
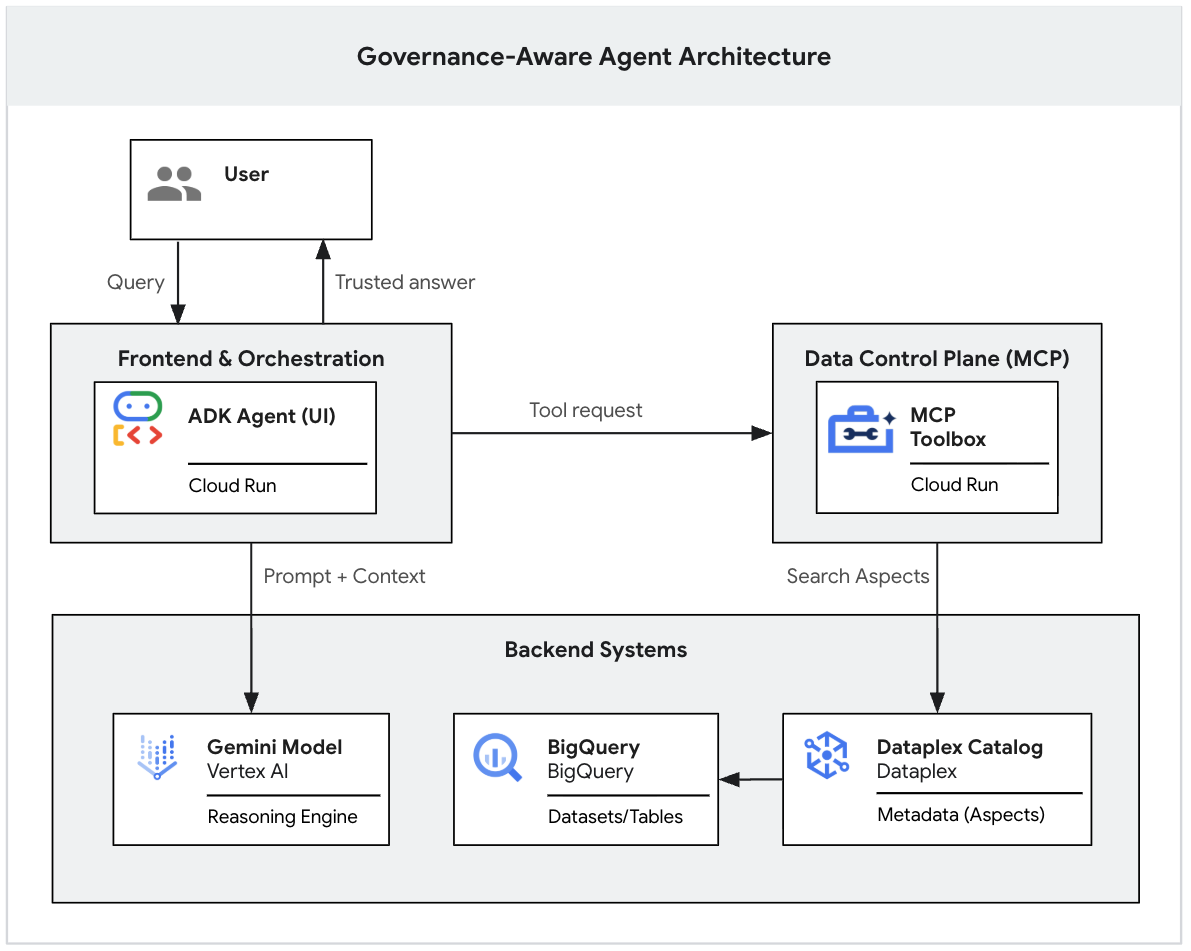
1- مقدمة
تتميّز نماذج الذكاء الاصطناعي التوليدي بقدرتها القوية على الاستنتاج، ولكنّها تفتقر إلى السياق المؤسسي. إذا سأل أحد المدراء التنفيذيين وكيل ذكاء اصطناعي: "ما هي إيراداتنا في الربع الأول؟"، قد يعثر الوكيل على عشرات الجداول التي تحمل الاسم "الإيرادات" في بحيرة البيانات. بعضها تقارير مالية دقيقة، وبعضها الآخر تقديرات تسويقية في الوقت الفعلي، ومن المرجّح أنّ العديد منها صناديق اختبار مهملة.
بدون تحديد مصدر واضح، سيختار وكيل الذكاء الاصطناعي جدولاً استنادًا إلى تشابه بسيط في الاسم، ما يؤدي إلى تقديم إجابات "خاطئة بشكل مقنع" مستندة إلى بيانات لم يتم التحقّق منها.
هذا الدرس التطبيقي حول الترميز هو جزء من سلسلة مكوّنة من جزأين، ويتناول كيفية إنشاء وكيل ذكاء اصطناعي توليدي يستوعب معايير الحوكمة.
في هذا الجزء الأول، ستنشئ الأساس للبيانات. ستعدّ بحيرة بيانات واقعية "غير منظّمة" في BigQuery، وتطبّق علامات وصفية صارمة (سمات Knowledge Catalog) للتمييز بين البيانات الصالحة والبيانات غير المهمة، وتستخدم Gemini CLI لاختبار ما إذا كان النموذج اللغوي الكبير يتبع قواعد الحوكمة بدقة على جهازك.
(يمكنك قراءة الجزء الثاني من هذه السلسلة الذي يتناول كيفية نشر هذا النموذج الأولي المحلي في تطبيق ويب آمن للمؤسسات باستخدام بروتوكول Model Context Protocol (MCP) وCloud Run. 👈 قراءة الجزء الثاني)
المتطلبات الأساسية
- مشروع على Google Cloud تم تفعيل الفوترة فيه
- فهم BigQuery وKnowledge Catalog Universal Catalog وTerraform والإلمام بها بشكل أساسي
- الوصول إلى Google Cloud Shell
ما ستتعلمه
- نشر بحيرة بيانات واقعية ومتعددة المستويات باستخدام Terraform
- تصميم نماذج وصفية صارمة (أنواع السمات) في Knowledge Catalog للتمييز بين منتجات البيانات الرسمية وجداول صناديق الاختبار الأولية
- التحقّق من قواعد الحوكمة محليًا باستخدام Gemini CLI قبل كتابة أي رمز برمجية للتطبيق
ما ستحتاج إليه
- الوصول إلى Google Cloud Shell
- Terraform (مثبّت مسبقًا في Cloud Shell)
- Gemini CLI (مثبّت مسبقًا في Cloud Shell)
المفاهيم الأساسية
- كتالوج Knowledge Catalog الشامل: خدمة موحّدة لإدارة البيانات الوصفية نستخدمها لإثراء البيانات الوصفية الفنية (المخططات) بالسياق التجاري (الحوكمة).
- نوع السمة: نموذج بيانات وصفية منظَّم على عكس العلامات النصية الحرة، تفرض السمات كتابة قوية (تعدادات، قيم منطقية)، ما يجعلها موثوقة للآلات لتقييمها.
2- الإعداد والمتطلبات
بدء Cloud Shell
يمكن تشغيل Google Cloud عن بُعد من الكمبيوتر المحمول، ولكن في هذا الدرس التطبيقي حول الترميز، ستستخدم Google Cloud Shell، وهي بيئة سطر أوامر تعمل في السحابة الإلكترونية.
من Google Cloud Console، انقر على رمز Cloud Shell في شريط الأدوات العلوي الأيسر:
سيستغرق توفير البيئة والاتصال بها بضع لحظات فقط. عند الانتهاء، من المفترض أن يظهر لك ما يلي:

يتم تحميل هذا الجهاز الافتراضي مزوّدة بكل أدوات التطوير التي ستحتاج إليها. توفّر هذه الآلة دليلًا رئيسيًا دائمًا بسعة 5 غيغابايت، وتعمل على Google Cloud، ما يحسّن بشكل كبير أداء الشبكة والمصادقة. يمكنك إكمال جميع مهامك في هذا الدرس التطبيقي حول الترميز داخل متصفّح. ولست بحاجة إلى تثبيت أي شيء.
إعداد البيئة
افتح Cloud Shell واضبط متغيّرات مشروعك لضمان استهداف جميع الأوامر للبنية الأساسية الصحيحة.
export PROJECT_ID=$(gcloud config get-value project)
gcloud config set project $PROJECT_ID
export REGION="us-central1"
تفعيل واجهات برمجة التطبيقات
فعِّل خدمات Google Cloud اللازمة لتنفيذ التعليمات التالية.
gcloud services enable \
artifactregistry.googleapis.com \
bigqueryunified.googleapis.com \
cloudaicompanion.googleapis.com \
cloudbuild.googleapis.com \
cloudresourcemanager.googleapis.com \
datacatalog.googleapis.com \
run.googleapis.com
إنشاء نسخة طبق الأصل من المستودع
احصل على رمز البنية الأساسية والنصوص البرمجية للتشغيل الآلي من مستودع GitHub. لتوفير مساحة على القرص في Cloud Shell، سننزّل المجلد المحدد اللازم لهذا المختبر فقط.
# Perform a shallow clone to get only the latest repository structure without the full history
git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/devrel-demos.git
cd devrel-demos
# Specify and download only the folder we need for this lab
git sparse-checkout set data-analytics/governance-context
cd data-analytics/governance-context
إنشاء بحيرة البيانات "غير المنظّمة"
نادرًا ما تكون بيئات البيانات في العالم الحقيقي منظّمة. لمحاكاة الواقع، نحتاج إلى مزيج من أسواق البيانات "الرسمية" وجداول "صناديق الاختبار" غير الموثوق بها.
سنستخدم Terraform لنشر هذه البيئة. تتعامل عملية الضبط مع مهمتَين:
- البنية الأساسية: إنشاء أنواع سمات Knowledge Catalog ومجموعات بيانات وجداول BigQuery
- تحميل البيانات: تشغيل مهام BigQuery INSERT لملء الجداول ببيانات نموذجية بعد إنشائها مباشرةً
- انتقِل إلى دليل
terraformواضبطه.
cd terraform
terraform init
- طبِّق عملية الضبط. قد يستغرق هذا الإجراء مدة تصل إلى دقيقة.
terraform apply -var="project_id=${PROJECT_ID}" -var="region=${REGION}" -auto-approve
نقطة التحقق: لديك الآن بحيرة بيانات مملوءة بالكامل، ولكنها غير خاضعة للحوكمة على الإطلاق. بالنسبة إلى الذكاء الاصطناعي، يبدو كل جدول متطابقًا تمامًا.
3- تطبيق الحوكمة
هذه هي الخطوة الهندسية المهمة. في الوقت الحالي، يبدو الجدولان finance_mart.fin_monthly_closing_internal وanalyst_sandbox.tmp_data_dump_v2_final_real متطابقَين بالنسبة إلى النموذج اللغوي الكبير. هما مجرد كائنَين يتضمّنان أعمدة.
بصفتك مهندس حوكمة، عليك إرفاق سمة (علامة بيانات وصفية معتمَدة) بهذين الجدولَين للتمييز بينهما. في مؤسسة حقيقية، يمكنك أتمتة هذه العملية من خلال عمليات التكامل المستمر/النشر المستمر. سنحاكي هذه الأتمتة باستخدام النصوص البرمجية.
إنشاء بيانات الحوكمة الأساسية
يجب أن تكون مفاتيح سمات Knowledge Catalog فريدة على مستوى العالم (مسبوقة برقم تعريف مشروعك). سينشئ النص البرمجي ./generate_payloads.sh ملفات البيانات الوصفية بتنسيق YAML بشكل ديناميكي.
cd ..
chmod +x ./generate_payloads.sh
./generate_payloads.sh
الإخراج:
يؤدي هذا الإجراء إلى إنشاء مجلد "./aspect_payloads" يحتوي على 4 ملفات بتنسيق YAML، تحدّد سيناريوهات الحوكمة (ذهبي/داخلي، ذهبي/علني، فضي/في الوقت الفعلي، برونزي/صندوق اختبار).
تطبيق السمات من خلال واجهة سطر الأوامر
قبل تشغيل النص البرمجي، لنلقِ نظرة على ما نطبّقه فعليًا لإزالة الغموض عن العملية. شغِّل الأمر التالي للاطّلاع على بنية البيانات الأساسية المالية الداخلية:
cat aspect_payloads/fin_internal.yaml
سيظهر لك المحتوى التالي.
your-project-id.us-central1.official-data-product-spec:
data:
product_tier: GOLD_CRITICAL
data_domain: FINANCE
usage_scope: INTERNAL_ONLY
update_frequency: DAILY_BATCH
is_certified: true
لاحظ كيف يحدّد ملف YAML هذا السياق التجاري بشكل صريح، مثل ضبط العلامة is_certified: true وتعيين المستوى GOLD_CRITICAL. يمنح هذا الإجراء الذكاء الاصطناعي قواعد واضحة ومنظَّمة لتقييمها بدلاً من مجرد التخمين استنادًا إلى أسماء الجداول.
الآن، شغِّل النص البرمجي للتطبيق. يؤدي هذا الإجراء إلى تكرار جداول BigQuery وتنفيذ الأمر gcloud dataplex entries update لإرفاق هذه البيانات الوصفية الصارمة.
chmod +x ./apply_governance.sh
./apply_governance.sh
التحقّق (اختياري)
قبل المتابعة، تأكَّد من تطبيق البيانات الوصفية بشكل صحيح في وحدة التحكّم.
- افتح صفحة كتالوج Knowledge Catalog الشامل في Google Cloud Console. إذا لم يظهر لك "كتالوج Knowledge Catalog الشامل" في قائمة التنقّل على يمين الصفحة، استخدِم شريط البحث في أعلى نافذة Google Cloud Console، واكتب Knowledge Catalog، واختَر النتيجة ضمن "أهم النتائج" أو "المنتجات والصفحات".
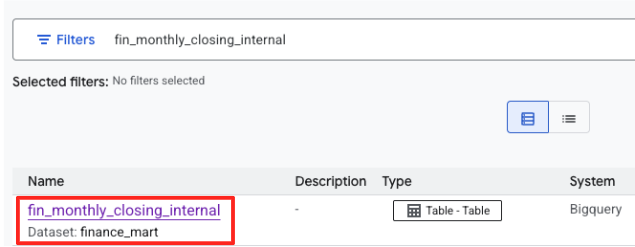
- ابحث عن
fin_monthly_closing_internal. من المفترض أن يظهر جدول BigQuery في النتائج. انقر على اسم الجدول للانتقال إلى صفحة التفاصيل.
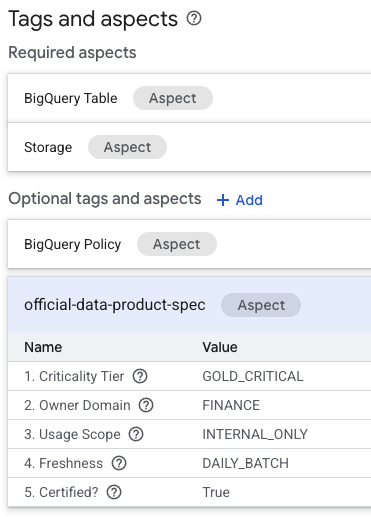
- في صفحة تفاصيل الجدول، ابحث عن قسم "العلامات والسمات الاختيارية" في أسفل الصفحة.
- ستعثر على السمة
official-data-product-spec. تأكَّد من أنّ القيم تتطابق مع سيناريو "ذهبي/داخلي" الذي طبقناه.
لقد أكدت الآن أنّ جداول BigQuery المتطابقة من الناحية الفنية (fin_monthly_closing_internal وtmp_data_dump_v2_final_real) يتم تمييزها منطقيًا من خلال بيانات وصفية قابلة للقراءة آليًا.
4- ضبط الوكيل وإنشاء نموذج أولي له
قبل إنشاء تطبيق ويب (سنفعل ذلك في الجزء الثاني)، سنتحقّق من منطق الحوكمة محليًا. علينا تثبيت إضافة Knowledge Catalog وضبط الرسالة الموجّهة للنظام.
تثبيت الإضافة
في Cloud Shell، ثبِّت إضافة Knowledge Catalog. سيُطلب منك التأكيد وتفاصيل الإعداد.
export DATAPLEX_PROJECT="${PROJECT_ID}"
gemini extensions install https://github.com/gemini-cli-extensions/dataplex
(اكتب Y لقبول التثبيت، وأدخِل رقم تعريف مشروعك عند ظهور الطلب).
تحديد ملف السياسة
يحتوي الملف GEMINI.md على المنطق الذي يترجم القواعد البشرية المجرّدة (مثل "أحتاج إلى بيانات آمنة") إلى عمليات بحث فنية صارمة.
هذا الملف عام حاليًا. يحتاج الوكيل إلى معرفة مشروع على السحابة الإلكترونية من Google Cloud الذي يجب البحث فيه بالضبط لمنعه من هلوسة جداول من الإنترنت العام أو سياقات أخرى.
- أدخِل
PROJECT_IDفي ملف السياسة.
envsubst < GEMINI.md > GEMINI.md.tmp && mv GEMINI.md.tmp GEMINI.md
- افحص الملف لفهم الخوارزمية التي نعلّمها للذكاء الاصطناعي.
cat GEMINI.md
لاحظ أمرين في هذا الملف:
- نطاق المشروع: راجِع المرحلة 2. تأكَّد من استبدال projectid:
${PROJECT_ID}برقم تعريف مشروعك الفعلي(e.g., projectid:my-lab-project). إذا لم يتم استبدال هذا المتغيّر، سيبحث الوكيل في كل مشروع يمكنك الوصول إليه، ما يؤدي إلى تقديم إجابات غير صحيحة. - الخوارزمية: لاحظ منطق المرحلة 1 / المرحلة 2. نطلب من النموذج صراحةً عدم تخمين لغة SQL. يجب أولاً البحث عن تعريف العلامة الصحيح (المرحلة 1)، ثم البحث عن البيانات (المرحلة 2).
بدء الوكيل واختبار السيناريوهات
ابدأ جلسة Gemini CLI، ولكن هذه المرة حمِّل سياسة الحوكمة كسياق النظام.
gemini
ملاحظة: قد تظهر لك ملفات سياق متعددة يتم تحميلها (مثل GEMINI.md وغيرها). هذا أمر طبيعي. تحمِّل واجهة سطر الأوامر ملف GEMINI.md المحلي للقواعد المحددة لهذا المشروع، بالإضافة إلى التعليمات التلقائية لإضافة Knowledge Catalog نفسها.
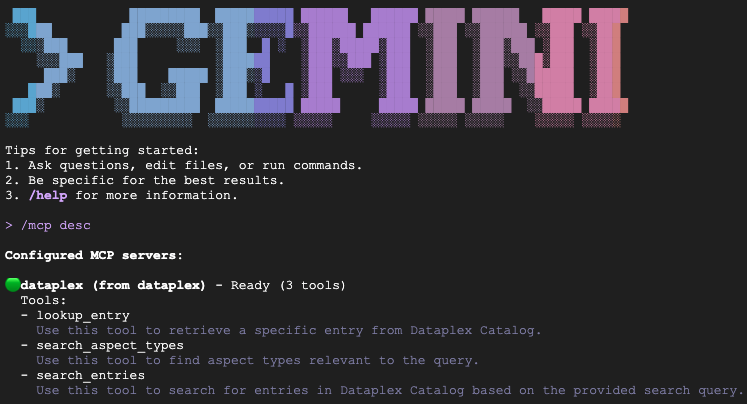
التحقّق من التثبيت
اكتب /mcp desc للتأكّد من أنّ إضافة Knowledge Catalog نشطة. من المفترض أن يظهر dataplex كخادم MCP تم ضبطه ويتضمّن أدوات متاحة.
سيناريوهات الاختبار (إنشاء نموذج أولي)
الصِق الطلبات التالية في جلسة الوكيل قيد التشغيل واحدًا تلو الآخر للتحقّق من التزامه بقواعدك.
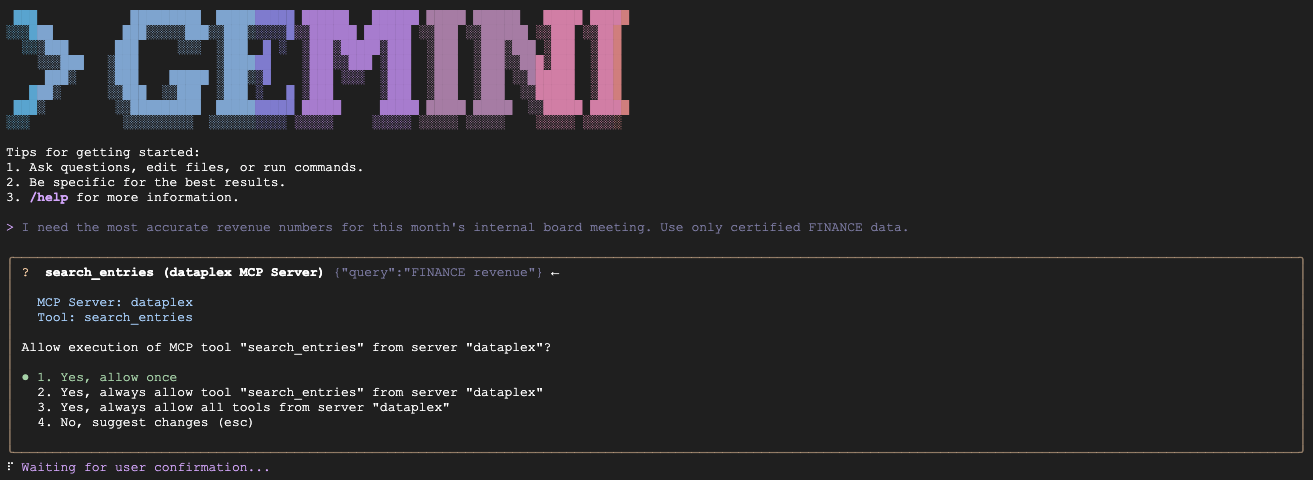
- السيناريو (أ) (اعتماد بيانات المدير المالي):
"We are preparing the deck for an internal Board of Directors meeting next week. I need the numbers to be absolutely finalized, trustworthy, and kept strictly confidential. Which table is safe to use?"
المتوقّع: يستعلم عن fin_monthly_closing_internal لأنّه يتطابق دلاليًا مع GOLD_CRITICAL (دقيق) وINTERNAL_ONLY (اجتماع مجلس الإدارة) في السمة.
- السيناريو (ب) (الإفصاح العلني):
"I need to share our quarterly financial summary with an external consulting firm. It is critical that we do not leak any raw or internal metrics. Which dataset is officially scrubbed and explicitly approved for external sharing?"
المتوقّع: يجب أن يتجاوز الوكيل الجدول الداخلي الشهري وأن يختار fin_quarterly_public_report بدقة لأنّه الأصل الوحيد الذي تم وضع علامة EXTERNAL_READY عليه.
- السيناريو (ج) (الاحتياجات التشغيلية):
"My dashboard needs to show what's happening right now with our ad spend. I can't wait for the overnight load. What do you recommend?"
المتوقّع: يختار الوكيل mkt_realtime_campaign_performance لأنّه يحدّد معدل التحديثات REALTIME_STREAMING، ما يمنحها الأولوية على المستوى GOLD_CRITICAL للبيانات المالية.
- السيناريو (د) (التجربة في صندوق الاختبار):
"I'm just playing around with some new ML models and need a lot of raw data. It doesn't need to be perfect, just a sandbox environment."
المتوقّع: يختار الوكيل tmp_data_dump_v2_final_real لأنّه يتطابق دلاليًا مع BRONZE_ADHOC (بيانات أولية) وis_certified: false (بيئة صندوق اختبار) في السمة.
(للخروج من جلسة Gemini، اكتب /quit)
5- تهانينا! ما هي الخطوات التالية؟
لقد أنشأت بنجاح أساسًا للبيانات خاضعًا للحوكمة وأثبتّ أنّ الذكاء الاصطناعي يمكنه اتّباع قواعد البيانات الوصفية بدقة باستخدام نموذج أولي محلي لواجهة سطر الأوامر.
لقد وصلت الآن إلى نقطة تحقّق. يُرجى اختيار الخطوة التالية:
الخيار (أ): أريد المتابعة إلى الجزء الثاني الآن.
إذا كنت مستعدًا لتحويل هذا النموذج الأولي المحلي إلى تطبيق ويب آمن للمؤسسات في مرحلة الإنتاج باستخدام بروتوكول Model Context Protocol (MCP) وCloud Run:
👈 رابط إلى الدرس التطبيقي حول الترميز في الجزء الثاني
الخيار (ب): سأكمل الجزء الثاني لاحقًا أو أردت إكمال الجزء الأول فقط.
إذا أردت التوقف اليوم وتجنُّب التكاليف على السحابة الإلكترونية، عليك تنظيف مواردك.
لا داعي للقلق. في الجزء الثاني، سنقدّم "نصًا برمجية سريعًا" يعيد إنشاء بيئة الجزء الأول هذه بالكامل في دقيقتَين فقط، ما يتيح لك المتابعة من حيث توقفت تمامًا.
👈 الانتقال إلى قسم التنظيف
6- التنظيف (للخيار "ب" فقط)
إذا كنت ستتوقف هنا، عليك إتلاف الموارد لتجنُّب تكبّد رسوم.
محو بحيرة البيانات (Terraform)
إذا كنت حاليًا في بيئة Gemini CLI، اخرج من الجلسة بالضغط على Ctrl+C مرّتَين أو كتابة /quit. بعد ذلك، شغِّل الأوامر التالية:
cd ~/devrel-demos/data-analytics/governance-context/terraform
terraform destroy -var="project_id=${PROJECT_ID}" -var="region=${REGION}" -auto-approve
إزالة تثبيت إضافة Gemini CLI وإزالة الملفات المحلية
gemini extensions uninstall dataplex
cd ~
rm -rf ~/devrel-demos