
1. Giới thiệu
Trong lớp học lập trình này, bạn sẽ tạo một quy trình thu thập kiến thức phân tán cho "Petverse". Bạn sẽ xử lý nội dung đa phương tiện phi cấu trúc (Âm thanh, Video, Hình ảnh, Văn bản/CSV) từ một nhóm lưu trữ trên đám mây, trích xuất thông tin chính về thú cưng (món ăn yêu thích, sở thích) và tạo một biểu đồ tri thức. Bạn sẽ mở rộng quy mô xử lý tệp đa phương tiện bằng cách sử dụng tính năng xử lý đa phương thức của Gemini trên Google Kubernetes Engine (GKE). Cuối cùng, bạn sẽ lưu trữ dữ liệu này trong BigQuery và sử dụng tính năng Biểu đồ tài sản BigQuery mới để phân tích các mối quan hệ.
Chúng tôi sẽ sử dụng sức mạnh của Google Kubernetes Engine để minh hoạ quy trình xử lý song song dữ liệu với số lượng lớn.
Tại sao nên sử dụng sơ đồ tri thức?
Biểu đồ tri thức phù hợp hơn cơ sở dữ liệu quan hệ truyền thống để thể hiện và phân tích các mối quan hệ phức tạp giữa các thực thể.
Chúng ta sẽ dùng Gemini 2.5 Flash để phân tích hình ảnh, tệp âm thanh và tệp video, đồng thời xác định thông tin thực tế về các loại thú cưng.
Bạn sẽ thực hiện
- Tạo và triển khai một công việc xử lý dữ liệu phân tán trên GKE.
- Dùng Gemini để trích xuất thực thể và mối quan hệ từ các tệp nội dung nghe nhìn.
- Lưu trữ dữ liệu biểu đồ tri thức trong BigQuery.
- Tạo và truy vấn Đồ thị thuộc tính trong BigQuery bằng Ngôn ngữ truy vấn đồ thị (GQL).
Bạn cần có
- Một trình duyệt web như Chrome
- Một dự án trên Google Cloud đã bật tính năng thanh toán
- Quyền trong dự án để tạo tài nguyên và sửa đổi chính sách IAM
Lớp học lập trình này dành cho nhà phát triển ở mọi cấp độ, kể cả người mới bắt đầu.
Thời lượng ước tính: 45 phút
Chi phí: Các tài nguyên được tạo trong lớp học lập trình này sẽ có chi phí dưới 5 USD.
2. Trước khi bắt đầu
Tạo một dự án trên Google Cloud
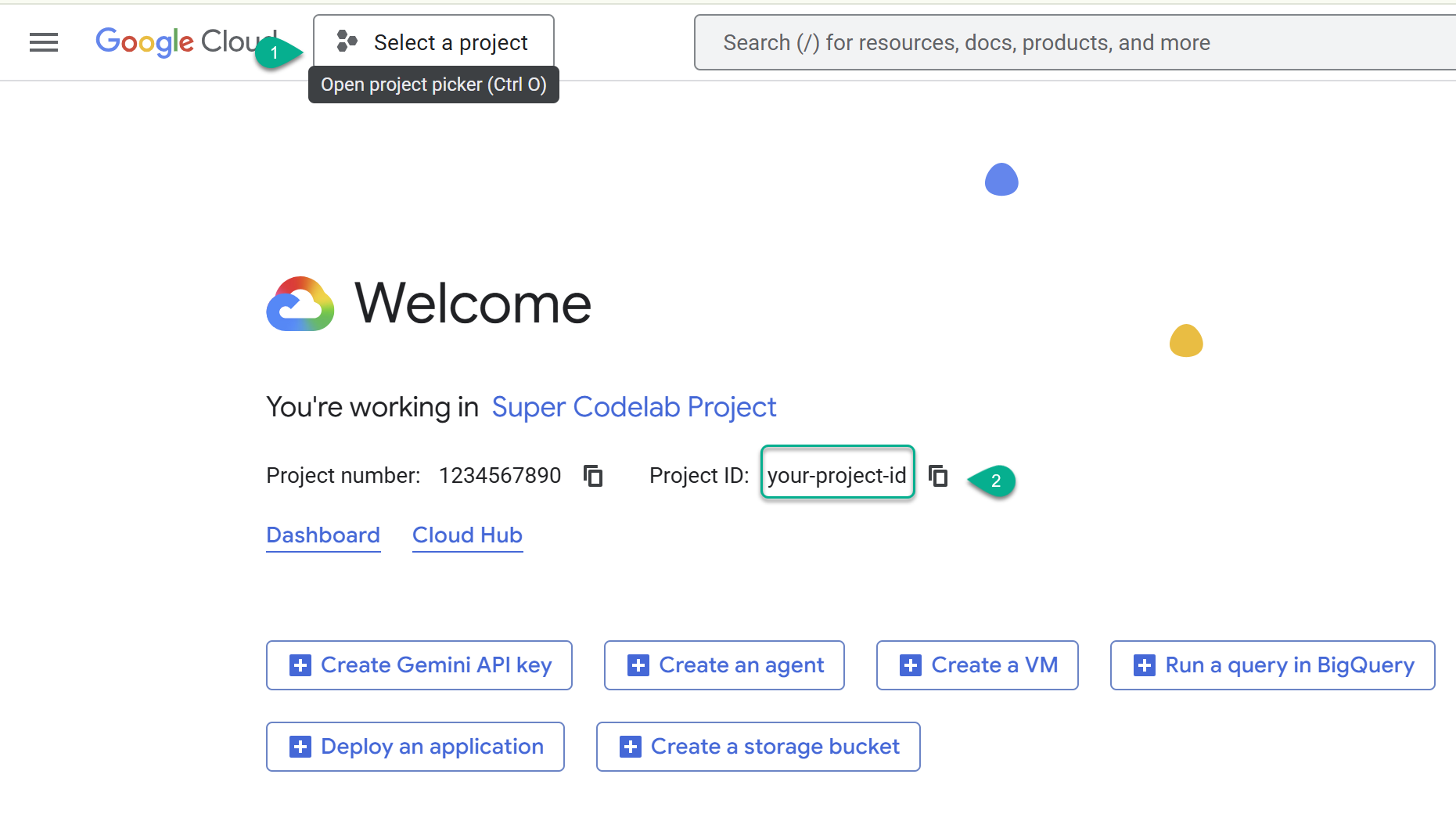
- Truy cập vào bảng điều khiển Cloud: https://console.cloud.google.com, rồi chọn hoặc tạo một dự án trên đám mây của Google Cloud.
- ⚠️ Ghi lại mã dự án. Bạn sẽ dùng lệnh này cho một số lệnh trong lớp học lập trình này.
Khởi động Cloud Shell
- Mở Cloud Shell trong một thẻ mới: https://shell.cloud.google.com/.
- Nếu được nhắc, hãy nhấp vào Uỷ quyền.
- Thay thế
PROJECT_IDvà dán lệnh sau vào cửa sổ dòng lệnh:
export PROJECT_ID="YOUR_PROJECT_ID"
gcloud config set project $PROJECT_ID
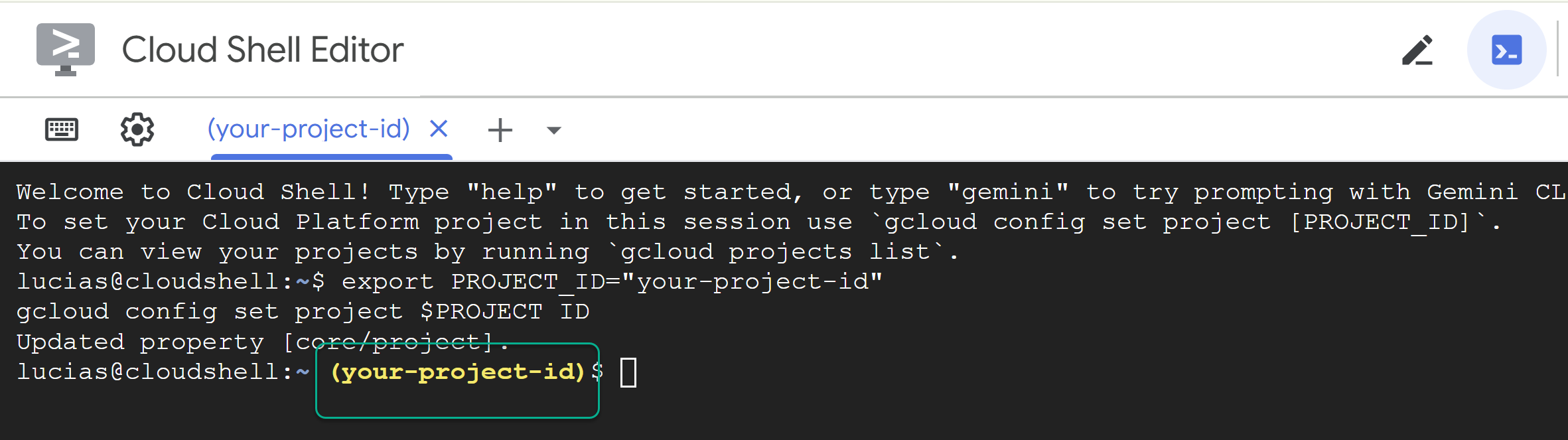
📝 Lưu ý Dự án của bạn sẽ xuất hiện bằng màu vàng trong dòng lệnh. Nếu phiên của bạn khởi động lại, hãy nhớ chạy lại lệnh ở trên để đặt mã dự án.
Bật API
Chạy lệnh này để bật tất cả các API bắt buộc:
gcloud services enable \
aiplatform.googleapis.com \
bigquery.googleapis.com \
artifactregistry.googleapis.com \
container.googleapis.com \
cloudbuild.googleapis.com \
pubsub.googleapis.com
Sao chép kho lưu trữ
Chạy các lệnh này để sao chép kho lưu trữ.
cd ~/
git clone --filter=blob:none --no-checkout https://github.com/GoogleCloudPlatform/devrel-demos.git
cd ~/devrel-demos
git sparse-checkout init --cone
git sparse-checkout set codelabs/gke-knowledge-graph
git checkout main
cd codelabs/gke-knowledge-graph/
Chạy tập lệnh thiết lập
Tập lệnh này tự động hoá cấu hình phụ trợ bằng cách:
- Tạo một hình ảnh vùng chứa và một kho lưu trữ Artifact Registry
- Tạo tập dữ liệu BigQuery
- Tạo mối kết nối BigQuery để thực thi các hàm AI của Gemini từ SQL
Chạy lệnh sau trong cửa sổ dòng lệnh:
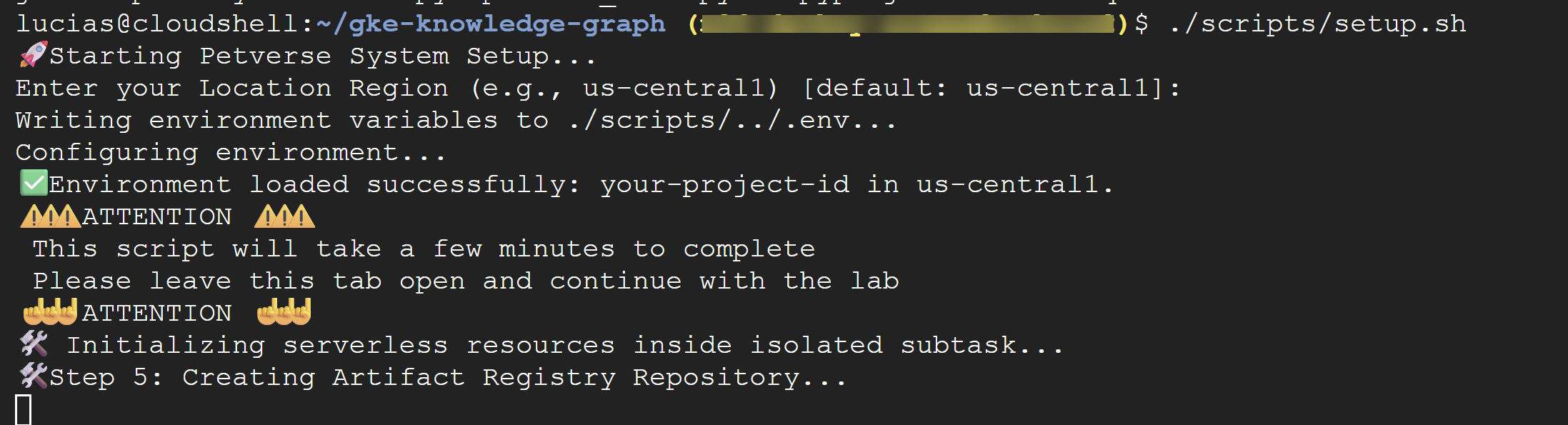
./scripts/setup.sh
Nếu tập lệnh nhắc bạn cung cấp thông tin chi tiết về cấu hình, hãy sử dụng các giá trị sau:
- Mã dự án: Sử dụng mã dự án mà bạn đã tạo ở bước trước.
- Khu vực:
us-central1
⚠️ Lưu ý quan trọng Tập lệnh sẽ mất vài phút để hoàn tất. Hãy mở cửa sổ dòng lệnh này để hoàn tất ở chế độ nền. Để tiếp tục với bước tiếp theo, hãy mở một thẻ hoặc cửa sổ dòng lệnh mới để chạy các lệnh tiếp theo.
3. Thiết lập Data Agent Kit
- Bật Cloud Shell Editor bằng biểu tượng bút chì ở góc trên cùng bên phải.
- Trong Cloud Shell Editor, hãy nhấp vào biểu tượng Tiện ích trong thanh bên trái.
- Tìm Google Cloud Data Agent Kit rồi nhấp vào Install (Cài đặt) nếu bạn chưa cài đặt.
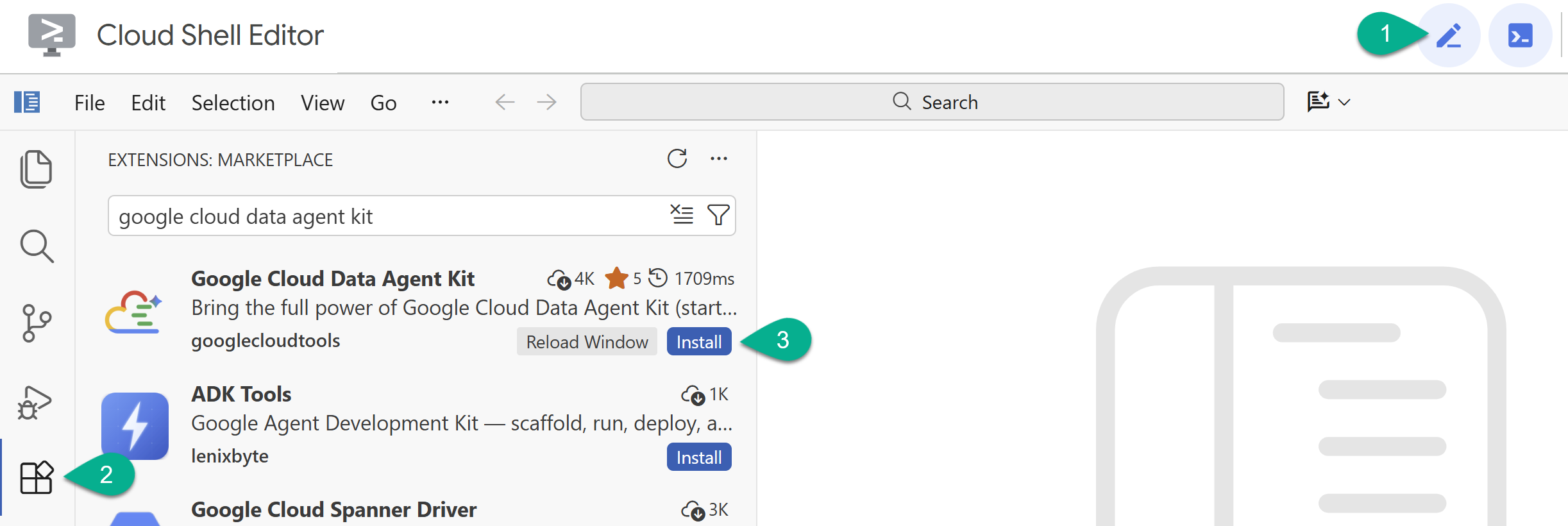
- Đăng nhập vào Tài khoản Google của bạn bằng tiện ích này.
- Trong phần Tóm tắt cấu hình, hãy nhập mã dự án và
us-central1làm khu vực.
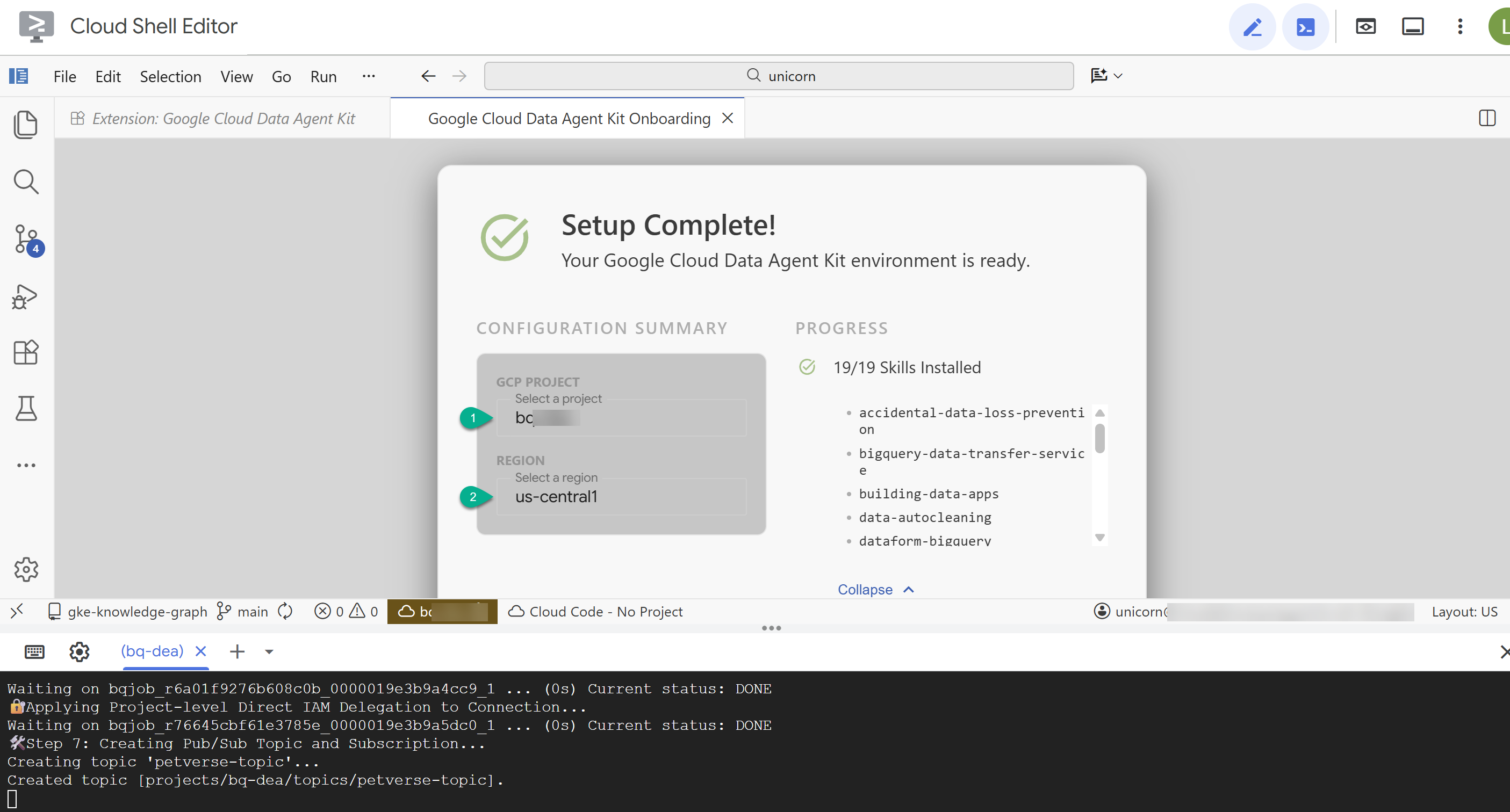
- Nhấp vào Định cấu hình máy chủ MCP. Bạn không cần thực hiện bất kỳ thay đổi nào đối với cửa sổ này, chỉ cần nhấp vào Bắt đầu.
- Tải lại cửa sổ nếu được nhắc. Bạn có thể đóng thẻ Hướng dẫn bắt đầu nhanh ngay bây giờ.
Thiết lập các bảng trong BigQuery
- Trên thanh bên, hãy quay lại trình khám phá. Nếu thư mục gốc của bạn (ví dụ:
/home/your_user_name/) chưa mở, hãy nhấp vào Mở thư mục rồi chọn thư mục đó.
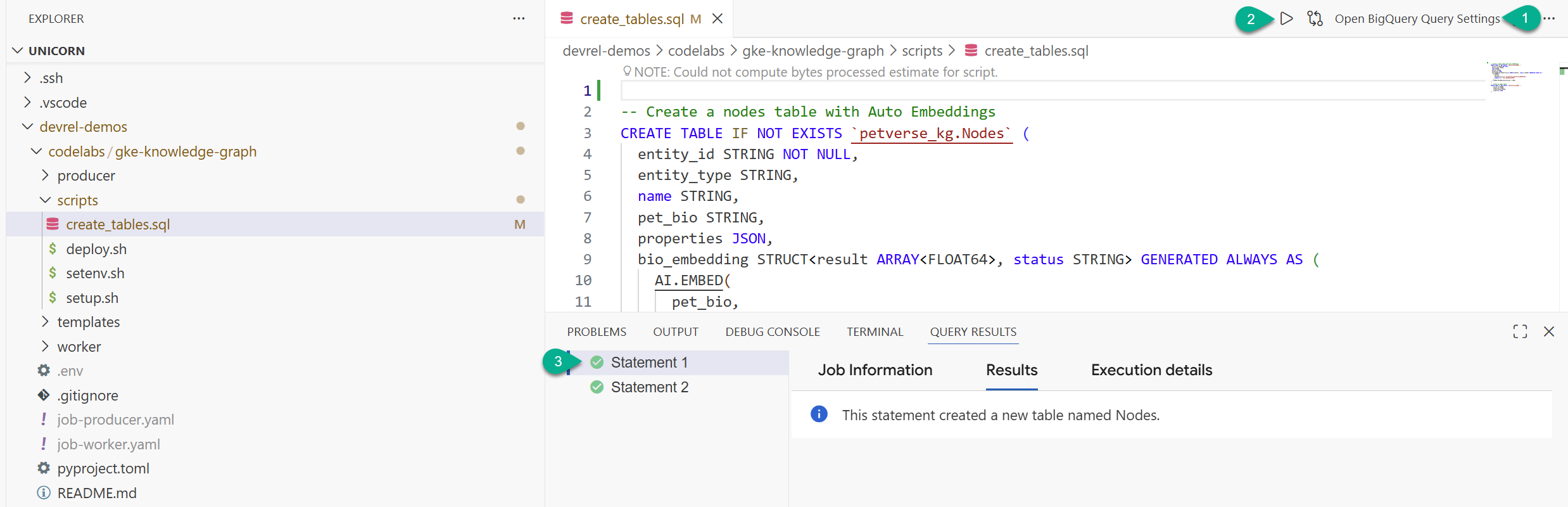
- Trong cửa sổ trình khám phá, hãy tìm thư mục bạn đã sao chép từ kho lưu trữ (
devrel-demos). Trongcodelabs/gke-knowledge-graph/scripts, bạn sẽ thấycreate_tables.sql. Mở tệp đó. - Ở trên cùng bên phải, hãy nhấp vào Mở phần Cài đặt truy vấn.
- Chọn BigQuery. Lưu và Đóng.
- Nhấp vào Chạy.
Bạn sẽ thấy 2 câu lệnh được thực thi thành công. Giờ đây, bạn đã tạo các bảng để lưu trữ các nút và cạnh cho biểu đồ tri thức của mình.
Bạn có thể đóng thẻ create_tables.sql và bảng điều khiển kết quả.
4. Khởi tạo cụm GKE
Chúng ta sẽ sử dụng tính năng tự động điều khiển GKE để chạy quy trình xử lý dữ liệu. Autopilot là phương pháp hay nhất nên dùng vì phương pháp này sẽ quản lý cơ sở hạ tầng cụm cho bạn.
Đến đây, tập lệnh thiết lập sẽ hoàn tất. Bạn sẽ thấy thông báo thành công: 🎉🦄 Setup successfully finished! 🎉🦄.
Dán lệnh này vào thiết bị đầu cuối để tạo cụm:
source scripts/setenv.sh
gcloud container clusters create-auto petverse-cluster \
--region=$REGION
🕓 Quá trình này sẽ mất khoảng 5 phút.
Nhận thông tin xác thực để tương tác với cụm:
source scripts/setenv.sh
gcloud container clusters get-credentials petverse-cluster --region $REGION
Bạn sẽ thấy kết quả sau:
Fetching cluster endpoint and auth data. kubeconfig entry generated for petverse-cluster.
5. Định cấu hình Workload Identity
Workload Identity Federation cho GKE (sử dụng Direct Resource Access) cho phép khối lượng công việc GKE của bạn truy cập an toàn vào các dịch vụ của Google Cloud mà không cần quản lý khoá tài khoản dịch vụ.
Thực thi deploy.sh để:
- Tạo tài khoản dịch vụ Kubernetes
- Cấp trực tiếp các vai trò IAM cần thiết cho chủ thể của Tài khoản dịch vụ Kubernetes
- Liên kết tài khoản dịch vụ IAM với tài khoản dịch vụ Kubernetes
- Chú thích tài khoản dịch vụ Kubernetes để hoàn tất quá trình liên kết
source scripts/setenv.sh
./scripts/deploy.sh
6. Triển khai các công việc xử lý tách rời
Trong bước này, bạn sẽ triển khai enqueuer (Producer) và các công cụ xử lý (Worker) vào GKE.
Kiến trúc tách rời mới của chúng tôi sử dụng Google Cloud Pub/Sub để xử lý các thành phần một cách không đồng bộ:
- Producer quét GCS và xếp tất cả đường dẫn tệp vào hàng đợi Pub/Sub.
- Một nhóm Worker (Nhân viên) sẽ mở rộng quy mô trong GKE, tự động kéo các tác vụ song song, xử lý các tác vụ đó thông qua Gemini và ghi vào BigQuery.
Tập lệnh setup.sh đã tạo và đẩy cả hình ảnh vùng chứa Producer và Worker, xếp hàng các chủ đề Pub/Sub và tạo động các tệp kê khai triển khai GKE: job-producer.yaml và job-worker.yaml.
- Áp dụng Producer Job để quét bộ chứa lưu trữ và xếp hàng tất cả thành phần:
kubectl apply -f job-producer.yaml
Tác vụ này chạy và hoàn tất nhanh chóng vì chỉ xếp hàng siêu dữ liệu.
- Triển khai Worker Job được định cấu hình để chạy 6 worker song song nhằm làm trống hàng đợi:
kubectl apply -f job-worker.yaml
GKE Autopilot sẽ tự động phát hiện các pod đang chờ xử lý, tăng quy mô động cho các nút tính toán và chạy các worker song song để xử lý âm thanh, video, hình ảnh và tệp CSV được đưa vào hàng đợi.
7. Xác minh kết quả
- Kiểm tra trạng thái của các công việc:
kubectl get jobs
Chờ cho đến khi cả petverse-producer-job và petverse-worker-job đều cho thấy đã hoàn tất thành công.
🕓 Quá trình này sẽ mất khoảng 10 phút. Bạn có thể xem tiến trình bằng các lệnh bên dưới.
- Kiểm tra nhật ký của Producer để xác minh rằng Producer đã xếp hàng các tệp thành công:
cd ~/devrel-demos/codelabs/gke-knowledge-graph
source scripts/setenv.sh
kubectl logs -l app=petverse-producer --tail=50
- Xem các worker song song xử lý tệp trong hàng đợi:
kubectl logs -l app=petverse-worker --tail=50
(Các worker có thời gian chờ là 60 giây và sẽ tự động tắt cũng như dọn dẹp khi hàng đợi Pub/Sub trống).
Xác minh dữ liệu trong BigQuery.
- Chuyển đến BigQuery Studio. Bạn sẽ thấy 2 bảng được tạo: petverse_kg.Nodes và petverse_kg.Edges.
- Để xem nội dung của các bảng, hãy nhấp đúp vào tên của các bảng đó rồi nhấp vào Xem trước.
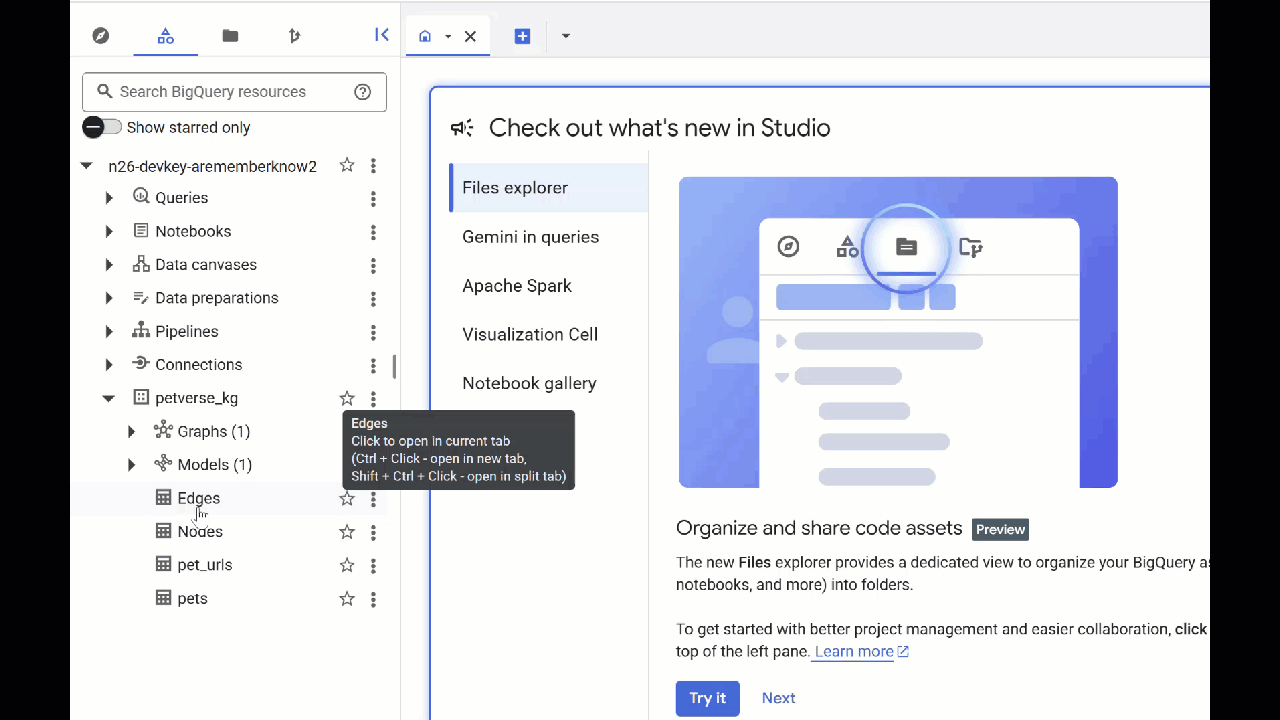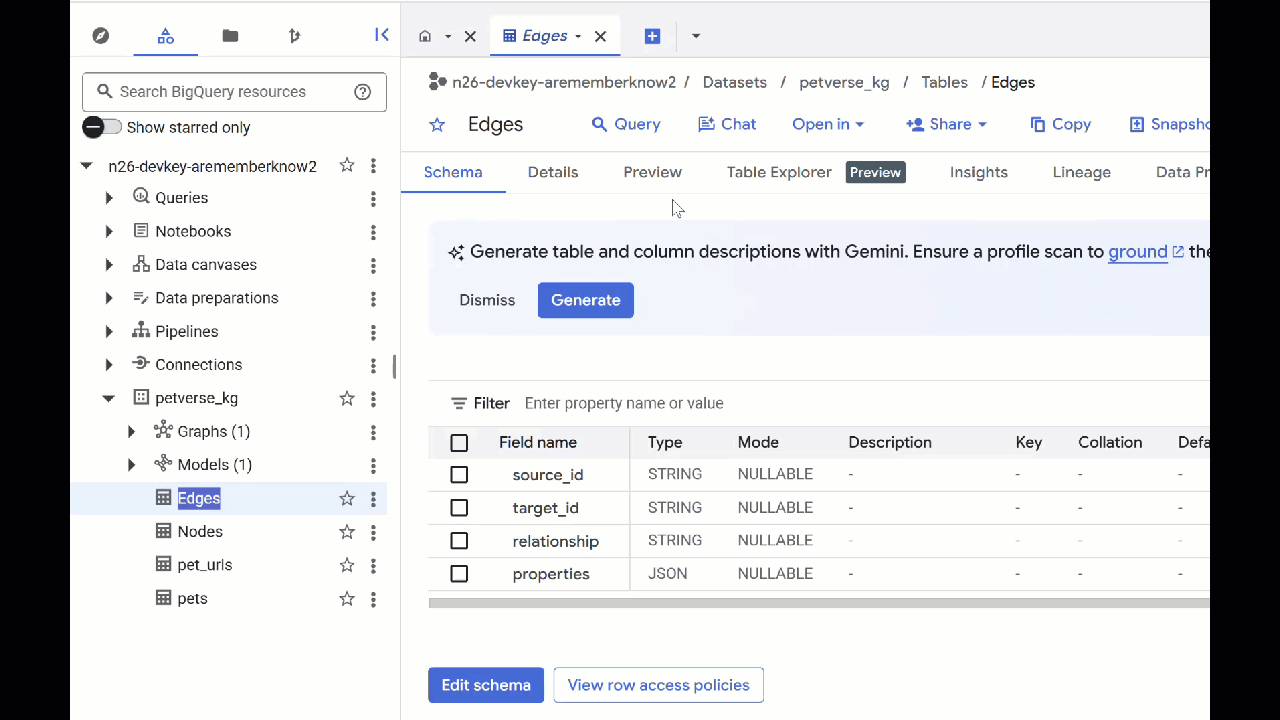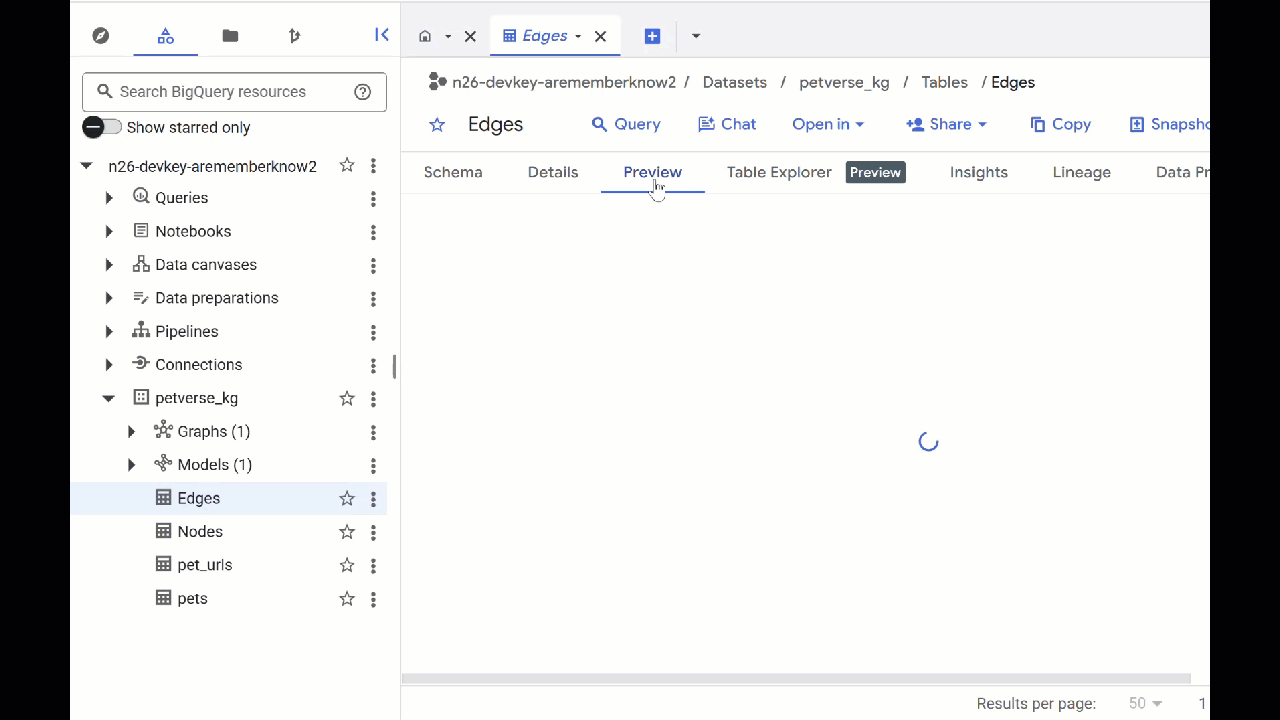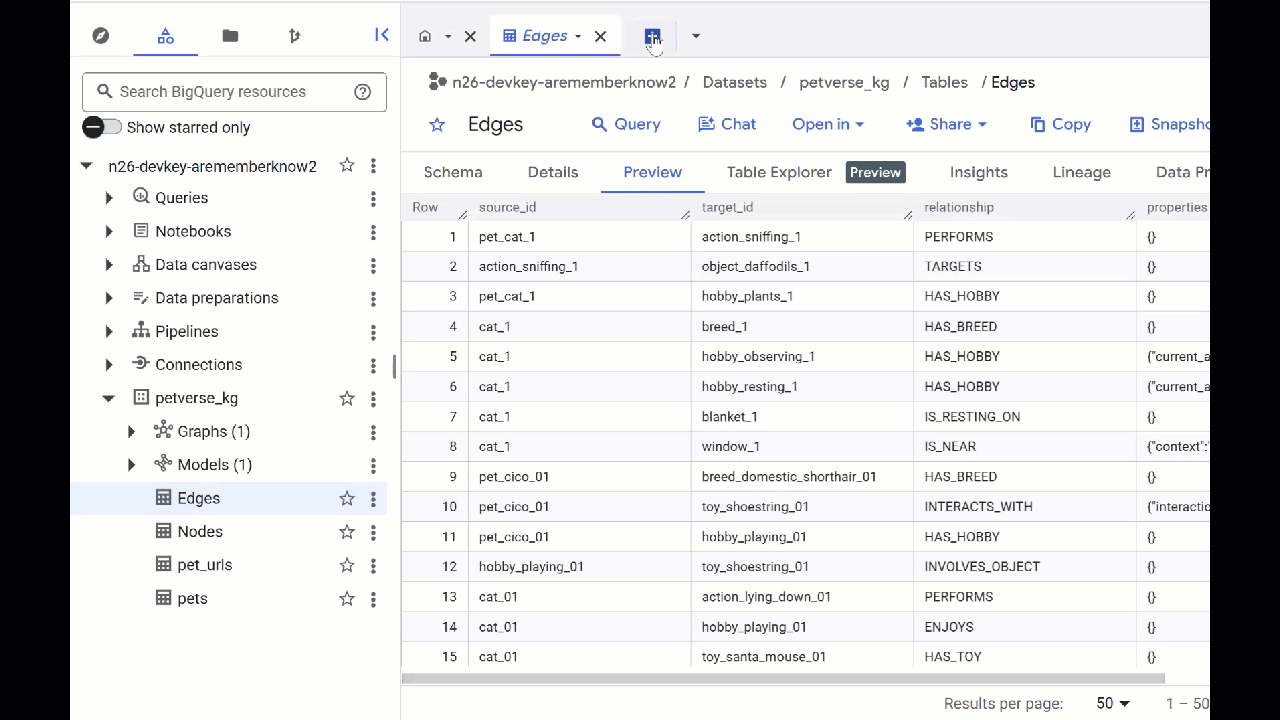
Bạn sẽ thấy bảng Nodes (Nút) có thông tin về các thực thể mà Gemini nhận dạng được trong âm thanh, video và hình ảnh. Bảng Edges chứa mối quan hệ giữa các bảng. Ví dụ: nếu nghe âm thanh của chú mèo tên là SQL, bạn sẽ biết chú thích chơi với dây giày và thích ăn cá sấy khô.
- Sử dụng nút + để tạo một truy vấn mới. Dán câu lệnh sau rồi nhấp vào Run (Chạy):
SELECT n.name, n.entity_id, e.relationship, e.target_id
FROM
`petverse_kg.Nodes` n
JOIN
`petverse_kg.Edges` e
ON n.entity_id = e.source_id
WHERE n.name = 'SQL'
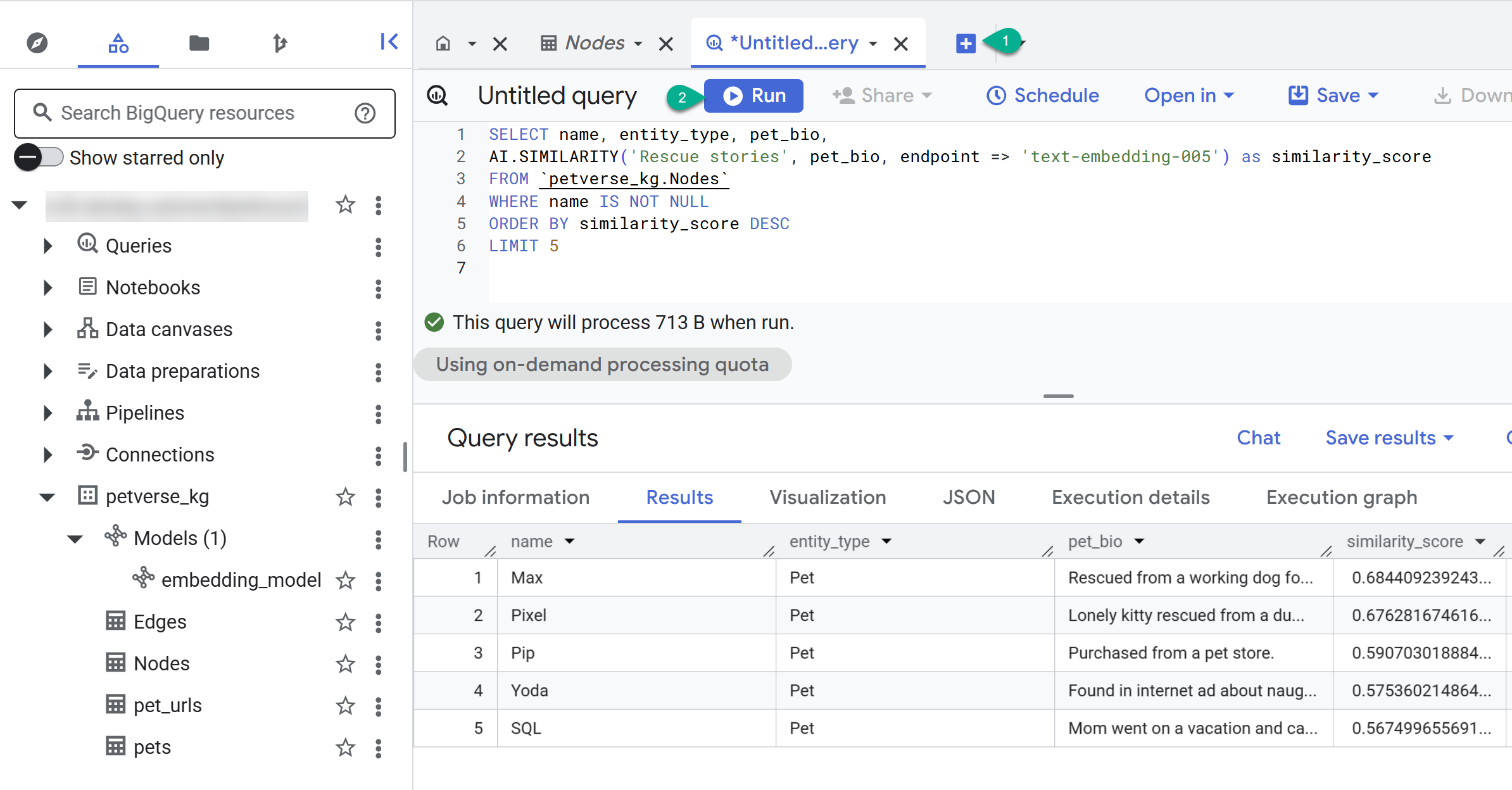
- Sử dụng nút + để tạo một truy vấn mới. Dán câu lệnh sau rồi nhấp vào Run (Chạy):
SELECT name, entity_type, pet_bio,
AI.SIMILARITY('Pets who like to relax', pet_bio, endpoint => 'text-embedding-005') as similarity_score
FROM `petverse_kg.Nodes`
WHERE name IS NOT NULL
ORDER BY similarity_score DESC
LIMIT 5
Bạn sẽ thấy các nút dành cho thú cưng thích thư giãn. Cụm từ tìm kiếm này đã thực hiện một tìm kiếm ngữ nghĩa bằng cách sử dụng chức năng AI AI.SIMILARITY để tìm những thú cưng có tiểu sử giống với văn bản của cụm từ tìm kiếm nhất.
Tạo biểu đồ tài sản
Giờ đây, khi đã có các nút và cạnh trong BigQuery, chúng ta có thể tạo một Đồ thị thuộc tính để dễ dàng truy vấn các mối quan hệ.
Tạo biểu đồ
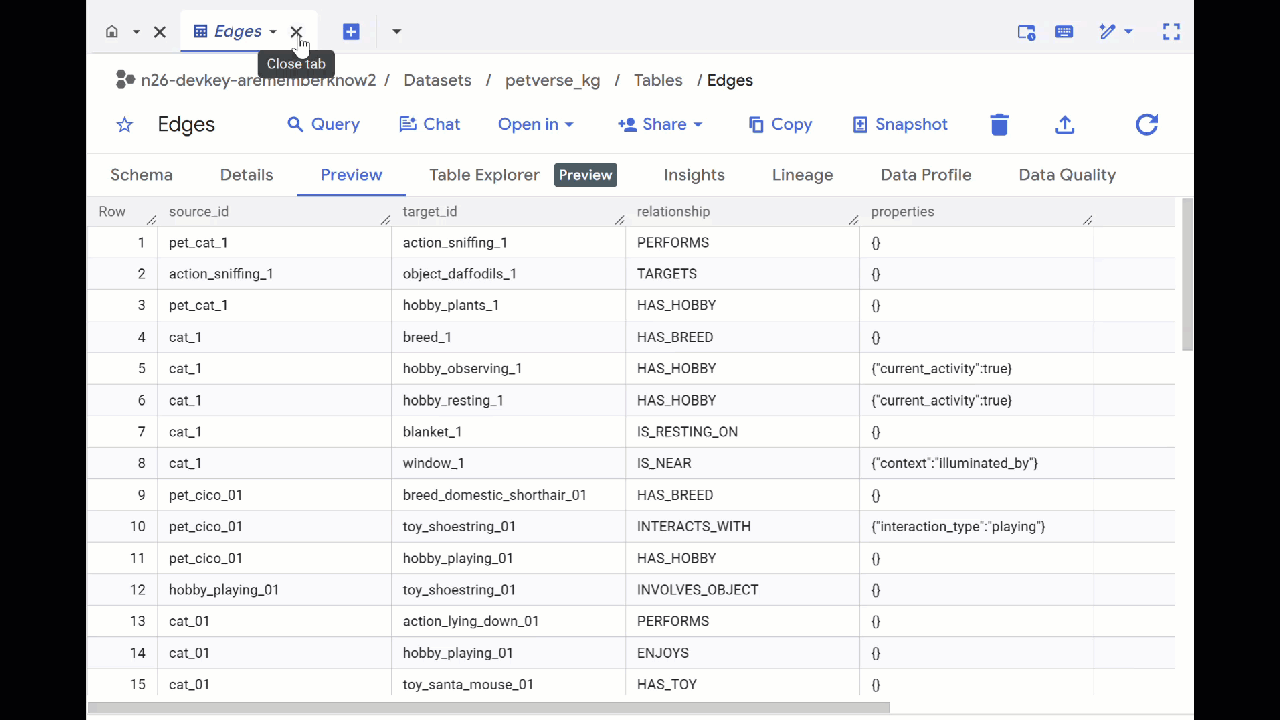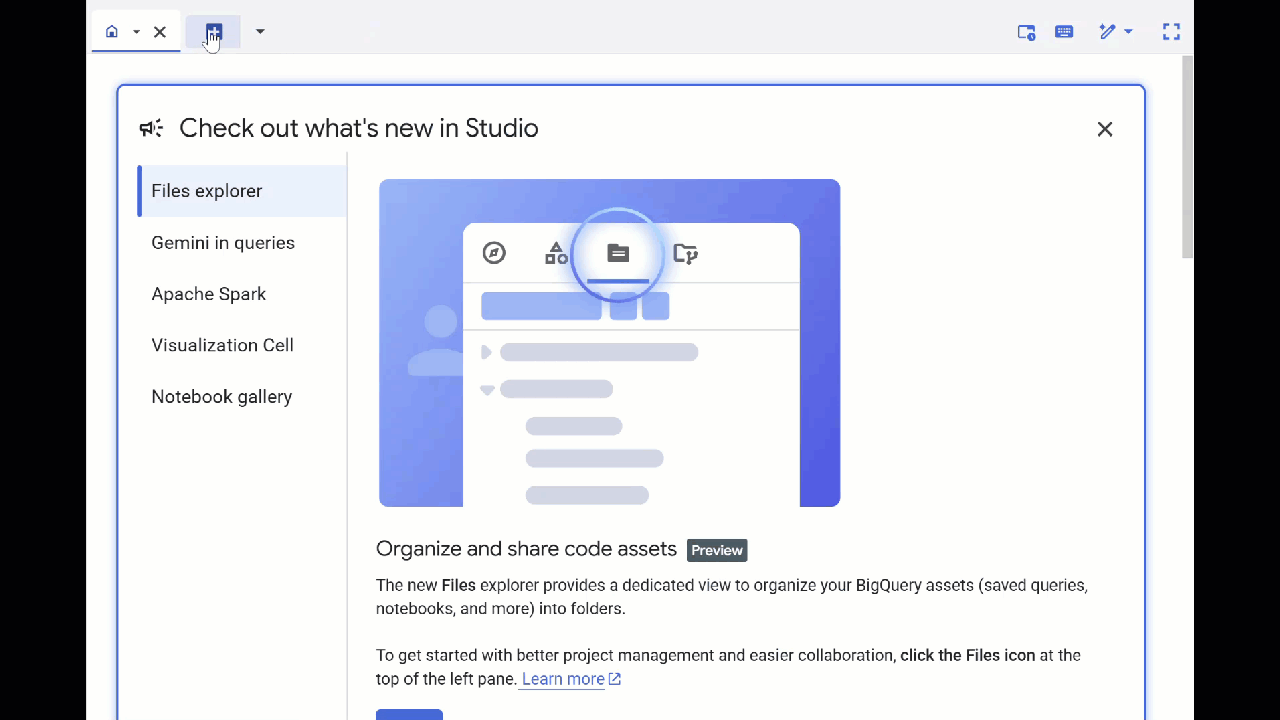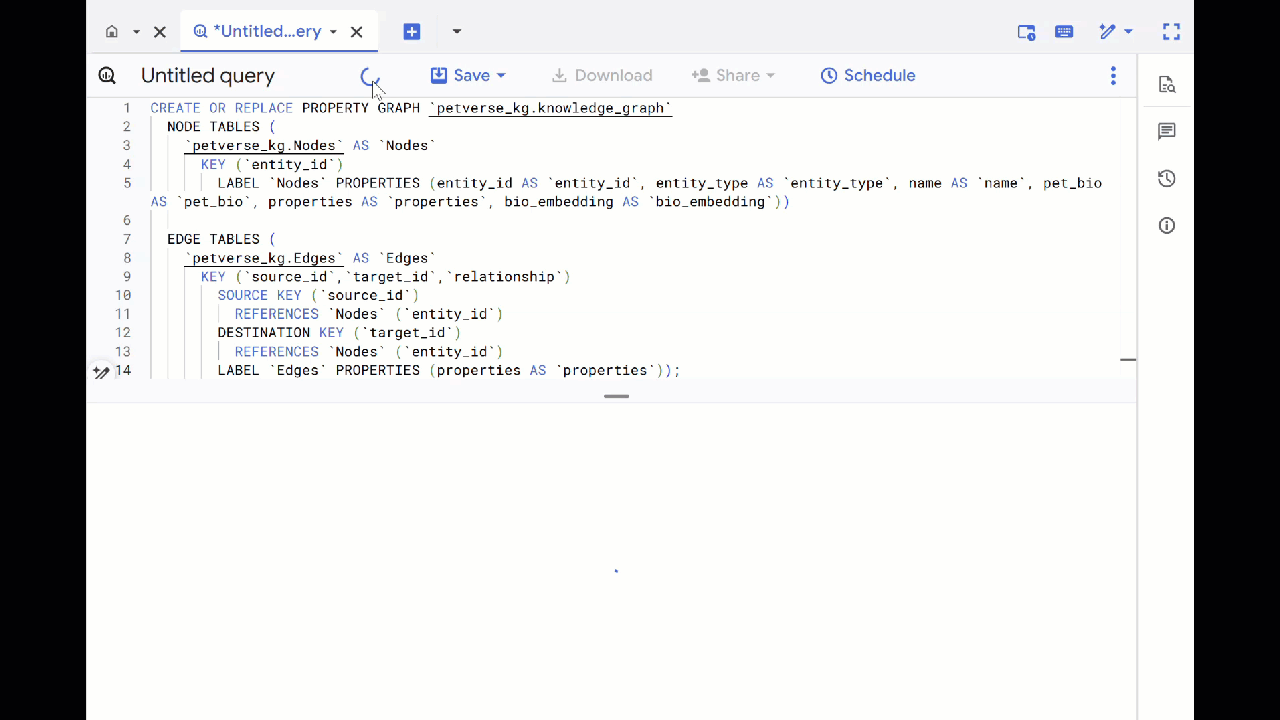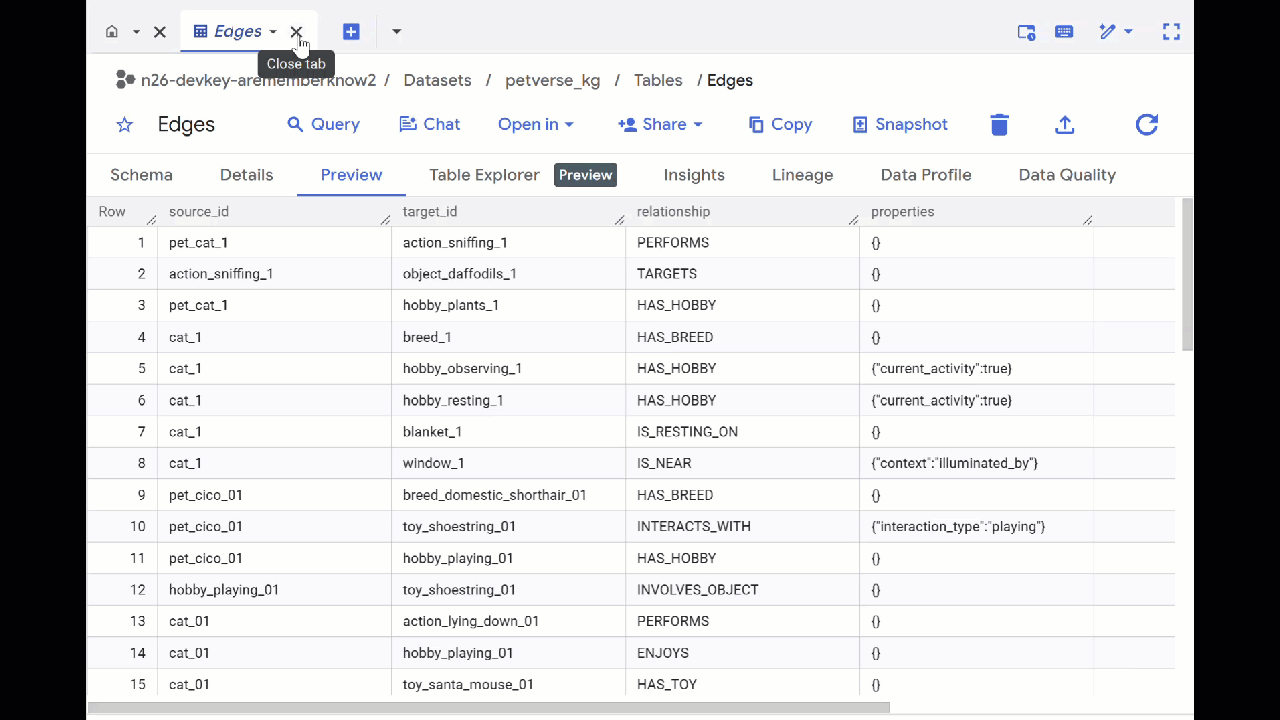
- Ghi đè truy vấn trước đó và chạy DDL sau đây để tạo biểu đồ tài sản:
CREATE OR REPLACE PROPERTY GRAPH `petverse_kg.knowledge_graph`
NODE TABLES (
`petverse_kg.Nodes` AS `Nodes`
KEY (`entity_id`)
LABEL `Nodes` PROPERTIES (entity_id AS `entity_id`, entity_type AS `entity_type`, name AS `name`, pet_bio AS `pet_bio`, properties AS `properties`, bio_embedding AS `bio_embedding`))
EDGE TABLES (
`petverse_kg.Edges` AS `Edges`
KEY (`source_id`,`target_id`,`relationship`)
SOURCE KEY (`source_id`)
REFERENCES `Nodes` (`entity_id`)
DESTINATION KEY (`target_id`)
REFERENCES `Nodes` (`entity_id`)
LABEL `Edges` PROPERTIES (properties AS `properties`));
- Nhấp vào Chuyển đến biểu đồ. Bạn sẽ thấy hình ảnh trực quan của biểu đồ có một nút có cạnh riêng. Lỗi này có thể xảy ra.
Truy vấn biểu đồ
- Bạn có thể đóng tất cả các truy vấn trước đó và mở một truy vấn mới, trống bằng nút +.
- Sử dụng GQL để tìm thú cưng có liên quan đến những thú cưng khác thông qua các mối quan tâm chung (chẳng hạn như sở thích, món ăn hoặc đồ chơi yêu thích). Truy vấn nhiều bước này khớp với 2 thú cưng khác nhau được kết nối với cùng một nút:
GRAPH `petverse_kg.knowledge_graph`
MATCH p = (pet1:Nodes)-[e1]->(interest:Nodes)<-[e2]-(pet2:Nodes)
WHERE pet1.entity_id != pet2.entity_id
AND (LOWER(pet1.entity_type) = 'pet' AND LOWER(pet2.entity_type) = 'pet')
AND LOWER(interest.entity_type) IN ('hobby', 'action', 'activity', 'food', 'toy')
RETURN TO_JSON(p) as res
LIMIT 100
- Bạn sẽ thấy hình ảnh trực quan của biểu đồ. Bạn có thể nhấp vào các nút để xem thuộc tính của các nút và cạnh.
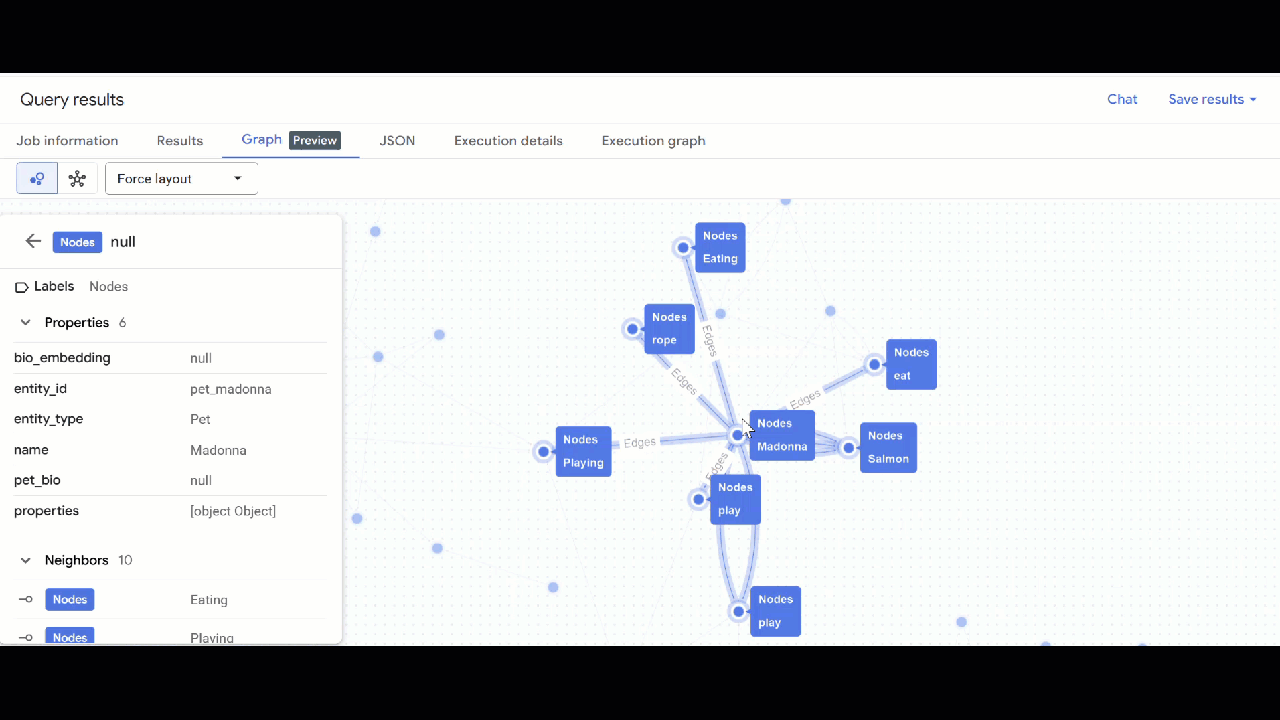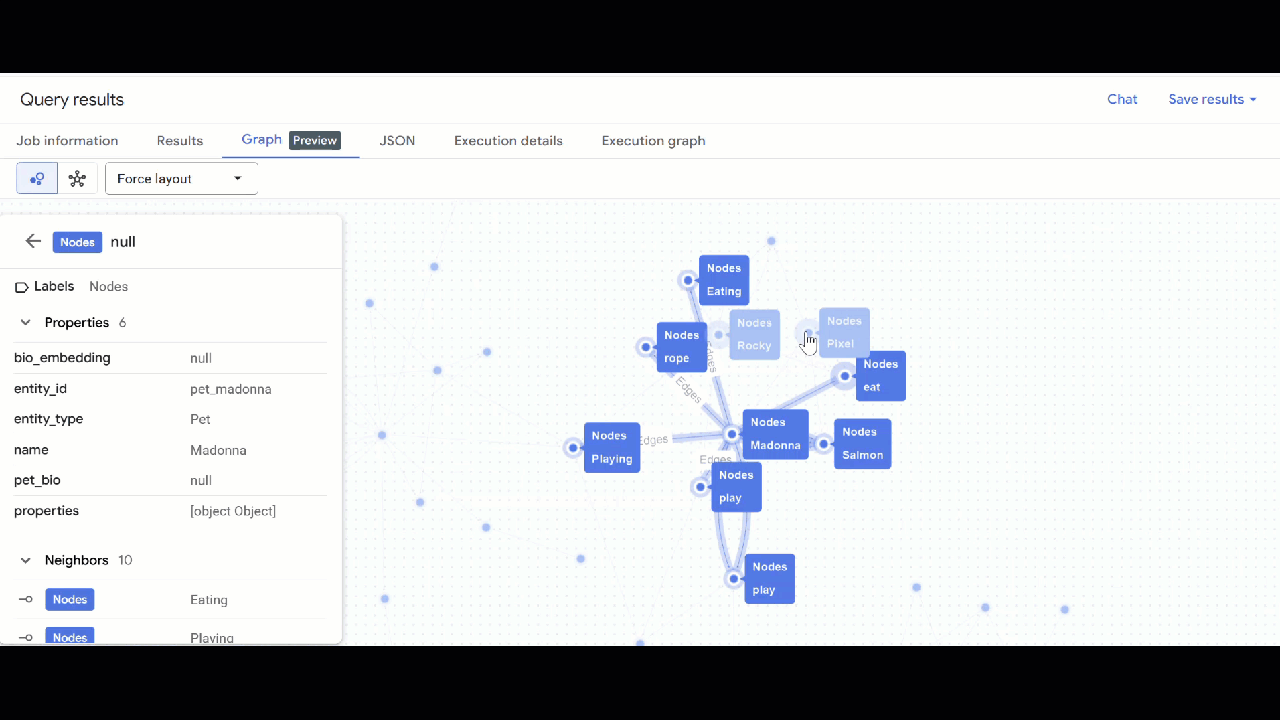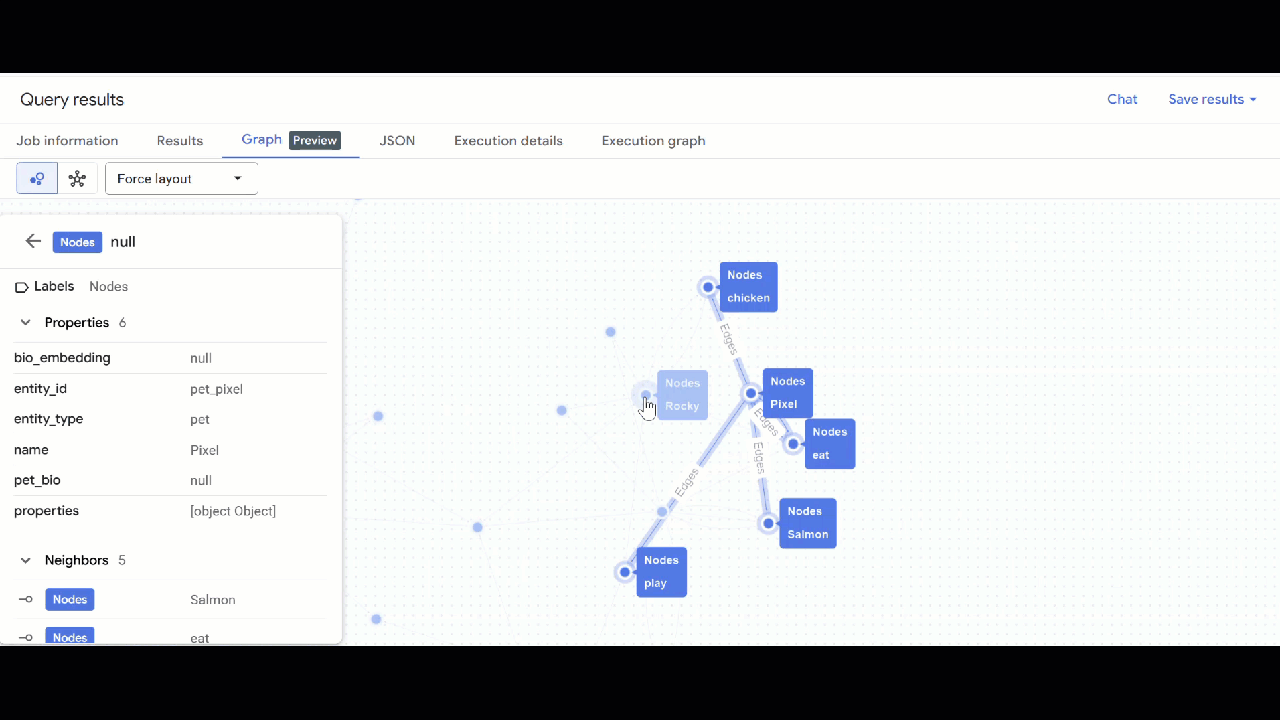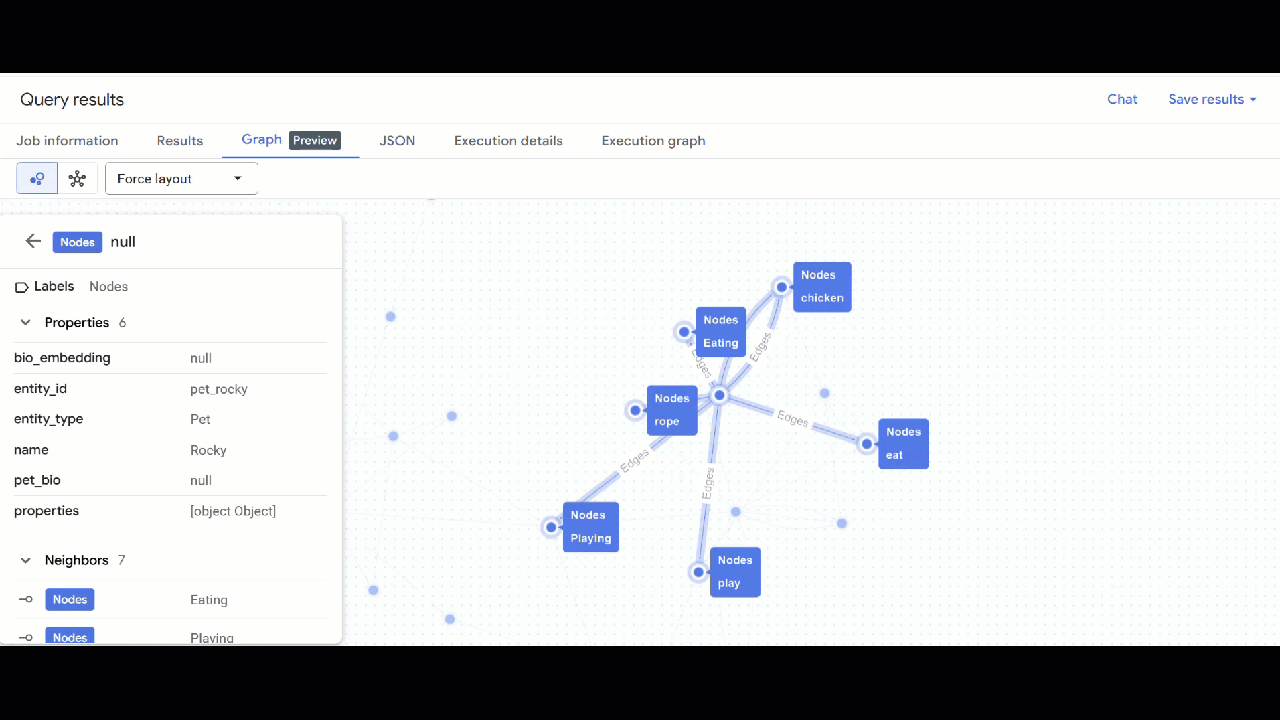
🕵️ Lưu ý: Bạn có thể điều chỉnh giá trị mà nút hiển thị bằng cách nhấp vào Chuyển sang chế độ xem lược đồ:
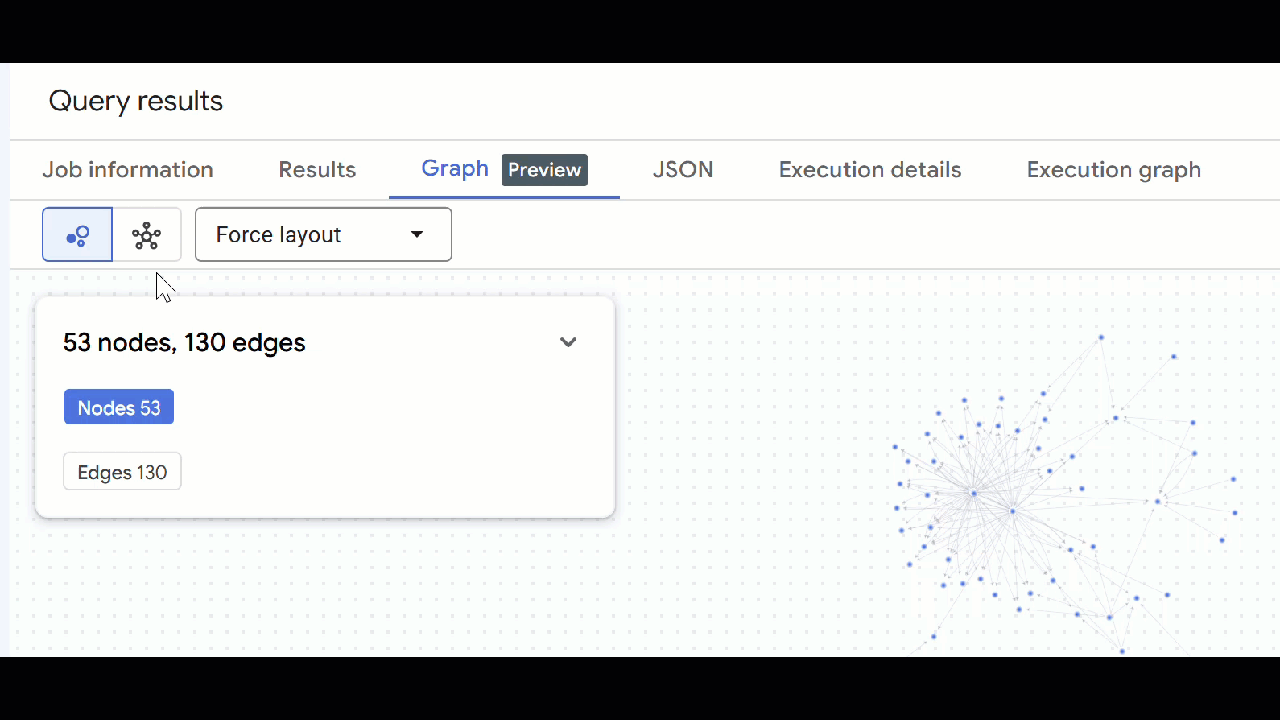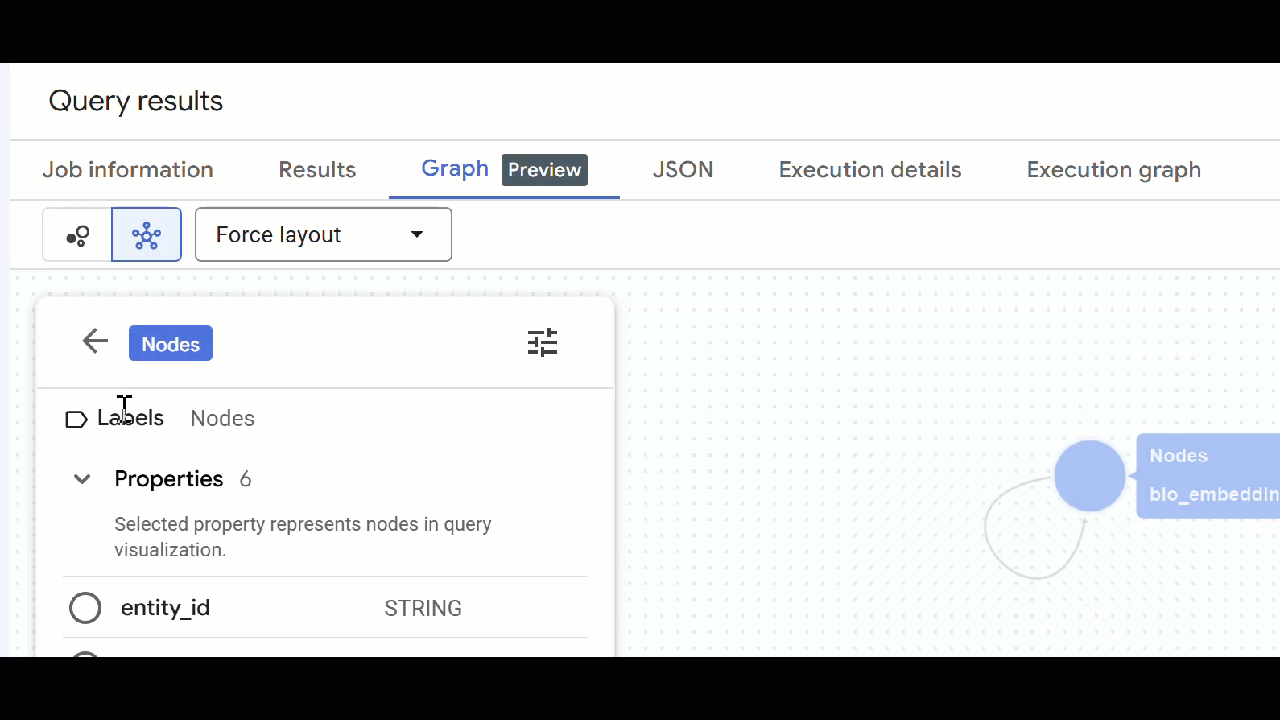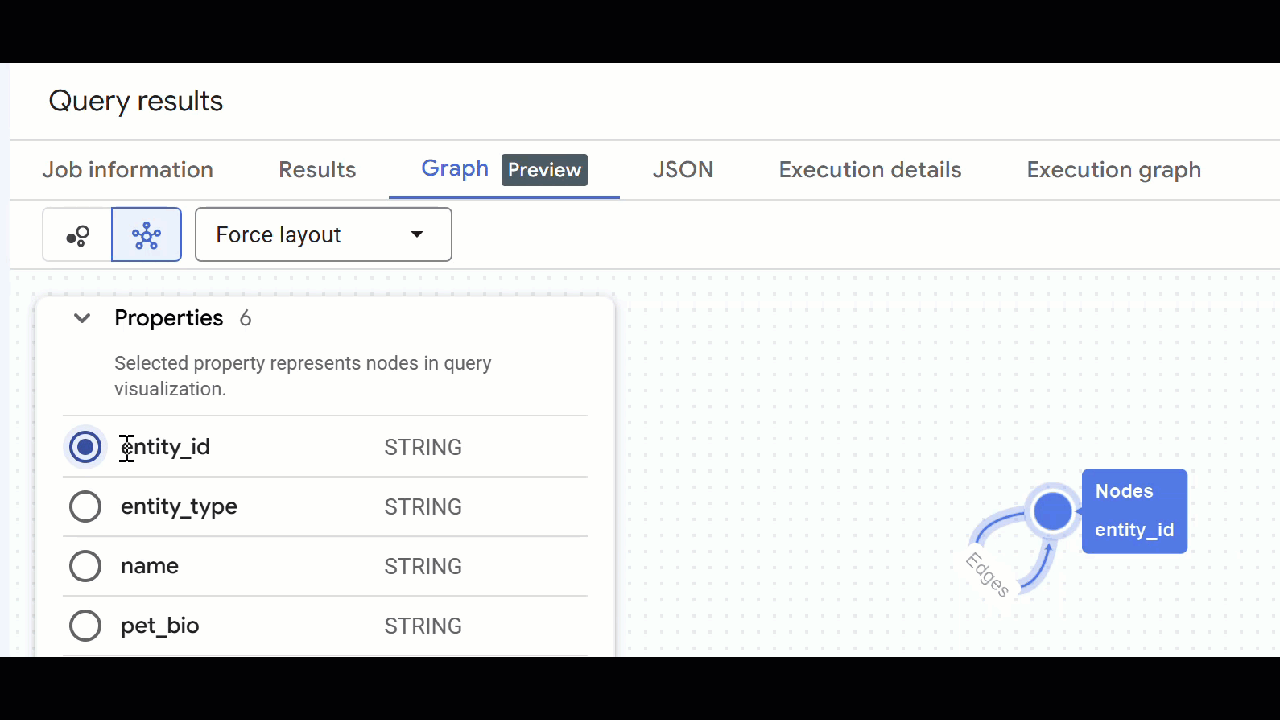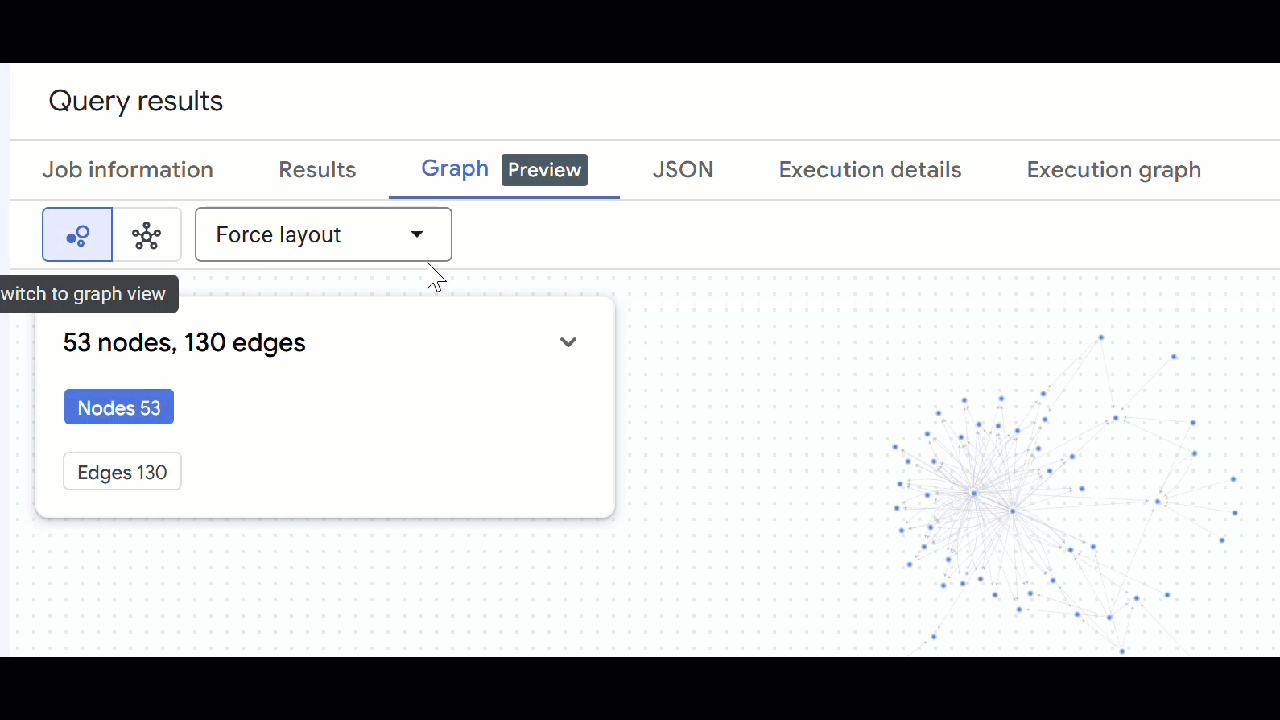
- Bạn có thể đóng tất cả các thẻ truy vấn đang mở.
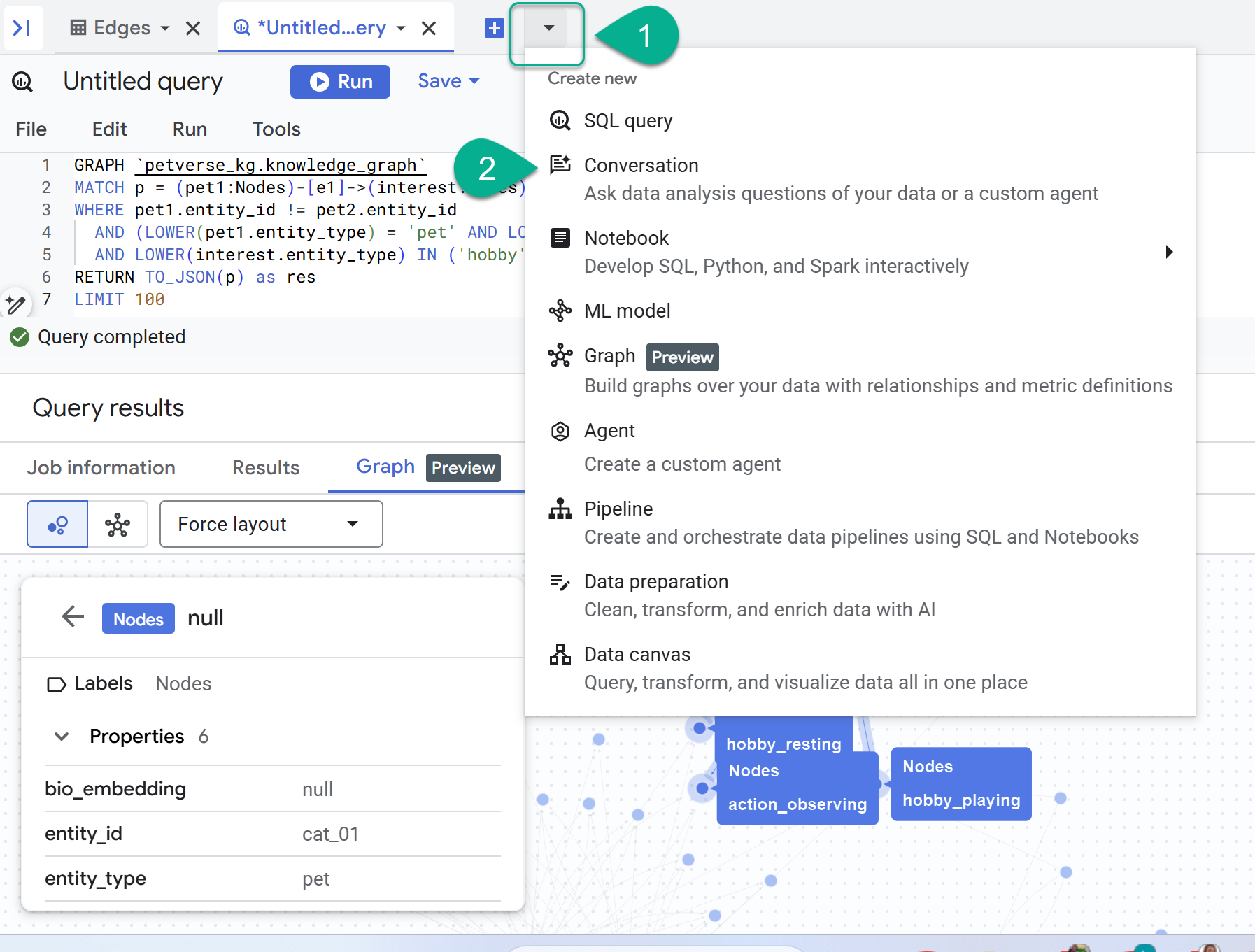
8. Trò chuyện với biểu đồ
- Bạn sẽ thấy một trình đơn thả xuống bên cạnh dấu +. Chọn Cuộc trò chuyện.
- Bạn sẽ được nhắc bật Data Analytics API bằng Gemini. Bật cả hai API. Sau khi quá trình này hoàn tất, hãy làm mới cửa sổ hoặc tạo một cuộc trò chuyện mới để xem tác tử.
- Nhấp vào New Agent (Nhân viên mới).
- Đặt tên cho nhân viên hỗ trợ, chẳng hạn như
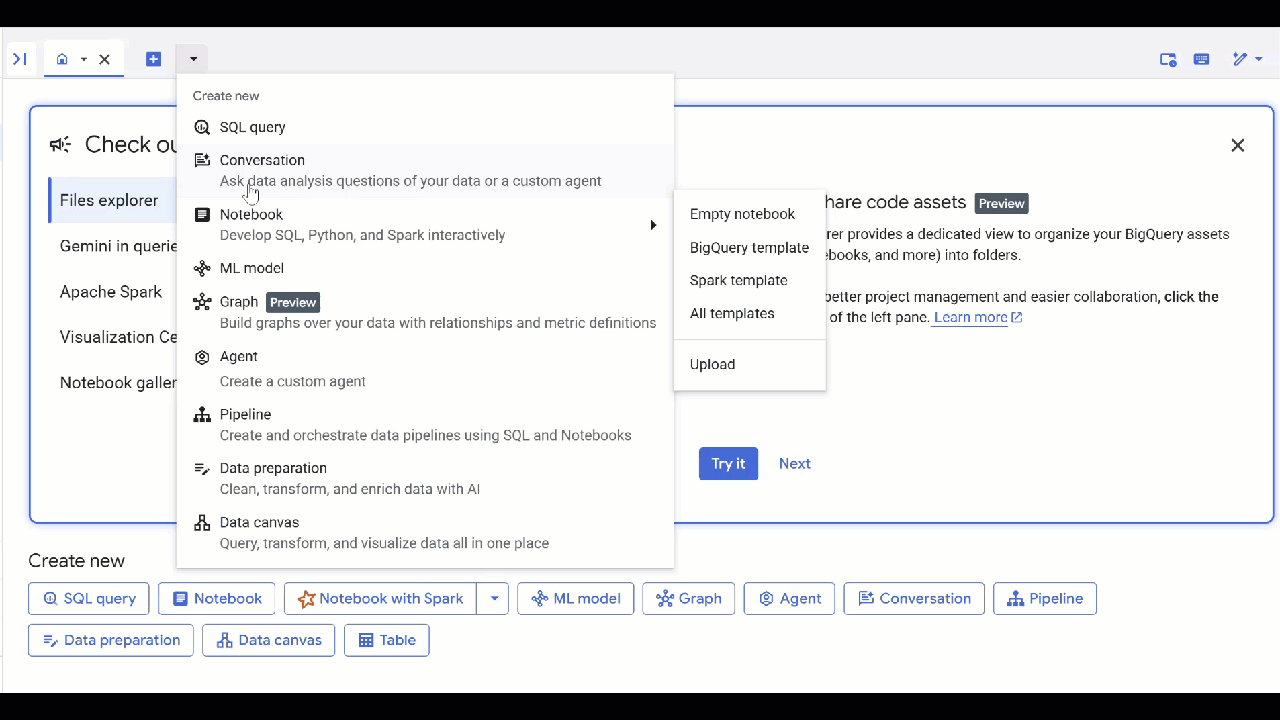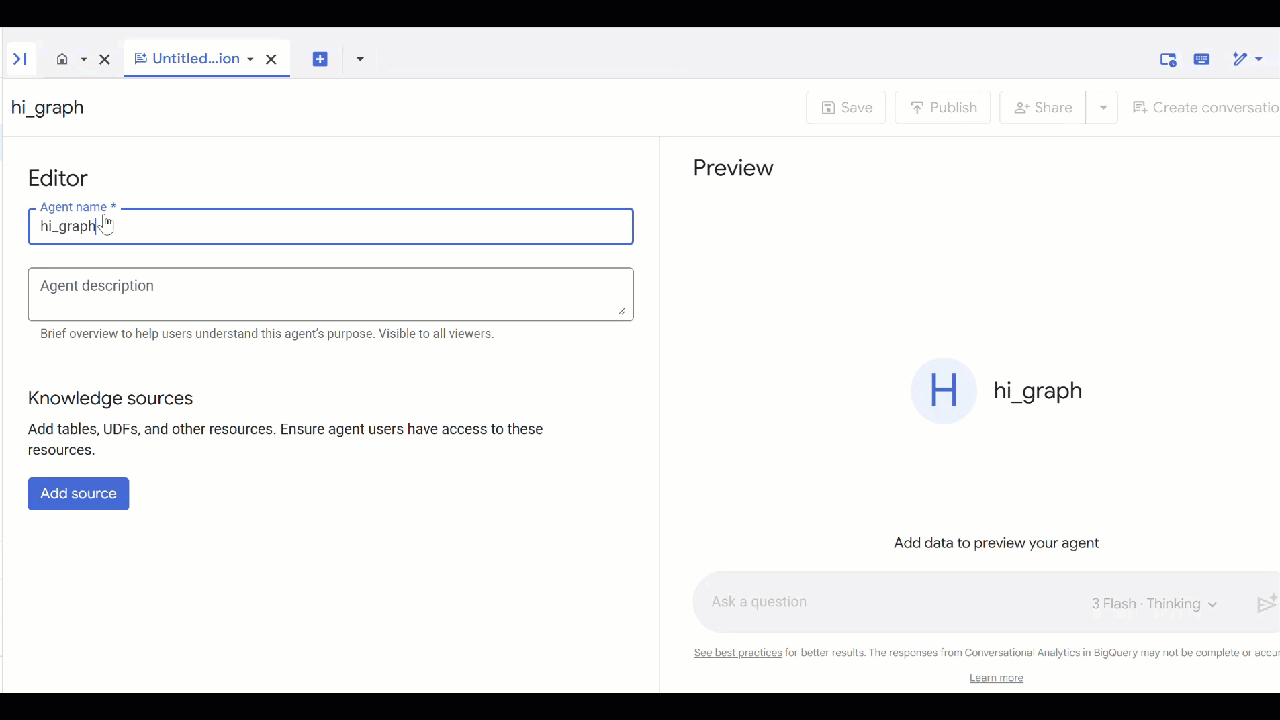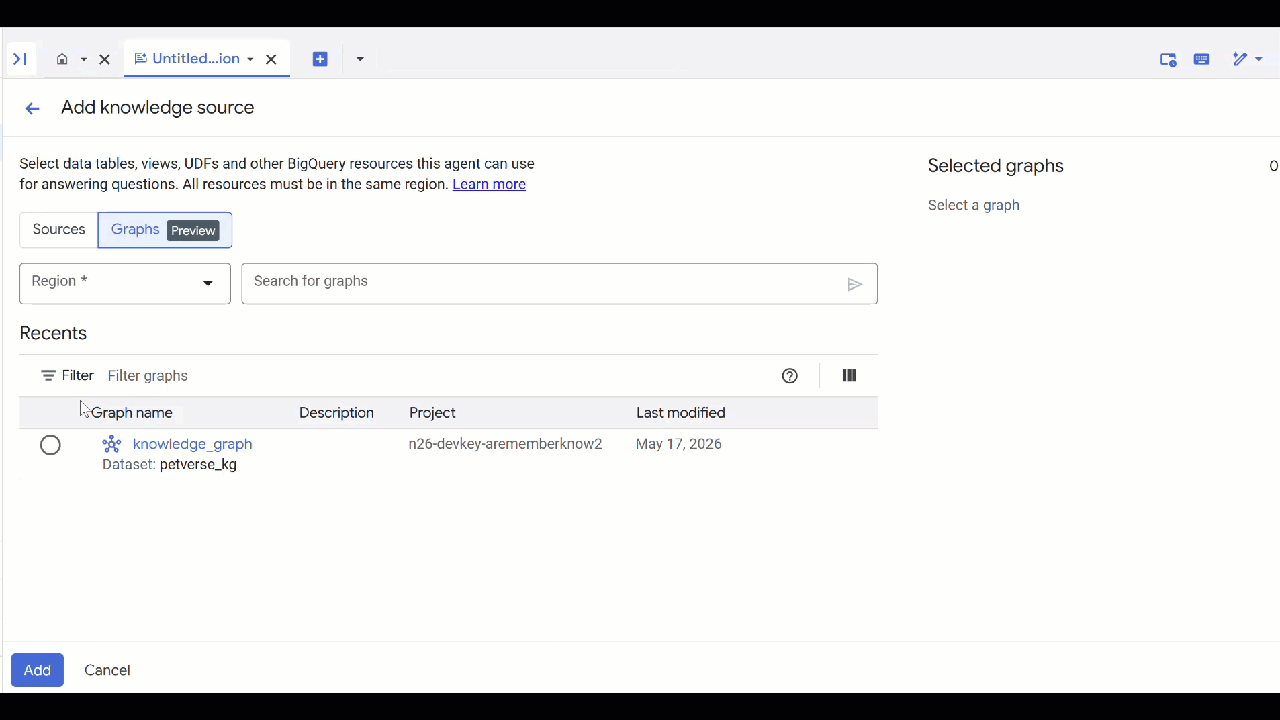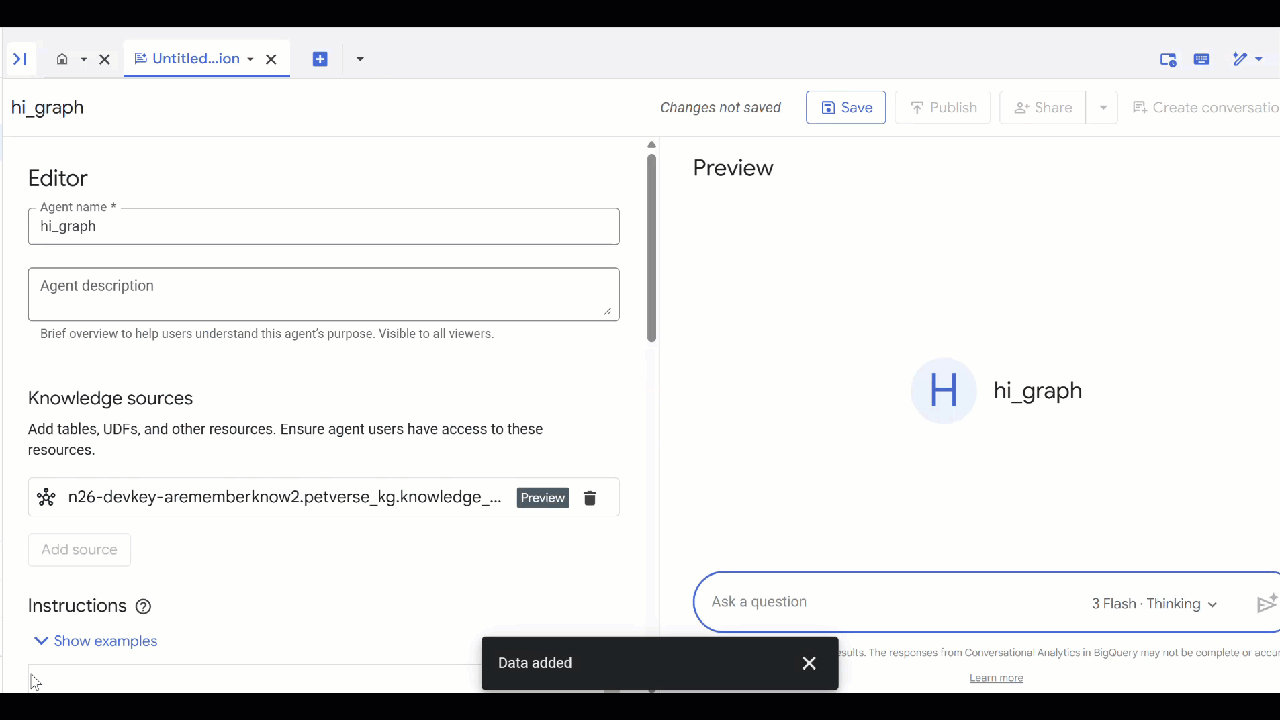
petverse. - Nhấp vào Thêm nguồn rồi nhấp vào Biểu đồ.
- Chọn
knowledge_graphbạn đã tạo rồi nhấp vào Thêm.
Giờ đây, bạn có thể đặt câu hỏi cho tác nhân và xem câu trả lời cũng như suy luận đằng sau câu trả lời đó. Sau đây là một số câu hỏi mẫu nếu bạn cần nguồn cảm hứng. Mô hình tư duy có thể mất nhiều thời gian hơn một chút nhưng có khả năng tạo ra một truy vấn GQL tốt hơn. Bạn có thể xem những nội dung mà tính năng này tạo ra bằng cách mở rộng Show Thinking.
- Tìm thú cưng có cùng chế độ ăn, hoặc là bạn bè với thú cưng thích ngủ trưa.
- Có thú cưng nào có cùng sở thích, món ăn hoặc đồ chơi yêu thích không? Liệt kê các cặp và mối quan tâm chung của họ.
- Tìm những thú cưng có cùng loài hoặc giống nhưng lại có sở thích hoàn toàn khác nhau.
9. Dọn dẹp
Để tránh các khoản phí phát sinh cho tài khoản Google Cloud của bạn, hãy xoá các tài nguyên đã tạo trong lớp học lập trình này.
- Xoá cụm GKE:
gcloud container clusters delete petverse-cluster --region $REGION --quiet
- Xoá tập dữ liệu BigQuery (thao tác này sẽ xoá tất cả các bảng):
bq rm -r -f -d $PROJECT_ID:petverse_kg
- Xoá tài nguyên hàng đợi Pub/Sub:
gcloud pubsub subscriptions delete petverse-sub --quiet
gcloud pubsub topics delete petverse-topic --quiet
- Xoá kho lưu trữ Artifact Registry:
gcloud artifacts repositories delete gke-cats-repo --location=$REGION --quiet
- Xoá bộ chứa GCS dành riêng cho dự án:
gcloud storage buckets delete gs://$PROJECT_ID-petverse --quiet
10. Xin chúc mừng
Xin chúc mừng! Bạn đã tạo thành công một quy trình sơ đồ tri thức phân tán bằng GKE và Gemini, đồng thời truy vấn quy trình đó bằng Biểu đồ thuộc tính BigQuery.
Kiến thức bạn học được
- Cách triển khai các công việc phân tán trên GKE Autopilot.
- Cách sử dụng Gemini để trích xuất dữ liệu đa phương thức.
- Cách sử dụng tính năng nhúng tự động của BigQuery.
- Cách tạo và truy vấn Biểu đồ thuộc tính trong BigQuery.