
1. Introduzione
I modelli di AI generativa sono potenti strumenti di ragionamento, ma non hanno un contesto istituzionale. Se un dirigente chiede a un agente AI: "Quali sono le nostre entrate del primo trimestre?", l'agente potrebbe trovare decine di tabelle denominate "entrate" nel tuo data lake. Alcuni sono report finanziari rigorosi, altri sono stime di marketing in tempo reale e molti sono probabilmente sandbox obsolete.
Senza un grounding esplicito, un agente AI selezionerà una tabella in base a una semplice somiglianza del nome, il che porterà a risposte "convincentemente errate" derivate da dati non verificati.
Questo codelab fa parte di una serie in due parti che esplora come creare un agente GenAI consapevole della governance.
In questa prima parte, creerai le basi dei dati. Configurerai un data lake "disordinato" e realistico in BigQuery, applicherai tag di metadati rigidi (aspetti di Knowledge Catalog) per distinguere i dati validi dal rumore e utilizzerai la Gemini CLI per verificare localmente se l'LLM segue rigorosamente le regole di governance.
Puoi leggere la seconda parte di questa serie, che spiega come eseguire il deployment di questo prototipo locale in un'applicazione web sicura di livello enterprise utilizzando Model Context Protocol (MCP) e Cloud Run. 👉 Leggi la parte 2)
Prerequisiti
- Un progetto Google Cloud con la fatturazione abilitata.
- Conoscenza di base e familiarità con BigQuery, Knowledge Catalog Universal Catalog e Terraform.
- Accesso a Google Cloud Shell.
Cosa imparerai a fare
- Esegui il deployment di un data lake realistico a più livelli utilizzando Terraform.
- Progetta modelli di metadati rigorosi (tipi di aspetti) in Knowledge Catalog per distinguere i prodotti di dati ufficiali dalle tabelle sandbox non elaborate.
- Verifica le regole di governance localmente utilizzando la CLI Gemini prima di scrivere qualsiasi codice dell'applicazione.
Che cosa ti serve
- Accesso a Google Cloud Shell
- Terraform (preinstallato in Cloud Shell).
- Gemini CLI (preinstallata in Cloud Shell).
Concetti fondamentali
- Knowledge Catalog Universal Catalog:il servizio di gestione dei metadati unificato. Lo utilizziamo per arricchire i metadati tecnici (schemi) con il contesto aziendale (governance).
- Tipo di aspetto:un modello di metadati strutturati. A differenza dei tag di testo libero, gli aspetti applicano una tipizzazione forte (enumerazioni, booleani), rendendoli affidabili per la valutazione da parte delle macchine.
2. Configurazione e requisiti
Avvia Cloud Shell
Sebbene Google Cloud possa essere gestito da remoto dal tuo laptop, in questo codelab utilizzerai Google Cloud Shell, un ambiente a riga di comando in esecuzione nel cloud.
Nella console Google Cloud, fai clic sull'icona di Cloud Shell nella barra degli strumenti in alto a destra:
Bastano pochi istanti per eseguire il provisioning e connettersi all'ambiente. Al termine, dovresti vedere un risultato simile a questo:

Questa macchina virtuale è caricata con tutti gli strumenti per sviluppatori di cui avrai bisogno. Offre una home directory permanente da 5 GB e viene eseguita su Google Cloud, migliorando notevolmente le prestazioni e l'autenticazione della rete. Tutto il lavoro in questo codelab può essere svolto all'interno di un browser. Non devi installare nulla.
Inizializza l'ambiente
Apri Cloud Shell e imposta le variabili del progetto per assicurarti che tutti i comandi abbiano come target l'infrastruttura corretta.
export PROJECT_ID=$(gcloud config get-value project)
gcloud config set project $PROJECT_ID
export REGION="us-central1"
Abilita le API
Abilita i servizi Google Cloud necessari per eseguire le istruzioni seguenti.
gcloud services enable \
artifactregistry.googleapis.com \
bigqueryunified.googleapis.com \
cloudaicompanion.googleapis.com \
cloudbuild.googleapis.com \
cloudresourcemanager.googleapis.com \
datacatalog.googleapis.com \
run.googleapis.com
Clona il repository
Recupera il codice dell'infrastruttura e gli script di automazione dal repository GitHub. Per risparmiare spazio su disco in Cloud Shell, scaricheremo solo la cartella specifica necessaria per questo lab.
# Perform a shallow clone to get only the latest repository structure without the full history
git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/devrel-demos.git
cd devrel-demos
# Specify and download only the folder we need for this lab
git sparse-checkout set data-analytics/governance-context
cd data-analytics/governance-context
Crea il data lake "disordinato"
Gli ambienti di dati reali sono raramente puliti. Per simulare la realtà, abbiamo bisogno di un mix di data mart "ufficiali" e tabelle "sandbox" non attendibili.
Utilizzeremo Terraform per eseguire il deployment di questo ambiente. La configurazione gestisce due attività:
- Infrastruttura:crea tipi di aspetti Knowledge Catalog e set di dati/tabelle BigQuery.
- Caricamento dei dati:esegue job BigQuery INSERT per popolare le tabelle con dati di esempio subito dopo la creazione.
- Vai alla directory
terraforme inizializzala.
cd terraform
terraform init
- Applica la configurazione. L'operazione potrebbe richiedere fino a un minuto.
terraform apply -var="project_id=${PROJECT_ID}" -var="region=${REGION}" -auto-approve
Checkpoint: ora hai un data lake completamente popolato, ma senza alcuna governance. Per un'IA, tutte le tabelle sono identiche.
3. Applicazione della governance
Questo è il passaggio di ingegneria fondamentale. Al momento, le tabelle finance_mart.fin_monthly_closing_internal e analyst_sandbox.tmp_data_dump_v2_final_real hanno lo stesso aspetto di un LLM. Sono solo oggetti con colonne.
In qualità di ingegnere della governance, devi collegare un aspetto (un'etichetta di metadati certificata) a queste tabelle per differenziarle. In un'azienda reale, automatizzeresti questa operazione tramite pipeline CI/CD. Simuleremo questa automazione con script.
Generare payload di governance
Le chiavi dell'aspetto del Knowledge Catalog devono essere univoche a livello globale (con il prefisso dell'ID progetto). Lo script ./generate_payloads.sh genererà dinamicamente i file di metadati YAML.
cd ..
chmod +x ./generate_payloads.sh
./generate_payloads.sh
Output:
Viene creata una cartella "./aspect_payloads" contenente quattro file YAML che definiscono gli scenari di governance (Gold/Internal, Gold/Public, Silver/Realtime, Bronze/Sandbox).
Applicare gli aspetti tramite la CLI
Prima di eseguire lo script, vediamo cosa stiamo effettivamente applicando per demistificare il processo. Esegui questo comando per visualizzare la struttura del payload di finanza interna:
cat aspect_payloads/fin_internal.yaml
Verranno visualizzati i seguenti contenuti.
your-project-id.us-central1.official-data-product-spec:
data:
product_tier: GOLD_CRITICAL
data_domain: FINANCE
usage_scope: INTERNAL_ONLY
update_frequency: DAILY_BATCH
is_certified: true
Nota come questo YAML definisca esplicitamente il contesto aziendale, ad esempio impostando il flag is_certified: true e assegnando il livello GOLD_CRITICAL. Fornendo all'AI regole chiare e strutturate da valutare anziché basarsi solo sui nomi delle tabelle.
Ora esegui lo script dell'applicazione. Questo ciclo itera le tabelle BigQuery ed esegue il comando gcloud dataplex entries update per allegare questi metadati rigidi.
chmod +x ./apply_governance.sh
./apply_governance.sh
Verifica (facoltativa)
Prima di procedere, verifica che i metadati siano stati applicati correttamente nella console.
- Apri la pagina Knowledge Catalog Universal Catalog nella console Google Cloud. Se non vedi "Knowledge Catalog Universal Catalog" nel menu di navigazione a sinistra, utilizza la barra di ricerca nella parte superiore della finestra della console Google Cloud, digita Knowledge Catalog e seleziona il risultato in "Risultati principali" o "Prodotti e pagine".
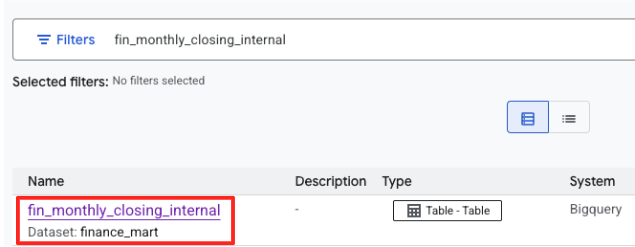
- Cerca
fin_monthly_closing_internal. Dovresti vedere la tabella BigQuery elencata nei risultati. Fai clic sul nome della tabella per accedere alla relativa pagina dei dettagli.
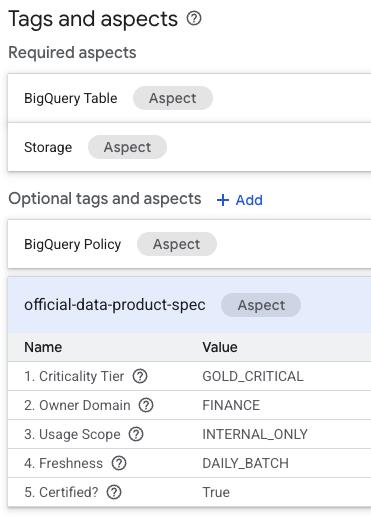
- Nella pagina dei dettagli della tabella, cerca la sezione "Tag e aspetti facoltativi" in basso.
- Troverai l'aspetto
official-data-product-spec. Verifica che i valori corrispondano allo scenario "Gold Internal" che abbiamo applicato.
Ora hai confermato che le tabelle BigQuery tecnicamente identiche (fin_monthly_closing_internal e tmp_data_dump_v2_final_real) sono differenziate logicamente dai metadati leggibili automaticamente.
4. Configura e prototipa l'agente
Prima di creare un'applicazione web (operazione che eseguiremo nella Parte 2), verificheremo la nostra logica di governance in locale. Dobbiamo installare l'estensione Knowledge Catalog e configurare il prompt di sistema.
Installare l'estensione
In Cloud Shell, installa l'estensione Knowledge Catalog. Ti verrà chiesto di confermare e di fornire i dettagli della configurazione.
export DATAPLEX_PROJECT="${PROJECT_ID}"
gemini extensions install https://github.com/gemini-cli-extensions/dataplex
(Digita Y per accettare l'installazione e inserisci l'ID progetto quando richiesto).
Definisci il file delle policy
Il file GEMINI.md contiene la logica che traduce regole umane astratte (ad es. "Ho bisogno di dati sicuri") in ricerche tecniche rigorose.
Questo file è attualmente generico. L'agente deve sapere esattamente in quale progetto Google Cloud cercare per evitare che generi tabelle da internet pubblico o da altri contesti.
- Inserisci il tuo
PROJECT_IDnel file delle norme.
envsubst < GEMINI.md > GEMINI.md.tmp && mv GEMINI.md.tmp GEMINI.md
- Ispeziona il file per comprendere l'algoritmo che stiamo insegnando all'AI.
cat GEMINI.md
In questo file nota due cose:
- Ambito del progetto:controlla la fase 2. Assicurati che projectid:
${PROJECT_ID}sia stato sostituito con il tuo ID progetto effettivo(e.g., projectid:my-lab-project). Se questa variabile non viene sostituita, l'agente eseguirà la ricerca in tutti i progetti a cui hai accesso, fornendo risposte errate. - L'algoritmo:nota la logica della fase 1 / fase 2. Abbiamo istruito esplicitamente il modello a NON indovinare l'SQL. Deve prima cercare la definizione del tag corretta (fase 1) e solo dopo cercare i dati (fase 2).
Avvia l'agente e testa gli scenari
Avvia la sessione di Gemini CLI, questa volta caricando le norme di governance come contesto di sistema.
gemini
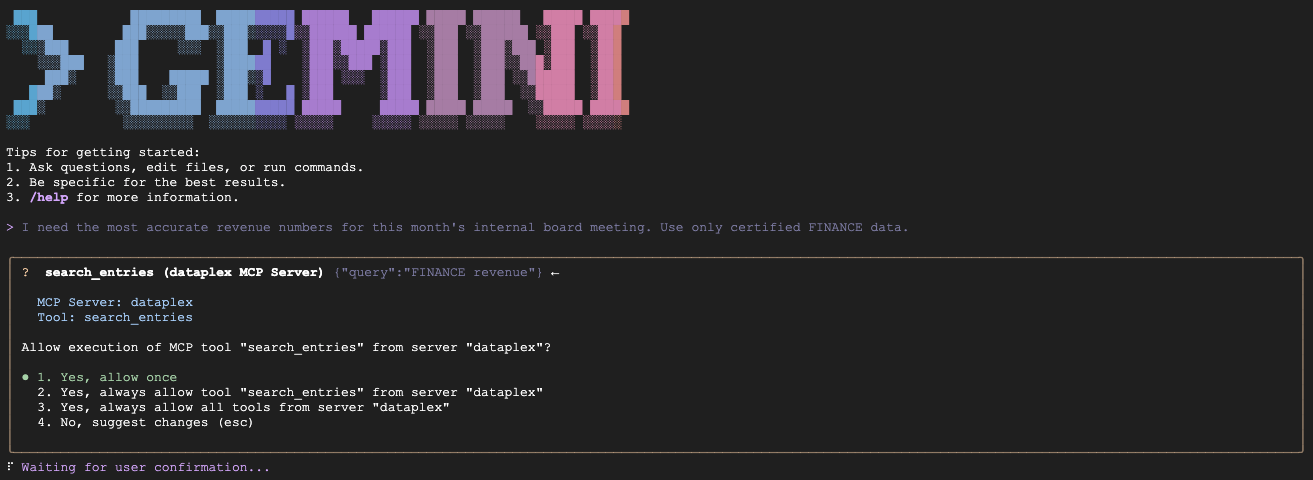
Nota: potresti vedere il caricamento di più file di contesto (ad es. GEMINI.md e altri). È normale. La CLI carica il file GEMINI.md locale per le regole specifiche di questo progetto, oltre alle istruzioni predefinite per l'estensione Knowledge Catalog stessa.
Verifica dell'installazione
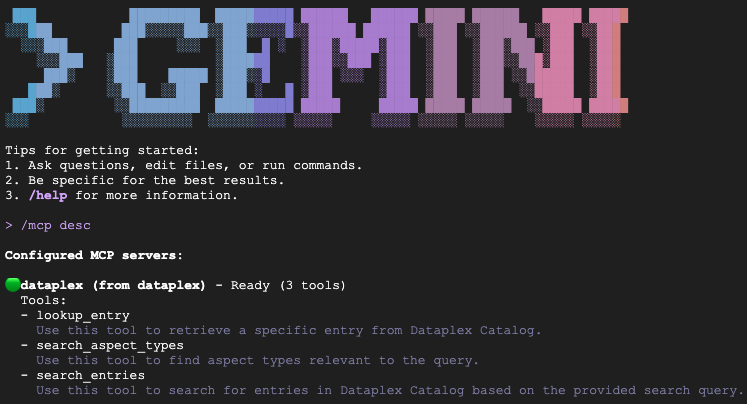
Digita /mcp desc per verificare che l'estensione Knowledge Catalog sia attiva. Dovresti visualizzare dataplex elencato come server MCP configurato con gli strumenti disponibili.
Scenari di test (prototipazione)
Incolla i seguenti prompt nella sessione dell'agente in esecuzione uno alla volta per verificare che rispetti le tue regole.
- Scenario A (certificazione dei dati del CFO):
"We are preparing the deck for an internal Board of Directors meeting next week. I need the numbers to be absolutely finalized, trustworthy, and kept strictly confidential. Which table is safe to use?"
Risultato previsto: query fin_monthly_closing_internal perché corrisponde semanticamente a GOLD_CRITICAL (accurate) e INTERNAL_ONLY (board meeting) nel suo aspetto.
- Scenario B (divulgazione pubblica):
"I need to share our quarterly financial summary with an external consulting firm. It is critical that we do not leak any raw or internal metrics. Which dataset is officially scrubbed and explicitly approved for external sharing?"
Risultato previsto:l'agente deve ignorare la tabella interna mensile e selezionare rigorosamente fin_quarterly_public_report perché è l'unica risorsa taggata EXTERNAL_READY.
- Scenario C (esigenze operative):
"My dashboard needs to show what's happening right now with our ad spend. I can't wait for the overnight load. What do you recommend?"
Previsto:l'agente seleziona mkt_realtime_campaign_performance perché identifica la frequenza di aggiornamento REALTIME_STREAMING, dando la priorità a questo valore rispetto al livello GOLD_CRITICAL dei dati finanziari.
- Scenario D (sperimentazione sandbox):
"I'm just playing around with some new ML models and need a lot of raw data. It doesn't need to be perfect, just a sandbox environment."
Risultato previsto:l'agente seleziona tmp_data_dump_v2_final_real perché corrisponde semanticamente a BRONZE_ADHOC (dati non elaborati) e is_certified: false (ambiente sandbox) nel suo aspetto.
(Per uscire dalla sessione di Gemini, digita /quit)
5. Complimenti! Passaggi successivi
Hai creato correttamente una base di dati controllata e dimostrato che un'AI può seguire rigorosamente le regole dei metadati utilizzando un prototipo CLI locale.
Ora hai raggiunto un punto di controllo. Scegli il prossimo passaggio:
Opzione A: voglio continuare subito con la seconda parte.
Se vuoi trasformare questo prototipo locale in un'applicazione web sicura e di livello di produzione utilizzando Model Context Protocol (MCP) e Cloud Run:
👉 Link al codelab della parte 2
Opzione B: farò la parte 2 in un secondo momento o volevo completare solo la parte 1.
Se vuoi interrompere l'attività per oggi ed evitare costi cloud, devi eseguire la pulizia delle risorse.
Non preoccuparti. Nella Parte 2, forniremo uno "Script di tracciamento rapido" che ricreerà completamente questo ambiente della Parte 1 in soli 2 minuti, in modo che tu possa riprendere esattamente da dove avevi interrotto.
👉 Vai alla sezione Liberare spazio.
6. Liberare spazio (solo per l'opzione B)
Se ti fermi qui, elimina le risorse per evitare addebiti.
Elimina il data lake (Terraform)
Se ti trovi nell'ambiente Gemini CLI, esci dalla sessione premendo Ctrl+C due volte o digitando /quit. Quindi, esegui questi comandi:
cd ~/devrel-demos/data-analytics/governance-context/terraform
terraform destroy -var="project_id=${PROJECT_ID}" -var="region=${REGION}" -auto-approve
Disinstallare l'estensione Gemini CLI e rimuovere i file locali
gemini extensions uninstall dataplex
cd ~
rm -rf ~/devrel-demos