
1. 소개
이 Codelab에서는 'Petverse'를 위한 분산 지식 획득 파이프라인을 빌드합니다. Cloud Storage 버킷에서 구조화되지 않은 멀티미디어 애셋 (오디오, 동영상, 이미지, 텍스트/CSV)을 처리하고, 반려동물에 관한 핵심 정보 (좋아하는 음식, 취미)를 추출하고, 지식 그래프를 만듭니다. Google Kubernetes Engine (GKE)에서 Gemini 멀티모달리티 처리를 사용하여 멀티미디어 파일의 처리를 확장합니다. 마지막으로 이 데이터를 BigQuery에 저장하고 새로운 BigQuery 속성 그래프 기능을 사용하여 관계를 분석합니다.
Google Kubernetes Engine의 기능을 사용하여 대량의 데이터를 병렬로 처리하는 방법을 보여드리겠습니다.
지식 그래프가 필요한 이유
지식 그래프는 항목 간의 복잡한 관계를 나타내고 분석하는 데 기존 관계형 데이터베이스보다 적합합니다.
Gemini 2.5 Flash를 사용하여 이미지, 오디오, 동영상 파일을 분석하고 다양한 반려동물에 관한 사실을 파악합니다.
실습할 내용
- GKE에서 분산 데이터 처리 작업을 빌드하고 배포합니다.
- Gemini를 사용하여 멀티미디어 파일에서 항목과 관계를 추출합니다.
- BigQuery에 지식 그래프 데이터를 저장합니다.
- Graph Query Language (GQL)를 사용하여 BigQuery에서 속성 그래프를 만들고 쿼리합니다.
필요한 항목
- 웹브라우저(예: Chrome)
- 결제가 사용 설정된 Google Cloud 프로젝트
- 리소스를 만들고 IAM 정책을 수정할 수 있는 프로젝트 권한
이 Codelab은 초보자를 포함한 모든 수준의 개발자를 대상으로 합니다.
예상 소요 시간: 45분
비용: 이 Codelab에서 만든 리소스의 비용은 5달러 미만입니다.
2. 시작하기 전에
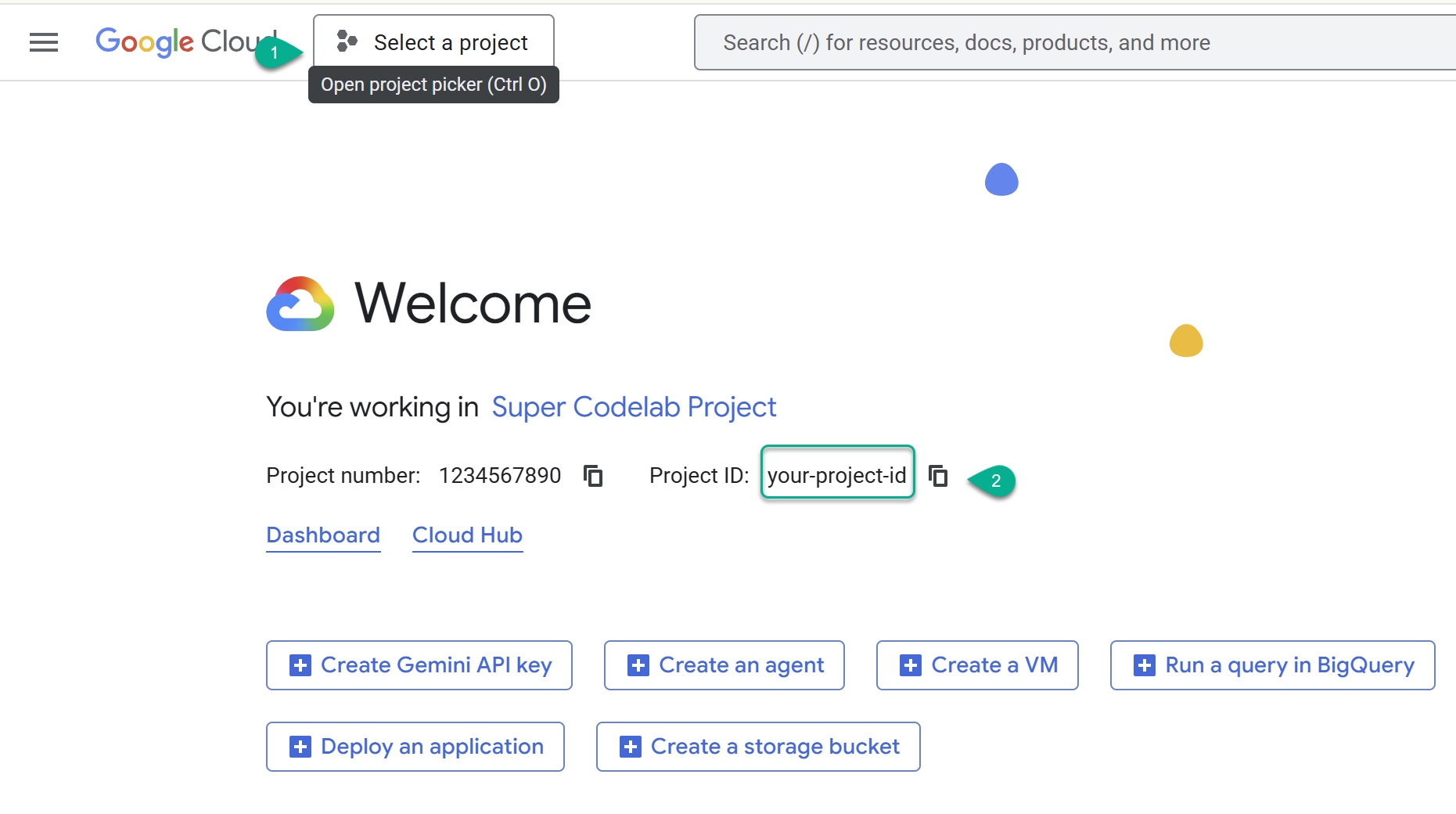
Google Cloud 프로젝트 만들기
- Google Cloud 콘솔(https://console.cloud.google.com)로 이동한 다음 Google Cloud 프로젝트를 선택하거나 만듭니다.
- ⚠️ 프로젝트 ID를 기록해 둡니다. 이 실습에서 여러 명령어에 사용됩니다.
Cloud Shell 시작
- 새 탭에서 Cloud Shell을 엽니다(https://shell.cloud.google.com/).
- 메시지가 표시되면 승인을 클릭합니다.
PROJECT_ID를 바꾸고 다음 명령어를 터미널에 붙여넣습니다.
export PROJECT_ID="YOUR_PROJECT_ID"
gcloud config set project $PROJECT_ID
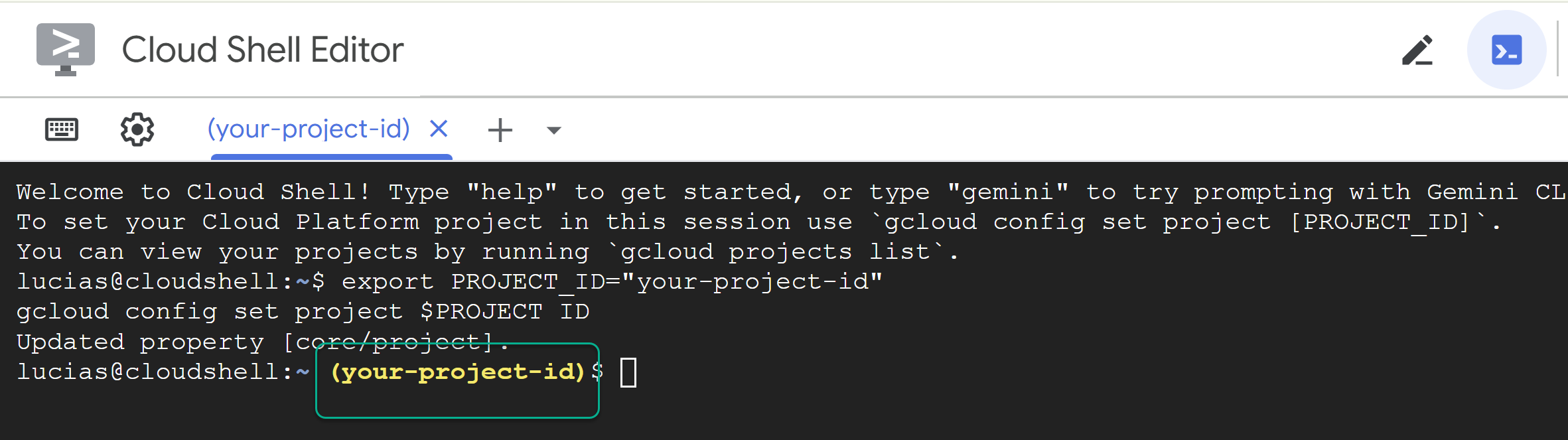
📝 참고 프로젝트가 명령줄에 노란색으로 표시됩니다. 세션이 다시 시작되면 위의 명령어를 다시 실행하여 프로젝트 ID를 설정해야 합니다.
API 사용 설정
다음 명령어를 실행하여 필요한 모든 API를 사용 설정합니다.
gcloud services enable \
aiplatform.googleapis.com \
bigquery.googleapis.com \
artifactregistry.googleapis.com \
container.googleapis.com \
cloudbuild.googleapis.com \
pubsub.googleapis.com
저장소 클론
다음 명령어를 실행하여 저장소를 클론합니다.
cd ~/
git clone --filter=blob:none --no-checkout https://github.com/GoogleCloudPlatform/devrel-demos.git
cd ~/devrel-demos
git sparse-checkout init --cone
git sparse-checkout set codelabs/gke-knowledge-graph
git checkout main
cd codelabs/gke-knowledge-graph/
설정 스크립트 실행
이 스크립트는 다음을 통해 백엔드 구성을 자동화합니다.
- 컨테이너 이미지 및 Artifact Registry 저장소 만들기
- BigQuery 데이터 세트 만들기
- SQL에서 Gemini AI 함수를 실행하기 위한 BigQuery 연결 만들기
터미널에서 다음 명령어를 실행합니다.
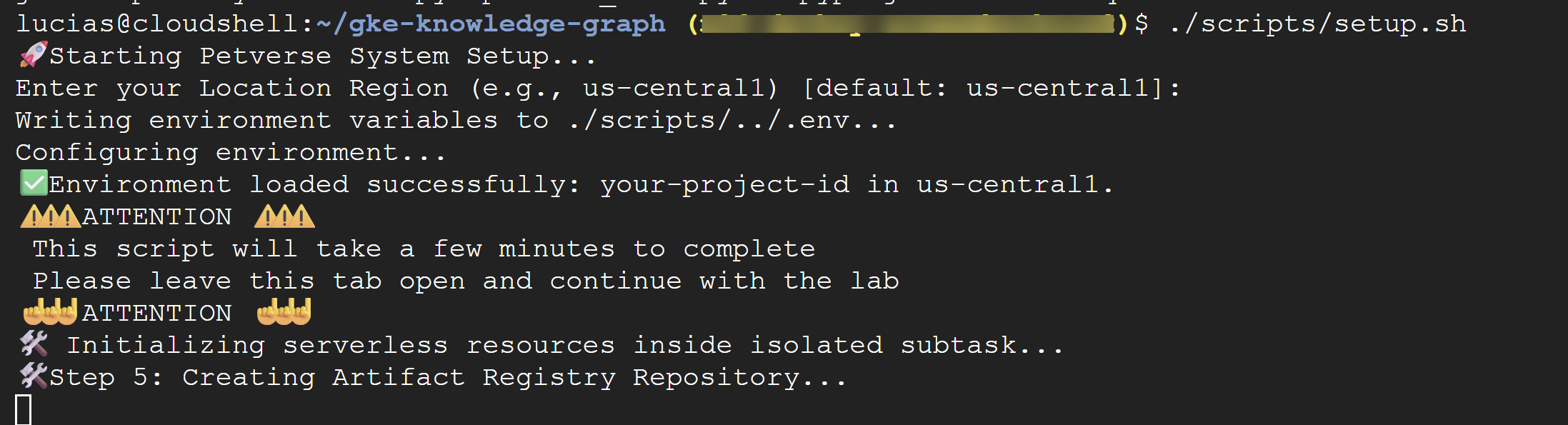
./scripts/setup.sh
스크립트에서 구성 세부정보를 묻는 메시지가 표시되면 다음 값을 사용하세요.
- 프로젝트 ID: 이전 단계에서 만든 ID를 사용합니다.
- 리전:
us-central1
⚠️ 중요 스크립트가 완료되는 데 몇 분 정도 걸립니다. 백그라운드에서 완료할 수 있도록 이 터미널 창을 열어 둡니다. 다음 단계를 계속하려면 새 터미널 탭이나 창을 열어 다음 명령어를 실행하세요.
3. 데이터 에이전트 키트 설정
- 오른쪽 상단에 있는 연필 아이콘으로 Cloud Shell 편집기를 사용 설정합니다.
- Cloud Shell 편집기에서 왼쪽 사이드바의 확장 프로그램 아이콘을 클릭합니다.
- Google Cloud Data Agent Kit을 검색하고 아직 설치되어 있지 않다면 설치를 클릭합니다.
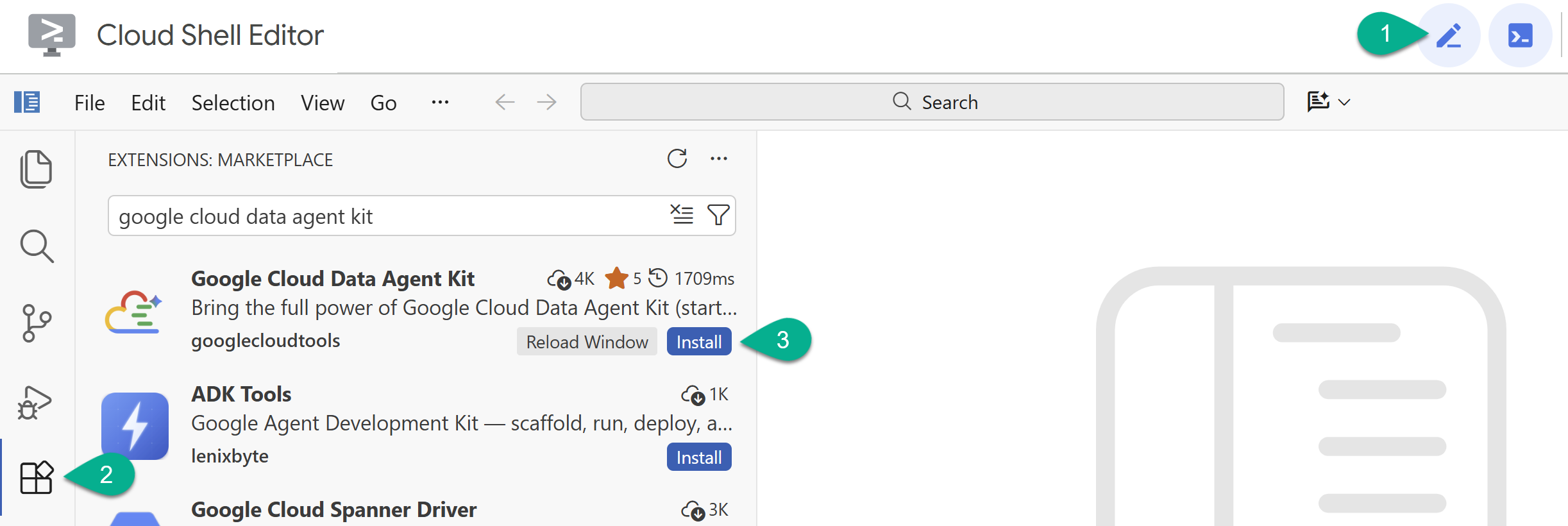
- 확장 프로그램으로 Google 계정에 로그인합니다.
- 구성 요약에서 프로젝트 ID와
us-central1를 리전으로 입력합니다.
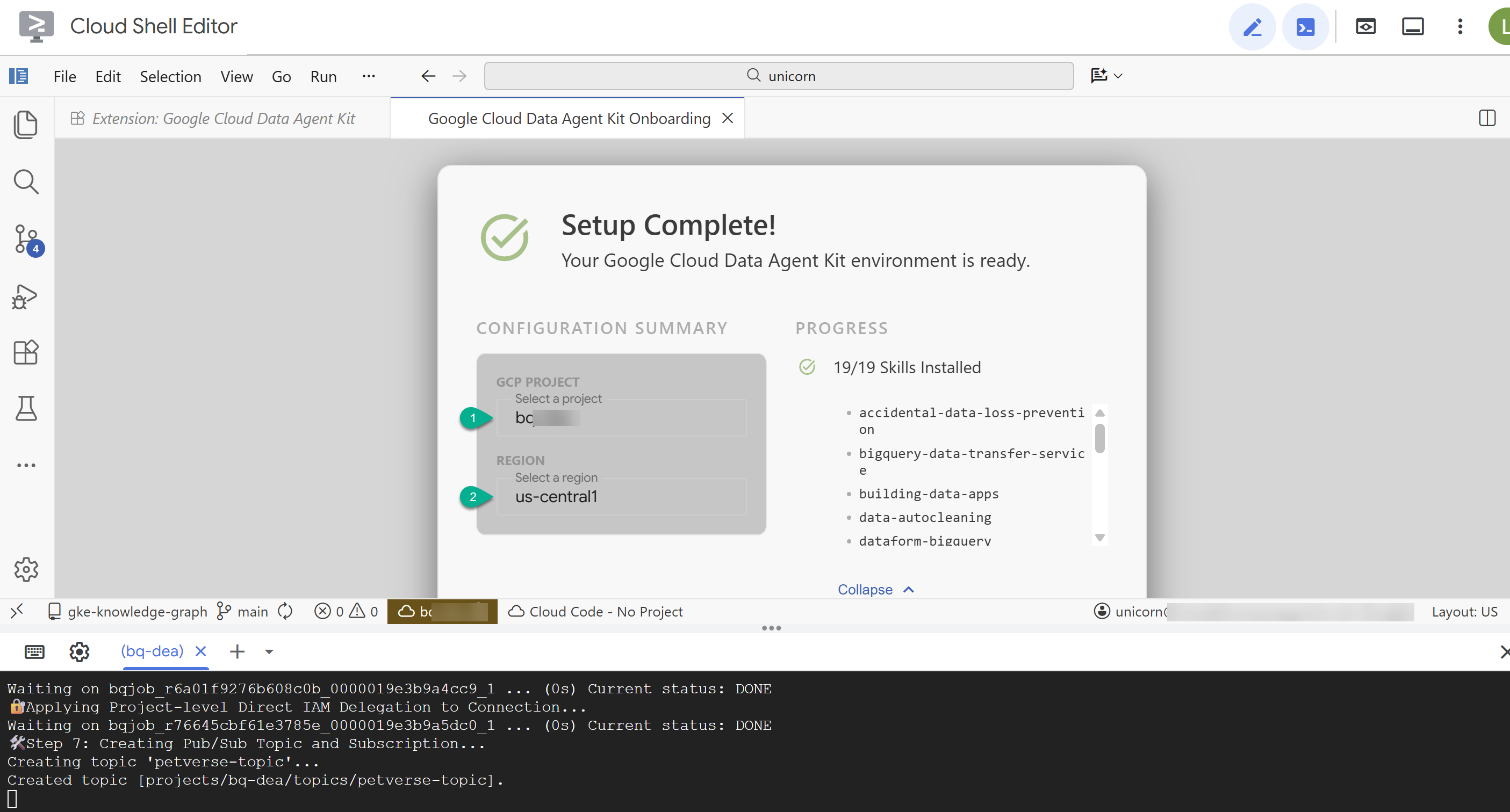
- MCP 서버 구성을 클릭합니다. 이 창은 변경할 필요가 없으며 시작하기를 클릭하면 됩니다.
- 메시지가 표시되면 창을 새로고침합니다. 지금은 빠른 시작 가이드 탭을 닫아도 됩니다.
BigQuery에서 테이블 설정
- 측면 막대에서 탐색기로 돌아갑니다. 홈 폴더 (예:
/home/your_user_name/)가 아직 열려 있지 않으면 폴더 열기를 클릭하고 선택합니다.
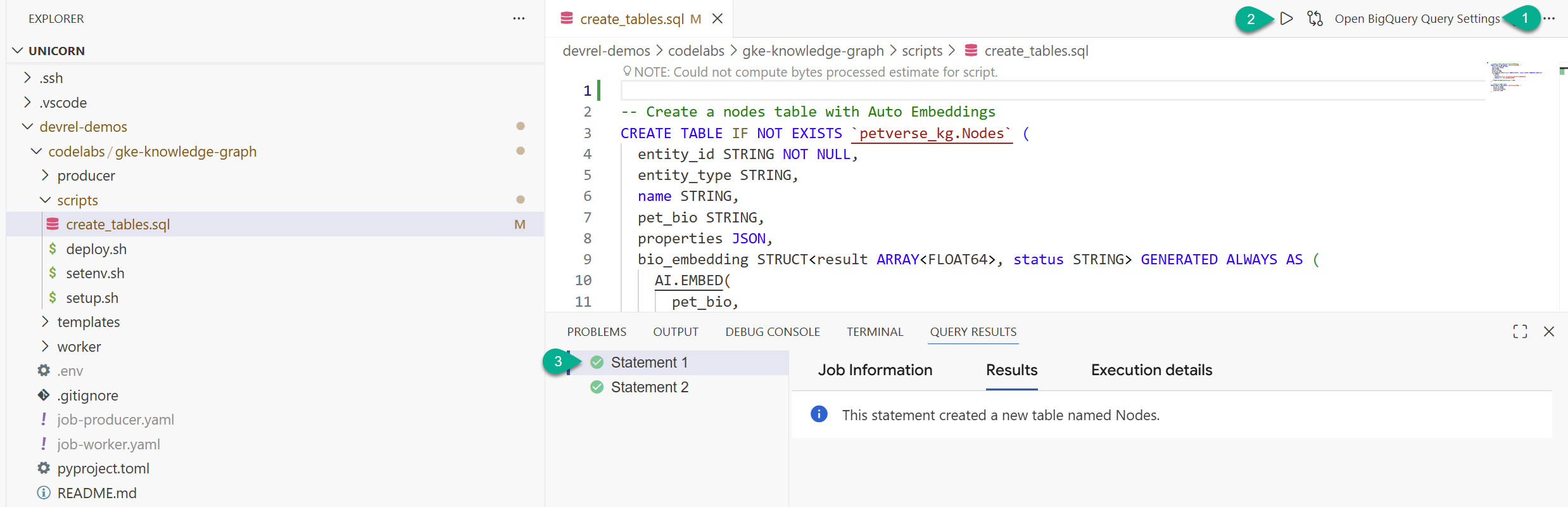
- 탐색기 창에서 저장소에서 클론한 폴더 (
devrel-demos)를 찾습니다.codelabs/gke-knowledge-graph/scripts아래에create_tables.sql가 있습니다. 해당 파일을 엽니다. - 오른쪽 상단에서 쿼리 설정 열기를 클릭합니다.
- BigQuery를 선택합니다. 저장 및 닫기를 클릭합니다.
- 실행을 클릭합니다.
두 개의 문이 성공적으로 실행됩니다. 이제 지식 그래프의 노드와 에지를 저장할 테이블을 만들었습니다.
create_tables.sql 탭과 결과 콘솔을 닫아도 됩니다.
4. GKE 클러스터 초기화
GKE Autopilot을 사용하여 데이터 처리 작업을 실행합니다. Autopilot은 클러스터 인프라를 관리하므로 권장되는 방법입니다.
이제 설정 스크립트가 완료되었을 것입니다. 🎉🦄 Setup successfully finished! 🎉🦄과 같은 성공 메시지가 표시됩니다.
터미널에 다음 명령어를 붙여넣어 클러스터를 만듭니다.
source scripts/setenv.sh
gcloud container clusters create-auto petverse-cluster \
--region=$REGION
🕓 5분 정도 걸립니다.
클러스터와 상호작용하기 위한 사용자 인증 정보를 가져옵니다.
source scripts/setenv.sh
gcloud container clusters get-credentials petverse-cluster --region $REGION
다음과 같은 출력을 볼 수 있습니다.
Fetching cluster endpoint and auth data. kubeconfig entry generated for petverse-cluster.
5. 워크로드 아이덴티티 구성
GKE용 워크로드 아이덴티티 제휴 (직접 리소스 액세스 사용)를 사용하면 서비스 계정 키를 관리할 필요 없이 GKE 워크로드가 Google Cloud 서비스에 안전하게 액세스할 수 있습니다.
deploy.sh를 실행하여 다음 작업을 할 수 있습니다.
- Kubernetes 서비스 계정 만들기
- Kubernetes 서비스 계정 주 구성원에 필요한 IAM 역할을 직접 부여
- IAM 서비스 계정을 Kubernetes 서비스 계정에 바인딩
- Kubernetes 서비스 계정에 주석을 달아 링크를 완료합니다.
source scripts/setenv.sh
./scripts/deploy.sh
6. 분리된 처리 작업 배포
이 단계에서는 enqueuer (생산자)와 처리 엔진 (작업자)을 GKE에 배포합니다.
새로운 분리된 아키텍처는 Google Cloud Pub/Sub를 사용하여 애셋을 비동기식으로 처리합니다.
- 생산자가 GCS를 스캔하고 모든 파일 경로를 Pub/Sub 큐에 대기열에 추가합니다.
- 작업자 풀이 GKE에서 확장되어 작업을 병렬로 동적으로 가져오고, Gemini를 통해 처리하고, BigQuery에 씁니다.
setup.sh 스크립트는 이미 Producer 및 Worker 컨테이너 이미지를 빌드하고 푸시했으며, Pub/Sub 주제를 대기열에 추가하고, GKE 배포 매니페스트(job-producer.yaml 및 job-worker.yaml)를 동적으로 생성했습니다.
- Producer Job을 적용하여 스토리지 버킷을 스캔하고 모든 애셋을 대기열에 추가합니다.
kubectl apply -f job-producer.yaml
이 작업은 메타데이터만 대기열에 추가하므로 빠르게 실행되고 완료됩니다.
- 6개의 병렬 작업자를 실행하여 대기열을 드레이닝하도록 구성된 작업자 작업을 배포합니다.
kubectl apply -f job-worker.yaml
GKE Autopilot은 대기 중인 포드를 자동으로 감지하고, 컴퓨팅 노드를 동적으로 확장하고, 대기열에 추가된 오디오, 동영상, 이미지, CSV를 처리하기 위해 작업자를 병렬로 실행합니다.
7. 결과 확인
- 작업 상태를 확인합니다.
kubectl get jobs
petverse-producer-job와 petverse-worker-job 모두 완료될 때까지 기다립니다.
🕓 10분 정도 걸립니다. 아래 명령어를 사용하여 진행 상황을 확인할 수 있습니다.
- 프로듀서의 로그를 확인하여 파일이 성공적으로 대기열에 추가되었는지 확인합니다.
cd ~/devrel-demos/codelabs/gke-knowledge-graph
source scripts/setenv.sh
kubectl logs -l app=petverse-producer --tail=50
- 병렬 작업자가 대기열에서 파일을 처리하는 것을 확인합니다.
kubectl logs -l app=petverse-worker --tail=50
(작업자에는 60초의 유휴 시간 제한이 있으며 Pub/Sub 대기열이 비어 있으면 자동으로 종료되고 정리됩니다.)
BigQuery에서 데이터를 확인합니다.
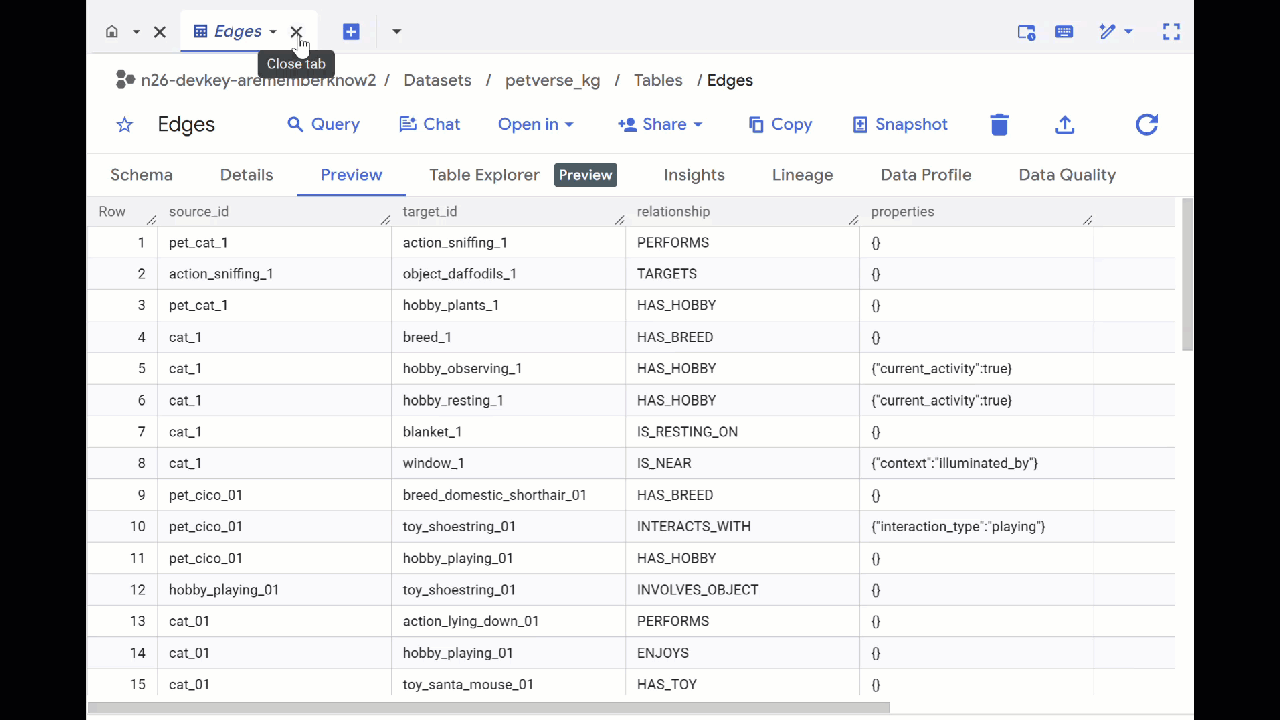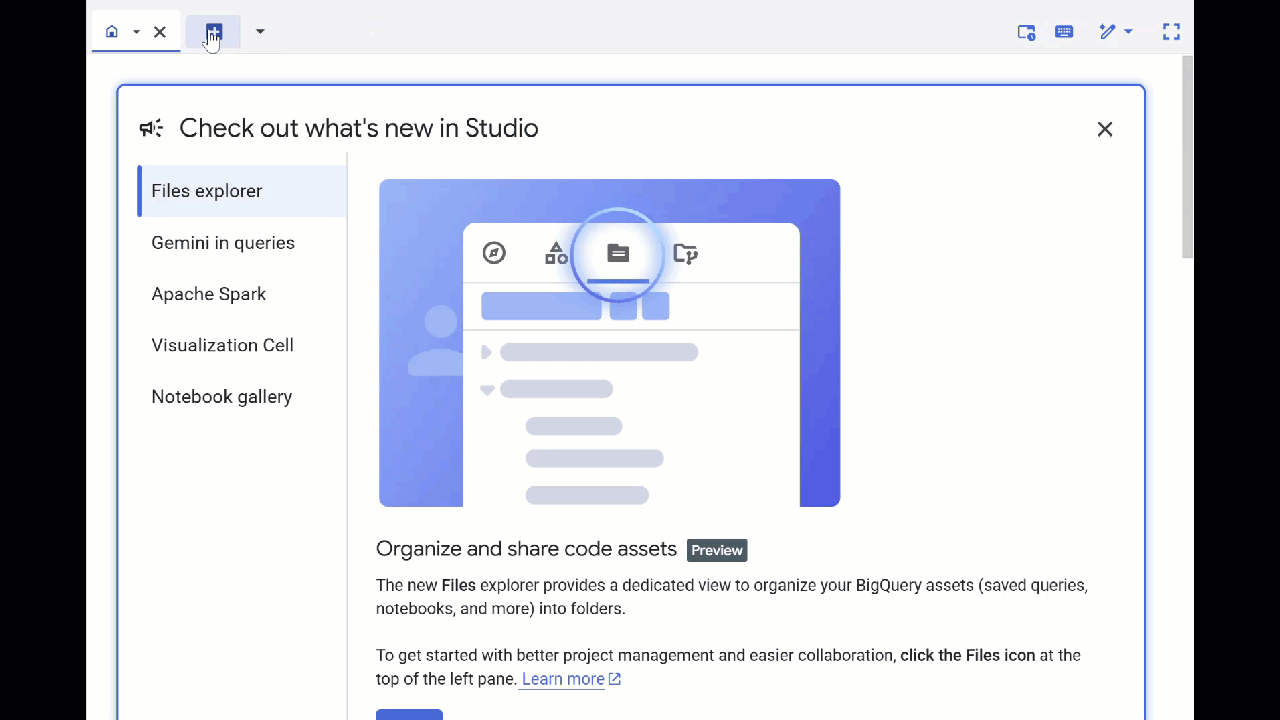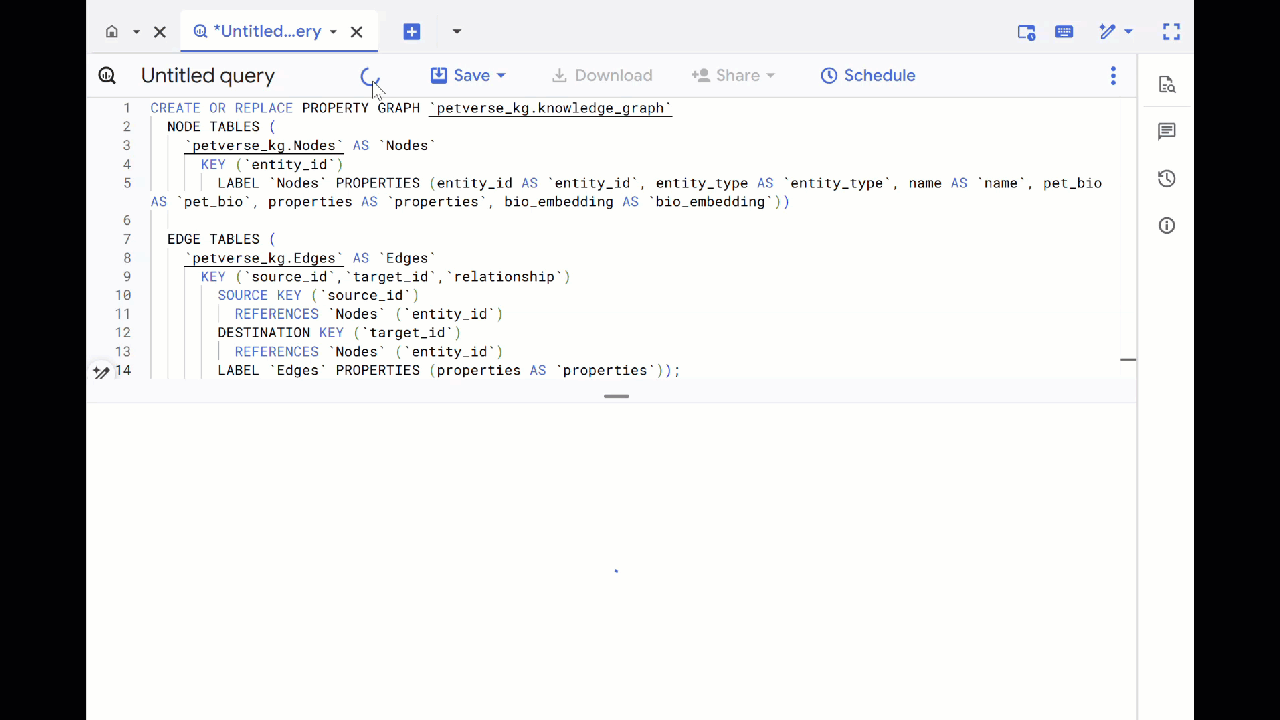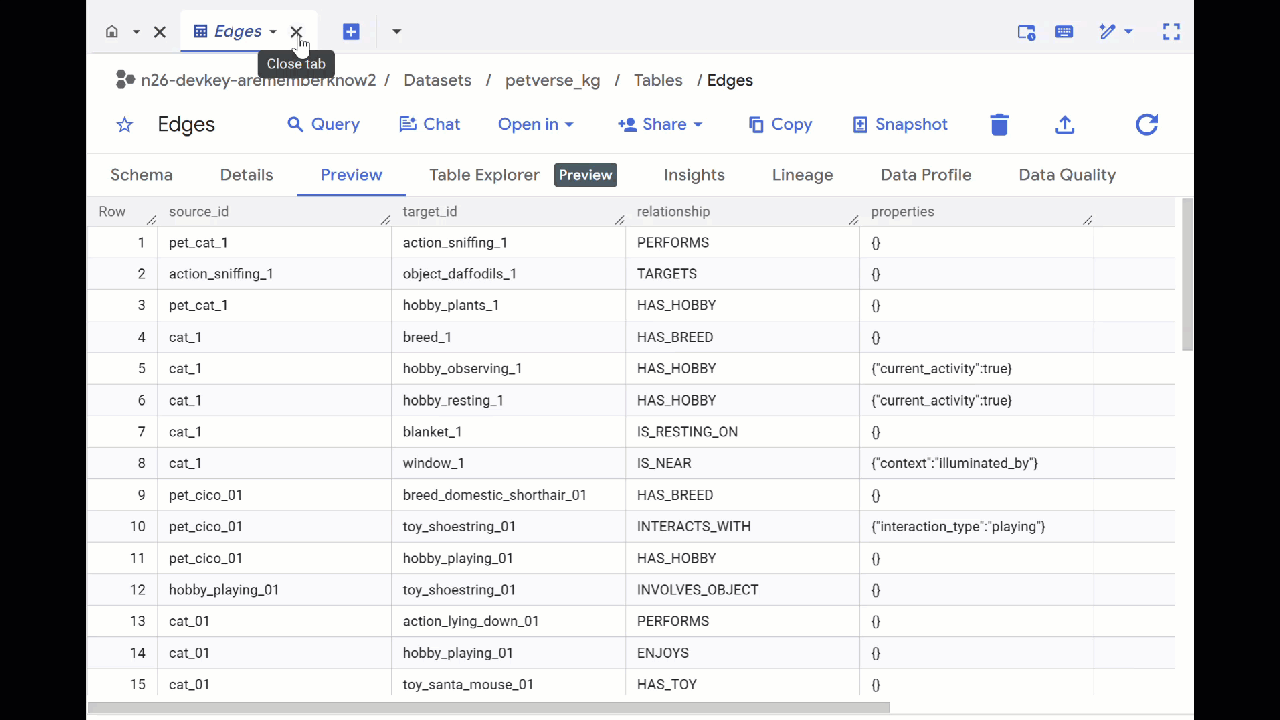
- BigQuery Studio로 이동합니다. petverse_kg.Nodes와 petverse_kg.Edges라는 두 개의 테이블이 생성됩니다.
- 표의 내용을 보려면 이름을 더블클릭한 다음 미리보기를 클릭합니다.
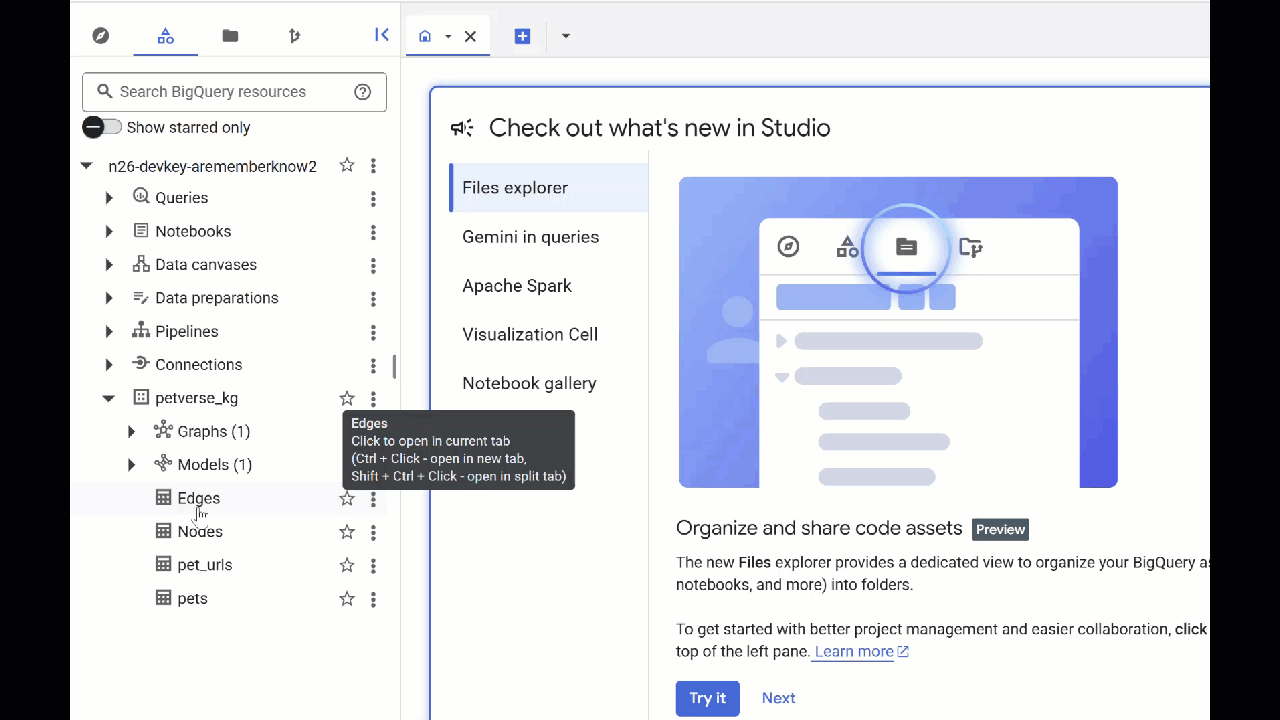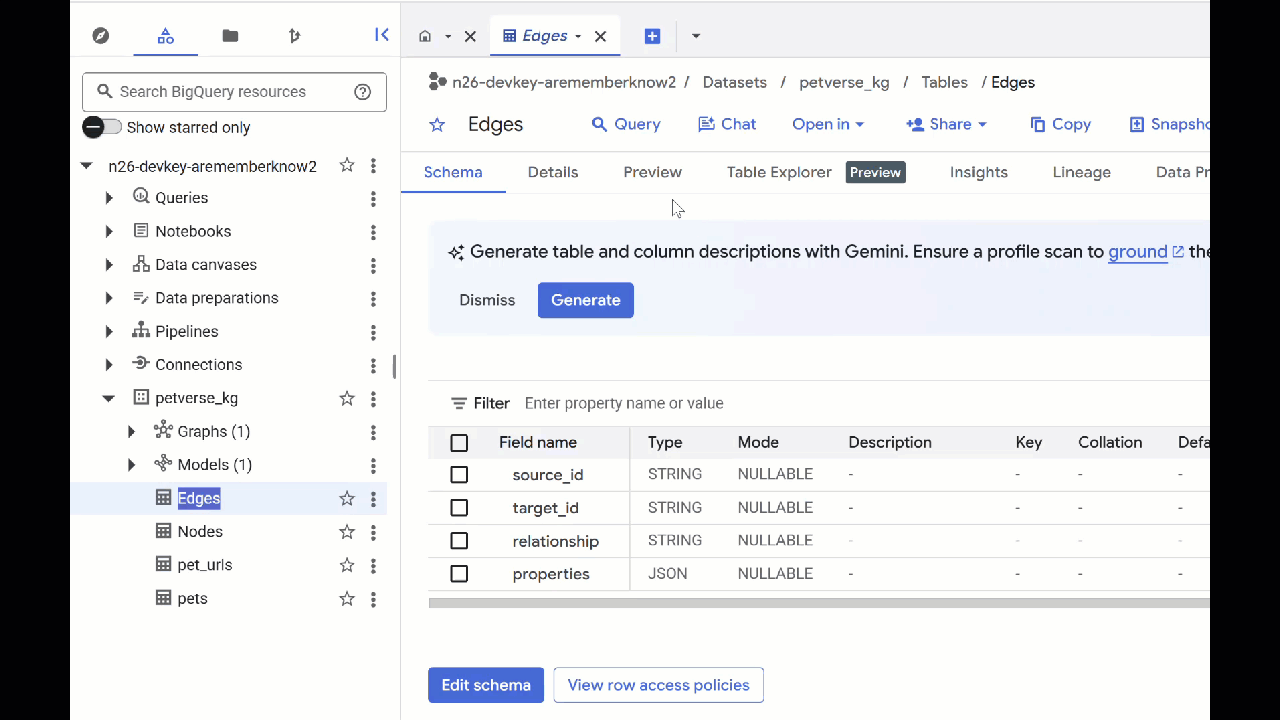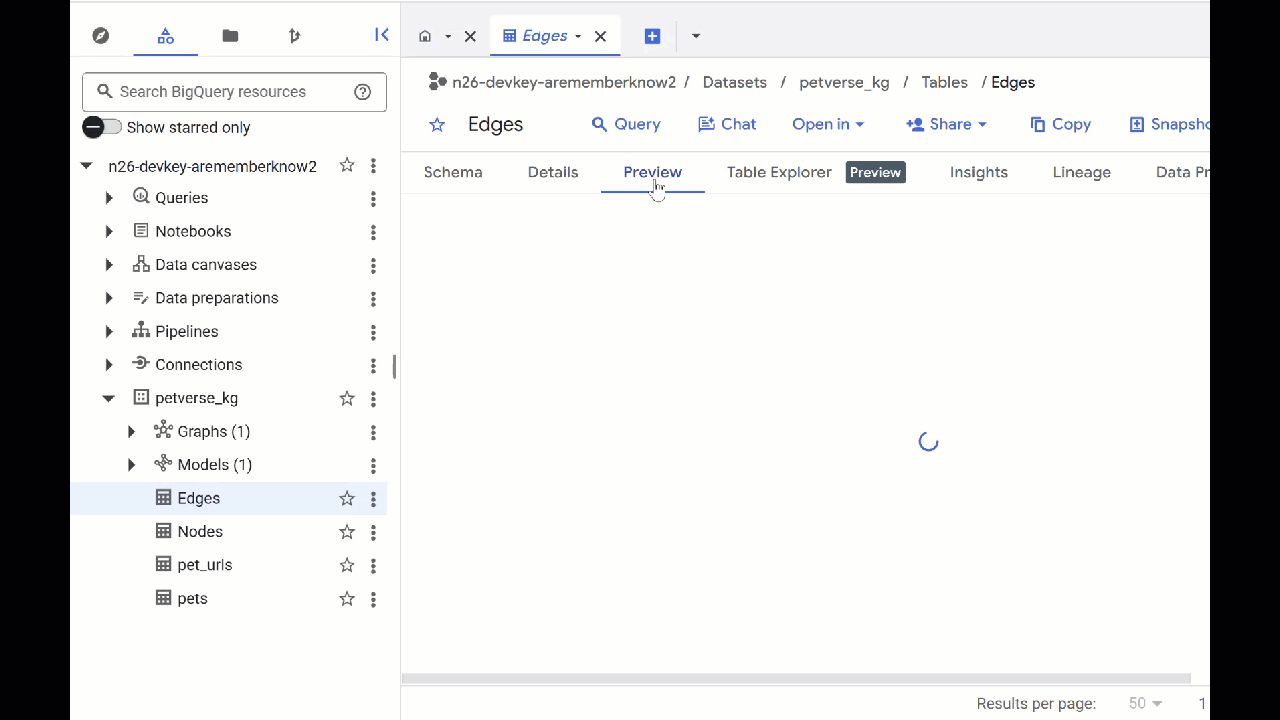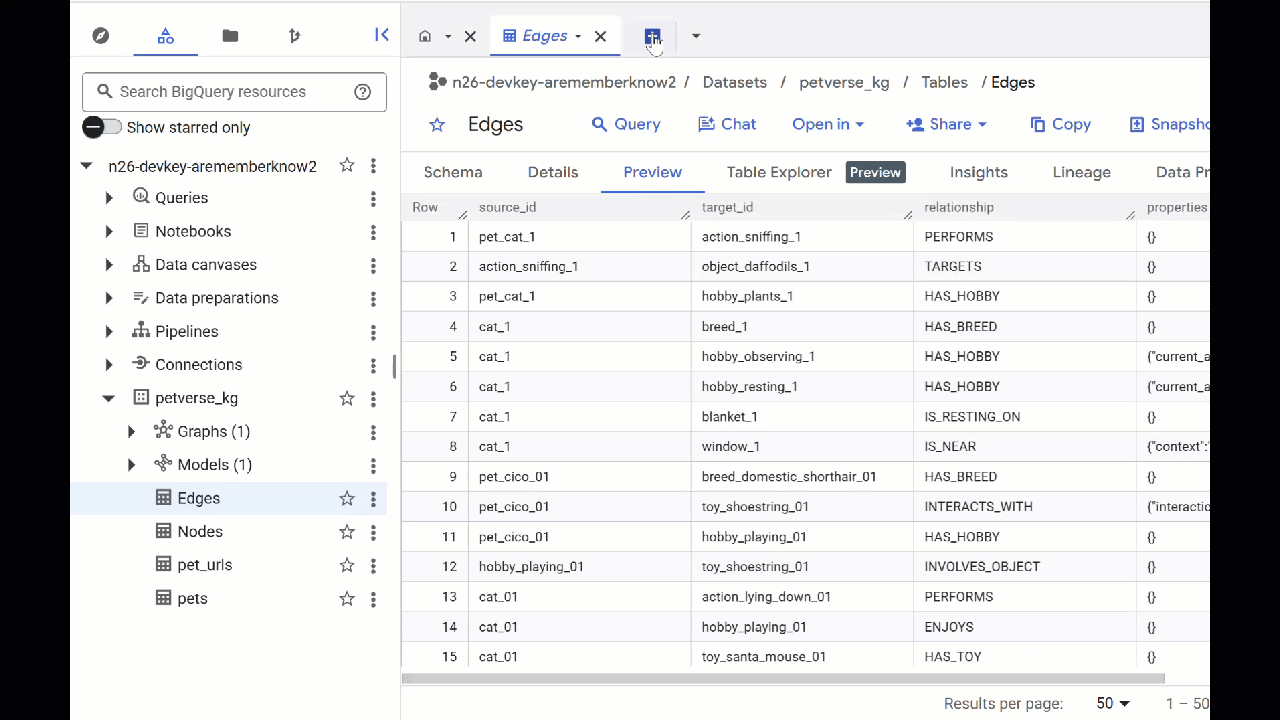
노드 표에는 오디오, 동영상, 사진에서 Gemini가 포착한 항목에 관한 정보가 표시됩니다. Edges 테이블에는 이러한 관계가 포함되어 있습니다. 예를 들어 SQL이라는 고양이의 오디오를 들으면 이 고양이는 신발끈으로 노는 것을 좋아하고 동결 건조된 생선을 즐겨 먹습니다.
- + 버튼을 사용하여 새 쿼리를 만듭니다. 다음 문을 붙여넣고 실행을 클릭합니다.
SELECT n.name, n.entity_id, e.relationship, e.target_id
FROM
`petverse_kg.Nodes` n
JOIN
`petverse_kg.Edges` e
ON n.entity_id = e.source_id
WHERE n.name = 'SQL'
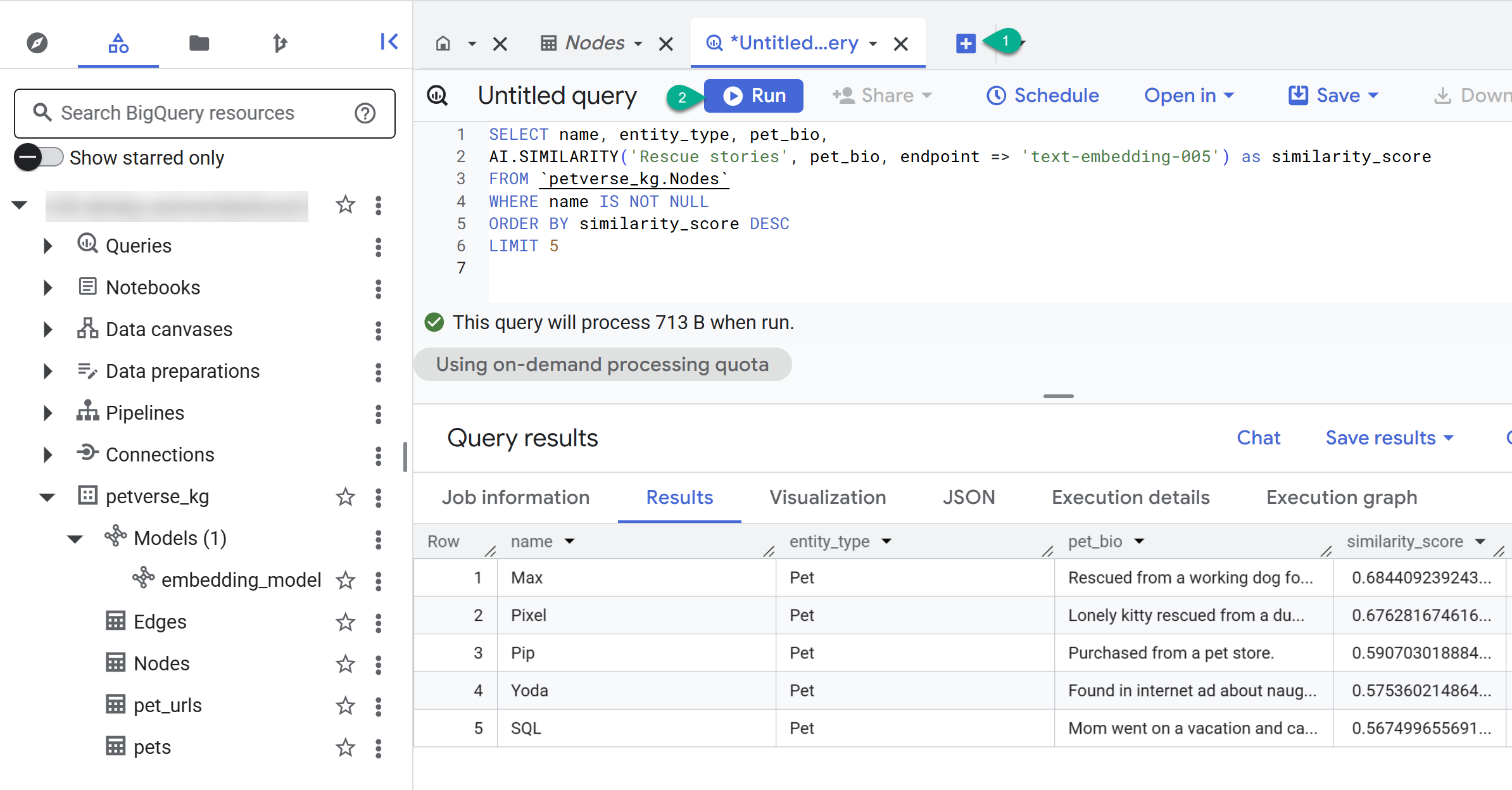
- + 버튼을 사용하여 새 쿼리를 만듭니다. 다음 문을 붙여넣고 실행을 클릭합니다.
SELECT name, entity_type, pet_bio,
AI.SIMILARITY('Pets who like to relax', pet_bio, endpoint => 'text-embedding-005') as similarity_score
FROM `petverse_kg.Nodes`
WHERE name IS NOT NULL
ORDER BY similarity_score DESC
LIMIT 5
휴식을 좋아하는 반려동물의 노드가 표시됩니다. 이 쿼리는 AI 함수 AI.SIMILARITY를 사용하여 시맨틱 검색을 실행하여 바이오가 쿼리 텍스트와 가장 유사한 반려동물을 찾았습니다.
속성 그래프 빌드
이제 BigQuery에 노드와 에지가 있으므로 속성 그래프를 만들어 관계를 쉽게 쿼리할 수 있습니다.
그래프 만들기
- 이전 쿼리를 덮어쓰고 다음 DDL을 실행하여 속성 그래프를 만듭니다.
CREATE OR REPLACE PROPERTY GRAPH `petverse_kg.knowledge_graph`
NODE TABLES (
`petverse_kg.Nodes` AS `Nodes`
KEY (`entity_id`)
LABEL `Nodes` PROPERTIES (entity_id AS `entity_id`, entity_type AS `entity_type`, name AS `name`, pet_bio AS `pet_bio`, properties AS `properties`, bio_embedding AS `bio_embedding`))
EDGE TABLES (
`petverse_kg.Edges` AS `Edges`
KEY (`source_id`,`target_id`,`relationship`)
SOURCE KEY (`source_id`)
REFERENCES `Nodes` (`entity_id`)
DESTINATION KEY (`target_id`)
REFERENCES `Nodes` (`entity_id`)
LABEL `Edges` PROPERTIES (properties AS `properties`));
- 그래프로 이동을 클릭합니다. 자체 에지가 있는 노드가 포함된 그래프 시각화가 표시됩니다. 이는 정상적인 동작입니다.
그래프 쿼리
- + 버튼을 사용하여 이전 쿼리를 모두 닫고 새 빈 쿼리를 열 수 있습니다.
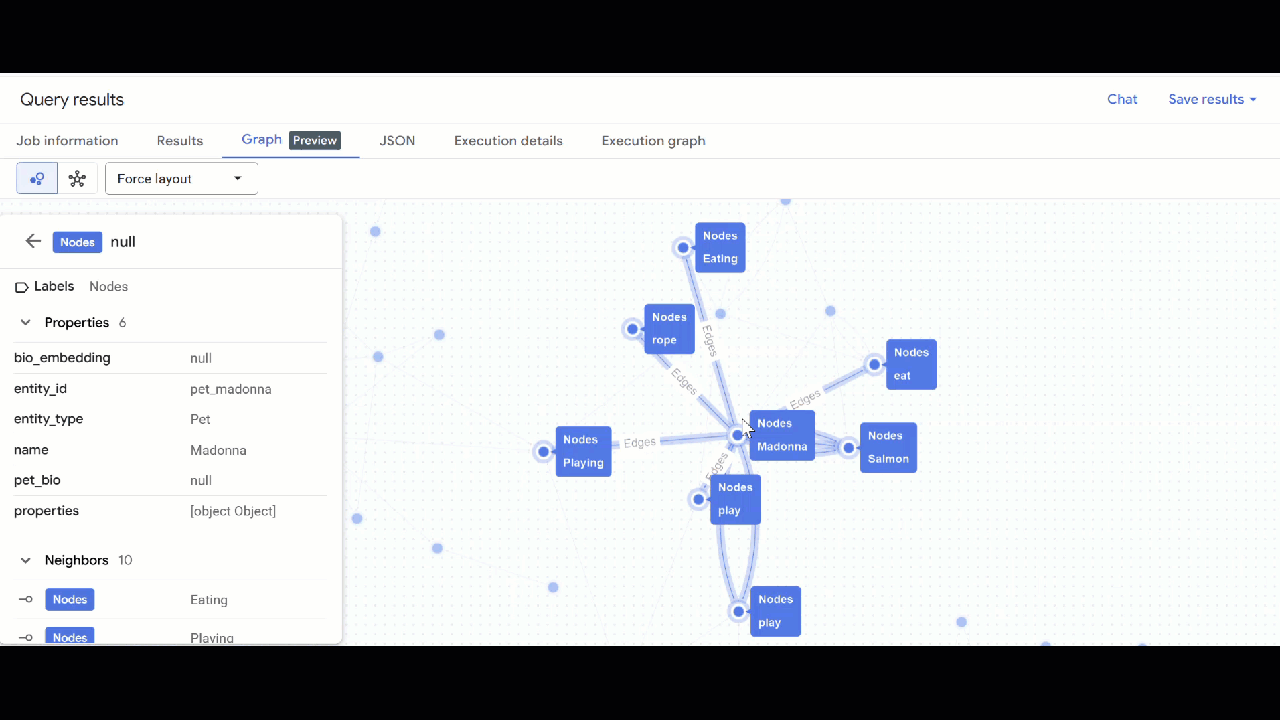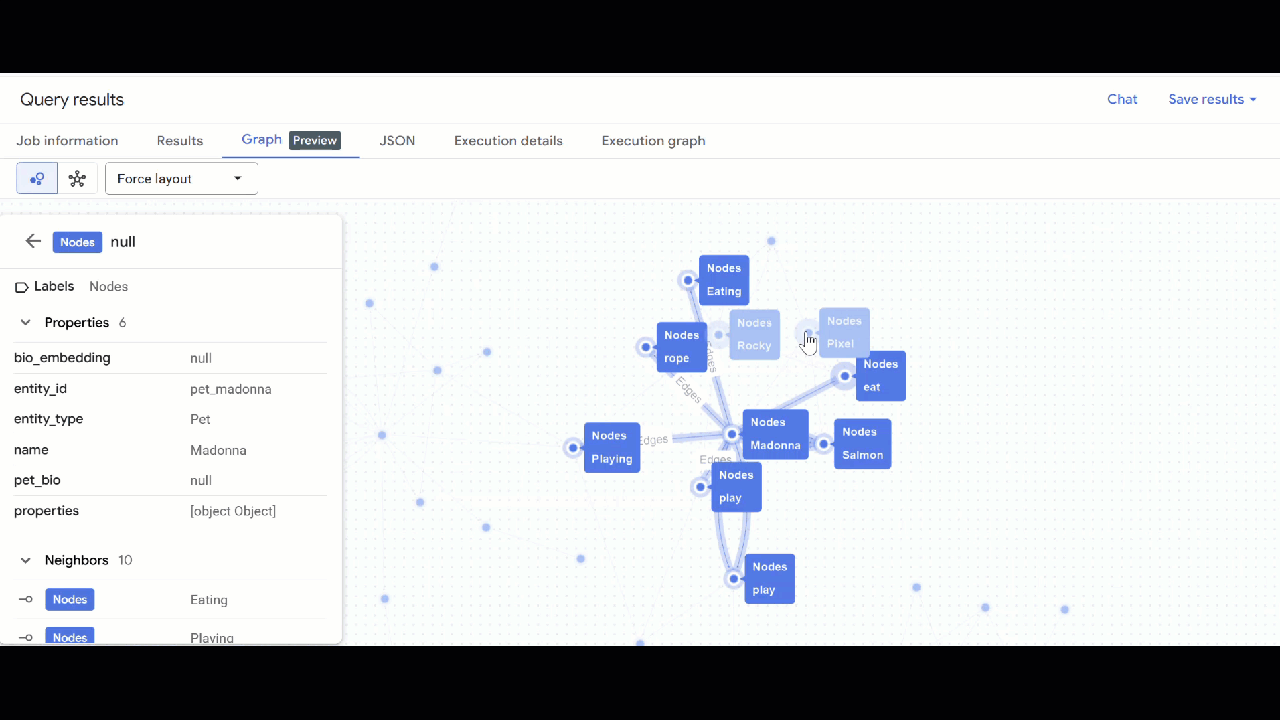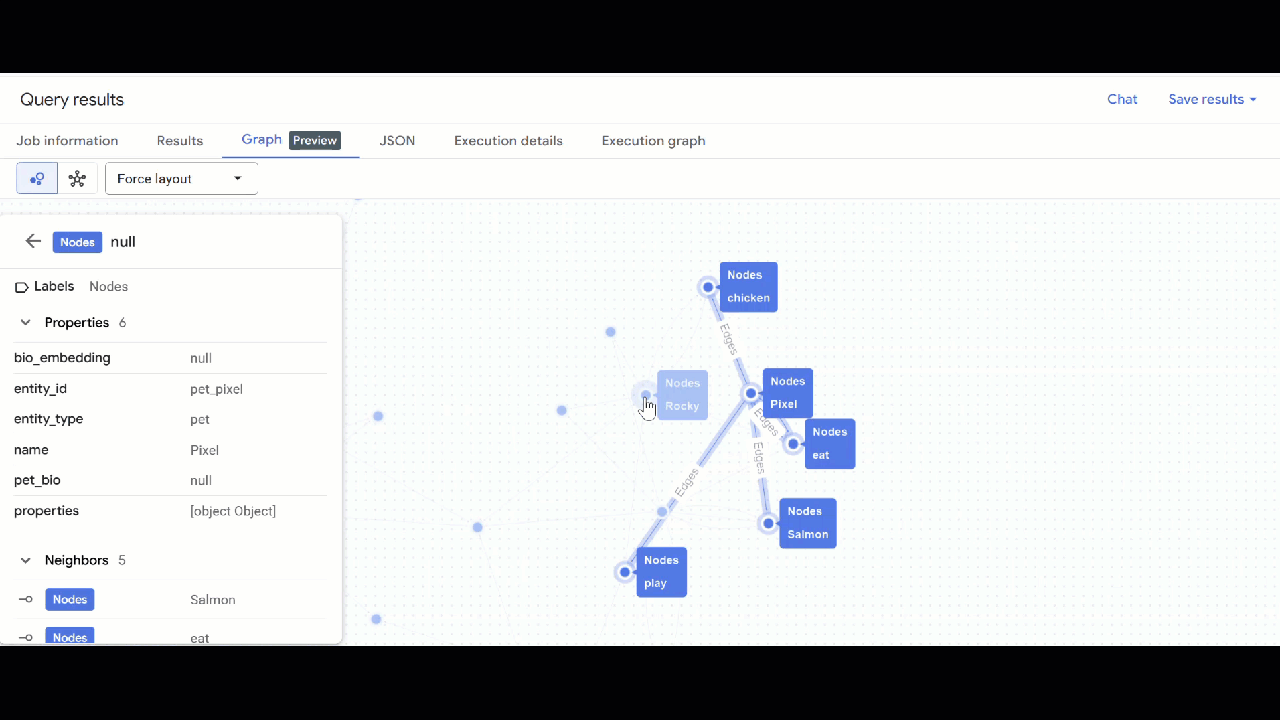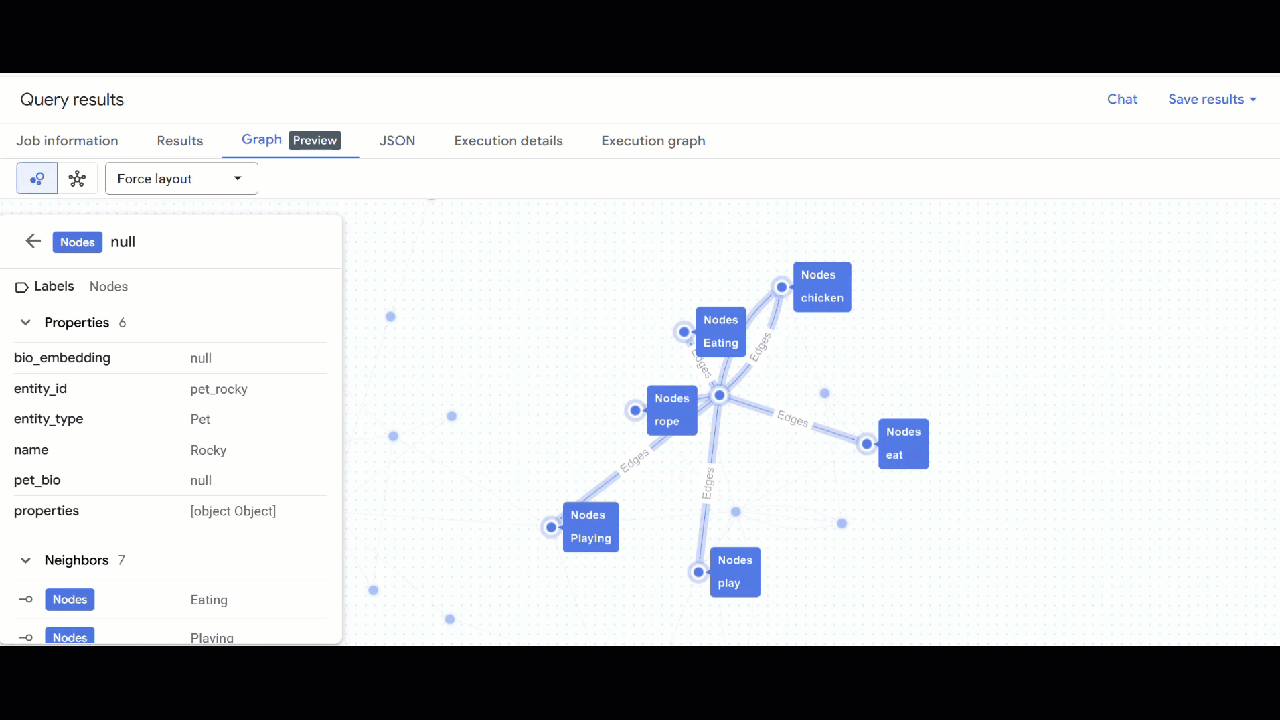
- GQL을 사용하여 취미, 좋아하는 음식, 장난감과 같은 공유 관심사를 통해 다른 반려동물과 관련된 반려동물을 찾습니다. 이 멀티 홉 쿼리는 동일한 노드에 연결된 두 개의 서로 다른 반려동물과 일치합니다.
GRAPH `petverse_kg.knowledge_graph`
MATCH p = (pet1:Nodes)-[e1]->(interest:Nodes)<-[e2]-(pet2:Nodes)
WHERE pet1.entity_id != pet2.entity_id
AND (LOWER(pet1.entity_type) = 'pet' AND LOWER(pet2.entity_type) = 'pet')
AND LOWER(interest.entity_type) IN ('hobby', 'action', 'activity', 'food', 'toy')
RETURN TO_JSON(p) as res
LIMIT 100
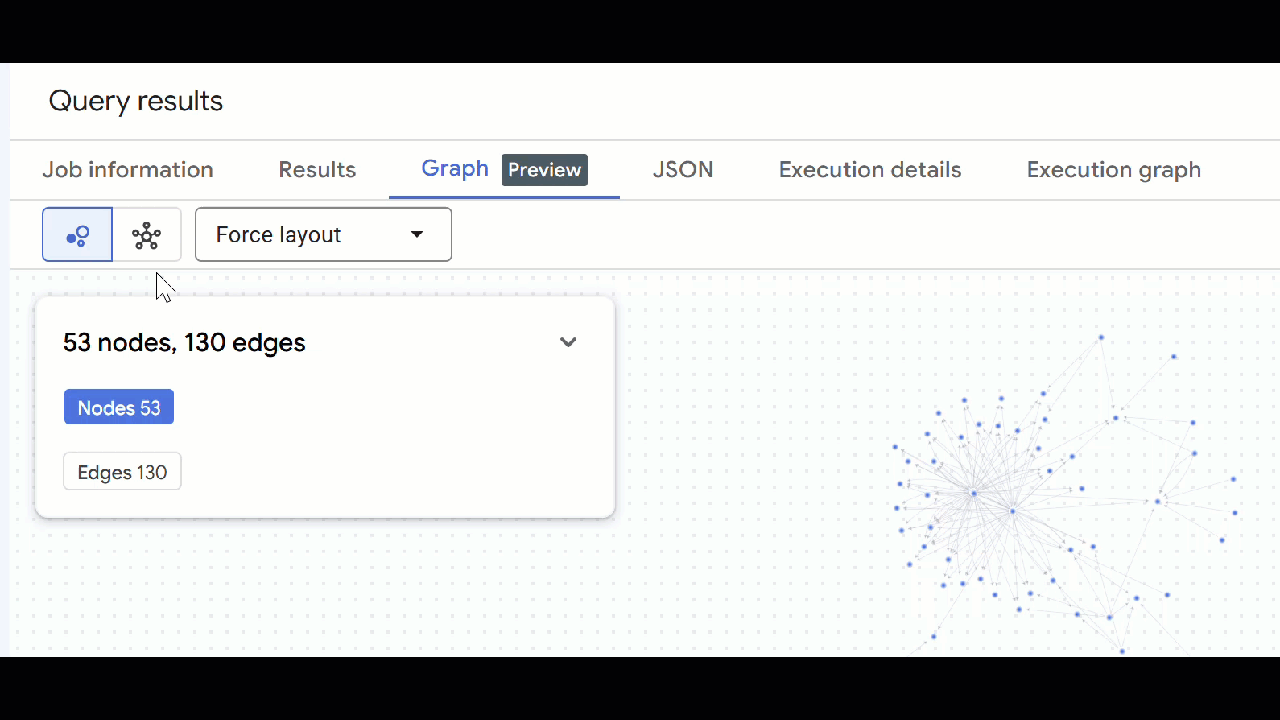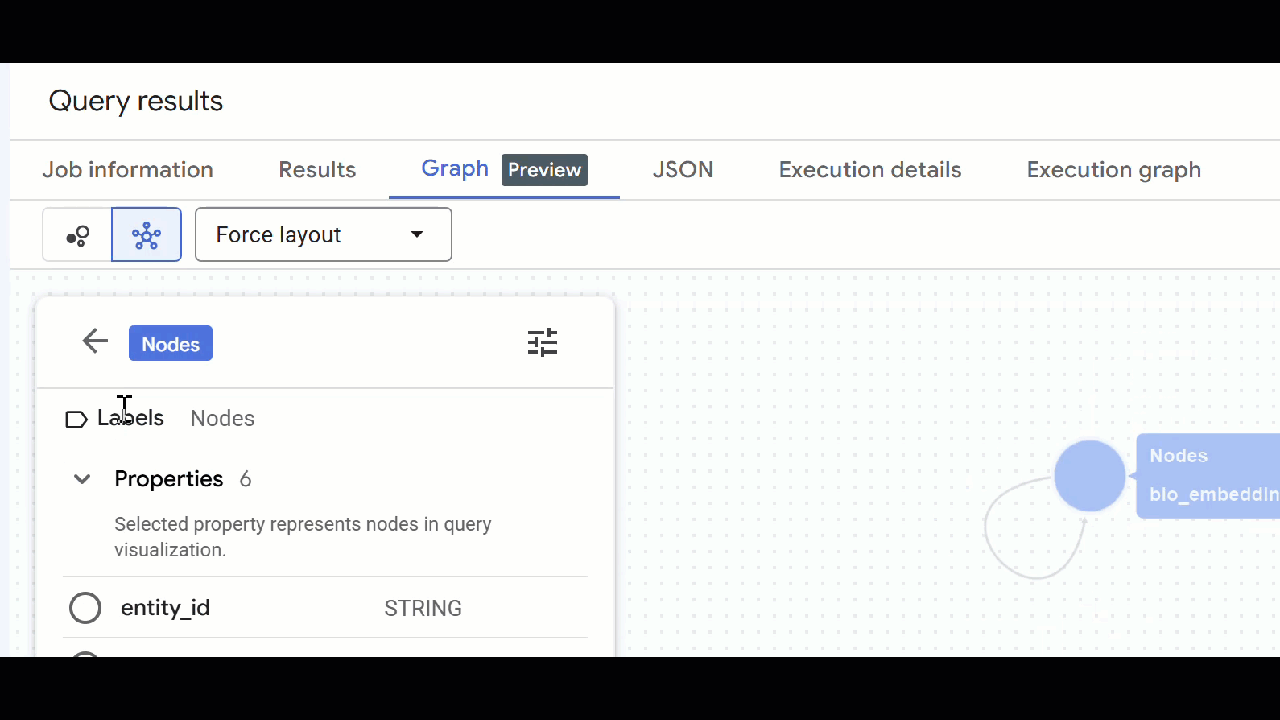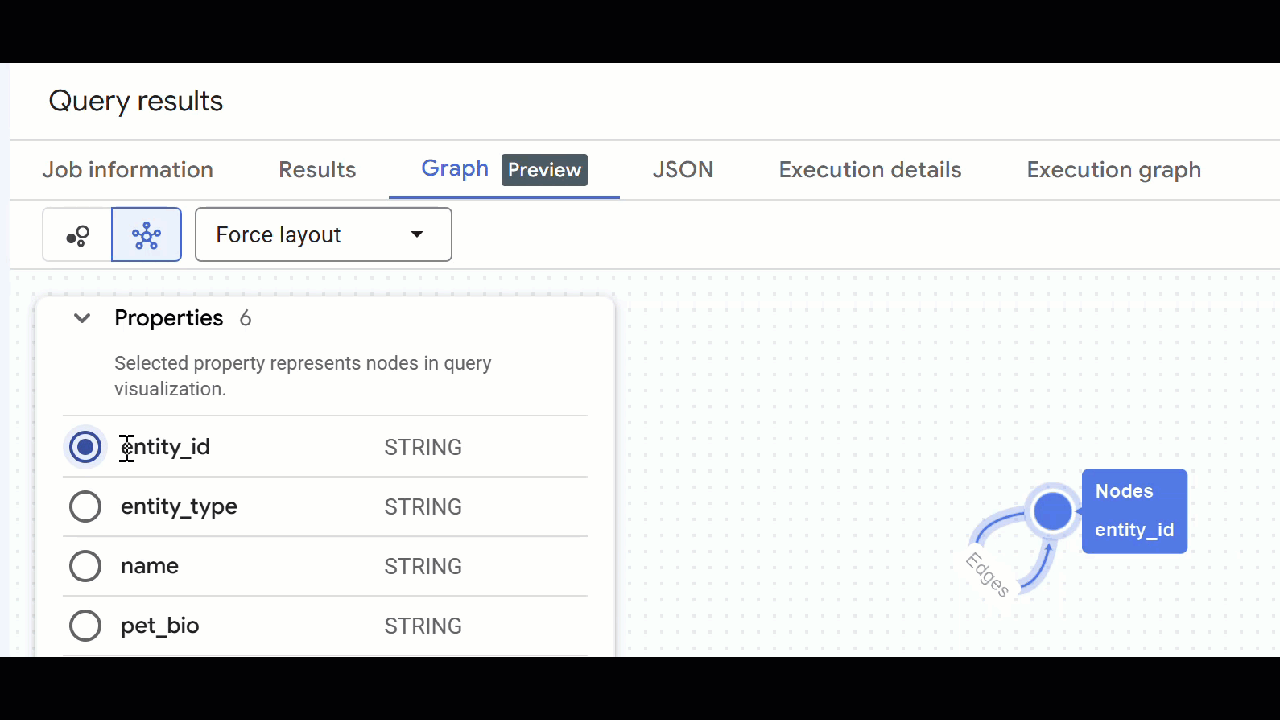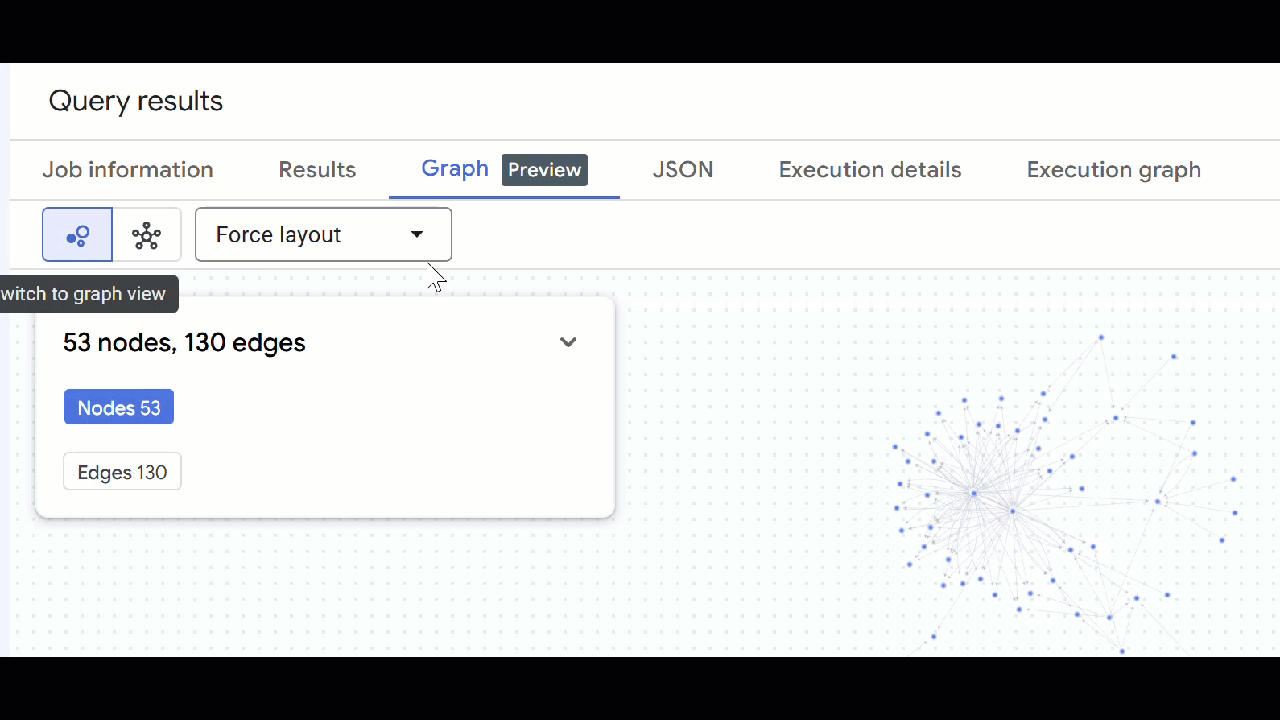
- 그래프 시각화가 표시됩니다. 노드를 클릭하여 노드와 가장자리의 속성을 확인할 수 있습니다.
🕵️ 도움말: 스키마 뷰로 전환을 클릭하여 노드에 표시되는 값을 조정할 수 있습니다.
- 열려 있는 모든 쿼리 탭을 닫을 수 있습니다.
8. 그래프와 채팅하기
- + 기호 옆에 드롭다운 메뉴가 있습니다. 대화를 선택합니다.
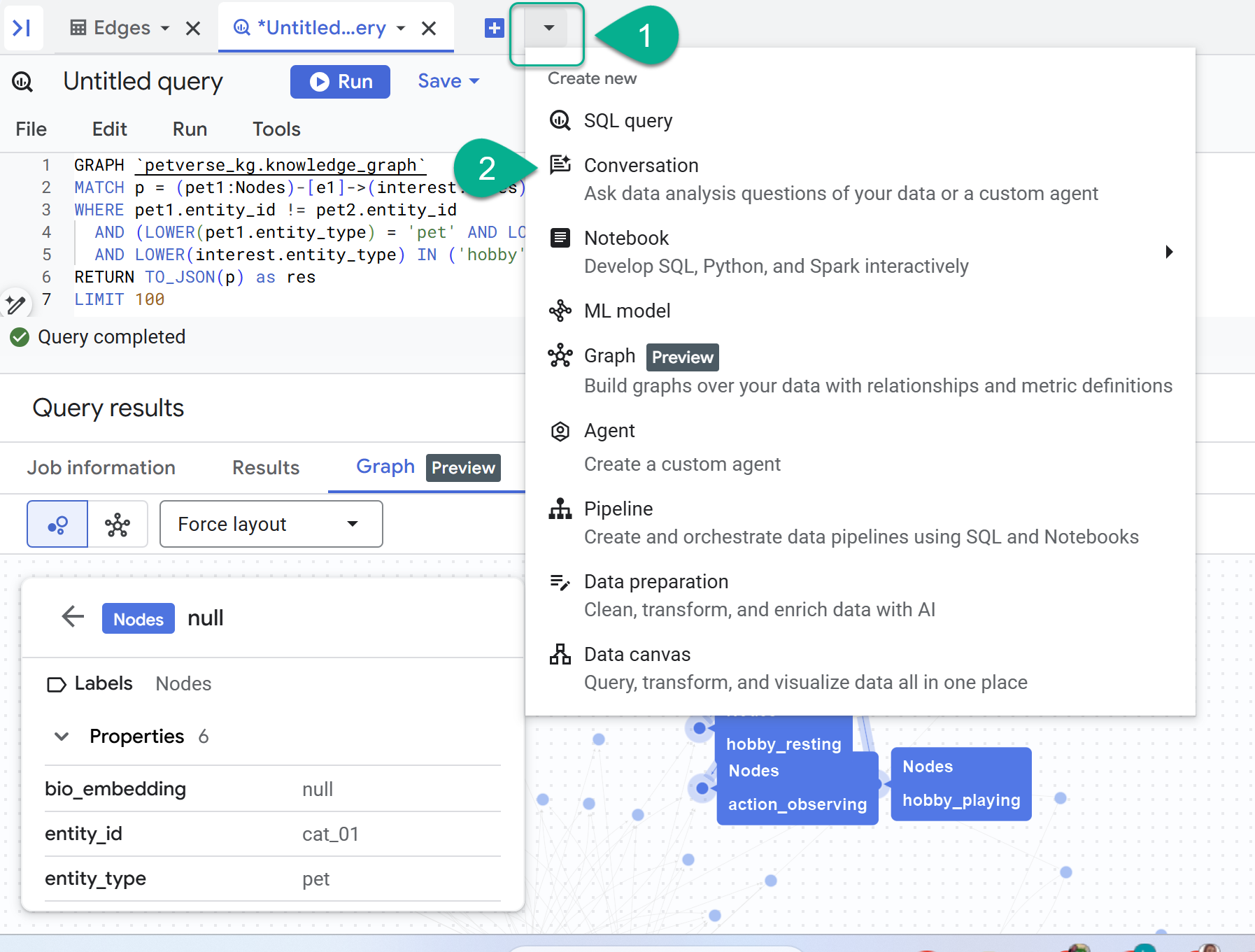
- Gemini 기반 Data Analytics API를 사용 설정하라는 메시지가 표시됩니다. 두 API를 모두 사용 설정합니다. 이 작업이 완료되면 창을 새로고침하거나 새 대화를 만들어 에이전트를 확인합니다.
- New Agent를 클릭합니다.
- 에이전트 이름을 지정합니다(예:
petverse). - 소스 추가를 클릭한 다음 그래프를 클릭합니다.
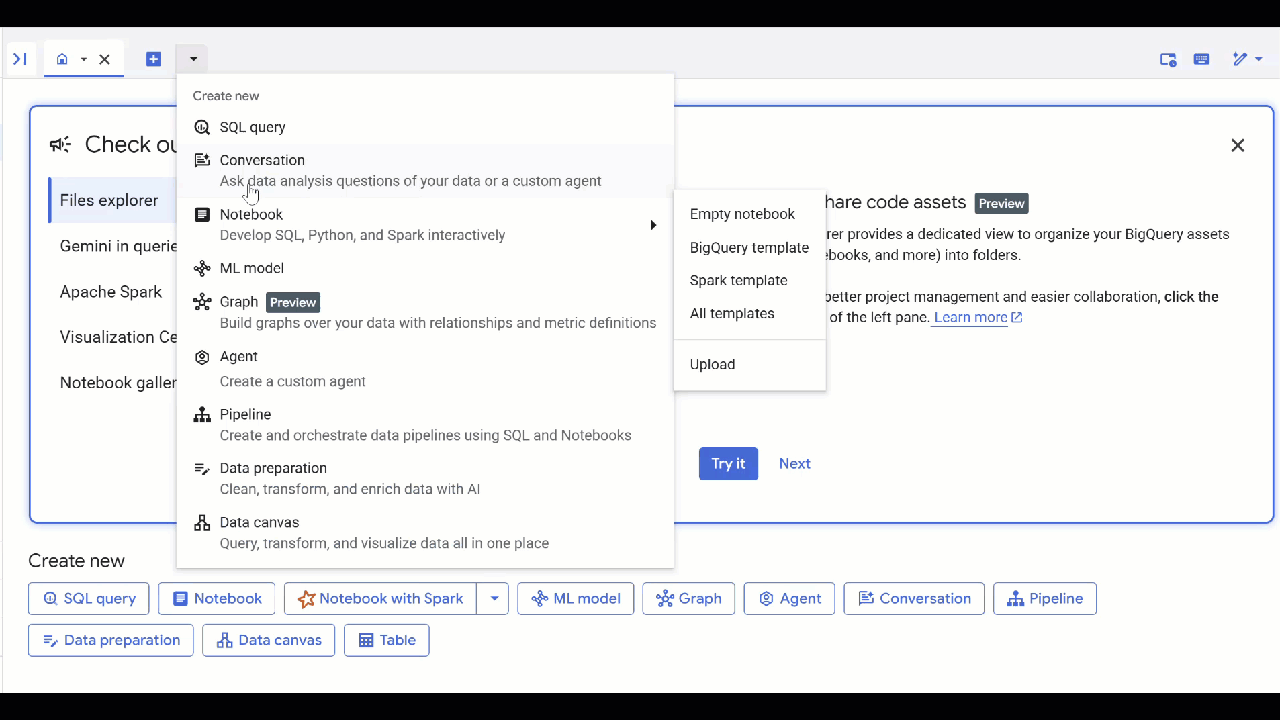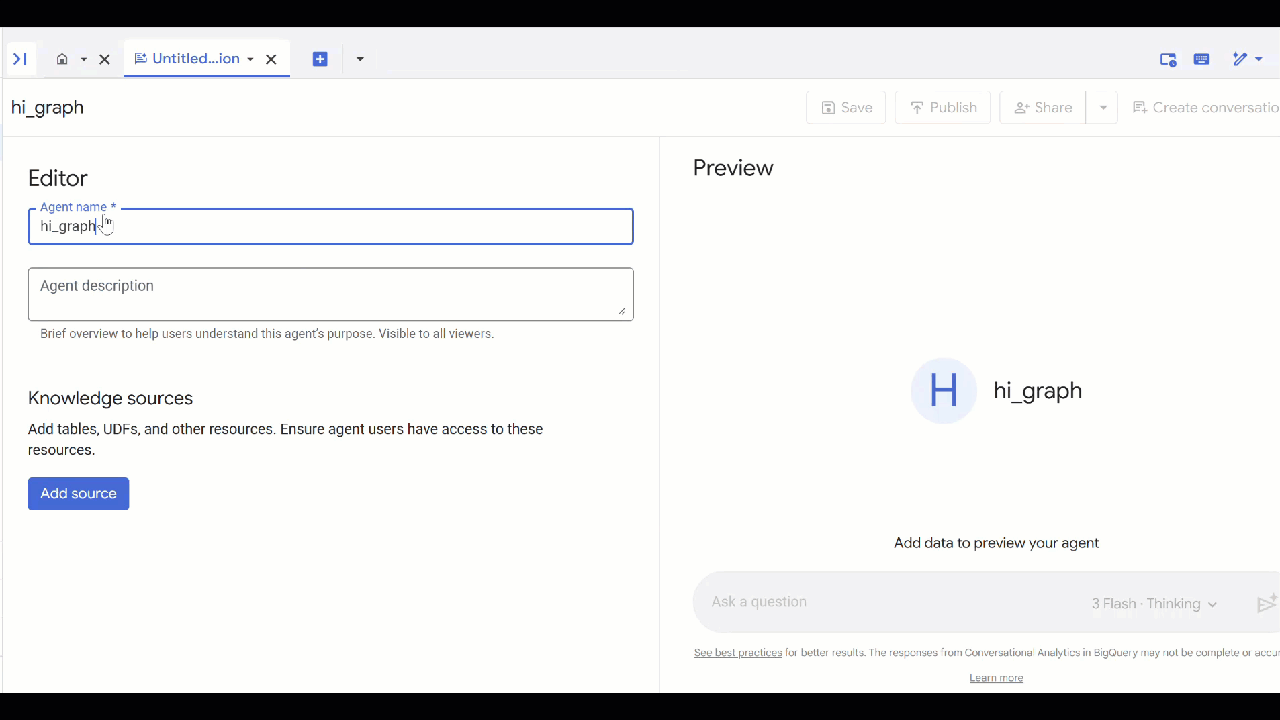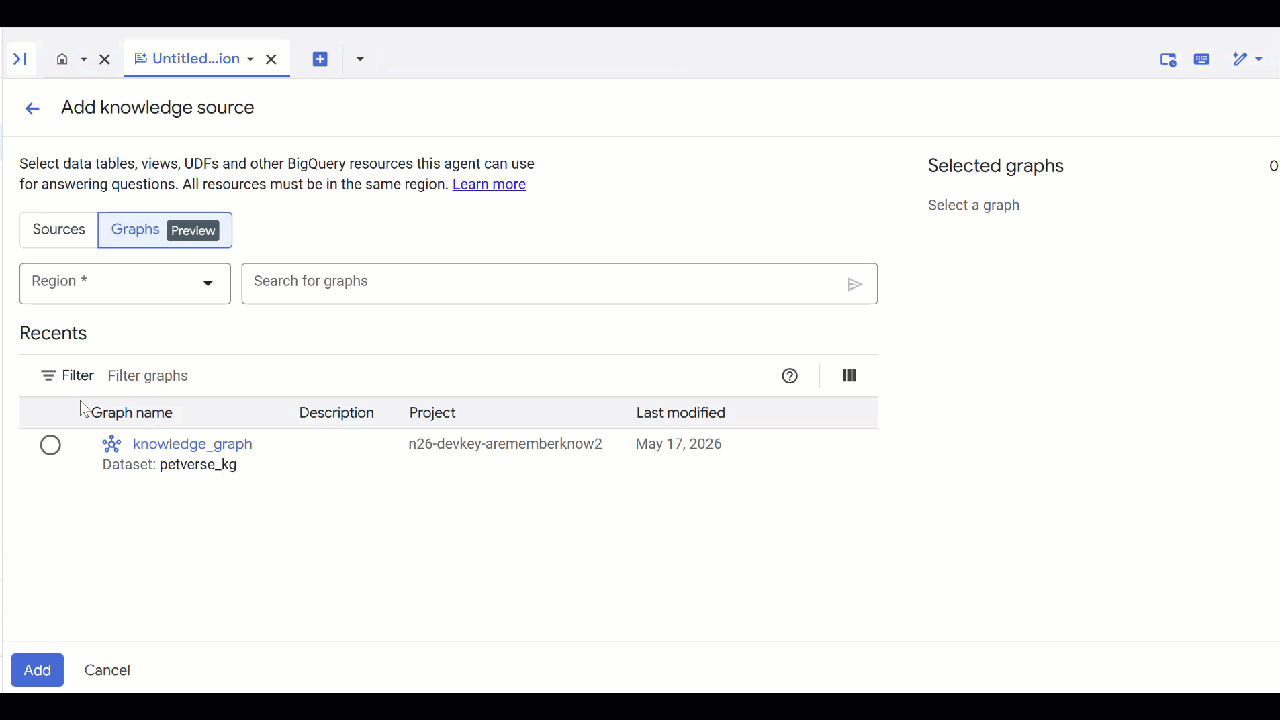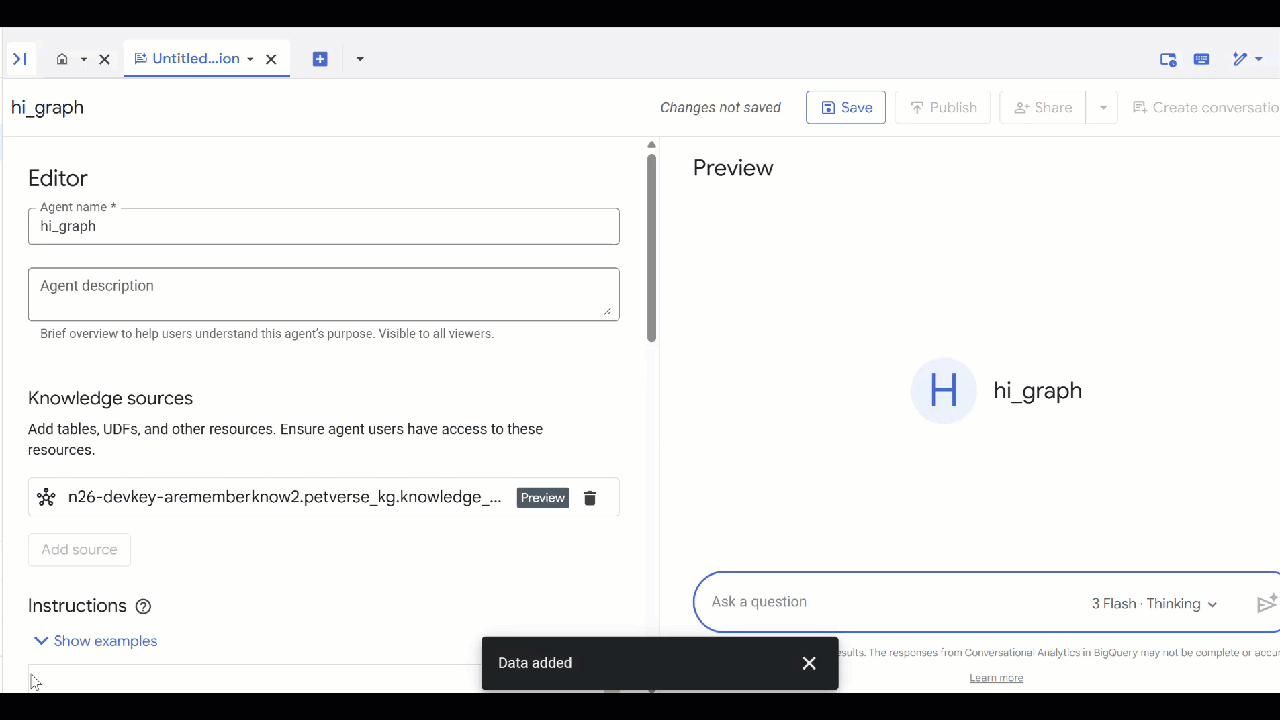
- 만든
knowledge_graph을 선택하고 추가를 클릭합니다.
이제 에이전트에게 질문하고 답변과 그 이유를 확인할 수 있습니다. 아이디어가 필요하다면 다음 샘플 질문을 참고하세요. 사고 모델은 시간이 조금 더 걸릴 수 있지만 더 나은 GQL 쿼리를 구성할 수 있습니다. Show Thinking를 펼쳐 빌드되는 항목을 확인할 수 있습니다.
- 비슷한 음식을 먹는 반려동물, 낮잠을 즐기는 반려동물과 친구인 반려동물을 찾아보세요.
- 취미, 좋아하는 음식, 장난감이 정확히 같은 반려동물이 있나요? 짝과 공유하는 관심분야를 나열합니다.
- 종이나 품종은 같지만 취미가 완전히 다른 반려동물을 찾아보세요.
9. 삭제
Google Cloud 계정에 지속적으로 비용이 청구되지 않도록 하려면 이 Codelab 중에 만든 리소스를 삭제하세요.
- GKE 클러스터를 삭제합니다.
gcloud container clusters delete petverse-cluster --region $REGION --quiet
- BigQuery 데이터 세트를 삭제합니다 (모든 테이블이 삭제됨).
bq rm -r -f -d $PROJECT_ID:petverse_kg
- Pub/Sub 대기열 리소스를 삭제합니다.
gcloud pubsub subscriptions delete petverse-sub --quiet
gcloud pubsub topics delete petverse-topic --quiet
- Artifact Registry 저장소를 삭제합니다.
gcloud artifacts repositories delete gke-cats-repo --location=$REGION --quiet
- 프로젝트별 GCS 버킷을 삭제합니다.
gcloud storage buckets delete gs://$PROJECT_ID-petverse --quiet
10. 축하합니다
축하합니다. GKE와 Gemini를 사용하여 분산 지식 그래프 파이프라인을 성공적으로 빌드하고 BigQuery 속성 그래프를 사용하여 쿼리했습니다.
학습한 내용
- GKE Autopilot에 분산 작업을 배포하는 방법
- 멀티모달 데이터 추출을 위해 Gemini를 사용하는 방법
- BigQuery 자동 삽입을 사용하는 방법
- BigQuery에서 속성 그래프를 만들고 쿼리하는 방법