
1. Einführung
In diesem Codelab erstellen Sie eine Pipeline für die verteilte Wissensbeschaffung für „Petverse“. Sie verarbeiten unstrukturierte Multimedia-Assets (Audio, Video, Bilder, Text/CSV) aus einem Cloud Storage-Bucket, extrahieren wichtige Informationen zu den Haustieren (Lieblingsfutter, Hobbys) und erstellen einen Wissensgraphen. Sie skalieren die Verarbeitung der Multimediadatei mit der multimodalen Verarbeitung von Gemini in Google Kubernetes Engine (GKE). Schließlich speichern Sie diese Daten in BigQuery und analysieren die Beziehungen mit der neuen BigQuery Property Graph-Funktion.
Wir nutzen die Leistungsfähigkeit von Google Kubernetes Engine, um die parallele Verarbeitung großer Datenmengen zu demonstrieren.
Warum Knowledge Graphs?
Knowledge Graphs eignen sich besser als herkömmliche relationale Datenbanken, um komplexe Beziehungen zwischen Entitäten darzustellen und zu analysieren.
Wir verwenden Gemini 2.5 Flash, um Bilder, Audio- und Videodateien zu analysieren und Fakten zu verschiedenen Haustieren zu ermitteln.
Aufgaben
- Einen verteilten Datenverarbeitungsjob in GKE erstellen und bereitstellen
- Mit Gemini können Sie Entitäten und Beziehungen aus Multimediadateien extrahieren.
- Speichern Sie die Knowledge Graph-Daten in BigQuery.
- Property Graph in BigQuery mit der Graph Query Language (GQL) erstellen und abfragen.
Voraussetzungen
- Ein Webbrowser wie Chrome
- Ein Google Cloud-Projekt mit aktivierter Abrechnung
- Berechtigungen im Projekt zum Erstellen von Ressourcen und Ändern von IAM-Richtlinien
Dieses Codelab richtet sich an Entwickler aller Erfahrungsstufen, auch an Anfänger.
Geschätzte Dauer:45 Minuten
Kosten:Die in diesem Codelab erstellten Ressourcen sollten weniger als 5 $ kosten.
2. Hinweis
Google Cloud-Projekt erstellen
- Rufen Sie die Google Cloud Console auf: https://console.cloud.google.com und wählen Sie dann ein Google Cloud-Projekt aus oder erstellen Sie eines.
- ⚠️ Notieren Sie sich die Projekt-ID. Sie verwenden sie für mehrere Befehle in diesem Lab.
Cloud Shell starten
- Cloud Shell in einem neuen Tab öffnen: https://shell.cloud.google.com/.
- Wenn Sie dazu aufgefordert werden, klicken Sie auf Autorisieren.
- Ersetzen Sie
PROJECT_IDund fügen Sie den folgenden Befehl in das Terminal ein:
export PROJECT_ID="YOUR_PROJECT_ID"
gcloud config set project $PROJECT_ID
📝 Hinweis: Ihr Projekt wird in der Befehlszeile gelb dargestellt. Wenn Ihre Sitzung neu gestartet wird, müssen Sie den oben genannten Befehl noch einmal ausführen, um die Projekt-ID festzulegen.
APIs aktivieren
Führen Sie diesen Befehl aus, um alle erforderlichen APIs zu aktivieren:
gcloud services enable \
aiplatform.googleapis.com \
bigquery.googleapis.com \
artifactregistry.googleapis.com \
container.googleapis.com \
cloudbuild.googleapis.com \
pubsub.googleapis.com
Repository klonen
Führen Sie diese Befehle aus, um das Repository zu klonen.
cd ~/
git clone --filter=blob:none --no-checkout https://github.com/GoogleCloudPlatform/devrel-demos.git
cd ~/devrel-demos
git sparse-checkout init --cone
git sparse-checkout set codelabs/gke-knowledge-graph
git checkout main
cd codelabs/gke-knowledge-graph/
Setupscript ausführen
Dieses Skript automatisiert die Backend-Konfiguration durch:
- Container-Image und Artifact Registry-Repository erstellen
- BigQuery-Dataset erstellen
- BigQuery-Verbindung erstellen, um Gemini AI-Funktionen über SQL auszuführen
Führen Sie in Ihrem Terminal den folgenden Befehl aus:
./scripts/setup.sh
Wenn Sie vom Skript zur Eingabe von Konfigurationsdetails aufgefordert werden, verwenden Sie die folgenden Werte:
- Projekt-ID:Verwenden Sie die ID, die Sie im vorherigen Schritt erstellt haben.
- Region :
us-central1
⚠️ Wichtig: Es dauert einige Minuten, bis das Skript ausgeführt ist. Lassen Sie dieses Terminalfenster geöffnet, damit der Vorgang im Hintergrund abgeschlossen werden kann. Öffnen Sie einen neuen Terminaltab oder ein neues Terminalfenster, um mit dem nächsten Schritt fortzufahren und die nächsten Befehle auszuführen.
3. Data Agent Kit einrichten
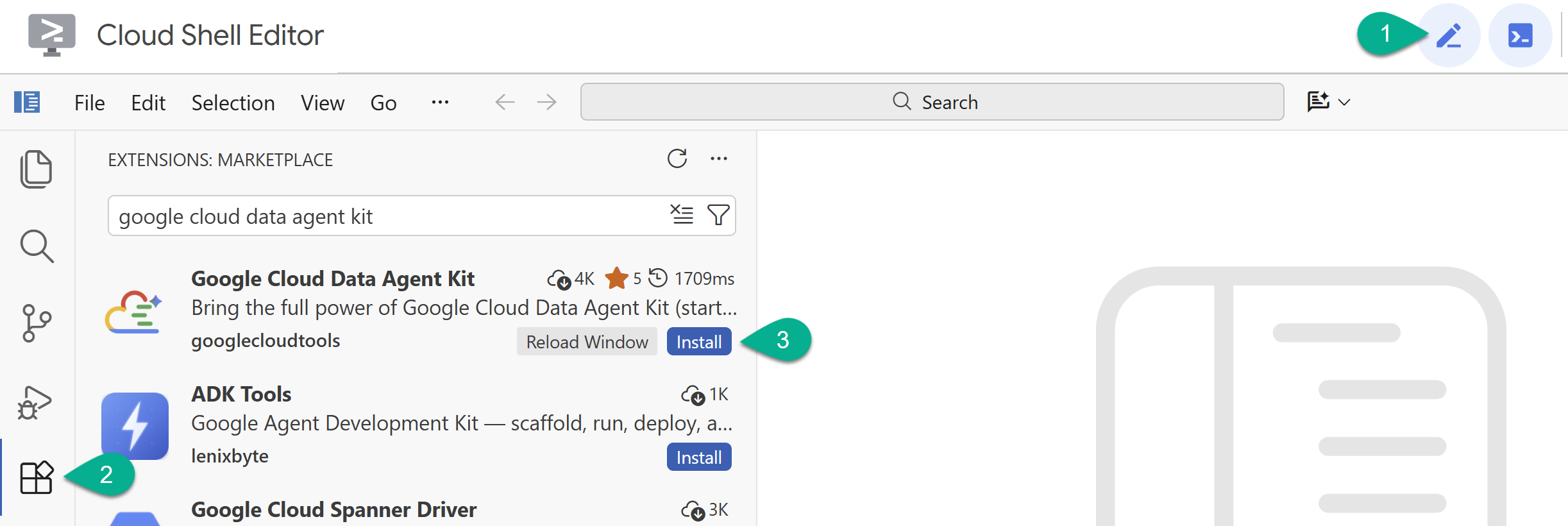
- Aktivieren Sie den Cloud Shell-Editor mit dem Stiftsymbol rechts oben.
- Klicken Sie im Cloud Shell-Editor in der linken Seitenleiste auf das Symbol Erweiterungen.
- Suchen Sie nach Google Cloud Data Agent Kit und klicken Sie auf Installieren, falls es noch nicht installiert ist.
- Melden Sie sich mit der Erweiterung in Ihrem Google-Konto an.
- Geben Sie in der Konfigurationsübersicht Ihre Projekt-ID und
us-central1als Region ein.
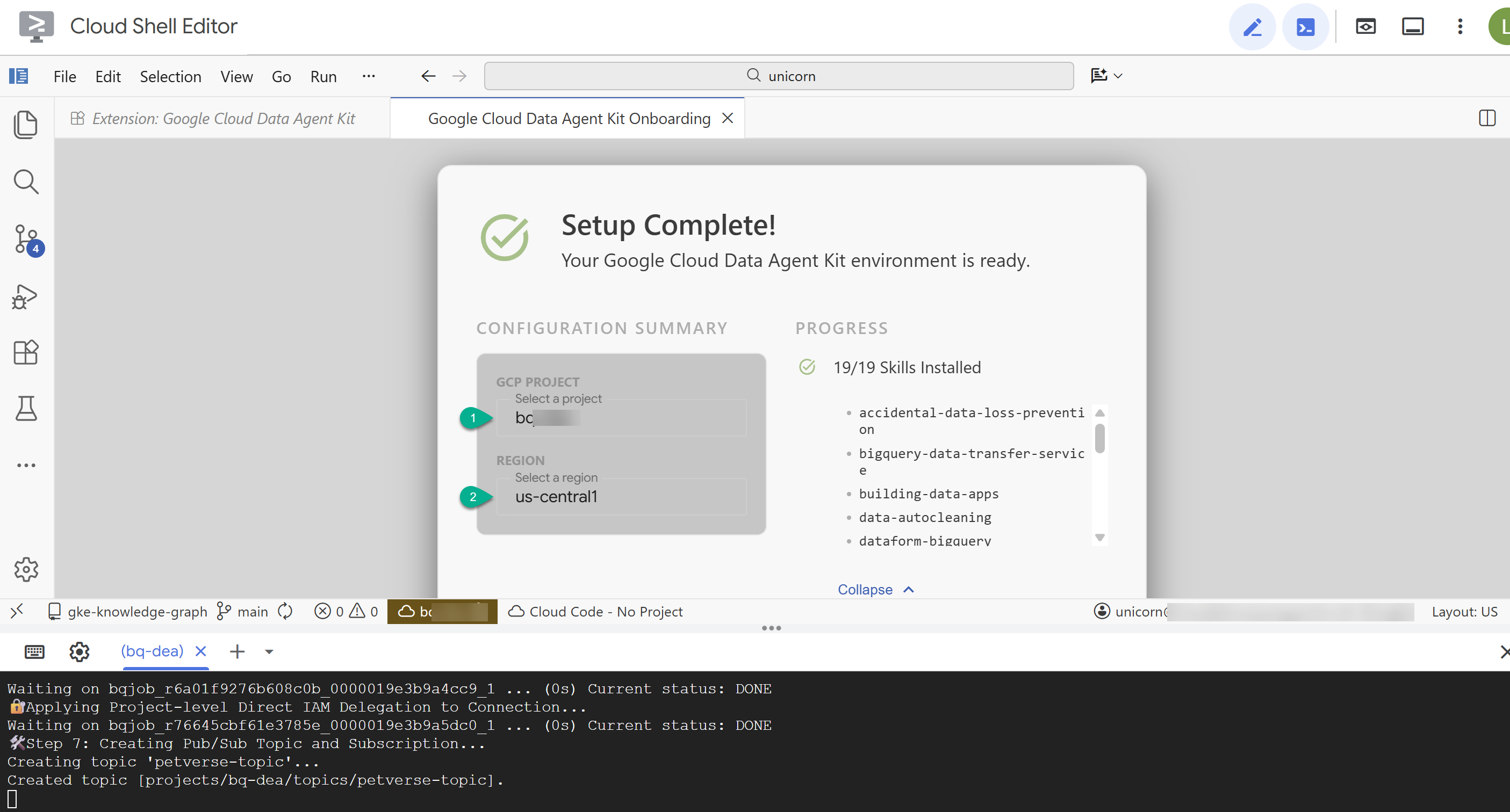
- Klicken Sie auf MCP-Server konfigurieren. Sie müssen in diesem Fenster keine Änderungen vornehmen. Klicken Sie einfach auf Jetzt starten.
- Aktualisieren Sie das Fenster, wenn Sie dazu aufgefordert werden. Sie können den Tab mit der Kurzanleitung jetzt schließen.
Tabellen in BigQuery einrichten
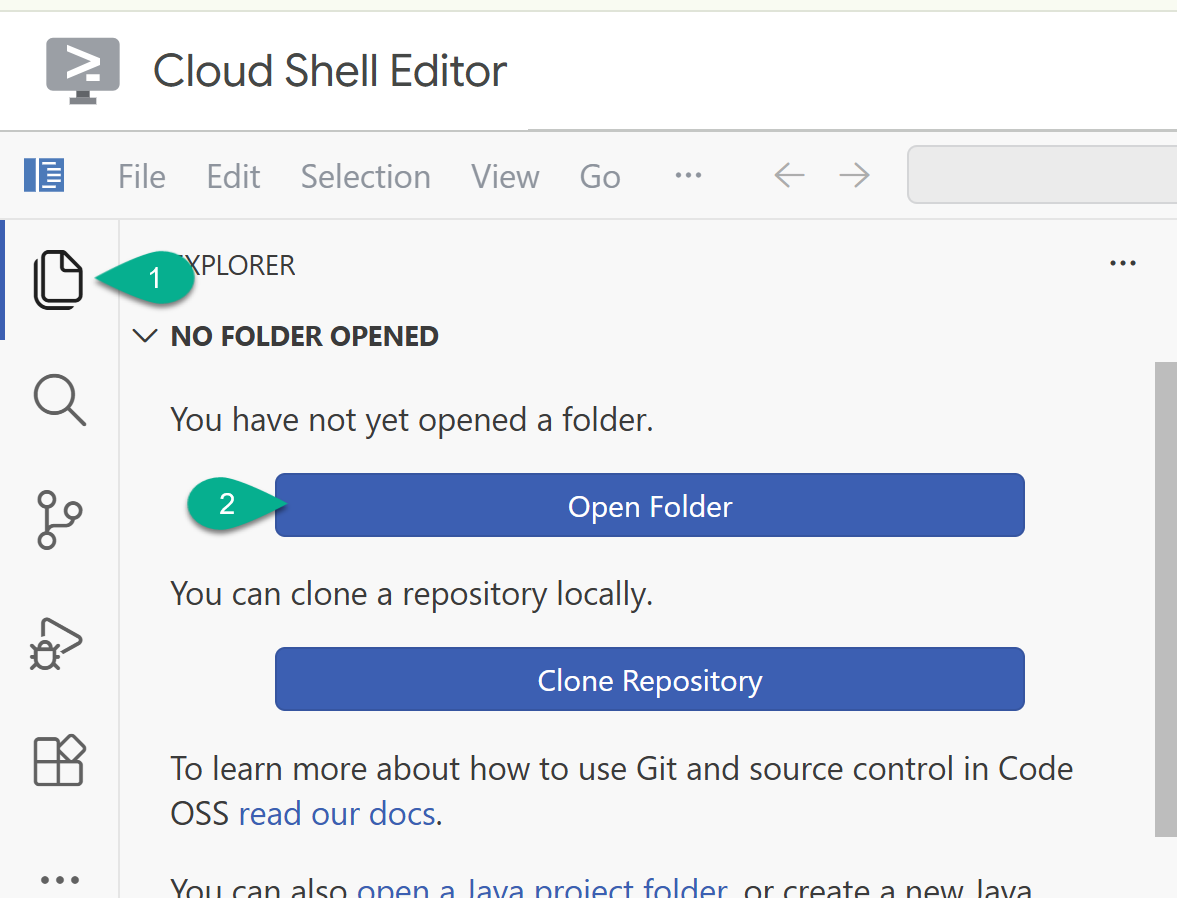
- Kehren Sie in der Seitenleiste zum Explorer zurück. Wenn Ihr Basisordner (z.B.
/home/your_user_name/) noch nicht geöffnet ist, klicken Sie auf Ordner öffnen und wählen Sie ihn aus.
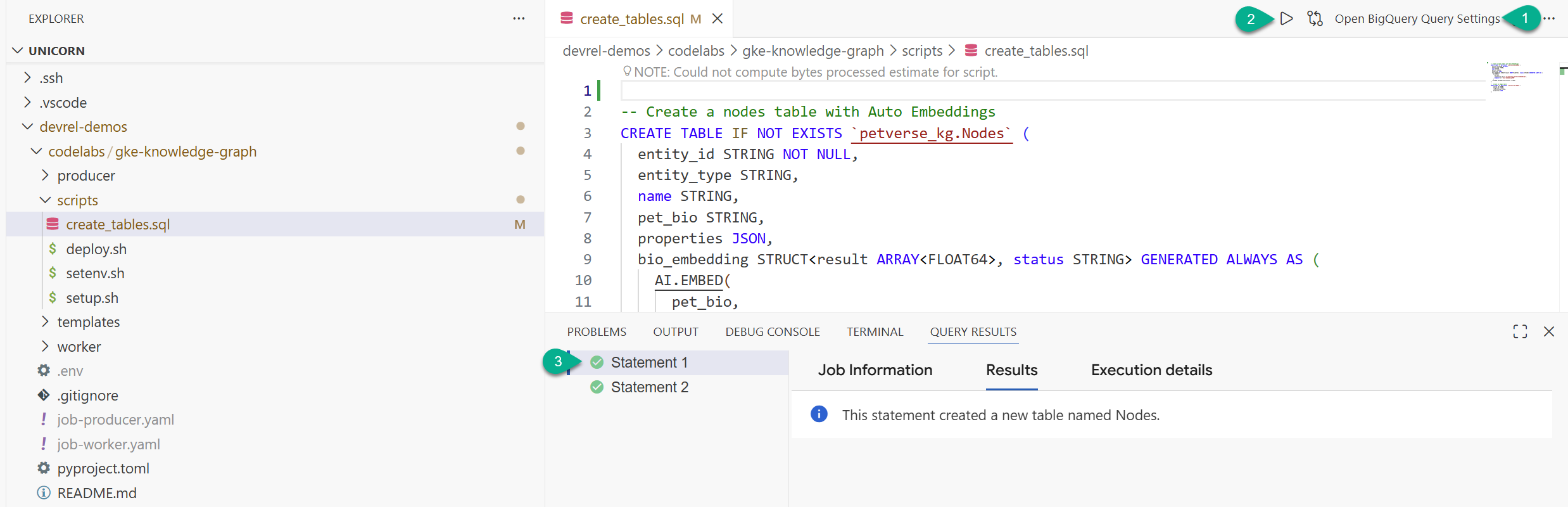
- Suchen Sie im Explorer-Fenster den Ordner, den Sie aus dem Repository geklont haben (
devrel-demos). Untercodelabs/gke-knowledge-graph/scriptsfinden Siecreate_tables.sql. Öffnen Sie die Datei. - Klicken Sie rechts oben auf Abfrageeinstellungen öffnen.
- Wählen Sie BigQuery aus. Klicken Sie auf Speichern und dann auf Schließen.
- Klicken Sie auf Ausführen.
Sie sollten sehen, dass zwei Anweisungen erfolgreich ausgeführt wurden. Sie haben jetzt die Tabellen zum Speichern von Knoten und Kanten für Ihren Knowledge Graph erstellt.
Sie können den Tab create_tables.sql und die Ergebniskonsole schließen.
4. GKE-Cluster initialisieren
Wir verwenden GKE Autopilot, um unseren Datenverarbeitungsjob auszuführen. Autopilot ist die empfohlene Best Practice, da die Clusterinfrastruktur für Sie verwaltet wird.
Das Setupscript sollte jetzt abgeschlossen sein. Sie sollten die Erfolgsmeldung 🎉🦄 Setup successfully finished! 🎉🦄 sehen.
Fügen Sie diesen Befehl in das Terminal ein, um den Cluster zu erstellen:
source scripts/setenv.sh
gcloud container clusters create-auto petverse-cluster \
--region=$REGION
🕓 Das dauert etwa 5 Minuten.
Rufen Sie Anmeldedaten ab, um mit dem Cluster zu interagieren:
source scripts/setenv.sh
gcloud container clusters get-credentials petverse-cluster --region $REGION
Es sollte folgende Ausgabe angezeigt werden:
Fetching cluster endpoint and auth data. kubeconfig entry generated for petverse-cluster.
5. Workload Identity konfigurieren
Mit Workload Identity Federation for GKE (mit direktem Ressourcenzugriff) können Ihre GKE-Arbeitslasten sicher auf Google Cloud-Dienste zugreifen, ohne dass Sie Dienstkontoschlüssel verwalten müssen.
Führen Sie deploy.sh aus, um:
- Kubernetes-Dienstkonto erstellen
- Weisen Sie dem Kubernetes-Dienstkonto-Prinzipal die erforderlichen IAM-Rollen direkt zu.
- IAM-Dienstkonto an das Kubernetes-Dienstkonto binden
- Kubernetes-Dienstkonto annotieren, um die Verknüpfung abzuschließen
source scripts/setenv.sh
./scripts/deploy.sh
6. Entkoppelte Verarbeitungsjobs bereitstellen
In diesem Schritt stellen Sie den Enqueuer (Producer) und die Verarbeitungs-Engines (Worker) in GKE bereit.
In unserer neuen entkoppelten Architektur wird Google Cloud Pub/Sub verwendet, um Assets asynchron zu verarbeiten:
- Der Producer scannt GCS und stellt alle Dateipfade in eine Pub/Sub-Warteschlange.
- Ein Pool von Workern wird in GKE skaliert, wobei Aufgaben dynamisch parallel abgerufen, mit Gemini verarbeitet und in BigQuery geschrieben werden.
Das setup.sh-Skript hat bereits die Container-Images für Producer und Worker erstellt und per Push übertragen, die Pub/Sub-Themen in die Warteschlange gestellt und die GKE-Bereitstellungsmanifeste job-producer.yaml und job-worker.yaml dynamisch generiert.
- Wende den Producer-Job an, um deinen Speicher-Bucket zu scannen und alle Assets in die Warteschlange zu stellen:
kubectl apply -f job-producer.yaml
Dieser Job wird schnell ausgeführt und abgeschlossen, da nur Metadaten in die Warteschlange gestellt werden.
- Stellen Sie den Worker-Job bereit, der für die Ausführung von 6 parallelen Workern konfiguriert ist, um die Warteschlange zu leeren:
kubectl apply -f job-worker.yaml
GKE Autopilot erkennt die ausstehenden Pods automatisch, skaliert die Rechenknoten dynamisch und führt die Worker parallel aus, um in die Warteschlange gestellte Audio-, Video-, Bild- und CSV-Dateien zu verarbeiten.
7. Ergebnisse prüfen
- Prüfen Sie den Status Ihrer Jobs:
kubectl get jobs
Warten Sie, bis für petverse-producer-job und petverse-worker-job jeweils eine erfolgreiche Ausführung angezeigt wird.
🕓 Das dauert etwa 10 Minuten. Mit den folgenden Befehlen können Sie den Fortschritt sehen.
- Prüfen Sie die Logs des Producers, um zu bestätigen, dass Dateien erfolgreich in die Warteschlange gestellt wurden:
cd ~/devrel-demos/codelabs/gke-knowledge-graph
source scripts/setenv.sh
kubectl logs -l app=petverse-producer --tail=50
- Beobachten Sie, wie Ihre parallelen Worker Dateien aus der Warteschlange verarbeiten:
kubectl logs -l app=petverse-worker --tail=50
Die Worker verfügen über ein Leerlauf-Zeitlimit von 60 Sekunden und werden automatisch heruntergefahren und bereinigt, wenn die Pub/Sub-Warteschlange leer ist.
Daten in BigQuery überprüfen
- Rufen Sie BigQuery Studio auf. Es werden zwei Tabellen erstellt: „petverse_kg.Nodes“ und „petverse_kg.Edges“.
- Wenn Sie den Inhalt der Tabellen sehen möchten, doppelklicken Sie auf die Namen und klicken Sie dann auf Vorschau.
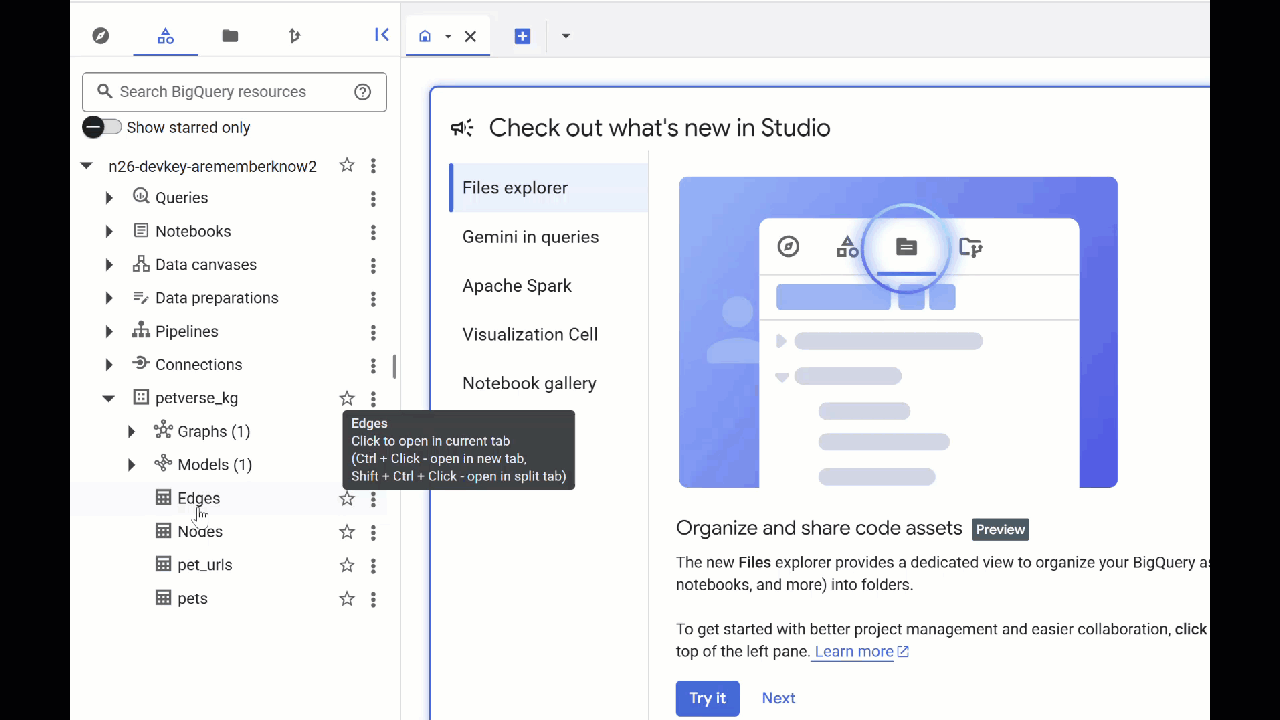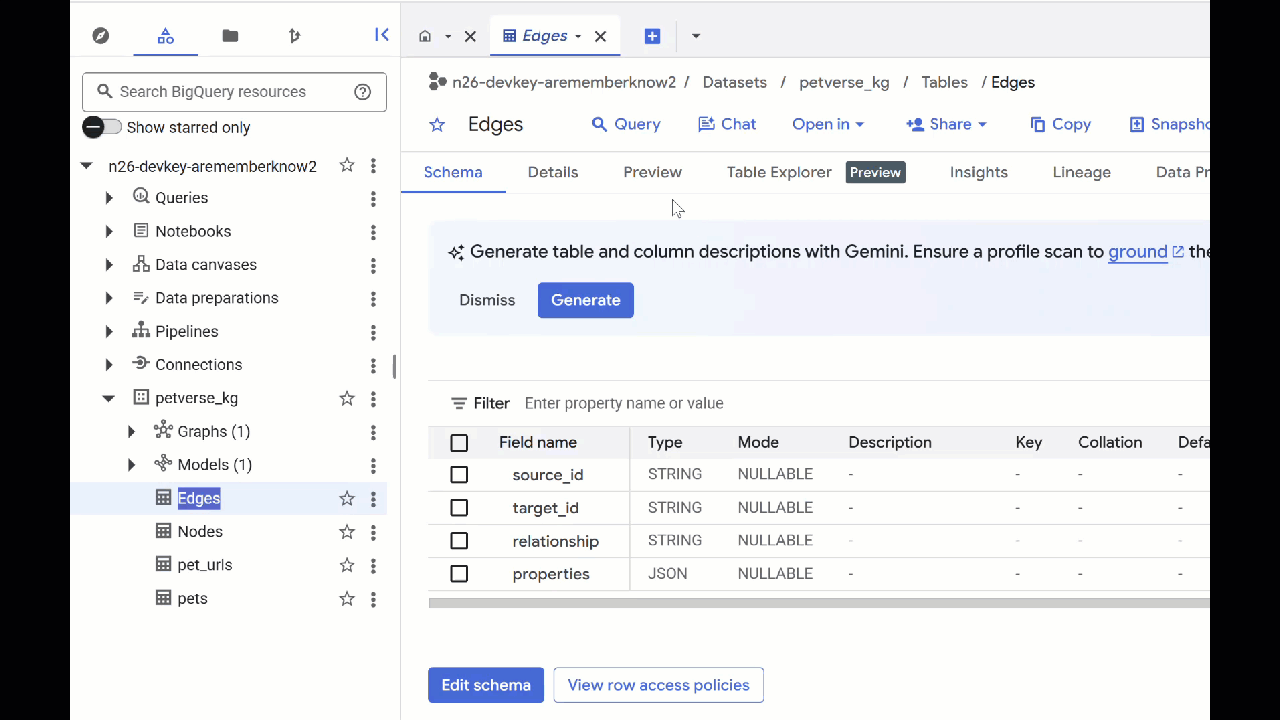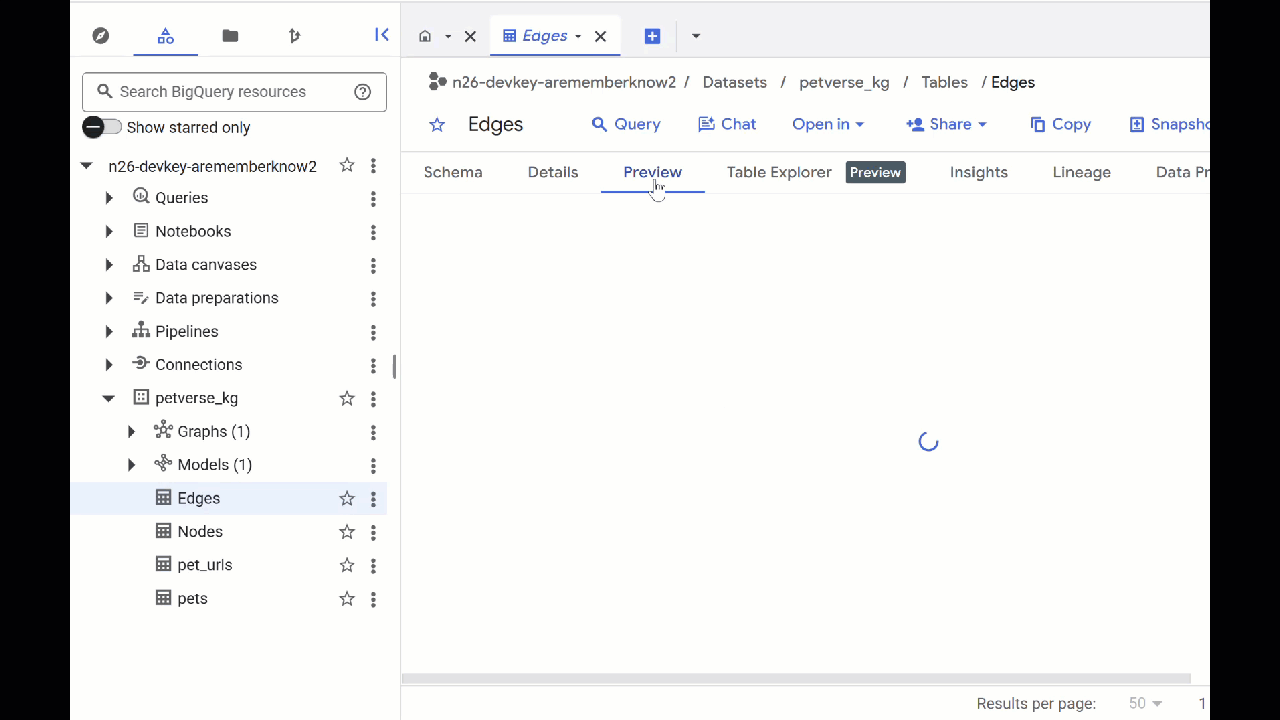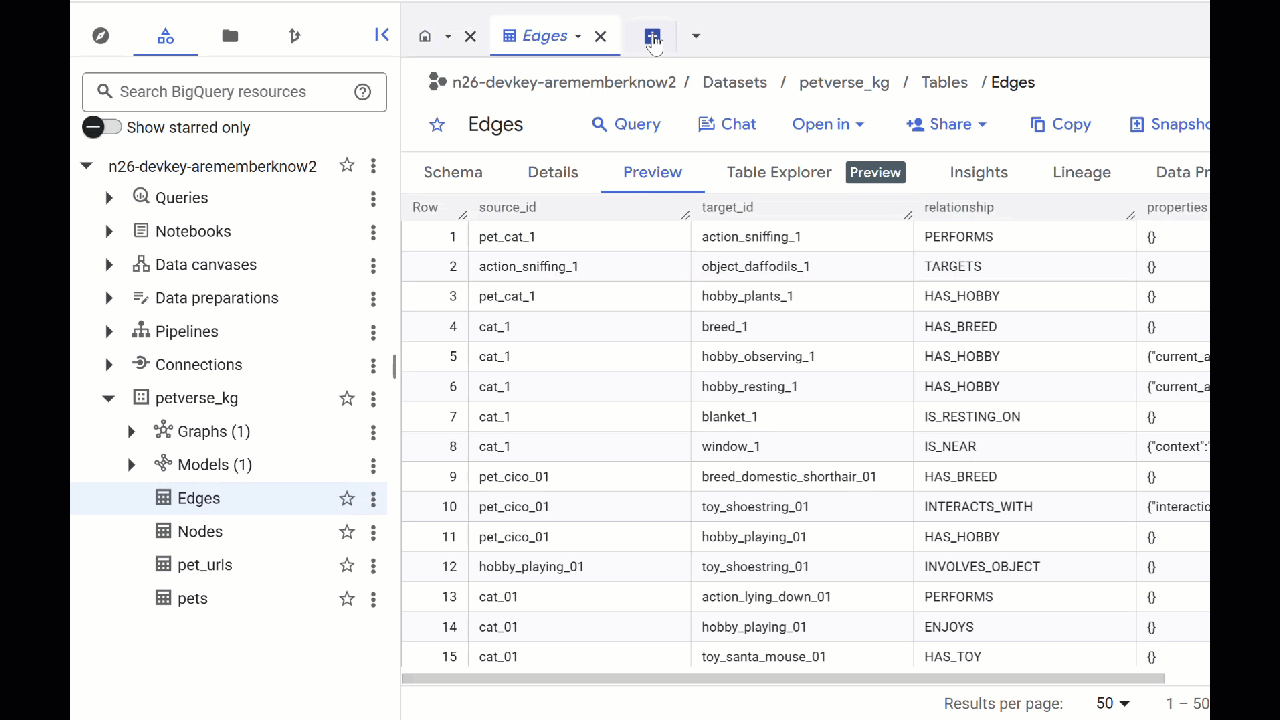
In der Tabelle „Knoten“ finden Sie Informationen zu den von Gemini in den Audio-, Video- und Bildinhalten erkannten Einheiten. Die Tabelle „Edges“ enthält die Beziehungen zwischen ihnen. Wenn Sie sich beispielsweise das Audio der Katze namens SQL anhören, erfahren Sie, dass sie gerne mit Schnürsenkeln spielt und gefriergetrocknete Fischchen mag.
- Klicken Sie auf den Button +, um eine neue Abfrage zu erstellen. Fügen Sie die folgende Anweisung ein und klicken Sie auf Ausführen:
SELECT n.name, n.entity_id, e.relationship, e.target_id
FROM
`petverse_kg.Nodes` n
JOIN
`petverse_kg.Edges` e
ON n.entity_id = e.source_id
WHERE n.name = 'SQL'
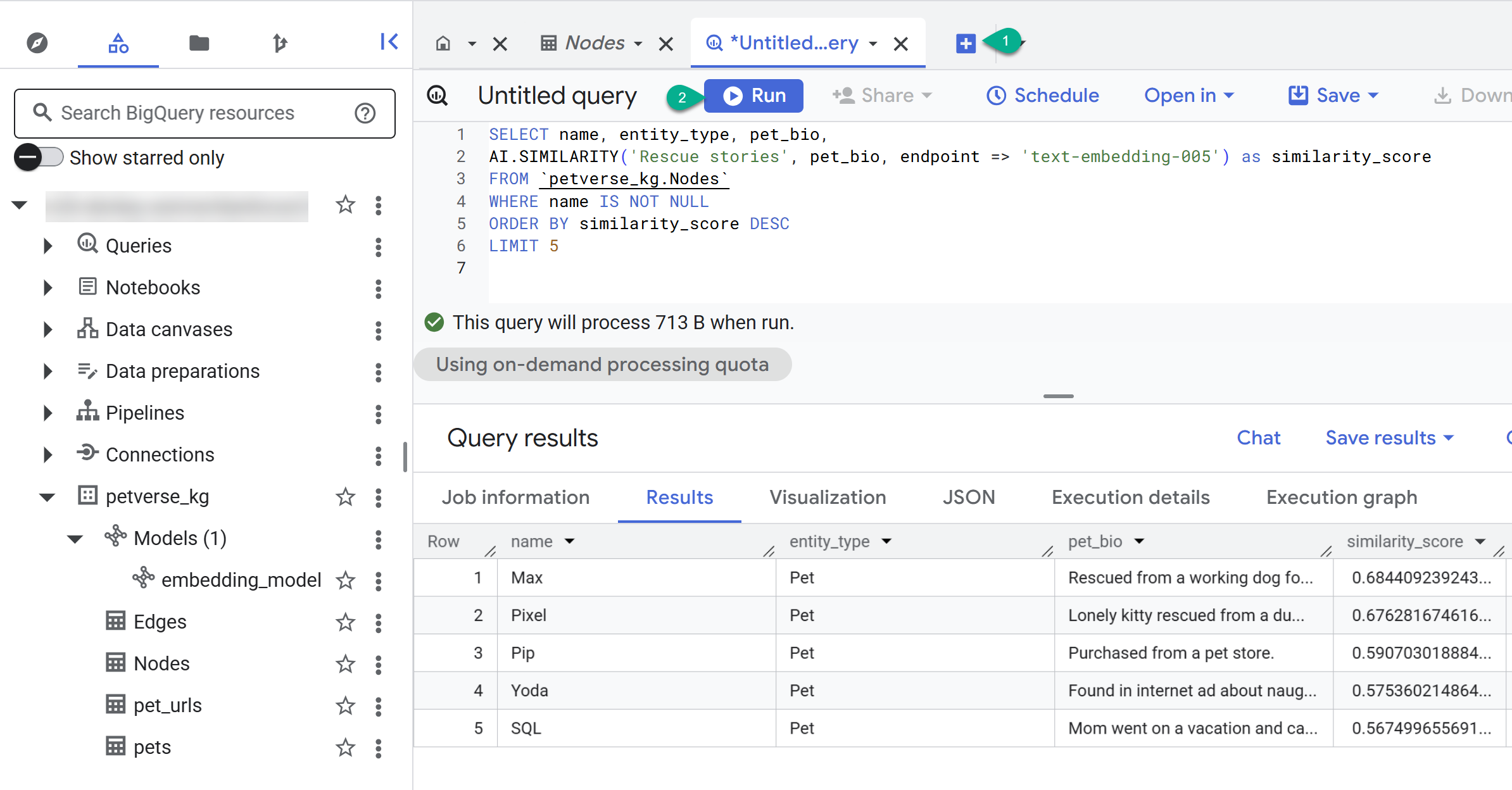
- Klicken Sie auf den Button +, um eine neue Abfrage zu erstellen. Fügen Sie die folgende Anweisung ein und klicken Sie auf Ausführen:
SELECT name, entity_type, pet_bio,
AI.SIMILARITY('Pets who like to relax', pet_bio, endpoint => 'text-embedding-005') as similarity_score
FROM `petverse_kg.Nodes`
WHERE name IS NOT NULL
ORDER BY similarity_score DESC
LIMIT 5
Sie sollten die Knoten für Haustiere sehen, die sich gern entspannen. Bei dieser Abfrage wurde eine semantische Suche mit der KI-Funktion AI.SIMILARITY durchgeführt, um Haustiere zu finden, deren Biografien dem Abfragetext am ähnlichsten sind.
Attributgrafik erstellen
Nachdem wir Knoten und Kanten in BigQuery haben, können wir einen Property Graph erstellen, um Beziehungen einfach abzufragen.
Graph erstellen
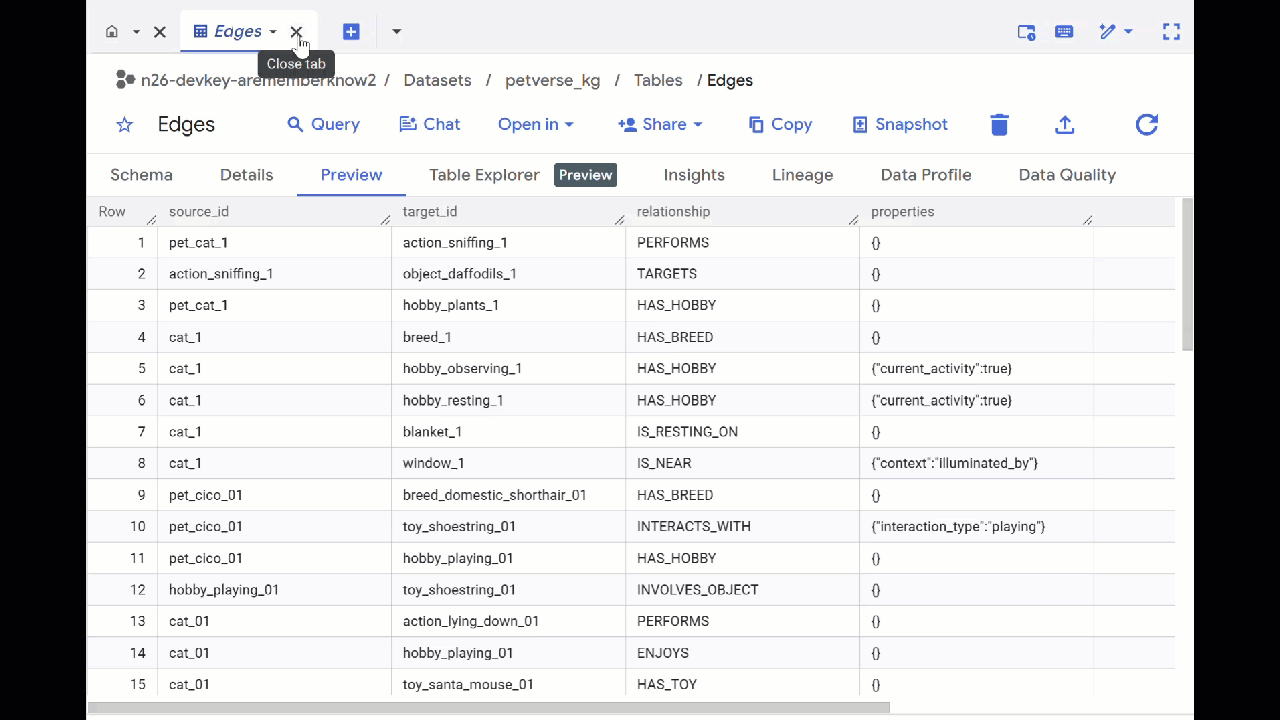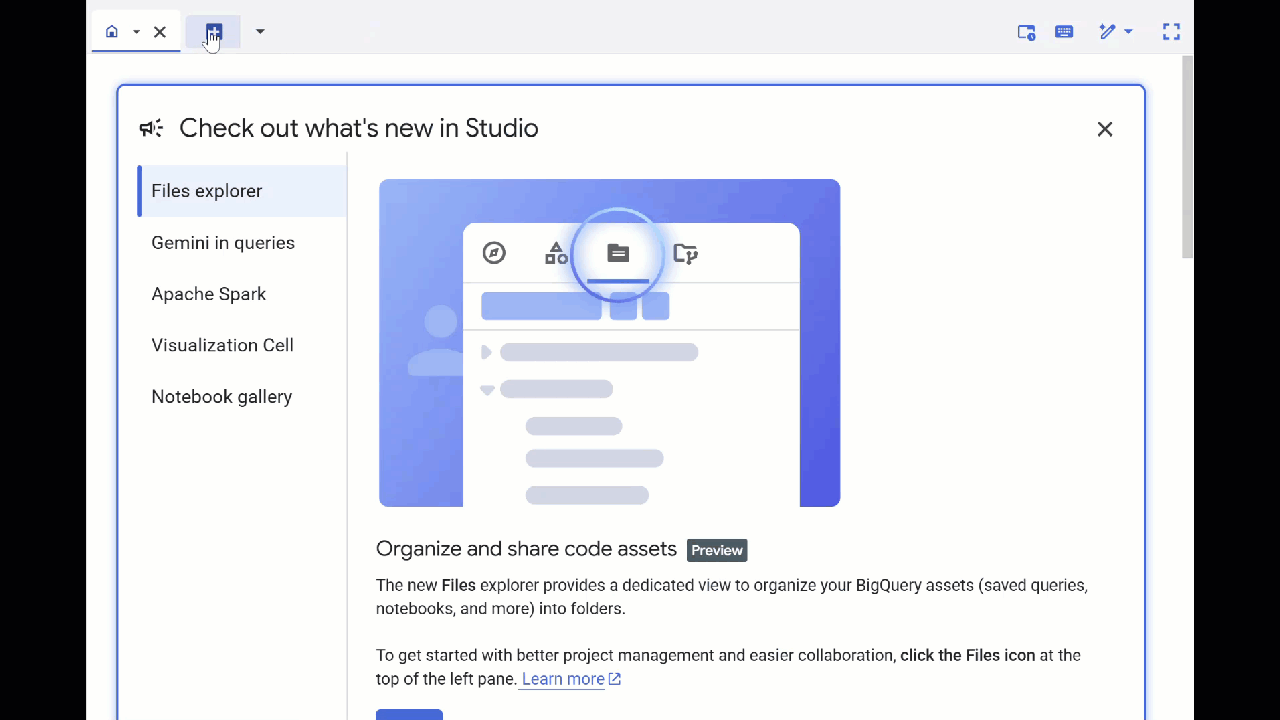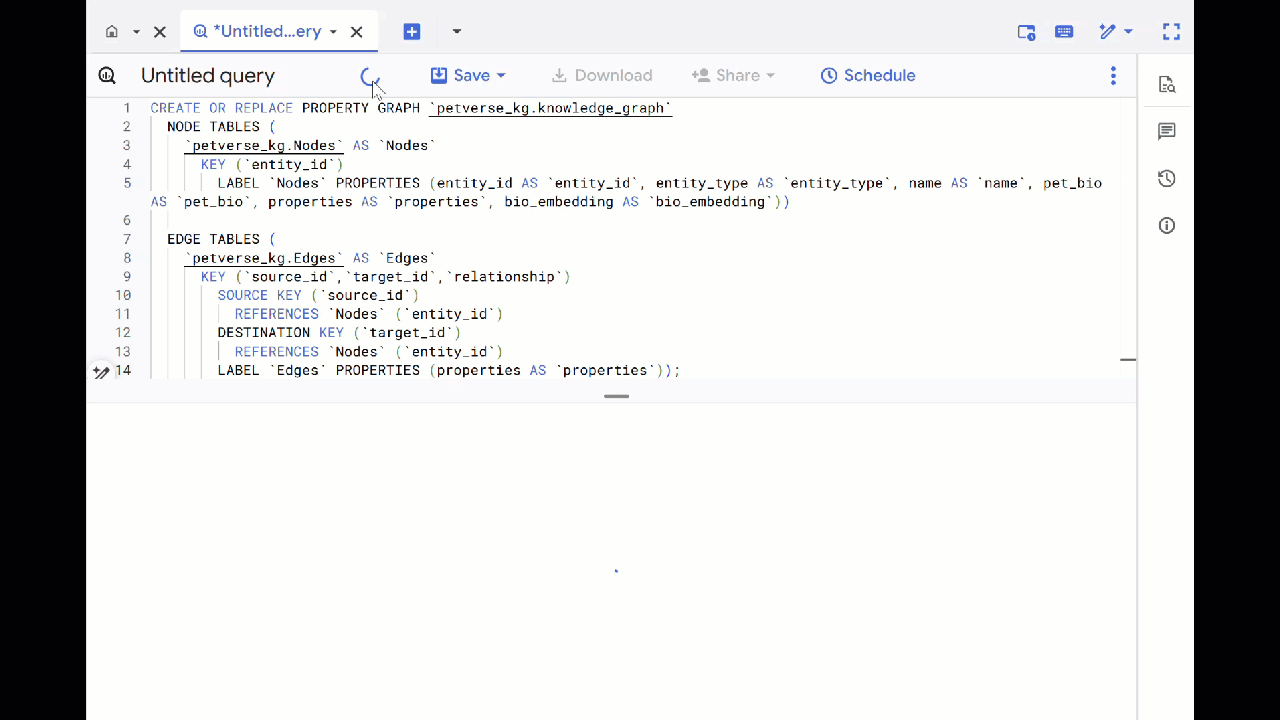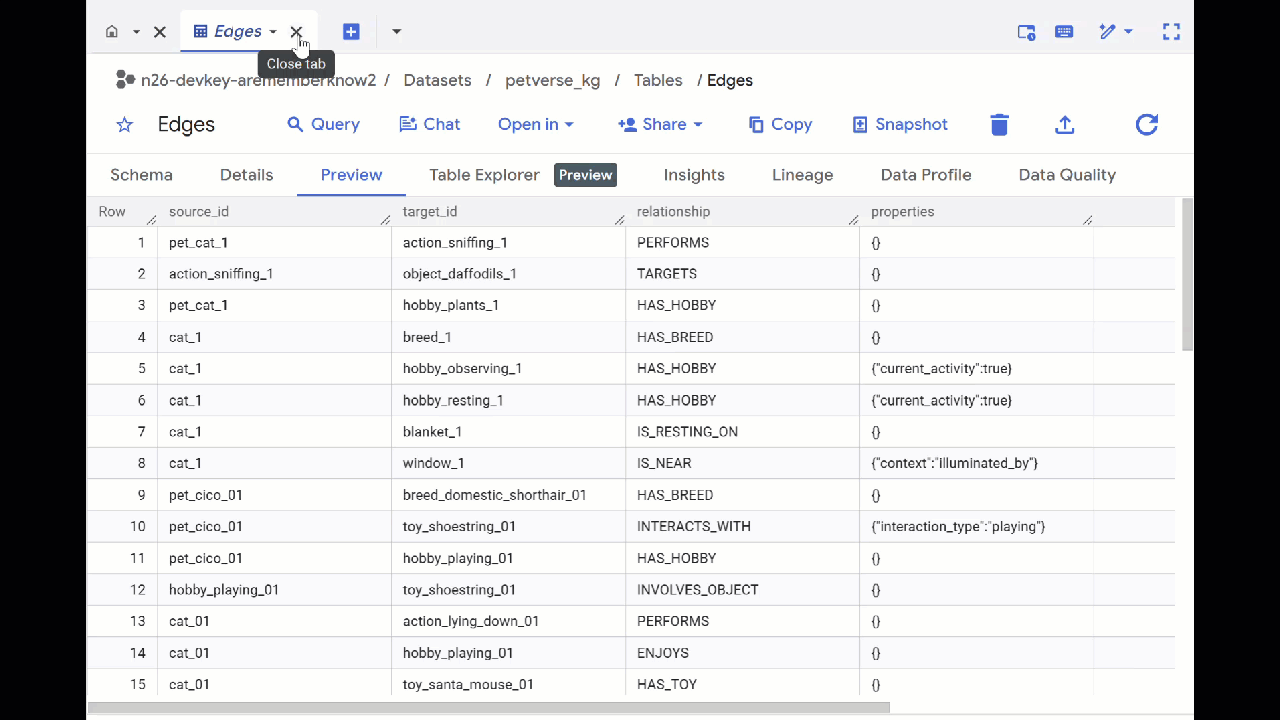
- Überschreiben Sie die vorherige Abfrage und führen Sie die folgende DDL aus, um den Attributgraphen zu erstellen:
CREATE OR REPLACE PROPERTY GRAPH `petverse_kg.knowledge_graph`
NODE TABLES (
`petverse_kg.Nodes` AS `Nodes`
KEY (`entity_id`)
LABEL `Nodes` PROPERTIES (entity_id AS `entity_id`, entity_type AS `entity_type`, name AS `name`, pet_bio AS `pet_bio`, properties AS `properties`, bio_embedding AS `bio_embedding`))
EDGE TABLES (
`petverse_kg.Edges` AS `Edges`
KEY (`source_id`,`target_id`,`relationship`)
SOURCE KEY (`source_id`)
REFERENCES `Nodes` (`entity_id`)
DESTINATION KEY (`target_id`)
REFERENCES `Nodes` (`entity_id`)
LABEL `Edges` PROPERTIES (properties AS `properties`));
- Klicken Sie auf Zum Diagramm. Sie sehen die Diagrammvisualisierung mit einem Knoten, der eine Kante zu sich selbst hat. Dies ist zu erwarten.
Graph abfragen
- Sie können alle vorherigen Anfragen schließen und mit der Schaltfläche + eine neue, leere Anfrage öffnen.
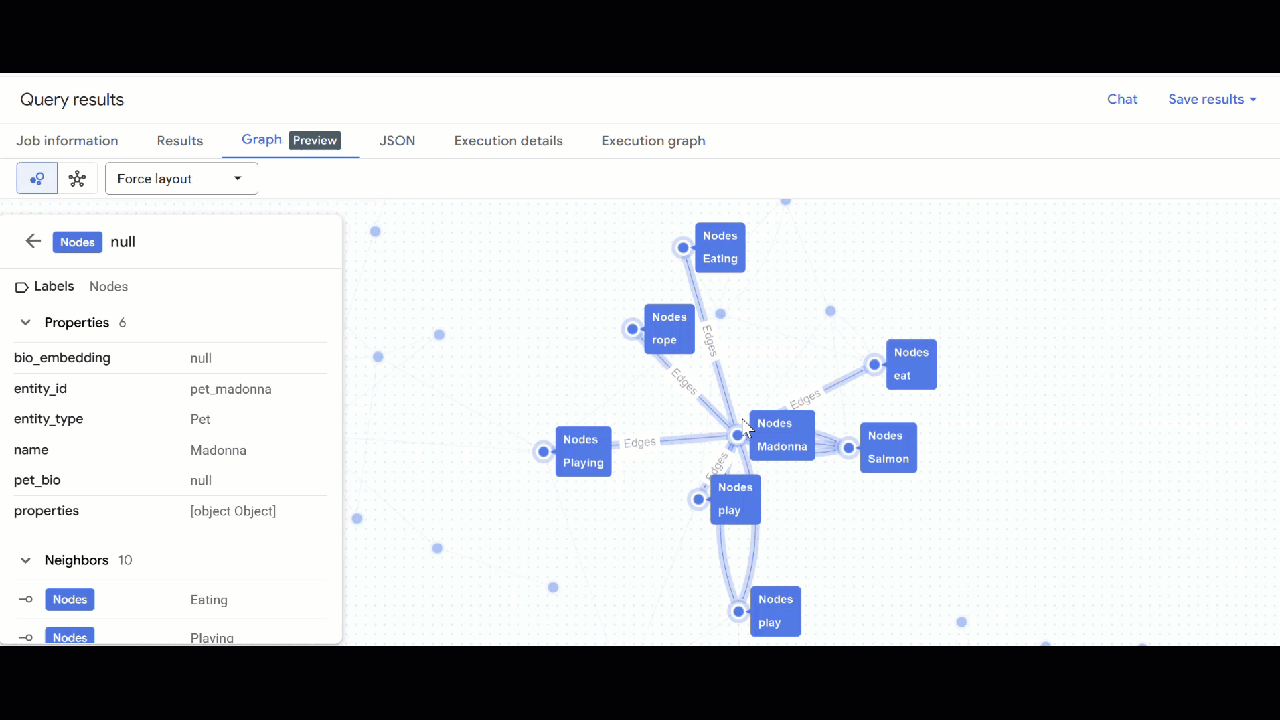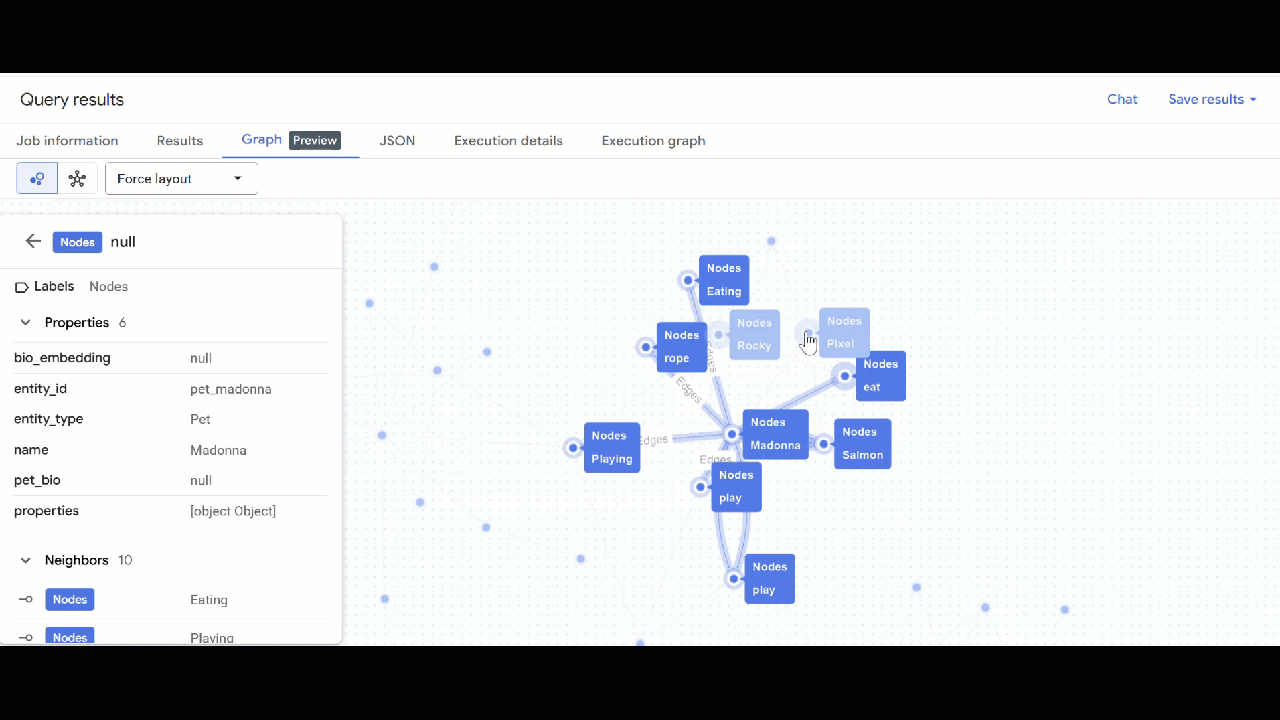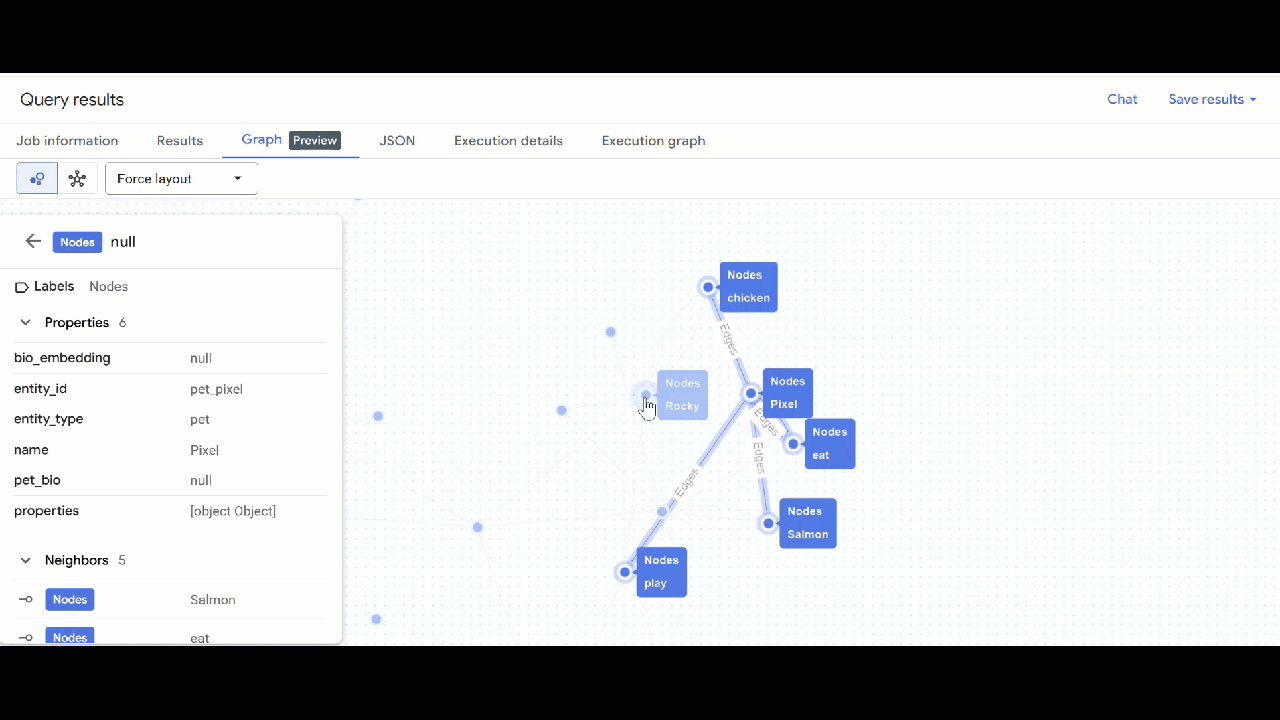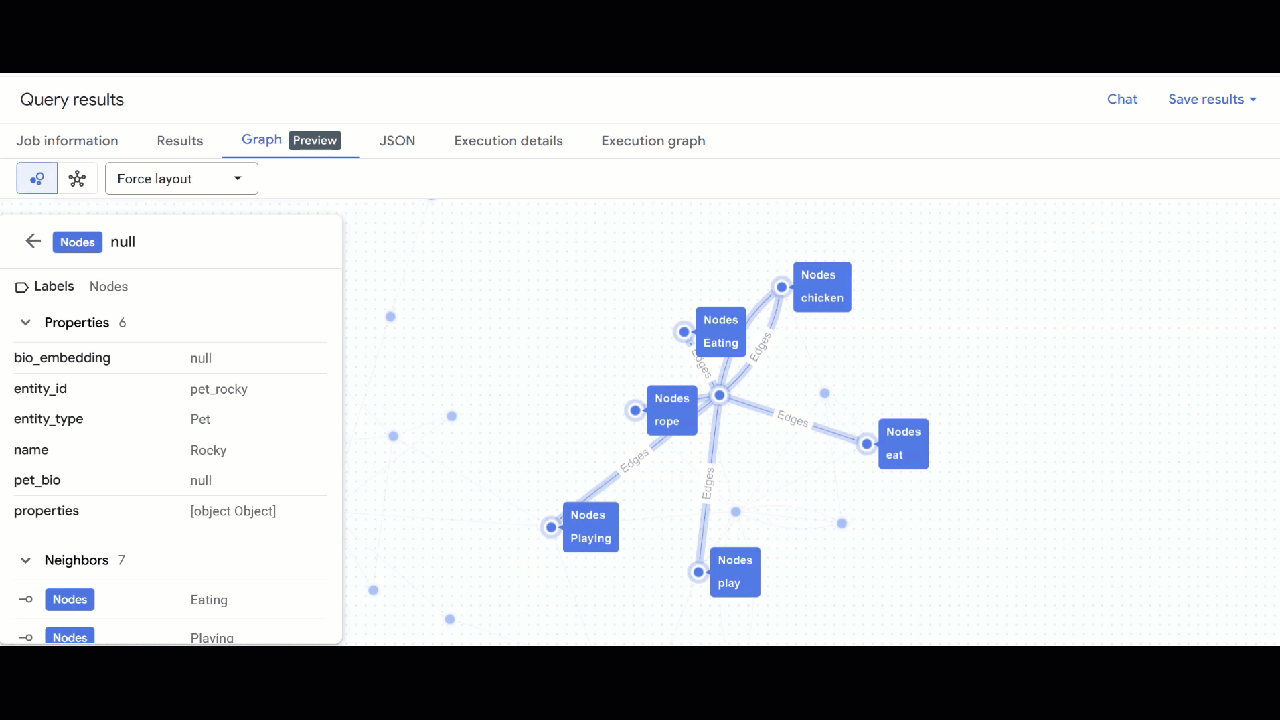
- Mit GQL können Sie Haustiere finden, die über gemeinsame Interessen (z. B. Hobbys, Lieblingsfutter oder Spielzeug) mit anderen Haustieren verbunden sind. Diese Multi-Hop-Abfrage entspricht zwei verschiedenen Haustieren, die mit demselben Knoten verbunden sind:
GRAPH `petverse_kg.knowledge_graph`
MATCH p = (pet1:Nodes)-[e1]->(interest:Nodes)<-[e2]-(pet2:Nodes)
WHERE pet1.entity_id != pet2.entity_id
AND (LOWER(pet1.entity_type) = 'pet' AND LOWER(pet2.entity_type) = 'pet')
AND LOWER(interest.entity_type) IN ('hobby', 'action', 'activity', 'food', 'toy')
RETURN TO_JSON(p) as res
LIMIT 100
- Die Visualisierung des Diagramms sollte angezeigt werden. Sie können auf die Knoten klicken, um die Eigenschaften der Knoten und Kanten aufzurufen.
🕵️ Hinweis: Sie können den vom Knoten angezeigten Wert anpassen, indem Sie auf Zur Schemadarstellung wechseln klicken:
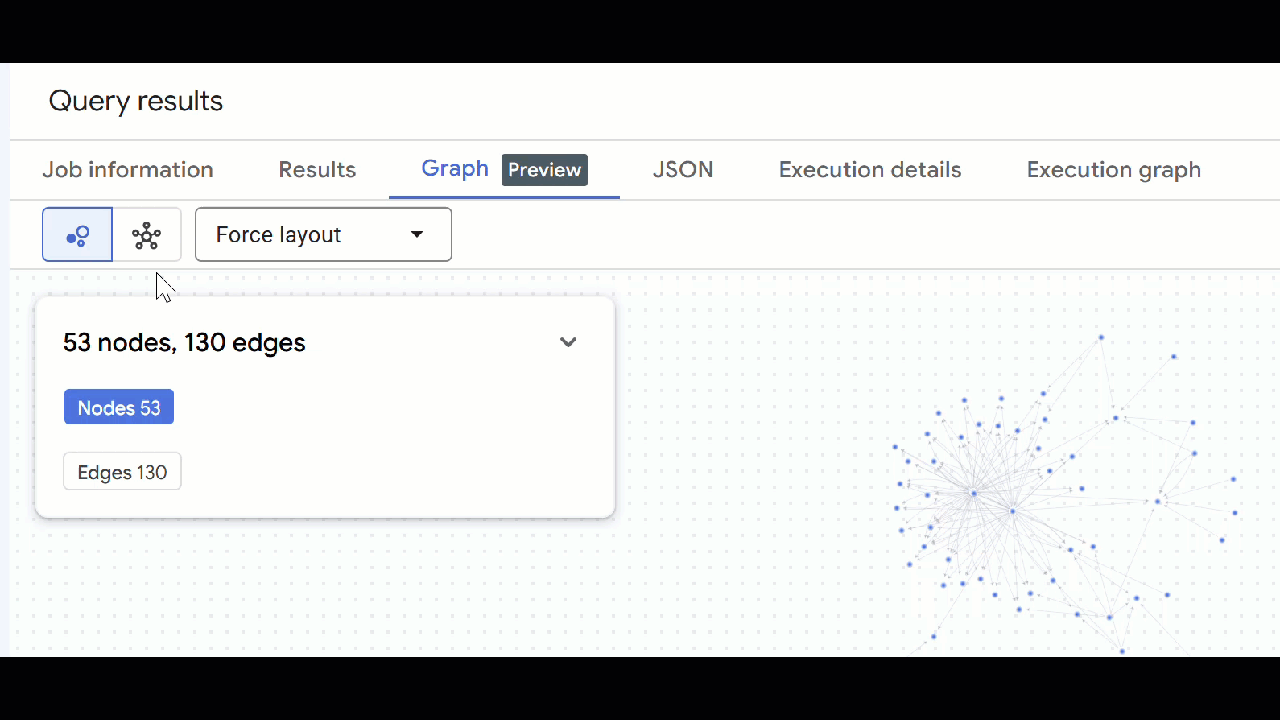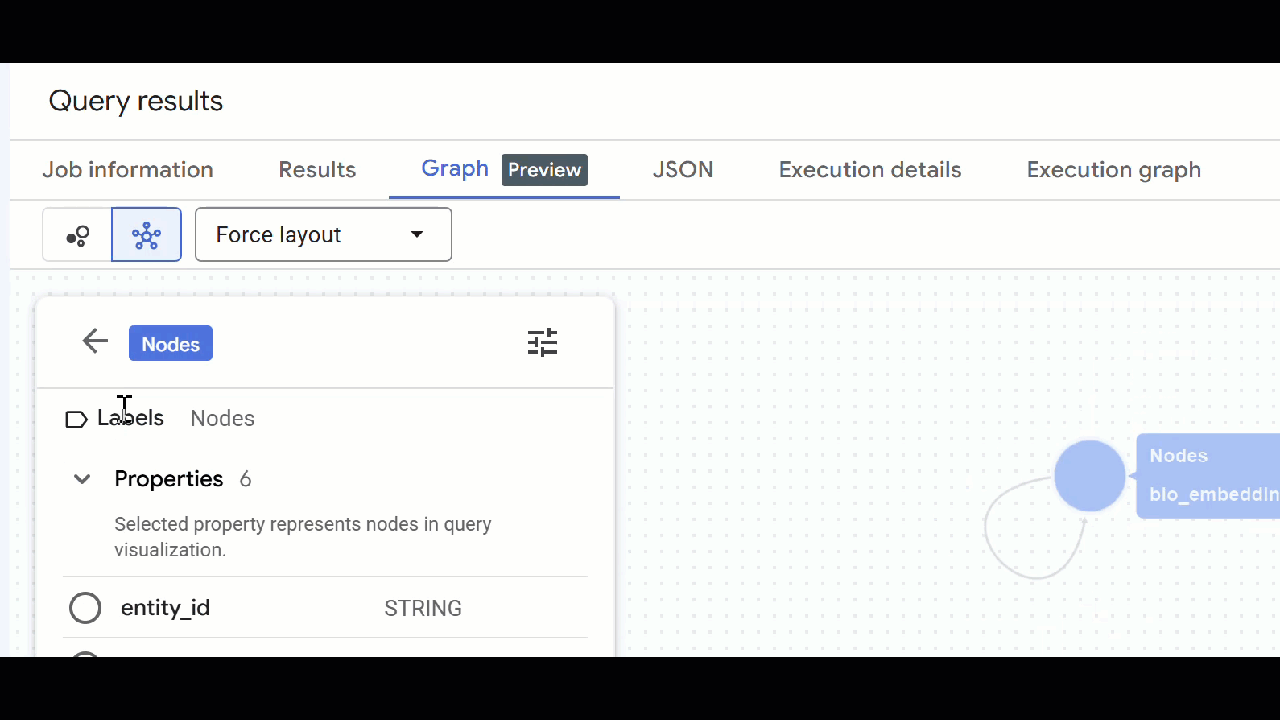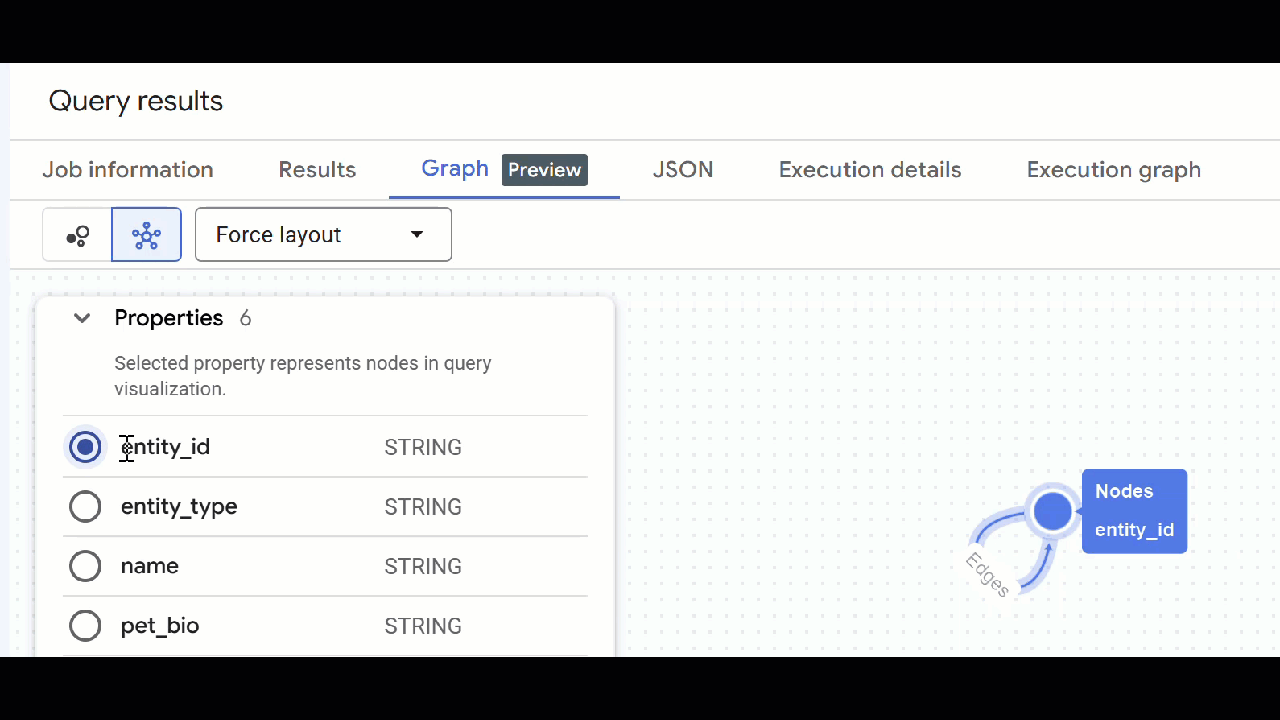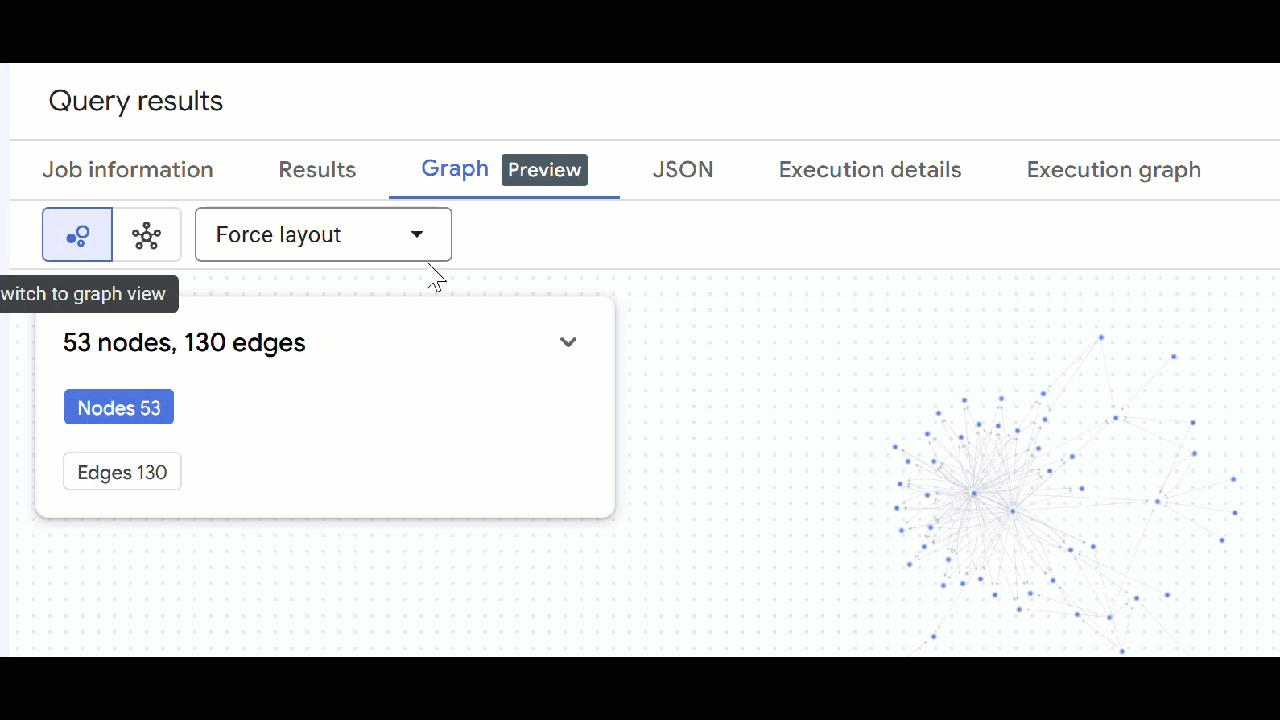
- Sie können alle geöffneten Abfragetabs schließen.
8. Mit dem Diagramm chatten
- Neben dem +-Zeichen befindet sich ein Drop-down-Menü. Wählen Sie Unterhaltung aus.
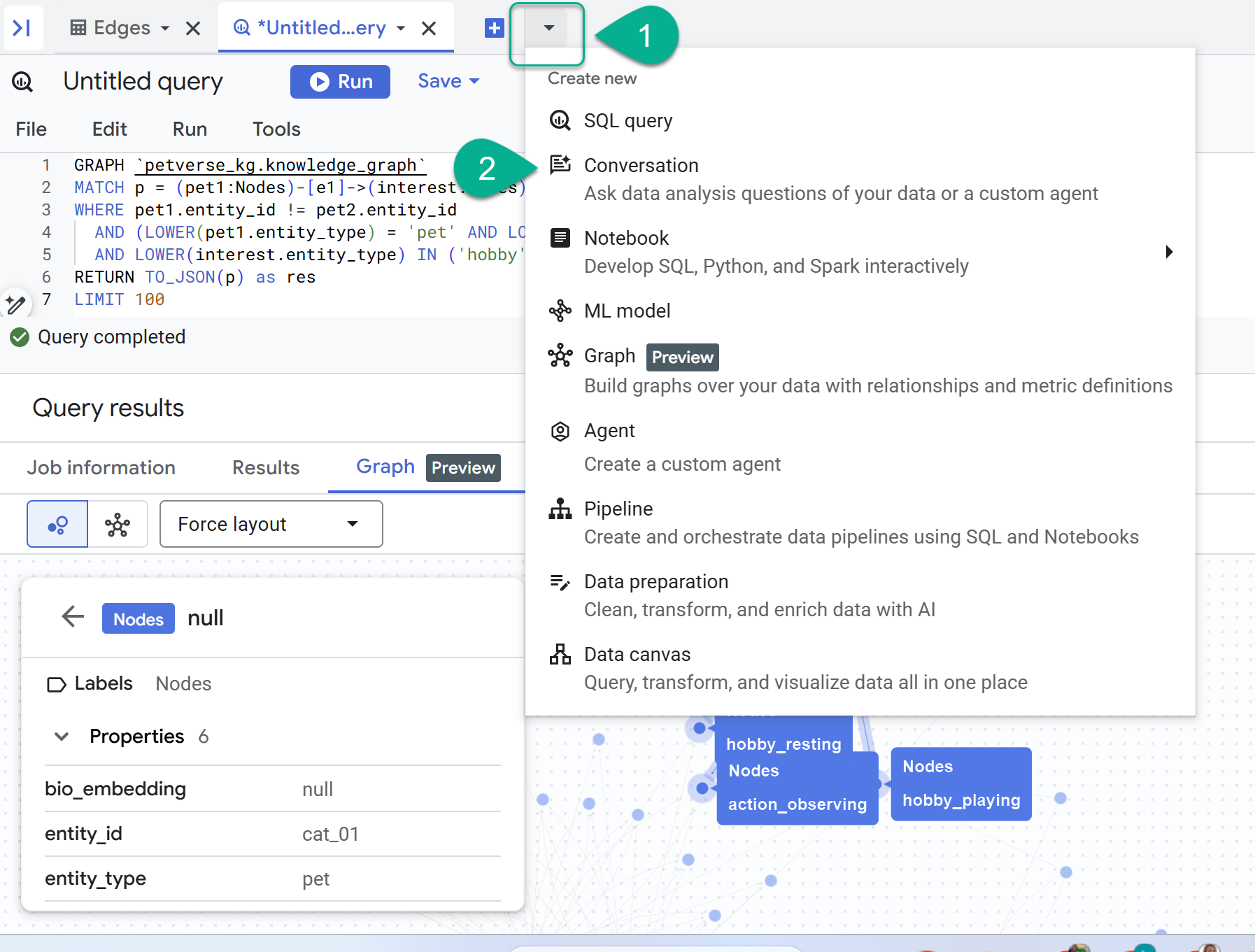
- Sie werden aufgefordert, die Data Analytics API with Gemini zu aktivieren. Aktivieren Sie beide APIs. Aktualisieren Sie das Fenster oder erstellen Sie eine neue Unterhaltung, um den Agenten zu sehen.
- Klicken Sie auf Neuer Agent.
- Geben Sie dem Agenten einen Namen, z. B.
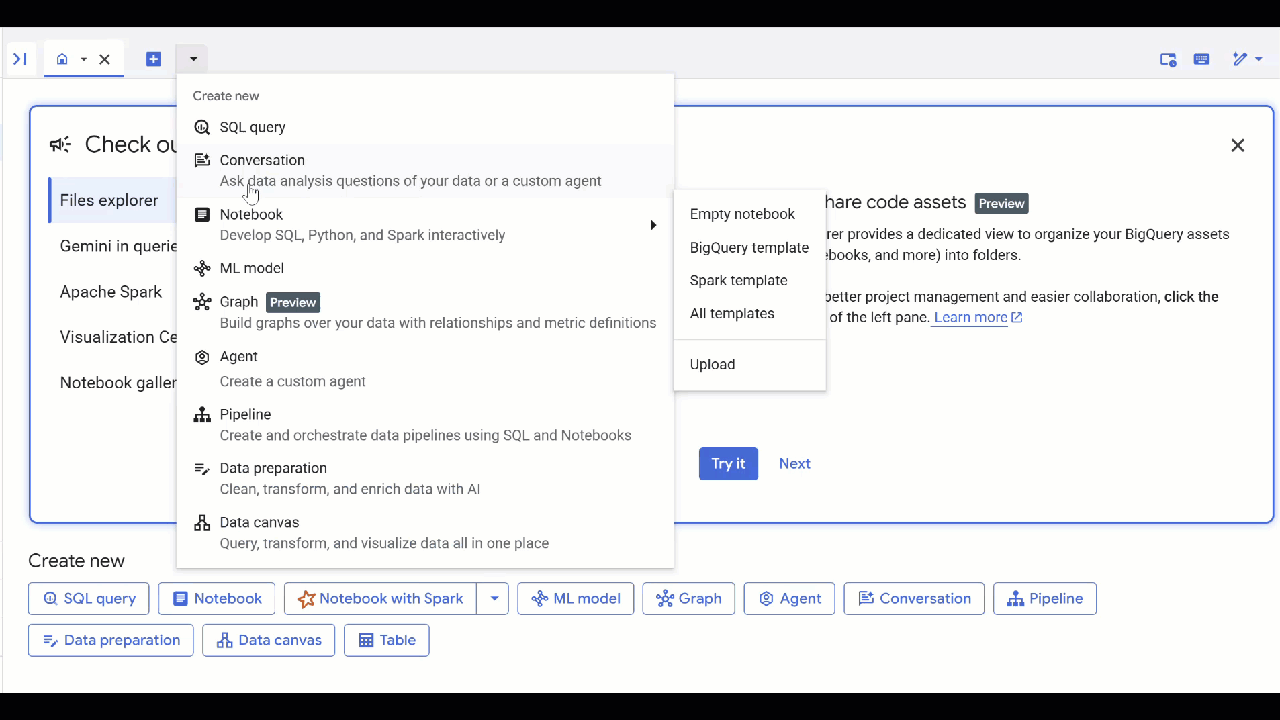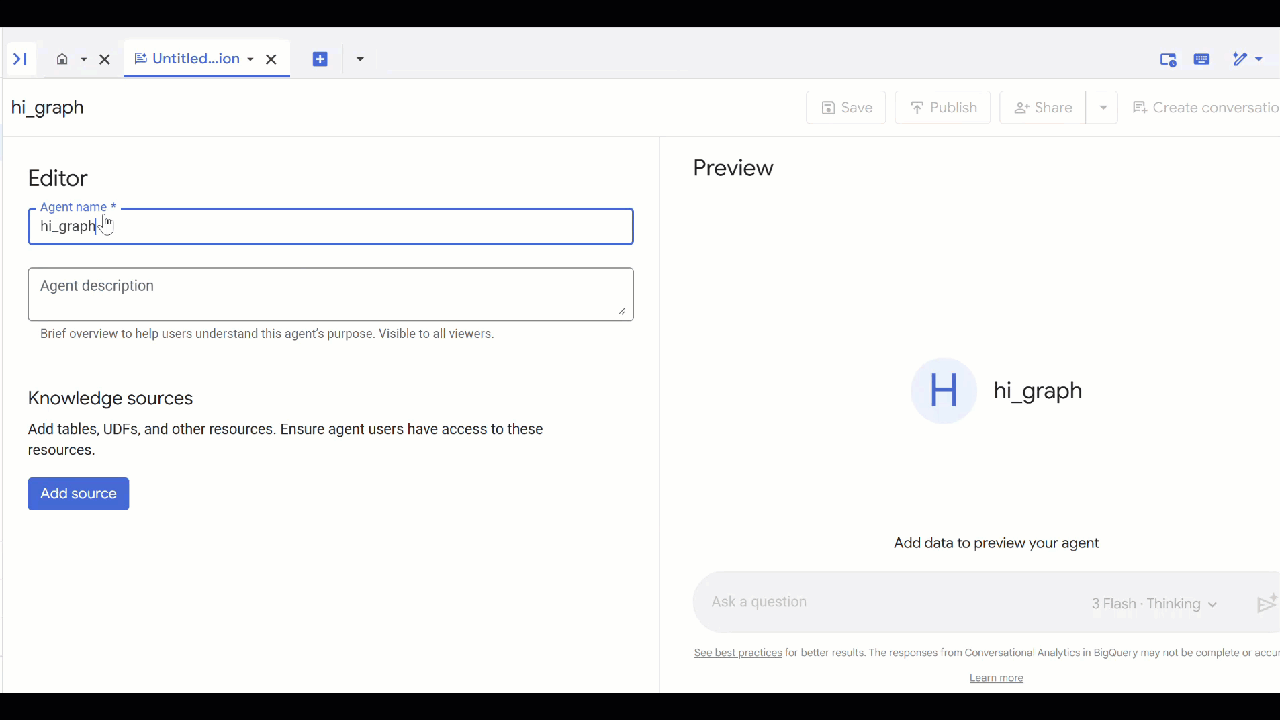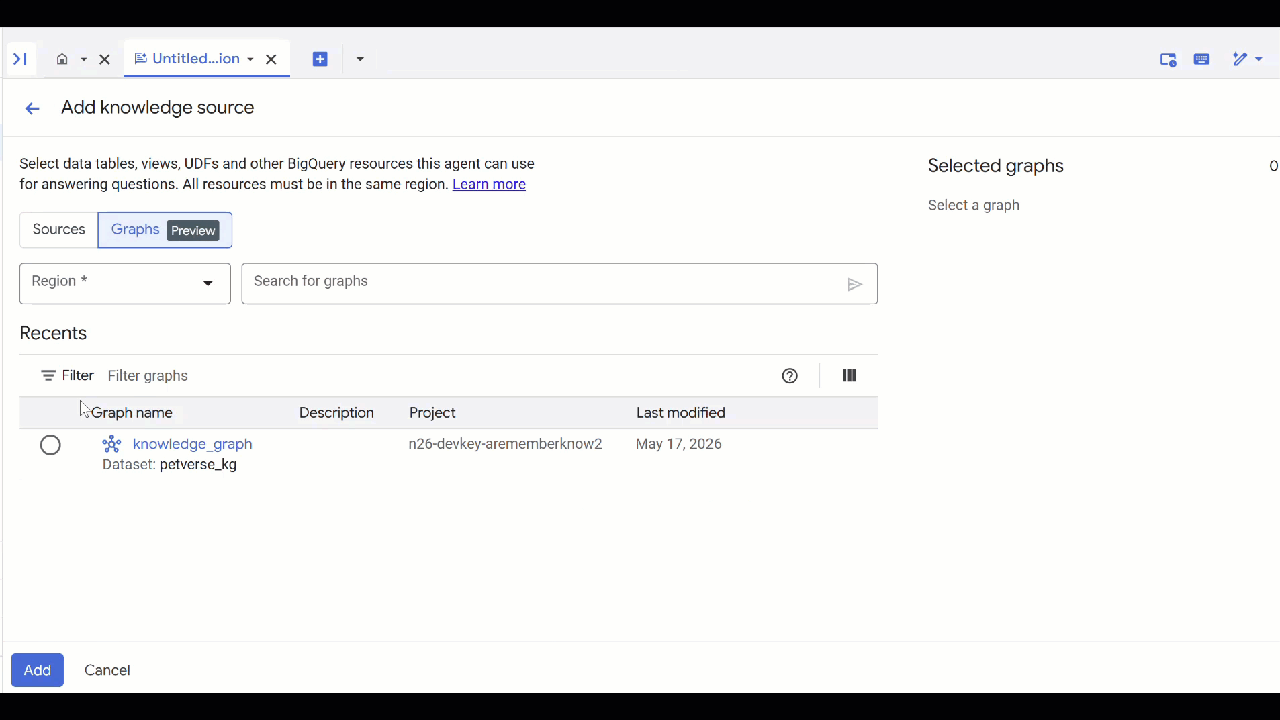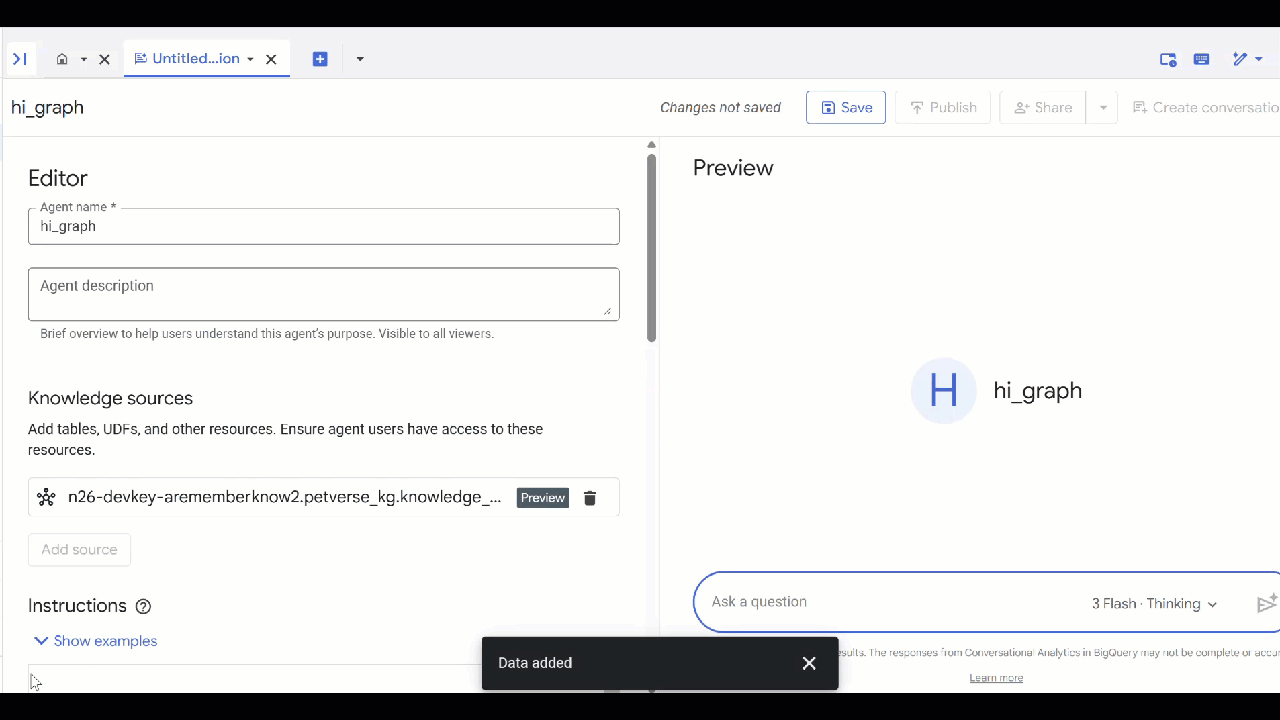
petverse. - Klicken Sie auf Quelle hinzufügen und dann auf Diagramm.
- Wählen Sie den erstellten Bucket
knowledge_graphaus und klicken Sie auf Hinzufügen.
Sie können dem Agenten jetzt eine Frage stellen und sich die Antworten und die Begründung dafür ansehen. Hier sind einige Beispielfragen, die als Inspiration dienen können. Ein Denkmodell kann etwas länger dauern, erstellt aber wahrscheinlich eine bessere GQL-Abfrage. Wenn Sie Show Thinking maximieren, sehen Sie, was erstellt wird.
- Finde Haustiere, die ähnliche Futtermittel fressen, oder Haustiere, die mit Haustieren befreundet sind, die gerne ein Nickerchen machen.
- Haben zwei Haustiere genau dasselbe Hobby, Lieblingsfutter oder Lieblingsspielzeug? Listen Sie die Paare und ihre gemeinsamen Interessen auf.
- Finde Haustiere, die derselben Art oder Rasse angehören, aber ganz andere Hobbys haben.
9. Bereinigen
Löschen Sie die in diesem Codelab erstellten Ressourcen, um laufende Gebühren für Ihr Google Cloud-Konto zu vermeiden.
- Löschen Sie den GKE-Cluster:
gcloud container clusters delete petverse-cluster --region $REGION --quiet
- Löschen Sie das BigQuery-Dataset. Dadurch werden alle Tabellen gelöscht:
bq rm -r -f -d $PROJECT_ID:petverse_kg
- Löschen Sie die Pub/Sub-Warteschlangenressourcen:
gcloud pubsub subscriptions delete petverse-sub --quiet
gcloud pubsub topics delete petverse-topic --quiet
- Löschen Sie das Artifact Registry-Repository:
gcloud artifacts repositories delete gke-cats-repo --location=$REGION --quiet
- Löschen Sie den projektspezifischen GCS-Bucket:
gcloud storage buckets delete gs://$PROJECT_ID-petverse --quiet
10. Glückwunsch
Glückwunsch! Sie haben erfolgreich eine Pipeline für verteilte Knowledge Graphs mit GKE und Gemini erstellt und mit BigQuery-Eigenschaftsgraphen abgefragt.
Das haben Sie gelernt
- Verteilte Jobs in GKE Autopilot bereitstellen
- Gemini für die multimodale Datenextraktion verwenden
- BigQuery verwenden
- Property Graphs in BigQuery erstellen und abfragen