
1. 簡介
在本程式碼研究室中,您將為「Petverse」建構分散式知識獲取管道。您將處理 Cloud Storage 值區中的非結構化多媒體資產 (音訊、影片、圖片、文字/CSV),擷取寵物的重要資訊 (最喜歡的食物、嗜好),並建立知識圖譜。您將在 Google Kubernetes Engine (GKE) 上使用 Gemini 多模態處理功能,擴充多媒體檔案的處理作業。最後,您會將這項資料儲存在 BigQuery 中,並使用新的 BigQuery 屬性圖表功能分析關係。
我們將運用 Google Kubernetes Engine 的強大功能,示範如何平行處理大量資料。
為什麼要使用知識圖譜?
知識圖譜比傳統關聯式資料庫更適合用於呈現及分析實體間的複雜關係。
我們會使用 Gemini 2.5 Flash 分析圖片、音訊和影片檔案,並建立不同寵物的相關事實。
學習內容
- 在 GKE 上建構及部署分散式資料處理工作。
- 使用 Gemini 從多媒體檔案中擷取實體和關係。
- 將知識圖譜資料儲存在 BigQuery 中。
- 使用 Graph Query Language (GQL),在 BigQuery 中建立及查詢屬性圖形。
軟硬體需求
- 網路瀏覽器,例如 Chrome
- 已啟用計費功能的 Google Cloud 雲端專案
- 在專案中建立資源及修改 IAM 政策的權限
本程式碼研究室適合各種程度的開發人員 (包括初學者)。
預估時間:45 分鐘
費用:本程式碼研究室中建立的資源費用應低於 $5 美元。
2. 事前準備
建立 Google Cloud 專案
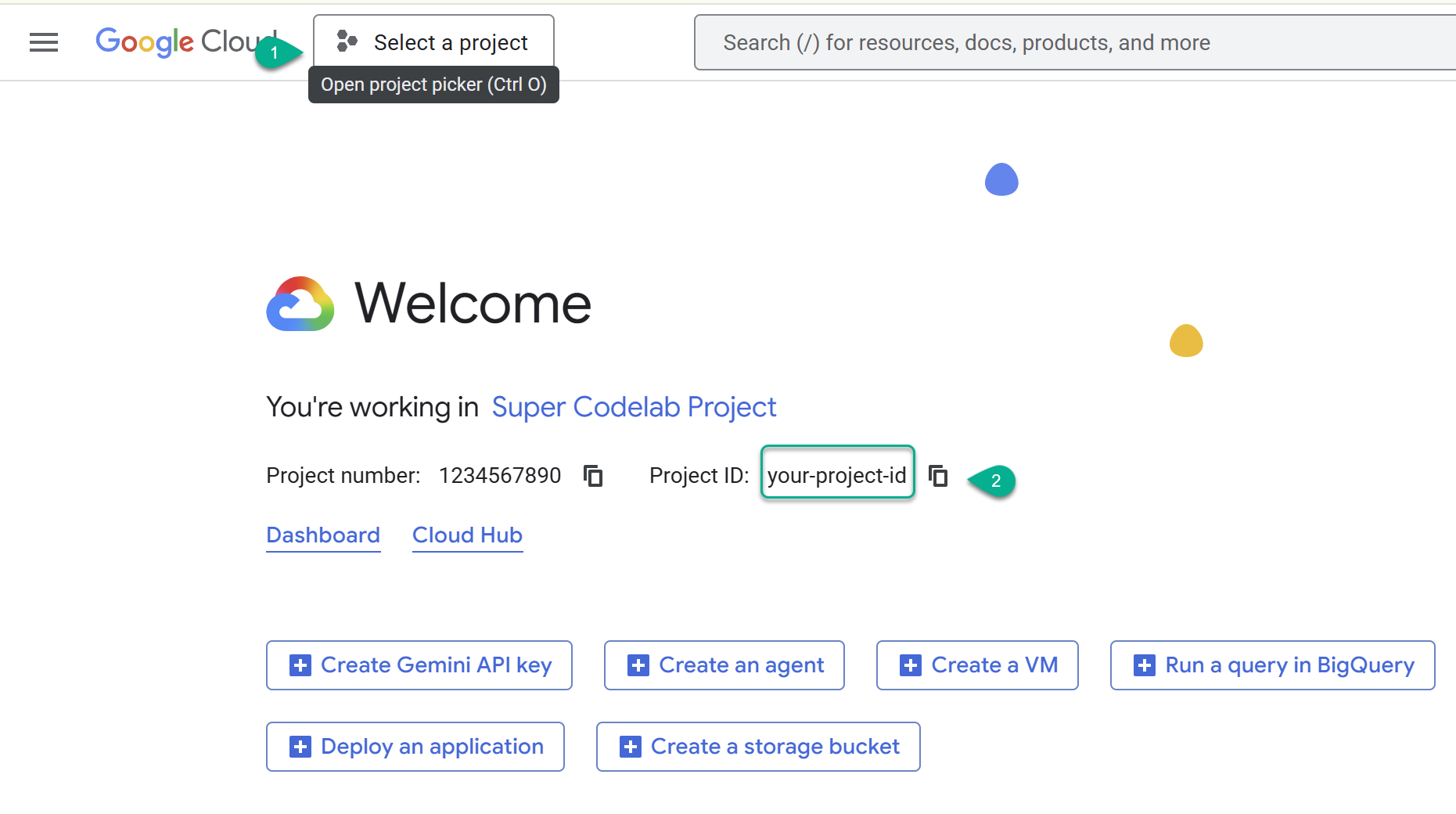
- 前往 Google Cloud 控制台:https://console.cloud.google.com,然後選取或建立 Google Cloud 專案。
- ⚠️ 請記下專案 ID。在本實驗室中,您會使用這個變數執行多個指令。
啟動 Cloud Shell
- 在新分頁中開啟 Cloud Shell:https://shell.cloud.google.com/。
- 如果出現提示訊息,請點選「授權」。
- 取代
PROJECT_ID,然後將下列指令貼到終端機:
export PROJECT_ID="YOUR_PROJECT_ID"
gcloud config set project $PROJECT_ID
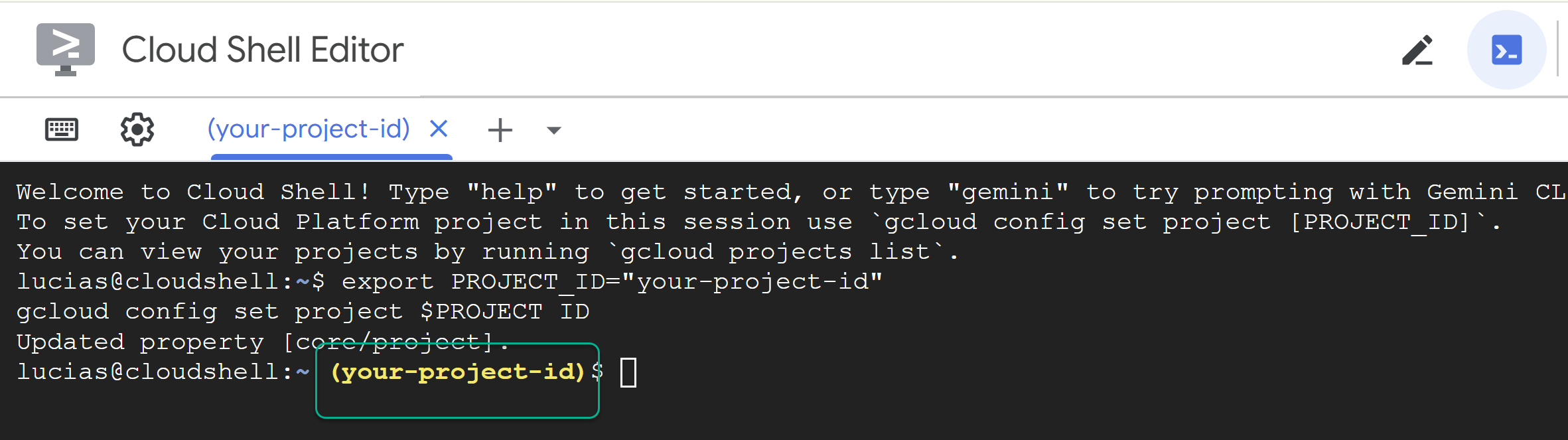
📝 注意:專案在指令列中會以黃色顯示。如果工作階段重新啟動,請務必重新執行上述指令來設定專案 ID。
啟用 API
執行下列指令,啟用所有必要的 API:
gcloud services enable \
aiplatform.googleapis.com \
bigquery.googleapis.com \
artifactregistry.googleapis.com \
container.googleapis.com \
cloudbuild.googleapis.com \
pubsub.googleapis.com
複製存放區
執行下列指令來複製存放區。
cd ~/
git clone --filter=blob:none --no-checkout https://github.com/GoogleCloudPlatform/devrel-demos.git
cd ~/devrel-demos
git sparse-checkout init --cone
git sparse-checkout set codelabs/gke-knowledge-graph
git checkout main
cd codelabs/gke-knowledge-graph/
執行設定指令碼
這個指令碼會自動執行下列後端設定:
- 建立容器映像檔和 Artifact Registry 存放區
- 建立 BigQuery 資料集
- 建立 BigQuery 連線,從 SQL 執行 Gemini AI 函式
在終端機中執行下列指令:
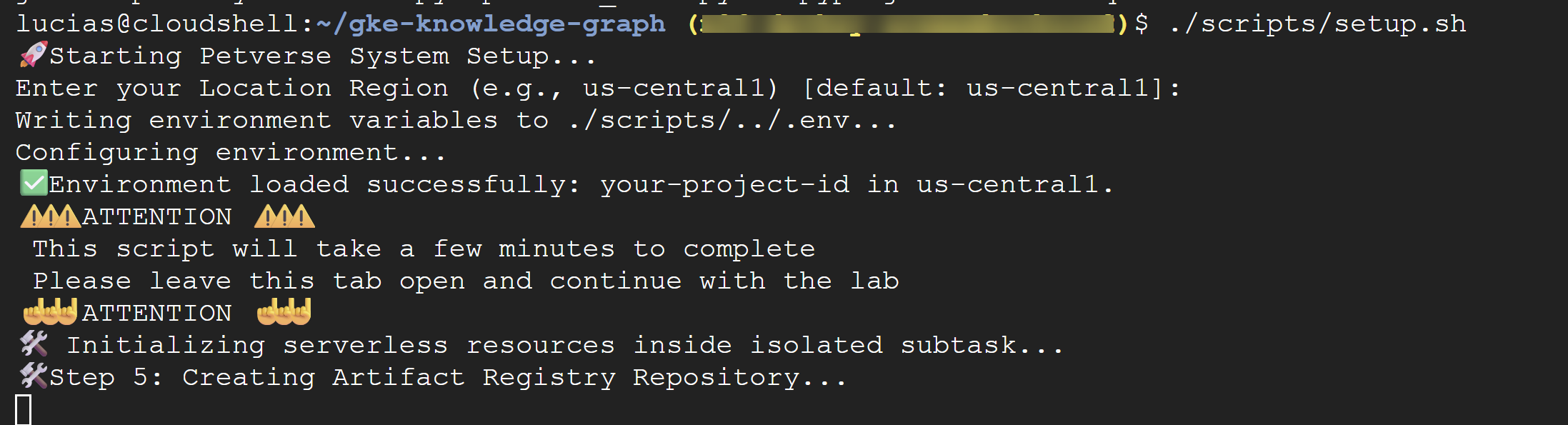
./scripts/setup.sh
如果指令碼提示您輸入設定詳細資料,請使用下列值:
- 專案 ID:使用您在上一個步驟中建立的 ID。
- 區域:
us-central1
⚠️ 重要事項:指令碼需要幾分鐘才能執行完畢。請勿關閉這個終端機視窗,讓作業在背景完成。如要繼續執行下一個步驟,請開啟新的終端機分頁或視窗,執行下一個指令。
3. 設定 Data Agent Kit
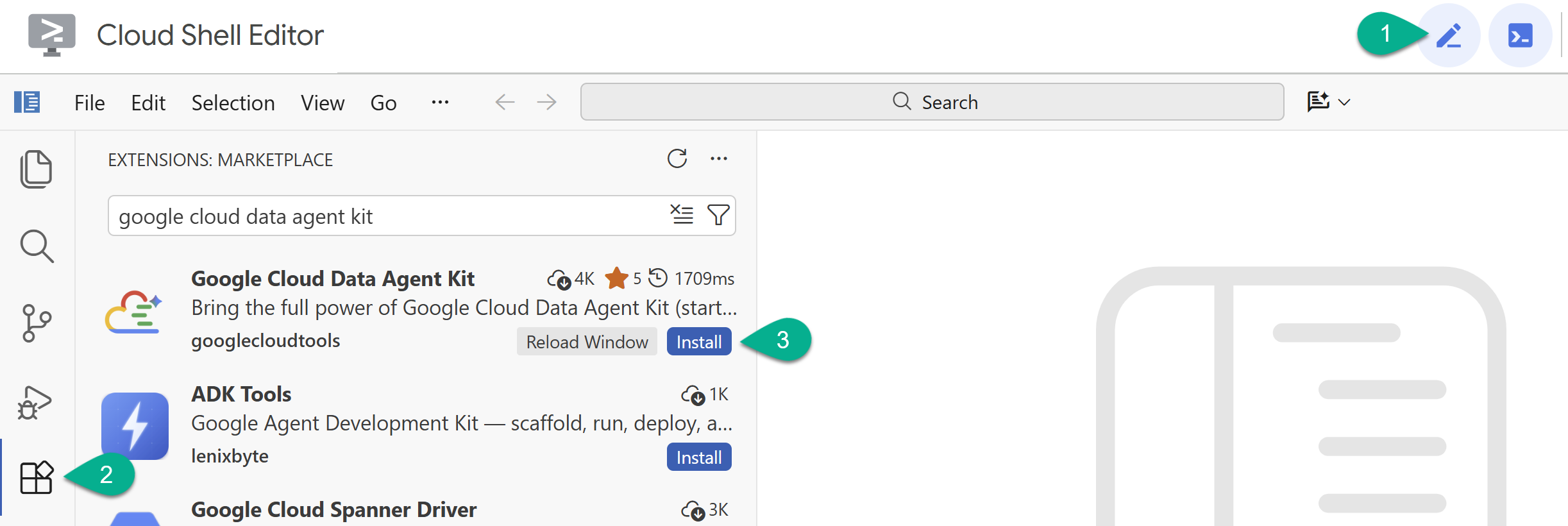
- 按一下右上角的鉛筆圖示,啟用 Cloud Shell 編輯器。
- 在 Cloud Shell 編輯器中,按一下左側邊欄的「擴充功能」圖示。
- 搜尋「Google Cloud Data Agent Kit」,然後按一下「Install」(安裝) (如果尚未安裝)。
- 使用擴充功能登入 Google 帳戶。
- 在「設定摘要」中,輸入專案 ID 和
us-central1做為區域。
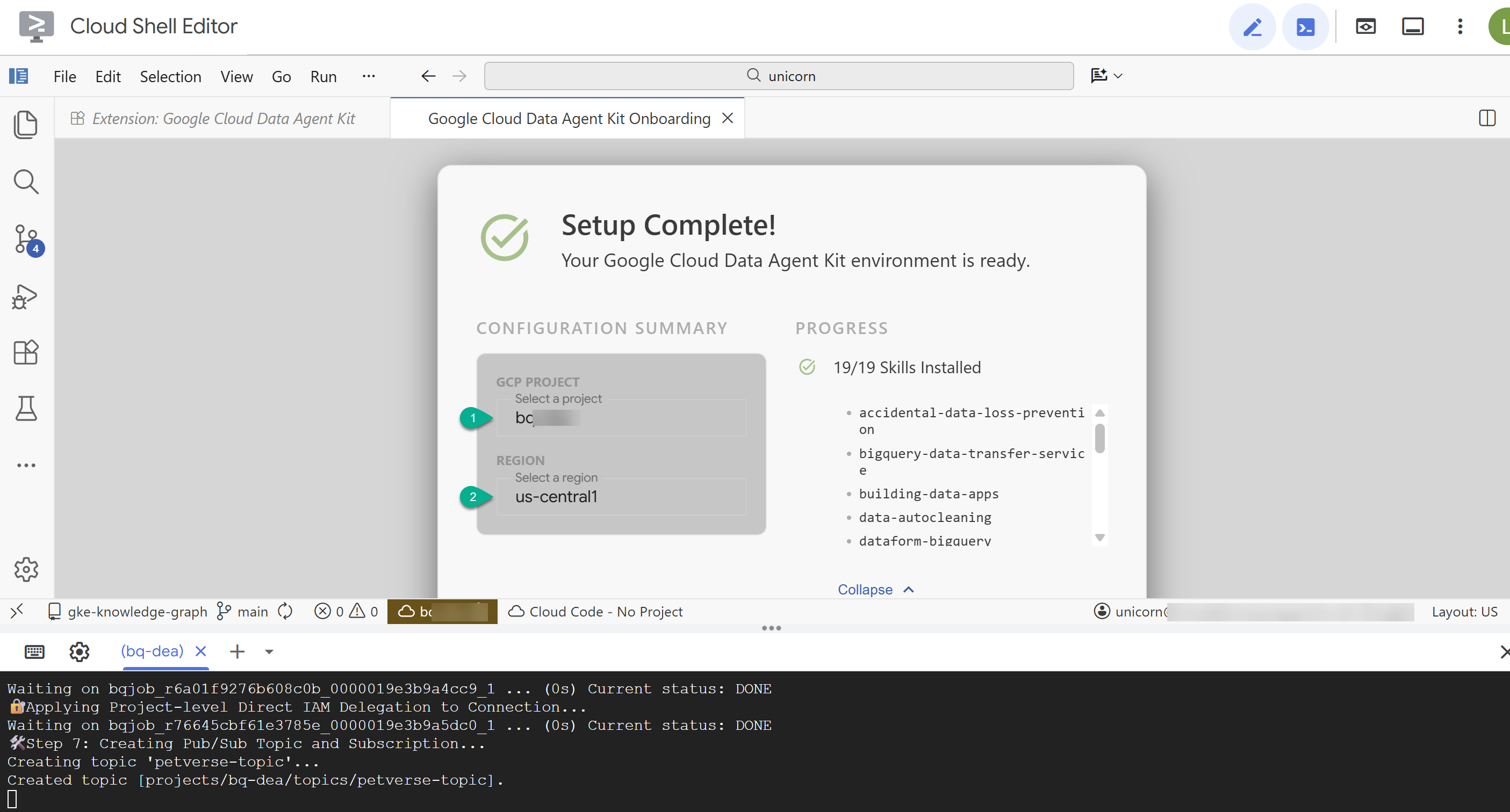
- 按一下「設定 MCP 伺服器」。您不需要變更這個視窗,只要按一下「開始使用」即可。
- 如果系統提示,請重新載入視窗。目前可以關閉快速入門指南分頁。
在 BigQuery 中設定資料表
- 在側邊欄中返回探索工具。如果主資料夾 (例如
/home/your_user_name/) 尚未開啟,請按一下「Open Folder」並選取該資料夾。
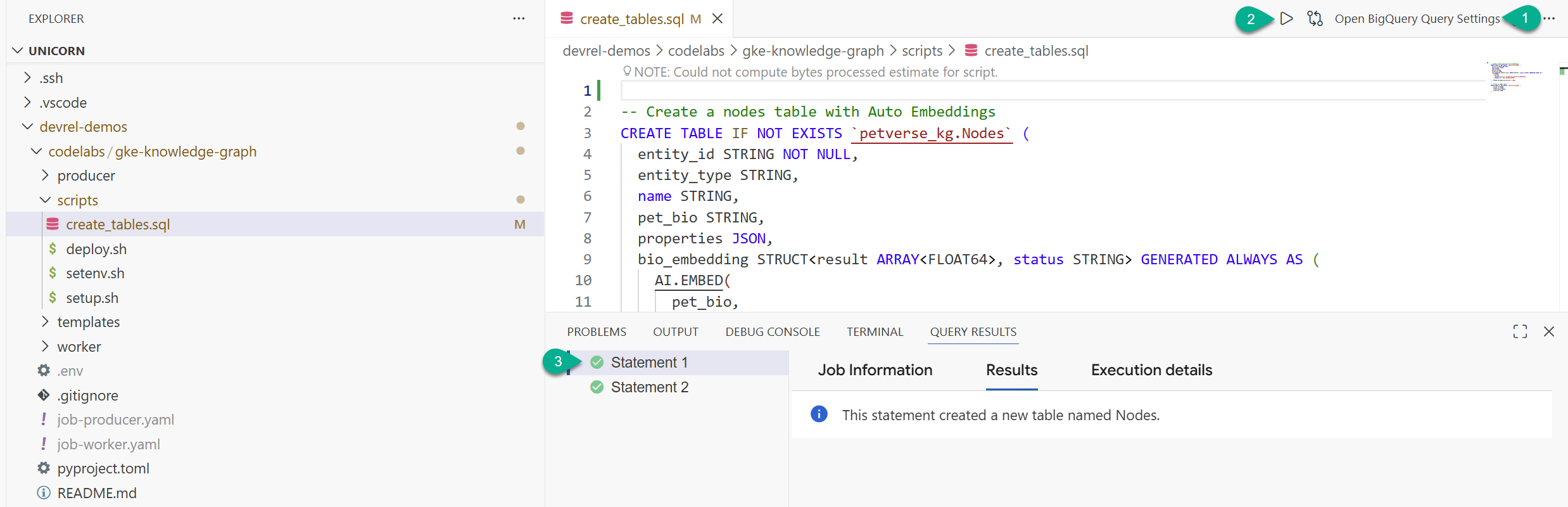
- 在檔案總管視窗中,找出您從存放區複製的資料夾 (
devrel-demos)。在codelabs/gke-knowledge-graph/scripts下方,您會看到create_tables.sql。開啟該檔案。 - 按一下右上方的「開啟查詢設定」。
- 選擇「BigQuery」BigQuery。依序點選「儲存」和「關閉」。
- 按一下「執行」。
畫面應會顯示兩項陳述式執行成功的訊息。您現在已建立資料表,可儲存知識圖譜的節點和邊緣。
你可以關閉 create_tables.sql 分頁和結果控制台。
4. 初始化 GKE 叢集
我們會使用 GKE Autopilot 執行資料處理工作。建議採用 Autopilot,因為這項功能會為您管理叢集基礎架構。
此時設定指令碼應已完成。畫面上應會顯示成功訊息:🎉🦄 Setup successfully finished! 🎉🦄。
在終端機中貼上這個指令,即可建立叢集:
source scripts/setenv.sh
gcloud container clusters create-auto petverse-cluster \
--region=$REGION
🕓 這項作業約需 5 分鐘。
取得憑證以與叢集互動:
source scripts/setenv.sh
gcloud container clusters get-credentials petverse-cluster --region $REGION
您應該會看見以下輸出結果:
Fetching cluster endpoint and auth data. kubeconfig entry generated for petverse-cluster.
5. 設定 Workload Identity
透過 GKE 適用的 Workload Identity Federation (使用直接資源存取),GKE 工作負載就能安全地存取 Google Cloud 服務,不必管理服務帳戶金鑰。
執行 deploy.sh 來:
- 建立 Kubernetes 服務帳戶
- 直接將必要的 IAM 角色授予 Kubernetes 服務帳戶主體
- 將 IAM 服務帳戶繫結至 Kubernetes 服務帳戶
- 為 Kubernetes 服務帳戶加上註解,完成連結
source scripts/setenv.sh
./scripts/deploy.sh
6. 部署分離式處理工作
在這個步驟中,您會將佇列器 (Producer) 和處理引擎 (Worker) 部署至 GKE。
我們的新分離式架構使用 Google Cloud Pub/Sub 非同步處理資產:
- Producer 會掃描 GCS,並將所有檔案路徑加入 Pub/Sub 佇列。
- GKE 中的 Worker 集區會擴大,動態平行提取工作、透過 Gemini 處理工作,然後寫入 BigQuery。
setup.sh 指令碼已建構並推送 Producer 和 Worker 容器映像檔、將 Pub/Sub 主題加入佇列,並動態產生 GKE 部署資訊清單:job-producer.yaml 和 job-worker.yaml。
- 套用 Producer Job 掃描儲存空間值區,並將所有資產加入佇列:
kubectl apply -f job-producer.yaml
這項工作只會將後設資料排入佇列,因此執行和完成速度很快。
- 部署設定為執行 6 個平行工作站的工作站工作,以排空佇列:
kubectl apply -f job-worker.yaml
GKE Autopilot 會自動偵測待處理的 Pod,動態調度運算節點,並平行執行工作站,處理已加入佇列的音訊、影片、圖片和 CSV 檔案。
7. 驗證結果
- 檢查工作狀態:
kubectl get jobs
等待 petverse-producer-job 和 petverse-worker-job 顯示成功完成。
🕓 這項作業約需 10 分鐘。您可以使用下列指令查看進度。
- 檢查 Producer 的記錄,確認檔案已成功加入佇列:
cd ~/devrel-demos/codelabs/gke-knowledge-graph
source scripts/setenv.sh
kubectl logs -l app=petverse-producer --tail=50
- 觀察平行工作站處理佇列中的檔案:
kubectl logs -l app=petverse-worker --tail=50
(工作站的閒置逾時時間為 60 秒,Pub/Sub 佇列為空時,工作站會自動關閉並清除)。
在 BigQuery 中驗證資料。
- 前往 BigQuery Studio。您會看到系統建立的兩個資料表:petverse_kg.Nodes 和 petverse_kg.Edges。
- 如要查看資料表內容,請按兩下資料表名稱,然後點選「預覽」。
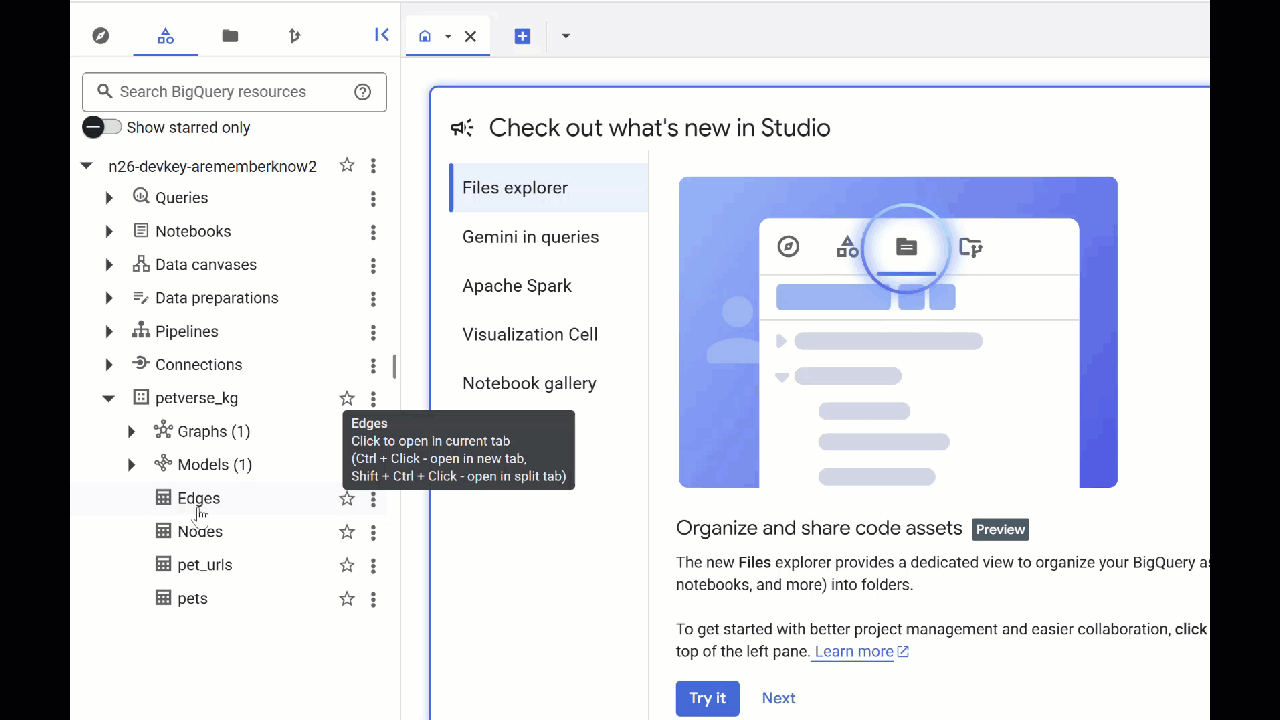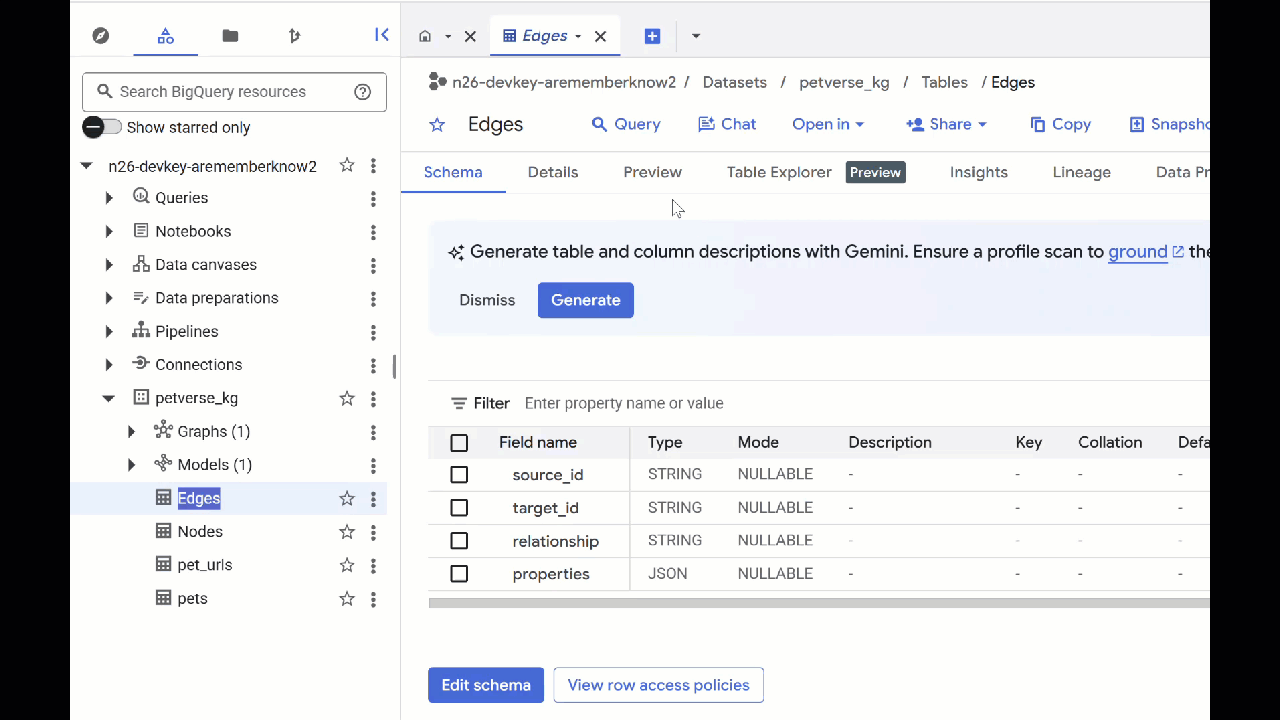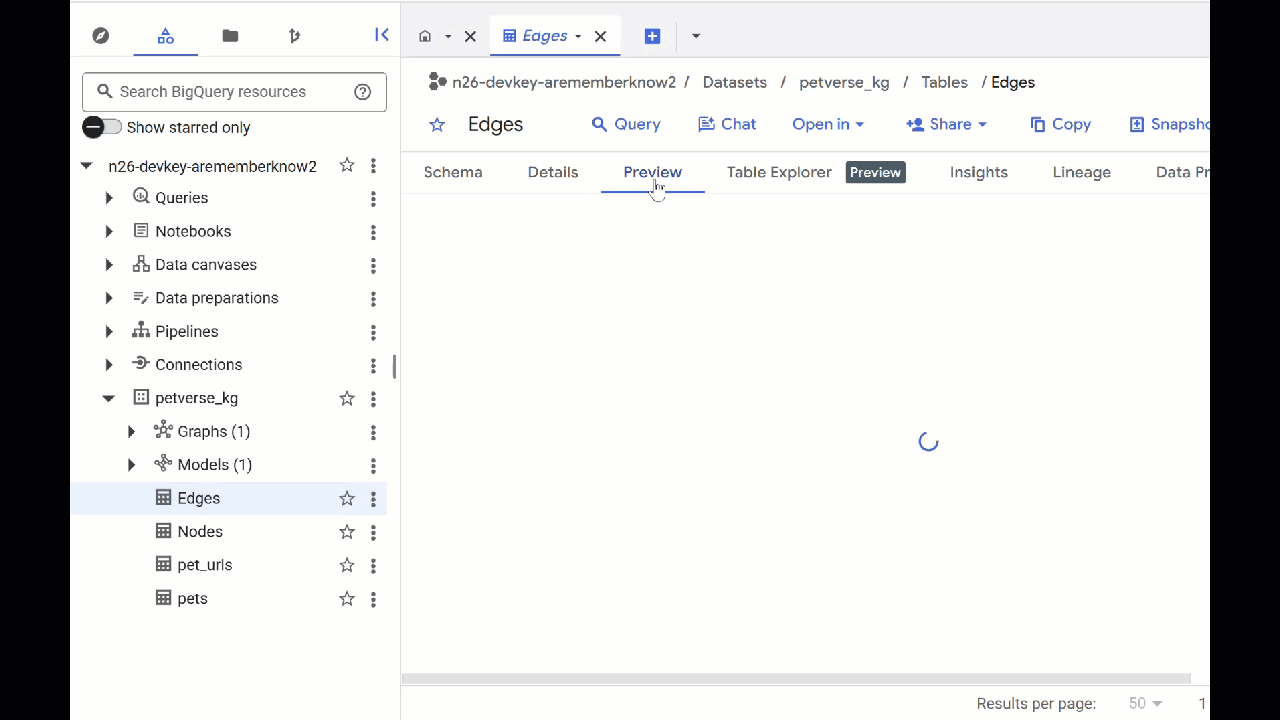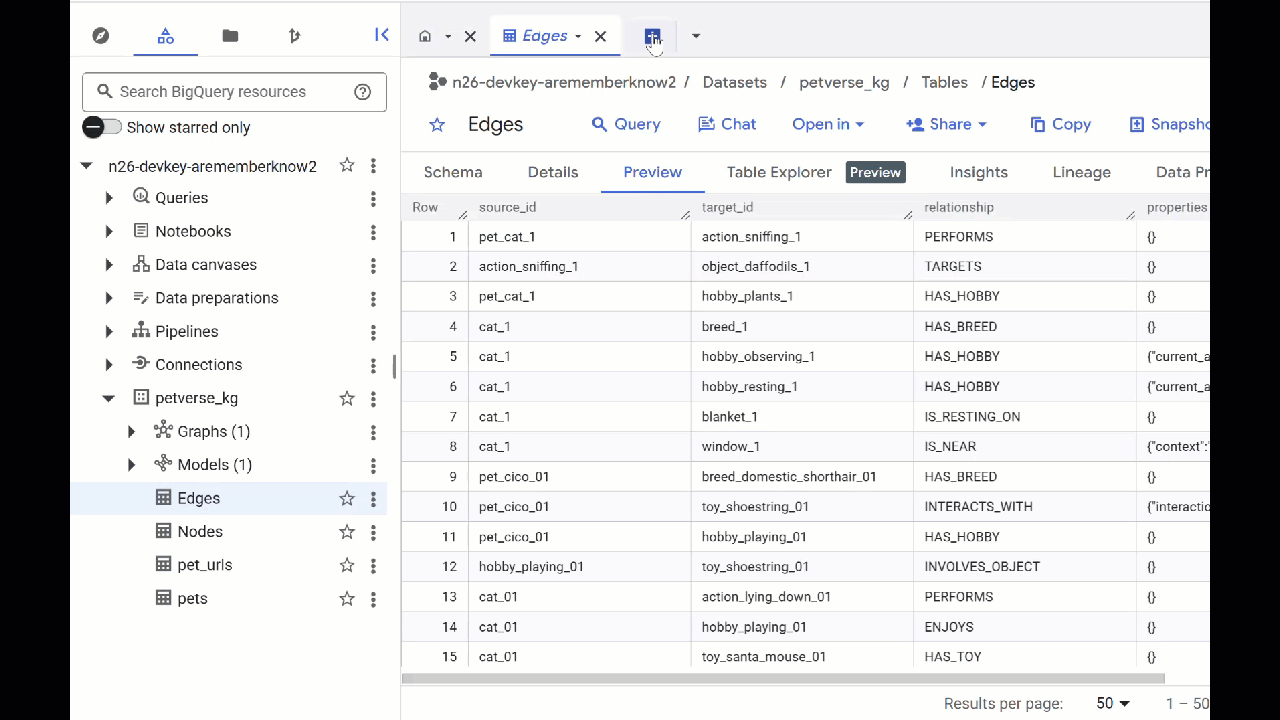
您會看到「節點」表格,其中包含 Gemini 在音訊、影片和圖片中擷取的實體相關資訊。「邊緣」資料表包含兩者之間的關係。舉例來說,如果聆聽名為 SQL 的貓咪的音訊,他喜歡玩鞋帶,也喜歡吃冷凍乾燥的魚。
- 使用「+」按鈕建立新查詢。貼上下列陳述式,然後點選「執行」:
SELECT n.name, n.entity_id, e.relationship, e.target_id
FROM
`petverse_kg.Nodes` n
JOIN
`petverse_kg.Edges` e
ON n.entity_id = e.source_id
WHERE n.name = 'SQL'
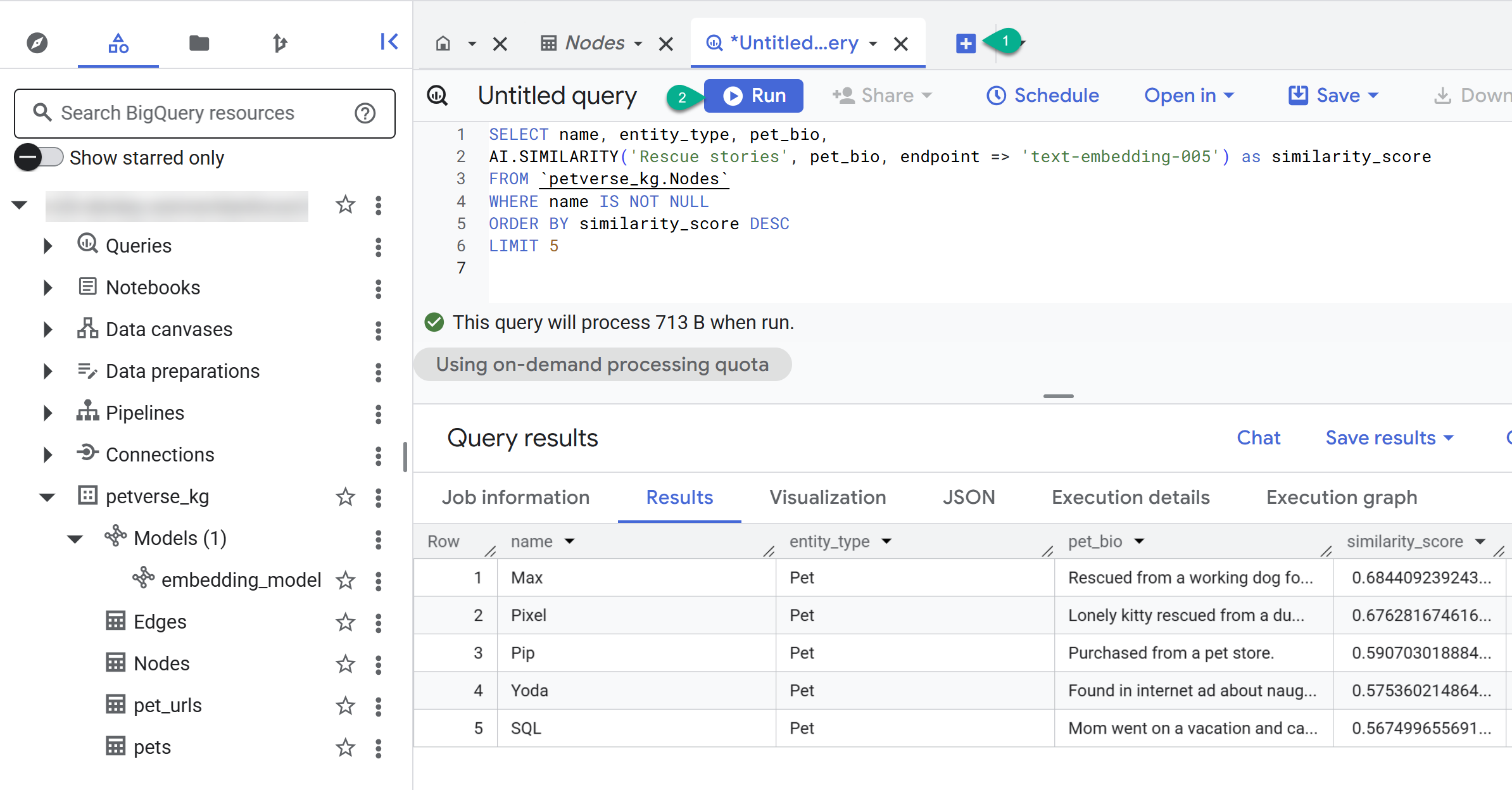
- 使用「+」按鈕建立新查詢。貼上下列陳述式,然後點選「執行」:
SELECT name, entity_type, pet_bio,
AI.SIMILARITY('Pets who like to relax', pet_bio, endpoint => 'text-embedding-005') as similarity_score
FROM `petverse_kg.Nodes`
WHERE name IS NOT NULL
ORDER BY similarity_score DESC
LIMIT 5
你應該會看到喜歡放鬆的寵物節點。這項查詢使用 AI 函式 AI.SIMILARITY 執行語意搜尋,找出簡介與查詢文字最相似的寵物。
建構屬性圖
現在 BigQuery 中已有節點和邊緣,我們可以建立屬性圖,輕鬆查詢關係。
建立圖表
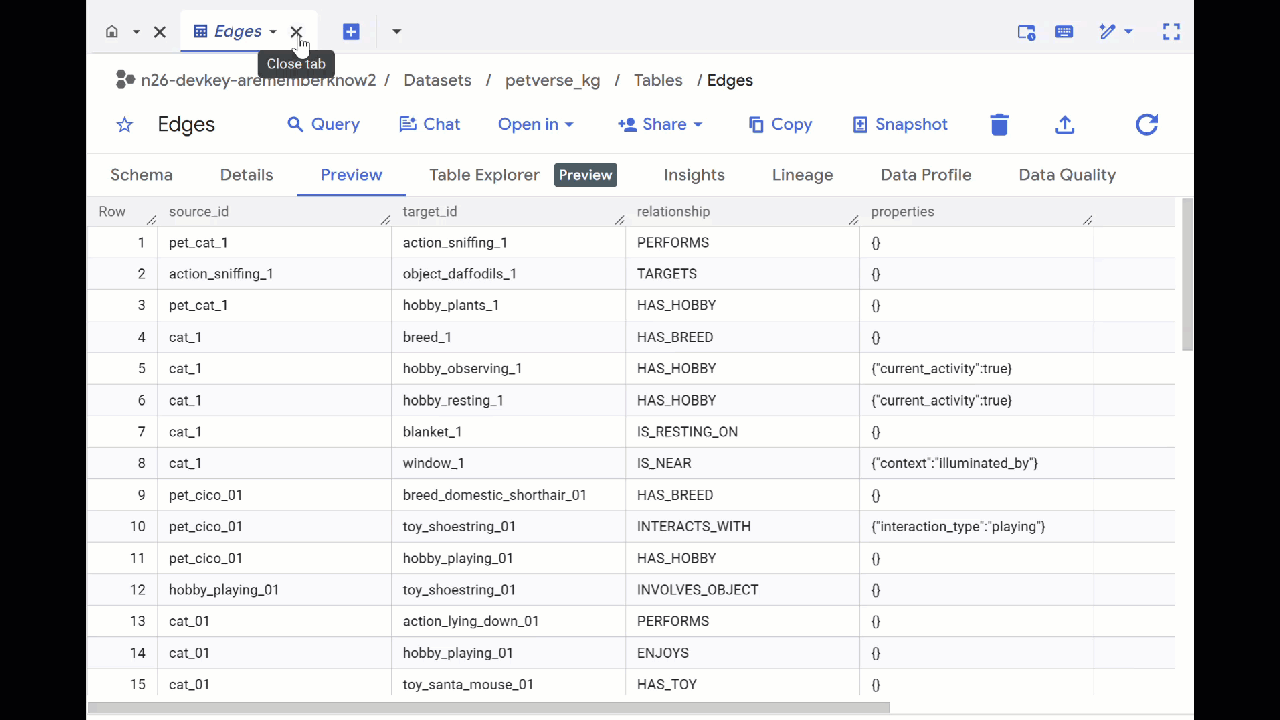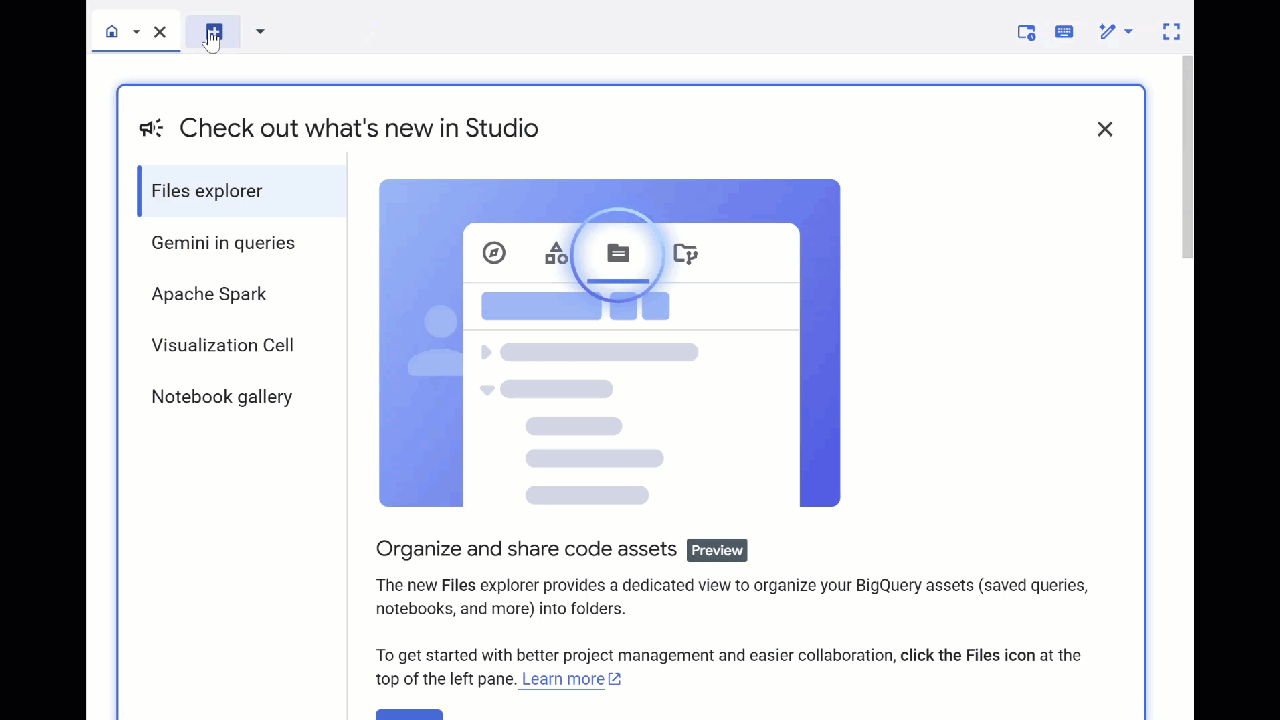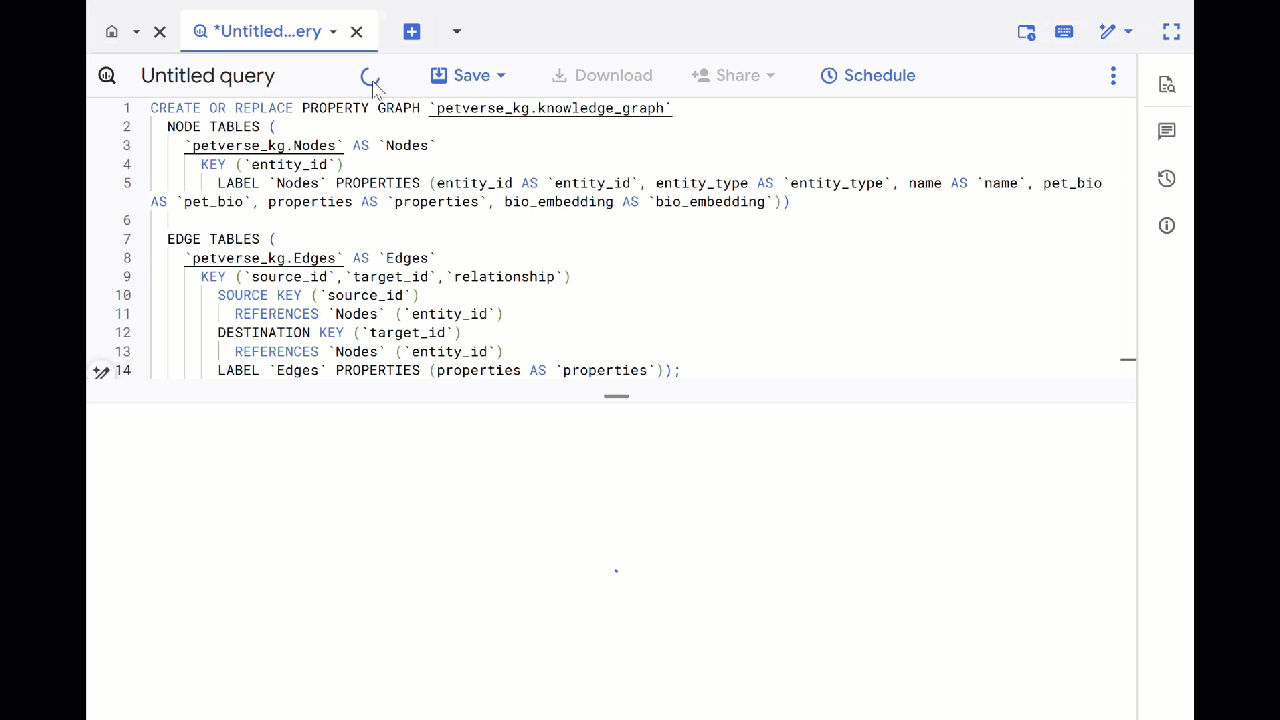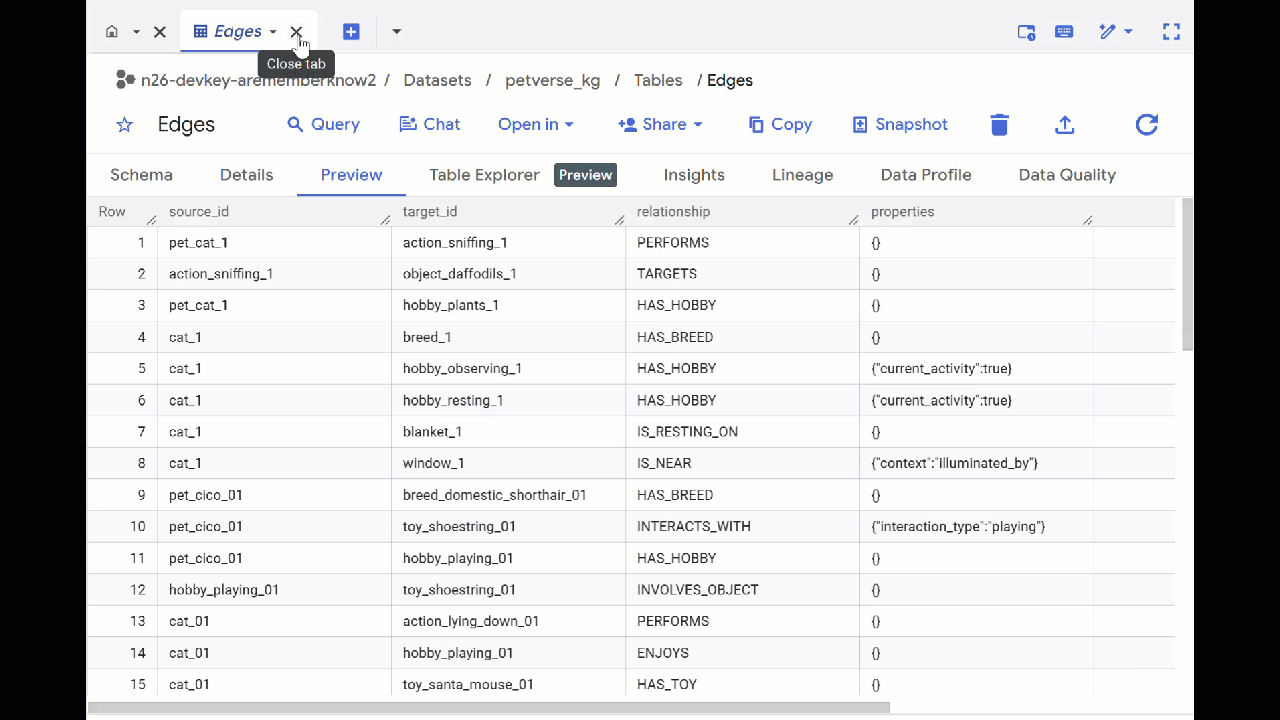
- 覆寫先前的查詢,然後執行下列 DDL 來建立屬性圖表:
CREATE OR REPLACE PROPERTY GRAPH `petverse_kg.knowledge_graph`
NODE TABLES (
`petverse_kg.Nodes` AS `Nodes`
KEY (`entity_id`)
LABEL `Nodes` PROPERTIES (entity_id AS `entity_id`, entity_type AS `entity_type`, name AS `name`, pet_bio AS `pet_bio`, properties AS `properties`, bio_embedding AS `bio_embedding`))
EDGE TABLES (
`petverse_kg.Edges` AS `Edges`
KEY (`source_id`,`target_id`,`relationship`)
SOURCE KEY (`source_id`)
REFERENCES `Nodes` (`entity_id`)
DESTINATION KEY (`target_id`)
REFERENCES `Nodes` (`entity_id`)
LABEL `Edges` PROPERTIES (properties AS `properties`));
- 按一下「前往圖表」。您會看到圖表,其中一個節點有連往自身的邊緣。這是可預期的情況。
查詢圖形
- 你可以使用「+」按鈕關閉所有先前的查詢,並開啟新的空白查詢。
- 使用 GQL 透過共同興趣 (例如嗜好、喜愛的食物或玩具) 尋找與其他寵物相關的寵物。這項多重躍點查詢會比對連線至相同節點的兩隻不同寵物:
GRAPH `petverse_kg.knowledge_graph`
MATCH p = (pet1:Nodes)-[e1]->(interest:Nodes)<-[e2]-(pet2:Nodes)
WHERE pet1.entity_id != pet2.entity_id
AND (LOWER(pet1.entity_type) = 'pet' AND LOWER(pet2.entity_type) = 'pet')
AND LOWER(interest.entity_type) IN ('hobby', 'action', 'activity', 'food', 'toy')
RETURN TO_JSON(p) as res
LIMIT 100
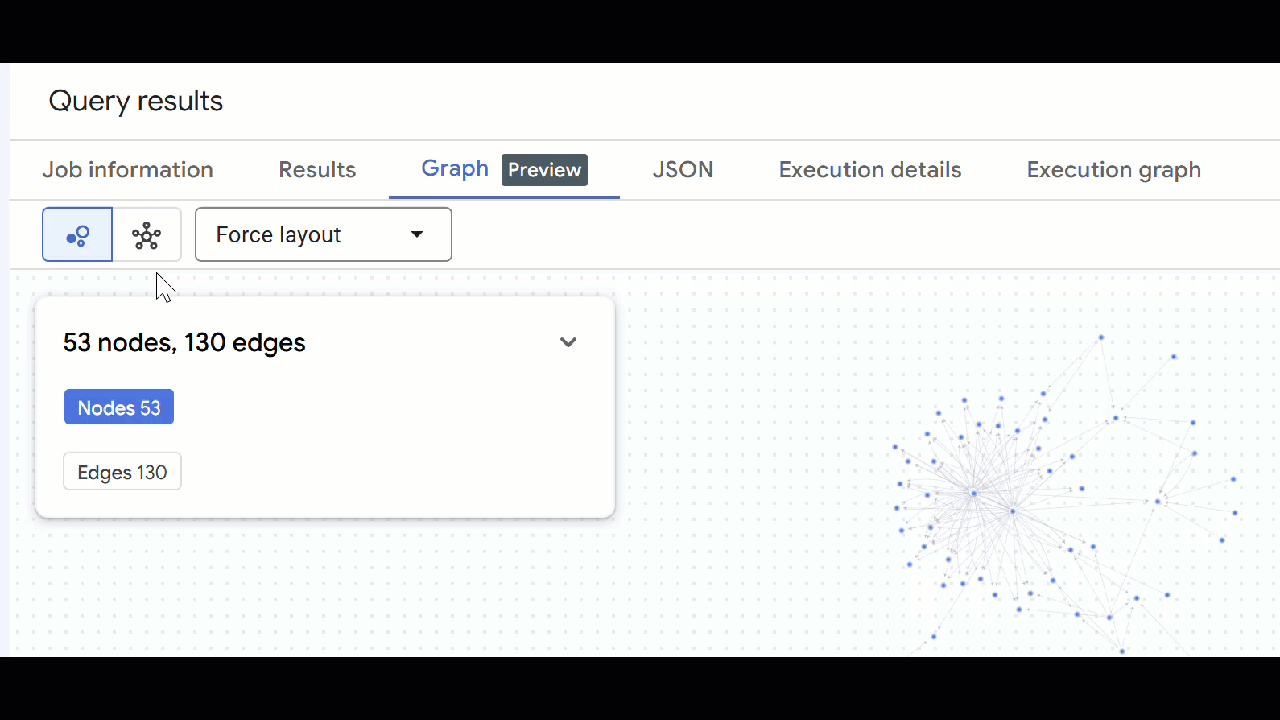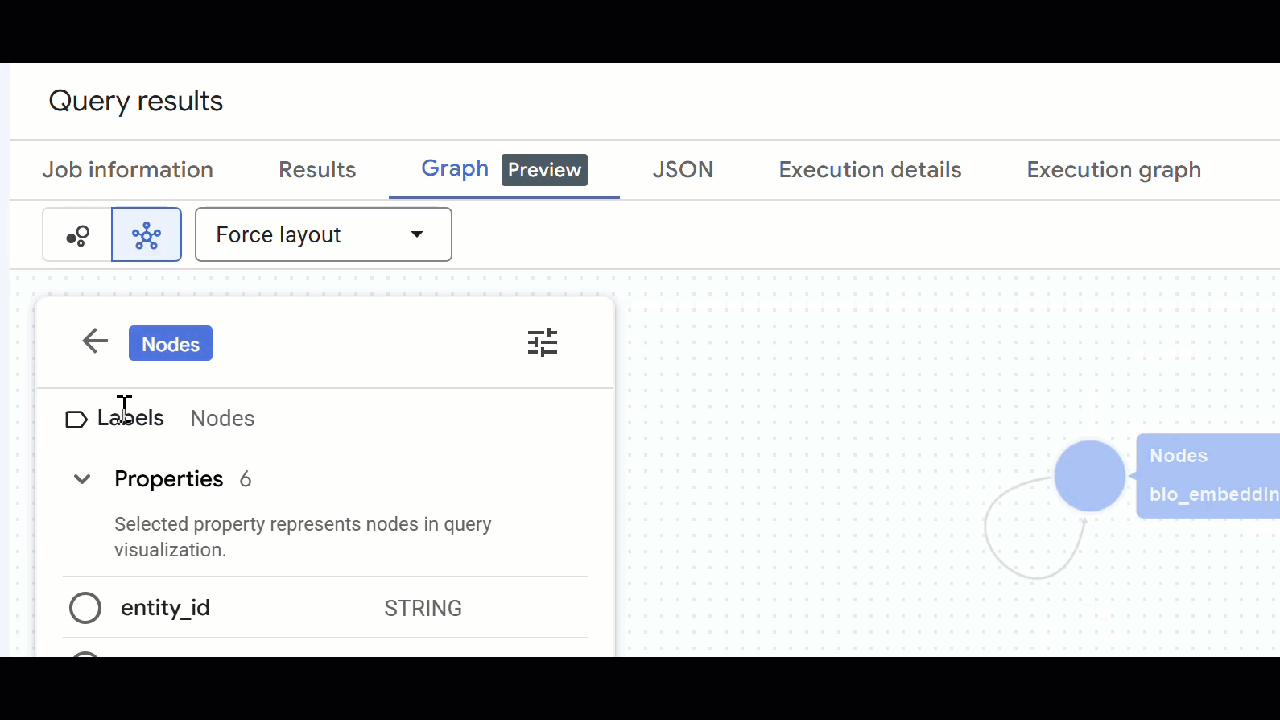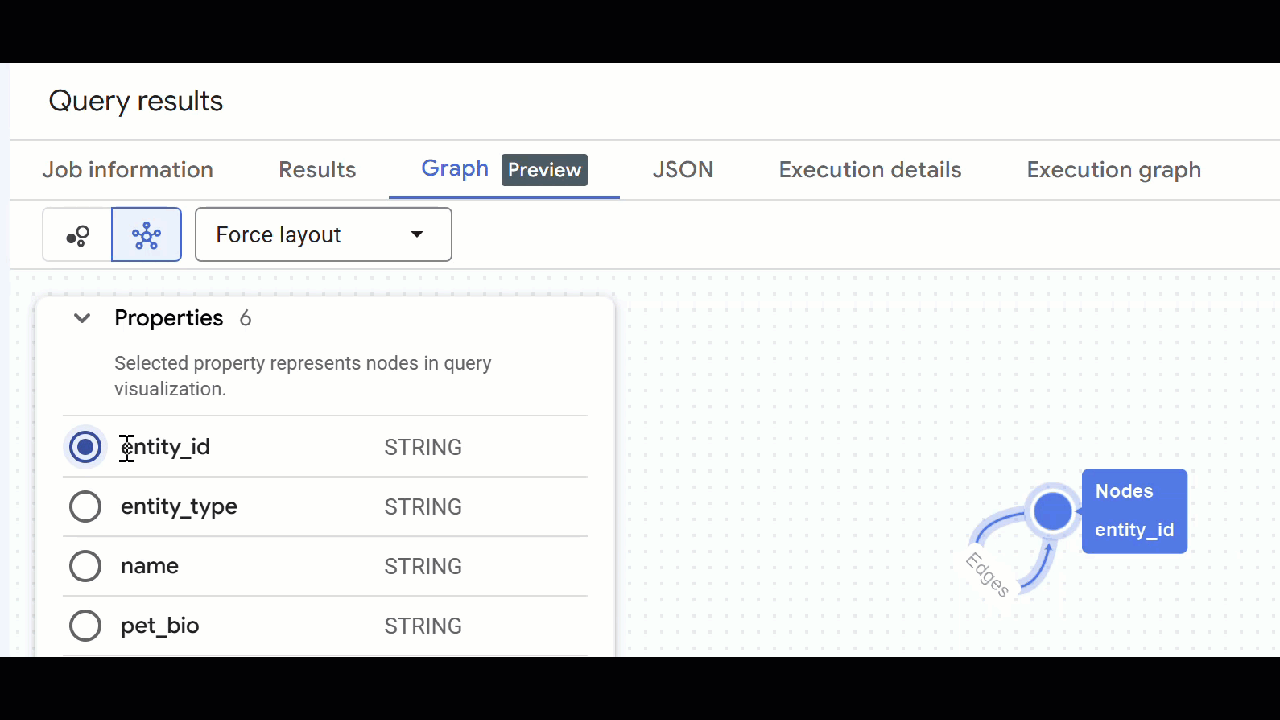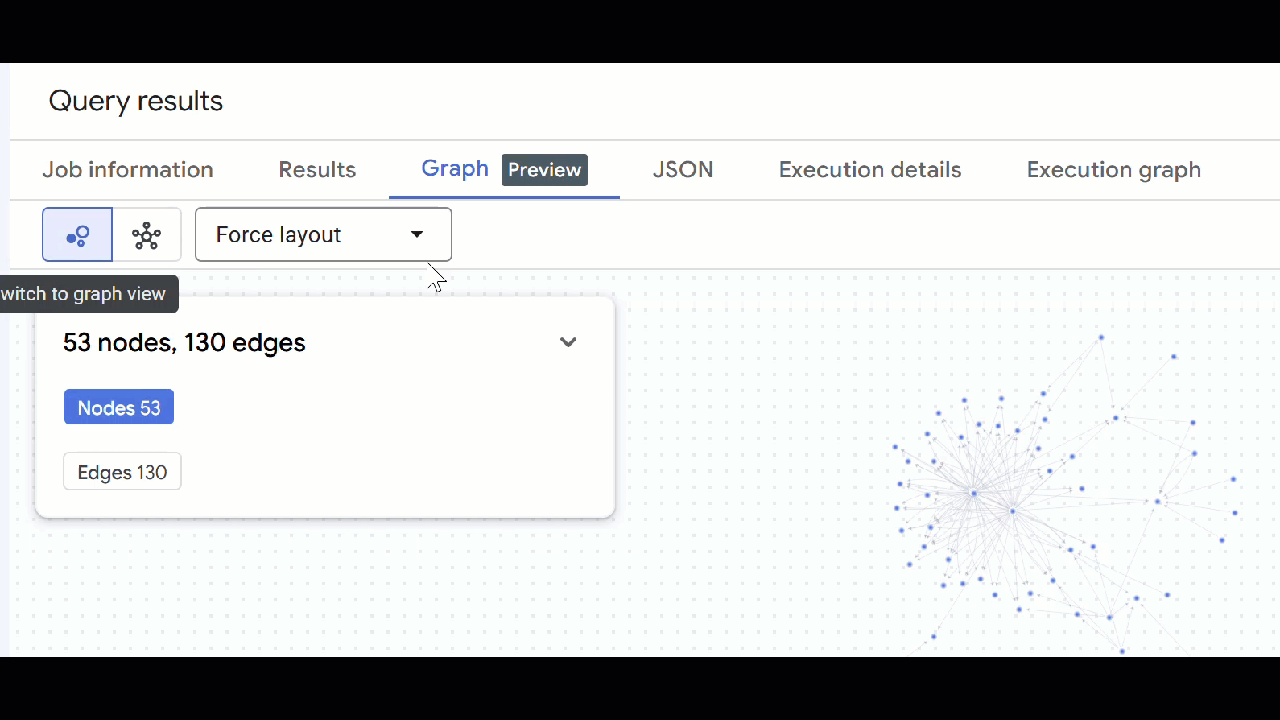
- 您應該會看到圖表的視覺化呈現方式。您可以點選節點,查看節點和邊緣的屬性。
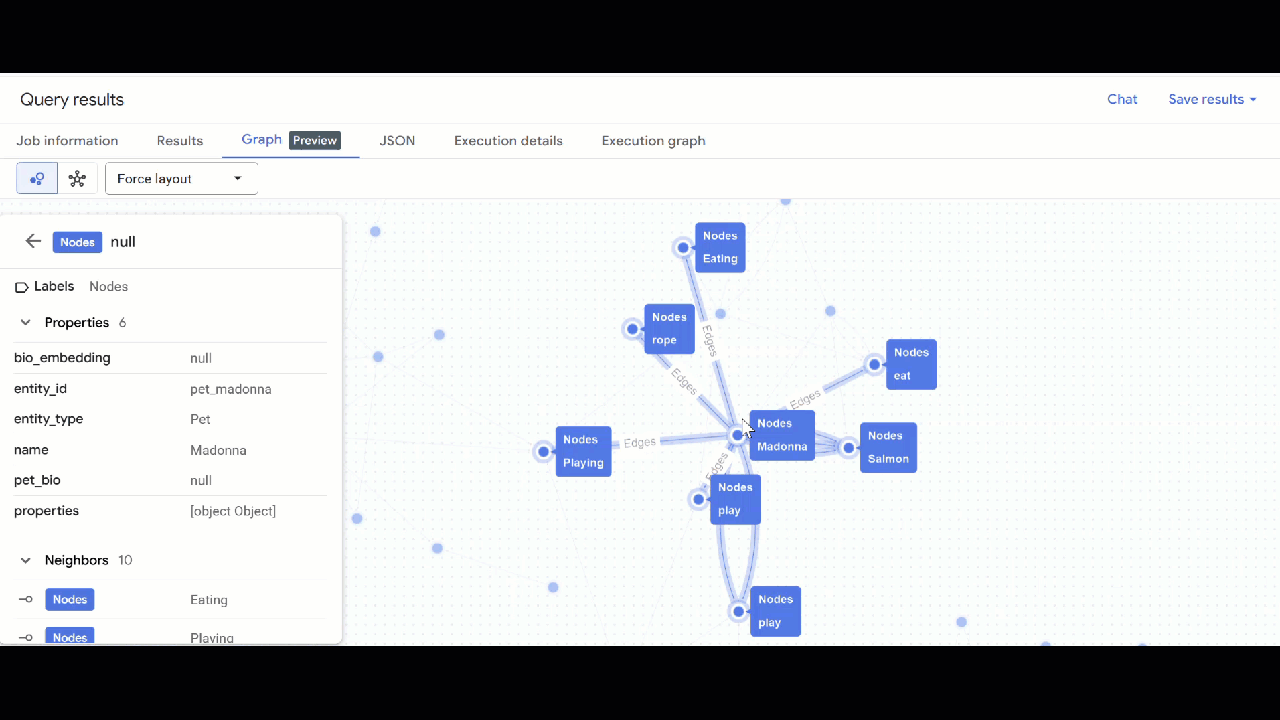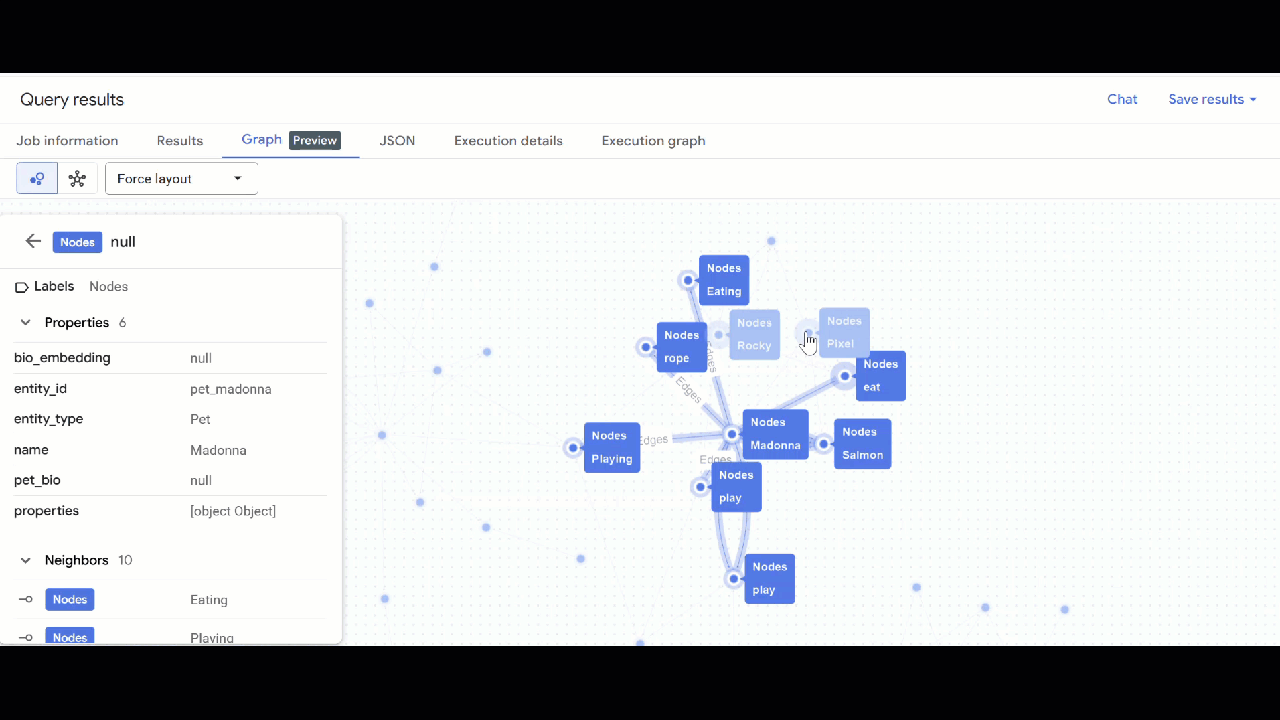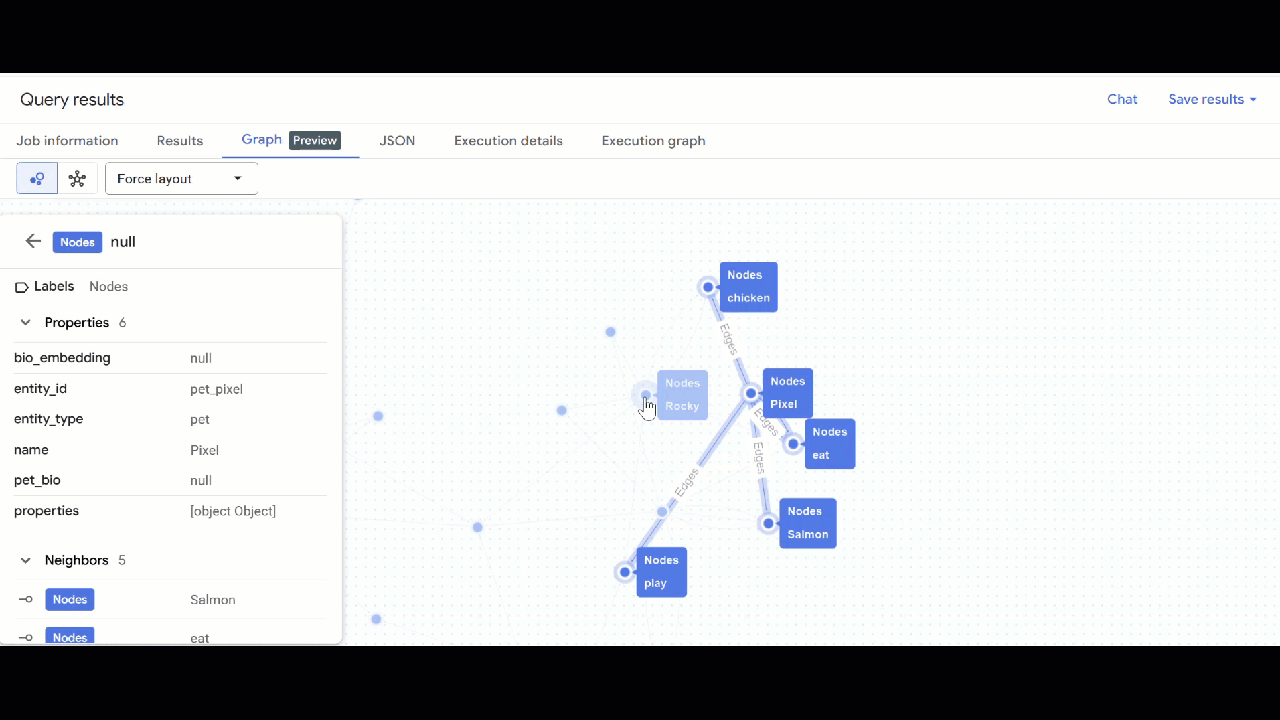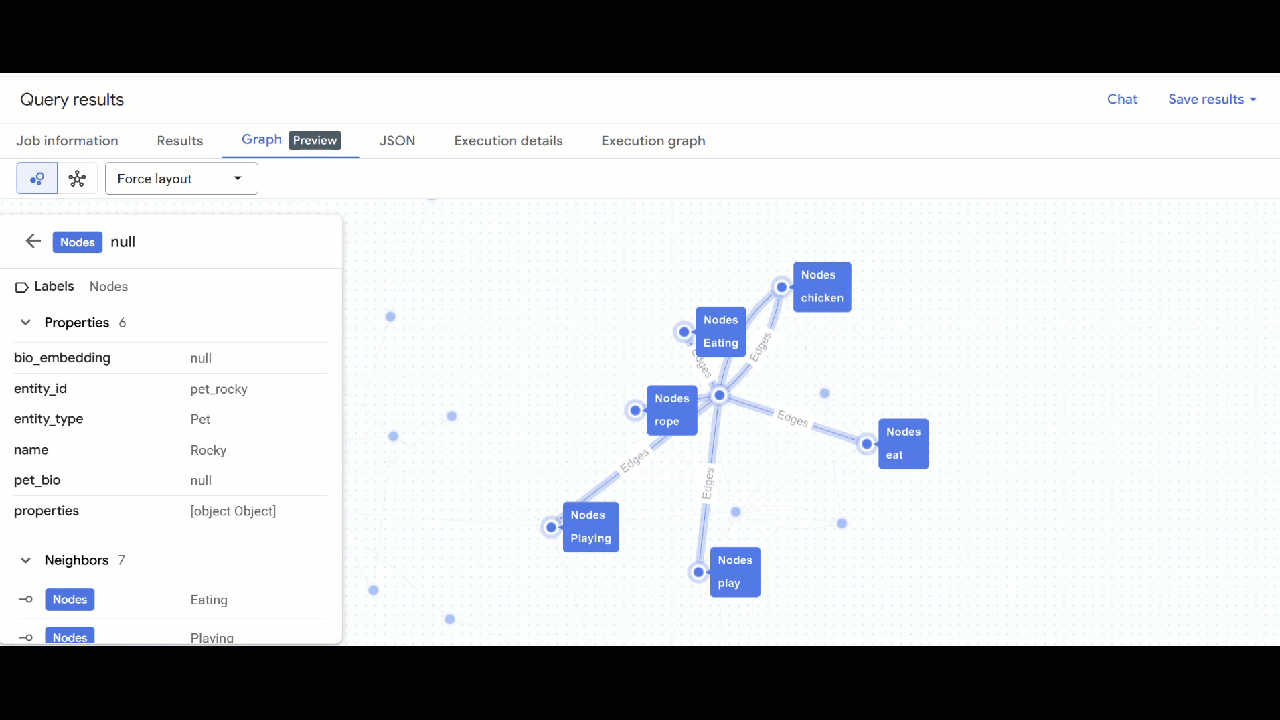
🕵️ 提示:如要調整節點顯示的值,請按一下「切換至結構定義檢視畫面」:
- 您可以關閉所有開啟的查詢分頁。
8. 與圖表對話
- 「+」符號旁邊會顯示下拉式選單。選取「對話」。
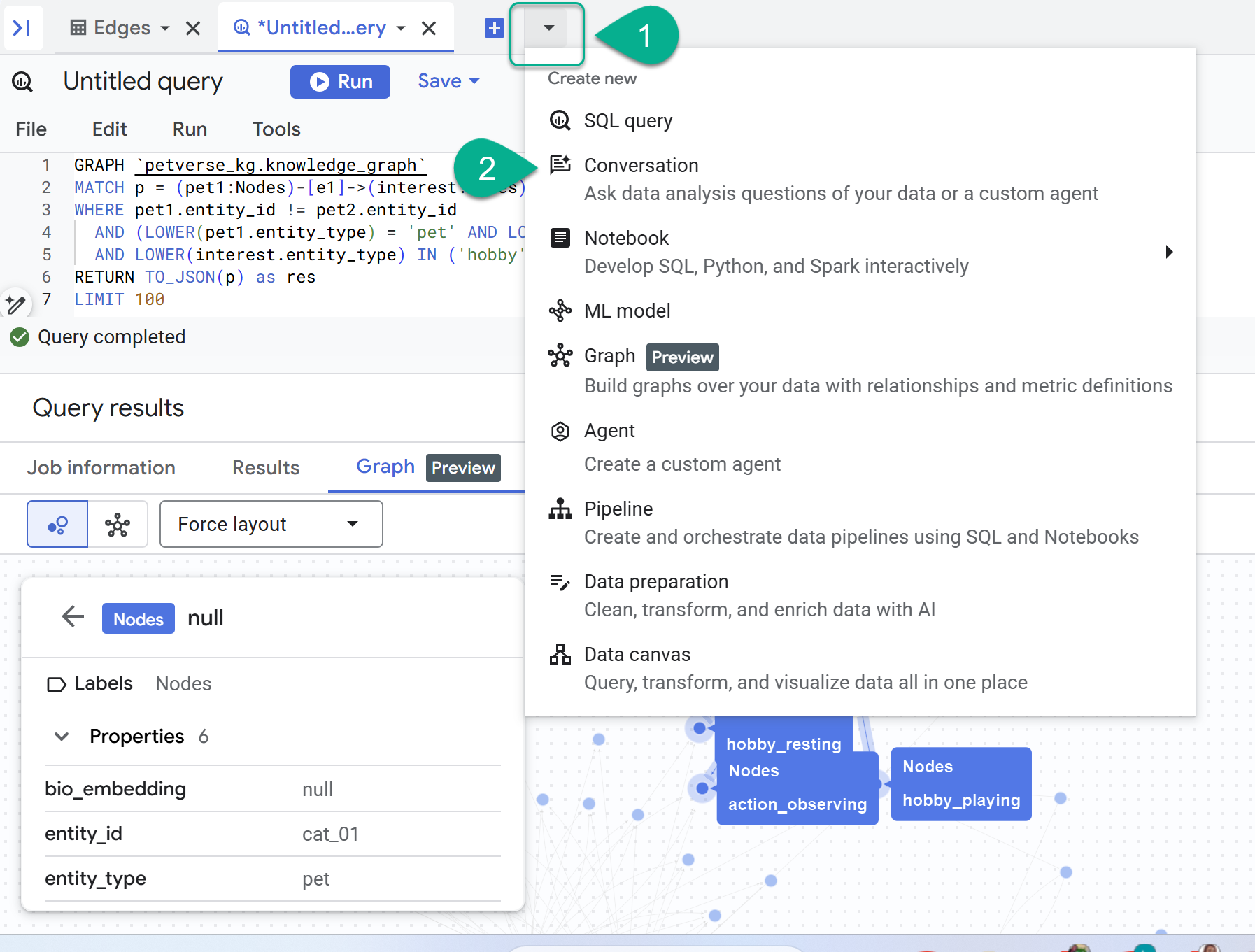
- 系統會提示您啟用 Data Analytics API with Gemini。啟用這兩個 API。完成後,請重新整理視窗或建立新對話,即可看到代理。
- 按一下「新增代理程式」。
- 為代理指定名稱,例如
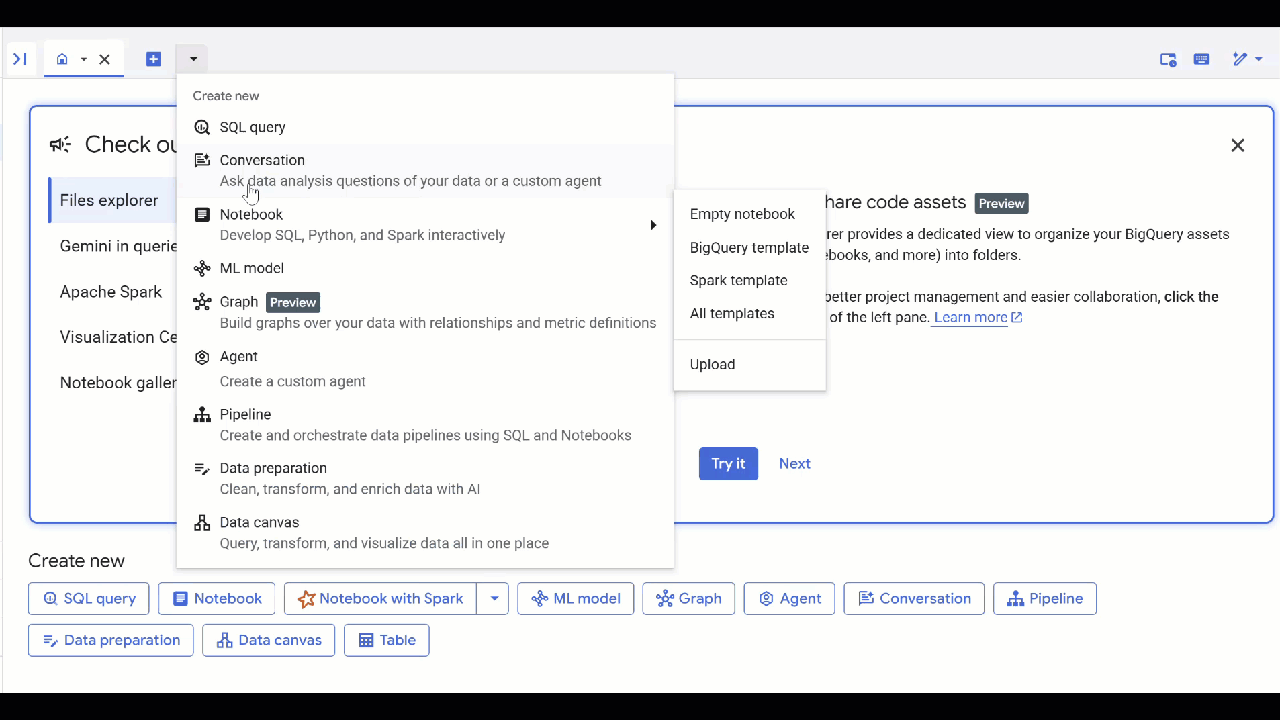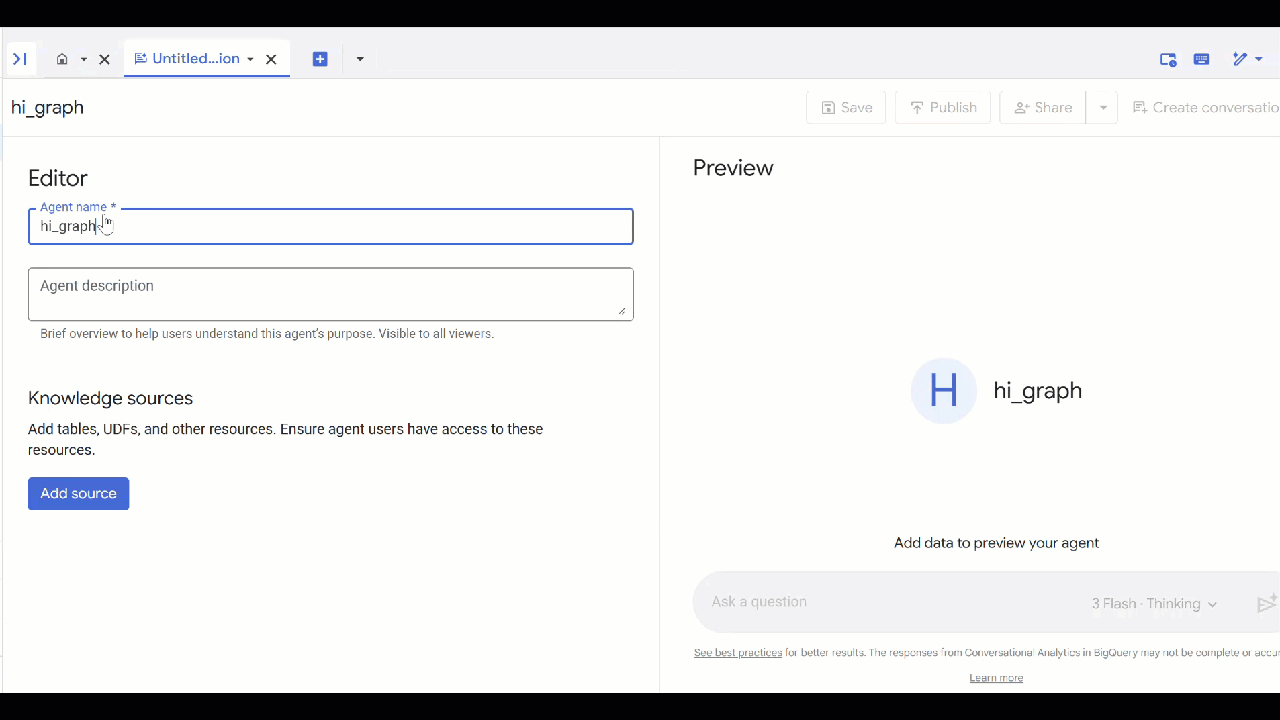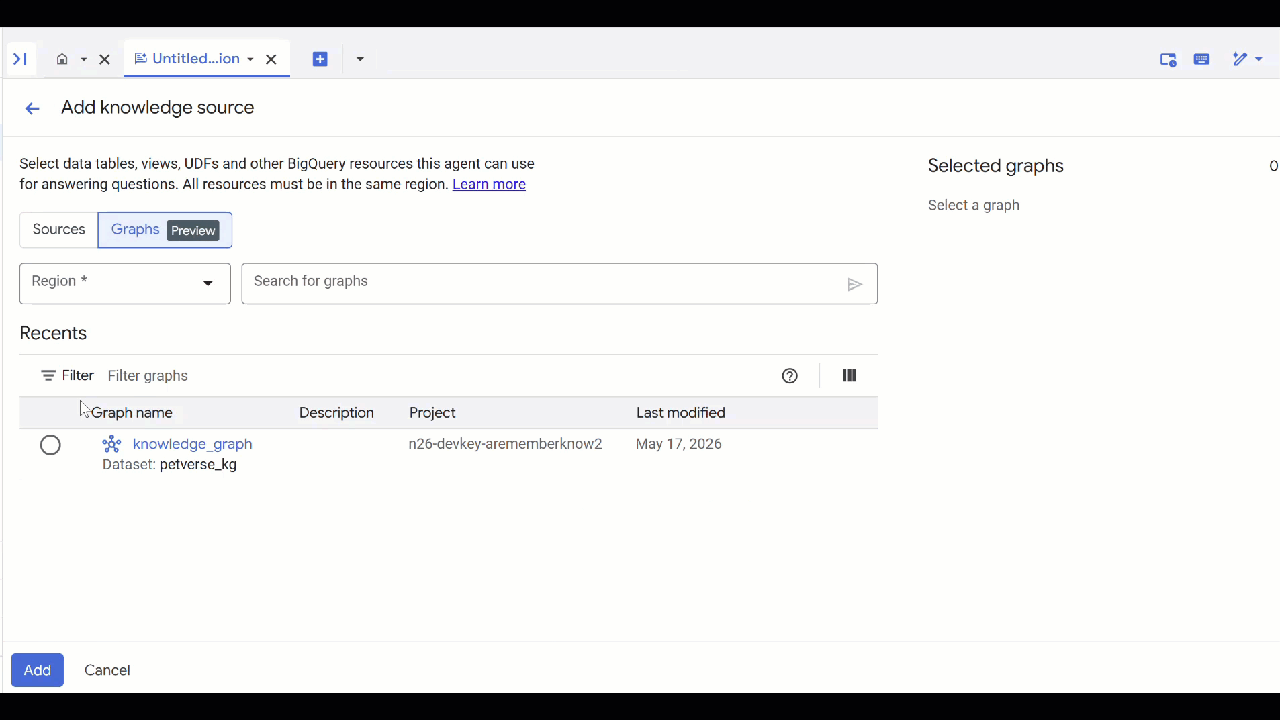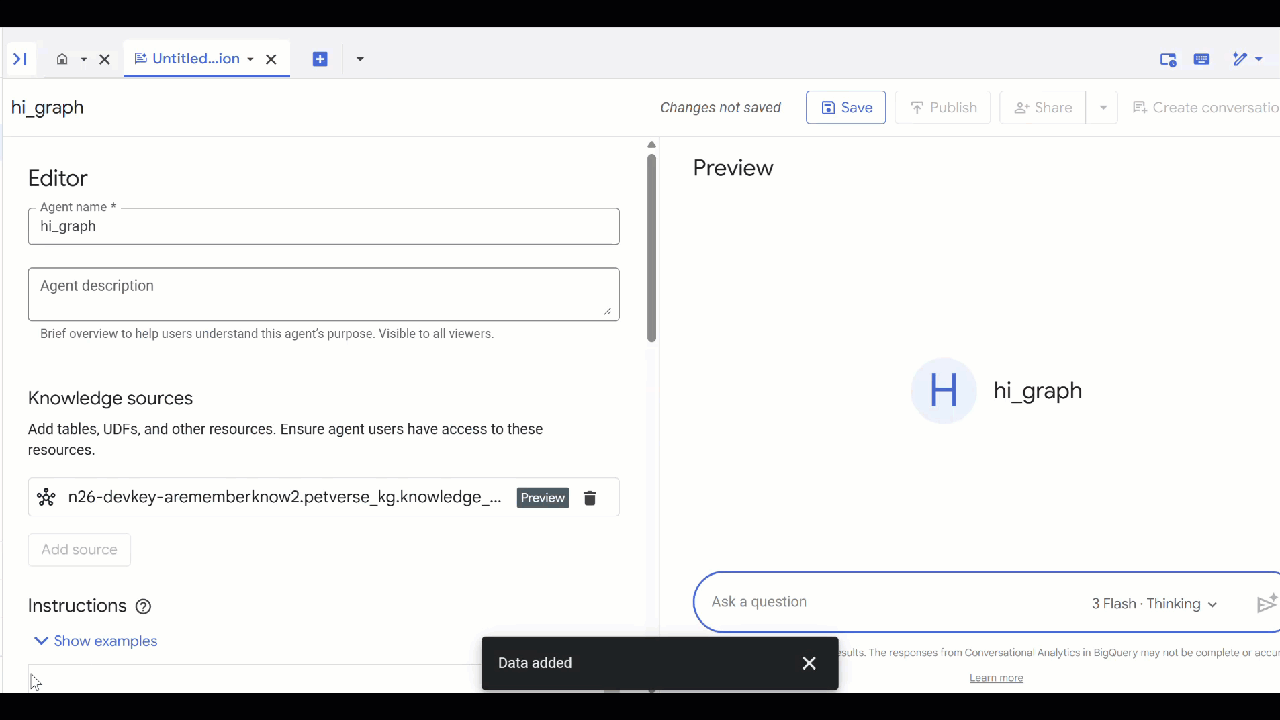
petverse。 - 依序點選「新增來源」和「圖表」。
- 選取您建立的
knowledge_graph,然後按一下「新增」。
現在你可以向代理程式提問,並查看答案和背後的推理過程。如需靈感,請參考以下範例問題。思考型模型可能需要較長時間,但較有可能建構出更完善的 GQL 查詢。展開 Show Thinking 即可查看建構內容。
- 尋找喜歡相同食物的寵物,或是與喜歡小睡的寵物交朋友。
- 是否有任何寵物有完全相同的嗜好、最喜歡的食物或玩具?列出配對對象和共同興趣。
- 尋找物種或品種相同,但嗜好完全不同的寵物。
9. 清理
如要避免系統持續向您的 Google Cloud 帳戶收費,請刪除本程式碼研究室建立的資源。
- 刪除 GKE 叢集:
gcloud container clusters delete petverse-cluster --region $REGION --quiet
- 刪除 BigQuery 資料集 (這會刪除所有資料表):
bq rm -r -f -d $PROJECT_ID:petverse_kg
- 刪除 Pub/Sub 佇列資源:
gcloud pubsub subscriptions delete petverse-sub --quiet
gcloud pubsub topics delete petverse-topic --quiet
- 刪除 Artifact Registry 存放區:
gcloud artifacts repositories delete gke-cats-repo --location=$REGION --quiet
- 刪除專案專屬的 GCS 值區:
gcloud storage buckets delete gs://$PROJECT_ID-petverse --quiet
10. 恭喜
恭喜!您已成功使用 GKE 和 Gemini 建構分散式知識圖譜管道,並使用 BigQuery 屬性圖查詢該管道。
目前所學內容
- 如何在 GKE Autopilot 上部署分散式工作。
- 如何使用 Gemini 擷取多模態資料。
- 如何使用 BigQuery 自動嵌入。
- 瞭解如何在 BigQuery 中建立及查詢屬性圖。