
1. Wprowadzenie
W tym ćwiczeniu w Codelabs utworzysz rozproszony potok pozyskiwania wiedzy na potrzeby „Petverse”. Przetworzysz nieustrukturyzowane zasoby multimedialne (audio, wideo, obrazy, tekst/CSV) z zasobnika Cloud Storage, wyodrębnisz kluczowe informacje o zwierzętach (ulubione jedzenie, hobby) i utworzysz wykres wiedzy. Skalujesz przetwarzanie pliku multimedialnego za pomocą przetwarzania wielomodowego Gemini w Google Kubernetes Engine (GKE). Na koniec zapiszesz te dane w BigQuery i użyjesz nowej funkcji BigQuery Property Graph do analizowania relacji.
Wykorzystamy możliwości Google Kubernetes Engine, aby zademonstrować równoległe przetwarzanie dużych ilości danych.
Dlaczego warto korzystać z grafów wiedzy?
Grafy wiedzy lepiej niż tradycyjne relacyjne bazy danych nadają się do reprezentowania i analizowania złożonych relacji między podmiotami.
Do analizowania obrazów, plików audio i wideo oraz ustalania faktów na temat różnych zwierząt domowych będziemy używać Gemini 2.5 Flash.
Jakie zadania wykonasz
- Tworzenie i wdrażanie rozproszonego zadania przetwarzania danych w GKE.
- Użyj Gemini, aby wyodrębniać encje i relacje z plików multimedialnych.
- Przechowuj dane z grafu wiedzy w BigQuery.
- Twórz grafy właściwości w BigQuery i wykonuj na nich zapytania za pomocą języka Graph Query Language (GQL).
Czego potrzebujesz
- przeglądarka, np. Chrome;
- projekt Google Cloud z włączonymi płatnościami;
- Uprawnienia w projekcie do tworzenia zasobów i modyfikowania uprawnień.
To ćwiczenie jest przeznaczone dla deweloperów na wszystkich poziomach zaawansowania, w tym dla początkujących.
Szacowany czas trwania: 45 minut
Koszt: zasoby utworzone w tym ćwiczeniu powinny kosztować mniej niż 5 USD.
2. Zanim zaczniesz
Tworzenie projektu Google Cloud
- Otwórz konsolę Google Cloud: https://console.cloud.google.com, a następnie wybierz lub utwórz projekt w chmurze Google Cloud.
- ⚠️ Zanotuj identyfikator projektu. Użyjesz go w kilku poleceniach w tym module.
Uruchamianie Cloud Shell
- Otwórz Cloud Shell na nowej karcie: https://shell.cloud.google.com/.
- Jeśli pojawi się prośba o autoryzację, kliknij Autoryzuj.
- Zastąp
PROJECT_IDi wklej to polecenie w terminalu:
export PROJECT_ID="YOUR_PROJECT_ID"
gcloud config set project $PROJECT_ID
📝 Uwaga: Twój projekt będzie widoczny w wierszu poleceń na żółto. Jeśli sesja zostanie ponownie uruchomiona, jeszcze raz uruchom powyższe polecenie, aby ustawić identyfikator projektu.
Włącz interfejsy API
Aby włączyć wszystkie wymagane interfejsy API, uruchom to polecenie:
gcloud services enable \
aiplatform.googleapis.com \
bigquery.googleapis.com \
artifactregistry.googleapis.com \
container.googleapis.com \
cloudbuild.googleapis.com \
pubsub.googleapis.com
Kopiuj repozytorium
Aby sklonować repozytorium, uruchom te polecenia.
cd ~/
git clone --filter=blob:none --no-checkout https://github.com/GoogleCloudPlatform/devrel-demos.git
cd ~/devrel-demos
git sparse-checkout init --cone
git sparse-checkout set codelabs/gke-knowledge-graph
git checkout main
cd codelabs/gke-knowledge-graph/
Uruchom skrypt konfiguracji
Ten skrypt automatyzuje konfigurację backendu przez:
- Tworzenie obrazu kontenera i repozytorium Artifact Registry
- Tworzenie zbioru danych BigQuery
- Tworzenie połączenia z BigQuery w celu wykonywania funkcji AI od Gemini z poziomu SQL
Uruchom w terminalu to polecenie:
./scripts/setup.sh
Jeśli skrypt poprosi Cię o szczegóły konfiguracji, użyj tych wartości:
- Identyfikator projektu: użyj identyfikatora utworzonego w poprzednim kroku.
- Region:
us-central1
⚠️ Ważne: wykonanie skryptu zajmie kilka minut. Nie zamykaj tego okna terminala, aby dokończyć proces w tle. Aby przejść do następnego kroku, otwórz nową kartę lub okno terminala i uruchom kolejne polecenia.
3. Konfigurowanie Data Agent Kit
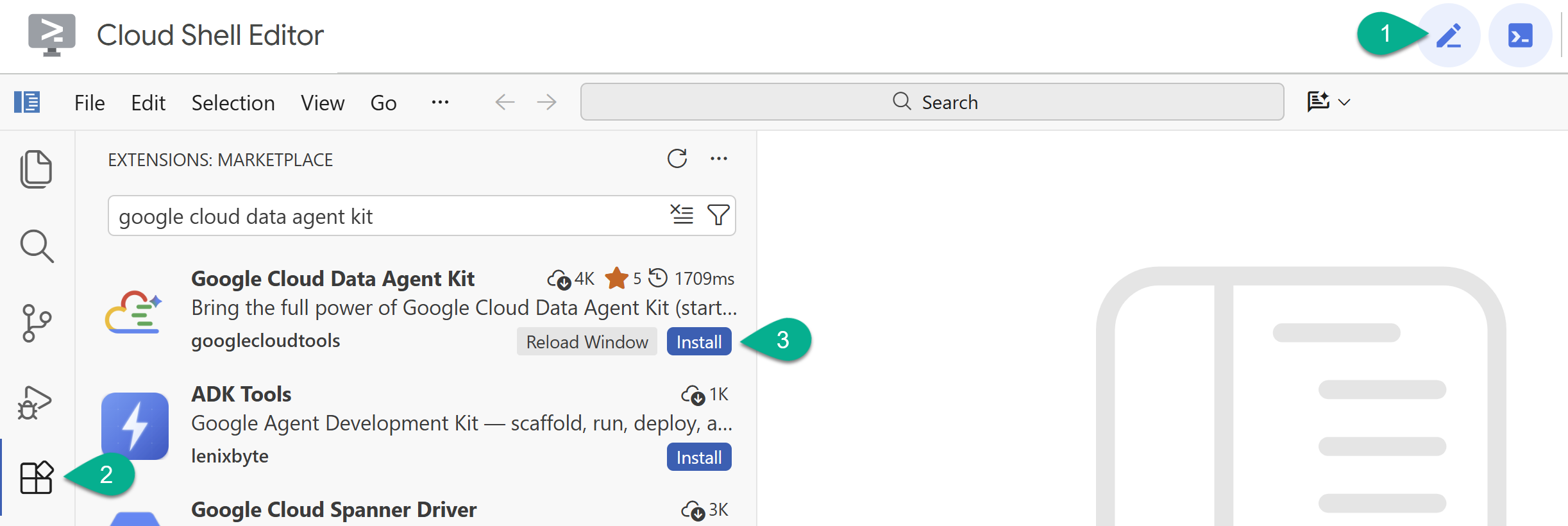
- Włącz edytor Cloud Shell, klikając ikonę ołówka w prawym górnym rogu.
- W edytorze Cloud Shell kliknij ikonę Rozszerzenia na pasku bocznym po lewej stronie.
- Wyszukaj Google Cloud Data Agent Kit i kliknij Zainstaluj, jeśli nie jest jeszcze zainstalowany.
- Zaloguj się na konto Google za pomocą rozszerzenia.
- W podsumowaniu konfiguracji wpisz identyfikator projektu i
us-central1jako region.
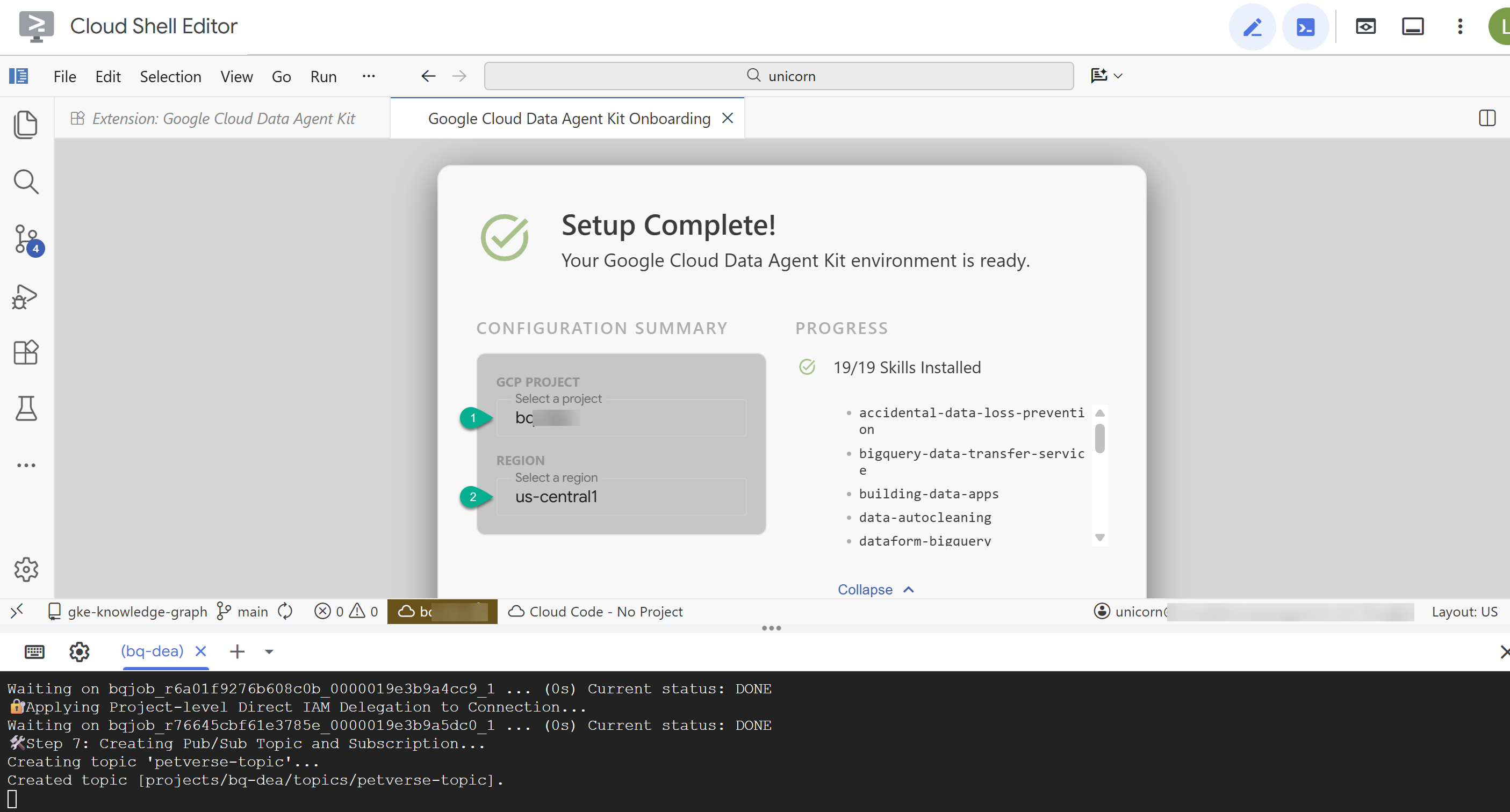
- Kliknij Configure MCP Servers (Skonfiguruj serwery MCP). Nie musisz wprowadzać w tym oknie żadnych zmian. Wystarczy, że klikniesz Rozpocznij.
- W razie potrzeby odśwież okno. Możesz teraz zamknąć kartę Przewodnik Szybki start.
Konfigurowanie tabel w BigQuery
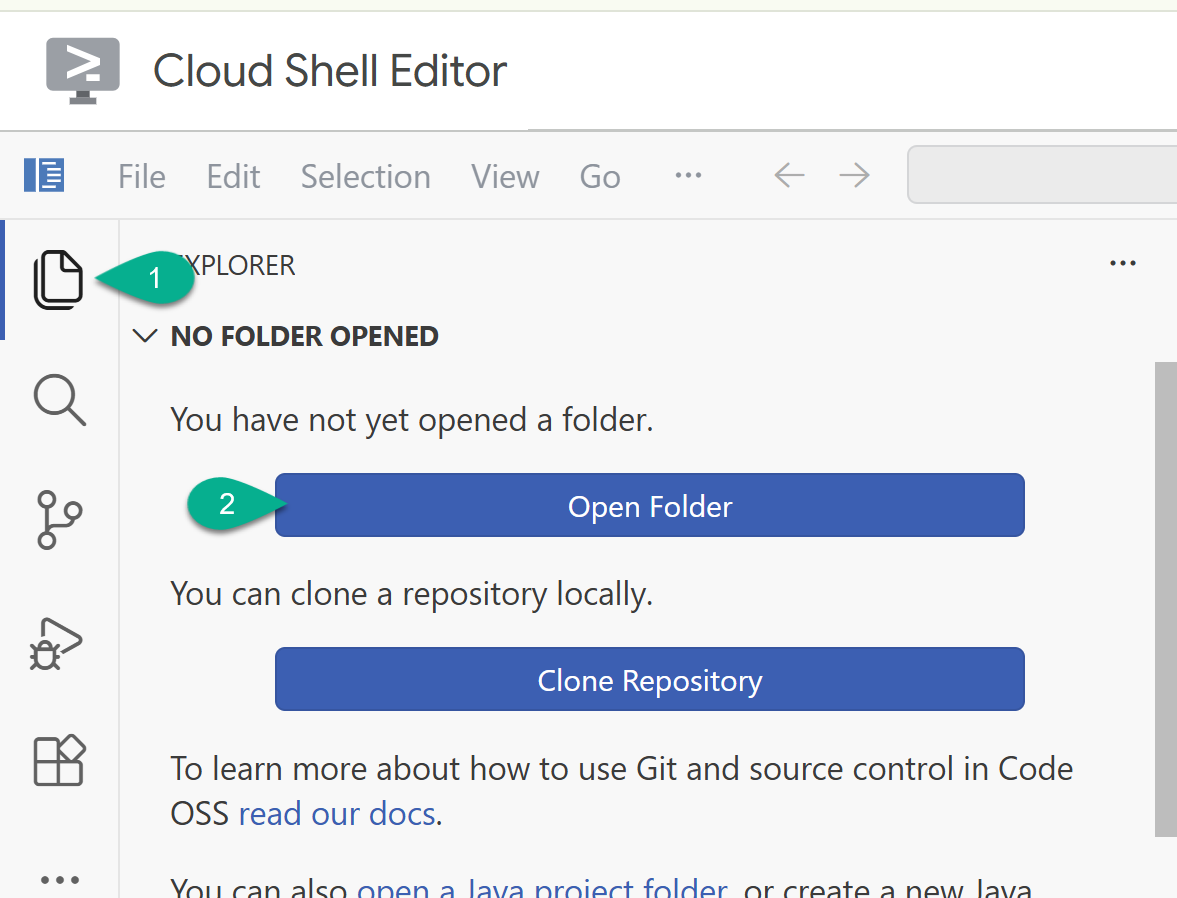
- Na pasku bocznym wróć do eksploratora. Jeśli folder domowy (np.
/home/your_user_name/) nie jest jeszcze otwarty, kliknij Otwórz folder i wybierz go.
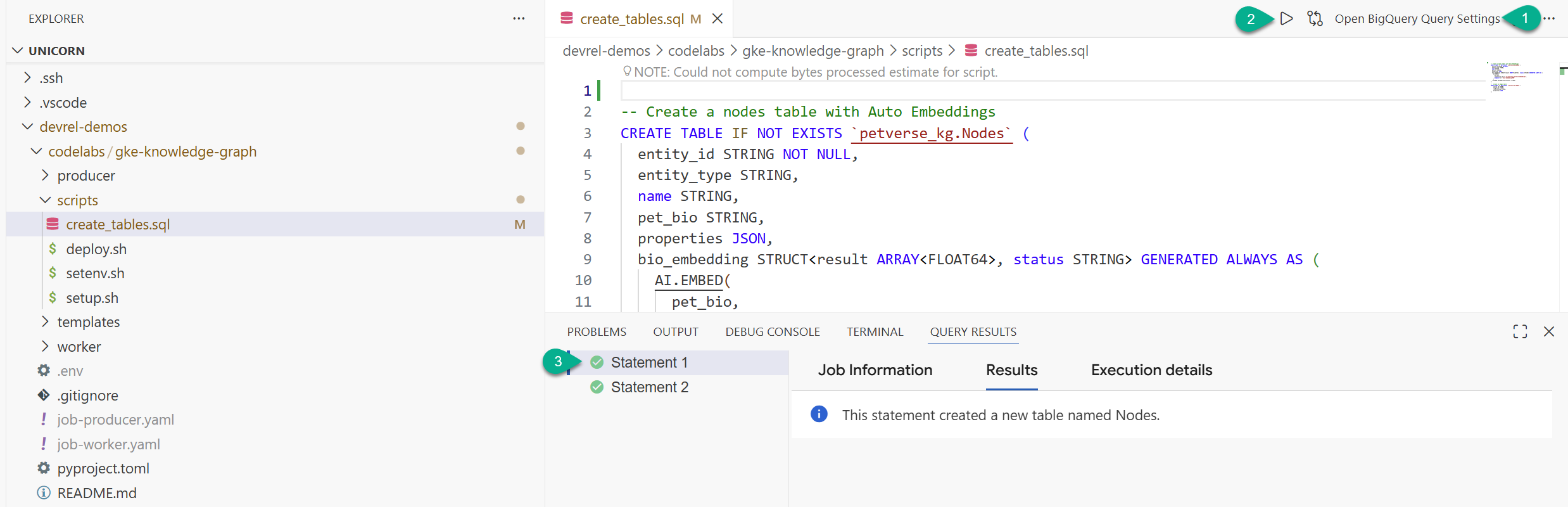
- W oknie eksploratora znajdź folder sklonowany z repozytorium (
devrel-demos). W sekcjicodelabs/gke-knowledge-graph/scriptsznajdzieszcreate_tables.sql. Otwórz ten plik. - W prawym górnym rogu kliknij Otwórz ustawienia zapytania.
- Wybierz BigQuery. Kliknij kolejno Zapisz i Zamknij.
- Kliknij Wykonaj.
Powinny zostać wyświetlone 2 instrukcje wykonane prawidłowo. Tabele do przechowywania węzłów i krawędzi grafu wiedzy zostały utworzone.
Możesz zamknąć kartę create_tables.sql i konsolę wyników.
4. Inicjowanie klastra GKE
Do uruchomienia zadania przetwarzania danych użyjemy Autopilota w GKE. Autopilot to zalecana sprawdzona metoda, ponieważ zarządza infrastrukturą klastra.
Skrypt konfiguracji powinien być już ukończony. Powinien wyświetlić się komunikat o powodzeniu: 🎉🦄 Setup successfully finished! 🎉🦄.
Wklej to polecenie w terminalu, aby utworzyć klaster:
source scripts/setenv.sh
gcloud container clusters create-auto petverse-cluster \
--region=$REGION
🕓 Zajmie to około 5 minut.
Uzyskaj dane logowania, aby korzystać z klastra:
source scripts/setenv.sh
gcloud container clusters get-credentials petverse-cluster --region $REGION
Powinny się wyświetlić te dane wyjściowe:
Fetching cluster endpoint and auth data. kubeconfig entry generated for petverse-cluster.
5. Konfigurowanie Workload Identity
Workload Identity Federation for GKE (z użyciem bezpośredniego dostępu do zasobów) umożliwia zadaniom GKE bezpieczny dostęp do usług Google Cloud bez konieczności zarządzania kluczami kont usługi.
Wykonaj deploy.sh, aby:
- Tworzenie konta usługi Kubernetes
- Przypisywanie niezbędnych ról uprawnień bezpośrednio do podmiotu konta usługi Kubernetes
- Powiąż konto usługi uprawnień z kontem usługi Kubernetes
- Dodaj adnotację do konta usługi Kubernetes, aby ukończyć link.
source scripts/setenv.sh
./scripts/deploy.sh
6. Wdrażanie zadań przetwarzania rozproszonego
W tym kroku wdrożysz w GKE moduł kolejkowania (producent) i silniki przetwarzania (procesy robocze).
Nasza nowa rozdzielona architektura wykorzystuje Google Cloud Pub/Sub do asynchronicznego przetwarzania komponentów:
- Producent skanuje GCS i umieszcza wszystkie ścieżki plików w kolejce Pub/Sub.
- Pula procesów roboczych skaluje się w GKE, dynamicznie pobierając zadania równolegle, przetwarzając je za pomocą Gemini i zapisując w BigQuery.
Skrypt setup.sh utworzył i wypchnął obrazy kontenerów Producer i Worker, dodał do kolejki tematy Pub/Sub oraz dynamicznie wygenerował pliki manifestu wdrożenia GKE: job-producer.yaml i job-worker.yaml.
- Zastosuj zadanie producenta, aby przeskanować zasobnik pamięci i umieścić w kolejce wszystkie komponenty:
kubectl apply -f job-producer.yaml
To zadanie jest wykonywane i kończy się szybko, ponieważ tylko dodaje metadane do kolejki.
- Wdróż zadanie Worker Job skonfigurowane do uruchamiania 6 równoległych procesów roboczych, aby opróżnić kolejkę:
kubectl apply -f job-worker.yaml
GKE Autopilot automatycznie wykrywa pody w stanie oczekiwania, dynamicznie skaluje w górę węzły obliczeniowe i uruchamia instancje robocze równolegle, aby przetwarzać umieszczone w kolejce pliki audio, wideo, obrazy i pliki CSV.
7. Weryfikowanie wyników
- Sprawdzanie stanu zadań:
kubectl get jobs
Poczekaj, aż zarówno petverse-producer-job, jak i petverse-worker-job zostaną ukończone.
🕓 Zajmie to około 10 minut. Postęp możesz sprawdzić za pomocą poniższych poleceń.
- Sprawdź logi producenta, aby upewnić się, że pliki zostały poprawnie umieszczone w kolejce:
cd ~/devrel-demos/codelabs/gke-knowledge-graph
source scripts/setenv.sh
kubectl logs -l app=petverse-producer --tail=50
- Obserwuj, jak równoległe procesy robocze przetwarzają pliki z kolejki:
kubectl logs -l app=petverse-worker --tail=50
(Instancje robocze mają 60-sekundowy limit czasu bezczynności i są automatycznie wyłączane oraz zwalniają miejsce, gdy kolejka Pub/Sub jest pusta).
sprawdzić dane w BigQuery;
- Otwórz BigQuery Studio. Zostaną utworzone 2 tabele: petverse_kg.Nodes i petverse_kg.Edges.
- Aby zobaczyć zawartość tabel, kliknij dwukrotnie ich nazwy, a potem kliknij Podgląd.
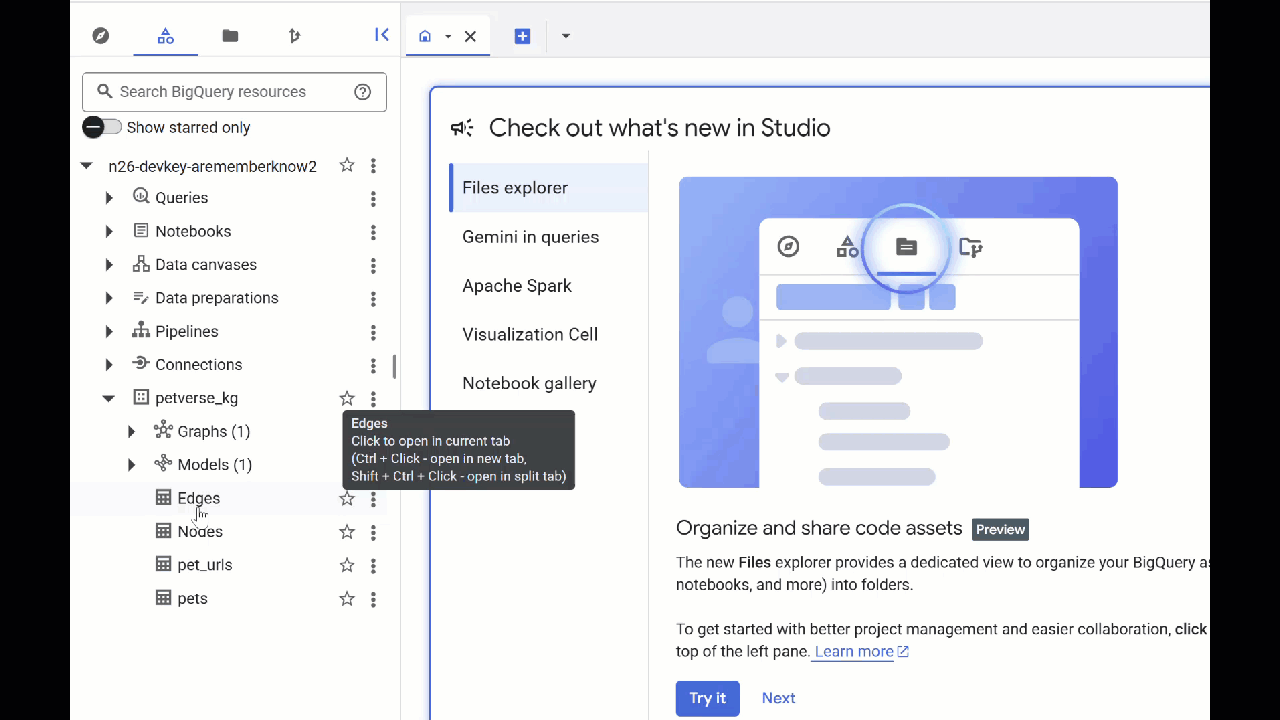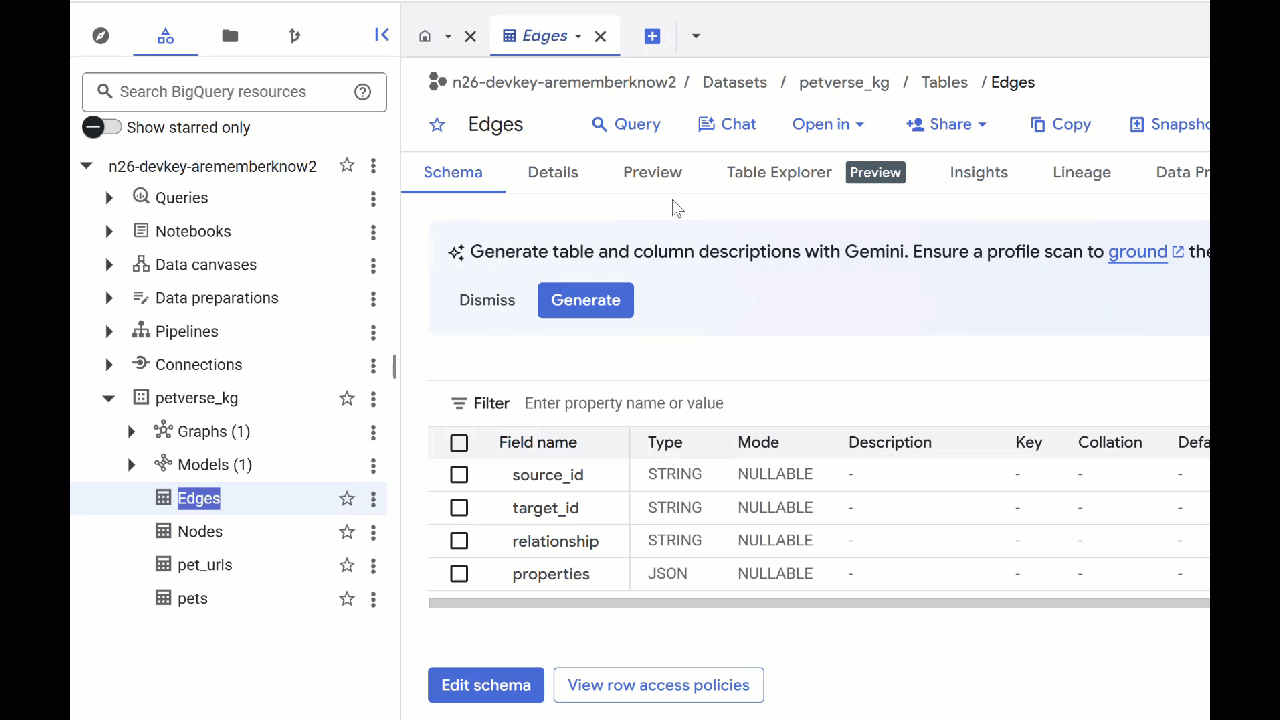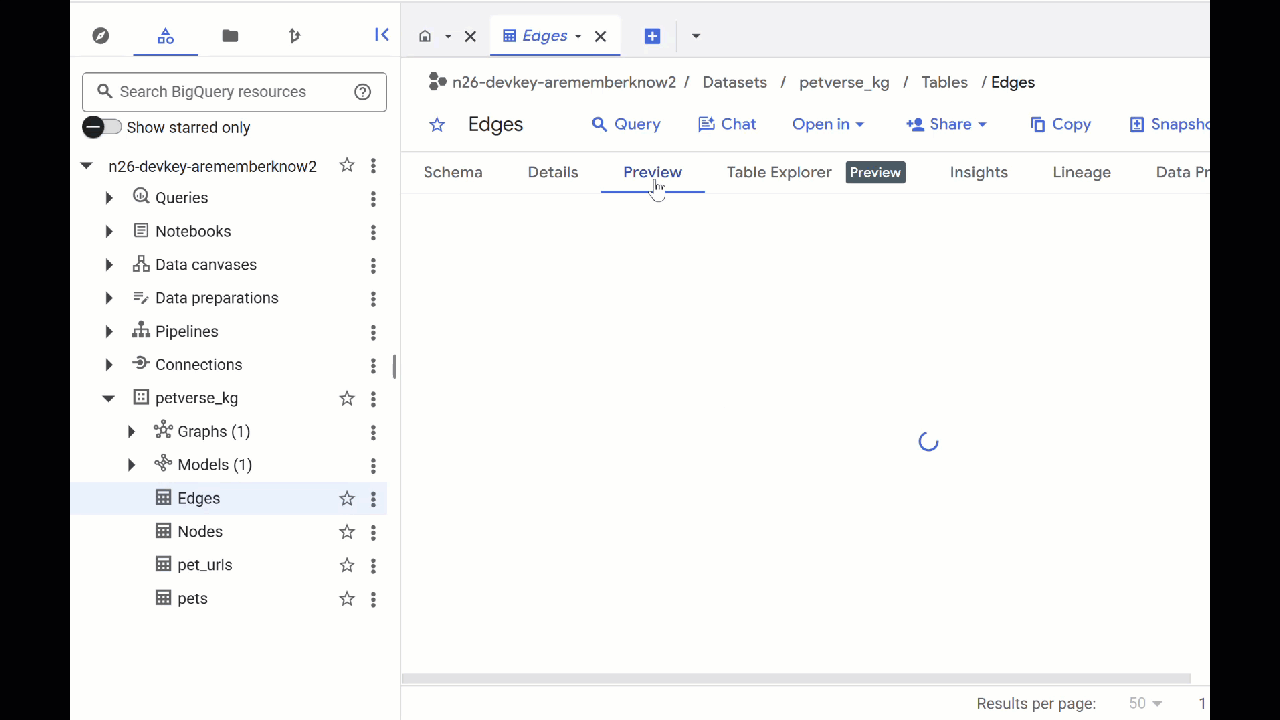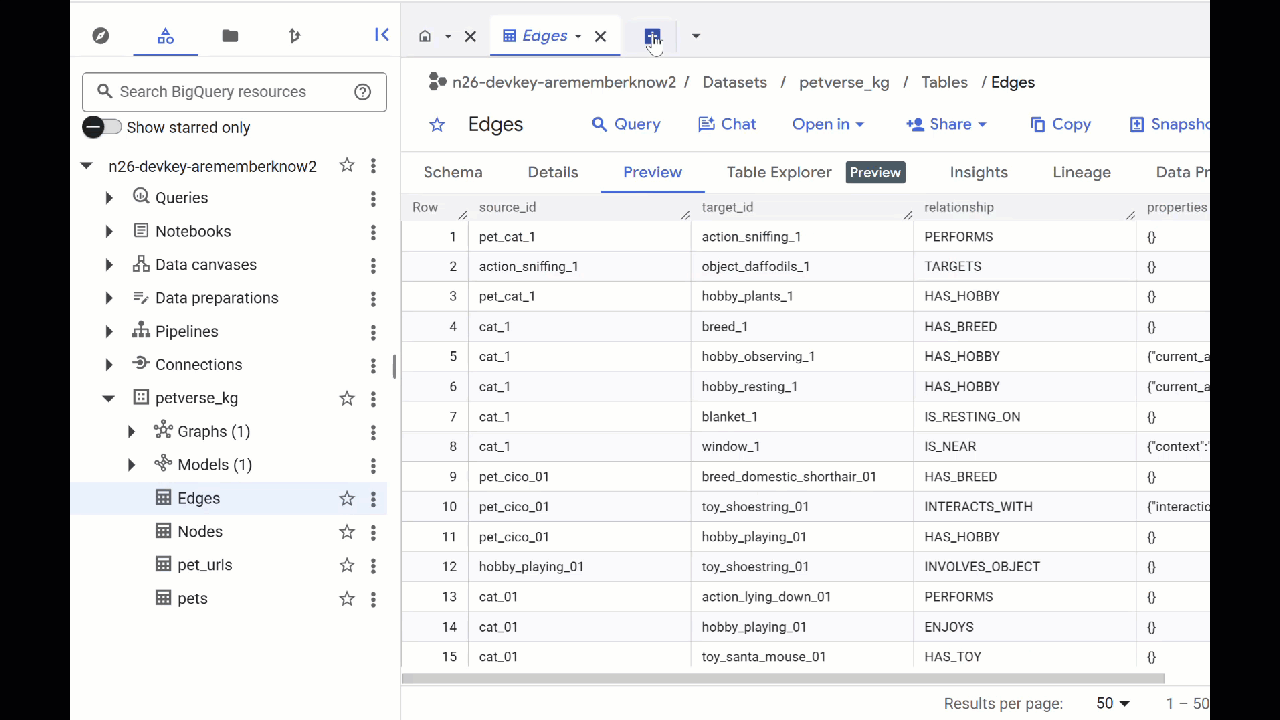
W tabeli Węzły znajdziesz informacje o podmiotach wykrytych przez Gemini w plikach audio, filmach i zdjęciach. Tabela Edges zawiera relacje między nimi. Jeśli na przykład posłuchasz audio o kocie o imieniu SQL, dowiesz się, że lubi on bawić się sznurówkami i jeść suszone rybki.
- Aby utworzyć nowe zapytanie, kliknij +. Wklej to stwierdzenie i kliknij Uruchom:
SELECT n.name, n.entity_id, e.relationship, e.target_id
FROM
`petverse_kg.Nodes` n
JOIN
`petverse_kg.Edges` e
ON n.entity_id = e.source_id
WHERE n.name = 'SQL'
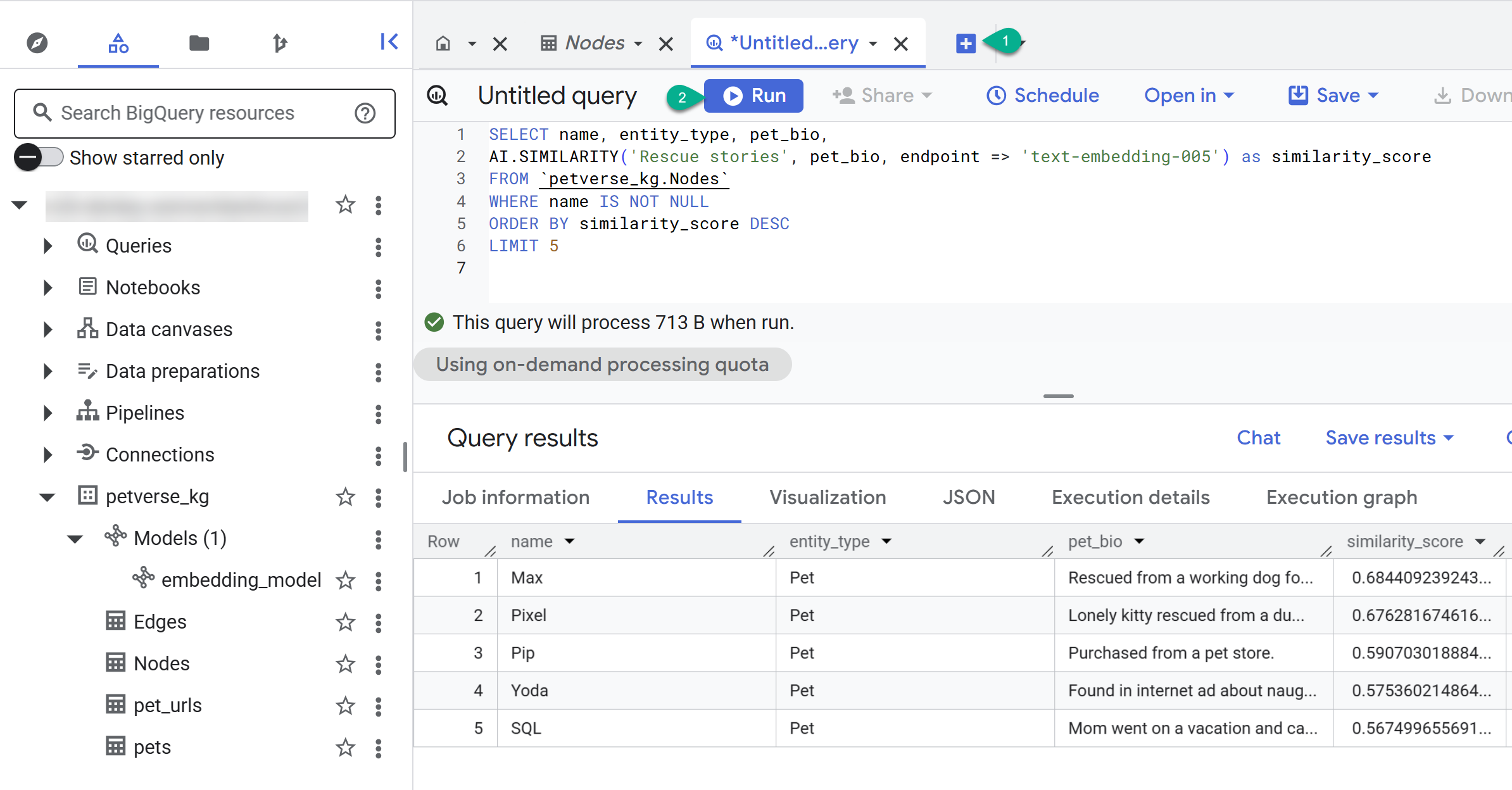
- Aby utworzyć nowe zapytanie, kliknij +. Wklej to stwierdzenie i kliknij Uruchom:
SELECT name, entity_type, pet_bio,
AI.SIMILARITY('Pets who like to relax', pet_bio, endpoint => 'text-embedding-005') as similarity_score
FROM `petverse_kg.Nodes`
WHERE name IS NOT NULL
ORDER BY similarity_score DESC
LIMIT 5
Powinny pojawić się węzły dla zwierząt, które lubią odpoczywać. To zapytanie przeprowadziło wyszukiwanie semantyczne za pomocą funkcji AI AI.SIMILARITY, aby znaleźć zwierzęta, których biografie są najbardziej podobne do tekstu zapytania.
Tworzenie wykresu właściwości
Teraz, gdy mamy węzły i krawędzie w BigQuery, możemy utworzyć wykres właściwości, aby łatwo wysyłać zapytania o relacje.
Tworzenie wykresu
- Zastąp poprzednie zapytanie i wykonaj ten kod DDL, aby utworzyć graf usługi:
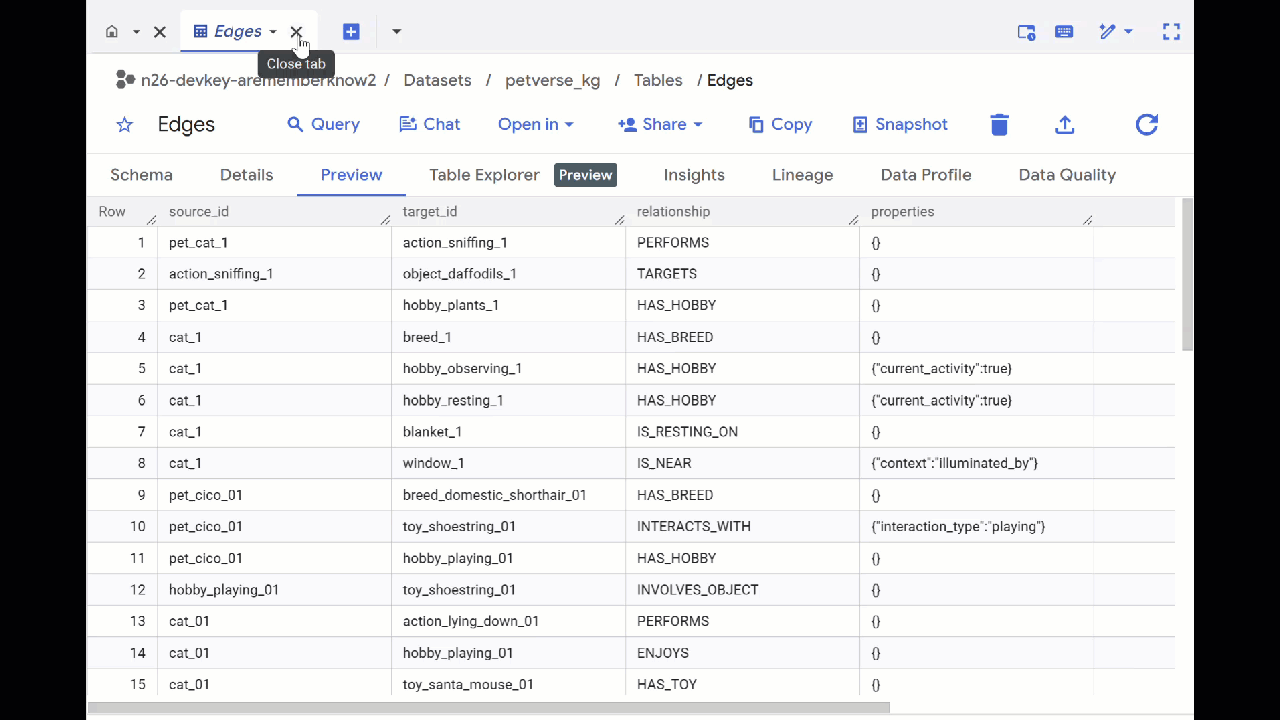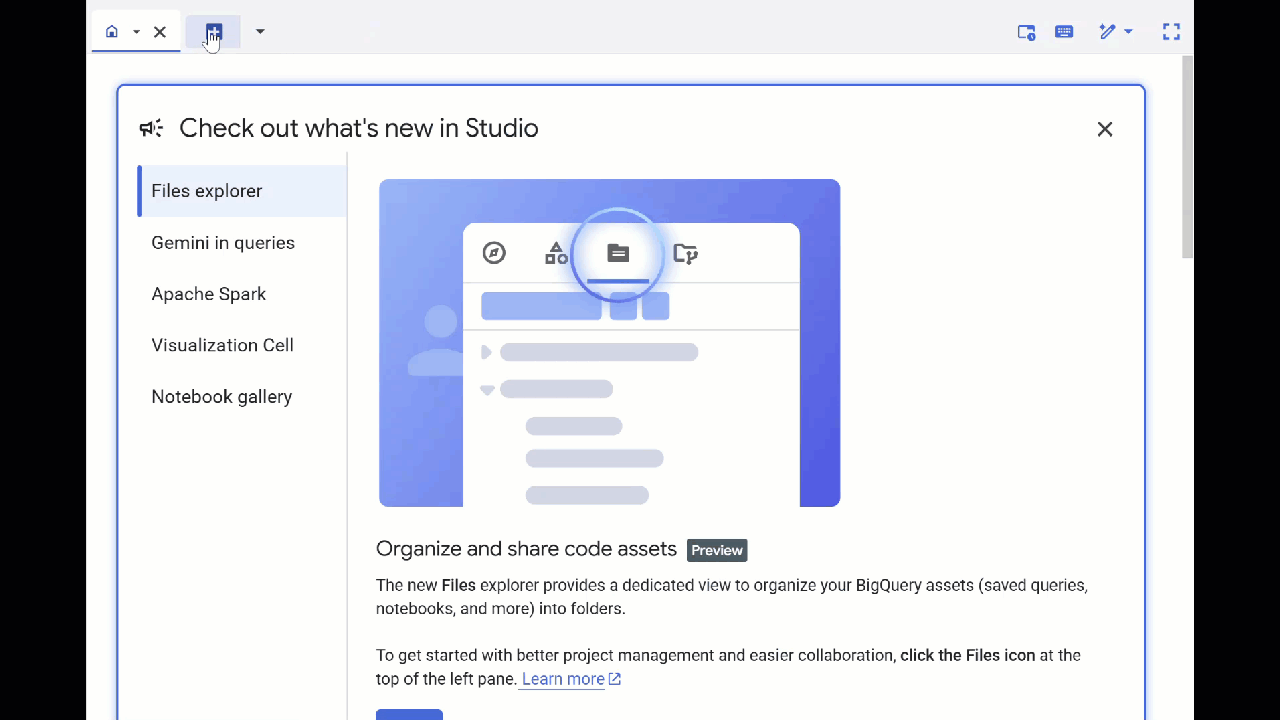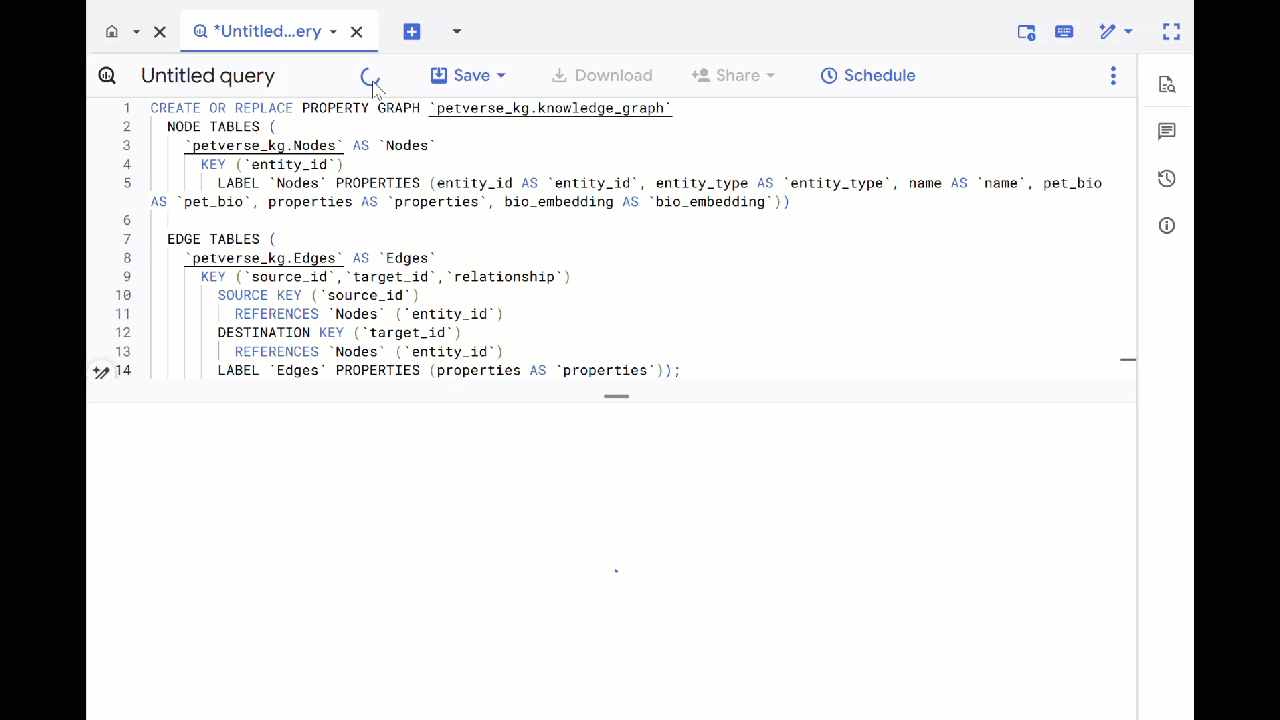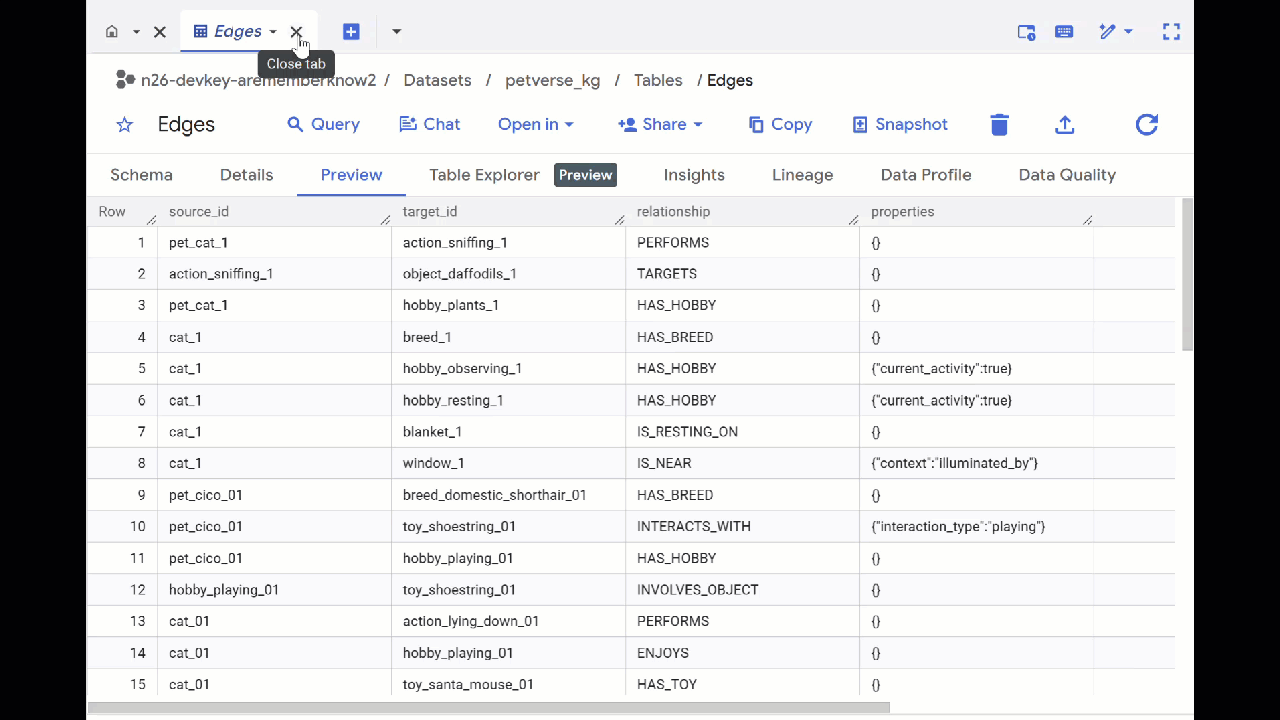
CREATE OR REPLACE PROPERTY GRAPH `petverse_kg.knowledge_graph`
NODE TABLES (
`petverse_kg.Nodes` AS `Nodes`
KEY (`entity_id`)
LABEL `Nodes` PROPERTIES (entity_id AS `entity_id`, entity_type AS `entity_type`, name AS `name`, pet_bio AS `pet_bio`, properties AS `properties`, bio_embedding AS `bio_embedding`))
EDGE TABLES (
`petverse_kg.Edges` AS `Edges`
KEY (`source_id`,`target_id`,`relationship`)
SOURCE KEY (`source_id`)
REFERENCES `Nodes` (`entity_id`)
DESTINATION KEY (`target_id`)
REFERENCES `Nodes` (`entity_id`)
LABEL `Edges` PROPERTIES (properties AS `properties`));
- Kliknij Otwórz wykres. Zobaczysz wizualizację grafu z węzłem, który ma krawędź do samego siebie. To normalne.
Wysyłanie zapytań do grafu
- Możesz zamknąć wszystkie poprzednie zapytania i otworzyć nowe, puste zapytanie, klikając przycisk +.
- Użyj GQL, aby znaleźć zwierzęta powiązane z innymi zwierzętami na podstawie wspólnych zainteresowań (takich jak hobby, ulubione jedzenie czy zabawki). To zapytanie wieloetapowe dopasowuje 2 różne zwierzęta połączone z tym samym węzłem:
GRAPH `petverse_kg.knowledge_graph`
MATCH p = (pet1:Nodes)-[e1]->(interest:Nodes)<-[e2]-(pet2:Nodes)
WHERE pet1.entity_id != pet2.entity_id
AND (LOWER(pet1.entity_type) = 'pet' AND LOWER(pet2.entity_type) = 'pet')
AND LOWER(interest.entity_type) IN ('hobby', 'action', 'activity', 'food', 'toy')
RETURN TO_JSON(p) as res
LIMIT 100
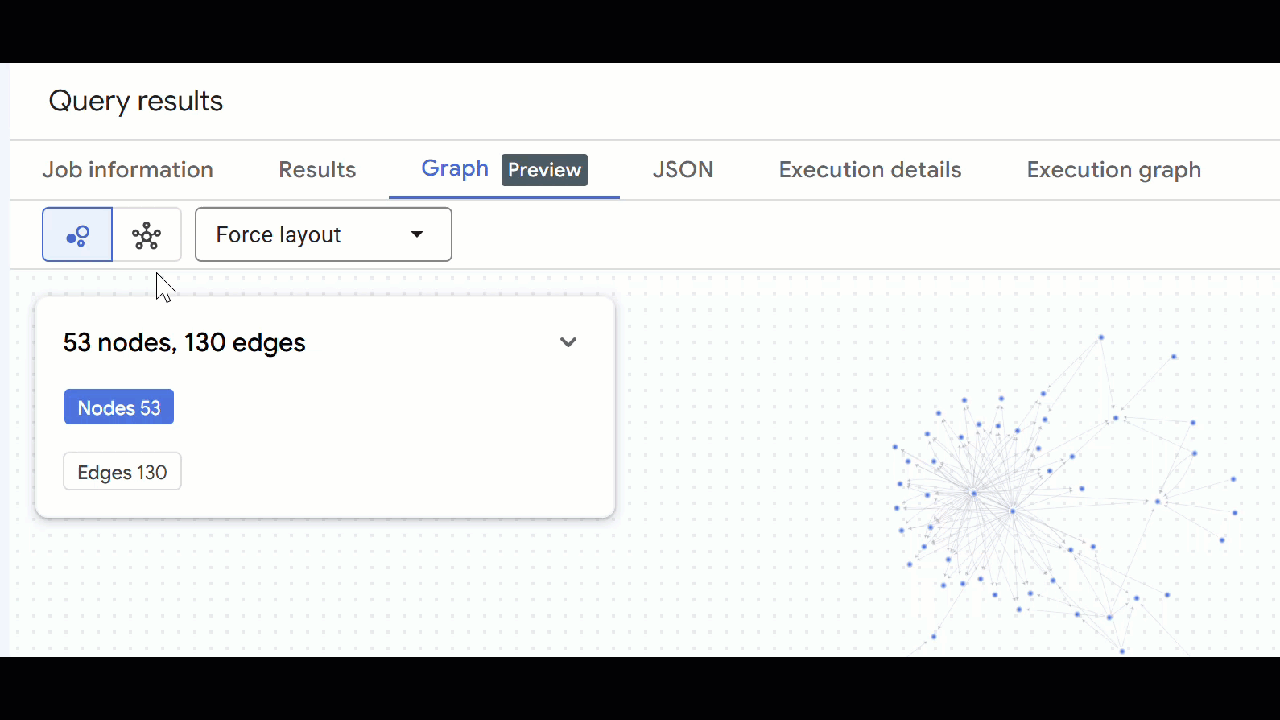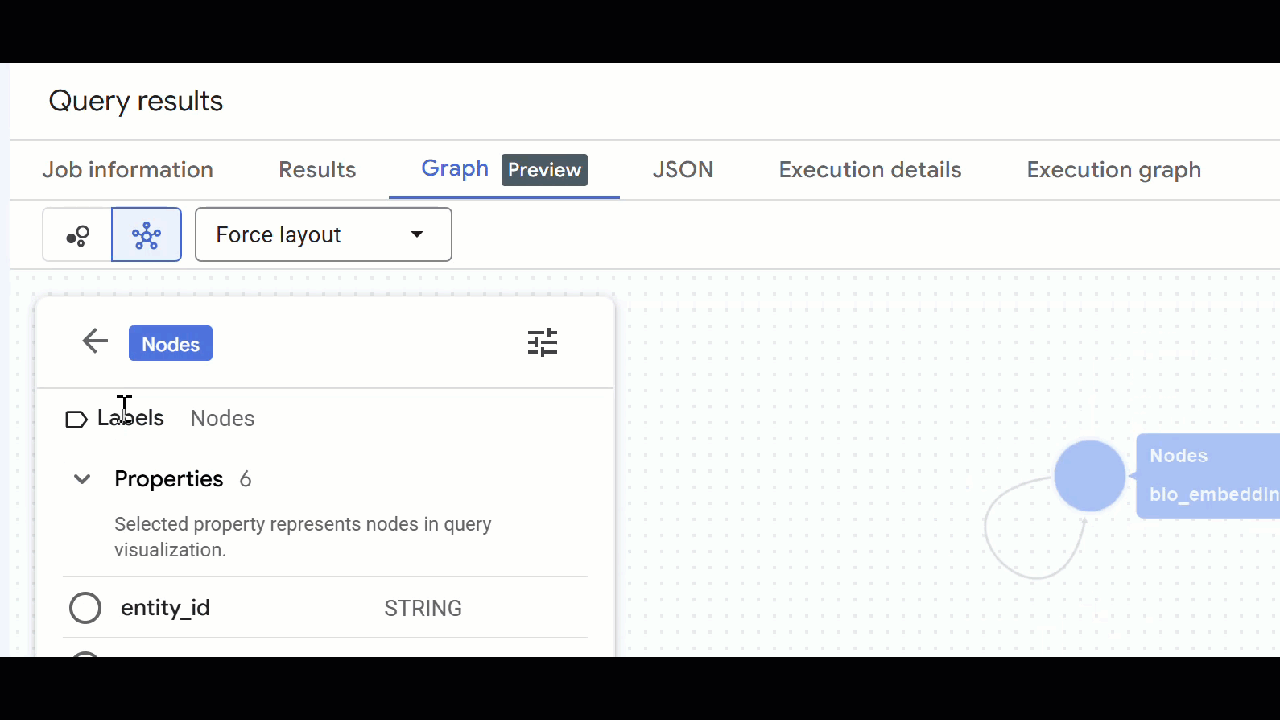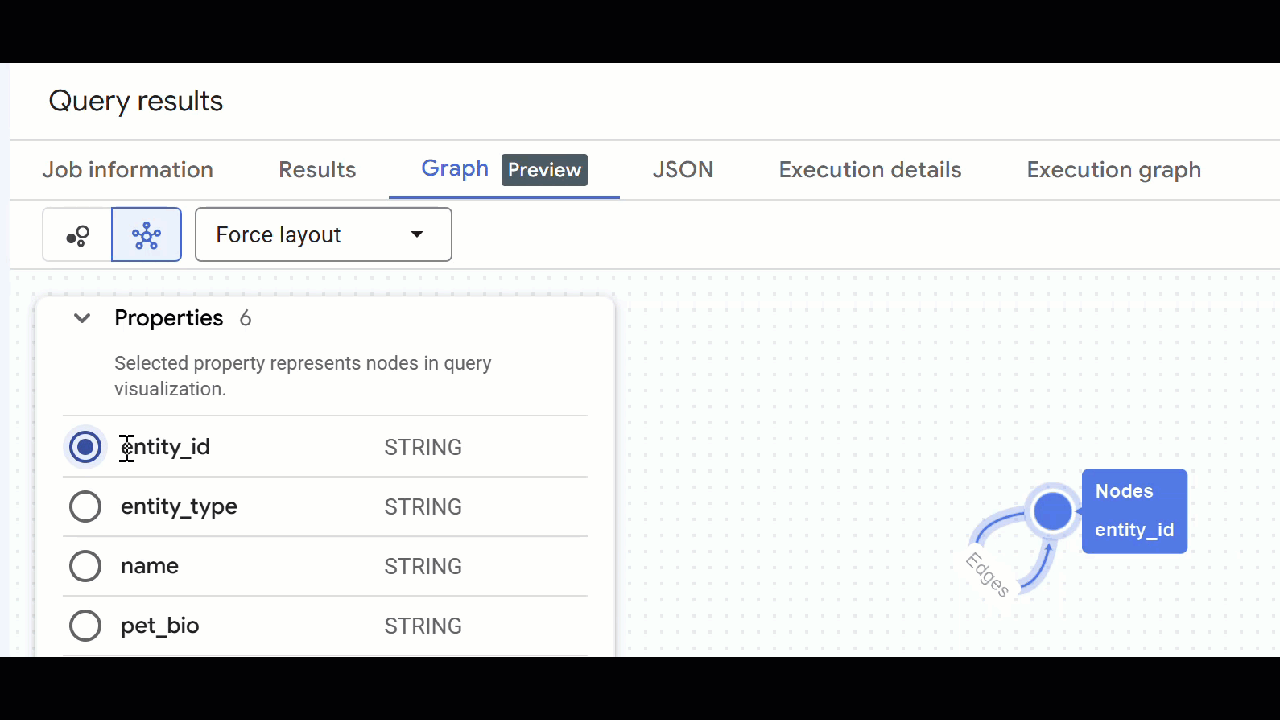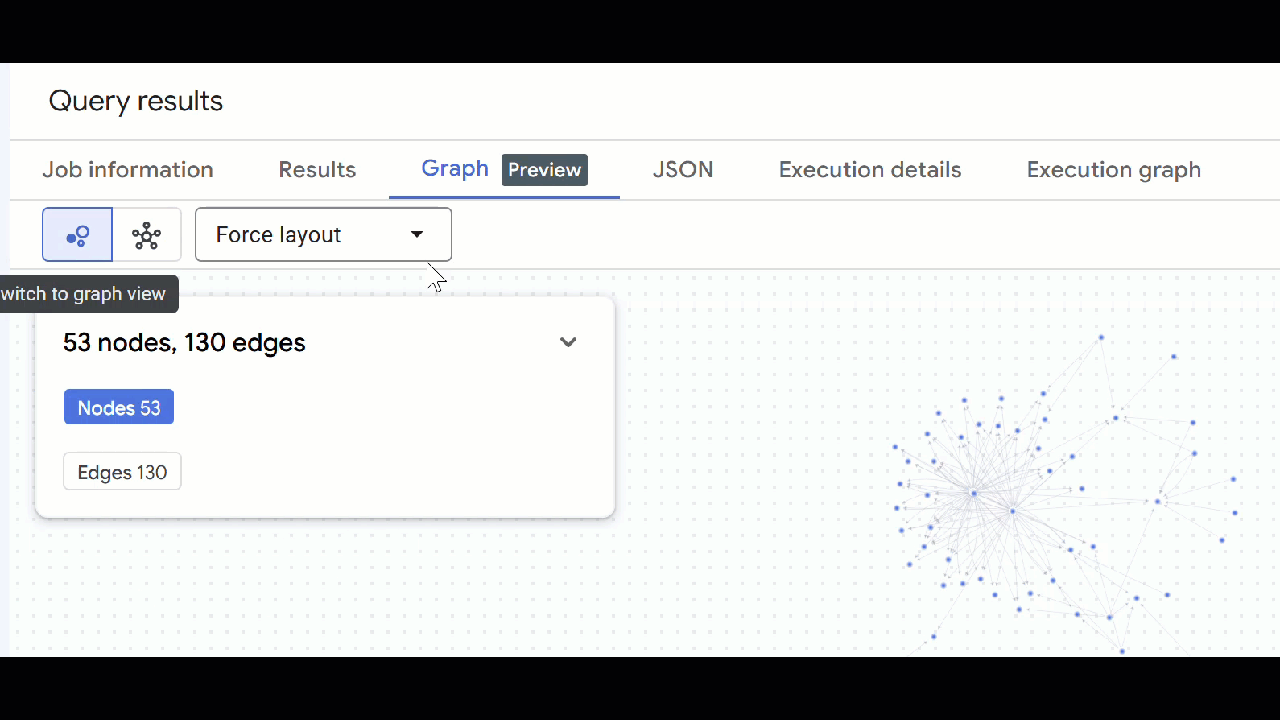
- Powinna być widoczna wizualizacja wykresu. Możesz klikać węzły, aby wyświetlać właściwości węzłów i krawędzi.
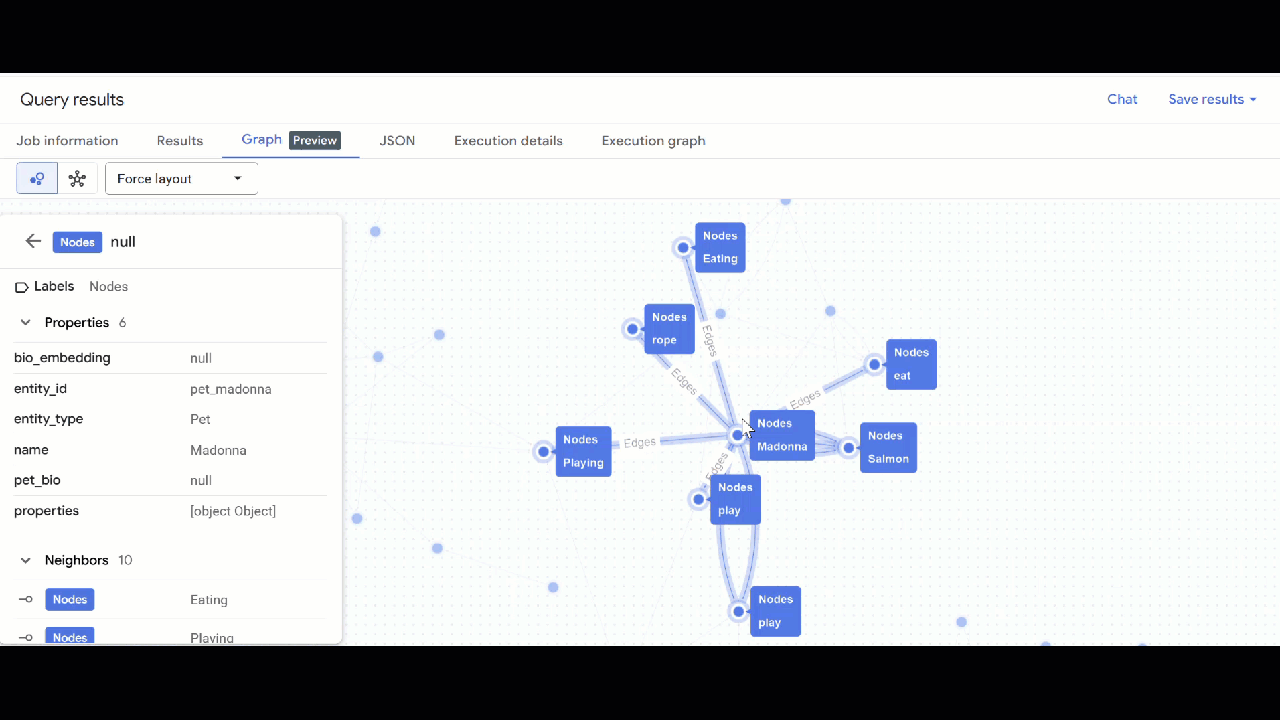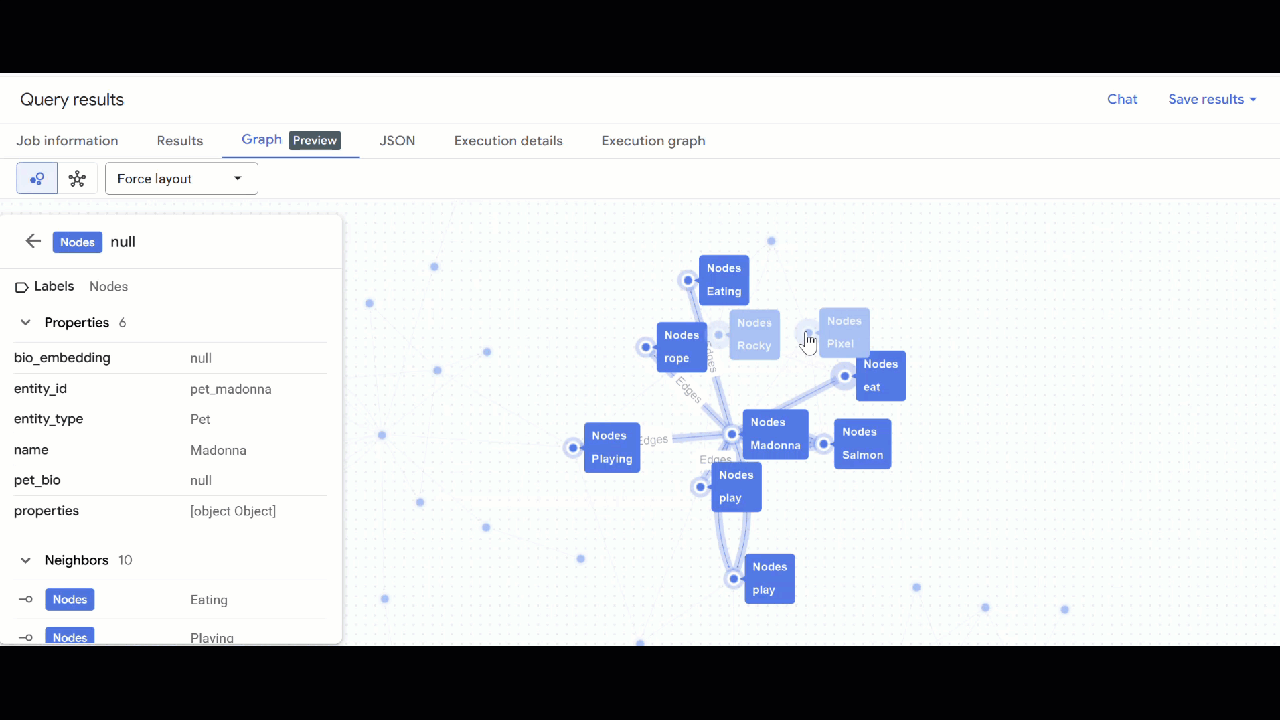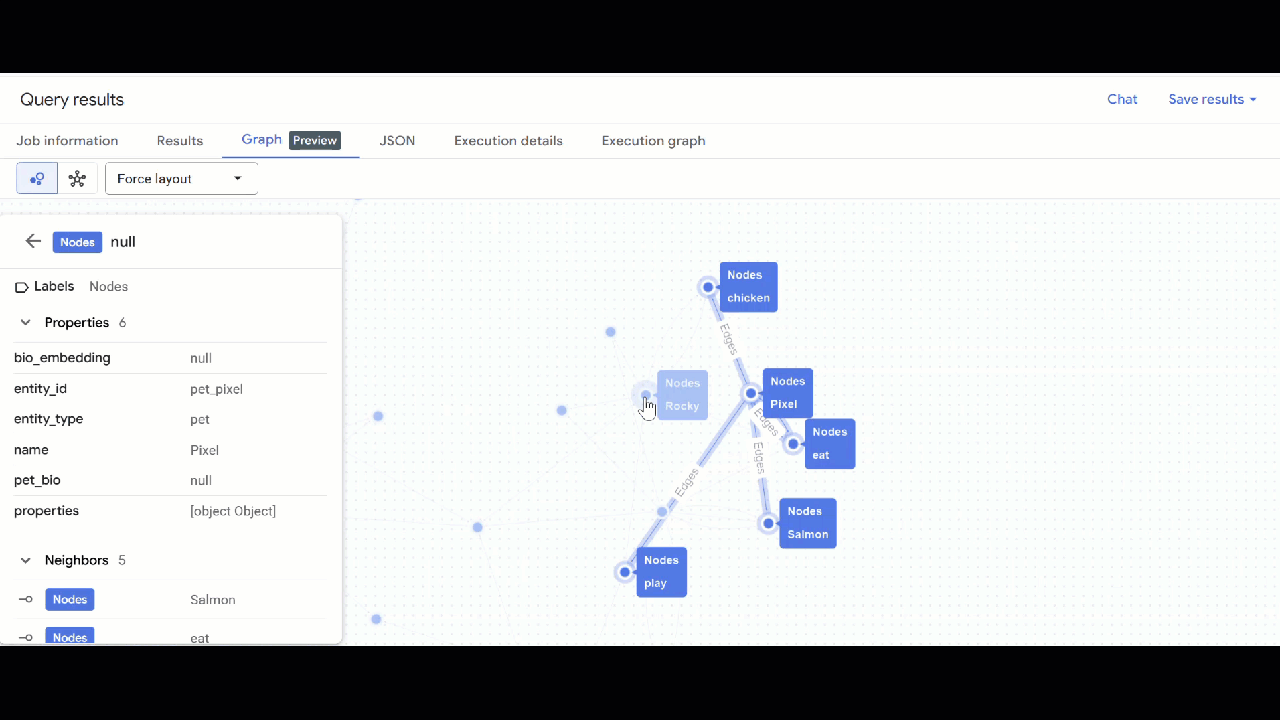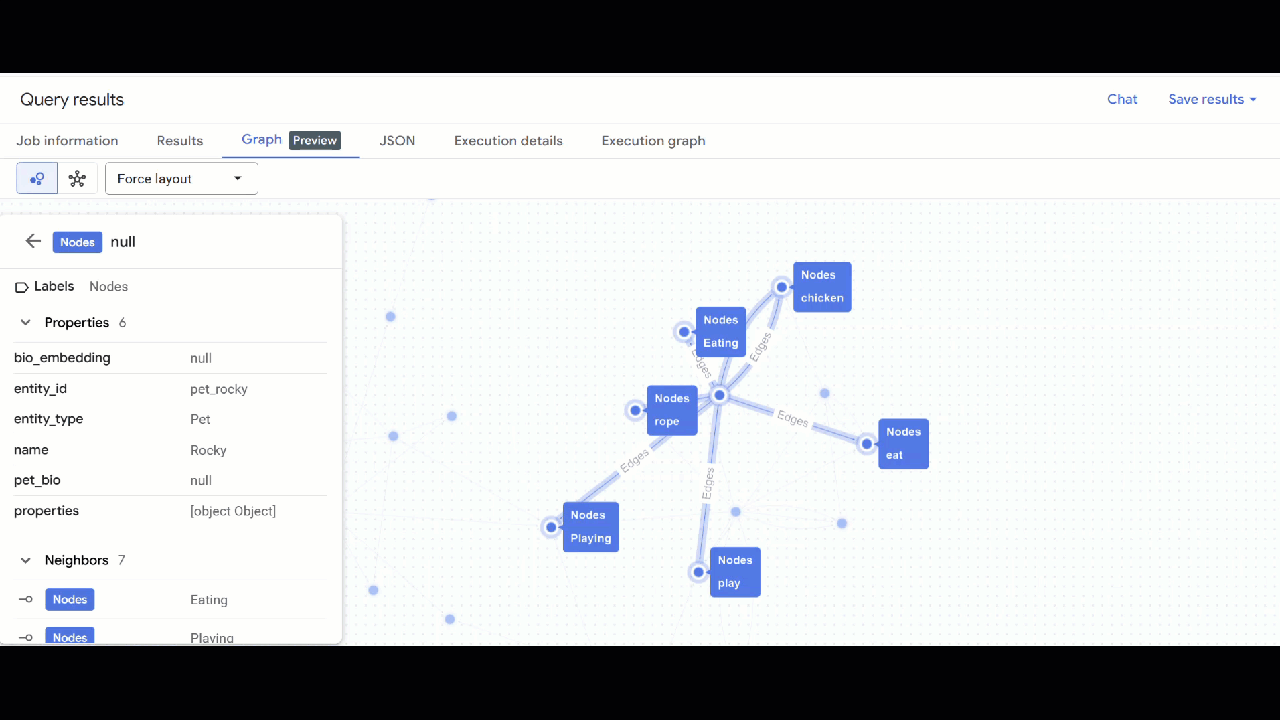
🕵️ Wskazówka: możesz dostosować wartość wyświetlaną przez węzeł, klikając Przełącz na widok schematu:
- Możesz zamknąć wszystkie otwarte karty z zapytaniami.
8. Czat z wykresem
- Obok znaku + znajdziesz menu. Wybierz Rozmowa.
- Pojawi się prośba o włączenie interfejsu API Data Analytics z Gemini. Włącz oba interfejsy API. Gdy to zrobisz, odśwież okno lub utwórz nową rozmowę, aby zobaczyć agenta.
- Kliknij Nowy agent.
- Nadaj agentowi nazwę, np.
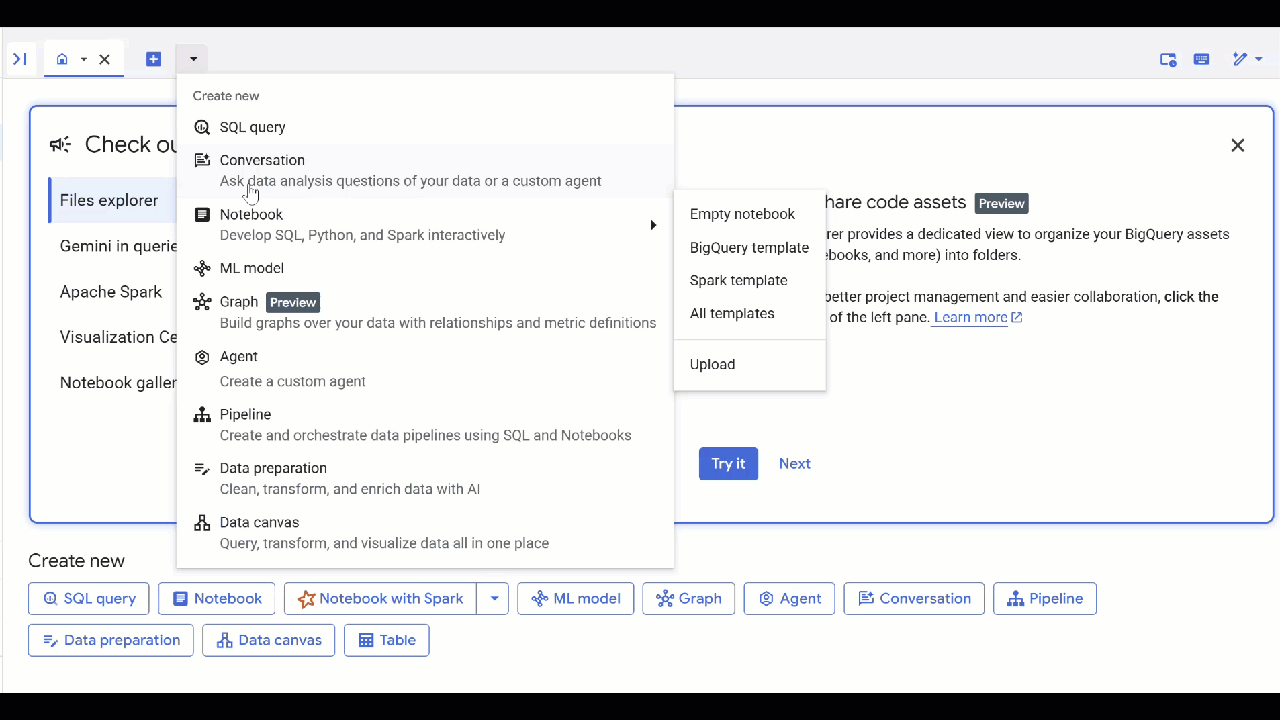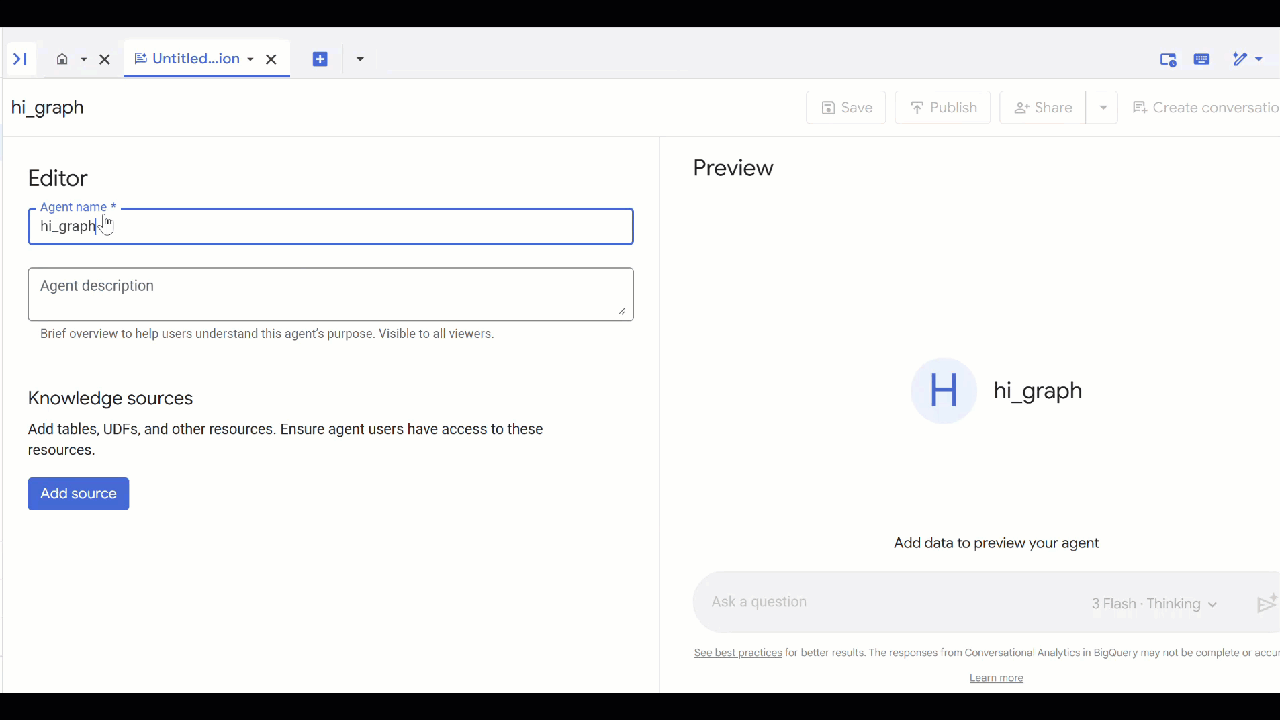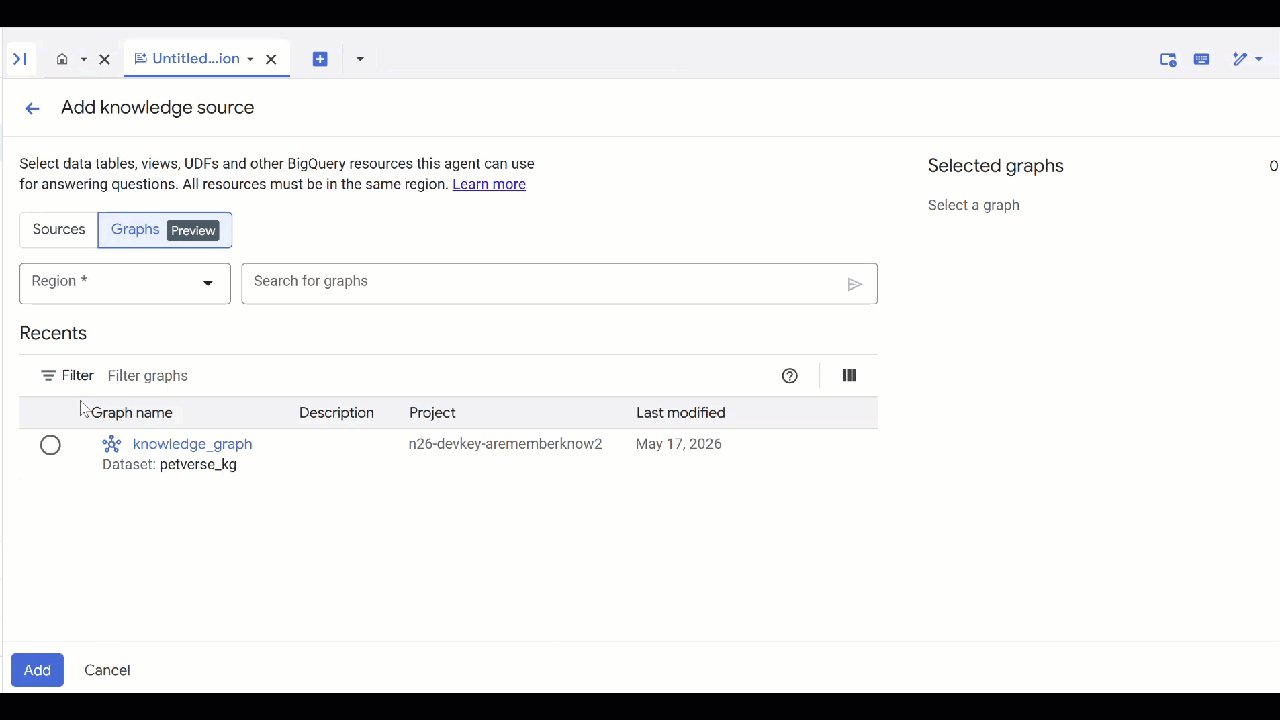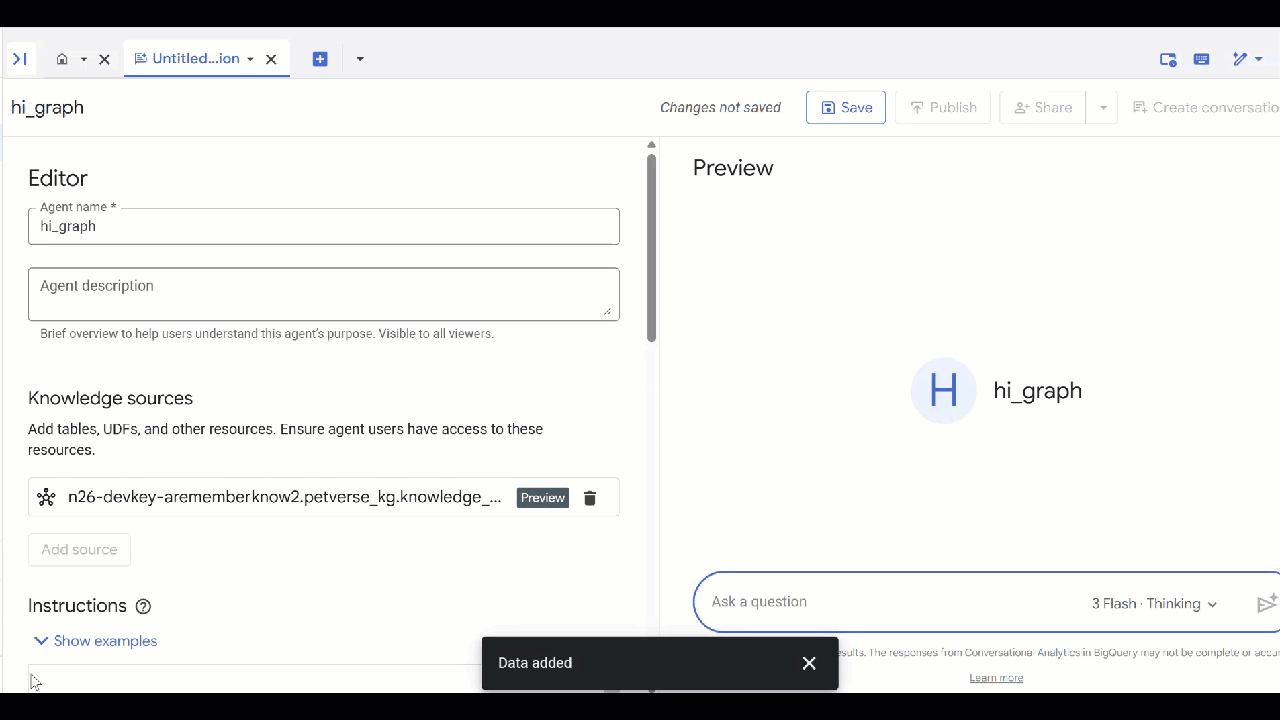
petverse. - Kliknij kolejno Dodaj źródło i Wykres.
- Wybierz utworzony
knowledge_graphi kliknij Dodaj.
Możesz teraz zadać agentowi pytanie i zobaczyć odpowiedzi oraz uzasadnienia. Jeśli potrzebujesz inspiracji, oto kilka przykładowych pytań. Model myślenia może działać nieco dłużej, ale prawdopodobnie utworzy lepsze zapytanie GQL. Aby zobaczyć, co buduje, rozwiń Show Thinking.
- znajdować zwierzęta, które jedzą podobne pokarmy lub przyjaźnią się ze zwierzętami lubiącymi drzemki.
- Czy któreś zwierzęta mają takie samo hobby, ulubione jedzenie lub zabawkę? Wymień pary i ich wspólne zainteresowania.
- Znajdź zwierzaki tego samego gatunku lub rasy, ale o zupełnie innych zainteresowaniach.
9. Czyszczenie danych
Aby uniknąć obciążenia konta Google Cloud bieżącymi opłatami, usuń zasoby utworzone podczas tego ćwiczenia.
- Usuń klaster GKE:
gcloud container clusters delete petverse-cluster --region $REGION --quiet
- Usuń zbiór danych BigQuery (spowoduje to usunięcie wszystkich tabel):
bq rm -r -f -d $PROJECT_ID:petverse_kg
- Usuń zasoby kolejki Pub/Sub:
gcloud pubsub subscriptions delete petverse-sub --quiet
gcloud pubsub topics delete petverse-topic --quiet
- Usuń repozytorium Artifact Registry:
gcloud artifacts repositories delete gke-cats-repo --location=$REGION --quiet
- Usuń zasobnik GCS powiązany z projektem:
gcloud storage buckets delete gs://$PROJECT_ID-petverse --quiet
10. Gratulacje
Gratulacje! Udało Ci się utworzyć rozproszony potok grafu wiedzy za pomocą GKE i Gemini oraz wykonać na nim zapytanie przy użyciu grafów właściwości BigQuery.
Czego się dowiedziałeś(-aś)
- Jak wdrażać zadania rozproszone w Autopilocie w GKE.
- Jak używać Gemini do wyodrębniania danych multimodalnych.
- Jak używać automatycznych wektorów osadzania BigQuery.
- Jak tworzyć wykresy właściwości i wysyłać do nich zapytania w BigQuery.