
1. מבוא
ב-Codelab הזה תבנו פייפליין מבוזר לרכישת ידע עבור Petverse. תעבדו נכסי מולטימדיה לא מובנים (אודיו, וידאו, תמונות, טקסט/CSV) מדלי אחסון של Cloud Storage, תחלצו מידע חשוב על חיות המחמד (האוכל המועדף, תחביבים) ותיצרו תרשים ידע. תגדילו את נפח העיבוד של קובץ המולטימדיה באמצעות עיבוד רב-אופני של Gemini ב-Google Kubernetes Engine (GKE). לבסוף, תאחסנו את הנתונים האלה ב-BigQuery ותשתמשו בתכונה החדשה של BigQuery Property Graph כדי לנתח את הקשרים.
נשתמש ביכולות של Google Kubernetes Engine כדי להדגים עיבוד של נתונים בכמויות גדולות במקביל.
למה כדאי להשתמש ב-Knowledge Graph?
תרשימי ידע מתאימים יותר ממסדי נתונים רלציוניים מסורתיים לייצוג ולניתוח של קשרים מורכבים בין ישויות.
אנחנו נשתמש ב-Gemini 2.5 Flash כדי לנתח תמונות, קובצי אודיו וקובצי וידאו, ולקבוע עובדות לגבי חיות מחמד שונות.
הפעולות שתבצעו:
- פיתוח ופריסה של משימת עיבוד נתונים מבוזרת ב-GKE.
- אפשר להשתמש ב-Gemini כדי לחלץ ישויות וקשרים מקובצי מולטימדיה.
- אחסון נתוני תרשים הידע ב-BigQuery.
- יצירה של תרשים מאפיינים ב-BigQuery והרצת שאילתות עליו באמצעות Graph Query Language (GQL).
הדרישות
- דפדפן אינטרנט כמו Chrome
- פרויקט ב-Google Cloud שהחיוב בו מופעל
- הרשאות בפרויקט ליצירת משאבים ולשינוי מדיניות IAM
שיעור ה-Codelab הזה מיועד למפתחים בכל הרמות, כולל מתחילים.
משך זמן משוער: 45 דקות
עלות: העלות של המשאבים שנוצרו ב-Codelab הזה צריכה להיות פחות מ-5$.
2. לפני שמתחילים
יצירת פרויקט ב-Google Cloud
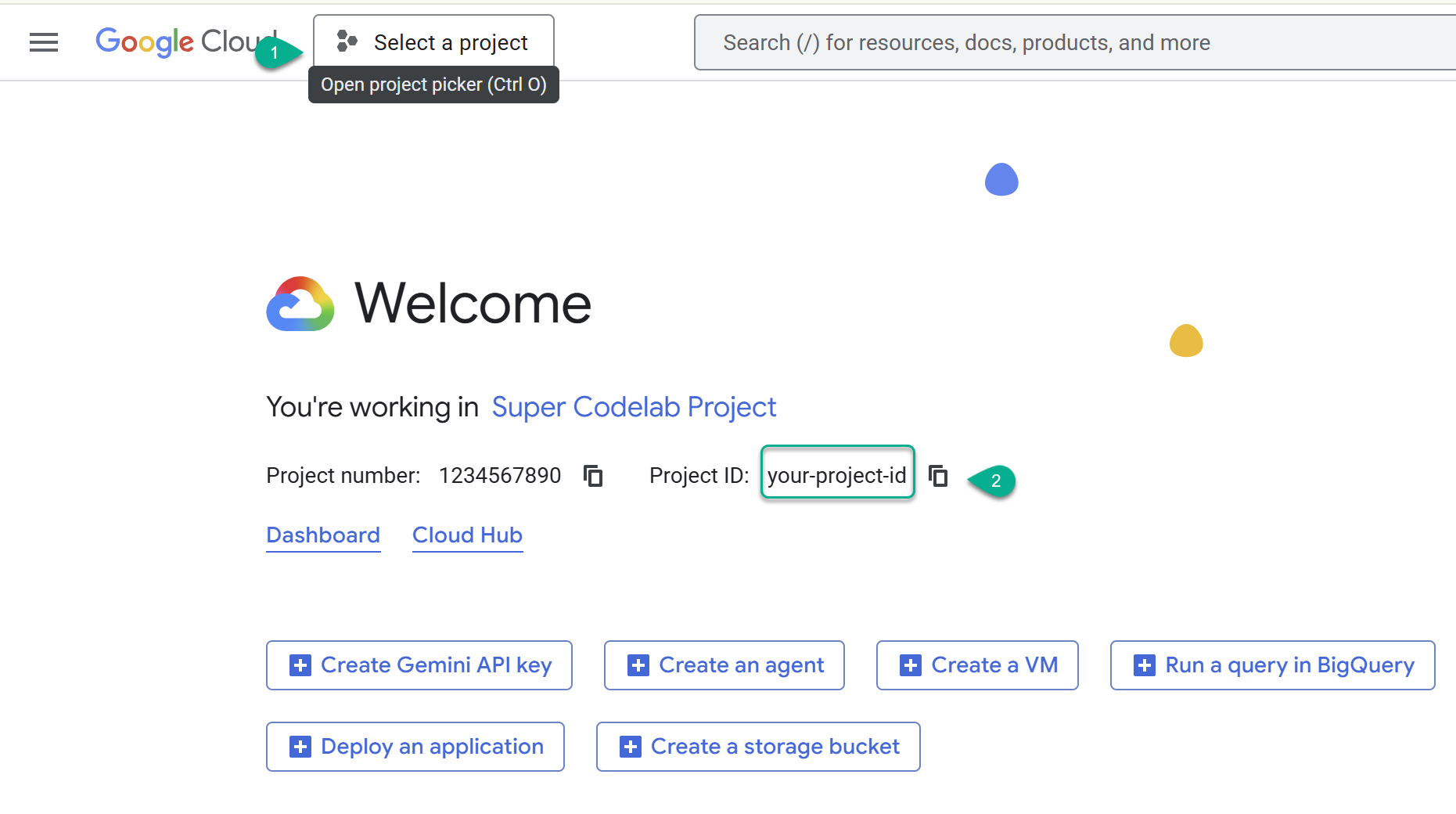
- עוברים אל מסוף Google Cloud: https://console.cloud.google.com, ואז בוחרים או יוצרים פרויקט ב-Google Cloud.
- ⚠️ שימו לב למזהה הפרויקט. תשתמשו בו לכמה פקודות ב-Lab הזה.
הפעלת Cloud Shell
- פותחים את Cloud Shell בכרטיסייה חדשה: https://shell.cloud.google.com/.
- אם מתבקשים, לוחצים על אישור.
- מחליפים את
PROJECT_IDומדביקים את הפקודה הבאה במסוף:
export PROJECT_ID="YOUR_PROJECT_ID"
gcloud config set project $PROJECT_ID
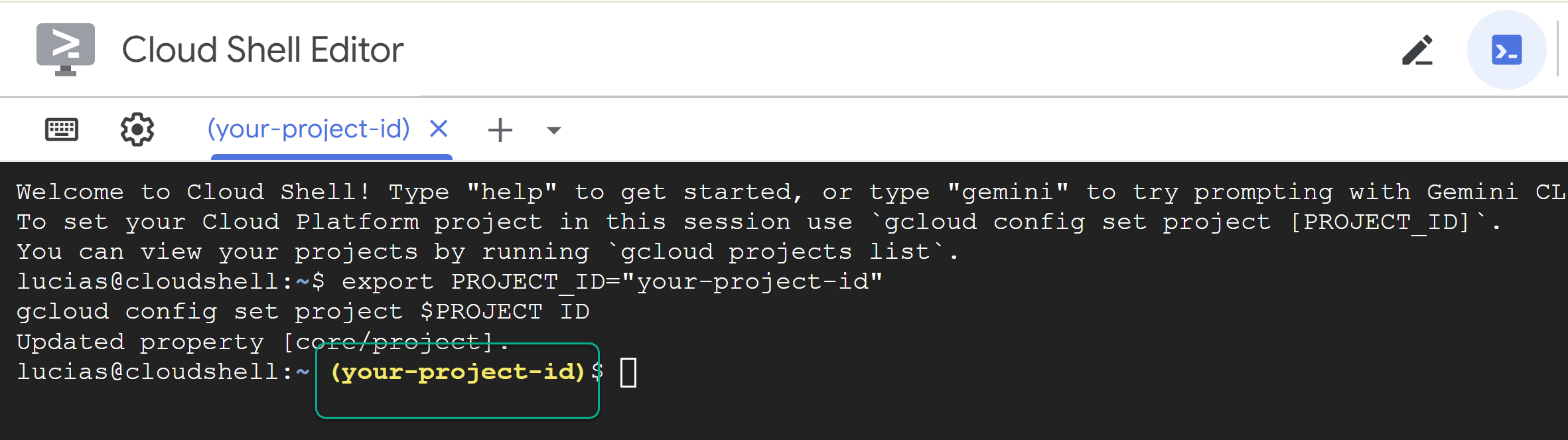
📝 הערה הפרויקט יופיע בצהוב בשורת הפקודה. אם הסשן מופעל מחדש, חשוב להריץ שוב את הפקודה שלמעלה כדי להגדיר את מזהה הפרויקט.
הפעלת ממשקי ה-API
מריצים את הפקודה הבאה כדי להפעיל את כל ממשקי ה-API הנדרשים:
gcloud services enable \
aiplatform.googleapis.com \
bigquery.googleapis.com \
artifactregistry.googleapis.com \
container.googleapis.com \
cloudbuild.googleapis.com \
pubsub.googleapis.com
שכפול מאגר
מריצים את הפקודות הבאות כדי לשכפל את המאגר.
cd ~/
git clone --filter=blob:none --no-checkout https://github.com/GoogleCloudPlatform/devrel-demos.git
cd ~/devrel-demos
git sparse-checkout init --cone
git sparse-checkout set codelabs/gke-knowledge-graph
git checkout main
cd codelabs/gke-knowledge-graph/
הפעלת סקריפט ההגדרה
הסקריפט הזה מבצע אוטומציה של הגדרת הקצה העורפי על ידי:
- יצירת קובץ אימג' של קונטיינר ומאגר ב-Artifact Registry
- יצירת מערך נתונים ב-BigQuery
- יצירת חיבור ל-BigQuery כדי להפעיל פונקציות של Gemini AI מ-SQL
מריצים את הפקודה הבאה בטרמינל:
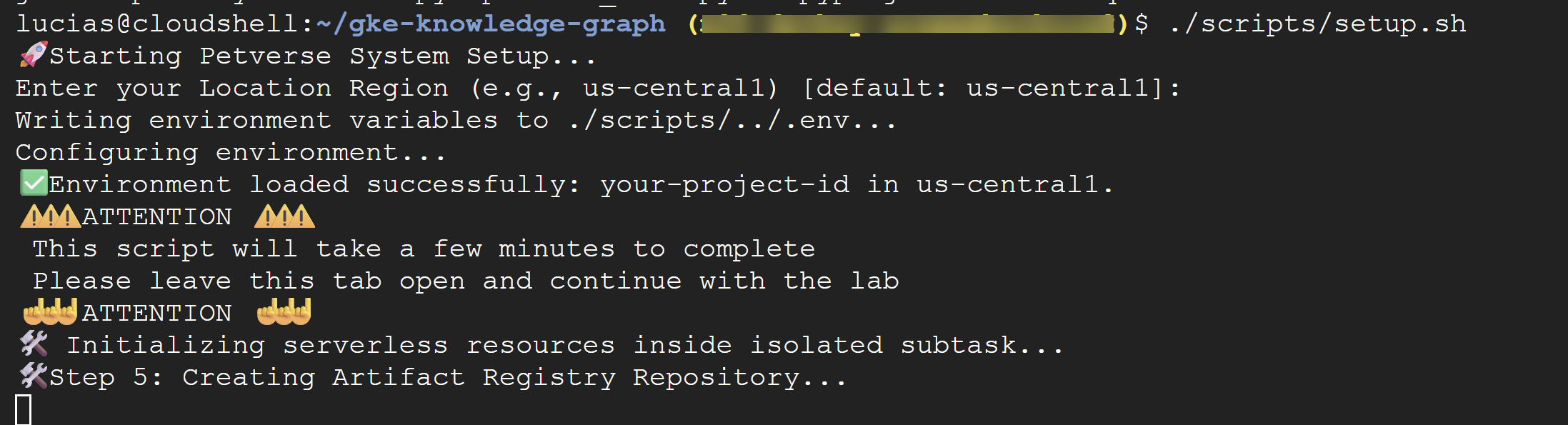
./scripts/setup.sh
אם התסריט מבקש פרטי הגדרה, משתמשים בערכים הבאים:
- מזהה הפרויקט: משתמשים במזהה שיצרתם בשלב הקודם.
- אזור:
us-central1
⚠️ חשוב יכול להיות שיחלפו כמה דקות עד שהסקריפט יושלם. משאירים את חלון הטרמינל פתוח כדי שהתהליך יסתיים ברקע. כדי להמשיך לשלב הבא, פותחים כרטיסייה או חלון חדשים במסוף כדי להריץ את הפקודות הבאות.
3. הגדרת Data Agent Kit
- מפעילים את Cloud Shell Editor באמצעות סמל העיפרון בפינה השמאלית העליונה.
- ב-Cloud Shell Editor, לוחצים על סמל התוספים בסרגל הצד הימני.
- מחפשים את Google Cloud Data Agent Kit ולוחצים על Install (התקנה) אם הוא עדיין לא מותקן.
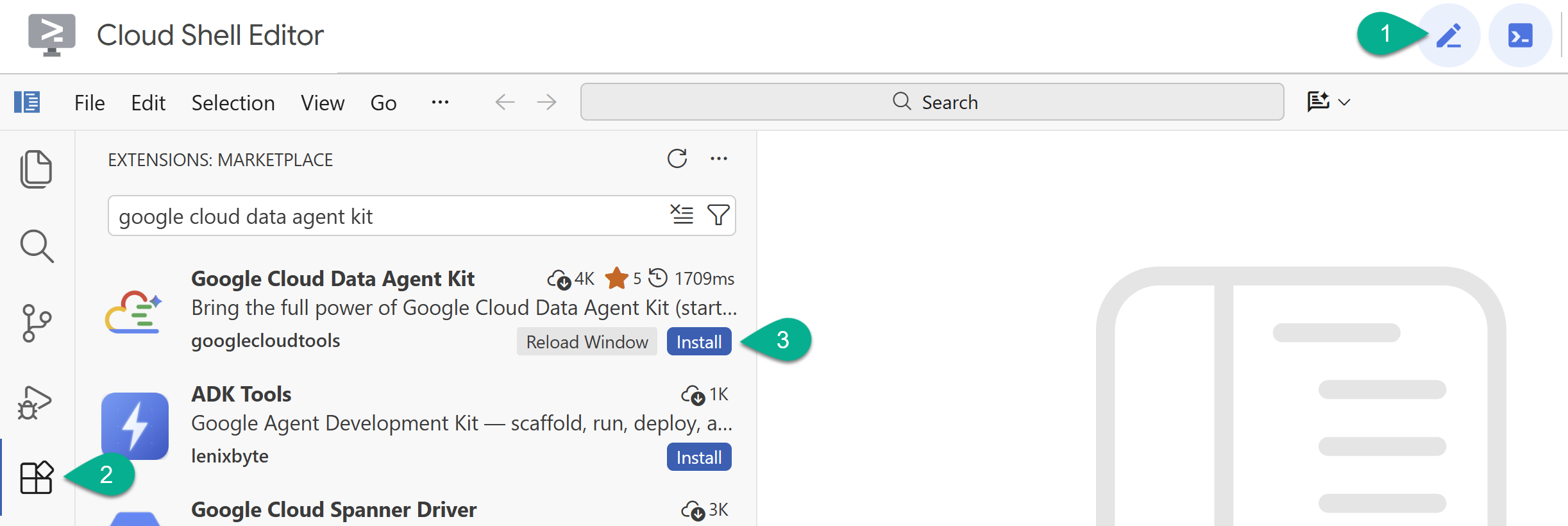
- נכנסים לחשבון Google באמצעות התוסף.
- בקטע Configuration Summary (סיכום ההגדרות), מזינים את מזהה הפרויקט ואת
us-central1כאזור.
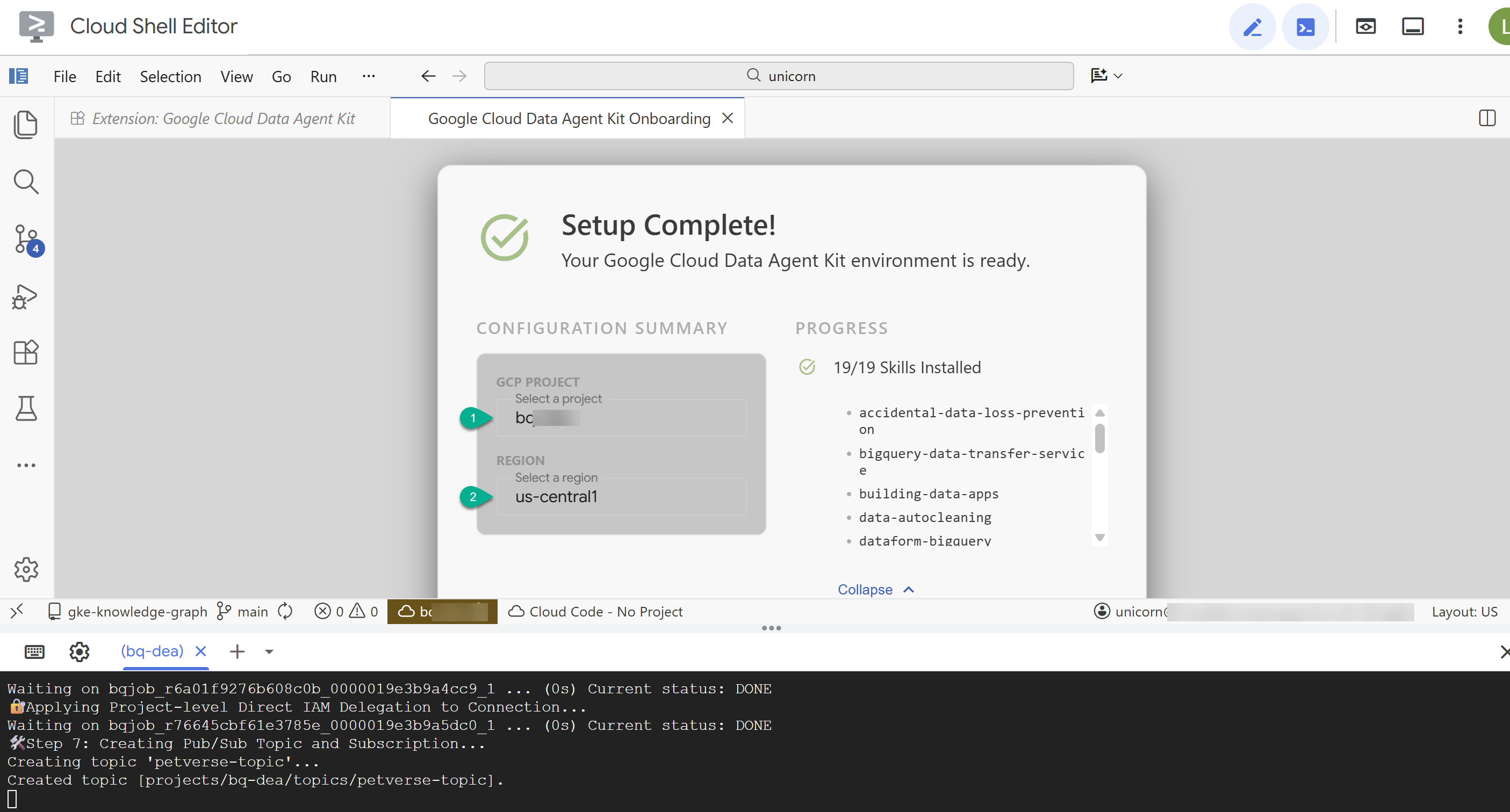
- לוחצים על Configure MCP Servers (הגדרת שרתי MCP). לא צריך לבצע שינויים בחלון הזה, פשוט לוחצים על מתחילים.
- אם מופיעה בקשה, טוענים מחדש את החלון. אפשר לסגור את הכרטיסייה של המדריך למתחילים.
הגדרת הטבלאות ב-BigQuery
- בסרגל הצד, חוזרים לכלי להשוואת תקציבים. אם תיקיית הבית (לדוגמה,
/home/your_user_name/) לא פתוחה, לוחצים על פתיחת תיקייה ובוחרים אותה.
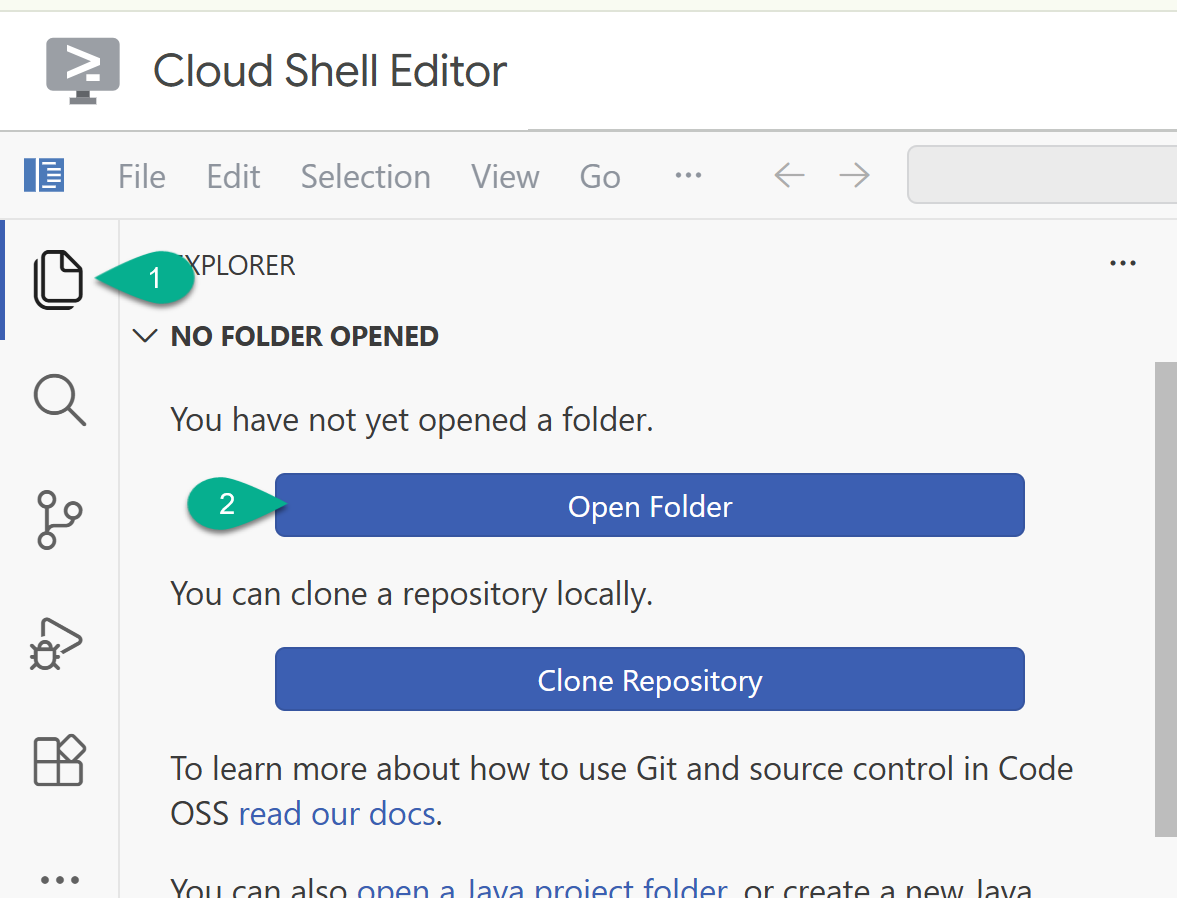
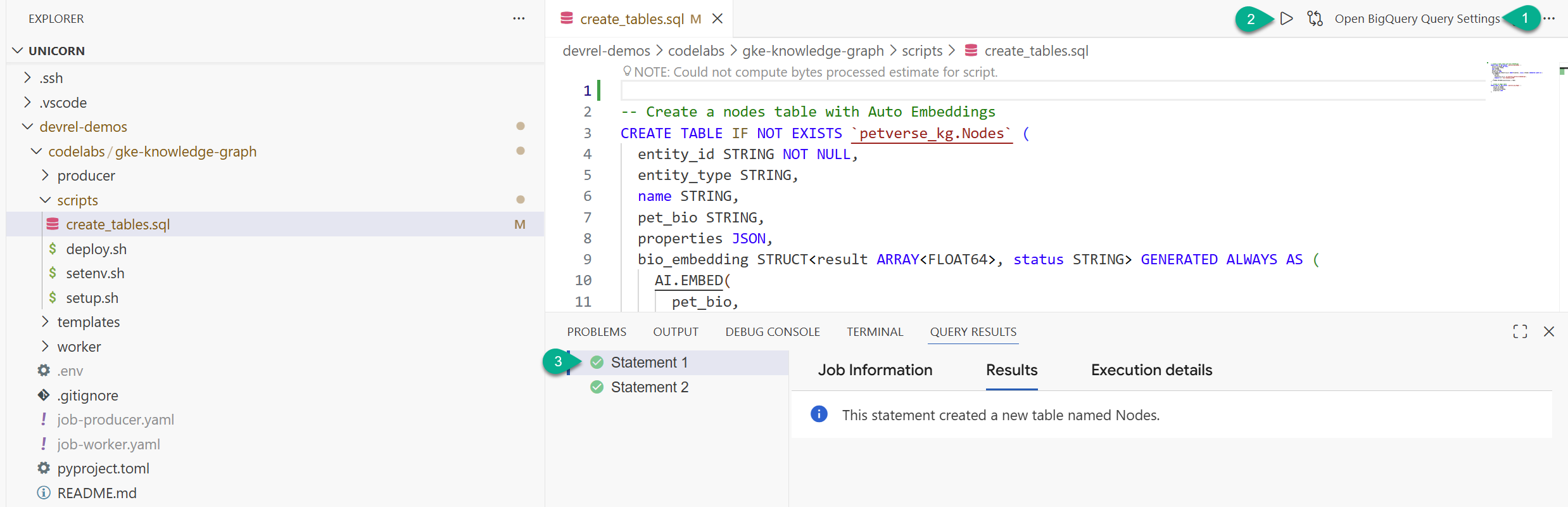
- בחלון הסייר, מאתרים את התיקייה ששיבטתם מהמאגר (
devrel-demos). מתחת ל-codelabs/gke-knowledge-graph/scripts, יופיעcreate_tables.sql. פותחים את הקובץ. - בפינה השמאלית העליונה, לוחצים על פתיחת הגדרות השאילתה.
- בוחרים באפשרות BigQuery. שמירה וסגירה.
- לוחצים על Run.
אמורות להופיע שתי הצהרות שהופעלו בהצלחה. יצרתם עכשיו את הטבלאות לאחסון הצמתים והקשתות של גרף הידע.
אפשר לסגור את הכרטיסייה create_tables.sql ואת מסוף התוצאות.
4. אתחול אשכול GKE
נשתמש ב-GKE Autopilot כדי להריץ את משימת עיבוד הנתונים. השיטה המומלצת היא להשתמש ב-Autopilot, כי הוא מנהל את תשתית האשכול בשבילכם.
בשלב הזה, סקריפט ההגדרה אמור להסתיים. אמורה להופיע הודעה על הצלחה: 🎉🦄 Setup successfully finished! 🎉🦄.
מדביקים את הפקודה הזו בטרמינל כדי ליצור את האשכול:
source scripts/setenv.sh
gcloud container clusters create-auto petverse-cluster \
--region=$REGION
🕓 התהליך יימשך כ-5 דקות.
מקבלים פרטי כניסה כדי לבצע אינטראקציה עם האשכול:
source scripts/setenv.sh
gcloud container clusters get-credentials petverse-cluster --region $REGION
הפלט שיוצג אמור להיות כזה:
Fetching cluster endpoint and auth data. kubeconfig entry generated for petverse-cluster.
5. הגדרת Workload Identity
איחוד שירותי אימות הזהות של עומסי עבודה ב-GKE (באמצעות גישה ישירה למשאבים) מאפשר לעומסי העבודה ב-GKE לגשת באופן מאובטח לשירותי Google Cloud בלי צורך לנהל מפתחות של חשבונות שירות.
מריצים את הפקודה deploy.sh כדי:
- יצירת חשבון שירות ב-Kubernetes
- מקצים את תפקידי ה-IAM הנדרשים ישירות לחשבון המשתמש של חשבון השירות של Kubernetes
- קישור חשבון השירות ב-IAM לחשבון השירות ב-Kubernetes
- הוספת הערה לחשבון השירות ב-Kubernetes כדי להשלים את הקישור
source scripts/setenv.sh
./scripts/deploy.sh
6. פריסת משימות עיבוד מנותקות
בשלב הזה תפרסו את מנגנון הוספת התורים (Producer) ואת מנועי העיבוד (Workers) ב-GKE.
הארכיטקטורה החדשה המופרדת שלנו משתמשת ב-Google Cloud Pub/Sub כדי לעבד נכסים באופן אסינכרוני:
- ה-Producer סורק את GCS ומכניס את כל נתיבי הקבצים לתור של Pub/Sub.
- מאגר של Workers מתרחב ב-GKE, שולף משימות במקביל באופן דינמי, מעבד אותן באמצעות Gemini וכותב אותן ל-BigQuery.
סקריפט setup.sh כבר יצר והעביר את קובצי האימג' בקונטיינר של Producer ו-Worker, הוסיף את הנושאים של Pub/Sub לתור ויצר באופן דינמי את מניפסטים הפריסה של GKE: job-producer.yaml ו-job-worker.yaml.
- מפעילים את Producer Job כדי לסרוק את קטגוריית האחסון ולהוסיף את כל הנכסים לתור:
kubectl apply -f job-producer.yaml
העבודה הזו מופעלת ומסתיימת במהירות כי היא רק מוסיפה מטא-נתונים לתור.
- פורסים את משימת ה-worker שהוגדרה להפעלת 6 workers מקבילים כדי לרוקן את התור:
kubectl apply -f job-worker.yaml
מצב Autopilot ב-GKE יזהה באופן אוטומטי את הפודים בהמתנה, יגדיל באופן דינמי את מספר צמתי החישוב ויפעיל את העובדים במקביל כדי לעבד אודיו, סרטונים, תמונות וקובצי CSV שהוכנסו לתור.
7. אימות התוצאות
- כדי לבדוק את הסטטוס של המשרות:
kubectl get jobs
מחכים עד שיוצג שהפעולות petverse-producer-job ו-petverse-worker-job הושלמו בהצלחה.
🕓 התהליך יימשך כ-10 דקות. אפשר לראות את ההתקדמות באמצעות הפקודות שבהמשך.
- בודקים את היומנים של ה-Producer כדי לוודא שהוא הוסיף קבצים לתור בהצלחה:
cd ~/devrel-demos/codelabs/gke-knowledge-graph
source scripts/setenv.sh
kubectl logs -l app=petverse-producer --tail=50
- צופים בעובדים המקבילים מעבדים קבצים מהתור:
kubectl logs -l app=petverse-worker --tail=50
(העובדים כוללים זמן קצוב לתפוגה של 60 שניות של חוסר פעילות, והם ייסגרו וינקו את עצמם באופן אוטומטי כשתור Pub/Sub יהיה ריק).
בודקים את הנתונים ב-BigQuery.
- עוברים אל BigQuery Studio. יוצרו שתי טבלאות: petverse_kg.Nodes ו-petverse_kg.Edges.
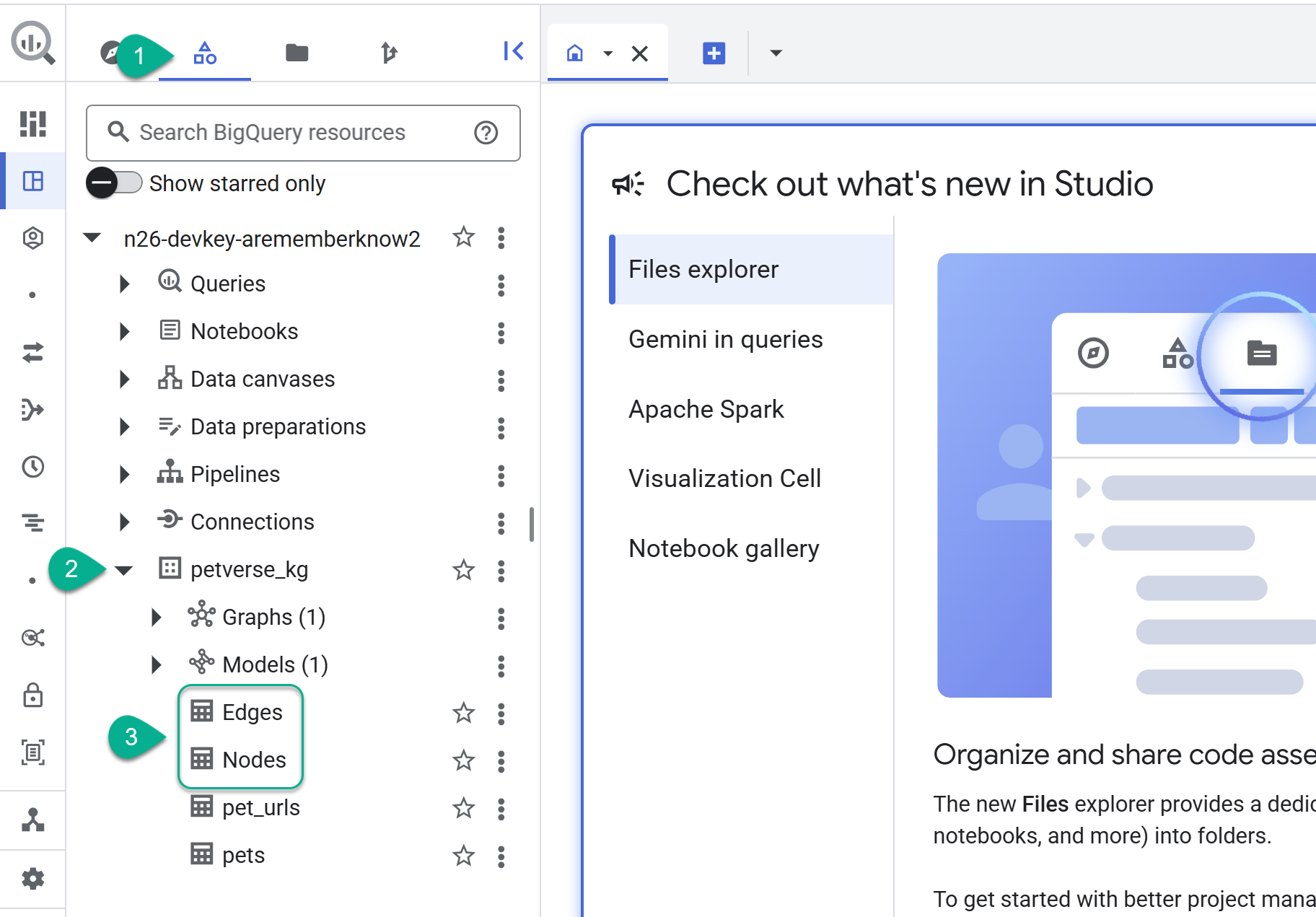
- כדי לראות את התוכן של הטבלאות, לוחצים לחיצה כפולה על השמות שלהן ואז לוחצים על תצוגה מקדימה.
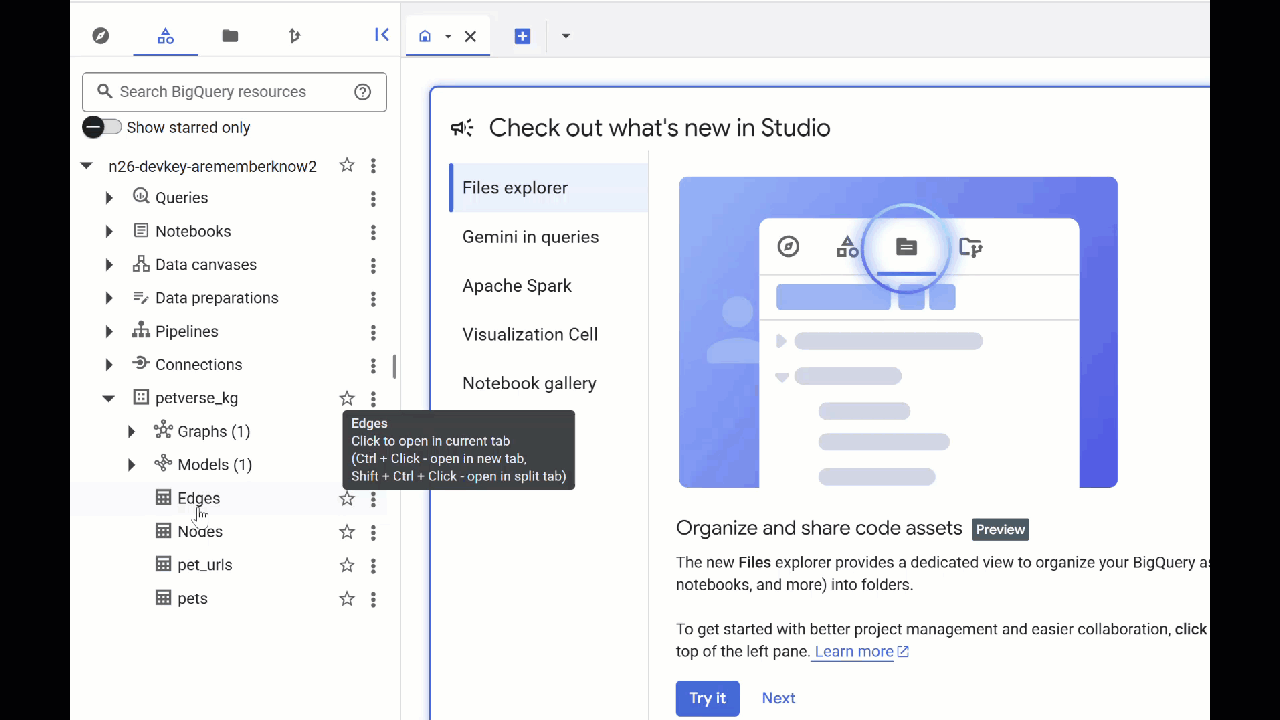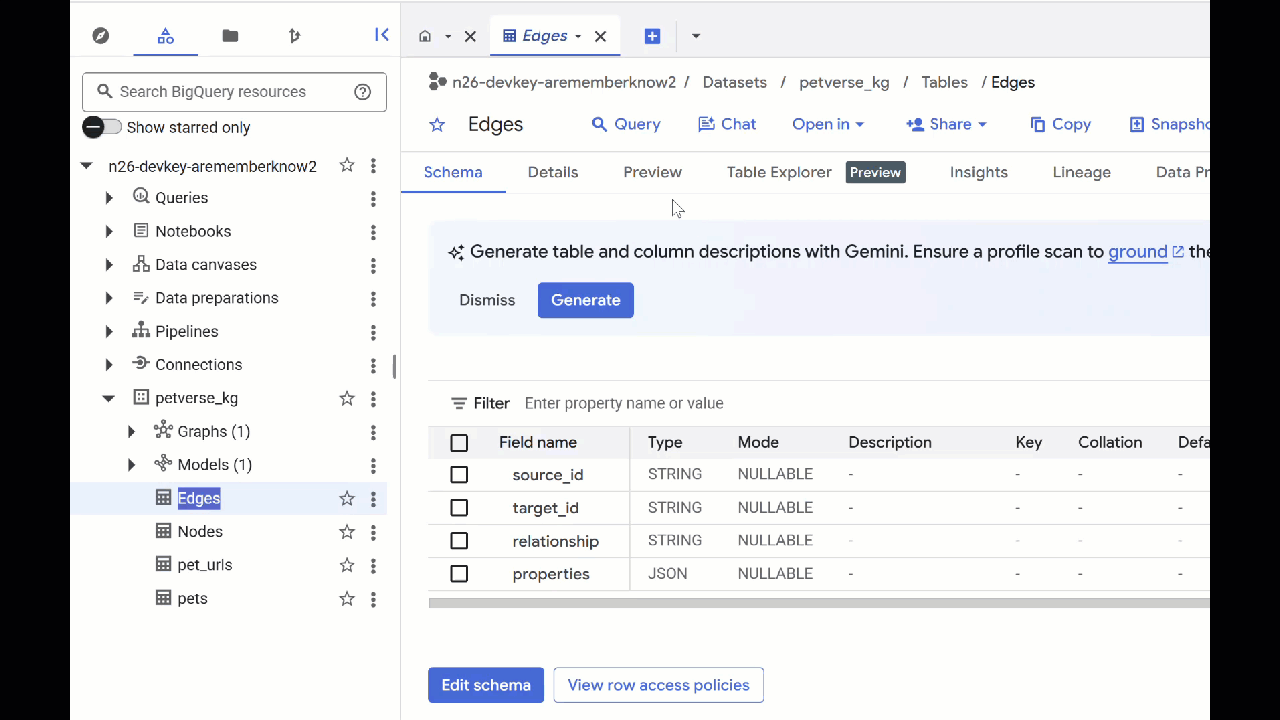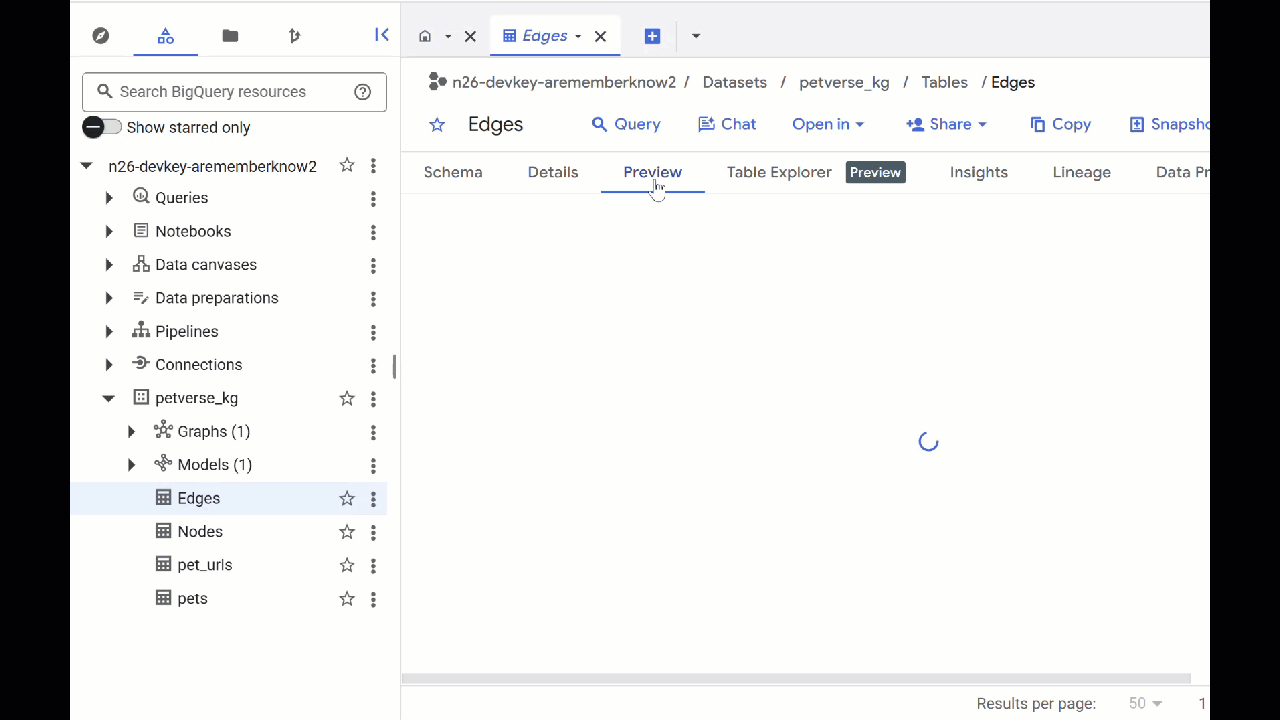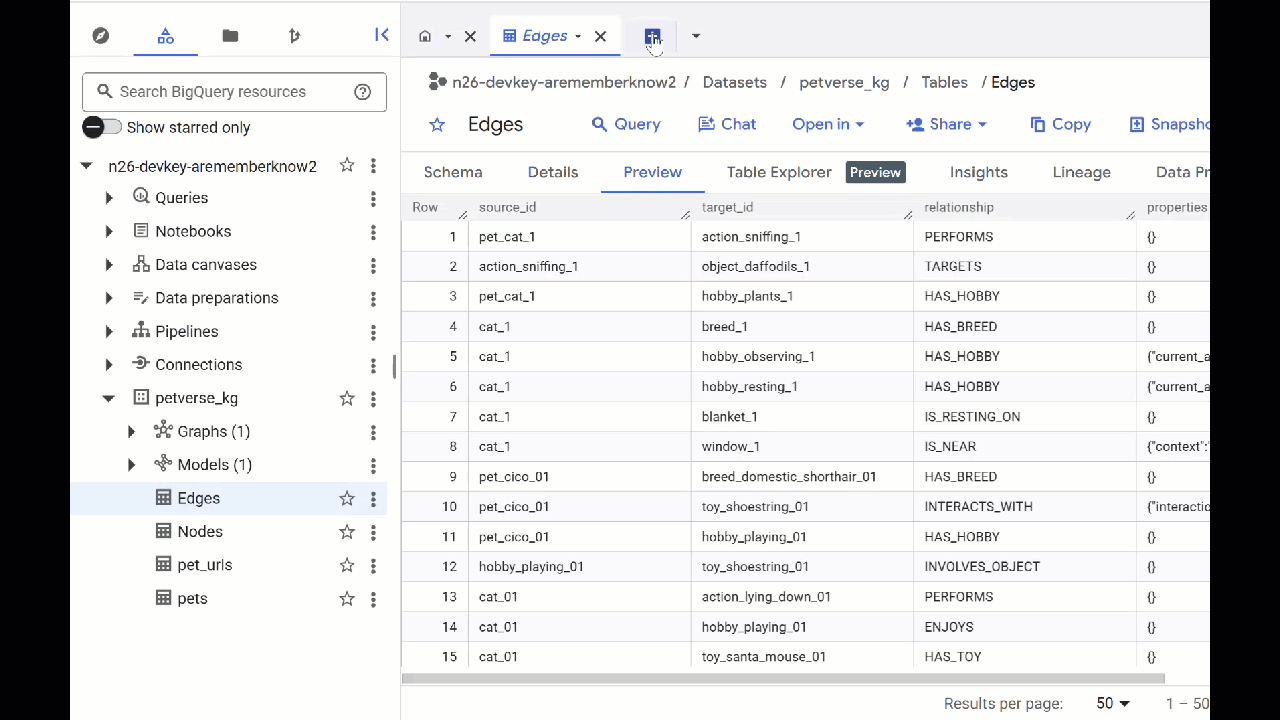
בטבלת הצמתים יופיע מידע על הישויות שזוהו על ידי Gemini בקובצי האודיו, בסרטונים ובתמונות. הטבלה Edges מכילה את הקשרים ביניהם. לדוגמה, אם תבקשו לשמוע את האודיו של החתול שנקרא SQL, תקבלו מידע על כך שהוא אוהב לשחק בשרוכי נעליים וליהנות מדגיגים מיובשים בהקפאה.
- משתמשים בלחצן + כדי ליצור שאילתה חדשה. מדביקים את ההצהרה הבאה ולוחצים על Run:
SELECT n.name, n.entity_id, e.relationship, e.target_id
FROM
`petverse_kg.Nodes` n
JOIN
`petverse_kg.Edges` e
ON n.entity_id = e.source_id
WHERE n.name = 'SQL'
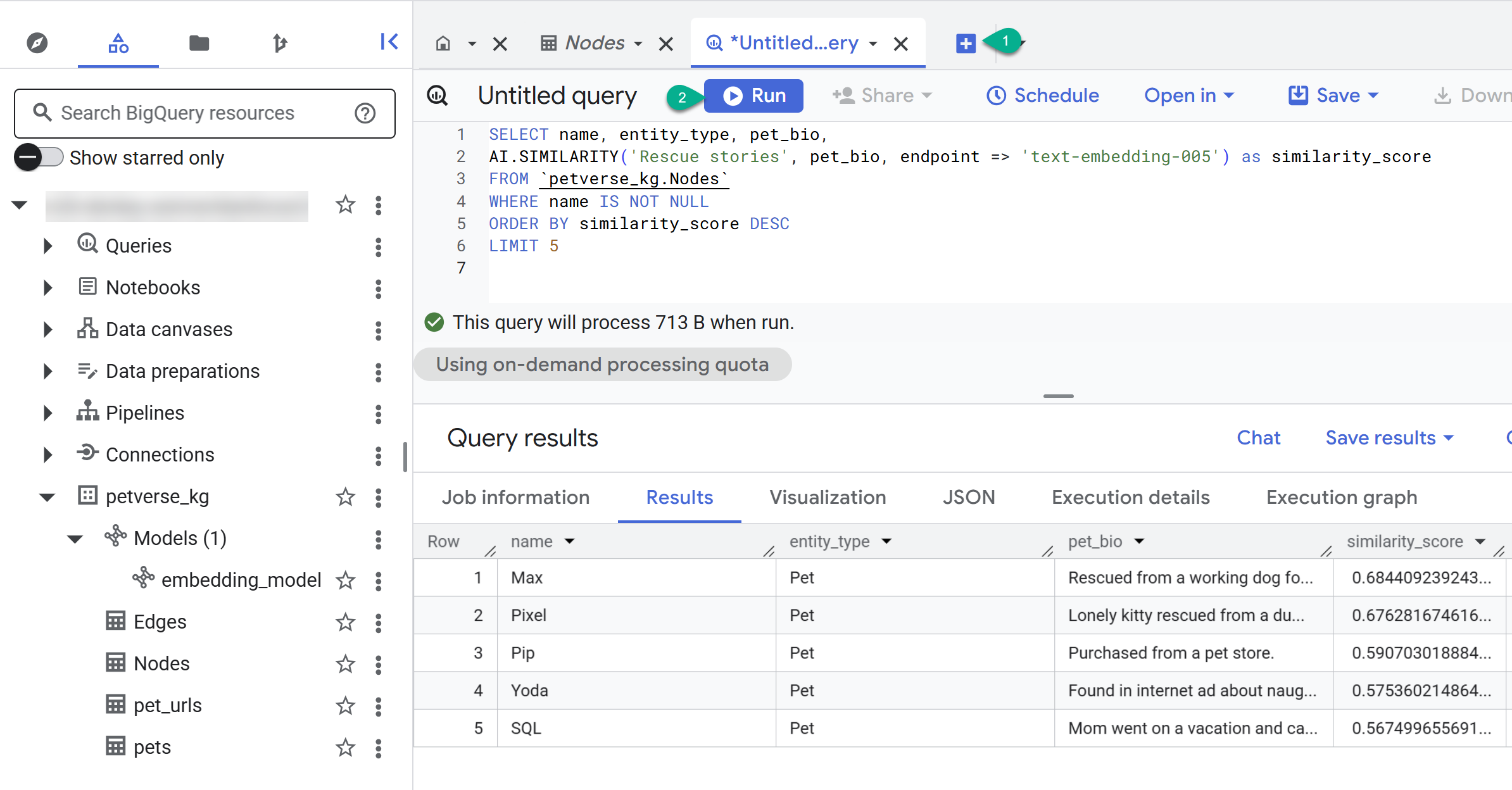
- משתמשים בלחצן + כדי ליצור שאילתה חדשה. מדביקים את ההצהרה הבאה ולוחצים על Run:
SELECT name, entity_type, pet_bio,
AI.SIMILARITY('Pets who like to relax', pet_bio, endpoint => 'text-embedding-005') as similarity_score
FROM `petverse_kg.Nodes`
WHERE name IS NOT NULL
ORDER BY similarity_score DESC
LIMIT 5
אמורים להופיע הצמתים של חיות מחמד שאוהבות להירגע. השאילתה הזו ביצעה חיפוש סמנטי באמצעות פונקציית ה-AI AI.SIMILARITY כדי למצוא חיות מחמד שהביוגרפיות שלהן הכי דומות לטקסט של השאילתה.
בניית גרף הנכסים
עכשיו כשיש לנו צמתים וקשתות ב-BigQuery, אנחנו יכולים ליצור תרשים מאפיינים כדי לשאול שאילתות על קשרים בקלות.
יצירת הגרף
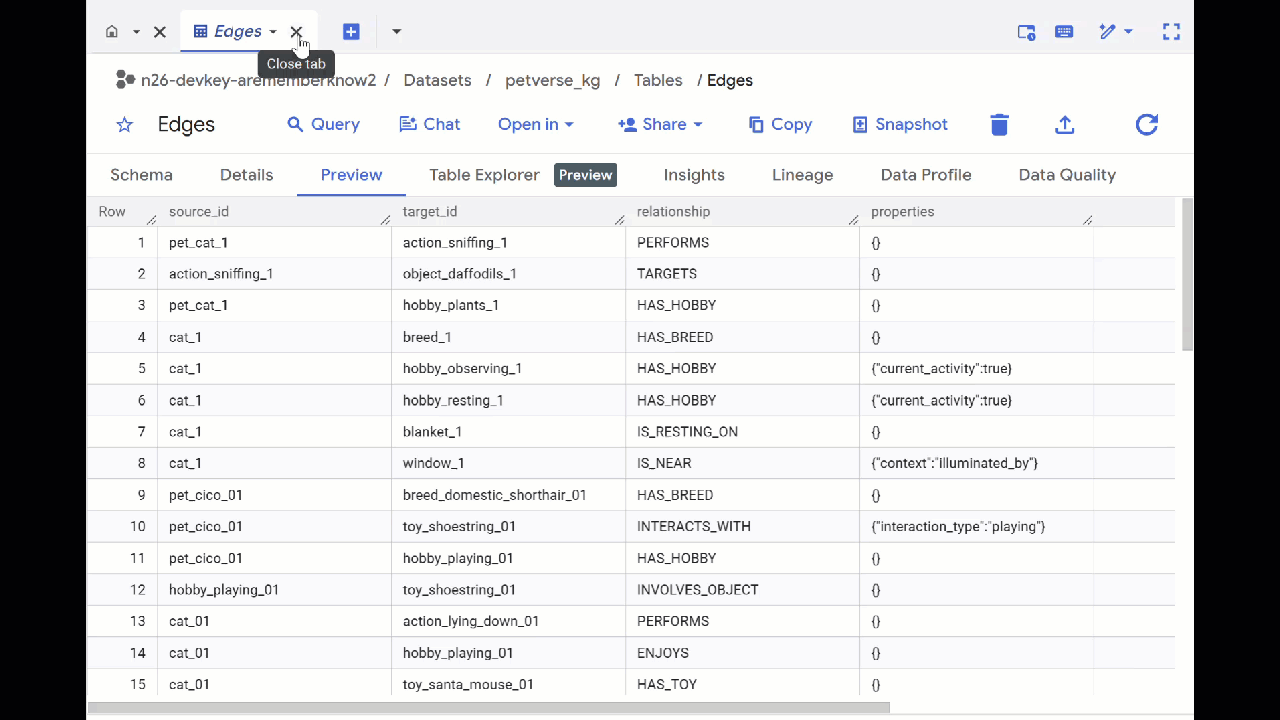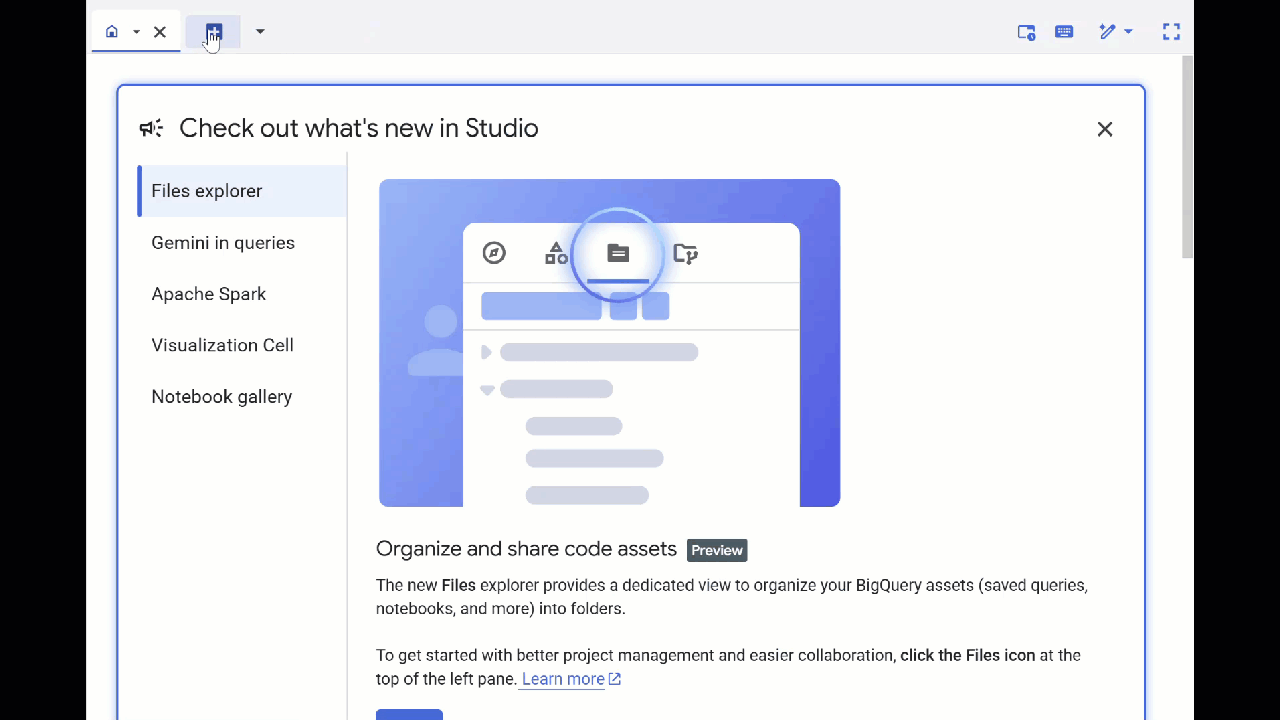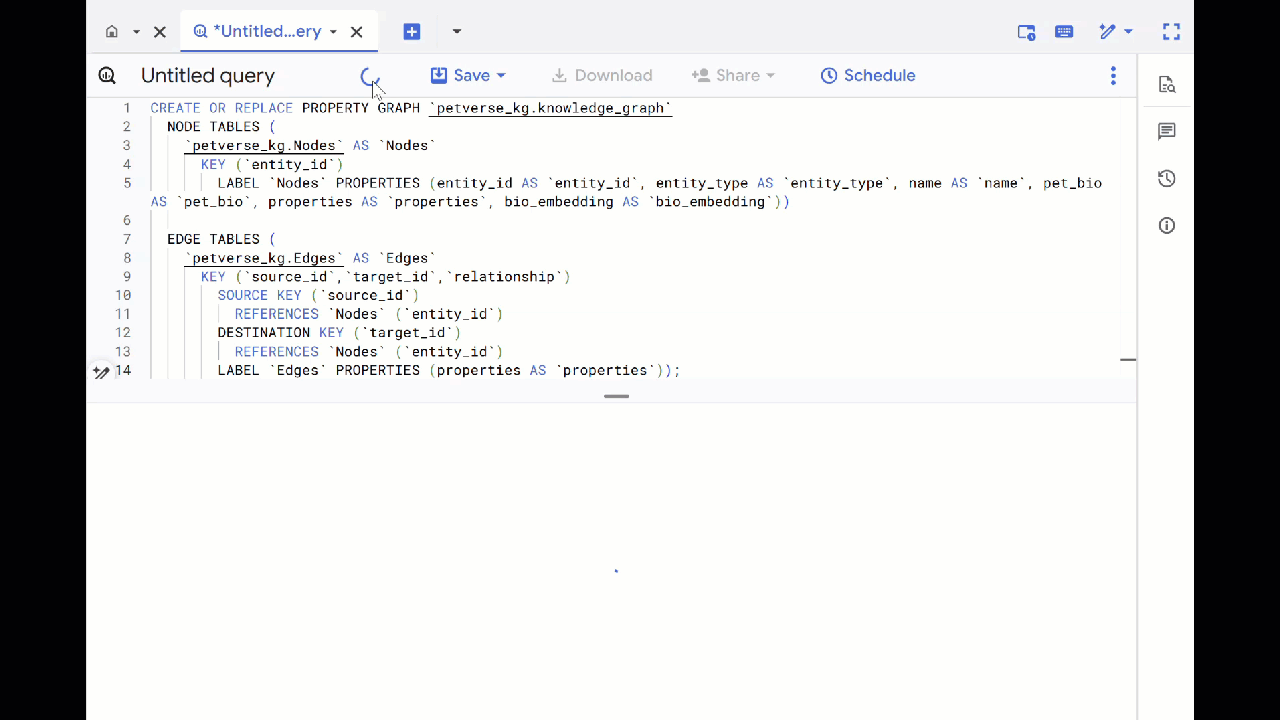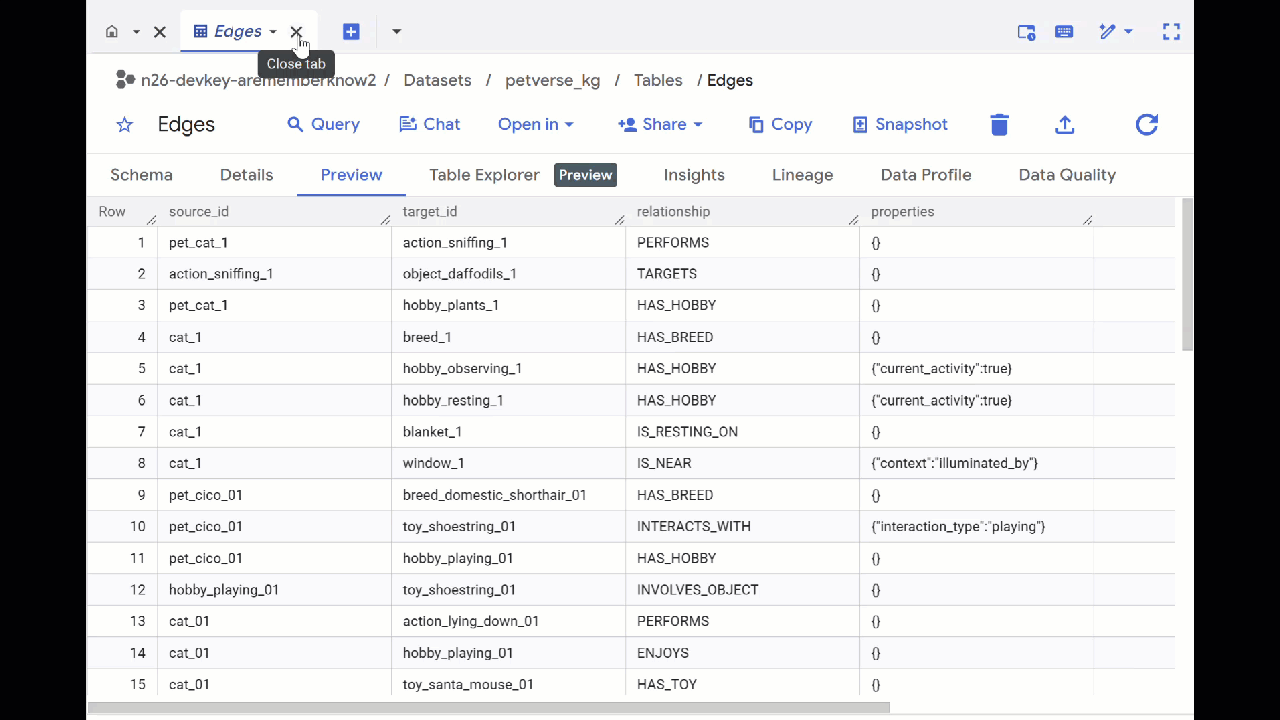
- מחליפים את השאילתה הקודמת ומריצים את ה-DDL הבא כדי ליצור את גרף הנכסים:
CREATE OR REPLACE PROPERTY GRAPH `petverse_kg.knowledge_graph`
NODE TABLES (
`petverse_kg.Nodes` AS `Nodes`
KEY (`entity_id`)
LABEL `Nodes` PROPERTIES (entity_id AS `entity_id`, entity_type AS `entity_type`, name AS `name`, pet_bio AS `pet_bio`, properties AS `properties`, bio_embedding AS `bio_embedding`))
EDGE TABLES (
`petverse_kg.Edges` AS `Edges`
KEY (`source_id`,`target_id`,`relationship`)
SOURCE KEY (`source_id`)
REFERENCES `Nodes` (`entity_id`)
DESTINATION KEY (`target_id`)
REFERENCES `Nodes` (`entity_id`)
LABEL `Edges` PROPERTIES (properties AS `properties`));
- לוחצים על מעבר לגרף. תוצג המחשה של הגרף עם צומת שיש לו קשת שמצביעה על עצמו. זו תופעה נורמלית.
שליחת שאילתה ל-Graph
- אפשר לסגור את כל השאילתות הקודמות ולפתוח שאילתה חדשה וריקה באמצעות הלחצן +.
- אפשר להשתמש ב-GQL כדי למצוא חיות מחמד שקשורות לחיות מחמד אחרות באמצעות תחומי עניין משותפים (כמו תחביבים, מאכלים או צעצועים אהובים). השאילתה הבאה עם כמה קפיצות מתאימה לשתי חיות מחמד שונות שמחוברות לאותו צומת:
GRAPH `petverse_kg.knowledge_graph`
MATCH p = (pet1:Nodes)-[e1]->(interest:Nodes)<-[e2]-(pet2:Nodes)
WHERE pet1.entity_id != pet2.entity_id
AND (LOWER(pet1.entity_type) = 'pet' AND LOWER(pet2.entity_type) = 'pet')
AND LOWER(interest.entity_type) IN ('hobby', 'action', 'activity', 'food', 'toy')
RETURN TO_JSON(p) as res
LIMIT 100
- אמורה להופיע המחשה של התרשים. אפשר ללחוץ על הצמתים כדי לראות את המאפיינים של הצמתים והקשתות.
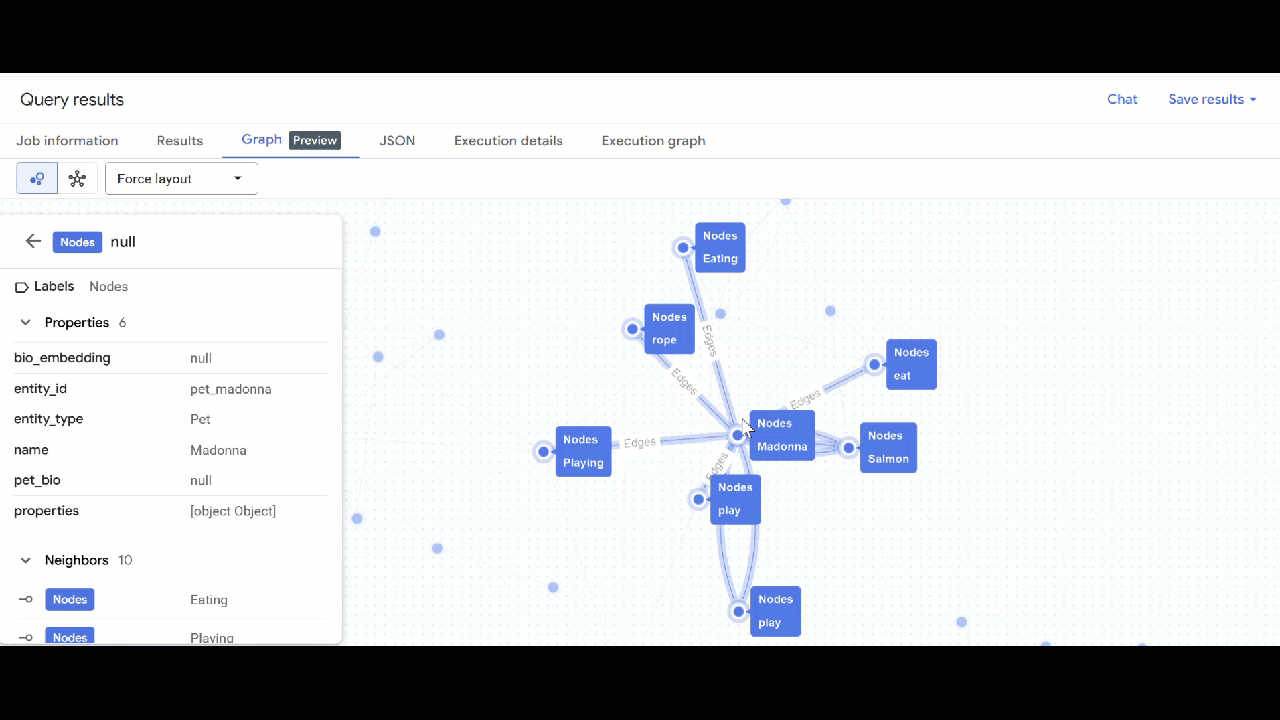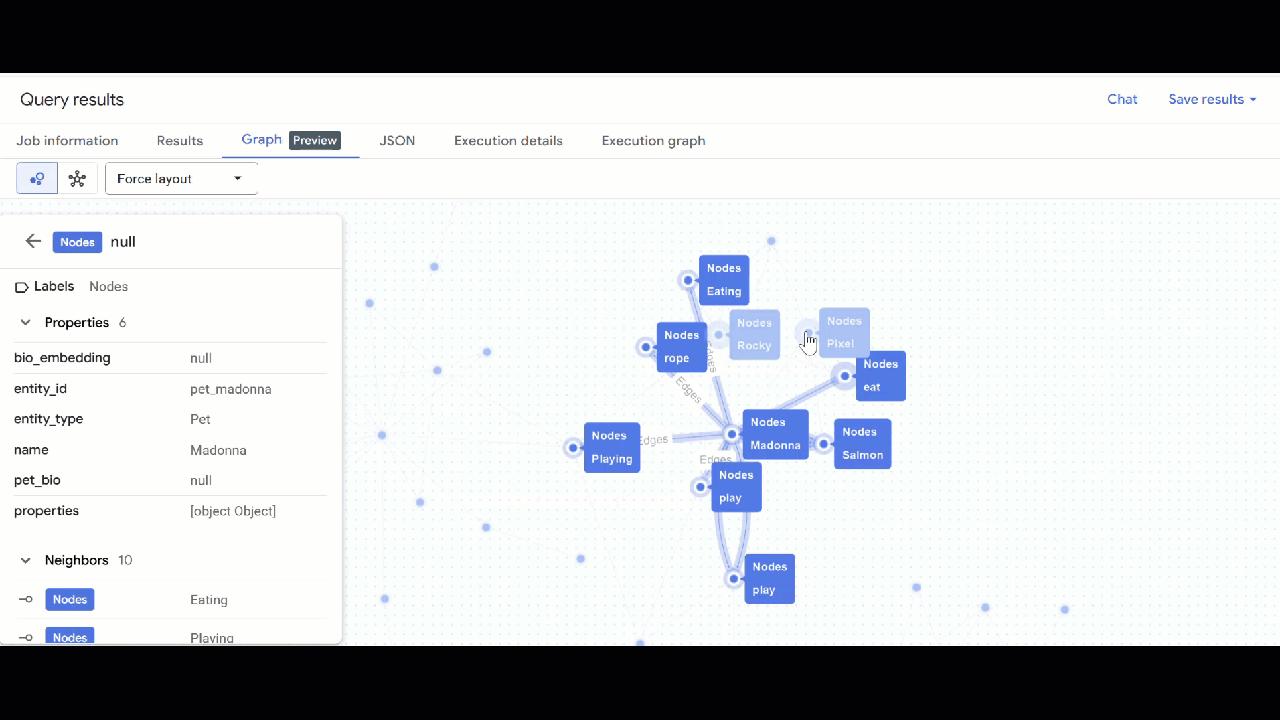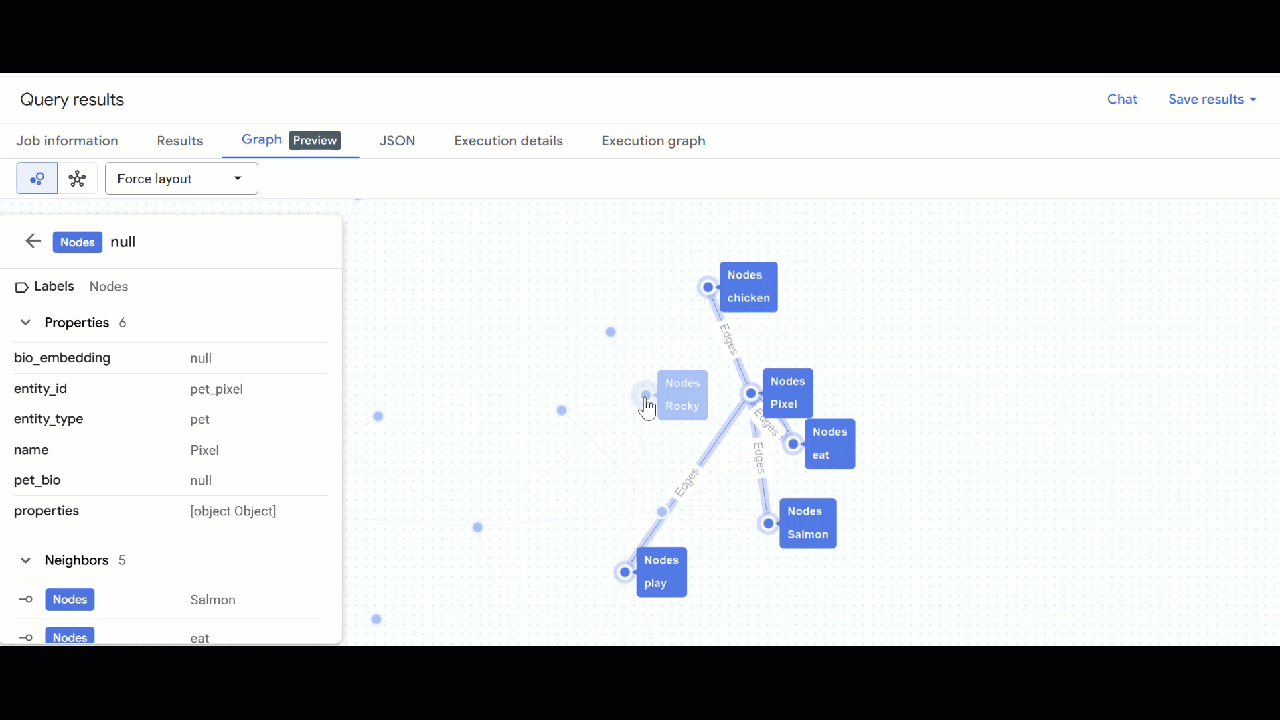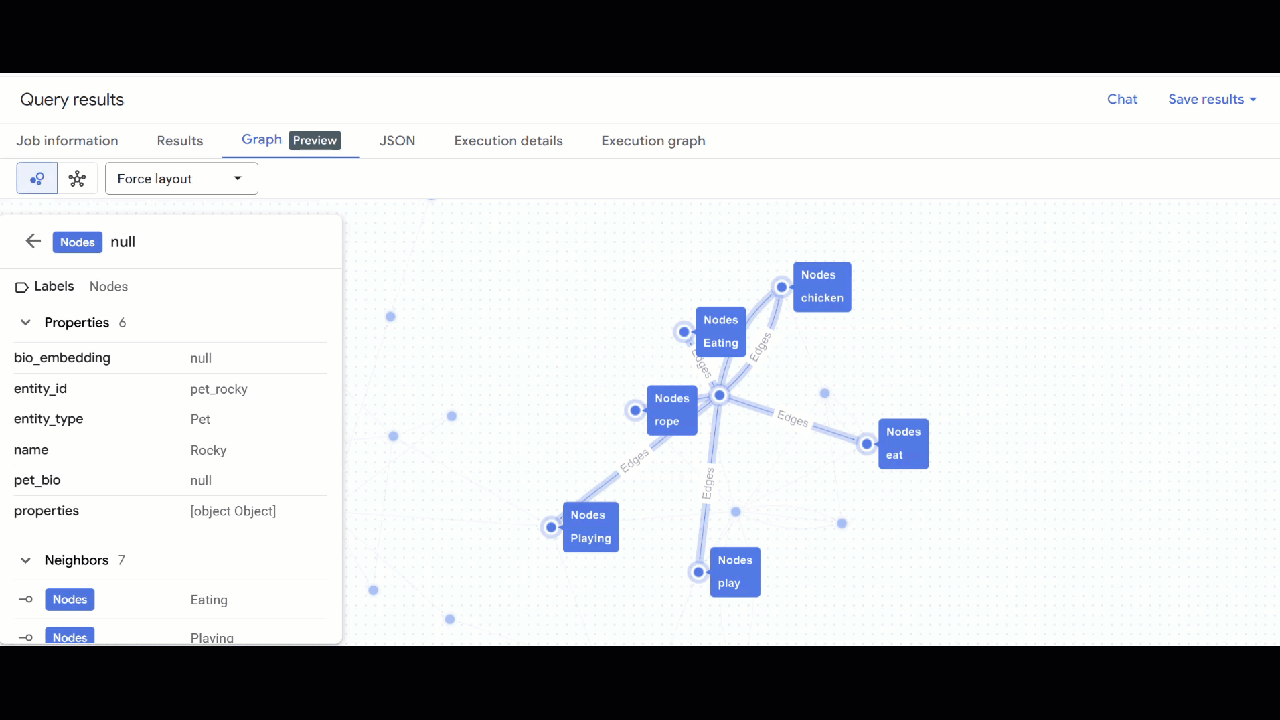
🕵️ הערה: כדי לשנות את הערך שמוצג בצומת, לוחצים על מעבר לתצוגת סכימה:
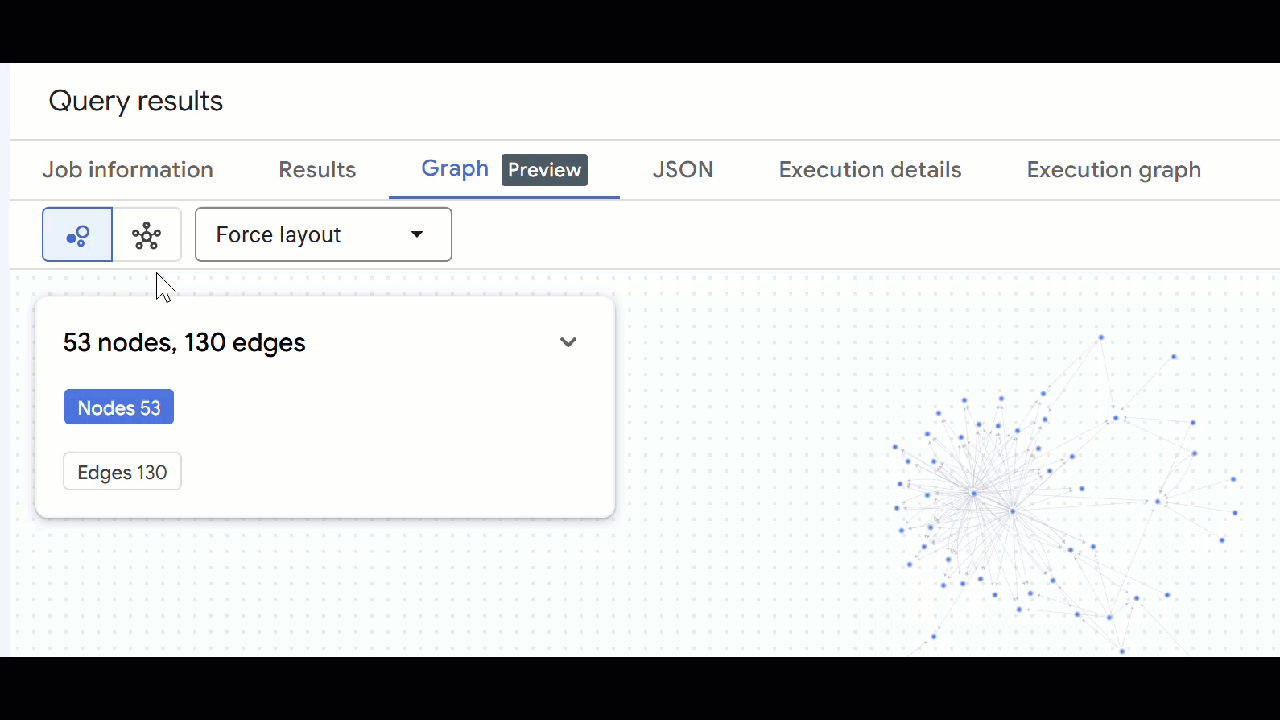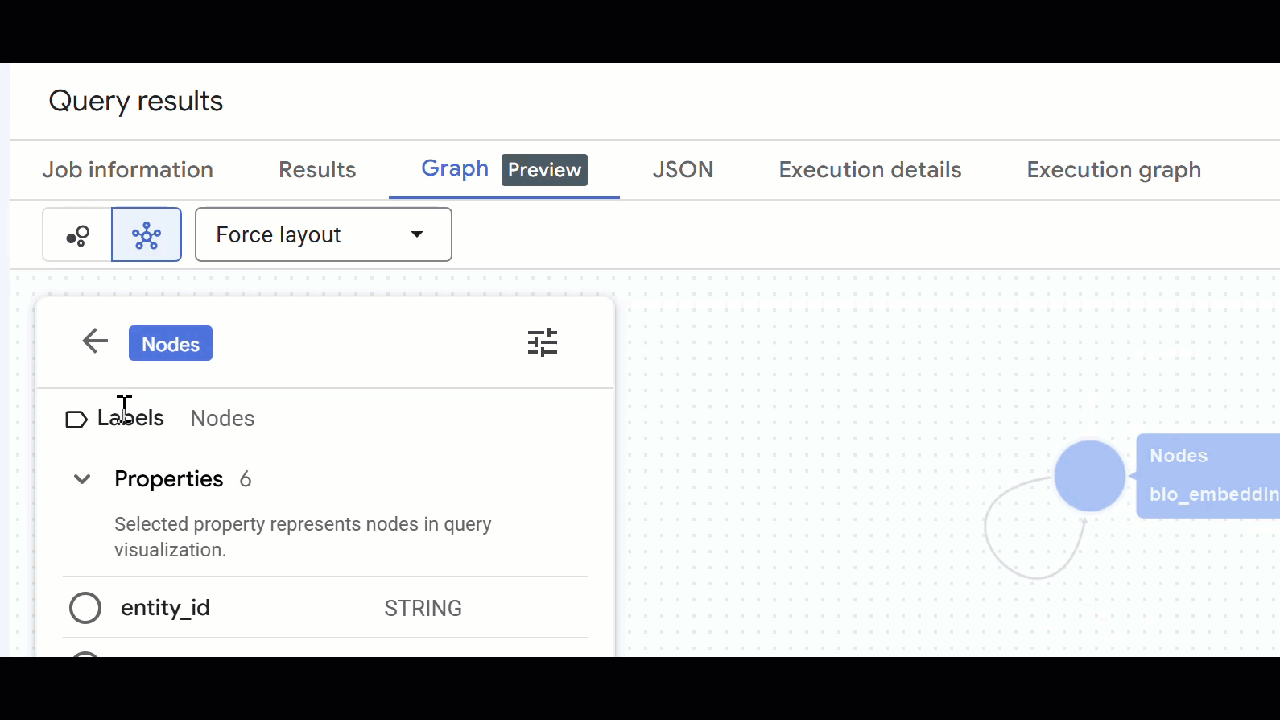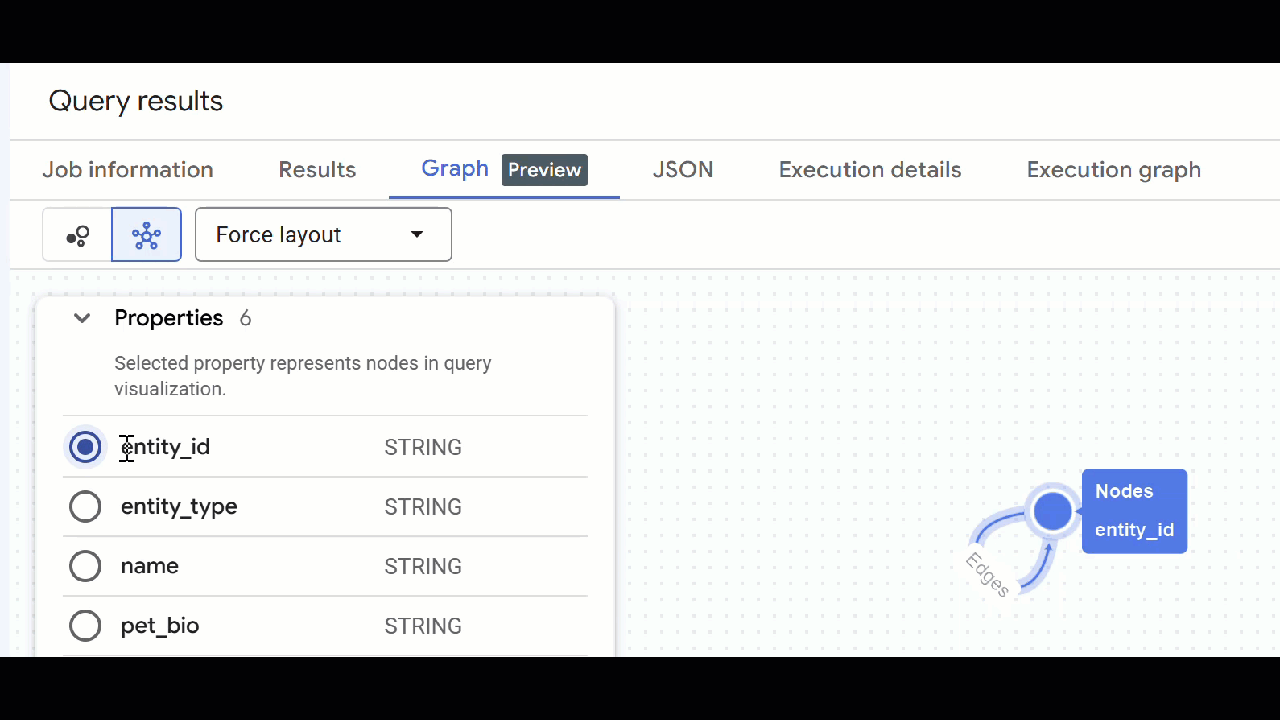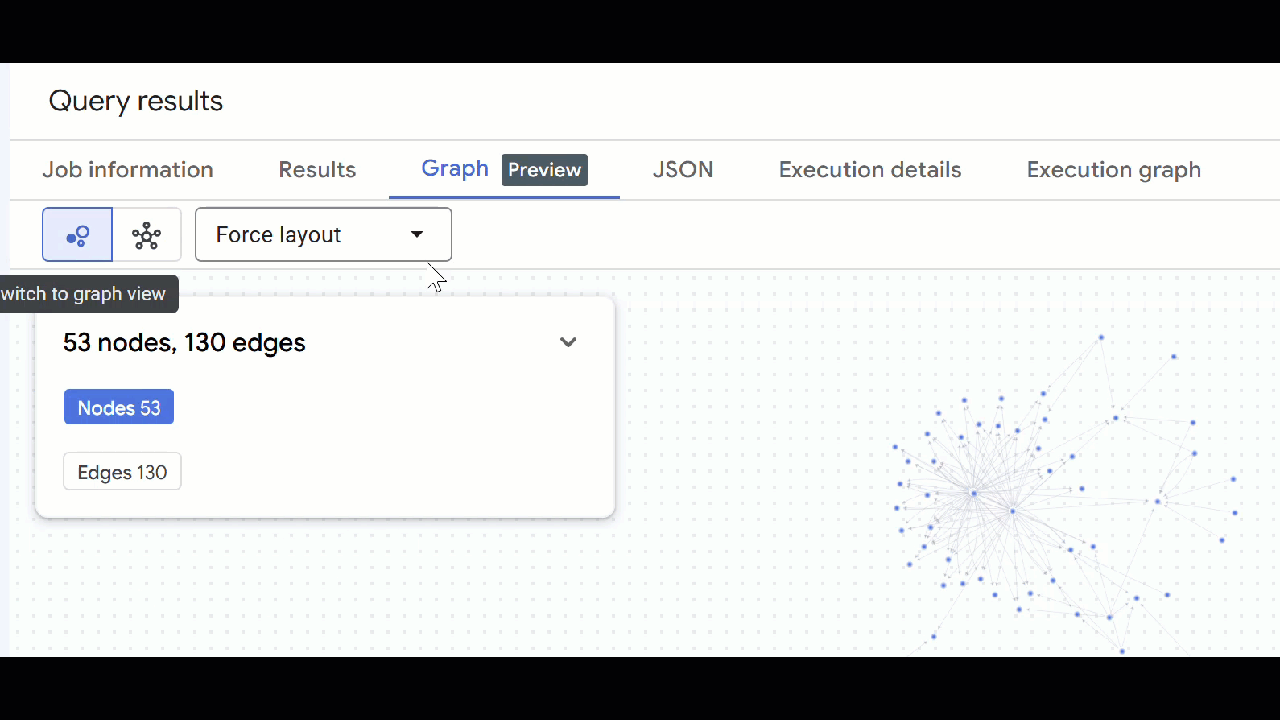
- אפשר לסגור את כל הכרטיסיות הפתוחות של השאילתות.
8. צ'אט עם הגרף
- לצד הסימן +, מופיע תפריט נפתח. בוחרים באפשרות שיחה.
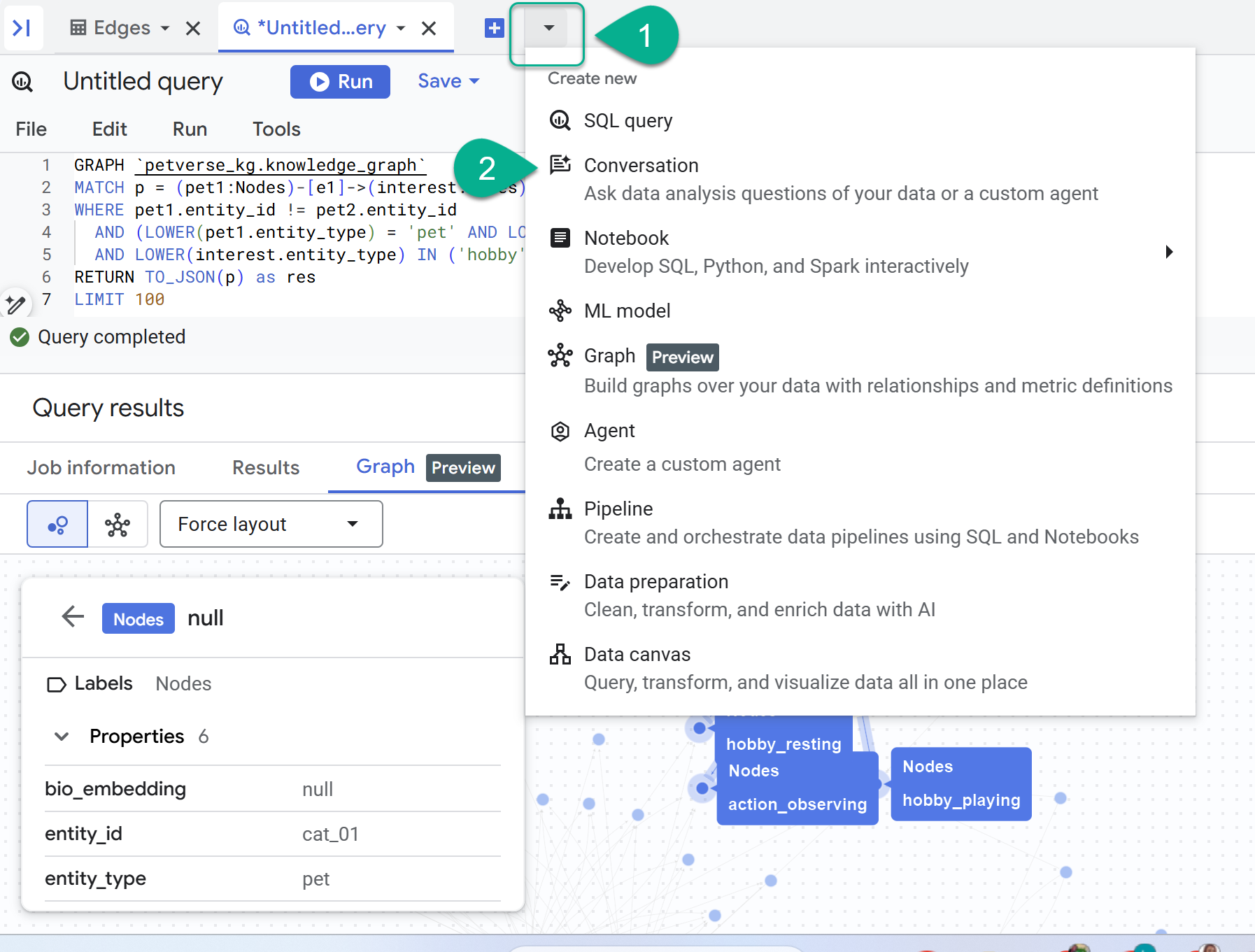
- תוצג בקשה להפעיל את Data Analytics API עם Gemini. מפעילים את שני ממשקי ה-API. אחרי שהפעולה הזו תסתיים, צריך לרענן את החלון או ליצור שיחה חדשה כדי לראות את הסוכן.
- לוחצים על סוכן חדש.
- נותנים לסוכן שם, למשל
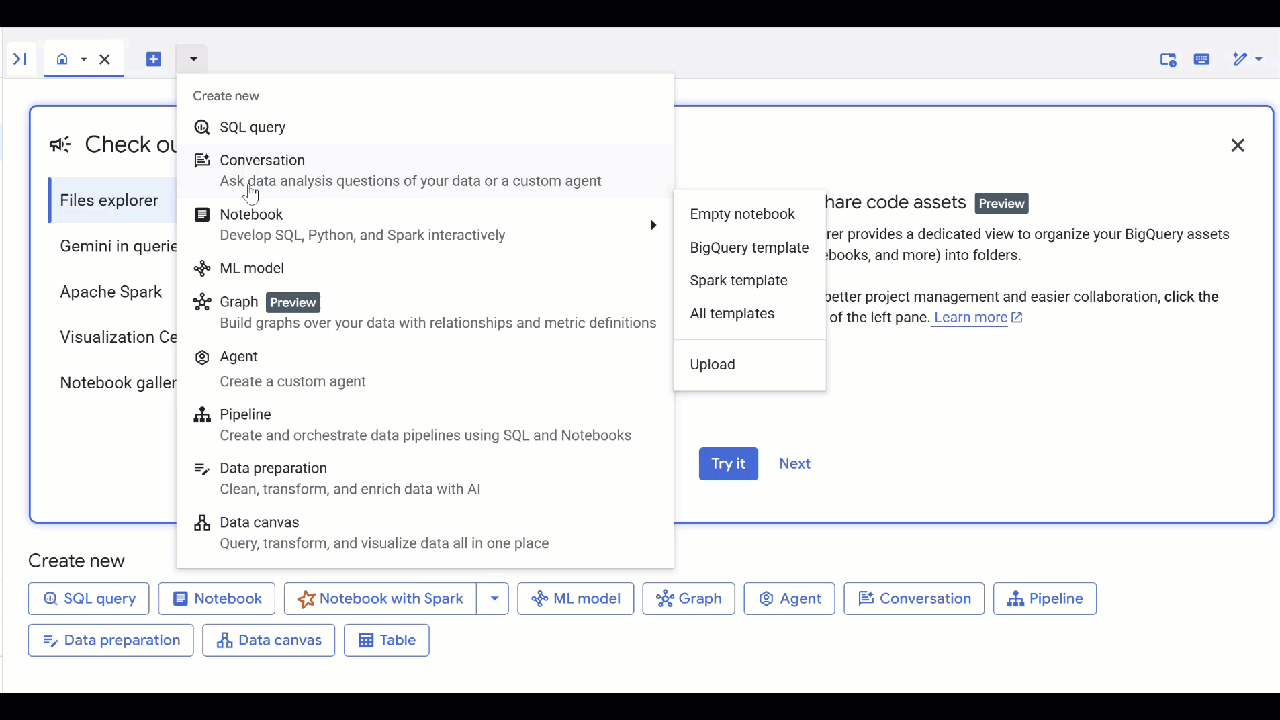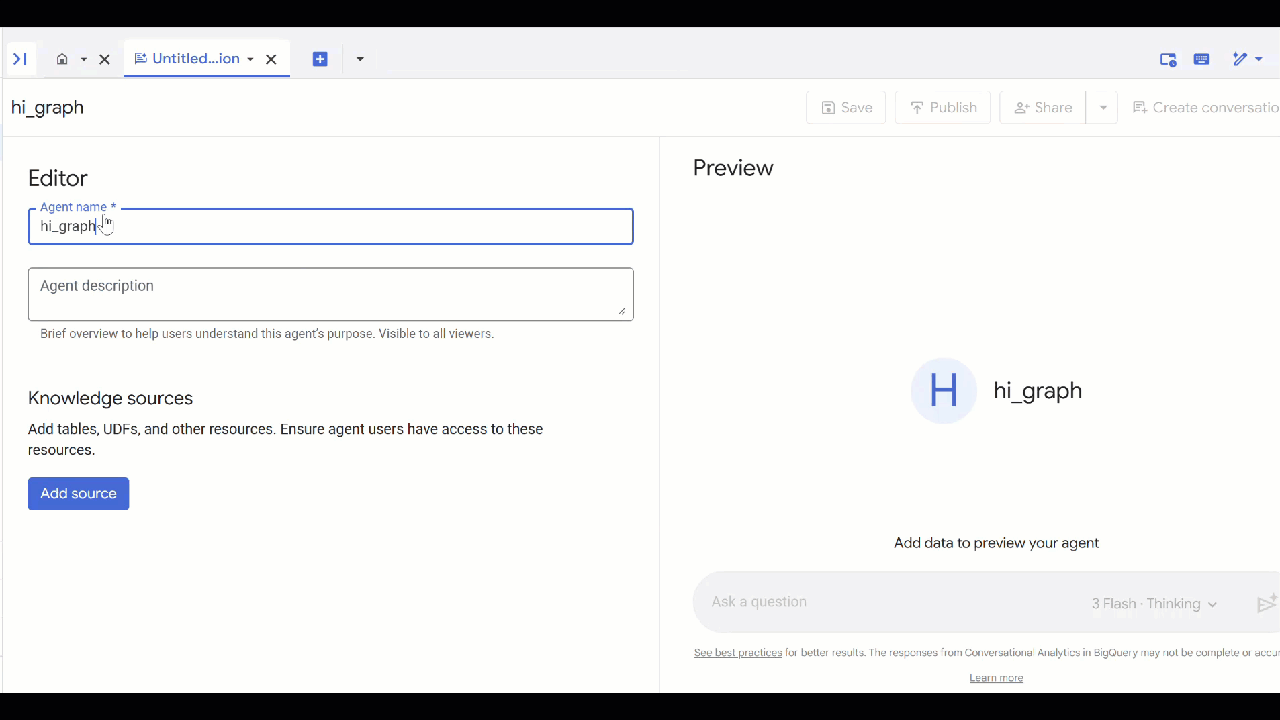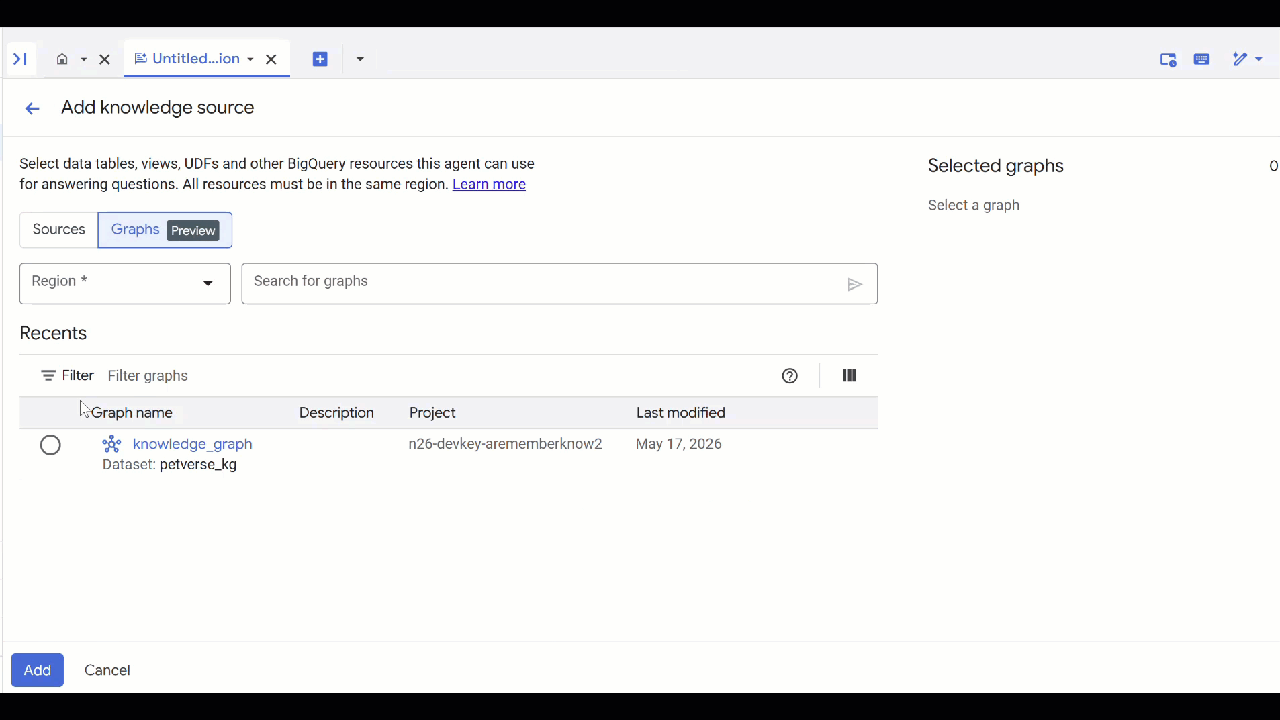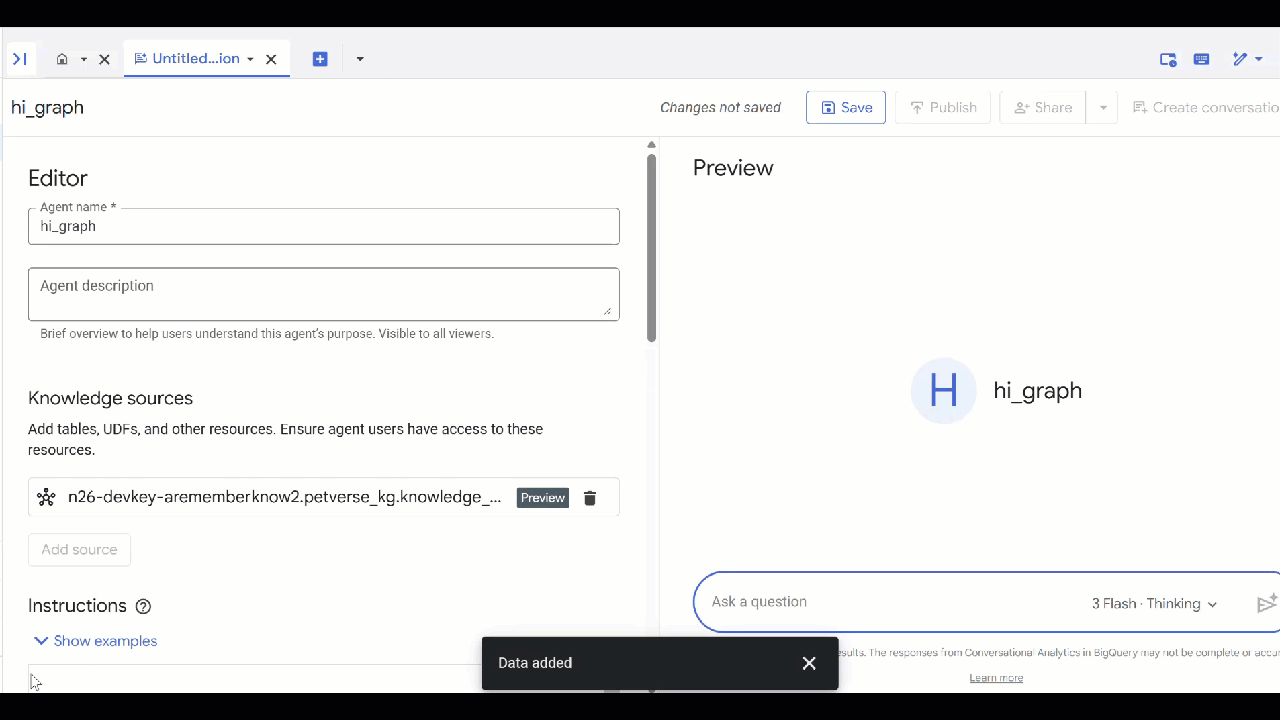
petverse. - לוחצים על הוספת מקור ואז על תרשים.
- בוחרים את
knowledge_graphשיצרתם ולוחצים על הוספה.
עכשיו אפשר לשאול את הסוכן שאלה ולראות את התשובות וההסברים שלהן. אם אתם צריכים השראה, הנה כמה דוגמאות לשאלות. יכול להיות שייקח קצת יותר זמן ליצור שאילתה ב-GQL באמצעות מודל חשיבה, אבל סביר להניח שהשאילתה תהיה טובה יותר. כדי לראות מה הוא יוצר, מרחיבים את Show Thinking.
- למצוא חיות מחמד שאוכלות אוכל דומה, או חיות מחמד שחברות עם חיות מחמד שאוהבות לנמנם.
- האם יש חיות מחמד שחולקות בדיוק את אותו תחביב, אותו מאכל אהוב או אותו צעצוע? תציג את הזוגות ואת תחומי העניין המשותפים שלהם.
- למצוא חיות מחמד מאותו מין או גזע, אבל עם תחביבים שונים לחלוטין.
9. הסרת המשאבים
כדי להימנע מחיובים שוטפים בחשבון Google Cloud, מוחקים את המשאבים שנוצרו במהלך ה-codelab הזה.
- מחיקת אשכול GKE:
gcloud container clusters delete petverse-cluster --region $REGION --quiet
- מוחקים את מערך הנתונים ב-BigQuery (פעולה שתמחק את כל הטבלאות):
bq rm -r -f -d $PROJECT_ID:petverse_kg
- מוחקים את משאבי התור של Pub/Sub:
gcloud pubsub subscriptions delete petverse-sub --quiet
gcloud pubsub topics delete petverse-topic --quiet
- מחיקת מאגר Artifact Registry:
gcloud artifacts repositories delete gke-cats-repo --location=$REGION --quiet
- מוחקים את קטגוריית ה-GCS הספציפית לפרויקט:
gcloud storage buckets delete gs://$PROJECT_ID-petverse --quiet
10. מזל טוב
מעולה! יצרתם בהצלחה צינור עיבוד נתונים מבוזר של תרשים ידע באמצעות GKE ו-Gemini, וביצעתם בו שאילתות באמצעות BigQuery Property Graphs.
מה למדתם
- איך פורסים משימות מבוזרות ב-GKE Autopilot.
- איך משתמשים ב-Gemini לחילוץ נתונים ממקורות שונים.
- איך משתמשים בהטמעות אוטומטיות של BigQuery.
- איך יוצרים גרפים של נכסים ב-BigQuery ושולחים אליהם שאילתות.