
۱. مقدمه
در این آزمایشگاه کد، شما یک خط لوله کسب دانش توزیعشده برای "Petverse" خواهید ساخت. شما داراییهای چندرسانهای بدون ساختار (صوت، ویدئو، تصاویر، متن/CSV) را از یک مخزن ذخیرهسازی ابری پردازش خواهید کرد، اطلاعات کلیدی در مورد حیوانات خانگی (غذای مورد علاقه، سرگرمیها) را استخراج خواهید کرد و یک نمودار دانش ایجاد خواهید کرد. شما پردازش فایل چندرسانهای را با استفاده از پردازش چندوجهی Gemini در موتور Google Kubernetes (GKE) مقیاسبندی خواهید کرد. در نهایت، این دادهها را در BigQuery ذخیره خواهید کرد و از ویژگی جدید BigQuery Property Graph برای تجزیه و تحلیل روابط استفاده خواهید کرد.
ما از قدرت موتور کوبرنتیز گوگل برای نمایش پردازش موازی دادههای با حجم بالا استفاده خواهیم کرد.
چرا نمودارهای دانش؟
نمودارهای دانش برای نمایش و تحلیل روابط پیچیده بین موجودیتها، نسبت به پایگاههای داده رابطهای سنتی، مناسبتر هستند.
ما از Gemini 2.5 Flash برای تجزیه و تحلیل تصاویر، فایلهای صوتی و تصویری و تعیین حقایق در مورد حیوانات خانگی مختلف استفاده خواهیم کرد.
کاری که انجام خواهید داد
- ساخت و استقرار یک کار پردازش داده توزیعشده روی GKE .
- از Gemini برای استخراج موجودیتها و روابط از فایلهای چندرسانهای استفاده کنید.
- دادههای نمودار دانش را در BigQuery ذخیره کنید.
- با استفاده از زبان جستجوی گراف (GQL) یک نمودار ویژگی در BigQuery ایجاد و پرس و جو کنید.
آنچه نیاز دارید
- یک مرورگر وب مانند کروم
- یک پروژه گوگل کلود با قابلیت پرداخت صورتحساب
- مجوزهای موجود در پروژه برای ایجاد منابع و تغییر سیاستهای IAM
این آزمایشگاه کد برای توسعهدهندگان در تمام سطوح، از جمله مبتدیان، مناسب است.
مدت زمان تخمینی: ۴۵ دقیقه
هزینه: منابع ایجاد شده در این آزمایشگاه کد باید کمتر از ۵ دلار هزینه داشته باشند.
۲. قبل از شروع
ایجاد یک پروژه ابری گوگل
- به کنسول گوگل کلود بروید: https://console.cloud.google.com ، و سپس یک پروژه گوگل کلود انتخاب یا ایجاد کنید .
- ⚠️ شناسه پروژه را یادداشت کنید. در این تمرین از آن برای چندین دستور استفاده خواهید کرد.
شروع پوسته ابری
- Cloud Shell را در یک برگه جدید باز کنید : https://shell.cloud.google.com/ .
- در صورت درخواست، روی «مجاز کردن» کلیک کنید.
-
PROJECT_IDرا جایگزین کنید و دستور زیر را در ترمینال وارد کنید:
export PROJECT_ID="YOUR_PROJECT_ID"
gcloud config set project $PROJECT_ID
📝 توجه داشته باشید که پروژه شما در خط فرمان با رنگ زرد نمایش داده خواهد شد. اگر جلسه شما مجدداً راهاندازی شد، حتماً دستور بالا را دوباره اجرا کنید تا شناسه پروژه تنظیم شود.
فعال کردن APIها
برای فعال کردن تمام API های مورد نیاز، این دستور را اجرا کنید:
gcloud services enable \
aiplatform.googleapis.com \
bigquery.googleapis.com \
artifactregistry.googleapis.com \
container.googleapis.com \
cloudbuild.googleapis.com \
pubsub.googleapis.com
مخزن کلون
برای کلون کردن مخزن، این دستورات را اجرا کنید.
cd ~/
git clone --filter=blob:none --no-checkout https://github.com/GoogleCloudPlatform/devrel-demos.git
cd ~/devrel-demos
git sparse-checkout init --cone
git sparse-checkout set codelabs/gke-knowledge-graph
git checkout main
cd codelabs/gke-knowledge-graph/
اجرای اسکریپت راهاندازی
این اسکریپت پیکربندی backend را به صورت خودکار انجام میدهد:
- ایجاد یک تصویر کانتینر و یک مخزن رجیستری مصنوعات
- ایجاد مجموعه داده BigQuery
- ایجاد یک اتصال BigQuery برای اجرای توابع Gemini AI از SQL
دستور زیر را در ترمینال خود اجرا کنید:
./scripts/setup.sh
اگر اسکریپت از شما جزئیات پیکربندی را درخواست کرد، از این مقادیر استفاده کنید:
- شناسه پروژه: از شناسهای که در مرحله قبل ایجاد کردید استفاده کنید.
- منطقه:
us-central1
⚠️ مهم: تکمیل اسکریپت چند دقیقه طول میکشد. این پنجره ترمینال را باز بگذارید تا در پسزمینه اجرا شود. برای ادامه مرحله بعدی، یک تب یا پنجره ترمینال جدید باز کنید تا دستورات بعدی خود را اجرا کنید.
۳. کیت عامل داده را راهاندازی کنید
- ویرایشگر Cloud Shell را با نماد مداد در گوشه بالا سمت راست فعال کنید.
- در ویرایشگر Cloud Shell، روی نماد Extensions در نوار کناری سمت چپ کلیک کنید.
- عبارت Google Cloud Data Agent Kit را جستجو کنید و اگر از قبل نصب نشده است، روی نصب کلیک کنید.
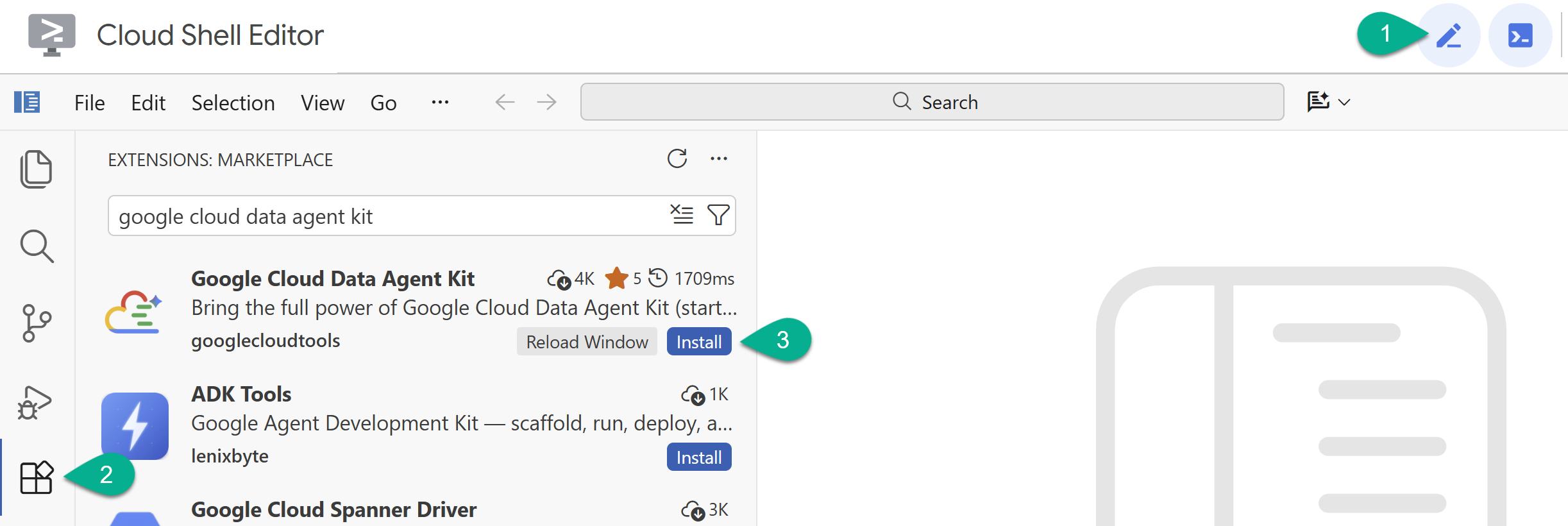
- با استفاده از افزونه، وارد حساب گوگل خود شوید.
- در خلاصه پیکربندی، شناسه پروژه خود و
us-central1را به عنوان منطقه وارد کنید.
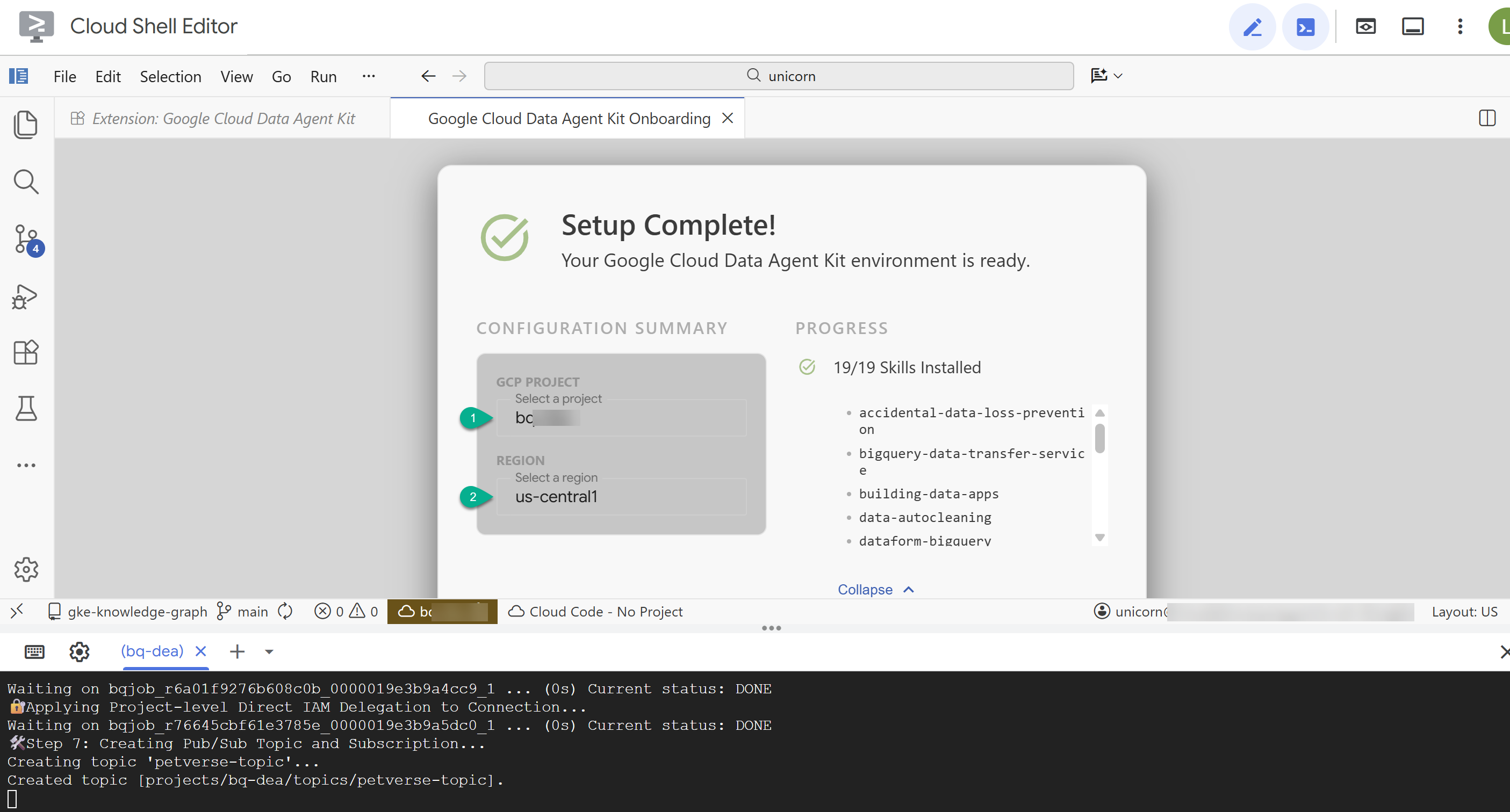
- روی «پیکربندی سرورهای MCP» کلیک کنید. نیازی به ایجاد هیچ تغییری در این پنجره نیست، کافیست روی «شروع» کلیک کنید.
- در صورت درخواست، پنجره را مجدداً بارگذاری کنید. فعلاً میتوانید برگه راهنمای شروع سریع را ببندید.
تنظیم جداول در BigQuery
- در نوار کناری، به اکسپلورر برگردید. اگر پوشه خانگی شما (مثلاً
/home/your_user_name/) از قبل باز نشده است، روی Open Folder کلیک کنید و آن را انتخاب کنید.
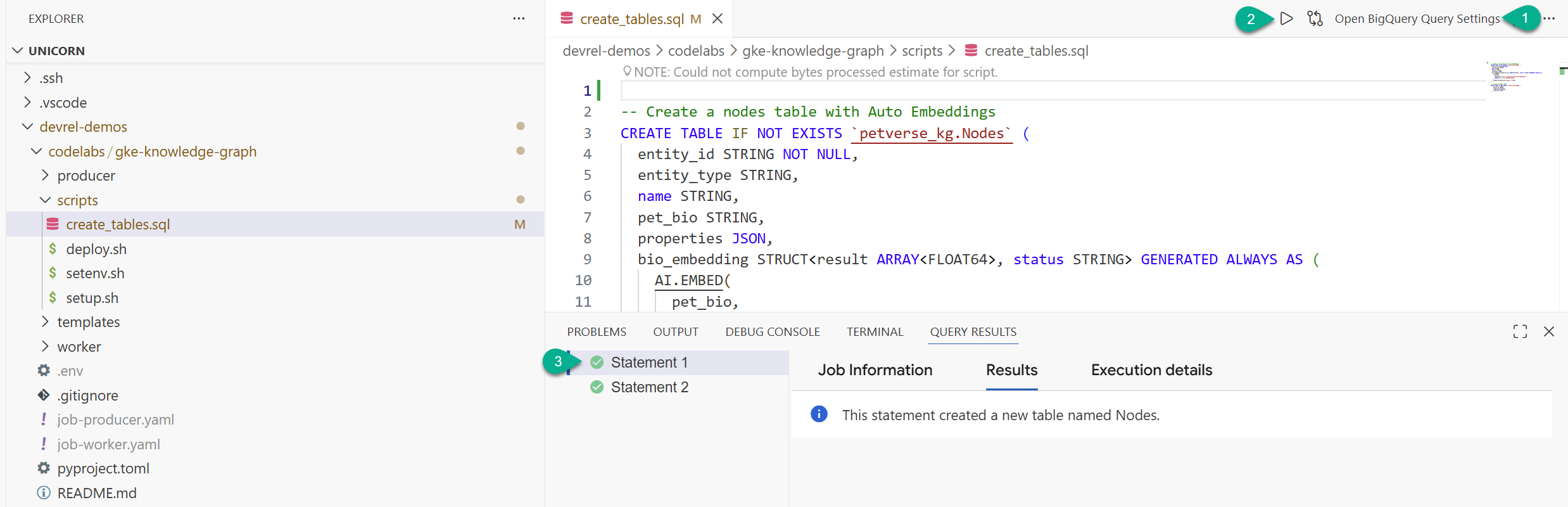
- در پنجره اکسپلورر، پوشهای که از مخزن (
devrel-demos) کپی کردهاید را پیدا کنید. در زیرcodelabs/gke-knowledge-graph/scripts، فایلcreate_tables.sqlخواهید یافت. آن فایل را باز کنید . - در بالا سمت راست، روی «باز کردن تنظیمات پرسوجو» کلیک کنید.
- BigQuery را انتخاب کنید. ذخیره کنید و ببندید .
- روی اجرا کلیک کنید.
باید دو دستور را ببینید که با موفقیت اجرا شدهاند. اکنون جداولی را برای ذخیره گرهها و لبههای نمودار دانش خود ایجاد کردهاید.
میتوانید تب create_tables.sql و کنسول نتایج را ببندید.
۴. مقداردهی اولیه خوشه GKE
ما از GKE Autopilot برای اجرای کار پردازش داده خود استفاده خواهیم کرد. Autopilot بهترین روش پیشنهادی است زیرا زیرساخت کلاستر را برای شما مدیریت میکند.
تا الان، اسکریپت راهاندازی باید تمام شده باشد. باید یک پیام موفقیتآمیز ببینید: 🎉🦄 Setup successfully finished! 🎉🦄 .
برای ایجاد خوشه، این دستور را در ترمینال وارد کنید:
source scripts/setenv.sh
gcloud container clusters create-auto petverse-cluster \
--region=$REGION
🕓 این کار حدود ۵ دقیقه طول خواهد کشید.
برای تعامل با کلاستر، اعتبارنامه دریافت کنید:
source scripts/setenv.sh
gcloud container clusters get-credentials petverse-cluster --region $REGION
شما باید این خروجی را ببینید:
Fetching cluster endpoint and auth data. kubeconfig entry generated for petverse-cluster.
۵. پیکربندی هویت بار کاری
فدراسیون هویت بار کاری برای GKE (با استفاده از دسترسی مستقیم به منابع) به بارهای کاری GKE شما اجازه میدهد تا بدون نیاز به مدیریت کلیدهای حساب سرویس، به طور ایمن به سرویسهای Google Cloud دسترسی داشته باشند.
deploy.sh به صورت زیر اجرا کنید:
- یک حساب کاربری سرویس Kubernetes ایجاد کنید
- نقشهای لازم IAM را مستقیماً به مدیر حساب سرویس Kubernetes اعطا کنید
- حساب سرویس IAM را به حساب سرویس Kubernetes متصل کنید
- برای تکمیل لینک، حساب سرویس Kubernetes را حاشیهنویسی کنید
source scripts/setenv.sh
./scripts/deploy.sh
۶. استقرار وظایف پردازشی مجزا
در این مرحله، شما enqueuer (تولیدکننده) و موتورهای پردازش (کارگران) را روی GKE مستقر خواهید کرد.
معماری جدید و مجزای ما از Google Cloud Pub/Sub برای پردازش ناهمگام داراییها استفاده میکند:
- تولیدکننده GCS را اسکن میکند و تمام مسیرهای فایل را در یک صف Pub/Sub قرار میدهد.
- مجموعهای از Workerها در GKE مقیاسپذیر میشوند، وظایف را به صورت پویا و موازی دریافت میکنند، آنها را از طریق Gemini پردازش میکنند و در BigQuery مینویسند.
اسکریپت setup.sh از قبل تصاویر کانتینر Producer و Worker را ساخته و ارسال کرده، تاپیکهای Pub/Sub را در صف قرار داده و مانیفستهای استقرار GKE شما را به صورت پویا ایجاد کرده است: job-producer.yaml و job-worker.yaml .
- برای اسکن سطل ذخیرهسازی و صفبندی همه داراییها، وظیفه تولیدکننده را اعمال کنید:
kubectl apply -f job-producer.yaml
این کار به سرعت اجرا و پایان مییابد زیرا فقط فرادادهها را در صف قرار میدهد.
- وظیفه Worker را طوری پیکربندی کنید که ۶ worker موازی را اجرا کند تا صف را خالی کند:
kubectl apply -f job-worker.yaml
GKE Autopilot به طور خودکار پادهای در حال انتظار را شناسایی میکند، گرههای محاسباتی را به صورت پویا افزایش مقیاس میدهد و Workerها را به صورت موازی اجرا میکند تا صداها، ویدیوها، تصاویر و CSVهای در صف را پردازش کند.
۷. نتایج را تأیید کنید
- وضعیت شغلهایتان را بررسی کنید:
kubectl get jobs
صبر کنید تا هر دو petverse-producer-job و petverse-worker-job تکمیل موفقیتآمیز را نشان دهند.
🕓 این کار حدود ۱۰ دقیقه طول خواهد کشید. میتوانید پیشرفت را با دستورات زیر مشاهده کنید.
- برای تأیید صحت درج موفقیتآمیز فایلها در صف انتظار، گزارشهای مربوط به تولیدکننده را بررسی کنید:
cd ~/devrel-demos/codelabs/gke-knowledge-graph
source scripts/setenv.sh
kubectl logs -l app=petverse-producer --tail=50
- نحوهی پردازش فایلها از صف انتظار توسط کارگران موازی خود را تماشا کنید:
kubectl logs -l app=petverse-worker --tail=50
(این Workerها دارای یک زمان انتظار ۶۰ ثانیهای برای عدم فعالیت هستند و وقتی صف Pub/Sub خالی شود، به طور خودکار خاموش و پاکسازی میشوند.)
تأیید دادهها در BigQuery
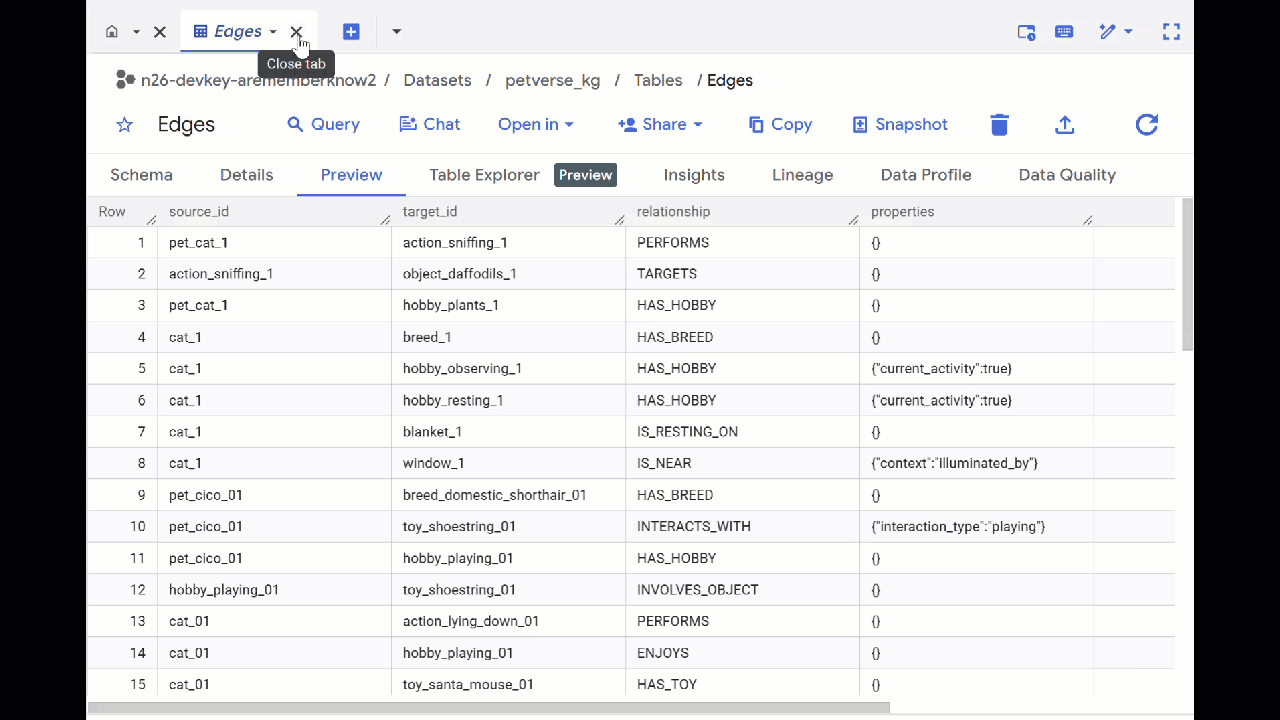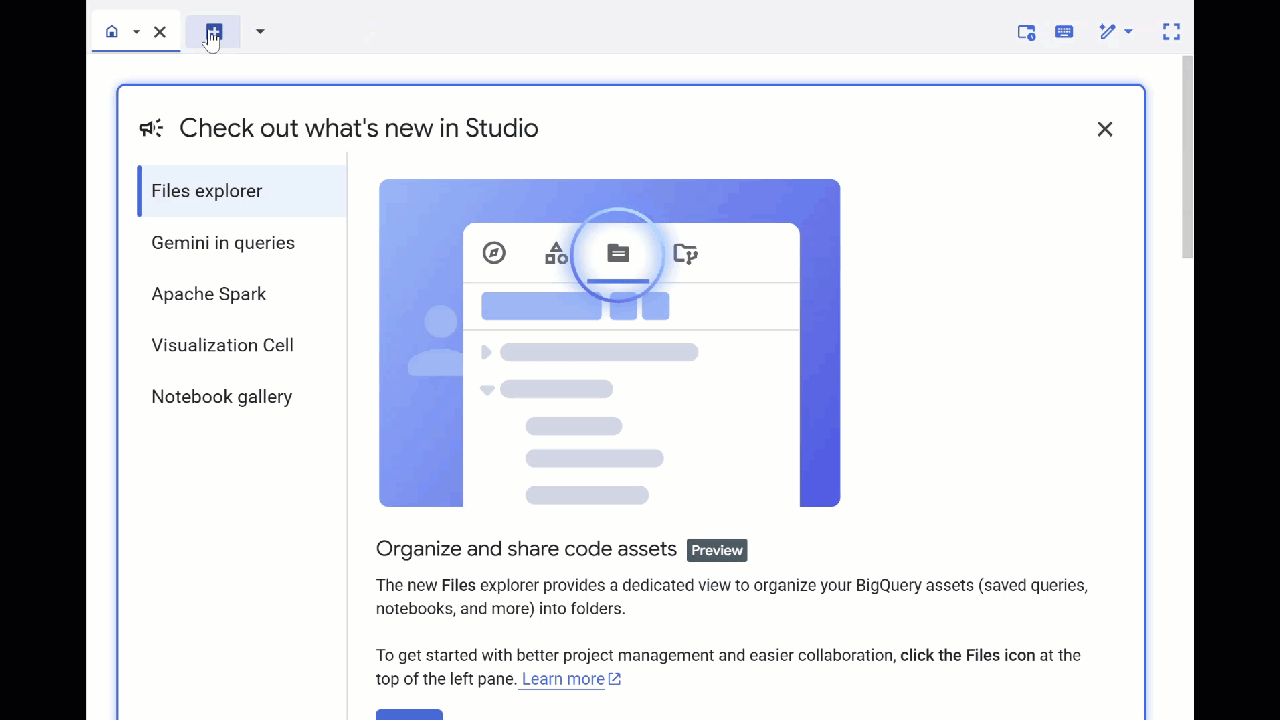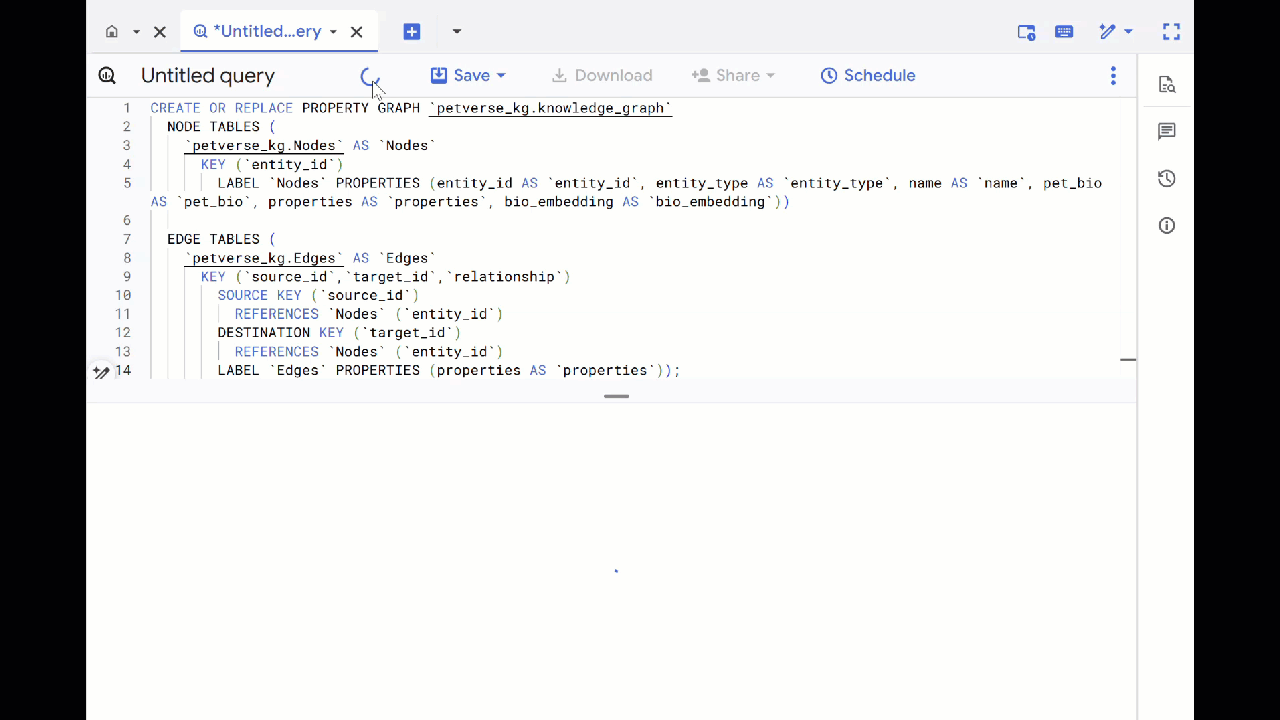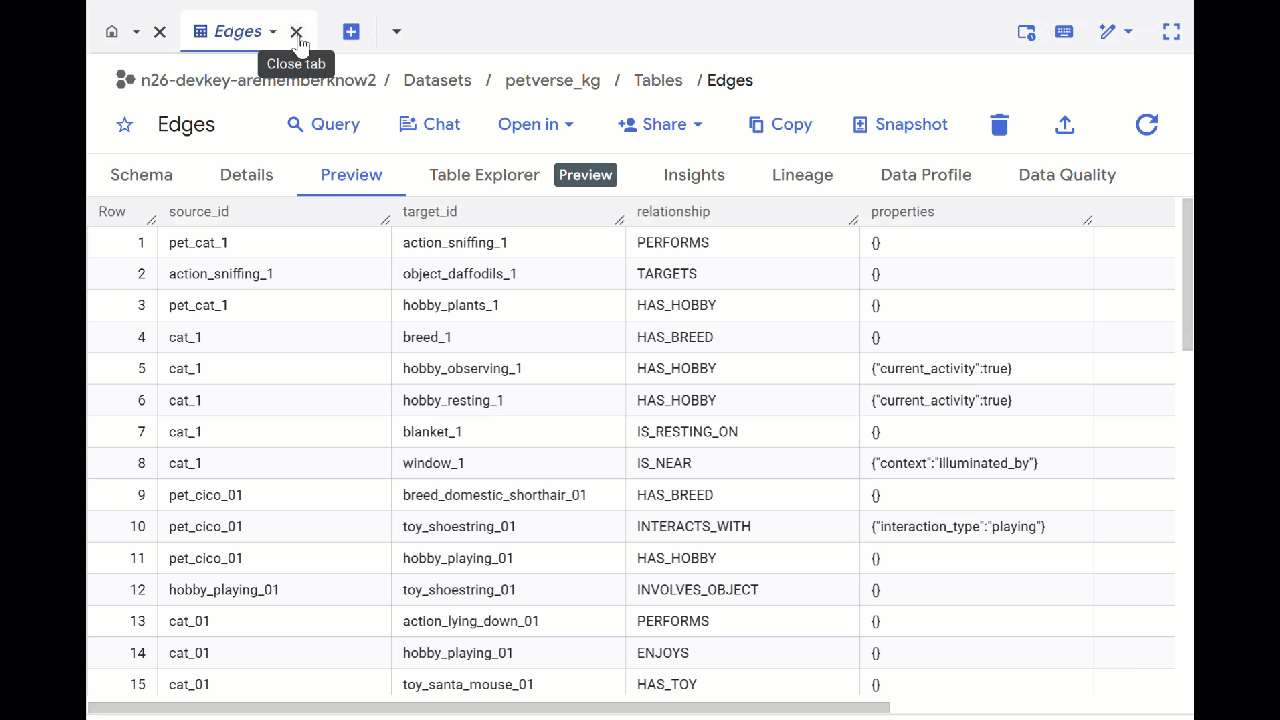
- به BigQuery Studio بروید. خواهید دید که دو جدول ایجاد شدهاند: petverse_kg.Nodes و petverse_kg.Edges.
- برای مشاهدهی محتویات جداول، روی نام آنها دوبار کلیک کنید و سپس روی پیشنمایش کلیک کنید.
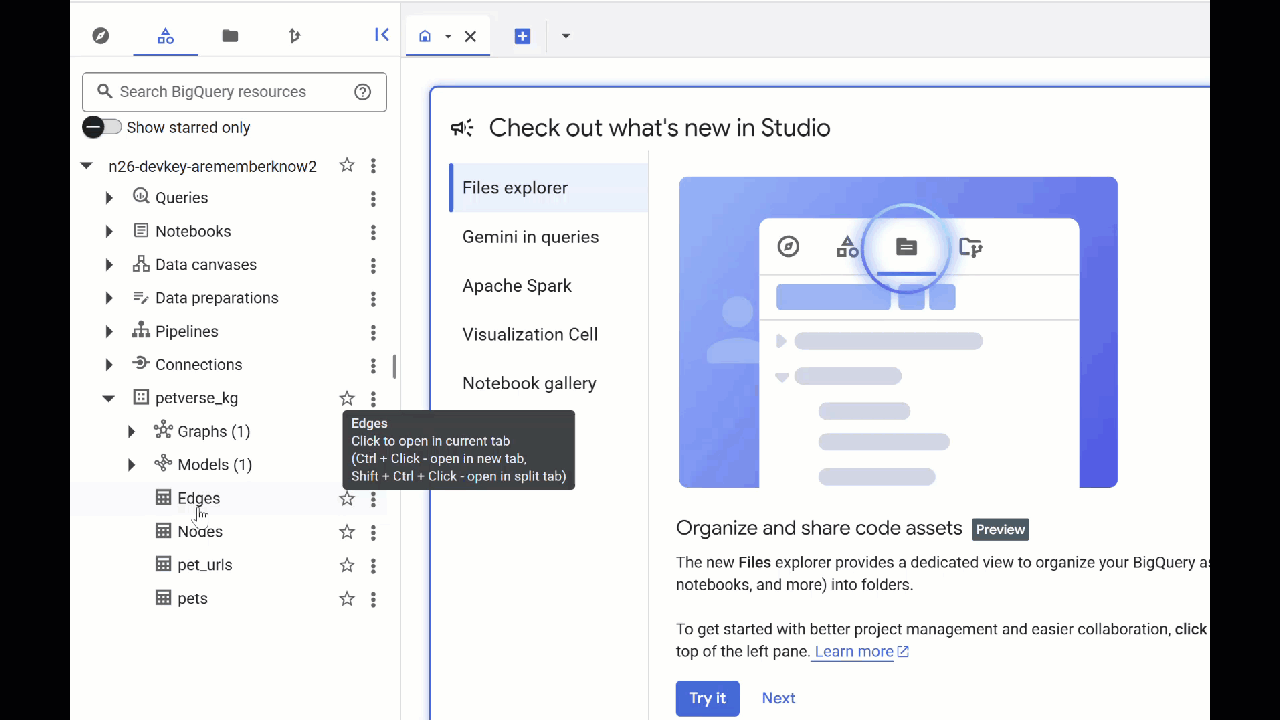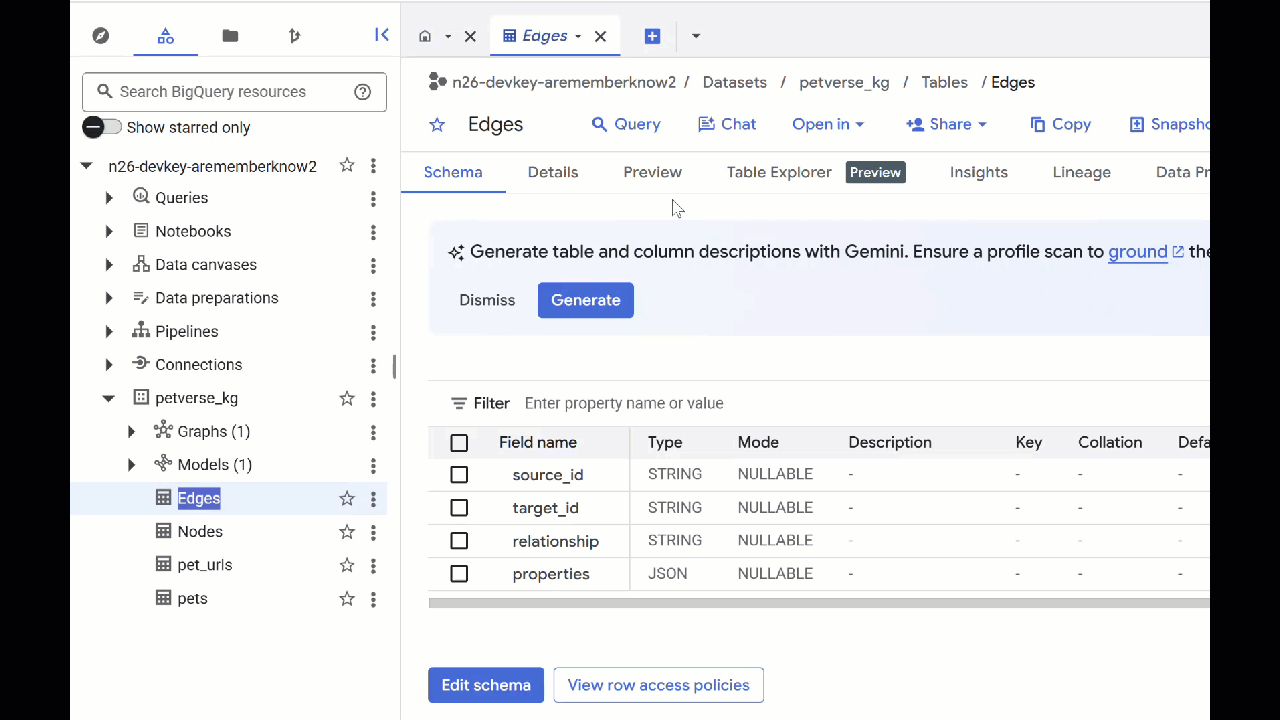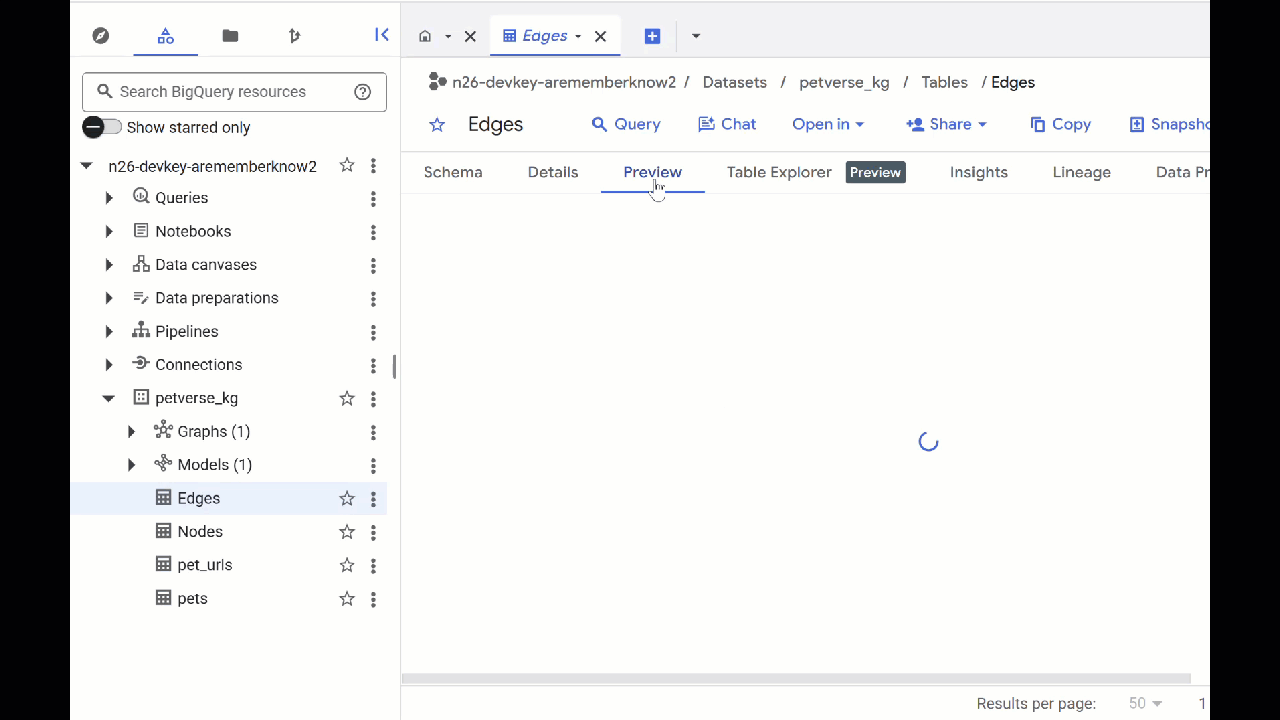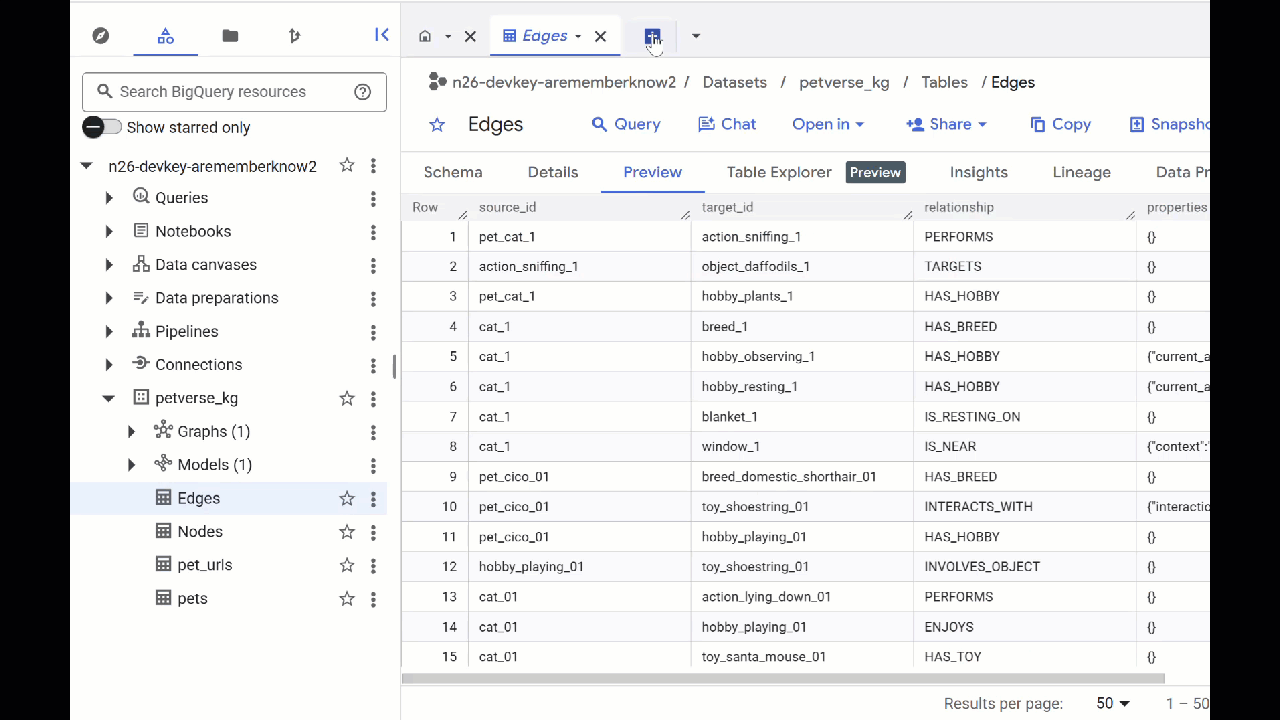
خواهید دید که جدول گرهها (Nodes) حاوی اطلاعاتی در مورد موجودیتهای انتخابشده توسط Gemini در صداها، ویدیوها و تصاویر است. جدول لبهها (Edges) شامل روابط بین آنهاست. بنابراین برای مثال، اگر به صدای گربهای به نام SQL گوش دهید، او دوست دارد با بند کفش بازی کند و از ماهیهای خشکشدهی منجمد لذت میبرد.
- برای ایجاد یک کوئری جدید از دکمه + استفاده کنید. عبارت زیر را در آن قرار دهید و روی Run کلیک کنید:
SELECT n.name, n.entity_id, e.relationship, e.target_id
FROM
`petverse_kg.Nodes` n
JOIN
`petverse_kg.Edges` e
ON n.entity_id = e.source_id
WHERE n.name = 'SQL'
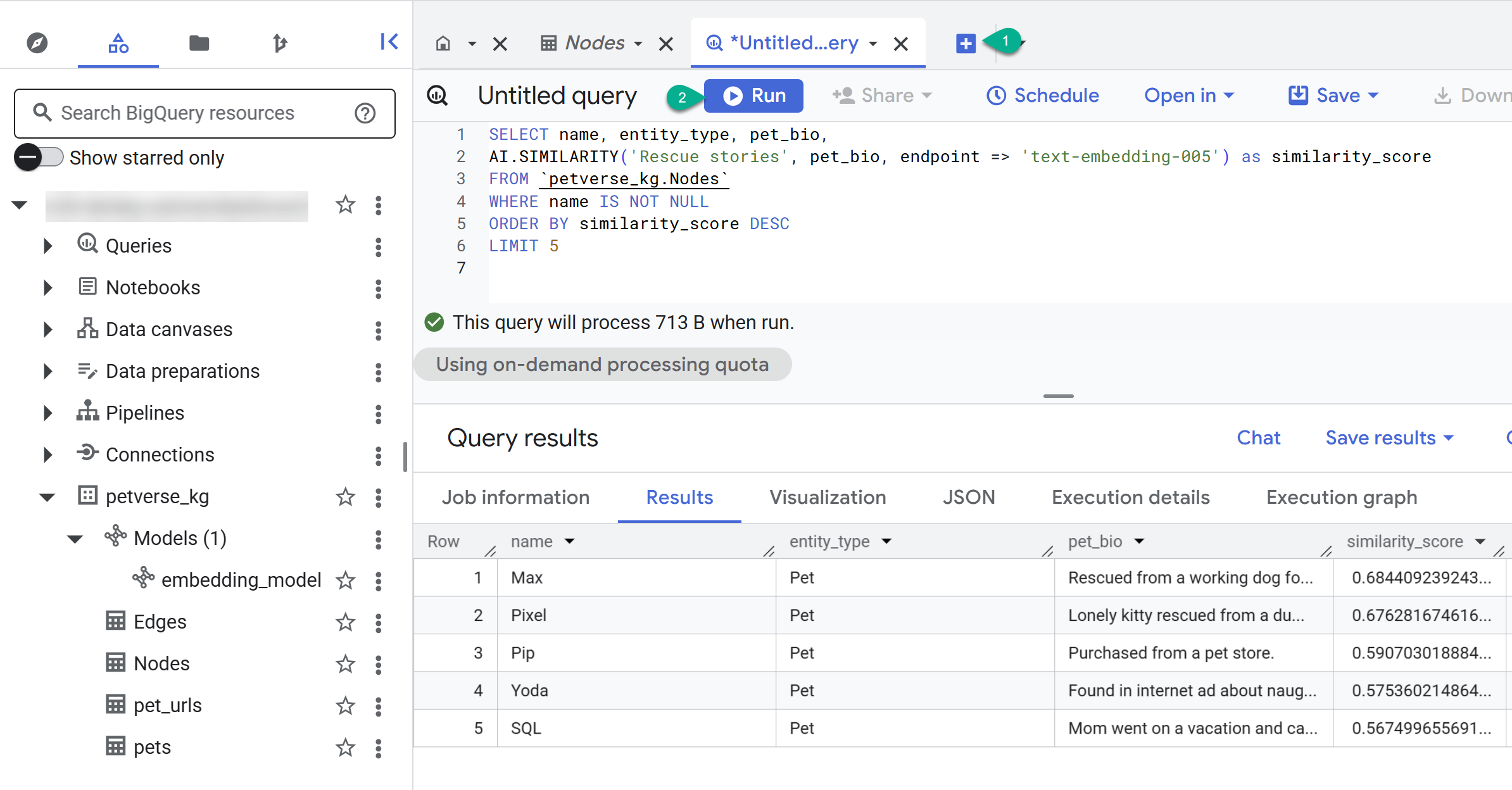
- برای ایجاد یک کوئری جدید از دکمه + استفاده کنید. عبارت زیر را در آن قرار دهید و روی Run کلیک کنید:
SELECT name, entity_type, pet_bio,
AI.SIMILARITY('Pets who like to relax', pet_bio, endpoint => 'text-embedding-005') as similarity_score
FROM `petverse_kg.Nodes`
WHERE name IS NOT NULL
ORDER BY similarity_score DESC
LIMIT 5
شما باید گرههای مربوط به حیوانات خانگی که دوست دارند استراحت کنند را ببینید. این پرسوجو با استفاده از تابع هوش مصنوعی AI.SIMILARITY یک جستجوی معنایی انجام داد تا حیوانات خانگیای را پیدا کند که بیوگرافی آنها بیشترین شباهت را به متن پرسوجو دارد.
نمودار ویژگیها را بسازید
حالا که گرهها و لبهها را در BigQuery داریم، میتوانیم یک نمودار ویژگی (Property Graph) ایجاد کنیم تا به راحتی روابط را جستجو کنیم.
نمودار را ایجاد کنید
- کوئری قبلی را بازنویسی کنید و DDL زیر را برای ایجاد نمودار ویژگی اجرا کنید:
CREATE OR REPLACE PROPERTY GRAPH `petverse_kg.knowledge_graph`
NODE TABLES (
`petverse_kg.Nodes` AS `Nodes`
KEY (`entity_id`)
LABEL `Nodes` PROPERTIES (entity_id AS `entity_id`, entity_type AS `entity_type`, name AS `name`, pet_bio AS `pet_bio`, properties AS `properties`, bio_embedding AS `bio_embedding`))
EDGE TABLES (
`petverse_kg.Edges` AS `Edges`
KEY (`source_id`,`target_id`,`relationship`)
SOURCE KEY (`source_id`)
REFERENCES `Nodes` (`entity_id`)
DESTINATION KEY (`target_id`)
REFERENCES `Nodes` (`entity_id`)
LABEL `Edges` PROPERTIES (properties AS `properties`));
- روی «برو به نمودار» کلیک کنید. نمودار را به صورت گرافیکی با گرهای که خودش یک یال دارد، مشاهده خواهید کرد. این قابل پیشبینی است.
پرس و جو در گراف
- شما میتوانید با دکمه + تمام کوئریهای قبلی را ببندید و یک کوئری جدید و خالی باز کنید.
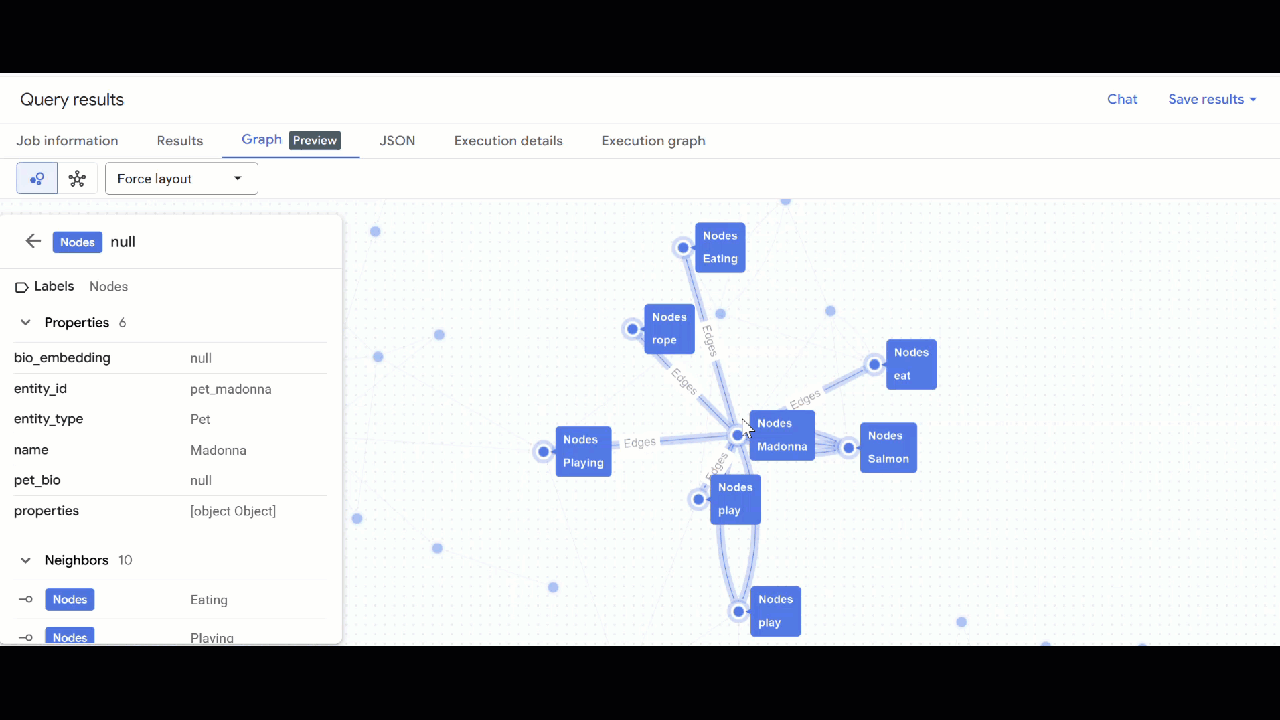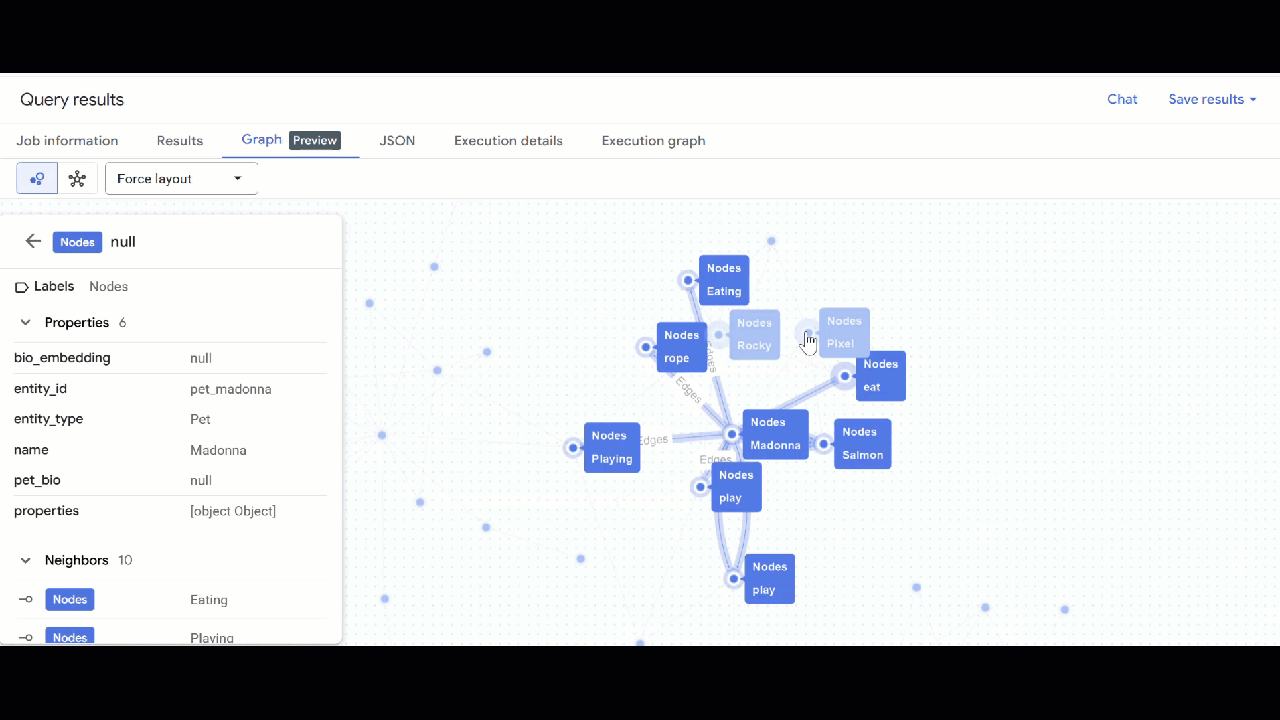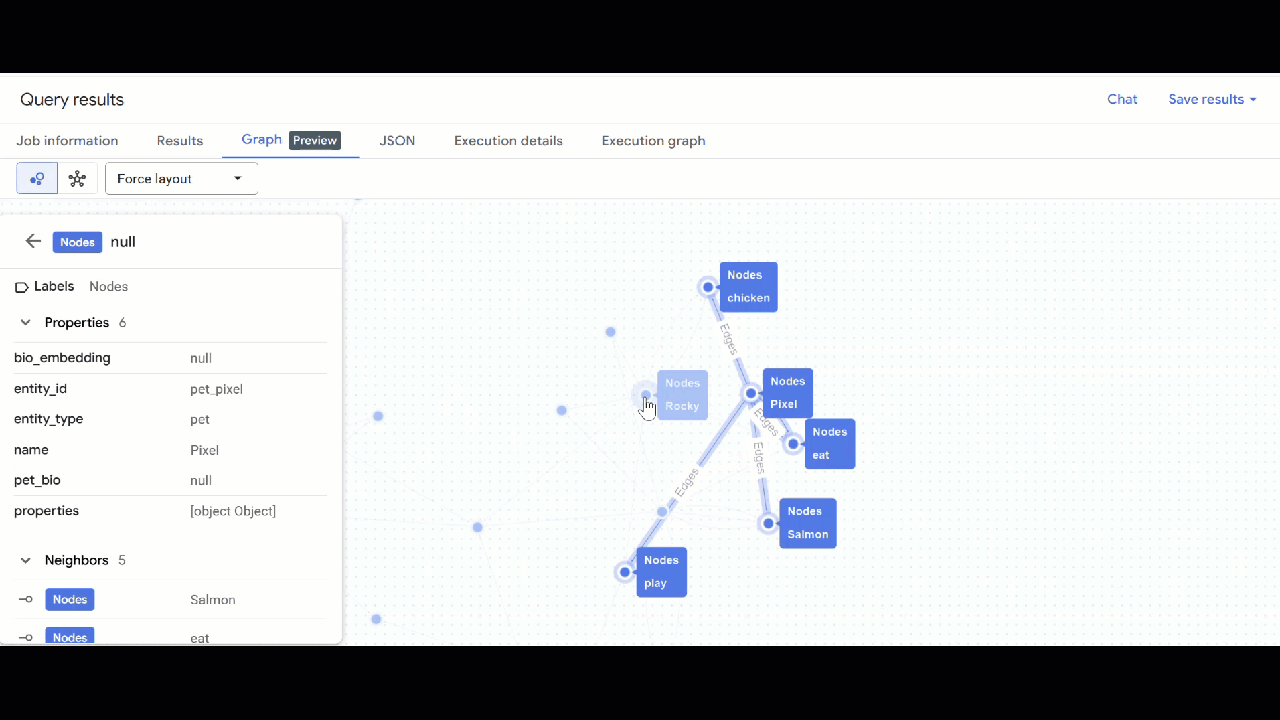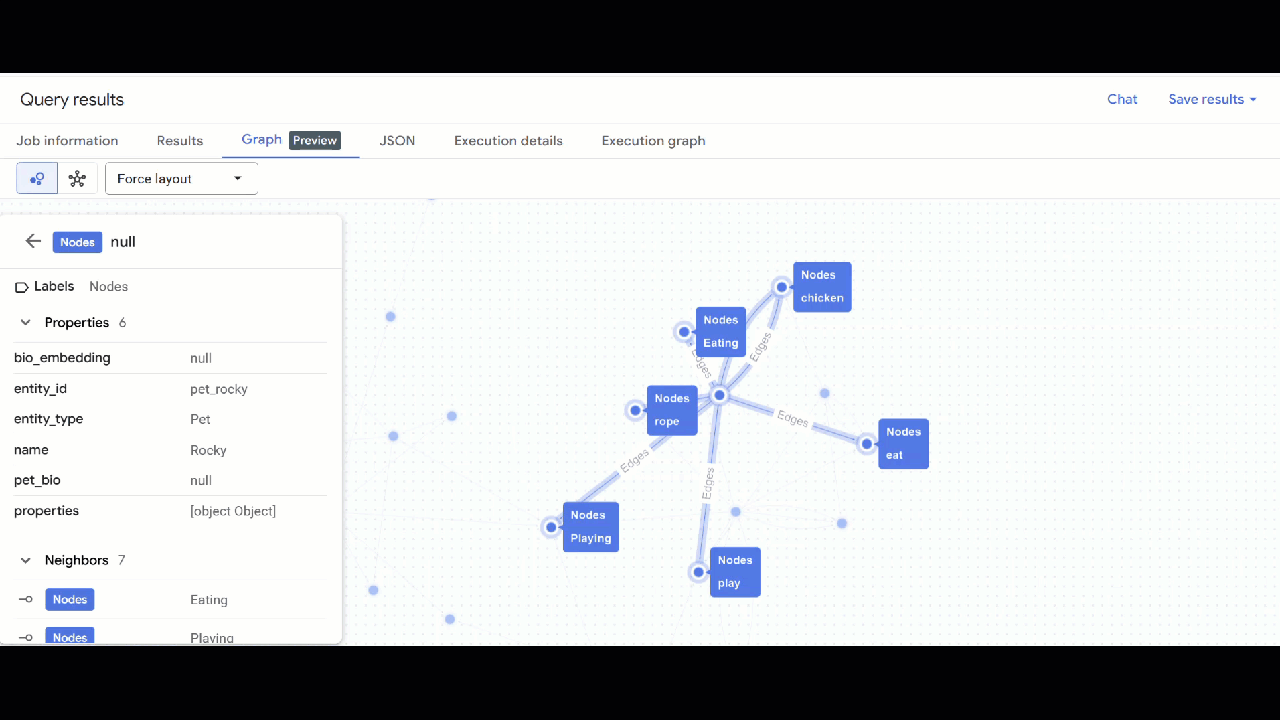
- از GQL برای یافتن حیوانات خانگی مرتبط با سایر حیوانات خانگی از طریق علایق مشترک (مانند سرگرمیها، غذاهای مورد علاقه یا اسباببازیها) استفاده کنید. این پرسوجوی چندگامی، دو حیوان خانگی مختلف را که به یک گره متصل هستند، مطابقت میدهد:
GRAPH `petverse_kg.knowledge_graph`
MATCH p = (pet1:Nodes)-[e1]->(interest:Nodes)<-[e2]-(pet2:Nodes)
WHERE pet1.entity_id != pet2.entity_id
AND (LOWER(pet1.entity_type) = 'pet' AND LOWER(pet2.entity_type) = 'pet')
AND LOWER(interest.entity_type) IN ('hobby', 'action', 'activity', 'food', 'toy')
RETURN TO_JSON(p) as res
LIMIT 100
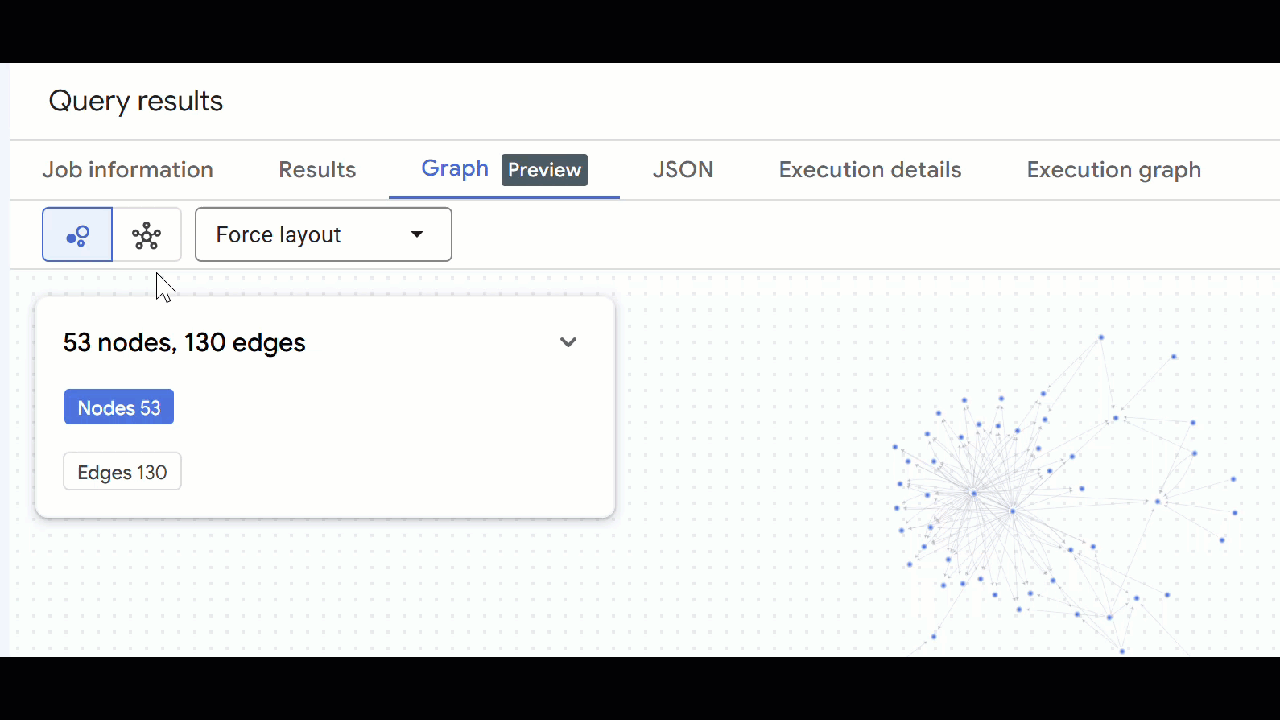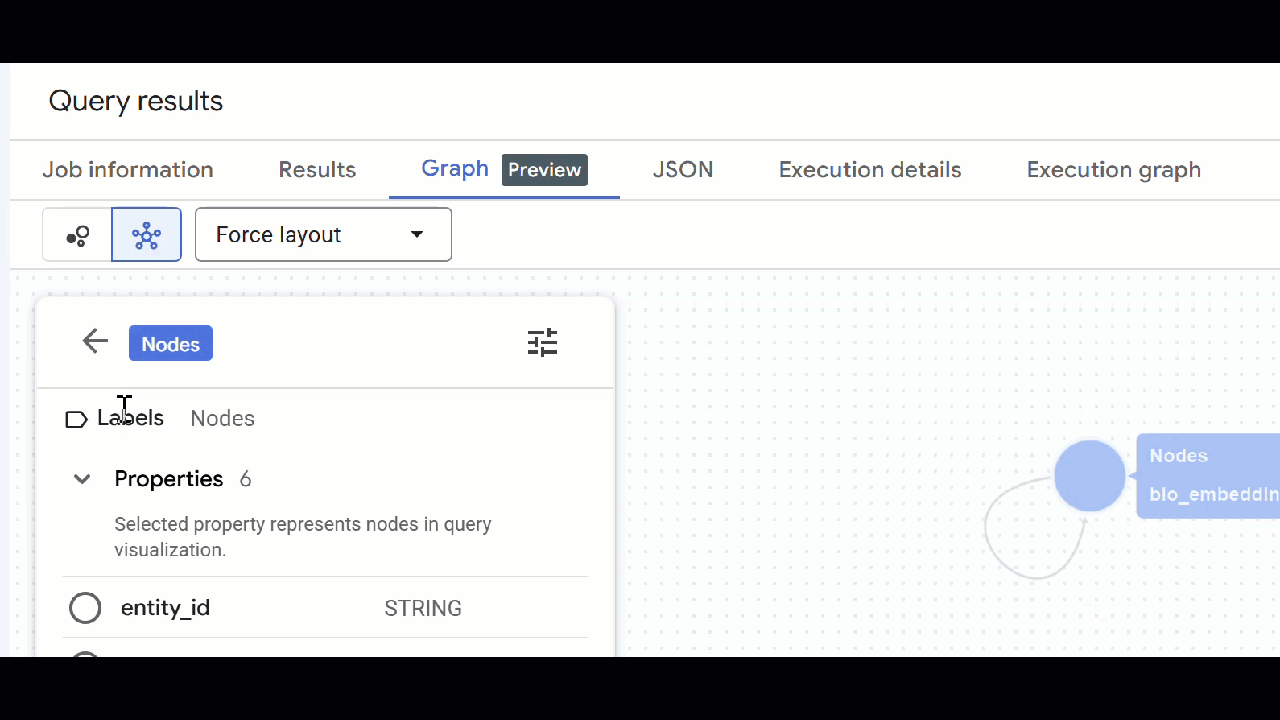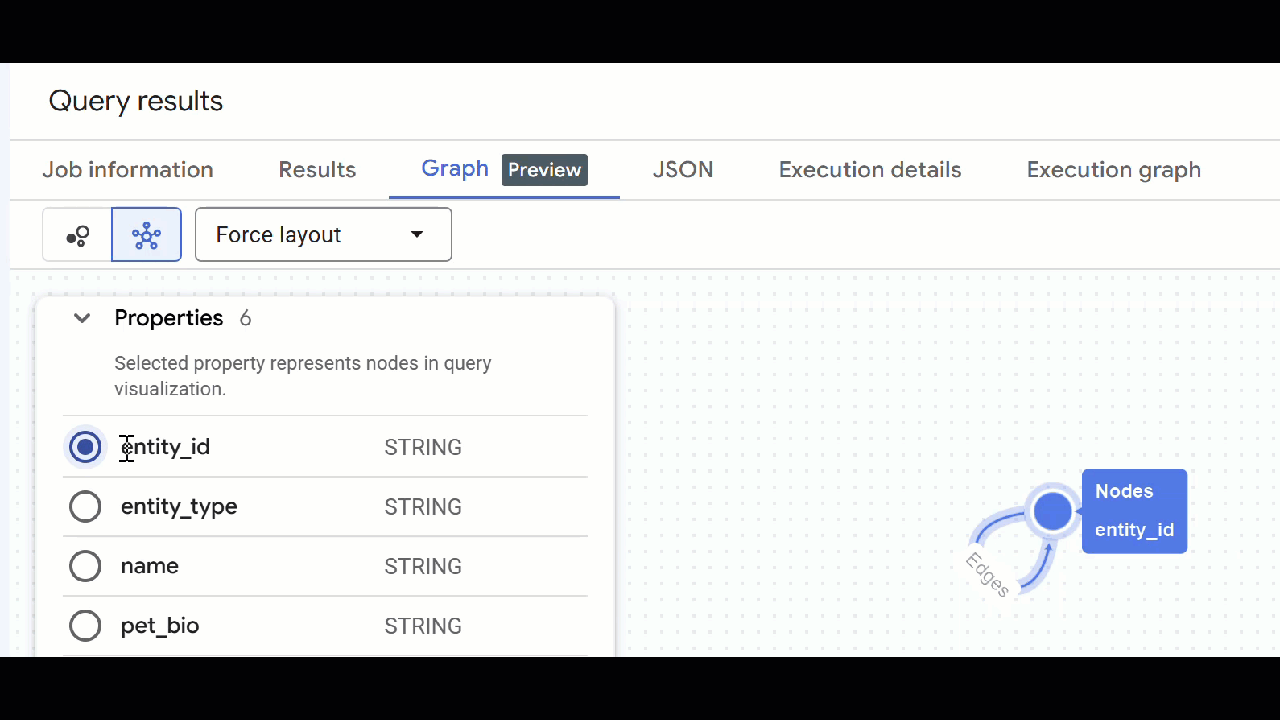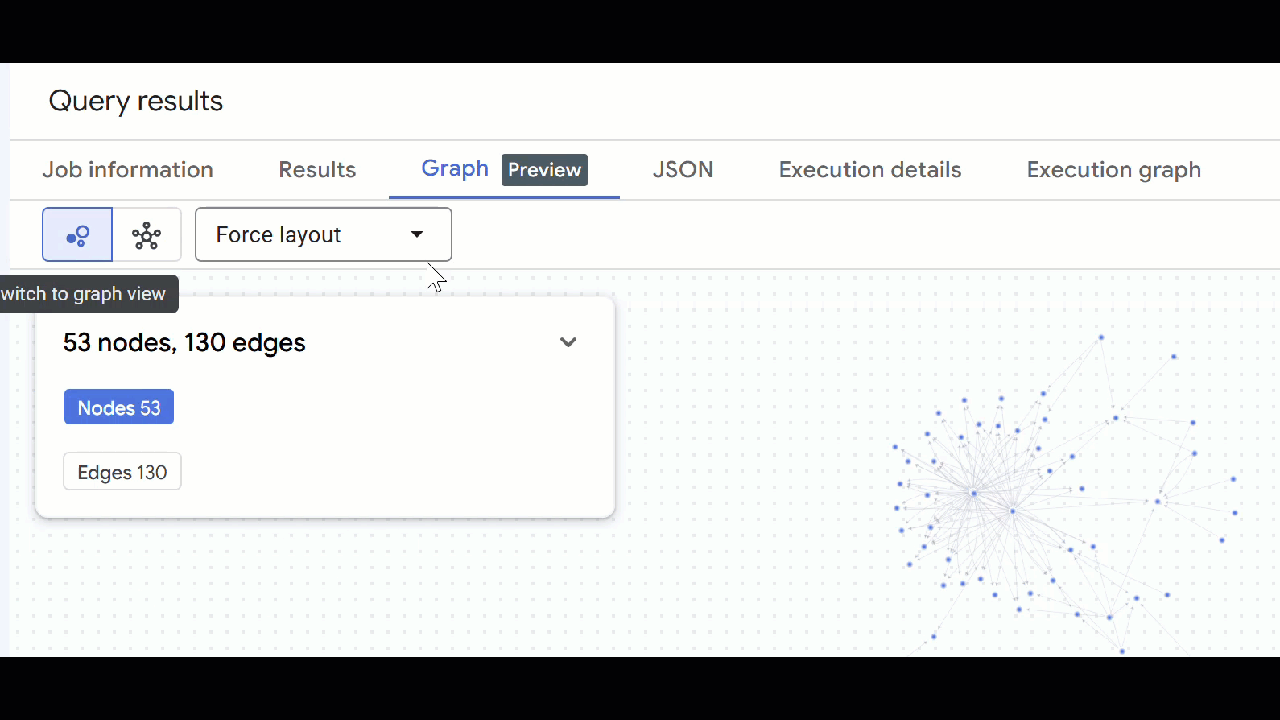
- شما باید تجسم نمودار را ببینید. میتوانید روی گرهها کلیک کنید تا ویژگیهای گرهها و لبهها را ببینید.
🕵️ نکته : میتوانید با کلیک روی «تغییر به نمای طرحواره» ، مقدار نشان داده شده توسط گره را تنظیم کنید:
- میتوانید تمام تبهای کوئری باز را ببندید .
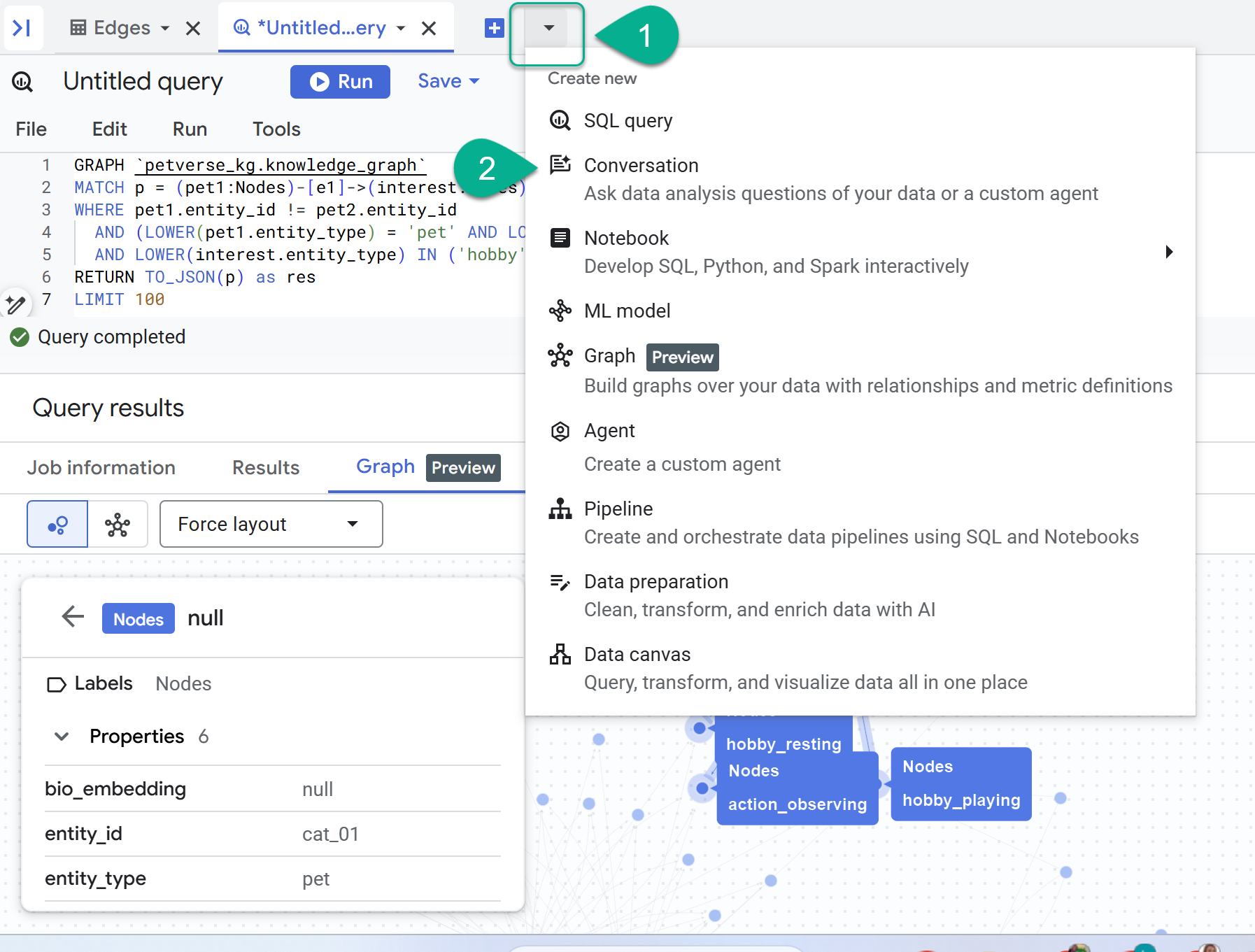
۸. با نمودار چت کنید
- در کنار علامت + ، یک منوی کشویی خواهید یافت. «مکالمه» را انتخاب کنید.
- از شما خواسته میشود که API تجزیه و تحلیل دادهها را با Gemini فعال کنید. هر دو API را فعال کنید. پس از اتمام این کار، پنجره را رفرش کنید یا یک مکالمه جدید ایجاد کنید تا بتوانید نماینده را ببینید.
- روی نماینده جدید کلیک کنید.
- به عامل اسمی مثل
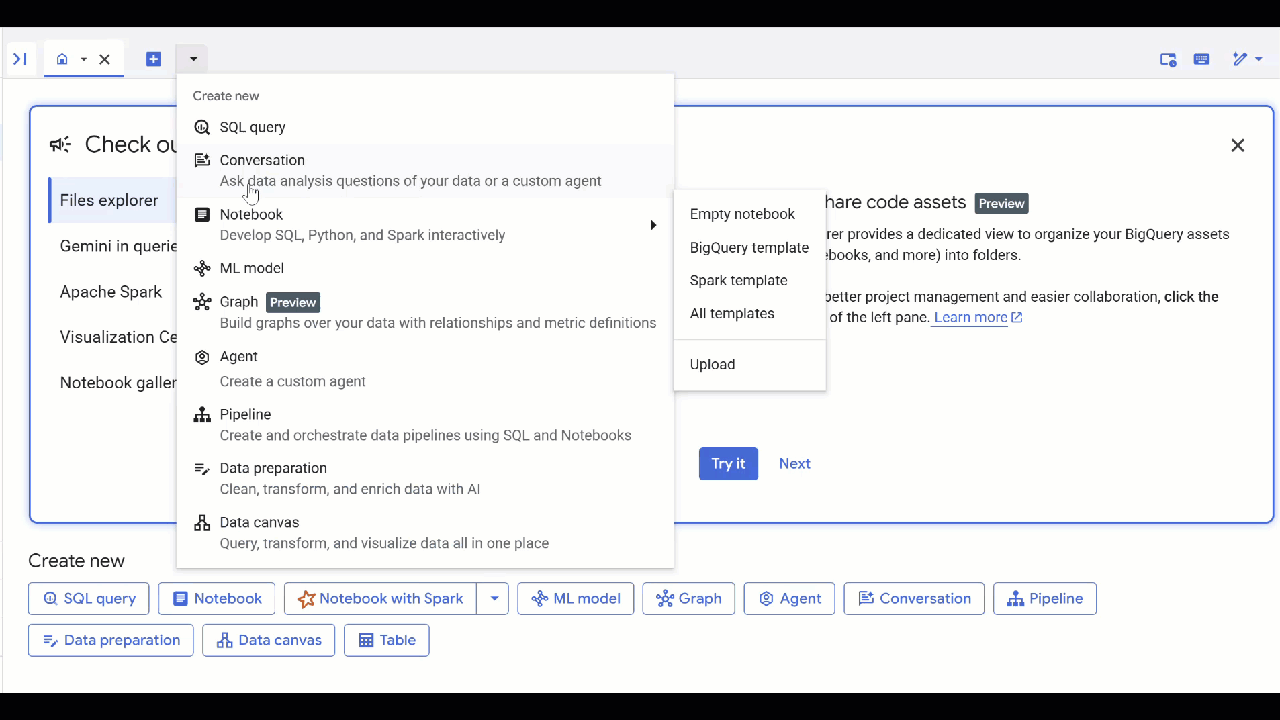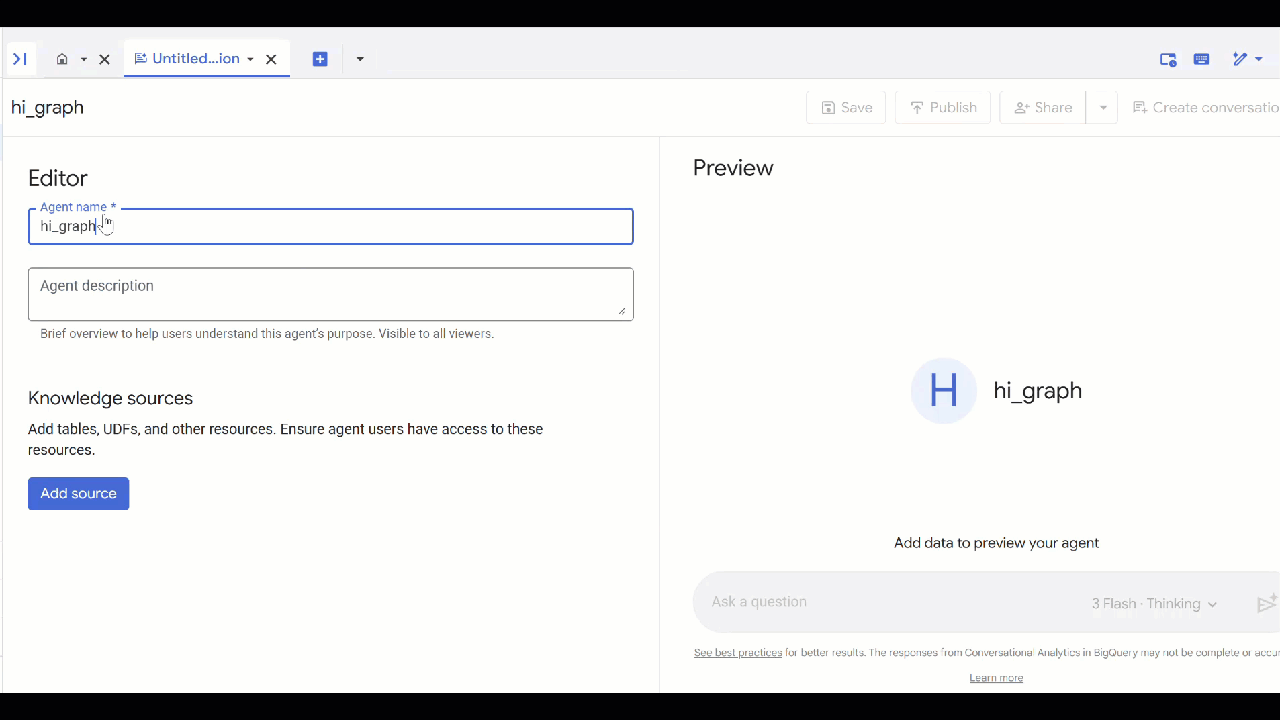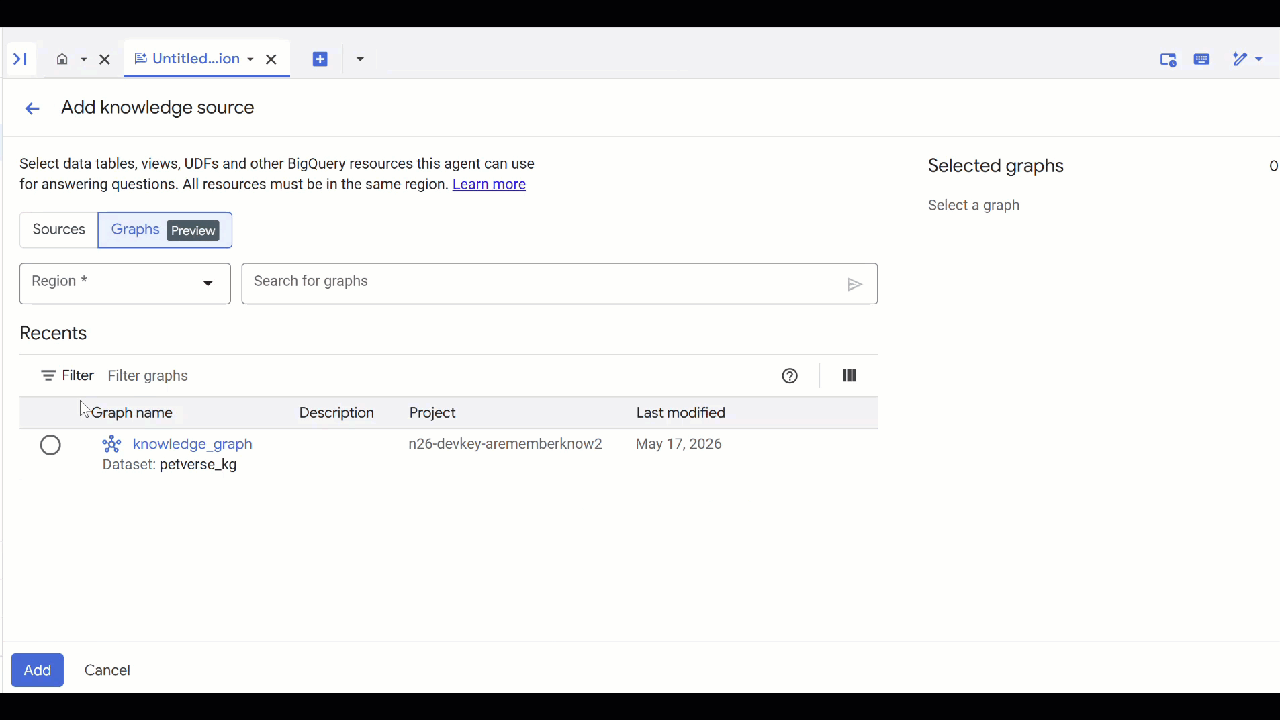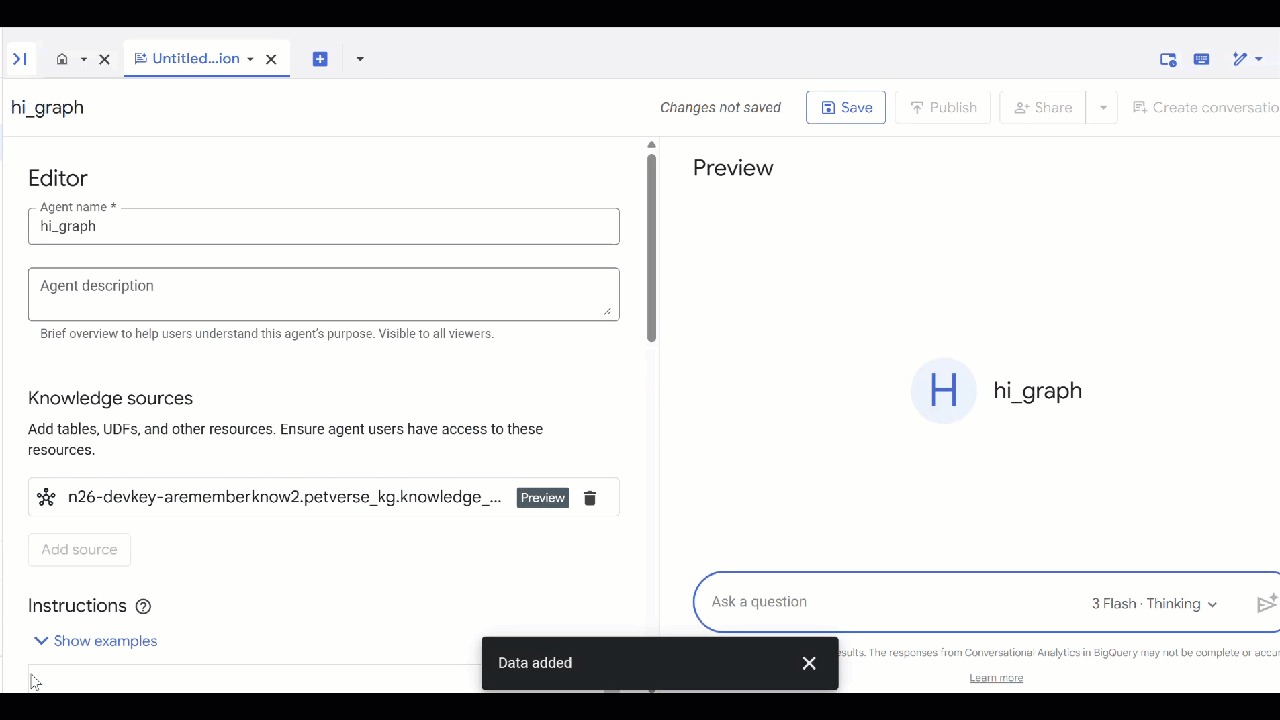
petverseبدهید. - روی افزودن منبع و سپس نمودار کلیک کنید.
-
knowledge_graphکه ایجاد کردهاید را انتخاب کنید و روی Add کلیک کنید.
اکنون میتوانید از عامل سوالی بپرسید و پاسخها و استدلال پشت آنها را ببینید. در اینجا چند نمونه سوال وجود دارد اگر به الهام نیاز دارید. یک مدل تفکر ممکن است کمی بیشتر طول بکشد اما احتمالاً یک پرس و جوی GQL بهتر ایجاد میکند. میتوانید با گسترش Show Thinking ببینید که چه چیزی ایجاد میکند.
- حیوانات خانگیای را پیدا کنید که غذاهای مشابهی میخورند، با حیوانات خانگیای دوست هستند که از چرت زدن لذت میبرند.
- آیا حیوانات خانگی دقیقاً سرگرمی، غذای مورد علاقه یا اسباببازی یکسانی دارند؟ جفتها و علایق مشترکشان را فهرست کنید.
- حیوانات خانگی را پیدا کنید که گونه یا نژاد یکسانی دارند، اما سرگرمیهای کاملاً متفاوتی دارند.
۹. تمیز کردن
برای جلوگیری از هزینههای مداوم برای حساب Google Cloud خود، منابع ایجاد شده در طول این codelab را حذف کنید.
- خوشه GKE را حذف کنید:
gcloud container clusters delete petverse-cluster --region $REGION --quiet
- مجموعه داده BigQuery را حذف کنید (این کار همه جداول را حذف خواهد کرد):
bq rm -r -f -d $PROJECT_ID:petverse_kg
- منابع صف Pub/Sub را حذف کنید:
gcloud pubsub subscriptions delete petverse-sub --quiet
gcloud pubsub topics delete petverse-topic --quiet
- مخزن رجیستری Artifact را حذف کنید:
gcloud artifacts repositories delete gke-cats-repo --location=$REGION --quiet
- سطل GCS مخصوص پروژه را حذف کنید:
gcloud storage buckets delete gs://$PROJECT_ID-petverse --quiet
۱۰. تبریک
تبریک! شما با موفقیت یک خط لوله نمودار دانش توزیعشده با استفاده از GKE و Gemini ساختید و آن را با استفاده از BigQuery Property Graphs پرسوجو کردید.
آنچه آموختهاید
- نحوه استقرار کارهای توزیعشده در GKE Autopilot
- نحوه استفاده از Gemini برای استخراج دادههای چندوجهی.
- نحوه استفاده از جاسازیهای خودکار BigQuery .
- نحوه ایجاد و پرس و جو از نمودارهای ویژگی در BigQuery.