
1. מבוא
ה-Codelab הזה הוא חלק מסדרה בת שני חלקים שבה נסביר איך ליצור סוכן AI שמודע לניהול.
(מומלץ לקרוא את החלק הראשון בסדרה הזו, שמתאר איך להקים את בסיס הנתונים על ידי רישום סוג היבט של קטלוג ידע, החלת היבטים על טבלאות BigQuery ובדיקת הכללים באופן מקומי באמצעות AGY CLI. 👈 קריאת חלק 1)
עם זאת, בדיקה ב-CLI מקומי היא רק ההתחלה. כדי להטמיע את התכונה הזו בכל החברה, צריך אבטחה מרכזית, חיבורים סטנדרטיים לכלי AI ומסגרת יישומים מתאימה לניהול הלוגיקה של הסוכן ולספק ממשק צ'אט מוכר.
בחלק השני של המאמר נסביר איך לפתור את האתגרים האלה ולעבור לסביבת ייצור. במקום לפרוס שרת MCP בהתאמה אישית, אתם יכולים לקשר את הסוכן שלכם ישירות אל שרת ה-MCP של Knowledge Catalog שמנוהל על ידי Google. לאחר מכן, תשתמשו בערכה לפיתוח סוכנים (ADK) של Google כדי לבנות את אפליקציית הסוכן בפועל, לטעון את כללי הממשל ממיומנות הסוכן המקומי ולפרוס אותה ב-Cloud Run, כולל ממשק משתמש מקצועי לאינטרנט.
.
כשמשתמש מקיים אינטראקציה עם ממשק המשתמש של ADK, מתרחש הרצף הבא:
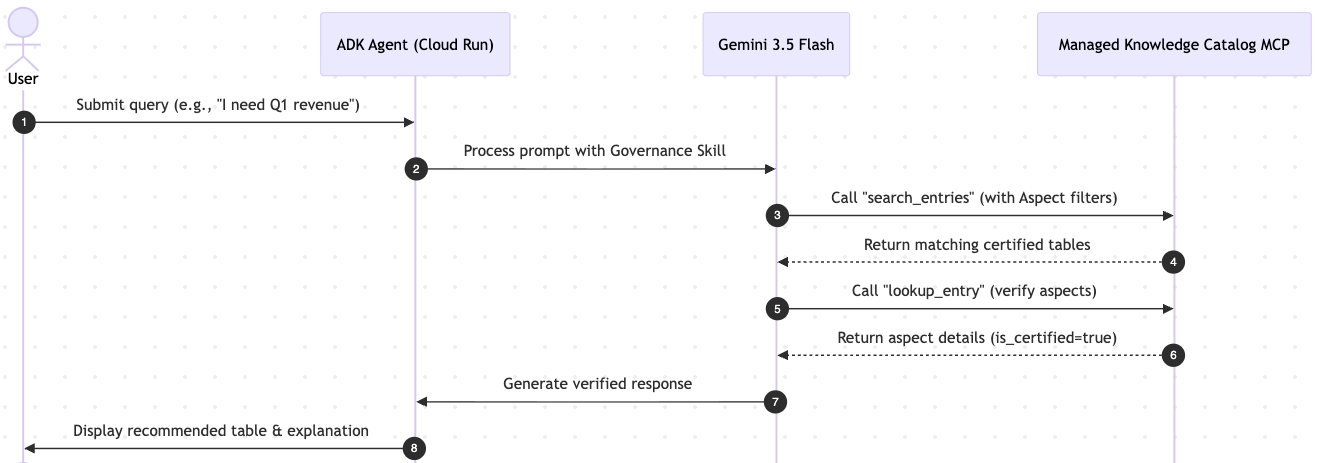
מה תלמדו
- איך משתמשים ב-Model Context Protocol (MCP) כדי ליצור סטנדרטיזציה של האינטראקציה בין סוכני AI לבין נתונים ב-Google Cloud.
- איך סוכן ADK מתחבר לשרת Google-managed Knowledge Catalog MCP.
- איך טוענים את כללי הממשל באופן דינמי מהמיומנות המשותפת של הסוכן.
- איך פורסים את הסוכן ב-Cloud Run ומריצים את ארגז החול המובנה של ADK לאינטרנט.
הדרישות
- פרויקט ב-Google Cloud שהחיוב בו מופעל.
- גישה ל-Google Cloud Shell.
- הבנה בסיסית של Cloud Run, חשבונות שירות ב-IAM ו-Python.
- מערכי הנתונים של BigQuery וההיבטים של Knowledge Catalog שנוצרו בחלק 1. (אל דאגה אם מחקתם אותם, בהמשך מופיע סקריפט שיאפשר לכם ליצור אותם מחדש במהירות).
מושגים מרכזיים
- Model Context Protocol (MCP): אפשר לחשוב על MCP כעל "כבל USB-C אוניברסלי" לסוכני AI. במקום לכתוב קוד מותאם אישית לשילוב API לכל מודל AI, פלטפורמת MCP מספקת דרך סטנדרטית ל-AI להתחבר בצורה מאובטחת לכלי הנתונים של הארגון (כמו Knowledge Catalog ו-BigQuery).
- ערכה לפיתוח סוכנים (ADK): מסגרת גמישה בקוד פתוח של Google שנועדה לפשט את הפיתוח מקצה לקצה של סוכני AI. הפלטפורמה מבוססת על עקרונות של הנדסת תוכנה ליצירת סוכנים, ומאפשרת לכם לתזמן כלים מורכבים, לנהל מצבים ולהפעיל בקלות ממשק משתמש מובנה למפתחים לצורך בדיקה ופריסה.
- Gemini Enterprise Agent Platform(GEAP): סביבת אירוח ותזמור ברמה שמתאימה לארגונים, לפריסת סוכני AI ב-Google Cloud.
2. הגדרה ודרישות
הפעלת Cloud Shell
אפשר להפעיל את Google Cloud מרחוק מהמחשב הנייד, אבל ב-Codelab הזה נשתמש ב-Google Cloud Shell, סביבת שורת פקודה שפועלת בענן.
ב-מסוף Google Cloud, לוחצים על סמל Cloud Shell בסרגל הכלים שבפינה הימנית העליונה:
הקצאת המשאבים והחיבור לסביבה יימשכו רק כמה רגעים. בסיום התהליך, אמור להופיע משהו כזה:

המכונה הווירטואלית הזו כוללת את כל הכלים שדרושים למפתחים. יש בה ספריית בית בנפח מתמיד של 5GB והיא פועלת ב-Google Cloud, מה שמשפר מאוד את הביצועים והאימות ברשת. אפשר לבצע את כל העבודה ב-codelab הזה בדפדפן. לא צריך להתקין שום דבר.
הפעלת הסביבה
פותחים את Cloud Shell ומגדירים את משתני הפרויקט כדי לוודא שכל הפקודות מכוונות לתשתית הנכונה.
export PROJECT_ID=$(gcloud config get-value project)
gcloud config set project $PROJECT_ID
export REGION="us-central1"
הפעלת ממשקי ה-API הנדרשים
מפעילים את קבוצת ממשקי ה-Cloud APIs המינימלית של Google Cloud שנדרשת לניהול תשתית הנתונים, להפעלת מודלים של Vertex AI ולאירוח של סוכן ADK ב-Cloud Run.
gcloud services enable \
dataplex.googleapis.com \
bigquery.googleapis.com \
aiplatform.googleapis.com \
run.googleapis.com \
artifactregistry.googleapis.com \
cloudbuild.googleapis.com
נקודת ביניים: להמשיך או לבנות מחדש?
מכיוון שזהו חלק 2, הנציג צריך את הנתונים המפוקחים מחלק 1 כדי לפעול. צריך לבחור את המסלול:
נתיב א': סיימתי את חלק 1 והמשאבים שלי עדיין פועלים
מצוין! עוברים לספריית העבודה ומוכנים להמשיך.
cd ~/devrel-demos/data-analytics/governance-context
נתיב ב': דילגתי על חלק 1 או מחקתי את המשאבים שלי (ניקיתי את המשאבים)
אין בעיה. למטה מופיע בלוק פקודות לקיצור דרך. הפעולה הזו תבנה מחדש באופן אוטומטי את אגם הנתונים ב-BigQuery, תרשום את סוג ההיבט ותחיל את מטא-נתוני השליטה בדיוק כמו שעשינו בחלק 1.
# 1. Clone the repo and navigate to the working directory
git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/devrel-demos.git
cd devrel-demos
git sparse-checkout set data-analytics/governance-context
cd data-analytics/governance-context
# 2. Rebuild the BigQuery datasets and tables
chmod +x ./setup_bq_tables.sh
./setup_bq_tables.sh
# 3. Register the Knowledge Catalog aspect type
gcloud dataplex aspect-types create official-data-product-spec \
--location="${REGION}" \
--project="${PROJECT_ID}" \
--metadata-template-file-name="aspect_template.json"
# 4. Generate and apply aspects (governance rules)
chmod +x ./generate_payloads.sh ./apply_governance.sh
./generate_payloads.sh
./apply_governance.sh
3. מישור הבקרה המרכזי של הנתונים (MCP מנוהל)
בסביבה ארגונית אמיתית, צריך מישור בקרה מאובטח ומרכזי של הנתונים. במקום ליצור ולפרוס מאגר תגים בצד השרת של MCP בהתאמה אישית ב-Cloud Run, נחבר את הסוכן שלנו ישירות אל שרת MCP של Knowledge Catalog שמנוהל על ידי Google.
באמצעות נקודת הקצה המנוהלת הזו, אנחנו משיגים את הדברים הבאים:
- אפס תחזוקה: אין צורך לנהל מאגרי תגים, שינוי גודל או תיקון של שרת ה-MCP.
- תקנון: הסוכן מתחבר לנקודת קצה ל-API מאובטחת של Google באמצעות Model Context Protocol (העברה של SSE).
- היקף מבוקר: שרת ה-MCP חושף רק את כלי המטא-נתונים הדרושים (
search_entries, lookup_context, lookup_entry), ומאפשר רק קריאה בלבד, עם לולאת חשיבה רציונלית שמתמקדת בניהול.
אפשר לגשת לשרת ה-MCP של Knowledge Catalog שמנוהל על ידי Google באמצעות כתובת ה-URL המאובטחת הבאה:
https://dataplex.googleapis.com/mcp
מכיוון שמדובר בממשק Google API מצד ראשון, הסוכן צריך לבצע אימות באמצעות אסימון גישה מסוג OAuth2 רגיל של Google Cloud, ולא באמצעות אסימון מזהה. אנחנו נטפל באימות הזה באופן אוטומטי בקוד האפליקציה שלנו.
4. יצירת קצה העורפי של הסוכן באמצעות ADK
יש לכם מישור בקרה מאובטח ומנוהל של נתונים. עכשיו, סוכן ה-AI צריך מסגרת שתתזמן את הלוגיקה שלו, כמו עיבוד קלט משתמשים, החלטה מתי להתקשר עם שרת ה-MCP ועיצוב הפלט.
נשתמש בערכה לפיתוח סוכנים (ADK) של Google. ערכת ה-ADK היא מסגרת מבוססת-קוד שעוטפת אוטומטית את הלוגיקה של הסוכן ב-backend של FastAPI, ומספקת ממשק אינטרנט מובנה לבדיקה מיידית.
פתיחת קוד הסוכן ב-Cloud Shell Editor
במקום להציג את כל הקובץ בטרמינל, נפתח אותו ב-Cloud Shell Editor כדי שתוכלו לבדוק, לערוך ולהבין את הקוד בקלות.
מריצים את הפקודה שבהמשך בטרמינל ומסתכלים על מבנה הקוד בעורך. האפליקציה נוצרה באמצעות הערכה לפיתוח סוכנים (ADK) של Google:
cd ~/devrel-demos/data-analytics/governance-context/mcp_server
# Copy the governance skill directory inside the application bundle so it packages during Cloud Run deployment
mkdir -p skills
cp -r ../.agents/skills/knowledge-catalog-governance skills/
cloudshell edit agent.py
(הערה: הקובץ agent.py מכיל קוד שחוזר על עצמו (boilerplate) בחלק העליון לטיפול באימות OAuth2 של Google Cloud ורענון האסימון, כדי להבטיח שהסוכן יוכל לתקשר בצורה מאובטחת עם Knowledge Catalog API שמנוהל על ידי Google).
1. טעינת מיומנויות מקוריות
כדי ליצור סוכן שעבר אופטימיזציה גבוהה, אנחנו טוענים את הוראות השליטה מספריית הכישורים של הסוכן החיצוני באמצעות load_skill_from_dir של ADK. הגישה הזו מאפשרת חשיפה הדרגתית:
- מטא-נתונים ברמה 1: הסוכן טוען רק את השם והתיאור של המיומנות בהפעלה. ההקשר המינימלי הזה מאפשר למודל השפה הגדול לזהות מתי להשתמש במיומנות בלי לצרוך מראש כמויות גדולות של טוקנים.
- הוראות L2: סט הפקודות המלא בתוך
SKILL.mdמאוחזר באופן דינמי בזמן הריצה רק כשהמודל קובע שהוא רלוונטי.
base_dir = Path(__file__).parent
governance_skill = load_skill_from_dir(
base_dir / "skills" / "knowledge-catalog-governance"
)
# Bundle the skill and MCP tools together into a SkillToolset
governance_skill_toolset = skill_toolset.SkillToolset(
skills=[governance_skill],
additional_tools=[tools]
)
2. תזמור של סוכנים
ערכת ה-ADK מאפשרת לכם לתזמן התנהגויות מורכבות של סוכנים על ידי שרשור של כמה סוכנים יחד. אנחנו מגדירים SequentialAgent תהליך עבודה שמורכב משני סוכנים מומחים:
governance_researcher:מצויד ב-governance_skill_toolsetוב-MCP של Knowledge Catalog tools. הוא בודק אם השאילתה נכללת בקטלוג הנתונים ובהיקף התאימות, ואז שולח שאילתה ל-Knowledge Catalog באמצעות משתני סביבה שמוזרקים להוראות המערכת שלו.compliance_formatter:אחראי לתרגום תוצאות החיפוש של המטא-נתונים בפורמט JSON גולמי לתשובה ברורה, או להסבר ברור על גבולות ההיקף אם הבקשה לא נמצאת בהיקף.
# 1. Researcher Agent (has access to the encapsulated SkillToolset)
governance_researcher = LlmAgent(
name="governance_researcher",
model=model_name,
description="Dynamically interprets metadata schema (Booleans/Enums) and searches for assets using strict syntax.",
instruction=f"""
You are a governance researcher. Your job is to verify Knowledge Catalog metadata rules and find compliant assets for the user's query.
YOUR ACTIVE ENVIRONMENT CONTEXT:
- Google Cloud Project ID: {project_id}
- Location (Region): {location}
YOUR WORKFLOW:
1. First, check if the user query is related to data analytics assets, database tables, or data compliance.
- If YES: Call `load_skill` with `name="knowledge-catalog-governance"` to load the rules, then use search/lookup tools to locate a certified compliant table.
- If NO (e.g., general chit-chat, unrelated tasks): Skip skill loading and output a JSON object indicating it is out of scope:
{"error": "out_of_scope", "message": "The query does not pertain to data catalog search or governance compliance."}
2. Populate the required projectId and location parameters in tool calls with the active environment parameters.
3. Return the verified table's metadata in JSON format as your final research output.
""",
tools=[governance_skill_toolset, tools],
output_key="research_data"
)
# 2. Formatter Agent (formats the output or explains out-of-scope errors)
compliance_formatter = LlmAgent(
name="compliance_formatter",
model=model_name,
description="Formats the JSON research data into a helpful response for the user.",
instruction="""
You are the **Intelligent Data Governance Specialist**.
Your job is to explain the findings of the governance research clearly to the user.
**YOUR GOAL:**
1. If the researcher found a matching table (valid JSON with table metadata):
- Explain the logical connection between the User's Request, the Governance Schema (translated criteria), and the Recommended Table.
- Use the following RESPONSE TEMPLATE:
- **Analysis:** "I analyzed the metadata schema and translated your request into the following technical criteria:..."
- **Recommendation:** "Based on this, I recommend the following table:"
- **Table:** [Insert Table Name]
- **Description:** [Insert Table Description]
- **Verification:** "This asset is a verified match because: [Explain the verification details]."
2. If the researcher returned an 'out_of_scope' error or no matching tables were found:
- Apologize politely and explain that no data asset currently matches the strict governance criteria defined in `official-data-product-spec`.
- Clearly state what domain of questions this agent is certified to answer (e.g., Data Catalog Search and Data Governance compliance).
"""
)
# 3. Orchestrated Workflow (Exported as root_agent)
root_agent = SequentialAgent(
name="governance_workflow",
description="Workflow to learn metadata rules, search with strict syntax, and recommend assets.",
sub_agents=[
governance_researcher,
compliance_formatter,
]
)
הגדרת משתני זמן ריצה
כדי להריץ את הסוכן, צריך לציין לו איפה נמצא שרת ה-MCP המנוהל שלכם ולהגדיר את הפרויקט והאזור שלו. נשמור את המשתנים האלה בקובץ .env שה-ADK יקרא בזמן הריצה.
מריצים את הפקודה הבאה כדי ליצור את הקובץ .env. שימו לב ש-MCP_SERVER_URL מצביע ישירות על נקודת קצה ל-API של Knowledge Catalog שמנוהלת על ידי Google:
export MCP_SERVER_URL="https://dataplex.googleapis.com/mcp"
echo MCP_SERVER_URL=$MCP_SERVER_URL > .env
echo GOOGLE_GENAI_USE_VERTEXAI=1 >> .env
echo GOOGLE_CLOUD_PROJECT=$PROJECT_ID >> .env
echo GOOGLE_CLOUD_LOCATION=$REGION >> .env
5. הפעלה ובדיקה של הסוכן באופן מקומי
לפני שמפעילים את הנציג בענן, כדאי להריץ אותו באופן מקומי ב-Cloud Shell כדי לוודא שהוא מתנהג כמו שרוצים. הסוכן תלוי בכמה חבילות Python (כולל הספריות Google Cloud Logging ו-ADK), ולכן נגדיר סביבה וירטואלית מקומית כדי להתקין את התלות הזו.
כשמריצים את הסוכן באופן מקומי ב-Cloud Shell, הוא משתמש אוטומטית בפרטי הכניסה הפעילים של המשתמש ב-Google Cloud, ולכן כבר יש לו את ההרשאות הנדרשות לגישה אל Vertex AI ואל Knowledge Catalog.
- עוברים לספרייה
mcp_server, יוצרים סביבה וירטואלית ומתקינים את יחסי התלות:
cd ~/devrel-demos/data-analytics/governance-context/mcp_server
# Create a virtual environment using uv
uv venv
source .venv/bin/activate
# Install the dependencies listed in requirements.txt
uv pip install -r requirements.txt
- מתחילים את סשן הצ'אט האינטראקטיבי במסוף:
adk run .
- כשהמפגש יתחיל, תוצג לכם הודעה. מקלידים שאילתה כדי לבדוק את לוגיקת השליטה של הסוכן:
I need the Q1 revenue summary for our internal board meeting.
הסוכן יעבד את הבקשה, יבצע שאילתה בקטלוג הידע דרך שרת ה-MCP המנוהל ויציג את ההמלצה וההסבר שלה ישירות במסוף.
- כדי לצאת מהסשן האינטראקטיבי, מקלידים
exitאוquit(או לוחצים עלCtrl+C). אחרי שיוצאים, אפשר להשבית את הסביבה הווירטואלית:
deactivate
6. פריסת הסוכן בסביבת הייצור
אחרי שמאמתים את הסוכן באופן מקומי, אפשר לפרוס אותו ב-Google Cloud לשימוש בסביבת הייצור.
יצירה של חשבון שירות
מטעמי אבטחה, הסוכן שנפרס לא צריך לפעול עם פרטי הכניסה האישיים שלכם. ניצור זהות נפרדת (knowledge-catalog-agent-sa) לסוכן, בהתאם לעיקרון של הרשאות מינימליות.
מריצים את הפקודות הבאות כדי ליצור את חשבון השירות:
export AGENT_SA=knowledge-catalog-agent-sa
export AGENT_SERVICE_ACCOUNT="${AGENT_SA}@${PROJECT_ID}.iam.gserviceaccount.com"
gcloud iam service-accounts create ${AGENT_SA} \
--display-name="Service Account for Knowledge Catalog Agent"
מתן הרשאות
למרות שהסוכן מעביר את בדיקות השליטה לשרת ה-MCP, הוא עדיין צריך הרשאות בסיסיות כדי לפעול.
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$AGENT_SERVICE_ACCOUNT" \
--role="roles/aiplatform.user"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$AGENT_SERVICE_ACCOUNT" \
--role="roles/dataplex.catalogAdmin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$AGENT_SERVICE_ACCOUNT" \
--role="roles/bigquery.dataViewer"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$AGENT_SERVICE_ACCOUNT" \
--role="roles/mcp.toolUser"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$AGENT_SERVICE_ACCOUNT" \
--role="roles/viewer"
פריסה ב-Cloud Run
לבסוף, פורסים את הסוכן ב-Cloud Run. הפקודה הבאה יוצרת את קובץ האימג' בקונטיינר באמצעות Dockerfile בספרייה הנוכחית, מעלה אותו ל-Artifact Registry ומפריסה אותו ב-Cloud Run. התהליך עשוי להימשך דקה עד 3 דקות.
gcloud run deploy knowledge-catalog-agent \
--source . \
--project=$PROJECT_ID \
--region=$REGION \
--service-account=$AGENT_SERVICE_ACCOUNT \
--allow-unauthenticated \
--clear-base-image \
--labels created-by=adk
אחרי שהפקודה הזו תסתיים, תופיע כתובת URL של השירות (לדוגמה, https://knowledge-catalog-agent-xyz.run.app). לוחצים על הקישור הזה כדי לפתוח את ממשק הצ'אט של ה-AI הגנרטיבי עם כללי המדיניות.
7. בדיקת נציג תמיכה
עכשיו שהסוכן שלכם פעיל, בואו נבדוק את תרחישי השליטה. הלוגיקה נשארת זהה, אבל עכשיו אתם מבצעים אינטראקציה עם ADK Web Playground שנפרס, שמציג באופן חזותי את המצב הפנימי ואת ההפעלות של כלי.
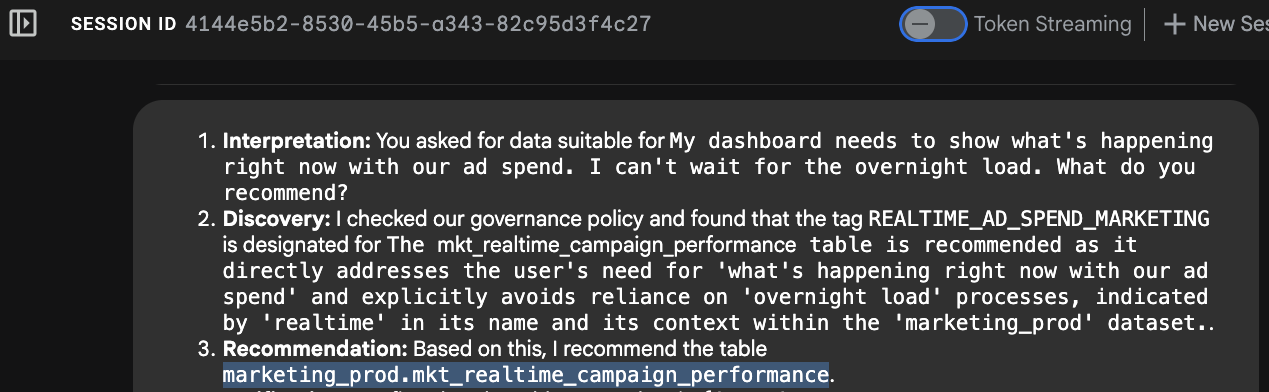
פותחים בדפדפן את כתובת ה-URL של השירות שנוצרה בשלב הקודם (למשל, https://knowledge-catalog-agent-xyz.run.app). מדביקים את ההנחיה הבאה:
"My dashboard needs to show what's happening right now with our ad spend. I can't wait for the overnight load. What do you recommend?"
אפשר לעקוב אחרי תהליך החשיבה של הסוכן בממשק המשתמש למפתחים:
- זיהוי כוונות: הסוכן מנתח את הביטויים "right now" (עכשיו) ו-"can't wait for overnight" (לא יכול לחכות עד מחר).
- חיפוש מטא-נתונים: הכלי קורא לפונקציה search_entries של כלי ה-MCP עם השאילתה:
[PROJECT_ID].us-central1.official-data-product-spec.update_frequency=REALTIME_STREAMING - בחירה: המערכת מזהה שהטבלה
mkt_realtime_campaign_performanceעומדת בקריטריונים האלה. - תשובה: הסוכן ממליץ על הטבלה בזמן אמת.
למה זה חשוב:
בלי מטא-נתונים כאלה של ניהול גישה, סביר להניח שמודל LLM ימליץ על הטבלה fin_monthly_closing_internal פשוט כי יש בה עמודה בשם ad_spend, בלי להתייחס לעובדה שהנתונים בני 24 שעות. הקשר של המטא-נתונים מנע שגיאה עסקית.
אפשר גם לבדוק את ההנחיה 'ישיבת דירקטוריון' כדי לראות איך הסוכן עובר לטבלאות שונות על סמך ההיבט 'רמת מוצר הנתונים':
"We are preparing the deck for an internal Board of Directors meeting next week. I need the numbers to be absolutely finalized, trustworthy, and kept strictly confidential. Which table is safe to use?"
8. הסרת המשאבים
כדי לא לצבור חיובים לחשבון Google Cloud, צריך לפעול לפי השלבים הבאים כדי להרוס את כל התשתית שנוצרה ב-codelab הזה.
השמדת אגם הנתונים
משתמשים בסקריפט הניקוי כדי להסיר את הטבלאות, מערכי הנתונים והגדרות ההיבטים של Knowledge Catalog ב-BigQuery.
cd ~/devrel-demos/data-analytics/governance-context
chmod +x ./cleanup_data_lake.sh
./cleanup_data_lake.sh
מחיקת שירותים ב-Cloud Run
מסירים את משאבי החישוב כדי להפסיק את החיוב הפעיל על הקונטיינר הפועל.
gcloud run services delete knowledge-catalog-agent --region=$REGION --quiet
ניקוי של ארטיפקטים של בנייה ואחסון זמני
כשפרסתם את סוכן ה-ADK, המערכת יצרה באופן אוטומטי קובץ אימג' של קונטיינר והעלתה את קוד המקור שלכם לקטגוריה של Cloud Storage זמנית.
מסירים את מאגר Artifact Registry ואת קטגוריית הביניים של Cloud Storage:
# Delete the repository used for the agent build
gcloud artifacts repositories delete cloud-run-source-deploy \
--location=$REGION \
--quiet
# Delete the staging bucket created by Cloud Run source deploy
gcloud storage rm --recursive gs://run-sources-${PROJECT_ID}-${REGION}
מחיקת הזהות וההרשאות
קודם מסירים את הקישורים של מדיניות IAM, ואז מוחקים את חשבונות השירות.
# Remove IAM roles granted to the Agent Service Account
gcloud projects remove-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$AGENT_SERVICE_ACCOUNT" \
--role="roles/aiplatform.user" --quiet
gcloud projects remove-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$AGENT_SERVICE_ACCOUNT" \
--role="roles/dataplex.catalogViewer" --quiet
gcloud projects remove-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$AGENT_SERVICE_ACCOUNT" \
--role="roles/mcp.toolUser" --quiet
gcloud projects remove-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$AGENT_SERVICE_ACCOUNT" \
--role="roles/bigquery.dataViewer" --quiet
# Delete the Service Account
gcloud iam service-accounts delete $AGENT_SERVICE_ACCOUNT --quiet
הסרת ההגדרה המקומית
לבסוף, מנקים את קובצי התצורה המקומיים ואת משתני הסביבה ב-Cloud Shell.
# Uninstall the AGY CLI plugin
agy plugin uninstall dataplex
# Remove local repository files and unset variables
cd ~
rm -rf ~/devrel-demos
unset MCP_SERVER_URL
unset AGENT_SERVICE_ACCOUNT
9. מעולה!
הצלחתם לפרוס סוכן GenAI מקצה לקצה שמודע לניהול.
ב-Codelab הזה, שמחולק לשני חלקים, עברנו מעבר להנדסת פרומפטים פשוטה כדי להטמיע ארכיטקטורה חזקה שמוכנה לייצור. הגדרתם את ניהול הנתונים כתנאי מוקדם לשימוש ב-AI גנרטיבי, וכך יצרתם שיטה שיטתית למניעת אחזור נתונים לא מאומתים או הזיות על ידי המודל.
מסקנות עיקריות
- AI דטרמיניסטי באמצעות מטא-נתונים: במקום להסתמך על ה-LLM כדי לנחש את הטבלה הנכונה על סמך שמות העמודות, השתמשתם בלולאת חשיבה רציונלית מחמירה באמצעות שרת MCP של Knowledge Catalog בניהול Google, וכך אילצתם את המודל לאמת את אישורי הנתונים לפני שהוא ממליץ על טבלאות.
- ארכיטקטורה מנותקת: סוכן הקצה הקדמי לא צריך להכיל לוגיקה של מסד נתונים, אלא רק לתקשר באמצעות תקן ה-MCP. כלומר, תוכלו לחבר כל מודל AI או לקוח עתידיים לאותו בק-אנד מנוהל.
- הפרדת תפקידים: יישמתם את העיקרון של הרשאות מינימליות על ידי בידוד זהויות IAM. סוכן ה-ADK שפונה למשתמשים פועל עם הרשאות שמוגבלות להפעלת המודל ולניתוב API.
- תזמור סוכנים עם קוד: השתמשתם בערכה לפיתוח סוכנים (ADK) של Google כדי לעטוף באופן מיידי את לוגיקת הסוכן של Python ב-FastAPI backend שניתן להרחבה, תוך שימוש בממשק המשתמש המובנה למפתחים כדי להמחיש ולנפות באגים בהפעלות של כלי פנימיים של הסוכן.
מה השלב הבא?
- Knowledge Catalog Foundational Governance Codelab: כדאי ללמוד את היסודות של ניהול נתונים ב-Knowledge Catalog לפני שמוסיפים את שכבת ה-AI.
- מסמכי הערכה לפיתוח סוכנים (ADK): אפשר לעיין במסמכים הרשמיים כדי ללמוד איך ליצור ולפרוס סוכנים באמצעות ADK.
- ניתוח מעמיק של MCP: כדאי לעיין במפרט הרשמי של MCP כדי להבין איך לבנות שרתים בהתאמה אישית עבור ממשקי API פנימיים של הארגון.