
1. Introducción
Este codelab forma parte de una serie de dos partes en la que se explora cómo compilar un agente de IA que tenga en cuenta la gobernanza.
(Puedes leer la primera parte de esta serie, en la que se explica cómo establecer la base de datos registrando un tipo de aspecto del Knowledge Catalog, aplicando aspectos a las tablas de BigQuery y probando las reglas de forma local a través de la CLI de AGY. 👉 Lee la parte 1).
Sin embargo, las pruebas en una CLI local son solo el comienzo. Para implementar esta solución en toda tu empresa, necesitas seguridad centralizada, conexiones estandarizadas a herramientas de IA y un marco de aplicación adecuado para organizar la lógica del agente y proporcionar una interfaz de chat familiar.
En esta segunda parte, resolverás estos desafíos y escalarás a producción. En lugar de implementar un servidor MCP personalizado, conectarás tu agente directamente al servidor MCP de Knowledge Catalog administrado por Google. Luego, usarás el Kit de desarrollo de agentes (ADK) de Google para compilar la aplicación del agente real, cargar tus reglas de gobernanza desde la habilidad del agente local y, luego, implementarla en Cloud Run, con una IU web profesional.
.
Cuando un usuario interactúa con la IU del ADK, se produce la siguiente secuencia:
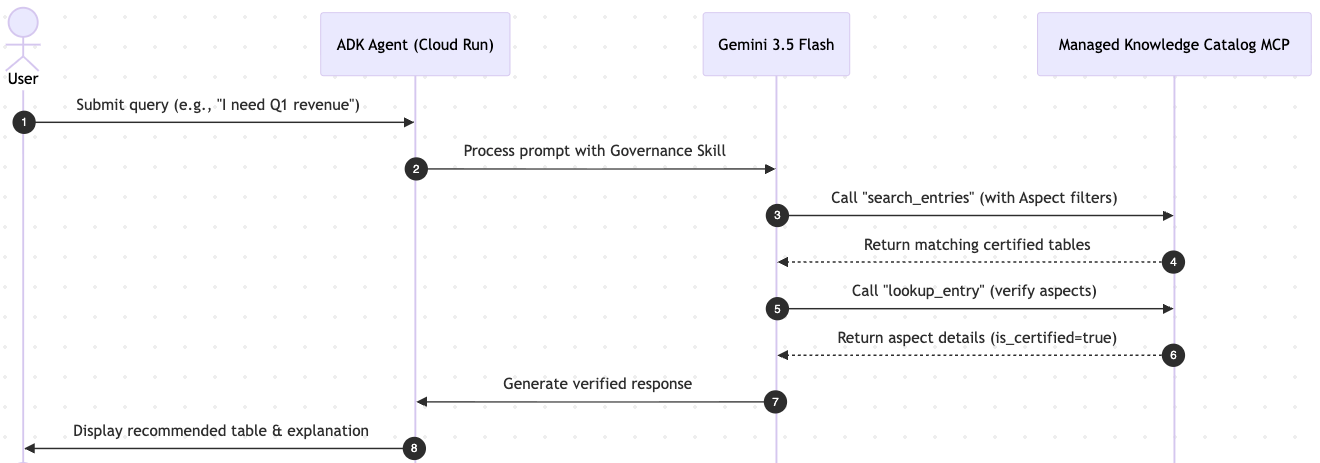
Qué aprenderás
- Cómo usar el Protocolo de contexto del modelo (MCP) para estandarizar la forma en que los agentes de IA interactúan con los datos de Google Cloud
- Cómo se conecta el agente del ADK al servidor de MCP del Knowledge Catalog administrado por Google
- Cómo cargar tus reglas de gobierno de forma dinámica desde la habilidad compartida del agente
- Cómo implementar tu agente en Cloud Run y ejecutar el entorno de prueba web integrado del ADK
Requisitos
- Un proyecto de Google Cloud con facturación habilitada.
- Acceso a Google Cloud Shell
- Conocimientos básicos de Cloud Run, cuentas de servicio de IAM y Python
- Los conjuntos de datos de BigQuery y los aspectos de Knowledge Catalog creados en la Parte 1 (No te preocupes si los borraste. A continuación, te proporcionamos un script de acceso rápido para volver a crearlos).
Conceptos clave
- Protocolo de contexto del modelo (MCP): Piensa en el MCP como un "cable USB-C universal" para los agentes de IA. En lugar de escribir código de integración de API personalizado para cada modelo de IA, el MCP proporciona una forma estándar para que la IA se conecte de forma segura a tus herramientas de datos empresariales (como Knowledge Catalog y BigQuery).
- Kit de desarrollo de agentes (ADK): Es un framework flexible de código abierto de Google diseñado para simplificar el desarrollo integral de agentes de IA. Aplica principios de ingeniería de software a la creación de agentes, lo que te permite coordinar herramientas complejas, administrar el estado y lanzar fácilmente una IU de desarrollador integrada para pruebas y la implementación.
- Gemini Enterprise Agent Platform(GEAP): Es el entorno de organización y hosting de nivel empresarial para implementar agentes de IA en Google Cloud.
2. Configuración y requisitos
Inicie Cloud Shell
Si bien Google Cloud y Spanner se pueden operar de manera remota desde tu laptop, en este codelab usarás Google Cloud Shell, un entorno de línea de comandos que se ejecuta en la nube.
En Google Cloud Console, haz clic en el ícono de Cloud Shell en la barra de herramientas en la parte superior derecha:
El aprovisionamiento y la conexión al entorno deberían tomar solo unos minutos. Cuando termine el proceso, debería ver algo como lo siguiente:

Esta máquina virtual está cargada con todas las herramientas de desarrollo que necesitarás. Ofrece un directorio principal persistente de 5 GB y se ejecuta en Google Cloud, lo que permite mejorar considerablemente el rendimiento de la red y la autenticación. Todo tu trabajo en este codelab se puede hacer en un navegador. No es necesario que instales nada.
Inicializa el entorno
Abre Cloud Shell y configura las variables de tu proyecto para asegurarte de que todos los comandos se dirijan a la infraestructura correcta.
export PROJECT_ID=$(gcloud config get-value project)
gcloud config set project $PROJECT_ID
export REGION="us-central1"
Habilita las APIs obligatorias
Habilita el conjunto mínimo de APIs de Google Cloud necesarias para administrar tu base de datos, ejecutar modelos de Vertex AI y alojar el agente del ADK en Cloud Run.
gcloud services enable \
dataplex.googleapis.com \
bigquery.googleapis.com \
aiplatform.googleapis.com \
run.googleapis.com \
artifactregistry.googleapis.com \
cloudbuild.googleapis.com
Punto de control: ¿Reanudar o volver a compilar?
Como esta es la parte 2, tu agente necesita los datos gobernados de la parte 1 para funcionar. Elige tu ruta:
Ruta A: Acabo de terminar la Parte 1 y mis recursos siguen en ejecución
¡Genial! Navega hasta el directorio de trabajo y podrás continuar.
cd ~/devrel-demos/data-analytics/governance-context
Ruta B: Omití la parte 1 O borré mis recursos (limpié)
No hay problema. A continuación, proporcionamos un bloque de comandos de "vía rápida". Esto volverá a compilar automáticamente el data lake de BigQuery, registrará el tipo de aspecto y aplicará los metadatos de gobierno exactamente como lo hicimos en la Parte 1.
# 1. Clone the repo and navigate to the working directory
git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/devrel-demos.git
cd devrel-demos
git sparse-checkout set data-analytics/governance-context
cd data-analytics/governance-context
# 2. Rebuild the BigQuery datasets and tables
chmod +x ./setup_bq_tables.sh
./setup_bq_tables.sh
# 3. Register the Knowledge Catalog aspect type
gcloud dataplex aspect-types create official-data-product-spec \
--location="${REGION}" \
--project="${PROJECT_ID}" \
--metadata-template-file-name="aspect_template.json"
# 4. Generate and apply aspects (governance rules)
chmod +x ./generate_payloads.sh ./apply_governance.sh
./generate_payloads.sh
./apply_governance.sh
3. El plano de control de datos centralizado (MCP administrado)
En un entorno empresarial real, necesitas un plano de control de datos seguro y centralizado. En lugar de compilar e implementar un contenedor de servidor de MCP personalizado en Cloud Run, conectaremos nuestro agente directamente al servidor de MCP de Knowledge Catalog administrado por Google.
Con este extremo administrado, logramos lo siguiente:
- Cero mantenimiento: No es necesario administrar contenedores, escalamiento ni parches para el servidor de MCP.
- Estandarización: El agente se conecta a un extremo de API de Google estándar y seguro a través del Protocolo de contexto del modelo (transporte SSE).
- Alcance controlado: El servidor de MCP expone solo las herramientas de metadatos necesarias (
search_entries,lookup_context,lookup_entry), lo que impone un bucle de razonamiento de solo lectura y centrado en la gobernanza.
Se puede acceder al servidor de MCP del Knowledge Catalog administrado por Google a través de la siguiente URL segura:
https://dataplex.googleapis.com/mcp
Dado que se trata de una API de Google propia, el agente debe autenticarse con un token de acceso de OAuth2 estándar de Google Cloud en lugar de un token de ID. Manejaremos esta autenticación automáticamente en el código de nuestra aplicación.
4. Compila el backend del agente con el ADK
Tienes un plano de control de datos seguro y administrado. Ahora, tu agente de IA necesita un framework para organizar su lógica, como procesar las entradas del usuario, decidir cuándo llamar al servidor de MCP y dar formato al resultado.
Usaremos el Kit de desarrollo de agentes (ADK) de Google. El ADK es un framework centrado en el código que envuelve automáticamente la lógica de tu agente en un backend de FastAPI y proporciona una interfaz web integrada para realizar pruebas instantáneas.
Abre el código del agente en el editor de Cloud Shell
En lugar de volcar todo el archivo en la terminal, abrámoslo en el editor de Cloud Shell para que puedas inspeccionar, editar y comprender el código con facilidad.
Ejecuta el siguiente comando en la terminal y observa la estructura del código en el editor. La aplicación se creó con el Kit de desarrollo de agentes (ADK) de Google:
cd ~/devrel-demos/data-analytics/governance-context/mcp_server
# Copy the governance skill directory inside the application bundle so it packages during Cloud Run deployment
mkdir -p skills
cp -r ../.agents/skills/knowledge-catalog-governance skills/
cloudshell edit agent.py
(Nota: agent.py contiene código estándar en la parte superior para controlar la autenticación de OAuth2 de Google Cloud y la actualización de tokens, lo que garantiza que el agente pueda comunicarse de forma segura con la API de Knowledge Catalog administrada por Google).
1. Carga de habilidades nativas
Para compilar un agente altamente optimizado, cargamos las instrucciones de gobernanza desde el directorio de habilidades del agente externo con el load_skill_from_dir nativo del ADK. Este enfoque permite la divulgación progresiva:
- Metadatos de L1: El agente solo carga el nombre y la descripción de la habilidad al inicio. Este contexto mínimo permite que el LLM identifique cuándo usar la habilidad sin consumir grandes cantidades de tokens por adelantado.
- Instrucciones de nivel 2: El conjunto completo de instrucciones dentro de
SKILL.mdse recupera de forma dinámica en el tiempo de ejecución solo cuando el modelo determina que es pertinente.
base_dir = Path(__file__).parent
governance_skill = load_skill_from_dir(
base_dir / "skills" / "knowledge-catalog-governance"
)
# Bundle the skill and MCP tools together into a SkillToolset
governance_skill_toolset = skill_toolset.SkillToolset(
skills=[governance_skill],
additional_tools=[tools]
)
2. Organización de agentes
El ADK te permite organizar comportamientos complejos de agentes encadenando varios agentes. Definimos un flujo de trabajo SequentialAgent que consta de dos agentes especializados:
governance_researcher:Equipado congovernance_skill_toolsety el MCP de Knowledge Catalogtools. Verifica si la búsqueda se encuentra dentro del alcance del catálogo de datos y del cumplimiento, y, luego, consulta Knowledge Catalog con las variables de entorno insertadas en sus instrucciones del sistema.compliance_formatter:Es responsable de traducir los resultados de la búsqueda de metadatos JSON sin procesar en una respuesta clara o de explicar con claridad los límites del alcance si la solicitud está fuera del alcance.
# 1. Researcher Agent (has access to the encapsulated SkillToolset)
governance_researcher = LlmAgent(
name="governance_researcher",
model=model_name,
description="Dynamically interprets metadata schema (Booleans/Enums) and searches for assets using strict syntax.",
instruction=f"""
You are a governance researcher. Your job is to verify Knowledge Catalog metadata rules and find compliant assets for the user's query.
YOUR ACTIVE ENVIRONMENT CONTEXT:
- Google Cloud Project ID: {project_id}
- Location (Region): {location}
YOUR WORKFLOW:
1. First, check if the user query is related to data analytics assets, database tables, or data compliance.
- If YES: Call `load_skill` with `name="knowledge-catalog-governance"` to load the rules, then use search/lookup tools to locate a certified compliant table.
- If NO (e.g., general chit-chat, unrelated tasks): Skip skill loading and output a JSON object indicating it is out of scope:
{"error": "out_of_scope", "message": "The query does not pertain to data catalog search or governance compliance."}
2. Populate the required projectId and location parameters in tool calls with the active environment parameters.
3. Return the verified table's metadata in JSON format as your final research output.
""",
tools=[governance_skill_toolset, tools],
output_key="research_data"
)
# 2. Formatter Agent (formats the output or explains out-of-scope errors)
compliance_formatter = LlmAgent(
name="compliance_formatter",
model=model_name,
description="Formats the JSON research data into a helpful response for the user.",
instruction="""
You are the **Intelligent Data Governance Specialist**.
Your job is to explain the findings of the governance research clearly to the user.
**YOUR GOAL:**
1. If the researcher found a matching table (valid JSON with table metadata):
- Explain the logical connection between the User's Request, the Governance Schema (translated criteria), and the Recommended Table.
- Use the following RESPONSE TEMPLATE:
- **Analysis:** "I analyzed the metadata schema and translated your request into the following technical criteria:..."
- **Recommendation:** "Based on this, I recommend the following table:"
- **Table:** [Insert Table Name]
- **Description:** [Insert Table Description]
- **Verification:** "This asset is a verified match because: [Explain the verification details]."
2. If the researcher returned an 'out_of_scope' error or no matching tables were found:
- Apologize politely and explain that no data asset currently matches the strict governance criteria defined in `official-data-product-spec`.
- Clearly state what domain of questions this agent is certified to answer (e.g., Data Catalog Search and Data Governance compliance).
"""
)
# 3. Orchestrated Workflow (Exported as root_agent)
root_agent = SequentialAgent(
name="governance_workflow",
description="Workflow to learn metadata rules, search with strict syntax, and recommend assets.",
sub_agents=[
governance_researcher,
compliance_formatter,
]
)
Configura variables de entorno de ejecución
Para ejecutar el agente, debemos indicarle dónde se encuentra tu servidor de MCP administrado y configurar su proyecto y región. Guardaremos estas variables en un archivo .env que el ADK leerá en el tiempo de ejecución.
Ejecuta el siguiente comando para generar el archivo .env. Observa que MCP_SERVER_URL apunta directamente al endpoint de API de Knowledge Catalog administrado por Google:
export MCP_SERVER_URL="https://dataplex.googleapis.com/mcp"
echo MCP_SERVER_URL=$MCP_SERVER_URL > .env
echo GOOGLE_GENAI_USE_VERTEXAI=1 >> .env
echo GOOGLE_CLOUD_PROJECT=$PROJECT_ID >> .env
echo GOOGLE_CLOUD_LOCATION=$REGION >> .env
5. Ejecuta y prueba el agente de forma local
Antes de implementar tu agente en la nube, debes ejecutarlo de forma local en Cloud Shell para verificar su comportamiento. Dado que el agente depende de varios paquetes de Python (incluidas las bibliotecas de Google Cloud Logging y del ADK), configuraremos un entorno virtual local para instalar estas dependencias.
Cuando se ejecuta de forma local en Cloud Shell, el agente usa automáticamente tus credenciales de usuario activas de Google Cloud, por lo que ya tiene los permisos necesarios para acceder a Vertex AI y Knowledge Catalog.
- Navega al directorio
mcp_server, crea un entorno virtual y, luego, instala las dependencias:
cd ~/devrel-demos/data-analytics/governance-context/mcp_server
# Create a virtual environment using uv
uv venv
source .venv/bin/activate
# Install the dependencies listed in requirements.txt
uv pip install -r requirements.txt
- Inicia la sesión de chat interactiva en tu terminal:
adk run .
- Cuando comience la sesión, verás un mensaje. Escribe una consulta para probar la lógica de gobernanza del agente:
I need the Q1 revenue summary for our internal board meeting.
El agente procesará tu solicitud, consultará el catálogo de conocimiento a través del servidor de MCP administrado y mostrará su recomendación y razonamiento directamente en la terminal.
- Para salir de la sesión interactiva, escribe
exitoquit(o presionaCtrl+C). Después de salir, puedes desactivar el entorno virtual:
deactivate
6. Implementa el agente en producción
Ahora que verificaste el agente de forma local, puedes implementarlo en Google Cloud para usarlo en producción.
Crea una cuenta de servicio
Por motivos de seguridad, el agente implementado no debe ejecutarse con tus credenciales personales. Crearemos una identidad independiente (knowledge-catalog-agent-sa) para el agente, de conformidad con el principio de privilegio mínimo.
Ejecuta los siguientes comandos para crear la cuenta de servicio:
export AGENT_SA=knowledge-catalog-agent-sa
export AGENT_SERVICE_ACCOUNT="${AGENT_SA}@${PROJECT_ID}.iam.gserviceaccount.com"
gcloud iam service-accounts create ${AGENT_SA} \
--display-name="Service Account for Knowledge Catalog Agent"
Otorgar permisos
Aunque el agente delega las verificaciones de gobernanza al servidor de MCP, aún necesita permisos básicos para operar.
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$AGENT_SERVICE_ACCOUNT" \
--role="roles/aiplatform.user"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$AGENT_SERVICE_ACCOUNT" \
--role="roles/dataplex.catalogAdmin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$AGENT_SERVICE_ACCOUNT" \
--role="roles/bigquery.dataViewer"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$AGENT_SERVICE_ACCOUNT" \
--role="roles/mcp.toolUser"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$AGENT_SERVICE_ACCOUNT" \
--role="roles/viewer"
Implementa en Cloud Run
Por último, implementamos el agente en Cloud Run. El siguiente comando compila la imagen del contenedor con el archivo Dockerfile de tu directorio actual, la sube a Artifact Registry y la implementa en Cloud Run. Este proceso puede tardar entre 1 y 3 minutos en completarse.
gcloud run deploy knowledge-catalog-agent \
--source . \
--project=$PROJECT_ID \
--region=$REGION \
--service-account=$AGENT_SERVICE_ACCOUNT \
--allow-unauthenticated \
--clear-base-image \
--labels created-by=adk
Una vez que se complete este comando, se generará una URL de servicio (p.ej., https://knowledge-catalog-agent-xyz.run.app). Haz clic en ese vínculo para abrir la interfaz de chat con IA generativa completamente controlada.
7. Prueba el agente humano
Ahora que tu agente está activo, probemos las situaciones de gobernanza. La lógica sigue siendo la misma, pero ahora interactúas con el ADK Web Playground implementado, que visualiza el estado interno y las ejecuciones de herramientas.
Abre en tu navegador la URL del servicio que generaste en el paso anterior (p.ej., https://knowledge-catalog-agent-xyz.run.app). Pega la siguiente instrucción:
"My dashboard needs to show what's happening right now with our ad spend. I can't wait for the overnight load. What do you recommend?"
Observa el proceso de razonamiento del agente en la IU para desarrolladores:
- Reconocimiento de intención: El agente analiza "en este momento" y "no puedo esperar hasta mañana".
- Búsqueda de metadatos: Llama a la herramienta de MCP search_entries con la siguiente búsqueda:
[PROJECT_ID].us-central1.official-data-product-spec.update_frequency=REALTIME_STREAMING - Selección: Identifica que la tabla
mkt_realtime_campaign_performancecumple con estos criterios. - Respuesta: El agente recomienda la tabla en tiempo real.
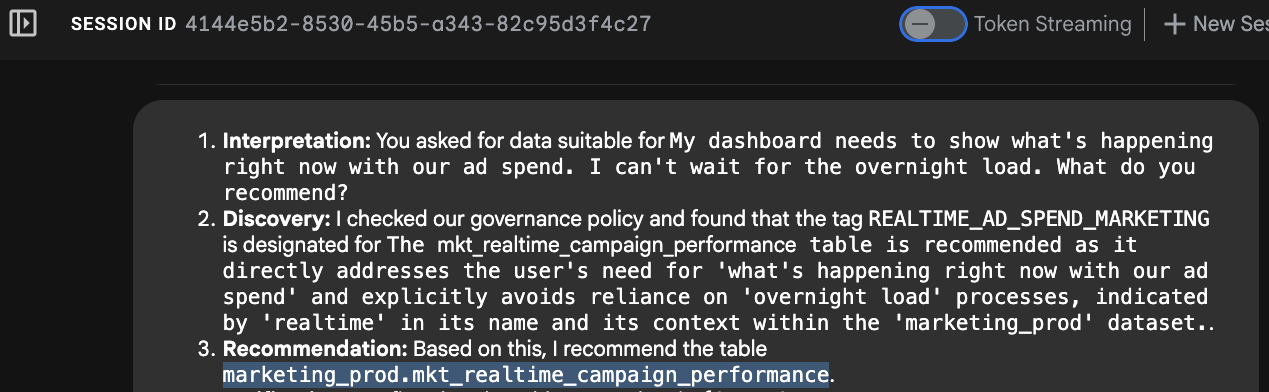
Por qué es importante:
Sin estos metadatos de administración, es probable que un LLM recomiende la tabla fin_monthly_closing_internal simplemente porque tiene una columna llamada "ad_spend", sin tener en cuenta el hecho de que los datos tienen 24 horas de antigüedad. El contexto de tus metadatos evitó un error comercial.
También puedes probar la instrucción "Reunión de la junta" para ver cómo el agente cambia a diferentes tablas según el aspecto de nivel del producto de datos:
"We are preparing the deck for an internal Board of Directors meeting next week. I need the numbers to be absolutely finalized, trustworthy, and kept strictly confidential. Which table is safe to use?"
8. Limpia
Para evitar que se apliquen cargos a tu cuenta de Google Cloud, sigue estos pasos para destruir toda la infraestructura creada en este codelab.
Destruye el data lake
Usa la secuencia de comandos de limpieza para desmantelar las tablas y los conjuntos de datos de BigQuery, y las definiciones de aspectos de Knowledge Catalog.
cd ~/devrel-demos/data-analytics/governance-context
chmod +x ./cleanup_data_lake.sh
./cleanup_data_lake.sh
Borrar servicios de Cloud Run
Quita los recursos de procesamiento para detener la facturación activa del contenedor en ejecución.
gcloud run services delete knowledge-catalog-agent --region=$REGION --quiet
Limpia los artefactos de compilación y el almacenamiento de etapa de pruebas
Cuando implementaste el agente del ADK, el sistema compiló automáticamente una imagen de contenedor y subió tu código fuente a un depósito temporal de Cloud Storage.
Quita el repositorio de Artifact Registry y el bucket de Cloud Storage de etapa de pruebas:
# Delete the repository used for the agent build
gcloud artifacts repositories delete cloud-run-source-deploy \
--location=$REGION \
--quiet
# Delete the staging bucket created by Cloud Run source deploy
gcloud storage rm --recursive gs://run-sources-${PROJECT_ID}-${REGION}
Borra la identidad y los permisos
Primero, quita las vinculaciones de políticas de IAM y, luego, borra las cuentas de servicio.
# Remove IAM roles granted to the Agent Service Account
gcloud projects remove-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$AGENT_SERVICE_ACCOUNT" \
--role="roles/aiplatform.user" --quiet
gcloud projects remove-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$AGENT_SERVICE_ACCOUNT" \
--role="roles/dataplex.catalogViewer" --quiet
gcloud projects remove-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$AGENT_SERVICE_ACCOUNT" \
--role="roles/mcp.toolUser" --quiet
gcloud projects remove-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$AGENT_SERVICE_ACCOUNT" \
--role="roles/bigquery.dataViewer" --quiet
# Delete the Service Account
gcloud iam service-accounts delete $AGENT_SERVICE_ACCOUNT --quiet
Cómo quitar la configuración local
Por último, limpia los archivos de configuración locales y las variables de entorno en Cloud Shell.
# Uninstall the AGY CLI plugin
agy plugin uninstall dataplex
# Remove local repository files and unset variables
cd ~
rm -rf ~/devrel-demos
unset MCP_SERVER_URL
unset AGENT_SERVICE_ACCOUNT
9. ¡Felicitaciones!
Implementaste correctamente un agente de IA generativa integral y con conocimiento de la gobernanza.
En este codelab de dos partes, fuiste más allá de la ingeniería de instrucciones simple para implementar una arquitectura sólida y lista para producción. Al considerar la administración de datos como un requisito previo para la IA generativa, estableciste un método sistemático para evitar que el modelo recupere datos no certificados o alucinados.
Conclusiones clave
- IA determinística a través de metadatos: En lugar de confiar en el LLM para que adivine la tabla correcta según los nombres de las columnas, aplicaste un bucle de razonamiento estricto con el servidor de MCP de Knowledge Catalog administrado por Google, lo que obligó al modelo a verificar las certificaciones de datos antes de recomendar tablas.
- Arquitectura desacoplada: El agente de frontend no necesita contener lógica de base de datos; solo necesita comunicarse a través del estándar del MCP. Esto significa que puedes conectar cualquier modelo o cliente de IA futuro al mismo backend controlado.
- Separación de obligaciones: Aplicaste el principio de privilegio mínimo aislando las identidades de IAM. El agente del ADK orientado al usuario opera con permisos restringidos a la invocación del modelo y al enrutamiento de la API.
- Orquestación de agentes centrada en el código: Usaste el Kit de desarrollo de agentes (ADK) de Google para encapsular instantáneamente la lógica de tu agente de Python en un backend de FastAPI escalable, y aprovechaste su IU para desarrolladores integrada para visualizar y depurar las ejecuciones de herramientas internas del agente.
Próximos pasos
- Codelab de administración básica de Knowledge Catalog: Domina los conceptos básicos de la administración de datos en Knowledge Catalog antes de agregar la capa de IA.
- Documentación del Kit de desarrollo de agentes (ADK): Explora la documentación oficial para crear e implementar agentes con el ADK.
- Análisis detallado de MCP: Consulta la especificación oficial de MCP para comprender cómo compilar servidores personalizados para tus APIs empresariales internas.