
1. 简介
在此 Codelab 中,您将为“Petverse”构建分布式知识获取流水线。您将处理 Cloud Storage 存储分区中的非结构化多媒体资源(音频、视频、图片、文本/CSV),提取有关宠物(最喜欢的食物、爱好)的关键信息,并创建知识图谱。您将使用 Google Kubernetes Engine (GKE) 上的 Gemini 多模态处理来扩缩多媒体文件的处理。最后,您将把这些数据存储在 BigQuery 中,并使用新的 BigQuery 属性图功能来分析关系。
我们将利用 Google Kubernetes Engine 的强大功能来演示并行处理大量数据。
为何要使用知识图谱?
与传统的关系型数据库相比,知识图谱更适合表示和分析实体之间复杂的关联。
我们将使用 Gemini 2.5 Flash 分析图片、音频和视频文件,并确定有关不同宠物的事实。
您将执行的操作
- 在 GKE 上构建和部署分布式数据处理作业。
- 使用 Gemini 从多媒体文件中提取实体和关系。
- 将知识图谱数据存储在 BigQuery 中。
- 使用 Graph Query Language (GQL) 在 BigQuery 中创建和查询属性图 。
所需条件
- 网络浏览器,例如 Chrome
- 启用了结算功能的 Google Cloud 项目
- 在项目中创建资源和修改 IAM 政策的权限
此 Codelab 适合各种水平的开发者,包括新手。
预计时长: 45 分钟
费用: 在此 Codelab 中创建的资源费用应低于 5 美元。
2. 准备工作
创建 Google Cloud 项目
- 前往 Google Cloud 控制台:https://console.cloud.google.com,然后选择或创建 Google Cloud 项目。
- ⚠️ 请记下项目 ID。您将在本实验中将其用于多个命令。
启动 Cloud Shell
- 在新标签页中打开 Cloud Shell:https://shell.cloud.google.com/。
- 如果出现提示,请点击授权 。
- 替换
PROJECT_ID,并将以下命令粘贴到终端中:
export PROJECT_ID="YOUR_PROJECT_ID"
gcloud config set project $PROJECT_ID
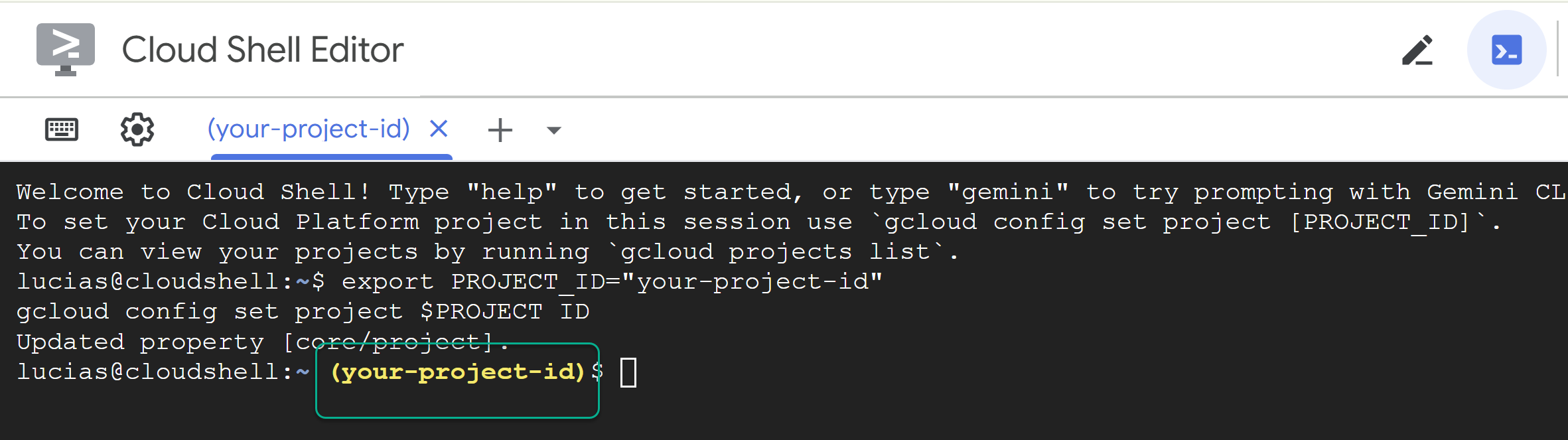
📝 注意 :您的项目在命令行中将以黄色显示。如果会话重启,请务必重新运行上述命令以设置项目 ID。
启用 API
运行以下命令以启用所有必需的 API:
gcloud services enable \
aiplatform.googleapis.com \
bigquery.googleapis.com \
artifactregistry.googleapis.com \
container.googleapis.com \
cloudbuild.googleapis.com \
pubsub.googleapis.com
克隆代码库
运行以下命令以克隆代码库。
cd ~/
git clone --filter=blob:none --no-checkout https://github.com/GoogleCloudPlatform/devrel-demos.git
cd ~/devrel-demos
git sparse-checkout init --cone
git sparse-checkout set codelabs/gke-knowledge-graph
git checkout main
cd codelabs/gke-knowledge-graph/
运行设置脚本
此脚本通过以下方式自动执行后端配置:
- 创建容器映像和 Artifact Registry 代码库
- 创建 BigQuery 数据集
- 创建 BigQuery 连接,以便从 SQL 执行 Gemini AI 函数
在终端中运行以下命令:
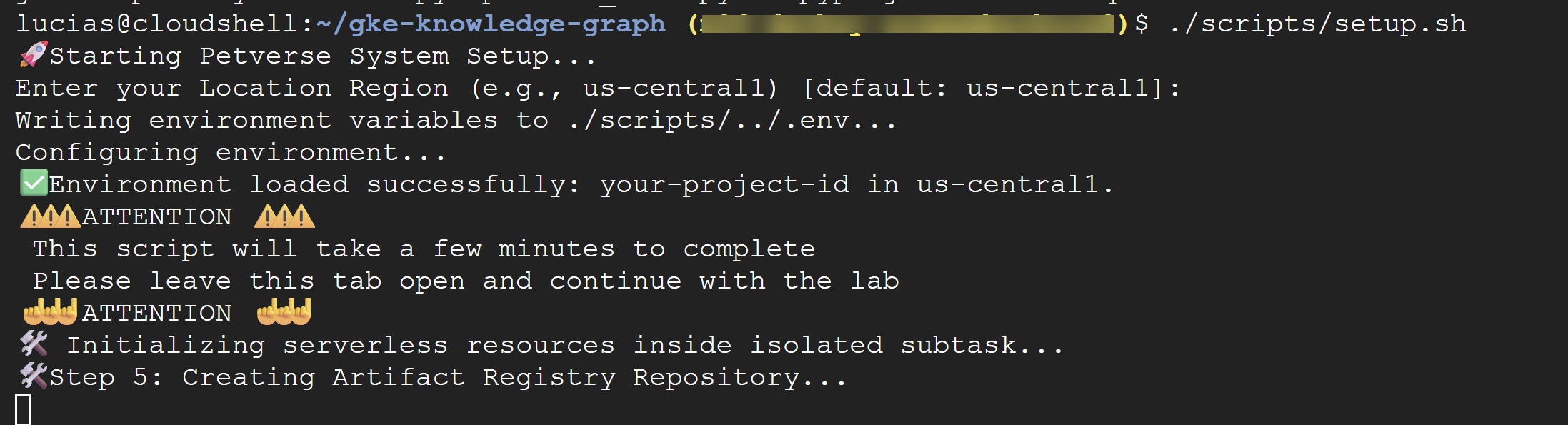
./scripts/setup.sh
如果脚本提示您输入配置详细信息,请使用以下值:
- 项目 ID: 使用您在上一步中创建的 ID。
- 区域:
us-central1
⚠️ 重要提示 :脚本需要几分钟才能完成。请保持此终端窗口处于打开状态,以便在后台完成。 __如需继续执行下一步,请打开新的终端标签页或窗口以运行下一个命令。要继续执行下一步,请打开新的终端标签页或窗口来运行后续命令。
3. 设置 Data Agent Kit
- 使用右上角的铅笔图标启用 Cloud Shell 编辑器。
- 在 Cloud Shell 编辑器中,点击左侧边栏中的扩展程序 图标。
- 搜索 Google Cloud Data Agent Kit ,如果尚未安装,请点击安装 。
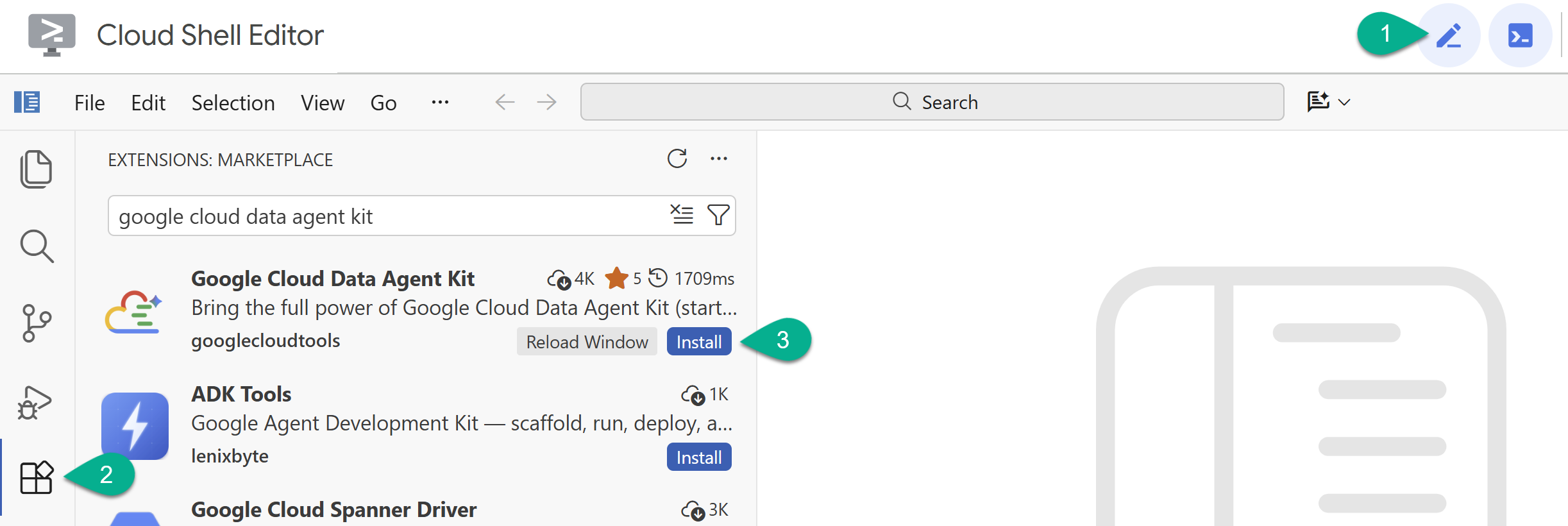
- 使用扩展程序登录您的 Google 账号。
- 在“配置摘要”中,输入您的项目 ID 和
us-central1作为区域。
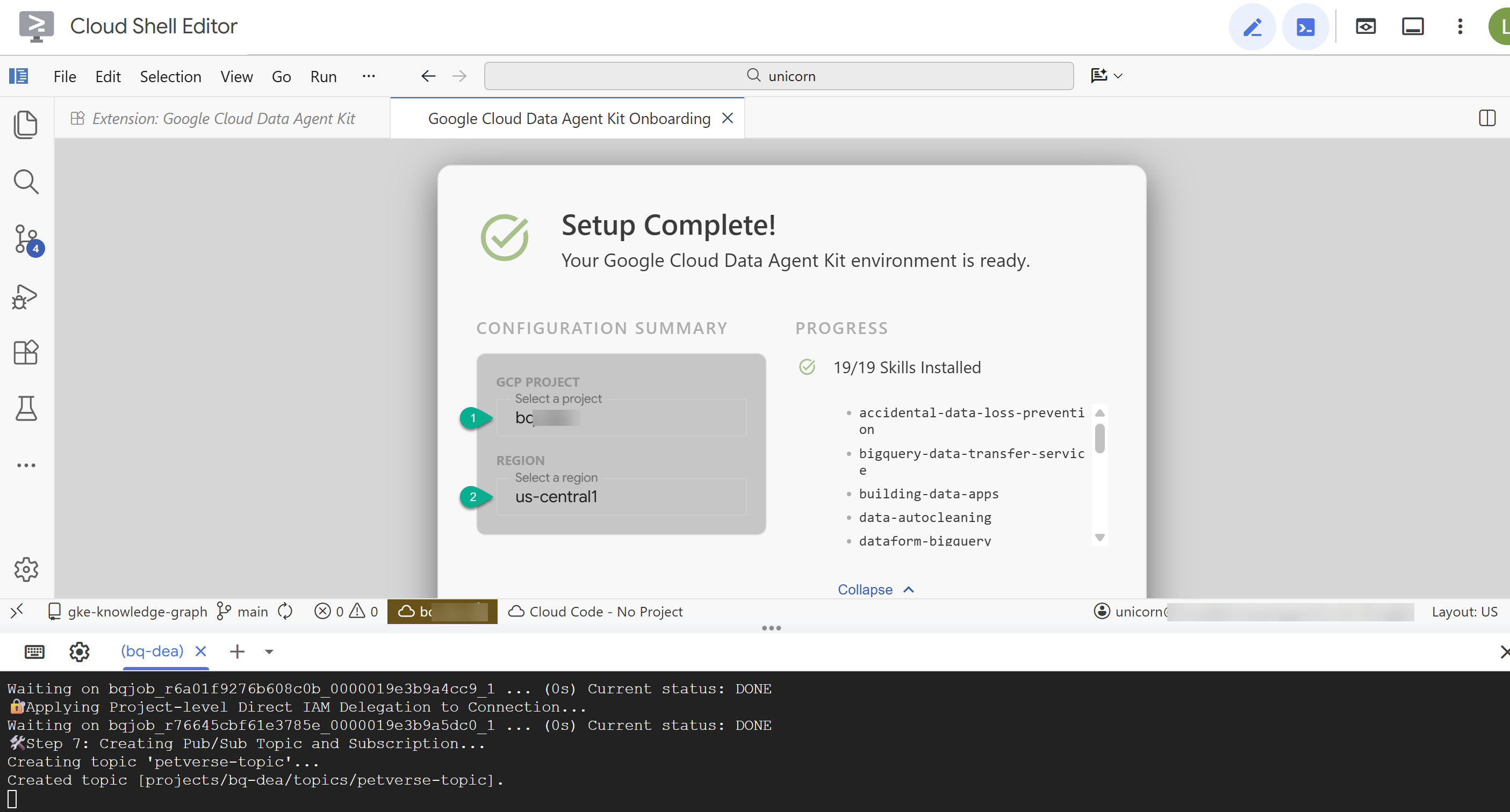
- 点击配置 MCP 服务器 。您无需对此窗口进行任何更改,只需点击开始使用 即可。
- 如果出现提示,请重新加载窗口。您现在可以关闭“快速入门指南”标签页。
在 BigQuery 中设置表
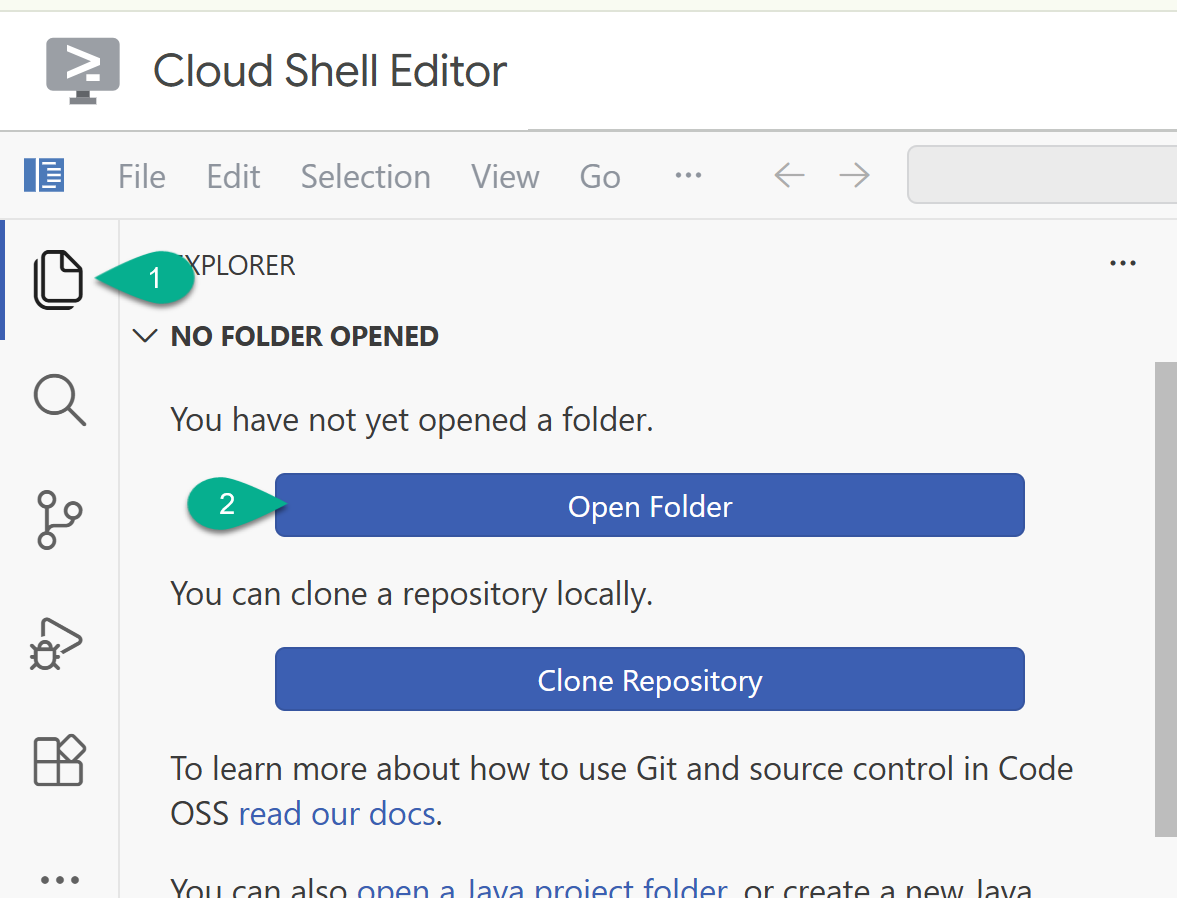
- 在边栏中,返回到探索器。如果您的主文件夹(例如
/home/your_user_name/)尚未打开,请点击打开文件夹 并选择该文件夹。
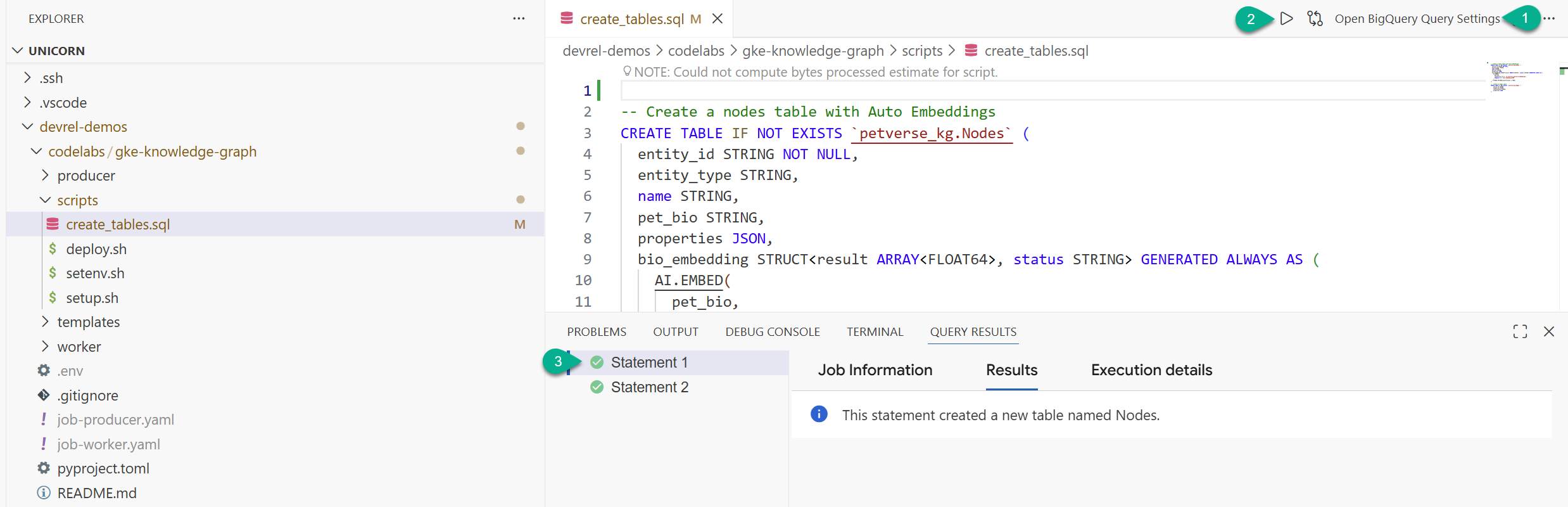
- 在探索器窗口中,找到您从代码库克隆的文件夹 (
devrel-demos)。在codelabs/gke-knowledge-graph/scripts下,您会找到create_tables.sql。打开该文件 。 - 点击右上角的打开查询设置 。
- 选择 BigQuery 。点击保存 和关闭 。
- 点击运行 。
您应该会看到两个语句已成功执行。您现在已创建用于存储知识图谱的节点和边的表。
您可以关闭 create_tables.sql 标签页和结果控制台。
4. 初始化 GKE 集群
我们将使用 GKE Autopilot 运行数据处理作业。Autopilot 是推荐的最佳实践,因为它会为您管理集群基础架构。
到目前为止,设置脚本应该已完成。您应该会看到一条成功消息:🎉🦄 Setup successfully finished! 🎉🦄。
将此命令粘贴到终端中以创建集群:
source scripts/setenv.sh
gcloud container clusters create-auto petverse-cluster \
--region=$REGION
🕓 这大约需要 5 分钟。
获取与集群交互的凭据:
source scripts/setenv.sh
gcloud container clusters get-credentials petverse-cluster --region $REGION
您应该会看到以下输出:
Fetching cluster endpoint and auth data. kubeconfig entry generated for petverse-cluster.
5. 配置 Workload Identity
适用于 GKE 的 Workload Identity Federation(使用直接资源访问)允许您的 GKE 工作负载安全地访问 Google Cloud 服务,而无需管理服务账号密钥。
执行 deploy.sh 以:
- 创建 Kubernetes 服务账号
- 直接向 Kubernetes 服务账号正文授予必要的 IAM 角色
- 将 IAM 服务账号绑定到 Kubernetes 服务账号
- 为 Kubernetes 服务账号添加注解以完成链接
source scripts/setenv.sh
./scripts/deploy.sh
6. 部署分离的处理作业
在此步骤中,您将把 enqueuer(生产者)和处理引擎(工作器)部署到 GKE 上。
我们新的分离式架构使用 Google Cloud Pub/Sub 异步处理资源:
- 生产者 扫描 GCS 并将所有文件路径排入 Pub/Sub 队列。
- 工作器 池在 GKE 中扩容,动态并行提取任务,通过 Gemini 处理任务,然后写入 BigQuery。
setup.sh 脚本已构建并推送生产者和工作器容器映像,将 Pub/Sub 主题排入队列,并动态生成 GKE 部署清单:job-producer.yaml 和 job-worker.yaml。
- 应用生产者作业以扫描存储分区并将所有资源排入队列:
kubectl apply -f job-producer.yaml
此作业运行并快速完成,因为它仅将元数据排入队列。
- 部署配置为运行 6 个并行工作器 以清空队列的工作器作业:
kubectl apply -f job-worker.yaml
GKE Autopilot 会自动检测待处理的 pod,动态扩容计算节点,并并行运行工作器以处理排入队列的音频、视频、图片和 CSV 文件。
7. 验证结果
- 检查作业的状态:
kubectl get jobs
等待 petverse-producer-job 和 petverse-worker-job 都显示成功完成。
🕓 这大约需要 10 分钟。您可以使用以下命令查看进度。
- 检查生产者的日志,验证其是否已成功将文件排入队列:
cd ~/devrel-demos/codelabs/gke-knowledge-graph
source scripts/setenv.sh
kubectl logs -l app=petverse-producer --tail=50
- 观察并行工作器处理队列中的文件:
kubectl logs -l app=petverse-worker --tail=50
(工作器具有 60 秒的空闲超时时间,当 Pub/Sub 队列为空时,会自动关闭并清理)。
验证 BigQuery 中的数据。
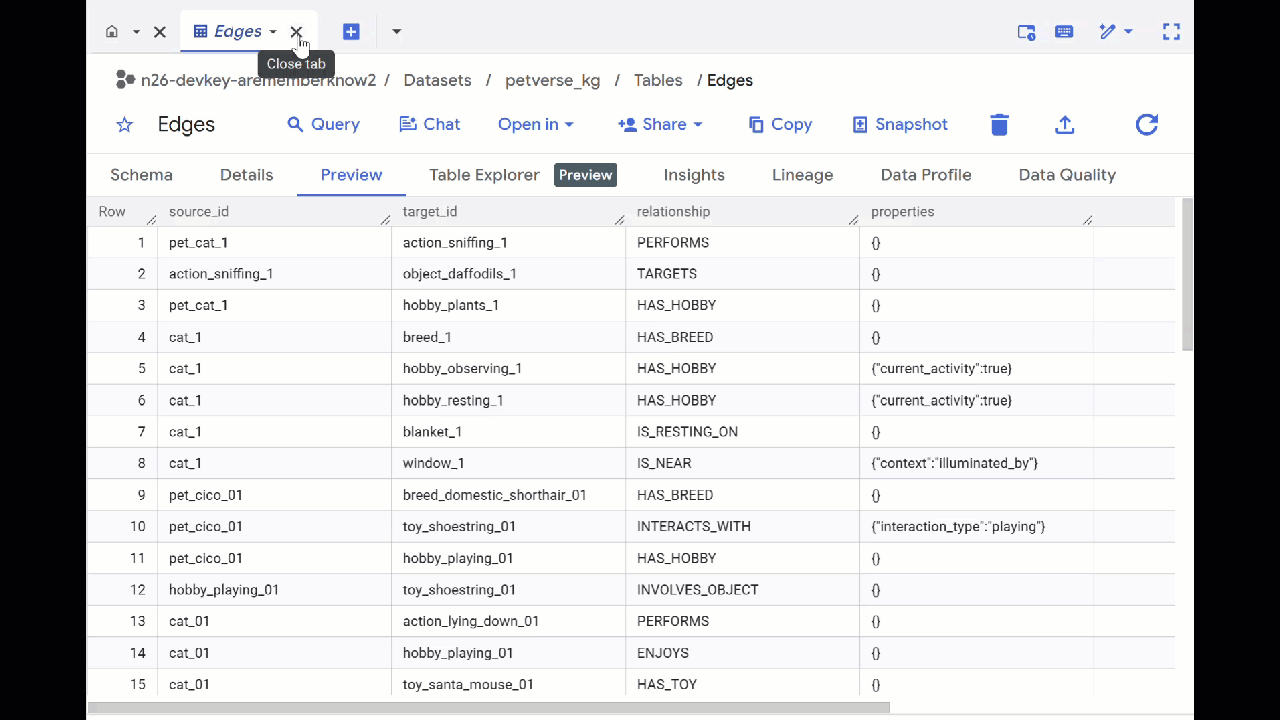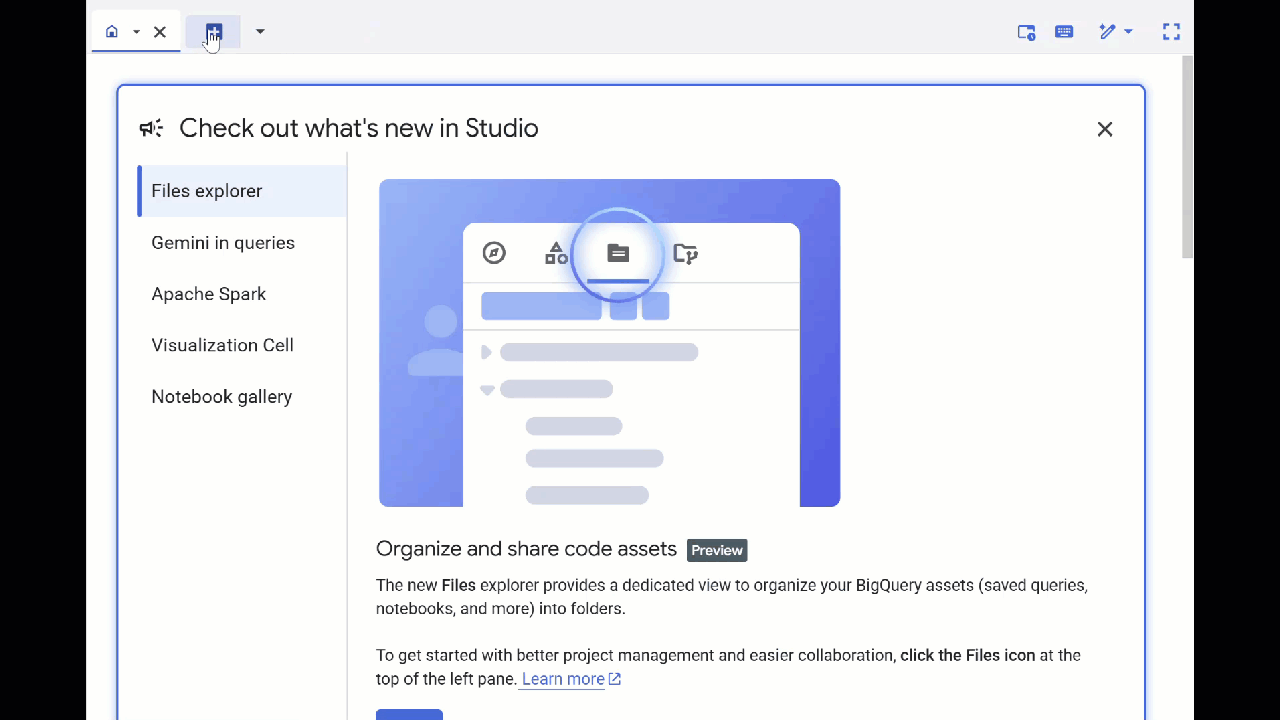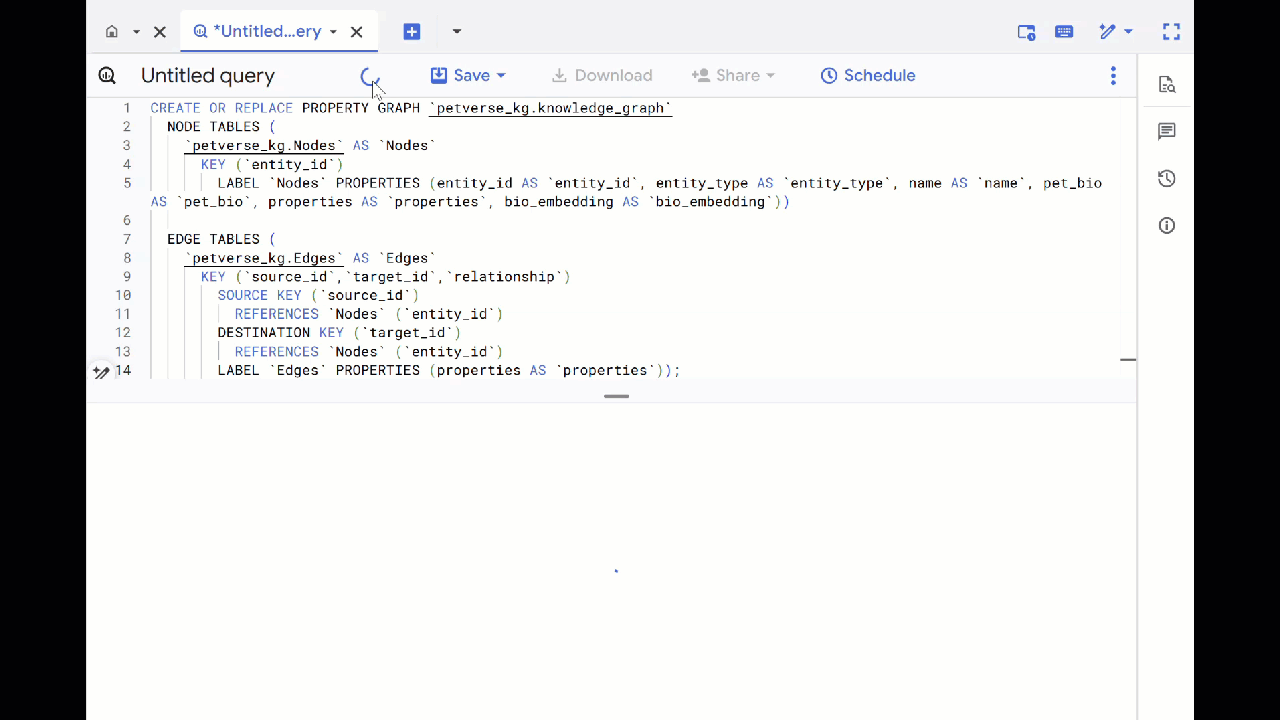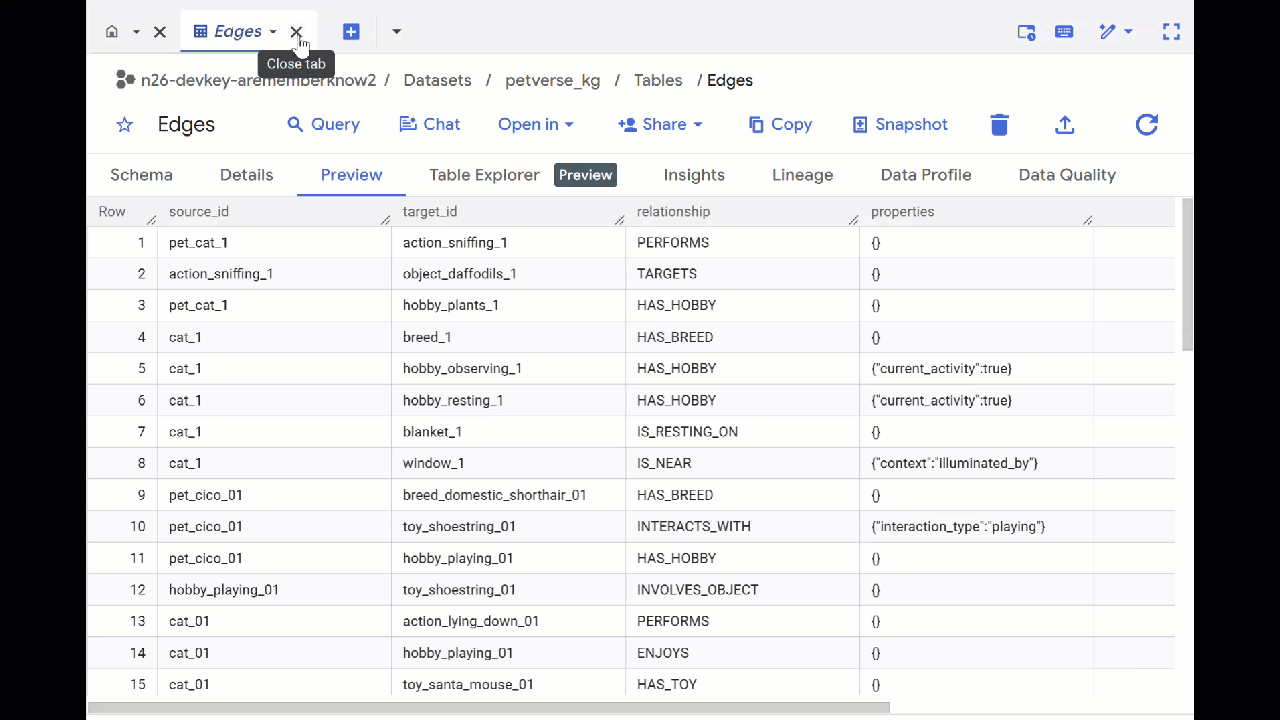
- 前往 BigQuery Studio。您将看到创建了两个表:petverse_kg.Nodes 和 petverse_kg.Edges。
- 如需查看表的内容,请双击其名称,然后点击预览 。
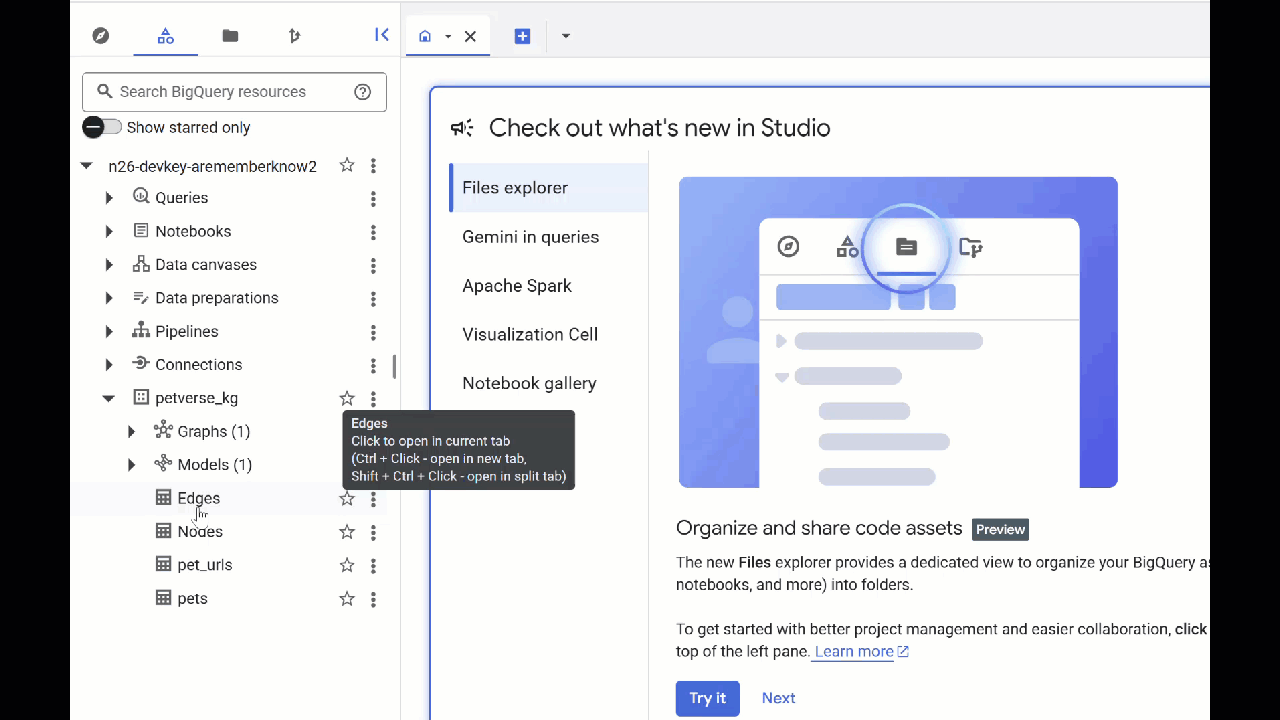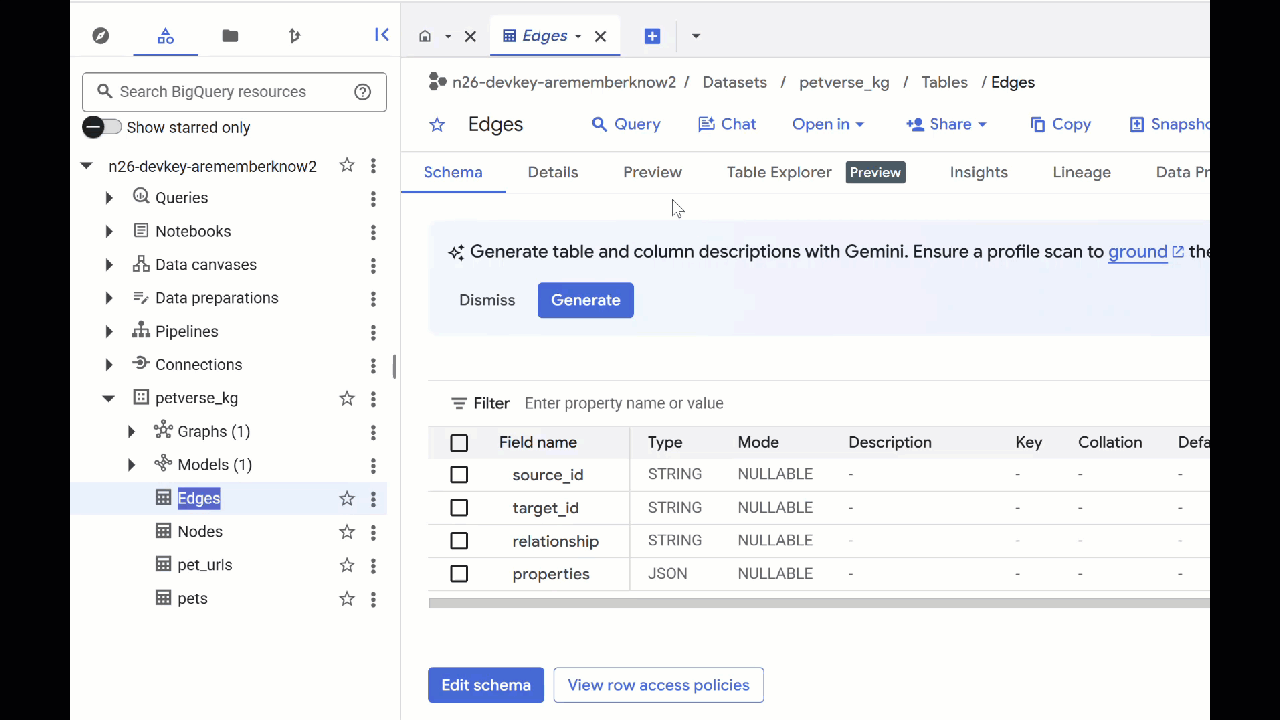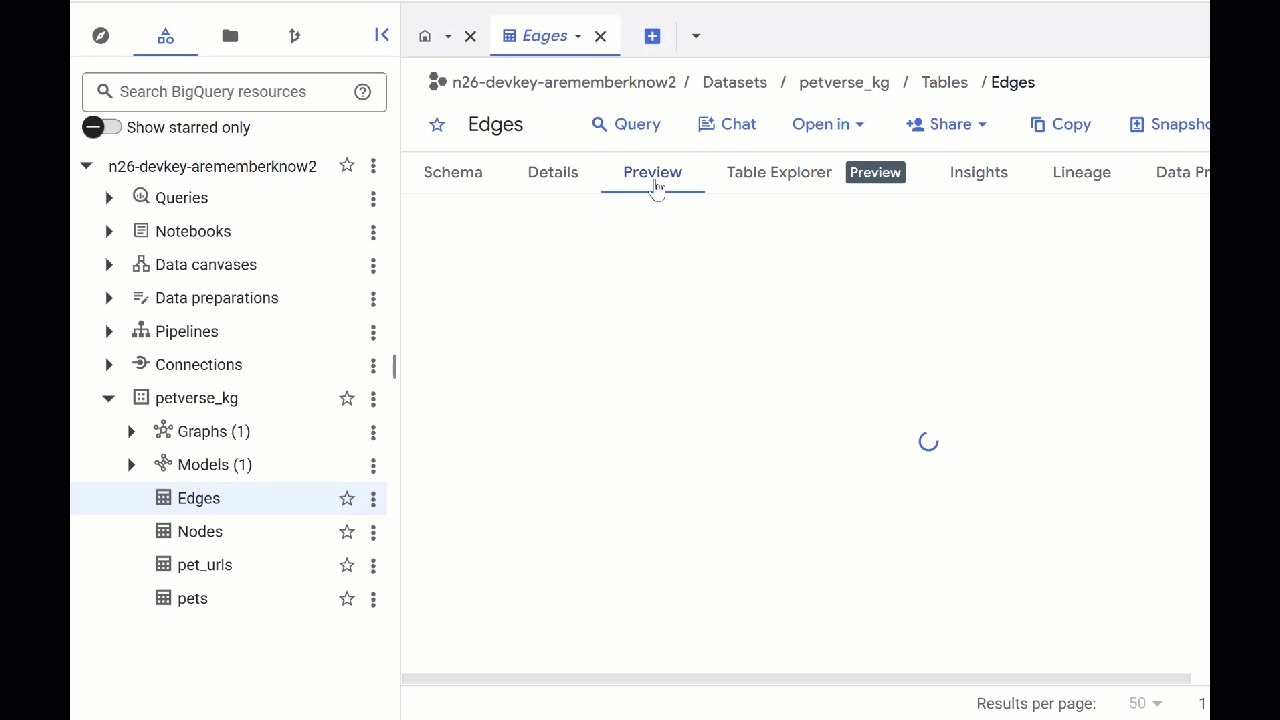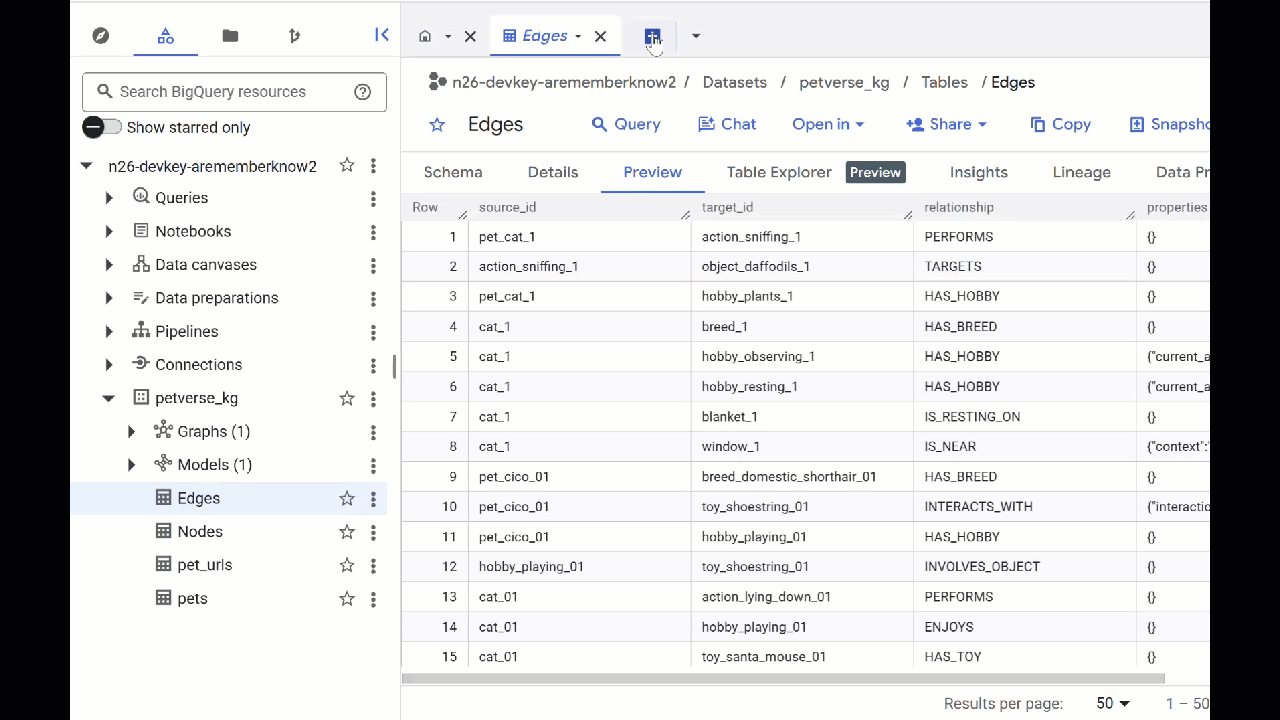
您将看到“节点”表包含有关 Gemini 在音频、视频和图片中提取的实体的信息。“边”表包含它们之间的关系。例如,如果您收听名为 SQL 的猫的音频,它喜欢玩鞋带,并且喜欢冻干的小鱼。
- 使用 + 按钮创建新查询。粘贴以下语句,然后点击运行:
SELECT n.name, n.entity_id, e.relationship, e.target_id
FROM
`petverse_kg.Nodes` n
JOIN
`petverse_kg.Edges` e
ON n.entity_id = e.source_id
WHERE n.name = 'SQL'
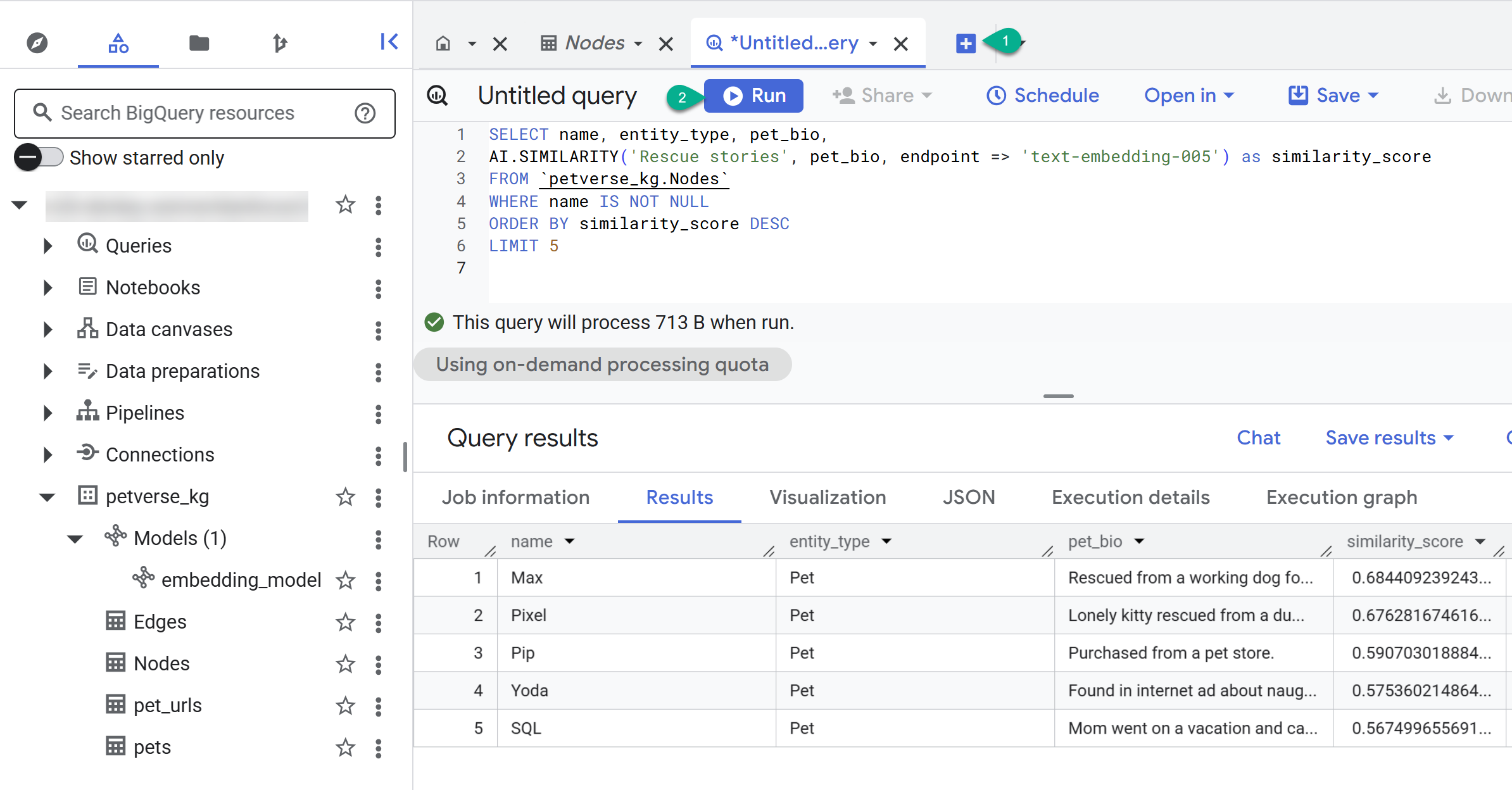
- 使用 + 按钮创建新查询。粘贴以下语句,然后点击运行:
SELECT name, entity_type, pet_bio,
AI.SIMILARITY('Pets who like to relax', pet_bio, endpoint => 'text-embedding-005') as similarity_score
FROM `petverse_kg.Nodes`
WHERE name IS NOT NULL
ORDER BY similarity_score DESC
LIMIT 5
您应该会看到喜欢放松的宠物的节点。此查询使用 AI 函数 AI.SIMILARITY 执行了语义搜索,以查找简历与查询文本最相似的宠物。
构建属性图
现在我们在 BigQuery 中有了节点和边,可以创建属性图来轻松查询关系。
创建图
- 覆盖之前的查询,然后运行以下 DDL 以创建属性图:
CREATE OR REPLACE PROPERTY GRAPH `petverse_kg.knowledge_graph`
NODE TABLES (
`petverse_kg.Nodes` AS `Nodes`
KEY (`entity_id`)
LABEL `Nodes` PROPERTIES (entity_id AS `entity_id`, entity_type AS `entity_type`, name AS `name`, pet_bio AS `pet_bio`, properties AS `properties`, bio_embedding AS `bio_embedding`))
EDGE TABLES (
`petverse_kg.Edges` AS `Edges`
KEY (`source_id`,`target_id`,`relationship`)
SOURCE KEY (`source_id`)
REFERENCES `Nodes` (`entity_id`)
DESTINATION KEY (`target_id`)
REFERENCES `Nodes` (`entity_id`)
LABEL `Edges` PROPERTIES (properties AS `properties`));
- 点击前往图 。您将看到图的可视化效果,其中包含一个具有指向自身的边的节点。这是正常现象。
查询图
- 您可以关闭所有之前的查询,然后使用 + 按钮打开新的空白查询。
- 使用 GQL 通过共同的兴趣(例如爱好、最喜欢的食物或玩具)查找与其他宠物相关的宠物。此多跳查询匹配连接到同一节点的两个不同的宠物:
GRAPH `petverse_kg.knowledge_graph`
MATCH p = (pet1:Nodes)-[e1]->(interest:Nodes)<-[e2]-(pet2:Nodes)
WHERE pet1.entity_id != pet2.entity_id
AND (LOWER(pet1.entity_type) = 'pet' AND LOWER(pet2.entity_type) = 'pet')
AND LOWER(interest.entity_type) IN ('hobby', 'action', 'activity', 'food', 'toy')
RETURN TO_JSON(p) as res
LIMIT 100
- 您应该会看到图的可视化效果。您可以点击节点以查看节点和边的属性。
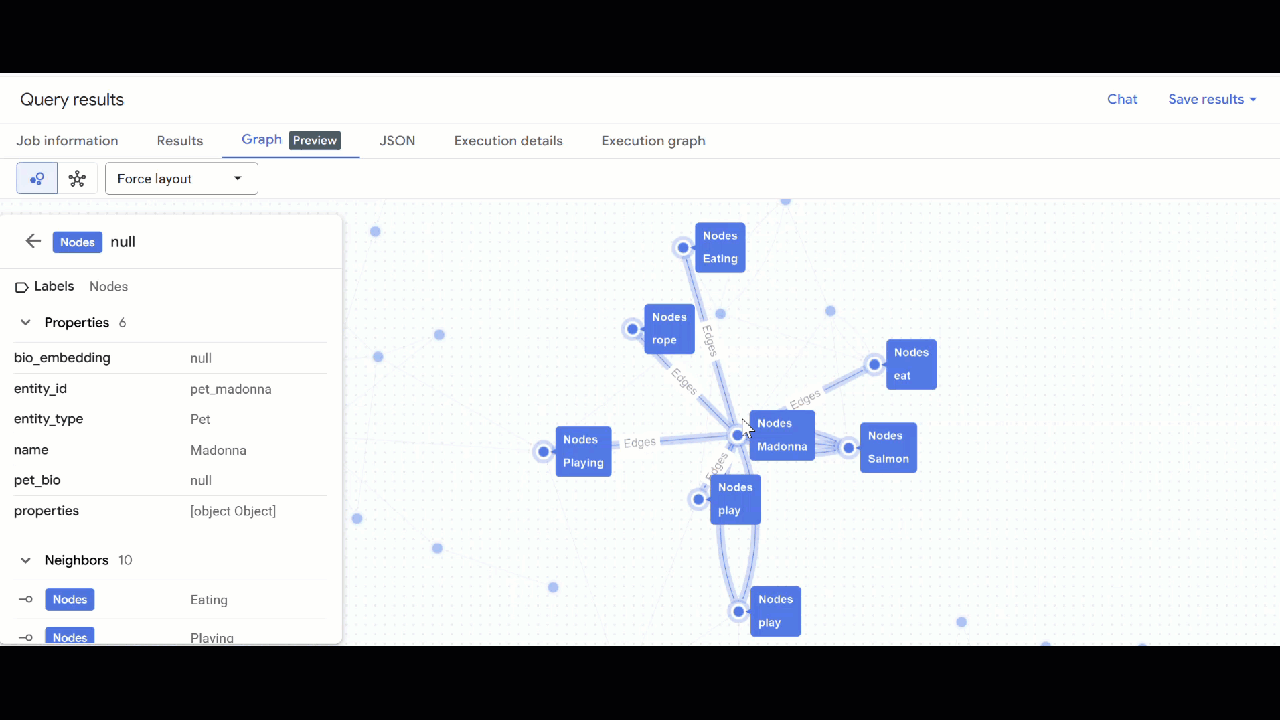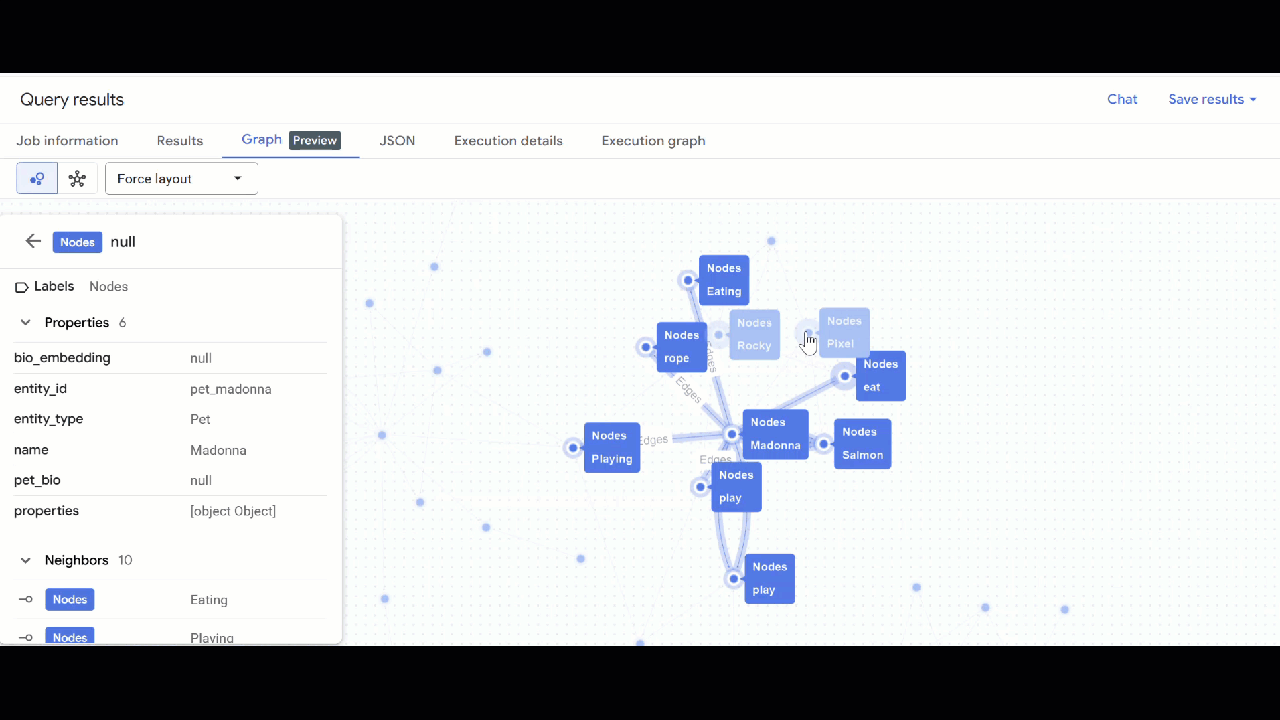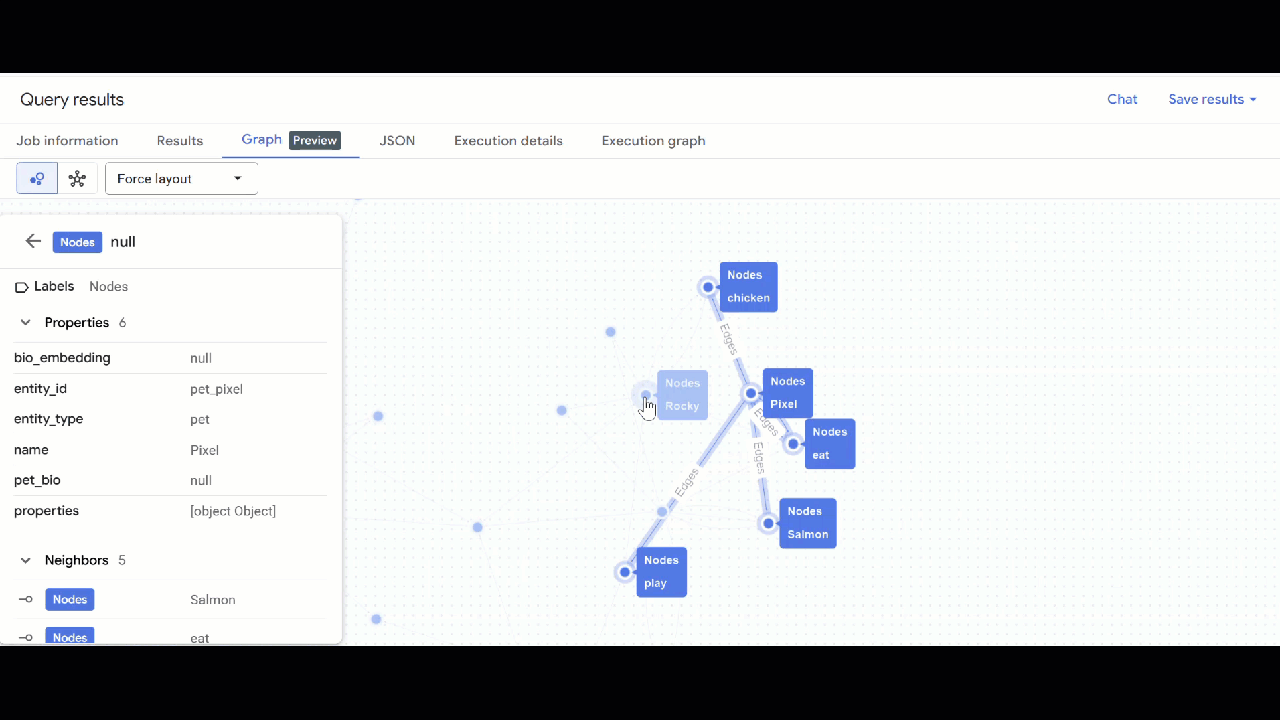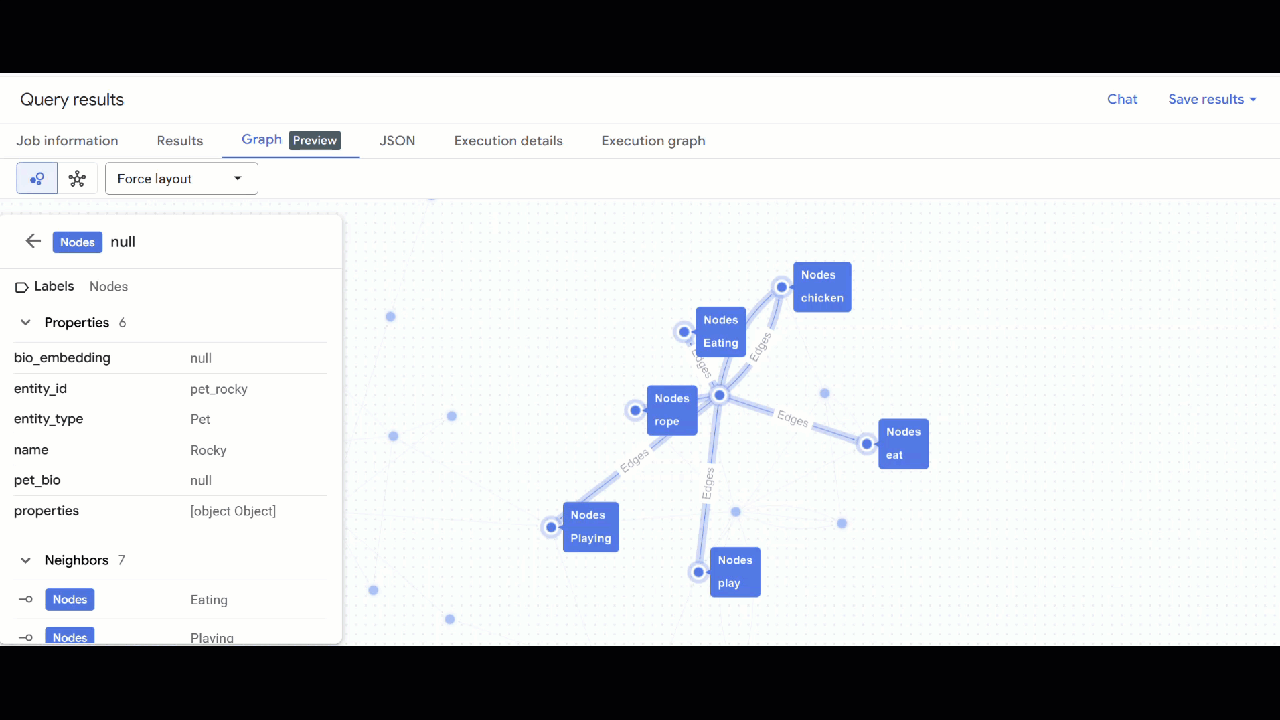
🕵️ 提示:您可以点击切换到架构视图 来调整节点显示的值:
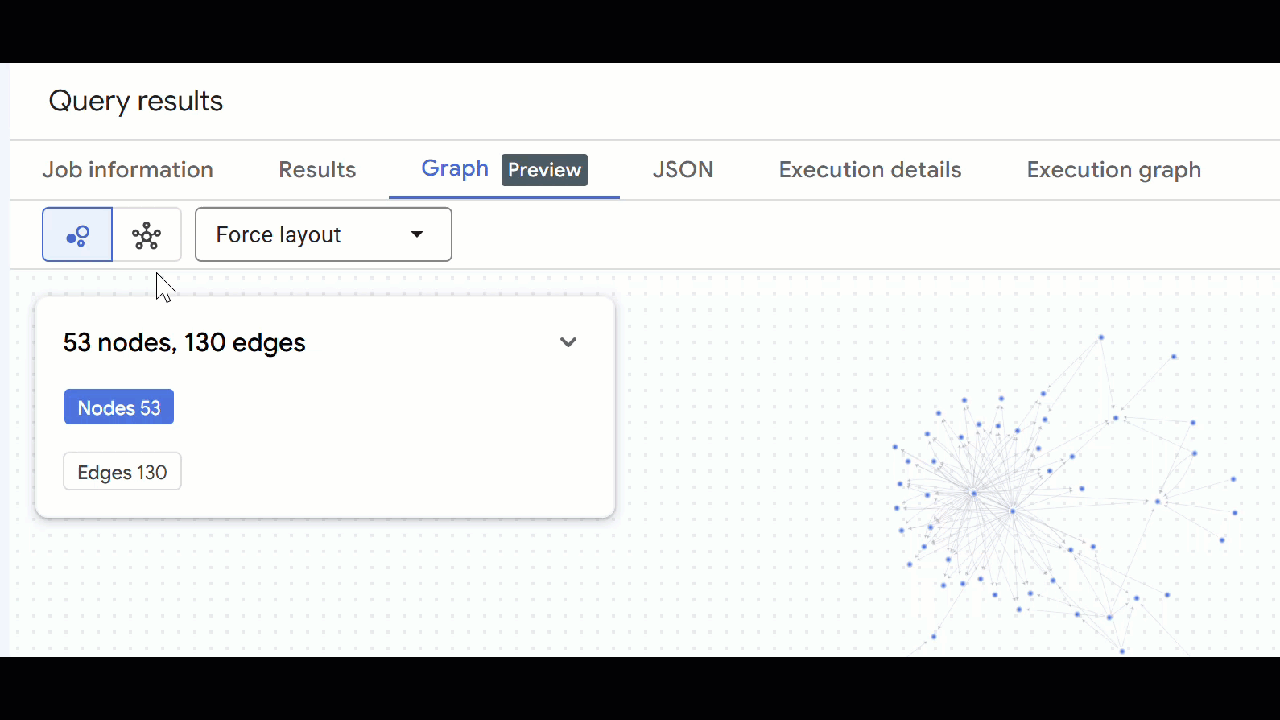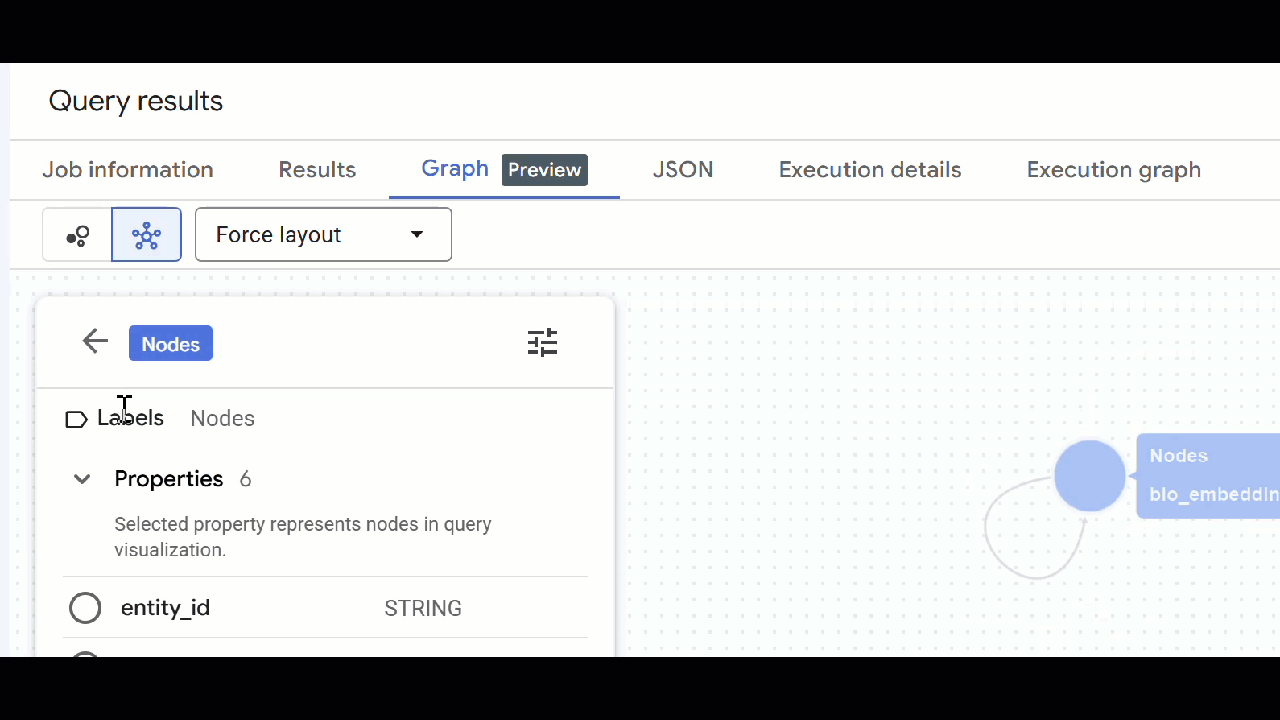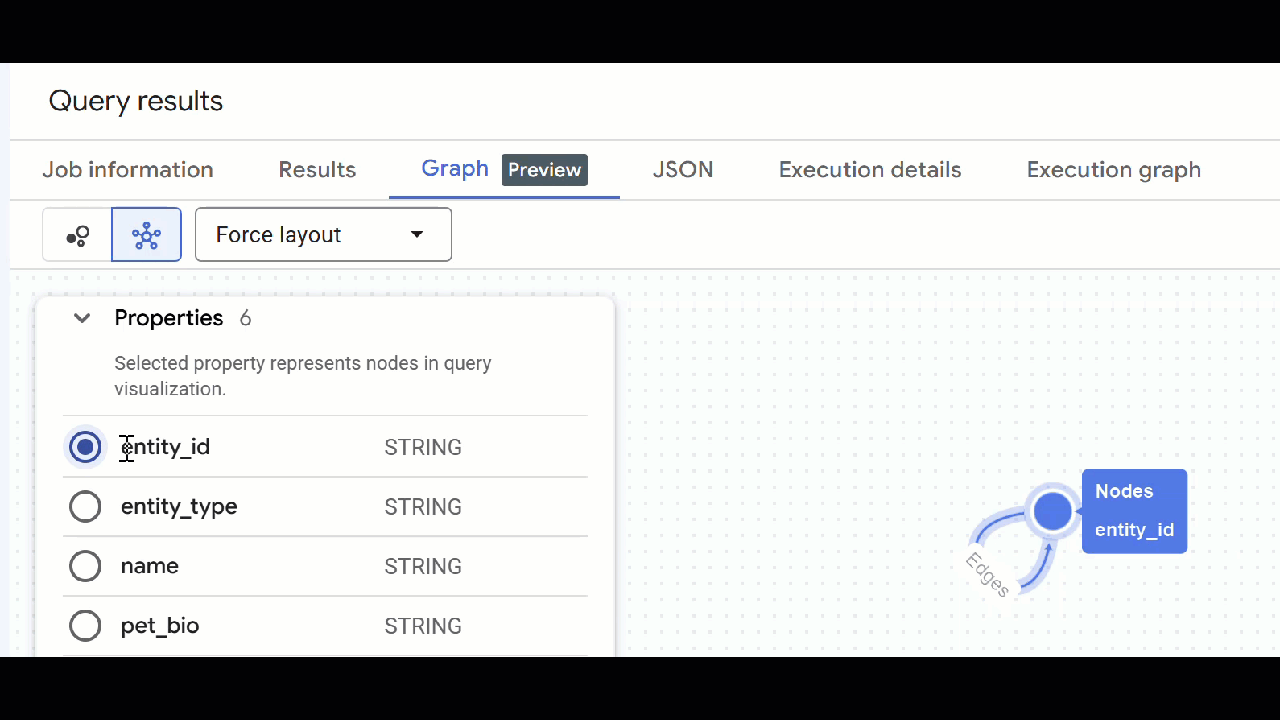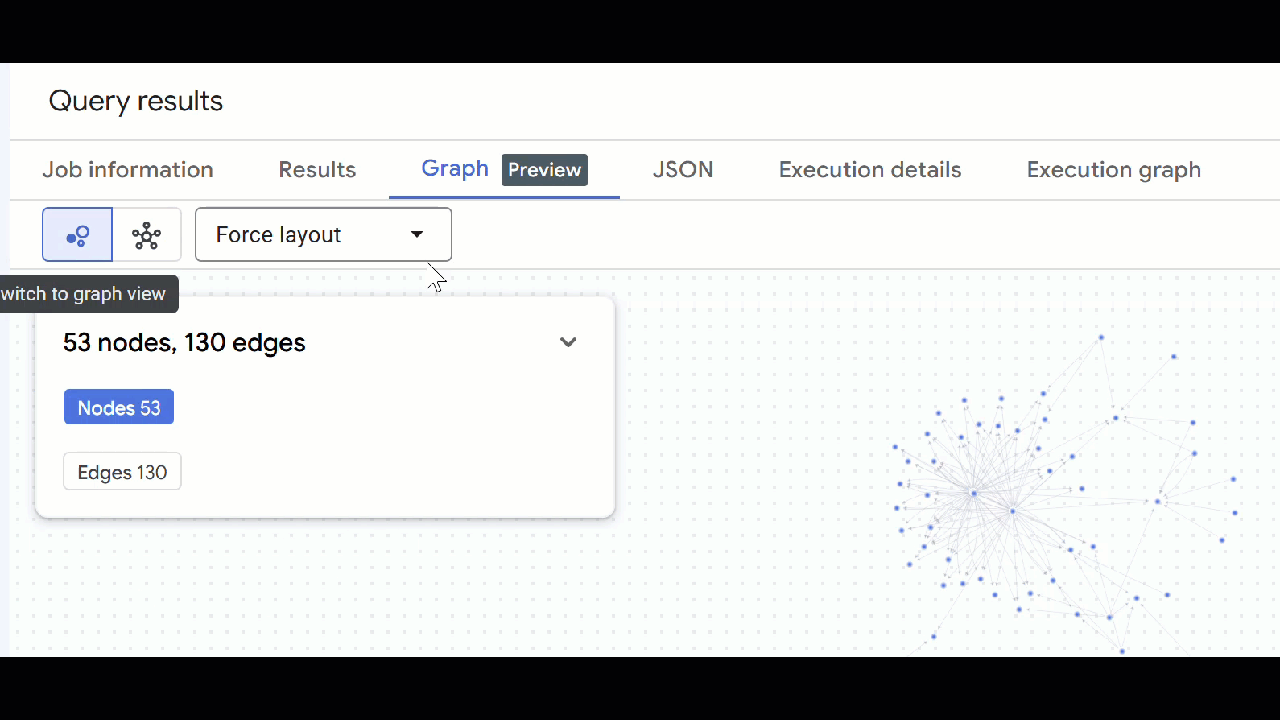
- 您可以关闭所有打开的查询标签页 。
8. 与图对话
- 在 + 符号旁边,您会找到一个下拉菜单。选择对话 。
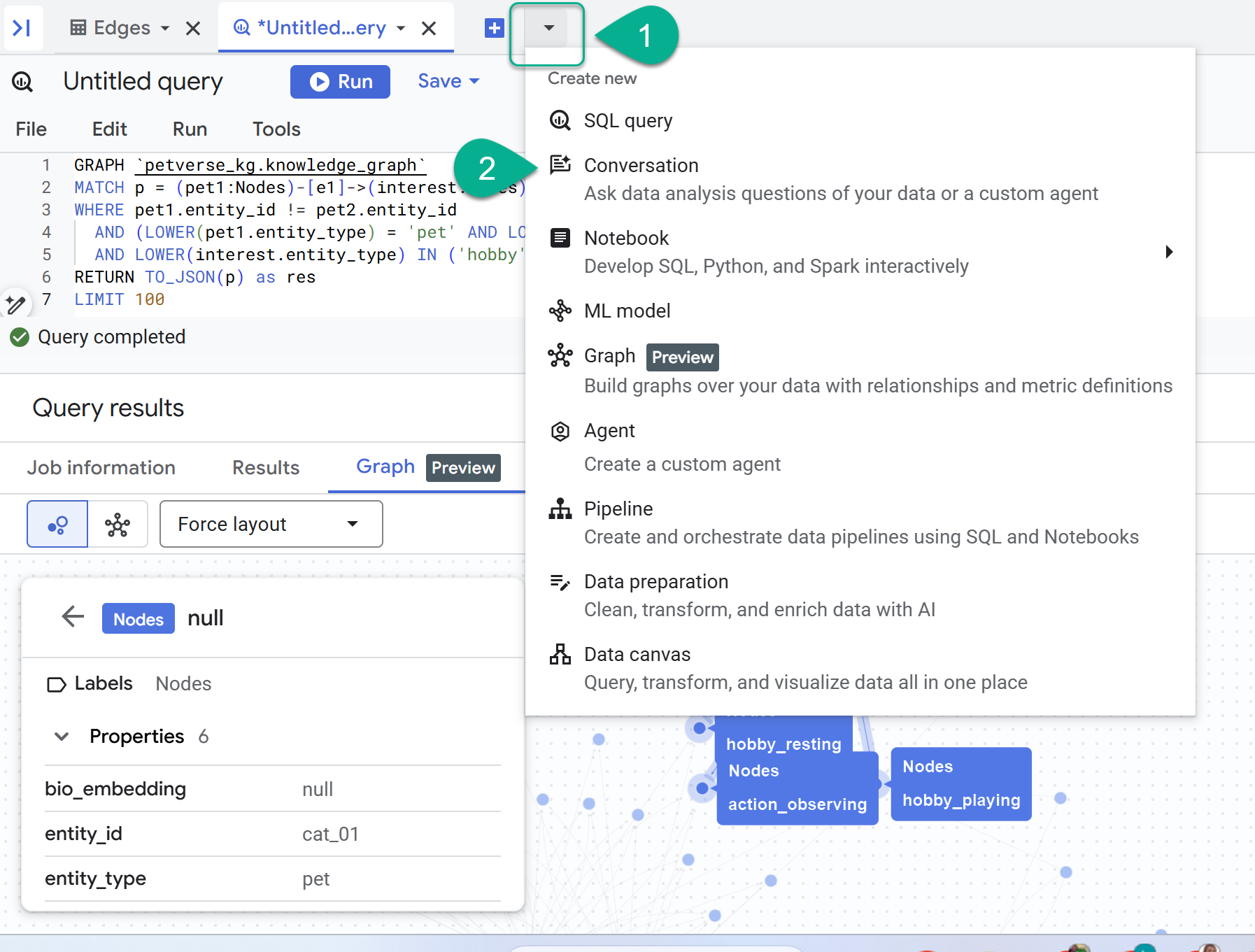
- 系统会提示您启用 Data Analytics API with Gemini。启用这两个 API。完成后,刷新窗口或创建新对话以查看代理。
- 点击新建代理 。
- 为代理命名,例如
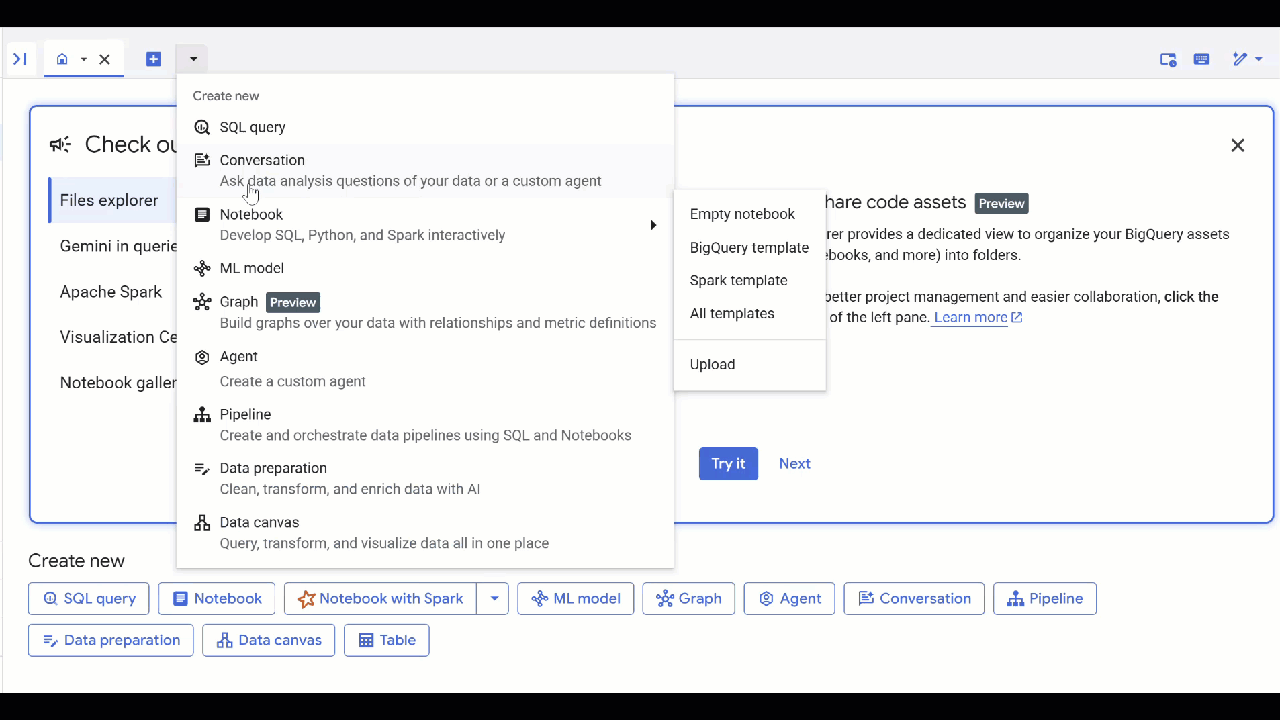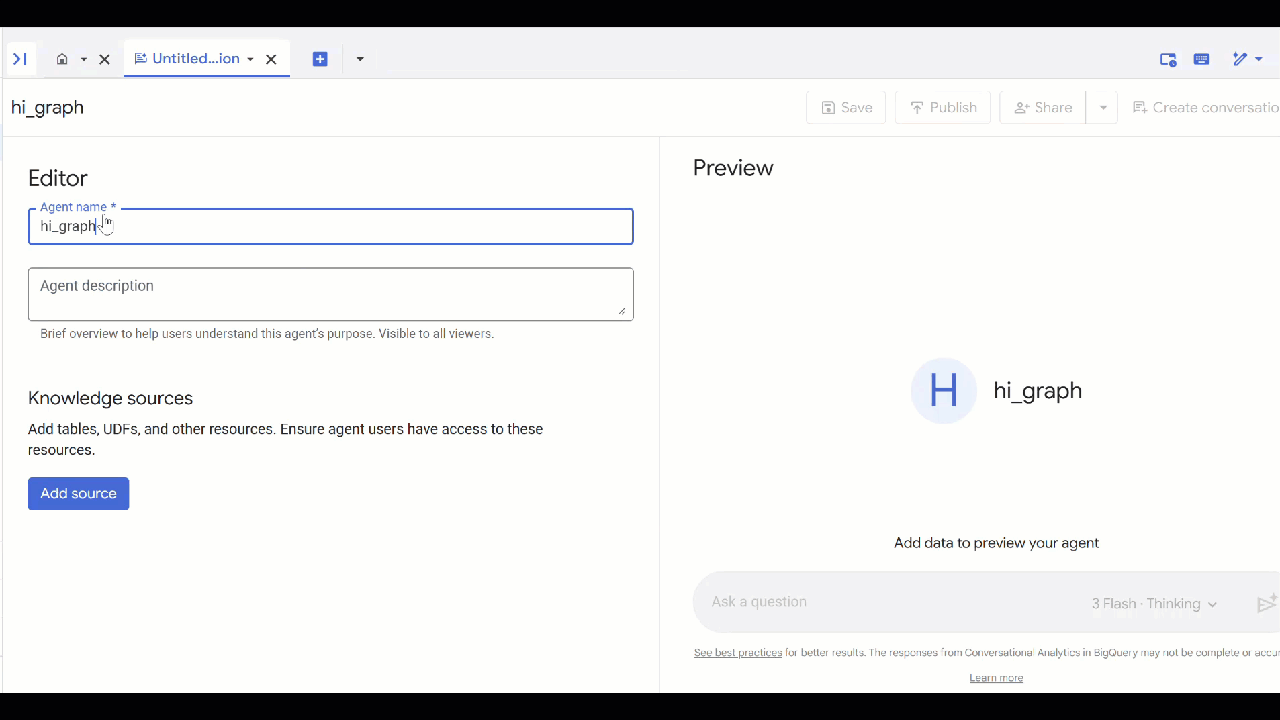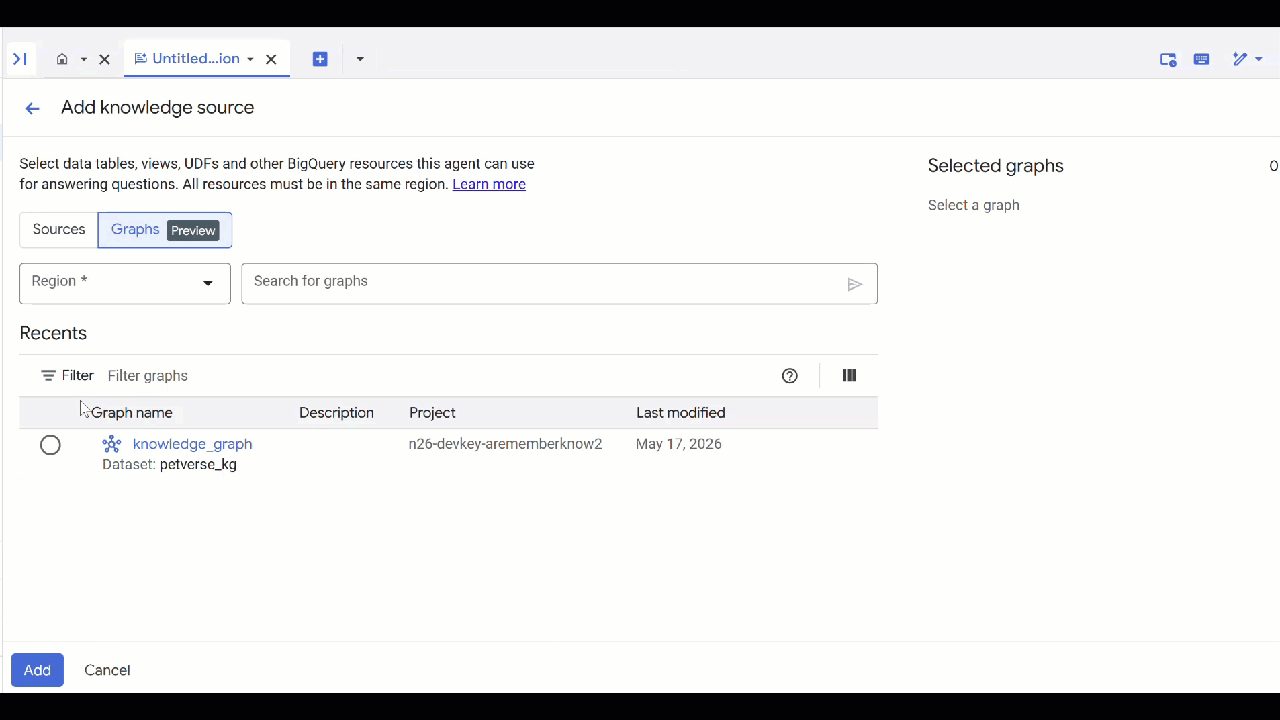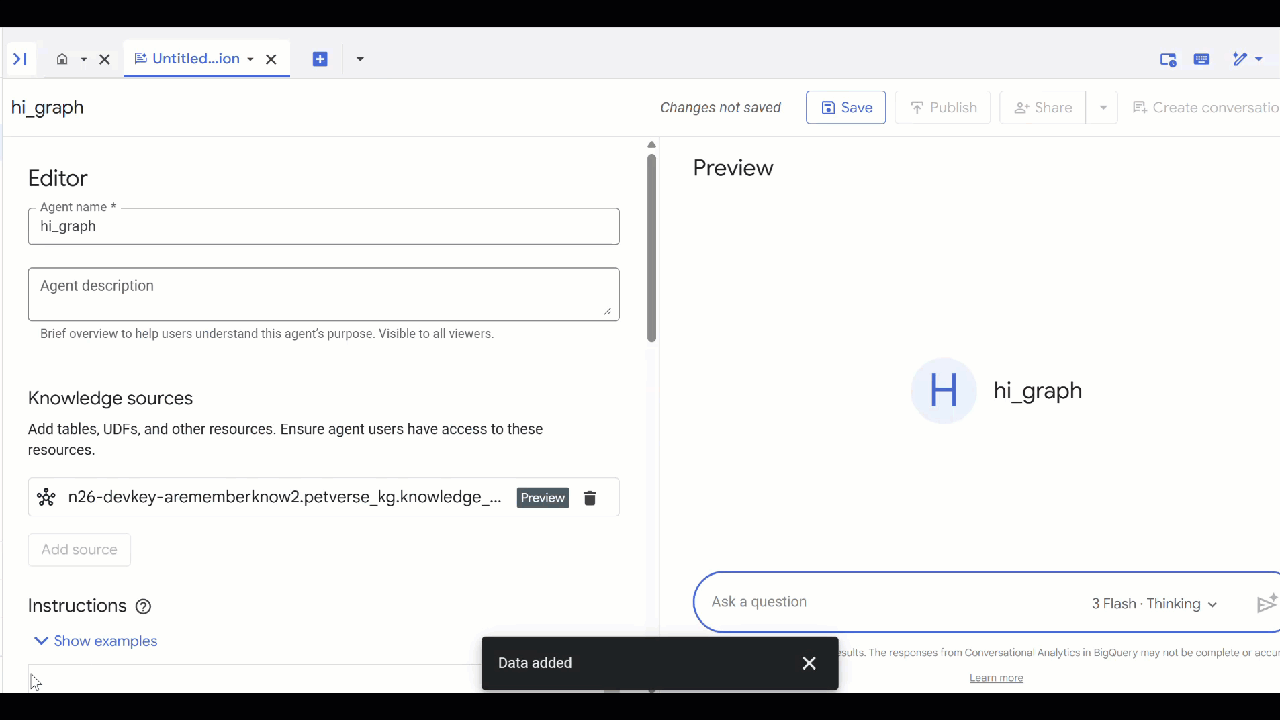
petverse。 - 依次点击添加来源 和图 。
- 选择您创建的
knowledge_graph,然后点击添加 。
您现在可以向代理提出问题,并查看答案及其背后的推理。如果您需要灵感,可以参考以下一些示例问题。思考模型可能需要更长的时间,但可能会构建更好的 GQL 查询。您可以展开 Show Thinking 来查看其构建的内容。
- 查找喜欢相同食物的宠物,这些宠物是喜欢小睡的宠物的朋友。
- 是否有任何宠物具有完全相同的爱好、最喜欢的食物或玩具?列出这些宠物对及其共同的兴趣。
- 查找具有相同物种或品种但爱好完全不同的宠物。
9. 清理
为避免系统持续向您的 Google Cloud 账号收费,请删除在此 Codelab 中创建的资源。
- 删除 GKE 集群:
gcloud container clusters delete petverse-cluster --region $REGION --quiet
- 删除 BigQuery 数据集(这将删除所有表):
bq rm -r -f -d $PROJECT_ID:petverse_kg
- 删除 Pub/Sub 队列资源:
gcloud pubsub subscriptions delete petverse-sub --quiet
gcloud pubsub topics delete petverse-topic --quiet
- 删除 Artifact Registry 代码库:
gcloud artifacts repositories delete gke-cats-repo --location=$REGION --quiet
- 删除特定于项目的 GCS 存储分区:
gcloud storage buckets delete gs://$PROJECT_ID-petverse --quiet
10. 恭喜
恭喜!您已成功使用 GKE 和 Gemini 构建了分布式知识图谱流水线,并使用 BigQuery 属性图对其进行了查询。
您学到的内容
- 如何在 GKE Autopilot 上部署分布式作业。
- 如何使用 Gemini 进行多模态数据提取。
- 如何使用 BigQuery 自动嵌入。
- 如何在 BigQuery 中创建和查询属性图 。