
1. Introduzione
In questo codelab, creerai una pipeline di acquisizione delle conoscenze distribuita per "Petverse". Elaborerai asset multimediali non strutturati (audio, video, immagini, testo/CSV) da un bucket Cloud Storage, estrarrai informazioni chiave sugli animali domestici (cibo preferito, hobby) e creerai un knowledge graph. Scalerai l'elaborazione del file multimediale utilizzando l'elaborazione multimodale di Gemini su Google Kubernetes Engine (GKE). Infine, archivierai questi dati in BigQuery e utilizzerai la nuova funzionalità BigQuery Property Graph per analizzare le relazioni.
Utilizzeremo la potenza di Google Kubernetes Engine per dimostrare l'elaborazione parallela di grandi volumi di dati.
Perché utilizzare i Knowledge Graph?
I Knowledge Graph sono più adatti dei database relazionali tradizionali per rappresentare e analizzare le relazioni complesse tra le entità.
Utilizzeremo Gemini 2.5 Flash per analizzare immagini, audio e file video e stabilire fatti su diversi animali domestici.
In questo lab proverai a:
- Crea ed esegui il deployment di un job di elaborazione dei dati distribuito su GKE.
- Utilizza Gemini per estrarre entità e relazioni dai file multimediali.
- Archivia i dati del knowledge graph in BigQuery.
- Crea ed esegui query su un grafico delle proprietà in BigQuery utilizzando Graph Query Language (GQL).
Che cosa ti serve
- Un browser web come Chrome
- Un progetto cloud Google Cloud con la fatturazione abilitata
- Autorizzazioni nel progetto per creare risorse e modificare i criteri IAM
Questo codelab è rivolto a sviluppatori di tutti i livelli, inclusi i principianti.
Durata stimata: 45 minuti
Costo:le risorse create in questo codelab dovrebbero costare meno di 5 $.
2. Prima di iniziare
Crea un progetto Google Cloud
- Vai alla console Google Cloud: https://console.cloud.google.com, quindi seleziona o crea un progetto Google Cloud.
- ⚠️ Prendi nota dell'ID progetto. Lo utilizzerai per diversi comandi in questo lab.
Avvia Cloud Shell
- Apri Cloud Shell in una nuova scheda: https://shell.cloud.google.com/.
- Se richiesto, fai clic su Autorizza.
- Sostituisci
PROJECT_IDe incolla il seguente comando nel terminale:
export PROJECT_ID="YOUR_PROJECT_ID"
gcloud config set project $PROJECT_ID
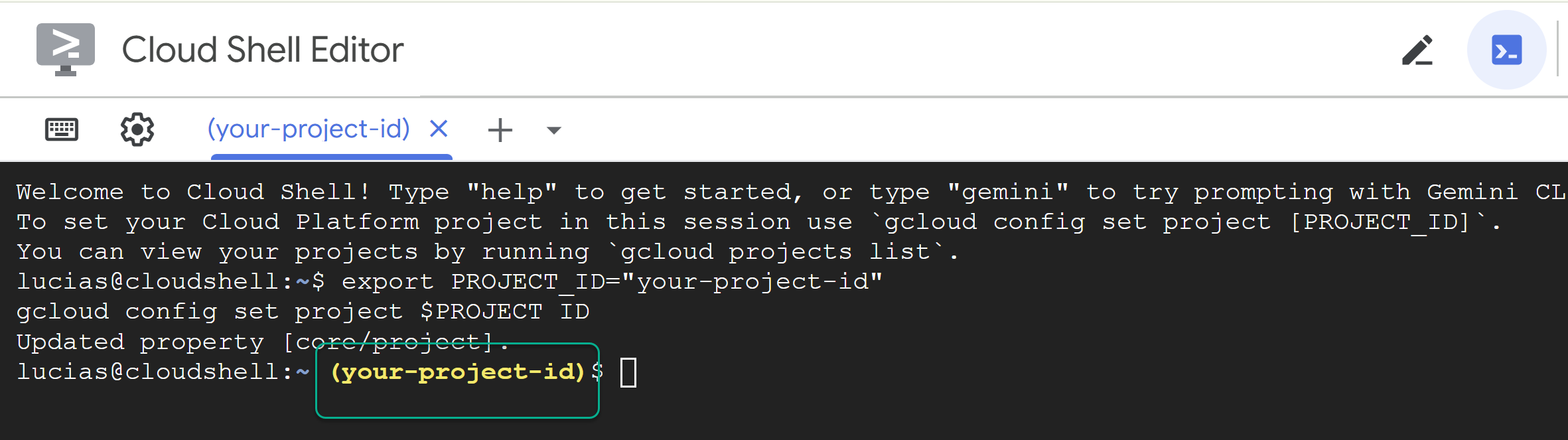
📝 Nota: il progetto verrà visualizzato in giallo nella riga di comando. Se la sessione viene riavviata, assicurati di eseguire di nuovo il comando precedente per impostare l'ID progetto.
Abilita API
Esegui questo comando per abilitare tutte le API richieste:
gcloud services enable \
aiplatform.googleapis.com \
bigquery.googleapis.com \
artifactregistry.googleapis.com \
container.googleapis.com \
cloudbuild.googleapis.com \
pubsub.googleapis.com
Clona repository
Esegui questi comandi per clonare il repository.
cd ~/
git clone --filter=blob:none --no-checkout https://github.com/GoogleCloudPlatform/devrel-demos.git
cd ~/devrel-demos
git sparse-checkout init --cone
git sparse-checkout set codelabs/gke-knowledge-graph
git checkout main
cd codelabs/gke-knowledge-graph/
Esegui lo script di configurazione
Questo script automatizza la configurazione del backend:
- Creazione di un'immagine container e di un repository Artifact Registry
- Creazione di un set di dati BigQuery
- Creazione di una connessione BigQuery per eseguire funzioni di Gemini AI da SQL
Esegui questo comando nel terminale:
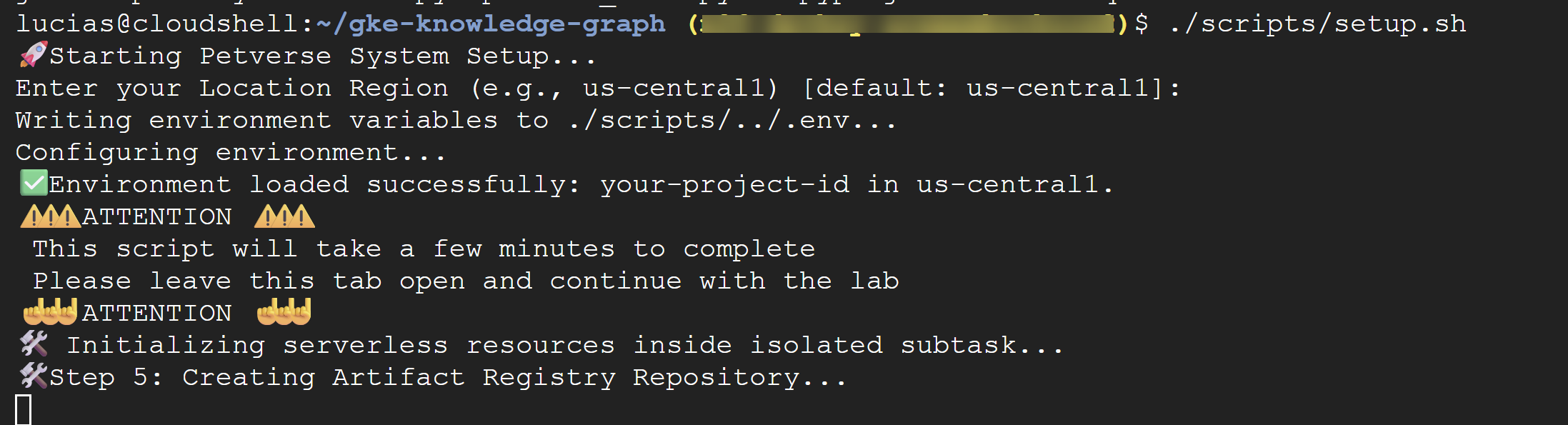
./scripts/setup.sh
Se lo script ti chiede i dettagli di configurazione, utilizza questi valori:
- ID progetto:utilizza l'ID creato nel passaggio precedente.
- Regione:
us-central1
⚠️ Importante: il completamento dello script richiederà alcuni minuti. Lascia aperta questa finestra del terminale per completare l'operazione in background. Per continuare con il passaggio successivo, apri una nuova scheda o finestra del terminale per eseguire i comandi successivi.
3. Configurare Data Agent Kit
- Attiva Cloud Shell Editor con l'icona a forma di matita nell'angolo in alto a destra.
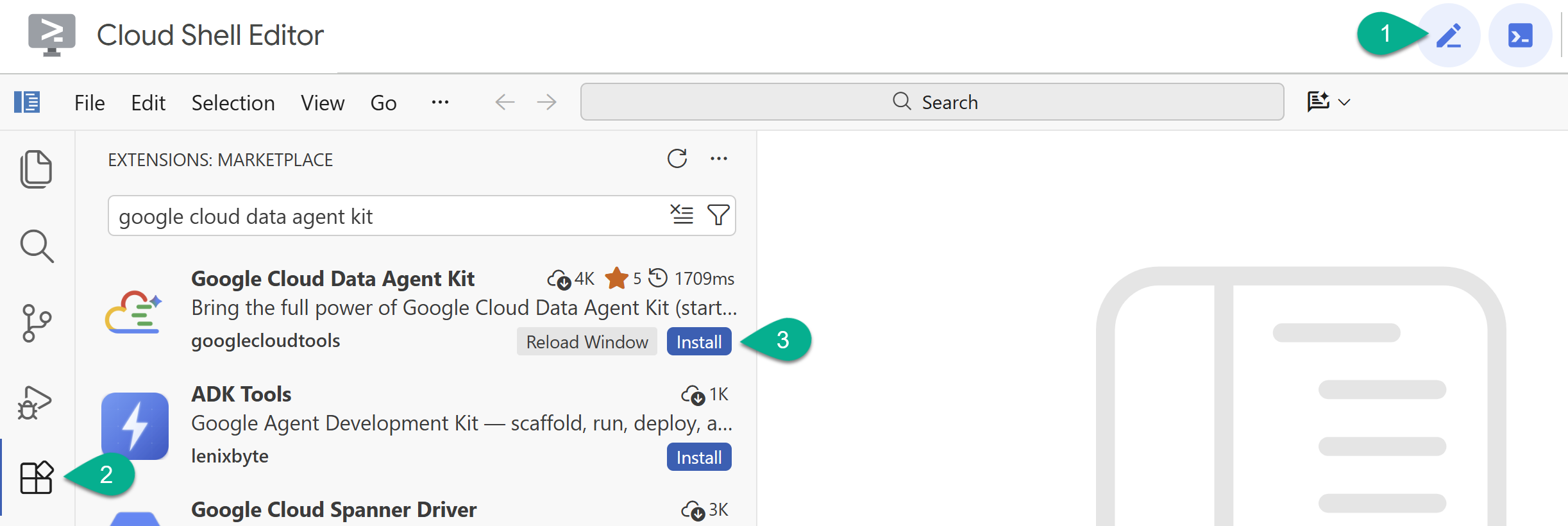
- Nell'editor di Cloud Shell, fai clic sull'icona Estensioni nella barra laterale a sinistra.
- Cerca Google Cloud Data Agent Kit e fai clic su Installa se non è già installato.
- Accedi al tuo Account Google con l'estensione.
- Nel riepilogo della configurazione, inserisci l'ID progetto e
us-central1come regione.
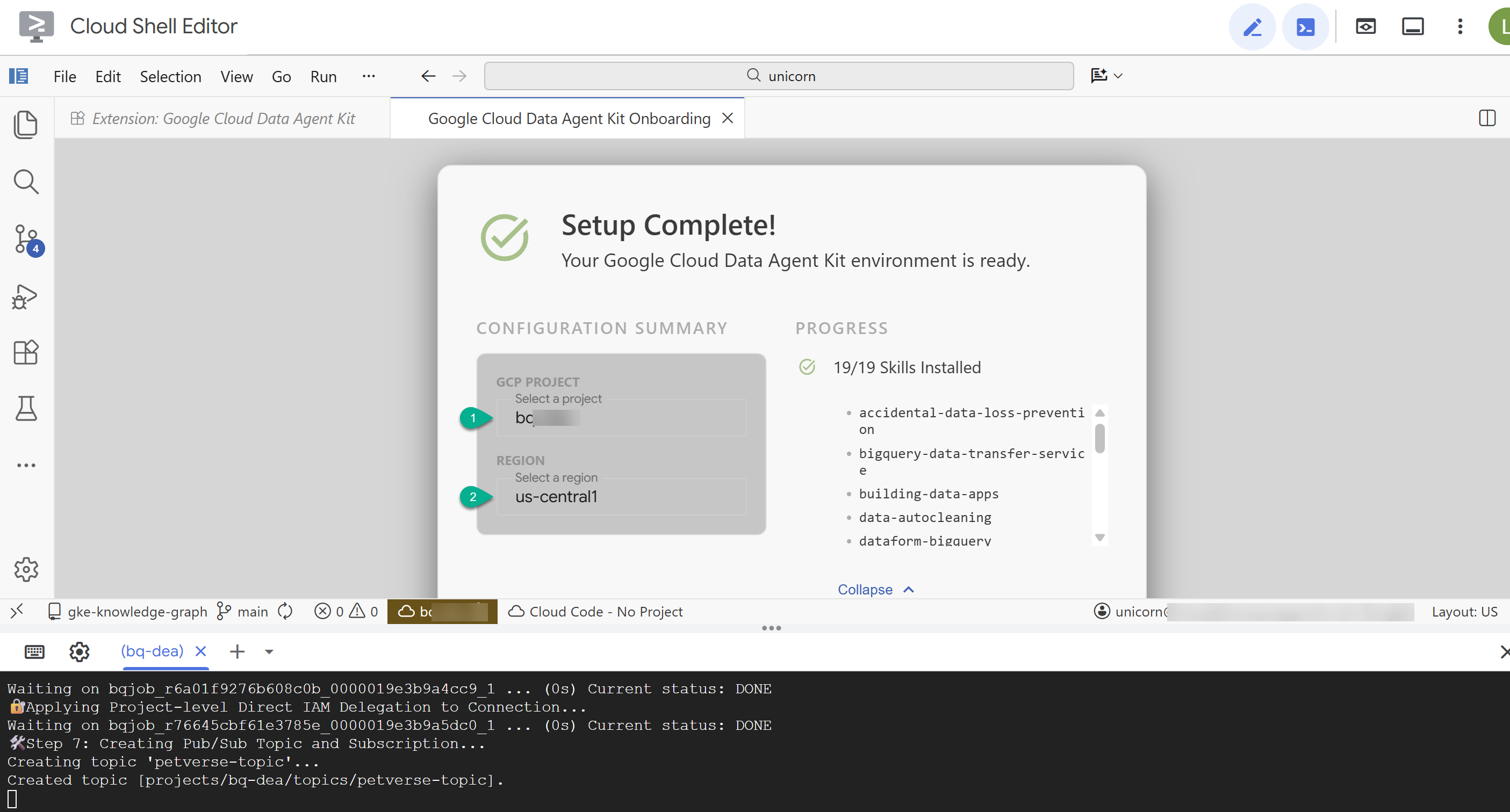
- Fai clic su Configura server MCP. Non devi apportare modifiche a questa finestra, fai semplicemente clic su Inizia.
- Ricarica la finestra se richiesto. Per il momento puoi chiudere la scheda della Guida rapida.
Configura le tabelle in BigQuery
- Nella barra laterale, torna allo spazio di esplorazione. Se la cartella Home (ad es.
/home/your_user_name/) non è già aperta, fai clic su Apri cartella e selezionala.
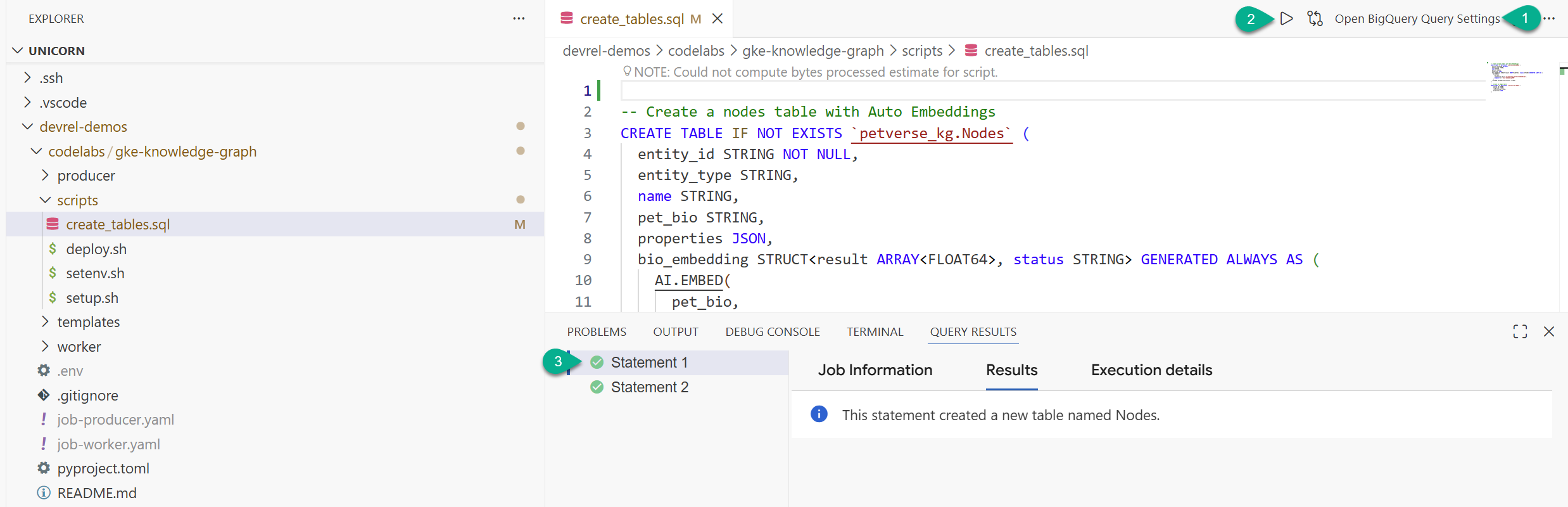
- Nella finestra di Esplora risorse, individua la cartella che hai clonato dal repository (
devrel-demos). Incodelabs/gke-knowledge-graph/scriptstroveraicreate_tables.sql. Apri il file. - In alto a destra, fai clic su Apri impostazioni query.
- Scegli BigQuery. Salva e Chiudi.
- Fai clic su Esegui.
Dovresti visualizzare due istruzioni eseguite correttamente. Ora hai creato le tabelle per archiviare nodi e archi per il tuo Knowledge Graph.
Puoi chiudere la scheda create_tables.sql e la console dei risultati.
4. Inizializza il cluster GKE
Utilizzeremo GKE Autopilot per eseguire il job di trattamento dati. Autopilot è la best practice consigliata perché gestisce l'infrastruttura del cluster per te.
A questo punto, lo script di configurazione dovrebbe essere stato completato. Dovresti visualizzare un messaggio di operazione riuscita: 🎉🦄 Setup successfully finished! 🎉🦄.
Incolla questo comando nel terminale per creare il cluster:
source scripts/setenv.sh
gcloud container clusters create-auto petverse-cluster \
--region=$REGION
🕓 L'operazione richiederà circa 5 minuti.
Recupera le credenziali per interagire con il cluster:
source scripts/setenv.sh
gcloud container clusters get-credentials petverse-cluster --region $REGION
Dovresti vedere questo output:
Fetching cluster endpoint and auth data. kubeconfig entry generated for petverse-cluster.
5. Configurazione di Workload Identity
Workload Identity Federation for GKE (che utilizza l'accesso diretto alle risorse) consente ai tuoi carichi di lavoro GKE di accedere in modo sicuro ai servizi Google Cloud senza dover gestire le chiavi del service account.
Esegui deploy.sh su:
- Crea un account di servizio Kubernetes
- Concedi i ruoli IAM necessari direttamente all'entità del service account Kubernetes
- Associa il service account IAM al service account Kubernetes
- Annota il service account Kubernetes per completare il collegamento
source scripts/setenv.sh
./scripts/deploy.sh
6. Esegui il deployment dei job di elaborazione disaccoppiata
In questo passaggio, eseguirai il deployment di enqueuer (produttore) e dei motori di elaborazione (worker) su GKE.
La nostra nuova architettura disaccoppiata utilizza Google Cloud Pub/Sub per elaborare gli asset in modo asincrono:
- Il Producer esegue la scansione di GCS e mette in coda tutti i percorsi dei file in una coda Pub/Sub.
- Un pool di worker viene scalato in GKE, estraendo dinamicamente le attività in parallelo, elaborandole tramite Gemini e scrivendole in BigQuery.
Lo script setup.sh ha già creato ed eseguito il push delle immagini container di Producer e Worker, messo in coda gli argomenti Pub/Sub e generato dinamicamente i manifest di deployment GKE: job-producer.yaml e job-worker.yaml.
- Applica il job Producer per analizzare il bucket di archiviazione e mettere in coda tutte le risorse:
kubectl apply -f job-producer.yaml
Questo job viene eseguito e completato rapidamente perché mette in coda solo i metadati.
- Esegui il deployment del job worker configurato per l'esecuzione di 6 worker paralleli per svuotare la coda:
kubectl apply -f job-worker.yaml
GKE Autopilot rileverà automaticamente i pod in attesa, farà lo scale up dinamico dei nodi di calcolo ed eseguirà i worker in parallelo per elaborare audio, video, immagini e file CSV in coda.
7. Verifica dei risultati
- Controllare lo stato dei job:
kubectl get jobs
Attendi che sia petverse-producer-job sia petverse-worker-job mostrino il completamento riuscito.
🕓 L'operazione richiederà circa 10 minuti. Puoi visualizzare l'avanzamento con i comandi riportati di seguito.
- Controlla i log del produttore per verificare che abbia messo in coda i file correttamente:
cd ~/devrel-demos/codelabs/gke-knowledge-graph
source scripts/setenv.sh
kubectl logs -l app=petverse-producer --tail=50
- Guarda i worker paralleli elaborare i file dalla coda:
kubectl logs -l app=petverse-worker --tail=50
(I worker hanno un timeout di inattività di 60 secondi e vengono arrestati e liberati automaticamente quando la coda Pub/Sub è vuota).
Verifica i dati in BigQuery.
- Vai a BigQuery Studio. Verranno create due tabelle: petverse_kg.Nodes e petverse_kg.Edges.
- Per visualizzare i contenuti delle tabelle, fai doppio clic sui relativi nomi e poi su Anteprima.
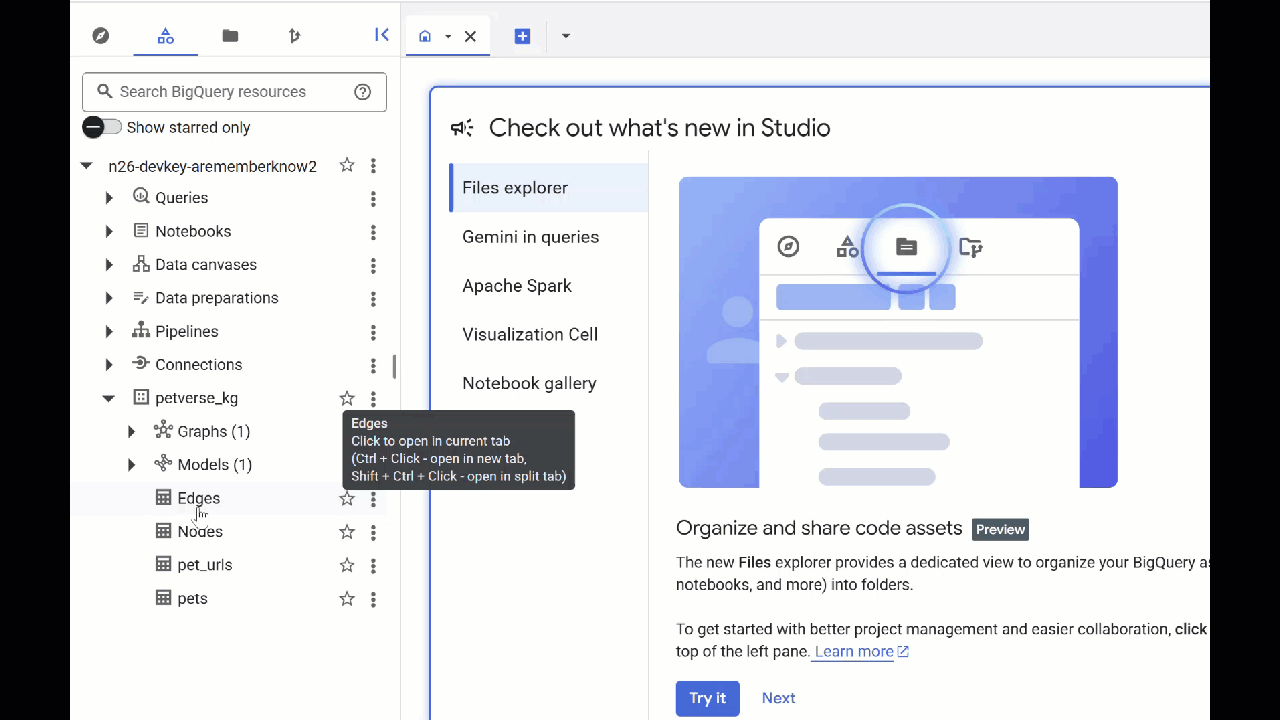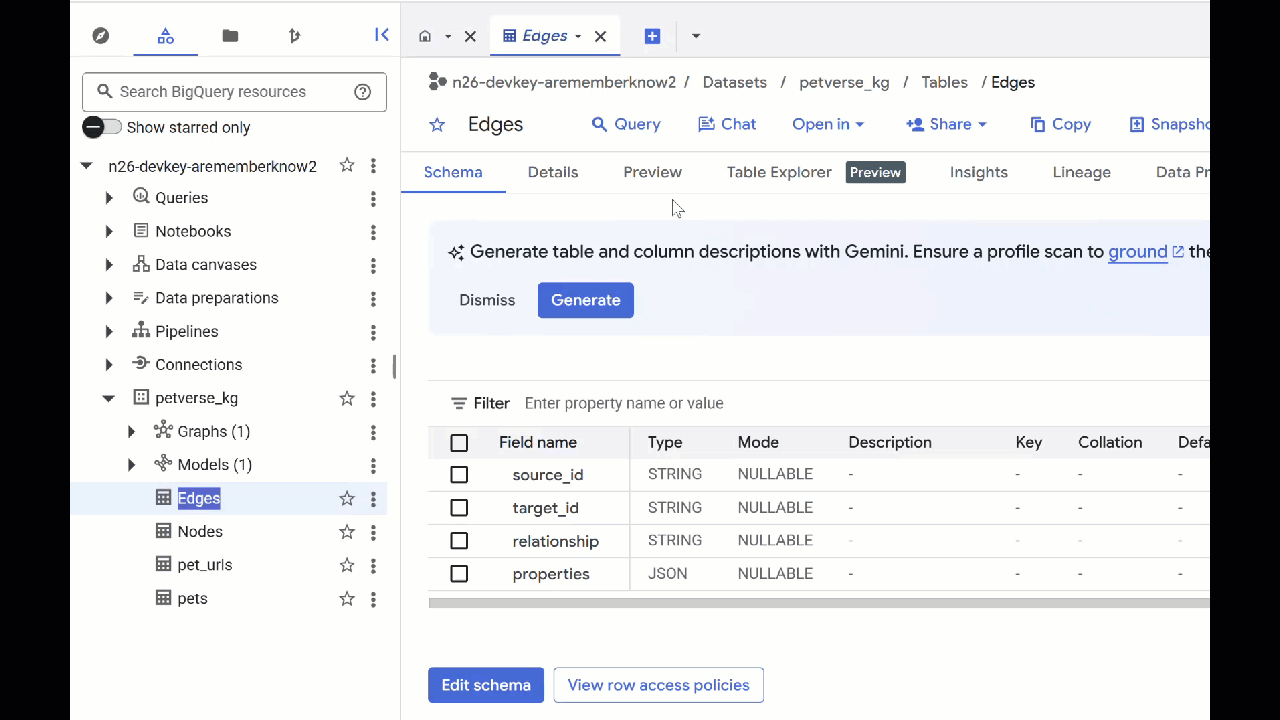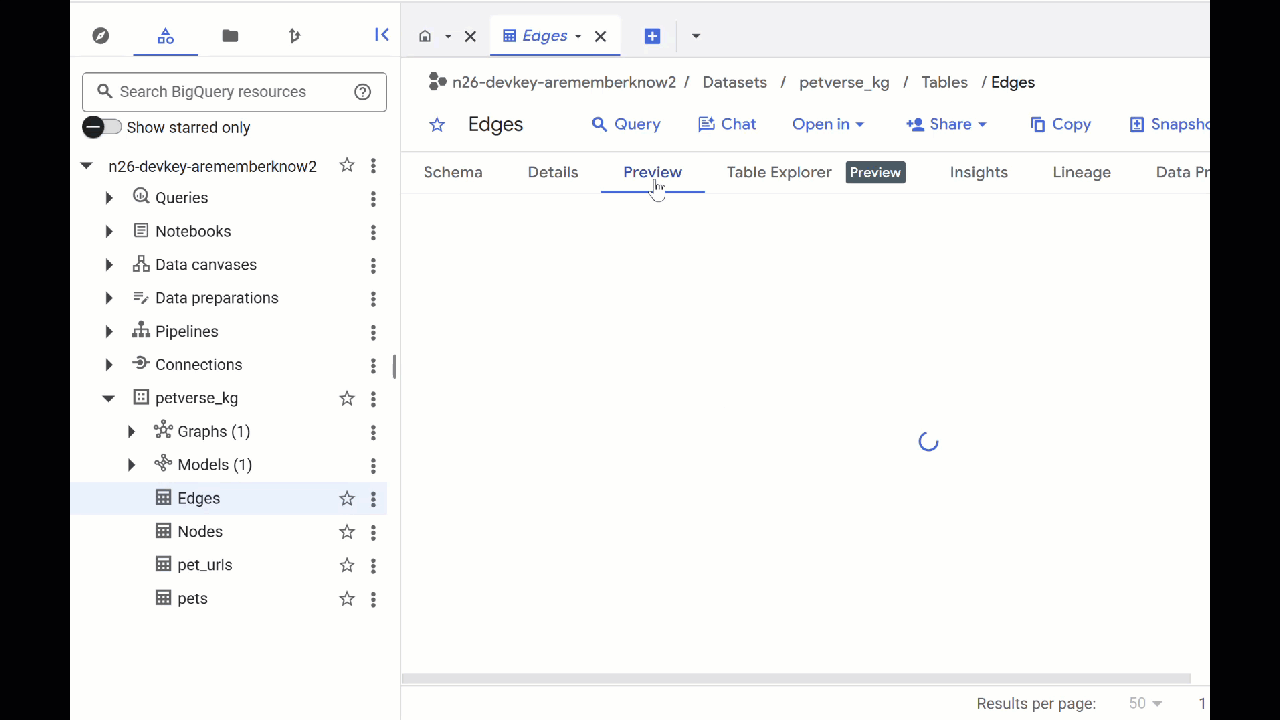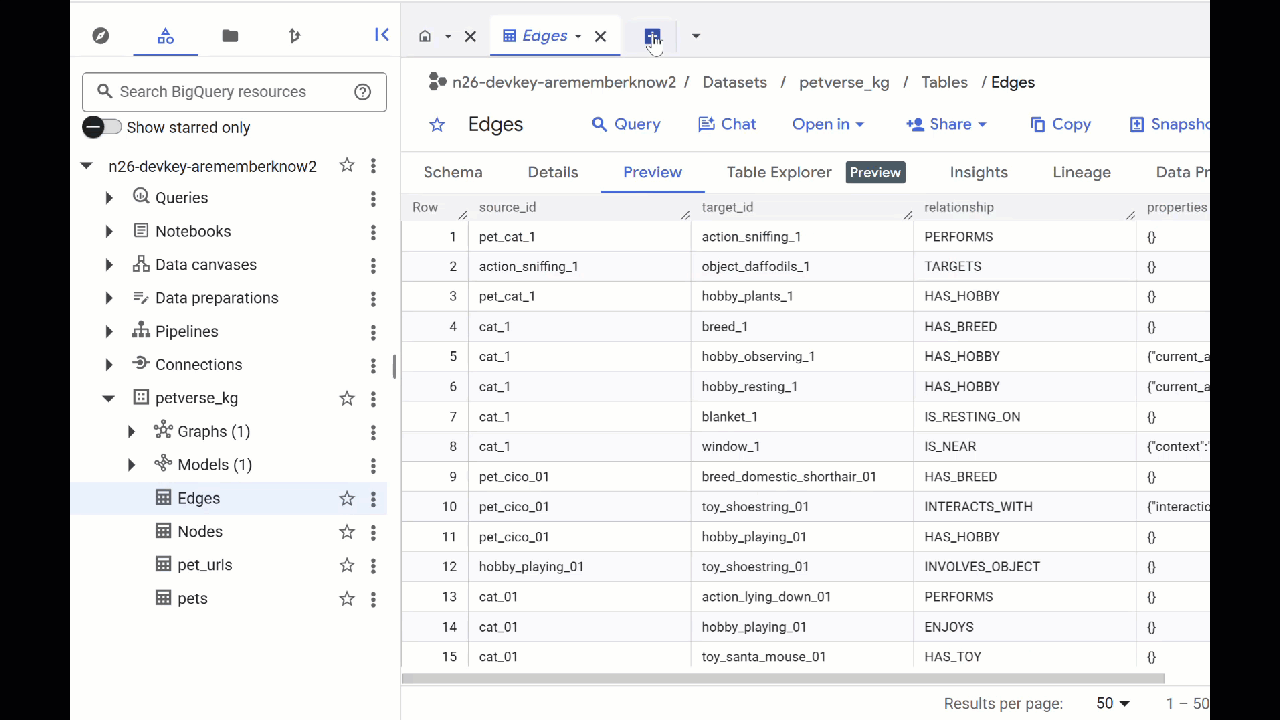
Nella tabella Nodi sono riportate le informazioni sulle entità rilevate da Gemini negli audio, nei video e nelle immagini. La tabella Edges contiene le relazioni tra loro. Ad esempio, se ascolti l'audio del gatto di nome SQL, scoprirai che ama giocare con i lacci delle scarpe e mangiare pesce liofilizzato.
- Utilizza il pulsante + per creare una nuova query. Incolla la seguente istruzione e fai clic su Esegui:
SELECT n.name, n.entity_id, e.relationship, e.target_id
FROM
`petverse_kg.Nodes` n
JOIN
`petverse_kg.Edges` e
ON n.entity_id = e.source_id
WHERE n.name = 'SQL'
- Utilizza il pulsante + per creare una nuova query. Incolla la seguente istruzione e fai clic su Esegui:
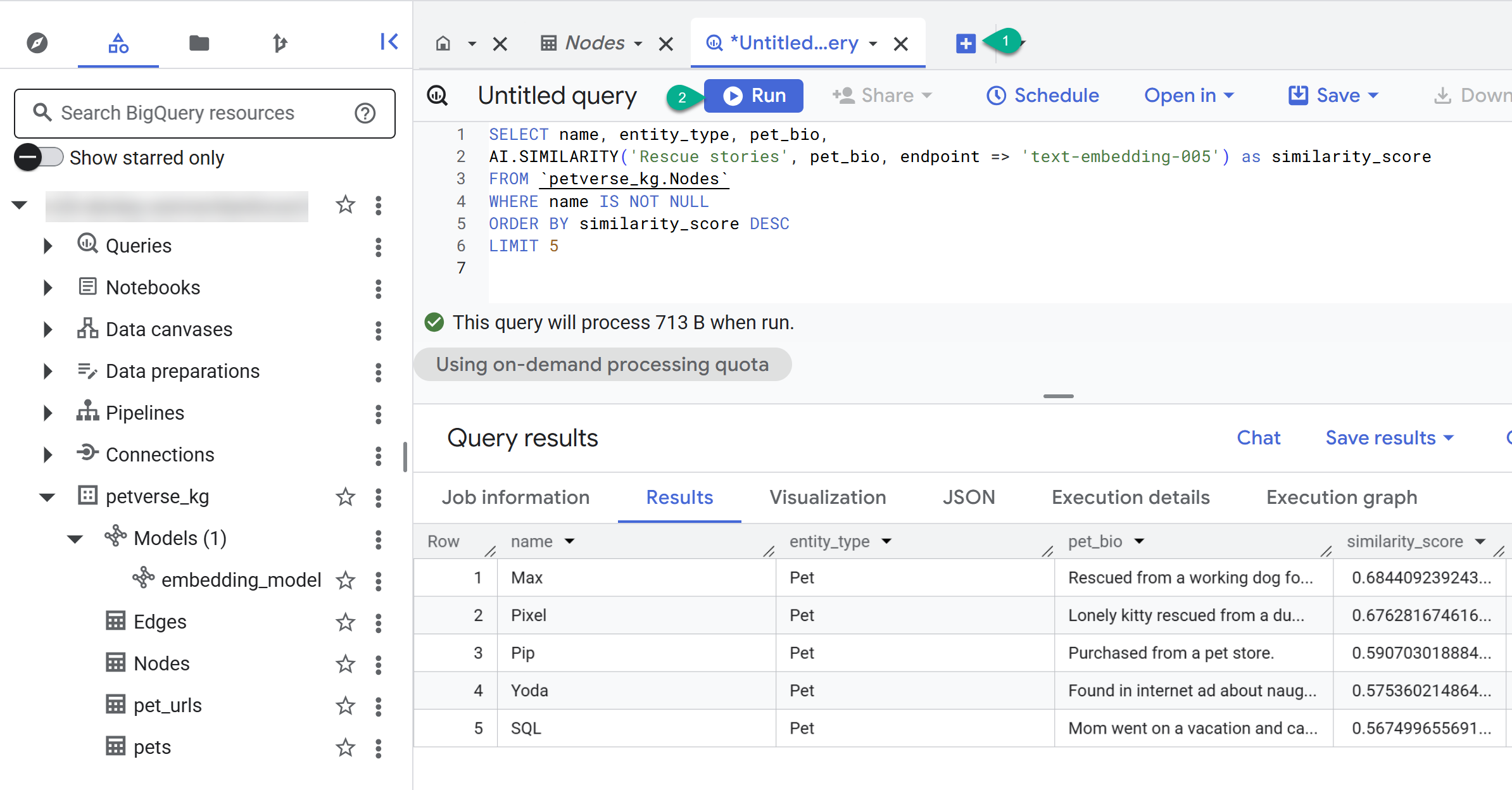
SELECT name, entity_type, pet_bio,
AI.SIMILARITY('Pets who like to relax', pet_bio, endpoint => 'text-embedding-005') as similarity_score
FROM `petverse_kg.Nodes`
WHERE name IS NOT NULL
ORDER BY similarity_score DESC
LIMIT 5
Dovresti vedere i nodi per gli animali domestici che amano rilassarsi. Questa query ha eseguito una ricerca semantica utilizzando la funzione AI AI.SIMILARITY per trovare animali domestici le cui biografie sono più simili al testo della query.
Creare il grafico delle proprietà
Ora che abbiamo nodi e archi in BigQuery, possiamo creare un grafico delle proprietà per eseguire facilmente query sulle relazioni.
Creare il grafico
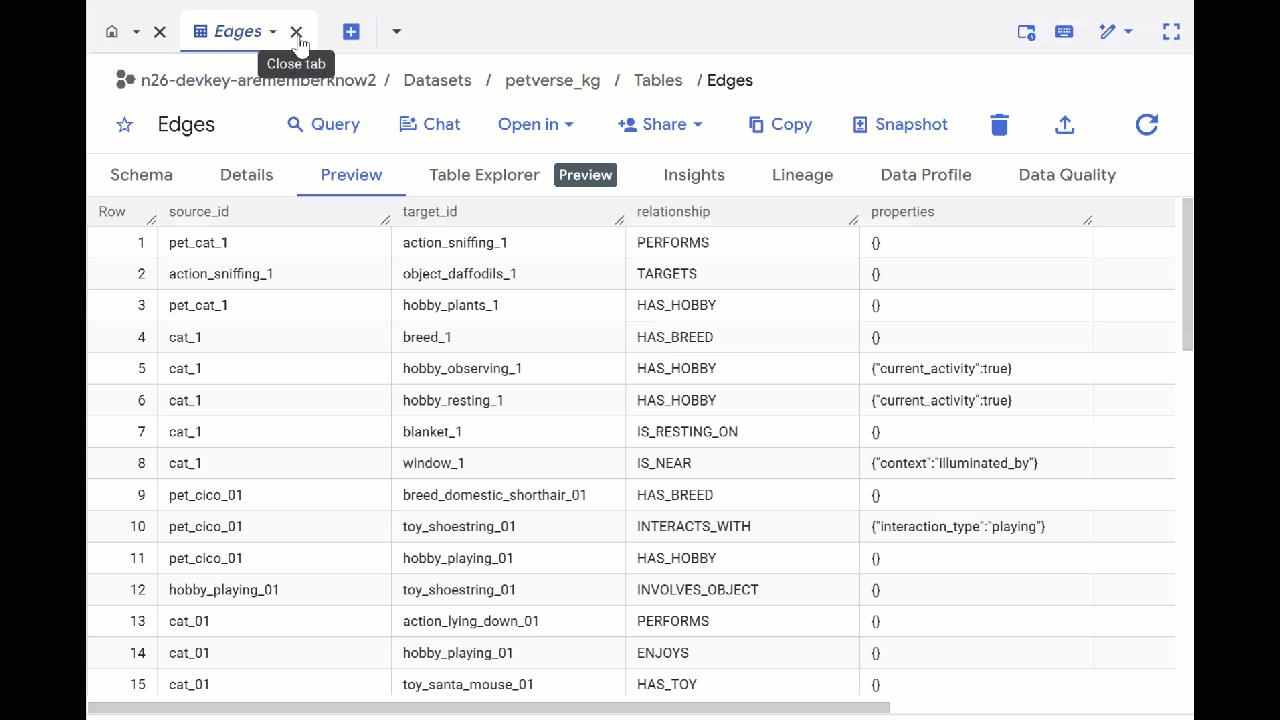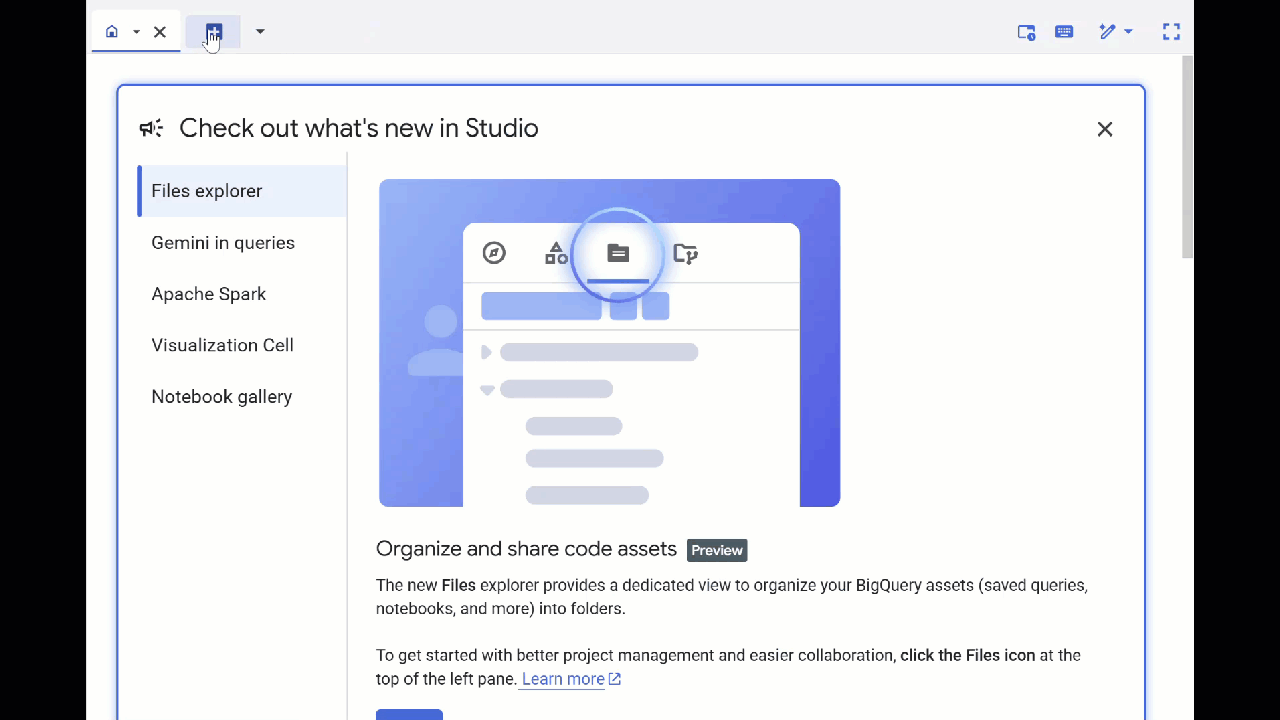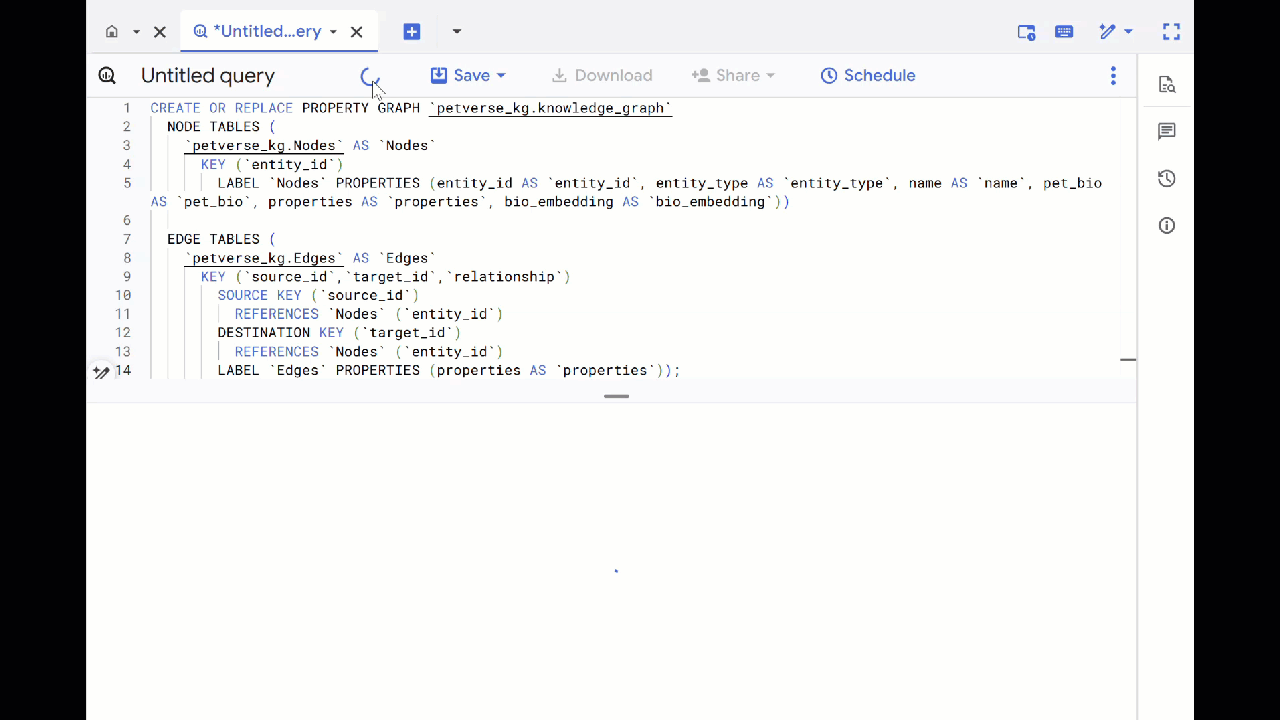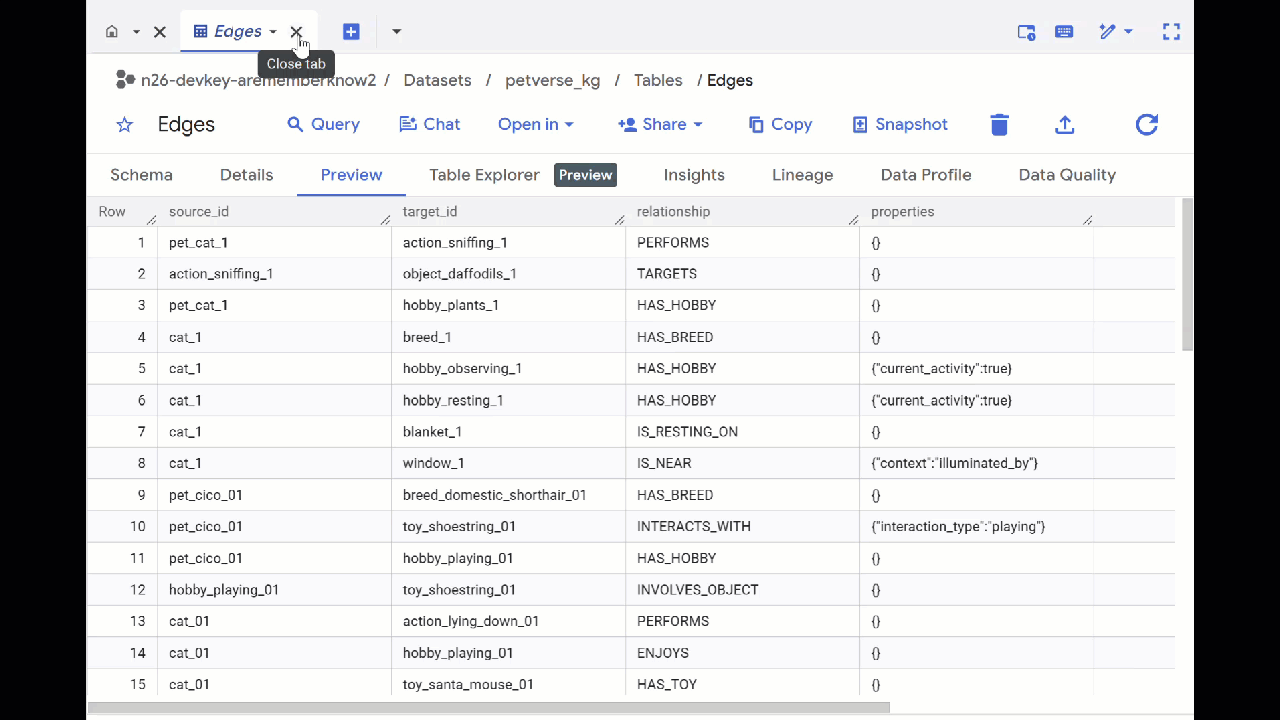
- Sovrascrivi la query precedente ed esegui il seguente DDL per creare il grafico delle proprietà:
CREATE OR REPLACE PROPERTY GRAPH `petverse_kg.knowledge_graph`
NODE TABLES (
`petverse_kg.Nodes` AS `Nodes`
KEY (`entity_id`)
LABEL `Nodes` PROPERTIES (entity_id AS `entity_id`, entity_type AS `entity_type`, name AS `name`, pet_bio AS `pet_bio`, properties AS `properties`, bio_embedding AS `bio_embedding`))
EDGE TABLES (
`petverse_kg.Edges` AS `Edges`
KEY (`source_id`,`target_id`,`relationship`)
SOURCE KEY (`source_id`)
REFERENCES `Nodes` (`entity_id`)
DESTINATION KEY (`target_id`)
REFERENCES `Nodes` (`entity_id`)
LABEL `Edges` PROPERTIES (properties AS `properties`));
- Fai clic su Vai al grafico. Vedrai la visualizzazione del grafico con un nodo che ha un bordo che punta a se stesso. È previsto.
Eseguire query sul grafico
- Puoi chiudere tutte le query precedenti e aprirne una nuova e vuota con il pulsante +.
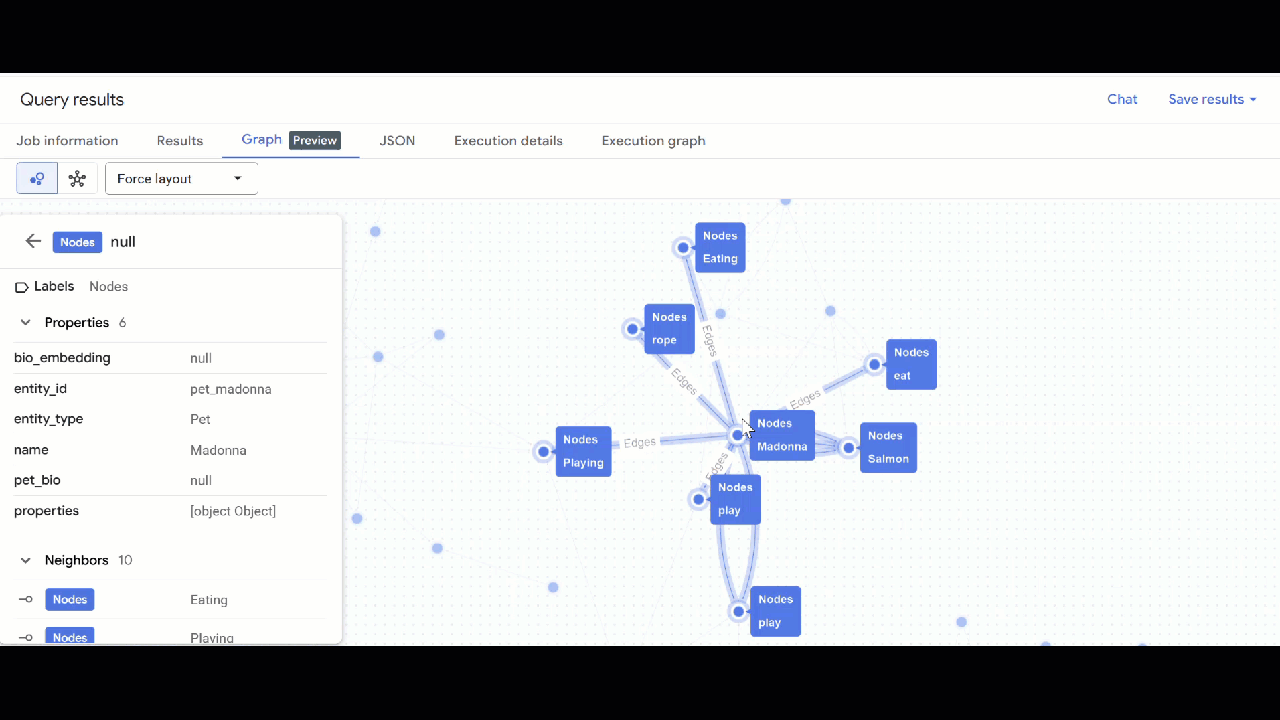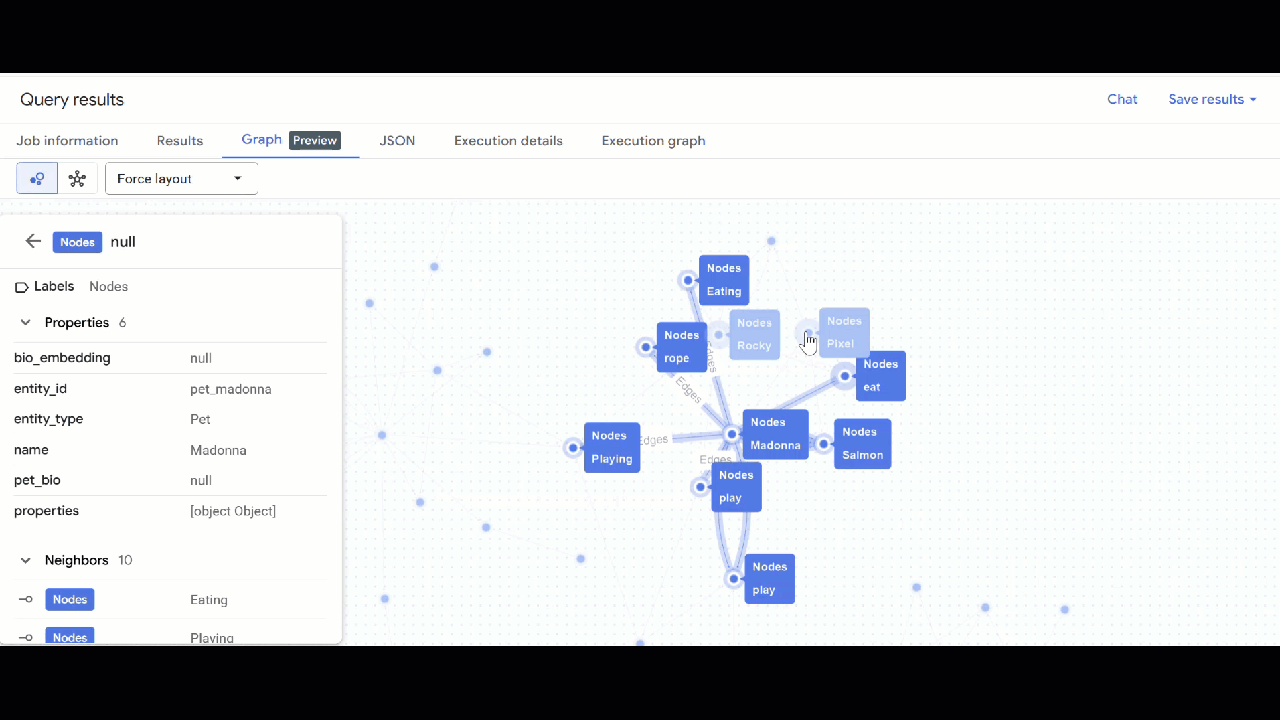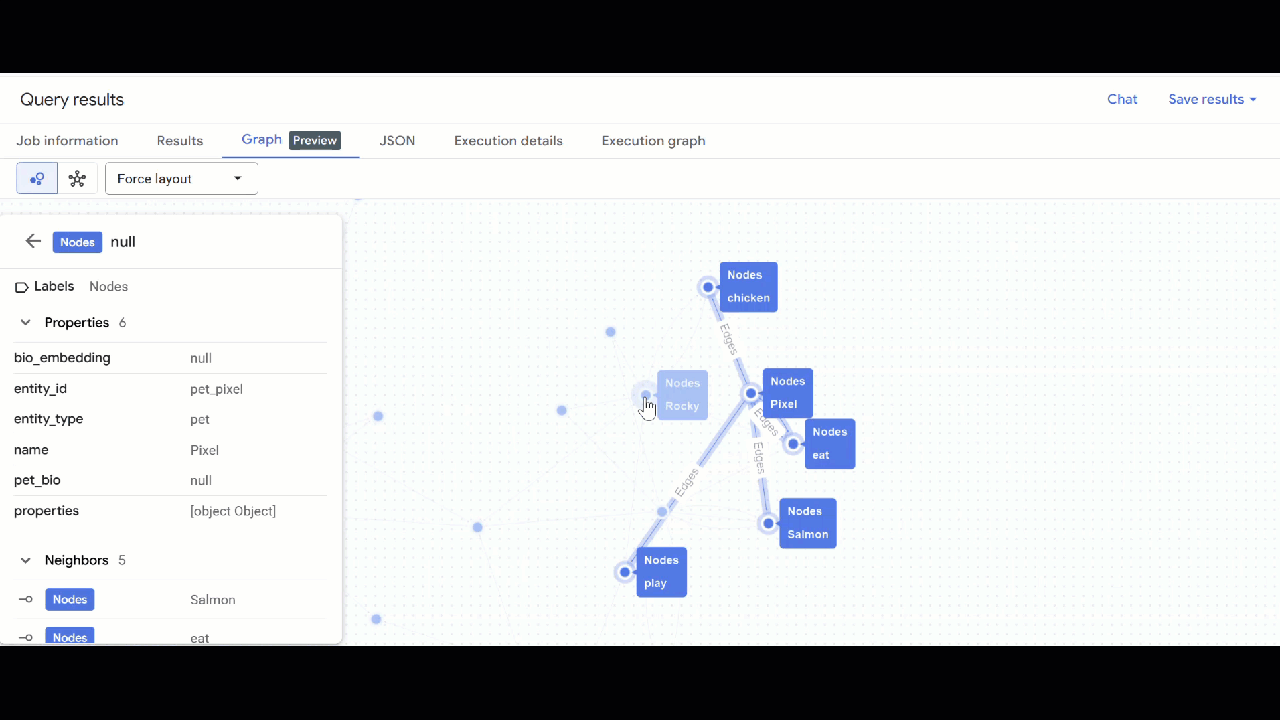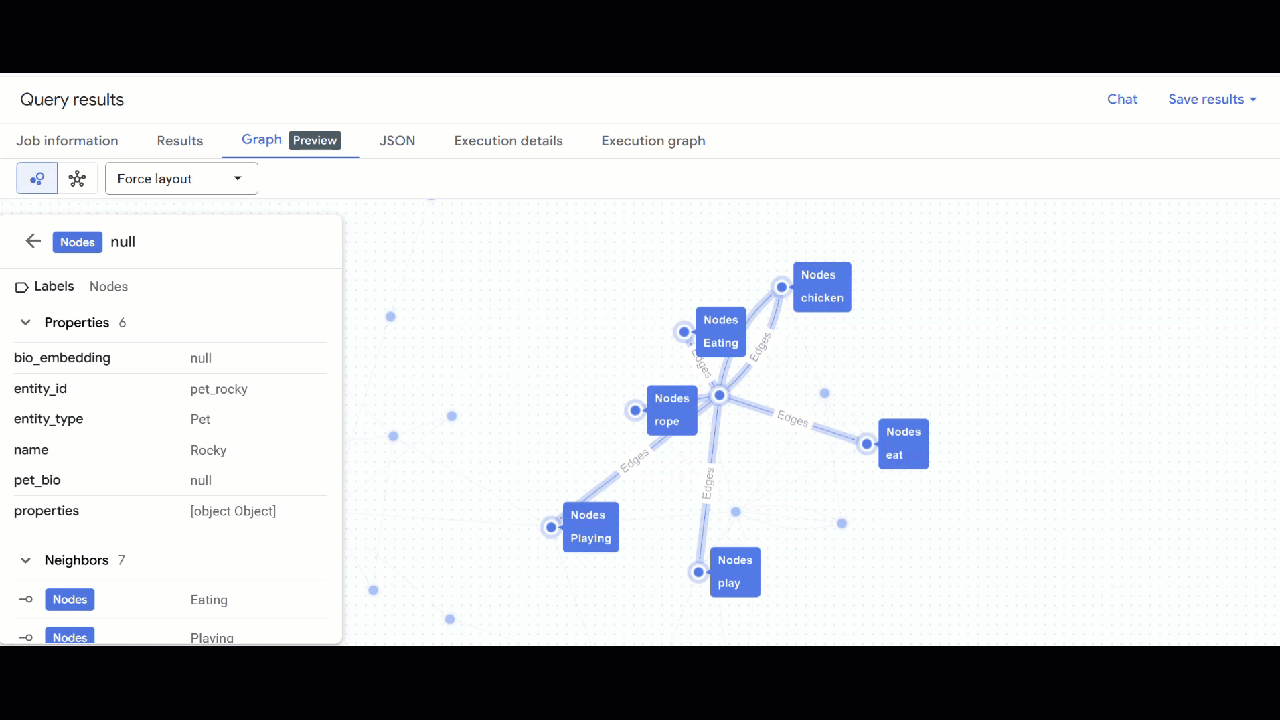
- Utilizza GQL per trovare animali domestici correlati ad altri animali domestici tramite interessi condivisi (come hobby, cibi o giocattoli preferiti). Questa query multihop corrisponde a due animali domestici diversi collegati allo stesso nodo:
GRAPH `petverse_kg.knowledge_graph`
MATCH p = (pet1:Nodes)-[e1]->(interest:Nodes)<-[e2]-(pet2:Nodes)
WHERE pet1.entity_id != pet2.entity_id
AND (LOWER(pet1.entity_type) = 'pet' AND LOWER(pet2.entity_type) = 'pet')
AND LOWER(interest.entity_type) IN ('hobby', 'action', 'activity', 'food', 'toy')
RETURN TO_JSON(p) as res
LIMIT 100
- Dovresti vedere la visualizzazione del grafico. Puoi fare clic sui nodi per visualizzare le proprietà dei nodi e dei bordi.
🕵️ Suggerimento: puoi regolare il valore mostrato dal nodo facendo clic su Passa alla visualizzazione schema:
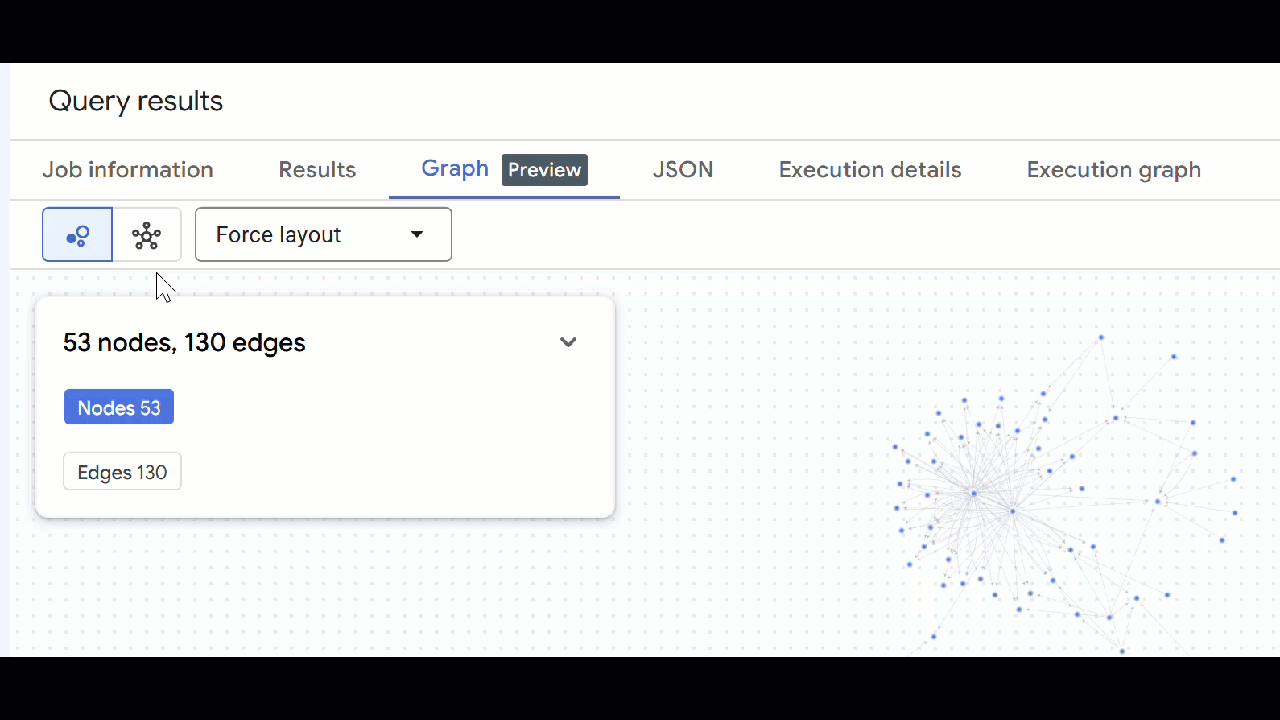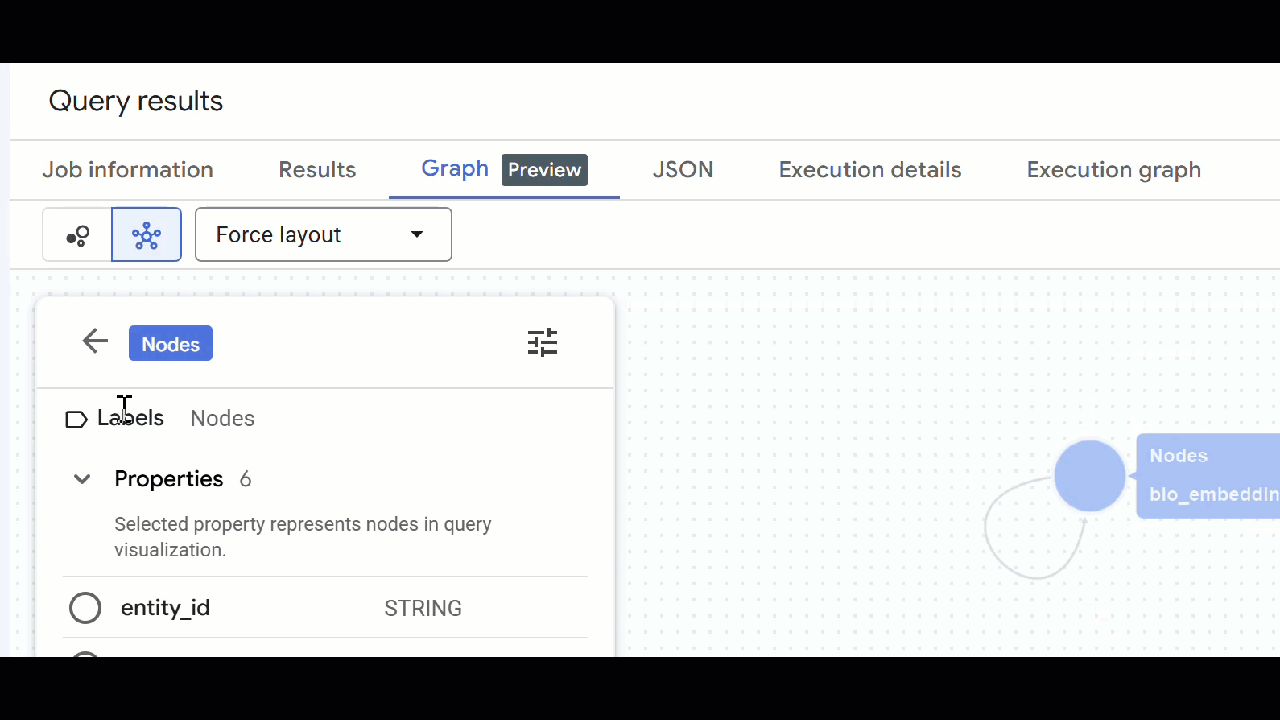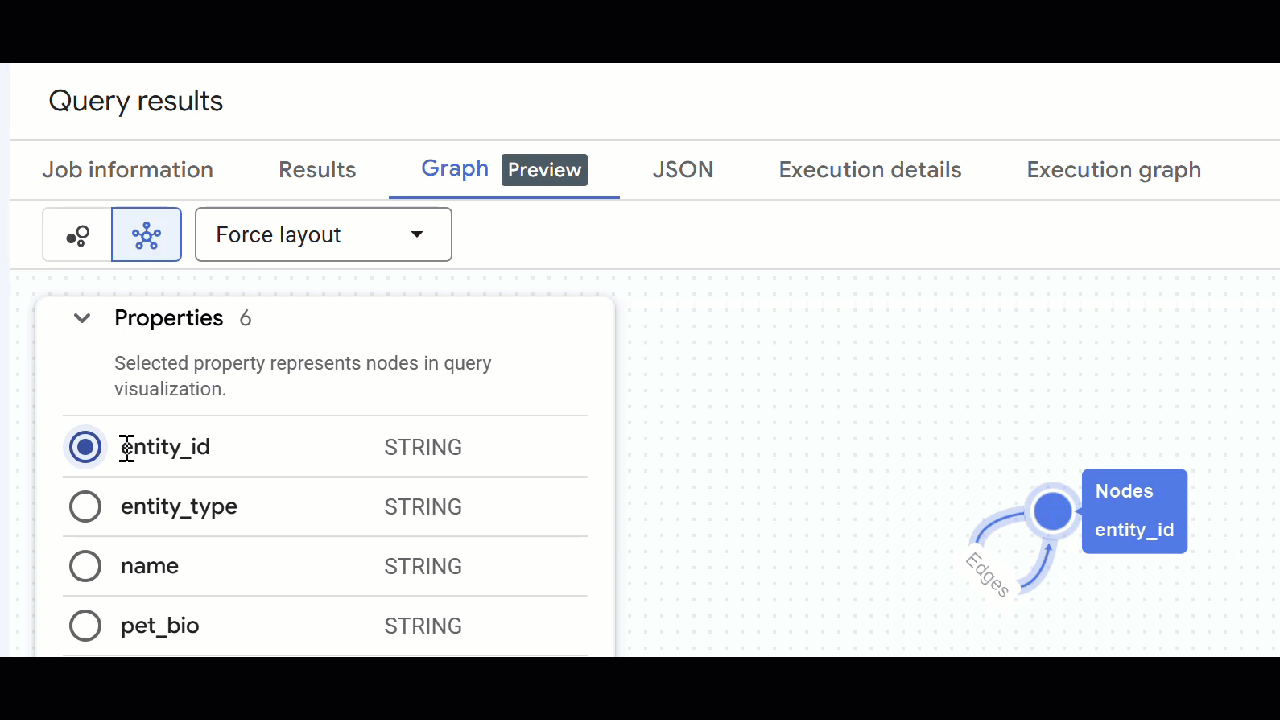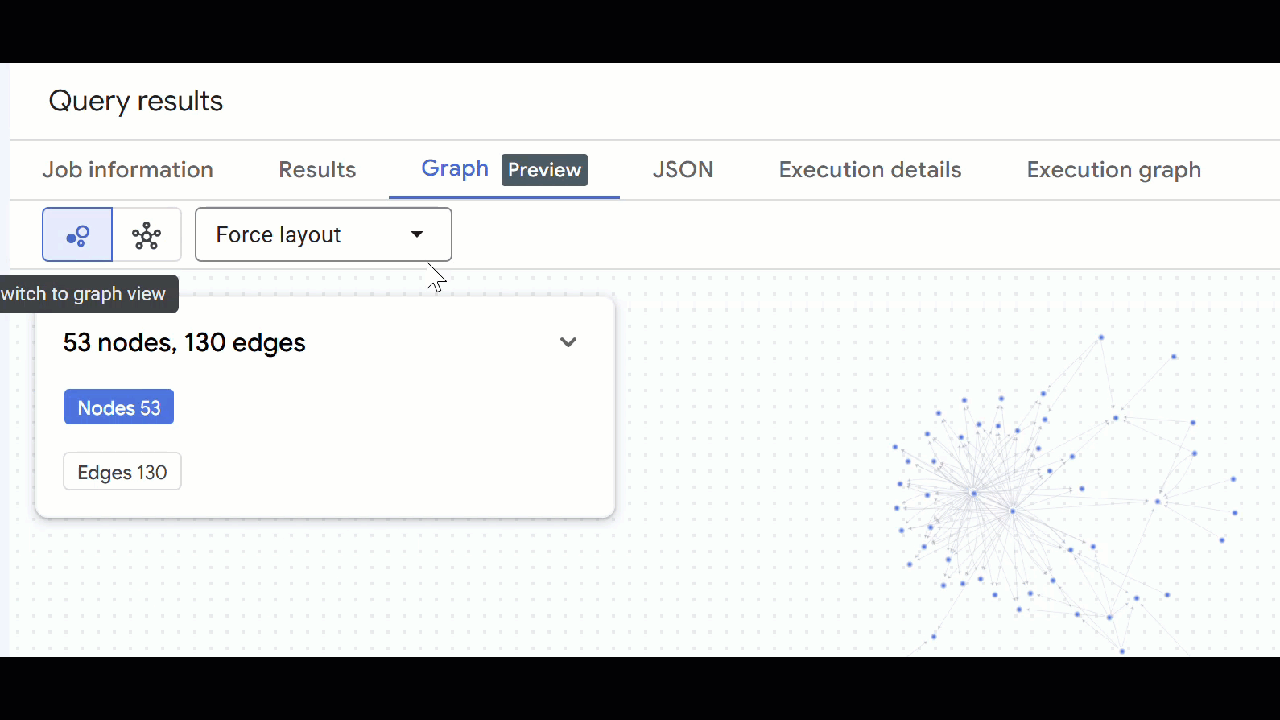
- Puoi chiudere tutte le schede di query aperte.
8. Chattare con il grafico
- Accanto al segno +, troverai un menu a discesa. Seleziona Conversazione.
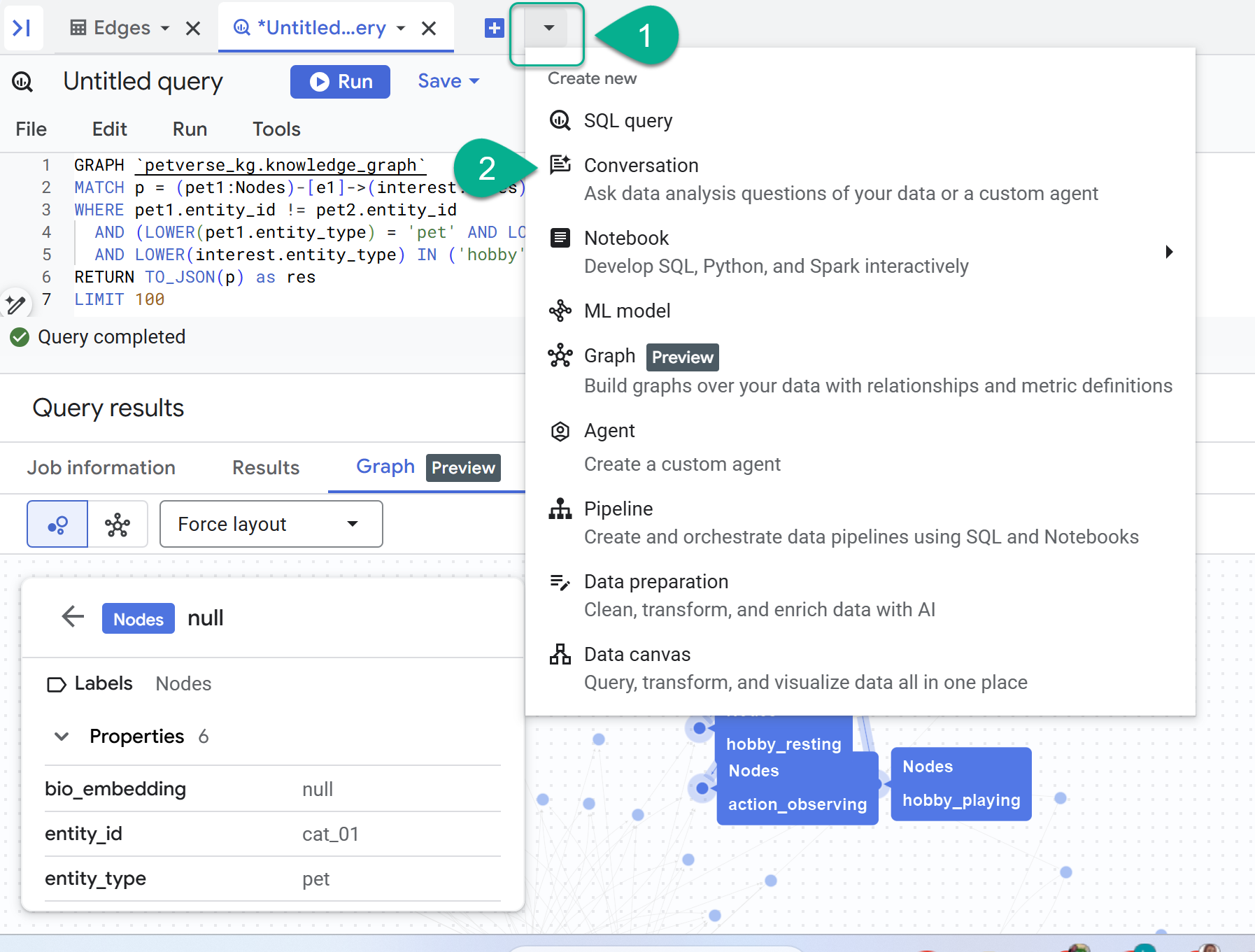
- Ti verrà chiesto di abilitare l'API Data Analytics con Gemini. Abilita entrambe le API. Al termine dell'operazione, aggiorna la finestra o crea una nuova conversazione per visualizzare l'agente.
- Fai clic su Nuovo agente.
- Assegna all'agente un nome come
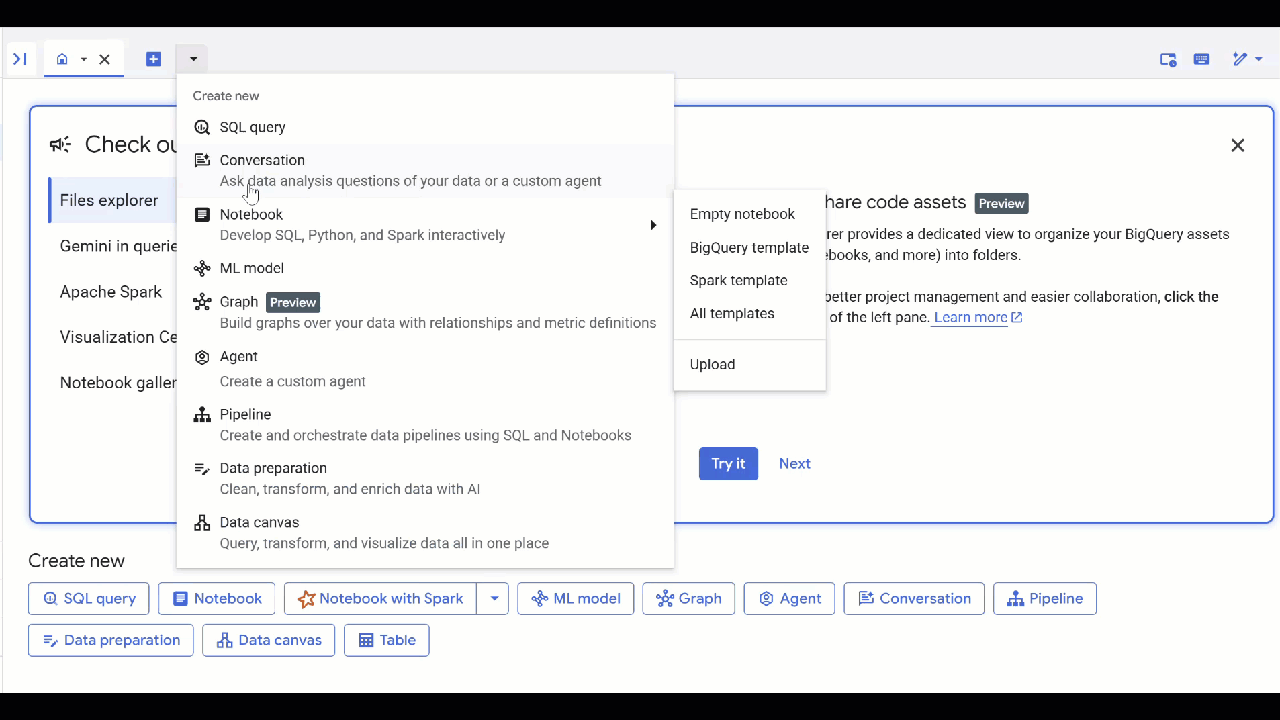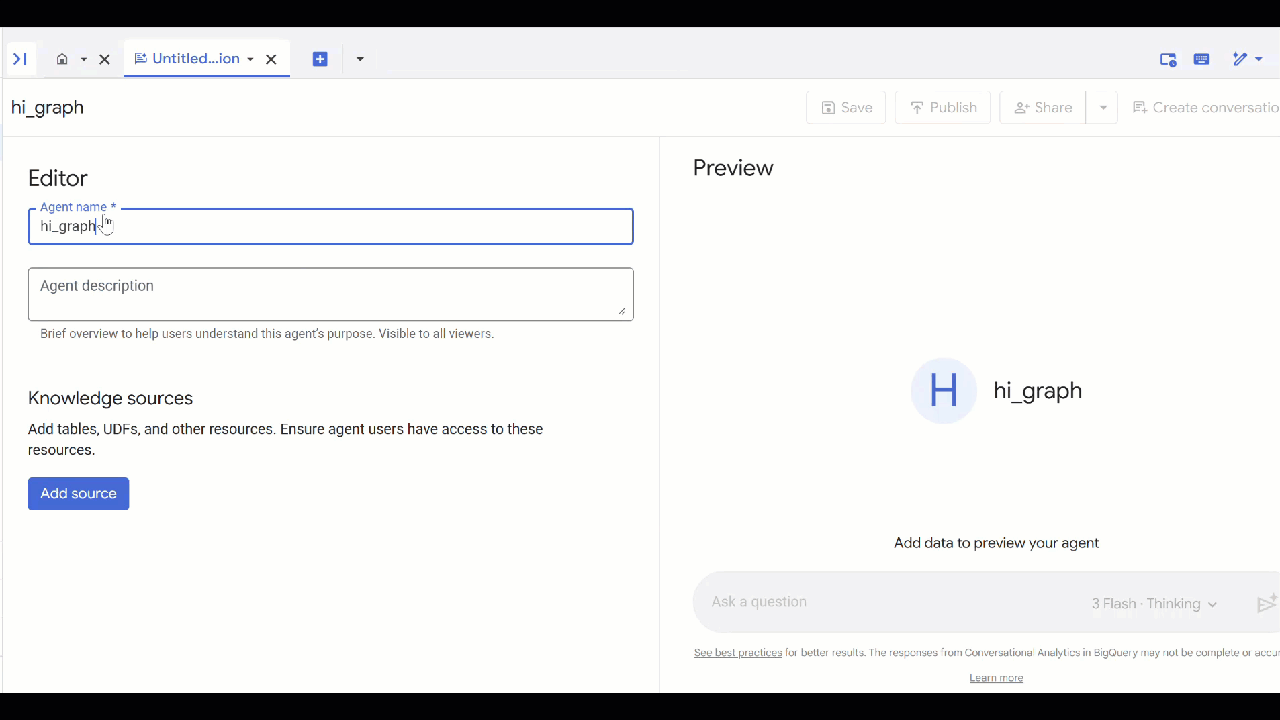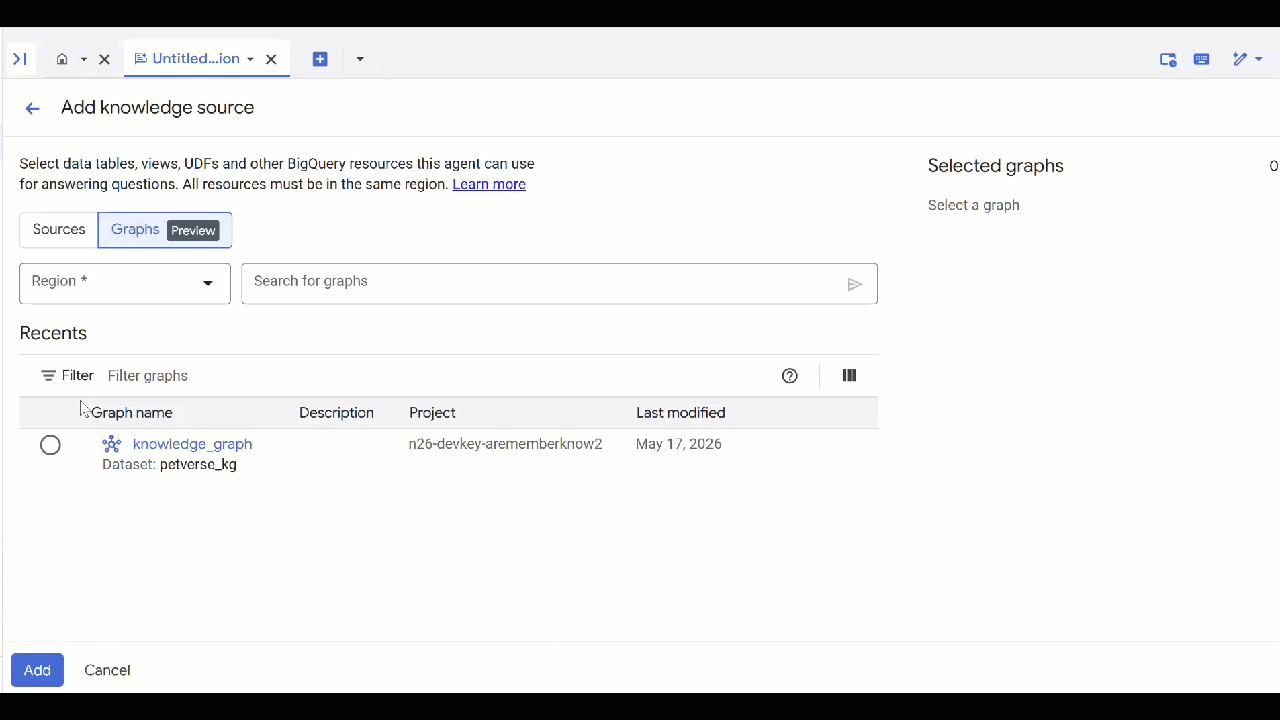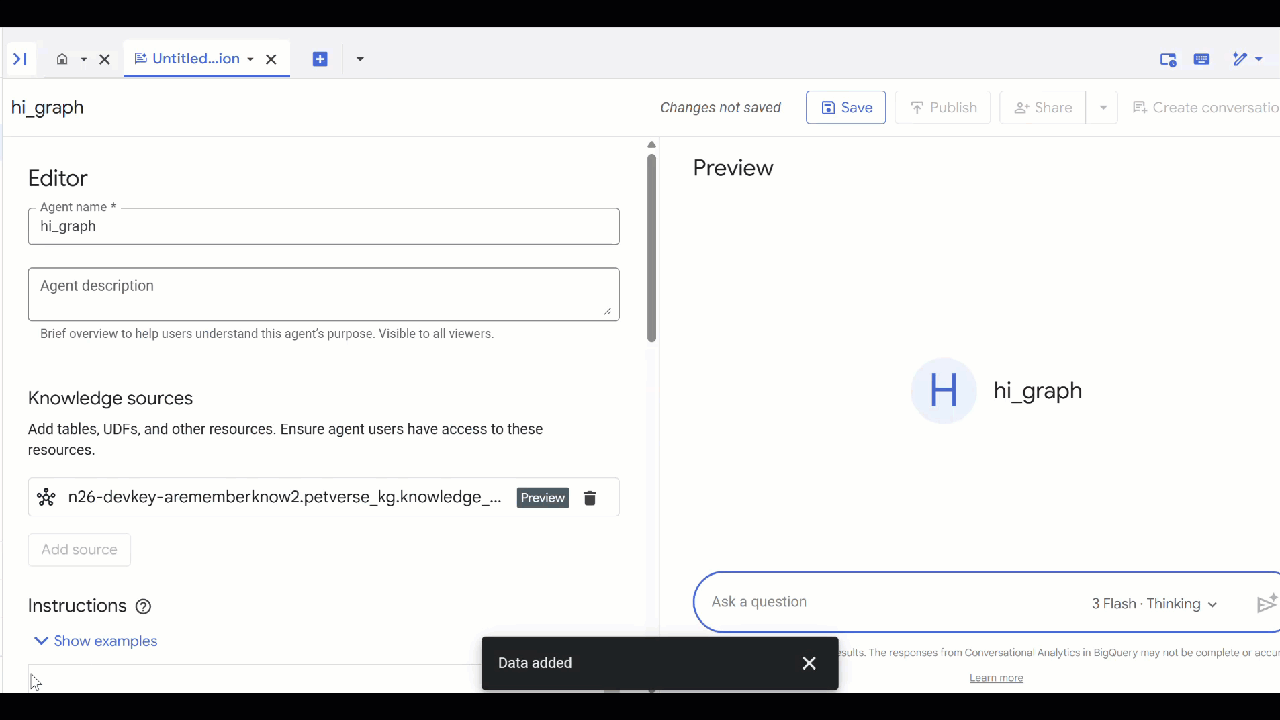
petverse. - Fai clic su Aggiungi origine e poi su Grafico.
- Seleziona il
knowledge_graphche hai creato e fai clic su Aggiungi.
Ora puoi fare una domanda all'agente e vedere le risposte e il ragionamento che le ha generate. Ecco alcune domande di esempio se hai bisogno di ispirazione. Un modello di ragionamento potrebbe richiedere un po' più di tempo, ma è probabile che crei una query GQL migliore. Puoi vedere cosa crea espandendo Show Thinking.
- Trova animali domestici che mangiano cibi simili, che sono amici di animali domestici che amano fare i pisolini.
- Ci sono animali domestici che condividono esattamente lo stesso hobby, cibo preferito o giocattolo? Elenca le coppie e i loro interessi condivisi.
- Trova animali domestici della stessa specie o razza, ma con hobby completamente diversi.
9. Esegui la pulizia
Per evitare addebiti continui al tuo account Google Cloud, elimina le risorse create durante questo codelab.
- Elimina il cluster GKE:
gcloud container clusters delete petverse-cluster --region $REGION --quiet
- Elimina il set di dati BigQuery (in questo modo verranno eliminate tutte le tabelle):
bq rm -r -f -d $PROJECT_ID:petverse_kg
- Elimina le risorse della coda Pub/Sub:
gcloud pubsub subscriptions delete petverse-sub --quiet
gcloud pubsub topics delete petverse-topic --quiet
- Elimina il repository Artifact Registry:
gcloud artifacts repositories delete gke-cats-repo --location=$REGION --quiet
- Elimina il bucket GCS specifico del progetto:
gcloud storage buckets delete gs://$PROJECT_ID-petverse --quiet
10. Complimenti
Complimenti! Hai creato correttamente una pipeline di grafici della conoscenza distribuita utilizzando GKE e Gemini e hai eseguito query utilizzando BigQuery Property Graphs.
Cosa hai imparato
- Come eseguire il deployment di job distribuiti su GKE Autopilot.
- Come utilizzare Gemini per l'estrazione di dati multimodali.
- Come utilizzare gli incorporamenti automatici di BigQuery.
- Come creare ed eseguire query sui grafi delle proprietà in BigQuery.