
1. Введение
Модели генеративного ИИ — мощные средства рассуждения, но им не хватает институционального контекста. Если руководитель спросит у ИИ-агента: «Какова наша выручка за первый квартал?», агент может обнаружить десятки таблиц с названием «выручка» в вашем хранилище данных. Некоторые из них представляют собой точные финансовые отчеты, другие — оценки маркетинговых показателей в реальном времени, а многие, вероятно, являются устаревшими тестовыми средами.
Без явного обоснования агент ИИ выберет стол на основе простого сходства названий, что приведет к « убедительно неверным » ответам, полученным из непроверенных данных.
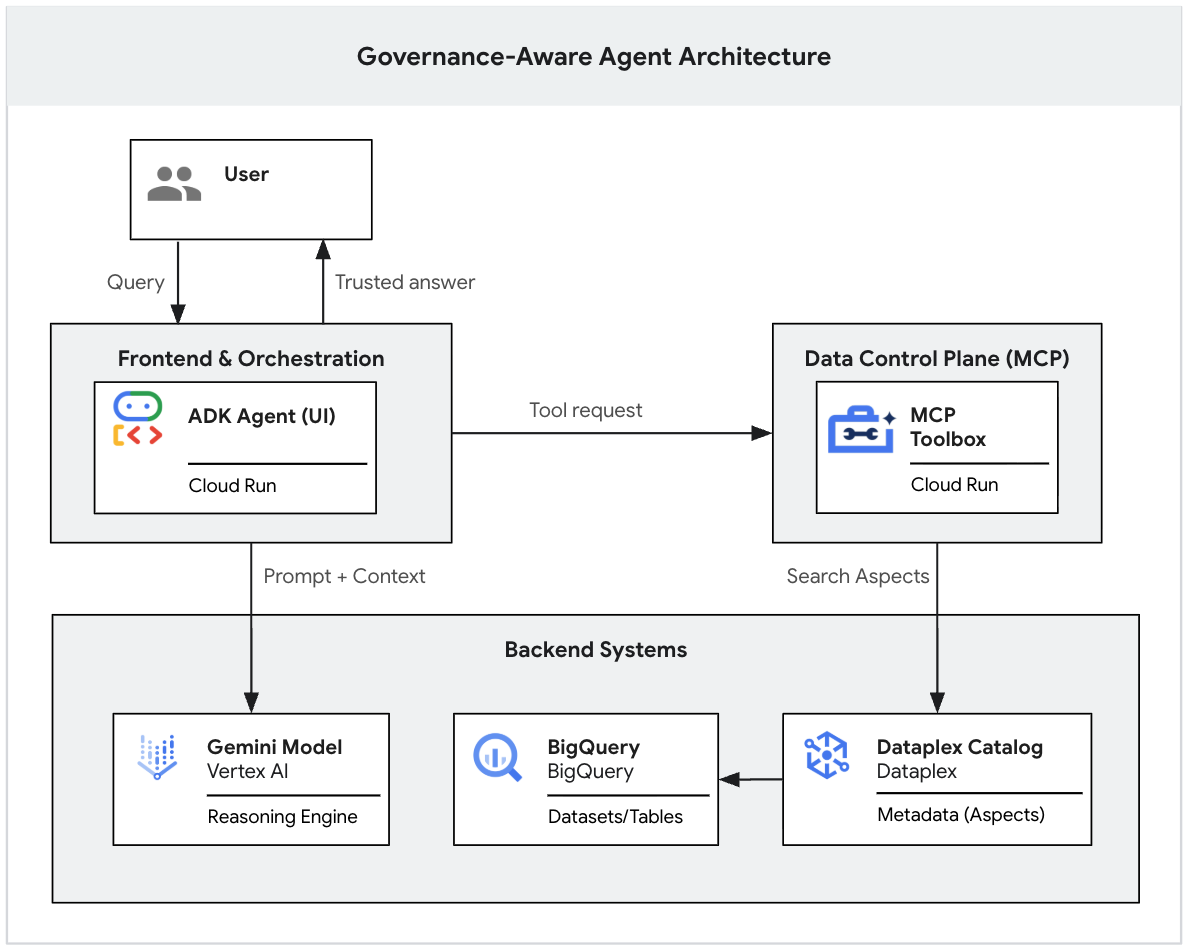
Данный практический урок является частью двухсерийного цикла, посвященного созданию агента GenAI, учитывающего особенности управления ИИ.
В первой части вы заложите основу для работы с данными. Вы создадите реалистичное, "неструктурированное" озеро данных в BigQuery, примените строгие метатеги (аспекты каталога знаний) для различения корректных данных от шума и используете CLI Gemini для локальной проверки того, строго ли LLM соответствует вашим правилам управления.
(Вы можете прочитать вторую часть этой серии, в которой рассказывается о том, как развернуть этот локальный прототип в защищенном веб-приложении корпоративного уровня с использованием протокола контекста модели (MCP) и Cloud Run. 👉 Читать часть 2 )
Предварительные требования
- Проект Google Cloud с включенной функцией выставления счетов.
- Базовое понимание и знакомство с BigQuery , Knowledge Catalog Universal Catalog и Terraform .
- Доступ к Google Cloud Shell.
Что вы узнаете
- Разверните реалистичное многоуровневое озеро данных с помощью Terraform.
- Разработайте строгие шаблоны метаданных (типы аспектов) в Каталоге знаний, чтобы отличать официальные продукты данных от необработанных таблиц в тестовой среде.
- Перед написанием кода приложения проверьте правила управления локально с помощью интерфейса командной строки Gemini .
Что вам понадобится
- Доступ к Google Cloud Shell
- Terraform (предустановлен в Cloud Shell).
- Gemini CLI (предустановлен в Cloud Shell).
Ключевые понятия
- Универсальный каталог знаний: унифицированная служба управления метаданными. Мы используем его для обогащения технических метаданных (схем) бизнес-контекстом (управлением).
- Тип аспекта: Структурированный шаблон метаданных. В отличие от тегов свободного текста, аспекты обеспечивают строгую типизацию (перечисления, логические значения), что делает их надежными для машинной оценки.
2. Настройка и требования
Запустить Cloud Shell
Хотя Google Cloud можно управлять удаленно с ноутбука, в этом практическом занятии вы будете использовать Google Cloud Shell — среду командной строки, работающую в облаке.
В консоли Google Cloud нажмите на значок Cloud Shell на панели инструментов в правом верхнем углу:
Подготовка и подключение к среде займут всего несколько минут. После завершения вы должны увидеть что-то подобное:

Эта виртуальная машина содержит все необходимые инструменты разработки. Она предоставляет постоянный домашний каталог объемом 5 ГБ и работает в облаке Google, что значительно повышает производительность сети и аутентификацию. Вся работа в этом практическом задании может выполняться в браузере. Вам не нужно ничего устанавливать.
Инициализация среды
Откройте Cloud Shell и настройте переменные проекта, чтобы все команды были направлены на правильную инфраструктуру.
export PROJECT_ID=$(gcloud config get-value project)
gcloud config set project $PROJECT_ID
export REGION="us-central1"
Включить API
Для выполнения следующей инструкции необходимо включить соответствующие службы Google Cloud.
gcloud services enable \
artifactregistry.googleapis.com \
bigqueryunified.googleapis.com \
cloudaicompanion.googleapis.com \
cloudbuild.googleapis.com \
cloudresourcemanager.googleapis.com \
datacatalog.googleapis.com \
run.googleapis.com
Клонируйте репозиторий
Получите код инфраструктуры и скрипты автоматизации из репозитория GitHub. Чтобы сэкономить место на диске в Cloud Shell, мы загрузим только ту папку, которая необходима для этой лабораторной работы.
# Perform a shallow clone to get only the latest repository structure without the full history
git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/devrel-demos.git
cd devrel-demos
# Specify and download only the folder we need for this lab
git sparse-checkout set data-analytics/governance-context
cd data-analytics/governance-context
Создайте "неупорядоченное" озеро данных.
В реальных условиях данные редко бывают чистыми. Для имитации реальности нам необходимо сочетание «официальных» хранилищ данных и ненадежных «песочниц».
Для развертывания этой среды мы будем использовать Terraform. Конфигурация выполняет две задачи:
- Инфраструктура: Создает типы аспектов каталога знаний и наборы данных/таблицы BigQuery.
- Загрузка данных: Запускает задания INSERT в BigQuery для заполнения таблиц тестовыми данными сразу после их создания.
- Перейдите в каталог
terraformи инициализируйте его.
cd terraform
terraform init
- Примените настройки. Это может занять до минуты.
terraform apply -var="project_id=${PROJECT_ID}" -var="region=${REGION}" -auto-approve
Контрольная точка : Теперь у вас есть полностью заполненное, но совершенно неуправляемое озеро данных. Для ИИ каждая таблица выглядит совершенно одинаково.
3. Применение принципов управления
Это критически важный этап проектирования. В настоящее время таблицы finance_mart.fin_monthly_closing_internal и analyst_sandbox.tmp_data_dump_v2_final_real выглядят идентично LLM. Это просто объекты со столбцами.
Как инженер по управлению данными, вы должны прикрепить к этим таблицам аспект (сертифицированную метку метаданных), чтобы различать их. В реальной корпоративной среде это можно автоматизировать с помощью конвейеров CI/CD. Мы смоделируем эту автоматизацию с помощью скриптов.
Сгенерировать полезную нагрузку управления
Ключи аспектов каталога знаний должны быть уникальными в глобальном масштабе (с префиксом в виде идентификатора вашего проекта). Скрипт ./generate_payloads.sh будет динамически генерировать файлы метаданных YAML.
cd ..
chmod +x ./generate_payloads.sh
./generate_payloads.sh
Выход:
В результате создается папка "./aspect_payloads", содержащая 4 YAML-файла, определяющих сценарии управления (Gold/Internal, Gold/Public, Silver/Realtime, Bronze/Sandbox).
Применение аспектов через командную строку
Прежде чем запускать скрипт, давайте разберемся, что именно мы используем, чтобы упростить процесс. Выполните следующую команду, чтобы увидеть структуру внутренних финансовых данных:
cat aspect_payloads/fin_internal.yaml
Здесь отобразится следующее содержимое.
your-project-id.us-central1.official-data-product-spec:
data:
product_tier: GOLD_CRITICAL
data_domain: FINANCE
usage_scope: INTERNAL_ONLY
update_frequency: DAILY_BATCH
is_certified: true
Обратите внимание, как этот YAML-файл явно определяет бизнес-контекст, например, устанавливая флаг is_certified : true и назначая уровень GOLD_CRITICAL . Это дает ИИ четкие, структурированные правила для оценки, вместо того чтобы просто угадывать на основе названий таблиц.
Теперь запустите скрипт приложения. Он перебирает таблицы BigQuery и выполняет команду gcloud dataplex entries update чтобы добавить эти необходимые метаданные.
chmod +x ./apply_governance.sh
./apply_governance.sh
Проверка (необязательно)
Прежде чем продолжить, убедитесь, что метаданные были корректно применены в консоли.
- Откройте страницу «Универсальный каталог знаний» в консоли Google Cloud. Если вы не видите «Универсальный каталог знаний» в левом навигационном меню, воспользуйтесь строкой поиска в верхней части окна консоли Google Cloud, введите «Каталог знаний» и выберите результат в разделе «Лучшие результаты» или «Продукты и страницы».
- Найдите таблицу
fin_monthly_closing_internal. В результатах поиска должна отобразиться соответствующая таблица BigQuery. Щелкните по названию таблицы, чтобы перейти на страницу с ее подробными сведениями.
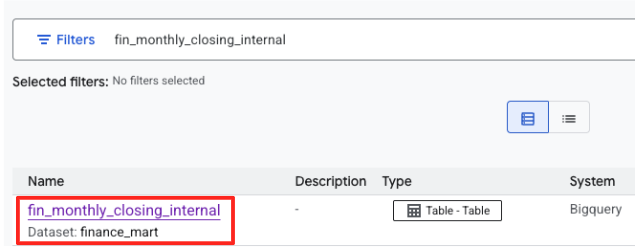
- На странице с подробными сведениями о таблице найдите раздел « Дополнительные теги и аспекты », расположенный внизу.
- Вы найдете раздел
official-data-product-spec». Убедитесь, что значения соответствуют сценарию « Gold Internal », который мы применили.
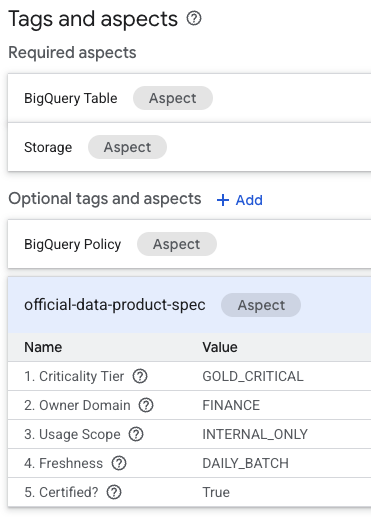
Теперь вы подтвердили, что технически идентичные таблицы BigQuery ( fin_monthly_closing_internal и tmp_data_dump_v2_final_real ) логически различаются машиночитаемыми метаданными.
4. Настройка и создание прототипа агента.
Прежде чем создавать веб-приложение (что мы сделаем во второй части), мы проверим нашу логику управления локально. Нам необходимо установить расширение Knowledge Catalog и настроить системную подсказку.
Установите расширение
В Cloud Shell установите расширение Knowledge Catalog. Вам будет предложено подтвердить установку и указать необходимые параметры.
export DATAPLEX_PROJECT="${PROJECT_ID}"
gemini extensions install https://github.com/gemini-cli-extensions/dataplex
(Введите Y, чтобы разрешить установку, и введите идентификатор вашего проекта, когда появится соответствующий запрос).
Определите файл политики.
Файл GEMINI.md содержит логику, которая преобразует абстрактные человеческие правила (например, «Мне нужны безопасные данные») в строгие технические запросы.
В настоящее время этот файл является универсальным. Агенту необходимо точно знать, в каком проекте Google Cloud следует выполнить поиск, чтобы избежать появления таблиц из общедоступного интернета или других источников.
- Добавьте свой
PROJECT_IDв файл политики.
envsubst < GEMINI.md > GEMINI.md.tmp && mv GEMINI.md.tmp GEMINI.md
- Изучите файл, чтобы понять алгоритм, которому мы обучаем ИИ.
cat GEMINI.md
Обратите внимание на две вещи в этом файле:
- Объем проекта: Проверьте этап 2. Убедитесь, что projectid:
${PROJECT_ID}заменен на ваш фактический идентификатор проекта(eg, projectid:my-lab-project). Если эта переменная не заменена, агент будет искать по всем проектам, к которым у вас есть доступ, что приведет к неверным результатам. - Алгоритм: Обратите внимание на логику Фазы 1 / Фазы 2. Мы явно указываем модели НЕ угадывать SQL. Сначала она должна найти правильное определение тега (Фаза 1), и только потом искать данные (Фаза 2).
Запустите агента и протестируйте сценарии.
Запустите сессию Gemini CLI, на этот раз загрузив свою политику управления в качестве контекста системы.
gemini
Примечание: Возможно, будет загружено несколько контекстных файлов (например, GEMINI.md и другие). Это нормально. Интерфейс командной строки загружает локальный файл GEMINI.md для правил, специфичных для этого проекта, а также инструкции по умолчанию для самого расширения каталога знаний.
Проверьте установку
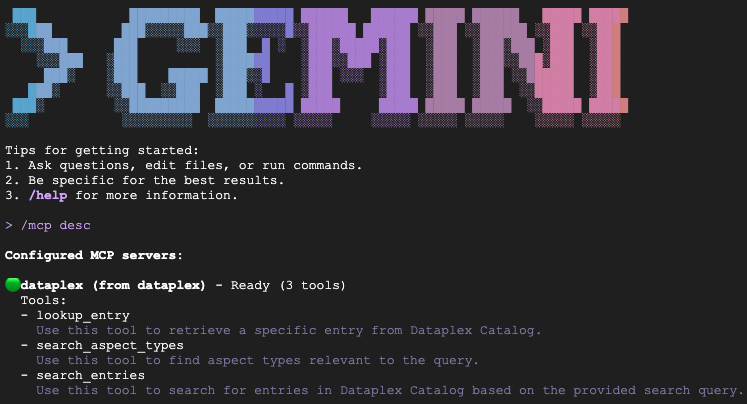
Введите /mcp desc чтобы убедиться в активности расширения каталога знаний. Вы должны увидеть dataplex в списке настроенных серверов MCP с доступными инструментами.
Тестовые сценарии (прототипирование)
Вставьте следующие подсказки в запущенную сессию агента по очереди, чтобы убедиться, что они соответствуют вашим правилам.
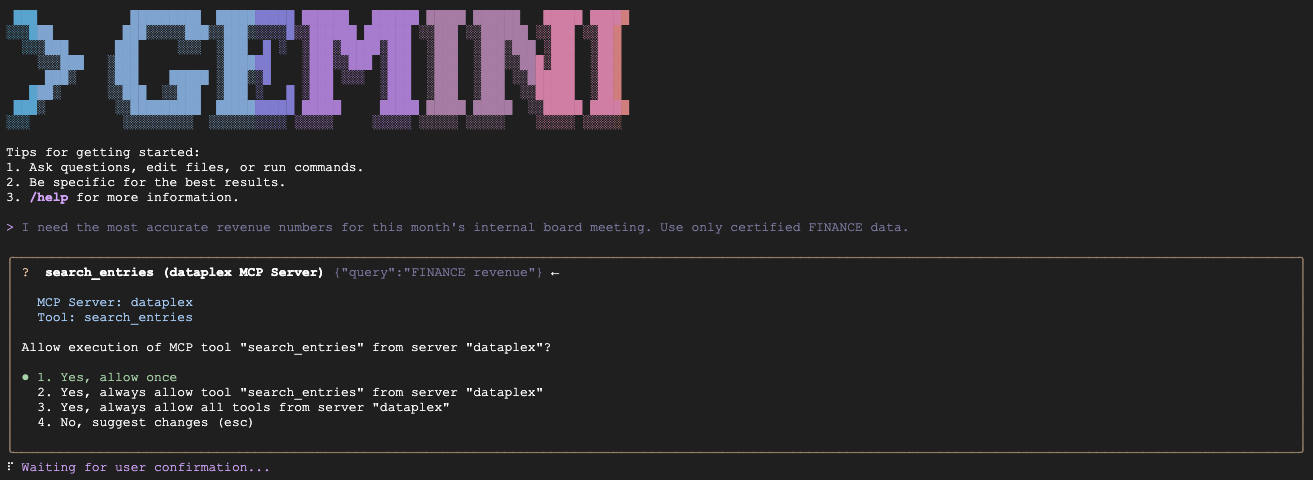
- Сценарий А (Подтверждение данных финансового директора):
"We are preparing the deck for an internal Board of Directors meeting next week. I need the numbers to be absolutely finalized, trustworthy, and kept strictly confidential. Which table is safe to use?"
Ожидается: Запрос fin_monthly_closing_internal выполняется, поскольку он семантически соответствует GOLD_CRITICAL (точно) и INTERNAL_ONLY (заседание совета директоров) в своем аспекте.
- Сценарий B (Публичное раскрытие информации):
"I need to share our quarterly financial summary with an external consulting firm. It is critical that we do not leak any raw or internal metrics. Which dataset is officially scrubbed and explicitly approved for external sharing?"
Ожидается: Агент должен обойти внутреннюю ежемесячную таблицу и выбрать исключительно fin_quarterly_public_report , поскольку это единственный актив с меткой EXTERNAL_READY .
- Сценарий C (Операционные потребности):
"My dashboard needs to show what's happening right now with our ad spend. I can't wait for the overnight load. What do you recommend?"
Ожидаемый результат: Агент выбирает mkt_realtime_campaign_performance поскольку этот параметр определяет частоту обновления REALTIME_STREAMING , отдавая ей приоритет перед уровнем GOLD_CRITICAL финансовых данных.
- Сценарий D (эксперимент в песочнице):
"I'm just playing around with some new ML models and need a lot of raw data. It doesn't need to be perfect, just a sandbox environment."
Ожидаемый результат: Агент выбирает tmp_data_dump_v2_final_real поскольку он семантически соответствует BRONZE_ADHOC (исходные данные) и is_certified: false (среда песочницы) в своем аспекте.
(Чтобы выйти из сессии Gemini, введите /quit)
5. Поздравляем! Что дальше?
Вы успешно создали управляемую базу данных и доказали, что ИИ может строго следовать вашим правилам метаданных, используя локальный прототип CLI!
Вы достигли контрольной точки. Пожалуйста, выберите следующий шаг:
Вариант А: Я хочу прямо сейчас перейти ко второй части!
Если вы готовы превратить этот локальный прототип в безопасное веб-приложение производственного уровня, используя протокол контекста модели (MCP) и Cloud Run:
👉 Ссылка на вторую часть Codelab
Вариант Б: Я выполню часть 2 позже, или я хотел бы завершить только часть 1.
Если вы хотите сегодня же прекратить использование облачных сервисов и избежать дополнительных расходов, вам следует оптимизировать свои ресурсы.
Не волнуйтесь! Во второй части мы предоставим «быстрый скрипт», который полностью восстановит среду из первой части всего за 2 минуты, чтобы вы могли продолжить работу с того места, где остановились.
👉 Перейдите к разделу «Уборка».
6. Уборка (только для варианта B)
Если вы остановились здесь, уничтожьте ресурсы, чтобы избежать дополнительных расходов.
Уничтожьте Озеро Дантейк (Терраформирование)
Если вы в данный момент находитесь в среде командной строки Gemini, выйдите из сессии, дважды нажав Ctrl+C или введя /quit . Затем выполните следующие команды:
cd ~/devrel-demos/data-analytics/governance-context/terraform
terraform destroy -var="project_id=${PROJECT_ID}" -var="region=${REGION}" -auto-approve
Удалите расширение Gemini CLI и локальные файлы.
gemini extensions uninstall dataplex
cd ~
rm -rf ~/devrel-demos