
1. Introduction
Dans cet atelier de programmation, vous allez créer un pipeline d'acquisition de connaissances distribué pour "Petverse". Vous allez traiter des éléments multimédias non structurés (audio, vidéo, images, texte/CSV) à partir d'un bucket Cloud Storage, extraire des informations clés sur les animaux de compagnie (nourriture préférée, loisirs) et créer un graphique de connaissances. Vous allez mettre à l'échelle le traitement du fichier multimédia à l'aide du traitement multimodal Gemini sur Google Kubernetes Engine (GKE). Enfin, vous stockerez ces données dans BigQuery et utiliserez la nouvelle fonctionnalité BigQuery Property Graph pour analyser les relations.
Nous allons utiliser la puissance de Google Kubernetes Engine pour vous montrer comment traiter de grands volumes de données en parallèle.
Pourquoi utiliser des graphiques de connaissances ?
Les knowledge graphs sont plus adaptés que les bases de données relationnelles traditionnelles pour représenter et analyser les relations complexes entre les entités.
Nous utiliserons Gemini 2.5 Flash pour analyser des fichiers image, audio et vidéo, et établir des faits sur différents animaux de compagnie.
Objectifs de l'atelier
- Créez et déployez un job de traitement de données distribuées sur GKE.
- Utilisez Gemini pour extraire des entités et des relations à partir de fichiers multimédias.
- Stockez les données du graphique de connaissances dans BigQuery.
- Créez et interrogez un graphique de propriétés dans BigQuery à l'aide du Graph Query Language (GQL).
Prérequis
- Un navigateur Web (par exemple, Chrome)
- Un projet Google Cloud avec facturation activée
- Autorisations dans le projet pour créer des ressources et modifier les stratégies IAM
Cet atelier de programmation s'adresse aux développeurs de tous niveaux, y compris aux débutants.
Durée estimée : 45 minutes
Coût : les ressources créées dans cet atelier de programmation devraient coûter moins de 5 $.
2. Avant de commencer
Créer un projet Google Cloud
- Accédez à la console Google Cloud : https://console.cloud.google.com, puis sélectionnez ou créez un projet Google Cloud.
- ⚠️ Notez l'ID du projet. Vous l'utiliserez pour plusieurs commandes de cet atelier.
Démarrer Cloud Shell
- Ouvrez Cloud Shell dans un nouvel onglet : https://shell.cloud.google.com/.
- Cliquez sur Autoriser si vous y êtes invité.
- Remplacez
PROJECT_IDet collez la commande suivante dans le terminal :
export PROJECT_ID="YOUR_PROJECT_ID"
gcloud config set project $PROJECT_ID
📝 Remarque : Votre projet s'affichera en jaune dans la ligne de commande. Si votre session redémarre, assurez-vous d'exécuter à nouveau la commande ci-dessus pour définir l'ID du projet.
Activer les API
Exécutez cette commande pour activer toutes les API requises :
gcloud services enable \
aiplatform.googleapis.com \
bigquery.googleapis.com \
artifactregistry.googleapis.com \
container.googleapis.com \
cloudbuild.googleapis.com \
pubsub.googleapis.com
Cloner le dépôt
Exécutez ces commandes pour cloner le dépôt.
cd ~/
git clone --filter=blob:none --no-checkout https://github.com/GoogleCloudPlatform/devrel-demos.git
cd ~/devrel-demos
git sparse-checkout init --cone
git sparse-checkout set codelabs/gke-knowledge-graph
git checkout main
cd codelabs/gke-knowledge-graph/
Exécuter le script de configuration
Ce script automatise la configuration du backend en effectuant les opérations suivantes :
- Créer une image de conteneur et un dépôt Artifact Registry
- Créer un ensemble de données BigQuery
- Créer une connexion BigQuery pour exécuter les fonctions IA Gemini à partir de SQL
Exécutez la commande suivante dans votre terminal :
./scripts/setup.sh
Si le script vous demande des informations de configuration, utilisez les valeurs suivantes :
- ID du projet : utilisez l'ID que vous avez créé à l'étape précédente.
- Région :
us-central1
⚠️ Important : L'exécution du script prendra quelques minutes. Laissez cette fenêtre de terminal ouverte pour terminer en arrière-plan. Pour passer à l'étape suivante, ouvrez un nouvel onglet ou une nouvelle fenêtre de terminal pour exécuter vos prochaines commandes.
3. Configurer le Data Agent Kit
- Activez l'éditeur Cloud Shell en cliquant sur l'icône en forme de crayon en haut à droite.
- Dans l'éditeur Cloud Shell, cliquez sur l'icône Extensions dans la barre latérale de gauche.
- Recherchez Google Cloud Data Agent Kit, puis cliquez sur Install (Installer) si ce n'est pas déjà fait.
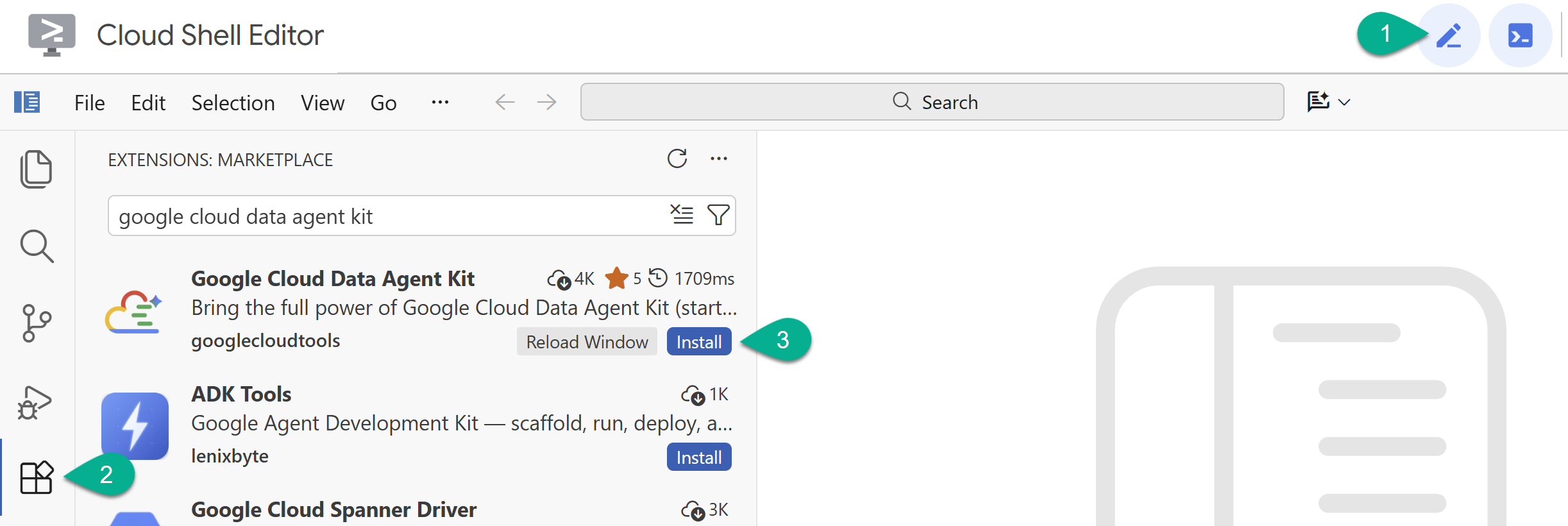
- Connectez-vous à votre compte Google avec l'extension.
- Dans le récapitulatif de la configuration, saisissez l'ID de votre projet et
us-central1comme région.
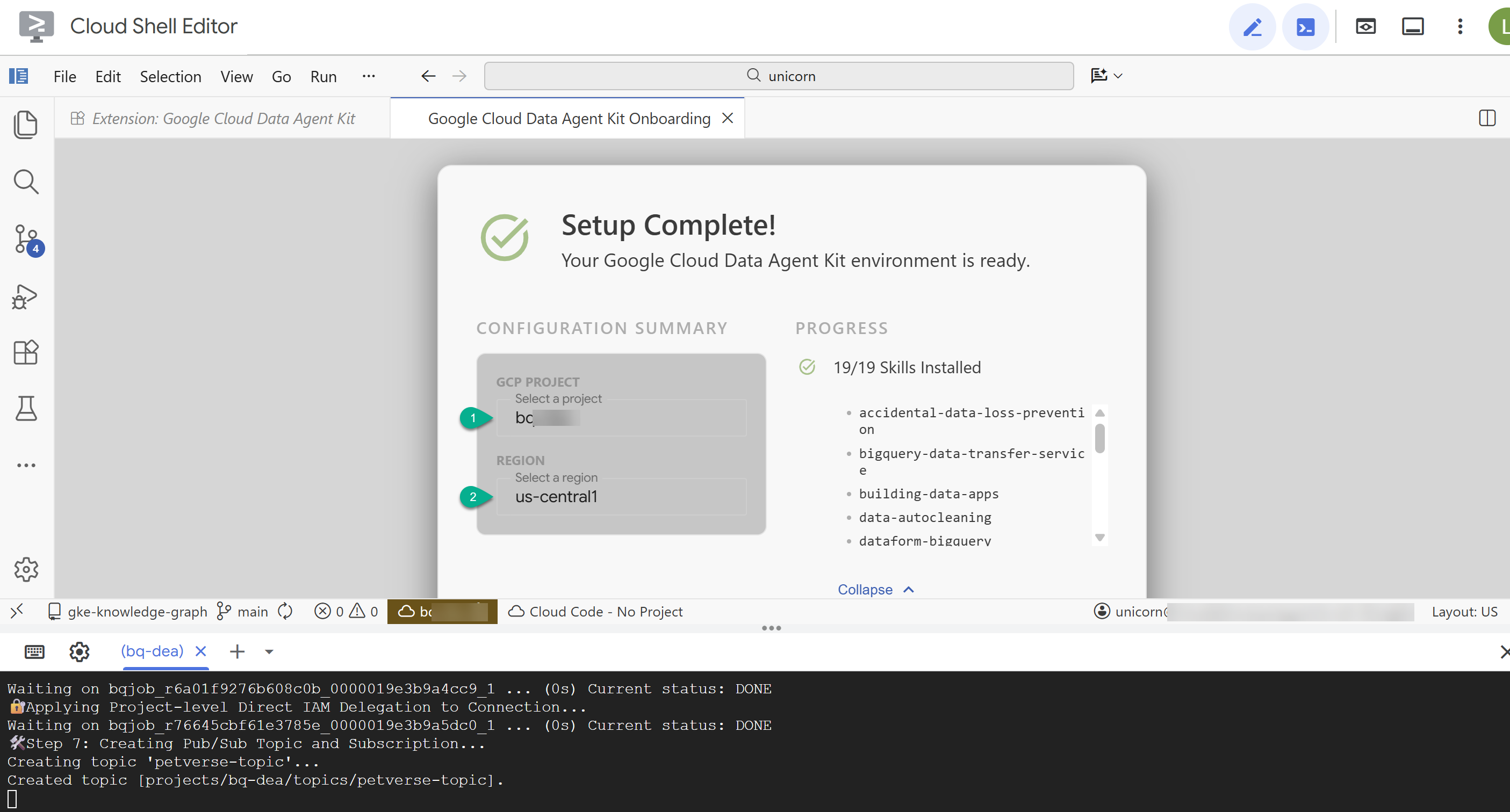
- Cliquez sur Configurer les serveurs MCP. Vous n'avez pas besoin de modifier le contenu de cette fenêtre. Il vous suffit de cliquer sur Commencer.
- Actualisez la fenêtre si vous y êtes invité. Vous pouvez fermer l'onglet "Guide de démarrage rapide" pour le moment.
Configurer les tables dans BigQuery
- Dans la barre latérale, revenez à l'explorateur. Si votre dossier personnel (par exemple,
/home/your_user_name/) n'est pas déjà ouvert, cliquez sur Ouvrir un dossier et sélectionnez-le.
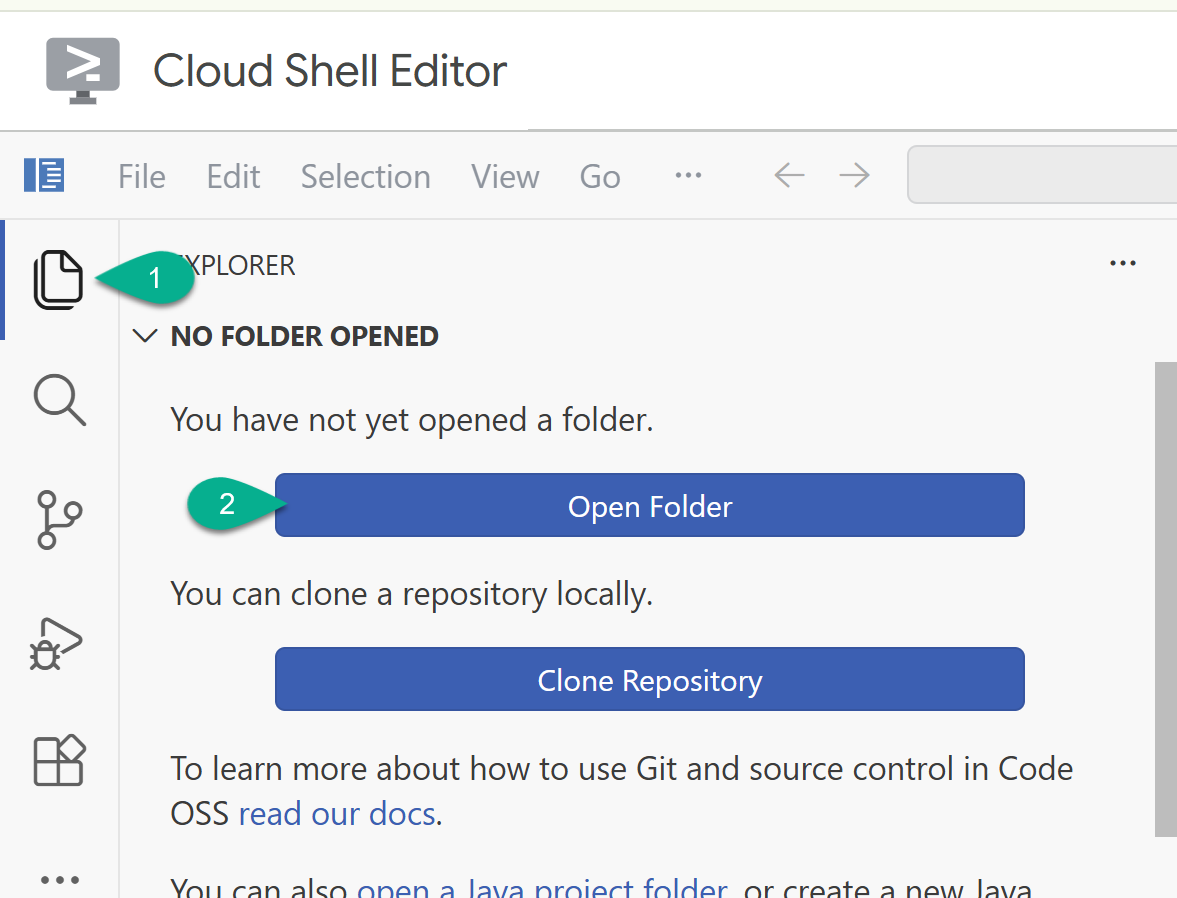
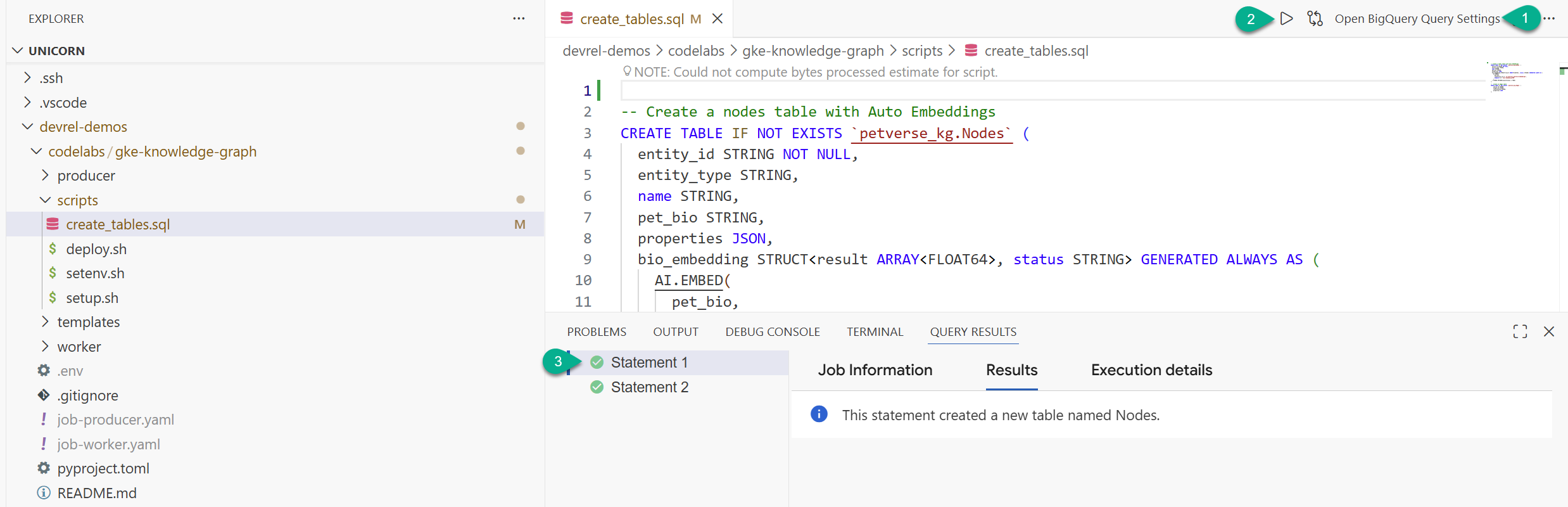
- Dans la fenêtre de l'explorateur, recherchez le dossier que vous avez cloné à partir du dépôt (
devrel-demos). Souscodelabs/gke-knowledge-graph/scripts, vous trouverezcreate_tables.sql. Ouvrez ce fichier. - En haut à droite, cliquez sur Ouvrir les paramètres de la requête.
- Sélectionnez BigQuery. Enregistrez et fermez.
- Cliquez sur Exécuter.
Deux instructions devraient s'exécuter avec succès. Vous avez maintenant créé les tables permettant de stocker les nœuds et les arêtes de votre knowledge graph.
Vous pouvez fermer l'onglet create_tables.sql et la console de résultats.
4. Initialiser le cluster GKE
Nous allons utiliser GKE Autopilot pour exécuter notre job de traitement des données. Autopilot est la bonne pratique recommandée, car il gère l'infrastructure de cluster pour vous.
Le script de configuration devrait maintenant être terminé. Un message confirmant le succès de l'opération doit s'afficher : 🎉🦄 Setup successfully finished! 🎉🦄.
Collez cette commande dans le terminal pour créer le cluster :
source scripts/setenv.sh
gcloud container clusters create-auto petverse-cluster \
--region=$REGION
🕓 Cela prendra environ cinq minutes.
Obtenez des identifiants pour interagir avec le cluster :
source scripts/setenv.sh
gcloud container clusters get-credentials petverse-cluster --region $REGION
Vous devriez voir le résultat suivant :
Fetching cluster endpoint and auth data. kubeconfig entry generated for petverse-cluster.
5. Configurer Workload Identity
La fédération d'identité de charge de travail pour GKE (avec accès direct aux ressources) permet à vos charges de travail GKE d'accéder de manière sécurisée aux services Google Cloud sans avoir à gérer les clés de compte de service.
Exécutez deploy.sh pour :
- Créer un compte de service Kubernetes
- Attribuer les rôles IAM nécessaires directement au compte de service Kubernetes
- Associer le compte de service IAM au compte de service Kubernetes
- Annoter le compte de service Kubernetes pour finaliser l'association
source scripts/setenv.sh
./scripts/deploy.sh
6. Déployer des jobs de traitement découplés
Dans cette étape, vous allez déployer l'enfileur (producteur) et les moteurs de traitement (workers) sur GKE.
Notre nouvelle architecture découplée utilise Google Cloud Pub/Sub pour traiter les composants de manière asynchrone :
- Le producteur analyse GCS et met en file d'attente tous les chemins d'accès aux fichiers dans une file d'attente Pub/Sub.
- Un pool de nœuds de calcul évolue dans GKE, en extrayant dynamiquement les tâches en parallèle, en les traitant via Gemini et en les écrivant dans BigQuery.
Le script setup.sh a déjà créé et transféré les images de conteneur Producer et Worker, mis en file d'attente les sujets Pub/Sub et généré dynamiquement vos fichiers manifestes de déploiement GKE : job-producer.yaml et job-worker.yaml.
- Appliquez le job de producteur pour analyser votre bucket de stockage et mettre en file d'attente tous les composants :
kubectl apply -f job-producer.yaml
Cette tâche s'exécute et se termine rapidement, car elle ne met en file d'attente que les métadonnées.
- Déployez le Worker Job configuré pour exécuter six nœuds de calcul en parallèle afin de vider la file d'attente :
kubectl apply -f job-worker.yaml
GKE Autopilot détecte automatiquement les pods en attente, augmente de manière dynamique le nombre de nœuds de calcul et exécute les workers en parallèle pour traiter les fichiers audio, vidéo, image et CSV mis en file d'attente.
7. Vérifier les résultats
- Vérifiez l'état de vos jobs :
kubectl get jobs
Attendez que petverse-producer-job et petverse-worker-job indiquent que les opérations ont été effectuées.
🕓 Cela prendra environ 10 minutes. Vous pouvez suivre la progression à l'aide des commandes ci-dessous.
- Consultez les journaux du producteur pour vérifier qu'il a bien mis les fichiers en file d'attente :
cd ~/devrel-demos/codelabs/gke-knowledge-graph
source scripts/setenv.sh
kubectl logs -l app=petverse-producer --tail=50
- Regardez vos nœuds de calcul parallèles traiter les fichiers de la file d'attente :
kubectl logs -l app=petverse-worker --tail=50
(Les nœuds de calcul disposent d'un délai d'inactivité de 60 secondes. Ils s'arrêtent et se nettoient automatiquement lorsque la file d'attente Pub/Sub est vide.)
Vérifiez les données dans BigQuery.
- Accédez à BigQuery Studio. Deux tables sont créées : petverse_kg.Nodes et petverse_kg.Edges.
- Pour afficher le contenu des tables, double-cliquez sur leur nom, puis cliquez sur Aperçu.
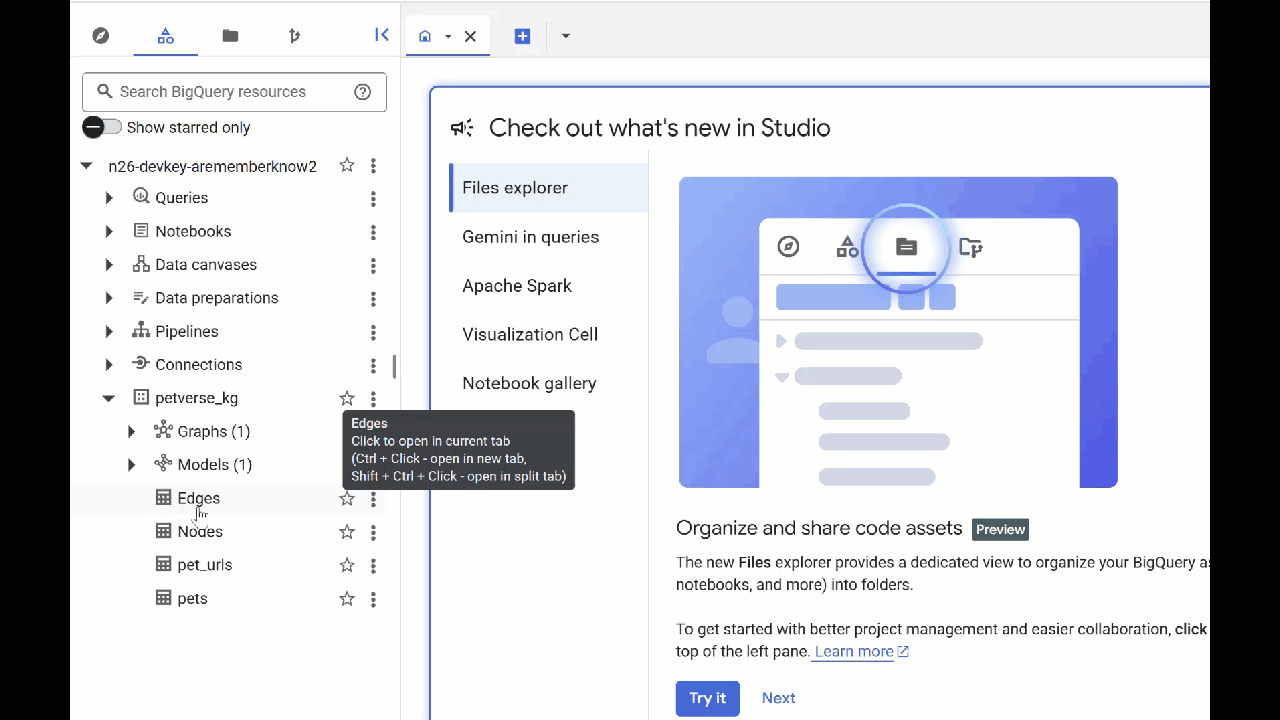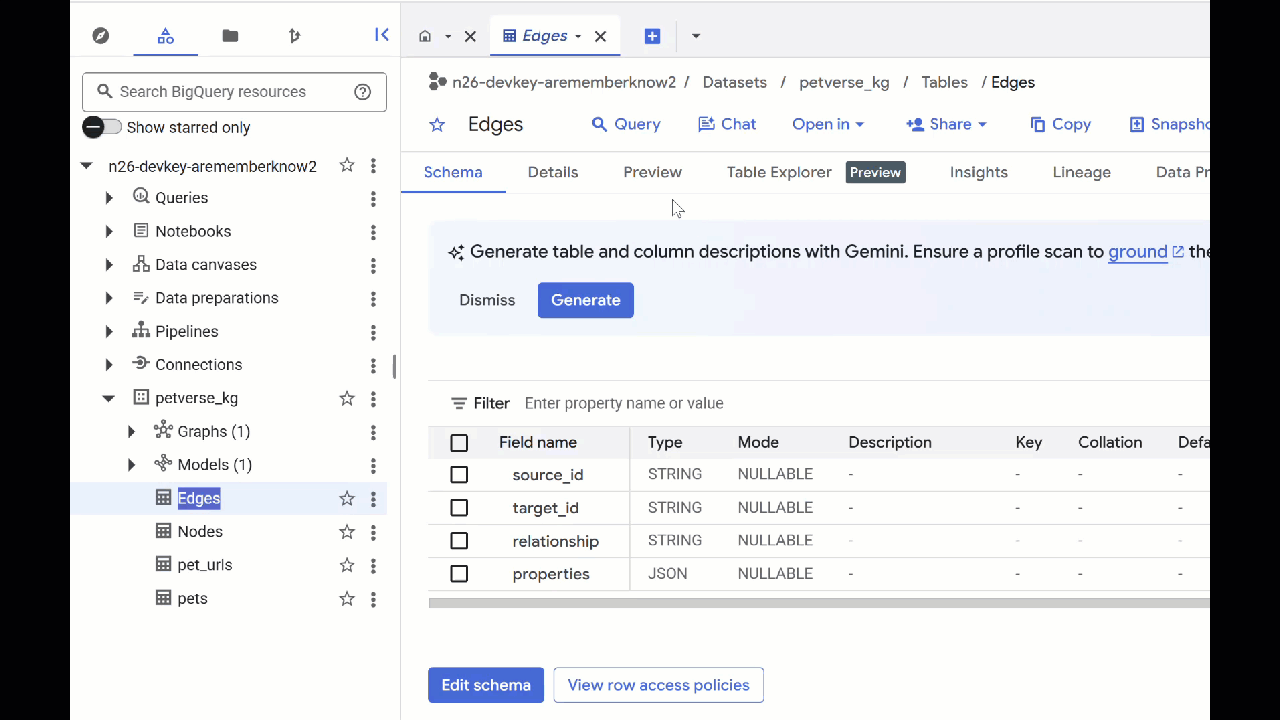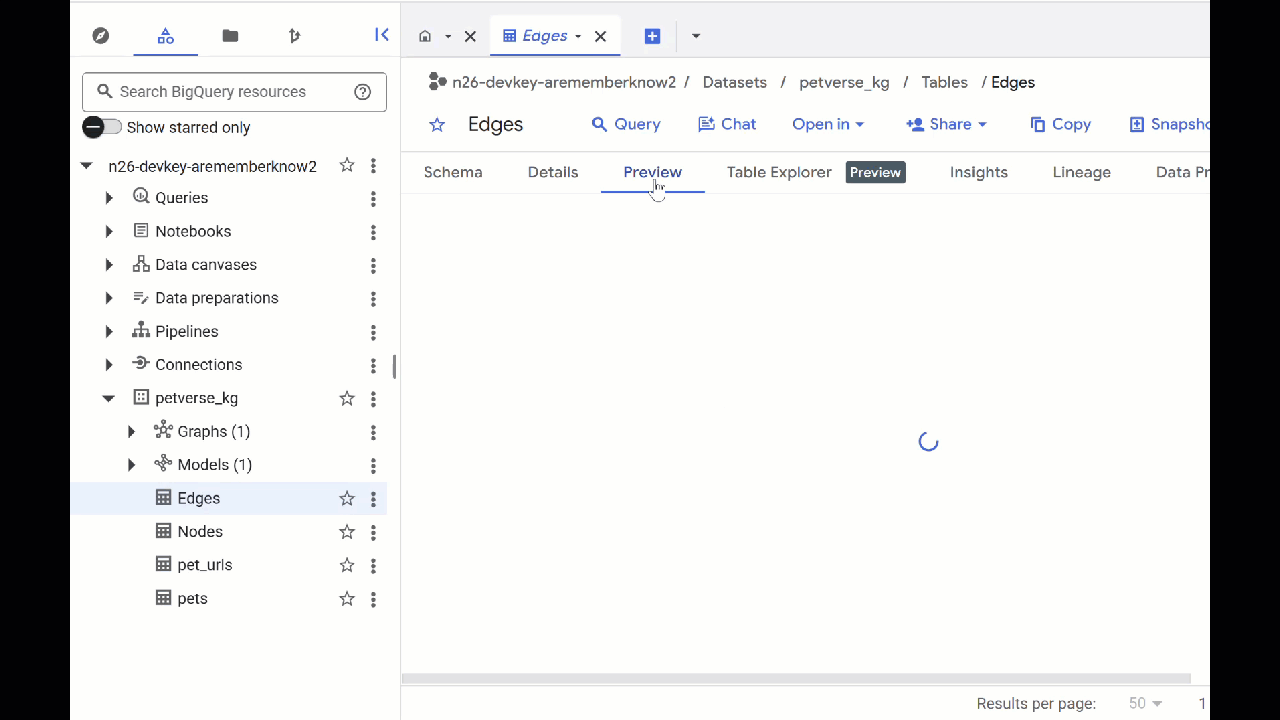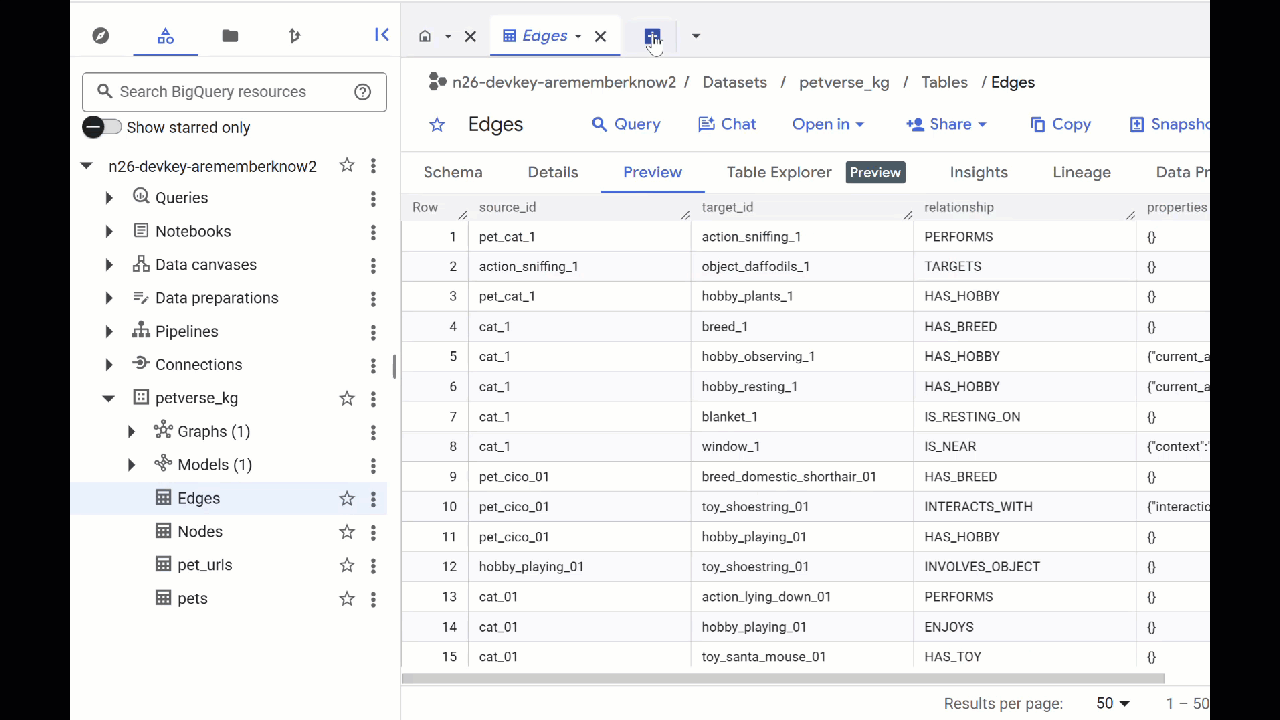
Le tableau "Nœuds" contient des informations sur les entités identifiées par Gemini dans les contenus audio, vidéo et les images. Le tableau "Edges" contient les relations entre eux. Par exemple, si vous écoutez l'audio du chat appelé SQL, il aime jouer avec des lacets et manger du poisson lyophilisé.
- Utilisez le bouton + pour créer une requête. Collez l'instruction suivante, puis cliquez sur Exécuter :
SELECT n.name, n.entity_id, e.relationship, e.target_id
FROM
`petverse_kg.Nodes` n
JOIN
`petverse_kg.Edges` e
ON n.entity_id = e.source_id
WHERE n.name = 'SQL'
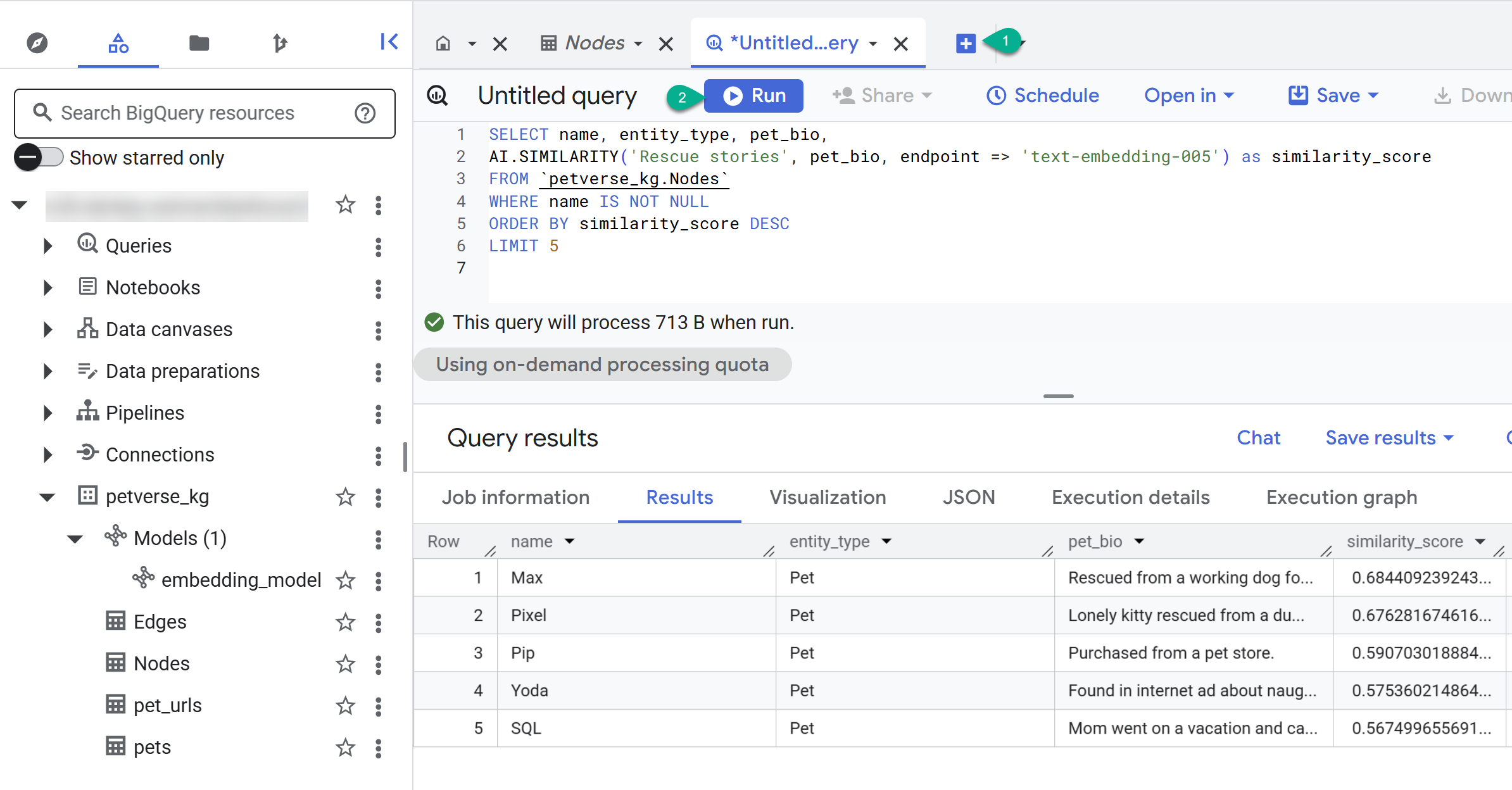
- Utilisez le bouton + pour créer une requête. Collez l'instruction suivante, puis cliquez sur Exécuter :
SELECT name, entity_type, pet_bio,
AI.SIMILARITY('Pets who like to relax', pet_bio, endpoint => 'text-embedding-005') as similarity_score
FROM `petverse_kg.Nodes`
WHERE name IS NOT NULL
ORDER BY similarity_score DESC
LIMIT 5
Vous devriez voir les nœuds des animaux qui aiment se détendre. Cette requête a effectué une recherche sémantique à l'aide de la fonction AI AI.SIMILARITY pour trouver les animaux dont les biographies sont les plus semblables au texte de la requête.
Créer le graphique de propriété
Maintenant que nous avons des nœuds et des arêtes dans BigQuery, nous pouvons créer un graphique de propriétés pour interroger facilement les relations.
Créer le graphique
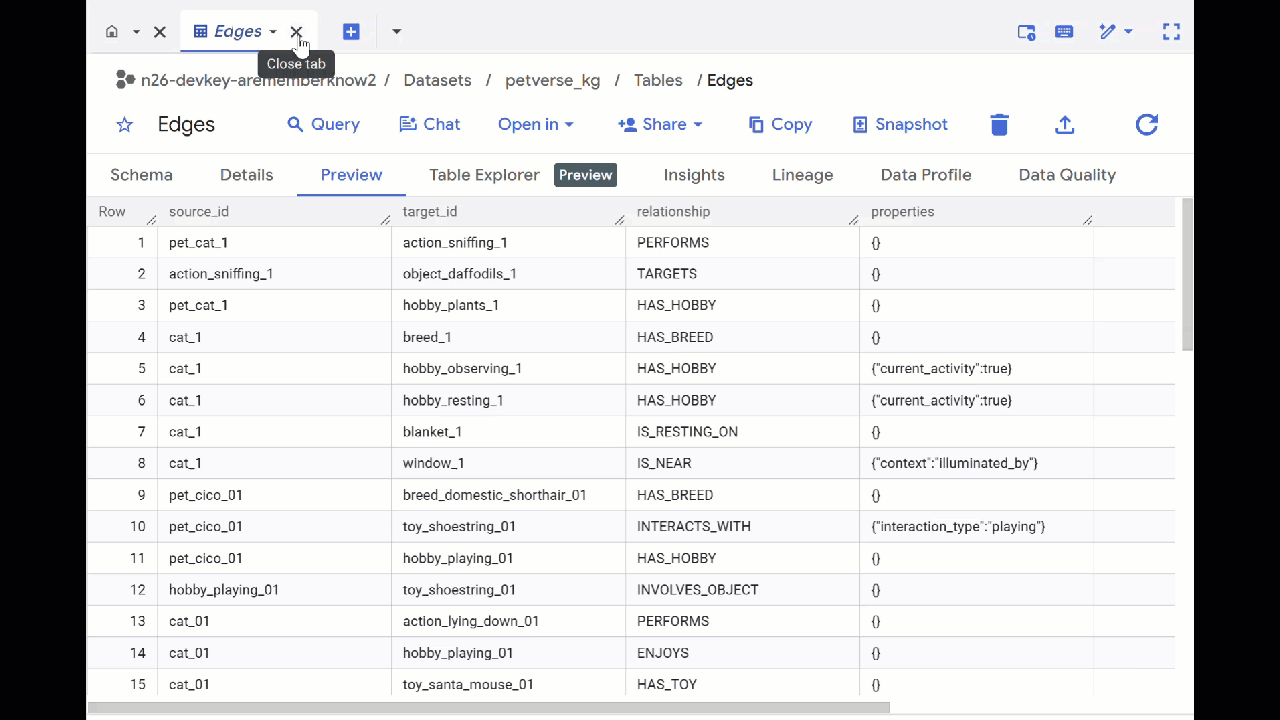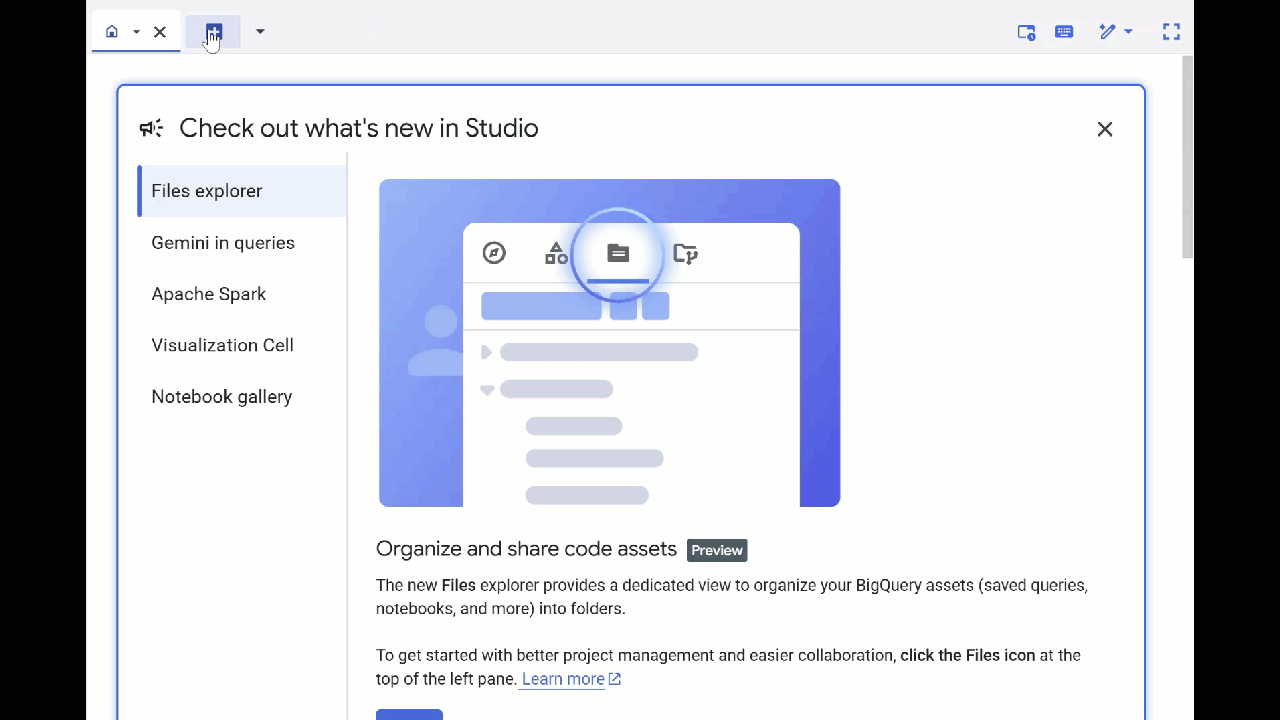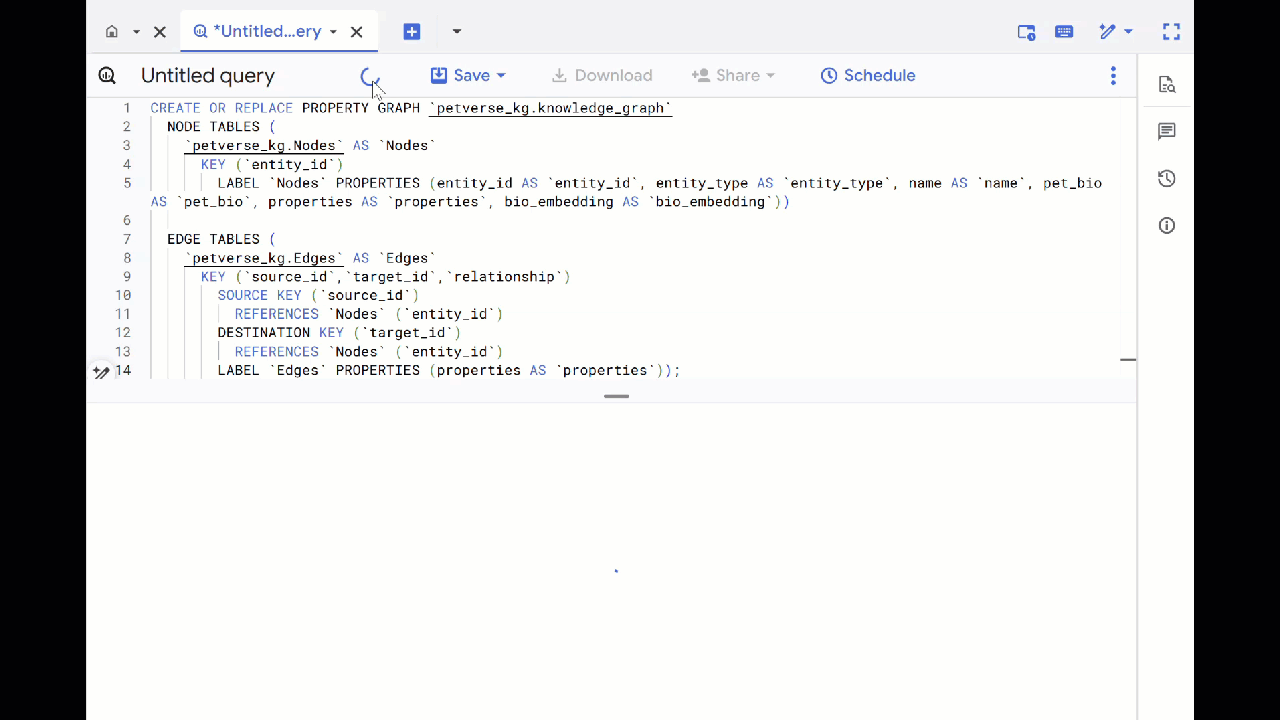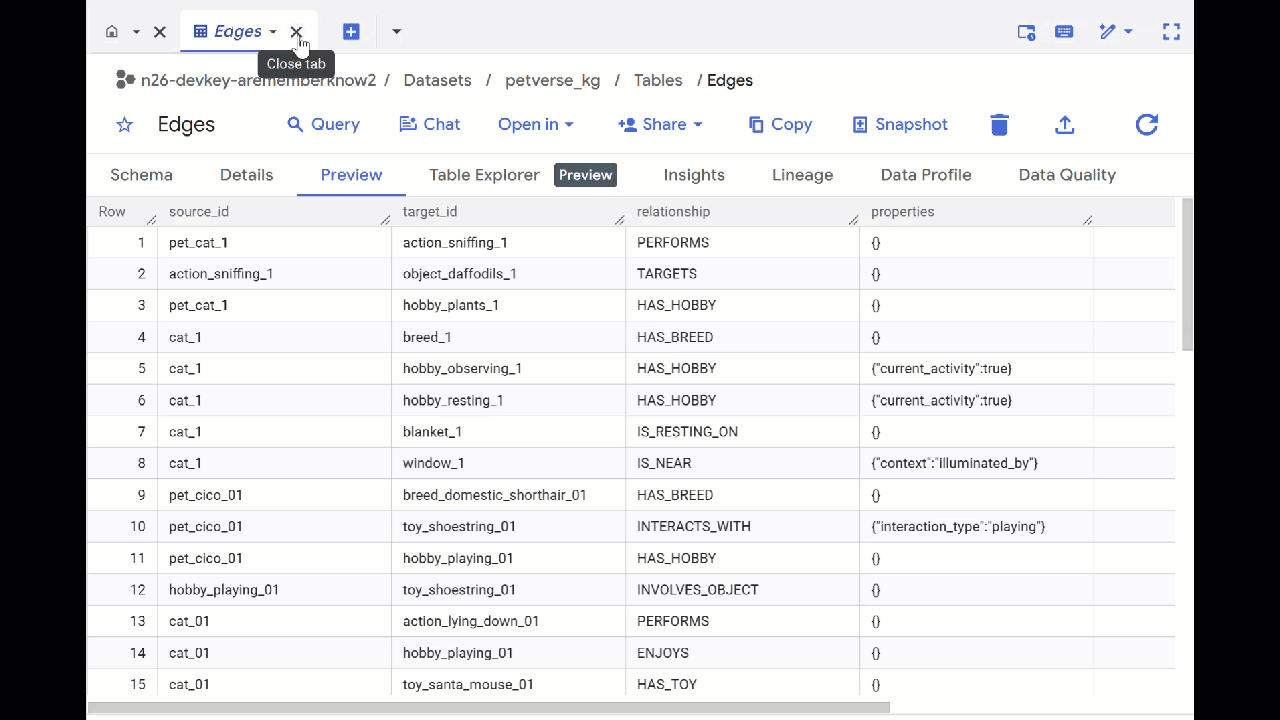
- Écrasez la requête précédente et exécutez le DDL suivant pour créer le graphique de propriétés :
CREATE OR REPLACE PROPERTY GRAPH `petverse_kg.knowledge_graph`
NODE TABLES (
`petverse_kg.Nodes` AS `Nodes`
KEY (`entity_id`)
LABEL `Nodes` PROPERTIES (entity_id AS `entity_id`, entity_type AS `entity_type`, name AS `name`, pet_bio AS `pet_bio`, properties AS `properties`, bio_embedding AS `bio_embedding`))
EDGE TABLES (
`petverse_kg.Edges` AS `Edges`
KEY (`source_id`,`target_id`,`relationship`)
SOURCE KEY (`source_id`)
REFERENCES `Nodes` (`entity_id`)
DESTINATION KEY (`target_id`)
REFERENCES `Nodes` (`entity_id`)
LABEL `Edges` PROPERTIES (properties AS `properties`));
- Cliquez sur Accéder au graphique. La visualisation du graphique s'affiche avec un nœud qui possède un bord vers lui-même. Ce comportement est normal.
Interroger le graphique
- Vous pouvez fermer toutes les requêtes précédentes et en ouvrir une nouvelle et vide à l'aide du bouton +.
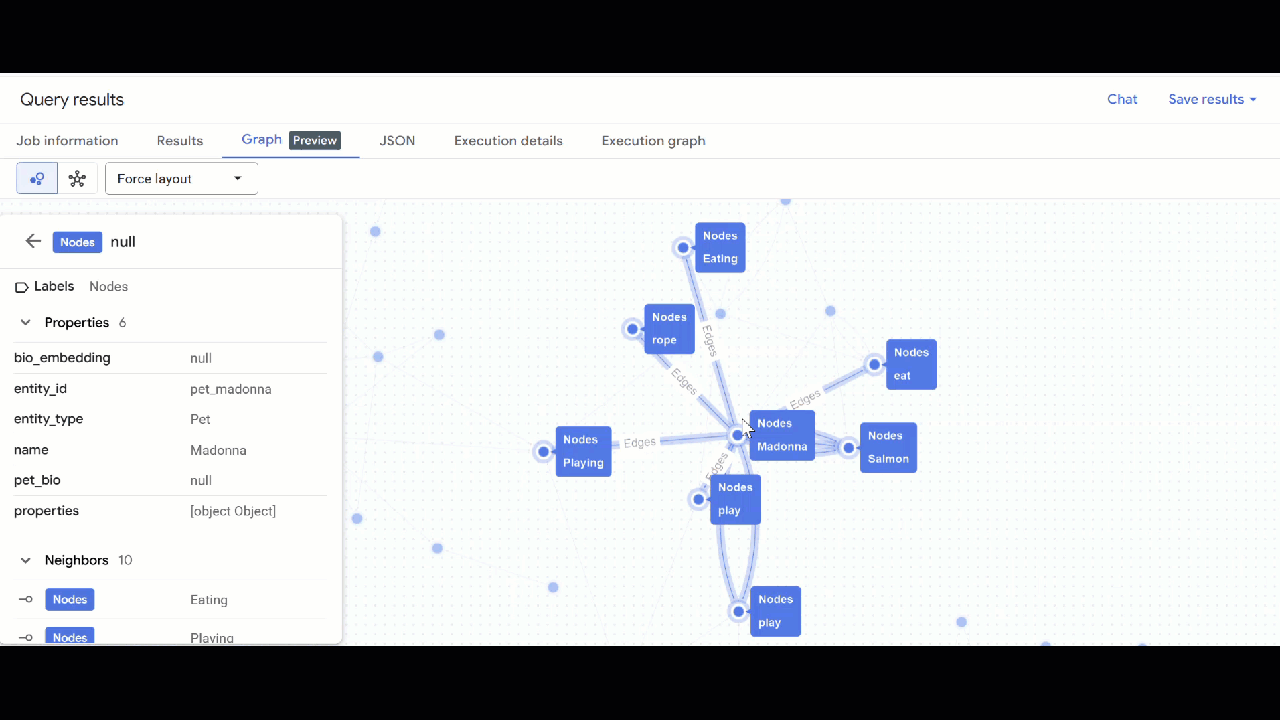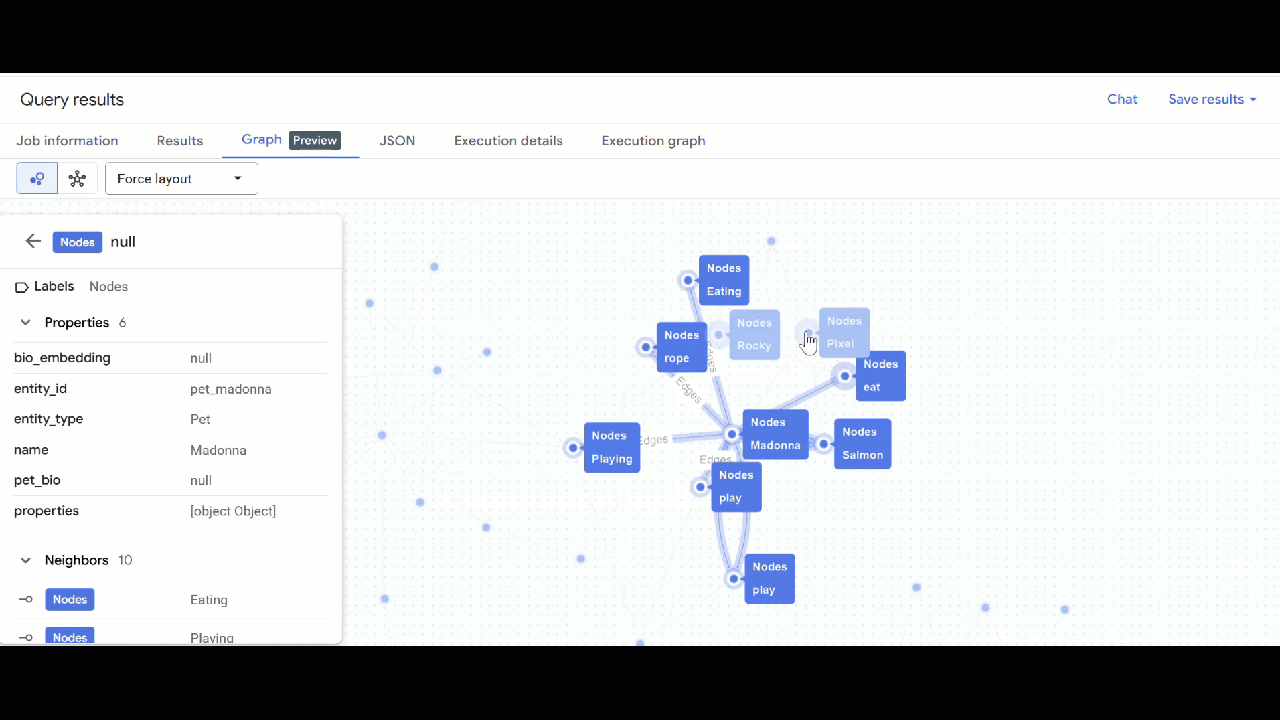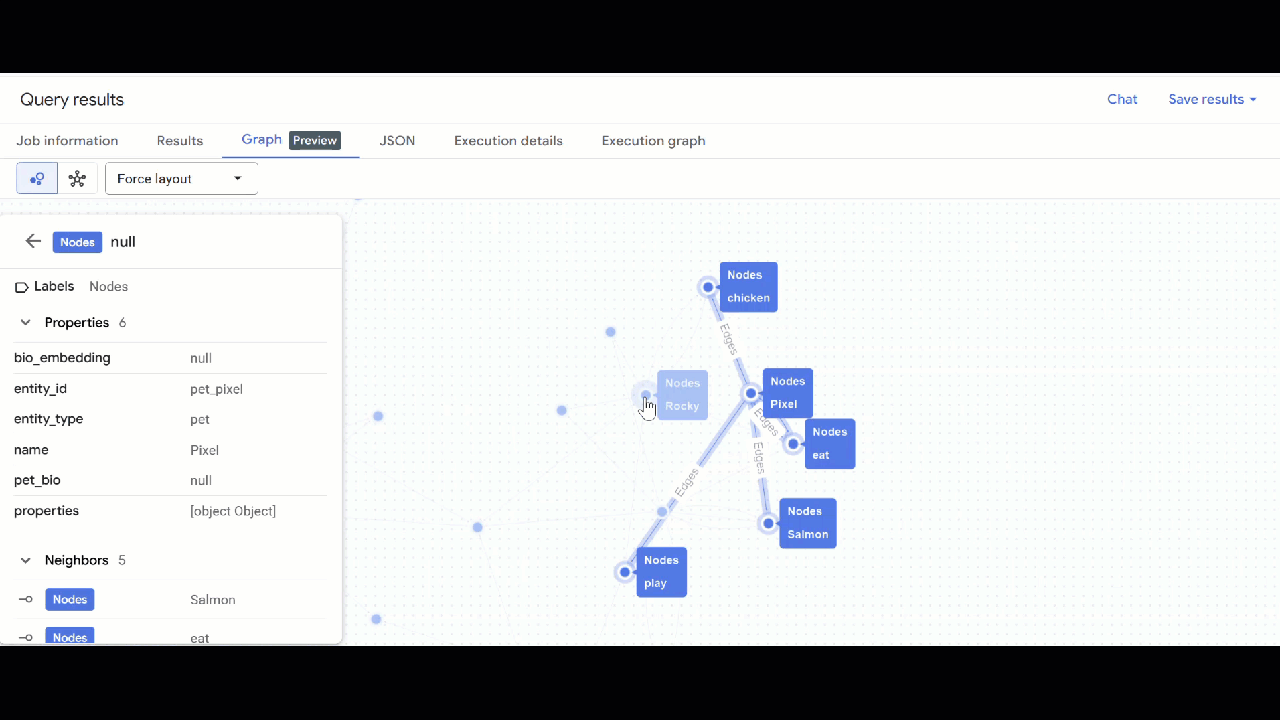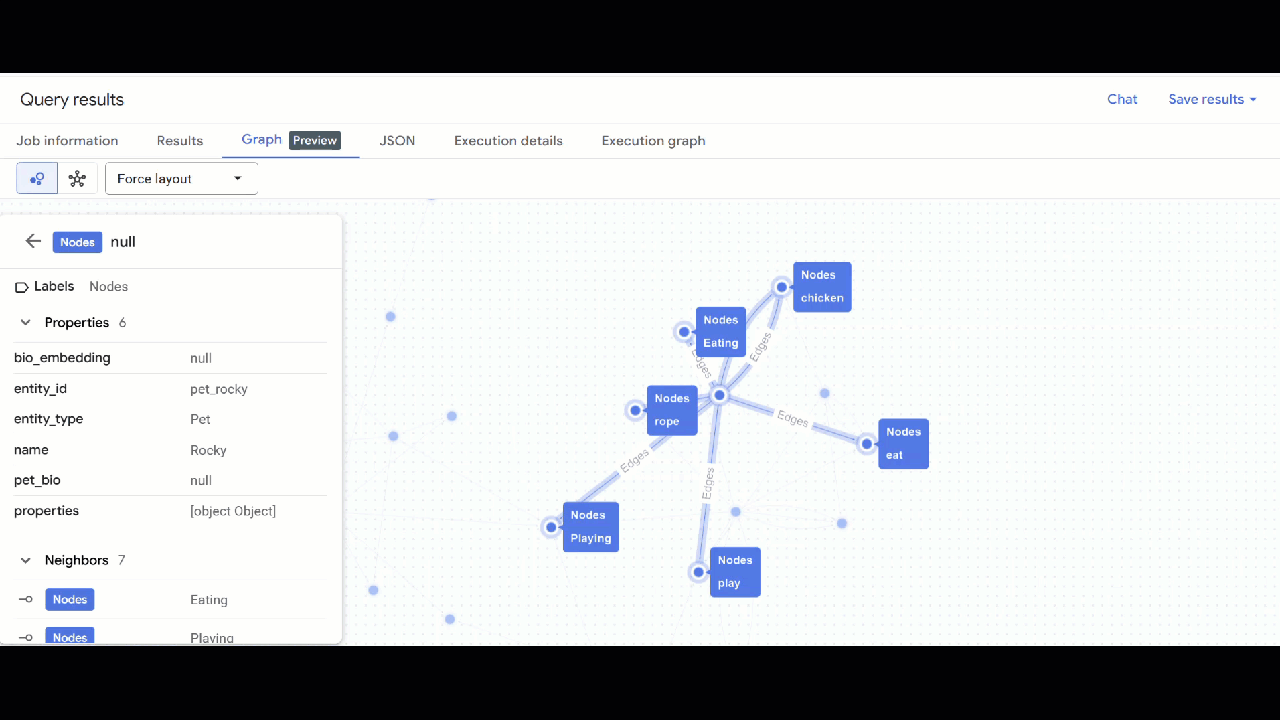
- Utilisez GQL pour trouver des animaux de compagnie associés à d'autres animaux de compagnie en fonction de leurs centres d'intérêt communs (comme les loisirs, les aliments préférés ou les jouets). Cette requête multihop met en correspondance deux animaux différents connectés au même nœud :
GRAPH `petverse_kg.knowledge_graph`
MATCH p = (pet1:Nodes)-[e1]->(interest:Nodes)<-[e2]-(pet2:Nodes)
WHERE pet1.entity_id != pet2.entity_id
AND (LOWER(pet1.entity_type) = 'pet' AND LOWER(pet2.entity_type) = 'pet')
AND LOWER(interest.entity_type) IN ('hobby', 'action', 'activity', 'food', 'toy')
RETURN TO_JSON(p) as res
LIMIT 100
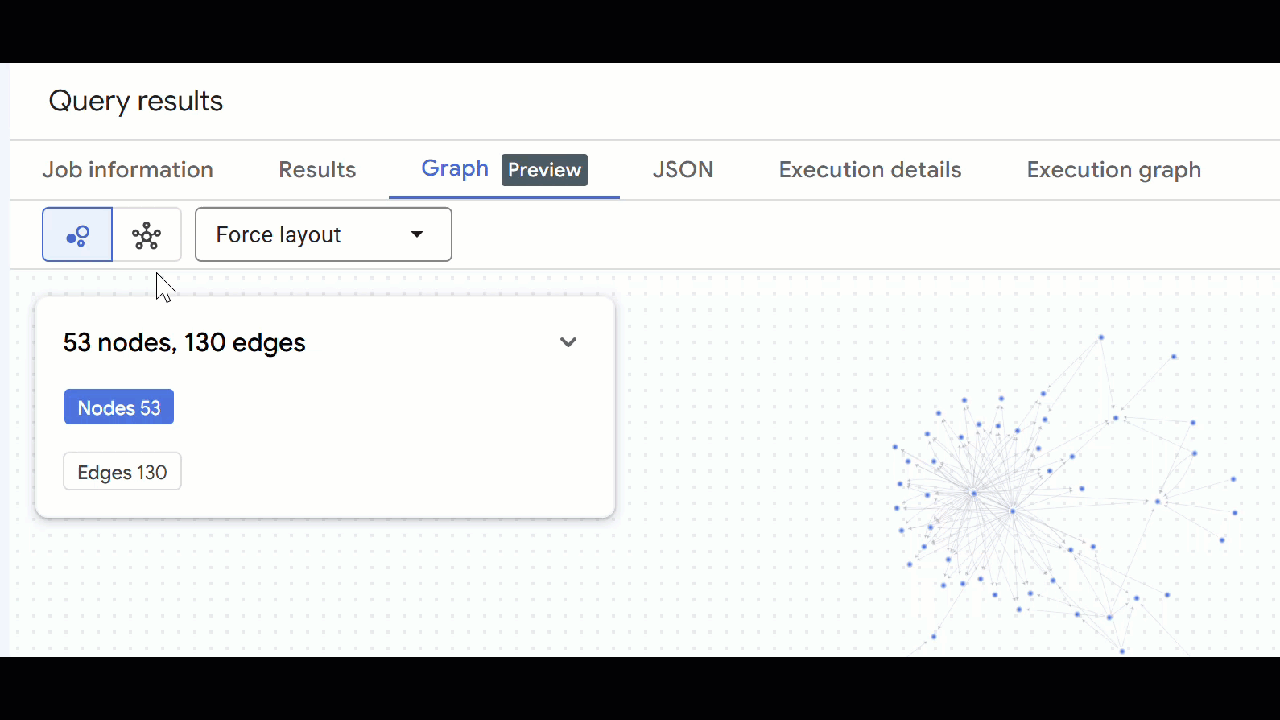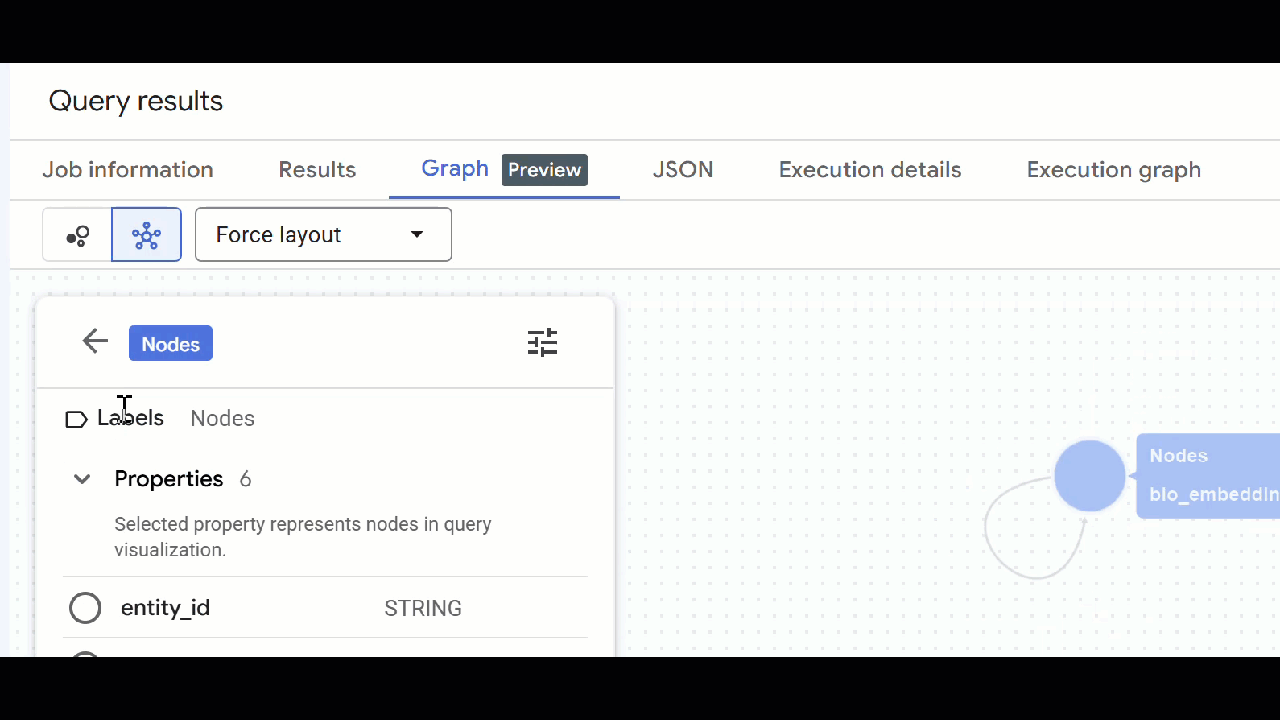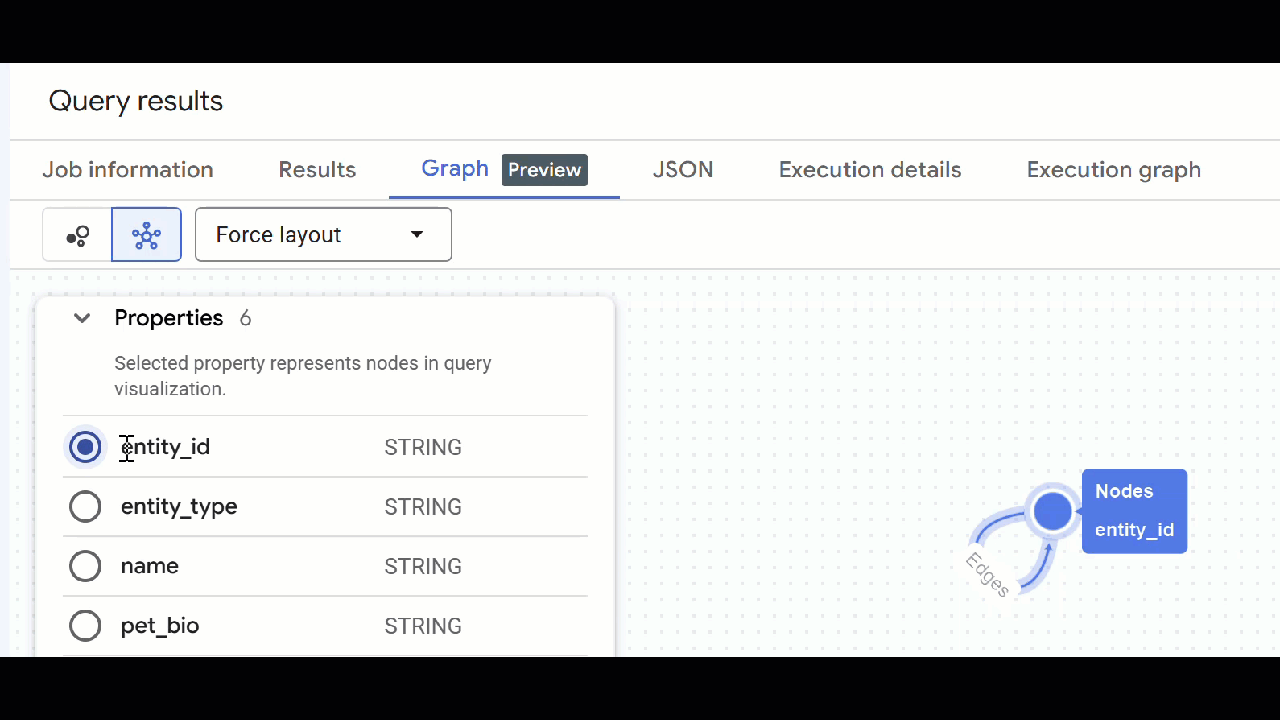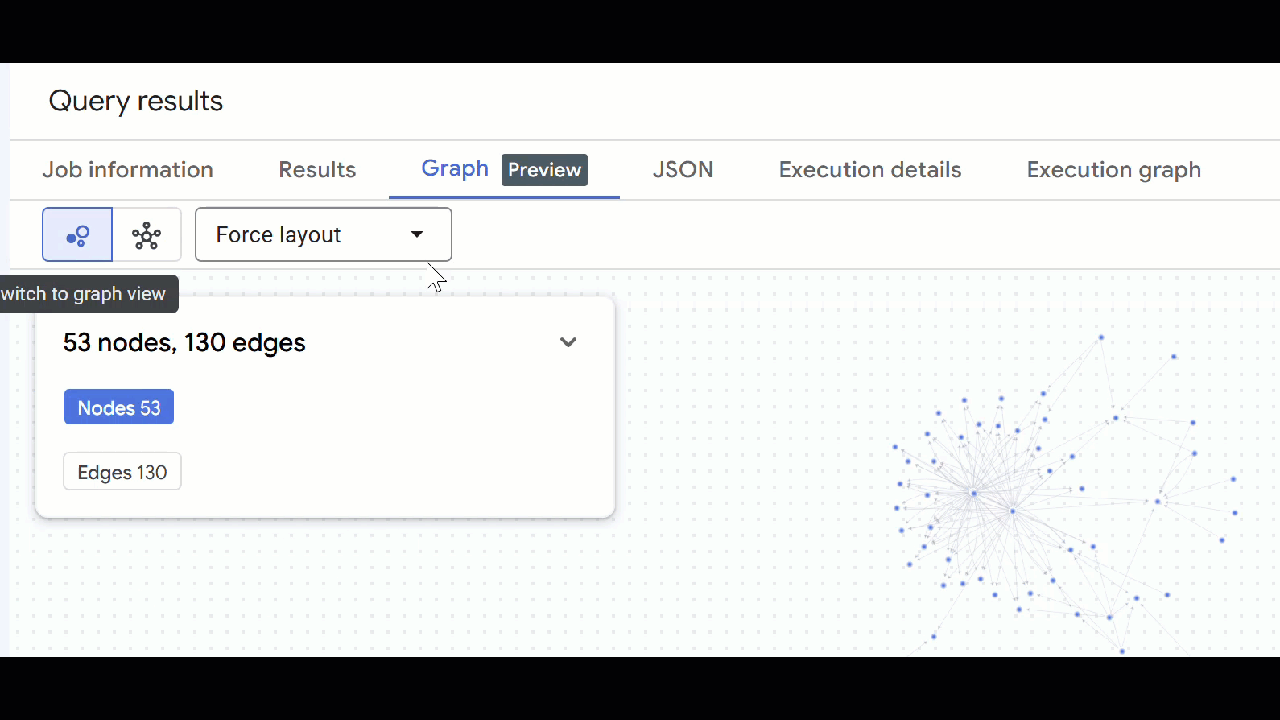
- La visualisation du graphique doit s'afficher. Vous pouvez cliquer sur les nœuds pour afficher les propriétés des nœuds et des arêtes.
🕵️ Conseil : Vous pouvez ajuster la valeur affichée par le nœud en cliquant sur Passer à la vue Schéma :
- Vous pouvez fermer tous les onglets de requête ouverts.
8. Discuter avec le graphique
- À côté du signe +, vous trouverez un menu déroulant. Sélectionnez Conversation.
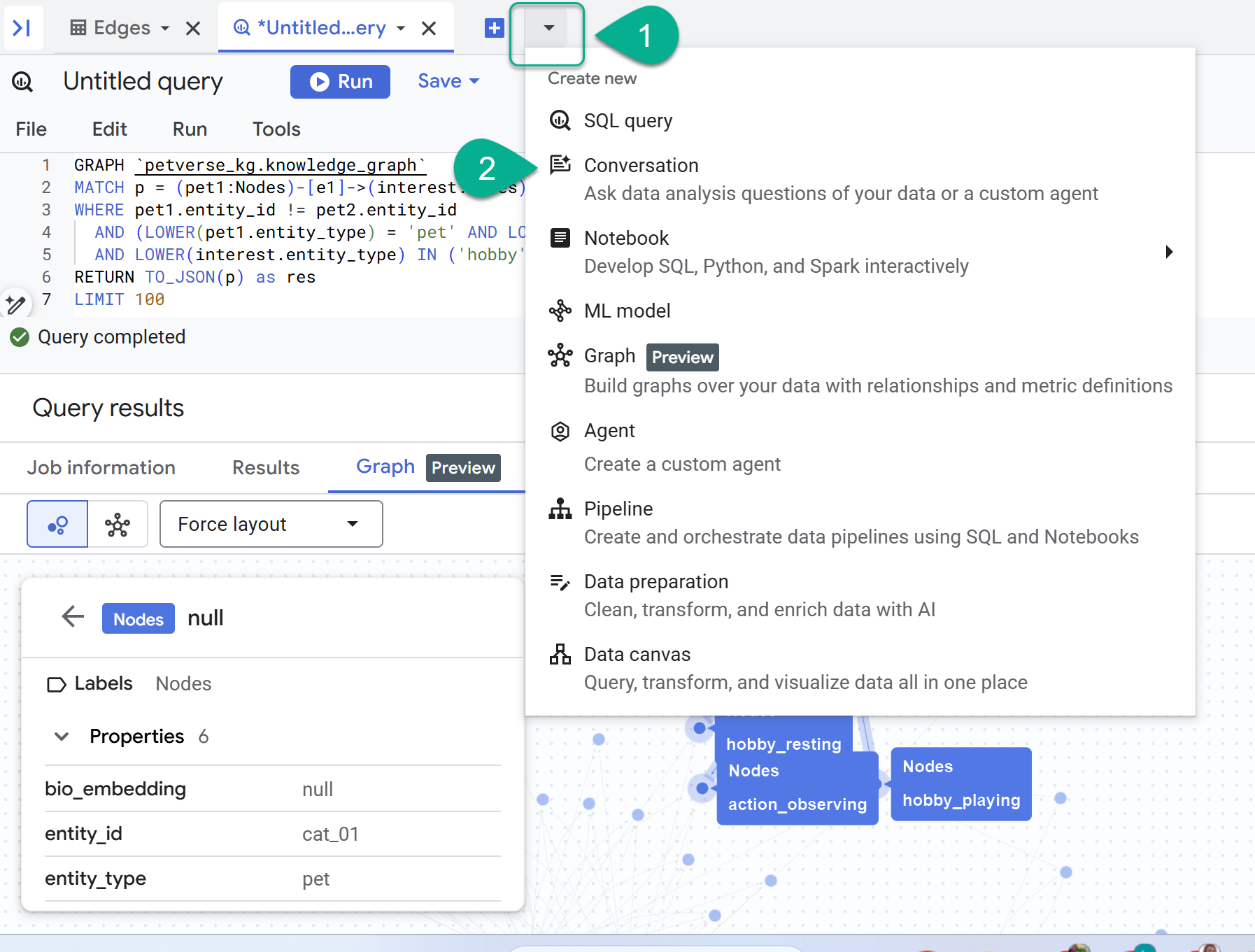
- Vous serez invité à activer l'API Data Analytics avec Gemini. Activez les deux API. Une fois l'opération terminée, actualisez la fenêtre ou créez une conversation pour voir l'agent.
- Cliquez sur New Agent (Nouvel agent).
- Attribuez un nom à l'agent, par exemple
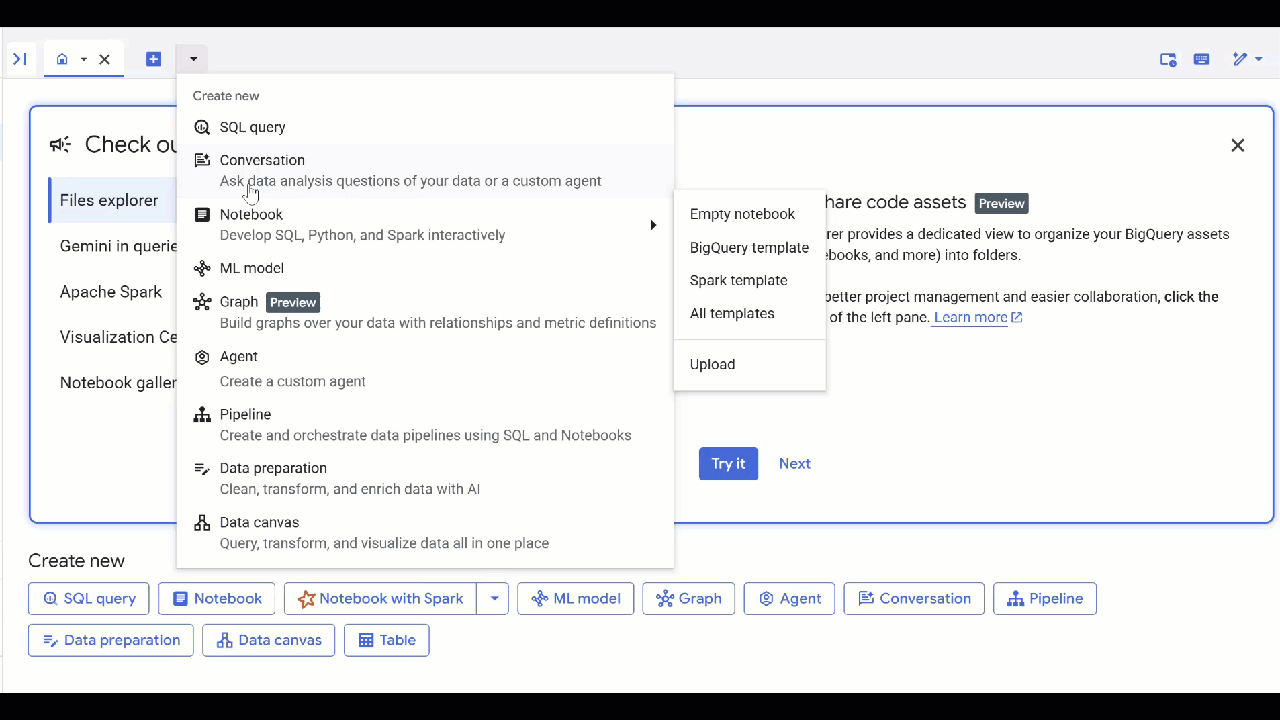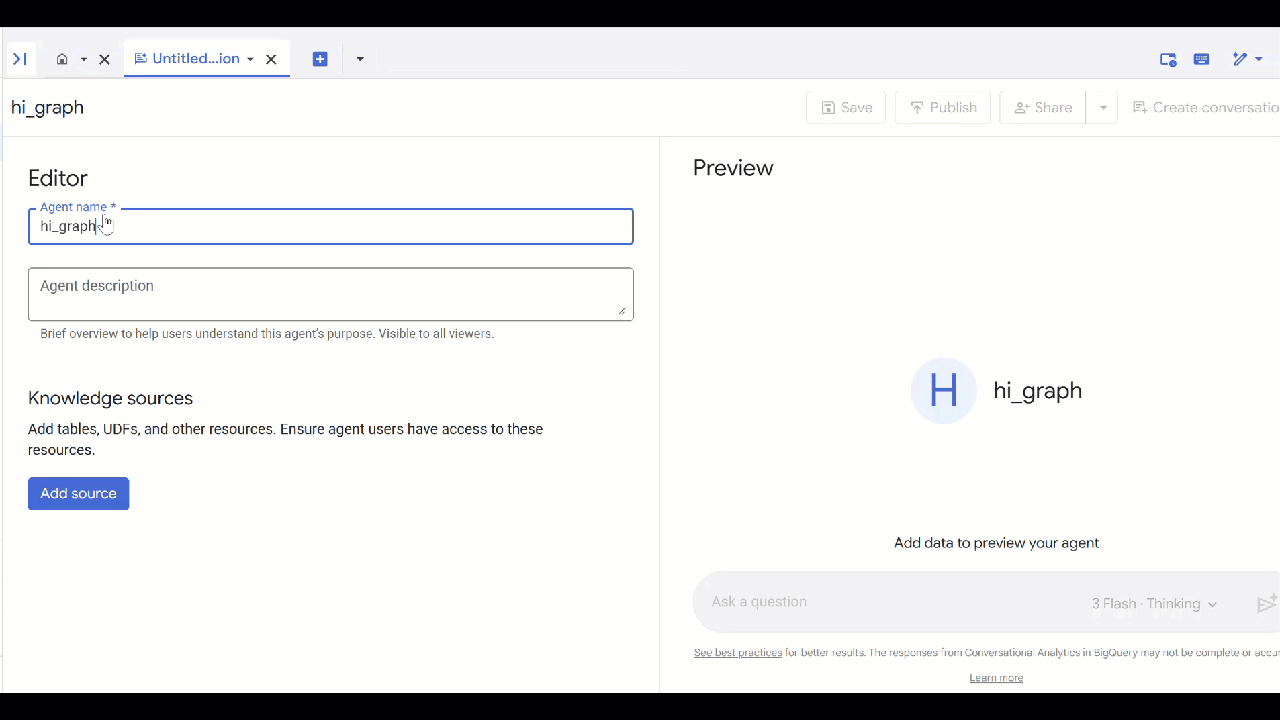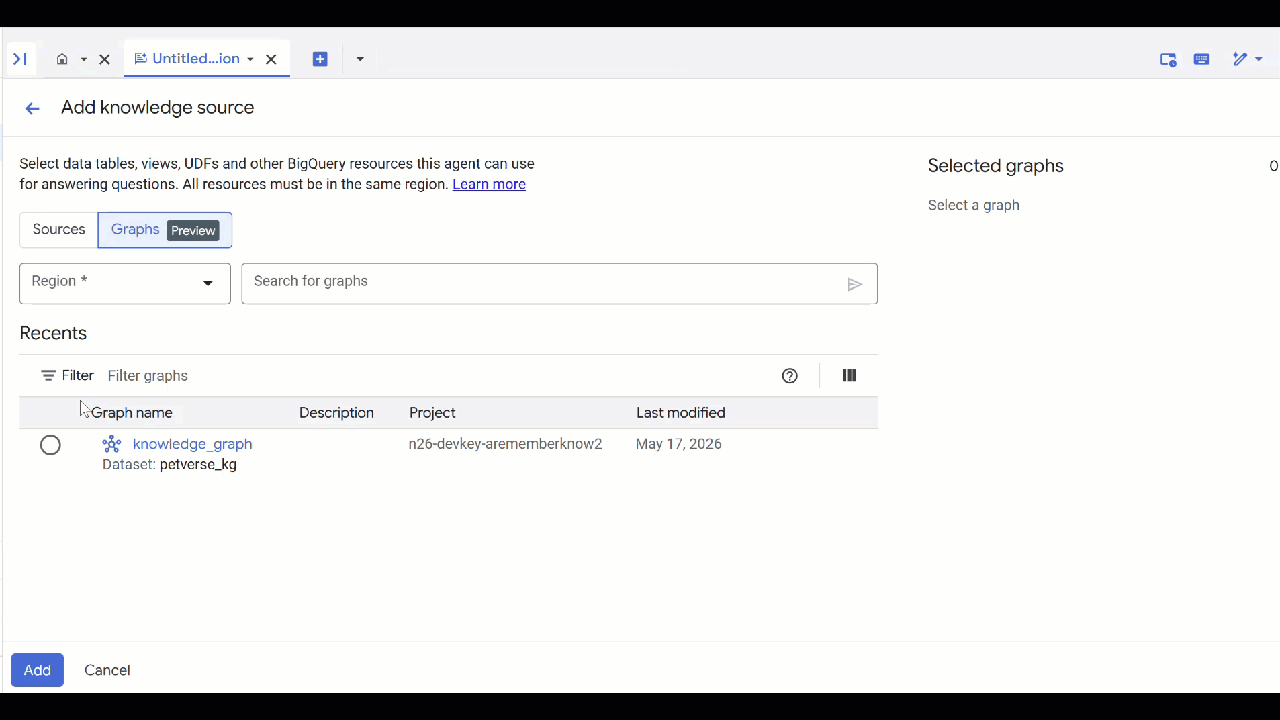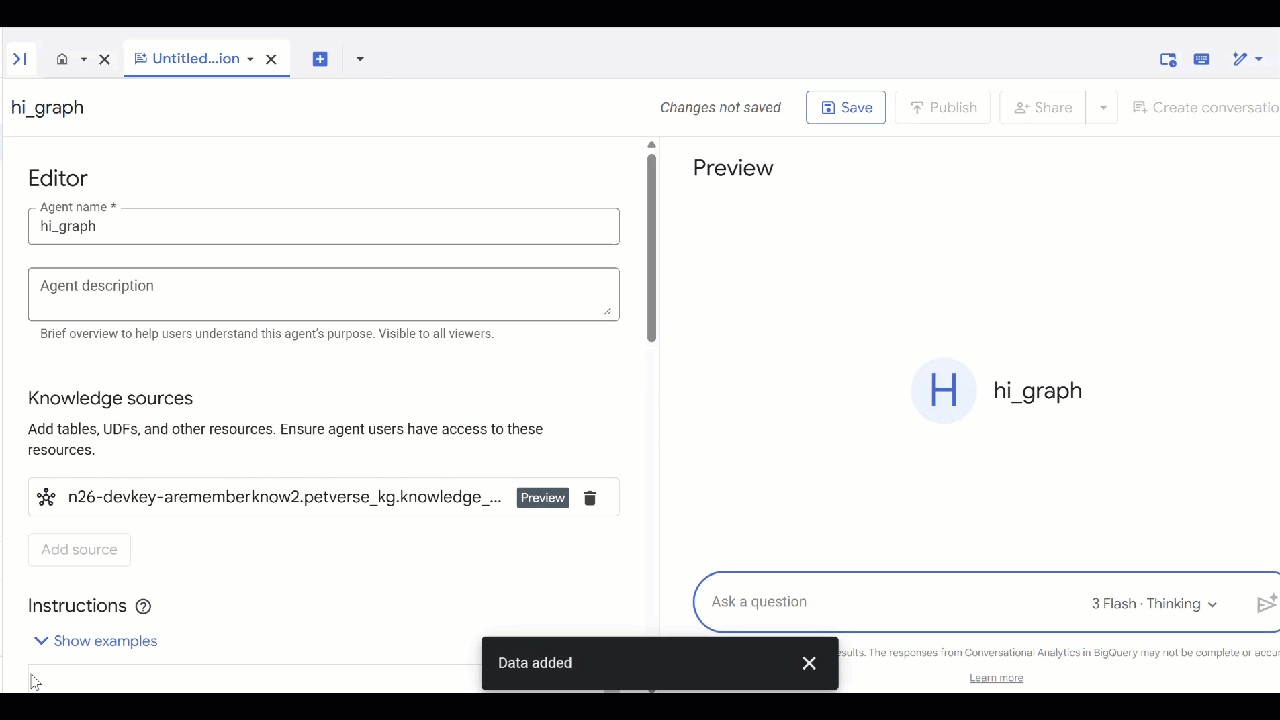
petverse. - Cliquez sur Ajouter une source, puis sur Graphique.
- Sélectionnez le
knowledge_graphque vous avez créé, puis cliquez sur Ajouter.
Vous pouvez maintenant poser une question à l'agent et voir les réponses et le raisonnement qui les sous-tend. Voici quelques exemples de questions pour vous inspirer. Un modèle de réflexion peut prendre un peu plus de temps, mais il est susceptible de construire une meilleure requête GQL. Vous pouvez voir ce qu'il crée en développant Show Thinking.
- Trouvez des animaux qui mangent les mêmes aliments ou qui sont amis avec des animaux qui aiment faire la sieste.
- Y a-t-il des animaux qui partagent exactement le même passe-temps, la même nourriture préférée ou le même jouet ? Listez les paires et leurs centres d'intérêt communs.
- Trouvez des animaux de compagnie de la même espèce ou race, mais ayant des loisirs complètement différents.
9. Effectuer un nettoyage
Pour éviter que les ressources créées lors de cet atelier de programmation ne soient facturées en permanence sur votre compte Google Cloud, supprimez-les.
- Supprimez le cluster GKE :
gcloud container clusters delete petverse-cluster --region $REGION --quiet
- Supprimez l'ensemble de données BigQuery (toutes les tables seront supprimées) :
bq rm -r -f -d $PROJECT_ID:petverse_kg
- Supprimez les ressources de la file d'attente Pub/Sub :
gcloud pubsub subscriptions delete petverse-sub --quiet
gcloud pubsub topics delete petverse-topic --quiet
- Supprimez le dépôt Artifact Registry :
gcloud artifacts repositories delete gke-cats-repo --location=$REGION --quiet
- Supprimez le bucket GCS spécifique au projet :
gcloud storage buckets delete gs://$PROJECT_ID-petverse --quiet
10. Félicitations
Félicitations ! Vous avez réussi à créer un pipeline de graphiques de connaissances distribués à l'aide de GKE et de Gemini, et à l'interroger à l'aide des graphiques de propriétés BigQuery.
Connaissances acquises
- Découvrez comment déployer des jobs distribués sur GKE Autopilot.
- Découvrez comment utiliser Gemini pour extraire des données multimodales.
- Utiliser les auto-intégrations BigQuery
- Comment créer et interroger des graphiques de propriétés dans BigQuery