
1. परिचय
इस कोडलैब में, "Petverse" के लिए डिस्ट्रिब्यूटेड नॉलेज ऐक्विज़िशन पाइपलाइन बनाई जाएगी. आपको Cloud Storage बकेट से, बिना किसी स्ट्रक्चर वाली मल्टीमीडिया ऐसेट (ऑडियो, वीडियो, इमेज, टेक्स्ट/CSV) प्रोसेस करनी होंगी. साथ ही, पालतू जानवरों के बारे में मुख्य जानकारी (पसंदीदा खाना, शौक) निकालनी होगी और एक नॉलेज ग्राफ़ बनाना होगा. Google Kubernetes Engine (GKE) पर Gemini की मल्टी-मॉडल प्रोसेसिंग का इस्तेमाल करके, मल्टीमीडिया फ़ाइल की प्रोसेसिंग को स्केल किया जाएगा. आखिर में, इस डेटा को BigQuery में सेव किया जाएगा. साथ ही, संबंधों का विश्लेषण करने के लिए, BigQuery की नई प्रॉपर्टी ग्राफ़ सुविधा का इस्तेमाल किया जाएगा.
हम Google Kubernetes Engine की मदद से, एक साथ ज़्यादा डेटा प्रोसेस करने का तरीका दिखाएंगे.
नॉलेज ग्राफ़ क्यों?
नॉलेज ग्राफ़, इकाइयों के बीच जटिल संबंधों को दिखाने और उनका विश्लेषण करने के लिए, पारंपरिक रिलेशनल डेटाबेस की तुलना में ज़्यादा बेहतर होते हैं.
हम इमेज, ऑडियो, और वीडियो फ़ाइलों का विश्लेषण करने के लिए Gemini 2.5 Flash का इस्तेमाल करेंगे. साथ ही, अलग-अलग पालतू जानवरों के बारे में तथ्यों का पता लगाएंगे.
आपको क्या करना होगा
- GKE पर डिस्ट्रिब्यूटेड डेटा प्रोसेसिंग जॉब बनाएं और डिप्लॉय करें.
- मल्टीमीडिया फ़ाइलों से इकाइयां और उनके बीच के संबंध निकालने के लिए, Gemini का इस्तेमाल करें.
- नॉलेज ग्राफ़ के डेटा को BigQuery में सेव करें.
- ग्राफ़ क्वेरी लैंग्वेज (GQL) का इस्तेमाल करके, BigQuery में प्रॉपर्टी ग्राफ़ बनाएं और उसकी क्वेरी करें.
आपको किन चीज़ों की ज़रूरत होगी
- कोई वेब ब्राउज़र, जैसे कि Chrome
- बिलिंग की सुविधा वाला Google Cloud प्रोजेक्ट
- संसाधन बनाने और आईएएम नीतियों में बदलाव करने के लिए, प्रोजेक्ट में अनुमतियां
यह कोडलैब, सभी लेवल के डेवलपर के लिए है. इसमें शुरुआती डेवलपर भी शामिल हैं.
अनुमानित अवधि: 45 मिनट
लागत: इस कोडलैब में बनाए गए संसाधनों की लागत, 5 डॉलर से कम होनी चाहिए.
2. शुरू करने से पहले
Google Cloud प्रोजेक्ट बनाना
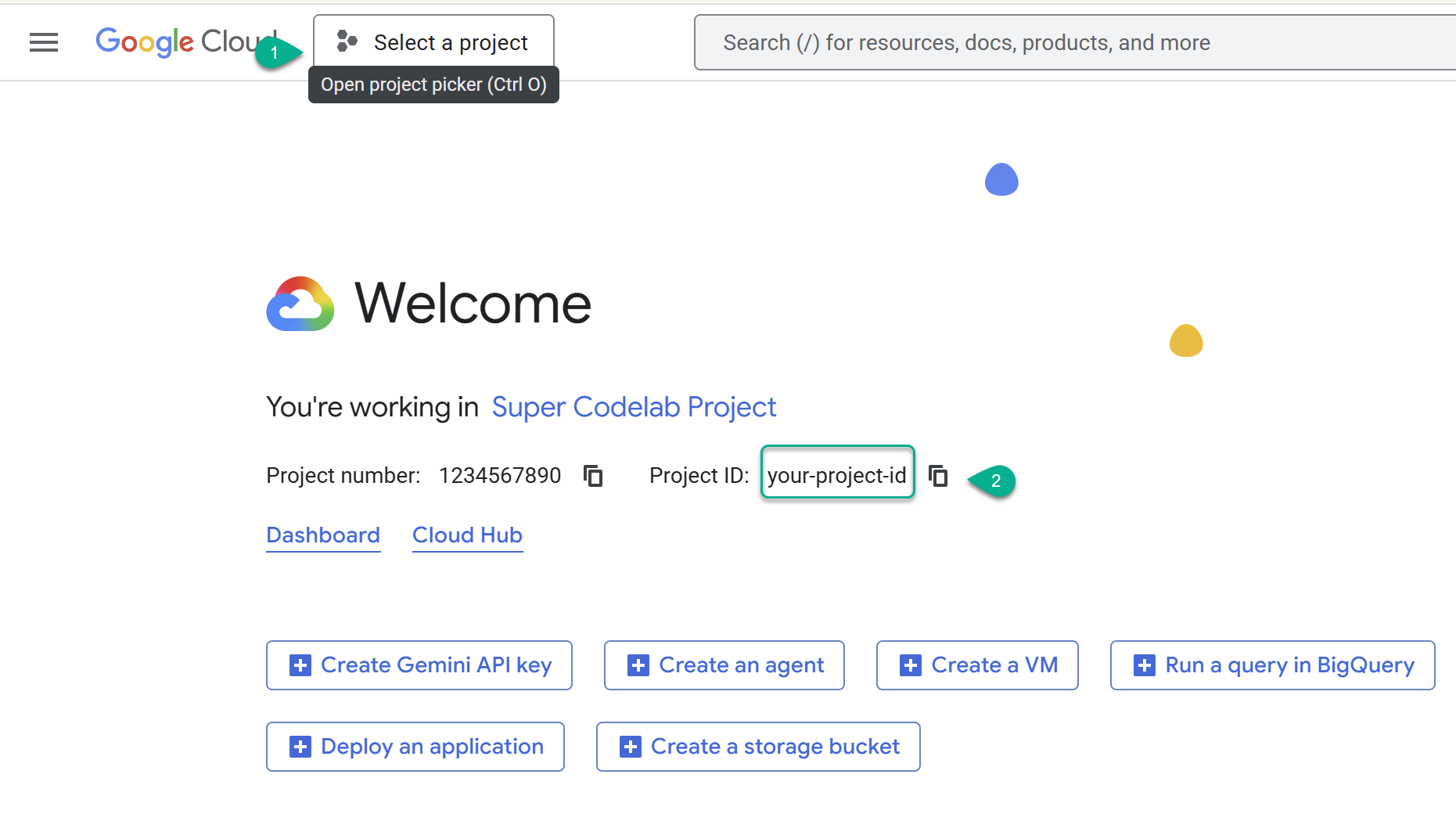
- Google Cloud Console पर जाएं: https://console.cloud.google.com. इसके बाद, Google Cloud प्रोजेक्ट चुनें या बनाएं.
- ⚠️ प्रोजेक्ट आईडी नोट करें. इस लैब में, इसका इस्तेमाल कई कमांड के लिए किया जाएगा.
Cloud Shell शुरू करना
- नए टैब में Cloud Shell खोलें: https://shell.cloud.google.com/.
- अगर कहा जाए, तो अनुमति दें पर क्लिक करें.
PROJECT_IDकी जगह पर, टर्मिनल में यह कमांड चिपकाएं:
export PROJECT_ID="YOUR_PROJECT_ID"
gcloud config set project $PROJECT_ID
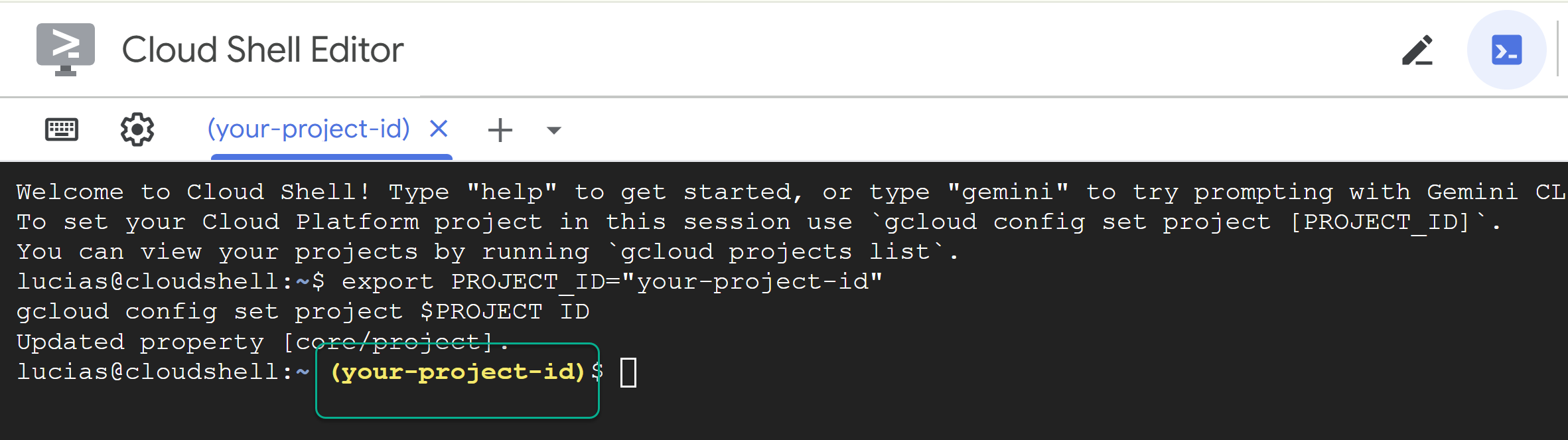
📝 ध्यान दें कमांड लाइन में आपका प्रोजेक्ट, पीले रंग में दिखेगा. अगर आपका सेशन रीस्टार्ट होता है, तो पक्का करें कि आपने प्रोजेक्ट आईडी सेट करने के लिए, ऊपर दिए गए निर्देश को फिर से चलाया हो.
एपीआई चालू करें
सभी ज़रूरी एपीआई चालू करने के लिए, यह निर्देश चलाएं:
gcloud services enable \
aiplatform.googleapis.com \
bigquery.googleapis.com \
artifactregistry.googleapis.com \
container.googleapis.com \
cloudbuild.googleapis.com \
pubsub.googleapis.com
डेटाबेस का क्लोन बनाना
रिपॉज़िटरी को क्लोन करने के लिए, इन कमांड को चलाएं.
cd ~/
git clone --filter=blob:none --no-checkout https://github.com/GoogleCloudPlatform/devrel-demos.git
cd ~/devrel-demos
git sparse-checkout init --cone
git sparse-checkout set codelabs/gke-knowledge-graph
git checkout main
cd codelabs/gke-knowledge-graph/
सेटअप स्क्रिप्ट चलाना
यह स्क्रिप्ट, बैकएंड कॉन्फ़िगरेशन को अपने-आप पूरा करती है. इसके लिए, यह स्क्रिप्ट:
- कंटेनर इमेज और Artifact Registry रिपॉज़िटरी बनाना
- BigQuery डेटासेट बनाना
- एसक्यूएल से Gemini के एआई फ़ंक्शन को लागू करने के लिए, BigQuery कनेक्शन बनाना
अपने टर्मिनल में यह कमांड चलाएं:
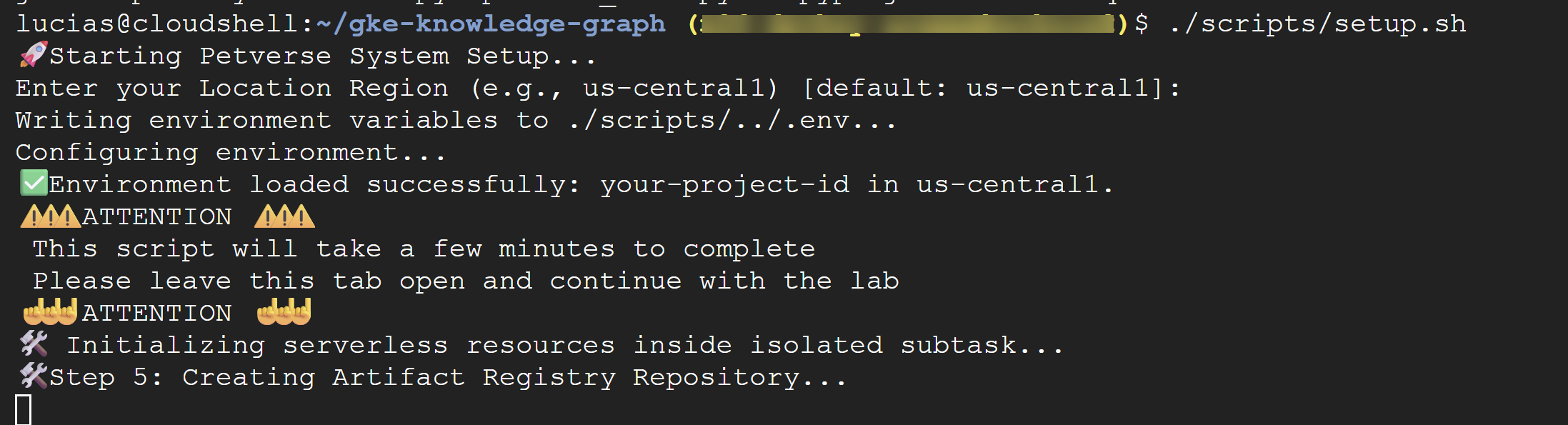
./scripts/setup.sh
अगर स्क्रिप्ट आपसे कॉन्फ़िगरेशन की जानकारी मांगती है, तो इन वैल्यू का इस्तेमाल करें:
- प्रोजेक्ट आईडी: पिछले चरण में बनाए गए आईडी का इस्तेमाल करें.
- देश/इलाका:
us-central1
⚠️ अहम जानकारी स्क्रिप्ट को पूरा होने में कुछ मिनट लगेंगे. इस टर्मिनल विंडो को खुला रखें, ताकि यह प्रोसेस बैकग्राउंड में पूरी हो सके. अगले चरण पर जाने के लिए, नई टर्मिनल टैब या विंडो खोलें, ताकि अगले निर्देश चलाए जा सकें.
3. डेटा एजेंट किट सेट अप करना
- सबसे ऊपर दाएं कोने में मौजूद पेंसिल आइकॉन का इस्तेमाल करके, Cloud Shell Editor चालू करें.
- Cloud Shell Editor में, बाईं ओर मौजूद साइडबार में एक्सटेंशन आइकॉन पर क्लिक करें.
- Google Cloud Data Agent Kit खोजें. अगर यह पहले से इंस्टॉल नहीं है, तो Install पर क्लिक करें.
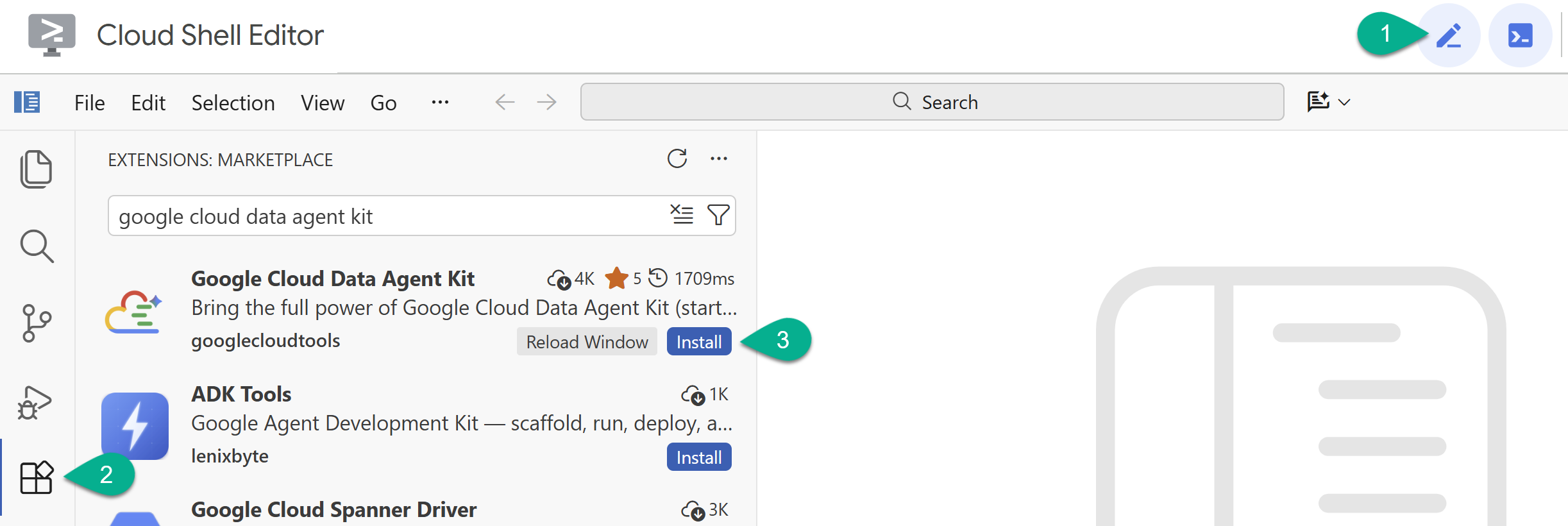
- एक्सटेंशन की मदद से, अपने Google खाते में साइन इन करें.
- कॉन्फ़िगरेशन की खास जानकारी में, अपना प्रोजेक्ट आईडी और
us-central1को क्षेत्र के तौर पर डालें.
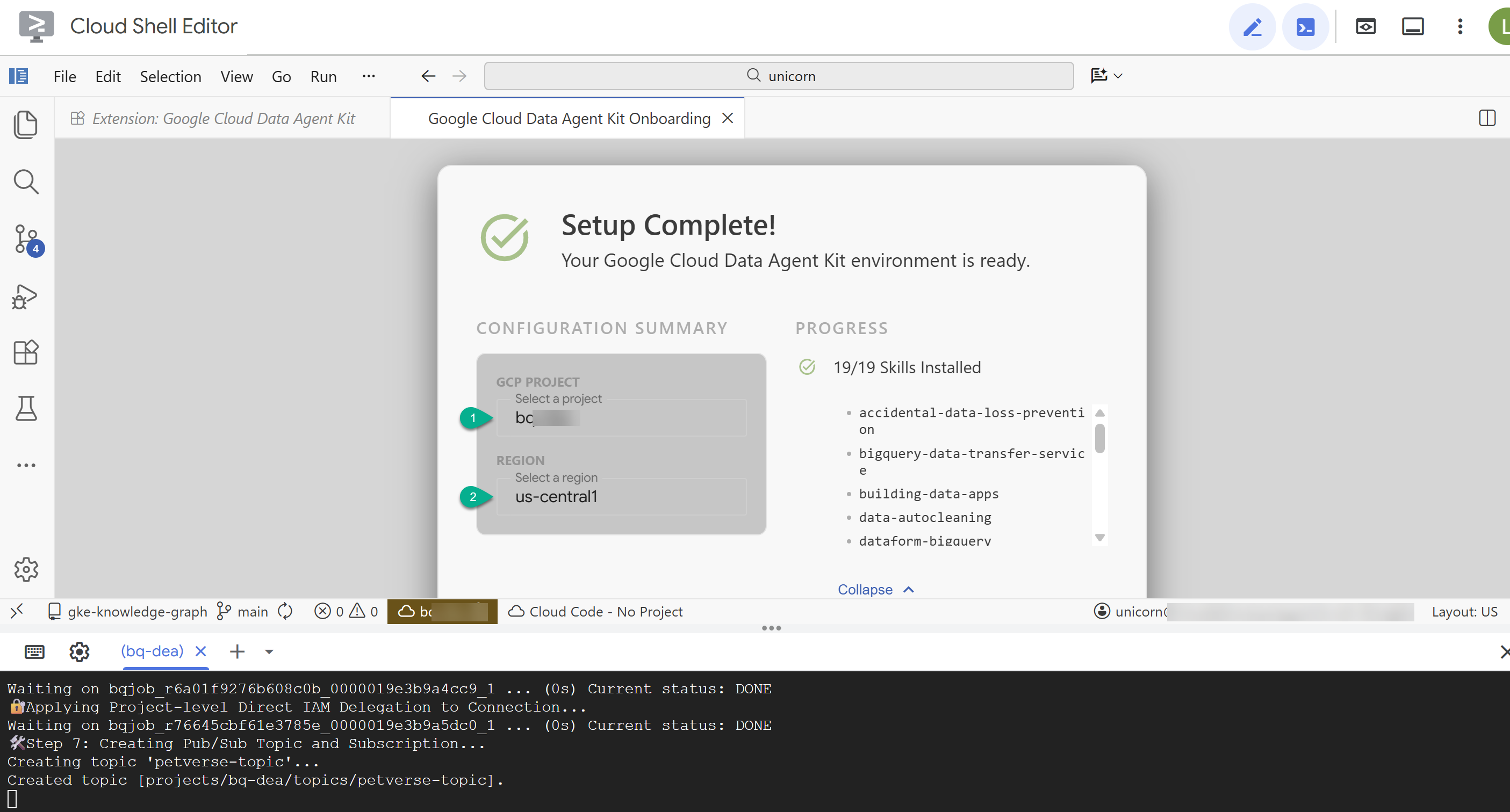
- MCP सर्वर कॉन्फ़िगर करें पर क्लिक करें. आपको इस विंडो में कोई बदलाव करने की ज़रूरत नहीं है. बस, शुरू करें पर क्लिक करें.
- अगर कहा जाए, तो विंडो को फिर से लोड करें. फ़िलहाल, क्विक स्टार्ट गाइड टैब को बंद किया जा सकता है.
BigQuery में टेबल सेट अप करना
- साइड बार में, एक्सप्लोरर पर वापस जाएं. अगर आपका होम फ़ोल्डर (जैसे,
/home/your_user_name/) पहले से खुला नहीं है, तो फ़ोल्डर खोलें पर क्लिक करें और उसे चुनें.
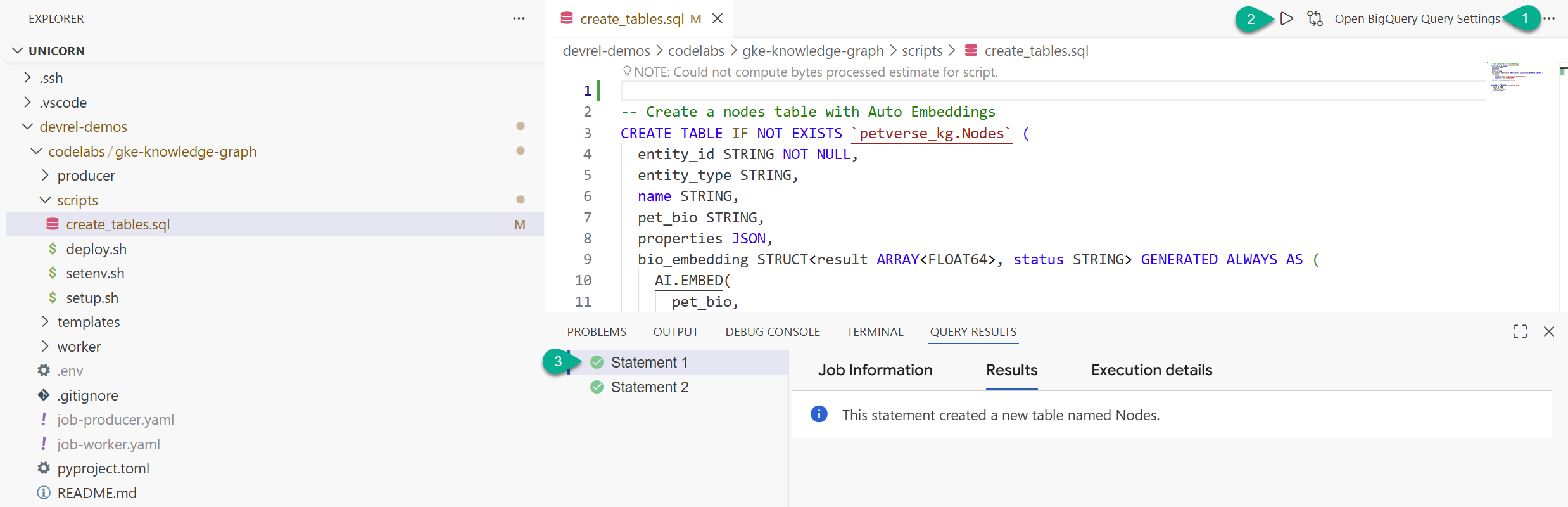
- एक्सप्लोरर विंडो में, उस फ़ोल्डर को ढूंढें जिसे आपने रिपॉज़िटरी (
devrel-demos) से क्लोन किया है. आपकोcodelabs/gke-knowledge-graph/scriptsमें जाकर,create_tables.sqlमिलेगा. उस फ़ाइल को खोलें. - सबसे ऊपर दाईं ओर, क्वेरी सेटिंग खोलें पर क्लिक करें.
- BigQuery चुनें. सेव करें और बंद करें पर क्लिक करें.
- चलाएं पर क्लिक करें.
आपको दो स्टेटमेंट के नतीजे दिखेंगे. आपने अब नॉलेज ग्राफ़ के लिए नोड और एज सेव करने के लिए टेबल बना ली हैं.
create_tables.sql टैब और नतीजों के कंसोल को बंद किया जा सकता है.
4. GKE क्लस्टर शुरू करना
हम डेटा प्रोसेसिंग के काम को पूरा करने के लिए, GKE Autopilot का इस्तेमाल करेंगे. ऑटोपायलट का इस्तेमाल करने का सुझाव दिया जाता है, क्योंकि यह आपके लिए क्लस्टर के इन्फ़्रास्ट्रक्चर को मैनेज करता है.
अब तक, सेटअप स्क्रिप्ट पूरी हो जानी चाहिए. आपको 'हो गया' मैसेज दिखेगा: 🎉🦄 Setup successfully finished! 🎉🦄.
क्लस्टर बनाने के लिए, इस कमांड को टर्मिनल में चिपकाएं:
source scripts/setenv.sh
gcloud container clusters create-auto petverse-cluster \
--region=$REGION
🕓 इसमें करीब 5 मिनट लगेंगे.
क्लस्टर के साथ इंटरैक्ट करने के लिए क्रेडेंशियल पाएं:
source scripts/setenv.sh
gcloud container clusters get-credentials petverse-cluster --region $REGION
आपको यह आउटपुट दिखेगा:
Fetching cluster endpoint and auth data. kubeconfig entry generated for petverse-cluster.
5. Workload Identity को कॉन्फ़िगर करना
GKE के लिए Workload Identity Federation (Direct Resource Access का इस्तेमाल करके) की मदद से, आपके GKE वर्कलोड, सेवा खाते की कुंजियों को मैनेज किए बिना, Google Cloud सेवाओं को सुरक्षित तरीके से ऐक्सेस कर सकते हैं.
deploy.sh को इस तरह से लागू करें:
- Kubernetes सेवा खाता बनाना
- ज़रूरी IAM भूमिकाएं सीधे तौर पर Kubernetes सेवा खाते के प्रिंसिपल को असाइन करें
- आईएएम सेवा खाते को Kubernetes सेवा खाते से बाइंड करना
- लिंक करने की प्रोसेस पूरी करने के लिए, Kubernetes सेवा खाते को एनोटेट करें
source scripts/setenv.sh
./scripts/deploy.sh
6. डिकपल्ड प्रोसेसिंग जॉब डिप्लॉय करना
इस चरण में, आपको GKE पर एनक्यूअर (प्रोड्यूसर) और प्रोसेसिंग इंजन (वर्कर) डिप्लॉय करने होंगे.
हमारे नए डीकपल्ड आर्किटेक्चर में, ऐसेट को एसिंक्रोनस तरीके से प्रोसेस करने के लिए Google Cloud Pub/Sub का इस्तेमाल किया जाता है:
- Producer, GCS को स्कैन करता है और सभी फ़ाइल पाथ को Pub/Sub queue में शामिल करता है.
- GKE में वर्कर का एक पूल, ज़रूरत के हिसाब से बढ़ता है. यह एक साथ कई टास्क को डाइनैमिक तरीके से खींचता है, उन्हें Gemini की मदद से प्रोसेस करता है, और BigQuery में लिखता है.
setup.sh स्क्रिप्ट ने पहले से ही Producer और Worker, दोनों कंटेनर इमेज बना ली हैं और उन्हें पुश कर दिया है. साथ ही, Pub/Sub विषयों को कतार में लगा दिया है. इसके अलावा, इसने आपके GKE डिप्लॉयमेंट मेनिफ़ेस्ट: job-producer.yaml और job-worker.yaml को डाइनैमिक तरीके से जनरेट किया है.
- अपने स्टोरेज बकेट को स्कैन करने और सभी ऐसेट को क्रम में लगाने के लिए, प्रोड्यूसर जॉब लागू करें:
kubectl apply -f job-producer.yaml
यह जॉब तेज़ी से पूरी हो जाती है, क्योंकि इसमें सिर्फ़ मेटाडेटा को लाइन में लगाया जाता है.
- कतार को खाली करने के लिए, एक साथ छह वर्कर चलाने के लिए कॉन्फ़िगर किए गए वर्कर जॉब को डिप्लॉय करें:
kubectl apply -f job-worker.yaml
GKE Autopilot, प्रोसेस होने के लिए लाइन में लगे पॉड का अपने-आप पता लगाएगा. साथ ही, कंप्यूट नोड को डाइनैमिक तरीके से स्केल अप करेगा. इसके अलावा, यह ऑडियो, वीडियो, इमेज, और CSV फ़ाइलों को प्रोसेस करने के लिए, वर्कर को एक साथ चलाएगा.
7. नतीजों की पुष्टि करना
- अपनी नौकरियों का स्टेटस देखें:
kubectl get jobs
जब तक petverse-producer-job और petverse-worker-job दोनों में 'प्रोसेस पूरी हुई' न दिख जाए, तब तक इंतज़ार करें.
🕓 इसमें करीब 10 मिनट लगेंगे. नीचे दिए गए निर्देशों की मदद से, प्रोग्रेस देखी जा सकती है.
- यह पुष्टि करने के लिए कि प्रोड्यूसर ने फ़ाइलों को सही तरीके से कतार में लगाया है, प्रोड्यूसर के लॉग देखें:
cd ~/devrel-demos/codelabs/gke-knowledge-graph
source scripts/setenv.sh
kubectl logs -l app=petverse-producer --tail=50
- देखें कि समानांतर वर्कर, फ़ाइलों को प्रोसेस करने के लिए क्यू का इस्तेमाल कैसे करते हैं:
kubectl logs -l app=petverse-worker --tail=50
(वर्कर 60 सेकंड तक कोई काम न होने पर बंद हो जाते हैं. साथ ही, Pub/Sub कतार खाली होने पर, वे अपने-आप बंद हो जाते हैं और साफ़ हो जाते हैं).
BigQuery में डेटा की पुष्टि करें.
- BigQuery Studio पर जाएं. आपको दो टेबल दिखेंगी: petverse_kg.Nodes और petverse_kg.Edges.
- टेबल का कॉन्टेंट देखने के लिए, उनके नामों पर दो बार क्लिक करें. इसके बाद, झलक देखें पर क्लिक करें.
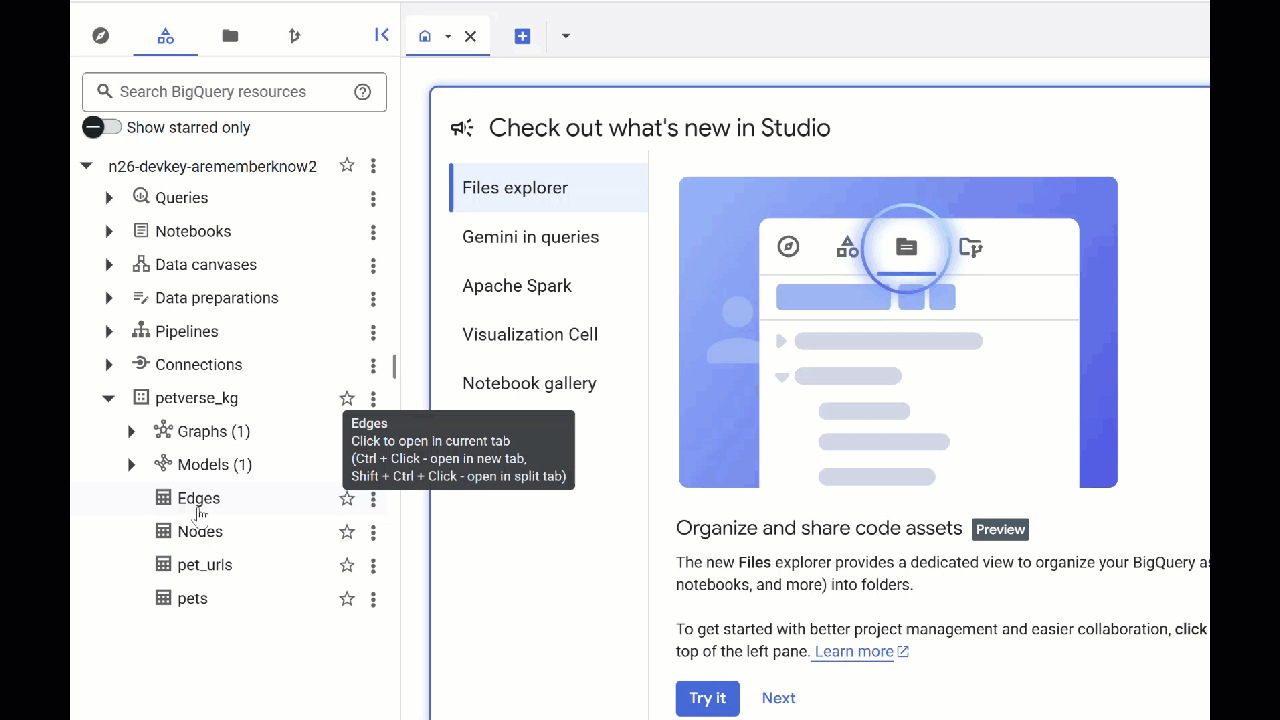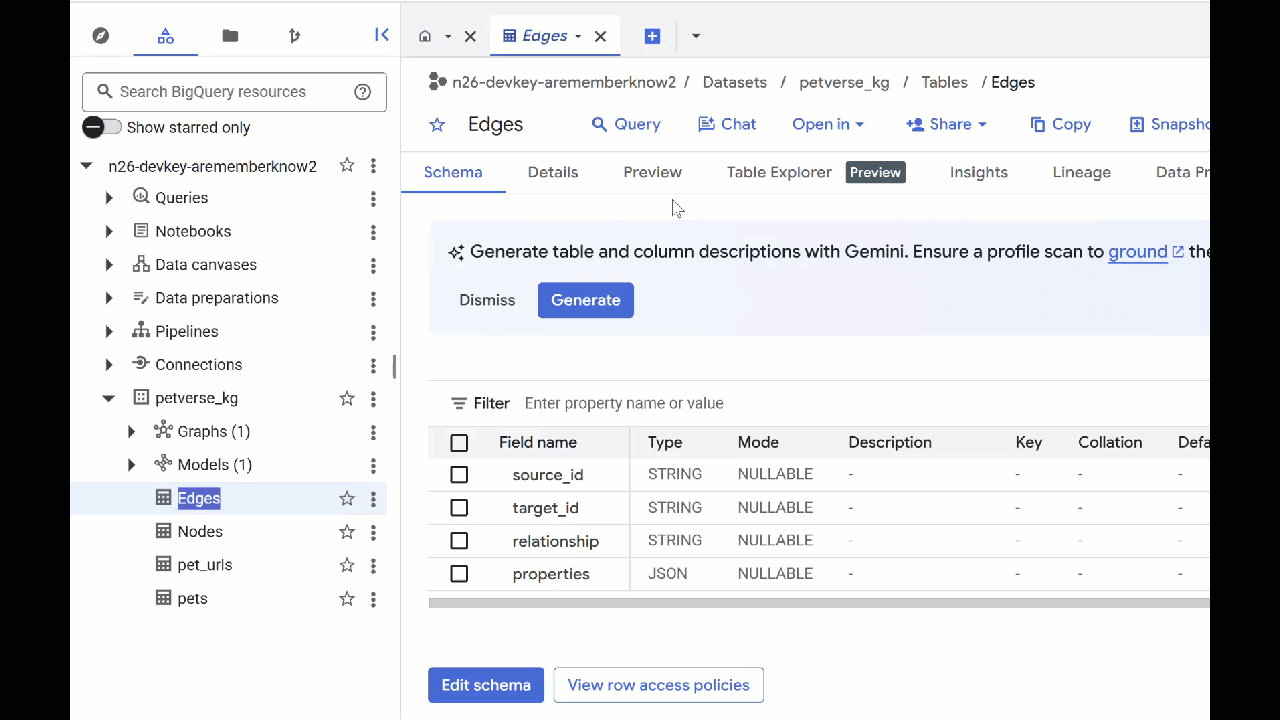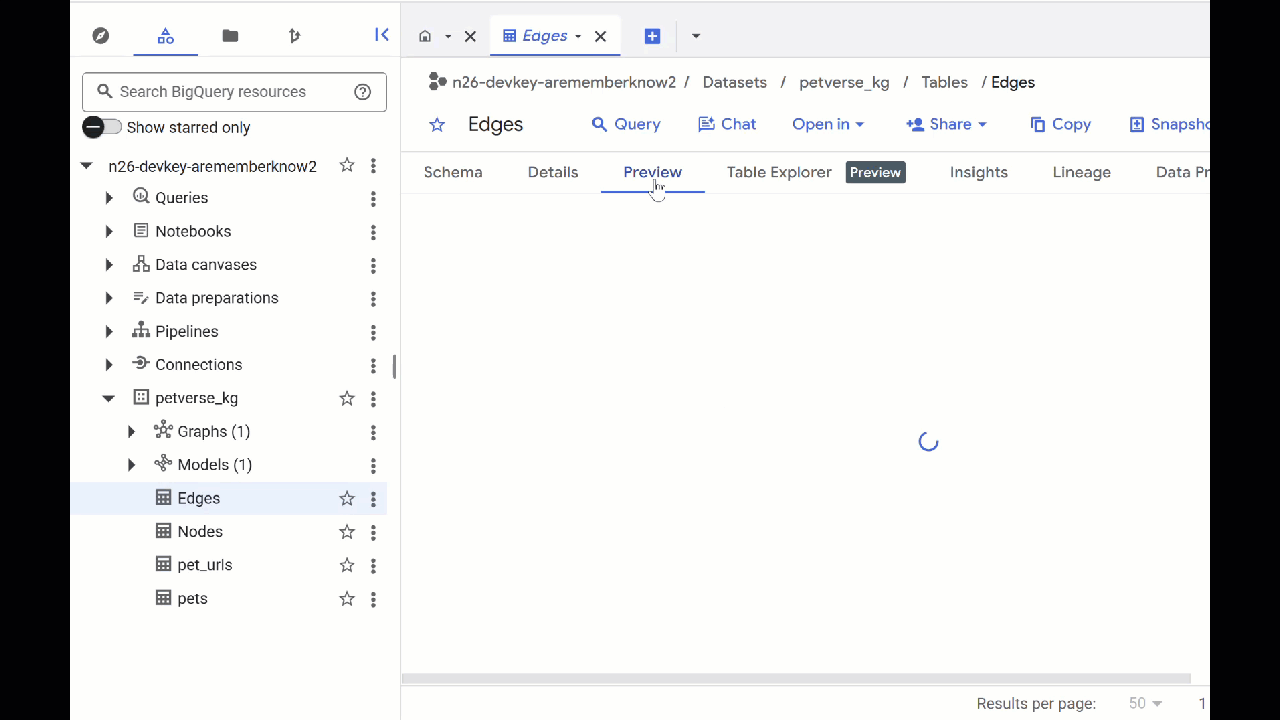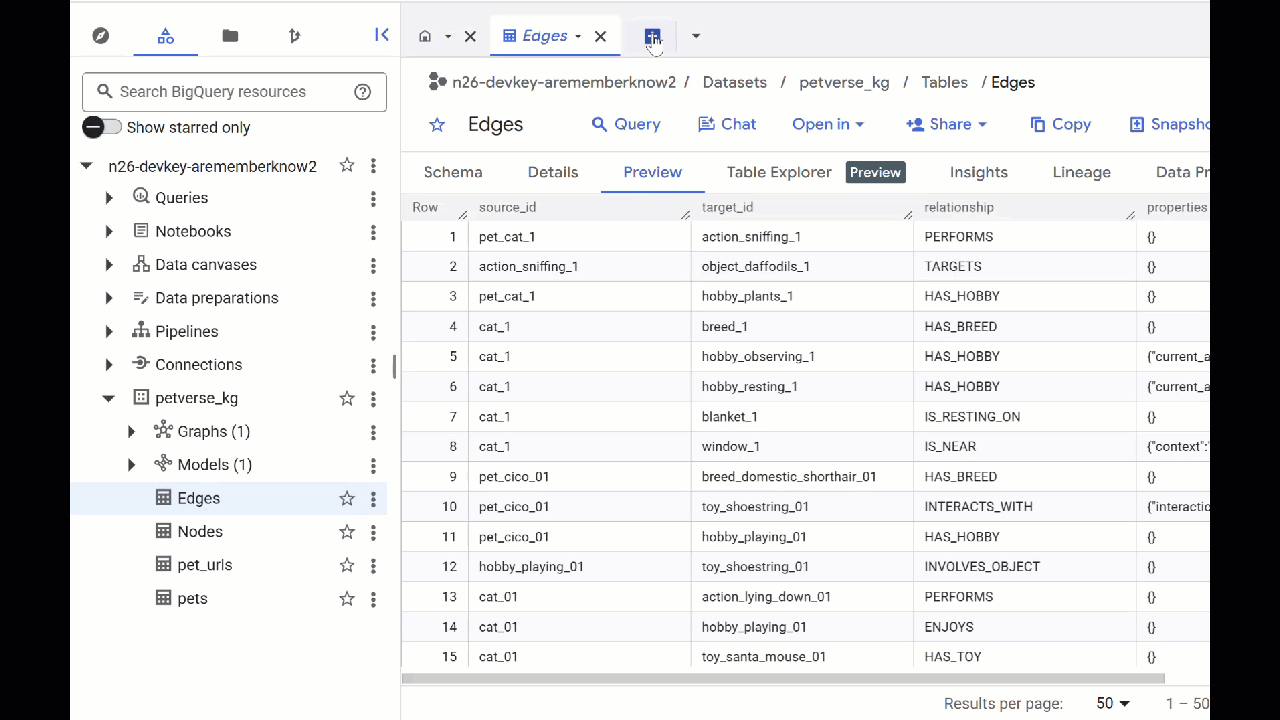
आपको नोड टेबल में, ऑडियो, वीडियो, और फ़ोटो में Gemini की ओर से चुनी गई इकाइयों के बारे में जानकारी दिखेगी. Edges टेबल में, उनके बीच के संबंध की जानकारी होती है. उदाहरण के लिए, अगर SQL नाम की बिल्ली की आवाज़ सुनी जाए, तो उसे जूतों के फ़ीते से खेलना पसंद है. साथ ही, उसे सूखी मछलियां खाना पसंद है.
- नई क्वेरी बनाने के लिए, + बटन का इस्तेमाल करें. यहां दिए गए स्टेटमेंट को चिपकाएं और चलाएं पर क्लिक करें:
SELECT n.name, n.entity_id, e.relationship, e.target_id
FROM
`petverse_kg.Nodes` n
JOIN
`petverse_kg.Edges` e
ON n.entity_id = e.source_id
WHERE n.name = 'SQL'
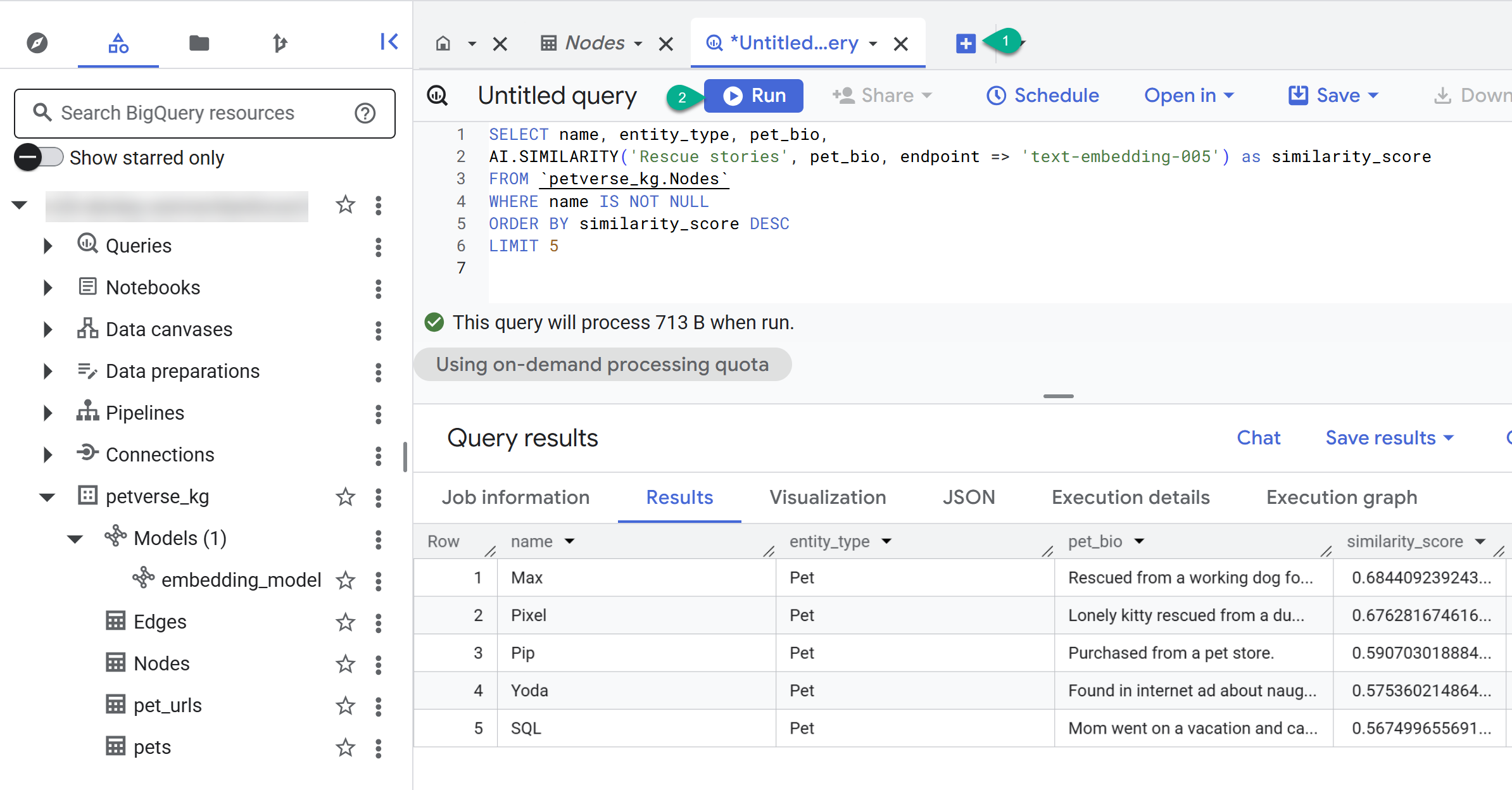
- नई क्वेरी बनाने के लिए, + बटन का इस्तेमाल करें. यहां दिए गए स्टेटमेंट को चिपकाएं और चलाएं पर क्लिक करें:
SELECT name, entity_type, pet_bio,
AI.SIMILARITY('Pets who like to relax', pet_bio, endpoint => 'text-embedding-005') as similarity_score
FROM `petverse_kg.Nodes`
WHERE name IS NOT NULL
ORDER BY similarity_score DESC
LIMIT 5
आपको ऐसे पालतू जानवरों के नोड दिखेंगे जिन्हें आराम करना पसंद है. इस क्वेरी में, एआई फ़ंक्शन AI.SIMILARITY का इस्तेमाल करके सिमैंटिक सर्च की गई है. इससे ऐसे पालतू जानवरों को ढूंढा गया है जिनके बायो, क्वेरी के टेक्स्ट से सबसे ज़्यादा मिलते-जुलते हैं.
प्रॉपर्टी ग्राफ़ बनाना
BigQuery में नोड और एज मौजूद होने की वजह से, अब हम आसानी से संबंधों के बारे में क्वेरी करने के लिए, प्रॉपर्टी ग्राफ़ बना सकते हैं.
ग्राफ़ बनाना
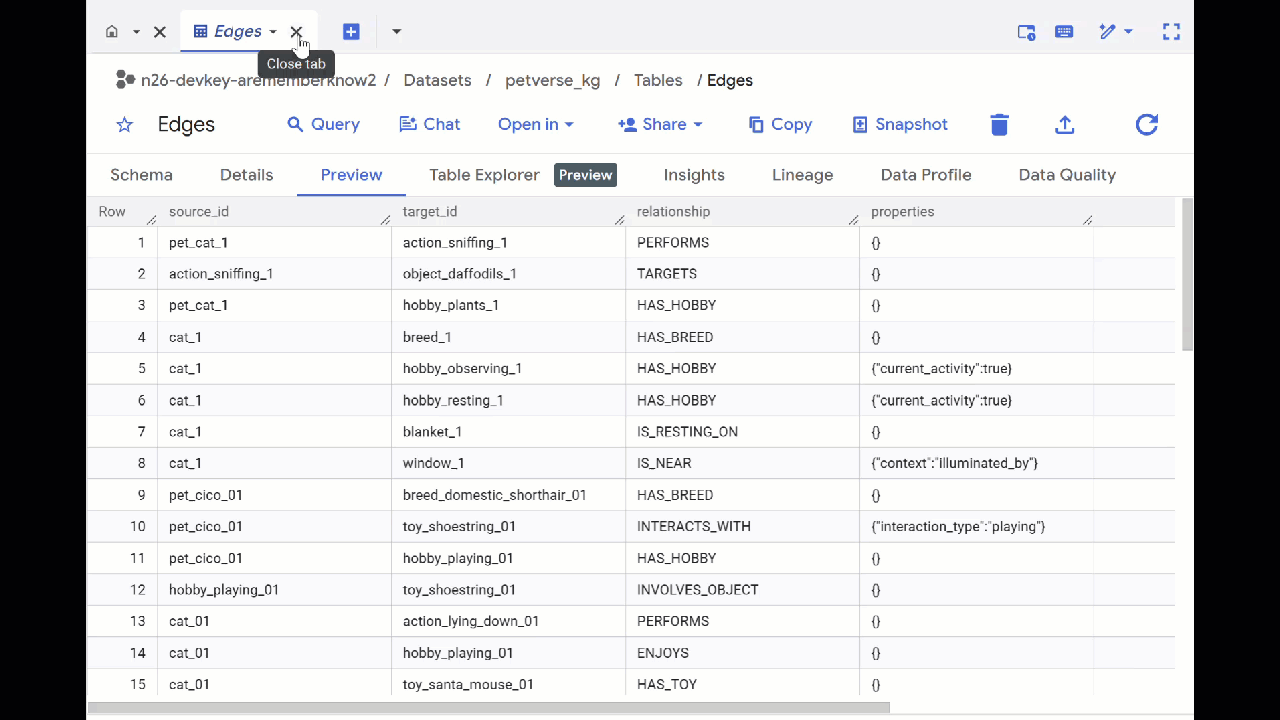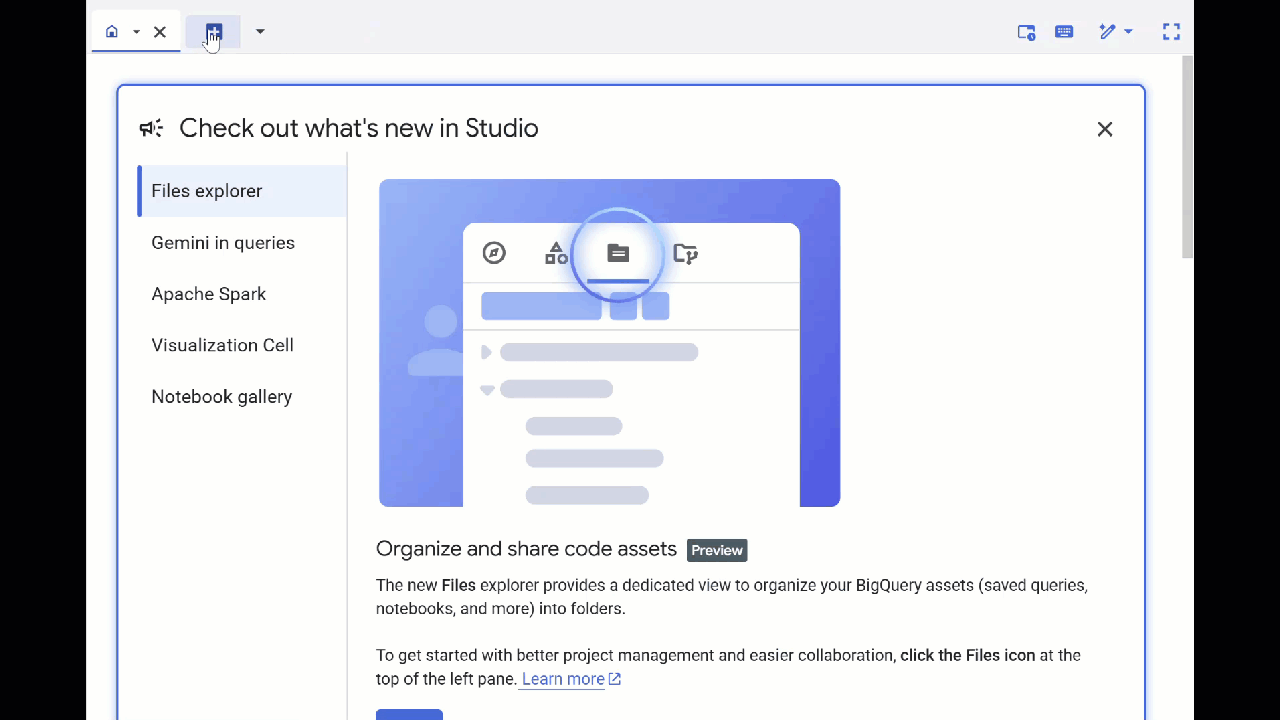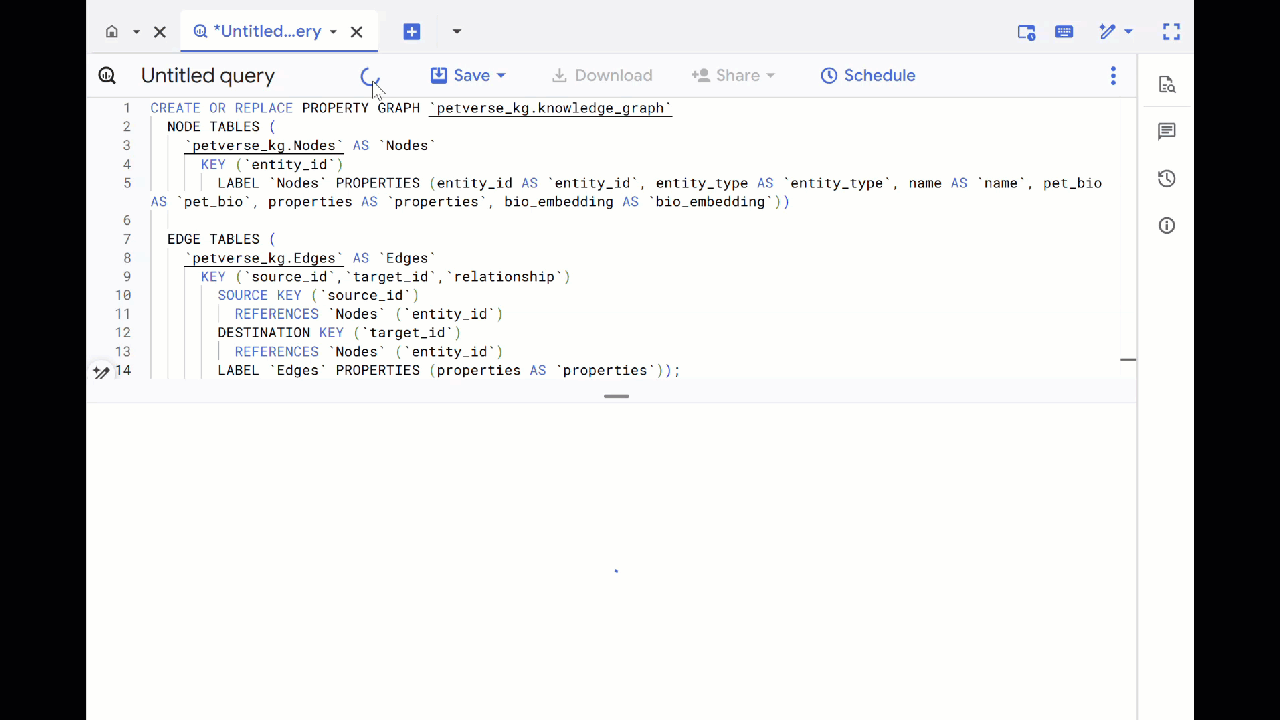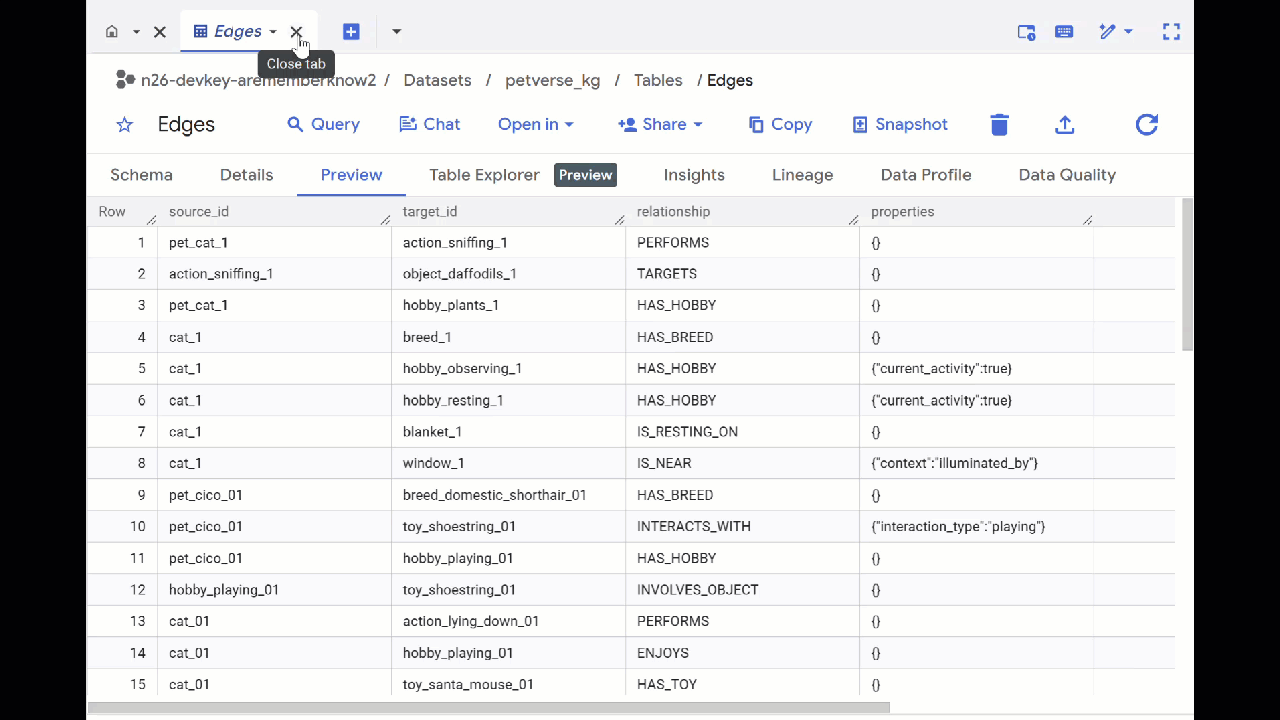
- पिछली क्वेरी को बदलें और प्रॉपर्टी ग्राफ़ बनाने के लिए, यहां दिया गया DDL चलाएं:
CREATE OR REPLACE PROPERTY GRAPH `petverse_kg.knowledge_graph`
NODE TABLES (
`petverse_kg.Nodes` AS `Nodes`
KEY (`entity_id`)
LABEL `Nodes` PROPERTIES (entity_id AS `entity_id`, entity_type AS `entity_type`, name AS `name`, pet_bio AS `pet_bio`, properties AS `properties`, bio_embedding AS `bio_embedding`))
EDGE TABLES (
`petverse_kg.Edges` AS `Edges`
KEY (`source_id`,`target_id`,`relationship`)
SOURCE KEY (`source_id`)
REFERENCES `Nodes` (`entity_id`)
DESTINATION KEY (`target_id`)
REFERENCES `Nodes` (`entity_id`)
LABEL `Edges` PROPERTIES (properties AS `properties`));
- ग्राफ़ पर जाएं पर क्लिक करें. आपको ग्राफ़ विज़ुअलाइज़ेशन दिखेगा. इसमें एक ऐसा नोड होगा जिसका किनारा खुद से जुड़ा होगा. ऐसा होता है.
ग्राफ़ से क्वेरी करना
- + बटन की मदद से, पिछली सभी क्वेरी बंद की जा सकती हैं और एक नई क्वेरी खोली जा सकती है.
- GQL का इस्तेमाल करके, मिलती-जुलती दिलचस्पी (जैसे, शौक, पसंदीदा खाना या खिलौने) के आधार पर, अन्य पालतू जानवरों से जुड़े पालतू जानवरों को खोजें. एक से ज़्यादा हॉप वाली इस क्वेरी में, एक ही नोड से कनेक्ट किए गए दो अलग-अलग पालतू जानवरों के बारे में पूछा गया है:
GRAPH `petverse_kg.knowledge_graph`
MATCH p = (pet1:Nodes)-[e1]->(interest:Nodes)<-[e2]-(pet2:Nodes)
WHERE pet1.entity_id != pet2.entity_id
AND (LOWER(pet1.entity_type) = 'pet' AND LOWER(pet2.entity_type) = 'pet')
AND LOWER(interest.entity_type) IN ('hobby', 'action', 'activity', 'food', 'toy')
RETURN TO_JSON(p) as res
LIMIT 100
- आपको ग्राफ़ का विज़ुअलाइज़ेशन दिखेगा. नोड और एज की प्रॉपर्टी देखने के लिए, नोड पर क्लिक करें.
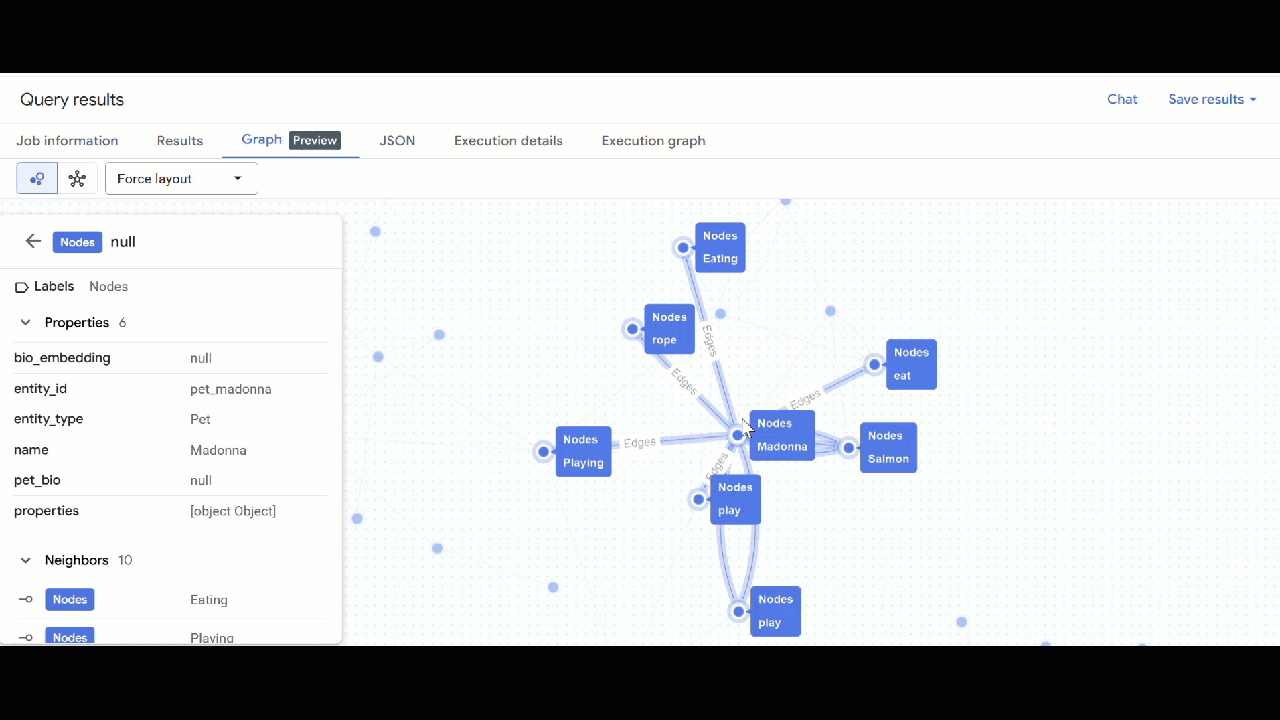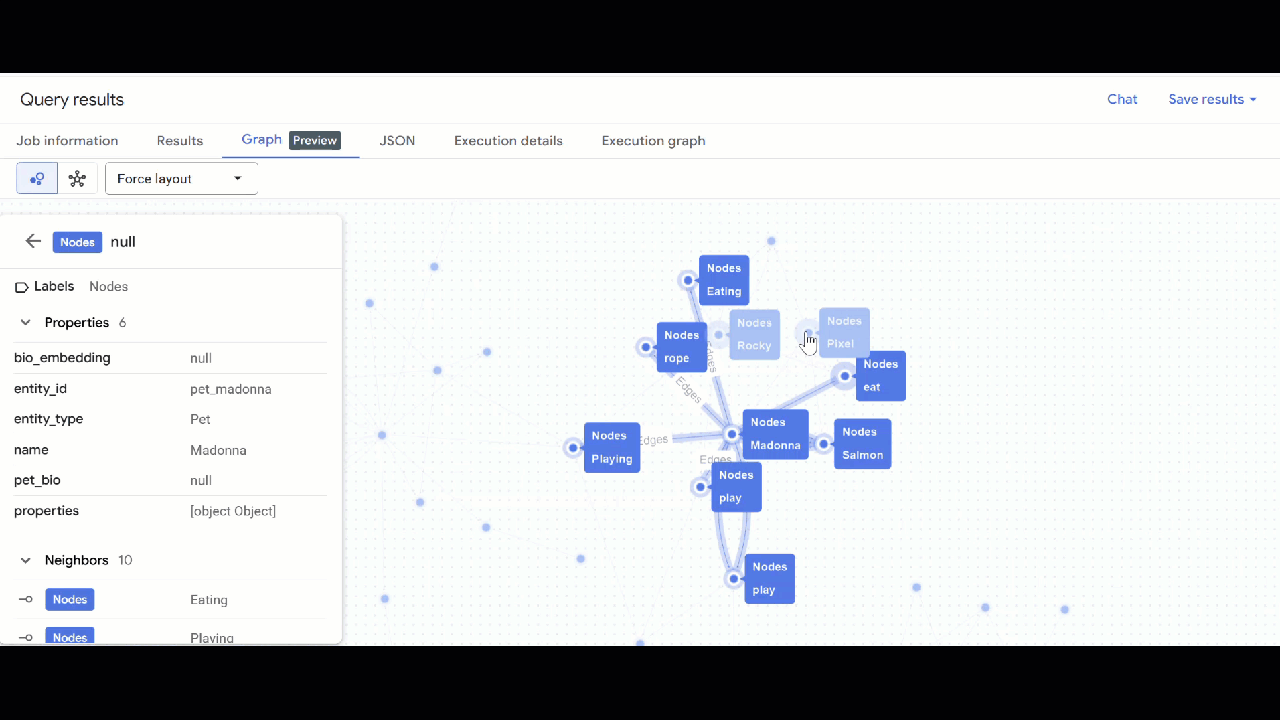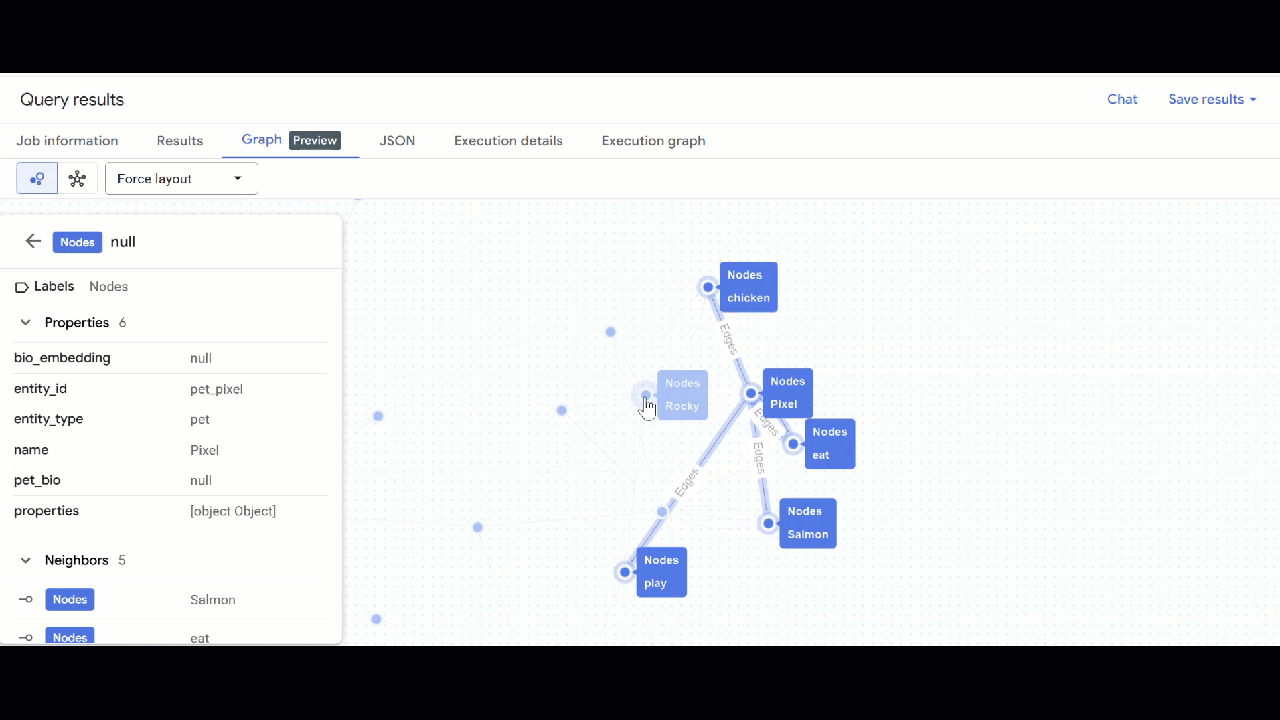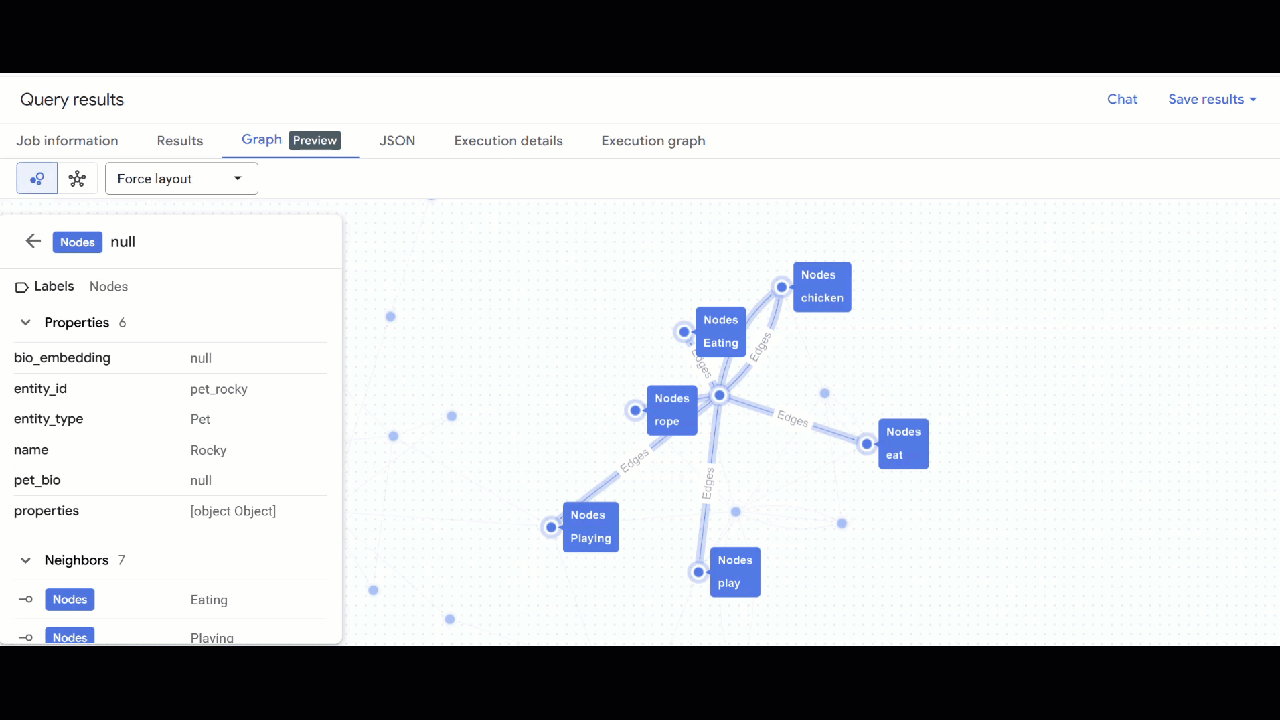
🕵️ अहम जानकारी: नोड में दिखाई गई वैल्यू में बदलाव करने के लिए, स्विच टू स्कीमा व्यू पर क्लिक करें:
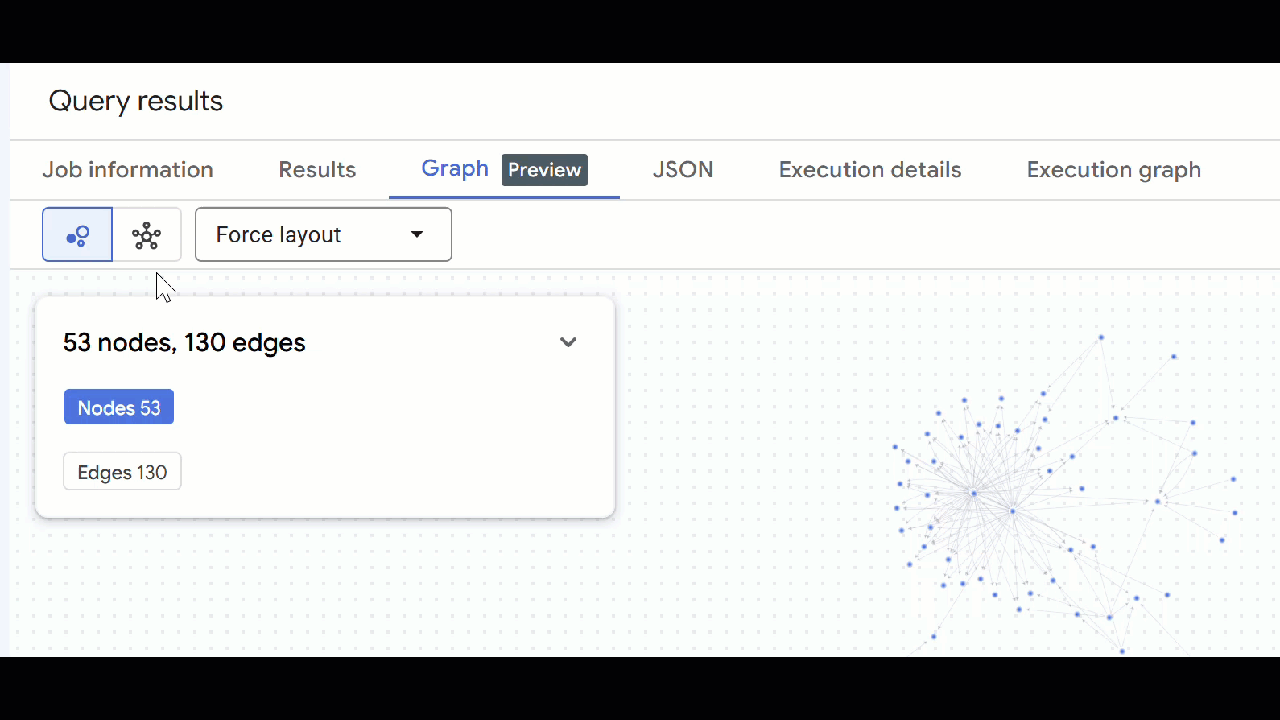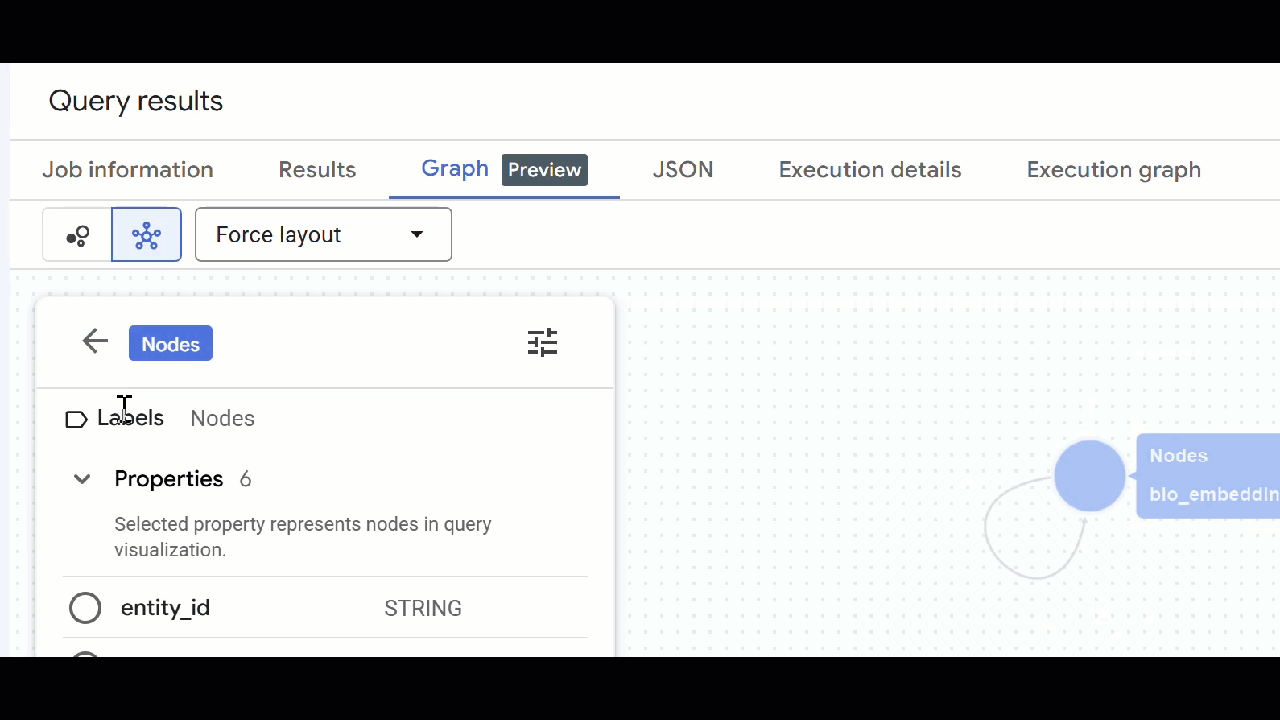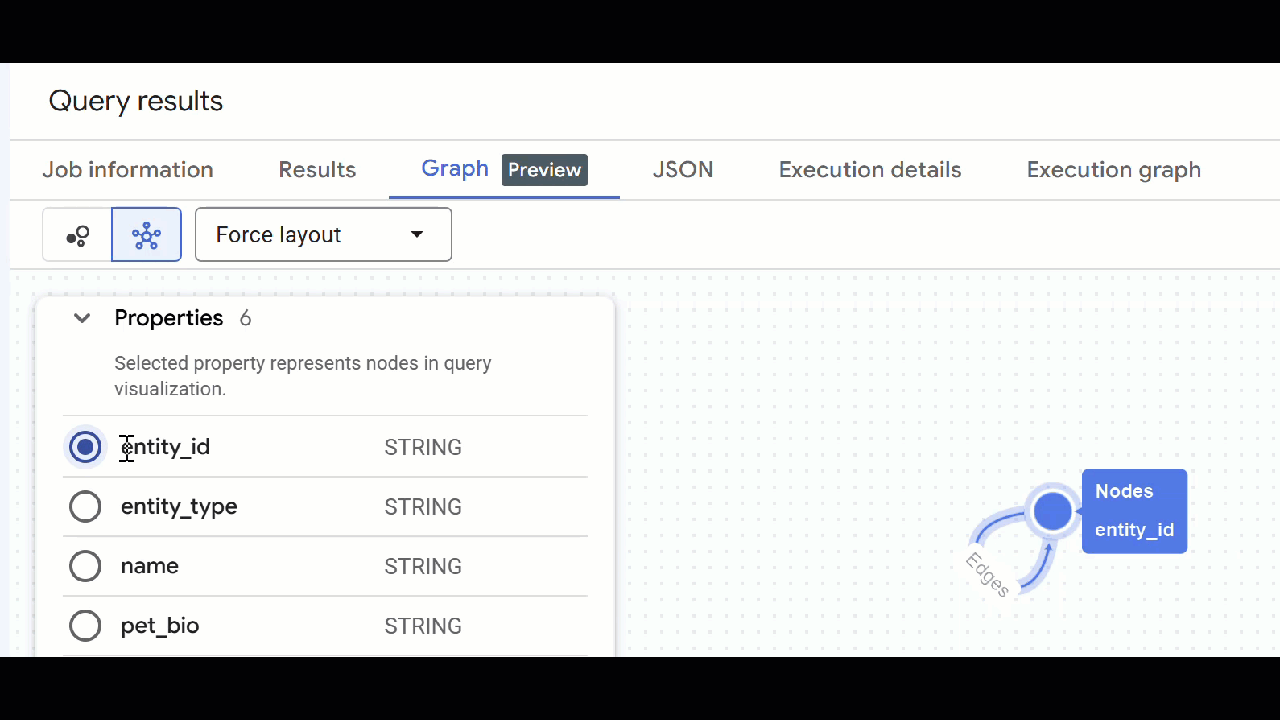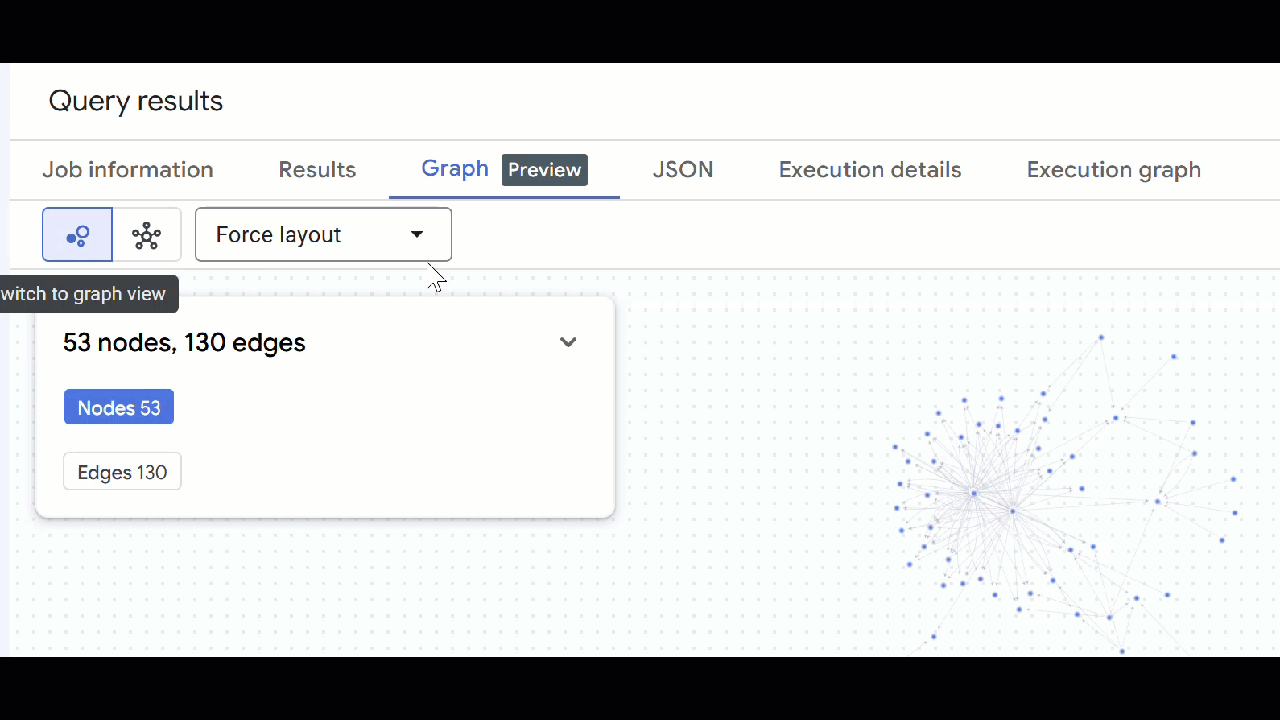
- खुले हुए सभी क्वेरी टैब बंद किए जा सकते हैं.
8. ग्राफ़ के बारे में चैट करना
- + के बगल में, आपको एक ड्रॉप-डाउन मेन्यू दिखेगा. बातचीत चुनें.
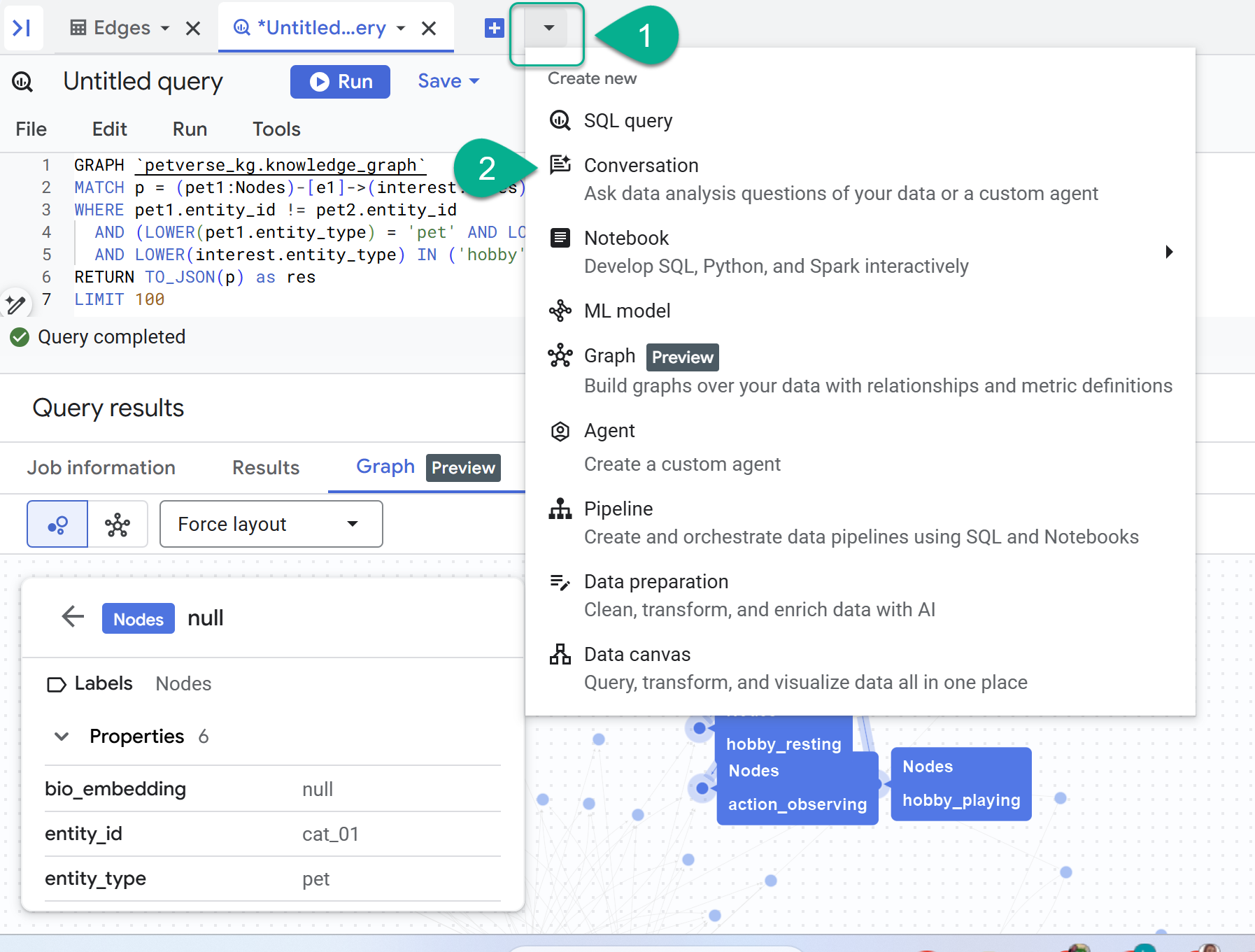
- आपको Gemini के साथ Data Analytics API चालू करने के लिए कहा जाएगा. दोनों एपीआई चालू करें. यह प्रोसेस पूरी होने के बाद, एजेंट को देखने के लिए विंडो को रीफ़्रेश करें या नई बातचीत शुरू करें.
- नया एजेंट पर क्लिक करें.
- एजेंट को कोई नाम दें, जैसे कि
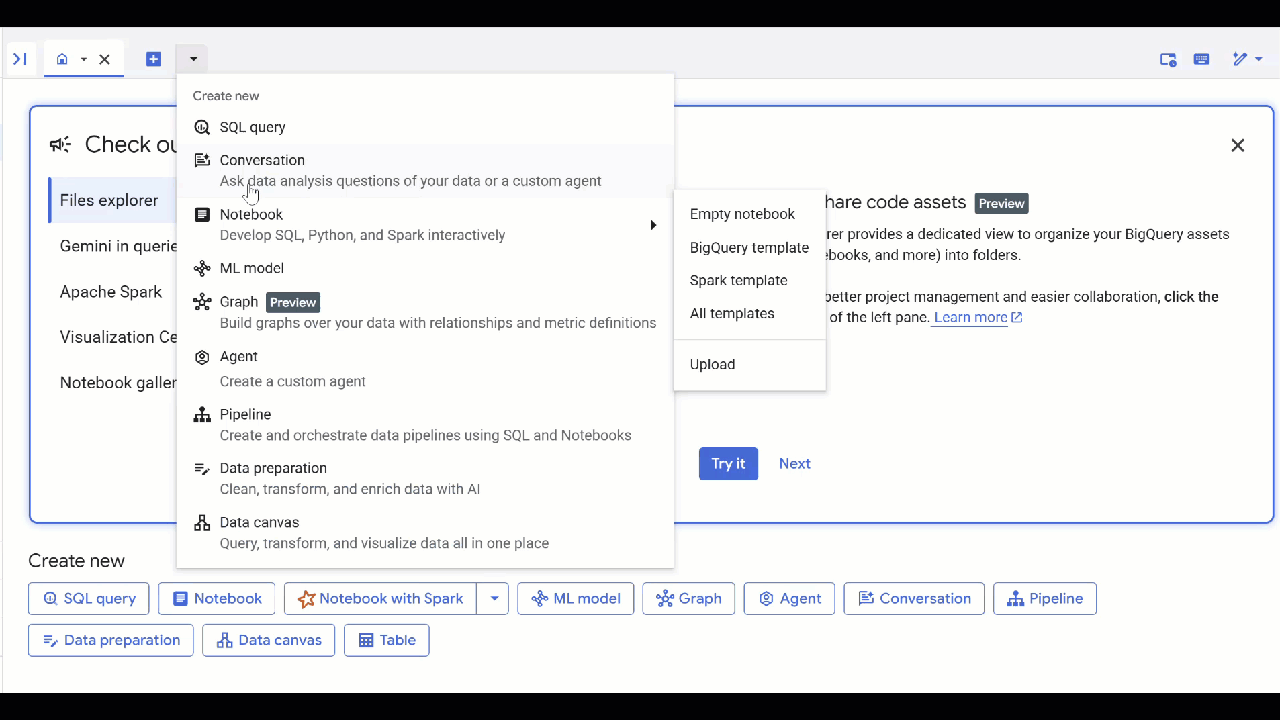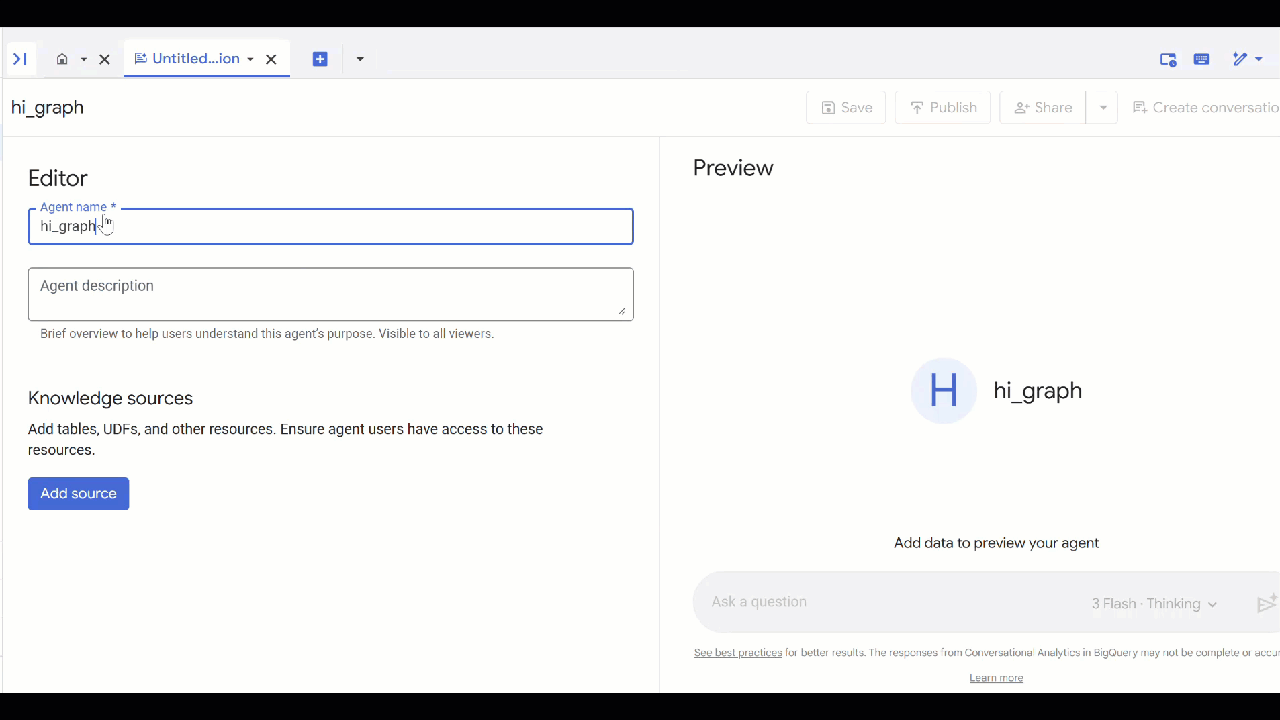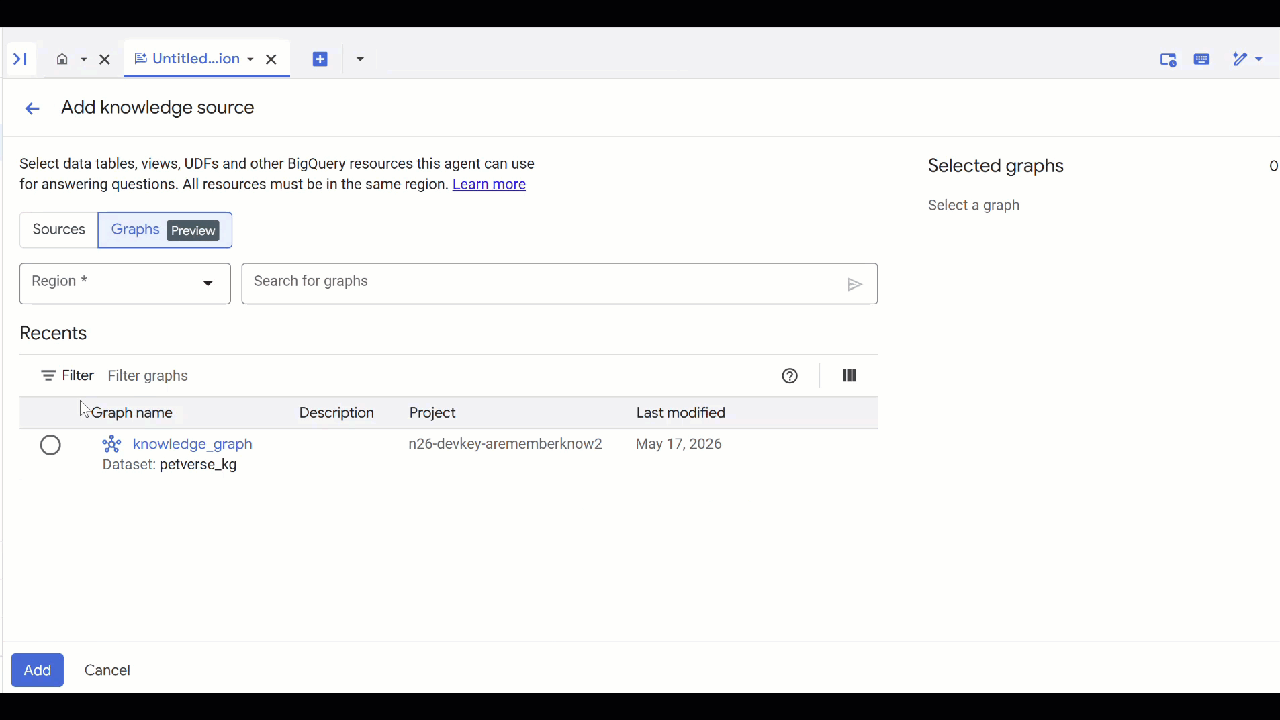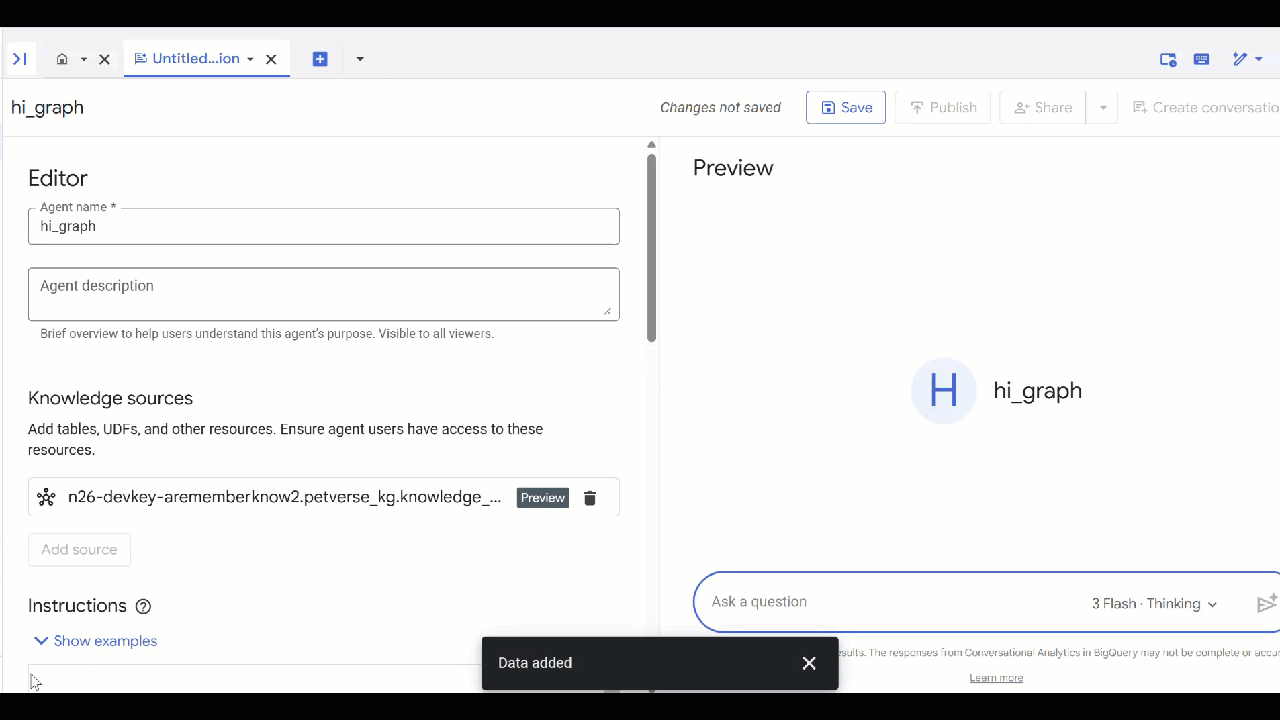
petverse. - सोर्स जोड़ें और फिर ग्राफ़ पर क्लिक करें.
- बनाया गया
knowledge_graphचुनें और जोड़ें पर क्लिक करें.
अब एजेंट से कोई सवाल पूछा जा सकता है. साथ ही, उसके जवाब और जवाब देने की वजह देखी जा सकती है. अगर आपको कुछ आइडिया चाहिए, तो यहां कुछ सैंपल सवाल दिए गए हैं. सोचने वाले मॉडल को क्वेरी तैयार करने में थोड़ा समय लग सकता है, लेकिन इससे बेहतर GQL क्वेरी तैयार होने की संभावना होती है. Show Thinking को बड़ा करके, यह देखा जा सकता है कि यह क्या बनाता है.
- ऐसे पालतू जानवर ढूंढें जो एक जैसा खाना खाते हों या जो ऐसे पालतू जानवरों के दोस्त हों जिन्हें झपकी लेना पसंद हो.
- क्या किसी पालतू जानवर की हॉबी, पसंदीदा खाना या खिलौना, किसी दूसरे पालतू जानवर से मिलता-जुलता है? जोड़ों और उनकी मिलती-जुलती रुचियों की सूची बनाएं.
- ऐसे पालतू जानवर ढूंढें जिनकी प्रजाति या नस्ल एक जैसी हो, लेकिन उनके शौक पूरी तरह से अलग हों.
9. व्यवस्थित करें
अपने Google Cloud खाते से लगातार शुल्क लिए जाने से बचने के लिए, इस कोडलैब के दौरान बनाई गई संसाधन मिटाएं.
- GKE क्लस्टर मिटाएं:
gcloud container clusters delete petverse-cluster --region $REGION --quiet
- BigQuery डेटासेट मिटाएं. इससे सभी टेबल मिट जाएंगी:
bq rm -r -f -d $PROJECT_ID:petverse_kg
- Pub/Sub कतार के संसाधन मिटाएं:
gcloud pubsub subscriptions delete petverse-sub --quiet
gcloud pubsub topics delete petverse-topic --quiet
- Artifact Registry की रिपॉज़िटरी मिटाएं:
gcloud artifacts repositories delete gke-cats-repo --location=$REGION --quiet
- प्रोजेक्ट के लिए बनाए गए GCS बकेट को मिटाएं:
gcloud storage buckets delete gs://$PROJECT_ID-petverse --quiet
10. बधाई हो
बधाई हो! आपने GKE और Gemini का इस्तेमाल करके, डिस्ट्रिब्यूटेड नॉलेज ग्राफ़ पाइपलाइन बना ली है. साथ ही, BigQuery प्रॉपर्टी ग्राफ़ का इस्तेमाल करके, उससे क्वेरी की है.
आपको क्या सीखने को मिला
- GKE Autopilot पर डिस्ट्रिब्यूट किए गए जॉब को डिप्लॉय करने का तरीका.
- मल्टीमॉडल डेटा निकालने के लिए, Gemini का इस्तेमाल कैसे करें.
- BigQuery की ऑटो-एम्बेडिंग सुविधा का इस्तेमाल करने का तरीका.
- BigQuery में प्रॉपर्टी ग्राफ़ बनाने और क्वेरी करने का तरीका.