
1. บทนำ
ในโค้ดแล็บนี้ คุณจะได้สร้างไปป์ไลน์การได้มาซึ่งความรู้แบบกระจายสำหรับ "Petverse" คุณจะประมวลผลชิ้นงานมัลติมีเดียที่ไม่มีโครงสร้าง (เสียง วิดีโอ รูปภาพ ข้อความ/CSV) จาก Bucket ของ Cloud Storage, แยกข้อมูลสำคัญเกี่ยวกับสัตว์เลี้ยง (อาหารโปรด งานอดิเรก) และสร้างกราฟความรู้ คุณจะปรับขนาดการประมวลผลไฟล์มัลติมีเดียโดยใช้การประมวลผลแบบหลายโมดัลของ Gemini ใน Google Kubernetes Engine (GKE) สุดท้าย คุณจะจัดเก็บข้อมูลนี้ใน BigQuery และใช้ฟีเจอร์กราฟพร็อพเพอร์ตี้ BigQuery ใหม่เพื่อวิเคราะห์ความสัมพันธ์
เราจะใช้ความสามารถของ Google Kubernetes Engine เพื่อสาธิตการประมวลผลข้อมูลปริมาณมากแบบขนาน
ทำไมต้องใช้กราฟความรู้
กราฟความรู้เหมาะกว่าฐานข้อมูลเชิงสัมพันธ์แบบดั้งเดิมในการแสดงและวิเคราะห์ความสัมพันธ์ที่ซับซ้อนระหว่างเอนทิตี
เราจะใช้ Gemini 2.5 Flash เพื่อวิเคราะห์ไฟล์รูปภาพ เสียง และวิดีโอ รวมถึงระบุข้อเท็จจริงเกี่ยวกับสัตว์เลี้ยงต่างๆ
สิ่งที่คุณต้องดำเนินการ
- สร้างและทำให้งานประมวลผลข้อมูลแบบกระจายใช้งานได้ใน GKE
- ใช้ Gemini เพื่อดึงข้อมูลเอนทิตีและความสัมพันธ์จากไฟล์มัลติมีเดีย
- จัดเก็บข้อมูลกราฟความรู้ใน BigQuery
- สร้างและค้นหากราฟเชิงคุณสมบัติใน BigQuery โดยใช้ Graph Query Language (GQL)
สิ่งที่คุณต้องมี
- เว็บเบราว์เซอร์ เช่น Chrome
- โปรเจ็กต์ Google Cloud ที่เปิดใช้การเรียกเก็บเงิน
- สิทธิ์ในโปรเจ็กต์ในการสร้างทรัพยากรและแก้ไขนโยบาย IAM
Codelab นี้มีไว้สำหรับนักพัฒนาซอฟต์แวร์ทุกระดับ รวมถึงผู้เริ่มต้น
ระยะเวลาโดยประมาณ: 45 นาที
ค่าใช้จ่าย: ทรัพยากรที่สร้างใน Codelab นี้ควรมีค่าใช้จ่ายน้อยกว่า $5
2. ก่อนเริ่มต้น
สร้างโปรเจ็กต์ Google Cloud
- ไปที่คอนโซล Google Cloud: https://console.cloud.google.com จากนั้นเลือกหรือสร้างโปรเจ็กต์ Google Cloud
- ⚠️ จดรหัสโปรเจ็กต์ไว้ คุณจะใช้รหัสนี้กับคำสั่งหลายคำสั่งในแล็บนี้
เริ่มต้น Cloud Shell
- เปิด Cloud Shell ในแท็บใหม่: https://shell.cloud.google.com/
- หากได้รับข้อความแจ้ง ให้คลิกให้สิทธิ์
- แทนที่
PROJECT_IDแล้ววางคำสั่งต่อไปนี้ลงในเทอร์มินัล
export PROJECT_ID="YOUR_PROJECT_ID"
gcloud config set project $PROJECT_ID
📝 หมายเหตุ โปรเจ็กต์จะแสดงเป็นสีเหลืองในบรรทัดคำสั่ง หากเซสชันรีสตาร์ท โปรดตรวจสอบว่าคุณได้เรียกใช้คำสั่งด้านบนอีกครั้งเพื่อตั้งค่ารหัสโปรเจ็กต์
เปิดใช้ API
เรียกใช้คำสั่งนี้เพื่อเปิดใช้ API ที่จำเป็นทั้งหมด
gcloud services enable \
aiplatform.googleapis.com \
bigquery.googleapis.com \
artifactregistry.googleapis.com \
container.googleapis.com \
cloudbuild.googleapis.com \
pubsub.googleapis.com
โคลนที่เก็บ
เรียกใช้คำสั่งต่อไปนี้เพื่อโคลนที่เก็บ
cd ~/
git clone --filter=blob:none --no-checkout https://github.com/GoogleCloudPlatform/devrel-demos.git
cd ~/devrel-demos
git sparse-checkout init --cone
git sparse-checkout set codelabs/gke-knowledge-graph
git checkout main
cd codelabs/gke-knowledge-graph/
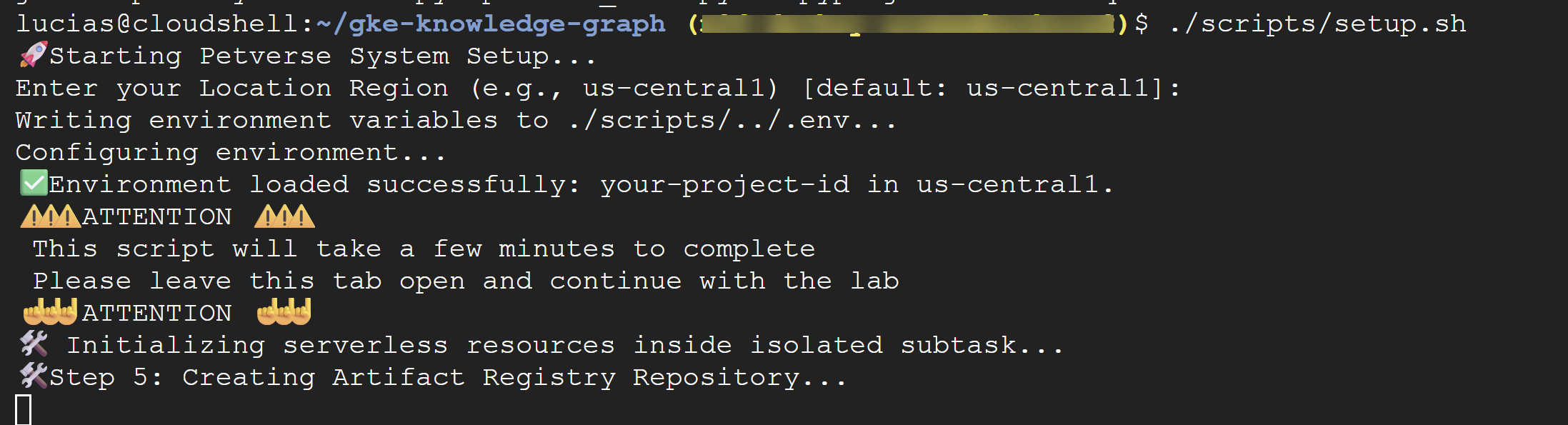
เรียกใช้สคริปต์การตั้งค่า
สคริปต์นี้จะกำหนดค่าแบ็กเอนด์โดยอัตโนมัติด้วยการดำเนินการต่อไปนี้
- การสร้างอิมเมจคอนเทนเนอร์และที่เก็บ Artifact Registry
- การสร้างชุดข้อมูล BigQuery
- การสร้างการเชื่อมต่อ BigQuery เพื่อเรียกใช้ฟังก์ชัน AI จาก Gemini จาก SQL
เรียกใช้คำสั่งต่อไปนี้ในเทอร์มินัล
./scripts/setup.sh
หากสคริปต์แจ้งให้คุณระบุรายละเอียดการกำหนดค่า ให้ใช้ค่าต่อไปนี้
- รหัสโปรเจ็กต์: ใช้รหัสที่คุณสร้างในขั้นตอนก่อนหน้า
- ภูมิภาค:
us-central1
⚠️ สำคัญ สคริปต์จะใช้เวลาสักครู่จึงจะเสร็จสมบูรณ์ โปรดเปิดหน้าต่างเทอร์มินัลนี้ไว้เพื่อดำเนินการต่อในเบื้องหลัง หากต้องการดำเนินการในขั้นตอนถัดไป ให้เปิดแท็บหรือหน้าต่างเทอร์มินัลใหม่เพื่อเรียกใช้คำสั่งถัดไป
3. ตั้งค่า Data Agent Kit
- เปิดใช้ Cloud Shell Editor ด้วยไอคอนดินสอที่มุมขวาบน
- ใน Cloud Shell Editor ให้คลิกไอคอนส่วนขยายในแถบด้านข้างซ้าย
- ค้นหา Google Cloud Data Agent Kit แล้วคลิกติดตั้งหากยังไม่ได้ติดตั้ง
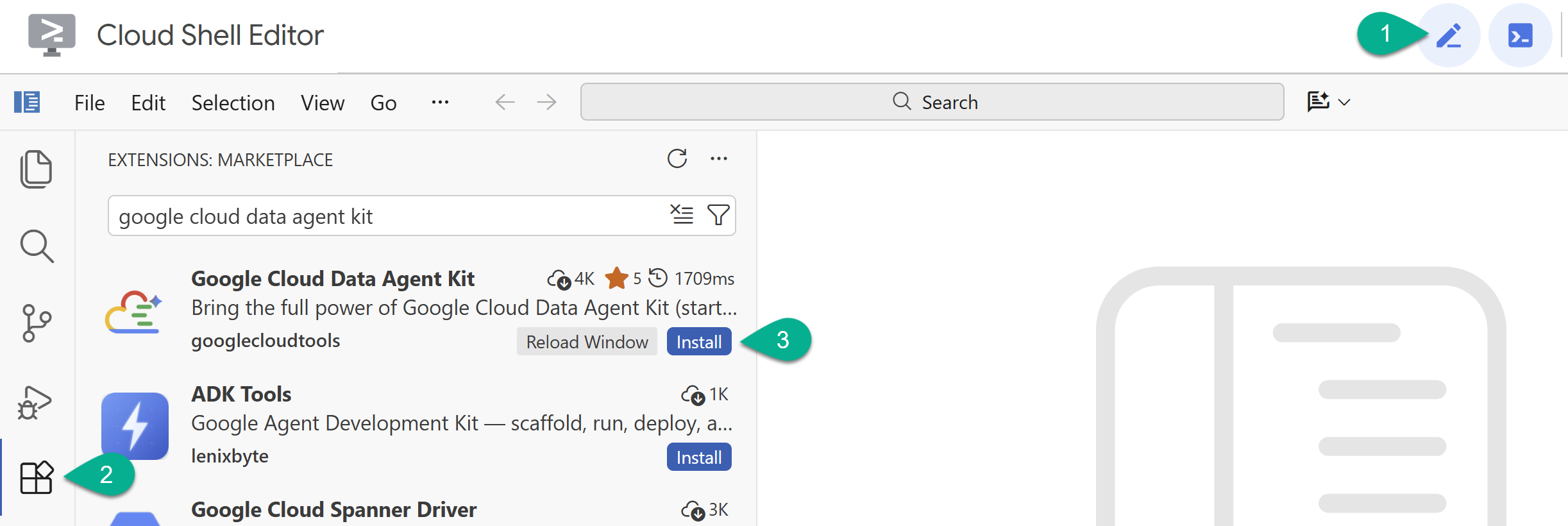
- ลงชื่อเข้าใช้บัญชี Google ด้วยส่วนขยาย
- ในสรุปการกำหนดค่า ให้ป้อนรหัสโปรเจ็กต์และ
us-central1เป็นภูมิภาค
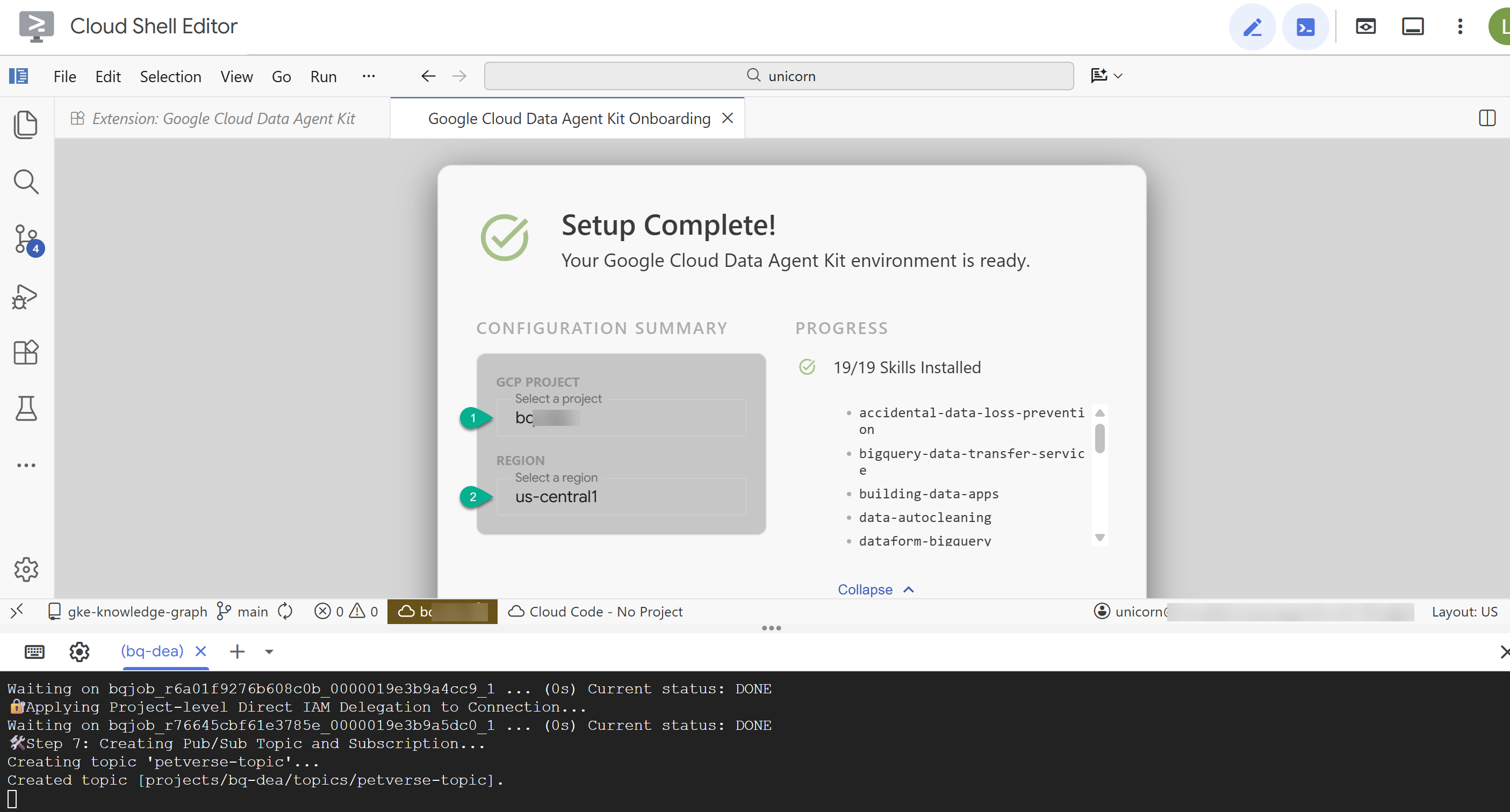
- คลิกกำหนดค่าเซิร์ฟเวอร์ MCP คุณไม่จำเป็นต้องทำการเปลี่ยนแปลงใดๆ ในหน้าต่างนี้ เพียงคลิกเริ่มต้นใช้งาน
- โหลดหน้าต่างซ้ำหากได้รับข้อความแจ้ง คุณปิดแท็บคู่มือเริ่มใช้งานฉบับย่อได้เลย
ตั้งค่าตารางใน BigQuery
- ในแถบด้านข้าง ให้กลับไปที่เครื่องมือสำรวจ หากโฟลเดอร์หน้าแรก (เช่น
/home/your_user_name/) ยังไม่ได้เปิด ให้คลิกเปิดโฟลเดอร์แล้วเลือก
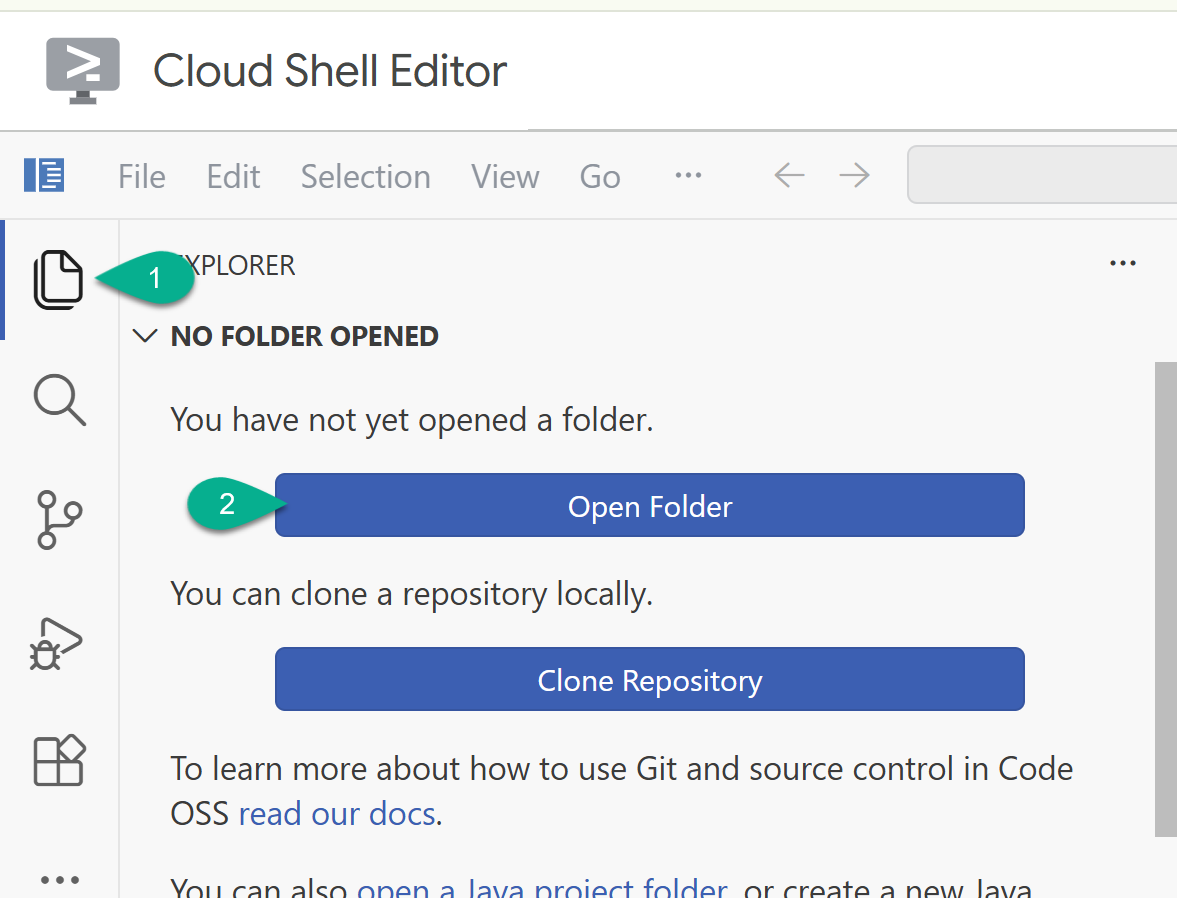
- ในหน้าต่าง Explorer ให้ค้นหาโฟลเดอร์ที่คุณโคลนจากที่เก็บ (
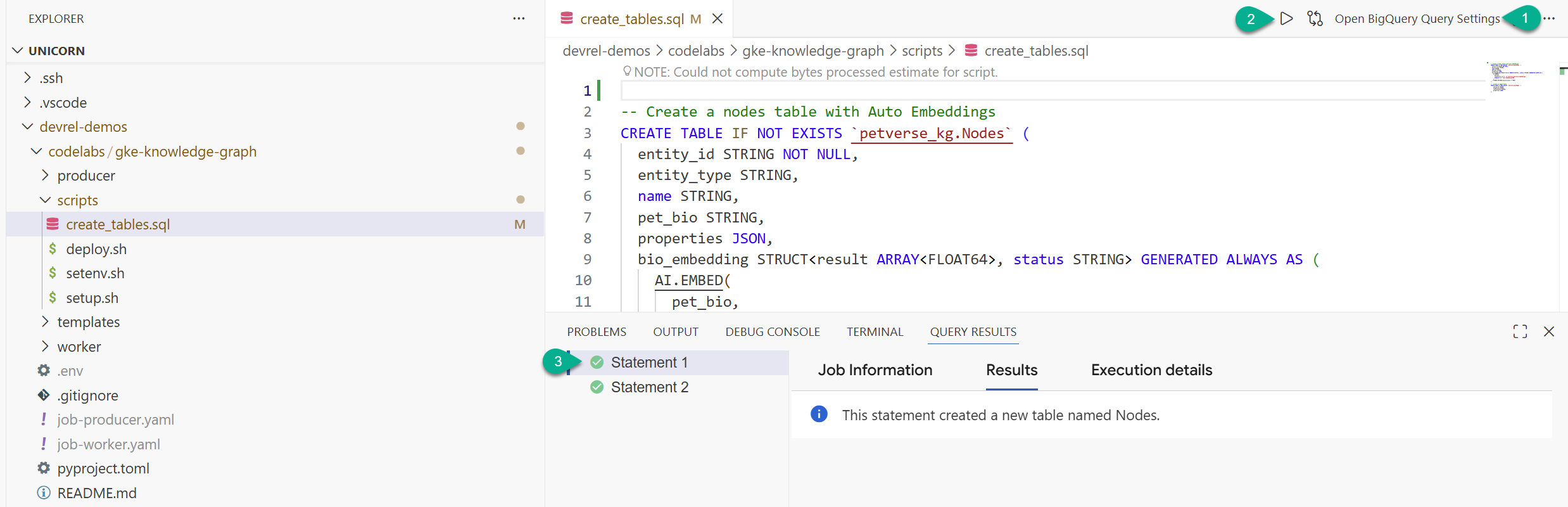
devrel-demos) คุณจะเห็นcreate_tables.sqlในส่วนcodelabs/gke-knowledge-graph/scriptsเปิดไฟล์นั้น - ที่ด้านขวาบน ให้คลิกเปิดการตั้งค่าการค้นหา
- เลือก BigQuery บันทึกและปิด
- คลิกเรียกใช้
คุณควรเห็นคำสั่ง 2 รายการที่ดำเนินการสำเร็จ ตอนนี้คุณได้สร้างตารางเพื่อจัดเก็บโหนดและขอบสำหรับกราฟความรู้แล้ว
คุณปิดแท็บ create_tables.sql และคอนโซลผลลัพธ์ได้
4. เริ่มต้นคลัสเตอร์ GKE
เราจะใช้ GKE Autopilot เพื่อเรียกใช้ชื่องานการประมวลผลข้อมูล Autopilot เป็นแนวทางปฏิบัติแนะนำเนื่องจากจะจัดการโครงสร้างพื้นฐานของคลัสเตอร์ให้คุณ
ตอนนี้สคริปต์การตั้งค่าควรจะเสร็จสิ้นแล้ว คุณควรเห็นข้อความแสดงความสำเร็จ: 🎉🦄 Setup successfully finished! 🎉🦄
วางคำสั่งนี้ในเทอร์มินัลเพื่อสร้างคลัสเตอร์
source scripts/setenv.sh
gcloud container clusters create-auto petverse-cluster \
--region=$REGION
🕓 การดำเนินการนี้จะใช้เวลาประมาณ 5 นาที
รับข้อมูลเข้าสู่ระบบเพื่อโต้ตอบกับคลัสเตอร์
source scripts/setenv.sh
gcloud container clusters get-credentials petverse-cluster --region $REGION
คุณควรเห็นเอาต์พุตนี้
Fetching cluster endpoint and auth data. kubeconfig entry generated for petverse-cluster.
5. กำหนดค่า Workload Identity
Workload Identity Federation สำหรับ GKE (ใช้การเข้าถึงทรัพยากรโดยตรง) ช่วยให้เวิร์กโหลด GKE เข้าถึงบริการ Google Cloud ได้อย่างปลอดภัยโดยไม่ต้องจัดการคีย์บัญชีบริการ
เรียกใช้ deploy.sh เพื่อทำสิ่งต่อไปนี้
- สร้างบัญชีบริการ Kubernetes
- มอบบทบาท IAM ที่จำเป็นให้กับผู้ใช้หลักของบัญชีบริการ Kubernetes โดยตรง
- เชื่อมโยงบัญชีบริการ IAM กับบัญชีบริการ Kubernetes
- ใส่คำอธิบายประกอบบัญชีบริการ Kubernetes เพื่อลิงก์ให้เสร็จสมบูรณ์
source scripts/setenv.sh
./scripts/deploy.sh
6. ทำให้งานประมวลผลที่แยกออกจากกันใช้งานได้
ในขั้นตอนนี้ คุณจะทำให้ Enqueuer (Producer) และเครื่องมือประมวลผล (Worker) ใช้งานได้ใน GKE
สถาปัตยกรรมที่แยกส่วนใหม่ของเราใช้ Google Cloud Pub/Sub เพื่อประมวลผลชิ้นงานแบบไม่พร้อมกัน
- Producer จะสแกน GCS และจัดคิวเส้นทางไฟล์ทั้งหมดลงในคิว Pub/Sub
- กลุ่มWorker จะปรับขนาดขึ้นใน GKE โดยจะดึงงานแบบขนานแบบไดนามิก ประมวลผลผ่าน Gemini และเขียนไปยัง BigQuery
setup.sh สคริปต์ได้สร้างและพุชทั้งอิมเมจคอนเทนเนอร์ Producer และ Worker คิวหัวข้อ Pub/Sub และสร้างไฟล์ Manifest การติดตั้งใช้งาน GKE แบบไดนามิกแล้ว: job-producer.yaml และ job-worker.yaml
- ใช้ Producer Job เพื่อสแกนที่เก็บข้อมูล Bucket และจัดคิวชิ้นงานทั้งหมด
kubectl apply -f job-producer.yaml
งานนี้จะทำงานและเสร็จสิ้นอย่างรวดเร็วเนื่องจากจะจัดคิวเฉพาะข้อมูลเมตา
- ทำให้งาน Worker ที่กำหนดค่าให้เรียกใช้ Worker แบบขนาน 6 รายการใช้งานได้เพื่อระบายคิว
kubectl apply -f job-worker.yaml
GKE Autopilot จะตรวจหาพ็อดที่รอดำเนินการโดยอัตโนมัติ เพิ่มทรัพยากรโหนดการประมวลผลแบบไดนามิก และเรียกใช้ Worker แบบขนานเพื่อประมวลผลเสียง วิดีโอ รูปภาพ และ CSV ที่อยู่ในคิว
7. ยืนยันผลลัพธ์
- วิธีตรวจสอบสถานะของงาน
kubectl get jobs
รอจนกว่าทั้ง petverse-producer-job และ petverse-worker-job จะแสดงว่าเสร็จสมบูรณ์
🕓 การดำเนินการนี้จะใช้เวลาประมาณ 10 นาที คุณดูความคืบหน้าได้ด้วยคำสั่งด้านล่าง
- ตรวจสอบบันทึกของ Producer เพื่อยืนยันว่าได้จัดคิวไฟล์เรียบร้อยแล้ว
cd ~/devrel-demos/codelabs/gke-knowledge-graph
source scripts/setenv.sh
kubectl logs -l app=petverse-producer --tail=50
- ดูการประมวลผลไฟล์จากคิวของ Worker ที่ทำงานแบบคู่ขนาน
kubectl logs -l app=petverse-worker --tail=50
(ฟีเจอร์ Worker มีการหมดเวลาเนื่องจากไม่มีการใช้งาน 60 วินาที และจะปิดตัวลงโดยอัตโนมัติและล้างข้อมูลเมื่อคิว Pub/Sub ว่าง)
ยืนยันข้อมูลใน BigQuery
- ไปที่ BigQuery Studio คุณจะเห็นตาราง 2 ตารางที่สร้างขึ้น ได้แก่ petverse_kg.Nodes และ petverse_kg.Edges
- หากต้องการดูเนื้อหาของตาราง ให้ดับเบิลคลิกชื่อตาราง แล้วคลิกแสดงตัวอย่าง
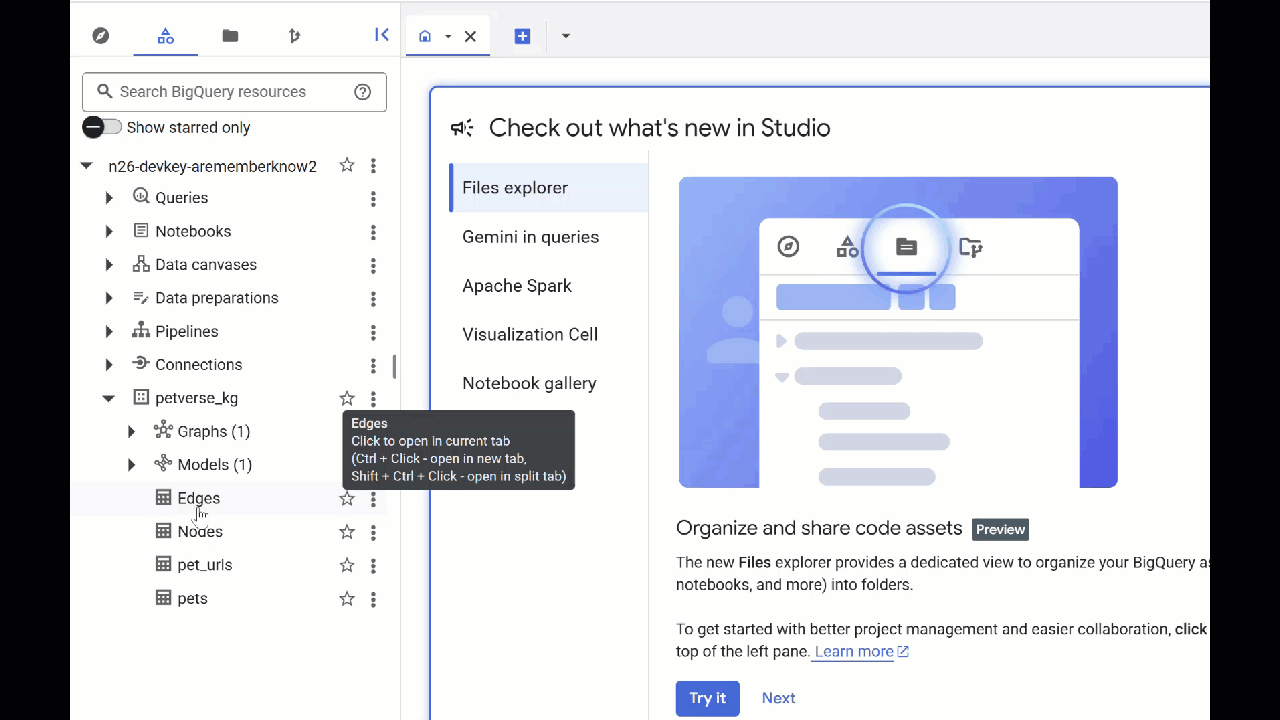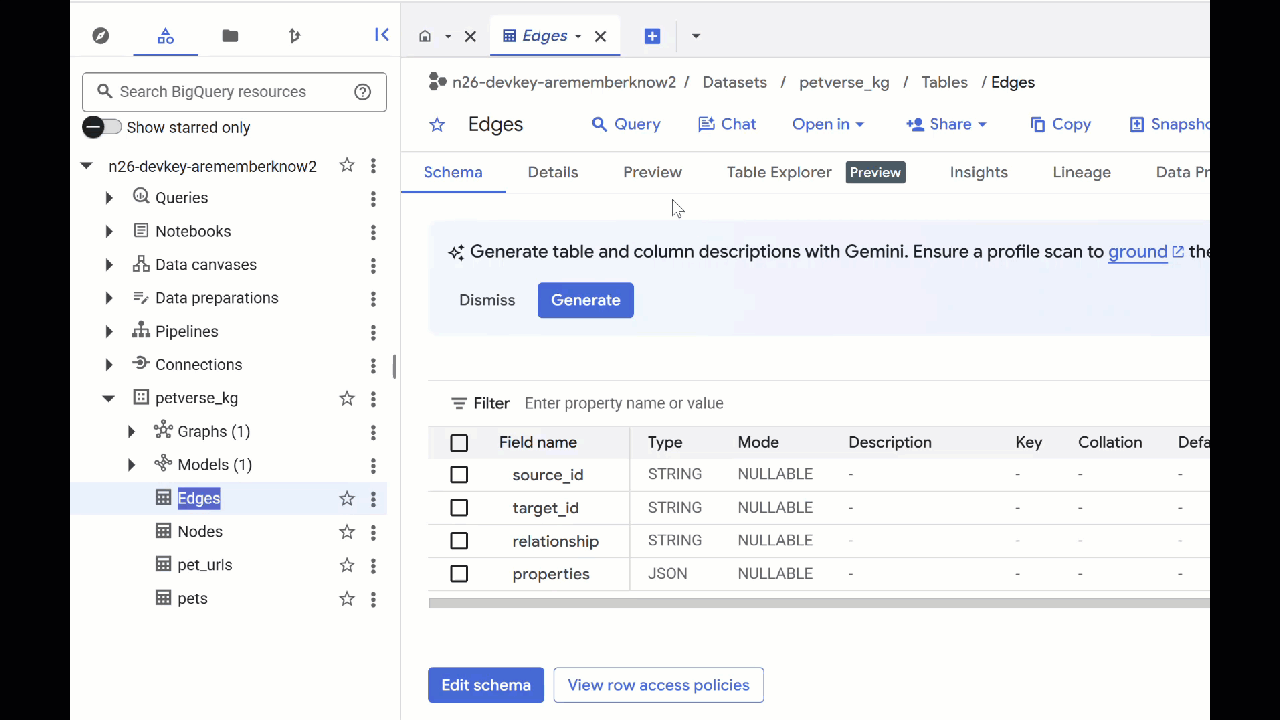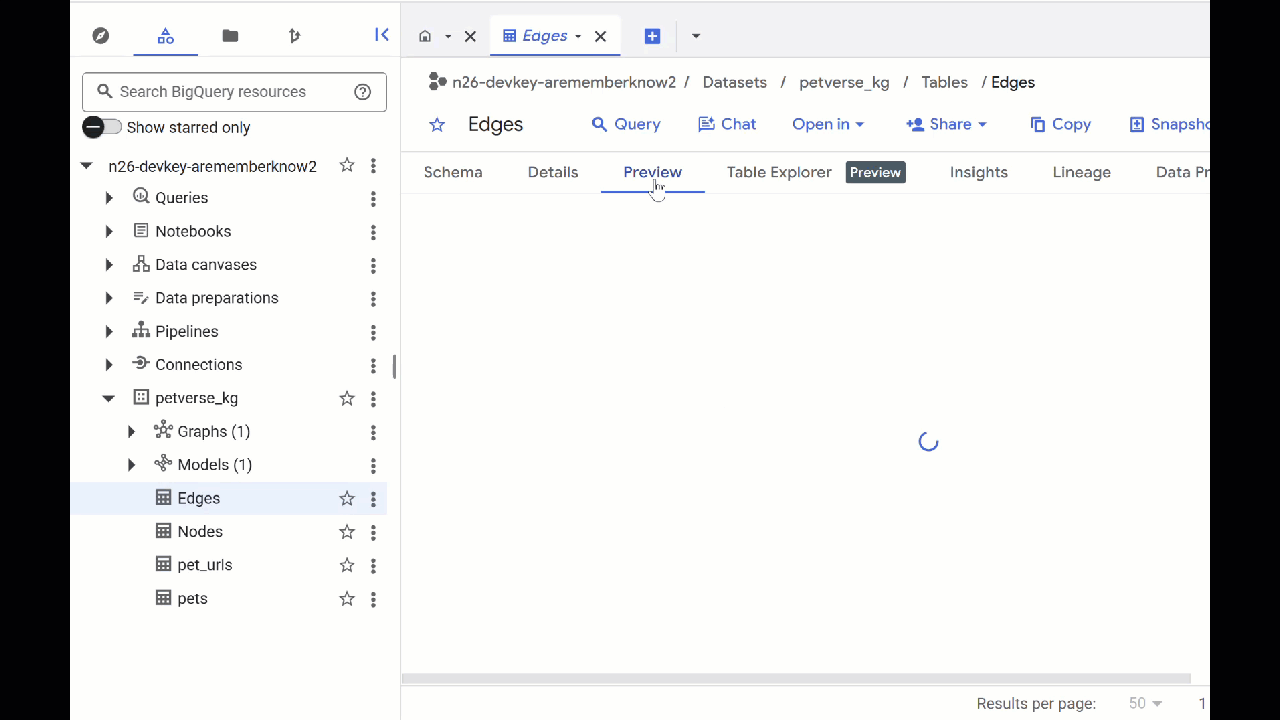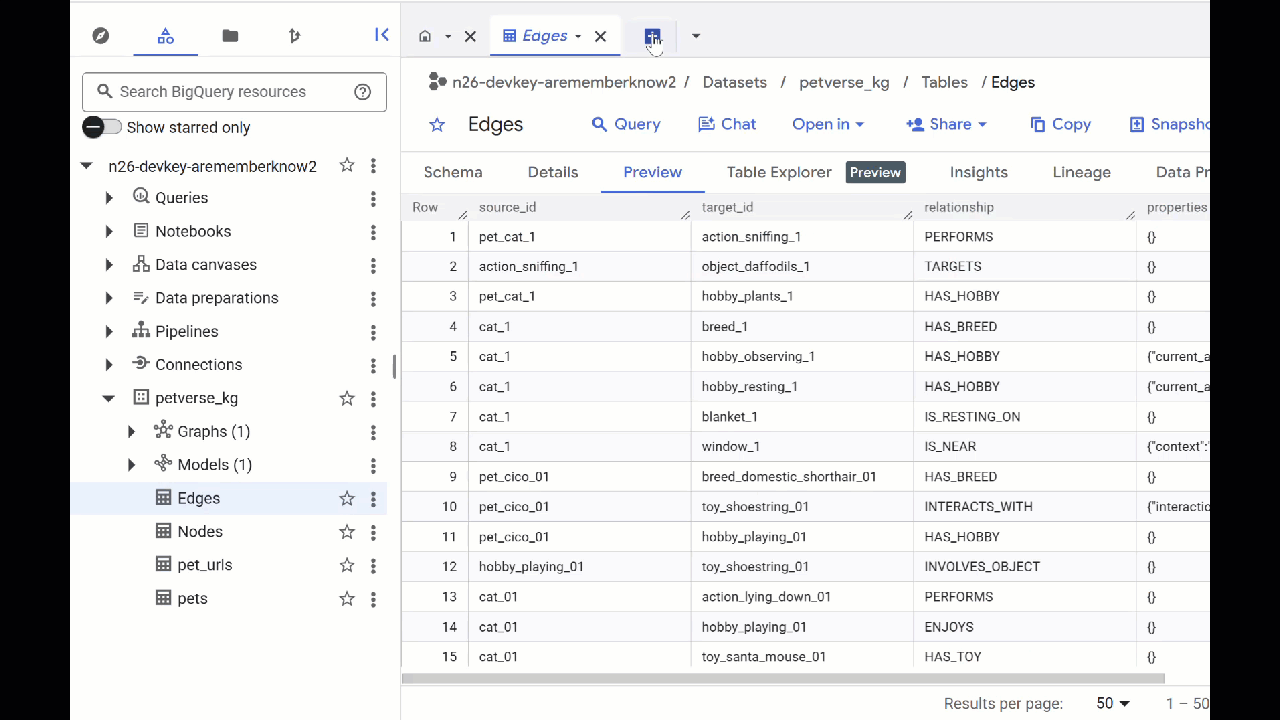
คุณจะเห็นว่าตารางโหนดมีข้อมูลเกี่ยวกับเอนทิตีที่ Gemini เลือกในเสียง วิดีโอ และรูปภาพ ตารางขอบมีข้อมูลความสัมพันธ์ระหว่างโหนด เช่น หากคุณฟังเสียงของแมวที่ชื่อ SQL คุณจะรู้ว่ามันชอบเล่นเชือกผูกรองเท้าและชอบกินปลาอบแห้ง
- ใช้ปุ่ม + เพื่อสร้างคำค้นหาใหม่ วางคำสั่งต่อไปนี้ แล้วคลิกเรียกใช้
SELECT n.name, n.entity_id, e.relationship, e.target_id
FROM
`petverse_kg.Nodes` n
JOIN
`petverse_kg.Edges` e
ON n.entity_id = e.source_id
WHERE n.name = 'SQL'
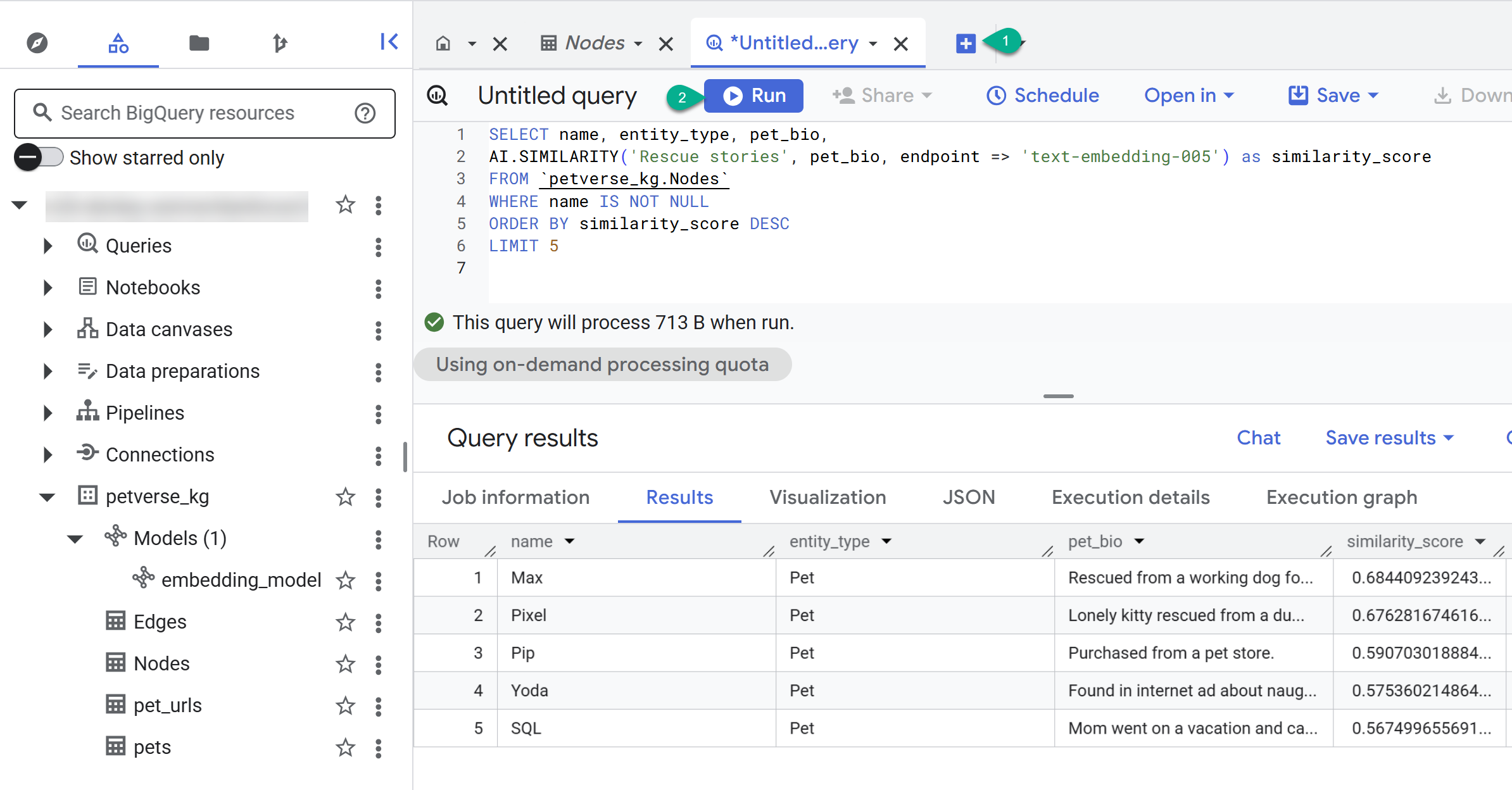
- ใช้ปุ่ม + เพื่อสร้างคำค้นหาใหม่ วางคำสั่งต่อไปนี้ แล้วคลิกเรียกใช้
SELECT name, entity_type, pet_bio,
AI.SIMILARITY('Pets who like to relax', pet_bio, endpoint => 'text-embedding-005') as similarity_score
FROM `petverse_kg.Nodes`
WHERE name IS NOT NULL
ORDER BY similarity_score DESC
LIMIT 5
คุณควรเห็นโหนดสำหรับสัตว์เลี้ยงที่ชอบพักผ่อน คำค้นหานี้ทำการค้นหาเชิงความหมายโดยใช้ฟังก์ชัน AI AI.SIMILARITY เพื่อค้นหาสัตว์เลี้ยงที่มีประวัติคล้ายกับข้อความค้นหามากที่สุด
สร้างกราฟพร็อพเพอร์ตี้
ตอนนี้เรามีโหนดและขอบใน BigQuery แล้ว เราจึงสร้างกราฟเชิงคุณสมบัติเพื่อค้นหาความสัมพันธ์ได้อย่างง่ายดาย
สร้างกราฟ
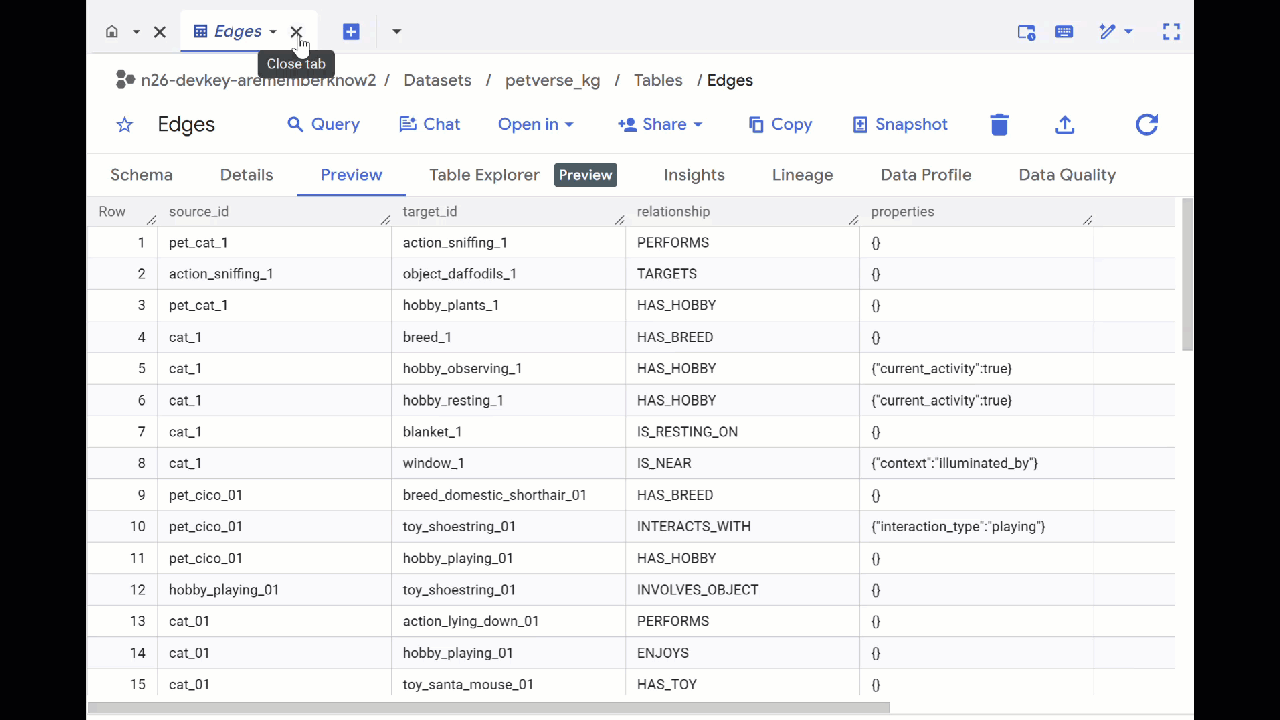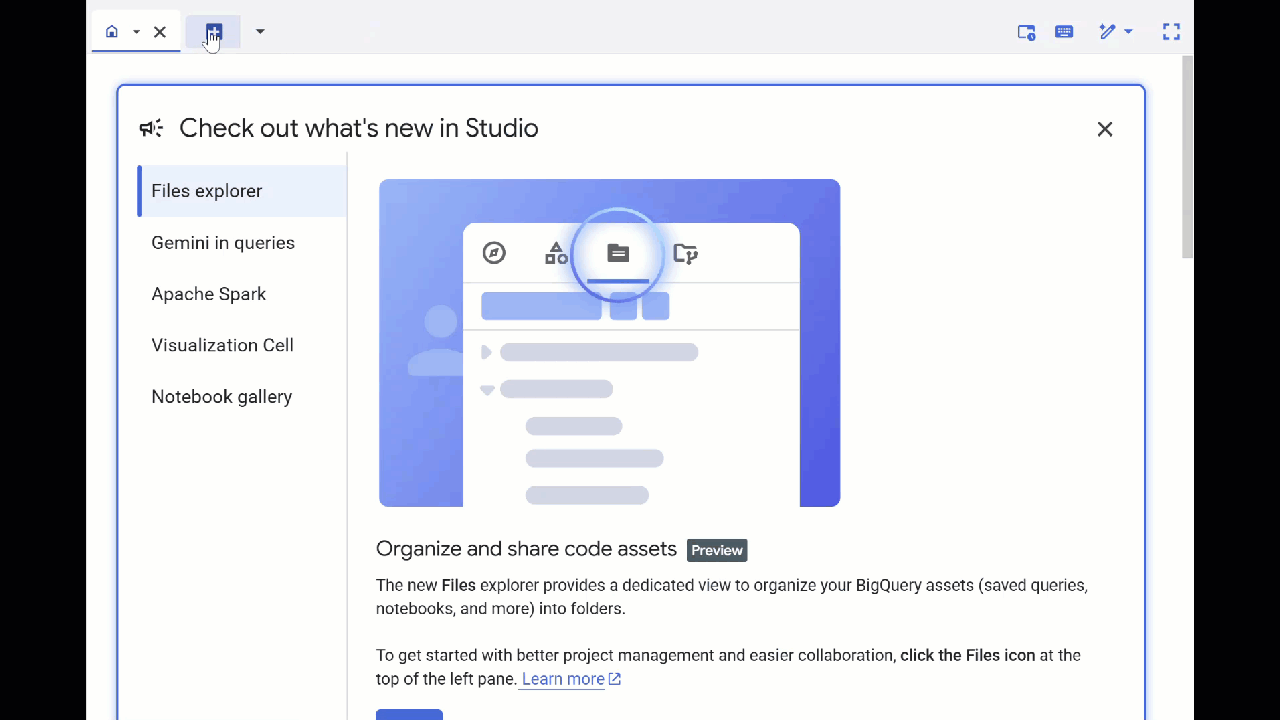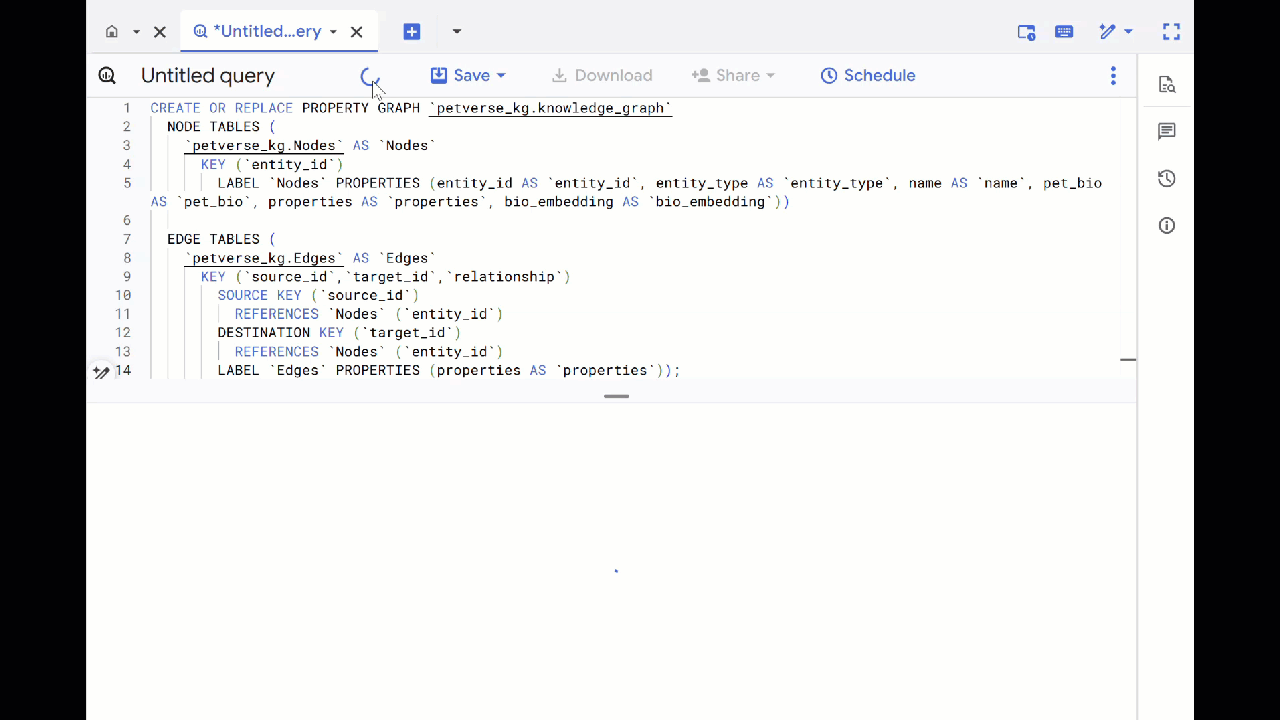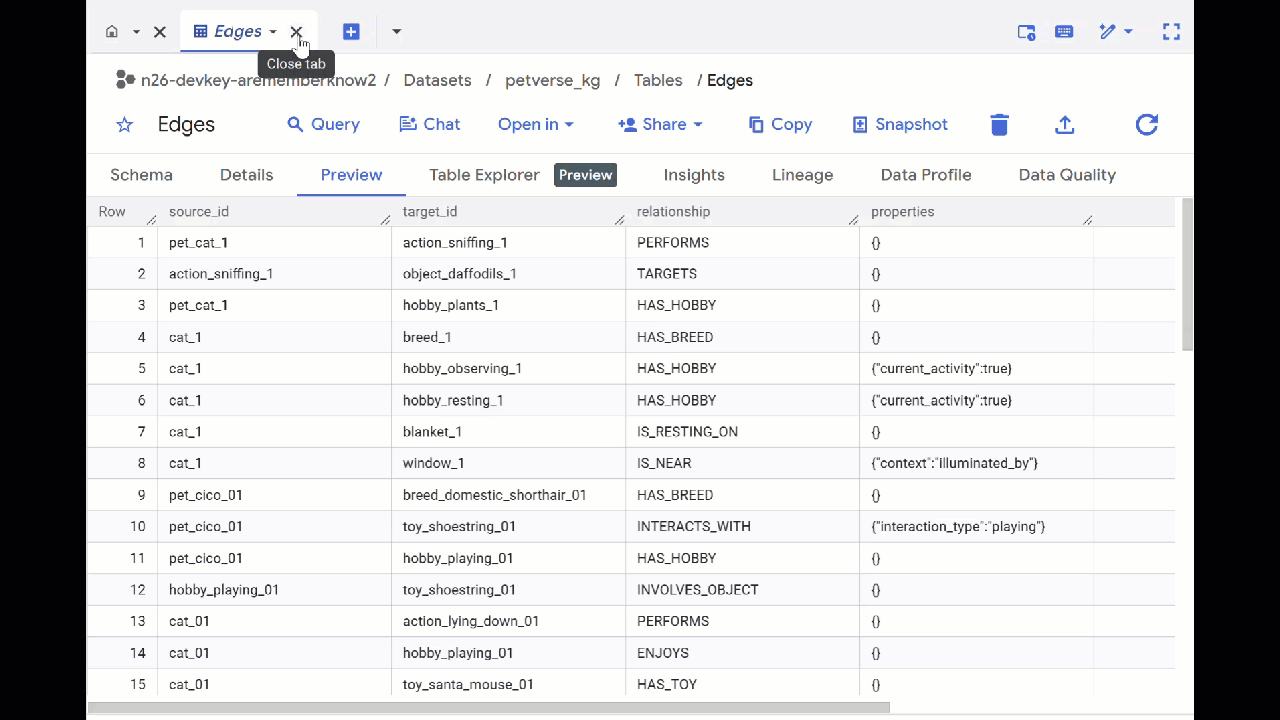
- เขียนทับการค้นหาก่อนหน้าและเรียกใช้ DDL ต่อไปนี้เพื่อสร้างกราฟพร็อพเพอร์ตี้
CREATE OR REPLACE PROPERTY GRAPH `petverse_kg.knowledge_graph`
NODE TABLES (
`petverse_kg.Nodes` AS `Nodes`
KEY (`entity_id`)
LABEL `Nodes` PROPERTIES (entity_id AS `entity_id`, entity_type AS `entity_type`, name AS `name`, pet_bio AS `pet_bio`, properties AS `properties`, bio_embedding AS `bio_embedding`))
EDGE TABLES (
`petverse_kg.Edges` AS `Edges`
KEY (`source_id`,`target_id`,`relationship`)
SOURCE KEY (`source_id`)
REFERENCES `Nodes` (`entity_id`)
DESTINATION KEY (`target_id`)
REFERENCES `Nodes` (`entity_id`)
LABEL `Edges` PROPERTIES (properties AS `properties`));
- คลิกไปที่กราฟ คุณจะเห็นการแสดงภาพกราฟที่มีโหนดที่มีขอบไปยังตัวมันเอง กรณีนี้เป็นสิ่งที่คาดว่าจะเกิดอยู่แล้ว
ค้นหากราฟ
- คุณปิดคำค้นหาก่อนหน้าทั้งหมดและเปิดคำค้นหาใหม่ที่ว่างเปล่าได้ด้วยปุ่ม +
- ใช้ GQL เพื่อค้นหาสัตว์เลี้ยงที่เกี่ยวข้องกับสัตว์เลี้ยงตัวอื่นๆ ผ่านความสนใจที่แชร์ (เช่น งานอดิเรก อาหารโปรด หรือของเล่น) การค้นหาแบบหลายช่วงนี้จะจับคู่สัตว์เลี้ยง 2 ตัวที่แตกต่างกันซึ่งเชื่อมต่อกับโหนดเดียวกัน
GRAPH `petverse_kg.knowledge_graph`
MATCH p = (pet1:Nodes)-[e1]->(interest:Nodes)<-[e2]-(pet2:Nodes)
WHERE pet1.entity_id != pet2.entity_id
AND (LOWER(pet1.entity_type) = 'pet' AND LOWER(pet2.entity_type) = 'pet')
AND LOWER(interest.entity_type) IN ('hobby', 'action', 'activity', 'food', 'toy')
RETURN TO_JSON(p) as res
LIMIT 100
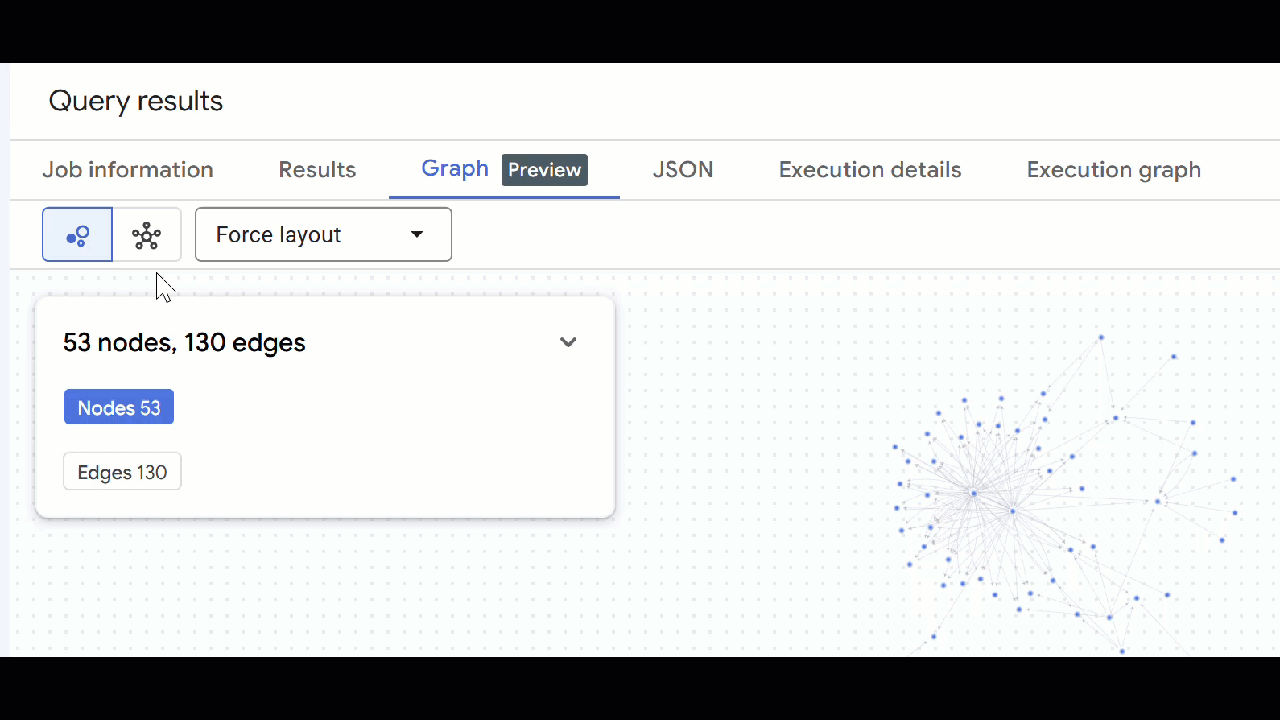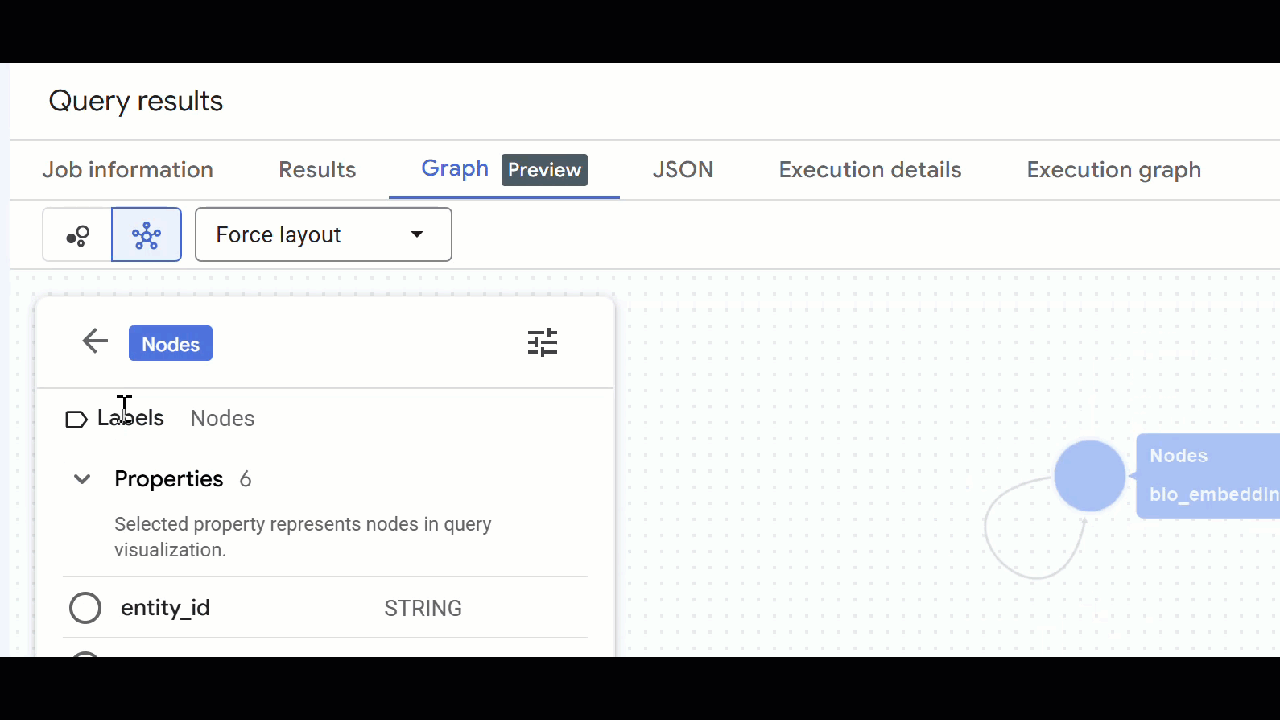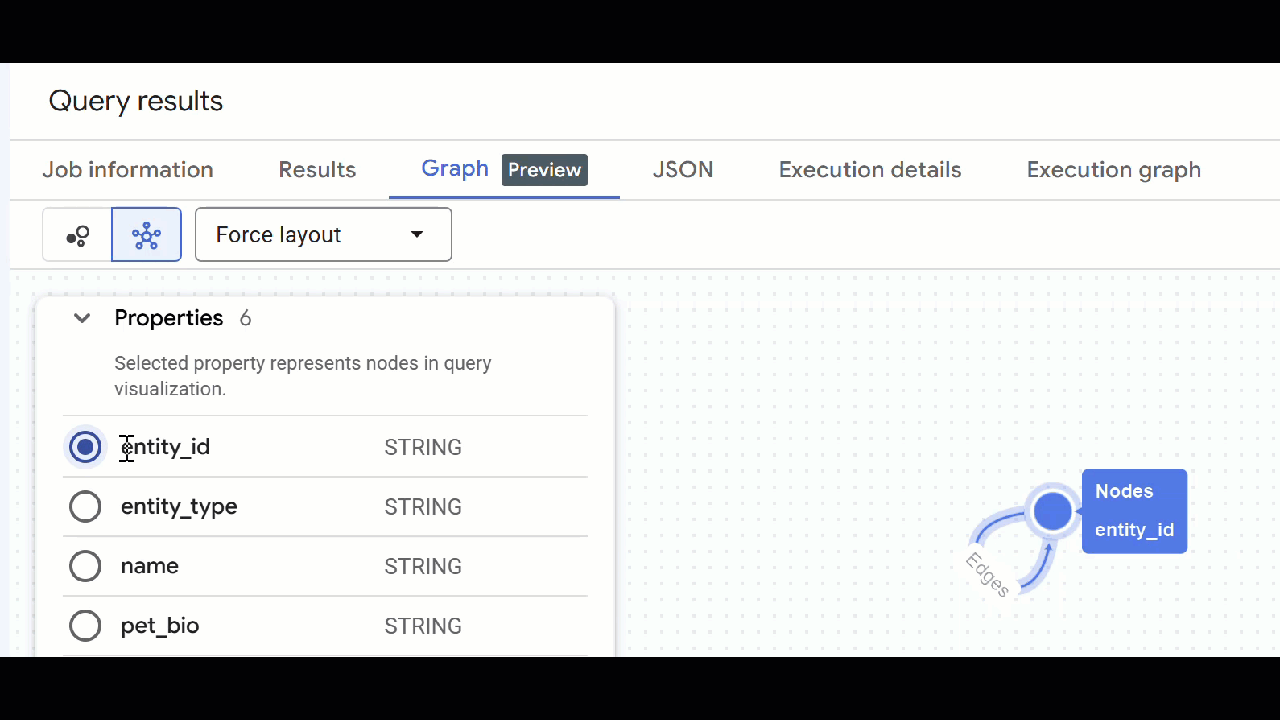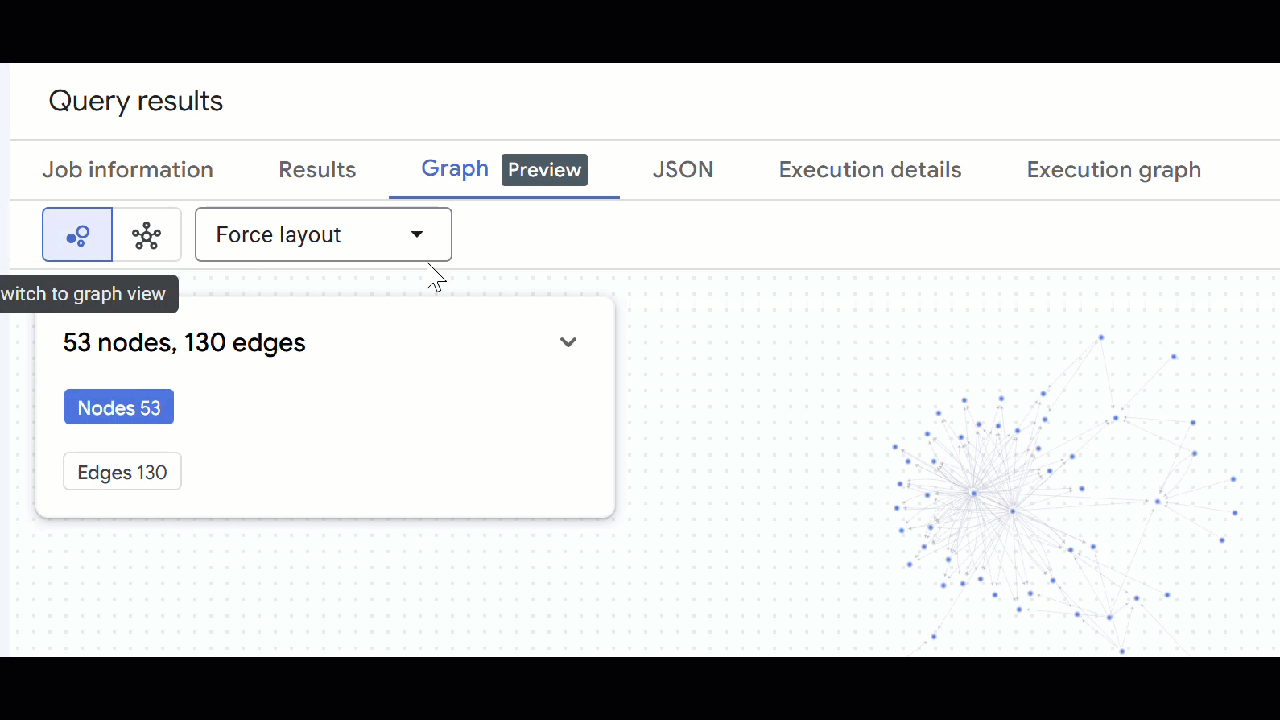
- คุณควรเห็นภาพกราฟ คุณคลิกโหนดเพื่อดูพร็อพเพอร์ตี้ของโหนดและขอบได้
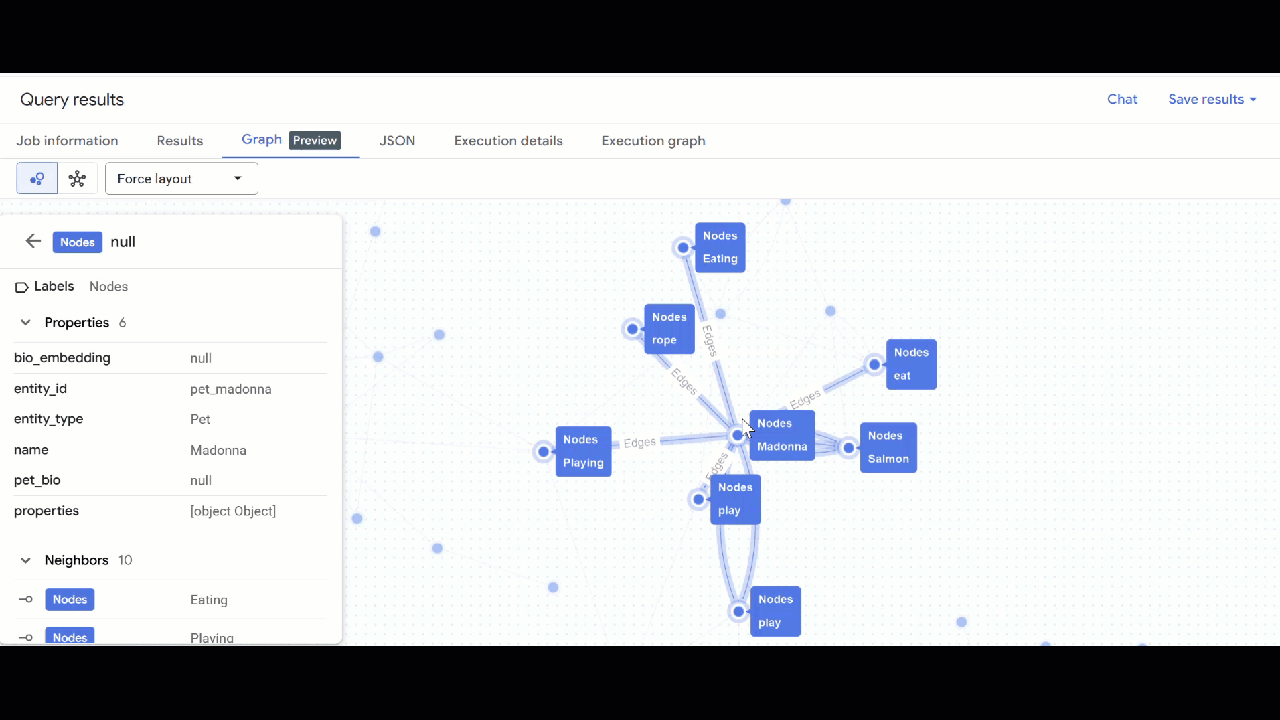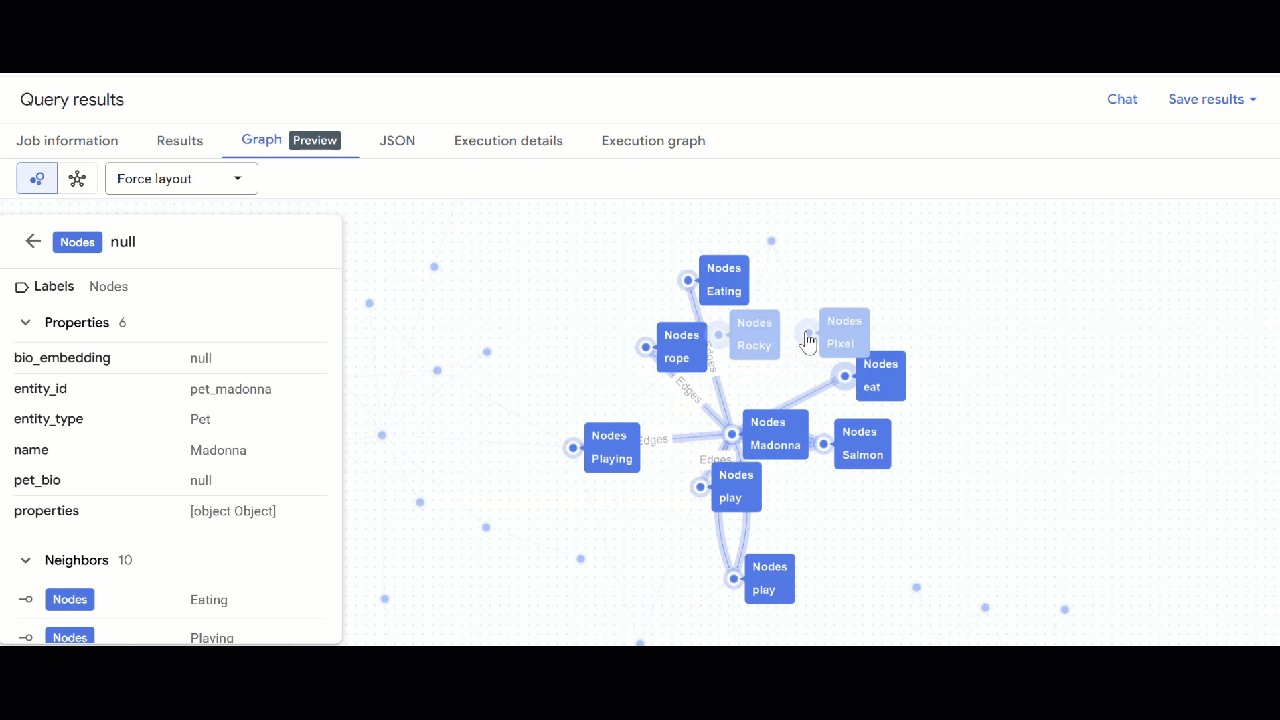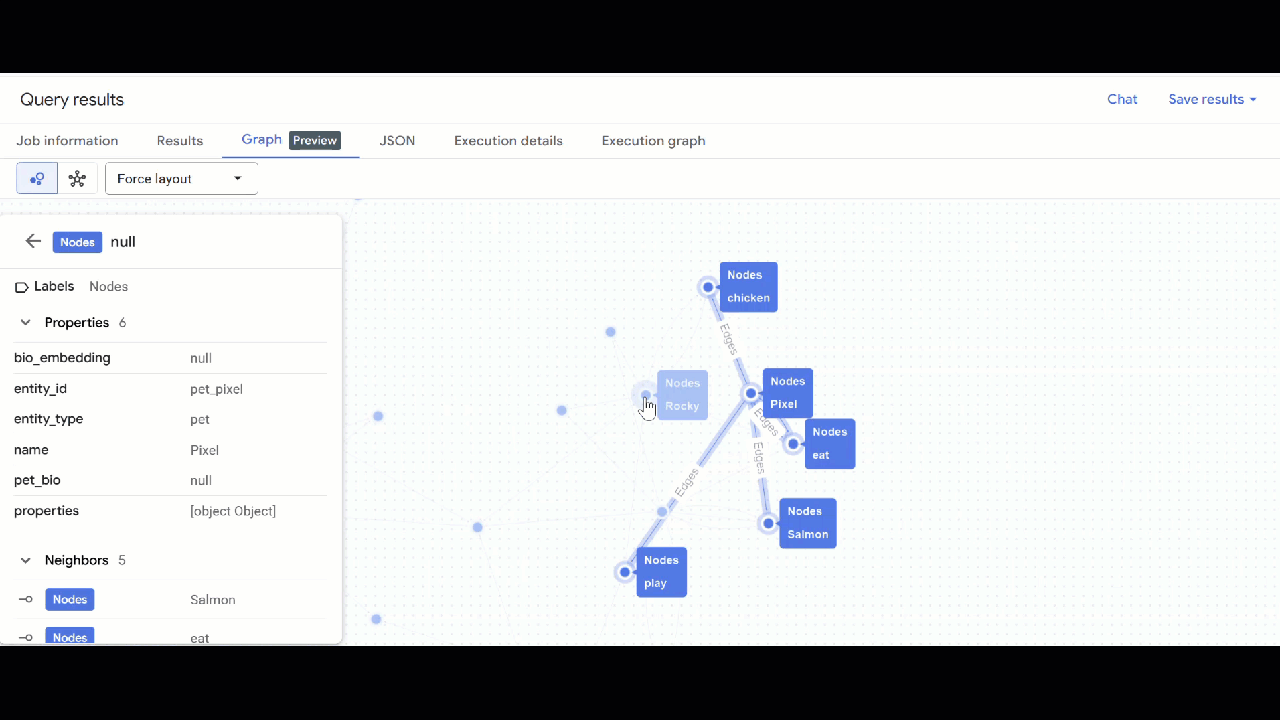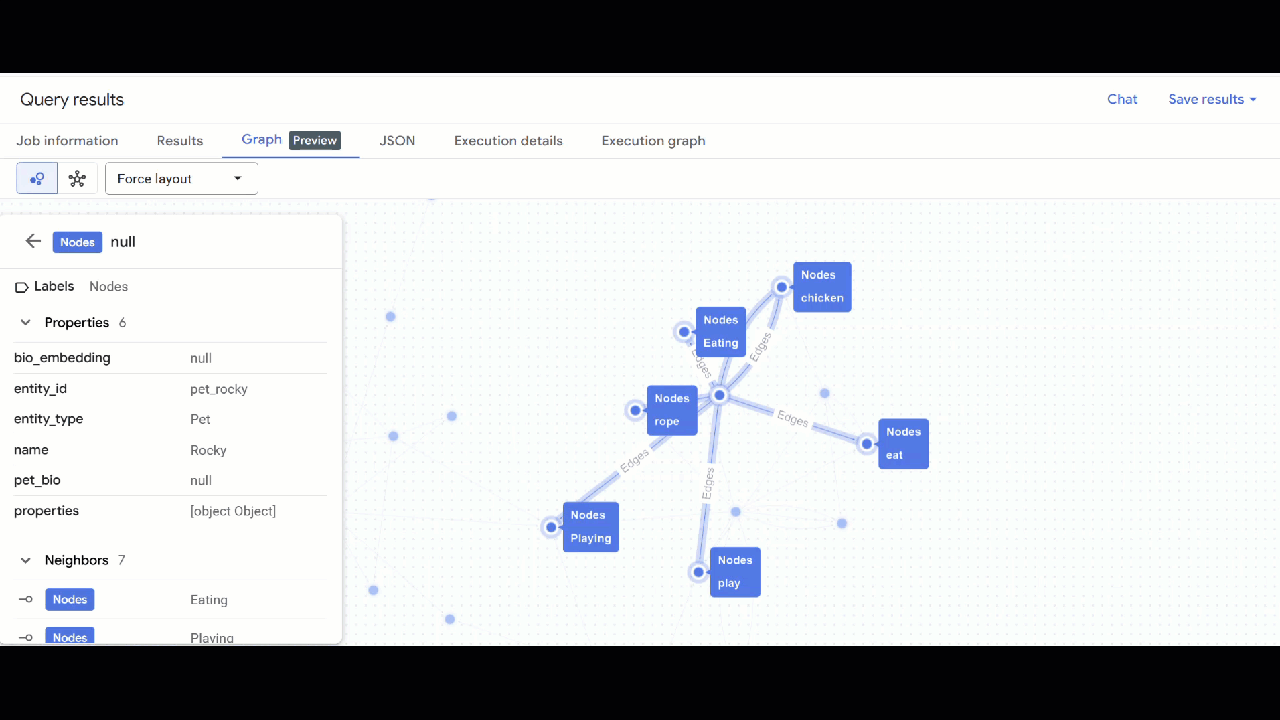
🕵️ เคล็ดลับ: คุณปรับค่าที่แสดงโดยโหนดได้โดยคลิกเปลี่ยนเป็นมุมมองสคีมา
- คุณปิดแท็บการค้นหาที่เปิดอยู่ทั้งหมดได้
8. แชทกับกราฟ
- คุณจะเห็นเมนูแบบเลื่อนลงข้างเครื่องหมาย + เลือกการสนทนา
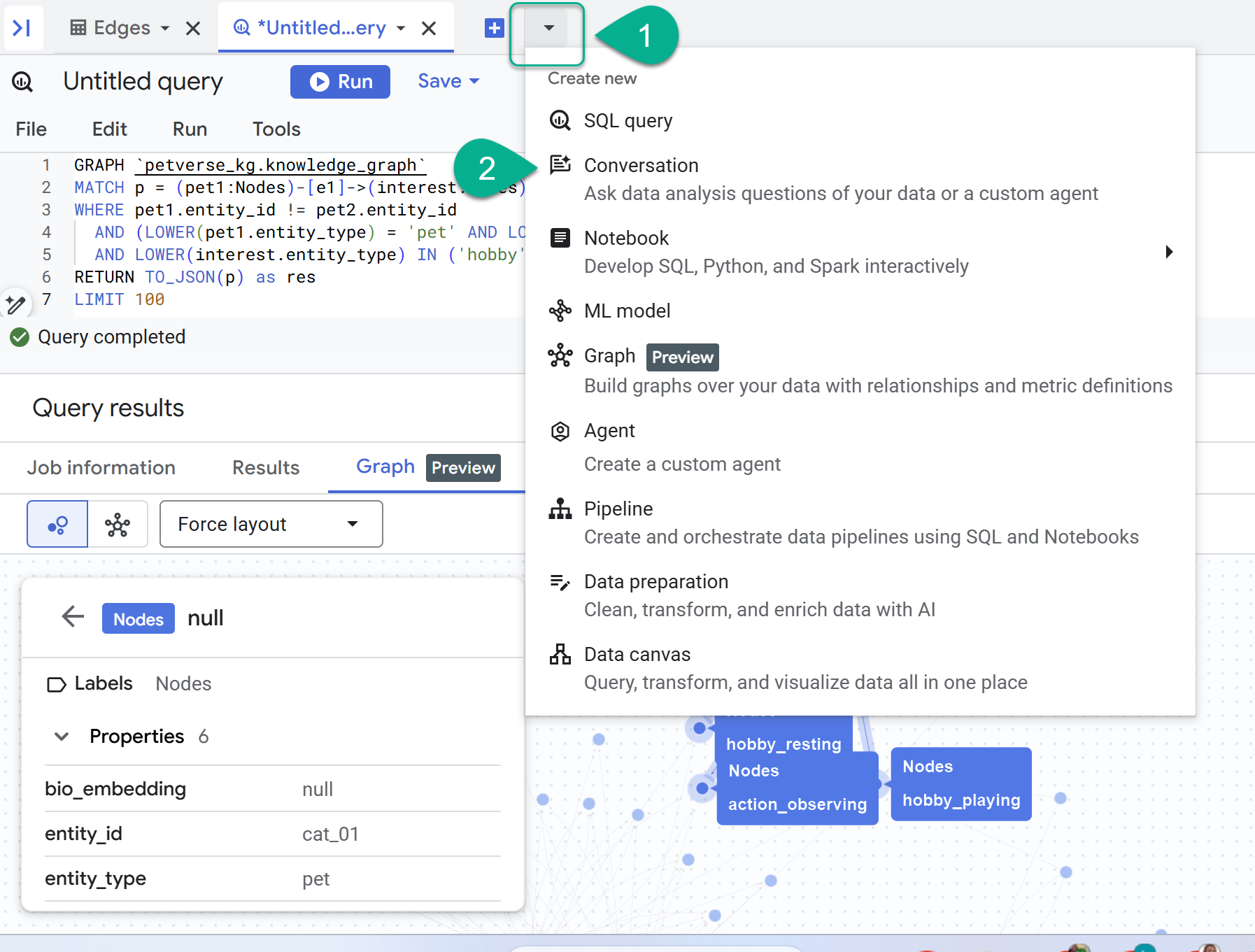
- ระบบจะแจ้งให้คุณเปิดใช้ Data Analytics API กับ Gemini เปิดใช้ทั้ง 2 API เมื่อการดำเนินการเสร็จสิ้น ให้รีเฟรชหน้าต่างหรือสร้างการสนทนาใหม่เพื่อดูตัวแทน
- คลิกตัวแทนใหม่
- ตั้งชื่อเอเจนต์ เช่น
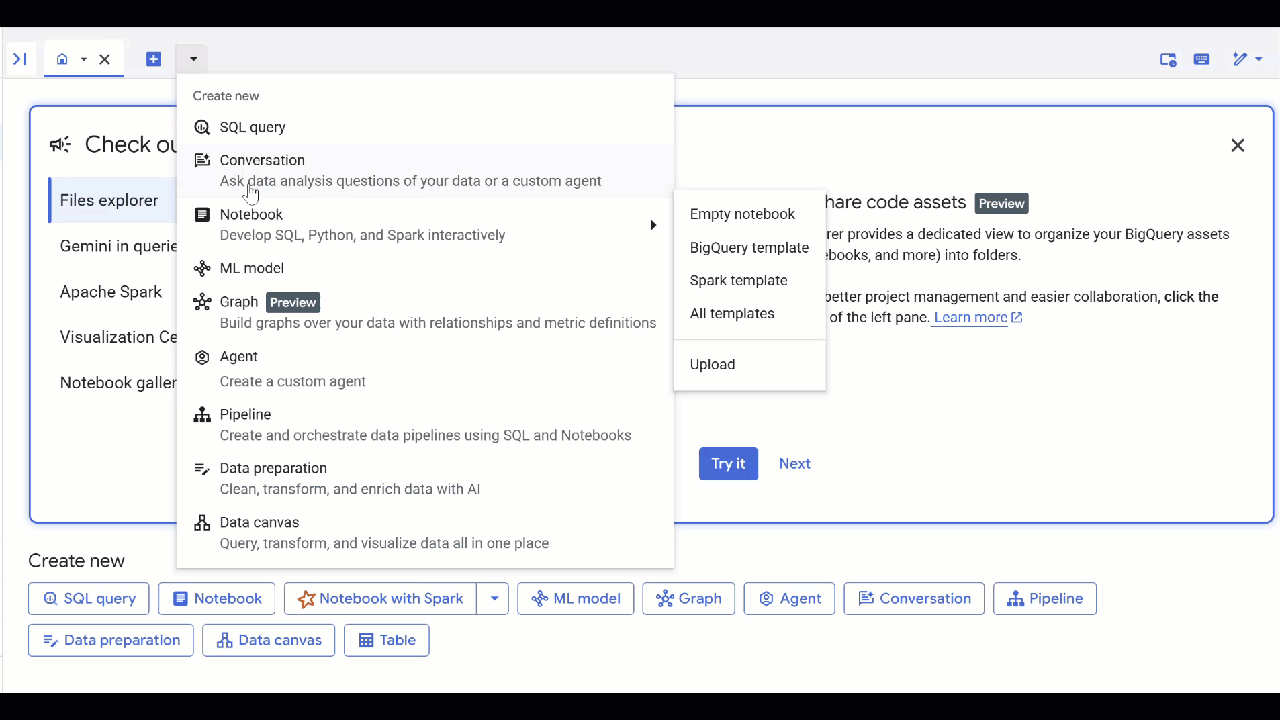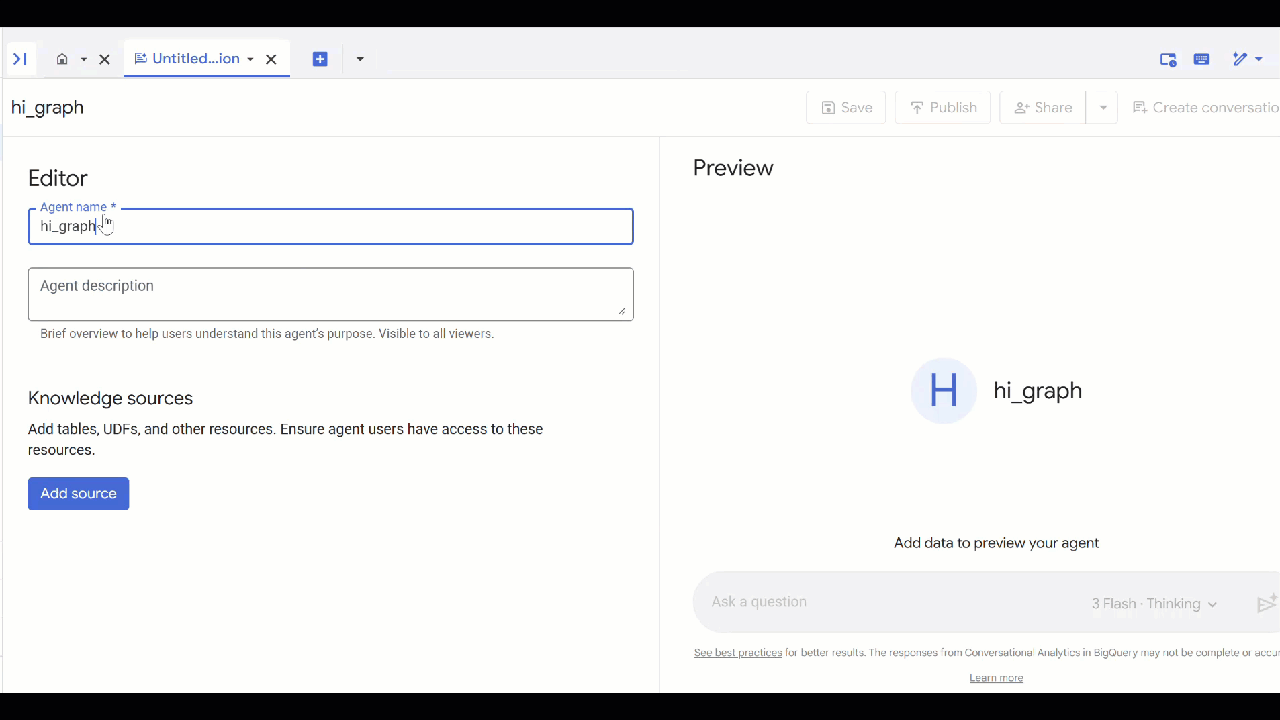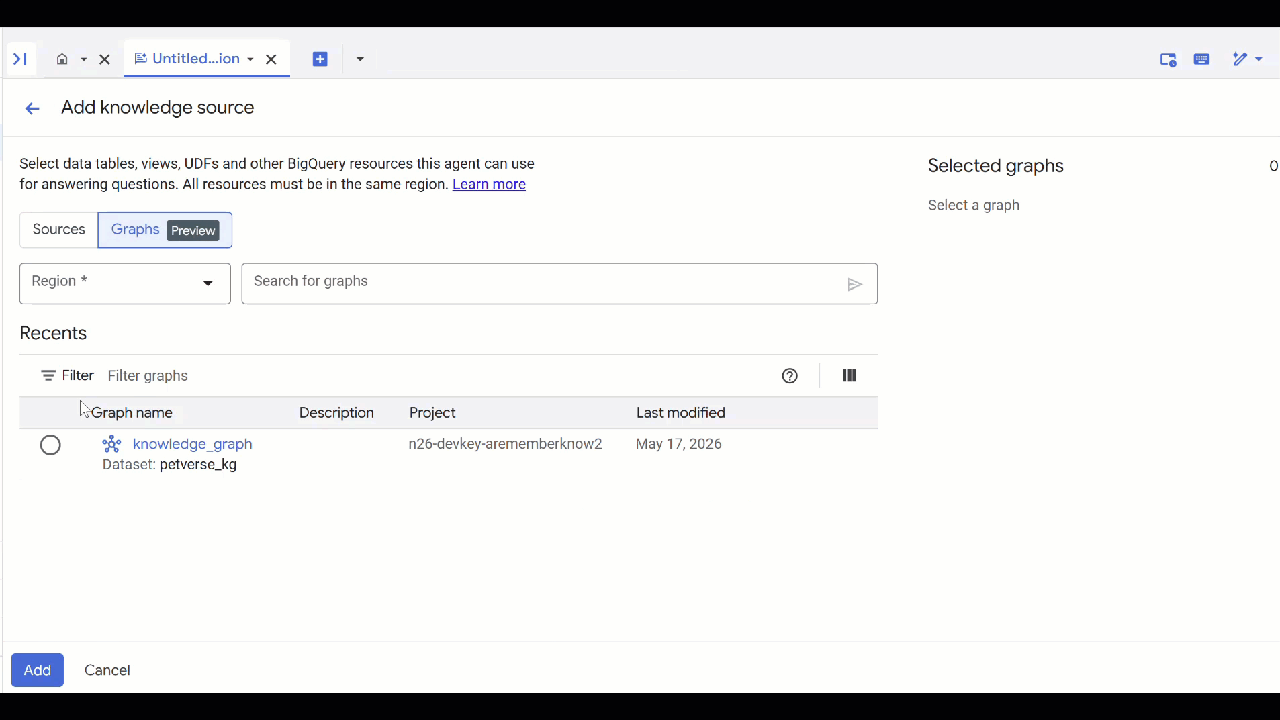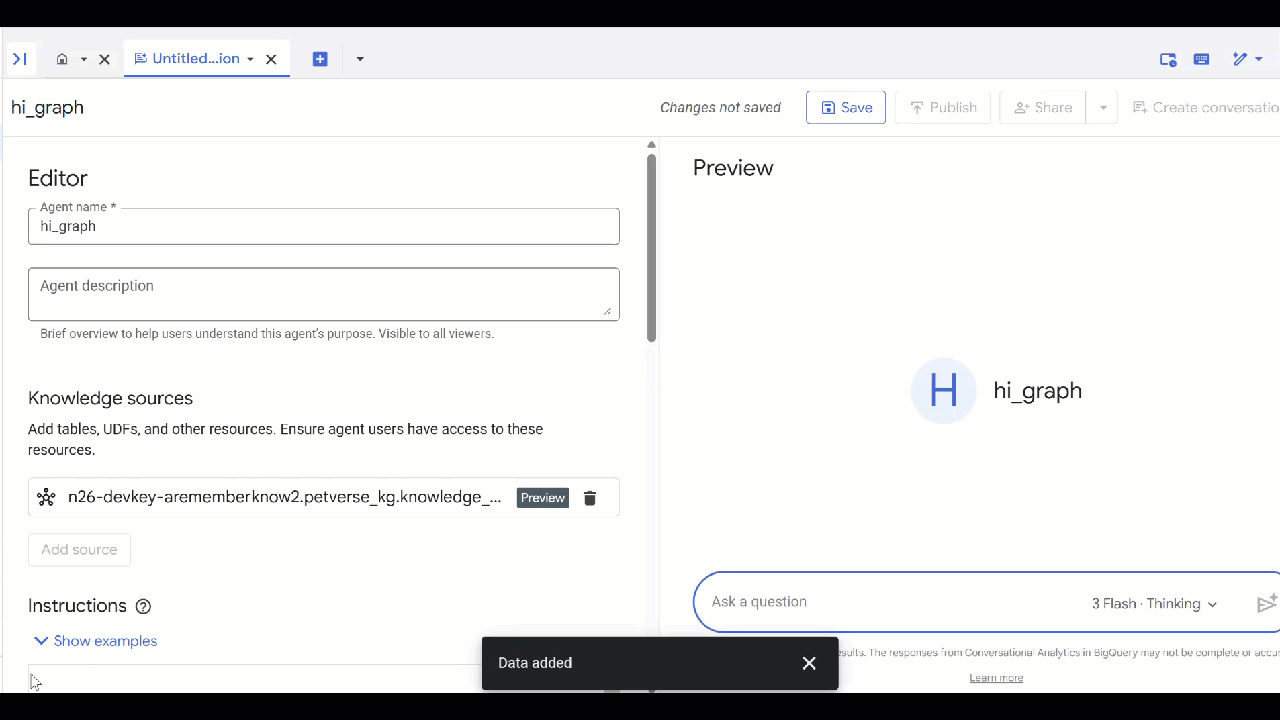
petverse - คลิกเพิ่มแหล่งข้อมูล แล้วคลิกกราฟ
- เลือก
knowledge_graphที่คุณสร้างขึ้น แล้วคลิกเพิ่ม
ตอนนี้คุณสามารถถามคำถามกับตัวแทนและดูคำตอบพร้อมเหตุผลเบื้องหลังได้แล้ว ตัวอย่างคำถามที่คุณนำไปใช้ได้หากต้องการแรงบันดาลใจมีดังนี้ โมเดลการคิดอาจใช้เวลานานกว่าเล็กน้อย แต่มีแนวโน้มที่จะสร้างคำค้นหา GQL ที่ดีกว่า คุณดูได้ว่าฟีเจอร์นี้สร้างอะไรบ้างโดยขยาย Show Thinking
- ค้นหาสัตว์เลี้ยงที่ชอบกินอาหารเหมือนกัน หรือเป็นเพื่อนกับสัตว์เลี้ยงที่ชอบงีบหลับ
- มีสัตว์เลี้ยงตัวใดที่มีงานอดิเรก อาหารโปรด หรือของเล่นเหมือนกันไหม ระบุคู่รักและสิ่งที่ทั้งคู่สนใจร่วมกัน
- หาสัตว์เลี้ยงที่มีสายพันธุ์หรือชนิดเดียวกัน แต่มีงานอดิเรกที่แตกต่างกันโดยสิ้นเชิง
9. ล้างข้อมูล
โปรดลบทรัพยากรที่สร้างขึ้นระหว่างการทำ Codelab นี้เพื่อหลีกเลี่ยงการเรียกเก็บเงินอย่างต่อเนื่องในบัญชี Google Cloud
- ลบคลัสเตอร์ GKE
gcloud container clusters delete petverse-cluster --region $REGION --quiet
- ลบชุดข้อมูล BigQuery (ซึ่งจะลบตารางทั้งหมด) โดยทำดังนี้
bq rm -r -f -d $PROJECT_ID:petverse_kg
- ลบทรัพยากรคิว Pub/Sub โดยทำดังนี้
gcloud pubsub subscriptions delete petverse-sub --quiet
gcloud pubsub topics delete petverse-topic --quiet
- ลบที่เก็บ Artifact Registry
gcloud artifacts repositories delete gke-cats-repo --location=$REGION --quiet
- ลบที่เก็บข้อมูล GCS เฉพาะโปรเจ็กต์
gcloud storage buckets delete gs://$PROJECT_ID-petverse --quiet
10. ขอแสดงความยินดี
ยินดีด้วย คุณสร้างไปป์ไลน์กราฟความรู้แบบกระจายโดยใช้ GKE และ Gemini รวมถึงค้นหาโดยใช้กราฟพร็อพเพอร์ตี้ BigQuery ได้สำเร็จแล้ว
สิ่งที่คุณได้เรียนรู้
- วิธีทำให้งานแบบกระจายใช้งานได้ใน GKE Autopilot
- วิธีใช้ Gemini เพื่อการดึงข้อมูลมัลติโมดัล
- วิธีใช้การฝังอัตโนมัติของ BigQuery
- วิธีสร้างและค้นหากราฟพร็อพเพอร์ตี้ใน BigQuery