
1. Einführung
In einer modernen Data Cloud für Unternehmen, in der Daten auf verschiedenen physischen Speichersystemen gespeichert sind, stellt die fragmentierte Sicherheit eine enorme architektonische Herausforderung dar.
Wie können Sie sicherstellen, dass vertrauliche Daten wie Beträge von Finanztransaktionen konsistent geschützt werden, wenn sie physisch in Open-Source-Formaten wie Parquet in Google Cloud Storage gespeichert und von mehreren verschiedenen Engines wie BigQuery SQL oder Apache Spark abgefragt werden?
In diesem Codelab erstellen Sie eine Governed Data Lakehouse-Architektur, die diese Probleme mit Apache Iceberg-Tabellen, BigQuery und Knowledge Catalog löst. Sie verwenden Infrastructure as Code (IaC), um Zero-Trust-Sicherheitsrichtlinien zu definieren und festzulegen, wie sie dynamisch in verschiedenen Compute-Engines durchgesetzt werden.
Voraussetzungen
- Google Cloud-Projekt mit aktivierter Abrechnungsfunktion.
- Grundlegende Kenntnisse in SQL, IAM und Cloud Storage.
Lerninhalte
- Sie erfahren, wie Sie Google Cloud Lakehouse-Tabellen für Apache Iceberg in BigQuery erstellen, in denen die Daten nativ in Cloud Storage gespeichert werden.
- Sie lernen, wie Sie zentralisierte Datenrichtlinien mit Richtlinien-Tags für die Sicherheit auf Spaltenebene und die Datenmaskierung durchsetzen.
- Sie erfahren, wie Sie den physischen Speicherzugriff vom logischen Datenzugriff entkoppeln, indem Sie eine Cloud-Ressourcenverbindung verwenden.
- Sie lernen, wie Sie die Zero-Trust-Compute-Delegierung mit Google Cloud Serverless für Apache Spark durchsetzen, um sicherzustellen, dass Open-Source-Engines die Governance nicht umgehen können.
- Sie erfahren, wie Sie die automatisierte Data Lineage visualisieren.
Architekturübersicht: Universelle Governance für Iceberg
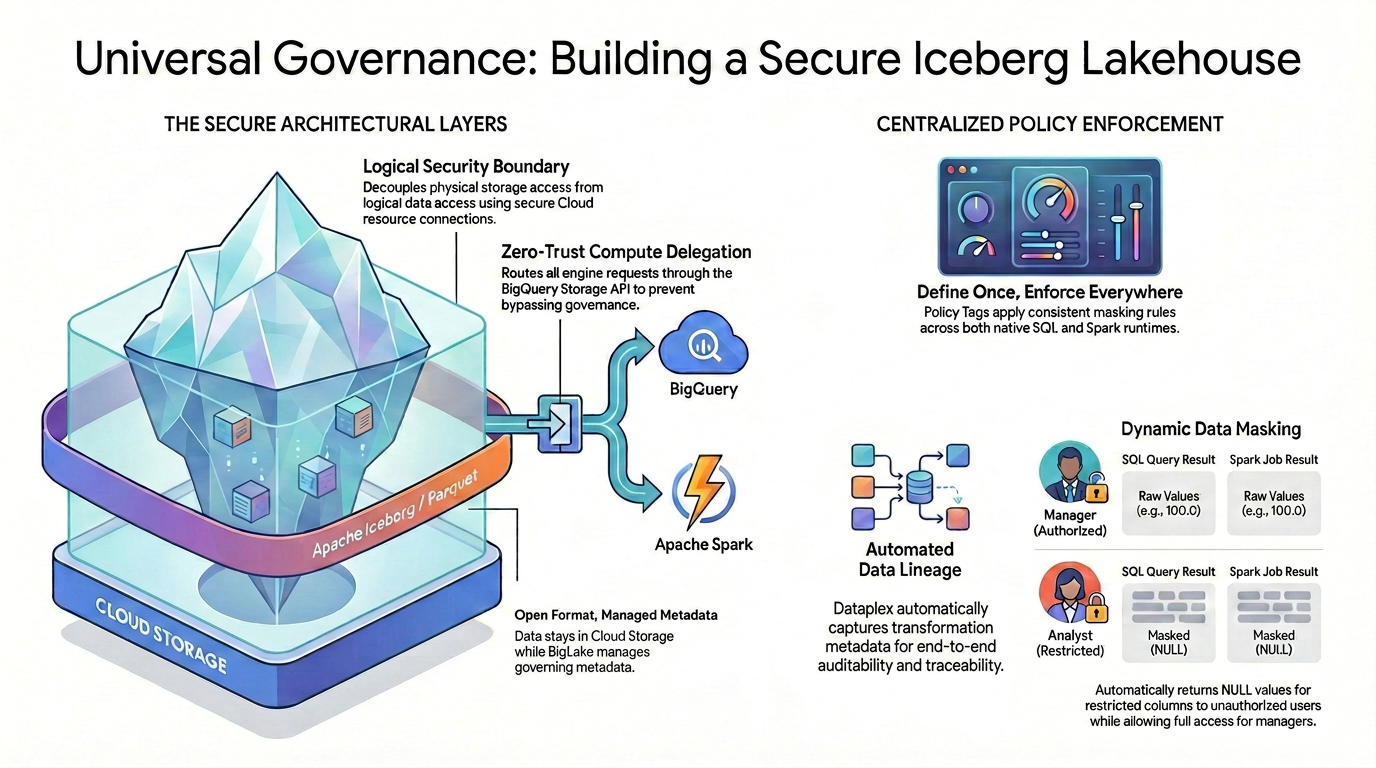
Um eine detaillierte Zugriffssteuerung (z. B. Sicherheit auf Spaltenebene und Datenmaskierung) für Open-Source-Datenformate zu erreichen, müssen Sie eine strenge und einheitliche Sicherheitsarchitektur einrichten.
Wie im Diagramm dargestellt, stützt sich dieses Governed Lakehouse-Muster auf zwei Hauptsäulen, um die Herausforderung der fragmentierten Sicherheit zu lösen:
🛡️ Sichere Architekturebenen (links)
Anstatt Nutzern oder externen Engines den direkten Zugriff auf Cloud Storage zu ermöglichen, das nur eine umfassende Sicherheit auf Bucket-Ebene unterstützt, schaffen Sie eine sichere Grundlage.
- Offenes Format, verwaltete Metadaten:Die Daten bleiben physisch in Cloud Storage im offenen Apache Iceberg-Format (Parquet), während Lakehouse die Governance-Metadaten nahtlos verwaltet.
- Logische Sicherheitsgrenze:Sie entkoppeln den physischen Speicherzugriff vom logischen Datenzugriff mithilfe einer sicheren Cloud-Ressourcenverbindung. Endnutzern wird niemals direkter physischer IAM-Zugriff auf die GCS-Rohdateien gewährt.
- Zero-Trust-Compute-Delegierung:Damit keine Ausführungs-Engine die Governance-Regeln umgehen kann, werden alle Lesevorgänge für Daten ausschließlich über die BigQuery Storage API weitergeleitet. Dies gilt unabhängig davon, ob die Abfrage aus nativem BigQuery SQL oder Open-Source-Apache Spark stammt.
🎯 Zentralisierte Durchsetzung von Richtlinien (rechts)
Mit der sicheren Grundlage fungiert Knowledge Catalog als einheitliche Governance-Zentrale:
- Einmal definieren, überall durchsetzen:Sie definieren Ihre Richtlinien-Tags nur einmal in Knowledge Catalog. Die Architektur wendet einheitliche Maskierungsregeln universell auf alle unterstützten Ausführungs-Runtimes an.
- Dynamische Datenmaskierung:Wenn Daten abgefragt werden, wird die Identität des Nutzers dynamisch ausgewertet. Autorisierte Nutzer sehen sowohl in SQL als auch in Spark die nicht maskierten Rohwerte (z.B. 100,0). Nutzer mit eingeschränkten Berechtigungen erhalten automatisch maskierte NULL-Werte für eingeschränkte Spalten in beiden Engines.
- Automatisierte Data Lineage:Wenn Daten fließen und transformiert werden, erfasst Knowledge Catalog automatisch Metadaten zur Transformation. So sind integrierte End-to-End-Prüfbarkeit und -Nachverfolgbarkeit ohne benutzerdefinierten Logging-Code möglich.
2. Einrichtung und Anforderungen
Cloud Shell starten
Sie können Google Cloud von Ihrem Laptop aus per Fernzugriff nutzen. In diesem Codelab verwenden Sie jedoch Google Cloud Shell, eine Befehlszeilenumgebung, die in der Cloud ausgeführt wird.
Klicken Sie in der Google Cloud Console in der Symbolleiste rechts oben auf das Cloud Shell-Symbol:
Die Bereitstellung und Verbindung mit der Umgebung sollte nur wenige Augenblicke dauern. Wenn der Vorgang abgeschlossen ist, sollte etwa Folgendes angezeigt werden:

Diese virtuelle Maschine verfügt über sämtliche Entwicklertools, die Sie benötigen. Sie bietet ein Basisverzeichnis mit 5 GB nichtflüchtigem Speicher und läuft in Google Cloud, was die Netzwerkleistung und Authentifizierung erheblich verbessert. Alle Aufgaben in diesem Codelab können in einem Browser ausgeführt werden. Sie müssen nichts installieren.
Umgebung initialisieren
Öffnen Sie Cloud Shell und legen Sie Ihre Projektvariablen fest, damit alle Befehle auf die richtige Infrastruktur ausgerichtet sind.
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-central1"
export ICEBERG_BUCKET="iceberg-retail-demo-${PROJECT_ID}"
export DATASET_ID="lakehouse_retail_demo"
export CONN_NAME="iceberg-bq-conn-demo"
Definieren Sie dann unsere beiden Personas.
export USER_ANALYST="retail-analyst-demo"
export EMAIL_ANALYST="${USER_ANALYST}@${PROJECT_ID}.iam.gserviceaccount.com"
export USER_MANAGER="retail-manager-demo"
export EMAIL_MANAGER="${USER_MANAGER}@${PROJECT_ID}.iam.gserviceaccount.com"
export CURRENT_USER=$(gcloud config get-value account)
APIs aktivieren
Aktivieren Sie die erforderlichen Google Cloud-Dienste.
gcloud services enable \
bigquery.googleapis.com \
bigqueryconnection.googleapis.com \
datacatalog.googleapis.com \
bigquerydatapolicy.googleapis.com \
datalineage.googleapis.com \
dataplex.googleapis.com \
dataproc.googleapis.com \
storage-component.googleapis.com
Quellcode des Codelabs herunterladen
Damit Ihre Cloud Shell nicht überladen wird, führen Sie einen Sparse-Checkout aus, um nur die erforderlichen Python-Skripts für dieses Codelab aus dem Google Cloud DevRel-Repository herunterzuladen.
# Shallow clone without full history
git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/devrel-demos.git
cd devrel-demos
# Download only the specific folder
git sparse-checkout set data-analytics/governed-lakehouse
cd data-analytics/governed-lakehouse
Speicher erstellen
Erstellen Sie den Bucket für die hochsicheren Governed Iceberg-Daten.
gcloud storage buckets create gs://${ICEBERG_BUCKET} --location=${REGION}
Identitäten und Sicherheit vorbereiten
Konfigurieren Sie die Cloud-Ressourcenverbindung. Dies ist die einzige Entität, die die permanenten physischen IAM-Schlüssel zum Lesen der Iceberg-Rohdateien enthält.
# Create the BigQuery connection
bq mk --connection \
--connection_type=CLOUD_RESOURCE \
--location=${REGION} \
${CONN_NAME}
# Retrieve the connection's automatically generated Service Account
export BQ_CONN_SVC_ACCT=$(bq show --format=json --connection ${REGION}.${CONN_NAME} \
| jq -r '.cloudResource.serviceAccountId')
# Grant Storage Object Admin to the connection for the Iceberg bucket
gcloud storage buckets add-iam-policy-binding gs://${ICEBERG_BUCKET} \
--member="serviceAccount:${BQ_CONN_SVC_ACCT}" \
--role="roles/storage.objectAdmin" \
--quiet
Richten Sie als Nächstes die Nutzer-Personas ein. Nutzern wird logischer Zugriff gewährt, nicht physischer Speicherzugriff. Um Fehler aufgrund von IAM-Verzögerungen zu vermeiden, erstellen Sie zuerst die Konten, warten einige Sekunden und weisen ihnen dann die Rollen zu.
echo "Creating Service Accounts..."
for USER in "${USER_ANALYST}" "${USER_MANAGER}"; do
gcloud iam service-accounts create ${USER} --display-name="Lakehouse ${USER}"
done
echo "⏳ Waiting 15 seconds for IAM propagation..."
sleep 15
echo "Granting IAM Roles to Service Accounts..."
for USER in "${USER_ANALYST}" "${USER_MANAGER}"; do
EMAIL="${USER}@${PROJECT_ID}.iam.gserviceaccount.com"
# Allow Cloud Shell to impersonate them for testing
gcloud iam service-accounts add-iam-policy-binding ${EMAIL} \
--member="user:${CURRENT_USER}" \
--role="roles/iam.serviceAccountTokenCreator" \
--quiet
# Allow logical viewing of the catalog, querying, and running Dataproc jobs
for ROLE in "roles/datacatalog.viewer" "roles/bigquery.dataViewer" "roles/bigquery.user" "roles/bigquery.connectionUser" "roles/serviceusage.serviceUsageConsumer" "roles/dataproc.worker"; do
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${EMAIL}" \
--role="${ROLE}" \
--quiet
done
done
# Grant the Manager data creation rights
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${EMAIL_MANAGER}" \
--role="roles/bigquery.dataEditor" \
--quiet
echo "✅ Identity and Security setup completed!"
3. Native Iceberg-Tabellen über Lakehouse erstellen
Sie verwenden die nativen Funktionen von Lakehouse, um die verwalteten Iceberg-Tabellen zu erstellen.
BigQuery-Dataset erstellen
Erstellen Sie zuerst ein BigQuery-Dataset, um unsere Iceberg-Tabellen logisch zu gruppieren.
echo "Creating BigQuery Dataset..."
bq mk --location=${REGION} --dataset ${PROJECT_ID}:${DATASET_ID}
Iceberg-Tabellen erstellen
Führen Sie als Nächstes die folgenden Befehle aus, um die Tabellen zu erstellen. Beachten Sie den Block OPTIONS, in dem wir table_format = 'ICEBERG' angeben und ihn direkt unserem Cloud Storage-Bucket und unserer Verbindung zuordnen.
echo "Creating Iceberg tables..."
# Inventory table
bq query --use_legacy_sql=false \
"CREATE OR REPLACE TABLE \`${PROJECT_ID}.${DATASET_ID}.inventory\` (
product_id INT64,
product_name STRING,
stock_count INT64
)
WITH CONNECTION \`${REGION}.${CONN_NAME}\`
OPTIONS (
file_format = 'PARQUET',
table_format = 'ICEBERG',
storage_uri = 'gs://${ICEBERG_BUCKET}/inventory/'
);"
# Transactions table
bq query --use_legacy_sql=false \
"CREATE OR REPLACE TABLE \`${PROJECT_ID}.${DATASET_ID}.transactions\` (
id INT64,
item STRING,
amount FLOAT64,
transaction_date DATE
)
WITH CONNECTION \`${REGION}.${CONN_NAME}\`
OPTIONS (
file_format = 'PARQUET',
table_format = 'ICEBERG',
storage_uri = 'gs://${ICEBERG_BUCKET}/transactions/'
);"
Tabellen mit Daten füllen
Fügen Sie schließlich Beispieldaten in die neu erstellten Iceberg-Tabellen ein.
echo "Inserting data into Iceberg tables..."
# Insert into Inventory table
bq query --use_legacy_sql=false \
"INSERT INTO \`${PROJECT_ID}.${DATASET_ID}.inventory\` (product_id, product_name, stock_count)
VALUES (101, 'Widget A', 500), (102, 'Widget B', 250), (103, 'Widget C', 800);"
# Insert into Transactions table
bq query --use_legacy_sql=false \
"INSERT INTO \`${PROJECT_ID}.${DATASET_ID}.transactions\` (id, item, amount, transaction_date)
VALUES
(1, 'Widget A', 100.0, DATE '2024-01-01'),
(2, 'Widget B', 150.0, DATE '2024-01-02'),
(3, 'Widget C', 50.0, DATE '2024-01-03');"
Sie haben jetzt zwei voll funktionsfähige Iceberg-Tabellen. Lakehouse verwaltet die Metadaten, aber die physischen Parquet-Dateien befinden sich sicher in Ihrem GCS-Bucket.
ETL-Pipeline simulieren
In der Praxis werden Rohdaten oft in Zusammenfassungstabellen für die Geschäftsberichterstattung aggregiert. Wir agieren als Data Engineer und erstellen eine tägliche Zusammenfassungstabelle für den Umsatz aus unseren Rohdaten zu Transaktionen.
(Hinweis: Führen Sie diesen Schritt jetzt aus, damit Google Cloud genügend Zeit hat, die Metadaten im Hintergrund zu verarbeiten. Warum das wichtig ist, erfahren Sie später im Codelab.)
echo "Creating transactions summary table..."
bq query --use_legacy_sql=false \
"CREATE TABLE \`${PROJECT_ID}.${DATASET_ID}.transactions_summary\` AS
SELECT transaction_date, SUM(amount) as total_sales, COUNT(id) as transaction_count
FROM \`${PROJECT_ID}.${DATASET_ID}.transactions\`
GROUP BY transaction_date;"
4. Zentralisierte Governance: Richtlinien mit Python definieren
In einer Produktionsumgebung ist die Konfiguration von Governance-Richtlinien über die Benutzeroberfläche schwer zu skalieren und zu verwalten. Stattdessen wird dringend empfohlen, Infrastructure as Code (IaC) zu verwenden.
In diesem Abschnitt verwenden Sie das Google Cloud Python SDK, um Ihre Zero-Trust-Governance-Regeln Schritt für Schritt programmatisch zu erstellen und durchzusetzen.
Python-Umgebung einrichten
Richten Sie zuerst eine isolierte Python-Umgebung (venv) ein, um Bibliothekskonflikte zu vermeiden, und installieren Sie die erforderlichen Google Cloud SDKs.
Führen Sie die folgenden Befehle in Cloud Shell aus:
# Create and activate a virtual environment
python3 -m venv lakehouse_env
source lakehouse_env/bin/activate
# Install required Knowledge Catalog and BigQuery governance libraries
pip install google-cloud-datacatalog google-cloud-bigquery-datapolicies google-cloud-bigquery --quiet
echo "✅ Python environment is ready!"
Taxonomie und Richtlinien-Tag erstellen
Eine Taxonomie ist ein logischer Container und ein Richtlinien-Tag ist das spezifische Label, das Sie an unsere vertrauliche Spalte anhängen. Um die Sicherheit auf Spaltenebene durchzusetzen, benötigen Sie zuerst einen logischen Container (eine Taxonomie) und ein bestimmtes Label (ein Richtlinien-Tag).
Wenn Sie in 1_create_taxonomy.py nachsehen, sehen Sie die folgende Kernlogik:
# Create Taxonomy with Fine-Grained Access Control enabled
taxonomy = datacatalog_v1.Taxonomy(
display_name="BusinessCritical",
activated_policy_types=[datacatalog_v1.Taxonomy.PolicyType.FINE_GRAINED_ACCESS_CONTROL]
)
created_taxonomy = client.create_taxonomy(parent=parent, taxonomy=taxonomy)
# Create Policy Tag inside the Taxonomy
policy_tag = datacatalog_v1.PolicyTag(display_name="RestrictedFinancial")
created_policy_tag = client.create_policy_tag(parent=created_taxonomy.name, policy_tag=policy_tag)
Durch das explizite Festlegen des Richtlinientyps FINE_GRAINED_ACCESS_CONTROL verwandeln Sie ein Standard-Metadaten-Tag in eine strenge Zero-Trust-Sicherheitsgrenze. Für jede Spalte mit diesem Tag wird der Zugriff für alle Nutzer standardmäßig verweigert.
Führen Sie das Skript aus, um die Ressourcen zu erstellen:
python 1_create_taxonomy.py
Maskierungsregel (Datenrichtlinie) konfigurieren
Jetzt definieren Sie, was passiert, wenn jemand ohne Berechtigungen die getaggte Spalte abfragt. Sie erstellen eine Datenrichtlinie , die erzwingt, dass der Wert als NULL zurückgegeben wird, und hängen diese Regel an die Analyst-Persona an.
In 2_create_masking.py sucht das Skript dynamisch nach der Richtlinien-Tag-ID, die Sie gerade erstellt haben, und wendet eine Datenrichtlinie an:
# Define a Masking Policy that always returns NULL
data_policy = bigquery_datapolicies_v1.DataPolicy(
data_policy_id="mask_financial_null",
policy_tag=policy_tag_id,
data_policy_type=bigquery_datapolicies_v1.DataPolicy.DataPolicyType.DATA_MASKING_POLICY,
data_masking_policy=bigquery_datapolicies_v1.DataMaskingPolicy(
predefined_expression=bigquery_datapolicies_v1.DataMaskingPolicy.PredefinedExpression.ALWAYS_NULL
)
)
# ... (Policy creation code) ...
# Bind the Masked Reader role to the Analyst
iam_policy.bindings.add(
role="roles/bigquerydatapolicy.maskedReader",
members=[f"serviceAccount:{analyst_email}"]
)
Dieser Code erstellt programmatisch eine Regel, die erzwingt, dass die zugrunde liegenden Werte als NULL zurückgegeben werden. Anschließend wird die IAM-Rolle „maskedReader“ speziell der Analyst-Persona zugewiesen, damit sie nur die maskierte Version der Daten sieht.
Führen Sie das Skript aus, um die Maskierungsregel zu konfigurieren:
python 2_create_masking.py
Detaillierten Zugriff gewähren
Aufgrund unserer Zero-Trust-Einrichtung kann derzeit niemand die getaggte Spalte lesen. Sie müssen dem Manager und Ihrem persönlichen Konto explizit Zugriff gewähren.
In 3_grant_access.py ändern Sie die IAM-Richtlinie des Richtlinien-Tags selbst:
# Grant original data read access
iam_policy.bindings.add(
role="roles/datacatalog.categoryFineGrainedReader",
members=[f"serviceAccount:{manager_email}", f"user:{current_user}"]
)
client.set_iam_policy(request=iam_policy_pb2.SetIamPolicyRequest(resource=policy_tag_id, policy=iam_policy))
Durch Hinzufügen der Rolle categoryFineGrainedReader können diese bestimmten Hauptkonten die Maskierungsregeln umgehen und die nicht maskierten Rohdaten lesen.
Führen Sie das Skript aus, um Zugriff zu gewähren:
python 3_grant_access.py
Richtlinien-Tag an die BigQuery-Tabelle anhängen
Schließlich müssen Sie dieses logische Richtlinien-Tag an unser physisches Iceberg-Tabellenschema anhängen.
Sehen Sie sich 4_attach_tag.py an. Das Skript ruft das BigQuery-Tabellenschema ab, durchläuft die Felder und hängt das Tag speziell an die Spalte amount an:
new_schema =[]
for field in table.schema:
if field.name == 'amount':
# Wrap the Policy Tag ID and attach it to the column
policy_tags_list = bigquery.PolicyTagList(names=[policy_tag_id])
new_field = bigquery.SchemaField(
name=field.name, field_type=field.field_type, mode=field.mode,
description=field.description, policy_tags=policy_tags_list
)
new_schema.append(new_field)
else:
new_schema.append(field)
# Update the table schema in BigQuery
table.schema = new_schema
client.update_table(table, ["schema"])
Wenn diese Schemaaktualisierung angewendet wird, überbrückt Lakehouse unsere logischen Knowledge Catalog-Tags sofort zu den physischen Parquet-Dateien, die in Ihrem Cloud Storage-Bucket gespeichert sind.
Führen Sie das Skript aus, um das Tabellenschema zu aktualisieren:
python 4_attach_tag.py
5. Knowledge Catalog-Richtlinien prüfen
Jetzt ist es an der Zeit zu testen, ob unsere zentralisierte Governance funktioniert. Sie testen dies in zwei verschiedenen Engines, um zu beweisen, dass Knowledge Catalog-Richtlinien universell durchgesetzt werden.
Mit nativem BigQuery SQL prüfen
Zuerst verwenden Sie Cloud Shell, um die Identität unserer beiden Personas anzunehmen und die Tabelle mit der nativen SQL-Engine von BigQuery abzufragen.
Als Manager testen (privilegierter Nutzer):
# Impersonate the manager
gcloud config set auth/impersonate_service_account ${EMAIL_MANAGER}
# Query the transactions table
bq query --use_legacy_sql=false "SELECT * FROM \`${PROJECT_ID}.${DATASET_ID}.transactions\`"
Da der Manager die Rolle „Detaillierter Lesezugriff“ hat, werden die Rohwerte für den Betrag angezeigt.
+----+----------+--------+------------------+
| id | item | amount | transaction_date |
+----+----------+--------+------------------+
| 1 | Widget A | 100.0 | 2024-01-01 |
| 3 | Widget C | 50.0 | 2024-01-03 |
| 2 | Widget B | 150.0 | 2024-01-02 |
+----+----------+--------+------------------+
Als Analyst testen (Nutzer mit eingeschränkten Berechtigungen):
gcloud config set auth/impersonate_service_account ${EMAIL_ANALYST}
bq query --use_legacy_sql=false "SELECT * FROM \`${PROJECT_ID}.${DATASET_ID}.transactions\`"
Aufgrund der Knowledge Catalog-Maskierungsregel wird die Spalte „amount“ für jede Zeile als NULL zurückgegeben.
+----+----------+--------+------------------+
| id | item | amount | transaction_date |
+----+----------+--------+------------------+
| 1 | Widget A | NULL | 2024-01-01 |
| 3 | Widget C | NULL | 2024-01-03 |
| 2 | Widget B | NULL | 2024-01-02 |
+----+----------+--------+------------------+
Identität wiederherstellen
Bereinigen Sie den Cloud Shell-Authentifizierungsstatus, um zu Ihrem Administratornutzer zurückzukehren.
# Unset impersonation
gcloud config unset auth/impersonate_service_account
Mit Apache Spark prüfen (Compute-Delegierung)
Was passiert, wenn ein Data Scientist diese Tabelle mit Apache Spark liest? Wenn Spark die physischen GCS-Parquet-Dateien direkt liest, werden die Knowledge Catalog-Maskierungsregeln vollständig umgangen, da Cloud Storage nur Berechtigungen auf Bucket-Ebene versteht.
Um dies zu verhindern, erzwingen Sie die Compute-Delegierung mit dem Spark-BigQuery-Connector. Dieser Connector fungiert als sichere Brücke und leitet die Spark-Leseanfragen über die BigQuery Storage API weiter, sodass die Knowledge Catalog-Governance-Regeln dynamisch ausgewertet werden, bevor Daten an den Spark-Cluster gesendet werden.
Sehen Sie sich die Kernlogik im Skript read_transactions.py an, das Sie heruntergeladen haben:
# Reading data via Compute Delegation (Knowledge Catalog policies are applied dynamically here)
df = spark.read \
.format("bigquery") \
.option("table", f"{project_id}.{dataset_id}.{table_name}") \
.load()
print("\n=== 📊 Data Preview ===")
df.show(truncate=False)
Beachten Sie, dass wir Spark nicht auf den gs://-Pfad der Iceberg-Dateien verweisen. Durch Angabe von .format("bigquery") fängt die BigQuery Storage API die Leseanfrage ab, prüft die Identität des Nutzers, der den Spark-Job ausführt, wendet die Knowledge Catalog-Maskierungsregeln an und gibt nur die autorisierten Daten an den Spark-DataFrame zurück.
Laden Sie dieses PySpark-Skript in Ihren Cloud Storage-Bucket hoch, damit Dataproc darauf zugreifen kann:
# Upload script to GCS
gsutil cp read_transactions.py gs://${ICEBERG_BUCKET}/scripts/read_transactions.py
Spark als Manager ausführen:
Sie verwenden Google Cloud Serverless für Apache Spark. Mit diesem verwalteten Dienst können Sie Spark-Arbeitslasten direkt ausführen, ohne dedizierte Cluster bereitstellen, konfigurieren oder verwalten zu müssen.
echo "🚀 Submitting Dataproc Serverless Job as [MANAGER]..."
gcloud dataproc batches submit pyspark gs://${ICEBERG_BUCKET}/scripts/read_transactions.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--service-account=${EMAIL_MANAGER} \
--version=2.3 \
-- ${PROJECT_ID} ${DATASET_ID} \
--format="value(name)"
Sehen Sie sich die Jobausgabe-Logs im Terminal an. Da der Manager die Rolle „Detaillierter Lesezugriff“ hat, ruft Spark die nicht maskierten Rohwerte ab.
=== 📊 Data Preview ===
+---+--------+------+-------------------+
|id |item |amount|transaction_date |
+---+--------+------+-------------------+
|1 |Widget A|100.0 |2024-01-01 |
|2 |Widget B|150.0 |2024-01-02 |
|3 |Widget C|50.0 |2024-01-03 |
+---+--------+------+-------------------+
Spark als Analyst ausführen:
Senden Sie jetzt denselben Spark-Job, aber geben Sie sich diesmal als Analyst-Persona aus.
echo "🚀 Submitting Dataproc Serverless Job as [ANALYST]..."
gcloud dataproc batches submit pyspark gs://${ICEBERG_BUCKET}/scripts/read_transactions.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--service-account=${EMAIL_ANALYST} \
--version=2.3 \
-- ${PROJECT_ID} ${DATASET_ID} \
--format="value(name)"
Prüfen Sie die Logs noch einmal. Obwohl der Analyst genau denselben Spark-Code ausgeführt hat, hat die BigQuery Storage API die Anfrage abgefangen und die Knowledge Catalog-Richtlinie durchgesetzt. Im Spark-DataFrame des Analysten wird für die Beträge null angezeigt.
=== 📊 Data Preview ===
+---+--------+------+-------------------+
|id |item |amount|transaction_date |
+---+--------+------+-------------------+
|1 |Widget A|null |2024-01-01 |
|2 |Widget B|null |2024-01-02 |
|3 |Widget C|null |2024-01-03 |
+---+--------+------+-------------------+
Architektonische Kompromisse: BigQuery SQL im Vergleich zu Spark
Sie haben gerade bewiesen, dass das Ergebnis unabhängig von der Engine identisch ist. Die Knowledge Catalog-Richtlinie wurde erfolgreich durchgesetzt. Aber was sollten Sie in der Produktion verwenden?
- BigQuery SQL:Ideal für Workflows, bei denen SQL die gewünschte Engine ist und Berechnungen direkt vor Ort ausgeführt werden. Es ist ideal für schnelle Analysen und Business Intelligence.
- Apache Spark:Ermöglicht komplexere Arbeitslasten durch die Verwendung von Python und eignet sich daher gut für erweiterte Machine Learning-Pipelines oder Legacy-Hadoop-Code.
Wichtige Erkenntnis:Unabhängig davon, welche Engine verwendet wird, kann die zentralisierte Zero-Trust-Governance-Ebene durch die Durchsetzung der Compute-Delegierung niemals umgangen werden.
6. Automatisierte Data Lineage
In jeder Datenarchitektur eines Unternehmens ist es wichtig zu wissen, woher Ihre Daten stammen und wie sie geändert wurden. Das ist entscheidend für die Compliance, das Debugging und die Vertrauensbildung. Dieses Konzept wird als Data Lineage bezeichnet. Es beantwortet grundlegende Fragen wie: „Wenn ein Manager einen täglichen Umsatzbericht ansieht, welche Rohdaten wurden verwendet, um diese Zahlen zu berechnen?“
Traditionell müssen Data Engineers benutzerdefinierten Logging-Code manuell schreiben oder komplexe Drittanbietertools verwenden, um SQL-Skripts zu parsen. In einem Governed Google Cloud Lakehouse ist diese Nachverfolgung jedoch integriert und erfordert keine manuellen Eingriffe.
Erinnern Sie sich an die Tabelle transactions_summary, die Sie zuvor im Codelab aus der Tabelle mit den Rohdaten zu Transaktionen erstellt haben? Als BigQuery diese CREATE TABLE AS SELECT-Anweisung ausgeführt hat, hat die Compute-Engine automatisch die Metadaten zur Transformation erfasst und an Knowledge Catalog gesendet. Sehen wir uns das Ergebnis an.
Herkunft visualisieren
- Rufen Sie in der Google Cloud Console Knowledge Catalog > Suche auf.
- Geben Sie
lakehouse_retail_demo.transactionsin die Suchleiste ein und klicken Sie auf die Tabelle. - Klicken Sie auf den Tab Herkunft.
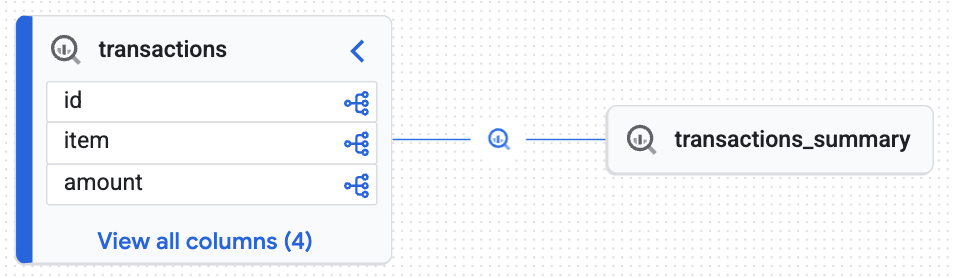
Sie sehen ein interaktives Diagramm, das von der Knowledge Engine generiert wurde und beweist, dass die Zieltabelle (transactions_summary) aus der Governed Iceberg-Rohdatentabelle (transactions) abgeleitet wurde. Sie haben eine End-to-End-Nachverfolgbarkeit erreicht, die für die Datenprüfung unerlässlich ist.
7. Bereinigen
So vermeiden Sie, dass Ihrem Google Cloud-Konto die in diesem Codelab verwendeten Ressourcen in Rechnung gestellt werden.
Knowledge Catalog-Governance-Ressourcen entfernen
Bevor Sie das BigQuery-Dataset oder den Cloud Storage-Bucket löschen, müssen Sie die logischen Governance-Regeln entfernen. Wenn Sie sich das Skript cleanup_governance.py aus dem Repository ansehen, sehen Sie die folgende Abbaufolge:
# 1. Delete Data Policy
data_policy_name = f"{parent_loc}/dataPolicies/mask_financial_null"
dp_client.delete_data_policy(name=data_policy_name)
# 2. Find and Delete Taxonomy (This auto-deletes child Policy Tags)
taxonomies = catalog_client.list_taxonomies(parent=parent_loc)
taxonomy_id = next((t.name for t in taxonomies if t.display_name == "BusinessCritical"), None)
catalog_client.delete_taxonomy(name=taxonomy_id)
Die Reihenfolge ist hier entscheidend. Das Skript löscht zuerst die Datenrichtlinie (Maskierungsregel), da sie auf dem Richtlinien-Tag basiert. Sobald die Richtlinie entfernt wurde, wird durch das Löschen der übergeordneten Taxonomie automatisch eine Kaskadierung ausgelöst und alle zugrunde liegenden Richtlinien-Tags werden gelöscht, ohne dass Fehler aufgrund von Ressourcenabhängigkeiten auftreten.
Führen Sie das Python-Bereinigungsskript aus:
python cleanup_governance.py
Identitäten, Speicher und Compute-Assets entfernen
Nachdem die Governance-Ebene getrennt wurde, können Sie die BigQuery-Tabellen, Cloud Storage-Buckets, Dienstkonten und die lokale Python-Umgebung sicher löschen.
Kopieren Sie den folgenden umfassenden Bereinigungsblock und führen Sie ihn in Ihrer Cloud Shell aus:
echo "Deleting Service Accounts and Impersonation Bindings..."
export CURRENT_USER=$(gcloud config get-value account)
for USER in "${USER_ANALYST}" "${USER_MANAGER}"; do
EMAIL="${USER}@${PROJECT_ID}.iam.gserviceaccount.com"
# Remove impersonation binding
gcloud iam service-accounts remove-iam-policy-binding ${EMAIL} \
--member="user:${CURRENT_USER}" \
--role="roles/iam.serviceAccountTokenCreator" \
--quiet > /dev/null 2>&1
# Delete the Service Account
gcloud iam service-accounts delete ${EMAIL} --quiet
done
echo "Removing BigQuery Dataset and Tables..."
bq rm -f ${DATASET_ID}.transactions_summary
bq rm -f ${DATASET_ID}.transactions
bq rm -f ${DATASET_ID}.inventory
bq rm -f -d ${DATASET_ID}
echo "Removing BigQuery Cloud Resource Connection..."
bq rm --connection --location=${REGION} ${CONN_NAME}
echo "Removing Iceberg Cloud Storage Bucket..."
gcloud storage rm --recursive gs://${ICEBERG_BUCKET} --quiet
echo "Removing Auto-generated Dataproc Staging & Temp Buckets..."
for BUCKET in $(gcloud storage ls | grep -E "gs://dataproc-(staging|temp)-${REGION}"); do
gcloud storage rm --recursive $BUCKET --quiet
done
echo "Deactivating and removing the local Python environment..."
deactivate
cd ../..
rm -rf devrel-demos
echo "✅ Clean up completed successfully!"
Wenn Sie diese Schritte ausführen, sind keine verwaisten Ressourcen oder verborgenen Richtlinien mehr in Ihrem Projekt vorhanden.
8. Glückwunsch!
Sie haben ein vollständig verwaltetes, auffindbares Data Lakehouse implementiert.
Sie haben Folgendes gelernt:
- Native Iceberg-Integration:Lakehouse kann Open-Source-Iceberg-Tabellen nativ verwalten und die physischen Dateien sicher in Cloud Storage speichern.
- Compute-Delegierung für die Sicherheit:Durch das Weiterleiten von Abfragen über die BigQuery Storage API haben Sie eine detaillierte dynamische Maskierung für physische Dateien erzwungen, bei denen der partielle Zugriff nativ nicht eingeschränkt werden kann.
- Engine-unabhängige Governance:Mit Richtlinien-Tags können Sie Regeln einmal definieren und sie universell durchsetzen, unabhängig davon, ob sie über native SQL- oder Apache Spark-Runtimes abgefragt werden.
- Auffindbarkeit von Daten:Die Knowledge Engine hat die Data Lineage automatisch nachverfolgt und so eine wichtige Prüfbarkeit für Unternehmen ermöglicht.
Nächste Schritte
- Erweiterte Zugriffssteuerung:Informationen zum Implementieren komplexerer Sicherheitsszenarien finden Sie in der offiziellen Dokumentation zum Anpassen von Lakehouse mit zusätzlichen Funktionen.
- Unstrukturierte Daten für generative KI verwalten: Informationen zu Objekttabellen. Erweitern Sie dieses sichere Brückenmuster auf unstrukturierte Dateien (PDFs, Bilder) in Cloud Storage, um eine sichere, verwaltete Datengrundlage für Vertex AI- und RAG-Pipelines zu schaffen.