
১. ভূমিকা
এই কোডল্যাবে, আপনি "পেটভার্স"-এর জন্য একটি ডিস্ট্রিবিউটেড নলেজ অ্যাকুইজিশন পাইপলাইন তৈরি করবেন। আপনি একটি ক্লাউড স্টোরেজ বাকেট থেকে আনস্ট্রাকচার্ড মাল্টিমিডিয়া অ্যাসেট (অডিও, ভিডিও, ছবি, টেক্সট/CSV) প্রসেস করবেন, পোষা প্রাণীগুলো সম্পর্কে মূল তথ্য (প্রিয় খাবার, শখ) বের করবেন এবং একটি নলেজ গ্রাফ তৈরি করবেন। আপনি গুগল কুবারনেটিস ইঞ্জিন (GKE)-এ জেমিনি মাল্টি-মোডালিটি প্রসেসিং ব্যবহার করে মাল্টিমিডিয়া ফাইলটির প্রসেসিং স্কেল করবেন। সবশেষে, আপনি এই ডেটা বিগকোয়েরিতে সংরক্ষণ করবেন এবং সম্পর্কগুলো বিশ্লেষণ করার জন্য বিগকোয়েরির নতুন প্রপার্টি গ্রাফ ফিচারটি ব্যবহার করবেন।
আমরা গুগল কুবারনেটিস ইঞ্জিনের শক্তি ব্যবহার করে সমান্তরালভাবে বিপুল পরিমাণ ডেটা প্রক্রিয়াকরণ প্রদর্শন করব।
নলেজ গ্রাফ কেন?
সত্তাগুলোর মধ্যকার জটিল সম্পর্ক উপস্থাপন ও বিশ্লেষণের জন্য প্রচলিত রিলেশনাল ডেটাবেসের চেয়ে নলেজ গ্রাফ বেশি উপযোগী।
আমরা ছবি, অডিও এবং ভিডিও ফাইল বিশ্লেষণ করতে ও বিভিন্ন পোষা প্রাণী সম্পর্কে তথ্য প্রতিষ্ঠা করতে জেমিনি ২.৫ ফ্ল্যাশ ব্যবহার করব।
আপনি যা করবেন
- GKE- তে একটি ডিস্ট্রিবিউটেড ডেটা প্রসেসিং জব তৈরি ও ডেপ্লয় করুন।
- মাল্টিমিডিয়া ফাইল থেকে সত্তা ও সম্পর্ক বের করতে জেমিনি ব্যবহার করুন।
- নলেজ গ্রাফের ডেটা BigQuery- তে সংরক্ষণ করুন।
- গ্রাফ কোয়েরি ল্যাঙ্গুয়েজ (GQL) ব্যবহার করে BigQuery-তে একটি প্রপার্টি গ্রাফ তৈরি করুন এবং তাতে কোয়েরি চালান।
আপনার যা যা লাগবে
- ক্রোমের মতো একটি ওয়েব ব্রাউজার
- বিলিং সক্ষম একটি গুগল ক্লাউড প্রজেক্ট
- প্রকল্পে রিসোর্স তৈরি এবং IAM নীতি পরিবর্তন করার অনুমতি।
এই কোডল্যাবটি নতুনদের সহ সকল স্তরের ডেভেলপারদের জন্য।
আনুমানিক সময়কাল: ৪৫ মিনিট
খরচ: এই কোডল্যাবে তৈরি রিসোর্সগুলোর খরচ $5-এর কম হওয়া উচিত।
২. শুরু করার আগে
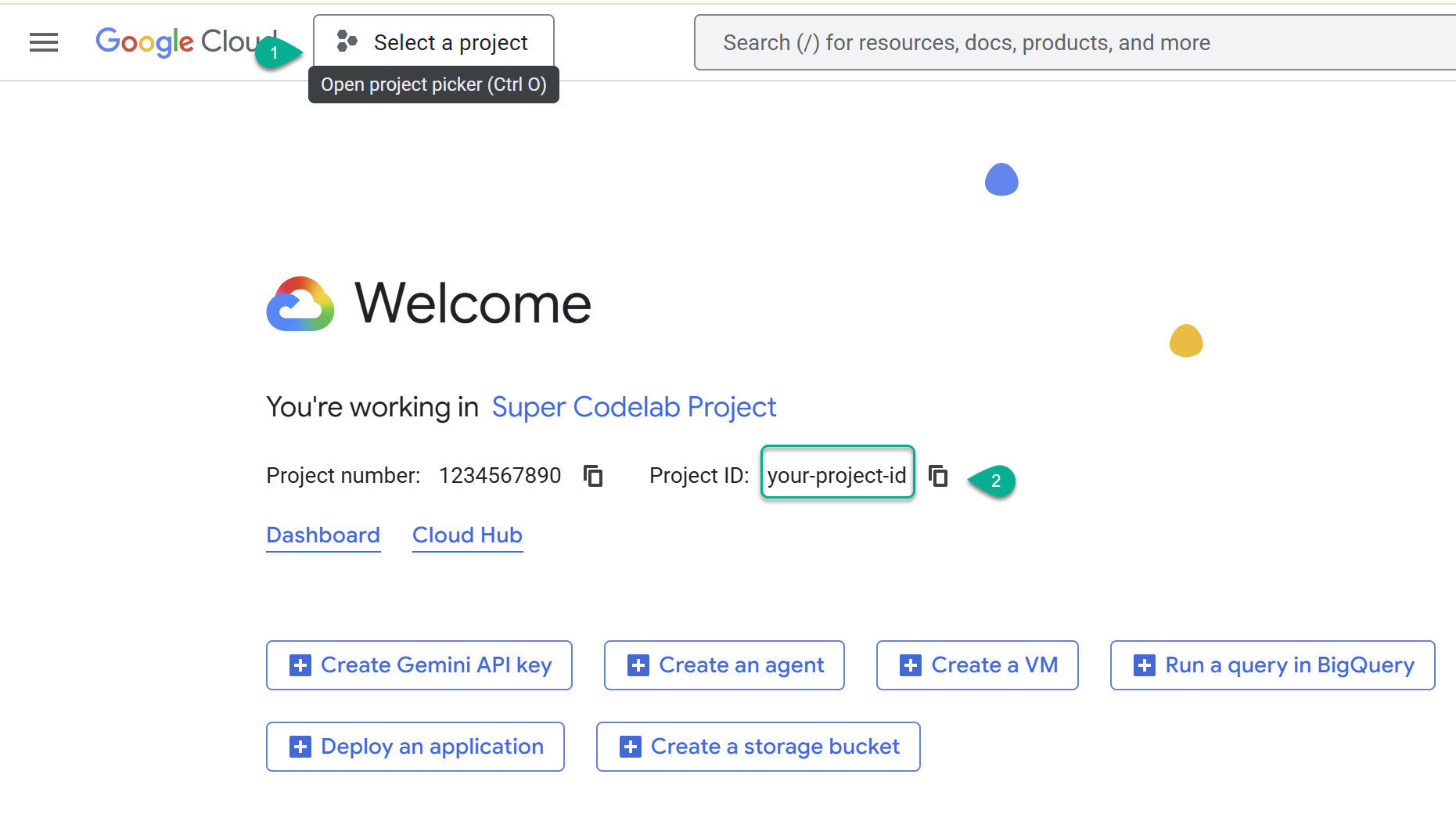
একটি গুগল ক্লাউড প্রজেক্ট তৈরি করুন
- Google Cloud Console-এ যান: https://console.cloud.google.com , এবং তারপর একটি Google Cloud প্রজেক্ট নির্বাচন করুন বা তৈরি করুন ।
- ⚠️ প্রজেক্ট আইডিটি লিখে রাখুন। এই ল্যাবে বিভিন্ন কমান্ডের জন্য এটি ব্যবহার করতে হবে।
ক্লাউড শেল শুরু করুন
- একটি নতুন ট্যাবে ক্লাউড শেল খুলুন : https://shell.cloud.google.com/ ।
- অনুরোধ করা হলে, অনুমোদন করুন-এ ক্লিক করুন।
-
PROJECT_IDপ্রতিস্থাপন করুন এবং নিম্নলিখিত কমান্ডটি টার্মিনালে পেস্ট করুন:
export PROJECT_ID="YOUR_PROJECT_ID"
gcloud config set project $PROJECT_ID
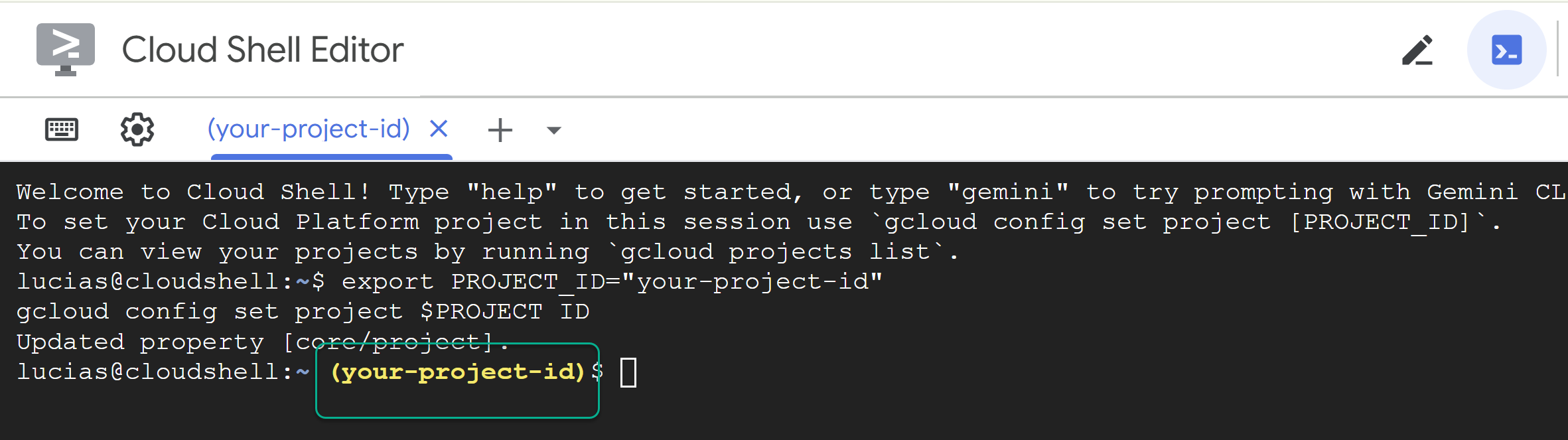
📝 দ্রষ্টব্য: আপনার প্রজেক্টটি কমান্ড লাইনে হলুদ রঙে দেখানো হবে। যদি আপনার সেশনটি রিস্টার্ট হয়, তাহলে প্রজেক্ট আইডি সেট করার জন্য উপরের কমান্ডটি আবার চালান।
এপিআই সক্ষম করুন
প্রয়োজনীয় সকল API সক্রিয় করতে এই কমান্ডটি চালান:
gcloud services enable \
aiplatform.googleapis.com \
bigquery.googleapis.com \
artifactregistry.googleapis.com \
container.googleapis.com \
cloudbuild.googleapis.com \
pubsub.googleapis.com
ক্লোন সংগ্রহস্থল
রিপোজিটরি ক্লোন করতে এই কমান্ডগুলো চালান।
cd ~/
git clone --filter=blob:none --no-checkout https://github.com/GoogleCloudPlatform/devrel-demos.git
cd ~/devrel-demos
git sparse-checkout init --cone
git sparse-checkout set codelabs/gke-knowledge-graph
git checkout main
cd codelabs/gke-knowledge-graph/
সেটআপ স্ক্রিপ্ট চালান
এই স্ক্রিপ্টটি নিম্নলিখিত উপায়ে ব্যাকএন্ড কনফিগারেশন স্বয়ংক্রিয় করে:
- একটি কন্টেইনার ইমেজ এবং একটি আর্টিফ্যাক্ট রেজিস্ট্রি রিপোজিটরি তৈরি করা
- একটি BigQuery ডেটাসেট তৈরি করা
- SQL থেকে Gemini AI ফাংশনগুলো কার্যকর করার জন্য একটি BigQuery সংযোগ তৈরি করা হচ্ছে
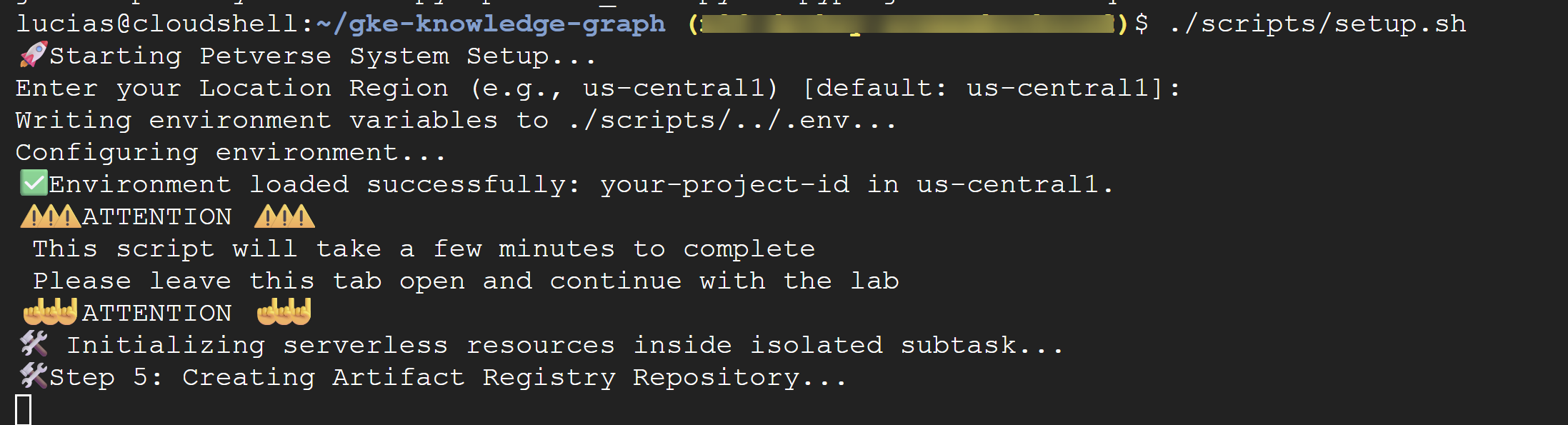
আপনার টার্মিনালে নিম্নলিখিত কমান্ডটি চালান:
./scripts/setup.sh
স্ক্রিপ্টটি যদি আপনার কাছে কনফিগারেশনের বিবরণ জানতে চায়, তাহলে এই মানগুলি ব্যবহার করুন:
- প্রজেক্ট আইডি: পূর্ববর্তী ধাপে তৈরি করা আইডিটি ব্যবহার করুন।
- অঞ্চল:
us-central1
⚠️ গুরুত্বপূর্ণ: স্ক্রিপ্টটি সম্পূর্ণ হতে কয়েক মিনিট সময় লাগবে। ব্যাকগ্রাউন্ডে কাজটি শেষ করার জন্য এই টার্মিনাল উইন্ডোটি খোলা রাখুন। পরবর্তী ধাপে যাওয়ার জন্য, আপনার পরবর্তী কমান্ডগুলো চালানোর জন্য একটি নতুন টার্মিনাল ট্যাব বা উইন্ডো খুলুন।
৩. ডেটা এজেন্ট কিট সেটআপ করুন
- উপরের ডান কোণায় থাকা পেন্সিল আইকনটি ব্যবহার করে ক্লাউড শেল এডিটর চালু করুন।
- ক্লাউড শেল এডিটরে, বাম সাইডবারে থাকা এক্সটেনশন আইকনটিতে ক্লিক করুন।
- Google Cloud Data Agent Kit অনুসন্ধান করুন এবং যদি এটি আগে থেকে ইনস্টল করা না থাকে তবে ইনস্টল-এ ক্লিক করুন।
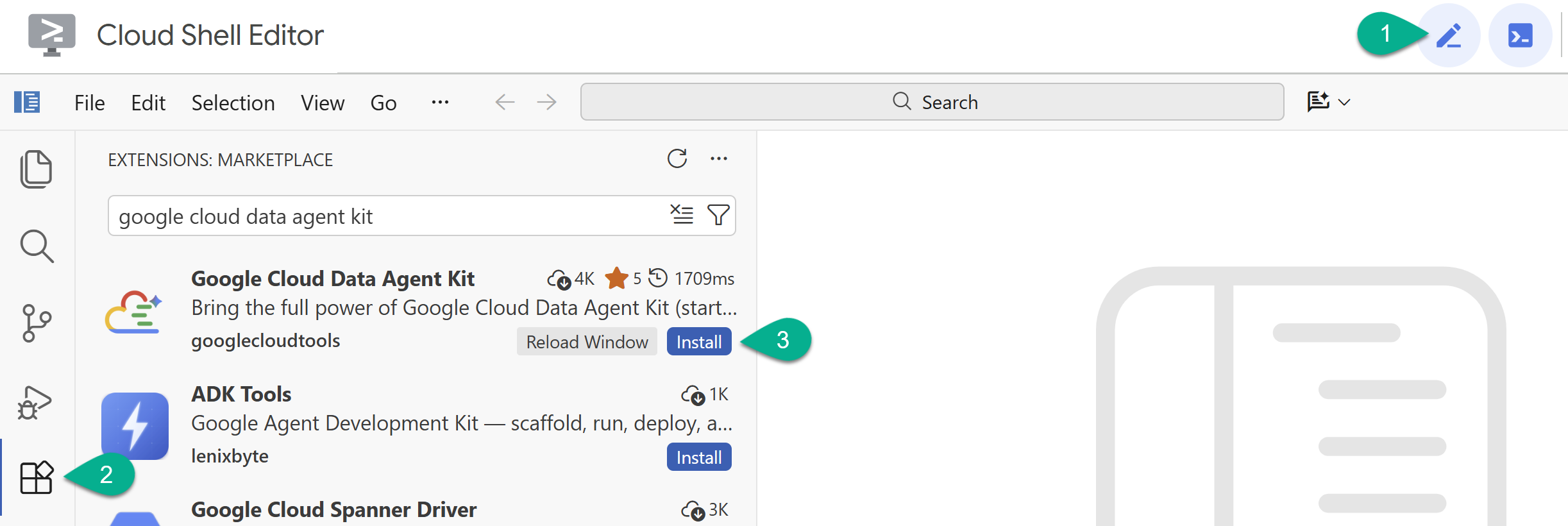
- এক্সটেনশনটি ব্যবহার করে আপনার গুগল অ্যাকাউন্টে সাইন ইন করুন।
- কনফিগারেশন সামারিতে আপনার প্রজেক্ট আইডি এবং অঞ্চল হিসেবে
us-central1লিখুন।
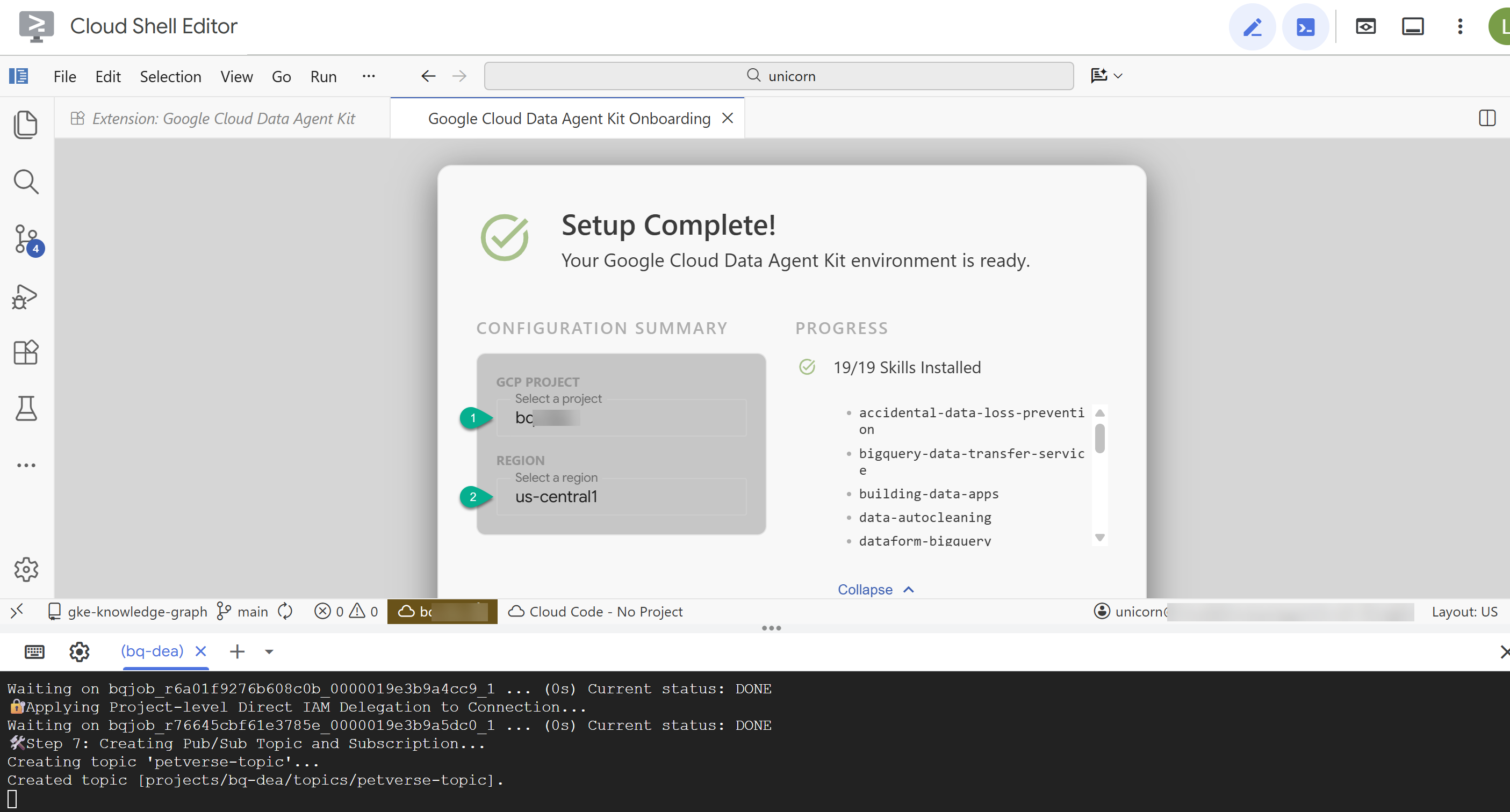
- ‘Configure MCP Servers’-এ ক্লিক করুন। এই উইন্ডোতে কোনো পরিবর্তন করার প্রয়োজন নেই, শুধু ‘Get started’- এ ক্লিক করুন।
- অনুরোধ করা হলে উইন্ডোটি রিলোড করুন। আপাতত কুইক স্টার্ট গাইড ট্যাবটি বন্ধ করতে পারেন।
BigQuery-তে টেবিলগুলো সেটআপ করুন
- সাইড বারে, এক্সপ্লোরারে ফিরে যান। যদি আপনার হোম ফোল্ডার (যেমন,
/home/your_user_name/) আগে থেকে খোলা না থাকে, তাহলে ওপেন ফোল্ডার-এ ক্লিক করে সেটি নির্বাচন করুন।
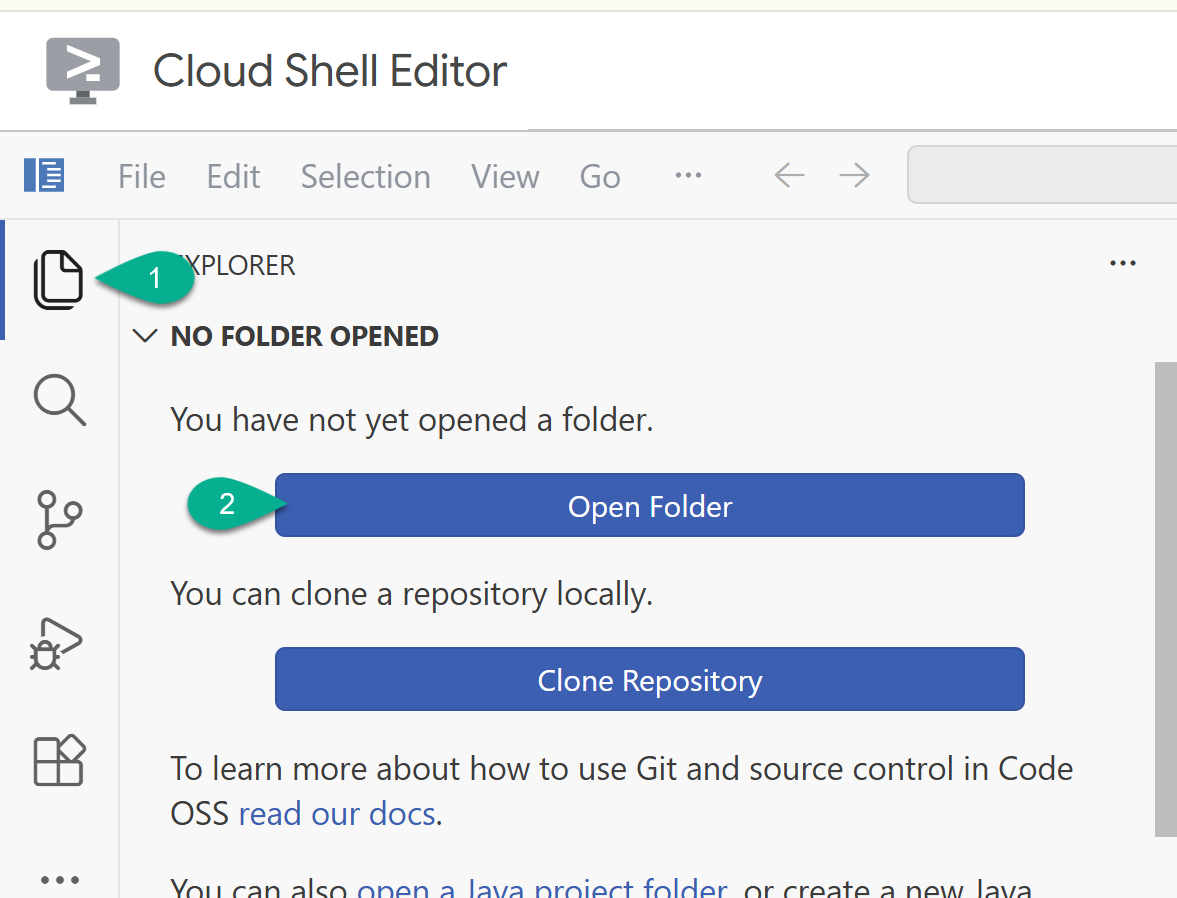
- এক্সপ্লোরার উইন্ডোতে, রিপোজিটরি (
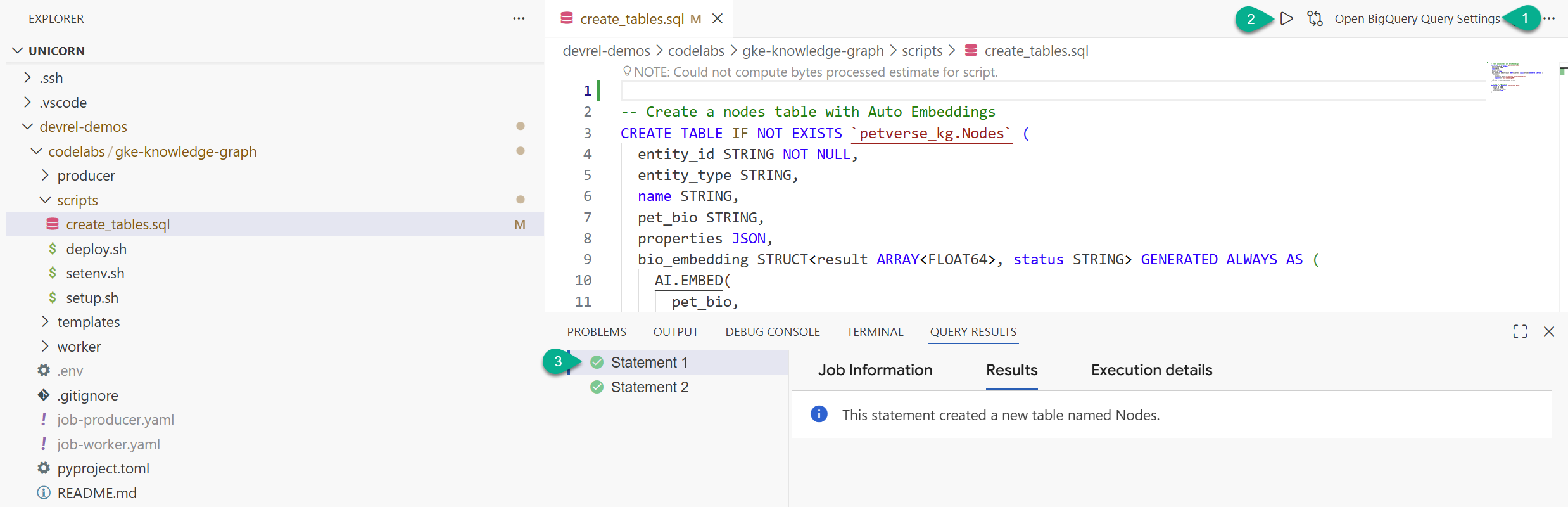
devrel-demos) থেকে ক্লোন করা ফোল্ডারটি খুঁজুন।codelabs/gke-knowledge-graph/scriptsএর অধীনে, আপনিcreate_tables.sqlফাইলটি পাবেন। ফাইলটি খুলুন । - উপরের ডানদিকে, ওপেন কোয়েরি সেটিংস-এ ক্লিক করুন।
- BigQuery নির্বাচন করুন। সংরক্ষণ করুন এবং বন্ধ করুন ।
- রান-এ ক্লিক করুন।
আপনি দেখবেন দুটি স্টেটমেন্ট সফলভাবে সম্পাদিত হয়েছে। আপনি এখন আপনার নলেজ গ্রাফের জন্য নোড এবং এজ সংরক্ষণের টেবিলগুলো তৈরি করে ফেলেছেন।
আপনি create_tables.sql ট্যাব এবং ফলাফল কনসোলটি বন্ধ করতে পারেন।
৪. GKE ক্লাস্টার শুরু করুন
আমরা আমাদের ডেটা প্রসেসিং কাজটি চালানোর জন্য GKE Autopilot ব্যবহার করব। Autopilot ব্যবহার করাই সর্বোত্তম পন্থা, কারণ এটি আপনার হয়ে ক্লাস্টার পরিকাঠামো পরিচালনা করে।
এতক্ষণে সেটআপ স্ক্রিপ্টটি শেষ হয়ে যাওয়ার কথা। আপনি একটি সফলতার বার্তা দেখতে পাবেন: 🎉🦄 Setup successfully finished! 🎉🦄 ।
ক্লাস্টার তৈরি করতে টার্মিনালে এই কমান্ডটি পেস্ট করুন:
source scripts/setenv.sh
gcloud container clusters create-auto petverse-cluster \
--region=$REGION
🕓 এতে প্রায় ৫ মিনিট সময় লাগবে।
ক্লাস্টারের সাথে যোগাযোগ করার জন্য ক্রেডেনশিয়াল সংগ্রহ করুন:
source scripts/setenv.sh
gcloud container clusters get-credentials petverse-cluster --region $REGION
আপনি এই আউটপুটটি দেখতে পাবেন:
Fetching cluster endpoint and auth data. kubeconfig entry generated for petverse-cluster.
৫. ওয়ার্কলোড আইডেন্টিটি কনফিগার করুন
GKE-এর জন্য ওয়ার্কলোড আইডেন্টিটি ফেডারেশন (ডাইরেক্ট রিসোর্স অ্যাক্সেস ব্যবহার করে) আপনার GKE ওয়ার্কলোডগুলিকে সার্ভিস অ্যাকাউন্ট কী পরিচালনা করার প্রয়োজন ছাড়াই নিরাপদে গুগল ক্লাউড পরিষেবাগুলি অ্যাক্সেস করার সুযোগ দেয়।
deploy.sh ফাইলটি চালান:
- একটি Kubernetes পরিষেবা অ্যাকাউন্ট তৈরি করুন
- প্রয়োজনীয় IAM রোলগুলি সরাসরি Kubernetes Service Account প্রিন্সিপালকে প্রদান করুন।
- IAM সার্ভিস অ্যাকাউন্টটিকে Kubernetes সার্ভিস অ্যাকাউন্টের সাথে সংযুক্ত করুন।
- লিঙ্কটি সম্পূর্ণ করতে Kubernetes পরিষেবা অ্যাকাউন্টটি টীকাযুক্ত করুন।
source scripts/setenv.sh
./scripts/deploy.sh
৬. বিচ্ছিন্ন প্রক্রিয়াকরণ কাজগুলি স্থাপন করুন
এই ধাপে, আপনি GKE-তে এনকিউয়ার (প্রডিউসার) এবং প্রসেসিং ইঞ্জিনগুলো (ওয়ার্কার) ডেপ্লয় করবেন।
আমাদের নতুন ডিকাপলড আর্কিটেকচার অ্যাসেটগুলোকে অ্যাসিঙ্ক্রোনাসভাবে প্রসেস করার জন্য গুগল ক্লাউড পাব/সাব ব্যবহার করে:
- প্রডিউসার GCS স্ক্যান করে সমস্ত ফাইল পাথ একটি Pub/Sub কিউতে যুক্ত করে।
- GKE-তে ওয়ার্কারদের একটি পুল ধীরে ধীরে বড় হতে থাকে, যা ডাইনামিকভাবে সমান্তরালভাবে টাস্ক গ্রহণ করে, Gemini-র মাধ্যমে সেগুলোকে প্রসেস করে এবং BigQuery-তে লেখে।
setup.sh স্ক্রিপ্টটি ইতিমধ্যেই Producer এবং Worker উভয় কন্টেইনার ইমেজ বিল্ড করে পুশ করেছে, Pub/Sub টপিকগুলো কিউতে যুক্ত করেছে এবং ডায়নামিকভাবে আপনার GKE ডিপ্লয়মেন্ট ম্যানিফেস্টগুলো— job-producer.yaml ও job-worker.yaml তৈরি করেছে।
- আপনার স্টোরেজ বাকেট স্ক্যান করতে এবং সমস্ত অ্যাসেট কিউতে যুক্ত করতে প্রোডিউসার জবটি প্রয়োগ করুন:
kubectl apply -f job-producer.yaml
এই কাজটি দ্রুত চলে এবং শেষ হয়, কারণ এটি শুধুমাত্র মেটাডেটা সারিবদ্ধ করে রাখে।
- কিউ খালি করার জন্য ৬টি সমান্তরাল ওয়ার্কার চালানোর জন্য কনফিগার করা ওয়ার্কার জবটি ডিপ্লয় করুন:
kubectl apply -f job-worker.yaml
GKE Autopilot স্বয়ংক্রিয়ভাবে অপেক্ষারত পডগুলো শনাক্ত করবে, ডায়নামিকভাবে কম্পিউট নোডগুলোর ক্ষমতা বাড়াবে এবং কিউতে থাকা অডিও, ভিডিও, ছবি ও CSV ফাইলগুলো প্রসেস করার জন্য ওয়ার্কারগুলোকে সমান্তরালভাবে চালাবে।
৭. ফলাফল যাচাই করুন
- আপনার কাজগুলোর অবস্থা যাচাই করুন:
kubectl get jobs
petverse-producer-job এবং petverse-worker-job উভয়ই সফলভাবে সম্পন্ন হওয়া পর্যন্ত অপেক্ষা করুন।
🕓 এতে প্রায় ১০ মিনিট সময় লাগবে। নিচের কমান্ডগুলোর সাহায্যে আপনি এর অগ্রগতি দেখতে পারবেন।
- প্রডিউসার সফলভাবে ফাইলগুলো কিউতে যুক্ত করেছে কিনা তা যাচাই করতে এর লগগুলো পরীক্ষা করুন:
cd ~/devrel-demos/codelabs/gke-knowledge-graph
source scripts/setenv.sh
kubectl logs -l app=petverse-producer --tail=50
- আপনার প্যারালাল ওয়ার্কারদের কিউ থেকে ফাইল প্রসেস করতে দেখুন:
kubectl logs -l app=petverse-worker --tail=50
(ওয়ার্কারগুলোর একটি ৬০-সেকেন্ডের নিষ্ক্রিয়তার সময়সীমা রয়েছে এবং পাব/সাব কিউ খালি হয়ে গেলে এগুলো স্বয়ংক্রিয়ভাবে বন্ধ হয়ে পরিষ্কার-পরিচ্ছন্নতার কাজ সম্পন্ন করবে)।
BigQuery-তে ডেটা যাচাই করুন।
- BigQuery Studio- তে যান। আপনি petverse_kg.Nodes এবং petverse_kg.Edges নামে দুটি টেবিল তৈরি হতে দেখবেন।
- টেবিলগুলোর বিষয়বস্তু দেখতে, সেগুলোর নামের উপর ডাবল-ক্লিক করুন এবং তারপর প্রিভিউ-তে ক্লিক করুন।
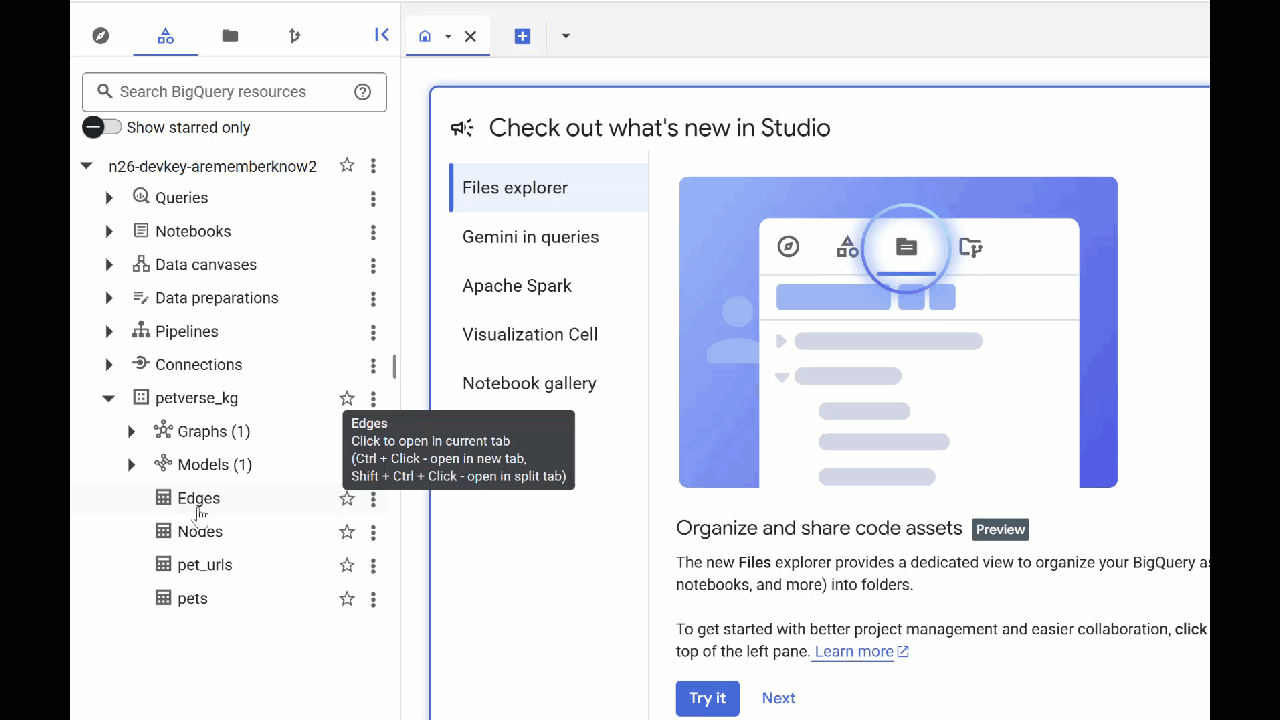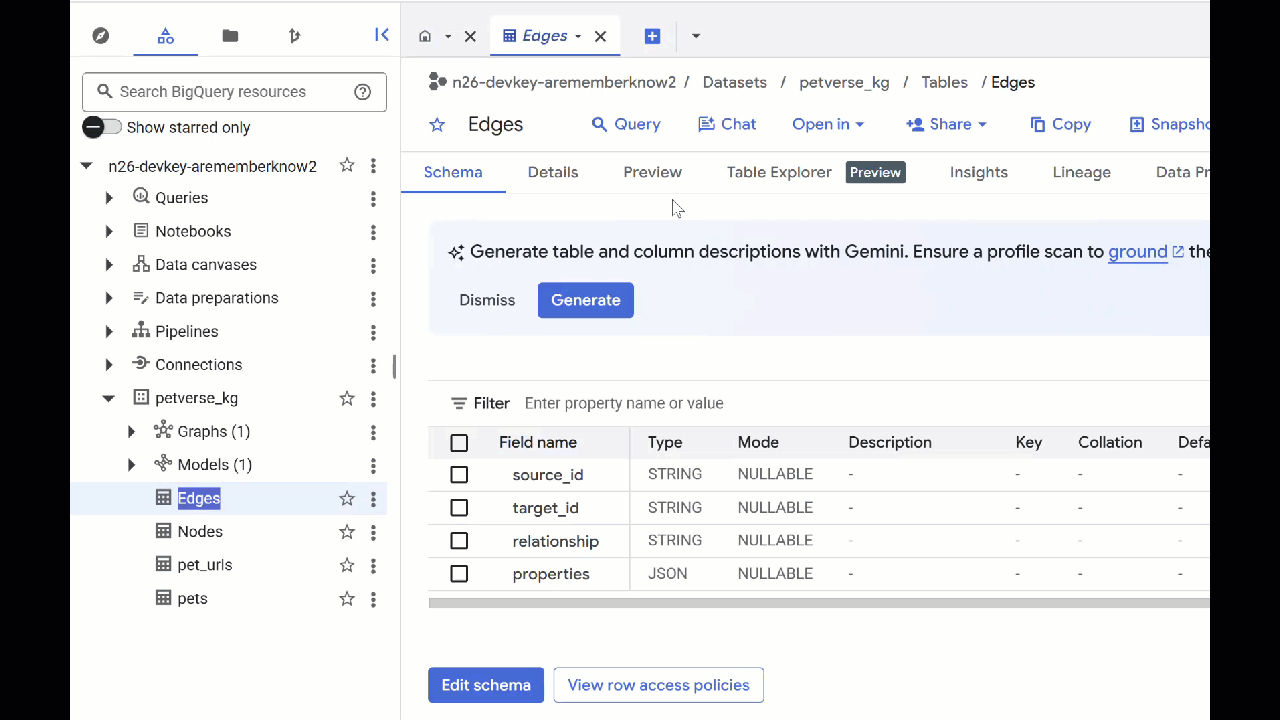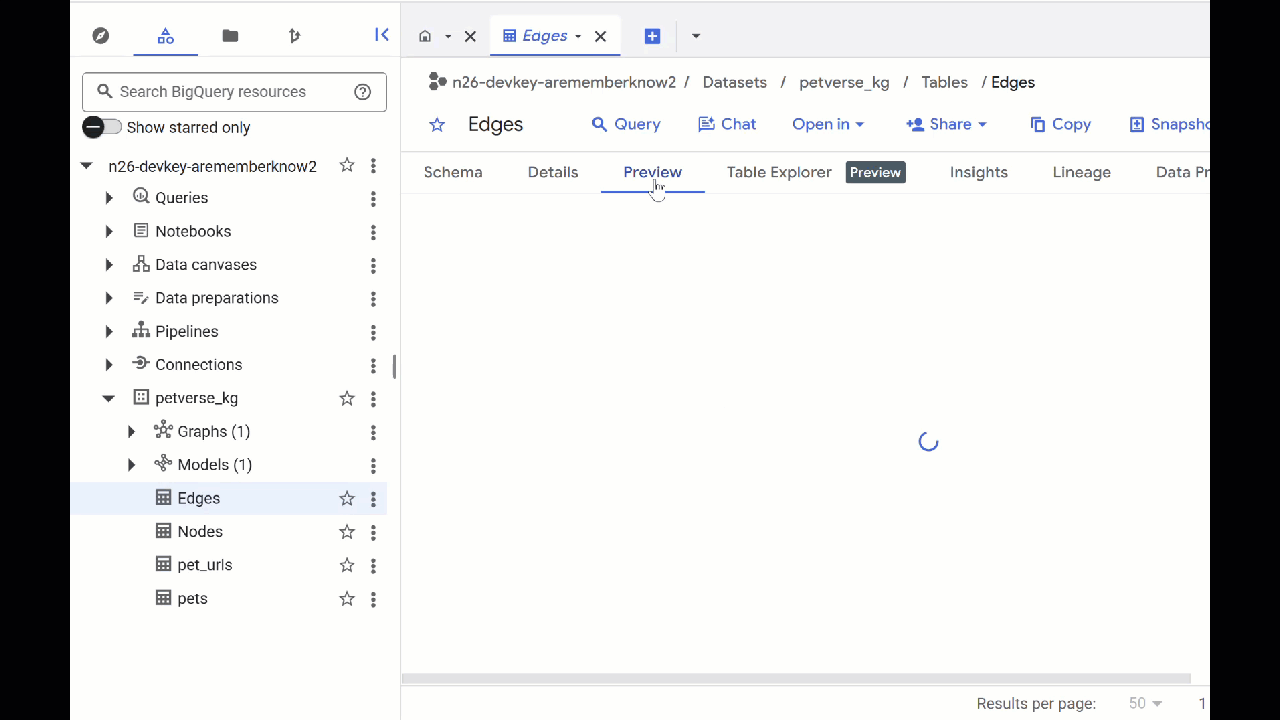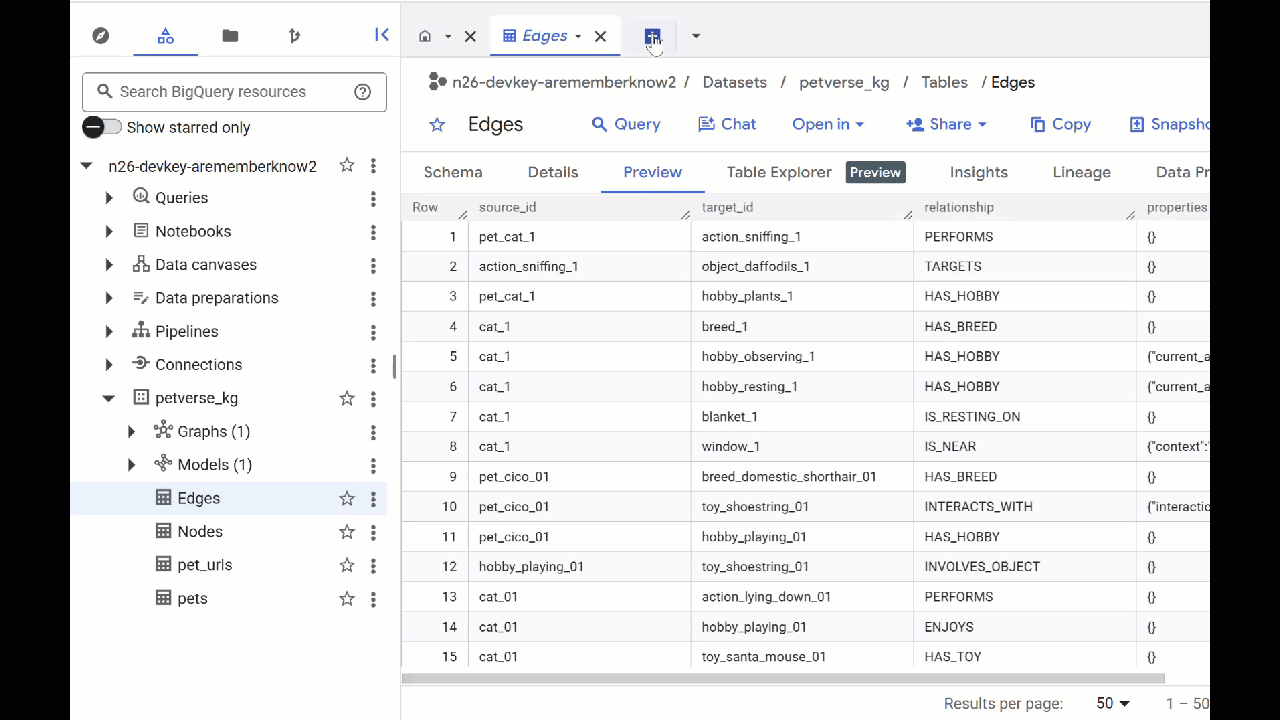
আপনি দেখবেন যে, অডিও, ভিডিও এবং ছবি থেকে জেমিনি দ্বারা শনাক্ত করা সত্তাগুলো সম্পর্কে তথ্য Nodes টেবিলে রয়েছে। Edges টেবিলে তাদের মধ্যকার সম্পর্কগুলো থাকে। সুতরাং, উদাহরণস্বরূপ, যদি আপনি SQL নামের বিড়ালটির অডিও শোনেন, সে জুতোর ফিতা নিয়ে খেলতে ভালোবাসে এবং হিমায়িত শুকনো মাছ খেতে পছন্দ করে।
- নতুন কোয়েরি তৈরি করতে + বোতামটি ব্যবহার করুন। নিচের স্টেটমেন্টটি পেস্ট করে রান-এ ক্লিক করুন:
SELECT n.name, n.entity_id, e.relationship, e.target_id
FROM
`petverse_kg.Nodes` n
JOIN
`petverse_kg.Edges` e
ON n.entity_id = e.source_id
WHERE n.name = 'SQL'
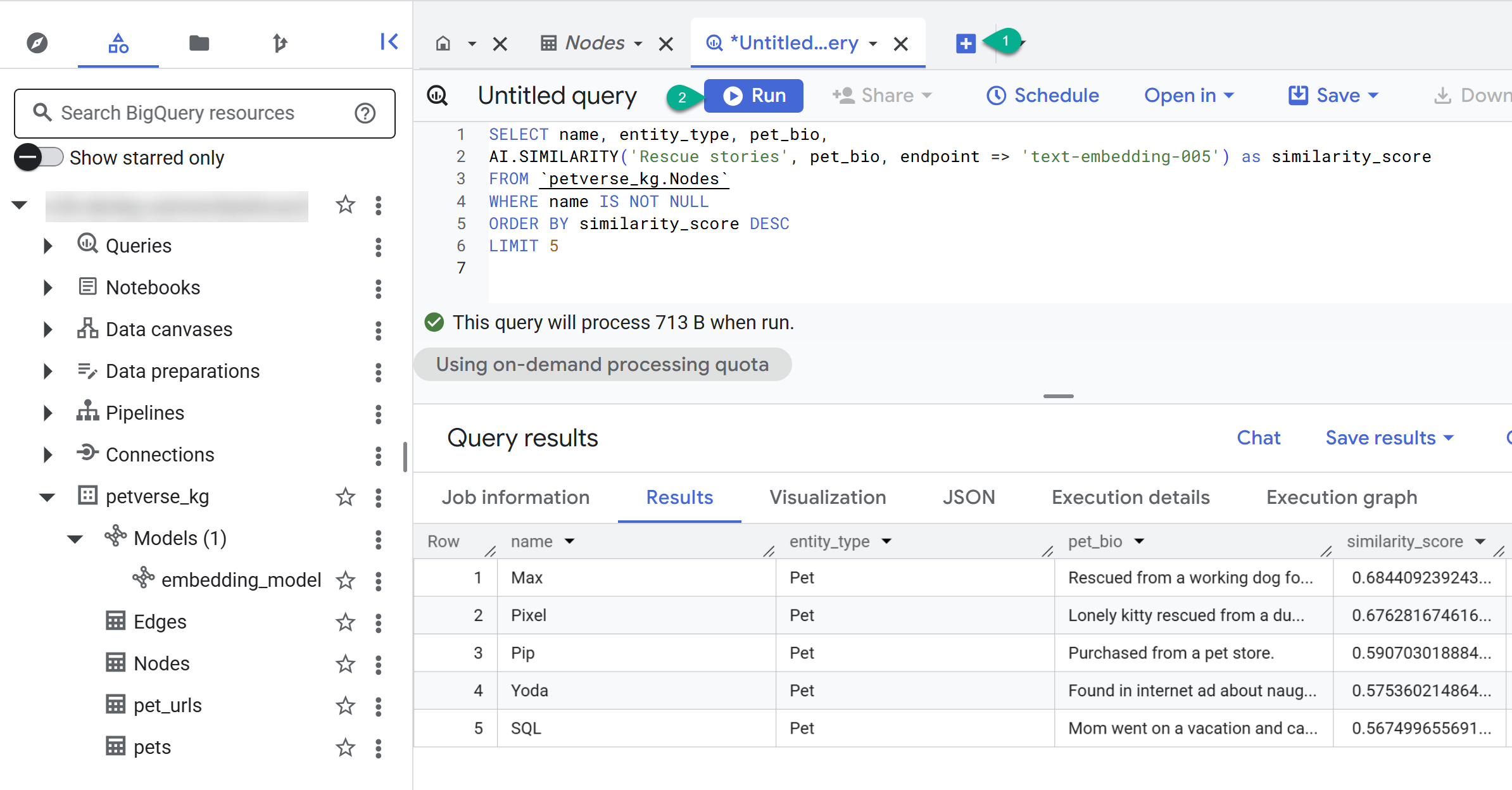
- নতুন কোয়েরি তৈরি করতে + বোতামটি ব্যবহার করুন। নিচের স্টেটমেন্টটি পেস্ট করে রান-এ ক্লিক করুন:
SELECT name, entity_type, pet_bio,
AI.SIMILARITY('Pets who like to relax', pet_bio, endpoint => 'text-embedding-005') as similarity_score
FROM `petverse_kg.Nodes`
WHERE name IS NOT NULL
ORDER BY similarity_score DESC
LIMIT 5
আপনি সেইসব পোষ্যদের নোড দেখতে পাবেন যারা আরাম করতে পছন্দ করে। এই কোয়েরিটি AI.SIMILARITY নামক AI ফাংশন ব্যবহার করে একটি সিমান্টিক সার্চ চালিয়েছে, যার মাধ্যমে এমন পোষ্যদের খুঁজে বের করা হয়েছে যাদের বায়ো কোয়েরি টেক্সটের সাথে সবচেয়ে বেশি সাদৃশ্যপূর্ণ।
প্রপার্টি গ্রাফ তৈরি করুন
এখন যেহেতু BigQuery-তে নোড এবং এজ রয়েছে, আমরা সহজেই সম্পর্কগুলো কোয়েরি করার জন্য একটি প্রপার্টি গ্রাফ তৈরি করতে পারি।
গ্রাফটি তৈরি করুন
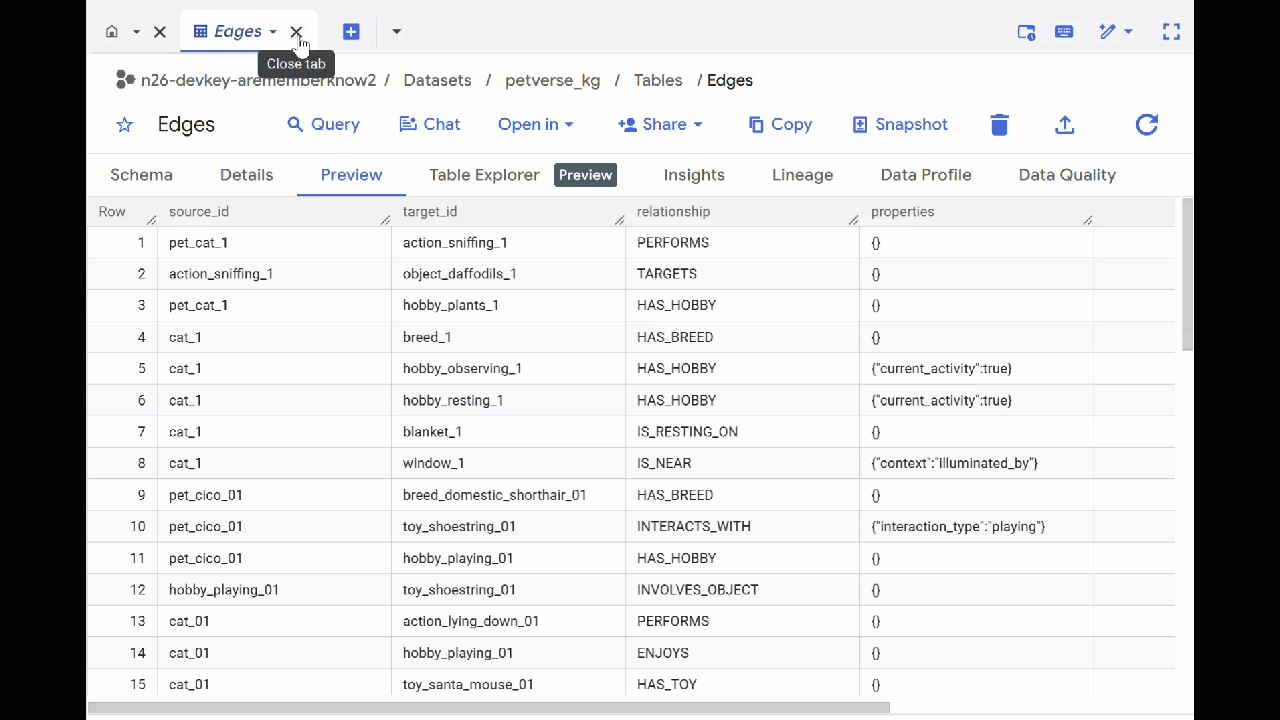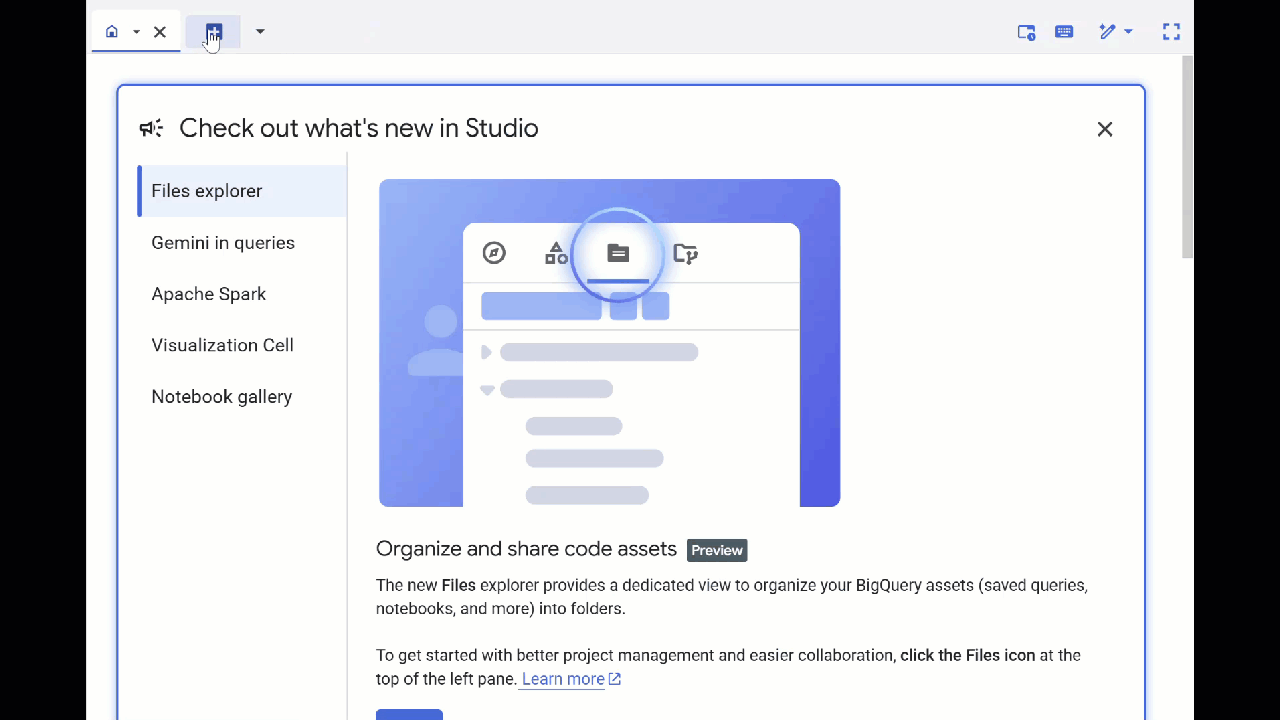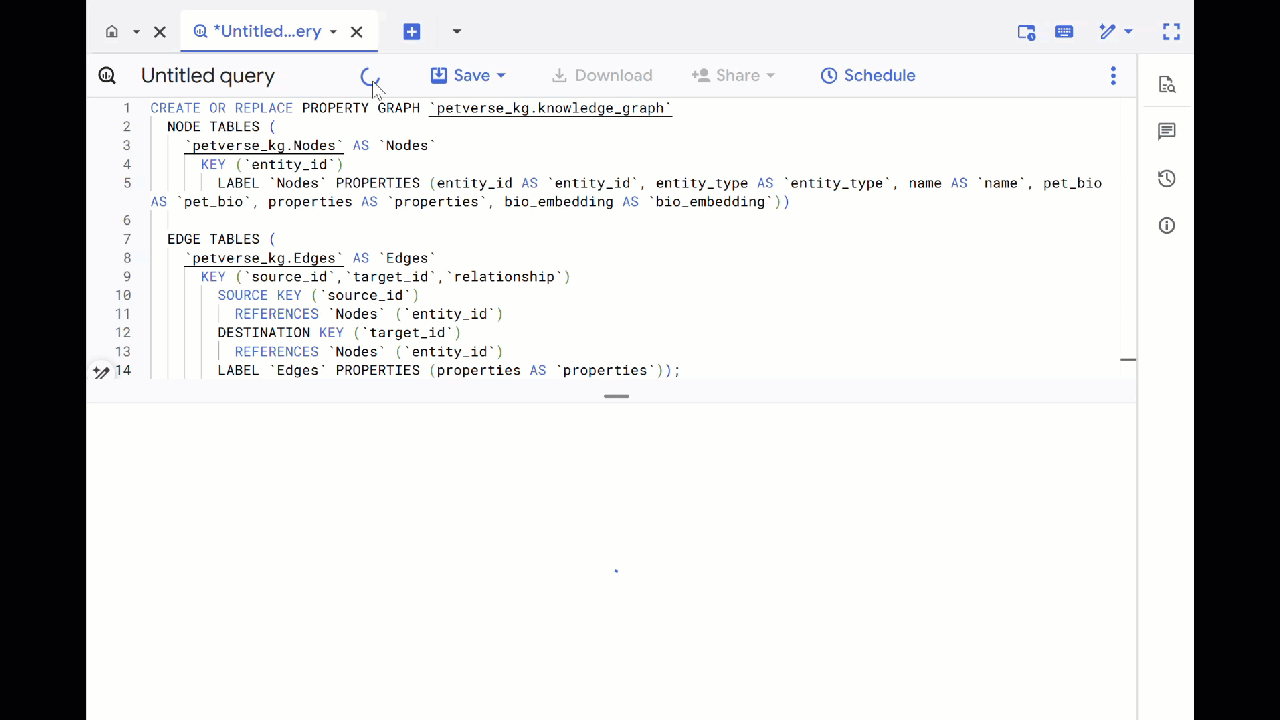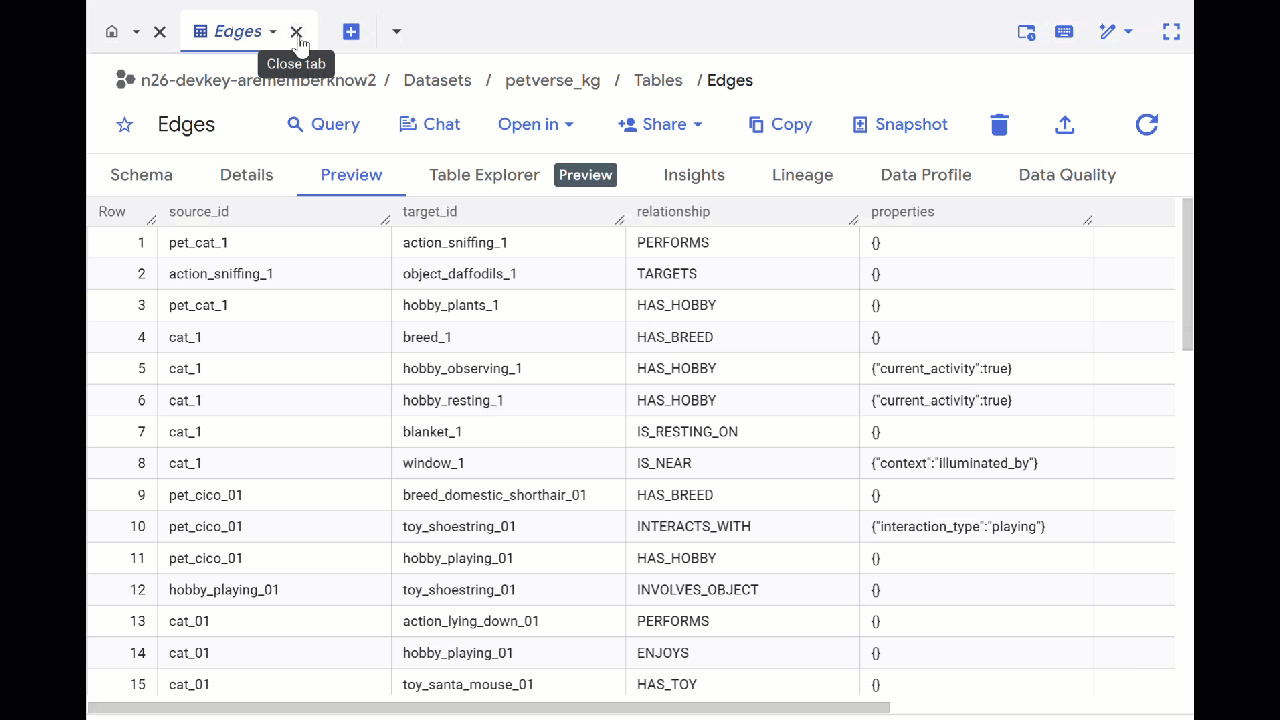
- পূর্ববর্তী কোয়েরিটি ওভাররাইট করুন এবং প্রপার্টি গ্রাফ তৈরি করতে নিম্নলিখিত DDL-টি চালান:
CREATE OR REPLACE PROPERTY GRAPH `petverse_kg.knowledge_graph`
NODE TABLES (
`petverse_kg.Nodes` AS `Nodes`
KEY (`entity_id`)
LABEL `Nodes` PROPERTIES (entity_id AS `entity_id`, entity_type AS `entity_type`, name AS `name`, pet_bio AS `pet_bio`, properties AS `properties`, bio_embedding AS `bio_embedding`))
EDGE TABLES (
`petverse_kg.Edges` AS `Edges`
KEY (`source_id`,`target_id`,`relationship`)
SOURCE KEY (`source_id`)
REFERENCES `Nodes` (`entity_id`)
DESTINATION KEY (`target_id`)
REFERENCES `Nodes` (`entity_id`)
LABEL `Edges` PROPERTIES (properties AS `properties`));
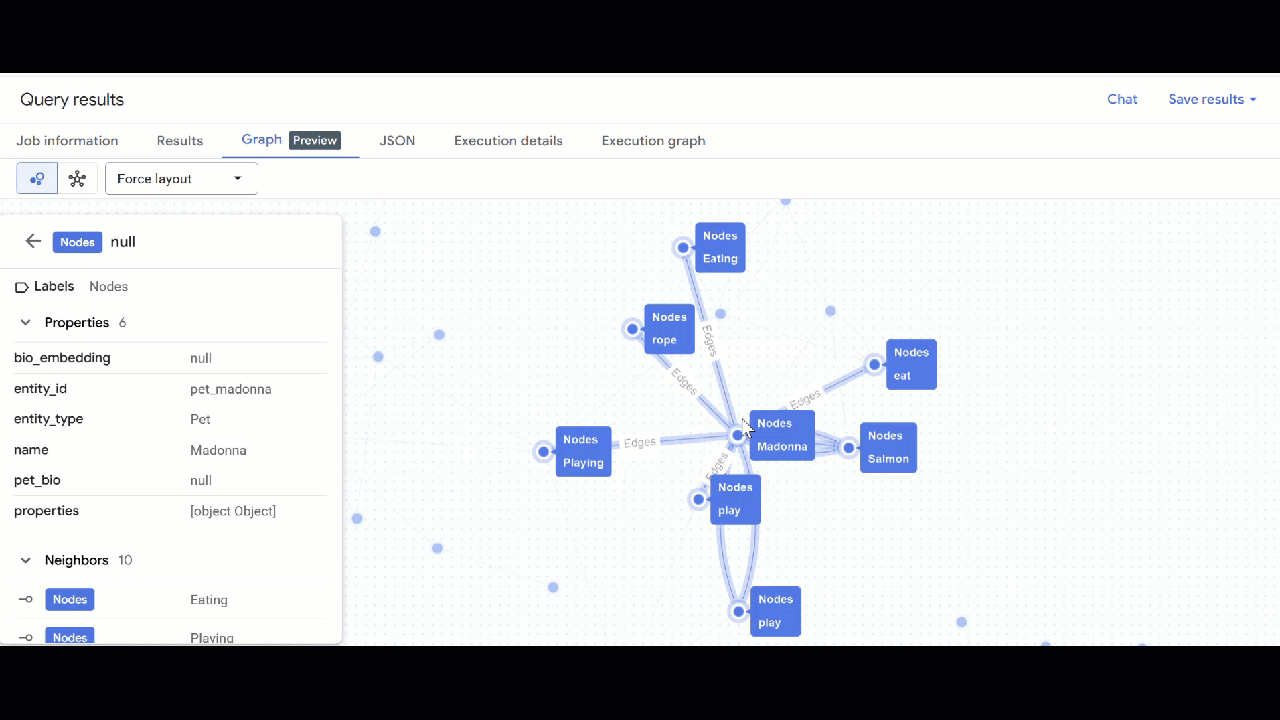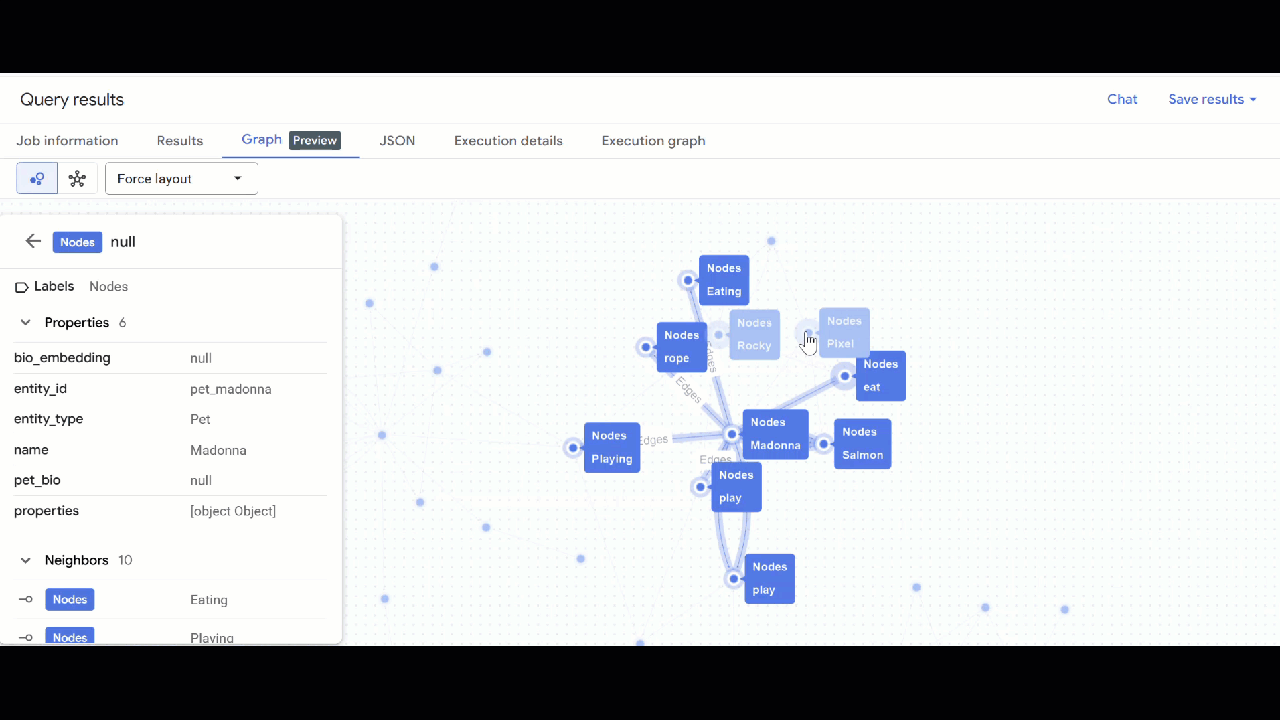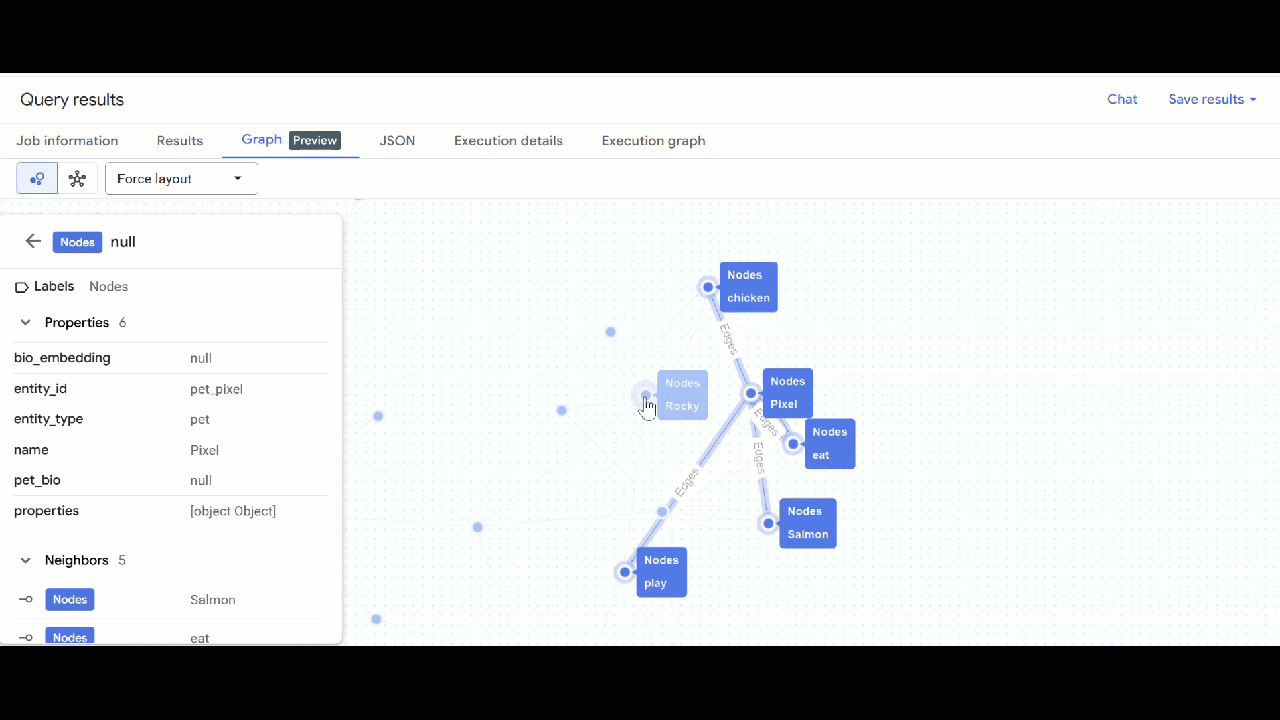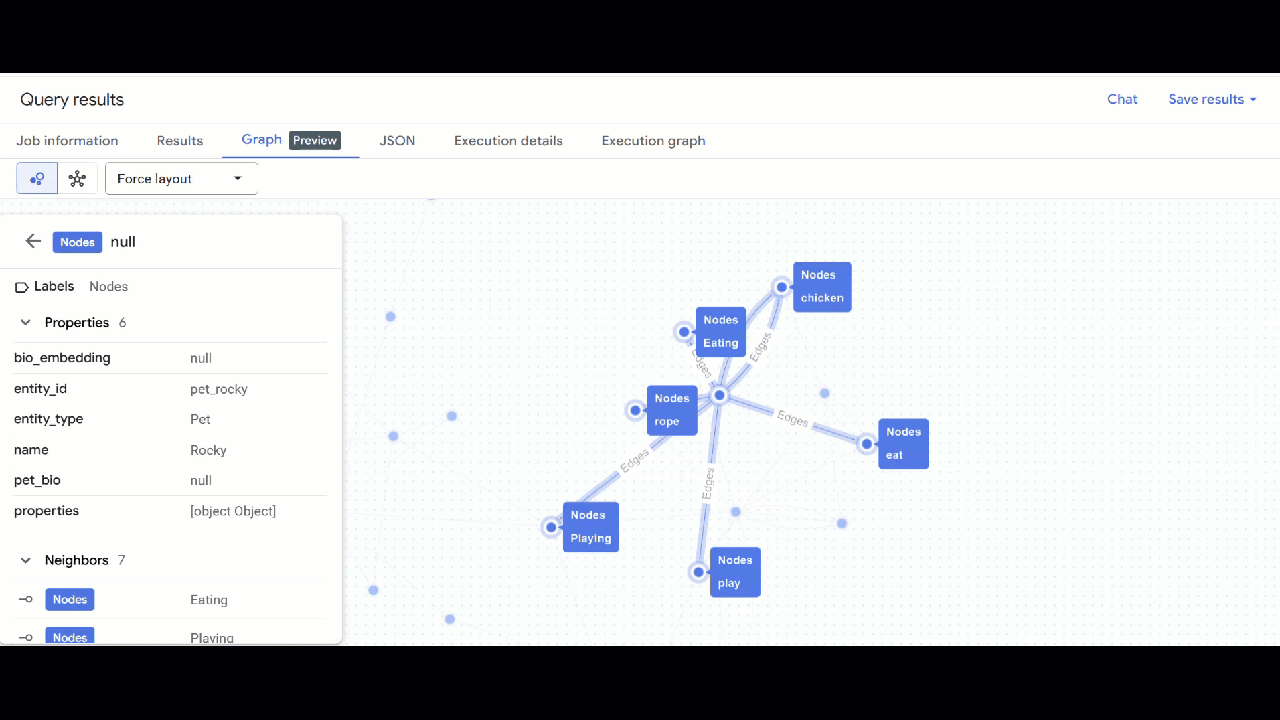
- 'গ্রাফে যান' (Go to Graph) -এ ক্লিক করুন। আপনি গ্রাফ ভিজ্যুয়ালাইজেশনটি দেখতে পাবেন, যেখানে একটি নোডের সাথে নিজেরই একটি এজ (edge) রয়েছে। এটাই প্রত্যাশিত।
গ্রাফটি অনুসন্ধান করুন
- আপনি + বোতামটি ব্যবহার করে পূর্ববর্তী সমস্ত অনুসন্ধান বন্ধ করতে এবং একটি নতুন, খালি অনুসন্ধান খুলতে পারেন।
- সাধারণ আগ্রহের (যেমন শখ, প্রিয় খাবার বা খেলনা) মাধ্যমে অন্যান্য পোষা প্রাণীর সাথে সম্পর্কিত পোষা প্রাণী খুঁজে বের করতে GQL ব্যবহার করুন। এই মাল্টি-হপ কোয়েরিটি একই নোডের সাথে সংযুক্ত দুটি ভিন্ন পোষা প্রাণীকে মেলায়:
GRAPH `petverse_kg.knowledge_graph`
MATCH p = (pet1:Nodes)-[e1]->(interest:Nodes)<-[e2]-(pet2:Nodes)
WHERE pet1.entity_id != pet2.entity_id
AND (LOWER(pet1.entity_type) = 'pet' AND LOWER(pet2.entity_type) = 'pet')
AND LOWER(interest.entity_type) IN ('hobby', 'action', 'activity', 'food', 'toy')
RETURN TO_JSON(p) as res
LIMIT 100
- আপনার গ্রাফটির ভিজ্যুয়ালাইজেশন দেখা উচিত। আপনি নোড এবং এজগুলোর বৈশিষ্ট্য দেখতে নোডগুলোতে ক্লিক করতে পারেন।
🕵️ ইঙ্গিত : আপনি "স্কিমা ভিউতে স্যুইচ করুন" এ ক্লিক করে নোড দ্বারা প্রদর্শিত মান সামঞ্জস্য করতে পারেন :
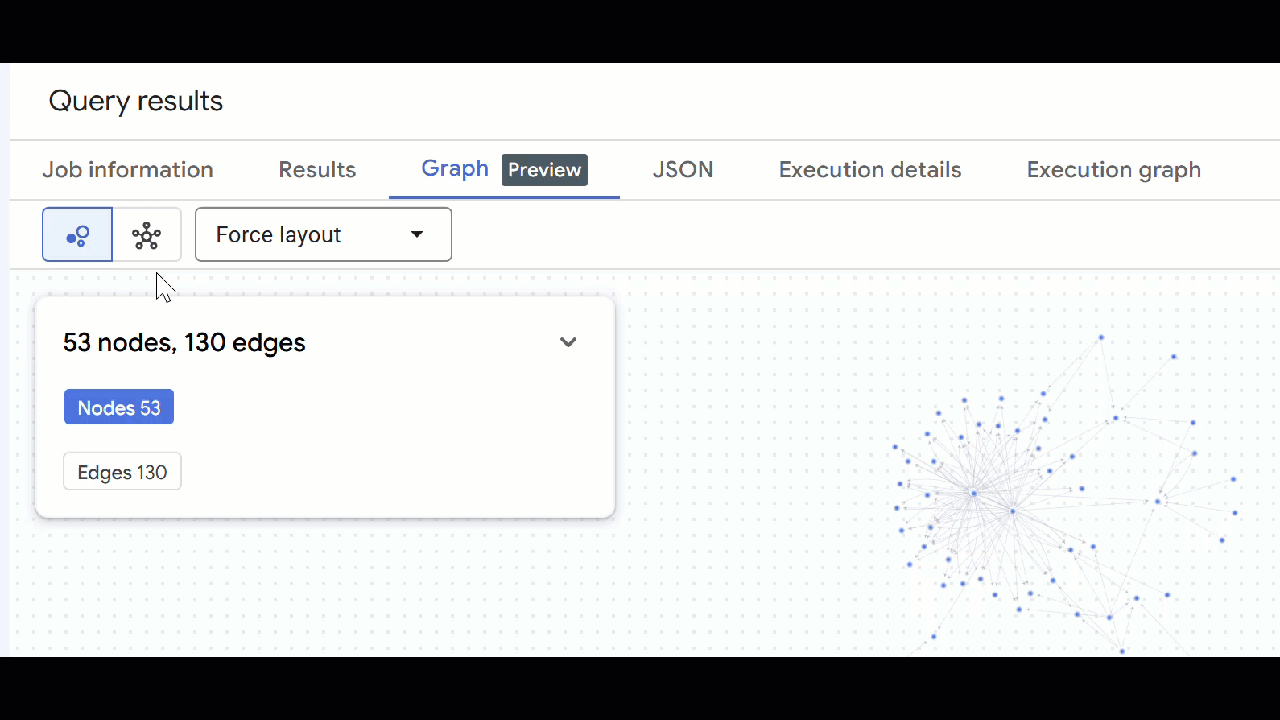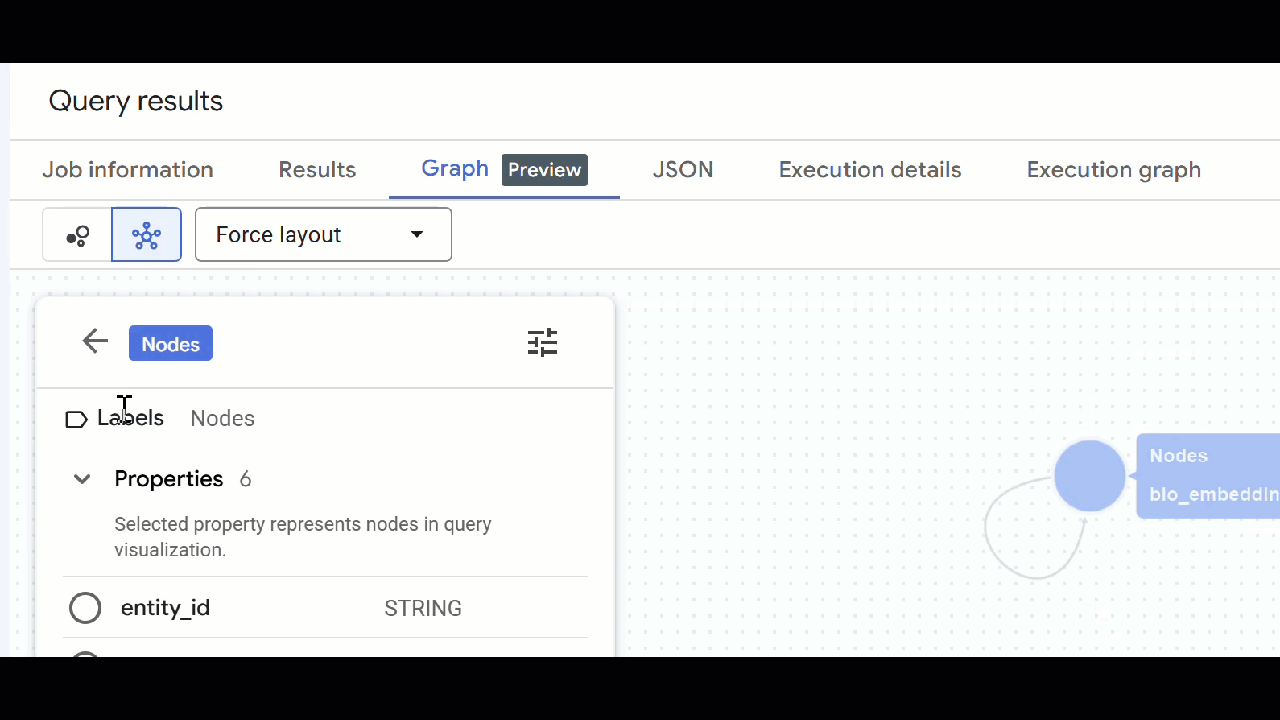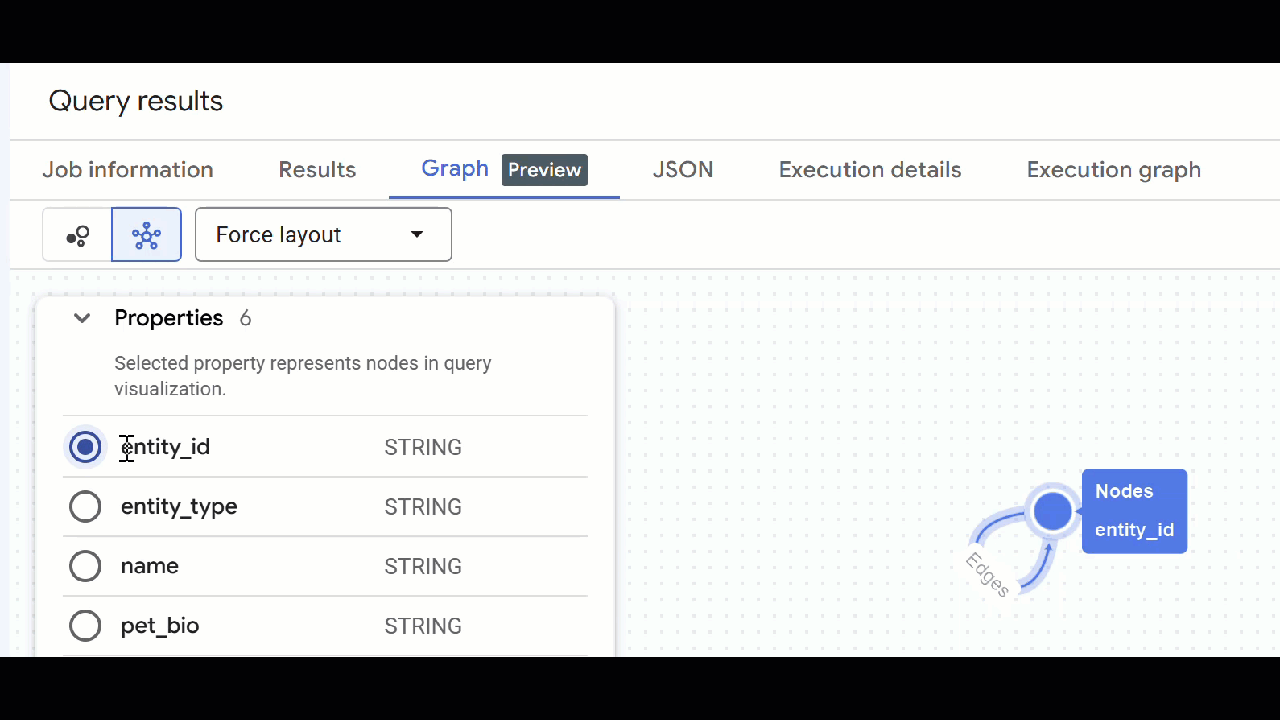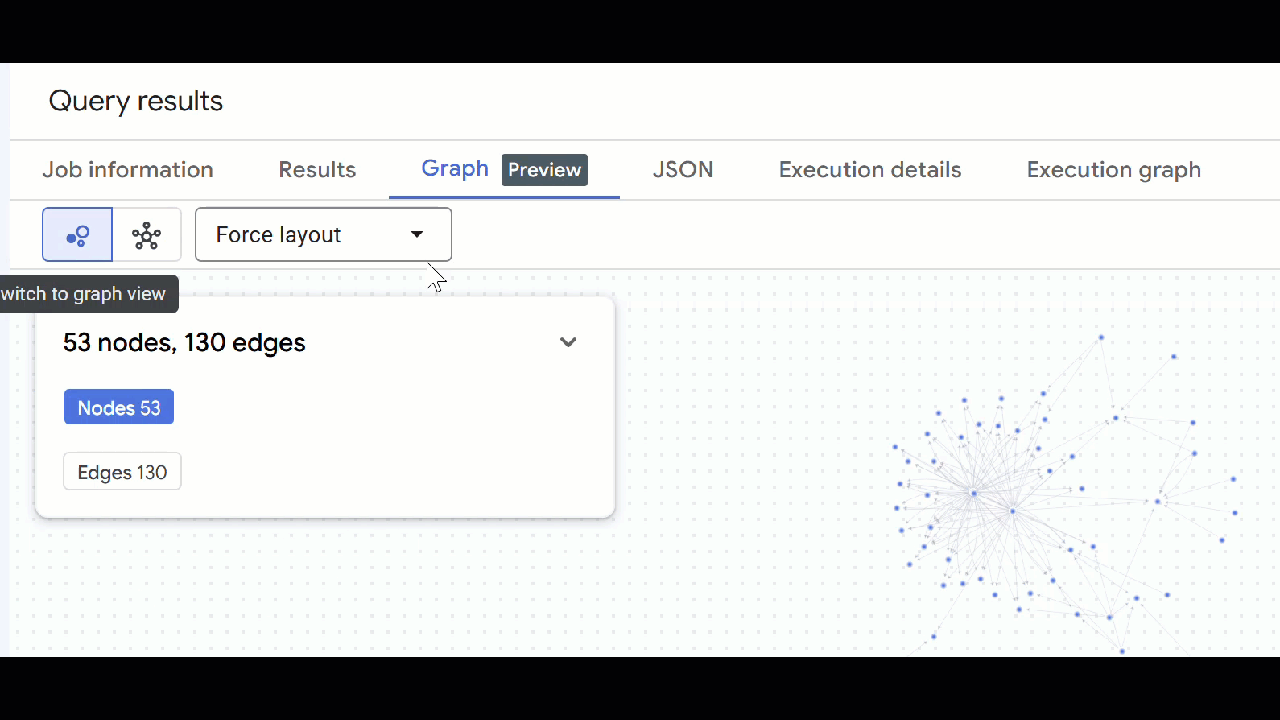
- আপনি খোলা সব কোয়েরি ট্যাব বন্ধ করতে পারেন।
৮. গ্রাফের সাথে চ্যাট করুন
- + চিহ্নের পাশে আপনি একটি ড্রপ-ডাউন মেনু পাবেন। ‘Conversation’ নির্বাচন করুন।
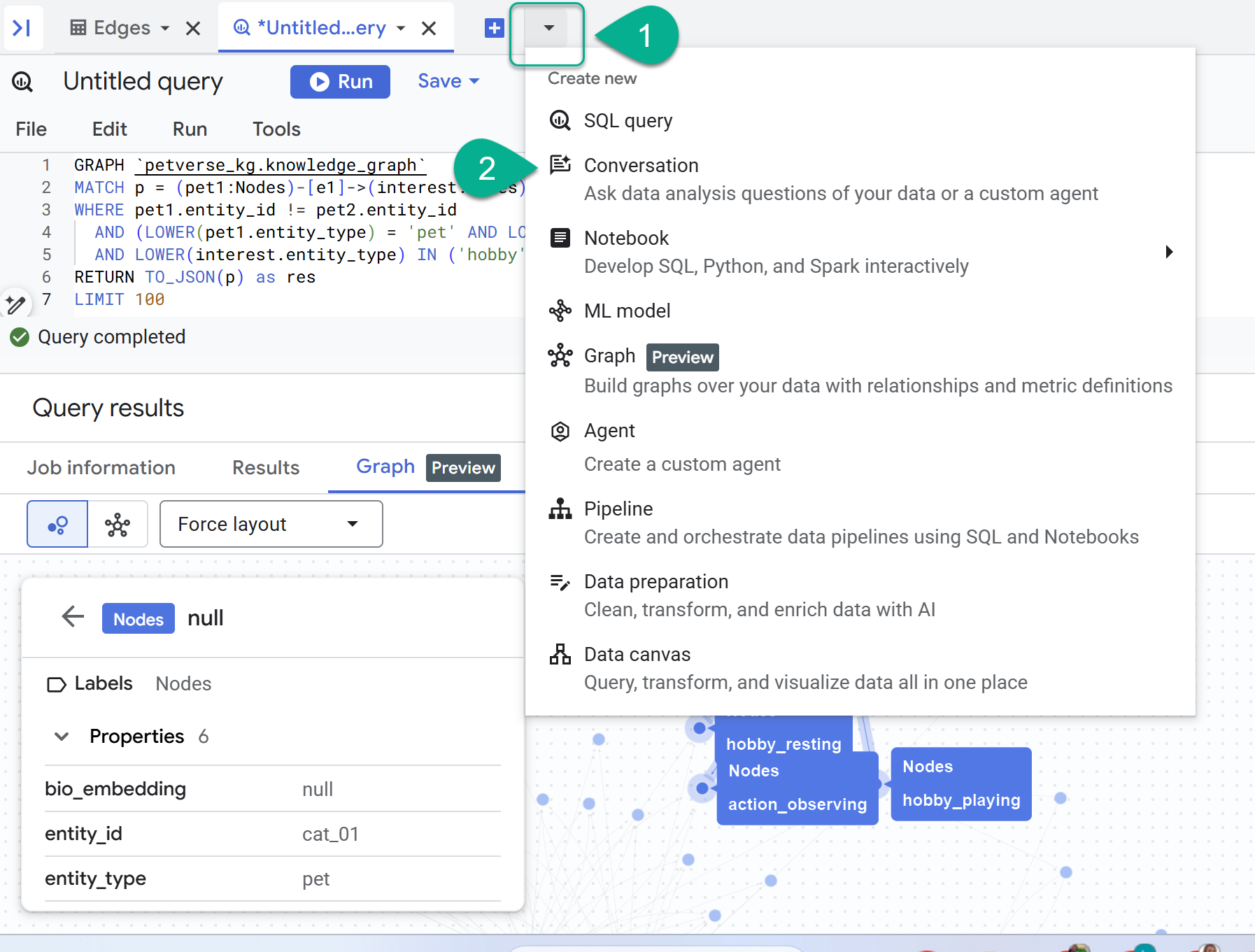
- আপনাকে জেমিনির সাথে ডেটা অ্যানালিটিক্স এপিআই (Data Analytics API) সক্রিয় করার জন্য অনুরোধ করা হবে। উভয় এপিআই সক্রিয় করুন। এটি সম্পন্ন হলে, এজেন্টকে দেখার জন্য উইন্ডোটি রিফ্রেশ করুন অথবা একটি নতুন কথোপকথন তৈরি করুন।
- নতুন এজেন্ট-এ ক্লিক করুন।
- এজেন্টটির একটি নাম দিন, যেমন,
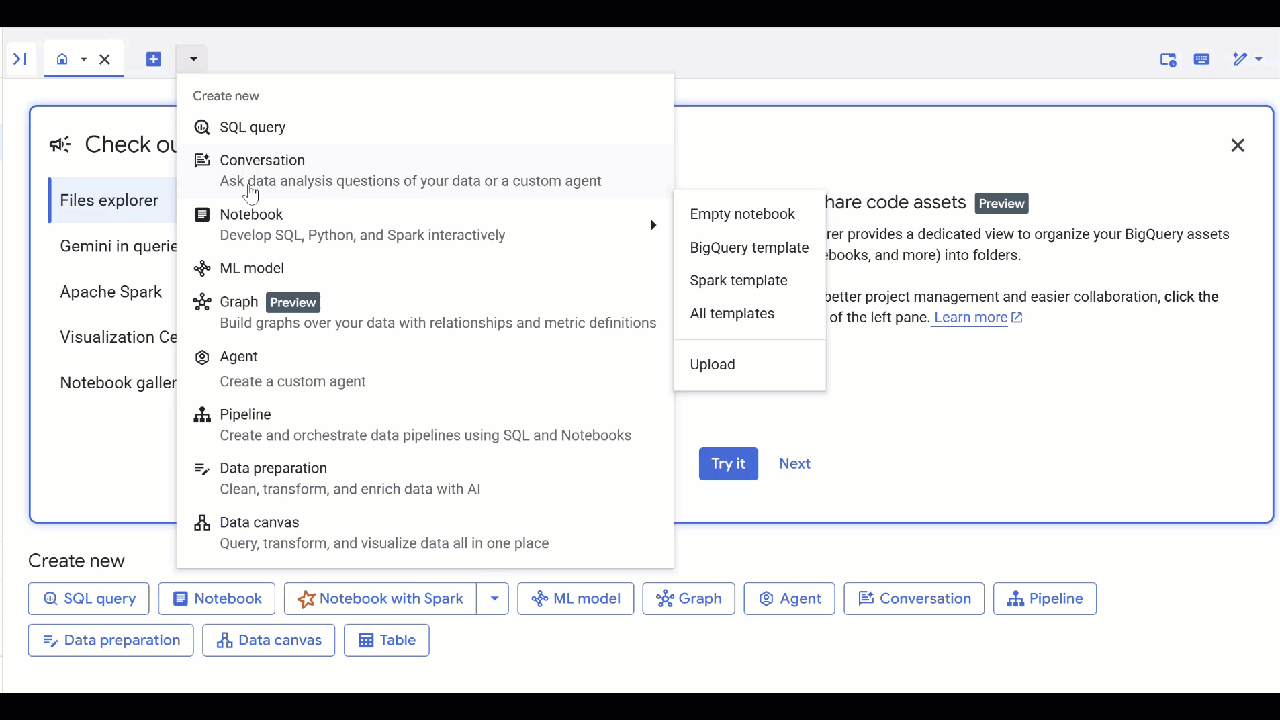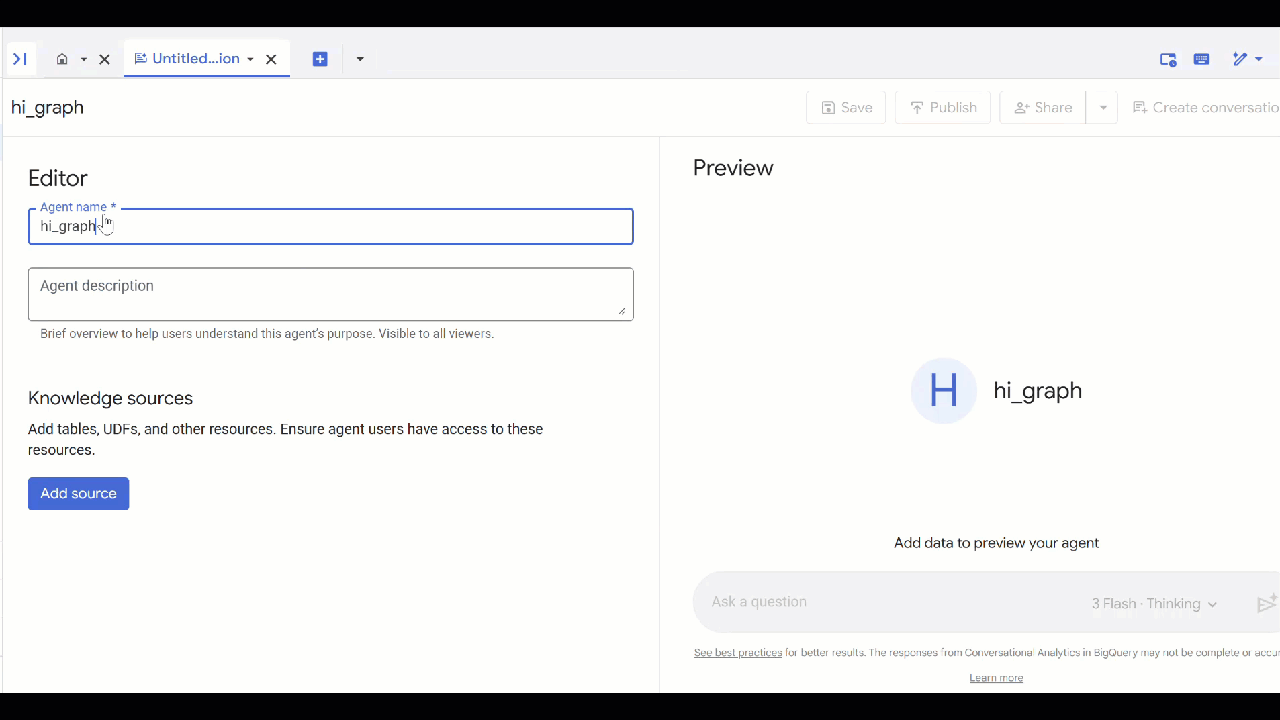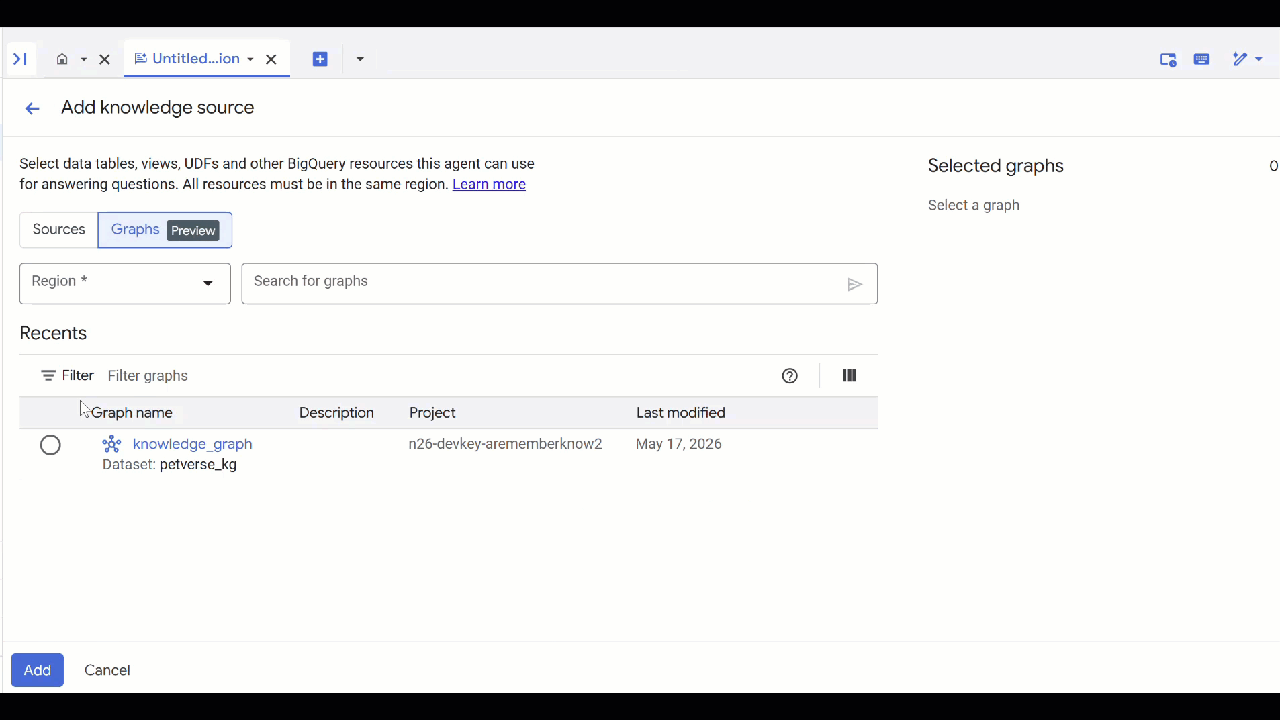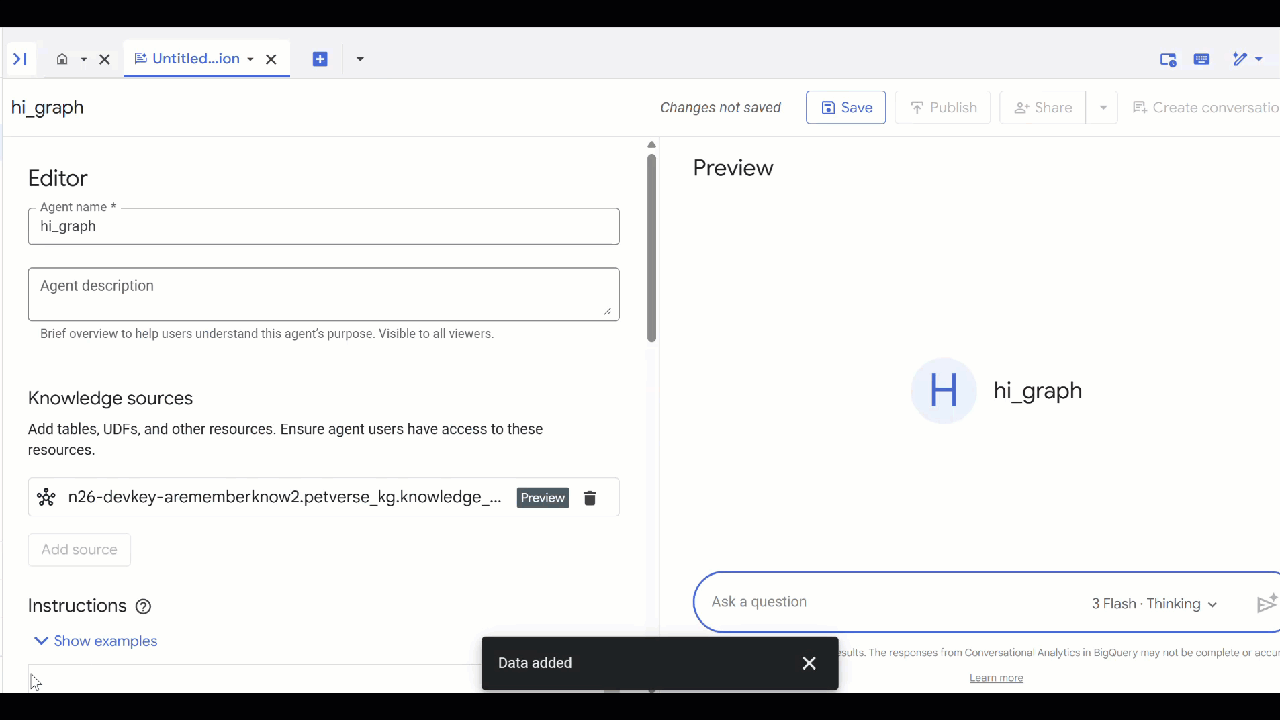
petverse। - Add source-এ ক্লিক করুন এবং তারপর Graph-এ ক্লিক করুন।
- আপনার তৈরি করা
knowledge_graphটি নির্বাচন করুন এবং Add-এ ক্লিক করুন।
এখন আপনি এজেন্টকে একটি প্রশ্ন করতে পারেন এবং তার উত্তর ও পেছনের যুক্তি দেখতে পারেন। আপনার অনুপ্রেরণার প্রয়োজন হলে এখানে কিছু নমুনা প্রশ্ন দেওয়া হলো। একটি থিঙ্কিং মডেল তৈরি হতে কিছুটা বেশি সময় লাগতে পারে, কিন্তু এটি সম্ভবত আরও ভালো একটি GQL কোয়েরি তৈরি করবে। Show Thinking প্রসারিত করে আপনি দেখতে পারেন এটি কী তৈরি করে।
- এমন পোষা প্রাণী খুঁজুন যারা একই ধরনের খাবার খায় এবং যারা দুপুরে ঘুমাতে ভালোবাসে এমন পোষা প্রাণীদের সাথে বন্ধুত্ব করে।
- কোনো পোষা প্রাণীর কি হুবহু একই শখ, প্রিয় খাবার বা খেলনা আছে? সেই জোড়াগুলো এবং তাদের অভিন্ন আগ্রহগুলোর একটি তালিকা তৈরি করুন।
- এমন পোষা প্রাণী খুঁজুন যেগুলো একই প্রজাতি বা জাতের, কিন্তু তাদের শখ সম্পূর্ণ ভিন্ন।
৯. পরিষ্কার করুন
আপনার গুগল ক্লাউড অ্যাকাউন্টে চলমান চার্জ এড়াতে, এই কোডল্যাব চলাকালীন তৈরি করা রিসোর্সগুলো মুছে ফেলুন।
- GKE ক্লাস্টারটি মুছে ফেলুন:
gcloud container clusters delete petverse-cluster --region $REGION --quiet
- BigQuery ডেটাসেটটি মুছে ফেলুন (এর ফলে সমস্ত টেবিল মুছে যাবে):
bq rm -r -f -d $PROJECT_ID:petverse_kg
- পাব/সাব কিউ রিসোর্সগুলো মুছে ফেলুন:
gcloud pubsub subscriptions delete petverse-sub --quiet
gcloud pubsub topics delete petverse-topic --quiet
- আর্টিফ্যাক্ট রেজিস্ট্রি রিপোজিটরিটি মুছে ফেলুন:
gcloud artifacts repositories delete gke-cats-repo --location=$REGION --quiet
- প্রজেক্ট-নির্দিষ্ট GCS বাকেটটি মুছে ফেলুন:
gcloud storage buckets delete gs://$PROJECT_ID-petverse --quiet
১০. অভিনন্দন
অভিনন্দন! আপনি সফলভাবে GKE এবং Gemini ব্যবহার করে একটি ডিস্ট্রিবিউটেড নলেজ গ্রাফ পাইপলাইন তৈরি করেছেন এবং BigQuery Property Graphs ব্যবহার করে সেটিতে কোয়েরি চালিয়েছেন।
আপনি যা শিখেছেন
- GKE Autopilot- এ কীভাবে ডিস্ট্রিবিউটেড জব স্থাপন করবেন।
- মাল্টিমোডাল ডেটা এক্সট্র্যাকশনের জন্য কীভাবে জেমিনি ব্যবহার করবেন।
- BigQuery অটো-এম্বেডিং কীভাবে ব্যবহার করবেন
- BigQuery-তে কীভাবে প্রপার্টি গ্রাফ তৈরি ও কোয়েরি করতে হয়।