
1. Introdução
Neste codelab, você vai criar um pipeline distribuído de aquisição de conhecimento para o "Petverse". Você vai processar recursos multimídia não estruturados (áudio, vídeo, imagens, texto/CSV) de um bucket do Cloud Storage, extrair informações importantes sobre os animais de estimação (comida favorita, hobbies) e criar um grafo de conhecimento. Você vai escalonar o processamento do arquivo multimídia usando o processamento multimodal do Gemini no Google Kubernetes Engine (GKE). Por fim, você vai armazenar esses dados no BigQuery e usar o novo recurso de gráfico de propriedades do BigQuery para analisar os relacionamentos.
Vamos usar o poder do Google Kubernetes Engine para demonstrar o processamento paralelo de grandes volumes de dados.
Por que usar mapas de informações?
Os gráficos de informações são mais adequados do que os bancos de dados relacionais tradicionais para representar e analisar relações complexas entre entidades.
Vamos usar o Gemini 2.5 Flash para analisar imagens, arquivos de áudio e vídeo e estabelecer fatos sobre diferentes animais de estimação.
Atividades deste laboratório
- Crie e implante um job de processamento de dados distribuído no GKE.
- Use o Gemini para extrair entidades e relações de arquivos multimídia.
- Armazene os dados do grafo de conhecimento no BigQuery.
- Criar e consultar um gráfico de propriedades no BigQuery usando a linguagem de consulta de gráficos (GQL, na sigla em inglês).
O que é necessário
- Um navegador da web, como o Chrome
- Tenha um projeto do Google Cloud com o faturamento ativado.
- Permissões no projeto para criar recursos e modificar políticas do IAM
Este codelab é destinado a desenvolvedores de todos os níveis, incluindo iniciantes.
Duração estimada:45 minutos
Custo:os recursos criados neste codelab custam menos de US $5.
2. Antes de começar
Criar um projeto do Google Cloud
- Acesse o console do Google Cloud: https://console.cloud.google.com e selecione ou crie um projeto na nuvem do Google Cloud.
- ⚠️ Anote o ID do projeto. Ele será usado em vários comandos neste laboratório.
Iniciar o Cloud Shell
- Abra o Cloud Shell em uma nova guia: https://shell.cloud.google.com/.
- Se for solicitado, clique em Autorizar.
- Substitua
PROJECT_IDe cole o seguinte comando no terminal:
export PROJECT_ID="YOUR_PROJECT_ID"
gcloud config set project $PROJECT_ID
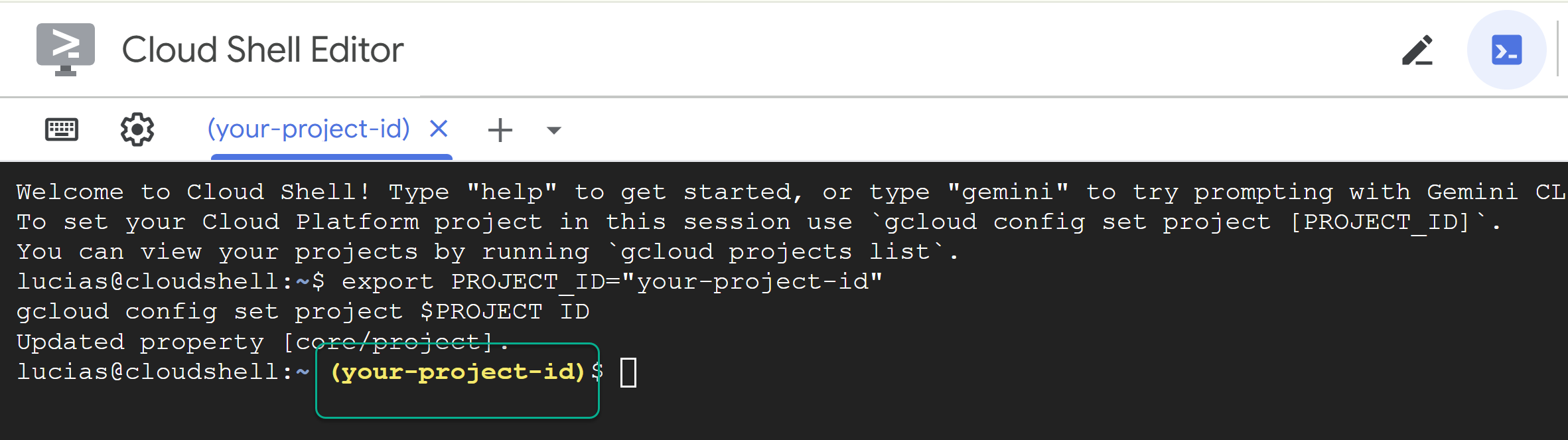
📝 Observação: seu projeto vai aparecer em amarelo na linha de comando. Se a sessão for reiniciada, execute o comando acima novamente para definir o ID do projeto.
Ativar APIs
Execute este comando para ativar todas as APIs necessárias:
gcloud services enable \
aiplatform.googleapis.com \
bigquery.googleapis.com \
artifactregistry.googleapis.com \
container.googleapis.com \
cloudbuild.googleapis.com \
pubsub.googleapis.com
Clonar repositório
Execute estes comandos para clonar o repositório.
cd ~/
git clone --filter=blob:none --no-checkout https://github.com/GoogleCloudPlatform/devrel-demos.git
cd ~/devrel-demos
git sparse-checkout init --cone
git sparse-checkout set codelabs/gke-knowledge-graph
git checkout main
cd codelabs/gke-knowledge-graph/
Executar script de configuração
Esse script automatiza a configuração de back-end fazendo o seguinte:
- Como criar uma imagem de contêiner e um repositório do Artifact Registry
- criar um conjunto de dados do BigQuery
- Como criar uma conexão do BigQuery para executar funções da IA do Gemini em SQL
Execute o comando a seguir no terminal.
./scripts/setup.sh
Se o script pedir detalhes de configuração, use estes valores:
- ID do projeto:use o ID criado na etapa anterior.
- Região :
us-central1
⚠️ Importante: o script leva alguns minutos para ser concluído. Deixe essa janela do terminal aberta para concluir em segundo plano. Para continuar com a próxima etapa, abra uma nova guia ou janela do terminal para executar os próximos comandos.
3. Configurar o Data Agent Kit
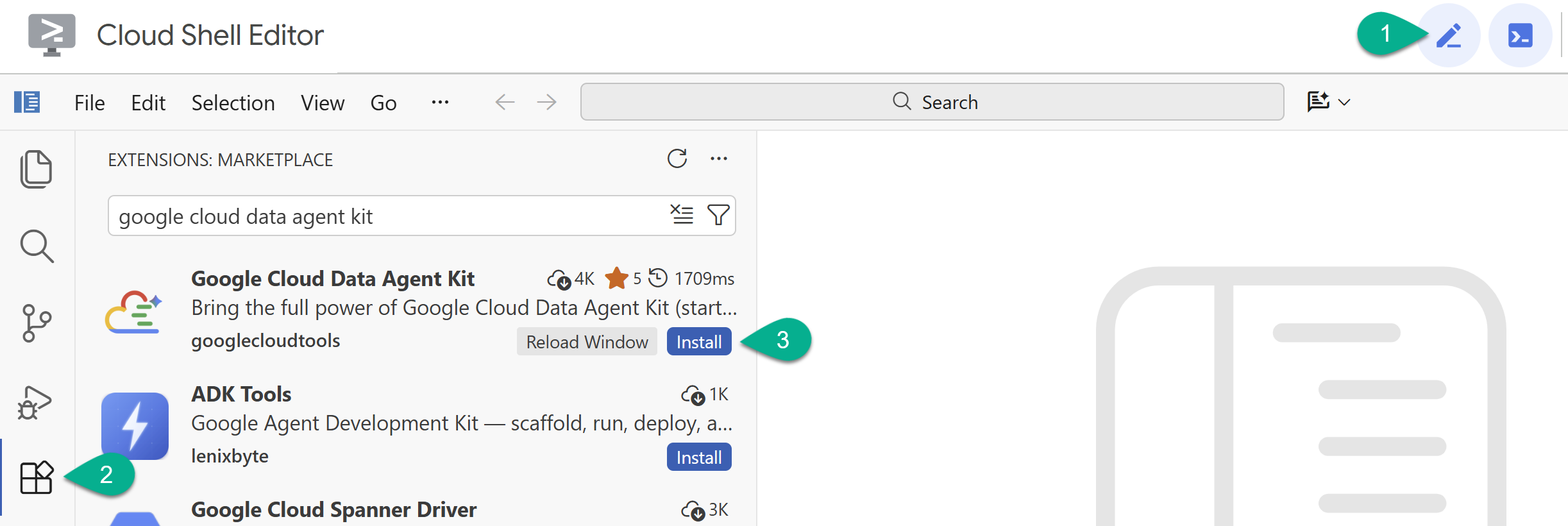
- Ative o editor do Cloud Shell com o ícone de lápis no canto superior direito.
- No editor do Cloud Shell, clique no ícone Extensões na barra lateral esquerda.
- Pesquise Kit do agente de dados do Google Cloud e clique em Instalar, se ainda não tiver feito isso.
- Faça login na sua Conta do Google com a extensão.
- No resumo da configuração, insira o ID do projeto e
us-central1como a região.
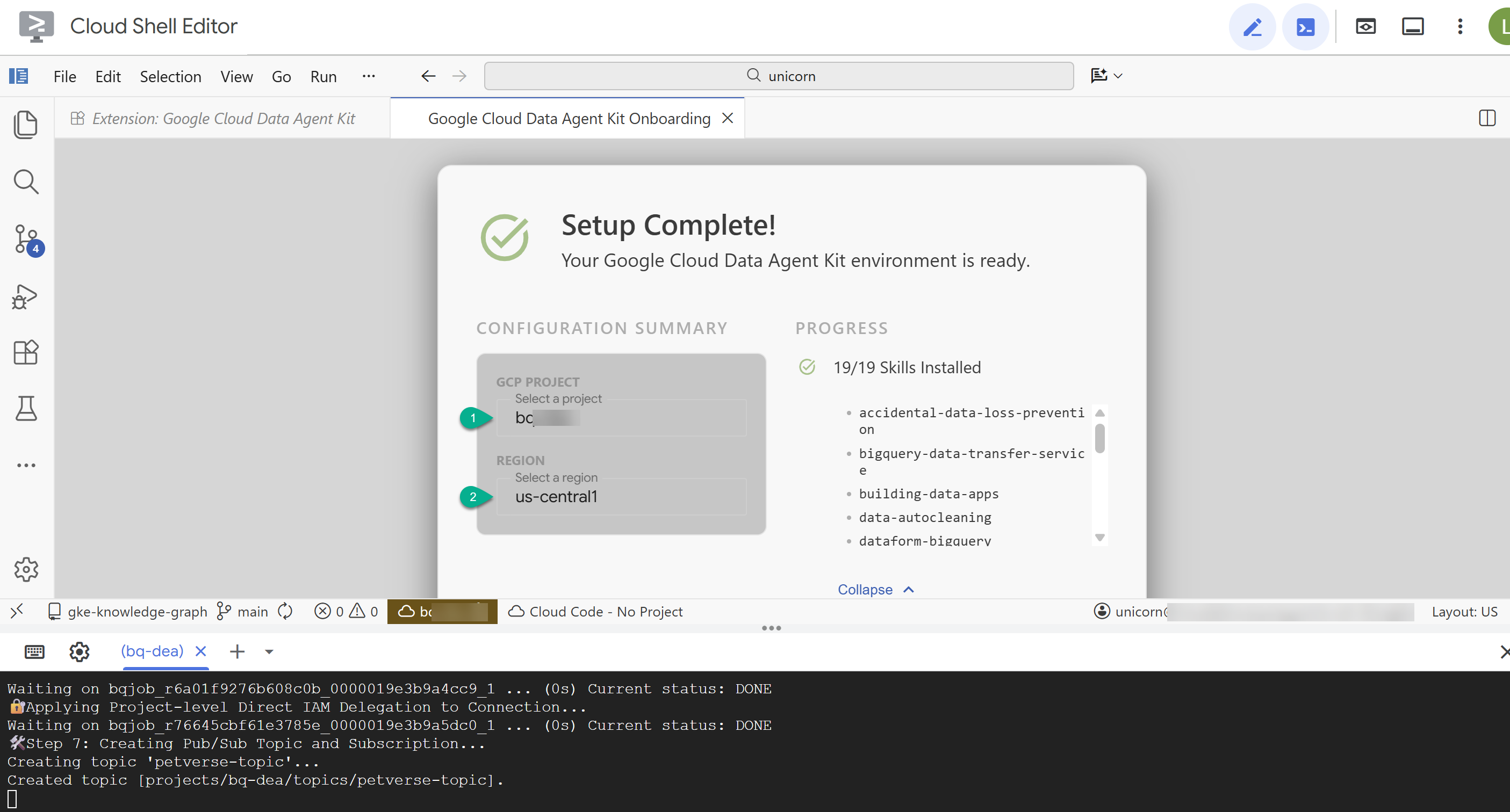
- Clique em Configurar servidores MCP. Não é preciso fazer mudanças nessa janela. Basta clicar em Começar.
- Atualize a janela se solicitado. Você pode fechar a guia do guia de início rápido por enquanto.
Configurar as tabelas no BigQuery
- Na barra lateral, volte para o explorador. Se a pasta inicial (por exemplo,
/home/your_user_name/) ainda não estiver aberta, clique em Abrir pasta e selecione-a.
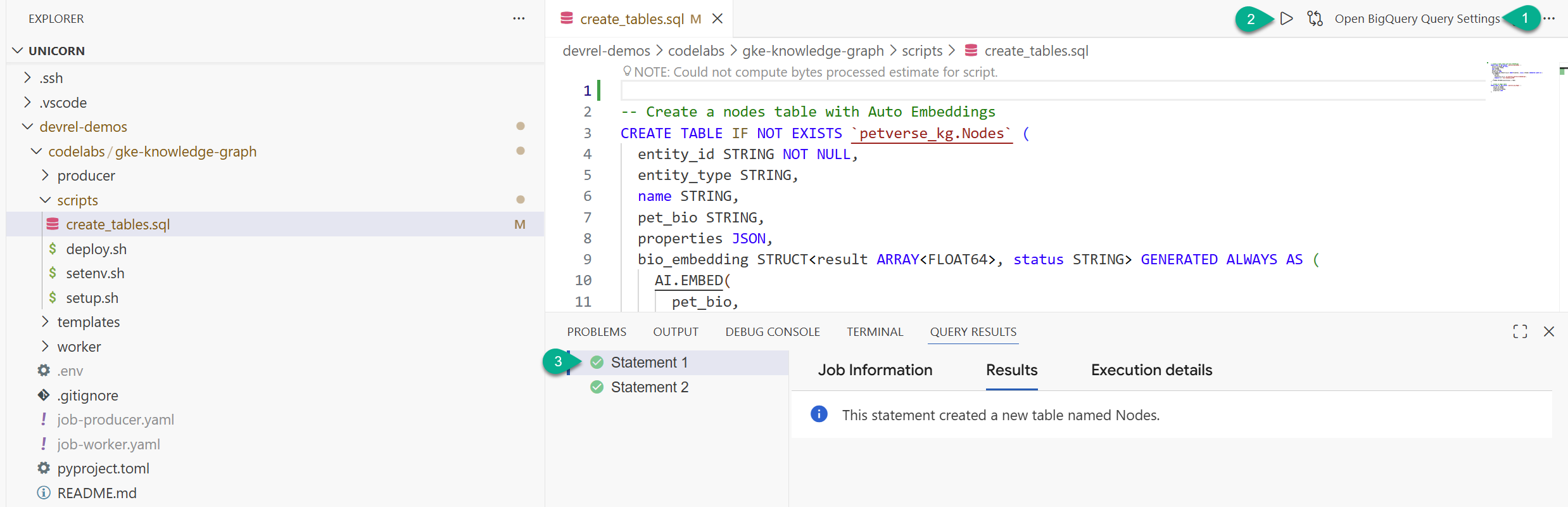
- Na janela do Explorer, localize a pasta que você clonou do repositório (
devrel-demos). Emcodelabs/gke-knowledge-graph/scripts, você vai encontrarcreate_tables.sql. Abra o arquivo. - No canto superior direito, clique em Abrir configurações de consulta.
- Escolha BigQuery. Salvar e Fechar.
- Clique em Executar.
Duas instruções serão executadas com sucesso. Você criou as tabelas para armazenar nós e arestas do gráfico de conhecimento.
Feche a guia create_tables.sql e o console de resultados.
4. Inicializar o cluster do GKE
Vamos usar o Autopilot do GKE para executar nosso job de processamento de dados. O Autopilot é a prática recomendada porque gerencia a infraestrutura do cluster para você.
Neste momento, o script de configuração já deve ter sido concluído. Você vai receber uma mensagem de sucesso: 🎉🦄 Setup successfully finished! 🎉🦄.
Cole este comando no terminal para criar o cluster:
source scripts/setenv.sh
gcloud container clusters create-auto petverse-cluster \
--region=$REGION
🕓 Isso vai levar cerca de 5 minutos.
Consiga as credenciais para interagir com o cluster:
source scripts/setenv.sh
gcloud container clusters get-credentials petverse-cluster --region $REGION
Você vai ver esta saída:
Fetching cluster endpoint and auth data. kubeconfig entry generated for petverse-cluster.
5. Configurar a Identidade da carga de trabalho
A federação de identidade da carga de trabalho para GKE (usando o acesso direto a recursos) permite que as cargas de trabalho do GKE acessem os serviços do Google Cloud com segurança sem precisar gerenciar chaves de conta de serviço.
Execute deploy.sh para:
- Criar uma conta de serviço do Kubernetes
- Conceda os papéis do IAM necessários diretamente ao principal da conta de serviço do Kubernetes
- Vincular a conta de serviço do IAM à conta de serviço do Kubernetes
- Anotar a conta de serviço do Kubernetes para concluir a vinculação
source scripts/setenv.sh
./scripts/deploy.sh
6. Implantar jobs de processamento desacoplados
Nesta etapa, você vai implantar o enfileirador (produtor) e os mecanismos de processamento (trabalhadores) no GKE.
Nossa nova arquitetura desacoplada usa o Google Cloud Pub/Sub para processar recursos de maneira assíncrona:
- O Producer verifica o GCS e enfileira todos os caminhos de arquivo em uma fila do Pub/Sub.
- Um pool de workers aumenta a escala no GKE, extraindo tarefas dinamicamente em paralelo, processando-as com o Gemini e gravando no BigQuery.
O script setup.sh já criou e enviou por push as imagens de contêiner do produtor e do worker, enfileirou os tópicos do Pub/Sub e gerou dinamicamente os manifestos de implantação do GKE: job-producer.yaml e job-worker.yaml.
- Aplique o job do produtor para verificar seu bucket de armazenamento e enfileirar todos os recursos:
kubectl apply -f job-producer.yaml
Esse job é executado e concluído rapidamente, já que apenas enfileira metadados.
- Implante o job do worker configurado para executar seis workers paralelos e drenar a fila:
kubectl apply -f job-worker.yaml
O Autopilot do GKE detecta automaticamente os pods pendentes, escalona verticalmente os nós de computação e executa os workers em paralelo para processar áudios, vídeos, imagens e arquivos CSV enfileirados.
7. Verificar resultados
- Verifique o status dos seus jobs:
kubectl get jobs
Aguarde até que petverse-producer-job e petverse-worker-job mostrem conclusões bem-sucedidas.
🕓 Isso vai levar cerca de 10 minutos. Confira o progresso com os comandos abaixo.
- Verifique os registros do produtor para confirmar se ele enfileirou os arquivos corretamente:
cd ~/devrel-demos/codelabs/gke-knowledge-graph
source scripts/setenv.sh
kubectl logs -l app=petverse-producer --tail=50
- Observe os workers paralelos processarem arquivos da fila:
kubectl logs -l app=petverse-worker --tail=50
Os workers têm um tempo limite de inatividade de 60 segundos e são desligados e limpos automaticamente quando a fila do Pub/Sub está vazia.
Verifique os dados no BigQuery.
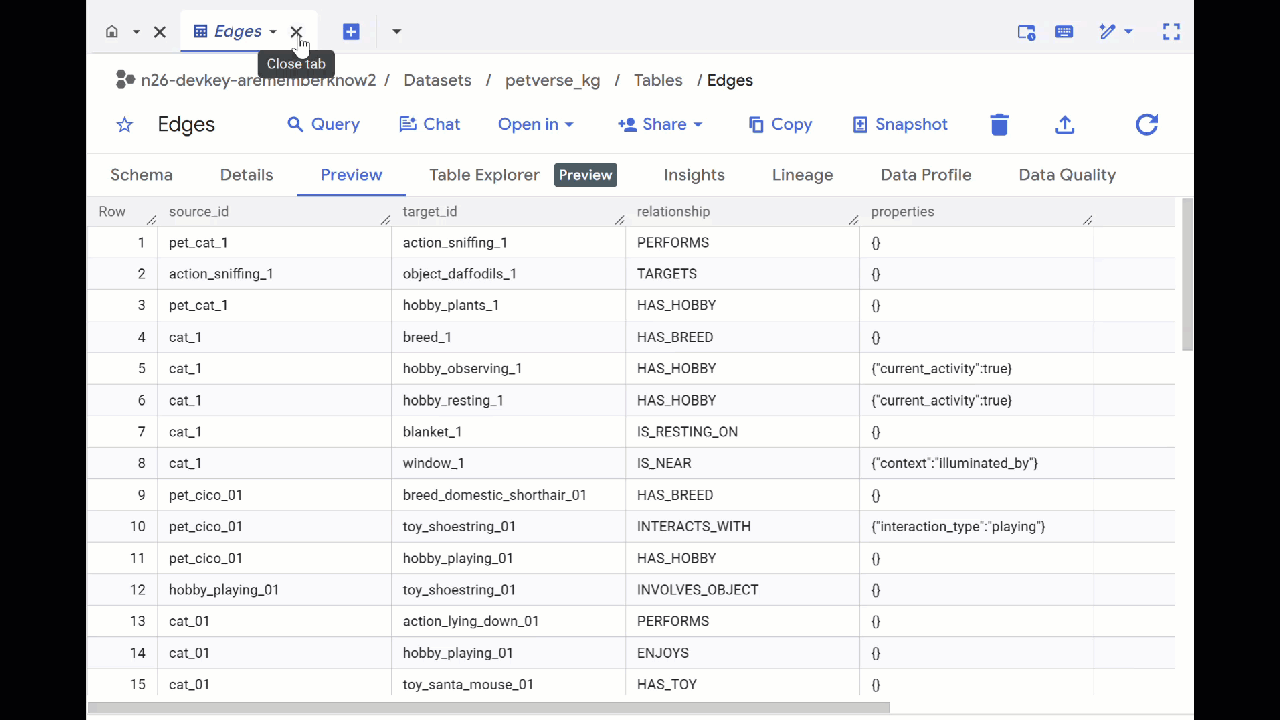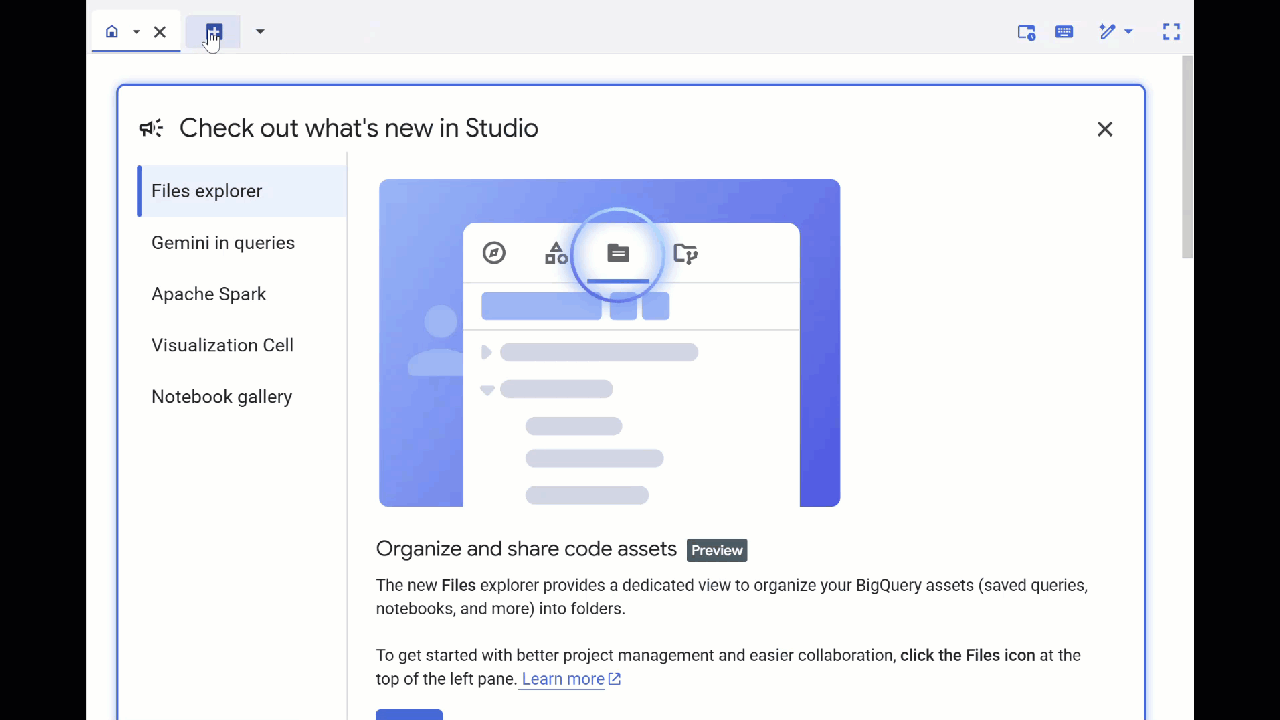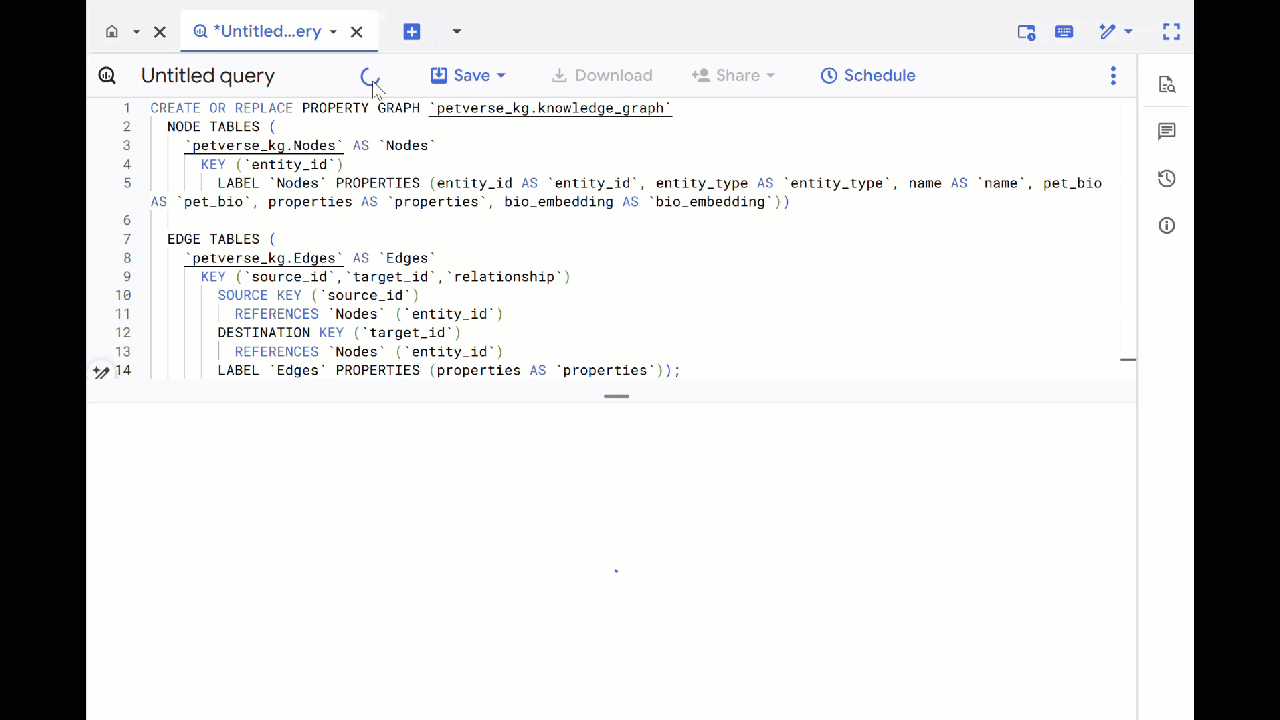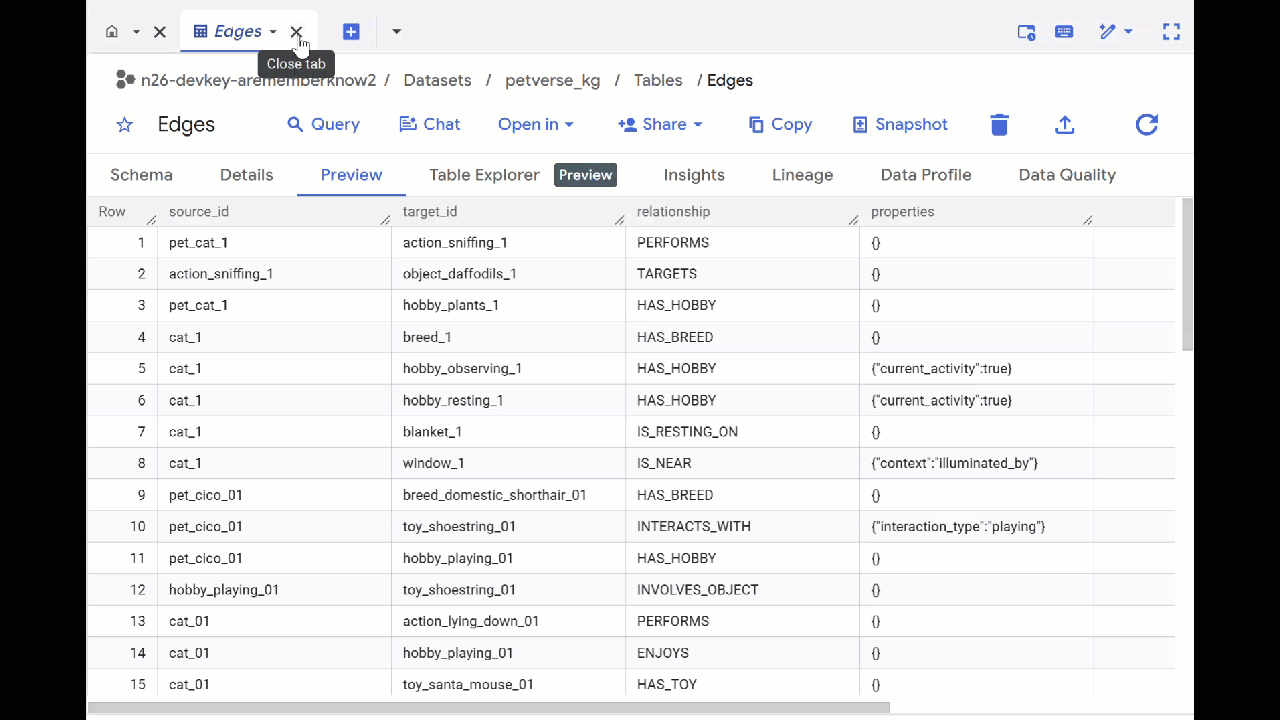
- Acesse o BigQuery Studio. Duas tabelas serão criadas: petverse_kg.Nodes e petverse_kg.Edges.
- Para ver o conteúdo das tabelas, clique duas vezes nos nomes delas e clique em Visualizar.
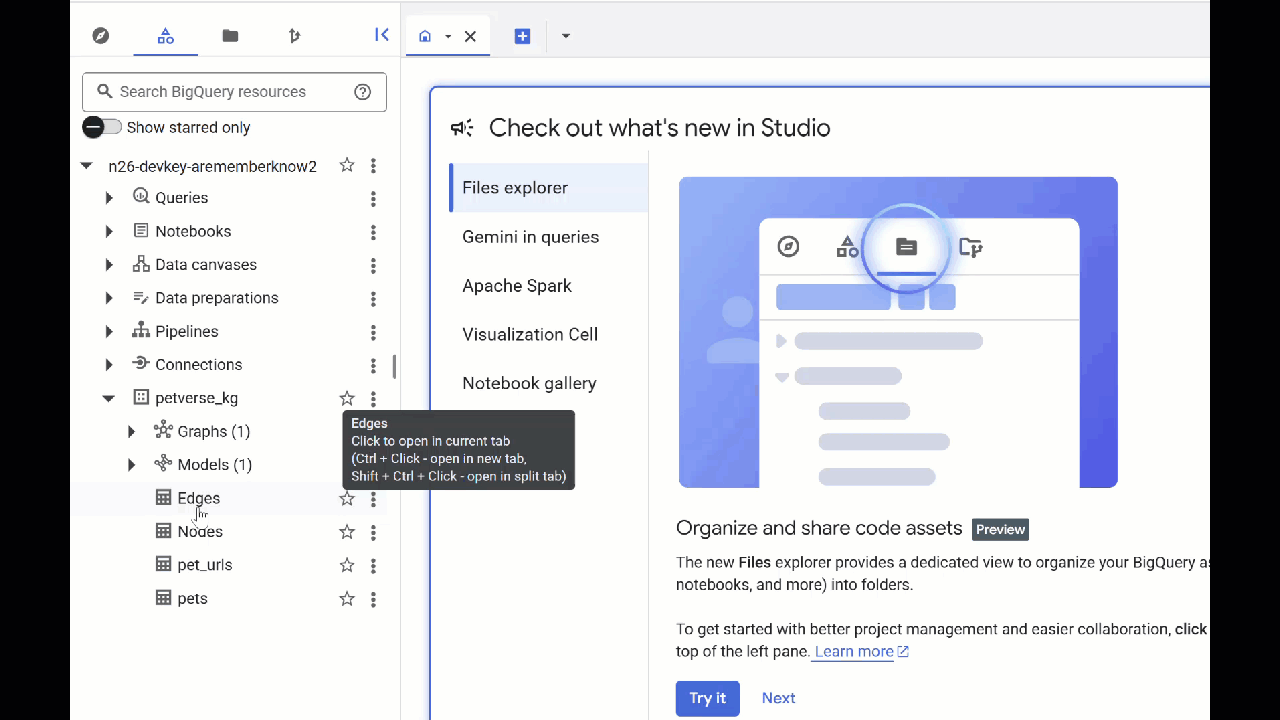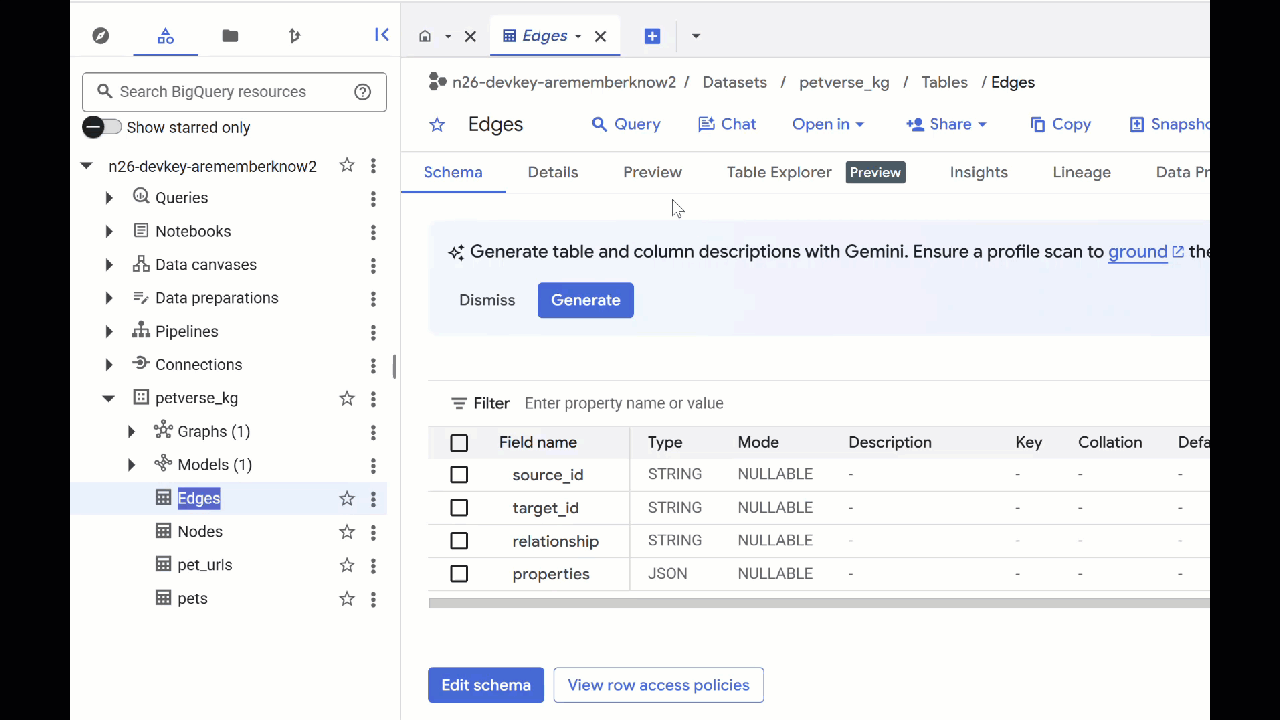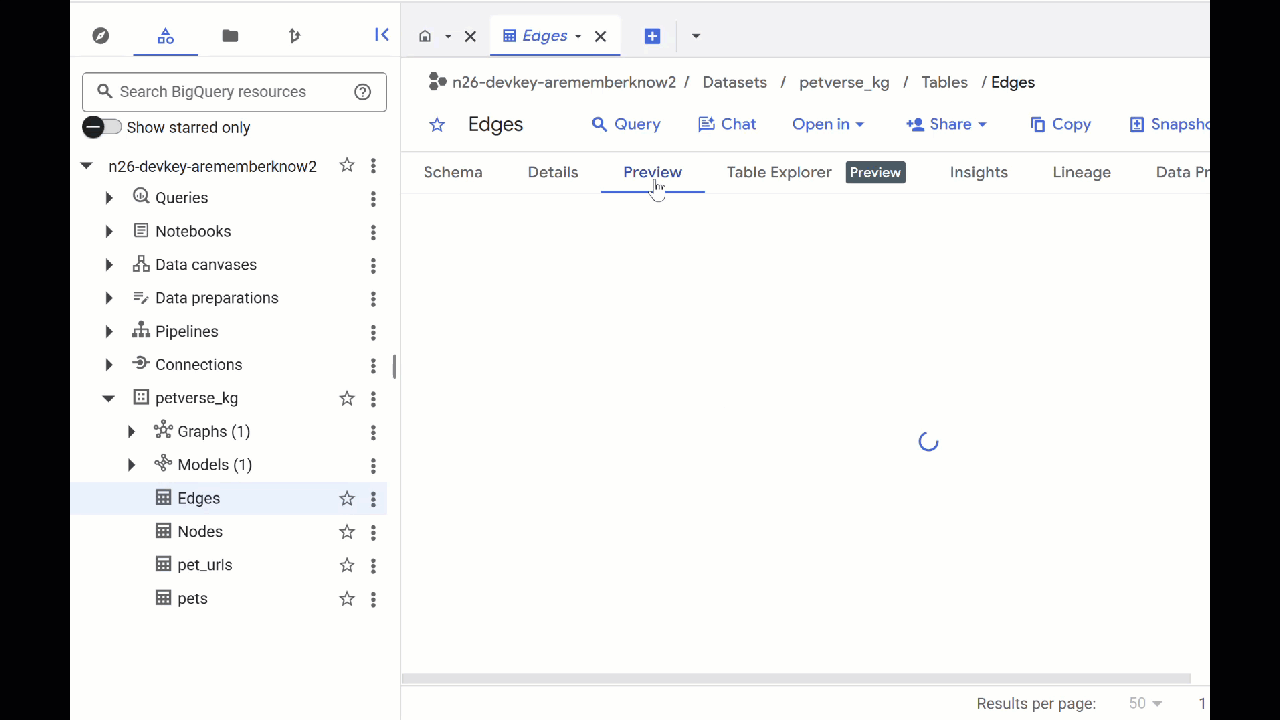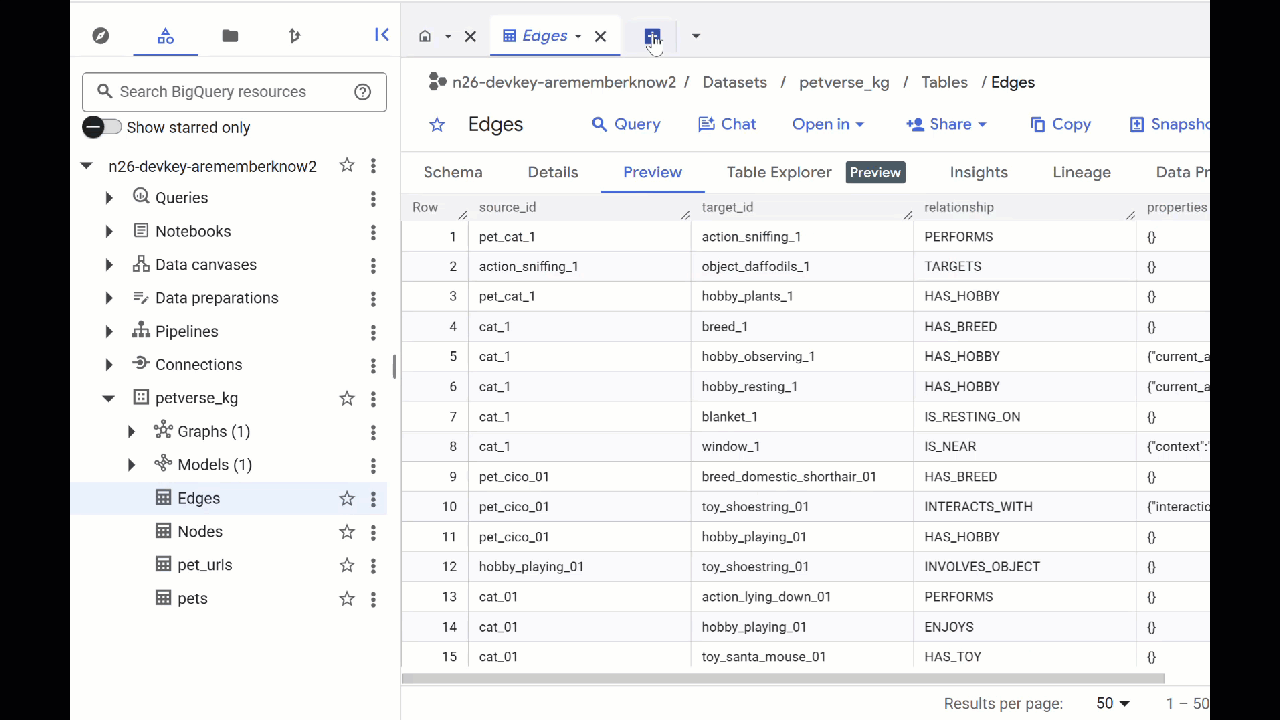
A tabela "Nós" tem informações sobre as entidades selecionadas pelo Gemini nos áudios, vídeos e imagens. A tabela "Edges" contém as relações entre eles. Por exemplo, se você ouvir o áudio do gato chamado SQL, vai saber que ele gosta de brincar com cadarços e adora peixinhos liofilizados.
- Use o botão + para criar uma consulta. Cole a instrução a seguir e clique em Executar:
SELECT n.name, n.entity_id, e.relationship, e.target_id
FROM
`petverse_kg.Nodes` n
JOIN
`petverse_kg.Edges` e
ON n.entity_id = e.source_id
WHERE n.name = 'SQL'
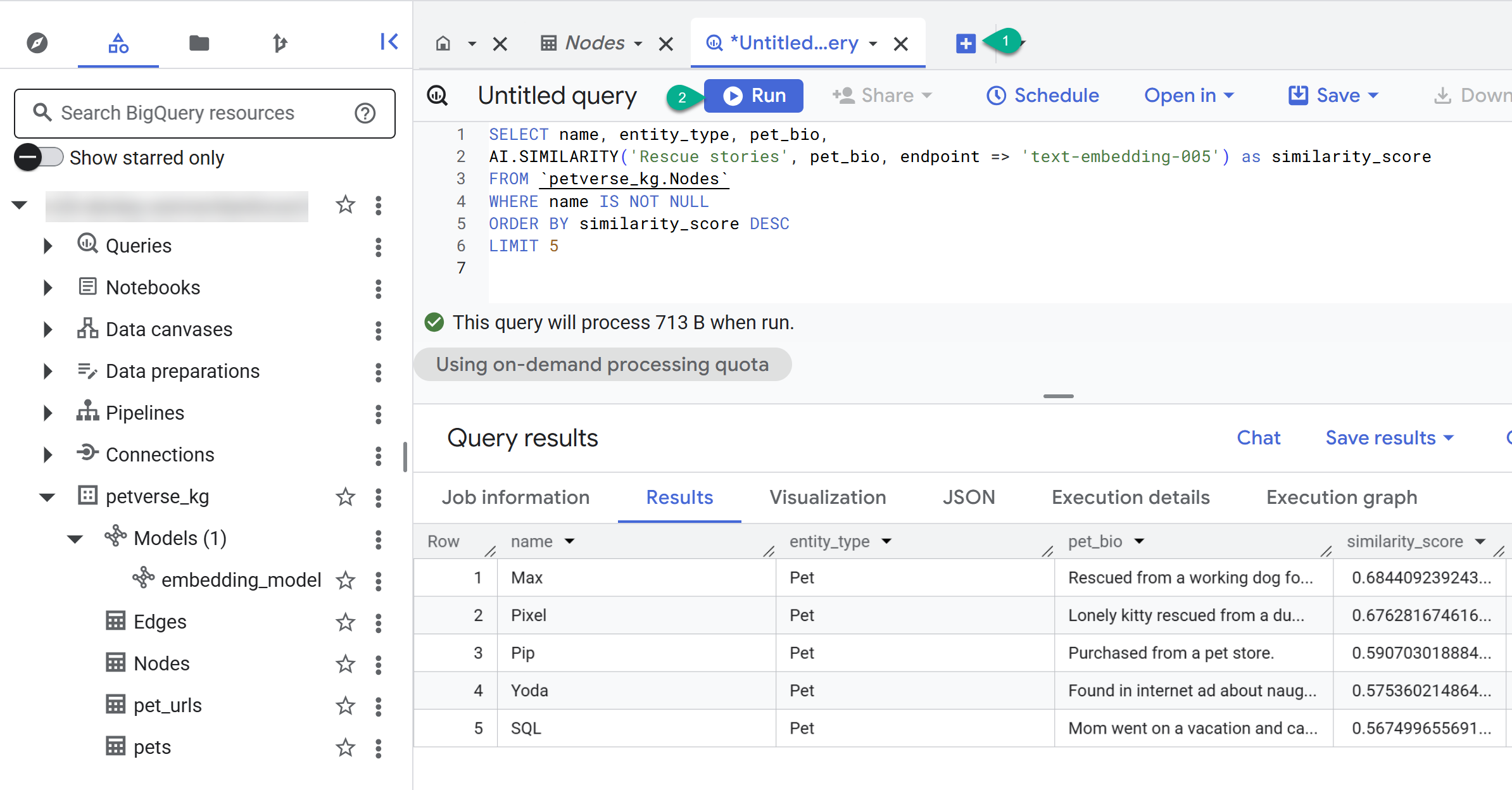
- Use o botão + para criar uma consulta. Cole a instrução a seguir e clique em Executar:
SELECT name, entity_type, pet_bio,
AI.SIMILARITY('Pets who like to relax', pet_bio, endpoint => 'text-embedding-005') as similarity_score
FROM `petverse_kg.Nodes`
WHERE name IS NOT NULL
ORDER BY similarity_score DESC
LIMIT 5
Você vai encontrar os nós para animais de estimação que gostam de relaxar. Essa consulta realizou uma pesquisa semântica usando a função de IA AI.SIMILARITY para encontrar animais de estimação cujas biografias são mais semelhantes ao texto da consulta.
Criar o gráfico de propriedades
Agora que temos nós e arestas no BigQuery, podemos criar um gráfico de propriedades para consultar relacionamentos com facilidade.
Criar o gráfico
- Substitua a consulta anterior e execute a seguinte DDL para criar o gráfico de propriedades:
CREATE OR REPLACE PROPERTY GRAPH `petverse_kg.knowledge_graph`
NODE TABLES (
`petverse_kg.Nodes` AS `Nodes`
KEY (`entity_id`)
LABEL `Nodes` PROPERTIES (entity_id AS `entity_id`, entity_type AS `entity_type`, name AS `name`, pet_bio AS `pet_bio`, properties AS `properties`, bio_embedding AS `bio_embedding`))
EDGE TABLES (
`petverse_kg.Edges` AS `Edges`
KEY (`source_id`,`target_id`,`relationship`)
SOURCE KEY (`source_id`)
REFERENCES `Nodes` (`entity_id`)
DESTINATION KEY (`target_id`)
REFERENCES `Nodes` (`entity_id`)
LABEL `Edges` PROPERTIES (properties AS `properties`));
- Clique em Acessar o gráfico. Você vai encontrar a visualização do gráfico com um nó que tem uma aresta para si mesmo. Isso já é esperado.
Consultar o gráfico
- É possível fechar todas as consultas anteriores e abrir uma nova em branco com o botão +.
- Use o GQL para encontrar pets relacionados a outros pets por interesses em comum (como hobbies, comidas favoritas ou brinquedos). Esta consulta de várias etapas corresponde a dois animais de estimação diferentes conectados ao mesmo nó:
GRAPH `petverse_kg.knowledge_graph`
MATCH p = (pet1:Nodes)-[e1]->(interest:Nodes)<-[e2]-(pet2:Nodes)
WHERE pet1.entity_id != pet2.entity_id
AND (LOWER(pet1.entity_type) = 'pet' AND LOWER(pet2.entity_type) = 'pet')
AND LOWER(interest.entity_type) IN ('hobby', 'action', 'activity', 'food', 'toy')
RETURN TO_JSON(p) as res
LIMIT 100
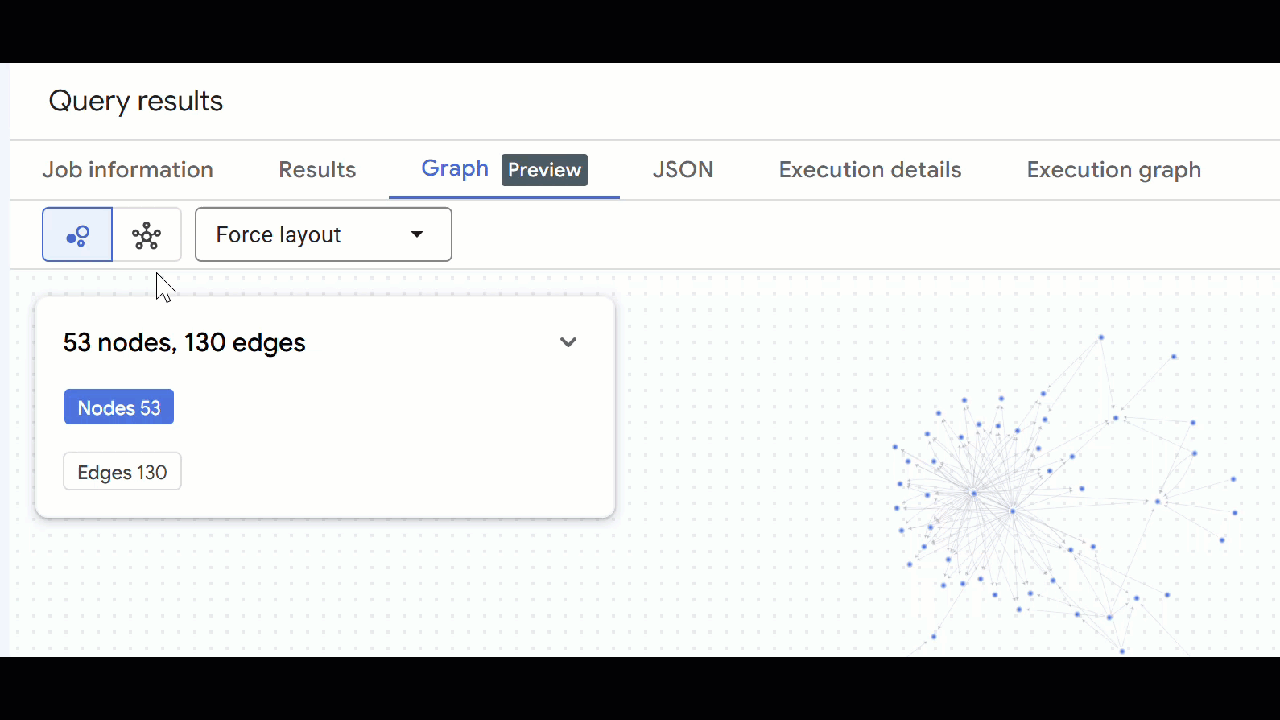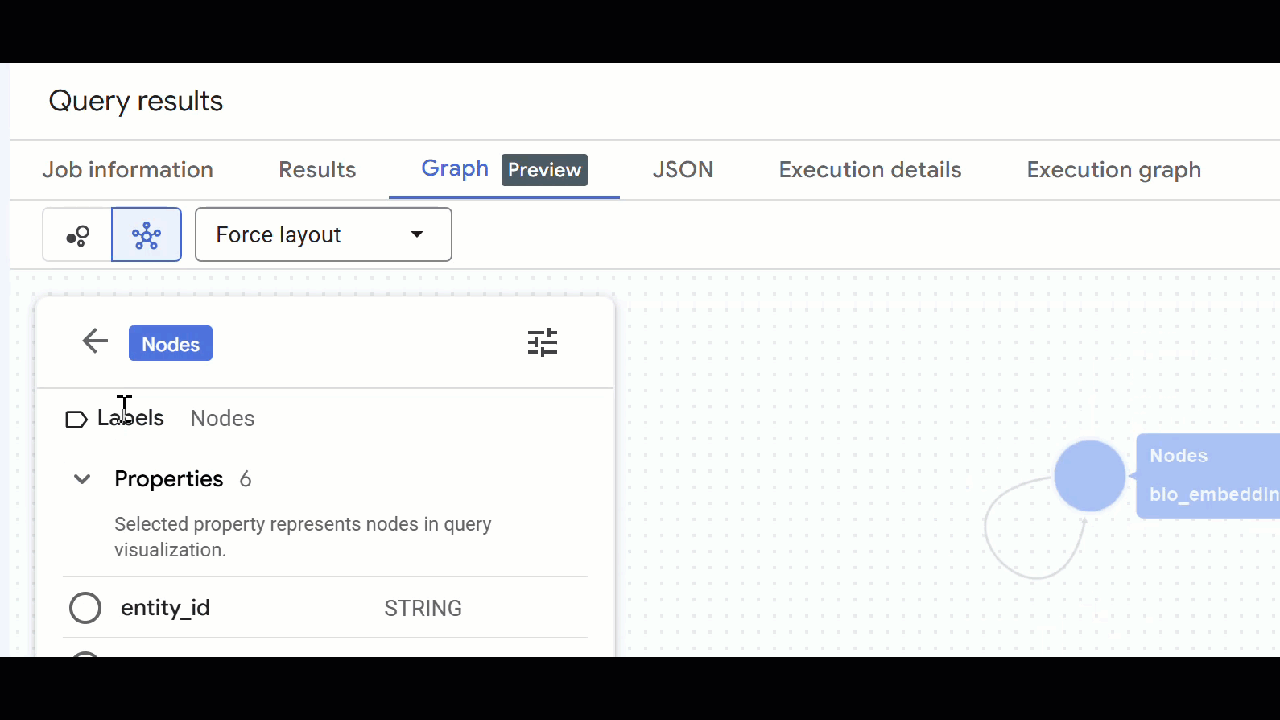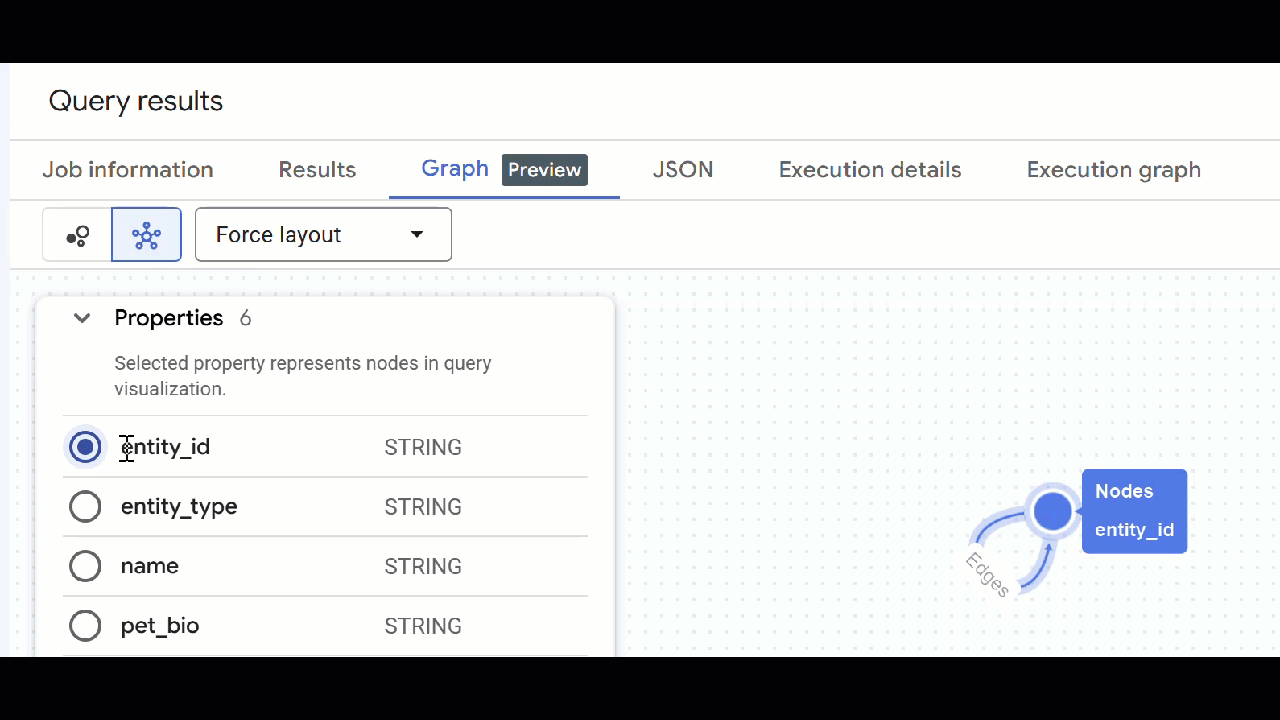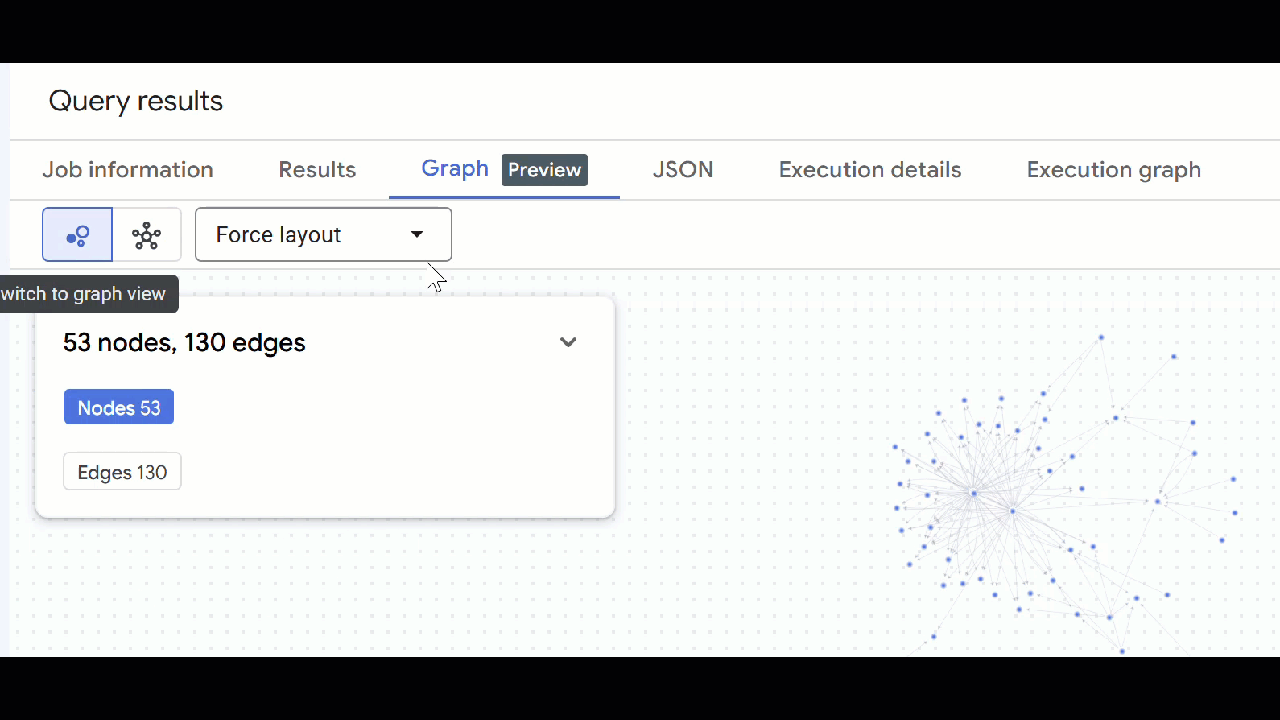
- A visualização do gráfico vai aparecer. Clique nos nós para ver as propriedades deles e das arestas.
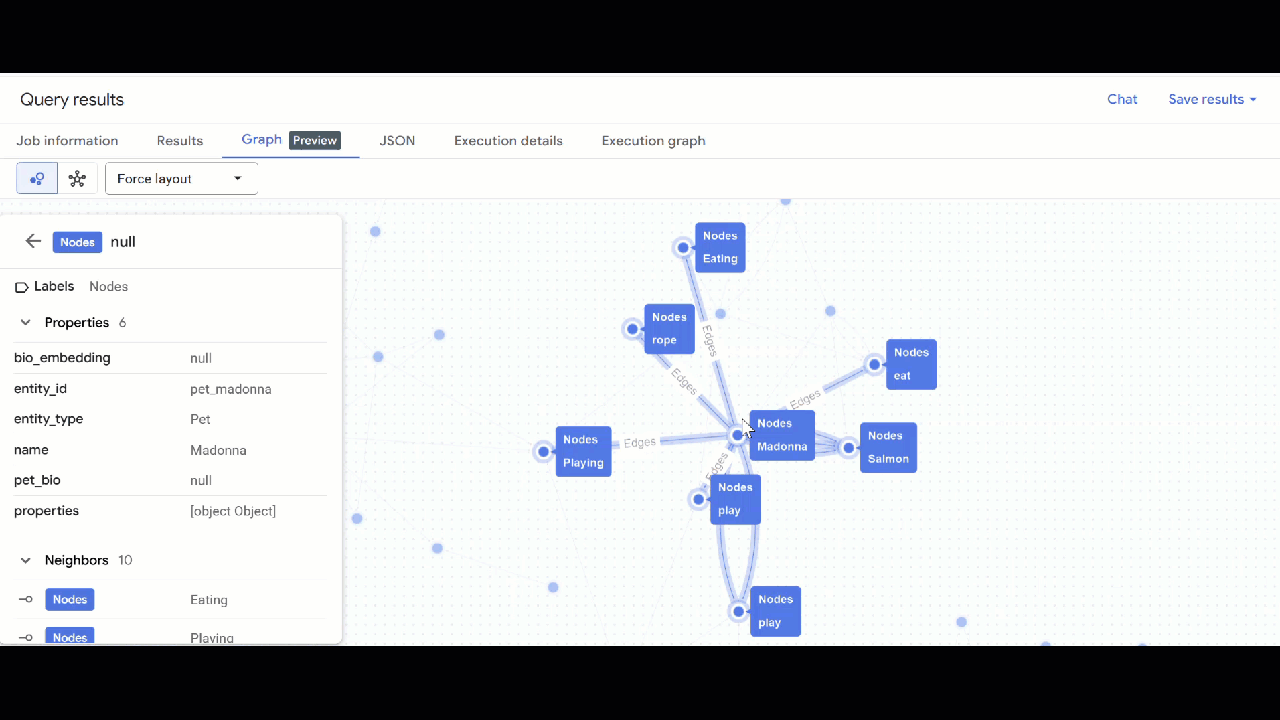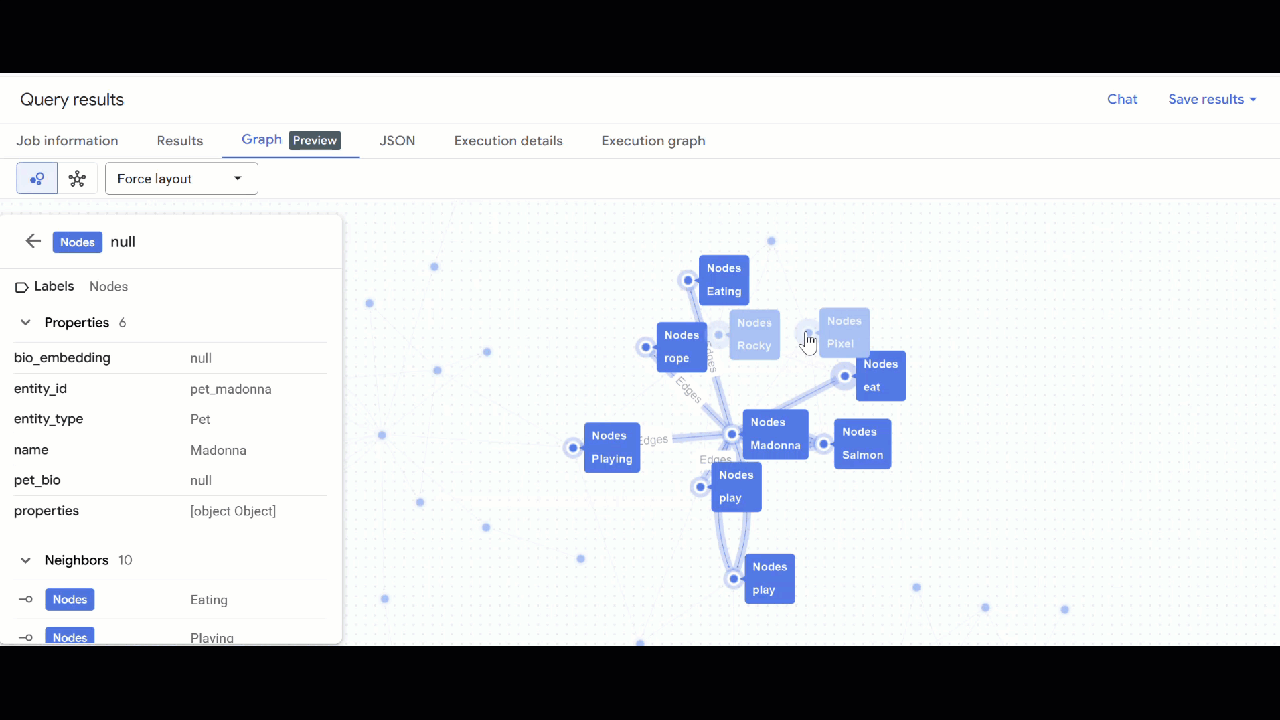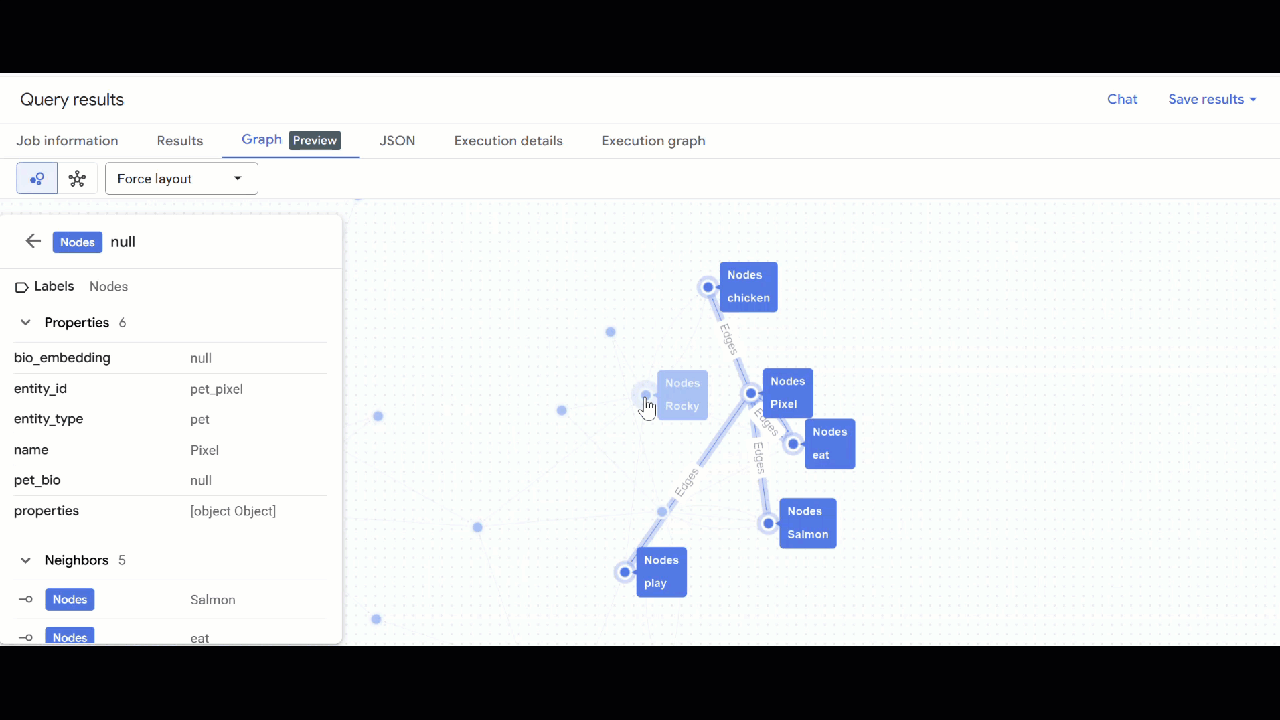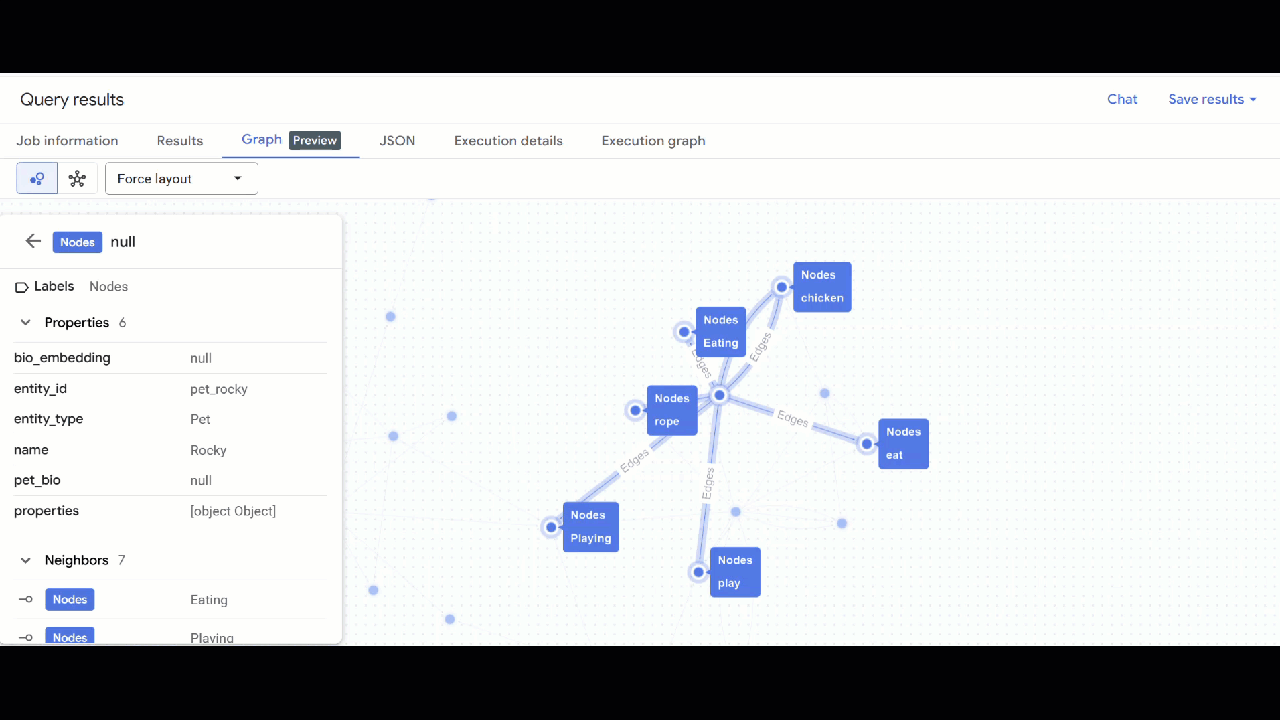
🕵️ Dica: para ajustar o valor mostrado pelo nó, clique em Mudar para a visualização de esquema:
- Você pode fechar todas as guias de consulta abertas.
8. Conversar com o gráfico
- Ao lado do sinal +, há um menu suspenso. Selecione Conversa.
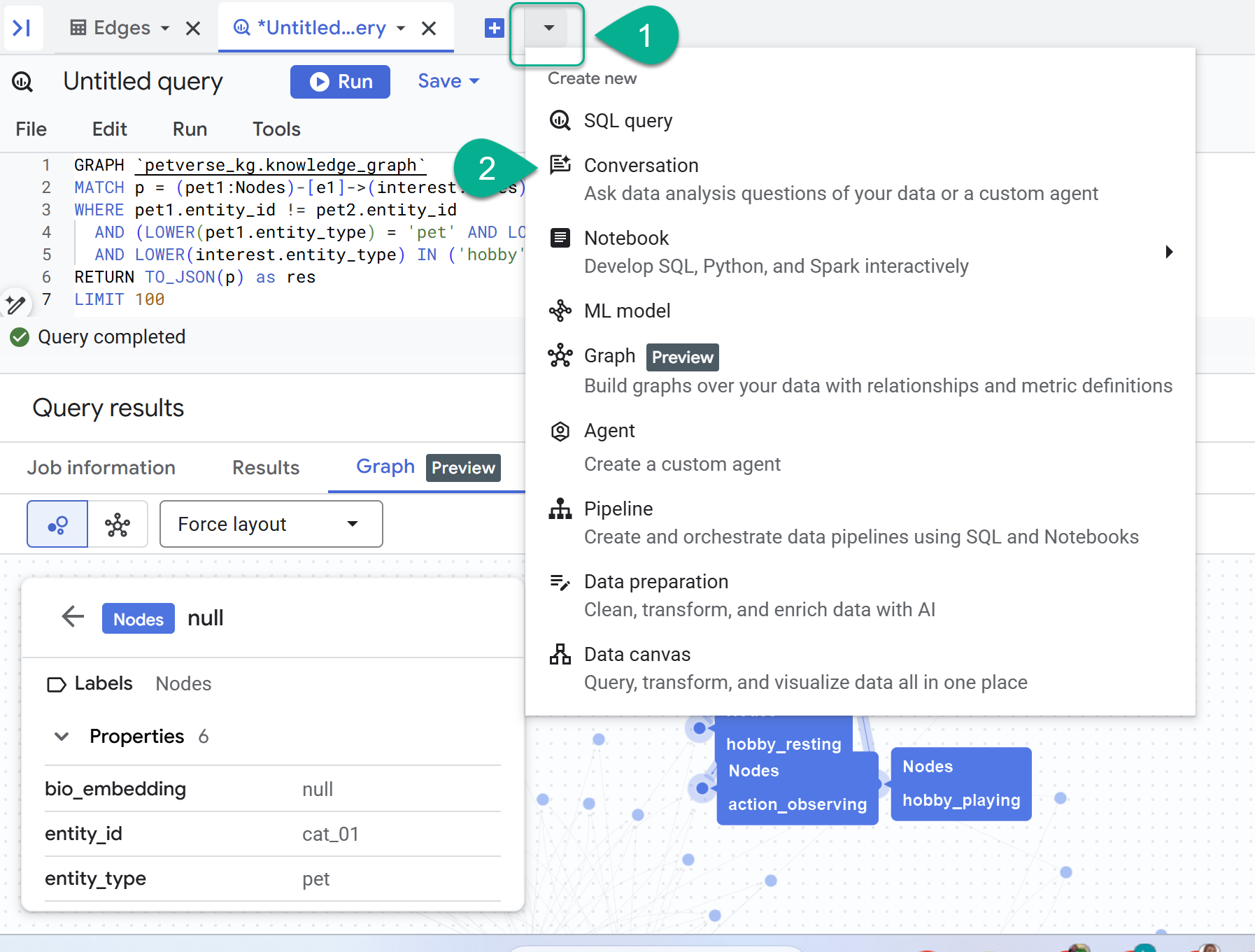
- Você vai receber uma solicitação para ativar a API Data Analytics com Gemini. Ative as duas APIs. Depois que isso terminar, atualize a janela ou crie uma nova conversa para ver o agente.
- Clique em New Agent.
- Dê um nome ao agente, como
petverse. - Clique em Adicionar origem e em Gráfico.
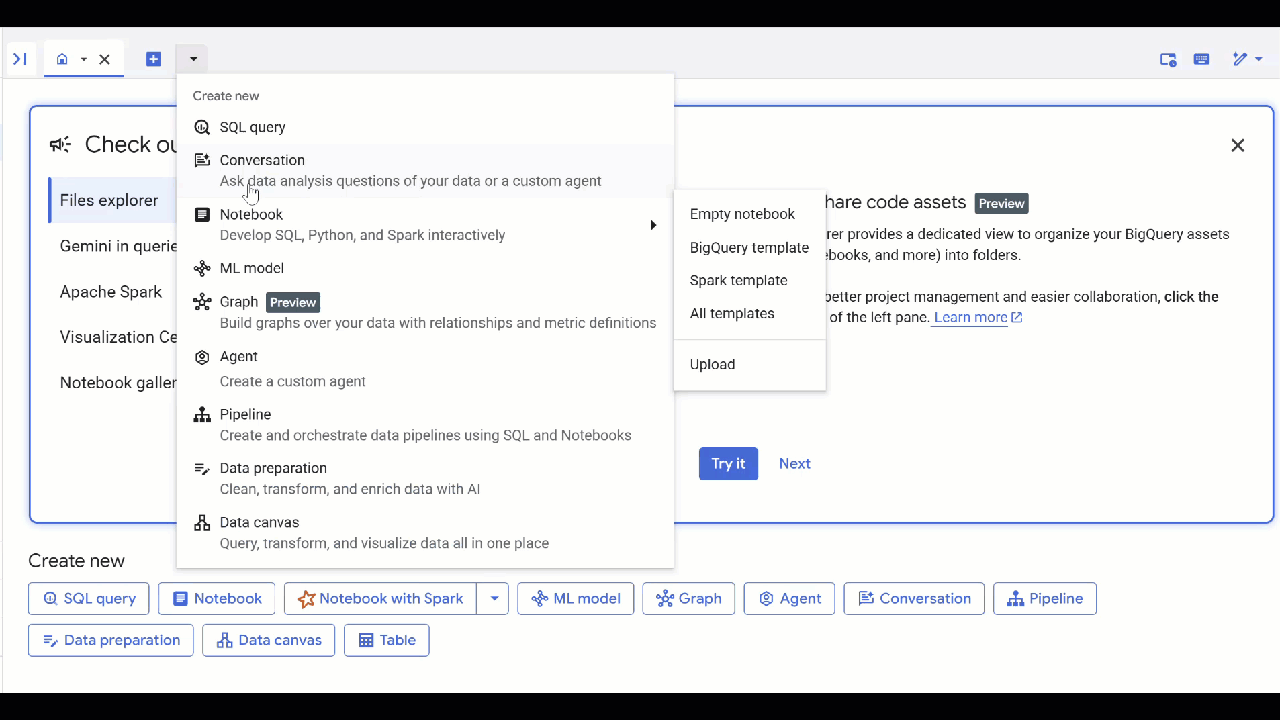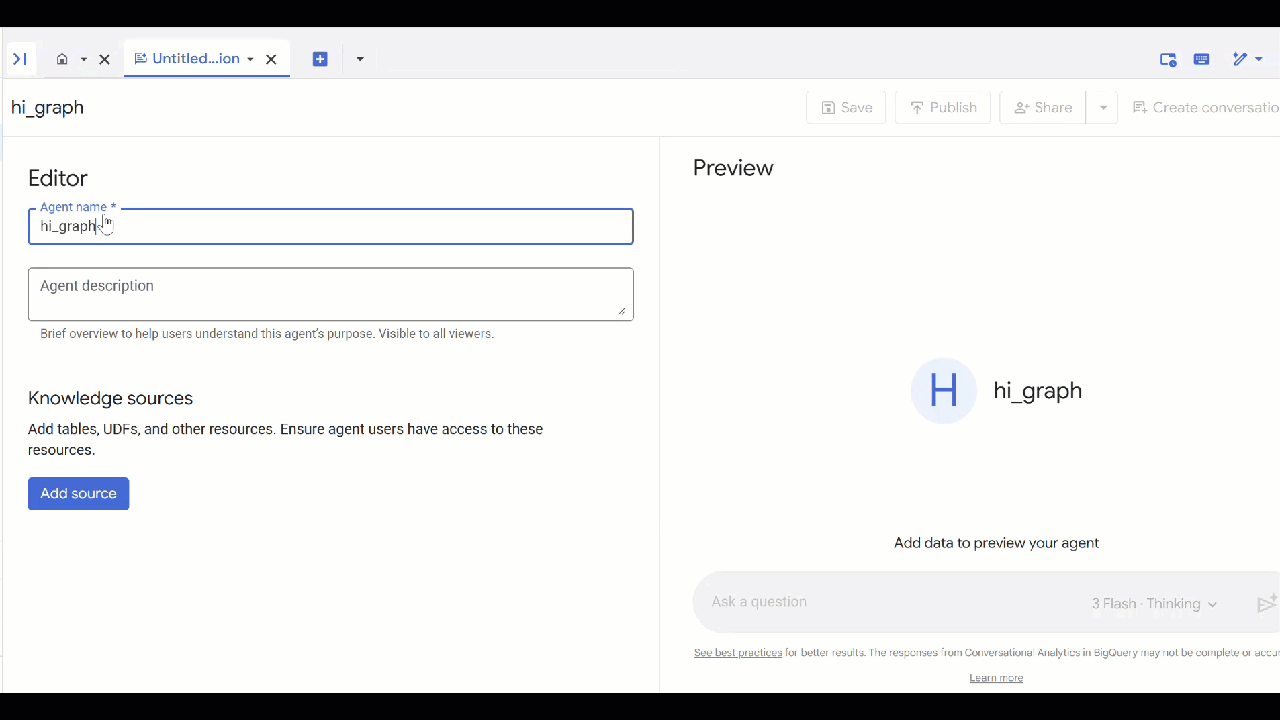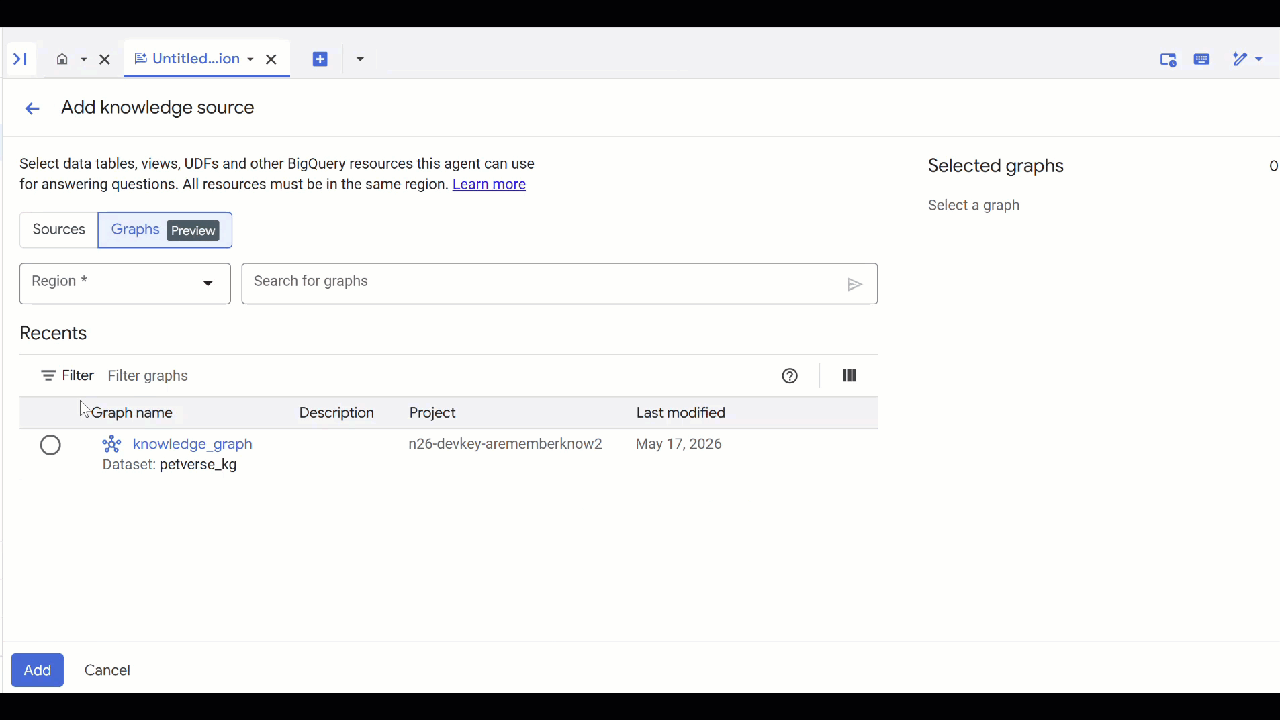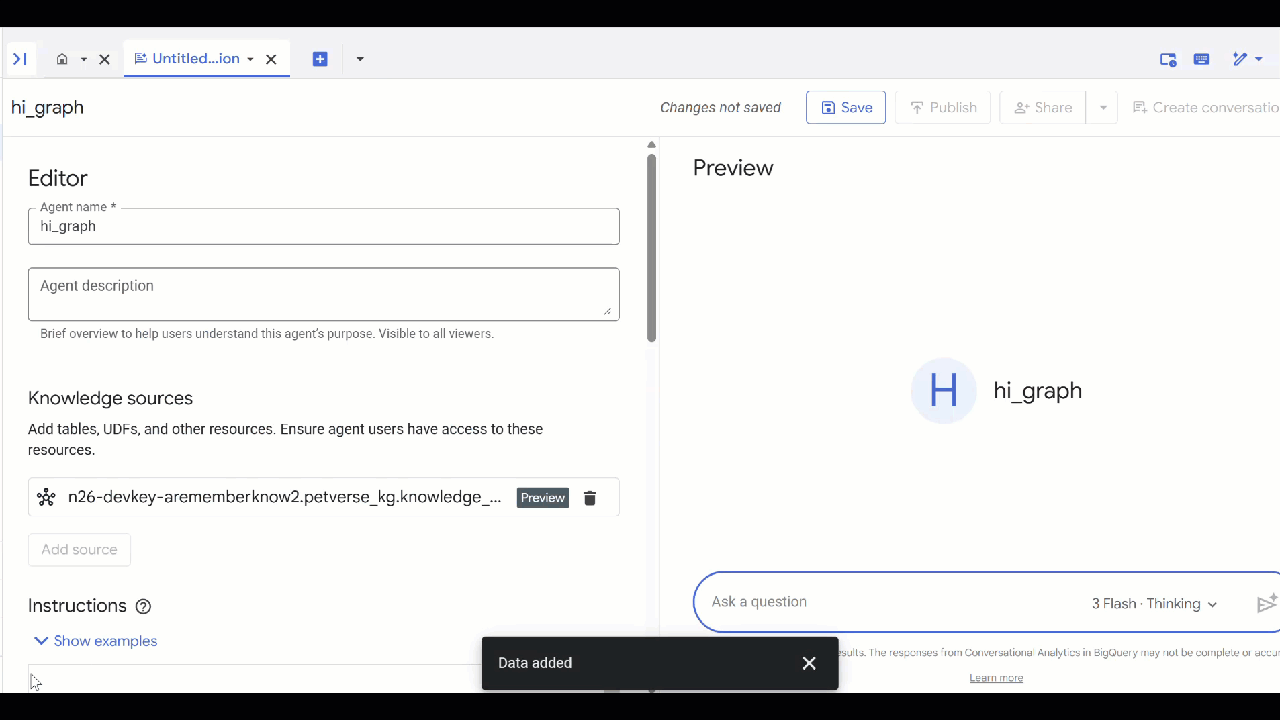
- Selecione o
knowledge_graphcriado e clique em Adicionar.
Agora você pode fazer uma pergunta ao agente e conferir as respostas e o raciocínio por trás delas. Confira algumas perguntas de exemplo se precisar de inspiração. Um modelo de pensamento pode levar um pouco mais de tempo, mas provavelmente vai criar uma consulta GQL melhor. Para ver o que ele cria, abra Show Thinking.
- Encontre animais de estimação que comem alimentos semelhantes ou que são amigos de animais que gostam de dormir.
- Algum dos pets tem exatamente o mesmo hobby, comida favorita ou brinquedo? Liste os pares e os interesses compartilhados.
- Encontre pets da mesma espécie ou raça, mas com hobbies completamente diferentes.
9. Limpar
Para evitar cobranças contínuas na sua conta do Google Cloud, exclua os recursos criados durante este codelab.
- Exclua o cluster do GKE:
gcloud container clusters delete petverse-cluster --region $REGION --quiet
- Exclua o conjunto de dados do BigQuery (isso vai excluir todas as tabelas):
bq rm -r -f -d $PROJECT_ID:petverse_kg
- Exclua os recursos da fila do Pub/Sub:
gcloud pubsub subscriptions delete petverse-sub --quiet
gcloud pubsub topics delete petverse-topic --quiet
- Exclua o repositório do Artifact Registry:
gcloud artifacts repositories delete gke-cats-repo --location=$REGION --quiet
- Exclua o bucket do GCS específico do projeto:
gcloud storage buckets delete gs://$PROJECT_ID-petverse --quiet
10. Parabéns
Parabéns! Você criou um pipeline de grafo de conhecimento distribuído usando o GKE e o Gemini e o consultou usando os gráficos de propriedades do BigQuery.
O que você aprendeu
- Como implantar jobs distribuídos no Autopilot do GKE.
- Como usar o Gemini para extração de dados multimodais.
- Como usar os encodings automáticos do BigQuery.
- Como criar e consultar gráficos de propriedades no BigQuery.