
1. Introducción
En este codelab, compilarás una canalización de adquisición de conocimiento distribuida para "Petverse". Procesarás recursos multimedia no estructurados (audio, video, imágenes, texto/CSV) desde un bucket de Cloud Storage, extraerás información clave sobre las mascotas (comida favorita, pasatiempos) y crearás un gráfico de conocimiento. Escalarás el procesamiento del archivo multimedia con el procesamiento multimodal de Gemini en Google Kubernetes Engine (GKE). Por último, almacenarás estos datos en BigQuery y usarás la nueva función BigQuery Property Graph para analizar las relaciones.
Usaremos la potencia de Google Kubernetes Engine para demostrar el procesamiento paralelo de grandes volúmenes de datos.
¿Por qué usar gráficos de conocimiento?
Los gráficos de conocimiento son más adecuados que las bases de datos relacionales tradicionales para representar y analizar relaciones complejas entre entidades.
Usaremos Gemini 2.5 Flash para analizar imágenes, archivos de audio y video, y establecer datos sobre diferentes mascotas.
Actividades
- Compila e implementa un trabajo de procesamiento de datos distribuido en GKE.
- Usa Gemini para extraer entidades y relaciones de archivos multimedia.
- Almacena los datos del gráfico de conocimiento en BigQuery.
- Crea y consulta un gráfico de propiedades en BigQuery con Graph Query Language (GQL).
Requisitos
- Un navegador web, como Chrome
- Un proyecto de Google Cloud con la facturación habilitada.
- Permisos en el proyecto para crear recursos y modificar políticas de IAM
Este codelab está dirigido a desarrolladores de todos los niveles, incluidos los principiantes.
Duración estimada: 45 minutos
Costo: Los recursos creados en este codelab deberían costar menos de USD 5.
2. Antes de comenzar
Crea un proyecto de Google Cloud
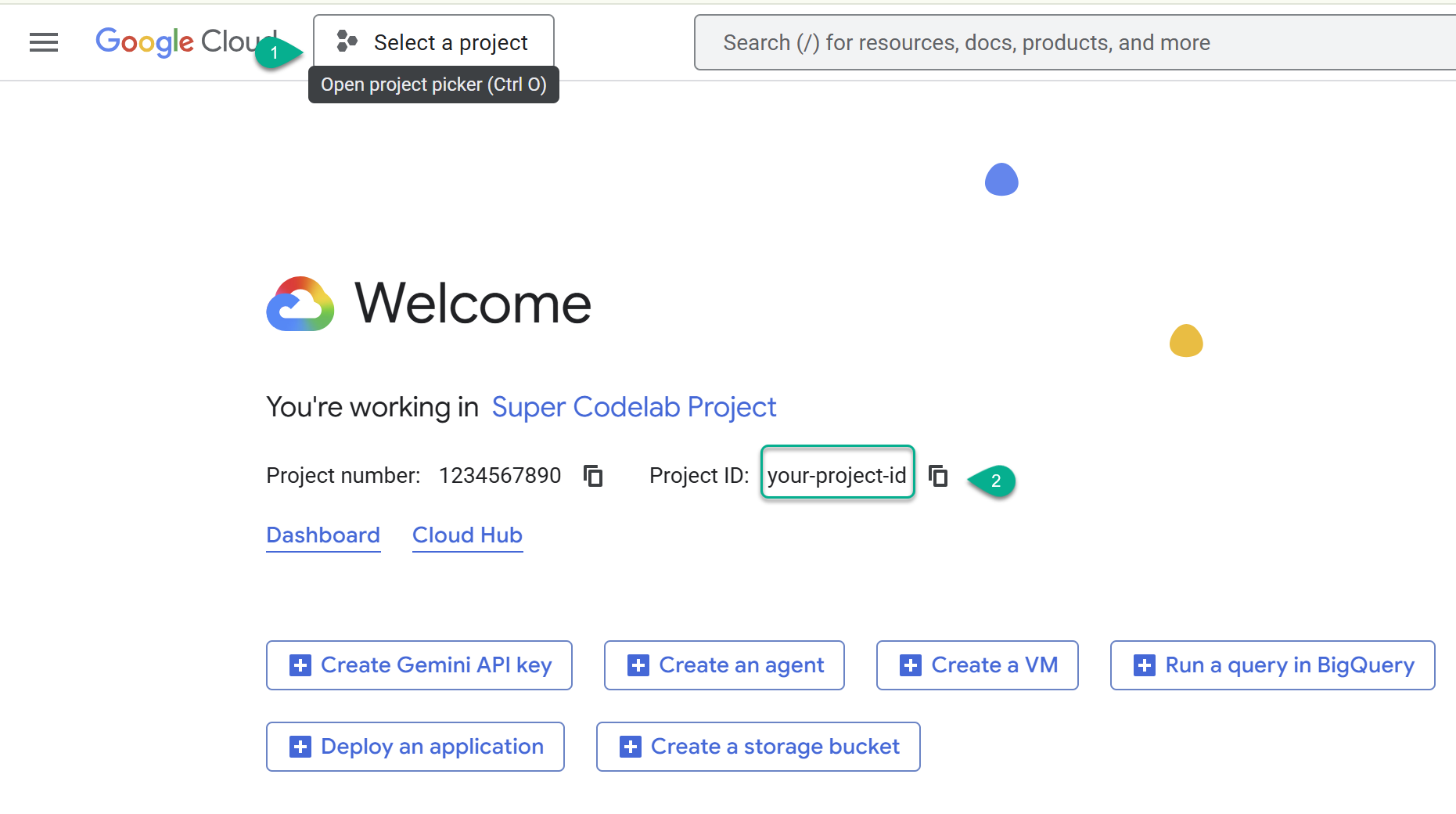
- Navega a la consola de Google Cloud: https://console.cloud.google.com y, luego, selecciona o crea un proyecto de Google Cloud.
- ⚠️ Anota el ID del proyecto. La usarás para varios comandos en este lab.
Inicie Cloud Shell
- Abre Cloud Shell en una pestaña nueva: https://shell.cloud.google.com/.
- Si se te solicita, haz clic en Autorizar.
- Reemplaza
PROJECT_IDy pega el siguiente comando en la terminal:
export PROJECT_ID="YOUR_PROJECT_ID"
gcloud config set project $PROJECT_ID
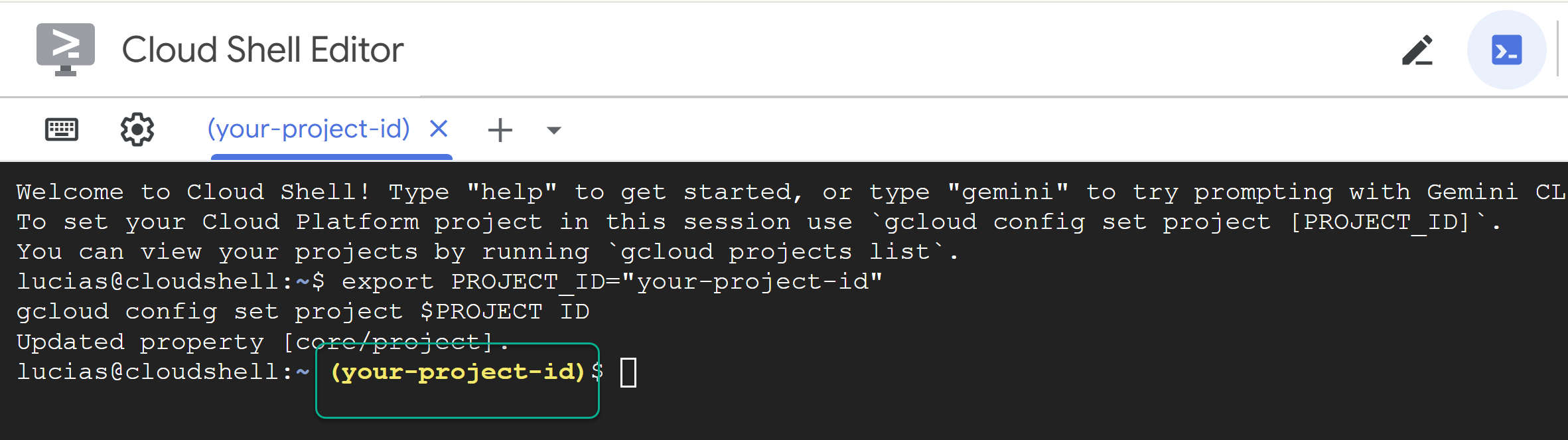
📝 Nota: Tu proyecto se mostrará en amarillo en la línea de comandos. Si se reinicia la sesión, asegúrate de volver a ejecutar el comando anterior para establecer el ID del proyecto.
Habilita las APIs
Ejecuta este comando para habilitar todas las APIs requeridas:
gcloud services enable \
aiplatform.googleapis.com \
bigquery.googleapis.com \
artifactregistry.googleapis.com \
container.googleapis.com \
cloudbuild.googleapis.com \
pubsub.googleapis.com
Clonar repositorio
Ejecuta estos comandos para clonar el repositorio.
cd ~/
git clone --filter=blob:none --no-checkout https://github.com/GoogleCloudPlatform/devrel-demos.git
cd ~/devrel-demos
git sparse-checkout init --cone
git sparse-checkout set codelabs/gke-knowledge-graph
git checkout main
cd codelabs/gke-knowledge-graph/
Ejecuta la secuencia de comandos de configuración
Esta secuencia de comandos automatiza la configuración del backend de la siguiente manera:
- Crea una imagen de contenedor y un repositorio de Artifact Registry
- Crea un conjunto de datos de BigQuery
- Crea una conexión de BigQuery para ejecutar funciones de IA de Gemini desde SQL
Ejecuta el siguiente comando en la terminal:
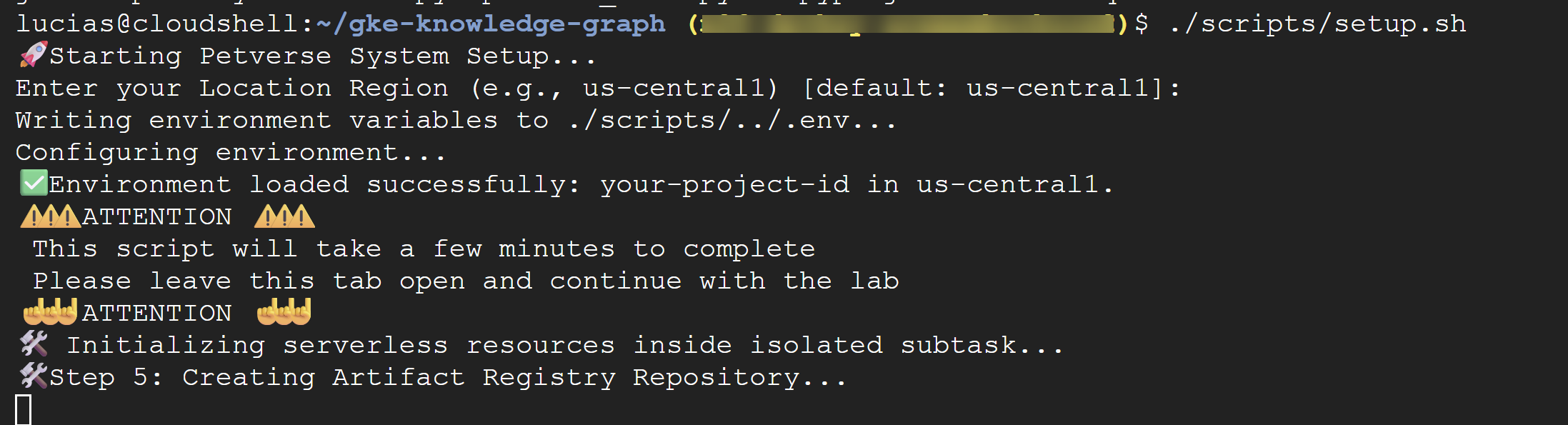
./scripts/setup.sh
Si la secuencia de comandos te solicita detalles de configuración, usa estos valores:
- ID del proyecto: Usa el ID que creaste en el paso anterior.
- Región:
us-central1
⚠️ Importante La secuencia de comandos tardará unos minutos en completarse. Deja esta ventana de terminal abierta para que se complete en segundo plano. Para continuar con el siguiente paso, abre una nueva pestaña o ventana de terminal para ejecutar los próximos comandos.
3. Configura el Data Agent Kit
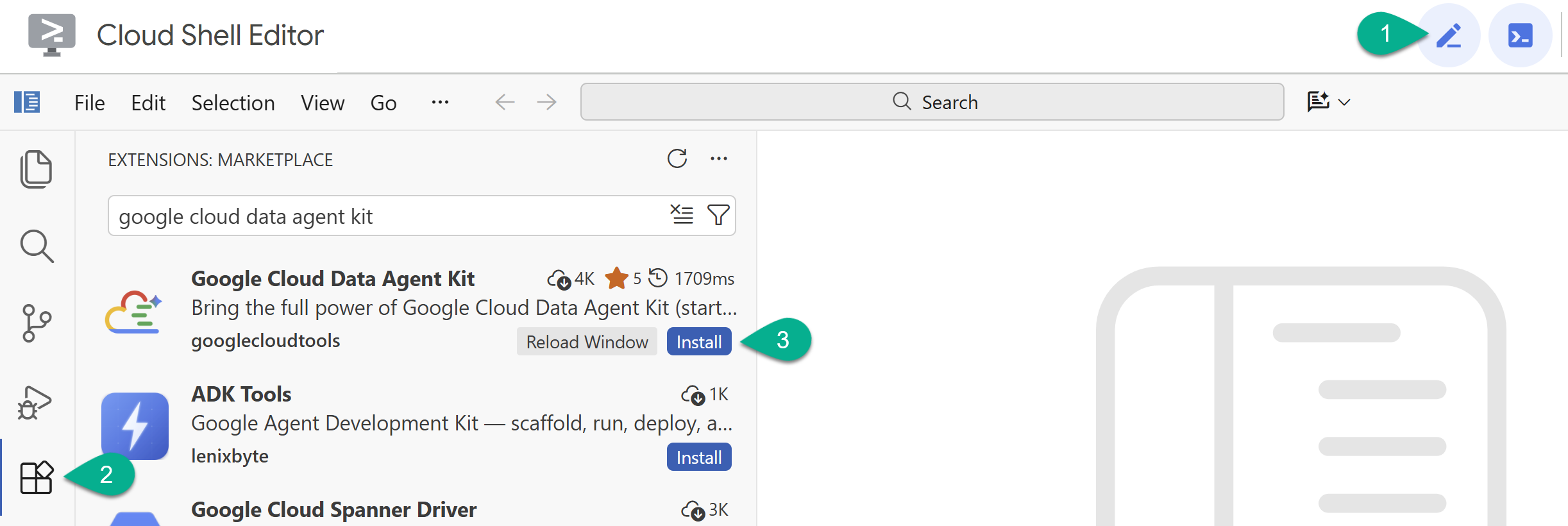
- Habilita el editor de Cloud Shell con el ícono de lápiz en la esquina superior derecha.
- En el editor de Cloud Shell, haz clic en el ícono de Extensiones en la barra lateral izquierda.
- Busca Google Cloud Data Agent Kit y haz clic en Install si aún no está instalado.
- Accede a tu Cuenta de Google con la extensión.
- En el Resumen de configuración, ingresa tu ID del proyecto y
us-central1como la región.
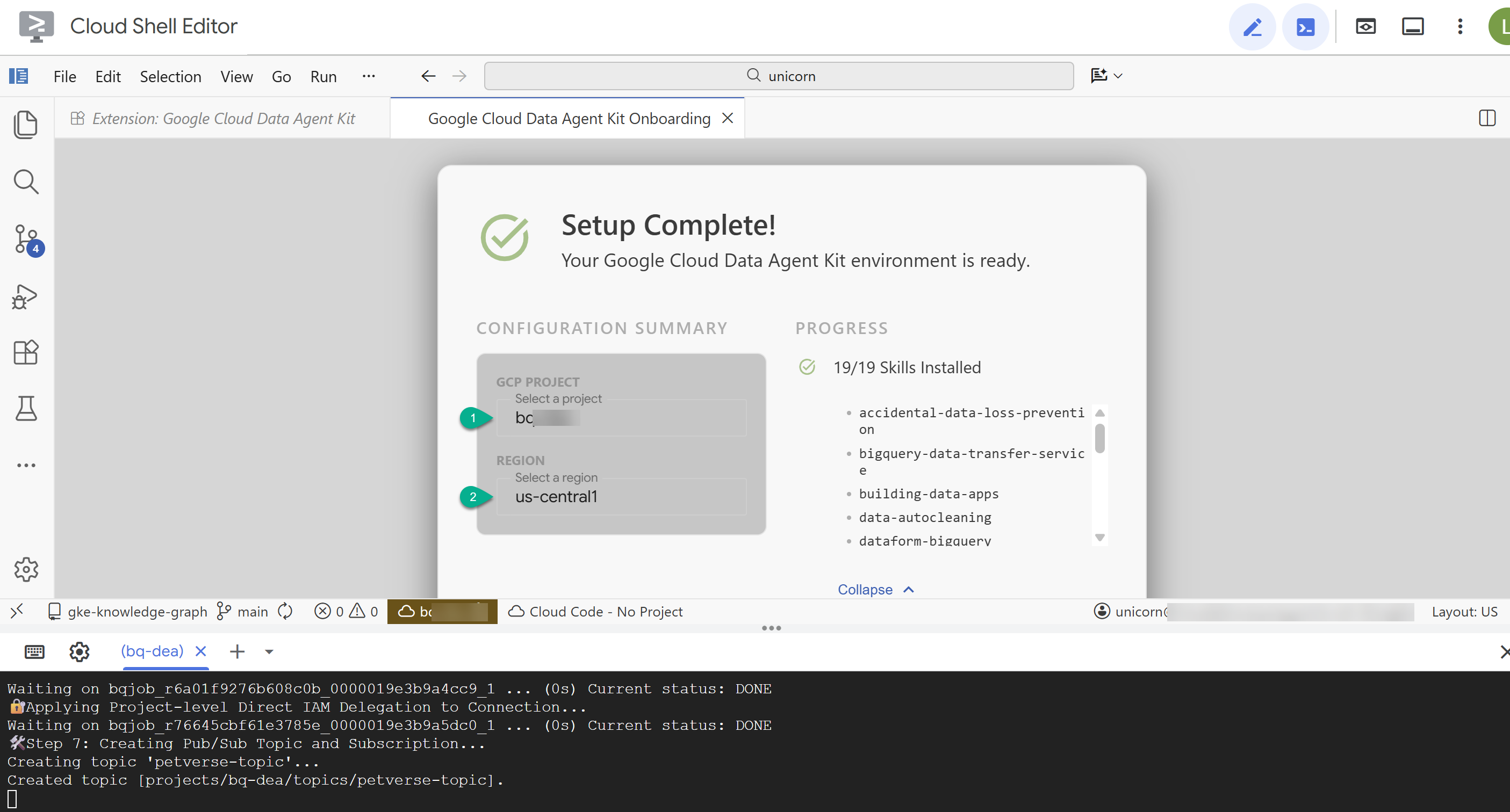
- Haz clic en Configurar servidores de MCP. No es necesario que realices ningún cambio en esta ventana. Simplemente haz clic en Comenzar.
- Vuelve a cargar la ventana si se te solicita. Por el momento, puedes cerrar la pestaña de la Guía de inicio rápido.
Configura las tablas en BigQuery
- En la barra lateral, vuelve al explorador. Si tu carpeta principal (p.ej.,
/home/your_user_name/) no está abierta, haz clic en Abrir carpeta y selecciónala.
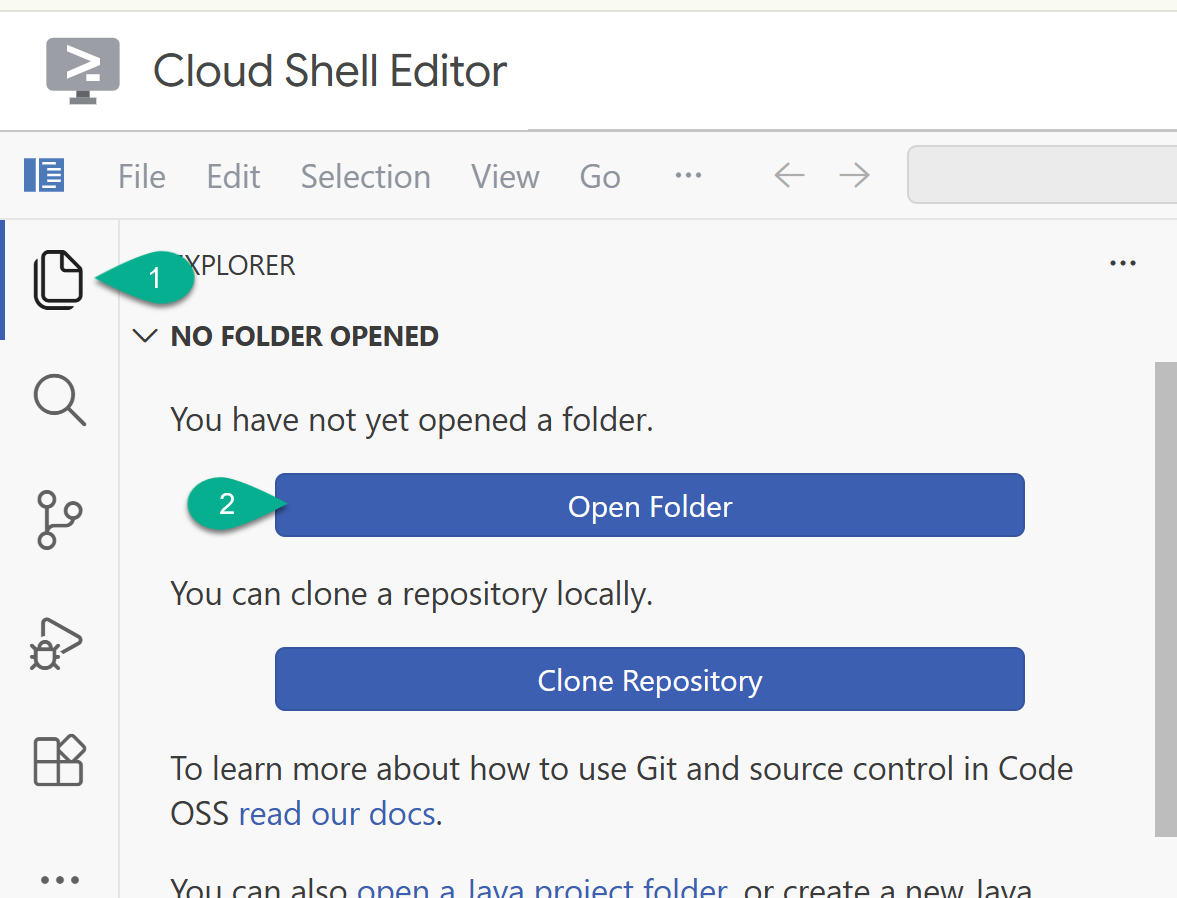
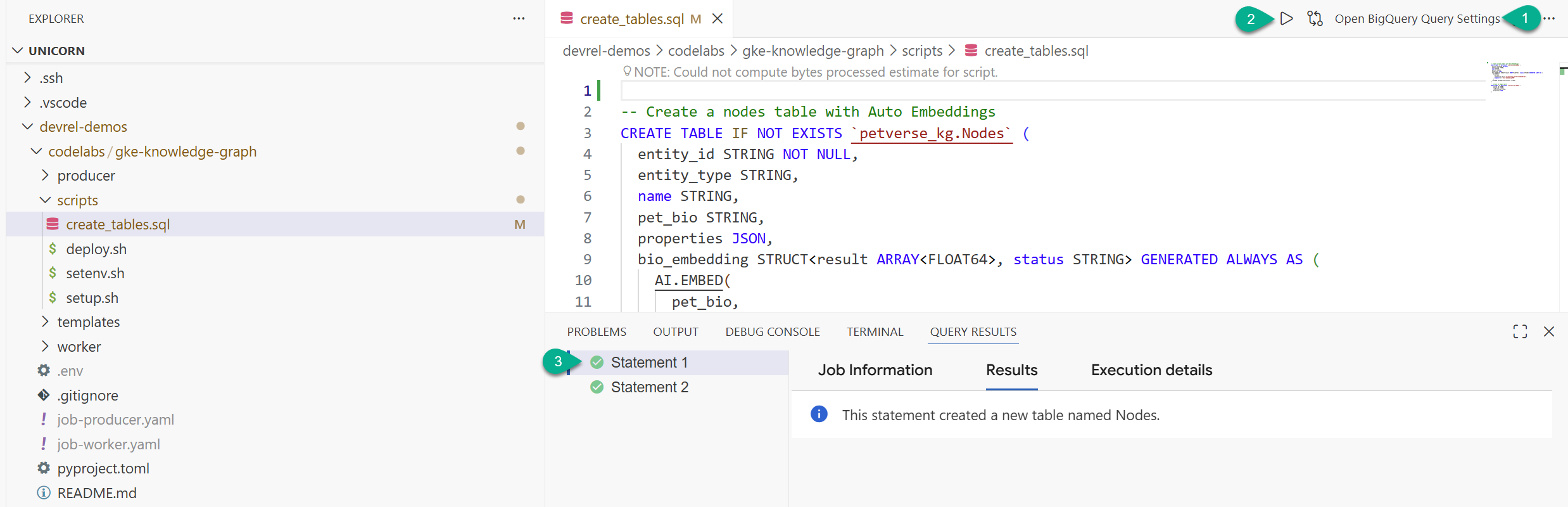
- En la ventana del explorador, busca la carpeta que clonaste del repositorio (
devrel-demos). Encodelabs/gke-knowledge-graph/scripts, encontraráscreate_tables.sql. Abre ese archivo. - En la esquina superior derecha, haz clic en Abrir configuración de la búsqueda.
- Elige BigQuery. Guardar y Cerrar
- Haz clic en Ejecutar.
Deberías ver dos instrucciones ejecutadas correctamente. Ahora creaste las tablas para almacenar nodos y aristas de tu gráfico de conocimiento.
Puedes cerrar la pestaña create_tables.sql y la consola de resultados.
4. Inicializa el clúster de GKE
Usaremos GKE Autopilot para ejecutar nuestro trabajo de procesamiento de datos. Autopilot es la práctica recomendada, ya que administra la infraestructura del clúster por ti.
A estas alturas, la secuencia de comandos de configuración debería haber finalizado. Deberías ver el mensaje de éxito: 🎉🦄 Setup successfully finished! 🎉🦄.
Pega este comando en la terminal para crear el clúster:
source scripts/setenv.sh
gcloud container clusters create-auto petverse-cluster \
--region=$REGION
🕓 El proceso tardará unos 5 minutos.
Obtén credenciales para interactuar con el clúster:
source scripts/setenv.sh
gcloud container clusters get-credentials petverse-cluster --region $REGION
Deberías ver este resultado:
Fetching cluster endpoint and auth data. kubeconfig entry generated for petverse-cluster.
5. Configura Workload Identity
Workload Identity Federation para GKE (con acceso directo a recursos) permite que tus cargas de trabajo de GKE accedan de forma segura a los servicios de Google Cloud sin necesidad de administrar claves de cuentas de servicio.
Ejecuta deploy.sh para hacer lo siguiente:
- Crea una cuenta de servicio de Kubernetes
- Otorga los roles de IAM necesarios directamente a la entidad principal de la cuenta de servicio de Kubernetes
- Vincula la cuenta de servicio de IAM a la cuenta de servicio de Kubernetes
- Anota la cuenta de servicio de Kubernetes para completar la vinculación
source scripts/setenv.sh
./scripts/deploy.sh
6. Implementa trabajos de procesamiento desacoplados
En este paso, implementarás el encolador (productor) y los motores de procesamiento (procesadores) en GKE.
Nuestra nueva arquitectura desacoplada usa Google Cloud Pub/Sub para procesar recursos de forma asíncrona:
- El productor analiza GCS y pone en cola todas las rutas de acceso a los archivos en una cola de Pub/Sub.
- Un grupo de trabajadores se ajusta verticalmente en GKE, extrae tareas de forma dinámica en paralelo, las procesa con Gemini y escribe en BigQuery.
La secuencia de comandos setup.sh ya compiló y envió las imágenes de contenedor de Producer y Worker, puso en cola los temas de Pub/Sub y generó de forma dinámica tus manifiestos de implementación de GKE: job-producer.yaml y job-worker.yaml.
- Aplica el trabajo de Producer para analizar tu bucket de almacenamiento y poner en cola todos los recursos:
kubectl apply -f job-producer.yaml
Este trabajo se ejecuta y finaliza rápidamente, ya que solo pone en cola los metadatos.
- Implementa el trabajo de Worker configurado para ejecutar 6 trabajadores paralelos para vaciar la cola:
kubectl apply -f job-worker.yaml
GKE Autopilot detectará automáticamente los Pods pendientes, escalará verticalmente los nodos de procesamiento de forma dinámica y ejecutará los trabajadores en paralelo para procesar los audios, los videos, las imágenes y los archivos CSV en cola.
7. Verifica los resultados
- Verifica el estado de tus trabajos:
kubectl get jobs
Espera hasta que petverse-producer-job y petverse-worker-job muestren que se completaron correctamente.
🕓 Esta operación tardará unos 10 minutos. Puedes ver el progreso con los siguientes comandos.
- Revisa los registros del productor para verificar que haya puesto en cola los archivos correctamente:
cd ~/devrel-demos/codelabs/gke-knowledge-graph
source scripts/setenv.sh
kubectl logs -l app=petverse-producer --tail=50
- Observa cómo tus trabajadores paralelos procesan los archivos de la cola:
kubectl logs -l app=petverse-worker --tail=50
(Los trabajadores tienen un tiempo de espera de inactividad de 60 segundos y se apagarán y limpiarán automáticamente cuando la cola de Pub/Sub esté vacía).
Verifica los datos en BigQuery.
- Navega a BigQuery Studio. Verás dos tablas creadas: petverse_kg.Nodes y petverse_kg.Edges.
- Para ver el contenido de las tablas, haz doble clic en sus nombres y, luego, haz clic en Vista previa.
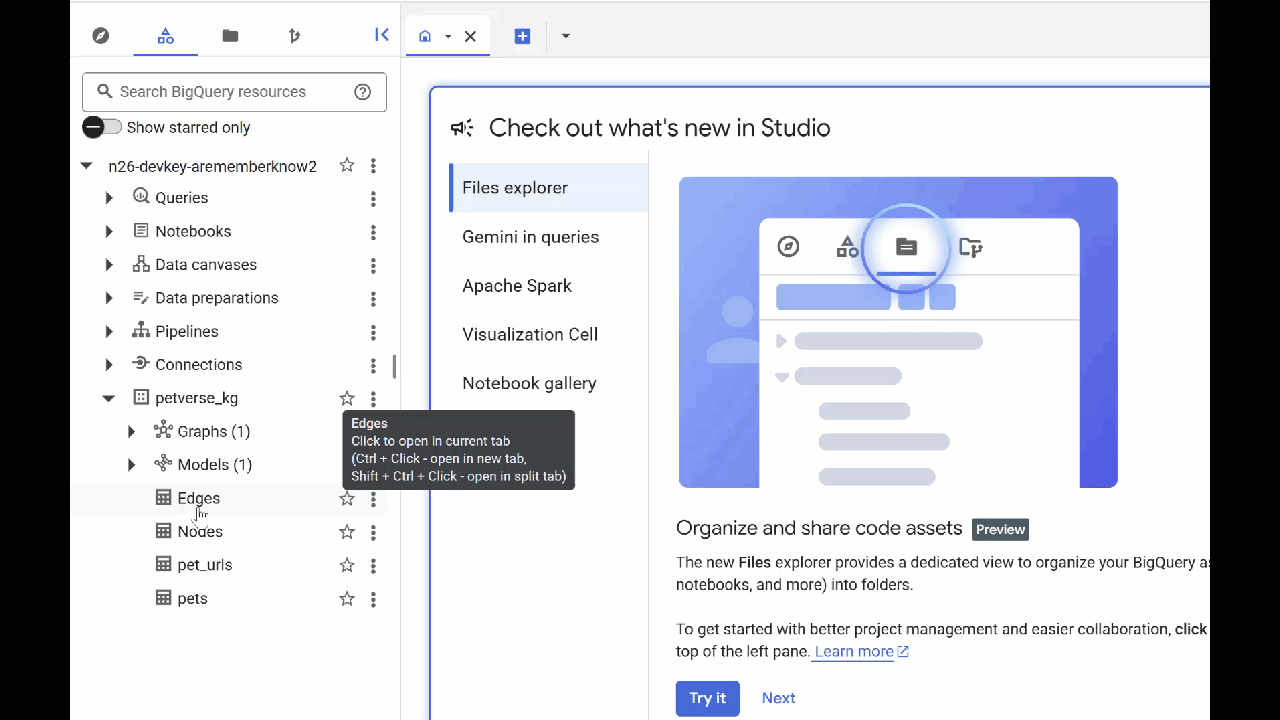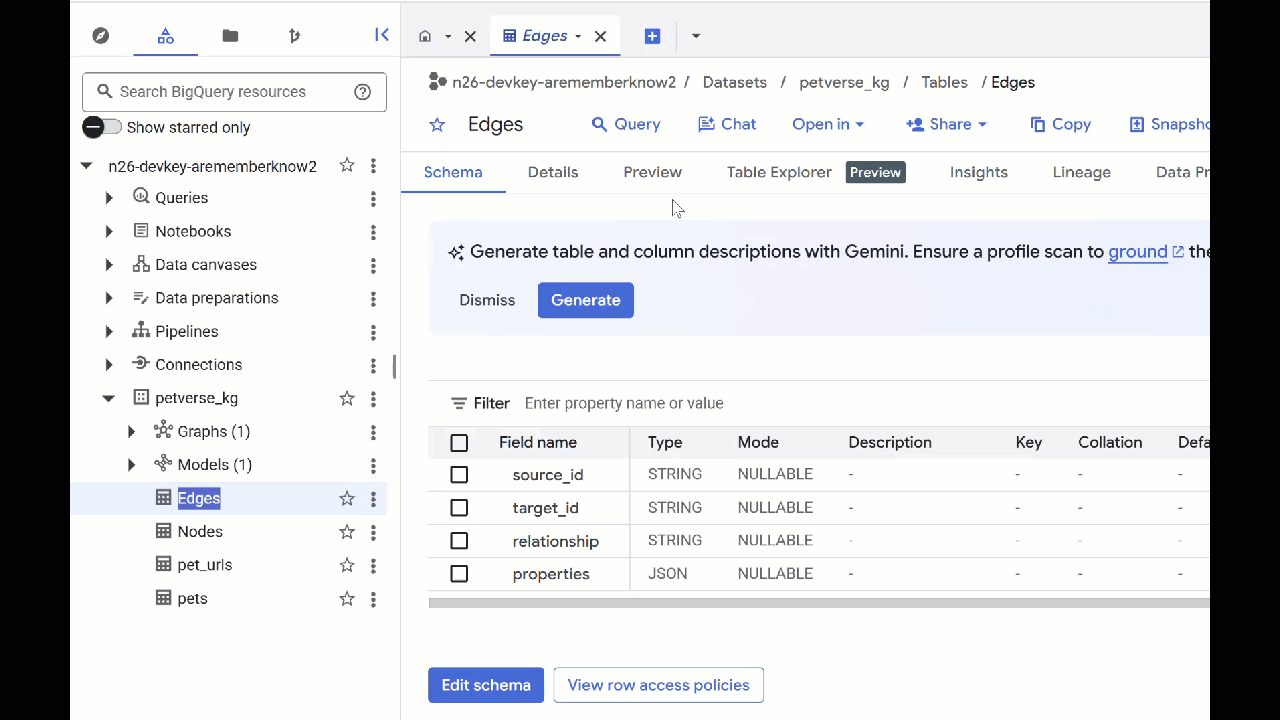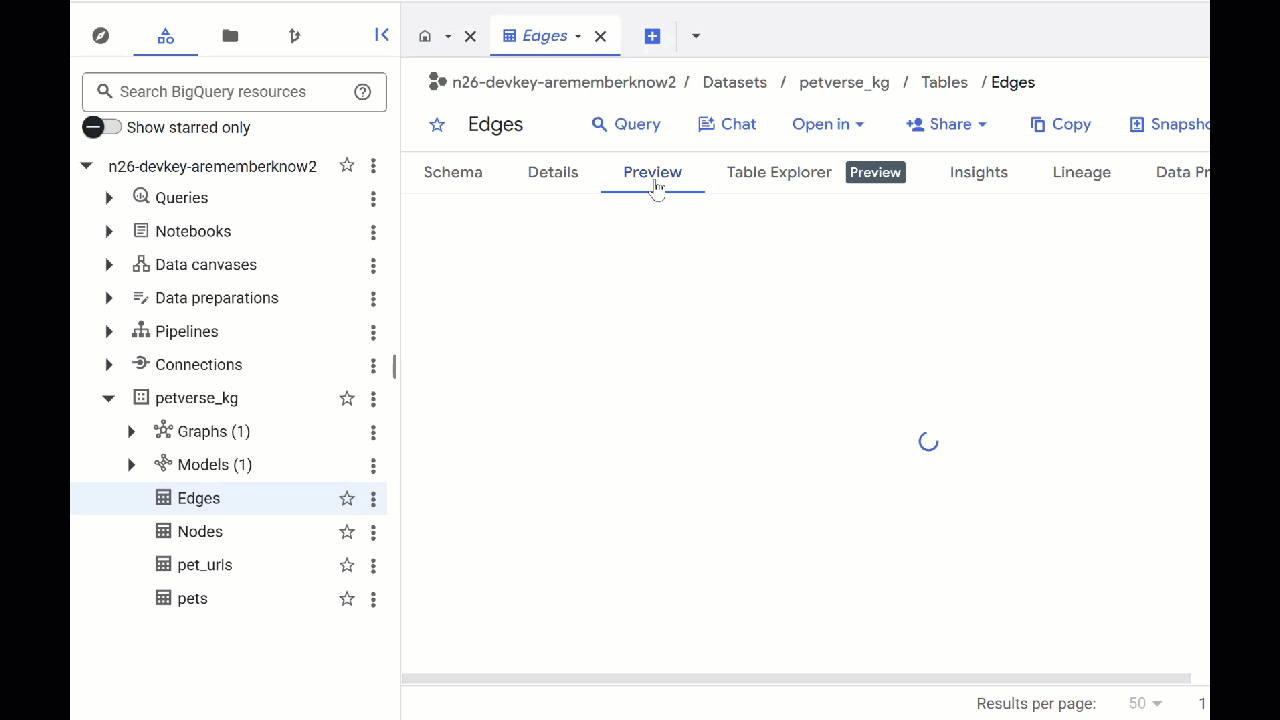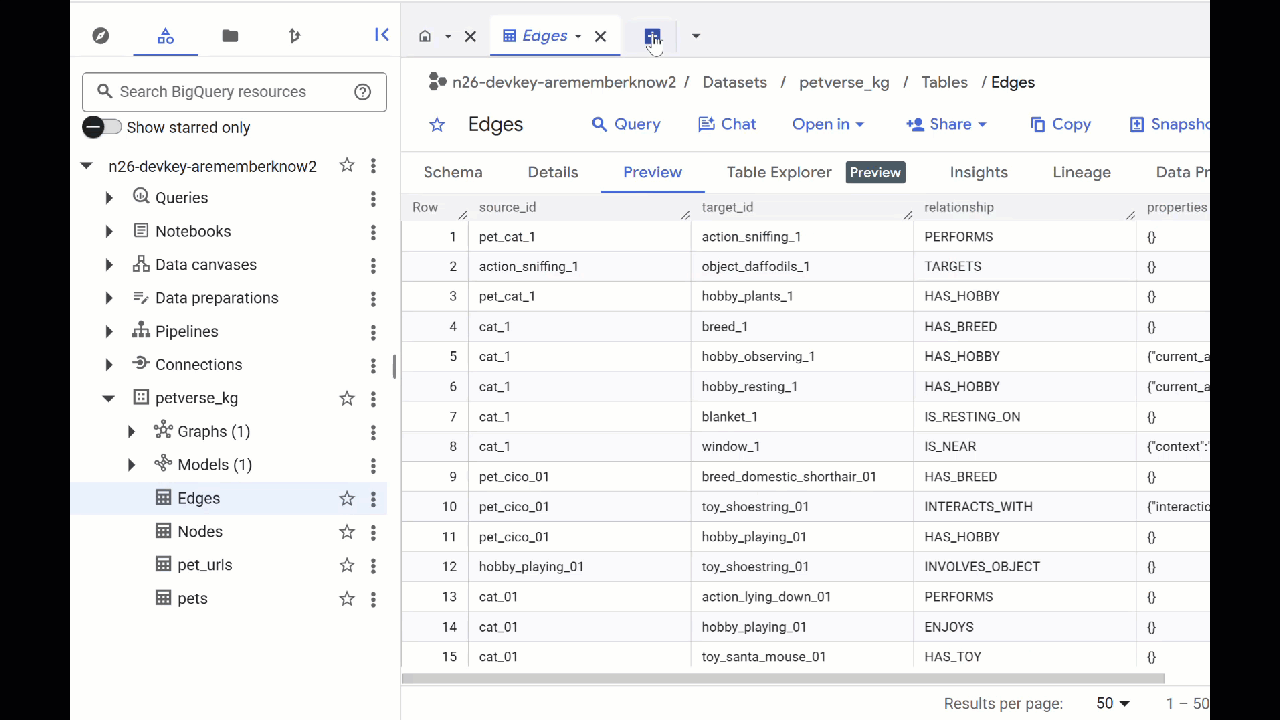
Verás que la tabla Nodos contiene información sobre las entidades que Gemini identificó en los audios, los videos y las imágenes. La tabla Edges contiene las relaciones entre ellos. Por ejemplo, si escuchas el audio del gato llamado SQL, sabrás que le gusta jugar con cordones y comer pescado liofilizado.
- Usa el botón + para crear una consulta nueva. Pega la siguiente instrucción y haz clic en Ejecutar:
SELECT n.name, n.entity_id, e.relationship, e.target_id
FROM
`petverse_kg.Nodes` n
JOIN
`petverse_kg.Edges` e
ON n.entity_id = e.source_id
WHERE n.name = 'SQL'
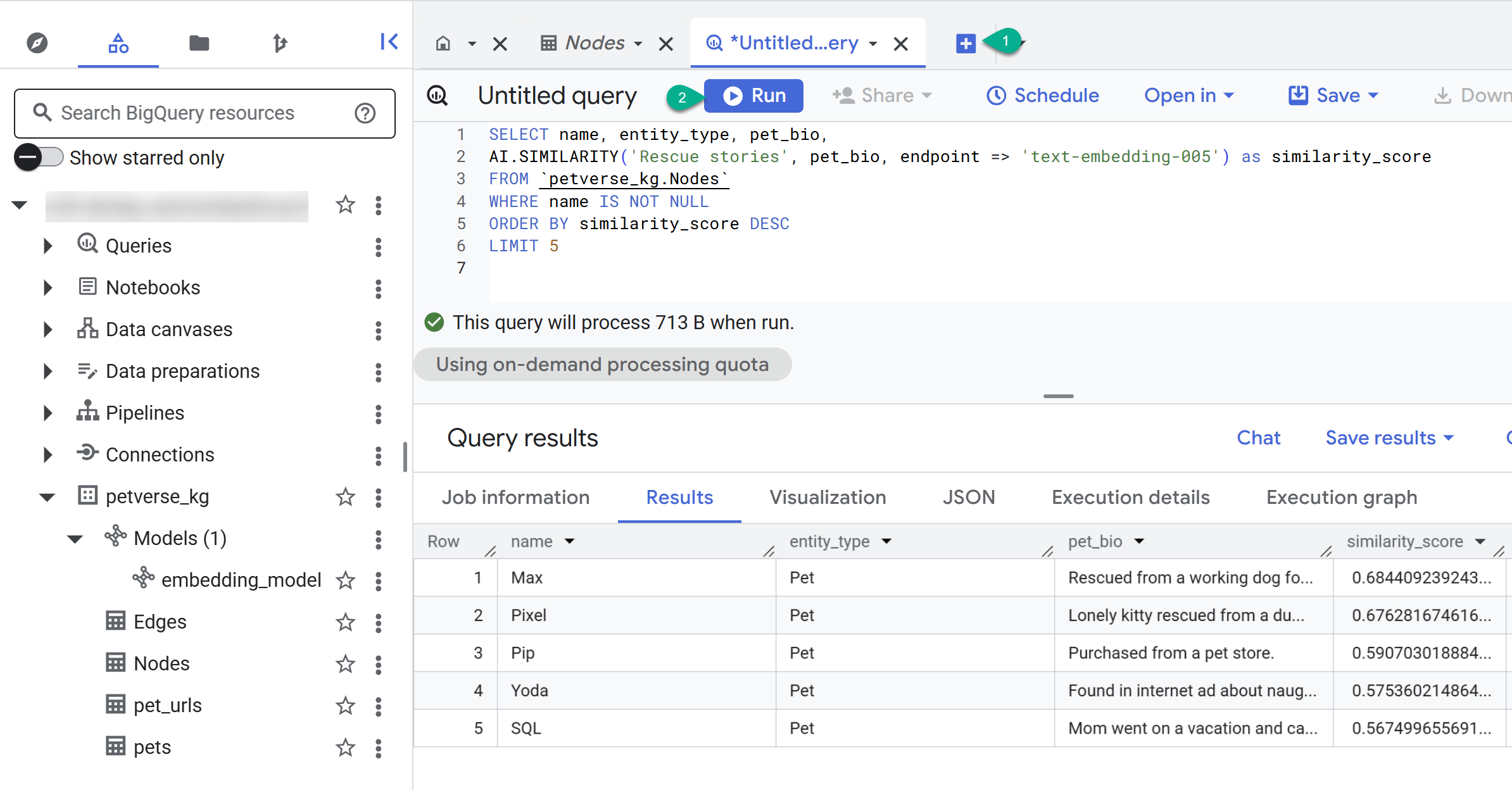
- Usa el botón + para crear una consulta nueva. Pega la siguiente instrucción y haz clic en Ejecutar:
SELECT name, entity_type, pet_bio,
AI.SIMILARITY('Pets who like to relax', pet_bio, endpoint => 'text-embedding-005') as similarity_score
FROM `petverse_kg.Nodes`
WHERE name IS NOT NULL
ORDER BY similarity_score DESC
LIMIT 5
Deberías ver los nodos de las mascotas a las que les gusta relajarse. Esta consulta realizó una búsqueda semántica con la función IA AI.SIMILARITY para encontrar las mascotas cuyas biografías son más similares al texto de la consulta.
Compila el gráfico de propiedades
Ahora que tenemos nodos y aristas en BigQuery, podemos crear un gráfico de propiedades para consultar relaciones fácilmente.
Crea el gráfico
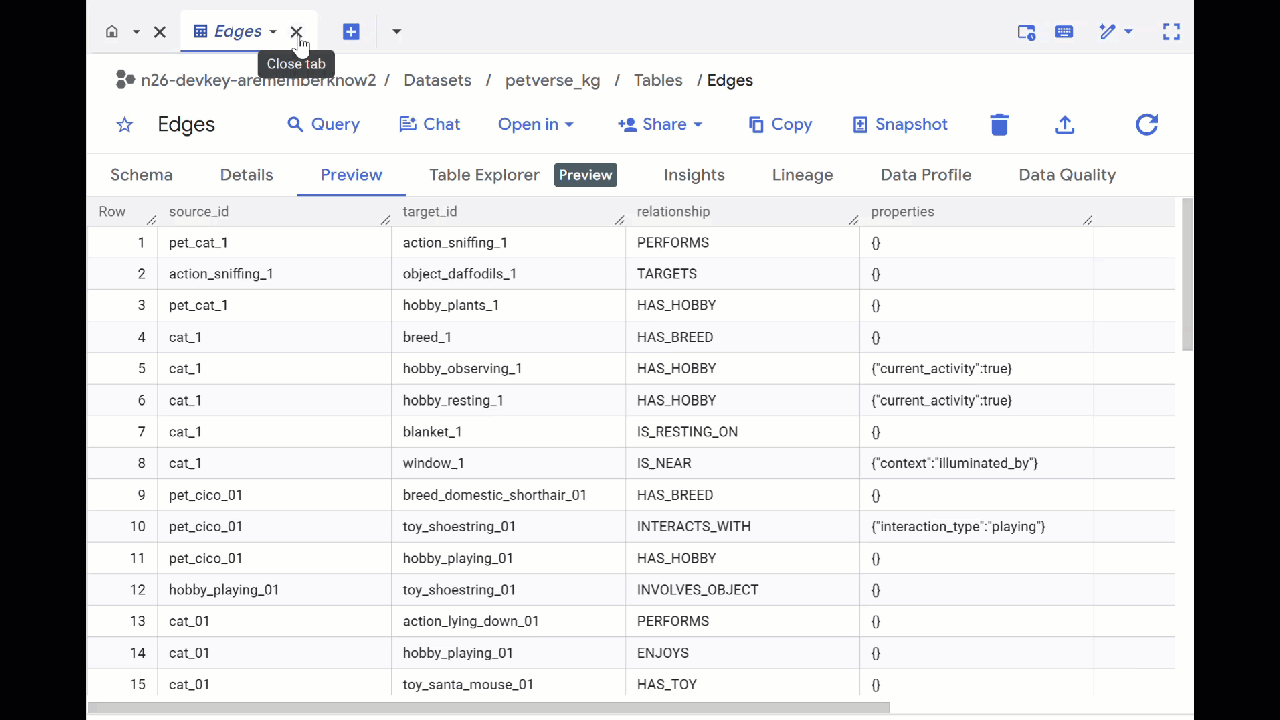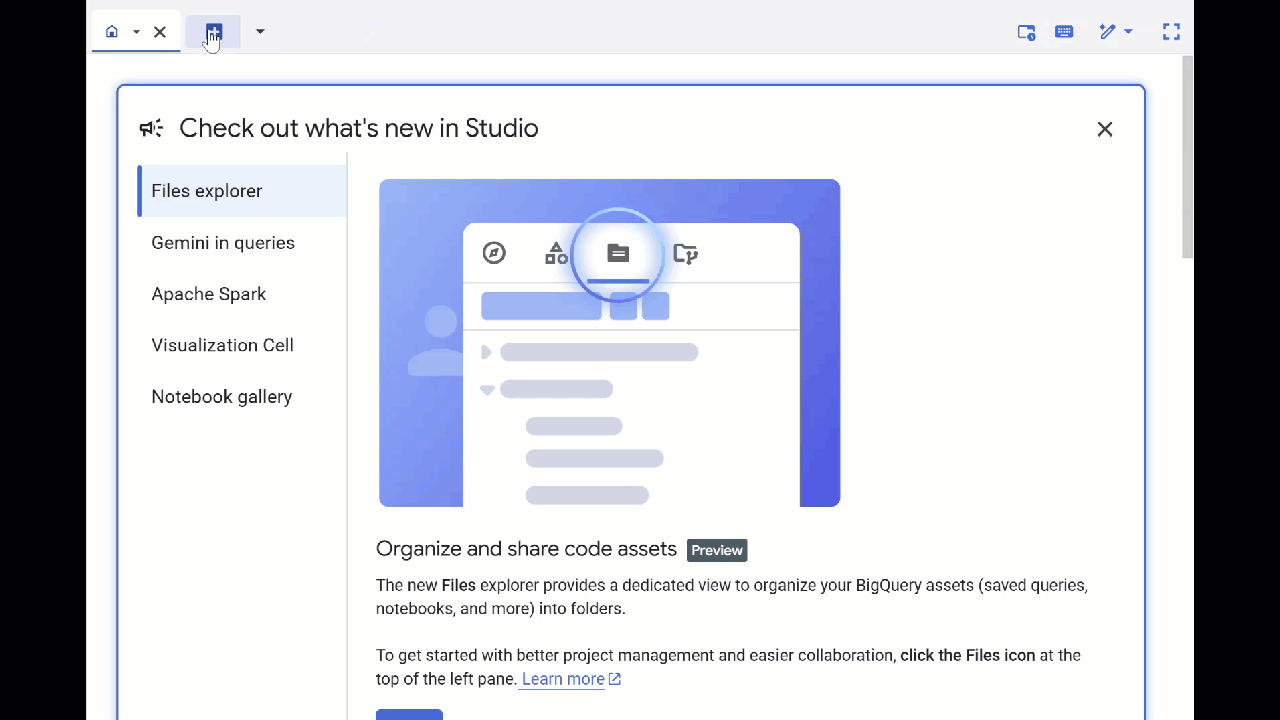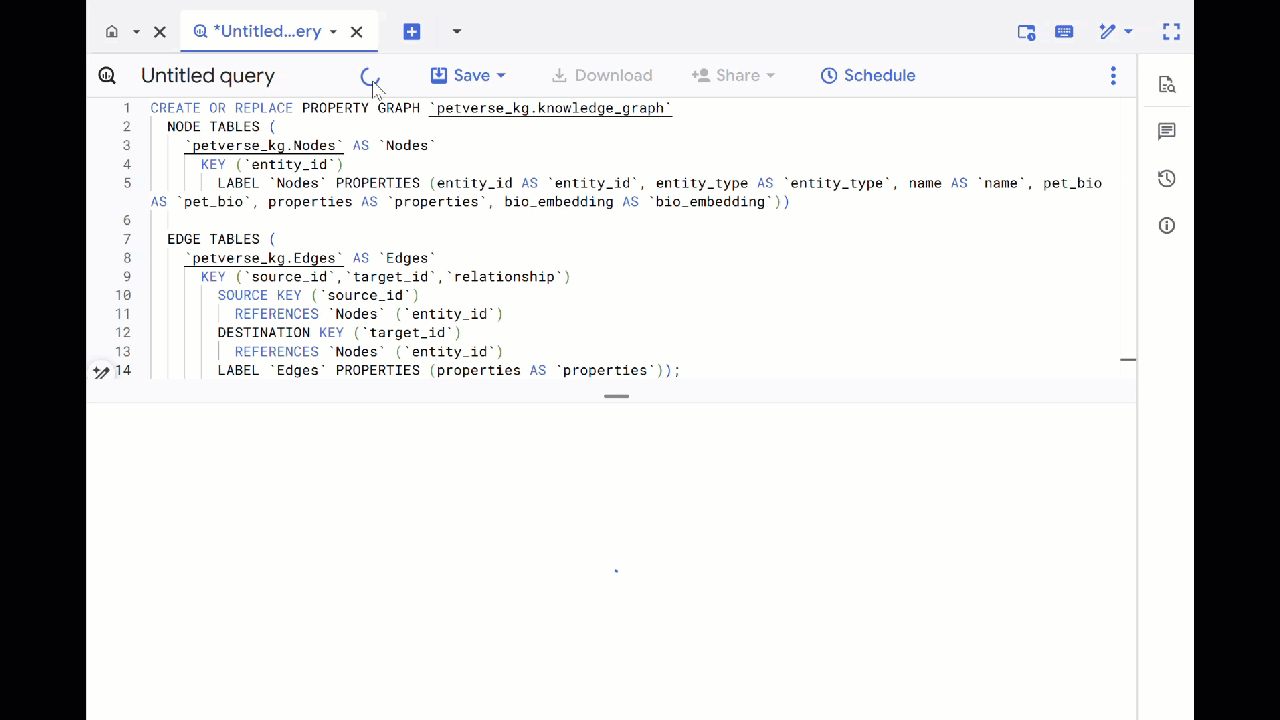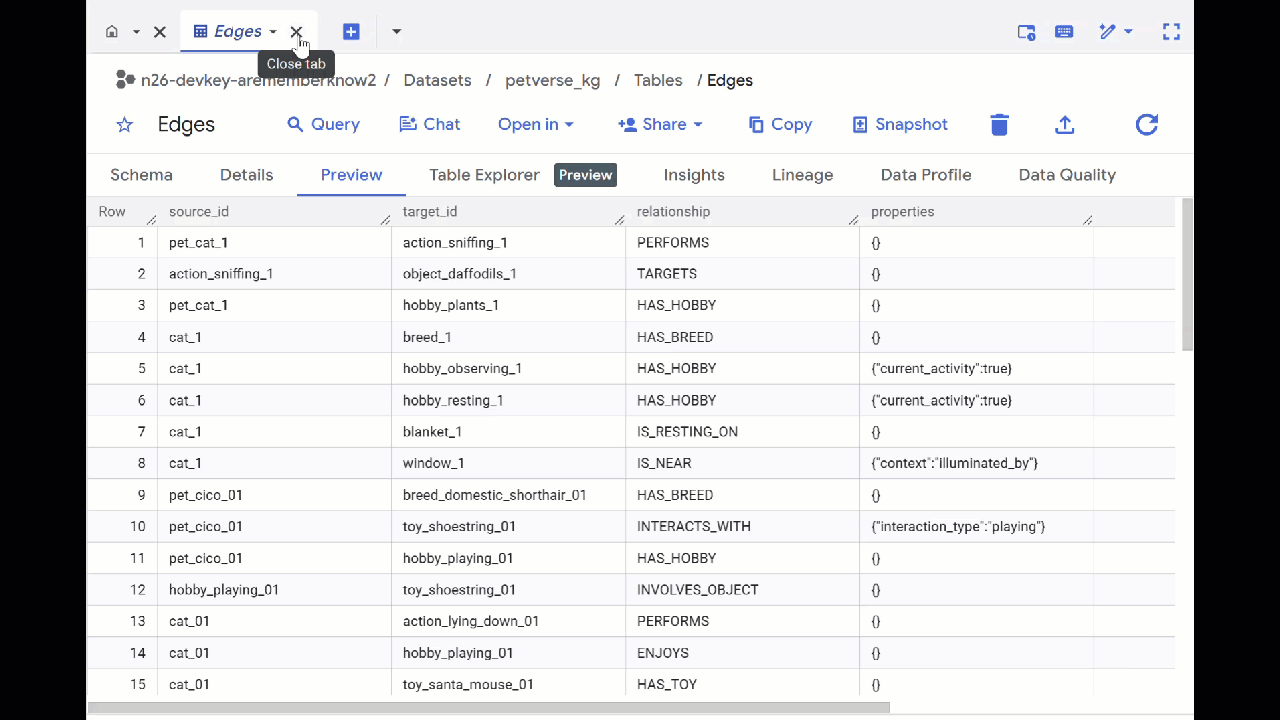
- Reemplaza la consulta anterior y ejecuta el siguiente DDL para crear el gráfico de propiedades:
CREATE OR REPLACE PROPERTY GRAPH `petverse_kg.knowledge_graph`
NODE TABLES (
`petverse_kg.Nodes` AS `Nodes`
KEY (`entity_id`)
LABEL `Nodes` PROPERTIES (entity_id AS `entity_id`, entity_type AS `entity_type`, name AS `name`, pet_bio AS `pet_bio`, properties AS `properties`, bio_embedding AS `bio_embedding`))
EDGE TABLES (
`petverse_kg.Edges` AS `Edges`
KEY (`source_id`,`target_id`,`relationship`)
SOURCE KEY (`source_id`)
REFERENCES `Nodes` (`entity_id`)
DESTINATION KEY (`target_id`)
REFERENCES `Nodes` (`entity_id`)
LABEL `Edges` PROPERTIES (properties AS `properties`));
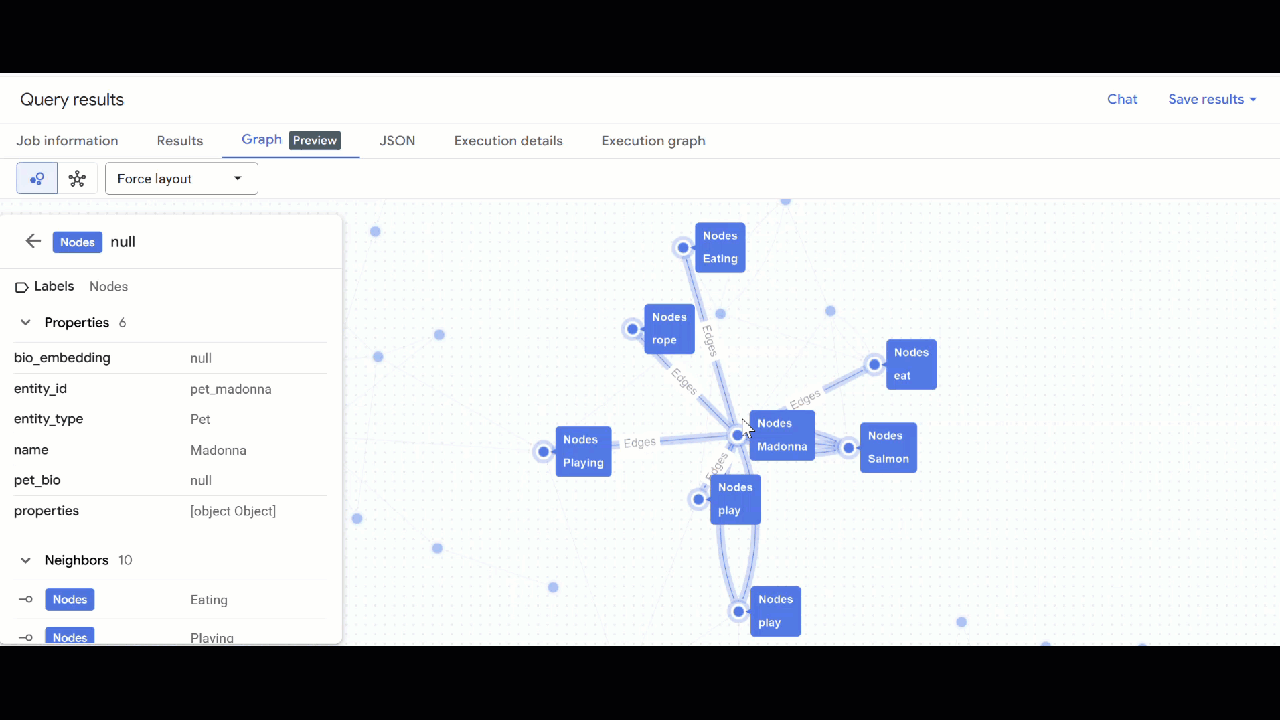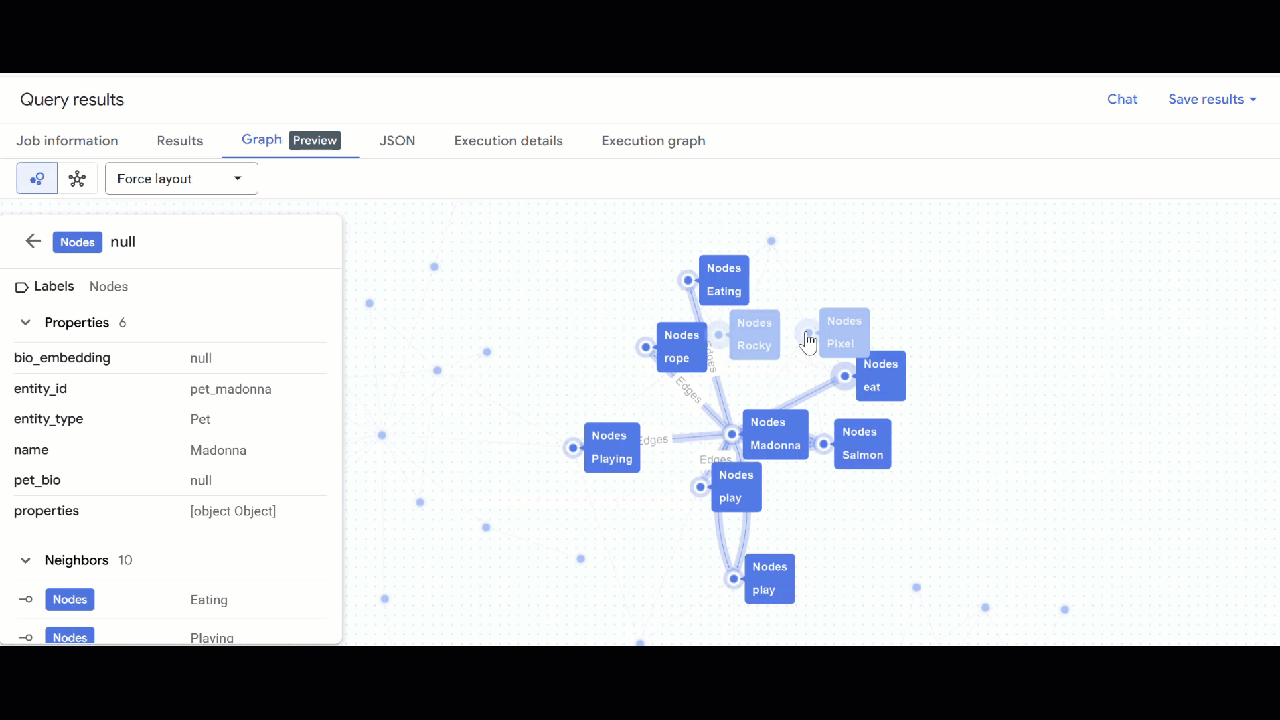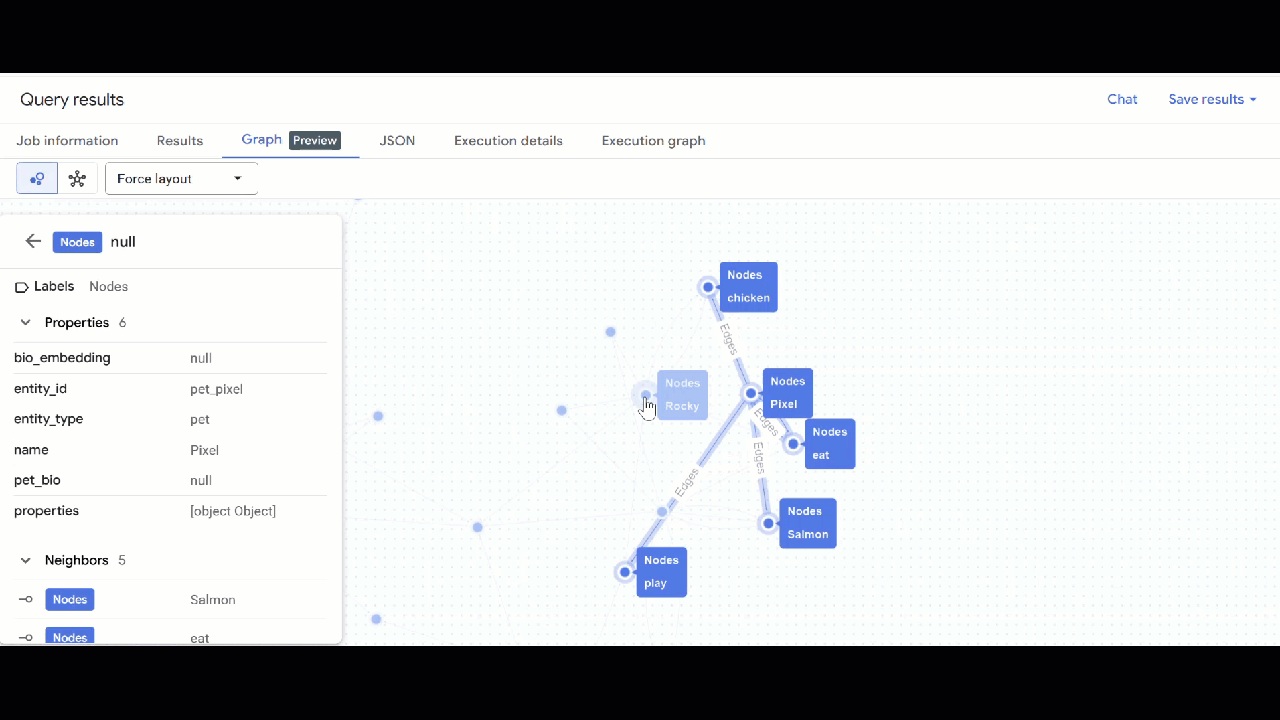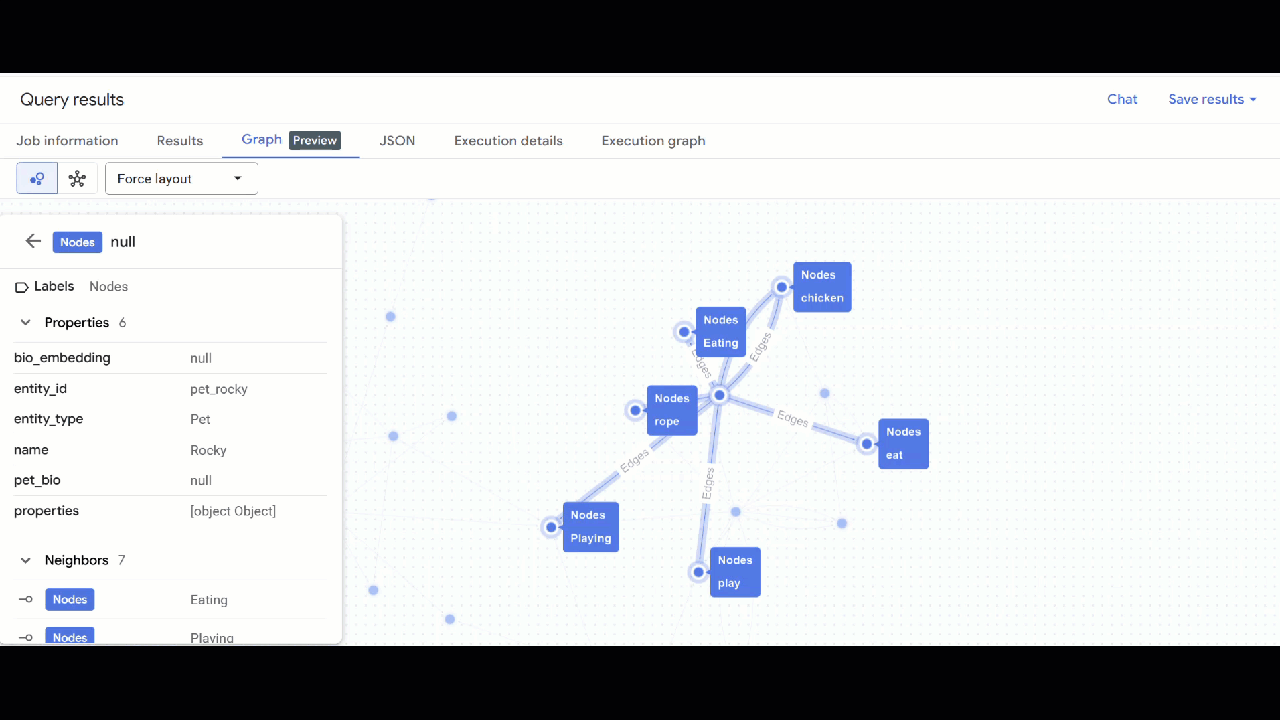
- Haz clic en Ir al gráfico. Verás la visualización del gráfico con un nodo que tiene una arista hacia sí mismo. Esta situación es esperable.
Cómo consultar el gráfico
- Puedes cerrar todas las búsquedas anteriores y abrir una nueva en blanco con el botón +.
- Usa GQL para encontrar mascotas relacionadas con otras mascotas a través de intereses compartidos (como pasatiempos, comidas favoritas o juguetes). Esta búsqueda de múltiples saltos coincide con dos mascotas diferentes que están conectadas al mismo nodo:
GRAPH `petverse_kg.knowledge_graph`
MATCH p = (pet1:Nodes)-[e1]->(interest:Nodes)<-[e2]-(pet2:Nodes)
WHERE pet1.entity_id != pet2.entity_id
AND (LOWER(pet1.entity_type) = 'pet' AND LOWER(pet2.entity_type) = 'pet')
AND LOWER(interest.entity_type) IN ('hobby', 'action', 'activity', 'food', 'toy')
RETURN TO_JSON(p) as res
LIMIT 100
- Deberías ver la visualización del gráfico. Puedes hacer clic en los nodos para ver sus propiedades y las de las aristas.
🕵️ Sugerencia: Puedes ajustar el valor que muestra el nodo haciendo clic en Cambiar a vista de esquema:
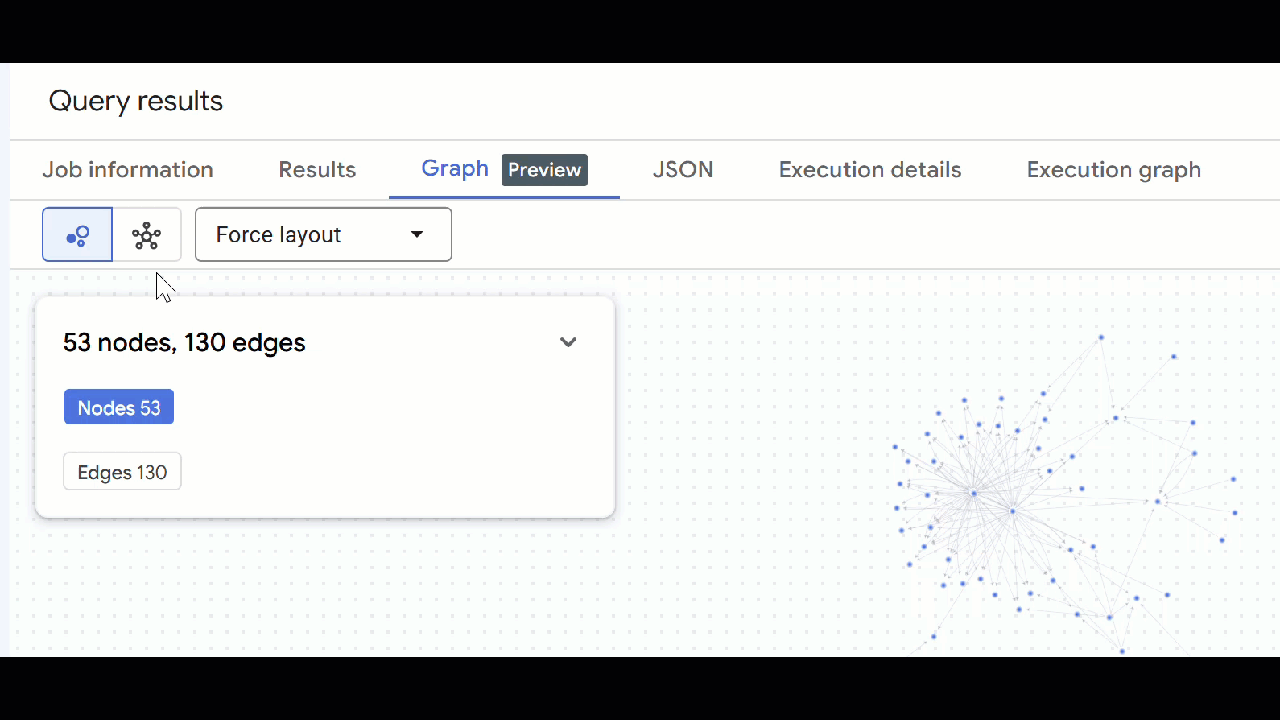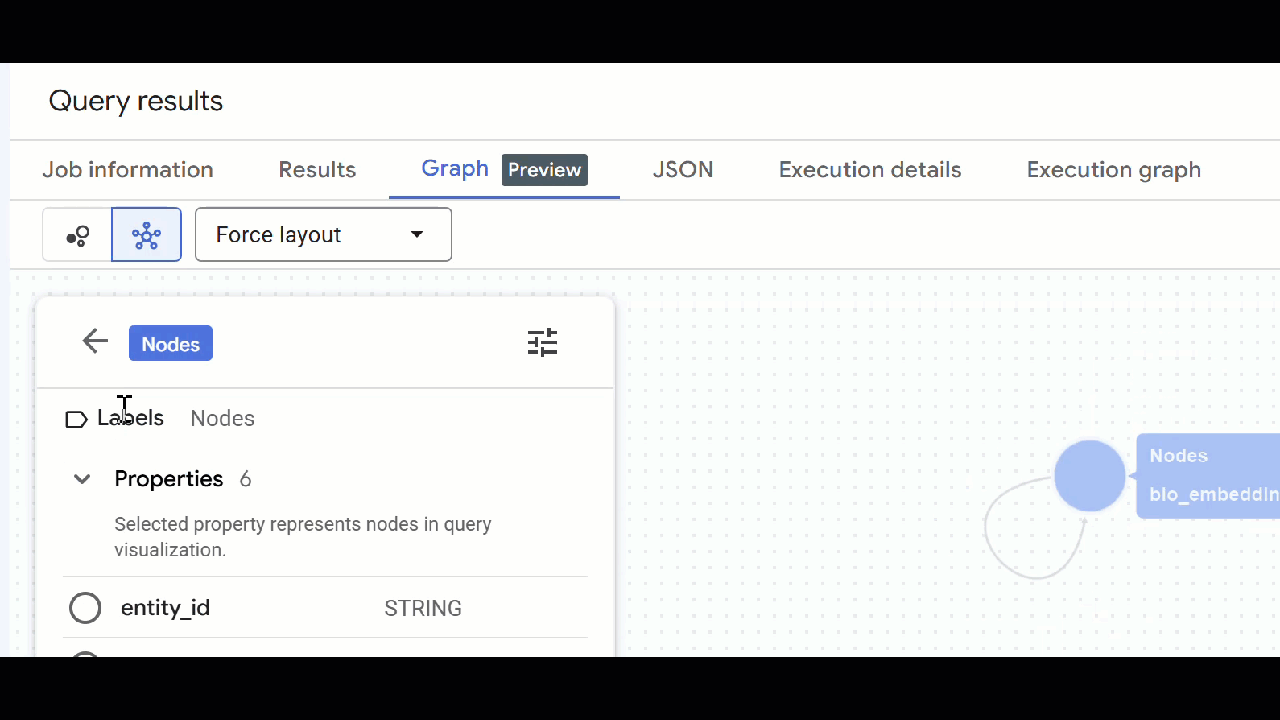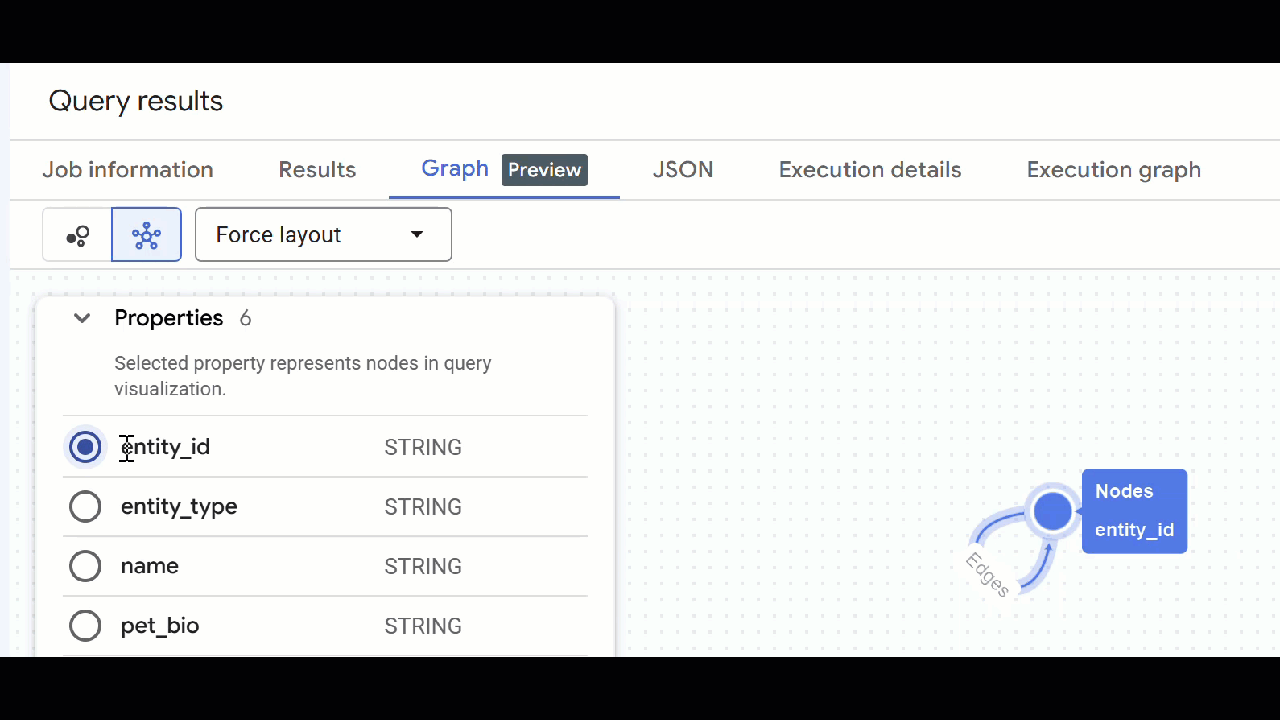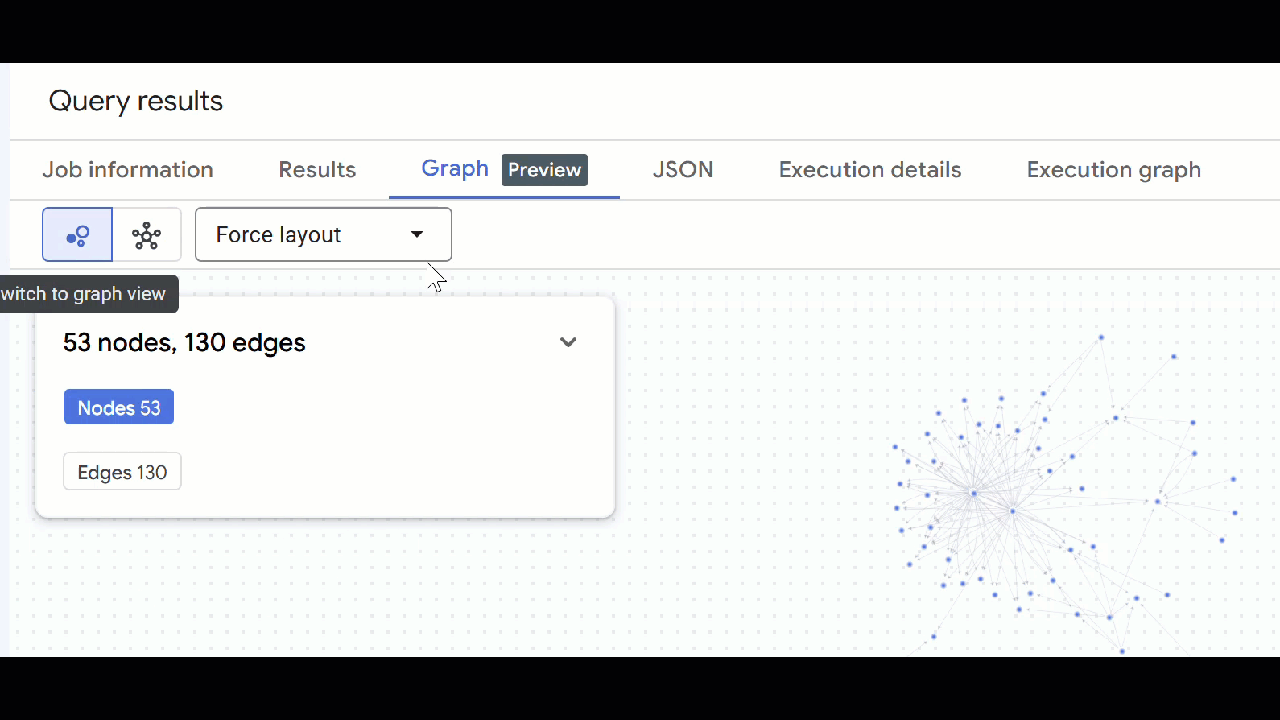
- Puedes cerrar todas las pestañas de consultas abiertas.
8. Chatea con el gráfico
- Junto al signo +, encontrarás un menú desplegable. Selecciona Conversación.
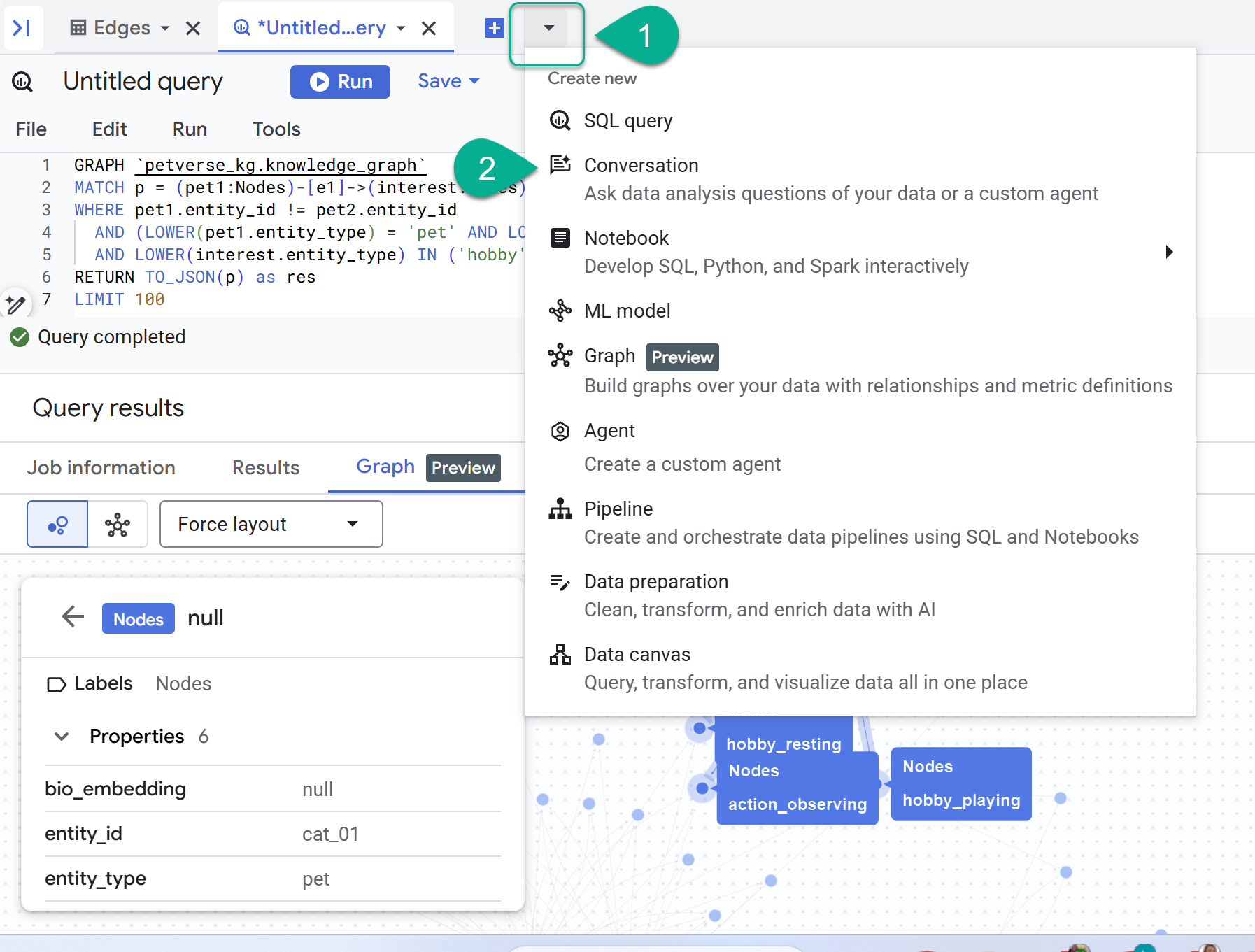
- Se te solicitará que habilites la API de Data Analytics with Gemini. Habilita ambas APIs. Cuando finalice el proceso, actualiza la ventana o crea una conversación nueva para ver el agente.
- Haz clic en Agente nuevo.
- Asigna un nombre al agente, por ejemplo,
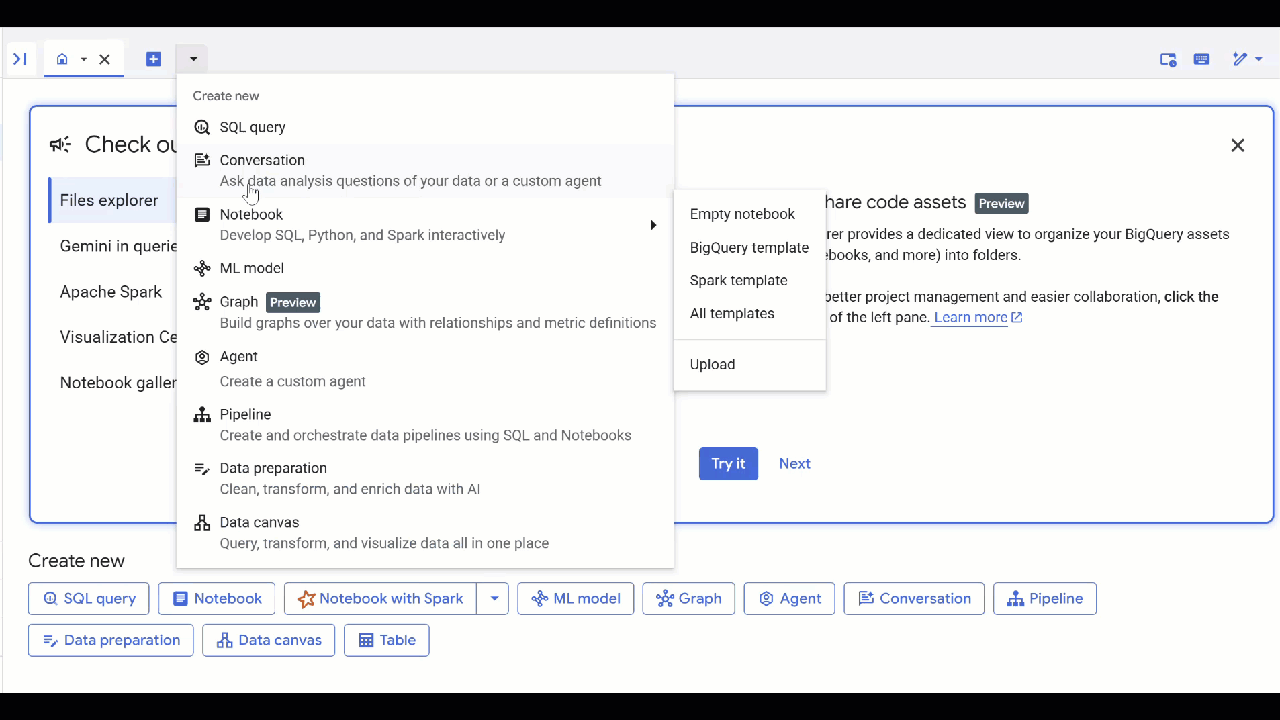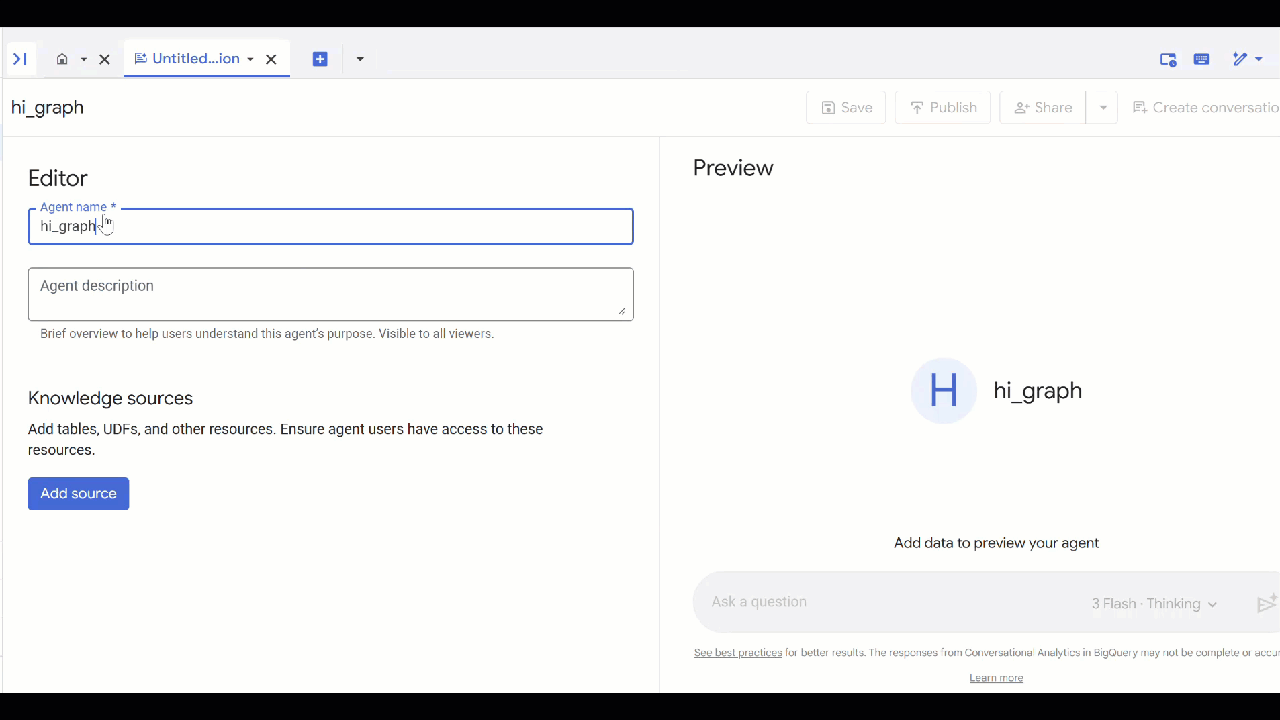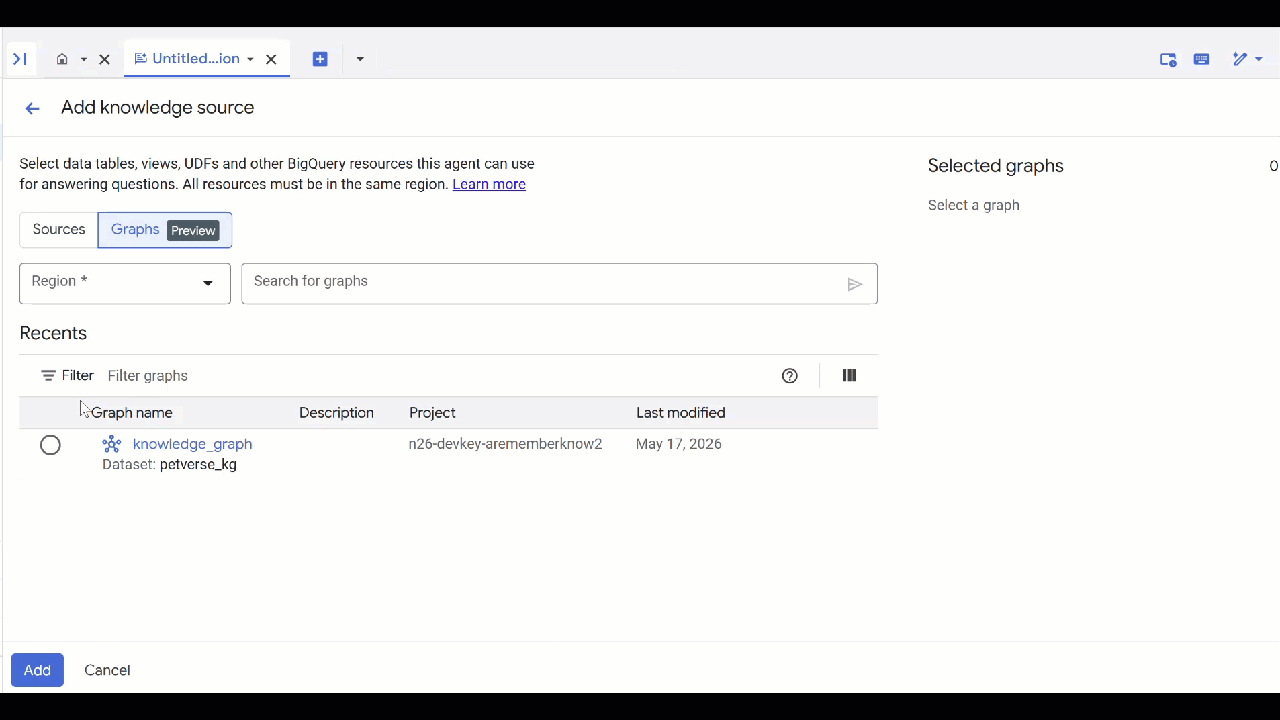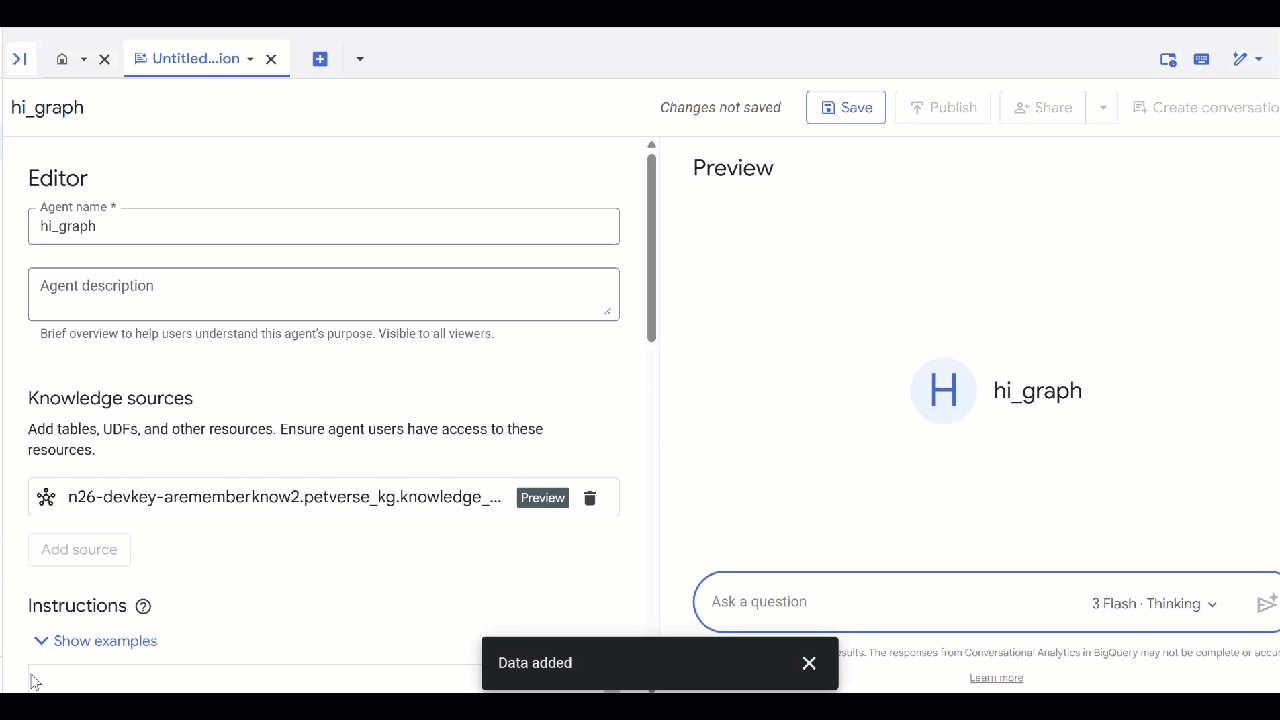
petverse. - Haz clic en Agregar fuente y, luego, en Gráfico.
- Selecciona el
knowledge_graphque creaste y haz clic en Agregar.
Ahora puedes hacerle una pregunta al agente y ver las respuestas y el razonamiento detrás de ellas. Aquí tienes algunas preguntas de ejemplo si necesitas inspiración. Un modelo de razonamiento puede tardar un poco más, pero es probable que cree una mejor consulta de GQL. Puedes ver lo que compila expandiendo Show Thinking.
- Encuentra mascotas que compartan alimentos similares, que sean amigas de mascotas que disfruten de las siestas.
- ¿Hay mascotas que compartan exactamente el mismo pasatiempo, comida o juguete favorito? Enumera los pares y sus intereses compartidos.
- Busca mascotas que tengan la misma especie o raza, pero pasatiempos completamente diferentes.
9. Limpia
Para evitar que se apliquen cargos a tu cuenta de Google Cloud, borra los recursos que creaste durante este codelab.
- Borra el clúster de GKE:
gcloud container clusters delete petverse-cluster --region $REGION --quiet
- Borra el conjunto de datos de BigQuery (esto borrará todas las tablas):
bq rm -r -f -d $PROJECT_ID:petverse_kg
- Borra los recursos de la cola de Pub/Sub:
gcloud pubsub subscriptions delete petverse-sub --quiet
gcloud pubsub topics delete petverse-topic --quiet
- Borra el repositorio de Artifact Registry:
gcloud artifacts repositories delete gke-cats-repo --location=$REGION --quiet
- Borra el bucket de GCS específico del proyecto:
gcloud storage buckets delete gs://$PROJECT_ID-petverse --quiet
10. Felicitaciones
¡Felicitaciones! Compilaste correctamente una canalización de gráfico de conocimiento distribuido con GKE y Gemini, y la consultaste con los gráficos de propiedades de BigQuery.
Qué aprendiste
- Cómo implementar trabajos distribuidos en GKE Autopilot
- Cómo usar Gemini para la extracción de datos multimodales
- Cómo usar las incorporaciones automáticas de BigQuery
- Cómo crear y consultar gráficos de propiedades en BigQuery