
1- مقدمة
في سحابة بيانات المؤسسة الحديثة، حيث تتوفّر البيانات على أنظمة تخزين فعلية مختلفة، يواجه المهندسون تحديًا كبيرًا في ما يتعلق بالهندسة المعمارية، وهو أمان البيانات المجزّأ.
كيف يمكنك ضمان حماية البيانات الحسّاسة (مثل مبالغ المعاملات المالية) بشكلٍ متّسق عندما يتم تخزين البيانات فعليًا بتنسيقات مفتوحة المصدر، مثل Parquet على Google Cloud Storage، ويتم الاستعلام عنها من خلال محركات مختلفة متعددة، مثل BigQuery SQL أو Apache Spark؟
في هذا الدرس التطبيقي حول الترميز، ستنشئ هندسة معمارية لمستودع بيانات مُدار يحلّ هذه المشاكل باستخدام جداول Apache Iceberg وBigQuery وكتالوج المعارف. ستستخدم البنية الأساسية كرمز (IaC) لتحديد سياسات الأمان المستندة إلى "نهج الثقة المعدومة" وكيفية تطبيقها ديناميكيًا على محركات الحوسبة المختلفة.
المتطلبات الأساسية
- مشروع على Google Cloud تم تفعيل الفوترة فيه
- فهم أساسي لمفاهيم لغة الاستعلامات البنيوية (SQL) وإدارة الهوية وإمكانية الوصول (IAM) وCloud Storage.
أهداف البرنامج
- كيفية إنشاء جداول Google Cloud Lakehouse لـ Apache Iceberg في BigQuery حيث يخزّن Cloud Storage البيانات بشكلٍ أصلي
- كيفية فرض سياسات البيانات المركزية باستخدام علامات السياسات للأمان على مستوى الأعمدة وإخفاء البيانات
- كيفية فصل الوصول إلى مساحة التخزين الفعلية عن الوصول إلى البيانات المنطقية باستخدام اتصال مورد السحابة الإلكترونية.
- كيفية فرض تفويض الحوسبة المستند إلى "نهج الثقة المعدومة" باستخدام Managed Service for Apache Spark لضمان عدم تمكّن المحركات المفتوحة المصدر من تجاوز الإدارة
- كيفية عرض مصدر البيانات المبرمَج بشكلٍ مرئي Data Lineage.
نظرة عامة على الهندسة المعمارية: الإدارة الشاملة على Iceberg
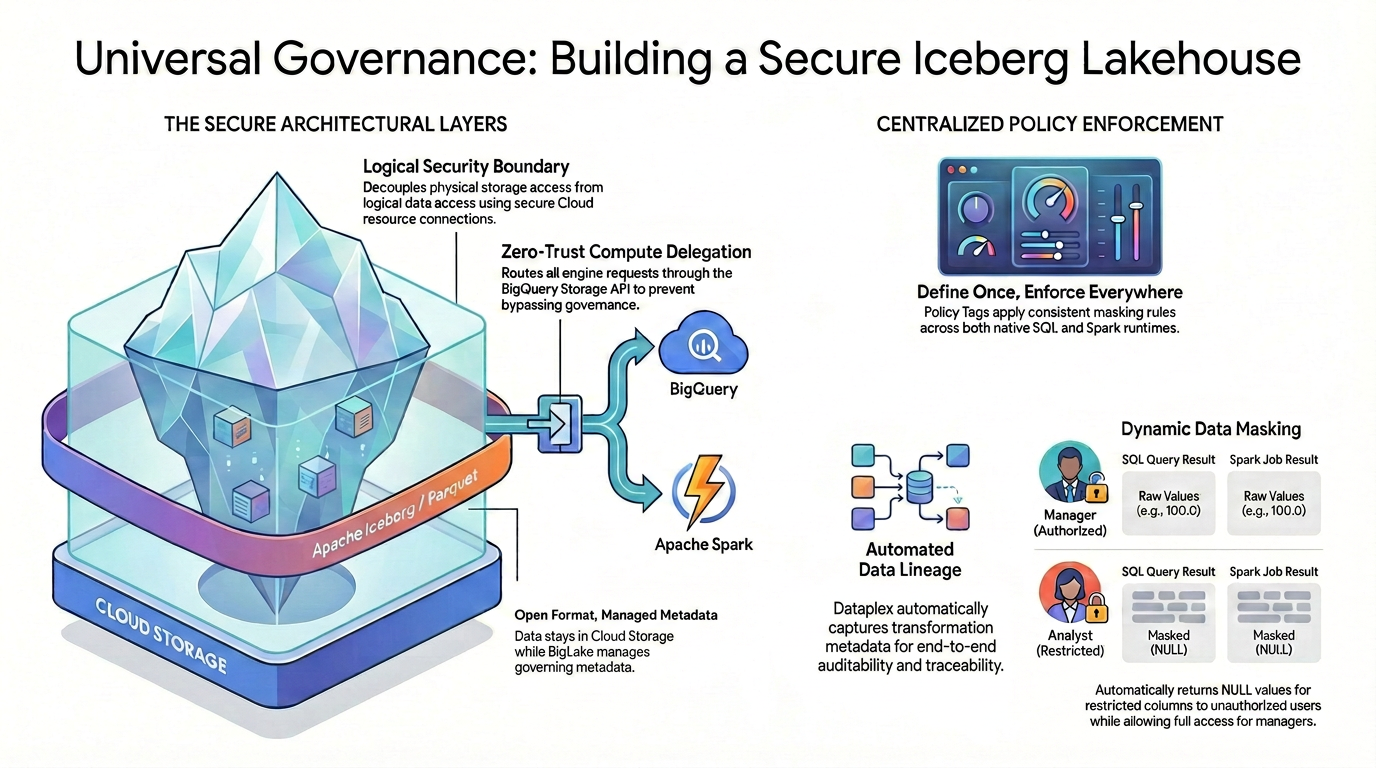
لتحقيق التحكّم الدقيق في الوصول (مثل الأمان على مستوى الأعمدة وإخفاء البيانات) على تنسيقات البيانات المفتوحة المصدر، يجب إنشاء هندسة معمارية أمنية صارمة وموحّدة.
كما هو موضّح في الرسم البياني، يعتمد نمط مستودع البيانات المُدار هذا على ركيزتَين أساسيتَين لحلّ تحدي الأمان المجزّأ:
🛡️ طبقات الهندسة المعمارية الآمنة (على اليمين)
بدلاً من السماح للمستخدمين أو المحركات الخارجية بالوصول إلى Cloud Storage مباشرةً، الذي لا يتيح سوى الأمان على مستوى الحزمة الواسع النطاق، يمكنك إنشاء أساس آمن.
- تنسيق مفتوح، بيانات وصفية مُدارة: تبقى البيانات فعليًا في Cloud Storage باستخدام تنسيق Apache Iceberg (Parquet) المفتوح، بينما يدير Lakehouse البيانات الوصفية الحاكمة بسلاسة.
- حدود الأمان المنطقي: يمكنك فصل الوصول إلى مساحة التخزين الفعلية عن الوصول إلى البيانات المنطقية باستخدام اتصال آمن بمورد السحابة الإلكترونية. لا يتم منح المستخدمين النهائيين أبدًا إذن وصول مباشر إلى ملفات GCS الأولية من خلال IAM.
- تفويض الحوسبة المستند إلى "نهج الثقة المعدومة": لضمان عدم تمكّن أي محرك تنفيذ من تجاوز قواعد الإدارة، يتم توجيه جميع طلبات قراءة البيانات بدقة من خلال BigQuery Storage API. ينطبق ذلك سواء كان طلب البحث صادرًا من BigQuery SQL الأصلي أو Apache Spark المفتوح المصدر.
🎯 فرض السياسات المركزية (على اليسار)
بعد إنشاء الأساس الآمن، يعمل كتالوج المعارف كمركز موحّد للإدارة:
- التعريف مرة واحدة، والفرض في كل مكان: يمكنك تحديد علامات السياسات في "كتالوج المعارف" مرة واحدة فقط، وتطبّق الهندسة المعمارية قواعد إخفاء متّسقة على مستوى جميع أوقات تشغيل التنفيذ المتوافقة.
- إخفاء البيانات الديناميكي: عند الاستعلام عن البيانات، يقيّم النظام هوية المستخدم أثناء التنفيذ. بينما يرى المستخدمون المصرّح لهم القيم الأولية غير المخفية (مثل 100.0) في كلّ من SQL وSpark، سيتلقّى المستخدمون المحظورون تلقائيًا قيمًا `NULL` مخفية للأعمدة المحظورة على مستوى كلا المحرّكَين.
- مصدر البيانات المبرمَج: أثناء تدفق البيانات وتحويلها، يسجّل "كتالوج المعارف" تلقائيًا البيانات الوصفية للتحويل، ما يوفّر إمكانية التدقيق والتتبُّع المضمّنة من البداية إلى النهاية بدون الحاجة إلى رمز تسجيل مخصّص.
2. الإعداد والمتطلبات
بدء Cloud Shell
يمكن تشغيل Google Cloud عن بُعد من الكمبيوتر المحمول، ولكن في هذا الدرس التطبيقي حول الترميز، ستستخدم Google Cloud Shell، وهي بيئة سطر أوامر تعمل في السحابة الإلكترونية.
من Google Cloud Console، انقر على رمز Cloud Shell في شريط الأدوات العلوي الأيسر:
يستغرق توفير البيئة والاتصال بها بضع لحظات فقط. عند الانتهاء، من المفترض أن يظهر لك ما يلي:

يتم تحميل هذا الجهاز الافتراضي مزوّدة بكل أدوات التطوير التي ستحتاج إليها. توفّر هذه الآلة دليلًا رئيسيًا دائمًا بسعة 5 غيغابايت، وتعمل على Google Cloud، ما يحسّن بشكلٍ كبير أداء الشبكة والمصادقة. يمكنك إنجاز جميع أعمالك في هذا الدرس التطبيقي حول الترميز ضِمن متصفّح. ولست بحاجة إلى تثبيت أي شيء.
إعداد البيئة
افتح Cloud Shell واضبط متغيّرات مشروعك لضمان استهداف جميع الأوامر للبنية الأساسية الصحيحة.
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-central1"
export ICEBERG_BUCKET="iceberg-retail-demo-${PROJECT_ID}"
export DATASET_ID="lakehouse_retail_demo"
export CONN_NAME="iceberg-bq-conn-demo"
بعد ذلك، حدِّد شخصيتَينا.
export USER_ANALYST="retail-analyst-demo"
export EMAIL_ANALYST="${USER_ANALYST}@${PROJECT_ID}.iam.gserviceaccount.com"
export USER_MANAGER="retail-manager-demo"
export EMAIL_MANAGER="${USER_MANAGER}@${PROJECT_ID}.iam.gserviceaccount.com"
export CURRENT_USER=$(gcloud config get-value account)
تفعيل واجهات برمجة التطبيقات
فعِّل خدمات Google Cloud اللازمة.
gcloud services enable \
bigquery.googleapis.com \
bigqueryconnection.googleapis.com \
datacatalog.googleapis.com \
bigquerydatapolicy.googleapis.com \
datalineage.googleapis.com \
dataplex.googleapis.com \
dataproc.googleapis.com \
storage-component.googleapis.com
تنزيل رمز المصدر للدرس التطبيقي حول الترميز
لتجنُّب إحداث فوضى في Cloud Shell، ستنفّذ عملية سحب جزئية لتنزيل نصوص Python البرمجية اللازمة فقط لهذا الدرس التطبيقي حول الترميز من مستودع Google Cloud DevRel.
# Shallow clone without full history
git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/devrel-demos.git
cd devrel-demos
# Download only the specific folder
git sparse-checkout set data-analytics/governed-lakehouse
cd data-analytics/governed-lakehouse
إنشاء مساحة تخزين
أنشئ الحزمة لتخزين بيانات Iceberg المُدارة الآمنة للغاية.
gcloud storage buckets create gs://${ICEBERG_BUCKET} --location=${REGION}
إعداد الهويات والأمان
اضبط اتصال مورد السحابة الإلكترونية. هذا هو الكيان الوحيد الذي يحتوي على مفاتيح IAM الفعلية الدائمة لقراءة ملفات Iceberg الأولية.
# Create the BigQuery connection
bq mk --connection \
--connection_type=CLOUD_RESOURCE \
--location=${REGION} \
${CONN_NAME}
# Retrieve the connection's automatically generated Service Account
export BQ_CONN_SVC_ACCT=$(bq show --format=json --connection ${REGION}.${CONN_NAME} \
| jq -r '.cloudResource.serviceAccountId')
# Grant Storage Object Admin to the connection for the Iceberg bucket
gcloud storage buckets add-iam-policy-binding gs://${ICEBERG_BUCKET} \
--member="serviceAccount:${BQ_CONN_SVC_ACCT}" \
--role="roles/storage.objectAdmin" \
--quiet
بعد ذلك، اضبط شخصيات المستخدمين. يتم منح المستخدمين إذن الوصول المنطقي، وليس إذن الوصول إلى مساحة التخزين الفعلية. لمنع حدوث أخطاء ناتجة عن التأخير في نشر IAM، ستنشئ الحسابات أولاً، وتنتظر بضع ثوانٍ، ثم تسند الأدوار إليها.
echo "Creating Service Accounts..."
for USER in "${USER_ANALYST}" "${USER_MANAGER}"; do
gcloud iam service-accounts create ${USER} --display-name="Lakehouse ${USER}"
done
echo "⏳ Waiting 15 seconds for IAM propagation..."
sleep 15
echo "Granting IAM Roles to Service Accounts..."
for USER in "${USER_ANALYST}" "${USER_MANAGER}"; do
EMAIL="${USER}@${PROJECT_ID}.iam.gserviceaccount.com"
# Allow Cloud Shell to impersonate them for testing
gcloud iam service-accounts add-iam-policy-binding ${EMAIL} \
--member="user:${CURRENT_USER}" \
--role="roles/iam.serviceAccountTokenCreator" \
--quiet
# Allow logical viewing of the catalog, querying, and running Dataproc jobs
for ROLE in "roles/datacatalog.viewer" "roles/bigquery.dataViewer" "roles/bigquery.user" "roles/bigquery.connectionUser" "roles/serviceusage.serviceUsageConsumer" "roles/dataproc.worker"; do
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${EMAIL}" \
--role="${ROLE}" \
--quiet
done
done
# Grant the Manager data creation rights
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${EMAIL_MANAGER}" \
--role="roles/bigquery.dataEditor" \
--quiet
echo "✅ Identity and Security setup completed!"
3. إنشاء جداول Iceberg الأصلية من خلال Lakehouse
ستستخدم الإمكانات الأصلية في Lakehouse لإنشاء جداول Iceberg المُدارة.
إنشاء مجموعة بيانات BigQuery
أولاً، أنشئ مجموعة بيانات BigQuery لتجميع جداول Iceberg منطقيًا.
echo "Creating BigQuery Dataset..."
bq mk --location=${REGION} --dataset ${PROJECT_ID}:${DATASET_ID}
إنشاء جداول Iceberg
بعد ذلك، شغِّل الأوامر التالية لإنشاء الجداول. لاحظ كتلة OPTIONS التي نحدّد فيها table_format = 'ICEBERG' ونربطها مباشرةً بحزمة Cloud Storage والاتصال.
echo "Creating Iceberg tables..."
# Inventory table
bq query --use_legacy_sql=false \
"CREATE OR REPLACE TABLE \`${PROJECT_ID}.${DATASET_ID}.inventory\` (
product_id INT64,
product_name STRING,
stock_count INT64
)
WITH CONNECTION \`${REGION}.${CONN_NAME}\`
OPTIONS (
file_format = 'PARQUET',
table_format = 'ICEBERG',
storage_uri = 'gs://${ICEBERG_BUCKET}/inventory/'
);"
# Transactions table
bq query --use_legacy_sql=false \
"CREATE OR REPLACE TABLE \`${PROJECT_ID}.${DATASET_ID}.transactions\` (
id INT64,
item STRING,
amount FLOAT64,
transaction_date DATE
)
WITH CONNECTION \`${REGION}.${CONN_NAME}\`
OPTIONS (
file_format = 'PARQUET',
table_format = 'ICEBERG',
storage_uri = 'gs://${ICEBERG_BUCKET}/transactions/'
);"
ملء الجداول بالبيانات
أخيرًا، أدرِج بيانات نموذجية في جداول Iceberg التي تم إنشاؤها حديثًا.
echo "Inserting data into Iceberg tables..."
# Insert into Inventory table
bq query --use_legacy_sql=false \
"INSERT INTO \`${PROJECT_ID}.${DATASET_ID}.inventory\` (product_id, product_name, stock_count)
VALUES (101, 'Widget A', 500), (102, 'Widget B', 250), (103, 'Widget C', 800);"
# Insert into Transactions table
bq query --use_legacy_sql=false \
"INSERT INTO \`${PROJECT_ID}.${DATASET_ID}.transactions\` (id, item, amount, transaction_date)
VALUES
(1, 'Widget A', 100.0, DATE '2024-01-01'),
(2, 'Widget B', 150.0, DATE '2024-01-02'),
(3, 'Widget C', 50.0, DATE '2024-01-03');"
لديك الآن جدولان يعملان بالكامل بتنسيق Iceberg. يدير Lakehouse البيانات الوصفية، ولكن ملفات Parquet الفعلية مخزّنة بأمان في حزمة GCS.
محاكاة مسار التعلّم لعملية نقل البيانات واستخراجها وتحويلها (ETL)
في سيناريو حقيقي، غالبًا ما يتم تجميع البيانات الأولية في جداول ملخّصات لإعداد تقارير المؤسسة. لنفترض أنّك مهندس بيانات وننشئ جدول ملخّص مبيعات يومي من بيانات المعاملات الأولية.
(ملاحظة: نفِّذ هذه الخطوة الآن ليحظى Google Cloud بوقت كافٍ لمعالجة البيانات الوصفية في الخلفية. ستكتشف سبب أهمية ذلك لاحقًا في الدرس التطبيقي حول الترميز).
echo "Creating transactions summary table..."
bq query --use_legacy_sql=false \
"CREATE TABLE \`${PROJECT_ID}.${DATASET_ID}.transactions_summary\` AS
SELECT transaction_date, SUM(amount) as total_sales, COUNT(id) as transaction_count
FROM \`${PROJECT_ID}.${DATASET_ID}.transactions\`
GROUP BY transaction_date;"
4. الإدارة المركزية: تحديد السياسات باستخدام Python
في بيئة التشغيل الفعلي، يصعب توسيع نطاق سياسات الإدارة والحفاظ عليها من خلال واجهة المستخدم. بدلاً من ذلك، يُنصح بشدة باستخدام البنية الأساسية كرمز (IaC).
في هذا القسم، ستستخدم حزمة Google Cloud Python SDK لإنشاء قواعد الإدارة المستندة إلى "نهج الثقة المعدومة" وفرضها برمجيًا خطوة بخطوة.
إعداد بيئة Python
أولاً، لنعدّ بيئة Python معزولة (venv) لتجنُّب تعارضات المكتبات وتثبيت حزم SDK المطلوبة من Google Cloud.
شغِّل الأوامر التالية في Cloud Shell:
# Create and activate a virtual environment
python3 -m venv lakehouse_env
source lakehouse_env/bin/activate
# Install required Knowledge Catalog and BigQuery governance libraries
pip install google-cloud-datacatalog google-cloud-bigquery-datapolicies google-cloud-bigquery --quiet
echo "✅ Python environment is ready!"
إنشاء التصنيف وعلامة السياسة
التصنيف هو حاوية منطقية، وعلامة السياسة هي التصنيف المحدّد الذي سترفقه بالعمود الحسّاس. لفرض الأمان على مستوى الأعمدة، تحتاج أولاً إلى حاوية منطقية (تصنيف) وتصنيف محدّد (علامة سياسة).
إذا نظرت داخل 1_create_taxonomy.py، سيظهر لك المنطق الأساسي التالي:
# Create Taxonomy with Fine-Grained Access Control enabled
taxonomy = datacatalog_v1.Taxonomy(
display_name="BusinessCritical",
activated_policy_types=[datacatalog_v1.Taxonomy.PolicyType.FINE_GRAINED_ACCESS_CONTROL]
)
created_taxonomy = client.create_taxonomy(parent=parent, taxonomy=taxonomy)
# Create Policy Tag inside the Taxonomy
policy_tag = datacatalog_v1.PolicyTag(display_name="RestrictedFinancial")
created_policy_tag = client.create_policy_tag(parent=created_taxonomy.name, policy_tag=policy_tag)
من خلال ضبط نوع سياسة FINE_GRAINED_ACCESS_CONTROL بشكلٍ صريح، يمكنك تحويل علامة البيانات الوصفية العادية إلى حدود أمان صارمة مستندة إلى "نهج الثقة المعدومة". سيؤدي أي عمود يحتوي على هذه العلامة إلى رفض الوصول إلى جميع المستخدمين تلقائيًا.
شغِّل النص البرمجي لإنشاء الموارد:
python 1_create_taxonomy.py
ضبط قاعدة الإخفاء (سياسة البيانات)
الآن، حدِّد ما يحدث عندما يستعلم مستخدم لا يملك امتيازات عن العمود الذي تم وضع علامة عليه. ستنشئ سياسة بيانات تفرض عرض القيمة على أنّها NULL وترفق هذه القاعدة بشخصية المحلّل.
داخل 2_create_masking.py، يبحث النص البرمجي ديناميكيًا عن رقم تعريف علامة السياسة الذي أنشأته للتو ويطبّق سياسة بيانات:
# Define a Masking Policy that always returns NULL
data_policy = bigquery_datapolicies_v1.DataPolicy(
data_policy_id="mask_financial_null",
policy_tag=policy_tag_id,
data_policy_type=bigquery_datapolicies_v1.DataPolicy.DataPolicyType.DATA_MASKING_POLICY,
data_masking_policy=bigquery_datapolicies_v1.DataMaskingPolicy(
predefined_expression=bigquery_datapolicies_v1.DataMaskingPolicy.PredefinedExpression.ALWAYS_NULL
)
)
# ... (Policy creation code) ...
# Bind the Masked Reader role to the Analyst
iam_policy.bindings.add(
role="roles/bigquerydatapolicy.maskedReader",
members=[f"serviceAccount:{analyst_email}"]
)
ينشئ هذا الرمز برمجيًا قاعدة تفرض عرض القيم الأساسية على أنّها `NULL`. بعد ذلك، يسند دور IAM maskedReader إلى شخصية المحلّل تحديدًا، ما يضمن عدم ظهور سوى النسخة المخفية من البيانات.
شغِّل النص البرمجي لضبط قاعدة الإخفاء:
python 2_create_masking.py
منح إذن وصول دقيق
بسبب الإعداد المستند إلى "نهج الثقة المعدومة"، لا يمكن لأي مستخدم قراءة العمود الذي تم وضع علامة عليه في الوقت الحالي. يجب منح إذن الوصول بشكلٍ صريح للمدير وحسابك الشخصي.
داخل 3_grant_access.py، يمكنك تعديل سياسة IAM لعلامة السياسة نفسها:
# Grant original data read access
iam_policy.bindings.add(
role="roles/datacatalog.categoryFineGrainedReader",
members=[f"serviceAccount:{manager_email}", f"user:{current_user}"]
)
client.set_iam_policy(request=iam_policy_pb2.SetIamPolicyRequest(resource=policy_tag_id, policy=iam_policy))
تتيح إضافة دور categoryFineGrainedReader لهذه الجهات الرئيسية المحدّدة تجاوز قواعد الإخفاء وقراءة البيانات الأولية غير المخفية.
شغِّل النص البرمجي لمنح إذن الوصول:
python 3_grant_access.py
إرفاق علامة السياسة بجدول BigQuery
أخيرًا، يجب إرفاق علامة السياسة المنطقية هذه بمخطط جدول Iceberg الفعلي.
ألقِ نظرة على 4_attach_tag.py. يجلب النص البرمجي مخطط جدول BigQuery، ويتكرّر خلال الحقول، ويرفق العلامة بعمود amount تحديدًا:
new_schema =[]
for field in table.schema:
if field.name == 'amount':
# Wrap the Policy Tag ID and attach it to the column
policy_tags_list = bigquery.PolicyTagList(names=[policy_tag_id])
new_field = bigquery.SchemaField(
name=field.name, field_type=field.field_type, mode=field.mode,
description=field.description, policy_tags=policy_tags_list
)
new_schema.append(new_field)
else:
new_schema.append(field)
# Update the table schema in BigQuery
table.schema = new_schema
client.update_table(table, ["schema"])
عند تطبيق تعديل المخطط هذا، يربط Lakehouse على الفور العلامات المنطقية في "كتالوج المعارف" بملفات Parquet الفعلية المخزّنة في حزمة Cloud Storage.
شغِّل النص البرمجي لتعديل مخطط الجدول:
python 4_attach_tag.py
5. التحقّق من سياسات "كتالوج المعارف"
حان الوقت لاختبار ما إذا كانت الإدارة المركزية تعمل. ستختبر ذلك على مستوى محرّكَين مختلفَين لإثبات أنّ سياسات "كتالوج المعارف" تُفرض بشكلٍ شامل.
التحقّق باستخدام BigQuery SQL الأصلي
أولاً، ستستخدم Cloud Shell لانتحال هوية شخصيتَينا والاستعلام عن الجدول باستخدام محرّك BigQuery SQL الأصلي.
الاختبار بصفتك المدير (مستخدم لديه امتيازات):
# Impersonate the manager
gcloud config set auth/impersonate_service_account ${EMAIL_MANAGER}
# Query the transactions table
bq query --use_legacy_sql=false "SELECT * FROM \`${PROJECT_ID}.${DATASET_ID}.transactions\`"
بما أنّ المدير لديه دور "قارئ دقيق"، سيظهر له قيم المبالغ الأولية
+----+----------+--------+------------------+
| id | item | amount | transaction_date |
+----+----------+--------+------------------+
| 1 | Widget A | 100.0 | 2024-01-01 |
| 3 | Widget C | 50.0 | 2024-01-03 |
| 2 | Widget B | 150.0 | 2024-01-02 |
+----+----------+--------+------------------+
الاختبار بصفتك المحلّل (مستخدم محظور):
gcloud config set auth/impersonate_service_account ${EMAIL_ANALYST}
bq query --use_legacy_sql=false "SELECT * FROM \`${PROJECT_ID}.${DATASET_ID}.transactions\`"
بسبب قاعدة الإخفاء في "كتالوج المعارف"، يعرض عمود المبلغ NULL لكل صف.
+----+----------+--------+------------------+
| id | item | amount | transaction_date |
+----+----------+--------+------------------+
| 1 | Widget A | NULL | 2024-01-01 |
| 3 | Widget C | NULL | 2024-01-03 |
| 2 | Widget B | NULL | 2024-01-02 |
+----+----------+--------+------------------+
استعادة هويتك
نظِّف حالة مصادقة Cloud Shell للعودة إلى حساب المشرف.
# Unset impersonation
gcloud config unset auth/impersonate_service_account
التحقّق باستخدام Apache Spark (تفويض الحوسبة)
ماذا لو استخدم أحد علماء البيانات Apache Spark لقراءة هذا الجدول؟ إذا قرأ Spark ملفات GCS Parquet الفعلية مباشرةً، يتم تجاوز قواعد الإخفاء في "كتالوج المعارف" بالكامل لأنّ Cloud Storage لا يفهم سوى الأذونات على مستوى الحزمة.
لمنع ذلك، يمكنك فرض تفويض الحوسبة باستخدام موصِّل Spark-BigQuery. يعمل هذا الموصِّل كجسر آمن، حيث يوجّه طلبات قراءة Spark من خلال BigQuery Storage API حتى يتم تقييم قواعد الإدارة في "كتالوج المعارف" ديناميكيًا قبل إرسال أي بيانات إلى مجموعة Spark.
ألقِ نظرة على المنطق الأساسي داخل النص البرمجي read_transactions.py الذي نزّلته:
# Reading data via Compute Delegation (Knowledge Catalog policies are applied dynamically here)
df = spark.read \
.format("bigquery") \
.option("table", f"{project_id}.{dataset_id}.{table_name}") \
.load()
print("\n=== 📊 Data Preview ===")
df.show(truncate=False)
لاحظ أنّنا لا نشير إلى Spark إلى مسار gs:// لملفات Iceberg. من خلال تحديد .format("bigquery")، تعترض BigQuery Storage API طلب القراءة، وتتحقّق من هوية المستخدم الذي يشغّل مهمة Spark، وتطبّق قواعد الإخفاء في "كتالوج المعارف"، ولا تعرض سوى البيانات المصرّح بها مرة أخرى إلى Spark DataFrame.
حمِّل نص PySpark البرمجي هذا إلى حزمة Cloud Storage ليتمكّن Managed Apache Spark من الوصول إليه:
# Upload script to GCS
gsutil cp read_transactions.py gs://${ICEBERG_BUCKET}/scripts/read_transactions.py
تشغيل Spark بصفتك المدير:
ستستخدم Managed Apache Spark. تتيح لك هذه الخدمة المُدارة تشغيل أحمال عمل Spark مباشرةً بدون الحاجة إلى توفير مجموعات مخصّصة أو ضبطها أو إدارتها.
echo "🚀 Submitting Managed Apache Spark Job as [MANAGER]..."
gcloud dataproc batches submit pyspark gs://${ICEBERG_BUCKET}/scripts/read_transactions.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--service-account=${EMAIL_MANAGER} \
--version=2.3 \
-- ${PROJECT_ID} ${DATASET_ID} \
--format="value(name)"
اطّلِع على سجلّات ناتج المهمة في المحطة الطرفية. بما أنّ المدير لديه دور "قارئ دقيق"، يستردّ Spark بنجاح المبالغ الأولية غير المخفية.
=== 📊 Data Preview ===
+---+--------+------+-------------------+
|id |item |amount|transaction_date |
+---+--------+------+-------------------+
|1 |Widget A|100.0 |2024-01-01 |
|2 |Widget B|150.0 |2024-01-02 |
|3 |Widget C|50.0 |2024-01-03 |
+---+--------+------+-------------------+
تشغيل Spark بصفتك المحلّل:
الآن، أرسِل مهمة Spark نفسها تمامًا، ولكن انتحِل هذه المرة شخصية المحلّل.
echo "🚀 Submitting Managed Apache Spark Job as [ANALYST]..."
gcloud dataproc batches submit pyspark gs://${ICEBERG_BUCKET}/scripts/read_transactions.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--service-account=${EMAIL_ANALYST} \
--version=2.3 \
-- ${PROJECT_ID} ${DATASET_ID} \
--format="value(name)"
تحقَّق من السجلّات مرة أخرى. على الرغم من أنّ المحلّل شغّل رمز Spark نفسه تمامًا، اعترضت BigQuery Storage API الطلب وفرضت سياسة "كتالوج المعارف". يعرض Spark DataFrame الخاص بالمحلّل null للمبالغ.
=== 📊 Data Preview ===
+---+--------+------+-------------------+
|id |item |amount|transaction_date |
+---+--------+------+-------------------+
|1 |Widget A|null |2024-01-01 |
|2 |Widget B|null |2024-01-02 |
|3 |Widget C|null |2024-01-03 |
+---+--------+------+-------------------+
المفاضلات في الهندسة المعمارية: BigQuery SQL مقابل Spark
لقد أثبتت للتو أنّ النتيجة متطابقة بغض النظر عن المحرّك. تم فرض سياسة "كتالوج المعارف" بنجاح. ولكن في بيئة الإنتاج، ما هو المحرّك الذي يجب استخدامه؟
- BigQuery SQL: مناسب لسير العمل الذي يكون فيه SQL هو المحرّك المطلوب ويشغّل عمليات الحوسبة مباشرةً في مكانها. وهو مثالي للإحصاءات السريعة وذكاء الأعمال.
- Apache Spark: يتيح أحمال عمل أكثر تعقيدًا بفضل استخدام Python، ما يجعله مناسبًا لخطوط أنابيب تعلُّم الآلة المتقدّمة أو رمز Hadoop القديم.
الخلاصة الرئيسية: بغض النظر عن المحرّك المستخدَم، من خلال فرض تفويض الحوسبة، لا يمكن أبدًا تجاوز طبقة الإدارة المركزية المستندة إلى "نهج الثقة المعدومة".
6. مصدر البيانات المبرمَج
في أي هندسة معمارية لبيانات المؤسسة، من المهم جدًا معرفة مصدر بياناتك وكيفية تغييرها من أجل الامتثال وتصحيح الأخطاء وإرساء الثقة. يُعرف هذا المفهوم باسم مصدر البيانات. ويجيب عن أسئلة أساسية مثل: "إذا كان المدير يطّلع على تقرير مبيعات يومي، ما هي الجداول الأولية التي تم استخدامها لحساب هذه الأرقام؟"
في العادة، يتطلّب تتبُّع دورة الحياة هذه من مهندسي البيانات كتابة رمز تسجيل مخصّص يدويًا أو استخدام أدوات معقّدة تابعة لجهات خارجية لتحليل نصوص SQL البرمجية. ومع ذلك، في مستودع بيانات Google Cloud المُدار، يكون هذا التتبُّع مضمّنًا ولا يتطلّب أي تدخل.
هل تتذكّر جدول transactions_summary الذي أنشأته من جدول المعاملات الأولية في وقت سابق من الدرس التطبيقي حول الترميز؟ عندما شغّل BigQuery عبارة CREATE TABLE AS SELECT، سجّل محرّك الحوسبة تلقائيًا البيانات الوصفية للتحويل وأرسلها إلى "كتالوج المعارف". لنلقِ نظرة على النتيجة.
عرض مصدر البيانات بشكلٍ مرئي
- في Google Cloud Console، انتقِل إلى كتالوج المعارف > بحث.
- اكتب
lakehouse_retail_demo.transactionsفي شريط البحث وانقر على الجدول. - انقر على علامة التبويب مصدر البيانات.
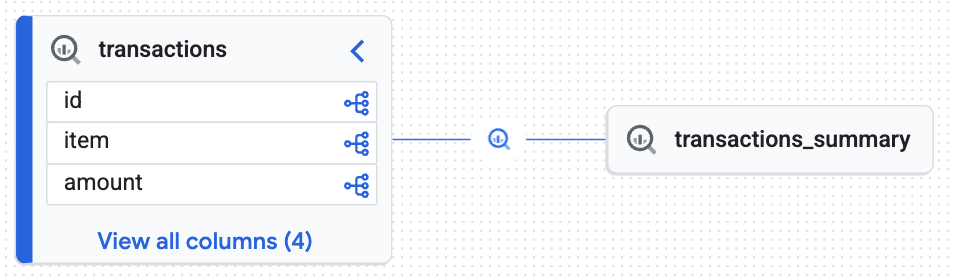
سيظهر لك رسم بياني تفاعلي أنشأه محرّك المعارف يثبت أنّ الجدول المستهدَف (transactions_summary) مشتق من جدول Iceberg المُدار الأولي (transactions). لقد حقّقت إمكانية التتبُّع من البداية إلى النهاية الضرورية لتدقيق البيانات.
7. تَنظيم
لتجنُّب تحمُّل رسوم على حساب Google Cloud الخاص بك مقابل الموارد المستخدَمة في هذا الدرس التطبيقي حول الترميز، اتّبِع الخطوات التالية.
إزالة موارد الإدارة في "كتالوج المعارف"
قبل حذف مجموعة بيانات BigQuery أو حزمة Cloud Storage، يجب إزالة قواعد الإدارة المنطقية. إذا نظرت داخل النص البرمجي cleanup_governance.py من المستودع، سيظهر لك تسلسل الإيقاف التالي:
# 1. Delete Data Policy
data_policy_name = f"{parent_loc}/dataPolicies/mask_financial_null"
dp_client.delete_data_policy(name=data_policy_name)
# 2. Find and Delete Taxonomy (This auto-deletes child Policy Tags)
taxonomies = catalog_client.list_taxonomies(parent=parent_loc)
taxonomy_id = next((t.name for t in taxonomies if t.display_name == "BusinessCritical"), None)
catalog_client.delete_taxonomy(name=taxonomy_id)
الترتيب هنا مهم جدًا. يحذف النص البرمجي أولاً "سياسة البيانات" (قاعدة الإخفاء) لأنّها تعتمد على علامة السياسة. بعد إزالة السياسة، سيؤدي حذف التصنيف الرئيسي تلقائيًا إلى حذف جميع علامات السياسات الأساسية بدون إطلاق أخطاء في تبعية الموارد.
شغِّل نص Python البرمجي للتنظيف:
python cleanup_governance.py
إزالة الهويات ومساحة التخزين ومواد عرض الحوسبة
بعد فصل طبقة الإدارة، يمكنك حذف جداول BigQuery وحزم Cloud Storage وحسابات الخدمة وبيئة Python المحلية بأمان.
انسخ كتلة التنظيف الشاملة التالية وشغِّلها في Cloud Shell:
echo "Deleting Service Accounts and Impersonation Bindings..."
export CURRENT_USER=$(gcloud config get-value account)
for USER in "${USER_ANALYST}" "${USER_MANAGER}"; do
EMAIL="${USER}@${PROJECT_ID}.iam.gserviceaccount.com"
# Remove impersonation binding
gcloud iam service-accounts remove-iam-policy-binding ${EMAIL} \
--member="user:${CURRENT_USER}" \
--role="roles/iam.serviceAccountTokenCreator" \
--quiet > /dev/null 2>&1
# Delete the Service Account
gcloud iam service-accounts delete ${EMAIL} --quiet
done
echo "Removing BigQuery Dataset and Tables..."
bq rm -f ${DATASET_ID}.transactions_summary
bq rm -f ${DATASET_ID}.transactions
bq rm -f ${DATASET_ID}.inventory
bq rm -f -d ${DATASET_ID}
echo "Removing BigQuery Cloud Resource Connection..."
bq rm --connection --location=${REGION} ${CONN_NAME}
echo "Removing Iceberg Cloud Storage Bucket..."
gcloud storage rm --recursive gs://${ICEBERG_BUCKET} --quiet
echo "Removing Auto-generated Dataproc Staging & Temp Buckets..."
for BUCKET in $(gcloud storage ls | grep -E "gs://dataproc-(staging|temp)-${REGION}"); do
gcloud storage rm --recursive $BUCKET --quiet
done
echo "Deactivating and removing the local Python environment..."
deactivate
cd ../..
rm -rf devrel-demos
echo "✅ Clean up completed successfully!"
من خلال إكمال هذه الخطوات، تكون قد ضمنت عدم بقاء أي موارد غير مرتبطة أو سياسات مخفية في مشروعك.
8- تهانينا!
لقد نفّذت بنجاح مستودع بيانات مُدارًا بالكامل وقابلاً للاكتشاف.
لقد تعرّفت على ما يلي:
- التكامل الأصلي مع Iceberg: يمكن لـ Lakehouse إدارة جداول Iceberg المفتوحة المصدر بشكلٍ أصلي مع تخزين الملفات الفعلية بأمان في Cloud Storage.
- تفويض الحوسبة للأمان: من خلال توجيه طلبات البحث من خلال BigQuery Storage API، فرضت إخفاءً ديناميكيًا دقيقًا على الملفات الفعلية التي لا يمكنها بشكلٍ أصلي حظر الوصول الجزئي.
- الإدارة المستقلة عن المحرّك: تتيح لك علامات السياسات تحديد القواعد مرة واحدة وفرضها بشكلٍ شامل سواء تم الاستعلام عنها من خلال أوقات تشغيل SQL الأصلية أو Apache Spark.
- إمكانية اكتشاف البيانات: تتبّع محرّك المعارف تلقائيًا مصدر البيانات، ما يوفّر إمكانية التدقيق الأساسية للمؤسسة.
ما هي الخطوات التالية؟
- استكشاف التحكّم المتقدّم في الوصول: لتنفيذ سيناريوهات أمان أكثر تعقيدًا، راجِع الوثائق الرسمية حول تخصيص Lakehouse بميزات إضافية.
- إدارة البيانات غير المنظَّمة للذكاء الاصطناعي التوليدي: يمكنك التعرّف على جداول الكائنات. وسِّع نطاق نمط الجسر الآمن هذا ليشمل الملفات غير المنظَّمة (ملفات PDF والصور) في Cloud Storage، ما يؤدي إلى إنشاء أساس بيانات آمن ومُدار لمحرّك وكيل Gemini Enterprise وخطوط أنابيب التوليد المعزّز بالاسترجاع (RAG).