
1. Introducción
Este codelab es parte de una serie de dos partes en la que se explora cómo compilar un agente de IA generativa que tenga en cuenta la gobernanza.
(Puedes leer la primera parte de esta serie, en la que se explica cómo establecer la base de datos aplicando aspectos del Knowledge Catalog a las tablas de BigQuery y probando las reglas de forma local a través de la Gemini CLI. 👉 Lee la parte 1).
Sin embargo, probar en una CLI local es solo el comienzo. Para implementar esta función en toda tu empresa, necesitas seguridad centralizada, conexiones estandarizadas a herramientas de IA y un marco de trabajo de aplicaciones adecuado para coordinar la lógica del agente y proporcionar una interfaz de chat familiar.
En esta segunda parte, resolverás estos desafíos y escalarás a producción. Implementarás tus reglas de administración en un servidor de MCP central alojado en Cloud Run. Luego, usarás el Kit de desarrollo de agentes (ADK) de Google para compilar la aplicación del agente real y conectarla a tus herramientas de MCP, con una IU web profesional.
Requisitos previos
- Un proyecto de Google Cloud con facturación habilitada.
- Conocimientos básicos de Cloud Run, cuentas de servicio de IAM y Python
- Los conjuntos de datos de BigQuery y los aspectos de Knowledge Catalog creados en la Parte 1 (No te preocupes si los borraste. A continuación, te proporcionamos un script de acceso rápido para volver a crearlos).
Qué aprenderás
- Cómo usar el Protocolo de contexto del modelo (MCP) para estandarizar la forma en que los agentes de IA interactúan con los datos de Google Cloud
- Cómo implementar un servidor de MCP seguro en Cloud Run
- Cómo compilar un agente de IA con el Kit de desarrollo de agentes (ADK) y conectarlo a tu backend de MCP
- Cómo ejecutar la IU para desarrolladores integrada del ADK para interactuar con tu agente gobernado
Requisitos
- Acceso a Google Cloud Shell
Conceptos clave
- Protocolo de contexto del modelo (MCP): Piensa en el MCP como un "cable USB-C universal" para los agentes de IA. En lugar de escribir código de integración de API personalizado para cada modelo de IA, el MCP proporciona una forma estándar para que la IA se conecte de forma segura a tus herramientas de datos empresariales (como Knowledge Catalog y BigQuery).
- Kit de desarrollo de agentes (ADK): Es un framework flexible de código abierto de Google diseñado para simplificar el desarrollo integral de agentes de IA. Aplica principios de ingeniería de software a la creación de agentes, lo que te permite coordinar herramientas complejas, administrar estados y lanzar fácilmente una IU integrada para desarrolladores para pruebas e implementación.
2. Configuración y requisitos
Inicia Cloud Shell
Si bien Google Cloud y Spanner se pueden operar de manera remota desde tu laptop, en este codelab usarás Google Cloud Shell, un entorno de línea de comandos que se ejecuta en la nube.
En Google Cloud Console, haz clic en el ícono de Cloud Shell en la barra de herramientas en la parte superior derecha:
El aprovisionamiento y la conexión al entorno deberían tomar solo unos minutos. Cuando termine el proceso, debería ver algo como lo siguiente:

Esta máquina virtual está cargada con todas las herramientas de desarrollo que necesitarás. Ofrece un directorio principal persistente de 5 GB y se ejecuta en Google Cloud, lo que permite mejorar considerablemente el rendimiento de la red y la autenticación. Todo tu trabajo en este codelab se puede hacer en un navegador. No es necesario que instales nada.
Inicializa el entorno
Abre Cloud Shell y configura las variables de tu proyecto para asegurarte de que todos los comandos se dirijan a la infraestructura correcta.
export PROJECT_ID=$(gcloud config get-value project)
gcloud config set project $PROJECT_ID
export REGION="us-central1"
Punto de control: ¿Reanudar o volver a compilar?
Como esta es la parte 2, tu agente necesita los datos gobernados de la parte 1 para funcionar. Elige tu ruta:
Ruta A: Acabo de terminar la Parte 1 y mis recursos siguen en ejecución.
¡Genial! Navega hasta el directorio de trabajo y podrás continuar.
cd ~/devrel-demos/data-analytics/governance-context
Ruta B: Omití la parte 1 O borré mis recursos (limpié).
No hay problema. A continuación, proporcionamos un bloque de comandos de "vía rápida". Esto volverá a compilar automáticamente el data lake de BigQuery y aplicará los metadatos de administración de Knowledge Catalog exactamente como lo hicimos en la Parte 1.
# 1. Clone the repo and navigate to the working directory
git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/devrel-demos.git
cd devrel-demos
git sparse-checkout set data-analytics/governance-context
cd data-analytics/governance-context
# 2. Rebuild the messy data lake with Terraform
cd terraform
terraform init
terraform apply -var="project_id=${PROJECT_ID}" -var="region=${REGION}" -auto-approve
# 3. Generate and apply Knowledge Catalog Aspects (Governance rules)
cd ..
chmod +x ./generate_payloads.sh ./apply_governance.sh
./generate_payloads.sh
./apply_governance.sh
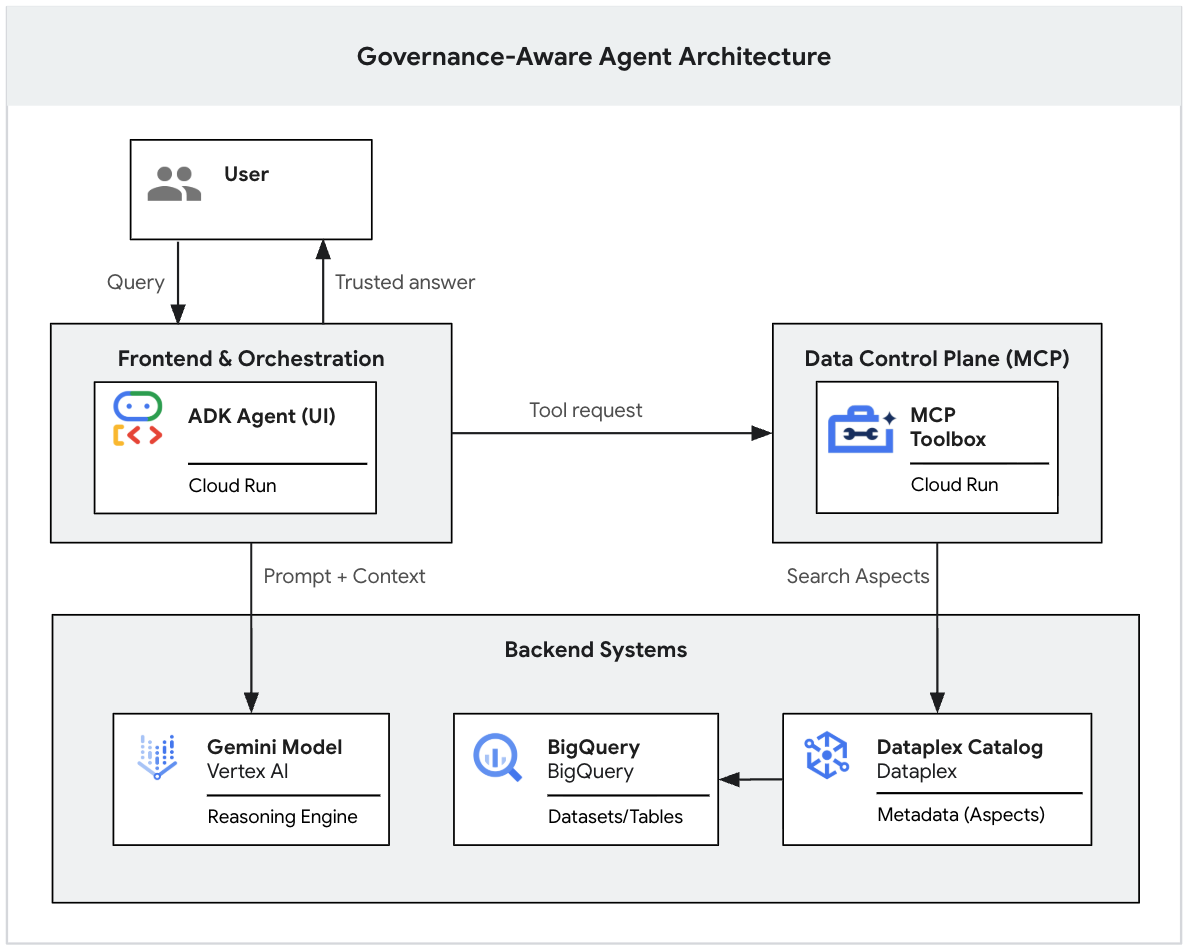
3. Escala con MCP: Compilación del plano de control de datos
Hasta ahora, probaste correctamente tu lógica de gobierno con la Gemini CLI. Esto es excelente para la creación rápida de prototipos, pero se ejecuta de forma local con tus credenciales de usuario personales.
En un entorno empresarial real, necesitas un plano de control de datos centralizado. Para compilarlo, usaremos la Toolbox para bases de datos de IA generativa, un proyecto oficial de código abierto de Google. Esta caja de herramientas proporciona un servidor de MCP prediseñado específicamente para conectar de forma segura los agentes de IA a las bases de datos y los servicios de metadatos de Google Cloud, como Knowledge Catalog.
Si implementamos esta caja de herramientas como nuestro servidor de MCP en Cloud Run, logramos lo siguiente:
- Identidad centralizada: El agente se ejecuta como una cuenta de servicio restringida, no como tu cuenta de usuario personal.
- Estandarización: Cualquier cliente (ADK, Gemini, apps personalizadas) puede "conectarse" a este servidor con el protocolo MCP estándar.
- Alcance controlado (privilegio mínimo): No le otorgamos al LLM acceso abierto a BigQuery. Forzamos la navegación primero por el catálogo de metadatos de Knowledge Catalog.
Configura la definición de la herramienta (tools.yaml)
La caja de herramientas de IA generativa requiere un archivo de configuración declarativo, tools.yaml. En este archivo, se definen sources (dónde conectarse) y tools (qué se le permite hacer a la IA).
- Navega al directorio del servidor y, luego, inyecta tu ID del proyecto en el archivo de configuración:
cd ~/devrel-demos/data-analytics/governance-context/mcp_server
envsubst < tools.yaml > tools.tmp && mv tools.tmp tools.yaml
cat tools.yaml
Debería verse idéntico al siguiente fragmento. Verifica que el campo del proyecto ahora coincida con tu ID del proyecto de Google Cloud real.
sources:
dataplex:
kind: dataplex
project: YOUR-PROJECT-ID
tools:
search_entries:
kind: dataplex-search-entries
source: dataplex
description: Search for entries in Knowledge Catalog.
lookup_entry:
kind: dataplex-lookup-entry
source: dataplex
description: Retrieve a specific entry from Knowledge Catalog.
search_aspect_types:
kind: dataplex-search-aspect-types
source: dataplex
description: Find aspect types relevant to a query.
toolsets:
dataplex-toolset:
- search_entries
- lookup_entry
- search_aspect_types
Si definimos estas tres herramientas, podemos obligar a la IA a ser de "solo lectura" y "priorizar la administración".
Protege la configuración (Secret Manager)
En la arquitectura empresarial, nunca debes incorporar archivos de configuración directamente en las imágenes de contenedor. Almacenaremos tools.yaml de forma segura en Google Cloud Secret Manager.
gcloud services enable secretmanager.googleapis.com
gcloud secrets create dataplex-tools-config --data-file=tools.yaml
Implementa el principio de privilegio mínimo (IAM)
A continuación, crearemos una cuenta de servicio dedicada para el servidor de MCP de GenAI Toolbox. Esta identidad solo tendrá los permisos exactos necesarios para leer el catálogo de Knowledge Catalog y acceder a los datos de BigQuery.
export MCP_SA=mcp-sa
gcloud iam service-accounts create ${MCP_SA} \
--display-name="Service Account for Knowledge Catalog MCP"
export MCP_SERVICE_ACCOUNT="${MCP_SA}@${PROJECT_ID}.iam.gserviceaccount.com"
# Allow the server to read its own config from Secret Manager
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$MCP_SERVICE_ACCOUNT" \
--role="roles/secretmanager.secretAccessor"
# Allow the server to read Knowledge Catalog Metadata and BigQuery Data
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$MCP_SERVICE_ACCOUNT" \
--role="roles/dataplex.catalogViewer"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$MCP_SERVICE_ACCOUNT" \
--role="roles/bigquery.dataViewer"
Implementa el servidor de MCP en Cloud Run
Ahora, implementaremos la Caja de herramientas de IA generativa. Usamos la imagen de contenedor prediseñada de Google (database-toolbox/toolbox) y montamos nuestra configuración desde Secret Manager (--set-secrets) en el tiempo de ejecución.
export IMAGE=us-central1-docker.pkg.dev/database-toolbox/toolbox/toolbox:latest
gcloud run deploy governance-mcp \
--image=$IMAGE \
--service-account $MCP_SERVICE_ACCOUNT \
--region=$REGION \
--no-allow-unauthenticated \
--set-secrets="/app/tools.yaml=dataplex-tools-config:latest" \
--args="--tools-file=/app/tools.yaml","--address=0.0.0.0","--port=8080"
Ya estableciste una API gobernada. En lugar de otorgarle a tu frontend de IA generativa acceso directo a la base de datos, se conectará a esta URL de Cloud Run. El agente solo puede ver lo que le permite ver esta Caja de herramientas.
4. Compila el backend del agente con el ADK
Estableciste un plano de control de datos (MCP) seguro y gobernado que se ejecuta en Cloud Run. Ahora tu agente de IA necesita un framework para organizar su lógica, como procesar las entradas del usuario, decidir cuándo llamar al servidor de MCP y dar formato al resultado.
En lugar de escribir todo este código estándar desde cero, usaremos el Kit de desarrollo de agentes (ADK) de Google. El ADK es un framework centrado en el código que envuelve automáticamente la lógica de tu agente en un backend de FastAPI. Además, incluye una IU para desarrolladores integrada que te permite visualizar al instante el proceso de razonamiento y las llamadas a herramientas del agente sin tener que crear primero un frontend personalizado.
Inspecciona la lógica del agente (agent.py)
Antes de configurar la infraestructura, veamos el núcleo de esta aplicación.
Navega al directorio y genera el contenido de agent.py. Este archivo es el "cerebro" de tu implementación del ADK.
cd ~/devrel-demos/data-analytics/governance-context/mcp_server
cat agent.py
Observa la estructura del código. Realiza tres funciones críticas con una cantidad mínima de código estándar:
- Integración de MCPToolset: En lugar de escribir clientes HTTP personalizados para interactuar con tus herramientas de Knowledge Catalog, el ADK usa
MCPToolset(server_url=mcp_url). Esto recupera de forma dinámica la definición detools.yamlde tu servidor de MCP implementado y la traduce en llamadas a funciones nativas para el LLM. - Instrucciones del sistema: El parámetro
instructionscontiene las reglas de gobernanza estrictas (la misma lógica que usamos en la CLIGEMINI.md). Ordena explícitamente al modelo que ejecute el bucle de razonamiento de la fase 1 (búsqueda de metadatos) a la fase 2 (consulta de datos). - Organización de agentes: La clase
Agent(...)vincula el modelo de Gemini, la instrucción del sistema y las herramientas del MCP. Cuando se implementa, el ADK convierte automáticamente este objeto en un extremo de FastAPI escalable.
Separación de obligaciones: Configura la identidad del frontend
Para ejecutar este código de forma segura, debemos indicarle al agente dónde se encuentra tu servidor de MCP. Construiremos la URL de forma dinámica y la guardaremos en un archivo .env que el ADK leerá en el tiempo de ejecución.
También crearemos una identidad independiente (dataplex-agent-sa) para esta aplicación orientada al usuario. Esta separación de funciones garantiza que el agente de frontend tenga permisos diferentes a los del servidor de administración de backend.
Ejecuta los siguientes comandos para configurar el entorno y la identidad:
export PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
export MCP_SERVER_URL=https://governance-mcp-${PROJECT_NUMBER}.${REGION}.run.app/mcp
export AGENT_SA=knowledge-catalog-agent-sa
export AGENT_SERVICE_ACCOUNT="${AGENT_SA}@${PROJECT_ID}.iam.gserviceaccount.com"
gcloud iam service-accounts create ${AGENT_SA} \
--display-name="Service Account for Knowledge Catalog Agent "
Cómo configurar variables de tiempo de ejecución
El framework del ADK depende de las variables de entorno para comprender su contexto. Debemos establecer de forma explícita el ID del proyecto y la región, y habilitar el uso de Gemini Enterprise Agent Engine. Agregamos estos datos al mismo archivo .env.
echo MCP_SERVER_URL=$MCP_SERVER_URL > .env
echo GOOGLE_GENAI_USE_VERTEXAI=1 >> .env
echo GOOGLE_CLOUD_PROJECT=$PROJECT_ID >> .env
echo GOOGLE_CLOUD_LOCATION=$REGION >> .env
Otorga permisos
Aunque el agente delega las verificaciones de gobernanza en el servidor de MCP, aún necesita permisos básicos para operar. Otorgamos exactamente dos roles:
- Usuario de Gemini Enterprise Agent Engine: Para invocar el modelo de Gemini y generar respuestas en lenguaje natural.
- Invocador de Cloud Run: Para llamar de forma segura a la API del servidor de MCP No obtiene acceso directo a BigQuery ni a Knowledge Catalog.
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$AGENT_SERVICE_ACCOUNT" \
--role="roles/aiplatform.user"
gcloud run services add-iam-policy-binding governance-mcp \
--region=$REGION \
--member="serviceAccount:$AGENT_SERVICE_ACCOUNT" \
--role="roles/run.invoker"
Implementa en Cloud Run
Por último, implementamos la pila completa en Cloud Run.
Usamos uvx para ejecutar la herramienta del ADK sin instalar dependencias de forma manual. El siguiente comando empaqueta la lógica de tu archivo agent.py, compila una imagen de contenedor, inyecta tu cuenta de servicio y lanza un servidor FastAPI. Si agregas la marca --with_ui, también se incluye el ADK Web Playground para la depuración.
Este comando compila el contenedor y lo implementa. Este proceso puede tardar entre 1 y 3 minutos en completarse.
uvx --from google-adk \
adk deploy cloud_run \
--project=$PROJECT_ID \
--region=$REGION \
--service_name=knowledge-catalog-agent \
--with_ui \
. \
-- \
--service-account=$AGENT_SERVICE_ACCOUNT \
--allow-unauthenticated
Una vez que se complete este comando, se generará una URL de servicio (e.g., https://dataplex-agent-xyz.run.app). Haz clic en ese vínculo para abrir la interfaz de chat con IA generativa completamente controlada.
Flujo de arquitectura integral
Ya completaste el sistema. Cuando un usuario interactúa con la IU del ADK, se produce la siguiente secuencia:
- El usuario envía una instrucción en el agente del ADK (IU de desarrollo).
- El agente del ADK (agent.py) procesa la entrada y llama al modelo de Gemini.
- Gemini determina que necesita contexto y le pide al servidor de MCP que ejecute las herramientas de Knowledge Catalog.
- El servidor de MCP aplica las reglas de administración de Knowledge Catalog y devuelve los metadatos.
- Gemini sintetiza la respuesta confiable en función de los metadatos y se la devuelve al usuario.
5. Prueba el agente empresarial
Ahora que tu agente está activo, volvamos a analizar las situaciones de gobernanza que probamos antes con la CLI. La lógica sigue siendo la misma, pero ahora interactúas con el ADK Web Playground implementado, que visualiza el estado interno y las ejecuciones de herramientas.
- Orquestación: El agente del ADK (que se ejecuta en Cloud Run) recibe tu texto.
- Enrutamiento de herramientas: Gemini reconoce que tu pregunta requiere contexto de datos y reenvía la solicitud al servidor de MCP.
- Verificación de gobernanza: El servidor de MCP (que se ejecuta en una instancia separada de Cloud Run) consulta Knowledge Catalog para obtener tipos de aspectos específicos.
- Síntesis: Los metadatos pertinentes se devuelven a Gemini para generar la respuesta final.
Verifica la lógica de gobierno
Abre la URL del servicio que generaste en el paso anterior (e.g., https://dataplex-agent-xyz.run.app) en tu navegador. Pega la siguiente instrucción:
"My dashboard needs to show what's happening right now with our ad spend. I can't wait for the overnight load. What do you recommend?"
Observa el proceso de razonamiento del agente en la IU para desarrolladores:
- Reconocimiento de intención: El agente analiza "en este momento" y "no puedo esperar hasta mañana".
- Búsqueda de metadatos: Llama a la herramienta
search_aspect_typesde MCP. Busca recursos de datos en los que el aspectoupdate_frequencyesté configurado como REALTIME o STREAMING, en lugar de DAILY o MONTHLY. - Selección: Identifica que la tabla
mkt_realtime_campaign_performancecumple con estos criterios, mientras quefin_monthly_closing_internal(a pesar de ser de alta calidad) es demasiado lenta para tu solicitud. - Respuesta: El agente recomienda la tabla en tiempo real.
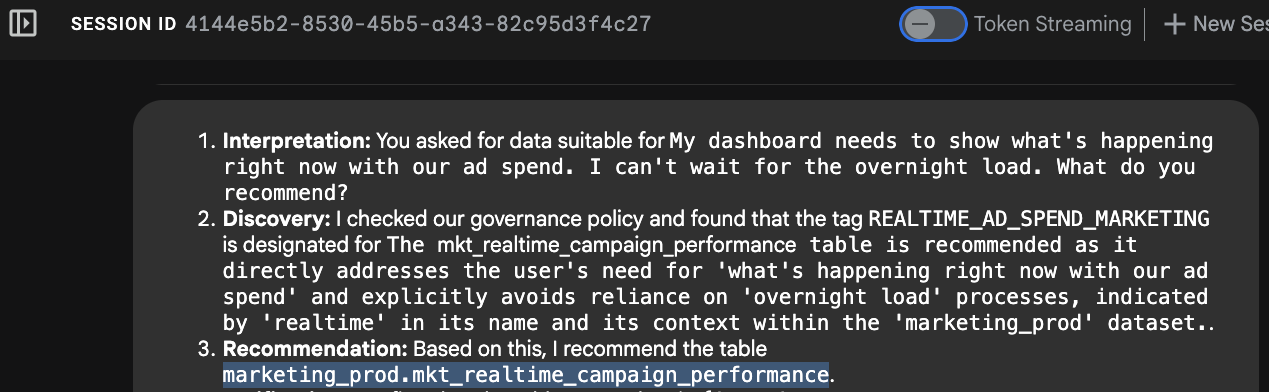
Por qué es importante:
Sin estos metadatos de administración, es probable que un LLM recomiende la tabla fin_monthly_closing_internal simplemente porque tiene una columna llamada "ad_spend", sin tener en cuenta el hecho de que los datos tienen 24 horas de antigüedad. El contexto de tus metadatos evitó un error comercial.
También puedes probar la instrucción "Reunión de la junta" para ver cómo el agente cambia a diferentes tablas según el aspecto de nivel del producto de datos:
"We are preparing the deck for an internal Board of Directors meeting next week. I need the numbers to be absolutely finalized, trustworthy, and kept strictly confidential. Which table is safe to use?"
6. Limpia
Para evitar que se apliquen cargos a tu cuenta de Google Cloud por los recursos que usaste en este codelab, sigue estos pasos para destruir toda la infraestructura que creaste en las partes 1 y 2.
Destruye el lago de datos (Terraform)
Usa Terraform para desmantelar las tablas, los conjuntos de datos y las definiciones de aspectos de Knowledge Catalog de BigQuery.
cd ~/devrel-demos/data-analytics/governance-context/terraform
terraform destroy -var="project_id=${PROJECT_ID}" -var="region=${REGION}" -auto-approve
Borra servicios de Cloud Run
Quita los recursos de procesamiento para detener la facturación activa de los contenedores en ejecución.
gcloud run services delete governance-mcp --region=$REGION --quiet
gcloud run services delete knowledge-catalog-agent --region=$REGION --quiet
Libera espacio de los artefactos de compilación y el almacenamiento provisional
Cuando implementaste el agente del ADK con uvx, el sistema compiló automáticamente una imagen de contenedor y subió tu código fuente a un bucket temporal de Cloud Storage. Estos artefactos persisten incluso después de que se borra el servicio de Cloud Run y generan costos de almacenamiento continuos.
Quita el repositorio de Artifact Registry y el bucket de Cloud Storage de etapa de pruebas:
# Delete the repository used for the agent build
gcloud artifacts repositories delete cloud-run-source-deploy \
--location=$REGION \
--quiet
# Delete the staging bucket created by Cloud Run source deploy
gcloud storage rm --recursive gs://run-sources-${PROJECT_ID}-${REGION}
Borra la identidad, los permisos y los secretos
Primero, quita las vinculaciones de políticas de IAM para evitar que queden entradas "tumba" (registros huérfanos) en la página de IAM de tu proyecto. Luego, borra las cuentas de servicio y los secretos de configuración.
# Remove IAM roles granted to the MCP Service Account
gcloud projects remove-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$MCP_SERVICE_ACCOUNT" \
--role="roles/secretmanager.secretAccessor" --quiet
gcloud projects remove-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$MCP_SERVICE_ACCOUNT" \
--role="roles/dataplex.catalogViewer" --quiet
gcloud projects remove-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$MCP_SERVICE_ACCOUNT" \
--role="roles/bigquery.dataViewer" --quiet
# Remove IAM roles granted to the Agent Service Account
gcloud projects remove-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$AGENT_SERVICE_ACCOUNT" \
--role="roles/aiplatform.user" --quiet
# Delete the Service Accounts
gcloud iam service-accounts delete $MCP_SERVICE_ACCOUNT --quiet
gcloud iam service-accounts delete $AGENT_SERVICE_ACCOUNT --quiet
# Delete the Secret Manager entry
gcloud secrets delete dataplex-tools-config --quiet
Cómo quitar la configuración local
Por último, limpia los archivos de configuración locales y las variables de entorno en Cloud Shell.
# Uninstall the Gemini CLI extension (installed in Part 1)
gemini extensions uninstall dataplex
# Remove local repository files and unset variables
cd ~
rm -rf ~/devrel-demos
unset MCP_SERVER_URL
unset MCP_SERVICE_ACCOUNT
unset AGENT_SERVICE_ACCOUNT
7. ¡Felicitaciones!
Implementaste correctamente un agente de IA generativa integral y con conocimiento de la gobernanza.
En este codelab de dos partes, fuiste más allá de la ingeniería de instrucciones simple para implementar una arquitectura sólida y lista para producción. Al considerar la administración de datos como un requisito previo para la IA generativa, estableciste un método sistemático para evitar que el modelo recupere datos no certificados o alucinados.
Conclusiones principales
- IA determinística a través de metadatos: En lugar de confiar en que el LLM adivine la tabla correcta según los nombres de las columnas, aplicaste un bucle de razonamiento estricto con la Caja de herramientas de IA generativa para bases de datos. Al exponer explícitamente solo tres herramientas del Catálogo de conocimiento (
search_aspect_types,search_entries,lookup_entry), obligaste al modelo a verificar las certificaciones de datos antes de sintetizar las respuestas. - Arquitectura desacoplada (MCP): Cuando implementaste el servidor del Protocolo de contexto del modelo (MCP) en Cloud Run, abstrajiste tus reglas de administración de datos en una API centralizada y estandarizada. El agente de frontend no necesita contener lógica de base de datos, solo necesita comunicarse a través del estándar de MCP. Esto significa que puedes conectar cualquier modelo o cliente de IA futuro al mismo backend controlado.
- Separación de obligaciones: Aplicaste el principio de privilegio mínimo aislando las identidades de IAM. El agente del ADK orientado al usuario opera con permisos restringidos a la invocación de modelos y al enrutamiento de APIs, mientras que el servidor de MCP de backend controla de forma segura las consultas del Knowledge Catalog y la recuperación de datos de BigQuery.
- Orquestación de agentes centrada en el código: Usaste el Kit de desarrollo de agentes (ADK) de Google para encapsular instantáneamente la lógica de tu agente de Python en un backend de FastAPI escalable, y aprovechaste su IU para desarrolladores integrada para visualizar y depurar las ejecuciones de herramientas internas del agente.
Próximos pasos
- Codelab de administración básica de Knowledge Catalog: Domina los conceptos básicos de la administración de datos en Knowledge Catalog antes de agregar la capa de IA.
- Documentación de las herramientas de Knowledge Catalog: Explora la documentación oficial de las herramientas y extensiones prediseñadas de Knowledge Catalog que se usan en este lab.
- Comienza a usar las extensiones de Gemini CLI: Aprende a compilar tus propias extensiones personalizadas para brindarles aún más capacidades a tus agentes de IA generativa.
- Análisis detallado de MCP: Consulta la especificación oficial de MCP para comprender cómo compilar servidores personalizados para tus APIs empresariales internas.