
1. はじめに
この Codelab では、「Petverse」用の分散型知識獲得パイプラインを構築します。Cloud Storage バケットから非構造化マルチメディア アセット(音声、動画、画像、テキスト/CSV)を処理し、ペットに関する重要な情報(好きな食べ物、趣味)を抽出して、ナレッジグラフを作成します。Google Kubernetes Engine(GKE)で Gemini マルチモーダル処理を使用して、マルチメディア ファイルの処理をスケーリングします。最後に、このデータを BigQuery に保存し、新しい BigQuery Property Graph 機能を使用して関係を分析します。
Google Kubernetes Engine の機能を使用して、大量のデータを並列処理する方法を説明します。
ナレッジグラフを使用する理由
ナレッジグラフは、エンティティ間の複雑な関係を表して分析するのに、従来のリレーショナル データベースよりも適しています。
Gemini 2.5 Flash を使用して、画像、音声、動画ファイルを分析し、さまざまなペットに関する事実を確立します。
演習内容
- GKE に分散データ処理ジョブを構築してデプロイします。
- Gemini を使用して、マルチメディア ファイルからエンティティと関係を抽出します。
- ナレッジグラフ データを BigQuery に保存します。
- Graph Query Language(GQL)を使用して、BigQuery でプロパティ グラフ を作成してクエリします。
必要なもの
- ウェブブラウザ(Chrome など)
- 課金を有効にした Google Cloud プロジェクト
- リソースを作成して IAM ポリシーを変更するためのプロジェクトの権限
この Codelab は、初心者を含むあらゆるレベルのデベロッパーを対象としています。
所要時間: 45 分
費用: この Codelab で作成するリソースの費用は 5 ドル未満です。
2. 始める前に
Google Cloud プロジェクトの作成
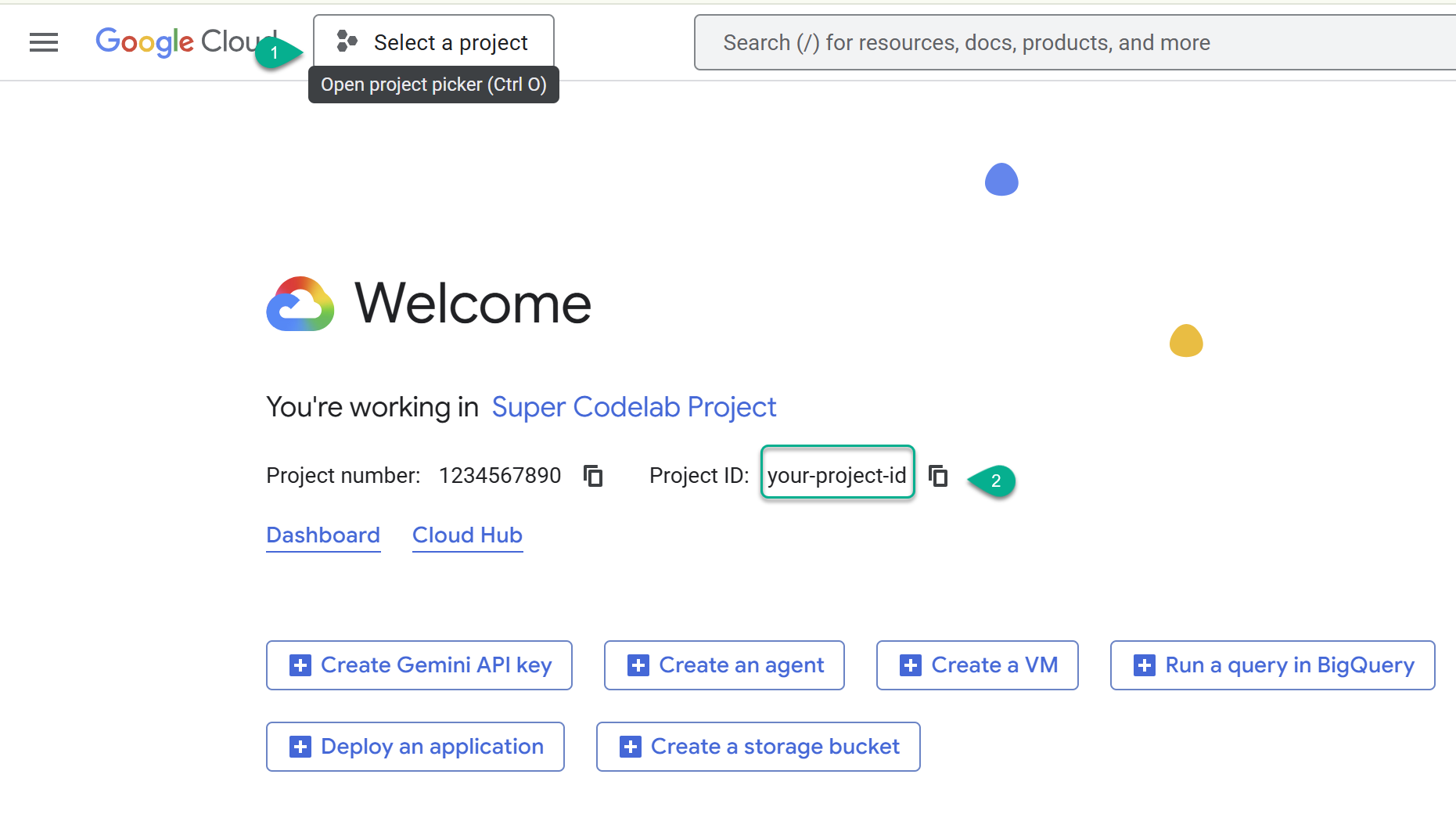
- Google Cloud コンソール(https://console.cloud.google.com)に移動し、Google Cloud プロジェクトを選択または作成 します。
- ⚠️ プロジェクト ID をメモしておきます。このラボでは、いくつかのコマンドで使用します。
Cloud Shell の起動
- https://shell.cloud.google.com/
- プロンプトが表示されたら、[承認] をクリックします。
PROJECT_IDを置き換えて、次のコマンドをターミナルに貼り付けます。
export PROJECT_ID="YOUR_PROJECT_ID"
gcloud config set project $PROJECT_ID
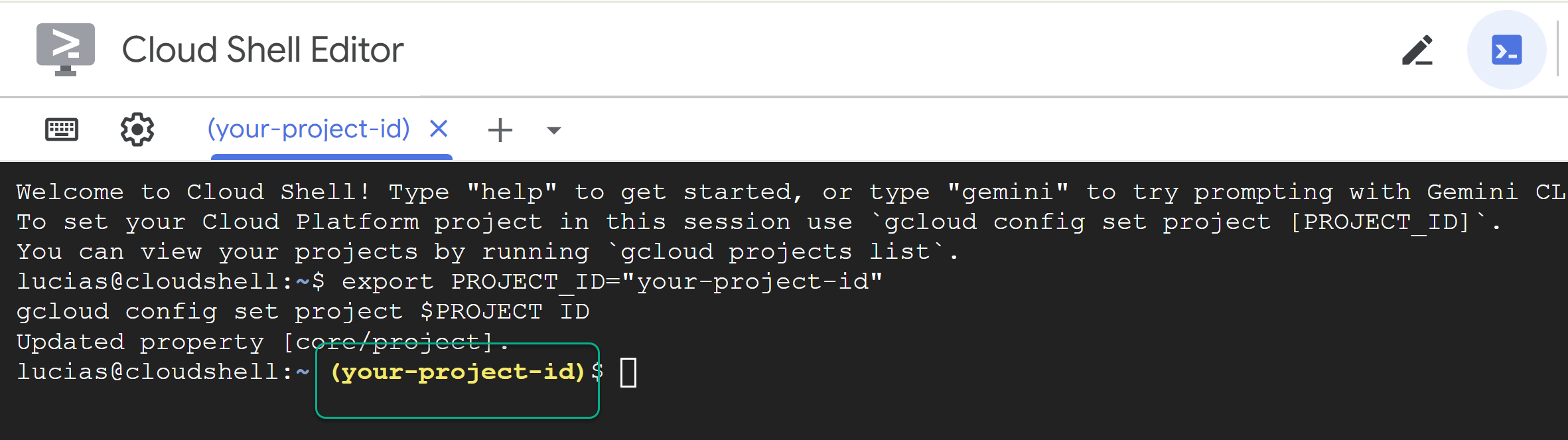
📝 注 コマンドラインでは、プロジェクトが黄色で表示されます。セッションが再起動した場合は、上記のコマンドを再実行してプロジェクト ID を設定してください。
API を有効にする
次のコマンドを実行して、必要なすべての API を有効にします。
gcloud services enable \
aiplatform.googleapis.com \
bigquery.googleapis.com \
artifactregistry.googleapis.com \
container.googleapis.com \
cloudbuild.googleapis.com \
pubsub.googleapis.com
リポジトリのクローンを作成
次のコマンドを実行して、リポジトリのクローンを作成します。
cd ~/
git clone --filter=blob:none --no-checkout https://github.com/GoogleCloudPlatform/devrel-demos.git
cd ~/devrel-demos
git sparse-checkout init --cone
git sparse-checkout set codelabs/gke-knowledge-graph
git checkout main
cd codelabs/gke-knowledge-graph/
設定スクリプトを実行する
このスクリプトは、次の方法でバックエンド構成を自動化します。
- コンテナ イメージと Artifact Registry リポジトリを作成する
- BigQuery データセットを作成する
- SQL から Gemini AI 関数を実行する BigQuery 接続を作成する
ターミナルで次のコマンドを実行します。
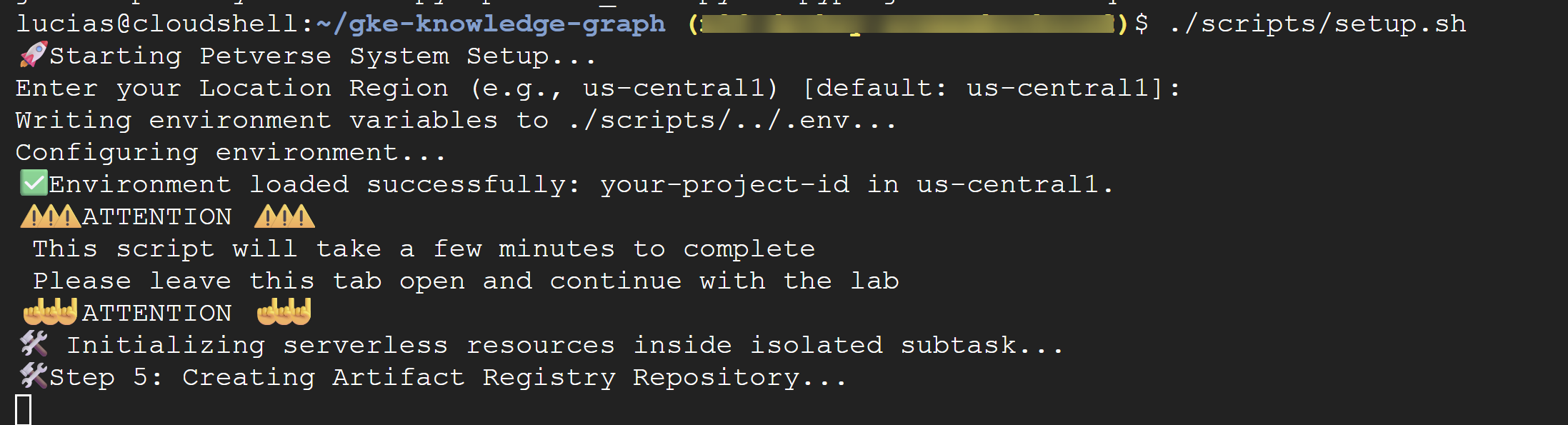
./scripts/setup.sh
スクリプトで構成の詳細情報の入力を求められた場合は、次の値を使用します。
- プロジェクト ID: 前の手順で作成した ID を使用します。
- リージョン:
us-central1
⚠️ 重要 スクリプトが完了するまでに数分かかります。このターミナル ウィンドウを開いたままにして、バックグラウンドで完了させます。次のステップに進むには、新しいターミナルタブまたはウィンドウを開いて、次のコマンドを実行します。
3. Data Agent Kit を設定する
- 右上の鉛筆アイコンを使用して、Cloud Shell エディタを有効にします。
- Cloud Shell エディタで、左側のサイドバーにある [拡張機能] アイコンをクリックします。
- Google Cloud Data Agent Kit を検索し、まだインストールされていない場合は [インストール] をクリックします。
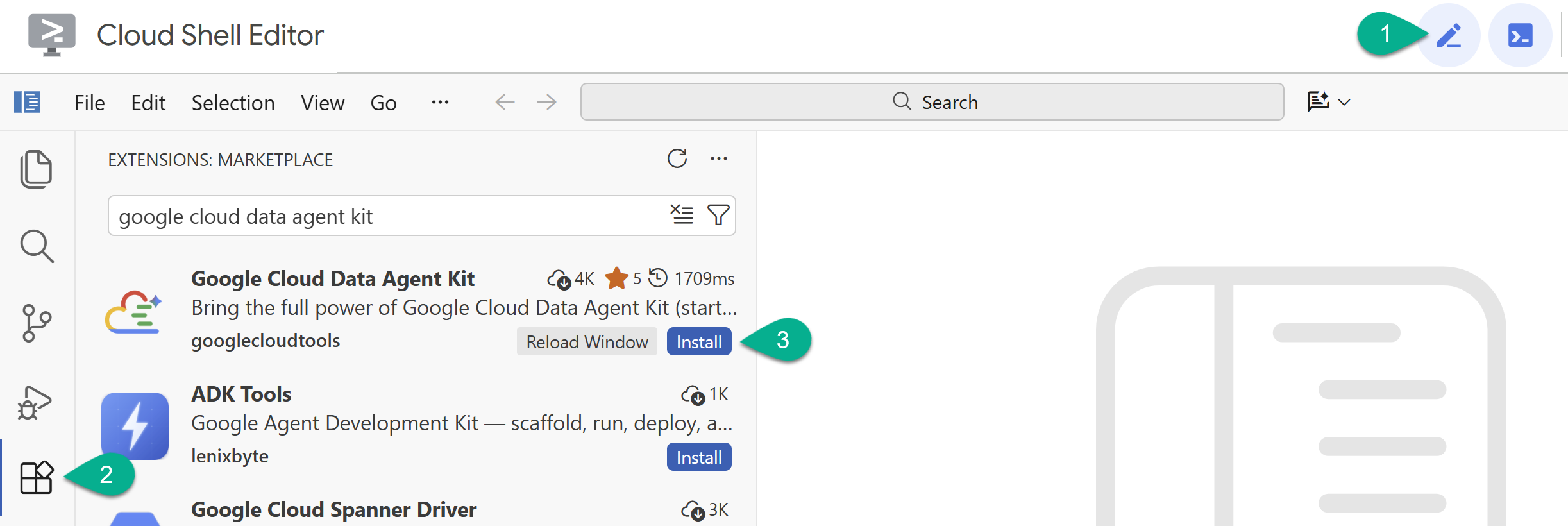
- 拡張機能を使用して Google アカウントにログインします。
- [構成の概要] で、プロジェクト ID とリージョンとして
us-central1を入力します。
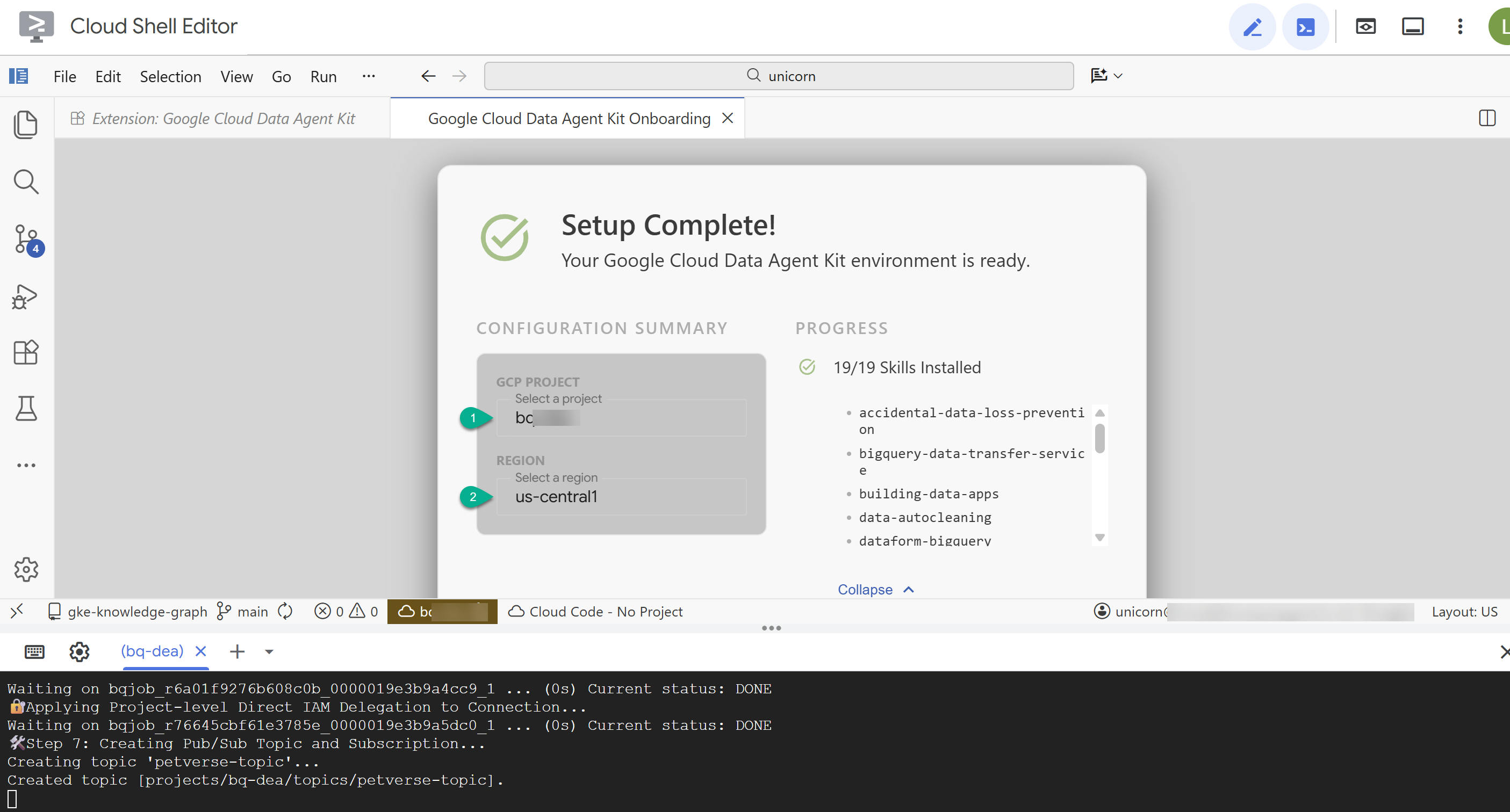
- [Configure MCP Servers] をクリックします。このウィンドウを変更する必要はありません。[使ってみる] をクリックしてください。
- プロンプトが表示されたら、ウィンドウを再読み込みします。クイックスタート ガイドのタブはここで閉じることができます。
BigQuery でテーブルを設定する
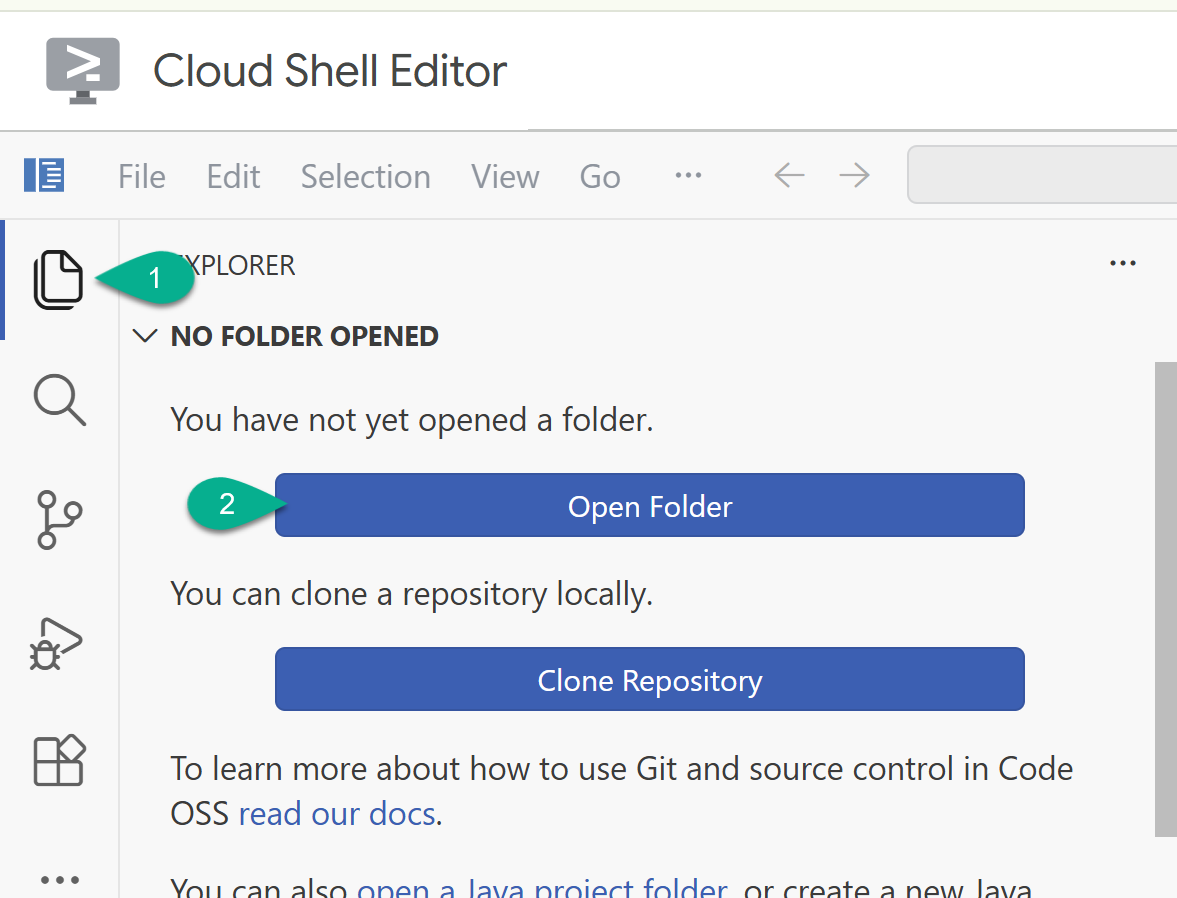
- サイドバーで、エクスプローラに戻ります。ホーム フォルダ(
/home/your_user_name/など)がまだ開いていない場合は、[フォルダを開く] をクリックして選択します。
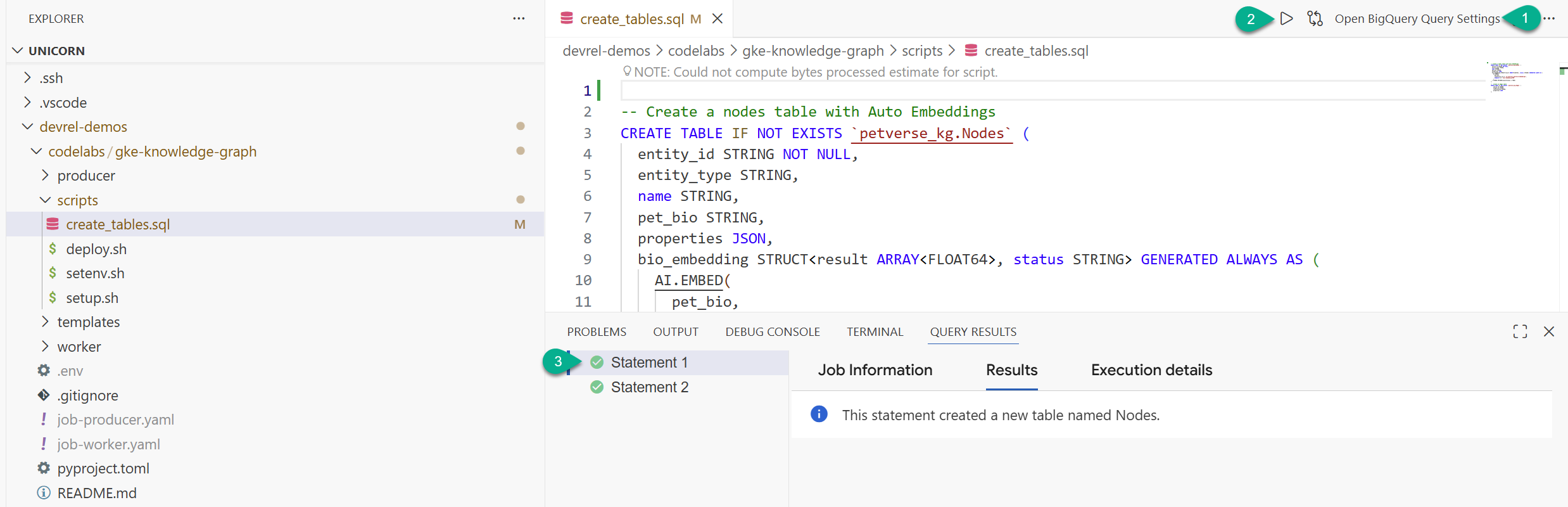
- エクスプローラ ウィンドウで、リポジトリからクローンしたフォルダ(
devrel-demos)を見つけます。codelabs/gke-knowledge-graph/scriptsにcreate_tables.sqlがあります。そのファイルを開きます 。 - 右上の [クエリ設定を開く] をクリックします。
- [BigQuery] を選択します。[保存]、[閉じる] の順にクリックします。
- [実行] をクリックします。
2 つのステートメントが正常に実行されたことを確認できます。これで、ナレッジグラフのノードとエッジを保存するテーブルが作成されました。
create_tables.sql タブと結果コンソールを閉じることができます。
4. GKE クラスタを初期化する
GKE Autopilot を使用してデータ処理ジョブを実行します。Autopilot はクラスタ インフラストラクチャを管理するため、おすすめの効果的な手法です。
これで、設定スクリプトが完了したはずです。🎉🦄 Setup successfully finished! 🎉🦄 という成功メッセージが表示されます。
次のコマンドをターミナルに貼り付けて、クラスタを作成します。
source scripts/setenv.sh
gcloud container clusters create-auto petverse-cluster \
--region=$REGION
🕓 これには約 5 分かかります。
クラスタとやり取りするための認証情報を取得します。
source scripts/setenv.sh
gcloud container clusters get-credentials petverse-cluster --region $REGION
以下のような出力が表示されます。
Fetching cluster endpoint and auth data. kubeconfig entry generated for petverse-cluster.
5. Workload Identity を構成する
GKE 用 Workload Identity 連携(直接リソース アクセスを使用)を使用すると、GKE ワークロードはサービス アカウント キーを管理しなくても、Google Cloud サービスに安全にアクセスできます。
deploy.sh を実行して、次の操作を行います。
- Kubernetes サービス アカウントを作成する
- 必要な IAM ロールを Kubernetes サービス アカウント プリンシパルに直接付与する
- IAM サービス アカウントを Kubernetes サービス アカウントにバインドする
- Kubernetes サービス アカウントにアノテーションを付けてリンクを完了する
source scripts/setenv.sh
./scripts/deploy.sh
6. 分離された処理ジョブをデプロイする
このステップでは、エンキューアー(プロデューサー)と処理エンジン(ワーカー)を GKE にデプロイします。
新しい分離型アーキテクチャでは、Google Cloud Pub/Sub を使用してアセットを非同期で処理します。
- プロデューサー は GCS をスキャンし、すべてのファイルパスを Pub/Sub キューにエンキューします。
- ワーカー のプールは GKE でスケールアップし、タスクを並行して動的に pull し、Gemini を介して処理して BigQuery に書き込みます。
setup.sh スクリプトは、プロデューサーとワーカーの両方のコンテナ イメージをビルドして push し、Pub/Sub トピックをエンキューし、GKE デプロイ マニフェスト job-producer.yaml と job-worker.yaml を動的に生成しました。
- プロデューサー ジョブを適用して、ストレージ バケットをスキャンし、すべてのアセットをキューに登録します。
kubectl apply -f job-producer.yaml
このジョブはメタデータのみをキューに入れるため、すぐに実行して完了します。
- 6 つの並列ワーカー を実行してキューを排出するように構成されたワーカー ジョブをデプロイします。
kubectl apply -f job-worker.yaml
GKE Autopilot は保留中の Pod を自動的に検出し、コンピューティング ノードを動的にスケールアップし、ワーカーを並行して実行して、エンキューされた音声、動画、画像、CSV を処理します。
7. 結果を検証する
- ジョブのステータスを確認します。
kubectl get jobs
petverse-producer-job と petverse-worker-job の両方が正常に完了するまで待ちます。
🕓 これには約 10 分かかります。次のコマンドで進行状況を確認できます。
- プロデューサーのログを確認して、ファイルが正常にエンキューされたことを確認します。
cd ~/devrel-demos/codelabs/gke-knowledge-graph
source scripts/setenv.sh
kubectl logs -l app=petverse-producer --tail=50
- 並列ワーカーがキューからファイルを処理する様子を確認します。
kubectl logs -l app=petverse-worker --tail=50
(ワーカーは 60 秒のアイドル タイムアウトがあり、Pub/Sub キューが空になると自動的にシャットダウンしてクリーンアップされます)。
BigQuery でデータを確認します。
- BigQuery Studio に移動します。petverse_kg.Nodes と petverse_kg.Edges の 2 つのテーブルが作成されます。
- テーブルの内容を表示するには、テーブル名をダブルクリックして [プレビュー] をクリックします。
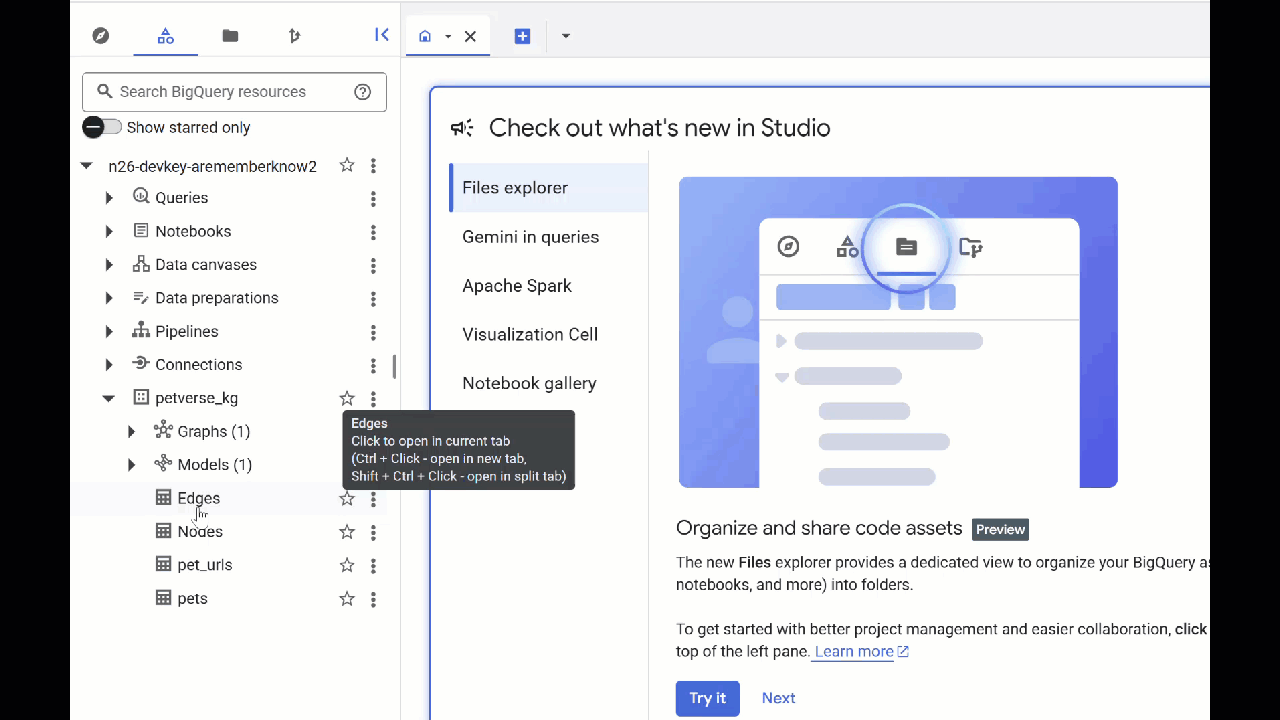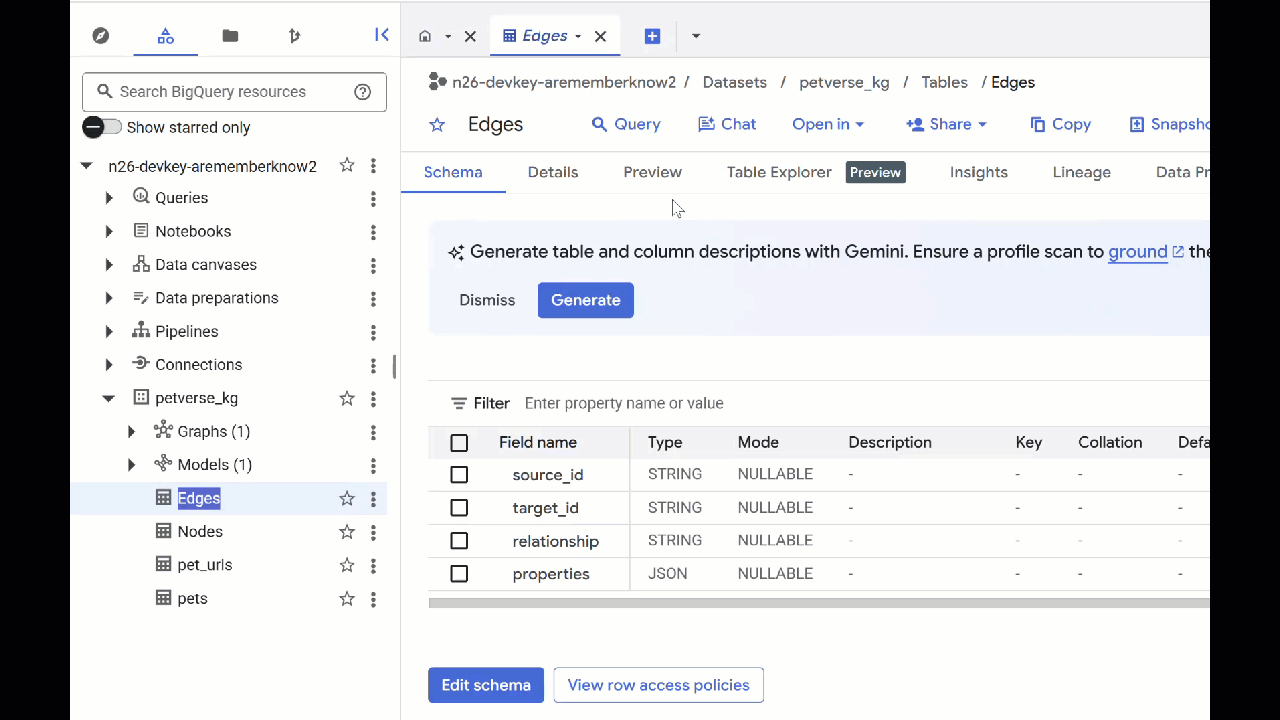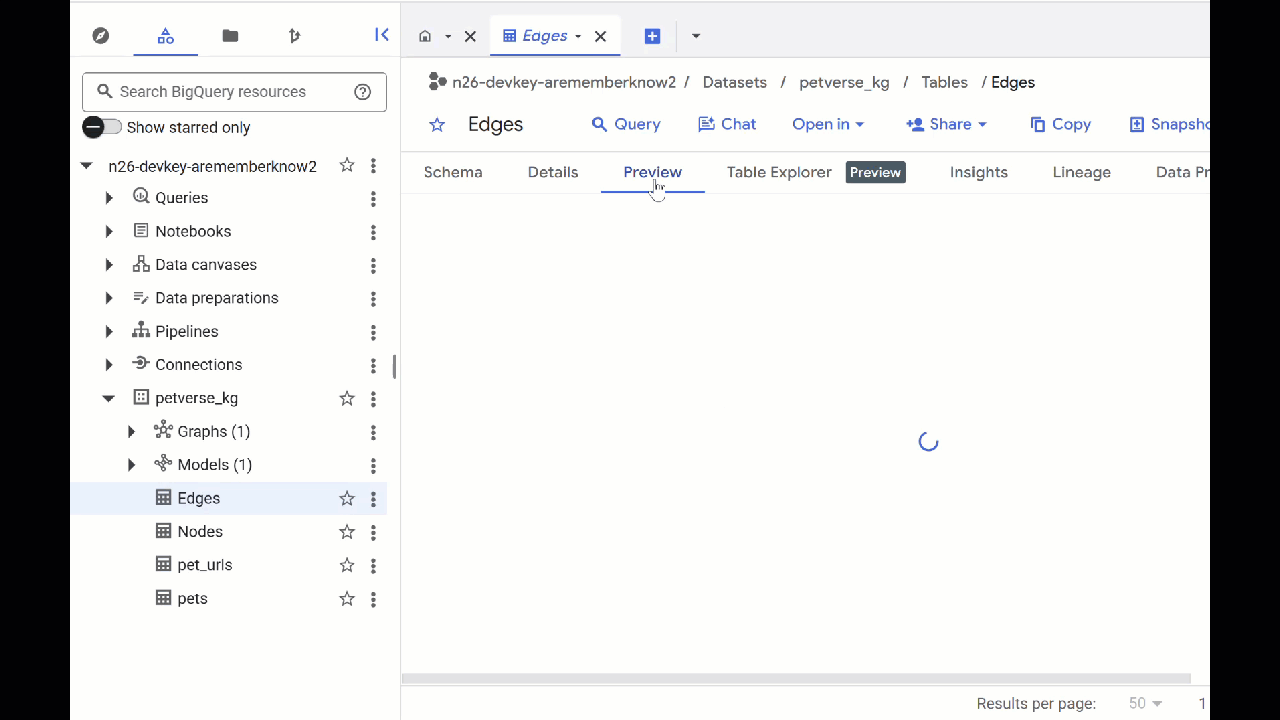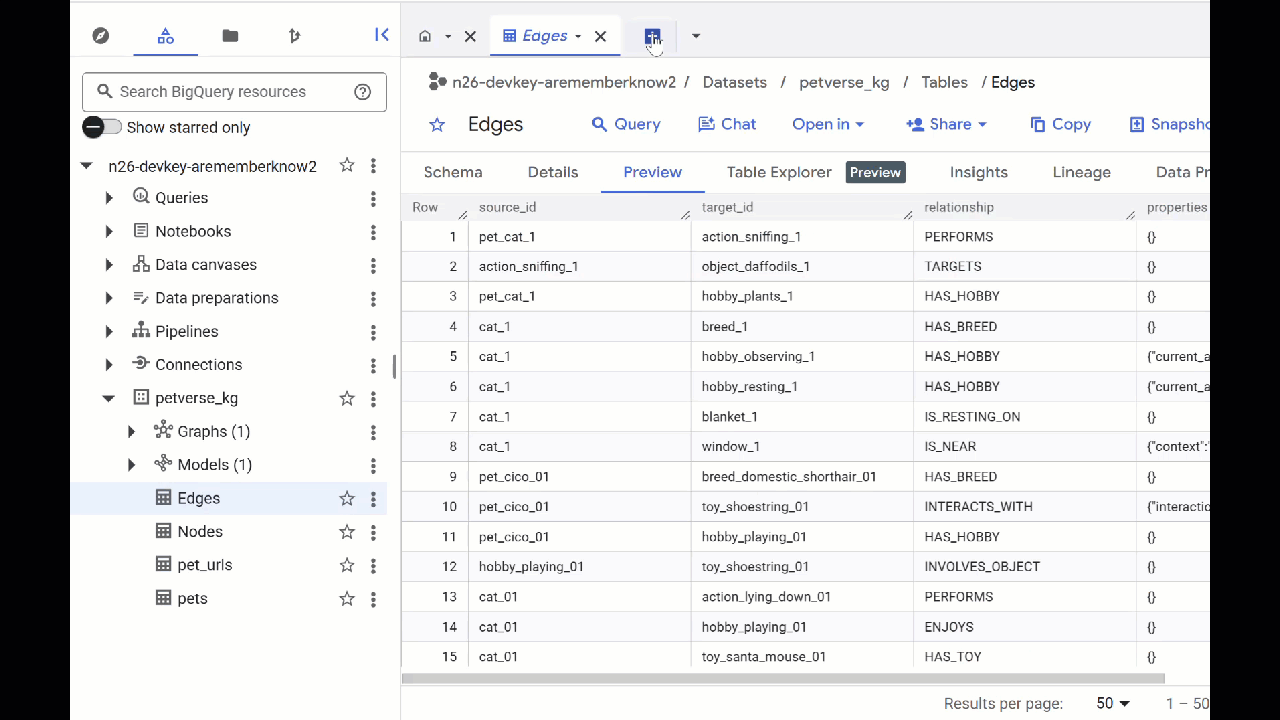
Nodes テーブルには、Gemini が音声、動画、画像で取得したエンティティに関する情報が含まれています。Edges テーブルには、それらの関係が含まれています。たとえば、SQL という名前の猫の音声を聞くと、靴ひもで遊ぶのが好きで、フリーズドライの魚が好きです。
- [+] ボタンを使用して、新しいクエリを作成します。次のステートメントを貼り付けて、[実行] をクリックします。
SELECT n.name, n.entity_id, e.relationship, e.target_id
FROM
`petverse_kg.Nodes` n
JOIN
`petverse_kg.Edges` e
ON n.entity_id = e.source_id
WHERE n.name = 'SQL'
- [+] ボタンを使用して、新しいクエリを作成します。次のステートメントを貼り付けて、[実行] をクリックします。
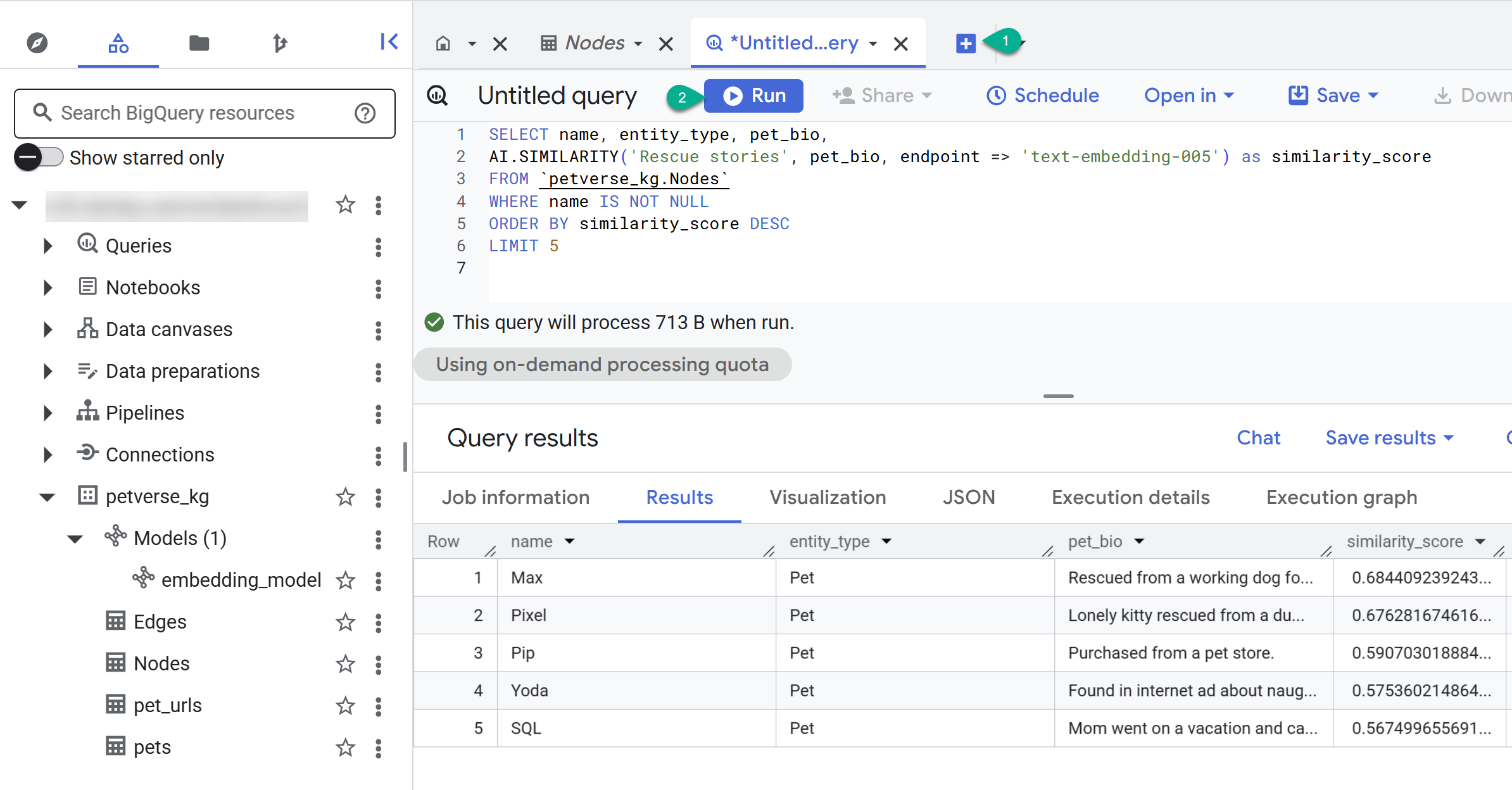
SELECT name, entity_type, pet_bio,
AI.SIMILARITY('Pets who like to relax', pet_bio, endpoint => 'text-embedding-005') as similarity_score
FROM `petverse_kg.Nodes`
WHERE name IS NOT NULL
ORDER BY similarity_score DESC
LIMIT 5
リラックスしたいペットのノードが表示されます。このクエリでは、AI 関数 AI.SIMILARITY を使用してセマンティック検索を行い、クエリテキストに最も類似したバイオを持つペットを検索しました。
プロパティ グラフを構築する
BigQuery にノードとエッジができたので、プロパティ グラフを作成して関係を簡単にクエリできます。
グラフを作成する
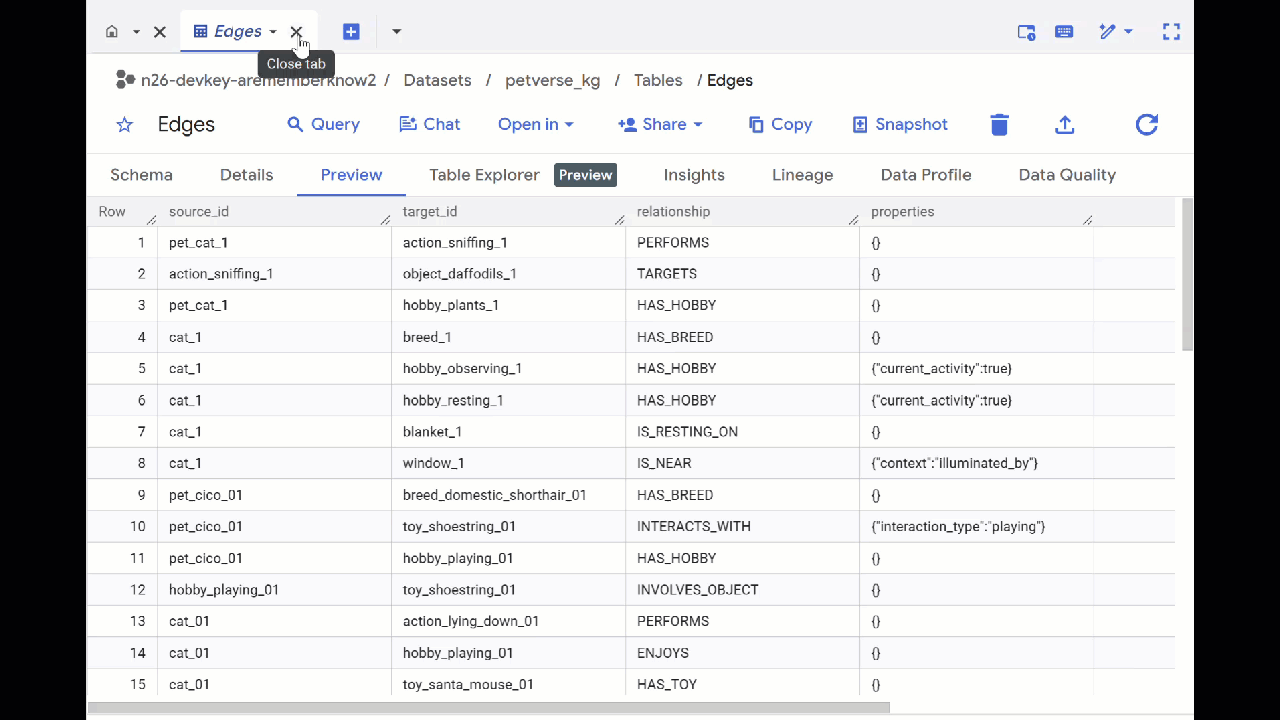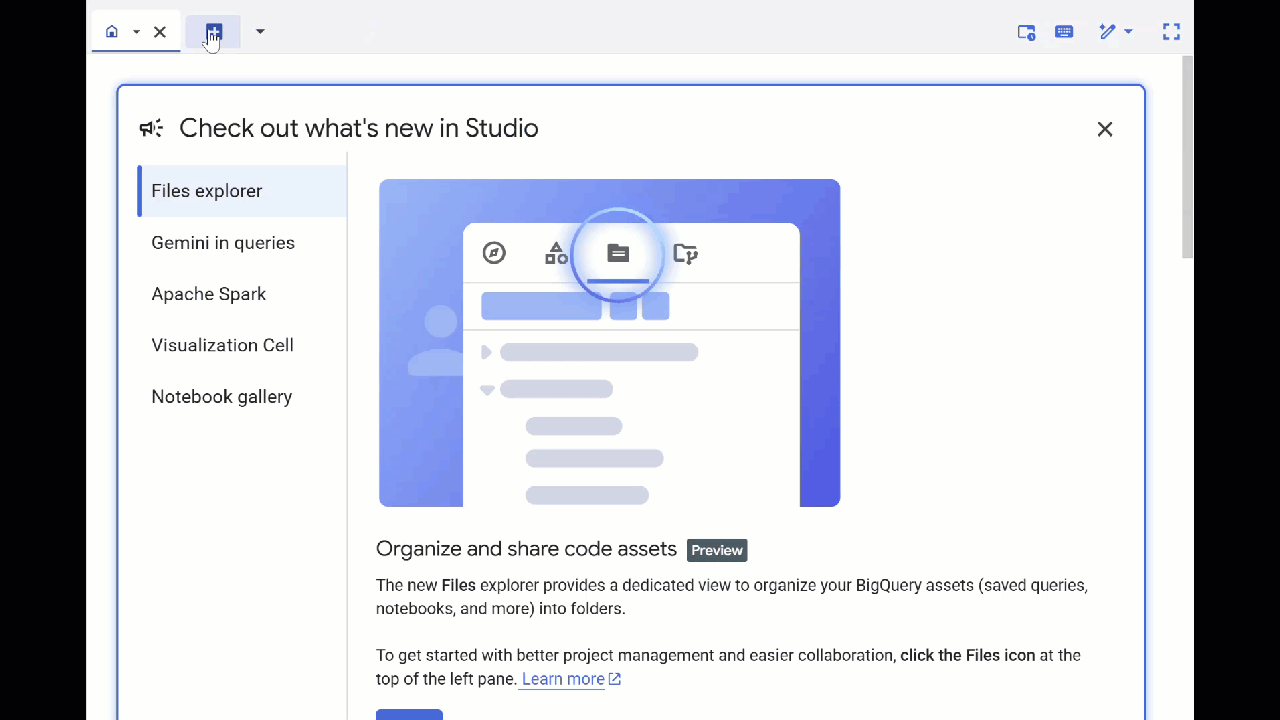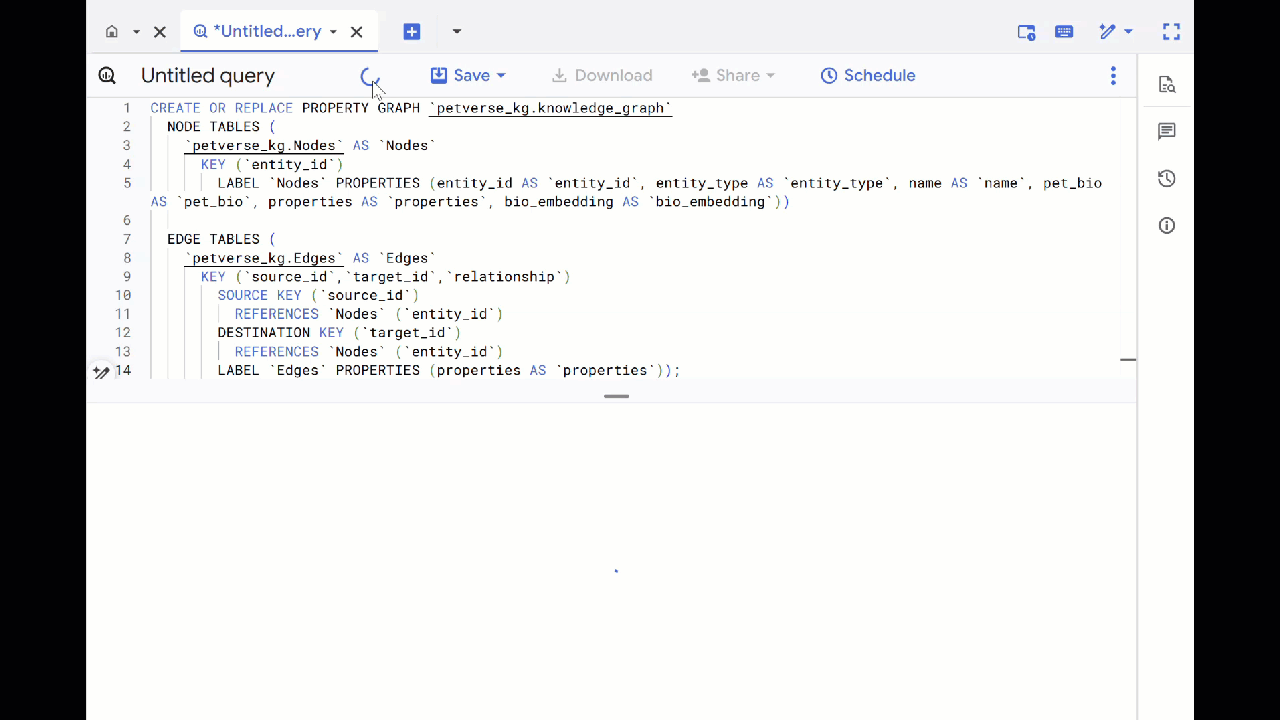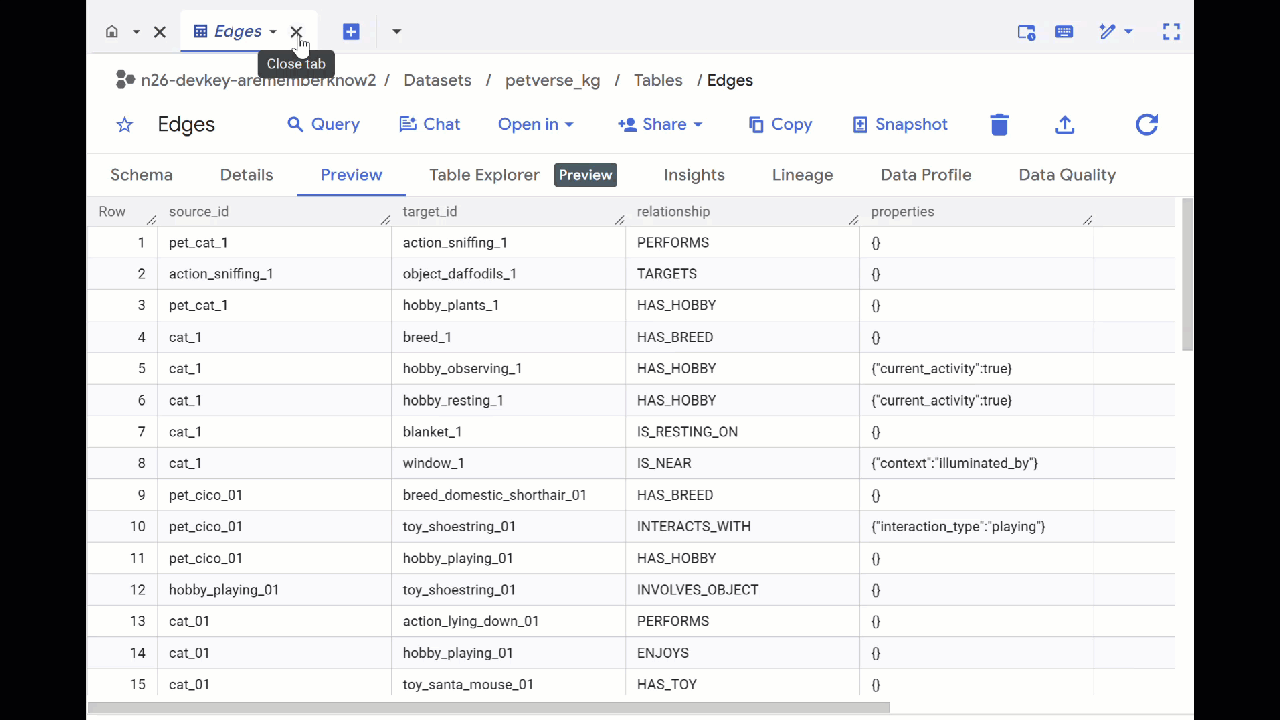
- 前のクエリを上書きし、次の DDL を実行してプロパティ グラフを作成します。
CREATE OR REPLACE PROPERTY GRAPH `petverse_kg.knowledge_graph`
NODE TABLES (
`petverse_kg.Nodes` AS `Nodes`
KEY (`entity_id`)
LABEL `Nodes` PROPERTIES (entity_id AS `entity_id`, entity_type AS `entity_type`, name AS `name`, pet_bio AS `pet_bio`, properties AS `properties`, bio_embedding AS `bio_embedding`))
EDGE TABLES (
`petverse_kg.Edges` AS `Edges`
KEY (`source_id`,`target_id`,`relationship`)
SOURCE KEY (`source_id`)
REFERENCES `Nodes` (`entity_id`)
DESTINATION KEY (`target_id`)
REFERENCES `Nodes` (`entity_id`)
LABEL `Edges` PROPERTIES (properties AS `properties`));
- [グラフに移動] をクリックします。グラフの可視化が表示され、エッジが自分自身に接続されたノードが表示されます。これは予期された状況です。
グラフをクエリする
- 以前のクエリをすべて閉じて、[+] ボタンで新しい空白のクエリを開くことができます。
- GQL を使用して、共通の興味(趣味、好きな食べ物、おもちゃなど)を介して他のペットに関連するペットを見つけます。このマルチホップ クエリは、同じノードに接続されている 2 匹の異なるペットと一致します。
GRAPH `petverse_kg.knowledge_graph`
MATCH p = (pet1:Nodes)-[e1]->(interest:Nodes)<-[e2]-(pet2:Nodes)
WHERE pet1.entity_id != pet2.entity_id
AND (LOWER(pet1.entity_type) = 'pet' AND LOWER(pet2.entity_type) = 'pet')
AND LOWER(interest.entity_type) IN ('hobby', 'action', 'activity', 'food', 'toy')
RETURN TO_JSON(p) as res
LIMIT 100
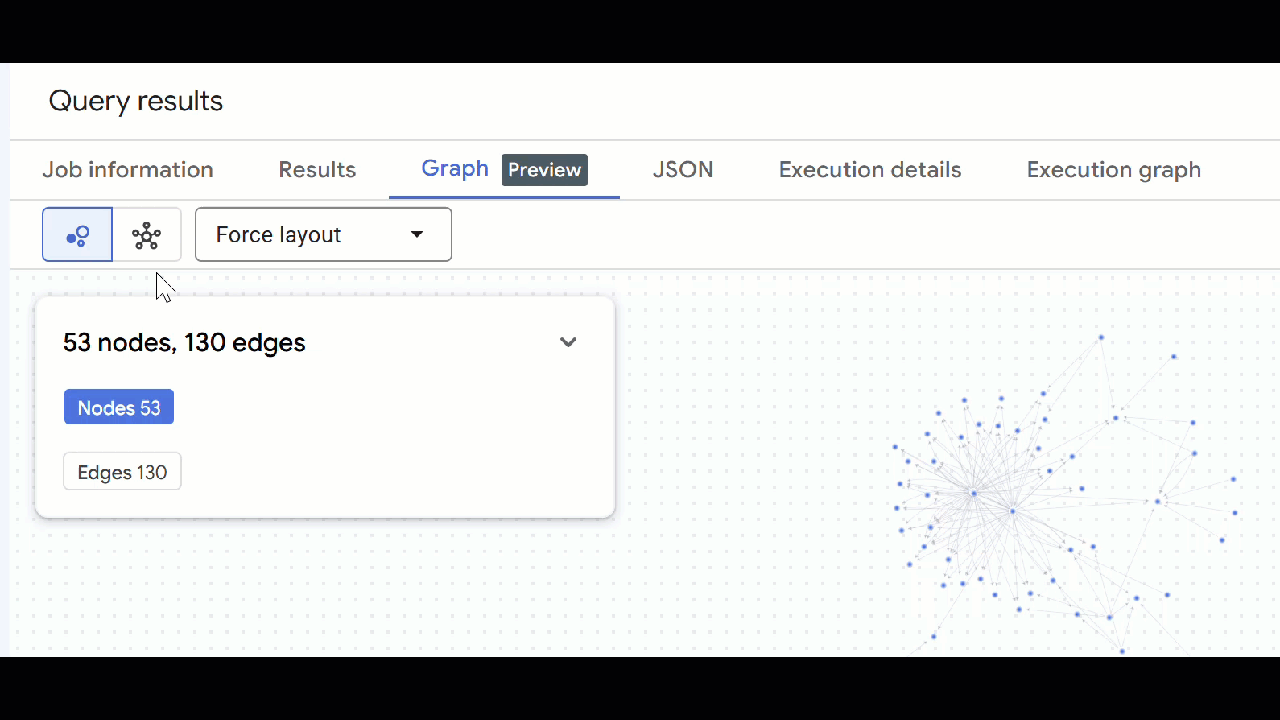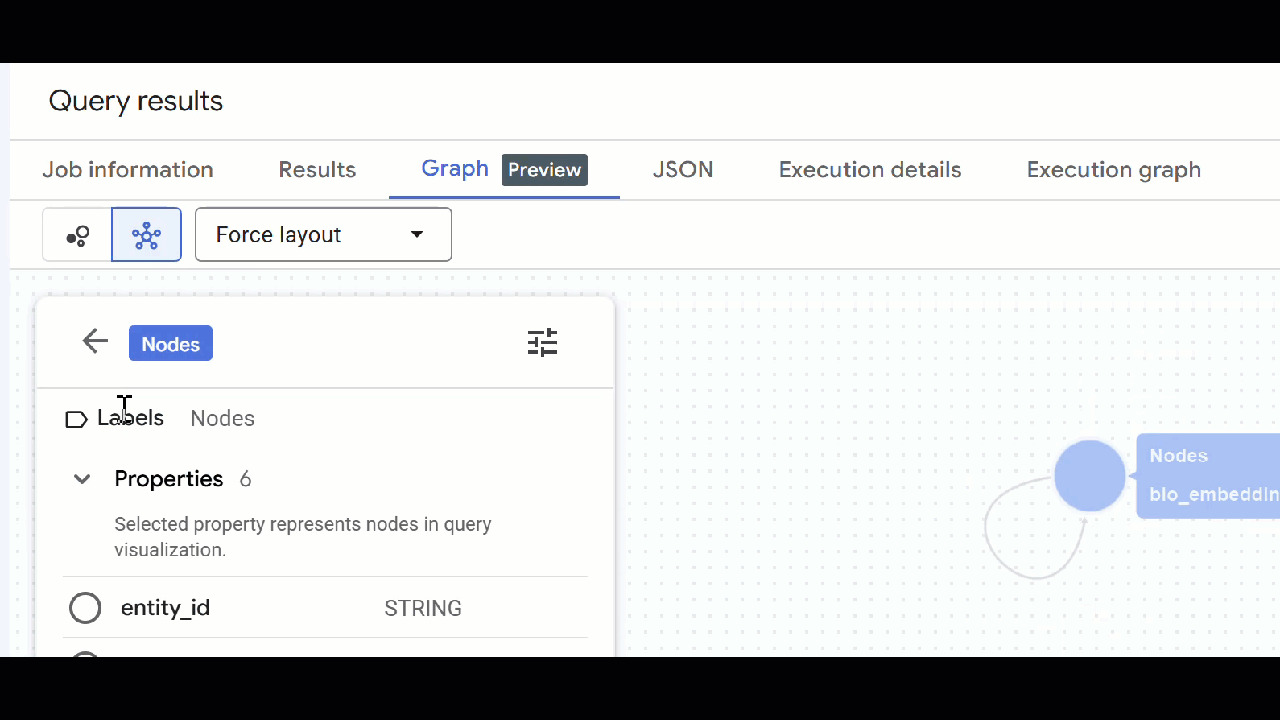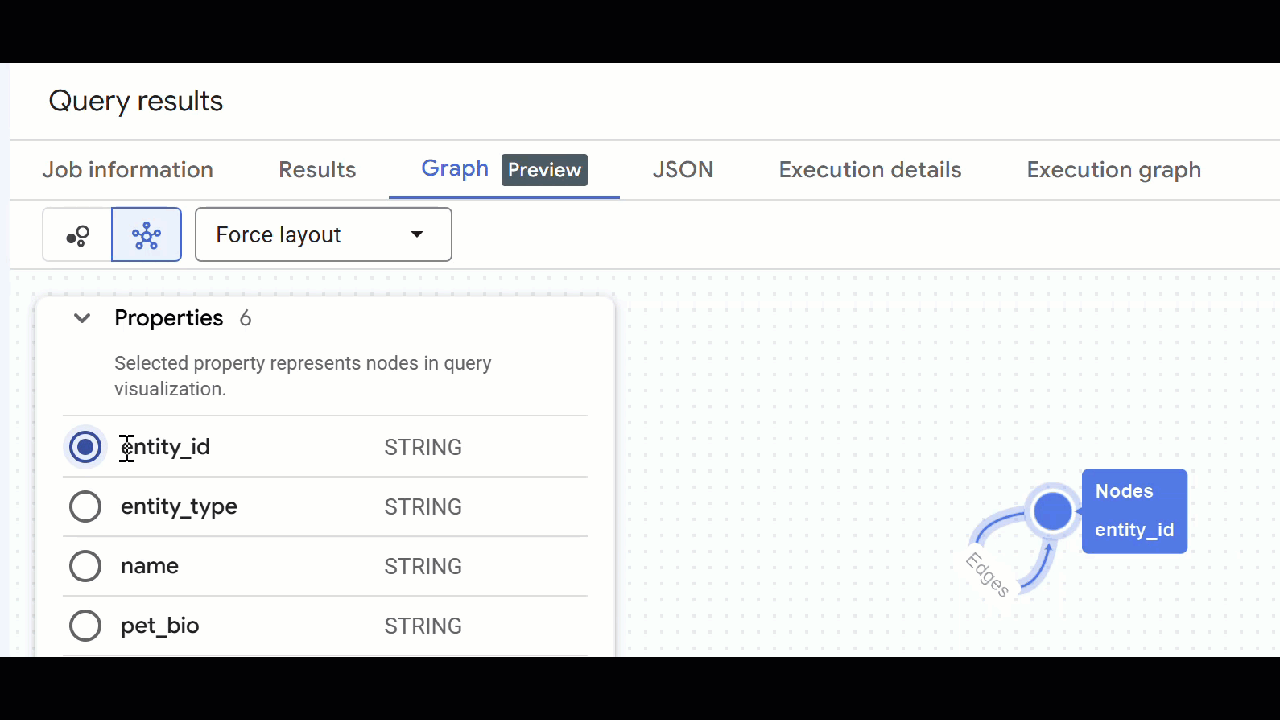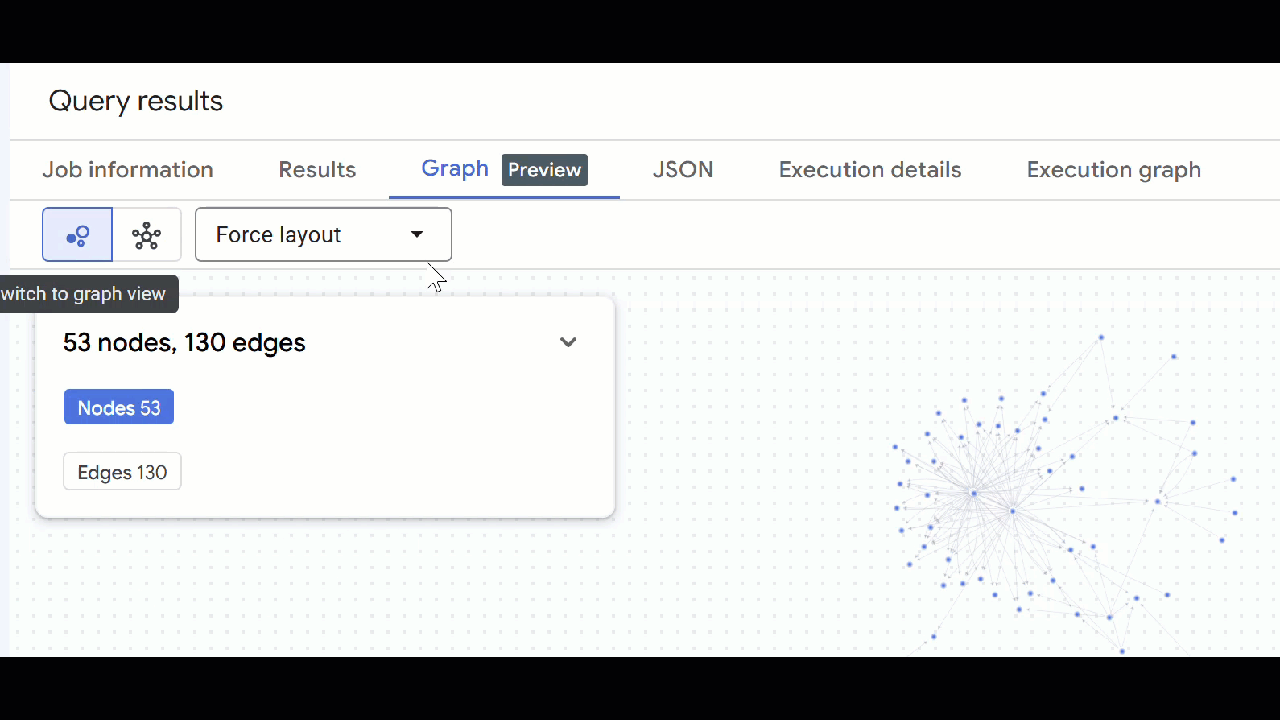
- グラフの可視化が表示されます。ノードをクリックすると、ノードとエッジのプロパティが表示されます。
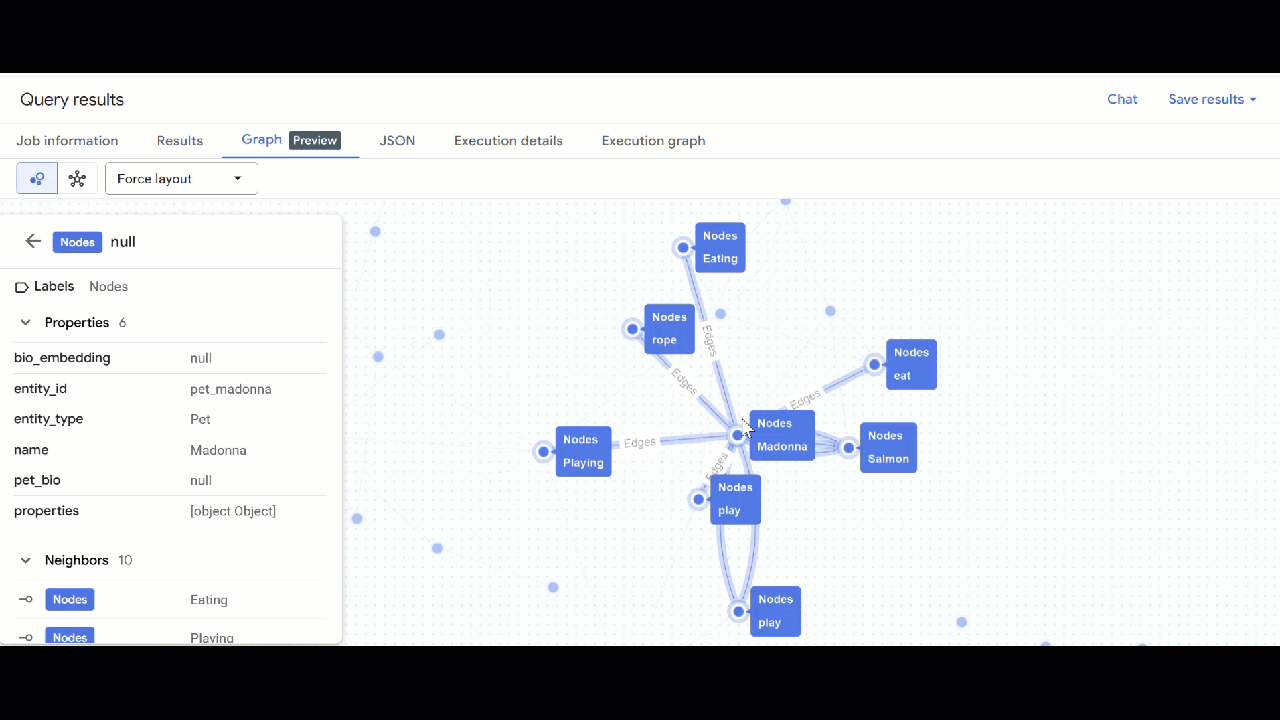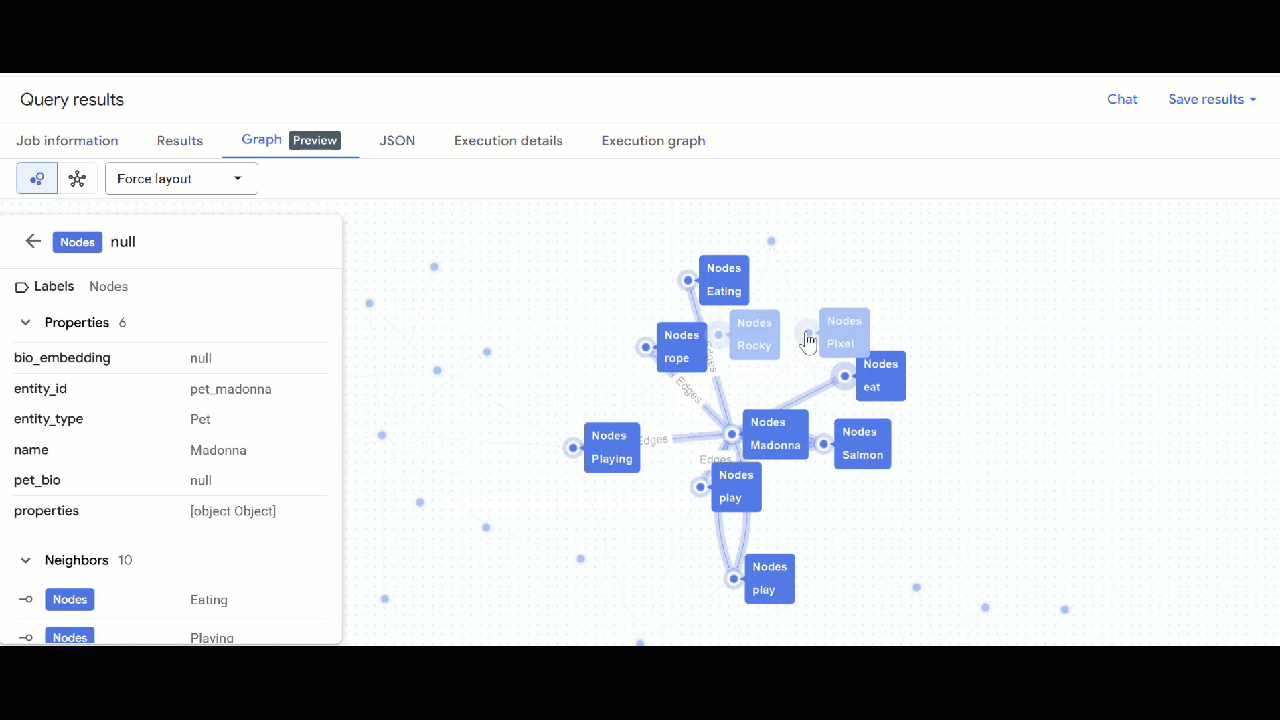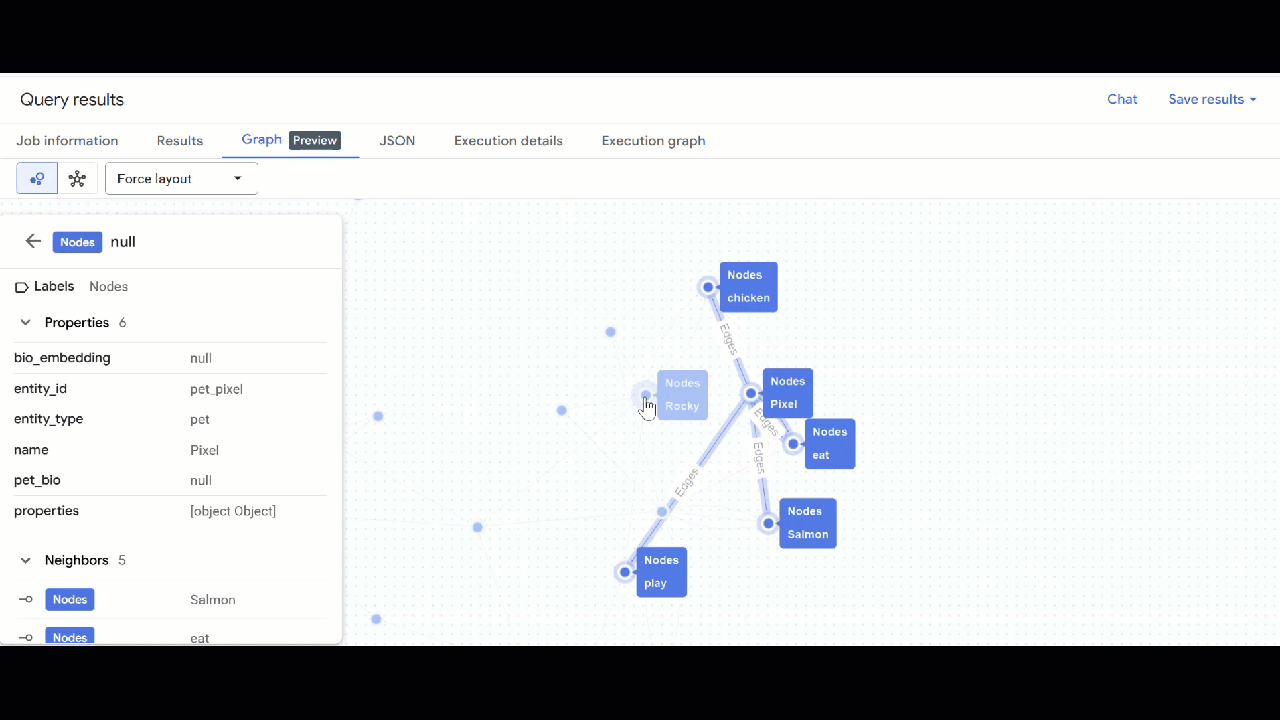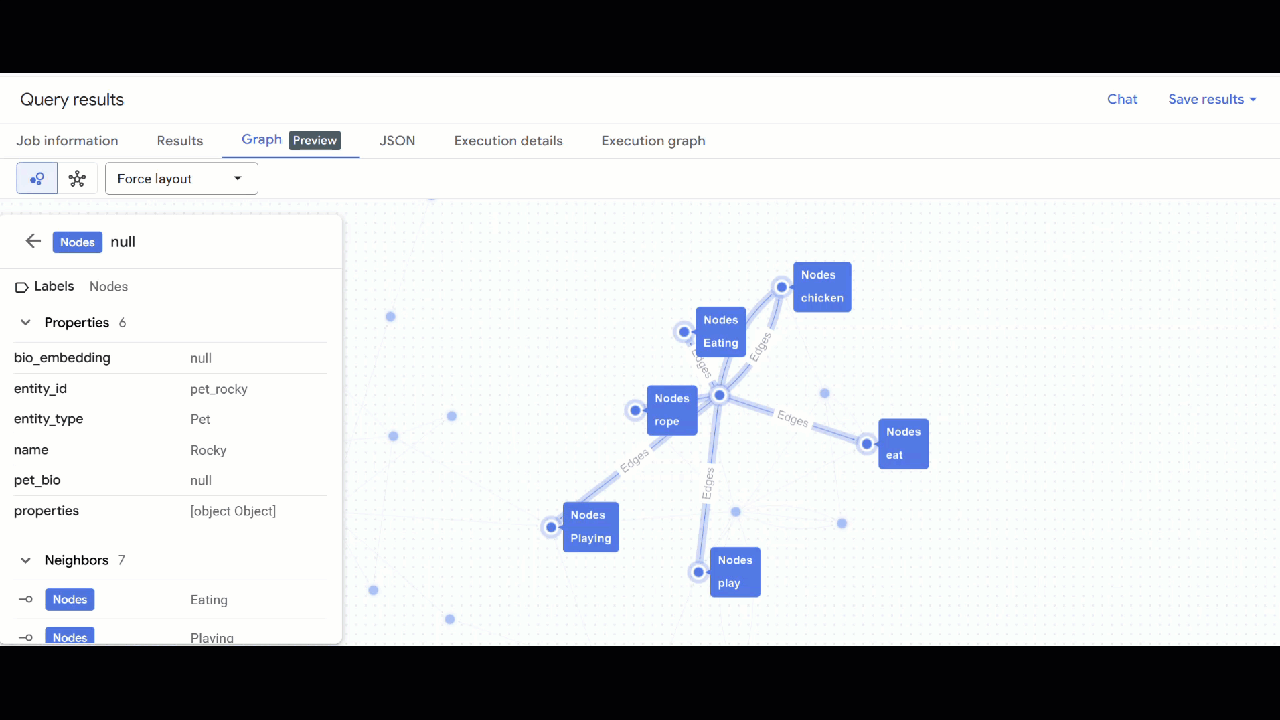
🕵️ ヒント: ノードをクリックして [スキーマビューに切り替え] をクリックすると、ノードに表示される値を調整できます。
- 開いているクエリタブをすべて閉じることができます 。
8. グラフでチャットする
- [+] 記号の横にプルダウン メニューがあります。[会話] を選択します。
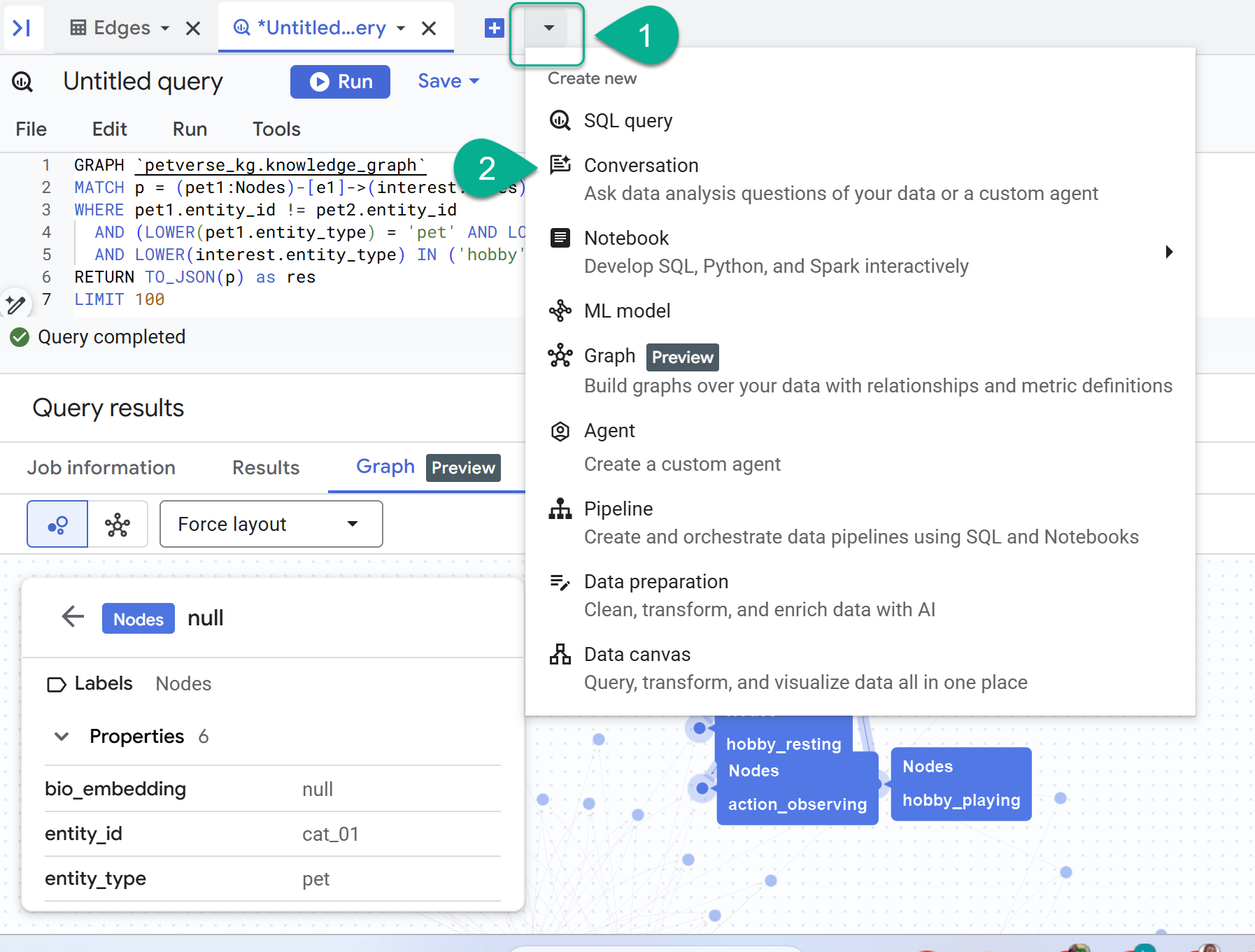
- Gemini で Data Analytics API を有効にするよう求められます。両方の API を有効にします。完了したら、ウィンドウを更新するか、新しい会話を作成してエージェントを表示します。
- [新しいエージェント] をクリックします。
- エージェントに
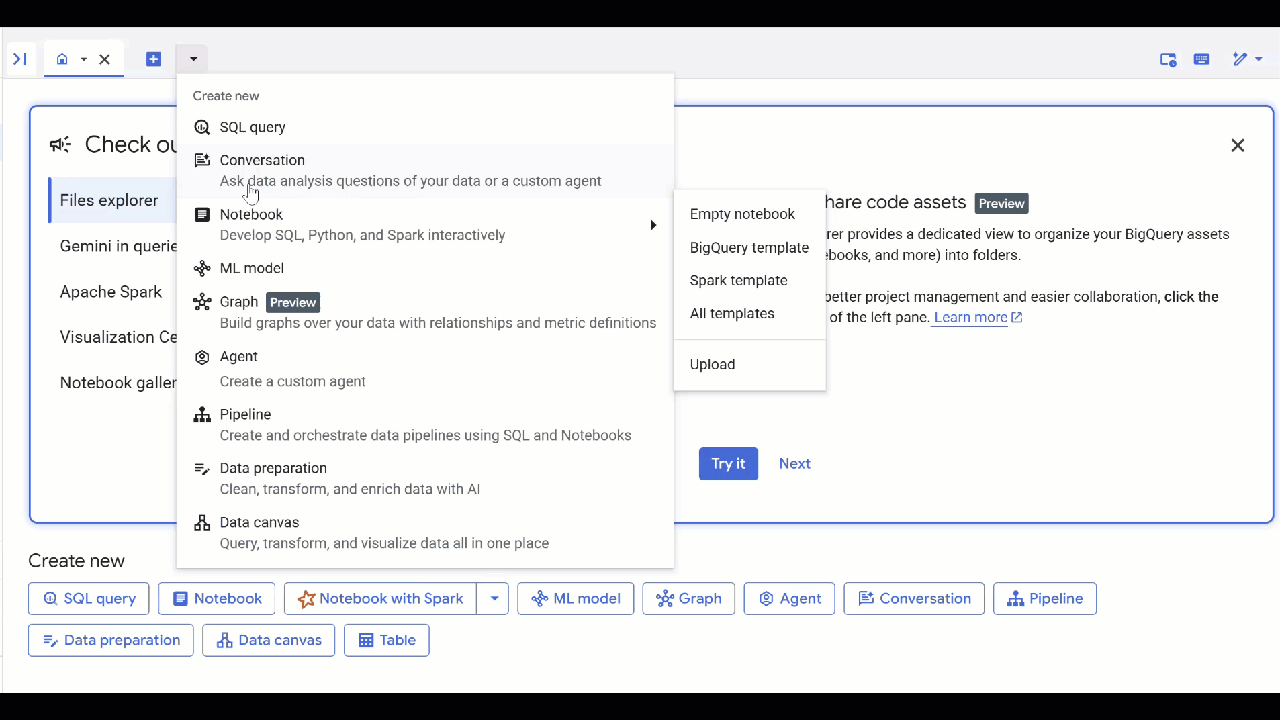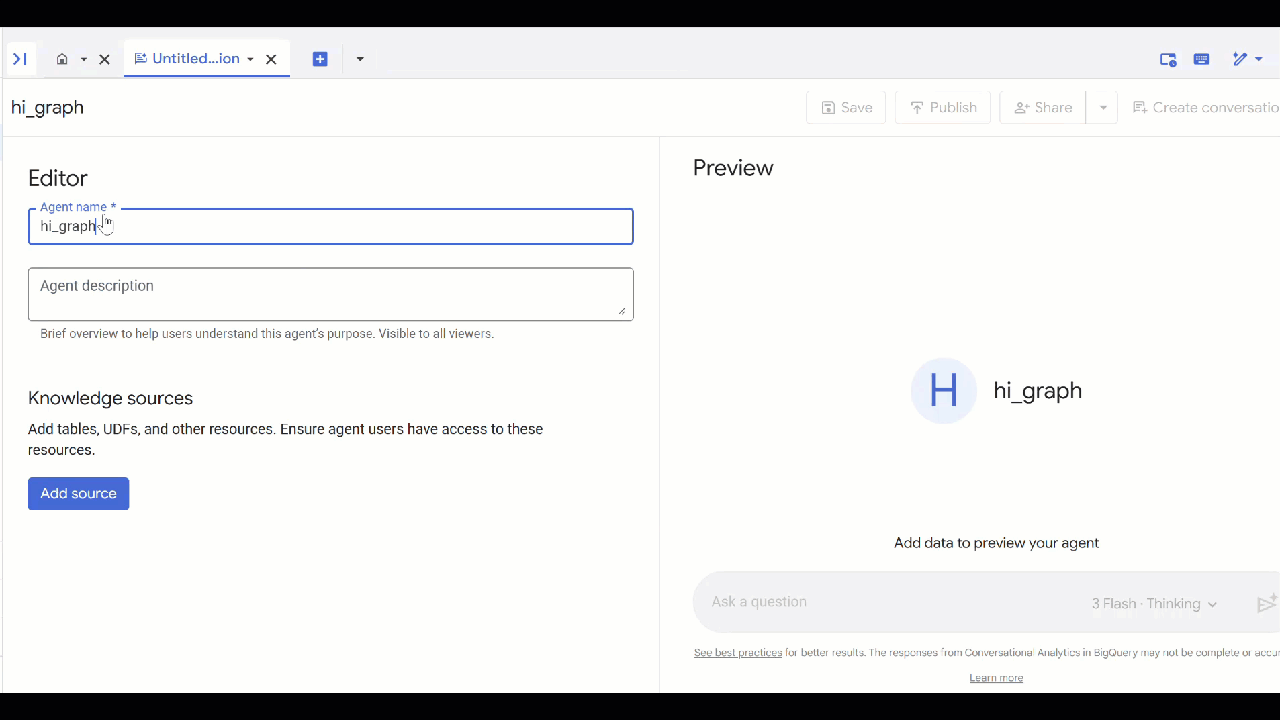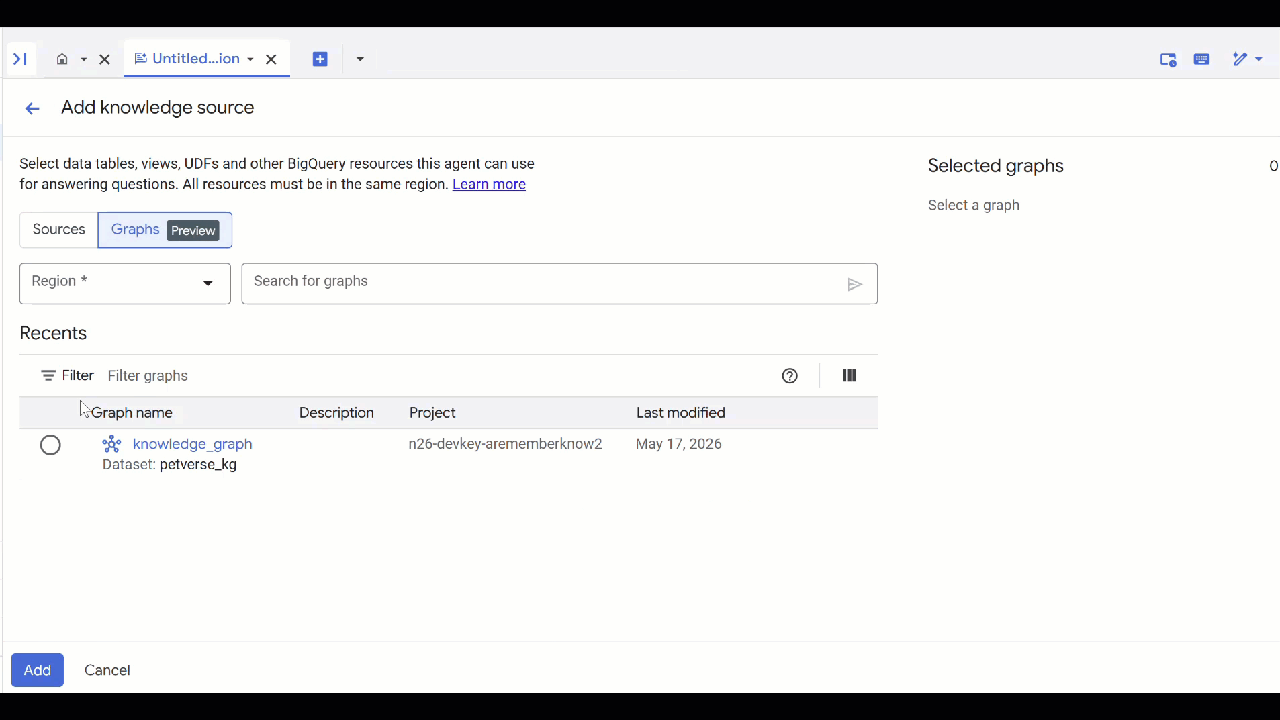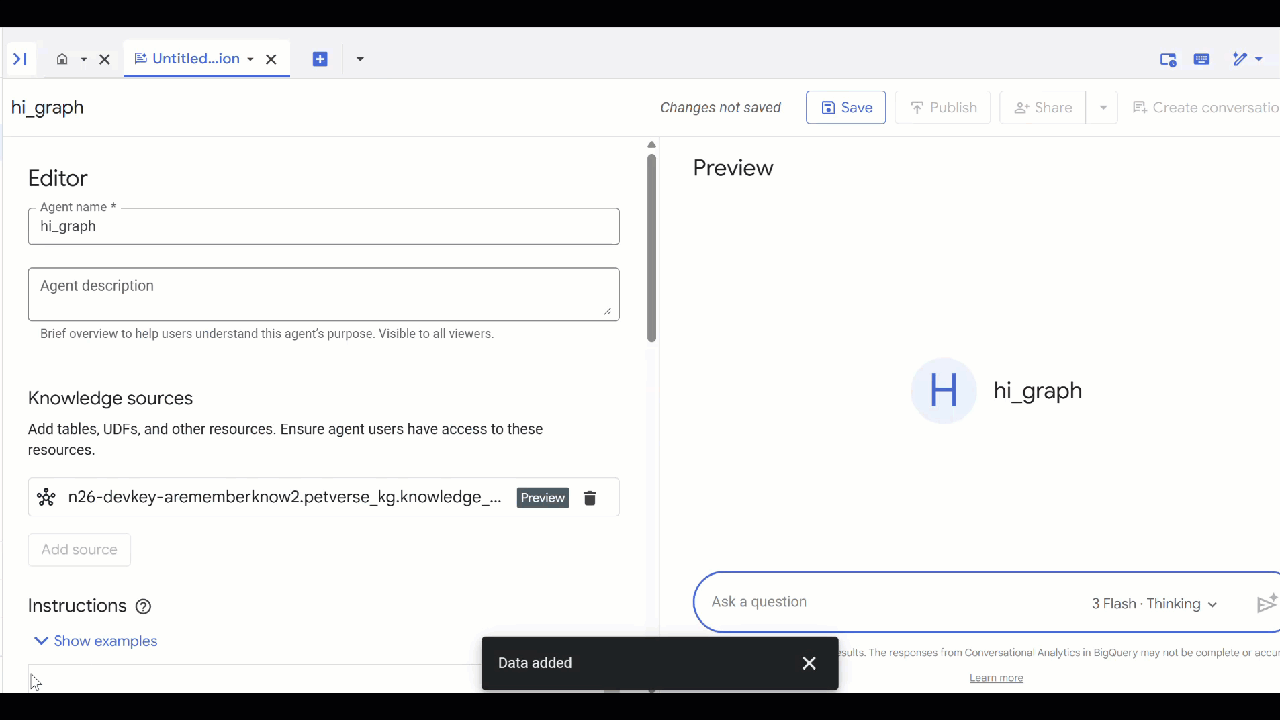
petverseなどの名前を付けます。 - [ソースを追加]、[グラフ] の順にクリックします。
- 作成した
knowledge_graphを選択して [追加] をクリックします。
エージェントに質問して、回答とその理由を確認できるようになりました。インスピレーションが必要な場合は、次の質問例をご覧ください。思考モデルは時間がかかる場合がありますが、より適切な GQL クエリを作成できる可能性があります。Show Thinking を展開すると、構築内容を確認できます。
- 似たような食べ物を共有しているペットや、昼寝好きなペットと友達になっているペットを見つけます。
- 趣味、好きな食べ物、おもちゃがまったく同じペットはいますか?ペアとその共通の興味を一覧表示します。
- 同じ種または品種で、趣味がまったく異なるペットを見つけます。
9. クリーンアップ
Google Cloud アカウントに継続的に課金されないようにするには、この Codelab で作成したリソースを削除します。
- GKE クラスタを削除します。
gcloud container clusters delete petverse-cluster --region $REGION --quiet
- BigQuery データセットを削除します(これにより、すべてのテーブルが削除されます)。
bq rm -r -f -d $PROJECT_ID:petverse_kg
- Pub/Sub キューリソースを削除します。
gcloud pubsub subscriptions delete petverse-sub --quiet
gcloud pubsub topics delete petverse-topic --quiet
- Artifact Registry リポジトリを削除します。
gcloud artifacts repositories delete gke-cats-repo --location=$REGION --quiet
- プロジェクト固有の GCS バケットを削除します。
gcloud storage buckets delete gs://$PROJECT_ID-petverse --quiet
10. 完了
おめでとうございます!GKE と Gemini を使用して分散型ナレッジグラフ パイプラインを構築し、BigQuery Property Graphs を使用してクエリを実行できました。
学習した内容
- GKE Autopilot に分散ジョブをデプロイする方法。
- マルチモーダル データ抽出に Gemini を使用する方法。
- BigQuery の自動エンベディングを使用する方法。
- BigQuery でプロパティ グラフ を作成してクエリする方法。