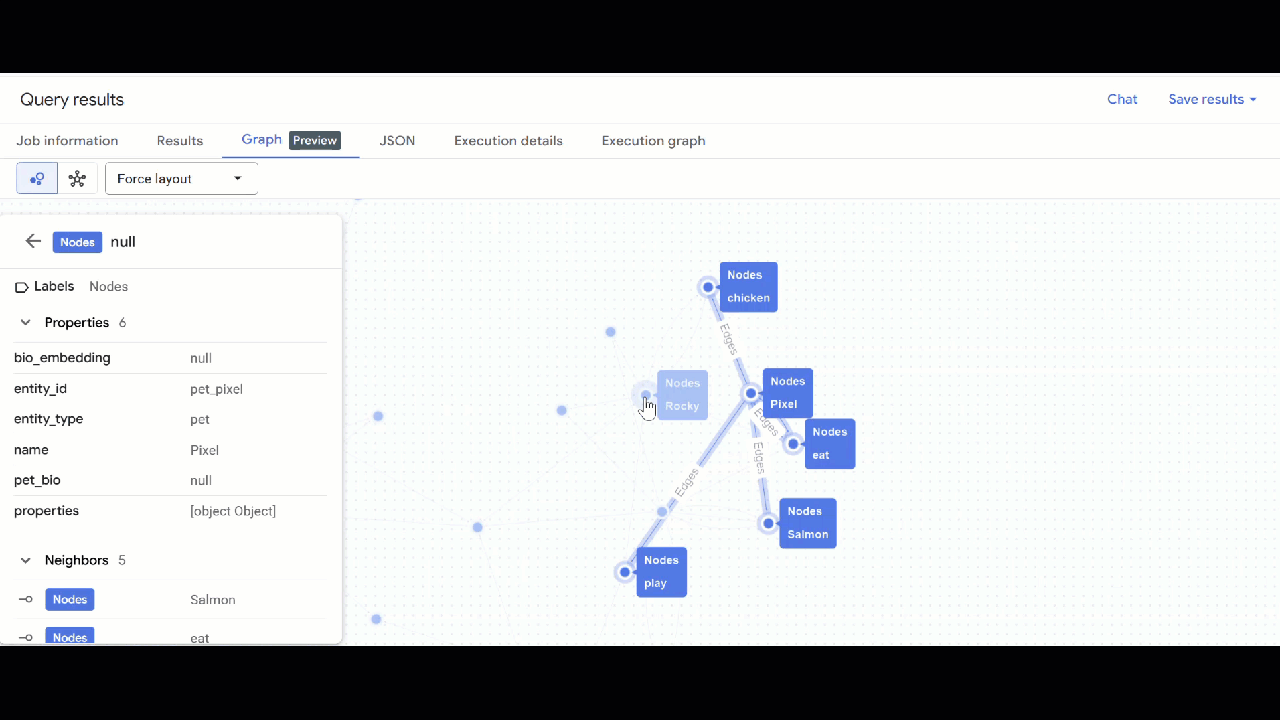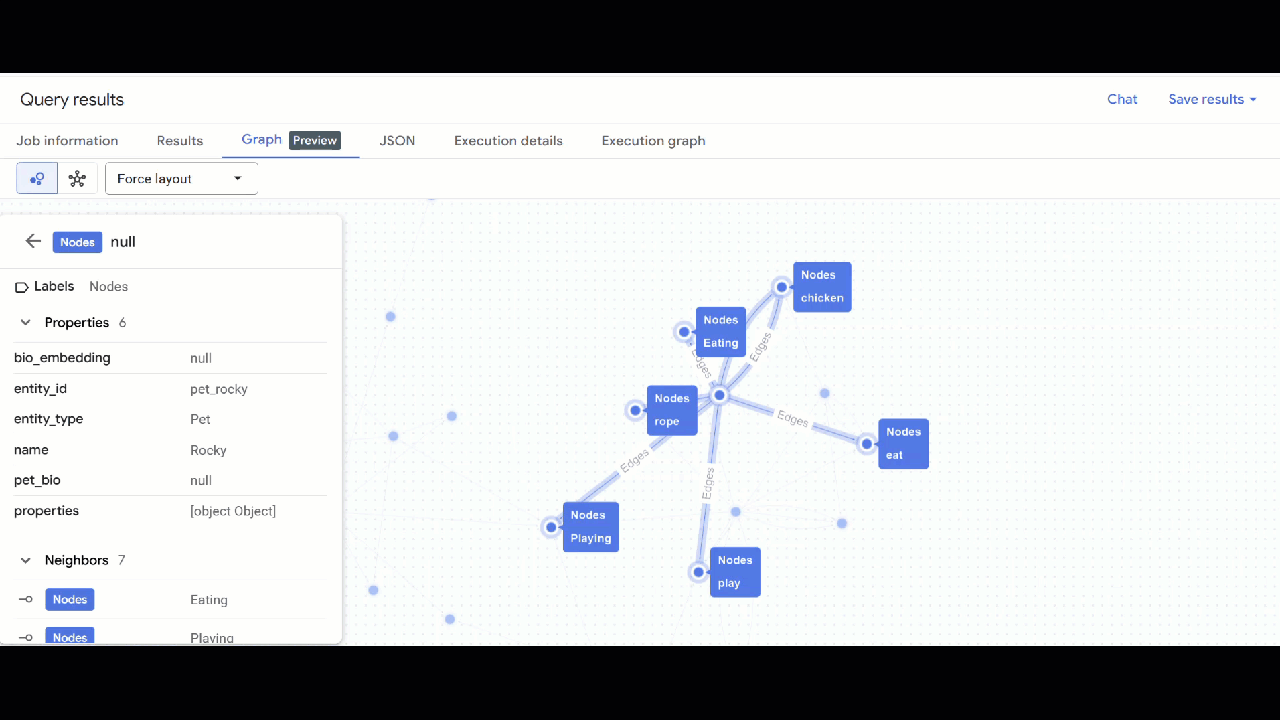
- استخدِم GQL للعثور على حيوانات أليفة مرتبطة بحيوانات أليفة أخرى من خلال الاهتمامات المشتركة (مثل الهوايات أو الأطعمة أو الألعاب المفضّلة). يتطابق طلب البحث المتعدد الخطوات هذا مع حيوانَين أليفَين مختلفَين مرتبطَين بالعقدة نفسها:
GRAPH `petverse_kg.knowledge_graph`
MATCH p = (pet1:Nodes)-[e1]->(interest:Nodes)<-[e2]-(pet2:Nodes)
WHERE pet1.entity_id != pet2.entity_id
AND (LOWER(pet1.entity_type) = 'pet' AND LOWER(pet2.entity_type) = 'pet')
AND LOWER(interest.entity_type) IN ('hobby', 'action', 'activity', 'food', 'toy')
RETURN TO_JSON(p) as res
LIMIT 100
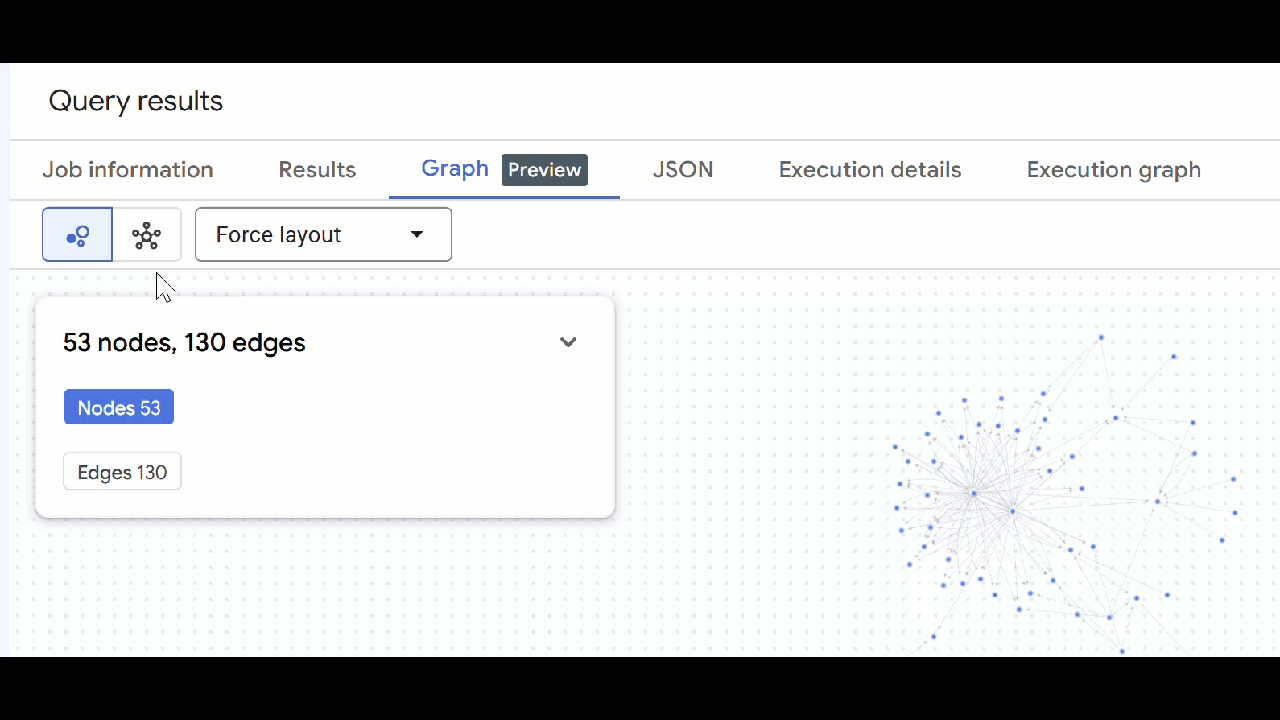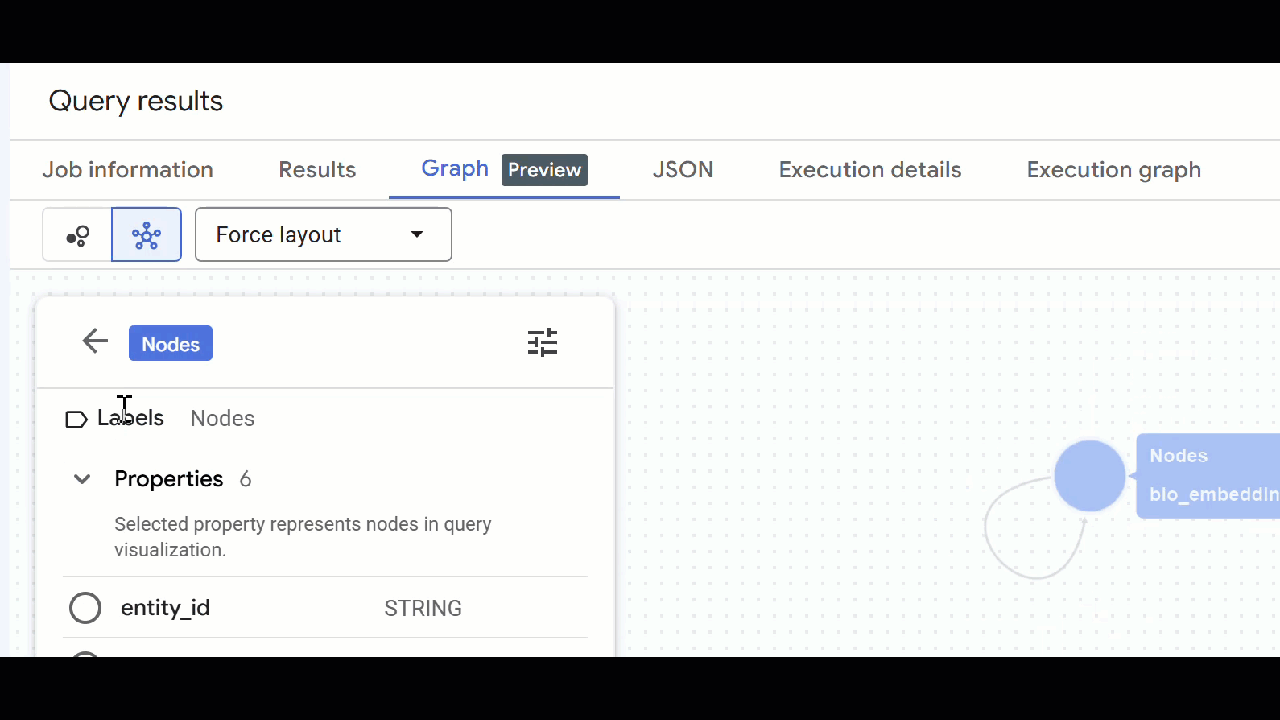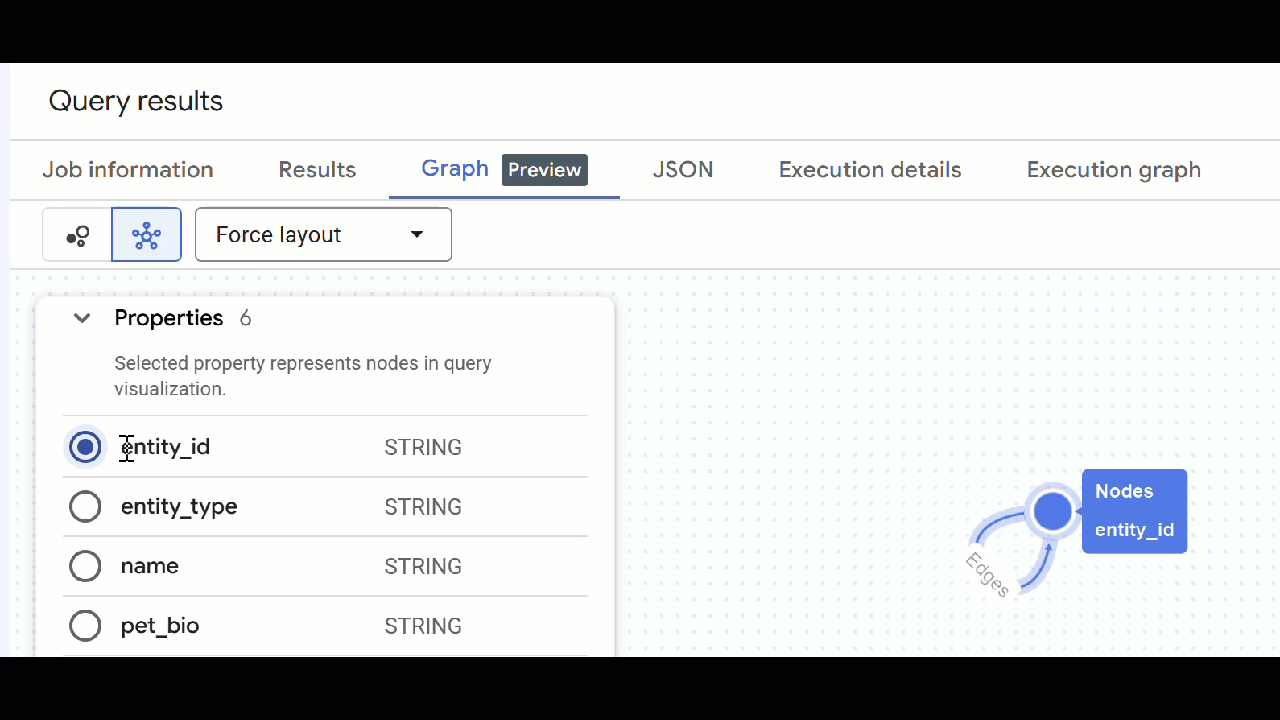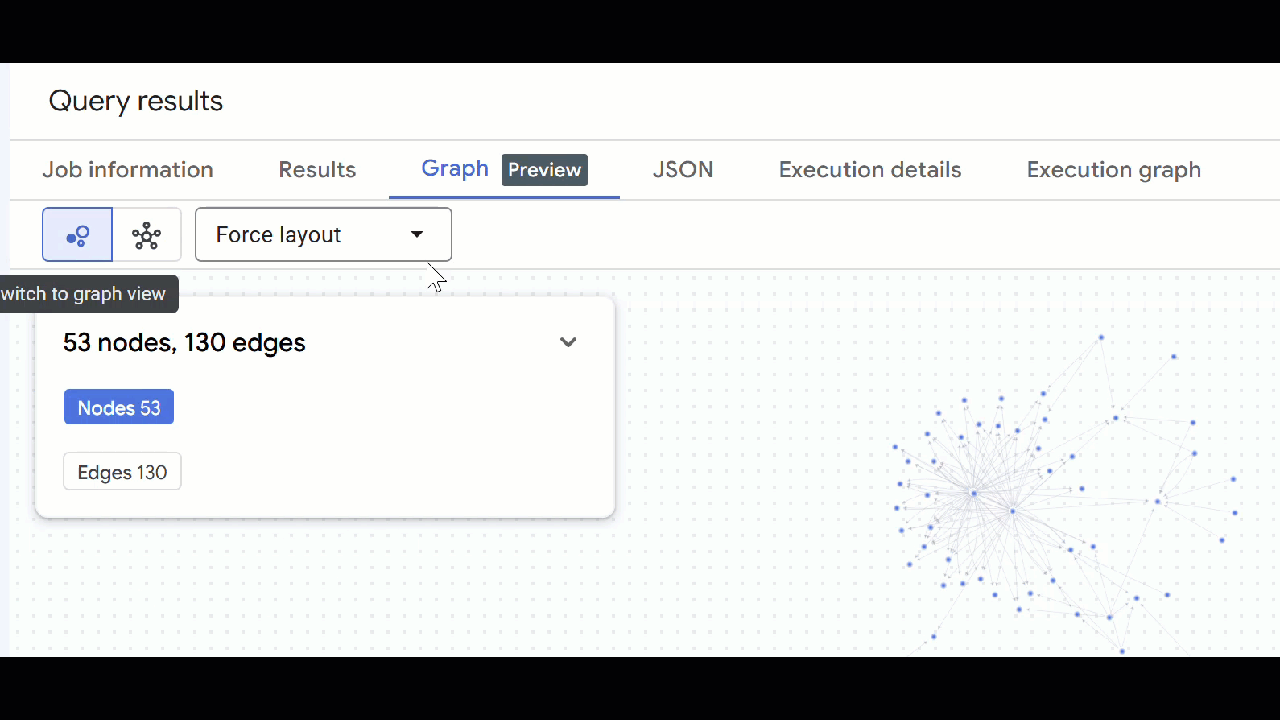
- من المفترض أن تظهر لك المرئيات الخاصة بالرسم البياني. يمكنك النقر على العُقد للاطّلاع على خصائص العُقد والحواف.
🕵️ تلميح: يمكنك تعديل القيمة المعروضة في العقدة من خلال النقر على التبديل إلى طريقة عرض المخطط:
- يمكنك إغلاق جميع علامات تبويب الطلبات المفتوحة.
8. الدردشة مع الرسم البياني
- بجانب علامة +، ستظهر لك قائمة منسدلة. اختَر محادثة.
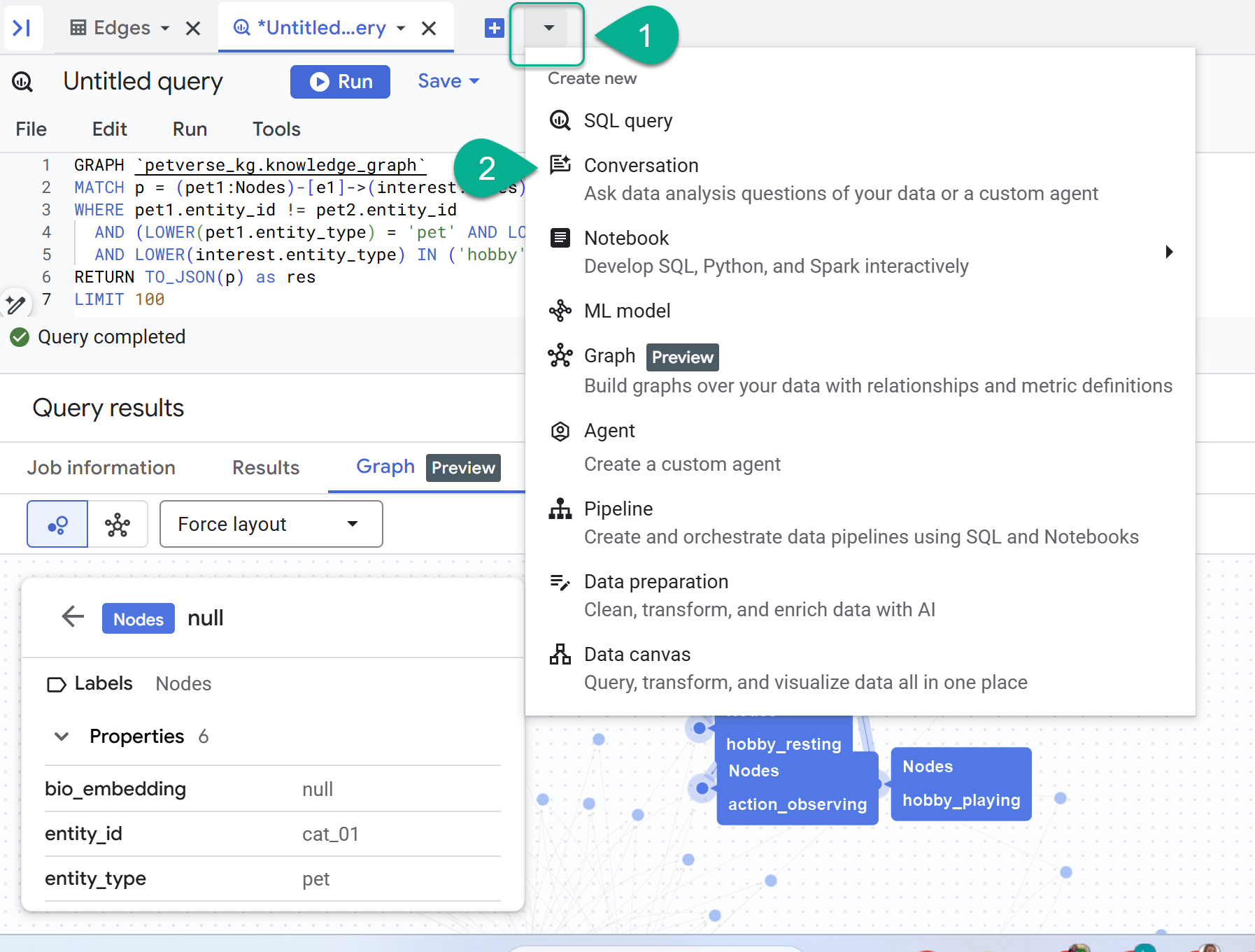
- سيُطلب منك تفعيل واجهة Data Analytics API باستخدام Gemini. فعِّل واجهتَي برمجة التطبيقات. بعد الانتهاء من ذلك، أعِد تحميل النافذة أو أنشئ محادثة جديدة لرؤية الوكيل.
- انقر على موظف دعم جديد.
- أدخِل اسمًا للوكيل، مثل
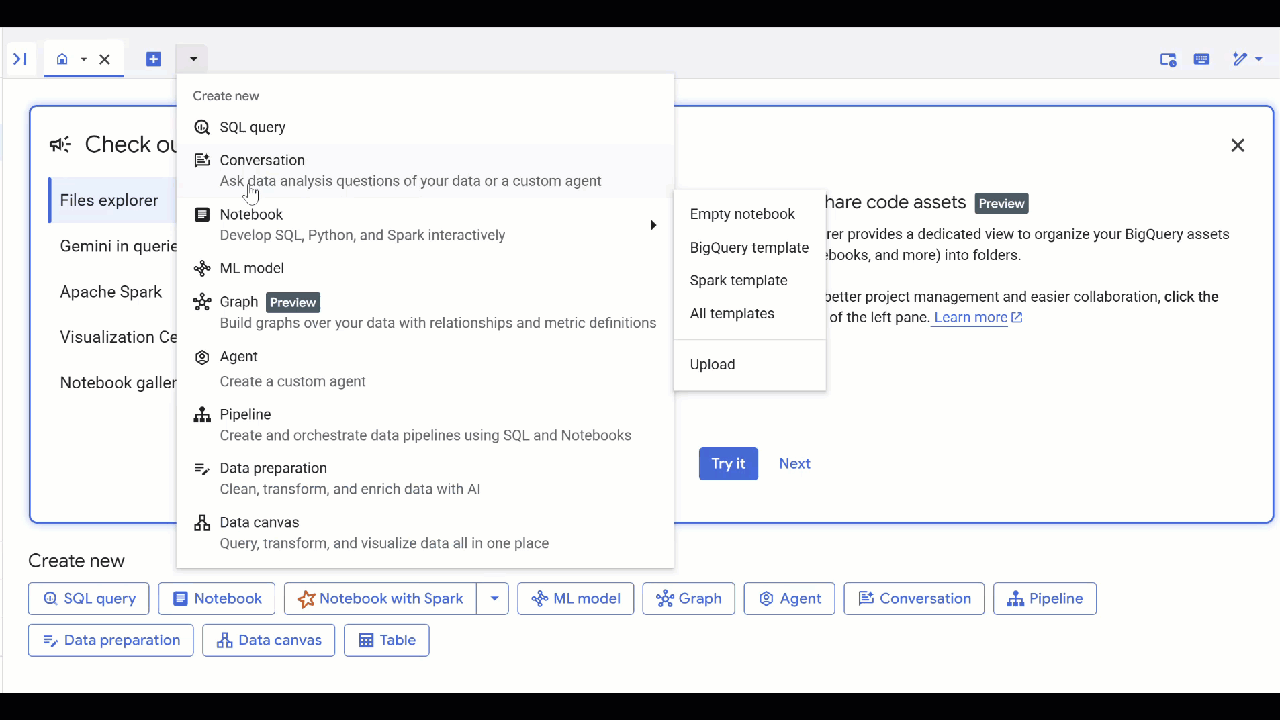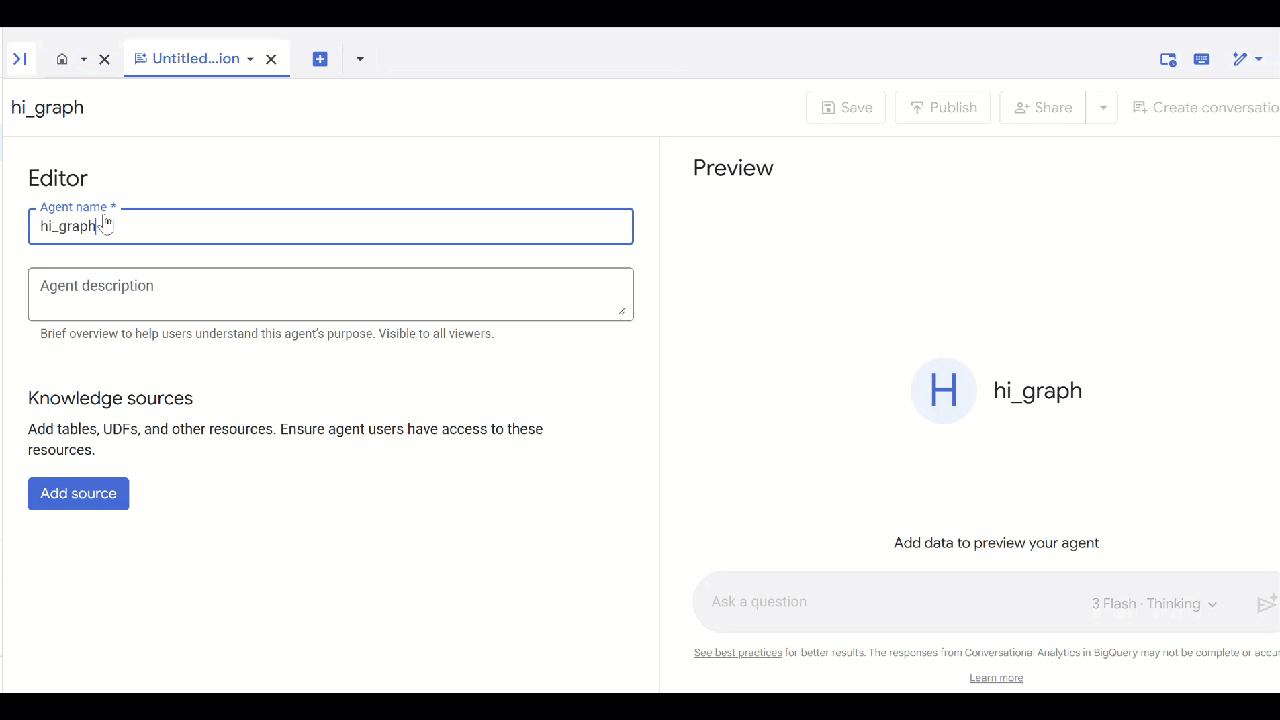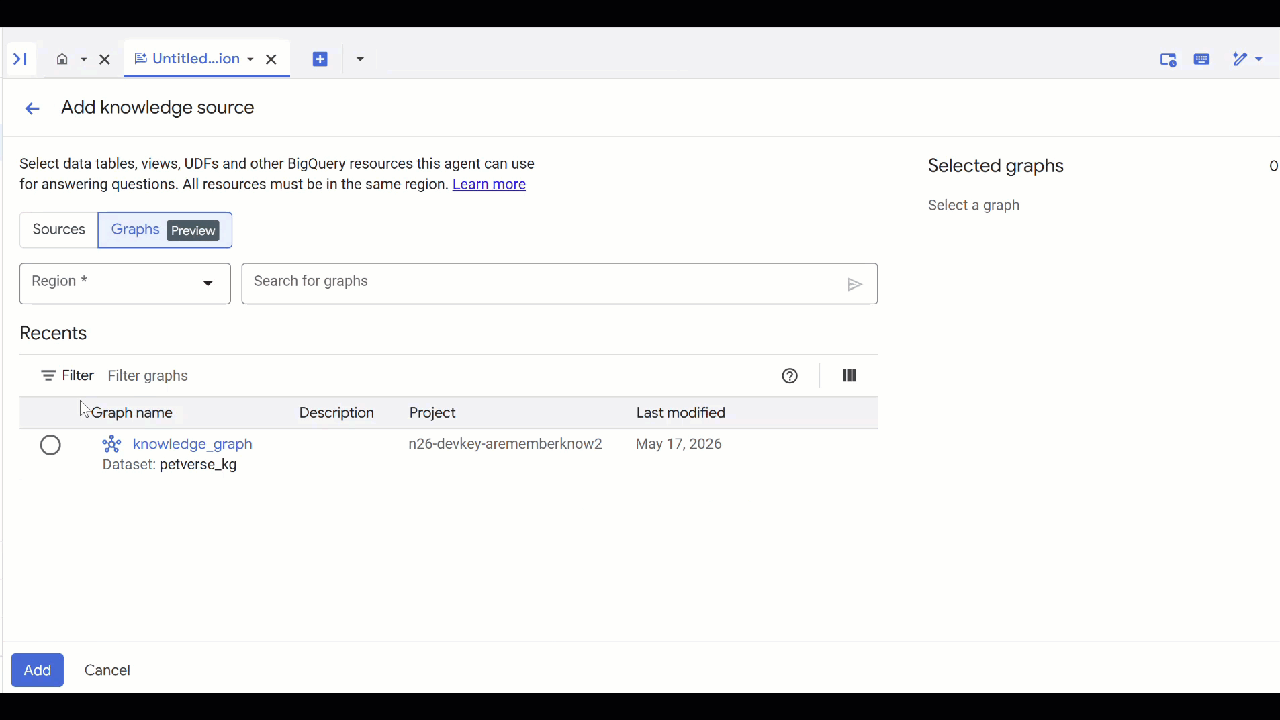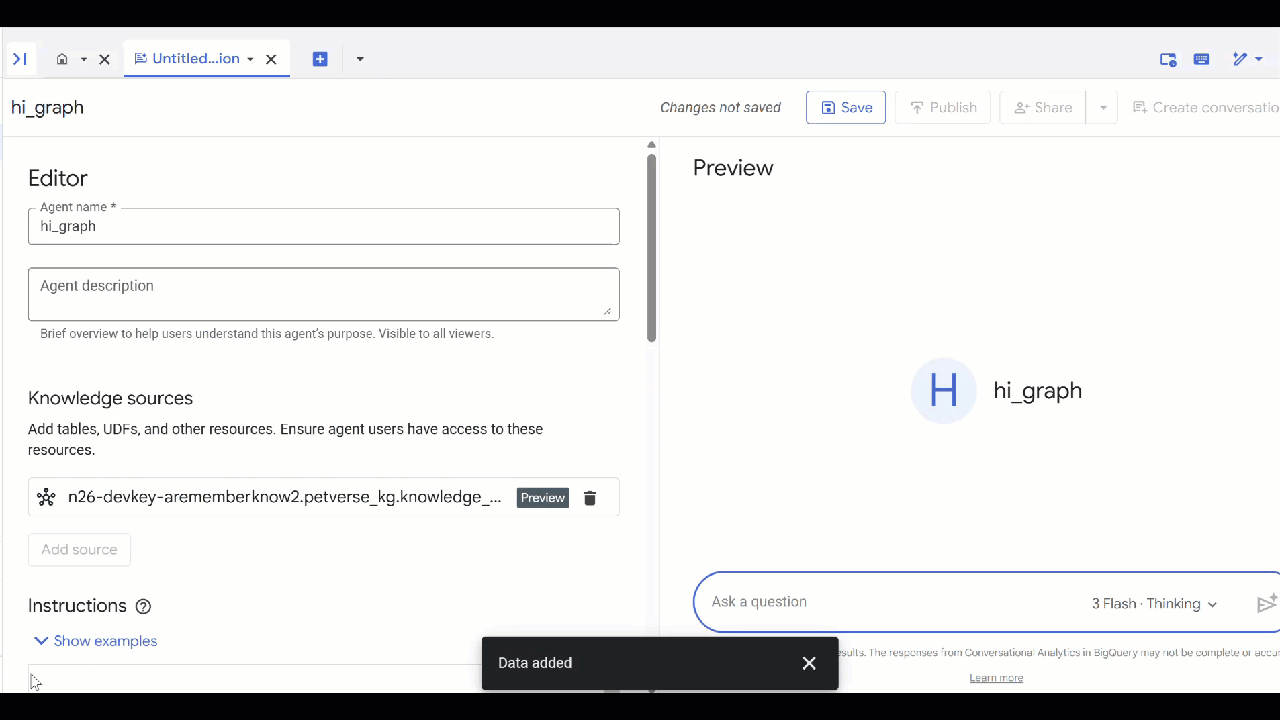
petverse. - انقر على إضافة مصدر ثم على رسم بياني.
- اختَر
knowledge_graphالذي أنشأته وانقر على إضافة.
يمكنك الآن طرح سؤال على الوكيل والاطّلاع على الإجابات والأسباب التي أدّت إلى تقديمها. في ما يلي بعض نماذج الأسئلة إذا كنت بحاجة إلى أفكار. قد يستغرق نموذج التفكير وقتًا أطول قليلاً، ولكن من المرجّح أن ينشئ طلب بحث GQL أفضل. يمكنك الاطّلاع على ما يتم إنشاؤه من خلال توسيع Show Thinking.
- ابحث عن حيوانات أليفة تتشارك الأطعمة نفسها، أو عن حيوانات أليفة صديقة لحيوانات أليفة تحب أخذ قيلولة.
- هل تشترك أي حيوانات أليفة في الهواية أو الطعام أو اللعبة المفضّلة نفسها؟ أدرِج الأزواج واهتماماتهم المشتركة.
- ابحث عن حيوانات أليفة من النوع أو السلالة نفسها، ولكن لديها هوايات مختلفة تمامًا.
9- تَنظيم
لتجنُّب الرسوم المستمرة على حسابك على Google Cloud، احذف الموارد التي تم إنشاؤها أثناء هذا الدرس العملي.
- احذف مجموعة GKE:
gcloud container clusters delete petverse-cluster --region $REGION --quiet
- احذف مجموعة بيانات BigQuery (سيؤدي ذلك إلى حذف جميع الجداول):
bq rm -r -f -d $PROJECT_ID:petverse_kg
- احذف موارد قائمة انتظار Pub/Sub:
gcloud pubsub subscriptions delete petverse-sub --quiet
gcloud pubsub topics delete petverse-topic --quiet
- احذف مستودع Artifact Registry:
gcloud artifacts repositories delete gke-cats-repo --location=$REGION --quiet
- احذف حزمة GCS الخاصة بالمشروع:
gcloud storage buckets delete gs://$PROJECT_ID-petverse --quiet
10. تهانينا
تهانينا! لقد أنشأت بنجاح مسارًا لمعالجة الرسم البياني المعرفي الموزّع باستخدام GKE وGemini، وأجريت طلب بحث فيه باستخدام "الرسومات البيانية للعلاقات" في BigQuery.
ما تعلّمته
- كيفية نشر المهام الموزّعة على GKE Autopilot
- كيفية استخدام Gemini لاستخراج البيانات المتعددة الوسائط
- كيفية استخدام ميزة التضمينات التلقائية في BigQuery
- كيفية إنشاء رسومات بيانية للمواقع وإجراء طلبات بحث فيها في BigQuery