
1. Введение
В этом практическом занятии вы создадите распределенный конвейер сбора знаний для «Petverse». Вы будете обрабатывать неструктурированные мультимедийные ресурсы (аудио, видео, изображения, текст/CSV) из хранилища Cloud Storage, извлекать ключевую информацию о питомцах (любимая еда, хобби) и создавать граф знаний. Вы масштабируете обработку мультимедийных файлов с помощью многомодальной обработки Gemini в Google Kubernetes Engine (GKE). Наконец, вы сохраните эти данные в BigQuery и используете новую функцию BigQuery Property Graph для анализа взаимосвязей.
Мы воспользуемся возможностями Google Kubernetes Engine, чтобы продемонстрировать параллельную обработку больших объемов данных.
Почему именно графы знаний?
Графы знаний лучше подходят, чем традиционные реляционные базы данных, для представления и анализа сложных взаимосвязей между сущностями.
Мы будем использовать Gemini 2.5 Flash для анализа изображений, аудио- и видеофайлов и установления фактов о различных домашних животных.
Что вы будете делать
- Создайте и разверните распределенное задание обработки данных в GKE .
- Используйте Gemini для извлечения сущностей и связей из мультимедийных файлов.
- Храните данные графа знаний в BigQuery .
- Создайте и выполните запросы к графу свойств в BigQuery, используя язык запросов к графам (GQL).
Что вам понадобится
- Веб-браузер, например Chrome.
- Проект Google Cloud с включенной функцией выставления счетов.
- Права доступа в проекте для создания ресурсов и изменения политик управления идентификацией и доступом (IAM).
Этот практический семинар предназначен для разработчиков всех уровней, включая начинающих.
Примерное время: 45 минут
Стоимость: Стоимость ресурсов, созданных в рамках этого практического занятия, должна составлять менее 5 долларов.
2. Прежде чем начать
Создайте проект в Google Cloud.
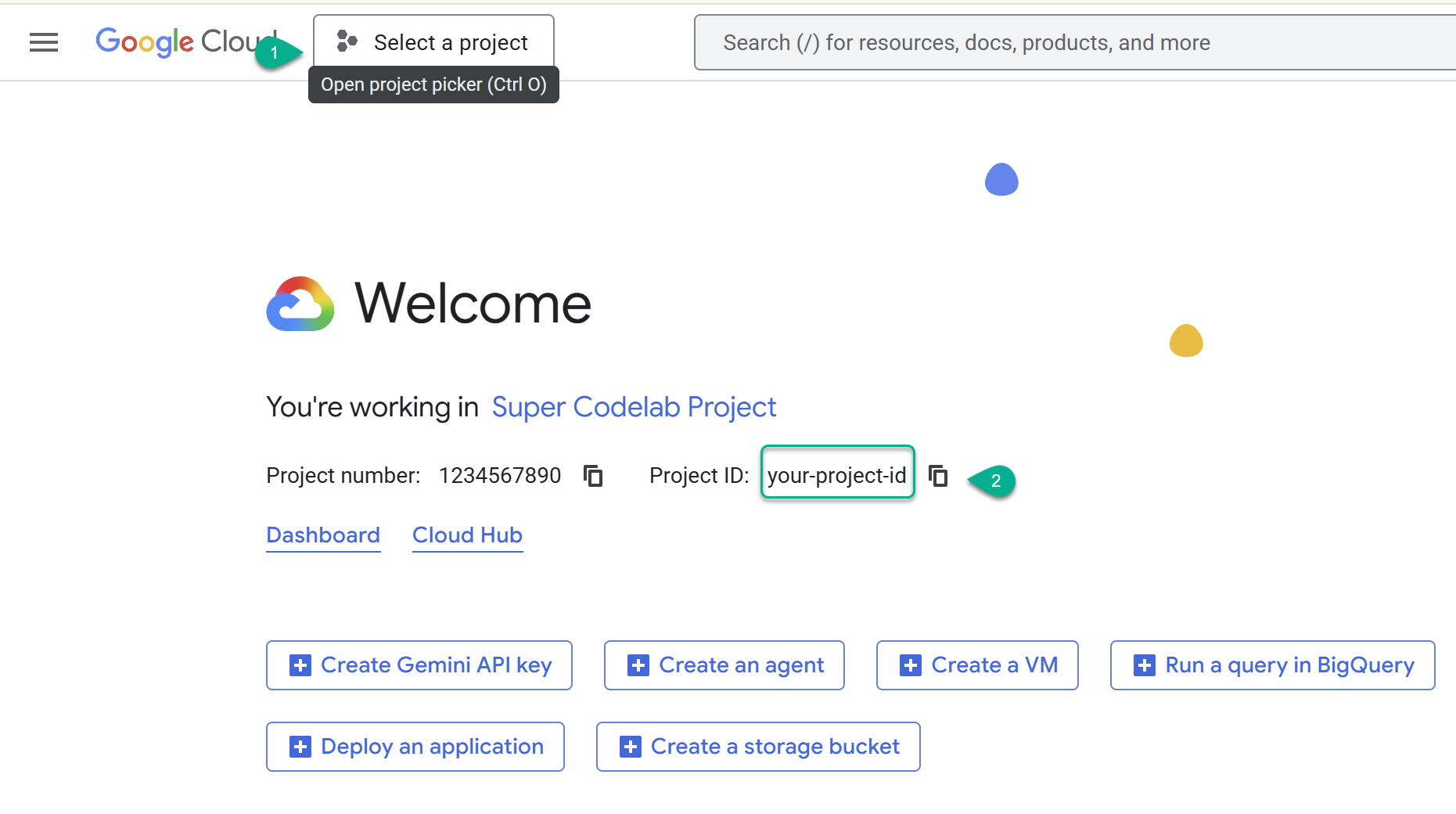
- Перейдите в консоль Google Cloud: https://console.cloud.google.com , а затем выберите или создайте проект Google Cloud .
- ⚠️ Обратите внимание на идентификатор проекта. Он понадобится вам для выполнения нескольких команд в этой лабораторной работе.
Запустить Cloud Shell
- Откройте Cloud Shell в новой вкладке: https://shell.cloud.google.com/ .
- Если появится запрос, нажмите «Авторизовать» .
- Замените
PROJECT_IDи вставьте следующую команду в терминал:
export PROJECT_ID="YOUR_PROJECT_ID"
gcloud config set project $PROJECT_ID
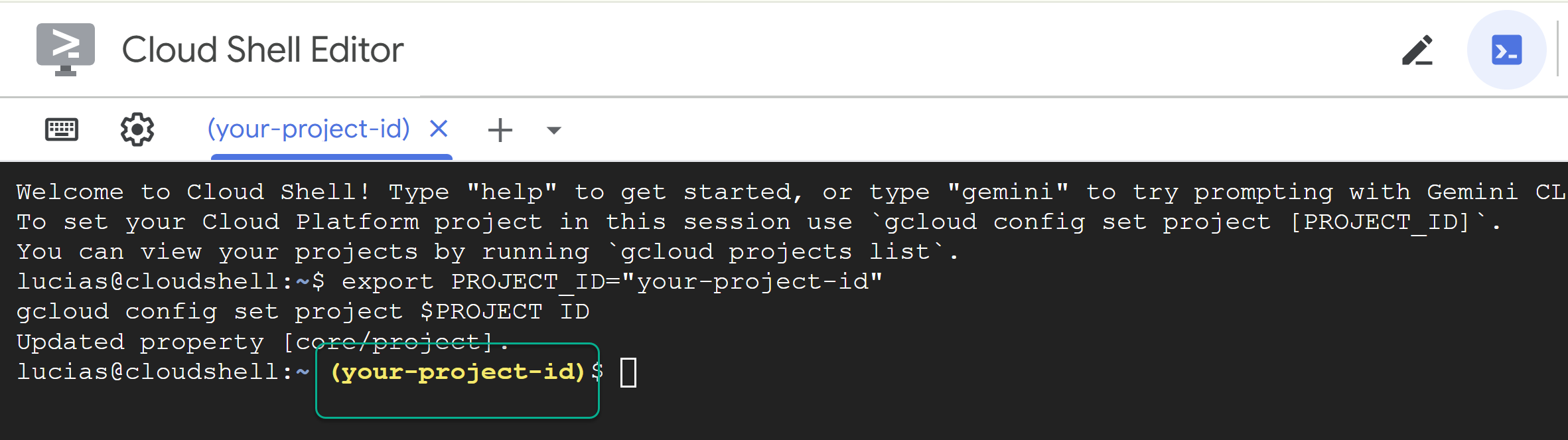
📝 Примечание: Ваш проект будет отображаться желтым цветом в командной строке. Если сессия перезапустится, обязательно повторно выполните указанную выше команду, чтобы установить идентификатор проекта.
Включить API
Выполните эту команду, чтобы включить все необходимые API:
gcloud services enable \
aiplatform.googleapis.com \
bigquery.googleapis.com \
artifactregistry.googleapis.com \
container.googleapis.com \
cloudbuild.googleapis.com \
pubsub.googleapis.com
Клонировать репозиторий
Выполните эти команды, чтобы клонировать репозиторий.
cd ~/
git clone --filter=blob:none --no-checkout https://github.com/GoogleCloudPlatform/devrel-demos.git
cd ~/devrel-demos
git sparse-checkout init --cone
git sparse-checkout set codelabs/gke-knowledge-graph
git checkout main
cd codelabs/gke-knowledge-graph/
Запустите скрипт установки
Этот скрипт автоматизирует настройку бэкэнда следующим образом:
- Создание образа контейнера и репозитория Artifact Registry.
- Создание набора данных BigQuery
- Создание подключения к BigQuery для выполнения функций Gemini AI из SQL.
Выполните следующую команду в терминале:
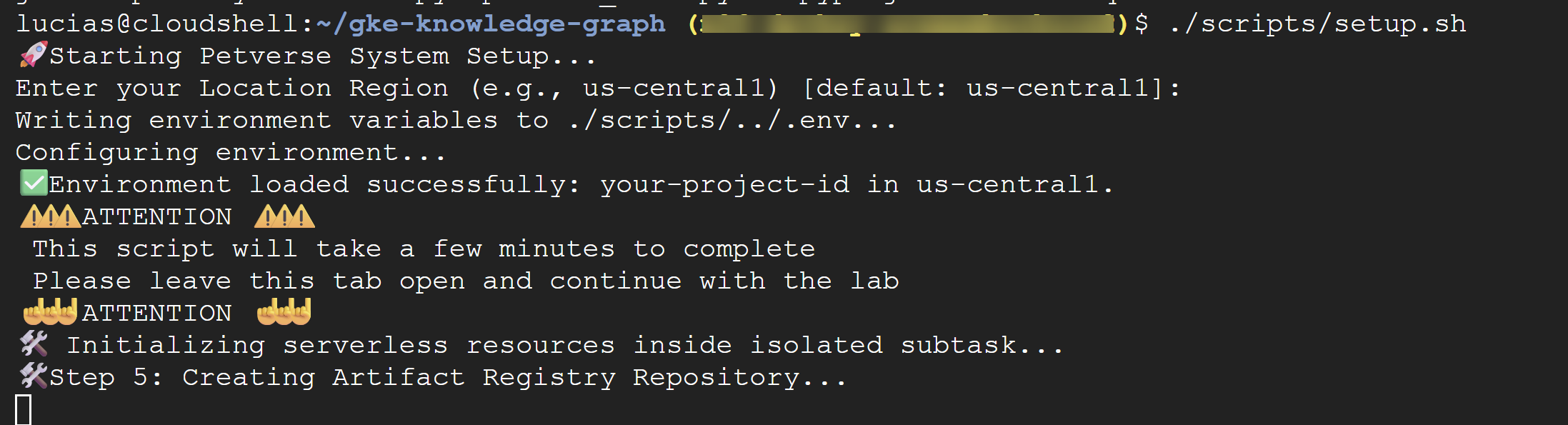
./scripts/setup.sh
Если скрипт запросит у вас данные для настройки, используйте следующие значения:
- Идентификатор проекта: Используйте идентификатор, созданный вами на предыдущем шаге.
- Регион:
us-central1
⚠️ Важно! Выполнение скрипта займет несколько минут. Оставьте это окно терминала открытым, чтобы завершить работу в фоновом режиме. Для перехода к следующему шагу откройте новую вкладку или окно терминала для выполнения следующих команд.
3. Настройка комплекта агента данных
- Активируйте редактор Cloud Shell с помощью значка карандаша в правом верхнем углу.
- В редакторе Cloud Shell нажмите значок «Расширения» на левой боковой панели.
- Найдите Google Cloud Data Agent Kit и нажмите «Установить» , если он еще не установлен.
- Войдите в свой аккаунт Google с помощью расширения.
- В разделе «Сводка по конфигурации» введите идентификатор вашего проекта и
us-central1в качестве региона.
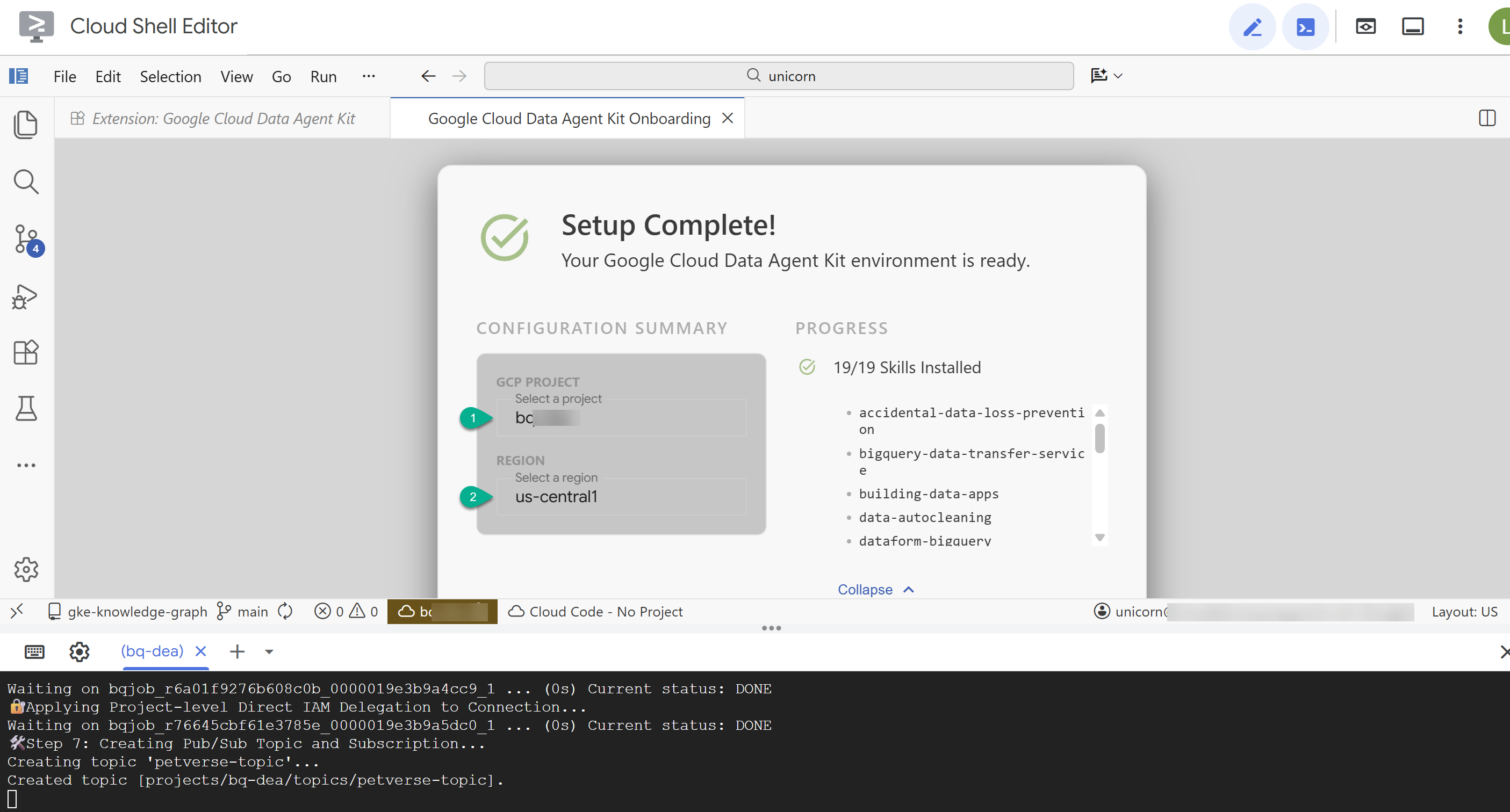
- Нажмите «Настроить серверы MCP» . Вносить какие-либо изменения в это окно не требуется, просто нажмите «Начать» .
- Перезагрузите окно, если появится соответствующее сообщение. Вкладку «Краткое руководство» можно пока закрыть.
Настройте таблицы в BigQuery.
- На боковой панели вернитесь в проводник. Если ваша домашняя папка (например,
/home/your_user_name/) еще не открыта, нажмите «Открыть папку» и выберите ее.
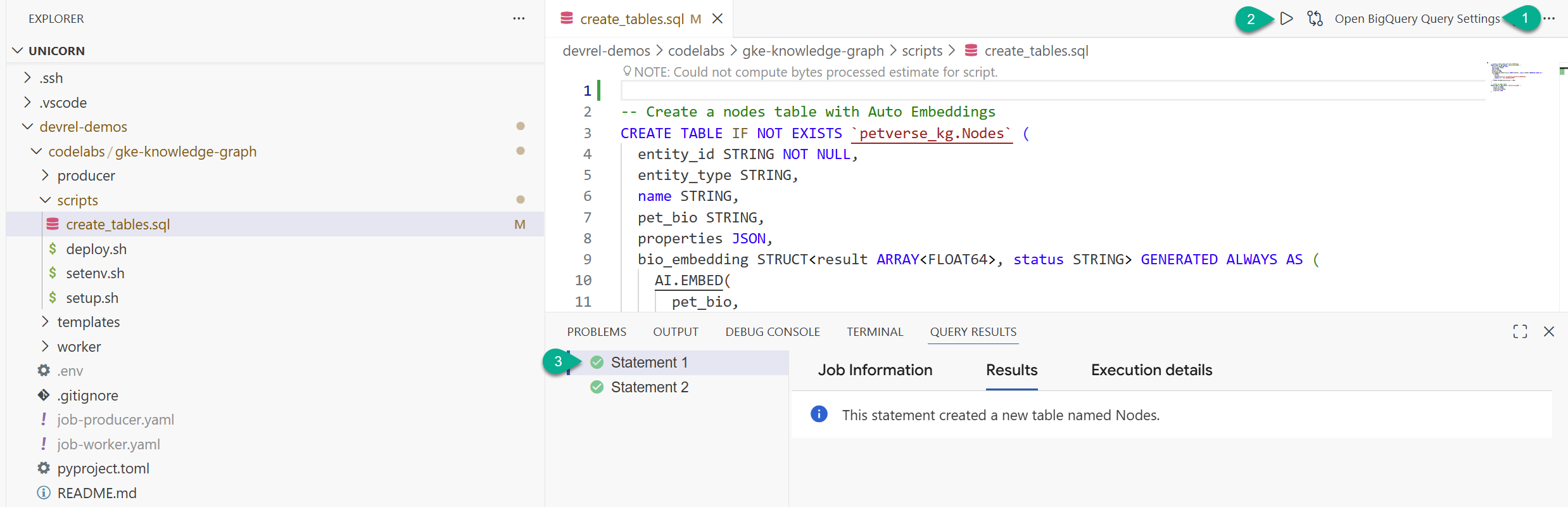
- В окне проводника найдите папку, которую вы клонировали из репозитория (
devrel-demos). Вcodelabs/gke-knowledge-graph/scriptsвы найдете файлcreate_tables.sql. Откройте этот файл . - В правом верхнем углу нажмите «Открыть настройки запроса» .
- Выберите BigQuery . Сохраните и закройте .
- Нажмите «Выполнить» .
Вы должны увидеть два успешно выполненных оператора. Теперь вы создали таблицы для хранения узлов и ребер вашего графа знаний.
Вы можете закрыть вкладку create_tables.sql и консоль результатов.
4. Инициализация кластера GKE.
Для выполнения задачи обработки данных мы будем использовать GKE Autopilot. Autopilot — это рекомендуемый передовой метод, поскольку он управляет инфраструктурой кластера за вас.
К этому моменту скрипт установки должен был завершиться. Вы должны увидеть сообщение об успешном завершении: 🎉🦄 Setup successfully finished! 🎉🦄 .
Вставьте эту команду в терминал, чтобы создать кластер:
source scripts/setenv.sh
gcloud container clusters create-auto petverse-cluster \
--region=$REGION
🕓 Это займет около 5 минут.
Получите учетные данные для взаимодействия с кластером:
source scripts/setenv.sh
gcloud container clusters get-credentials petverse-cluster --region $REGION
Вы должны увидеть следующий результат:
Fetching cluster endpoint and auth data. kubeconfig entry generated for petverse-cluster.
5. Настройка идентификации рабочей нагрузки
Федерация идентификации рабочих нагрузок для GKE (с использованием прямого доступа к ресурсам) позволяет вашим рабочим нагрузкам GKE безопасно получать доступ к сервисам Google Cloud без необходимости управления ключами учетных записей служб.
Выполните deploy.sh по следующему пути:
- Создайте учетную запись службы Kubernetes.
- Предоставьте необходимые роли IAM непосредственно субъекту учетной записи службы Kubernetes.
- Привяжите учетную запись службы IAM к учетной записи службы Kubernetes.
- Добавьте аннотацию к учетной записи службы Kubernetes, чтобы завершить привязку.
source scripts/setenv.sh
./scripts/deploy.sh
6. Развертывание заданий с раздельной обработкой данных.
На этом этапе вы развернете блок постановки в очередь (Producer) и механизмы обработки (Workers) в GKE.
Наша новая децентрализованная архитектура использует Google Cloud Pub/Sub для асинхронной обработки ресурсов:
- Программа-производитель сканирует GCS и добавляет все пути к файлам в очередь публикации/подписки.
- В GKE пул рабочих процессов масштабируется, динамически извлекая задачи параллельно, обрабатывая их через Gemini и записывая в BigQuery.
Скрипт setup.sh уже собрал и загрузил образы контейнеров Producer и Worker, поставил в очередь темы Pub/Sub и динамически сгенерировал ваши манифесты развертывания GKE: job-producer.yaml и job-worker.yaml .
- Запустите задание производителя для сканирования вашего хранилища и постановки в очередь всех ресурсов:
kubectl apply -f job-producer.yaml
Эта задача выполняется и завершается быстро, поскольку она ставит в очередь только метаданные.
- Для очистки очереди выполните задание Worker Job, настроенное на запуск 6 параллельных рабочих процессов :
kubectl apply -f job-worker.yaml
GKE Autopilot автоматически обнаружит ожидающие выполнения поды, динамически увеличит вычислительные узлы и запустит рабочие процессы параллельно для обработки аудио-, видео-, графических и CSV-файлов, находящихся в очереди.
7. Проверка результатов
- Проверьте статус ваших заданий:
kubectl get jobs
Дождитесь, пока задания petverse-producer-job и petverse-worker-job не покажут успешное завершение.
🕓 Это займет около 10 минут. Вы можете отслеживать ход выполнения с помощью команд ниже.
- Проверьте журналы процесса "Производитель", чтобы убедиться, что файлы были успешно поставлены в очередь:
cd ~/devrel-demos/codelabs/gke-knowledge-graph
source scripts/setenv.sh
kubectl logs -l app=petverse-producer --tail=50
- Наблюдайте за тем, как ваши параллельные обработчики обрабатывают файлы из очереди:
kubectl logs -l app=petverse-worker --tail=50
(Рабочие процессы имеют 60-секундный тайм-аут простоя и автоматически отключаются и очищают систему, когда очередь Pub/Sub опустеет).
Проверьте данные в BigQuery.
- Перейдите в BigQuery Studio . Вы увидите две созданные таблицы: petverse_kg.Nodes и petverse_kg.Edges.
- Чтобы просмотреть содержимое таблиц, дважды щелкните по их названиям, а затем нажмите «Предварительный просмотр» .
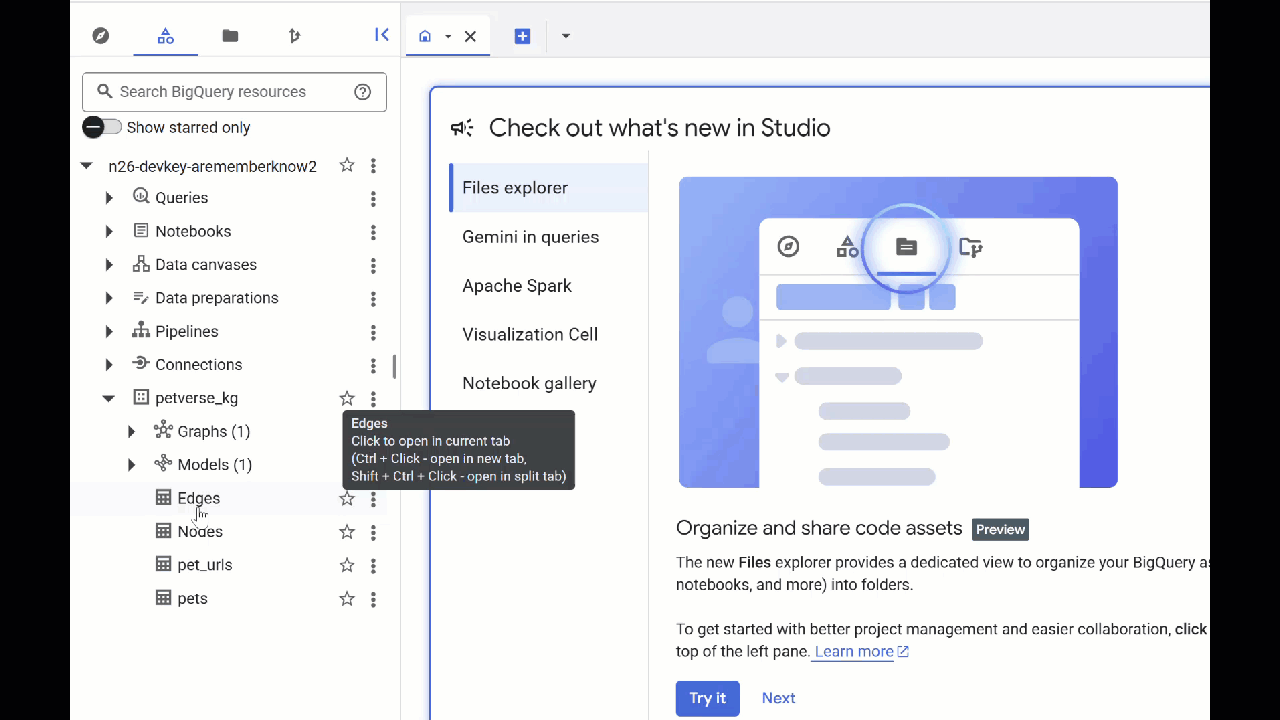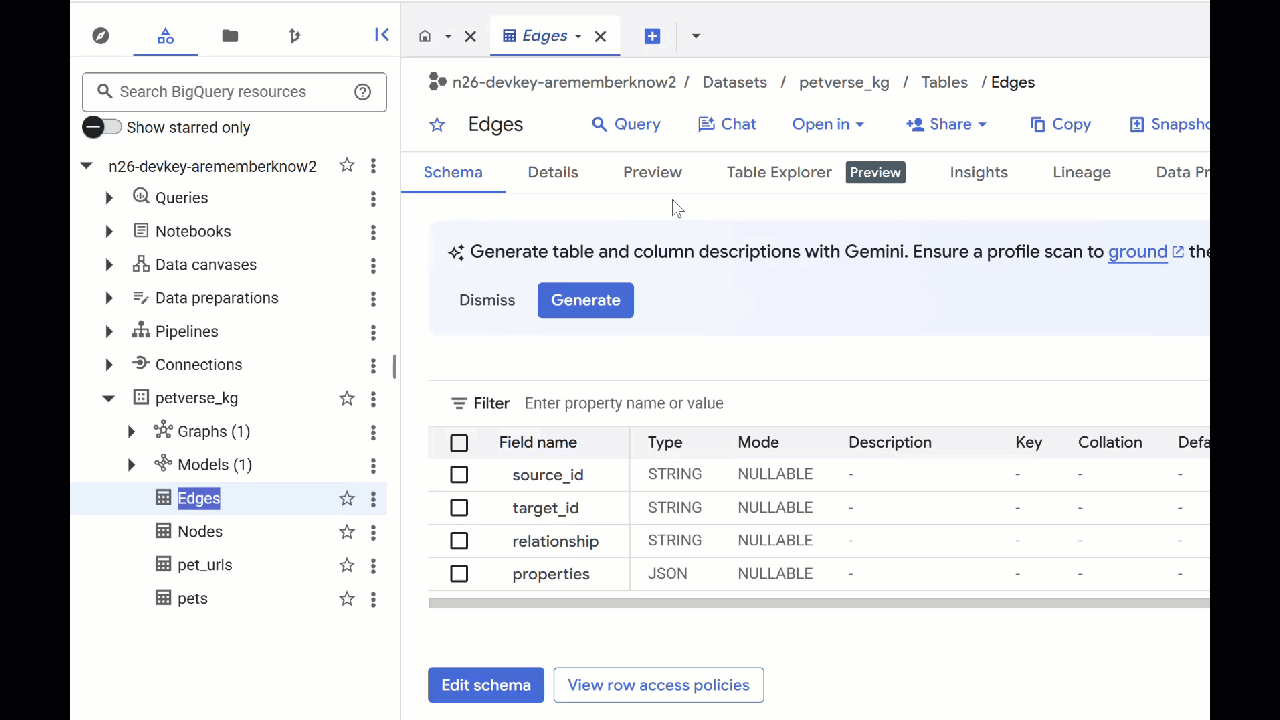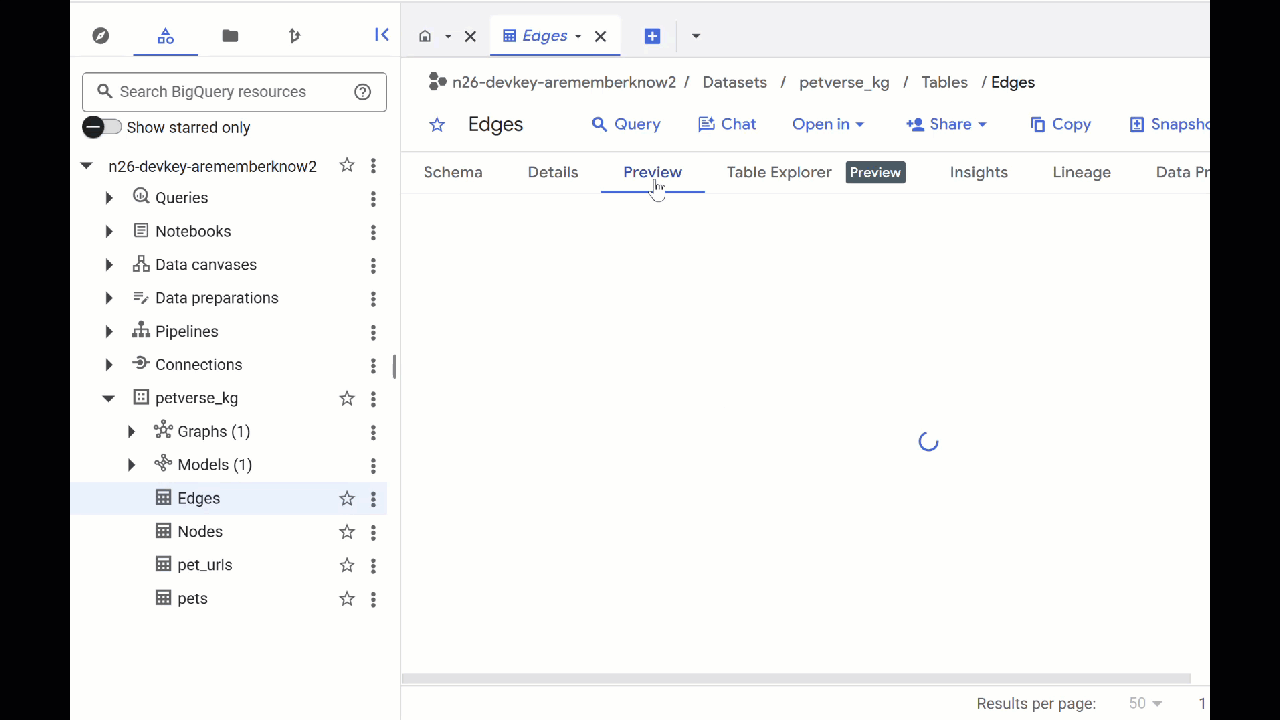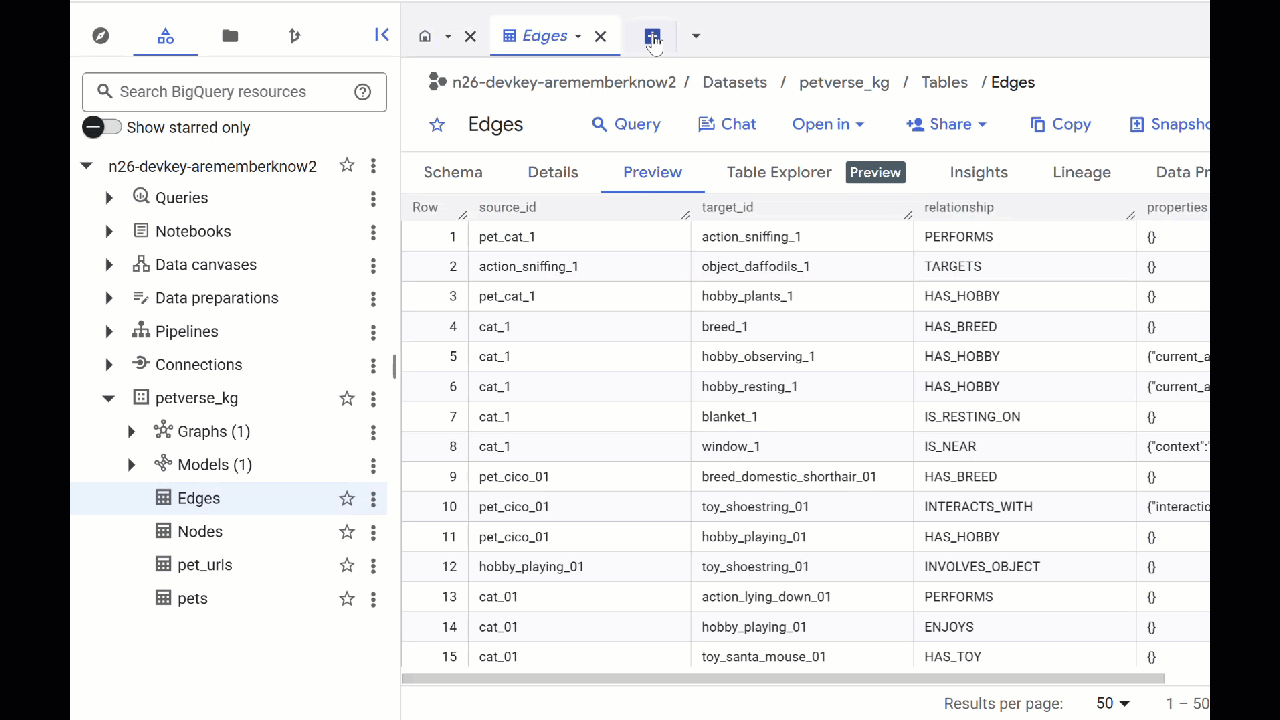
Вы увидите, что в таблице Nodes содержится информация об объектах, обнаруженных Gemini в аудио, видео и изображениях. В таблице Edges содержатся связи между ними. Например, если вы послушаете аудиозапись кота по кличке SQL , то увидите, что он любит играть со шнурками и обожает сушеных рыбок.
- Используйте кнопку «+» , чтобы создать новый запрос. Вставьте следующее выражение и нажмите «Выполнить» :
SELECT n.name, n.entity_id, e.relationship, e.target_id
FROM
`petverse_kg.Nodes` n
JOIN
`petverse_kg.Edges` e
ON n.entity_id = e.source_id
WHERE n.name = 'SQL'
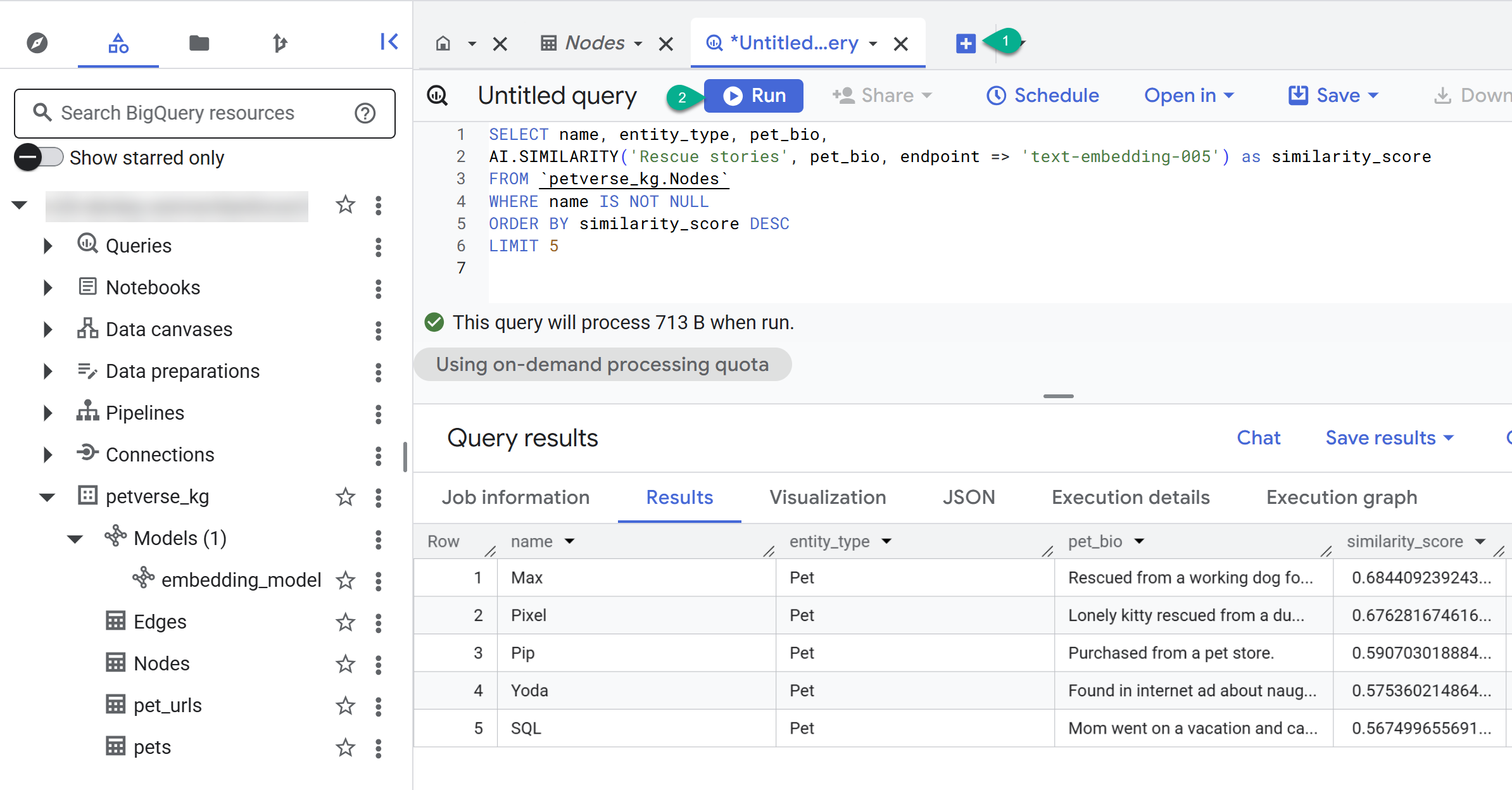
- Используйте кнопку «+» , чтобы создать новый запрос. Вставьте следующее выражение и нажмите «Выполнить» :
SELECT name, entity_type, pet_bio,
AI.SIMILARITY('Pets who like to relax', pet_bio, endpoint => 'text-embedding-005') as similarity_score
FROM `petverse_kg.Nodes`
WHERE name IS NOT NULL
ORDER BY similarity_score DESC
LIMIT 5
Вы должны увидеть узлы, относящиеся к питомцам, которые любят отдыхать. Этот запрос выполнил семантический поиск с использованием функции искусственного интеллекта AI.SIMILARITY для поиска питомцев, чьи биографии наиболее похожи на текст запроса.
Постройте граф свойств
Теперь, когда в BigQuery есть узлы и ребра, мы можем создать граф свойств для удобного запроса связей.
Создайте график
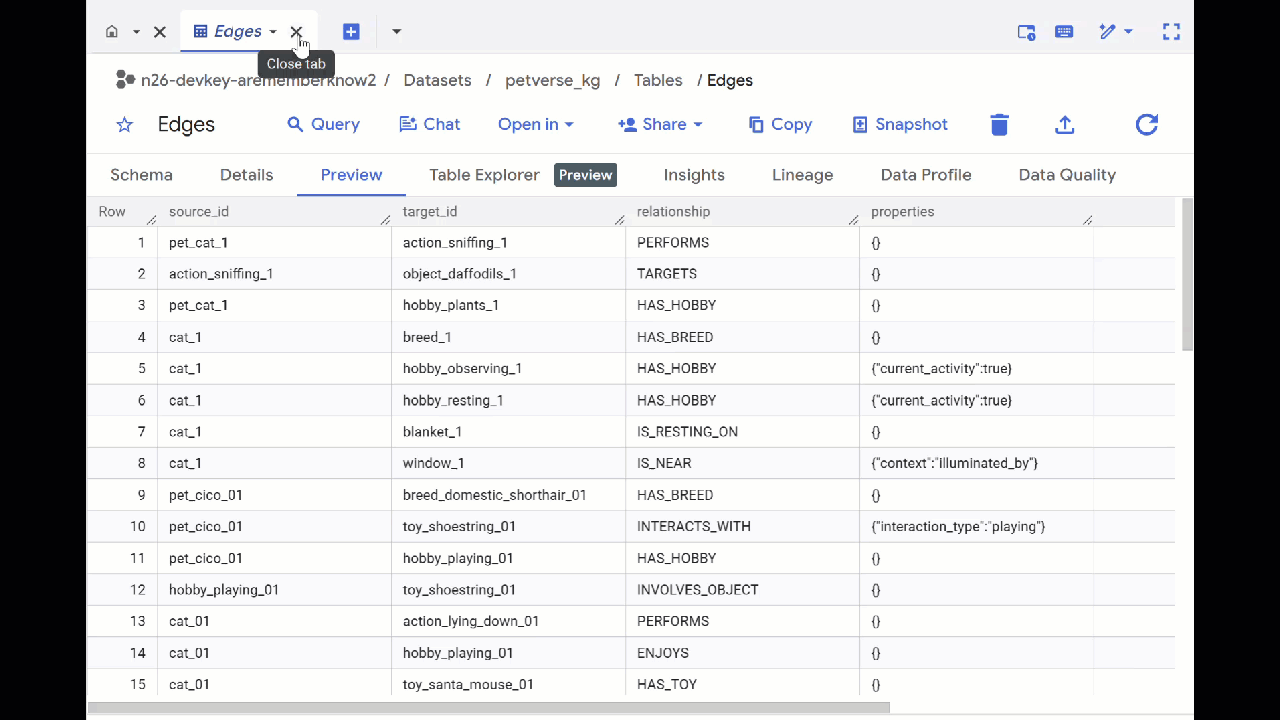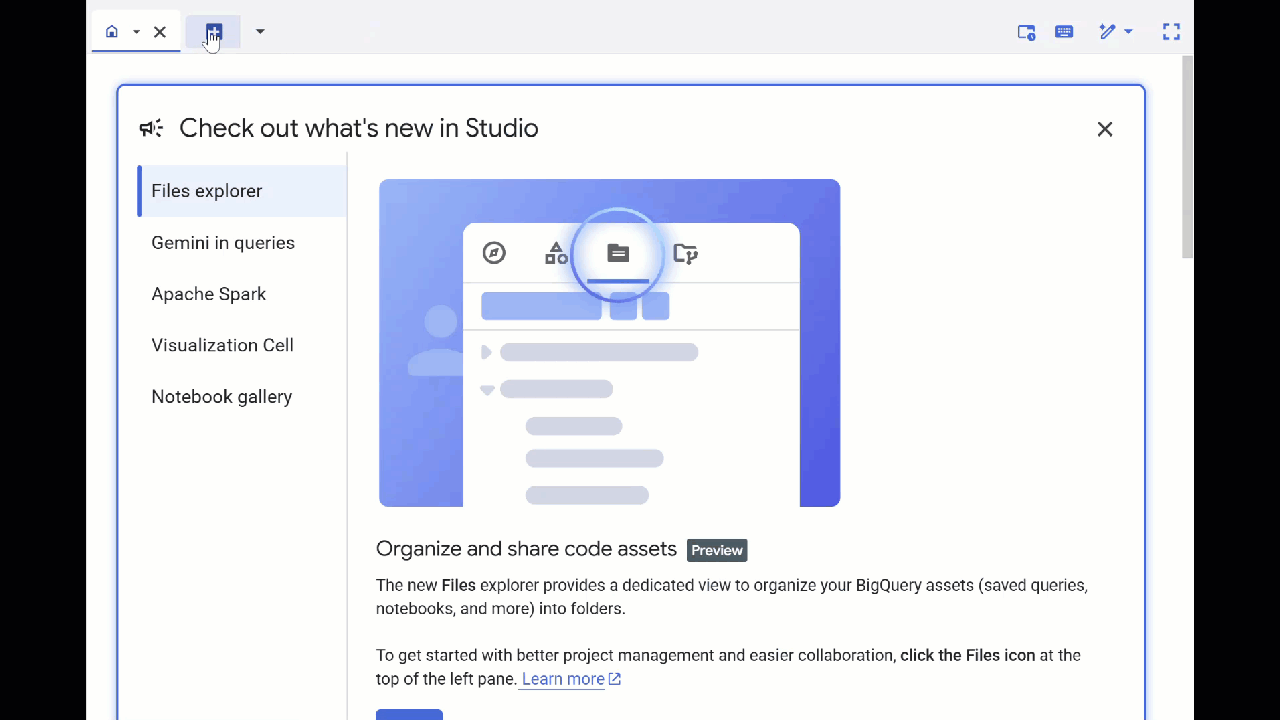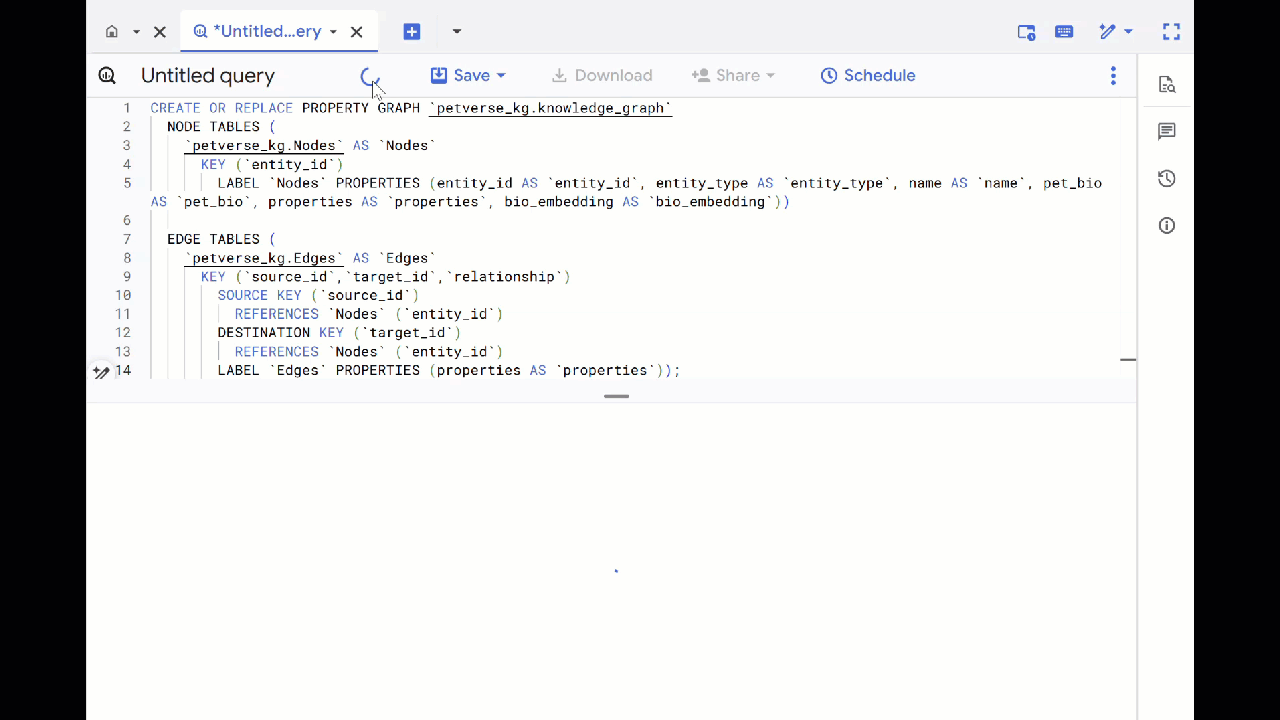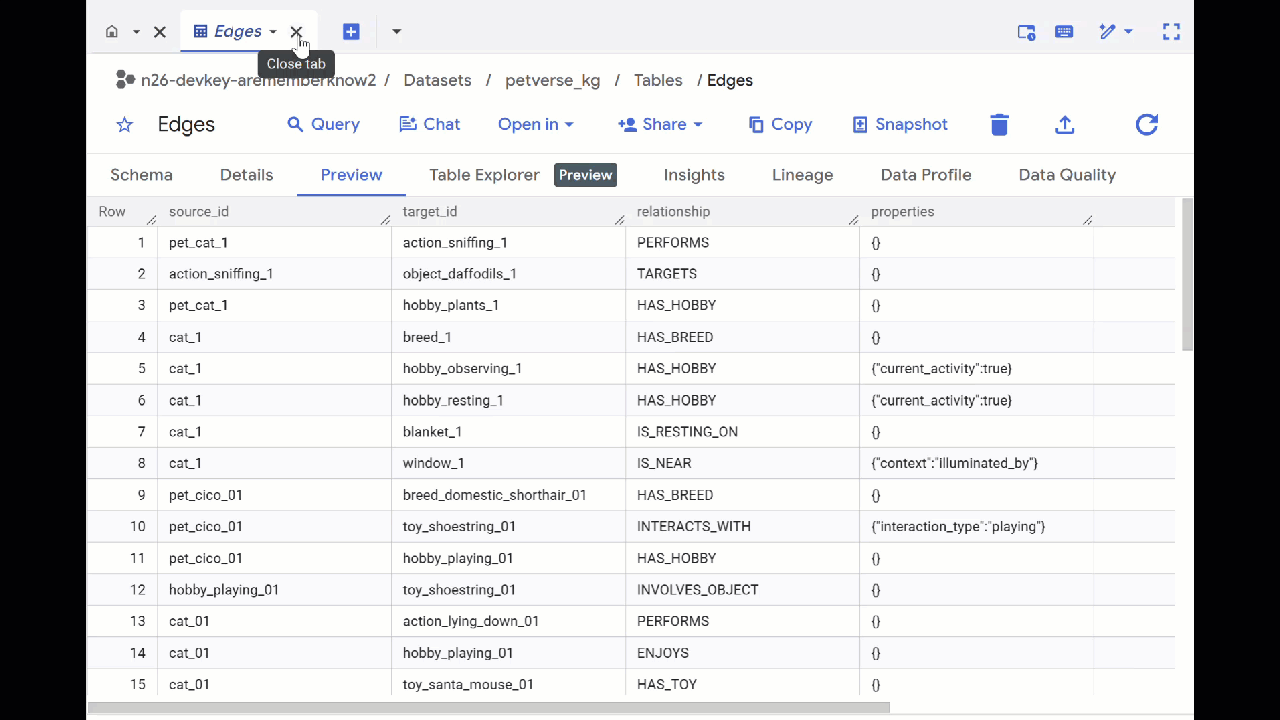
- Перезапишите предыдущий запрос и выполните следующий DDL-скрипт для создания графа свойств:
CREATE OR REPLACE PROPERTY GRAPH `petverse_kg.knowledge_graph`
NODE TABLES (
`petverse_kg.Nodes` AS `Nodes`
KEY (`entity_id`)
LABEL `Nodes` PROPERTIES (entity_id AS `entity_id`, entity_type AS `entity_type`, name AS `name`, pet_bio AS `pet_bio`, properties AS `properties`, bio_embedding AS `bio_embedding`))
EDGE TABLES (
`petverse_kg.Edges` AS `Edges`
KEY (`source_id`,`target_id`,`relationship`)
SOURCE KEY (`source_id`)
REFERENCES `Nodes` (`entity_id`)
DESTINATION KEY (`target_id`)
REFERENCES `Nodes` (`entity_id`)
LABEL `Edges` PROPERTIES (properties AS `properties`));
- Нажмите « Перейти к графу» . Вы увидите визуализацию графа с узлом, имеющим ребро, ведущее к самому себе. Это нормально.
Запрос к графу
- С помощью кнопки «+» вы можете закрыть все предыдущие запросы и открыть новый, пустой.
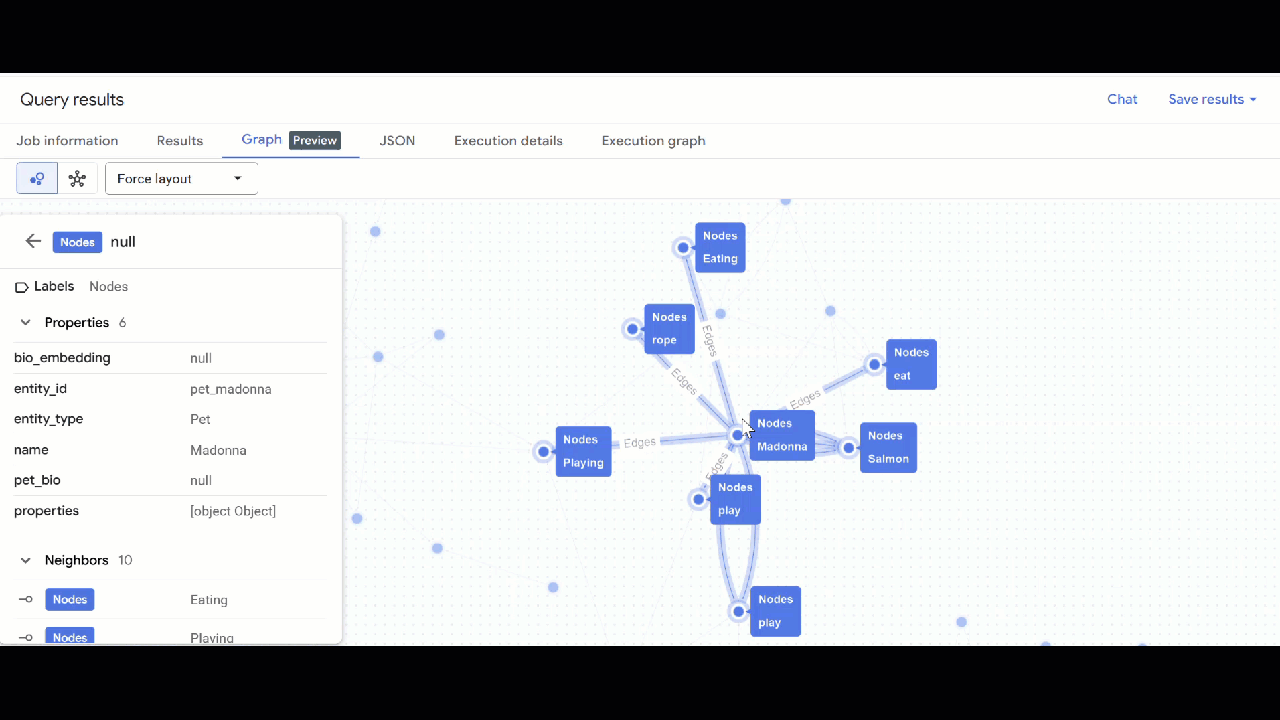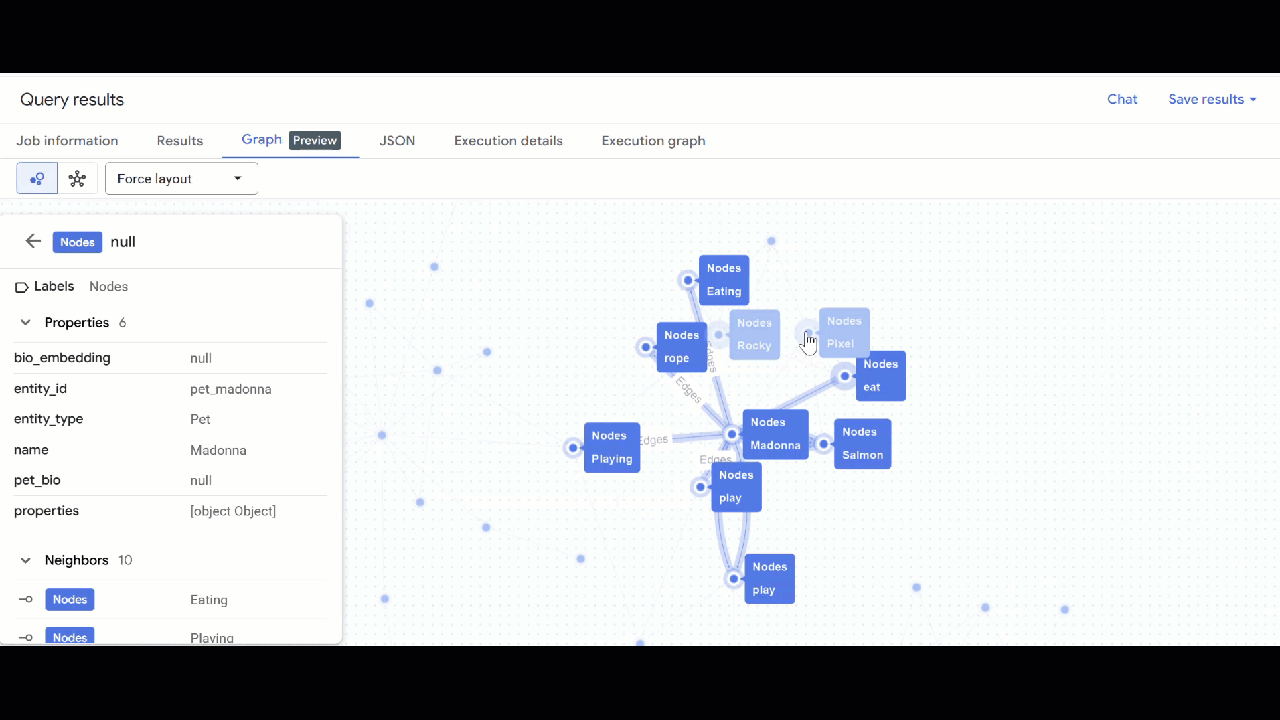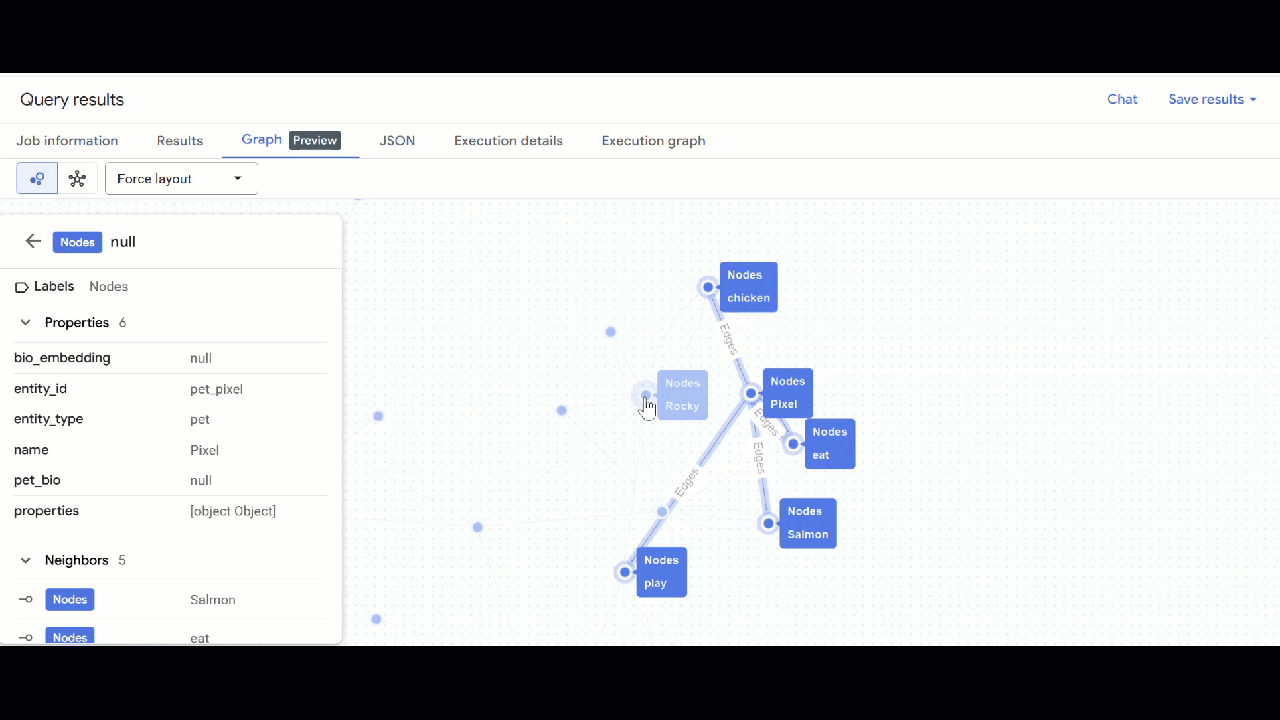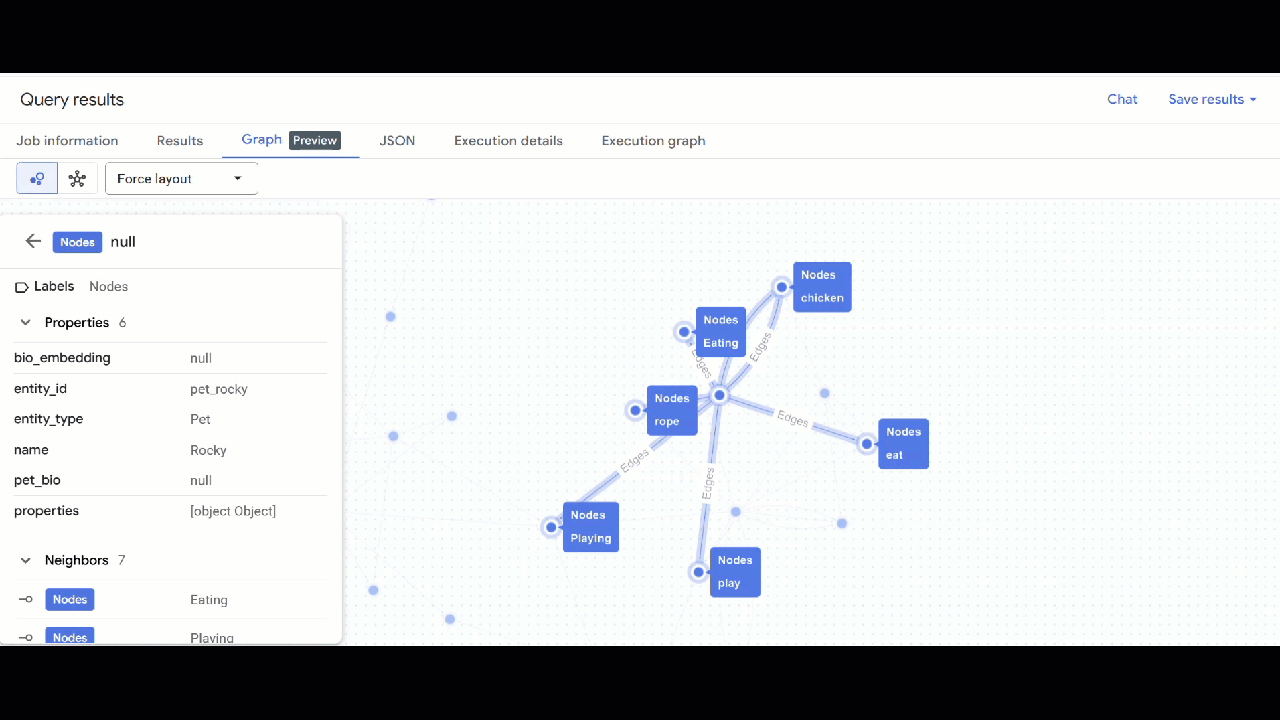
- Используйте GQL для поиска питомцев, связанных друг с другом по общим интересам (например, хобби, любимая еда или игрушки). Этот многошаговый запрос соответствует двум разным питомцам, связанным с одним и тем же узлом:
GRAPH `petverse_kg.knowledge_graph`
MATCH p = (pet1:Nodes)-[e1]->(interest:Nodes)<-[e2]-(pet2:Nodes)
WHERE pet1.entity_id != pet2.entity_id
AND (LOWER(pet1.entity_type) = 'pet' AND LOWER(pet2.entity_type) = 'pet')
AND LOWER(interest.entity_type) IN ('hobby', 'action', 'activity', 'food', 'toy')
RETURN TO_JSON(p) as res
LIMIT 100
- Вы должны увидеть визуализацию графа. Вы можете щелкнуть по узлам, чтобы просмотреть свойства узлов и ребер.
🕵️ Подсказка : Вы можете изменить значение, отображаемое узлом, нажав кнопку «Переключиться в режим схемы» :
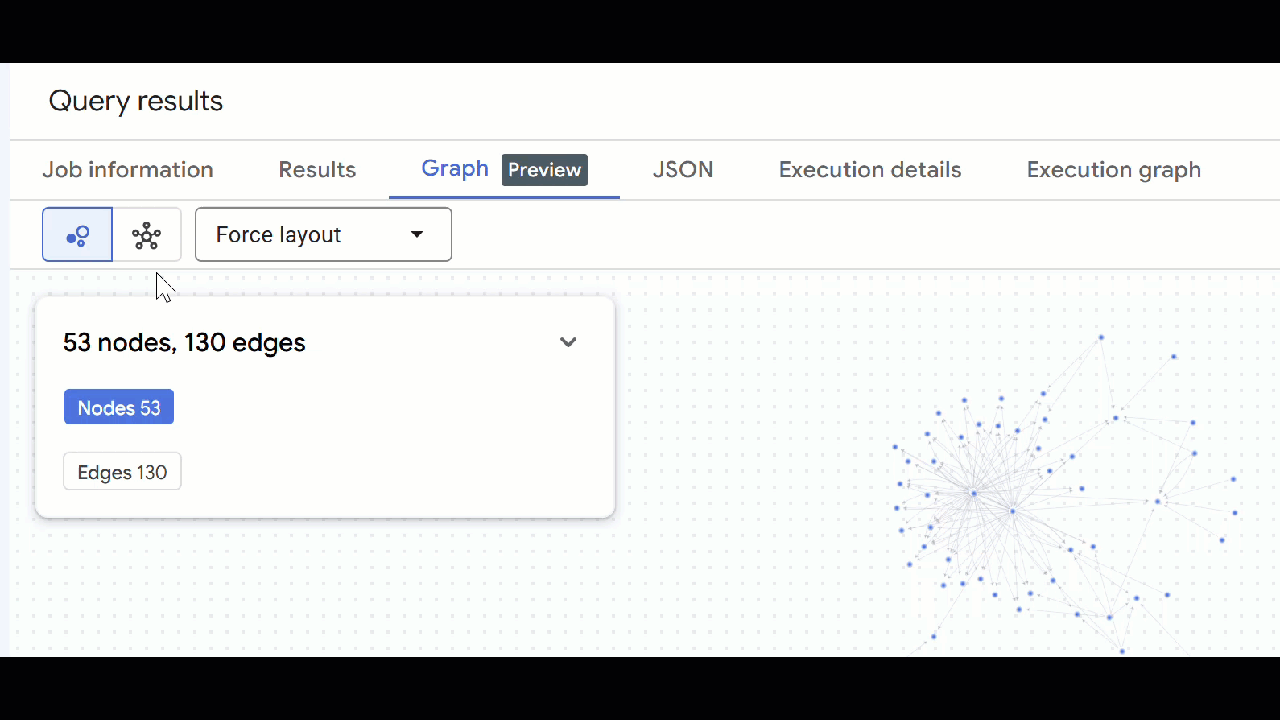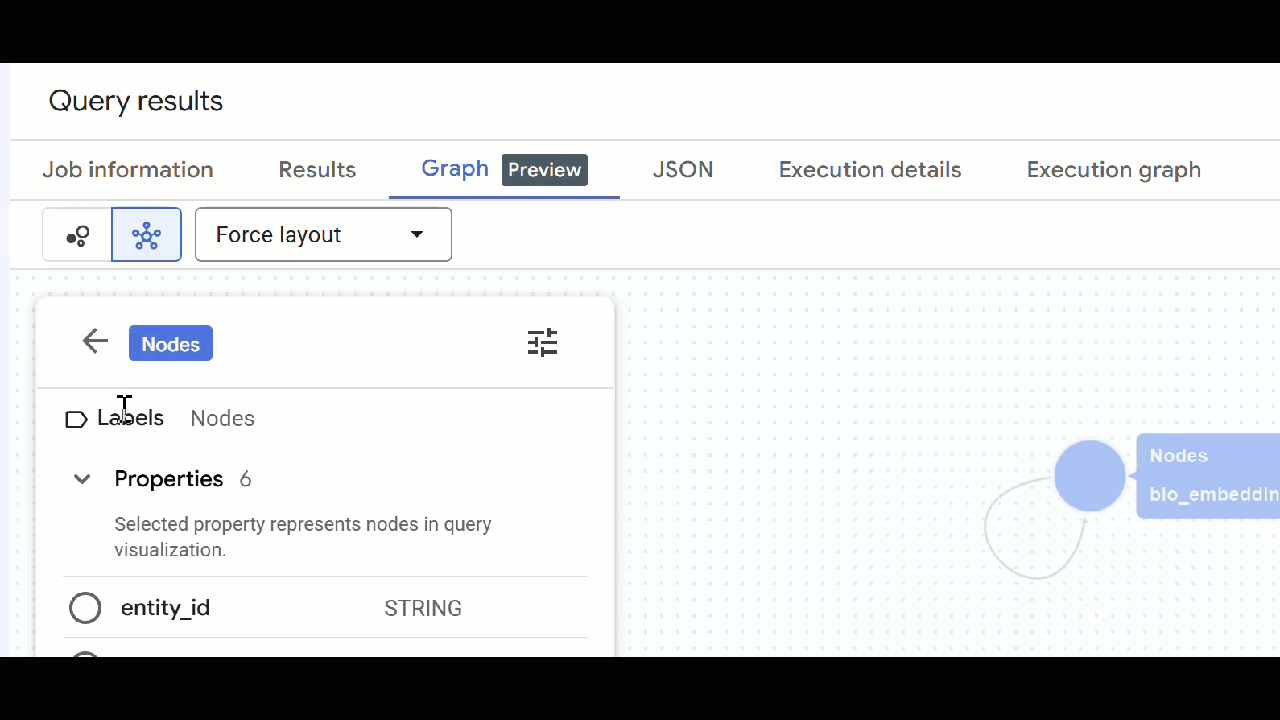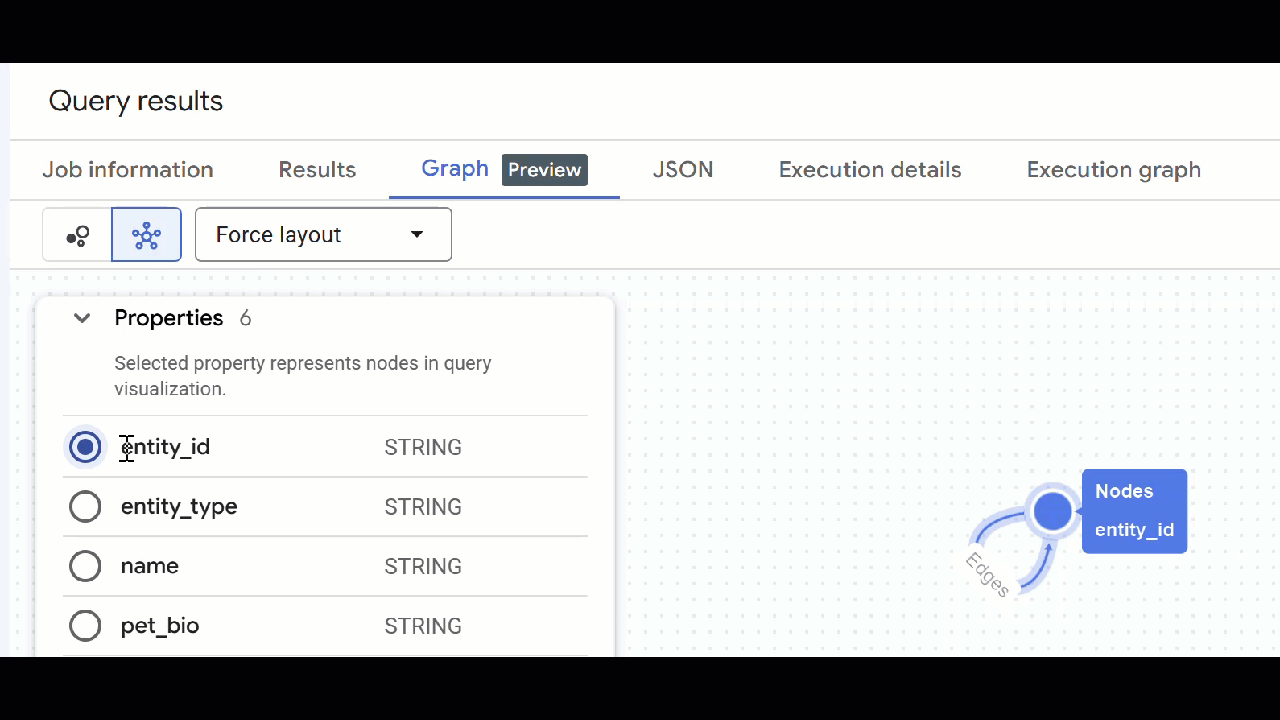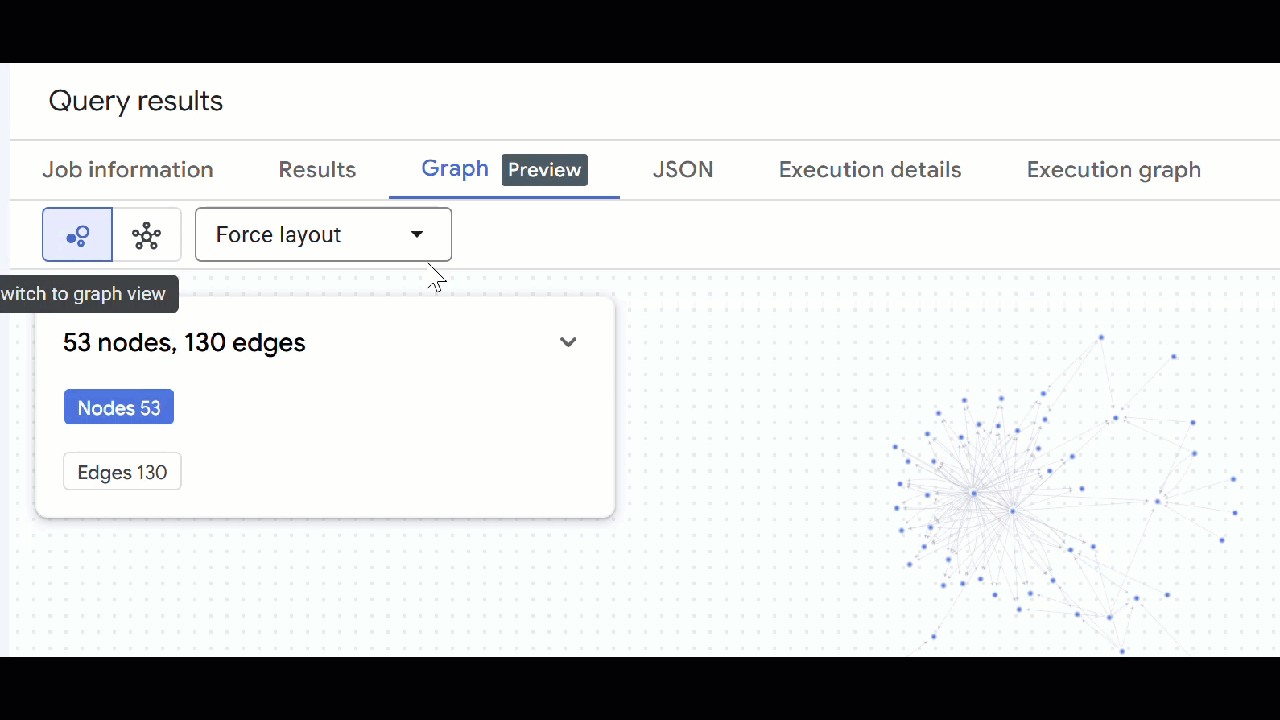
- Вы можете закрыть все открытые вкладки с запросами .
8. Пообщайтесь с графиком.
- Рядом со знаком «+» вы найдете выпадающее меню. Выберите «Разговор» .
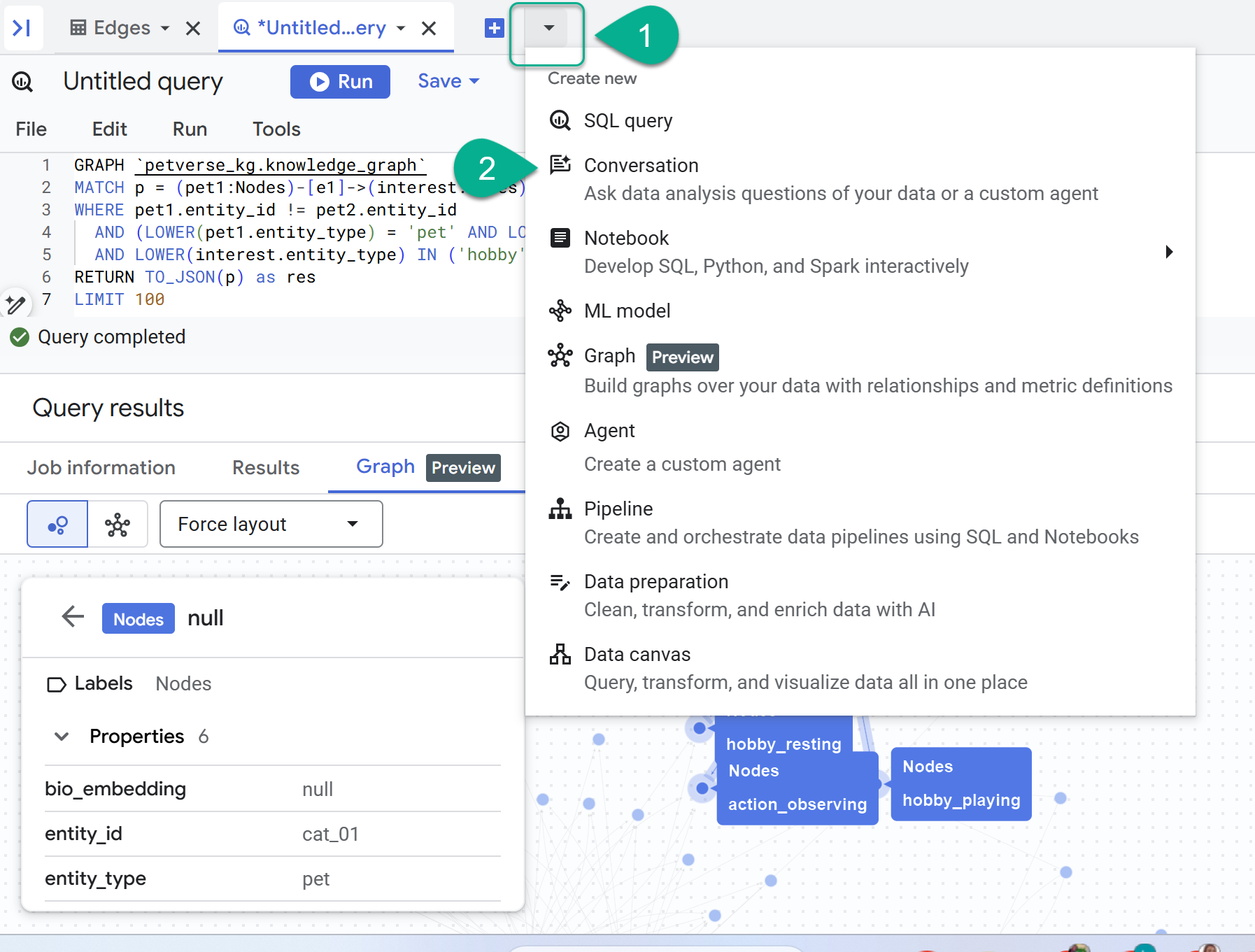
- Вам будет предложено включить API анализа данных в Gemini. Включите оба API. После завершения обновите окно или создайте новый диалог, чтобы увидеть агента.
- Нажмите «Новый агент» .
- Дайте агенту имя, например,
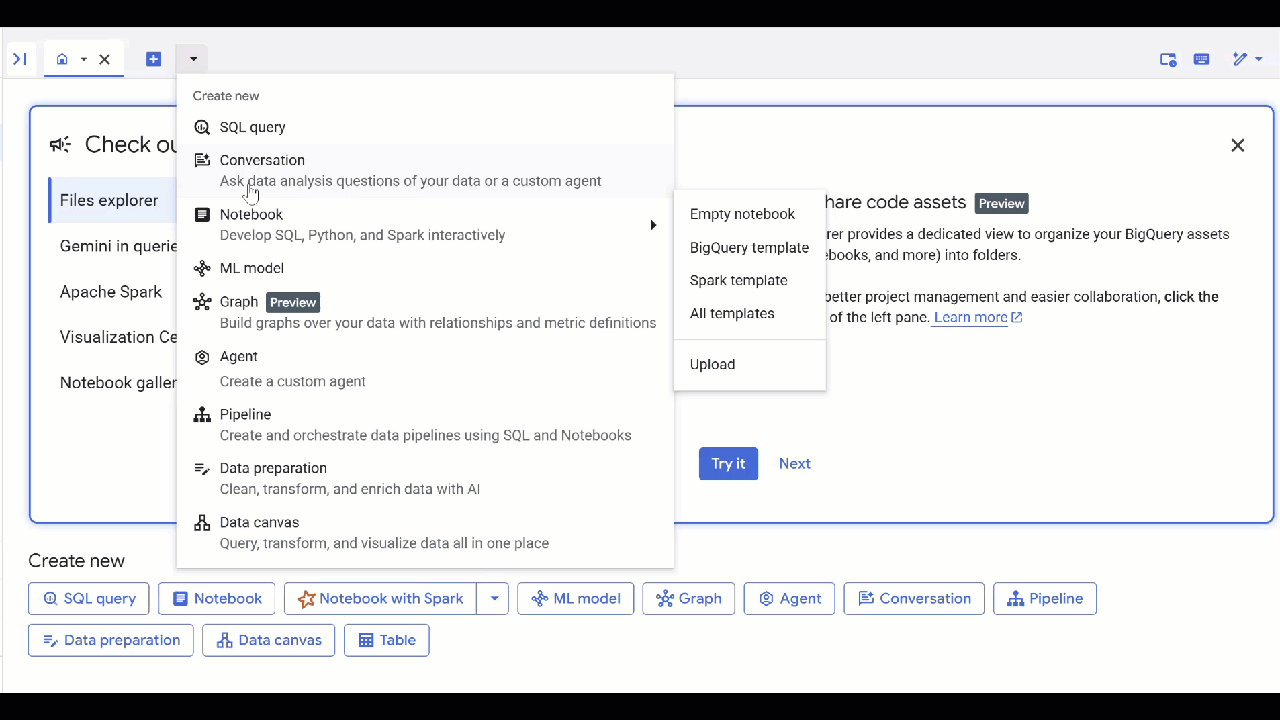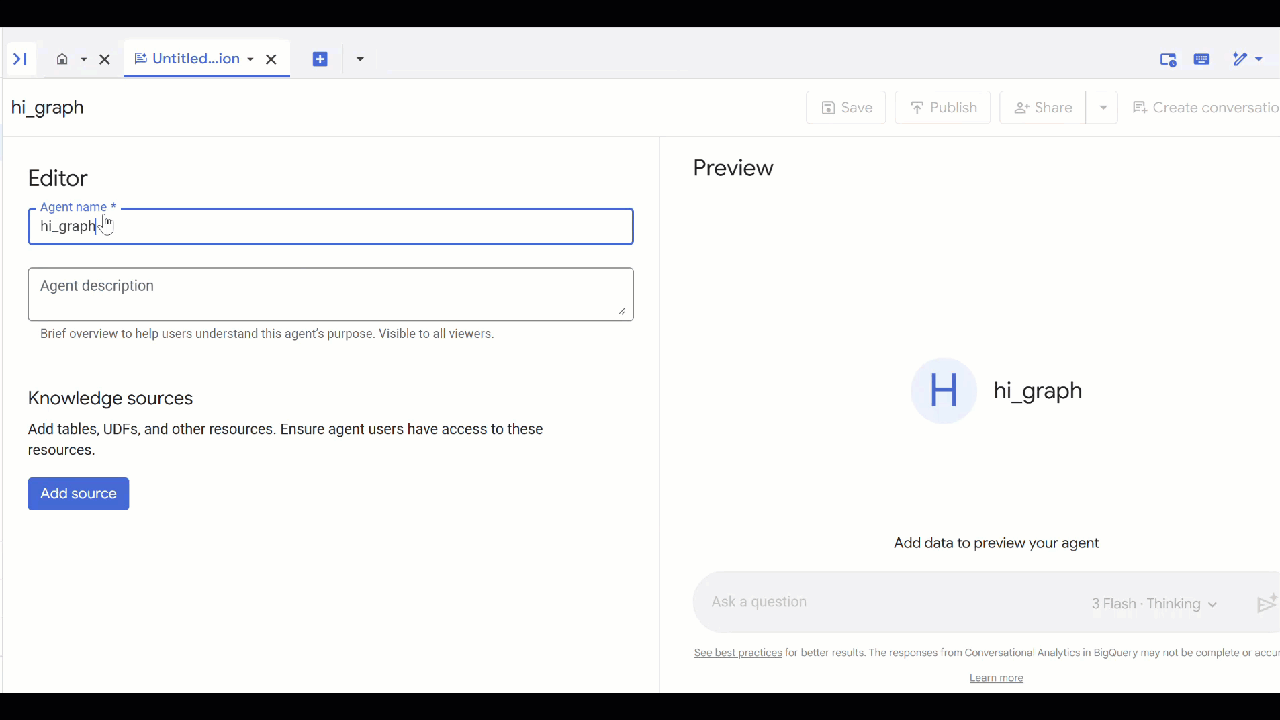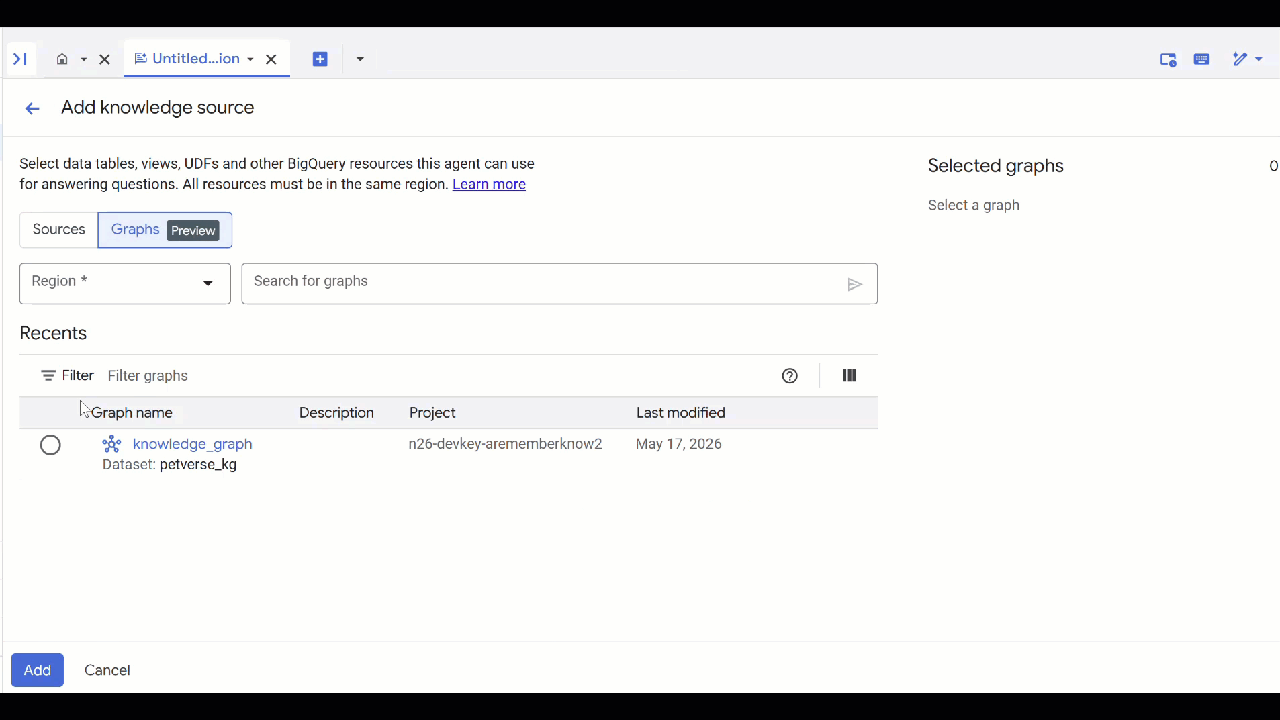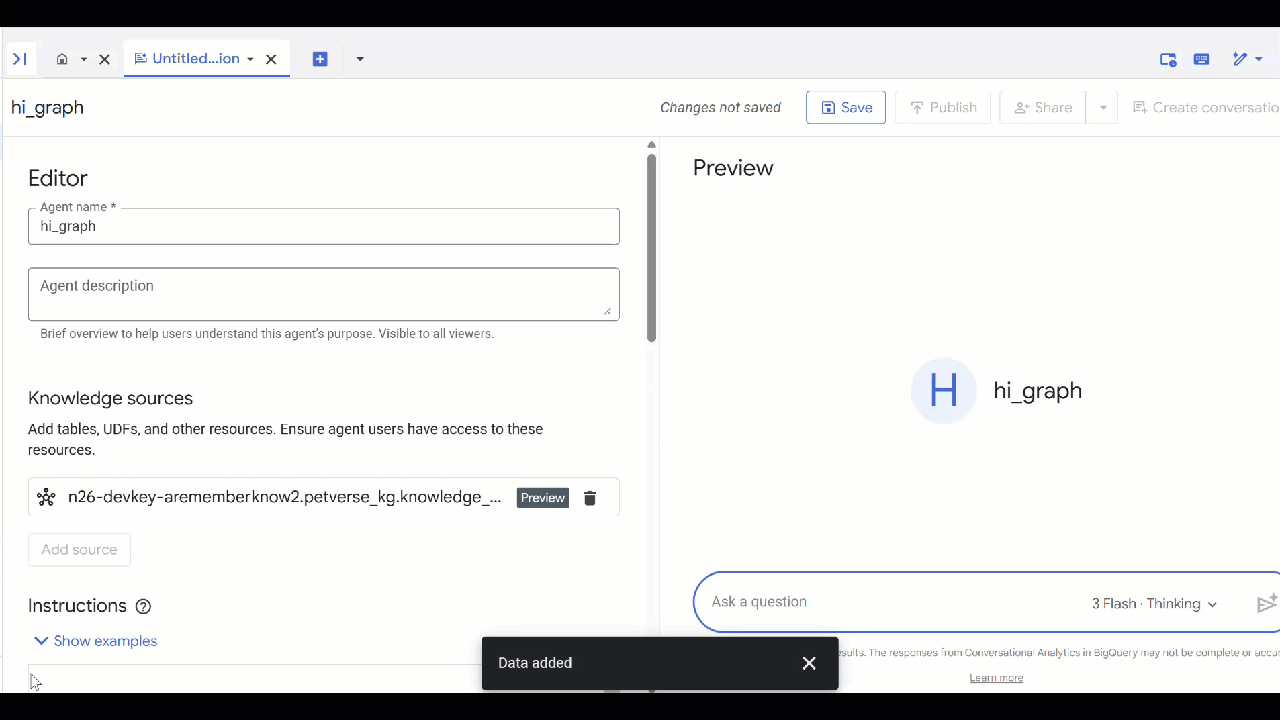
petverse. - Нажмите «Добавить источник» , а затем «График» .
- Выберите созданный вами граф
knowledge_graphи нажмите «Добавить» .
Теперь вы можете задать агенту вопрос и увидеть ответы и обоснование к ним. Вот несколько примеров вопросов, если вам нужно вдохновение. Создание модели мышления может занять немного больше времени, но, скорее всего, позволит построить более качественный GQL-запрос. Вы можете увидеть, что она строит, развернув Show Thinking .
- Найдите питомцев, которые едят похожую пищу, и которые дружат с животными, любящими поспать.
- Есть ли среди домашних животных те, у кого одно и то же хобби, любимая еда или игрушка? Перечислите пары и их общие интересы.
- Найдите питомцев одного вида или породы, но с совершенно разными увлечениями.
9. Уборка
Чтобы избежать дальнейших списаний средств с вашего аккаунта Google Cloud, удалите ресурсы, созданные в ходе этого практического занятия.
- Удалите кластер GKE:
gcloud container clusters delete petverse-cluster --region $REGION --quiet
- Удалите набор данных BigQuery (это приведет к удалению всех таблиц):
bq rm -r -f -d $PROJECT_ID:petverse_kg
- Удалите ресурсы очереди публикации/подписки:
gcloud pubsub subscriptions delete petverse-sub --quiet
gcloud pubsub topics delete petverse-topic --quiet
- Удалите репозиторий реестра артефактов:
gcloud artifacts repositories delete gke-cats-repo --location=$REGION --quiet
- Удалите корзину GCS, относящуюся к конкретному проекту:
gcloud storage buckets delete gs://$PROJECT_ID-petverse --quiet
10. Поздравляем!
Поздравляем! Вы успешно создали распределенный конвейер обработки графов знаний с использованием GKE и Gemini и выполнили запросы к нему с помощью графов свойств BigQuery.
Что вы узнали
- Как развернуть распределенные задания в GKE Autopilot .
- Как использовать Gemini для извлечения мультимодальных данных.
- Как использовать автоматическое встраивание данных в BigQuery .
- Как создавать и запрашивать данные из графов свойств в BigQuery.