
1. Introducción
En una nube de datos empresarial moderna, en la que los datos residen en varios sistemas de almacenamiento físico, existe un enorme desafío arquitectónico de seguridad fragmentada.
¿Cómo te aseguras de que los datos sensibles (como los importes de las transacciones financieras) estén protegidos de manera coherente cuando se almacenan físicamente en formatos de código abierto como Parquet en el almacenamiento de Google Cloud y se consultan con varios motores diferentes, como BigQuery SQL o Apache Spark?
En este codelab, crearás una arquitectura de lakehouse de datos administrada que resuelve estos problemas con tablas de Apache Iceberg, BigQuery y Knowledge Catalog. Usarás la infraestructura como código (IaC) para definir políticas de seguridad de confianza cero y cómo se aplican de forma dinámica en diferentes motores de procesamiento.
Requisitos previos
- Un proyecto de Google Cloud con facturación habilitada.
- Conocimientos básicos de los conceptos de SQL, IAM y Cloud Storage.
Qué aprenderás
- Cómo crear tablas de Google Cloud Lakehouse para Apache Iceberg en BigQuery, donde Cloud Storage almacena los datos de forma nativa.
- Cómo aplicar políticas de datos centralizadas con etiquetas de política para la seguridad a nivel de columnas y el enmascaramiento de datos.
- Cómo desacoplar el acceso al almacenamiento físico del acceso lógico a los datos con la conexión de recursos de Cloud.
- Cómo aplicar la delegación de procesamiento de confianza cero con Managed Service para Apache Spark para garantizar que los motores de código abierto no puedan omitir la administración.
- Cómo visualizar el linaje de datos automatizado Data Lineage.
Descripción general de la arquitectura: Administración universal en Iceberg
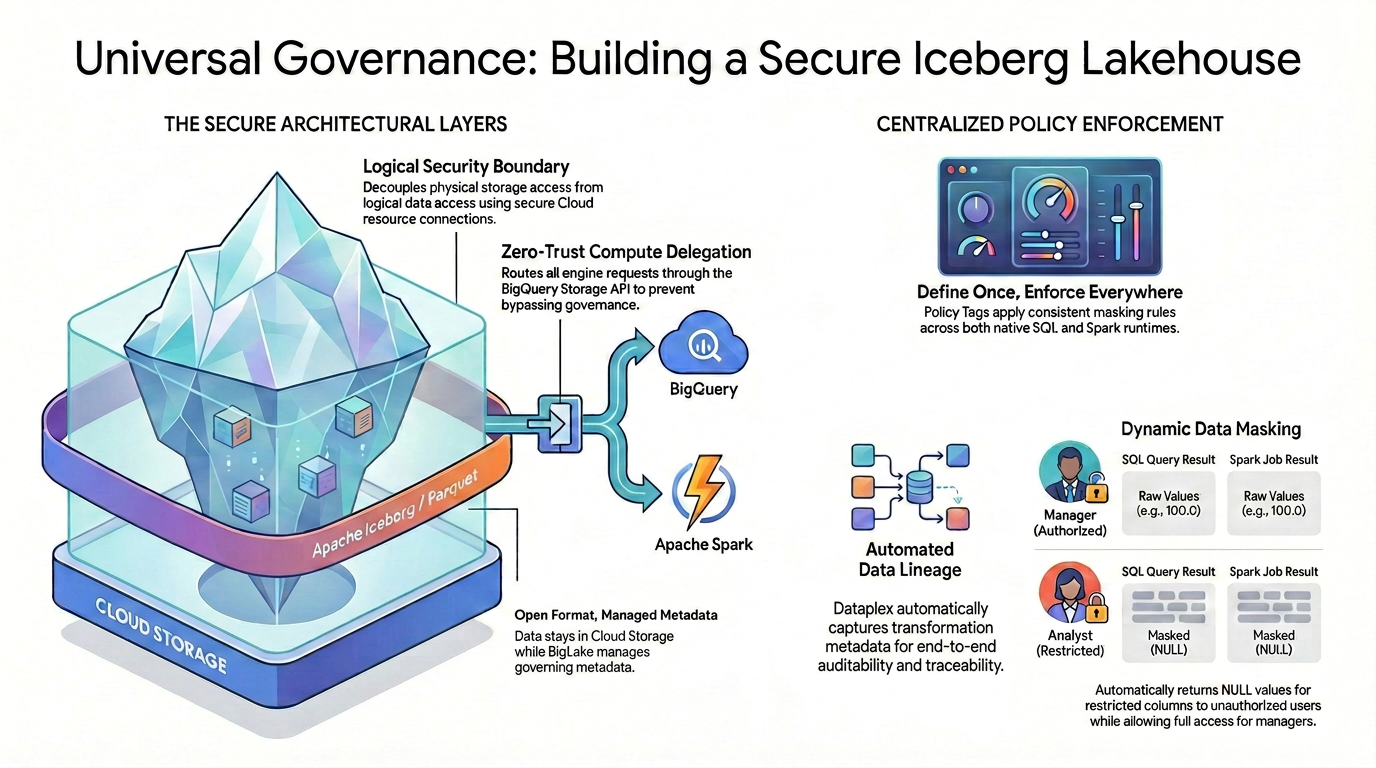
Para lograr un control de acceso detallado (como la seguridad a nivel de columnas y el enmascaramiento de datos) en formatos de datos de código abierto, debes establecer una arquitectura de seguridad estricta y unificada.
Como se ilustra en el diagrama, este patrón de lakehouse administrado se basa en dos pilares principales para resolver el desafío de seguridad fragmentada:
🛡️ Las capas arquitectónicas seguras (izquierda)
En lugar de permitir que los usuarios o los motores externos accedan directamente a Cloud Storage, que solo admite una seguridad amplia a nivel de buckets, debes crear una base segura.
- Formato abierto, metadatos administrados: Los datos permanecen físicamente en Cloud Storage con el formato abierto de Apache Iceberg (Parquet), mientras que Lakehouse administra sin problemas los metadatos de administración.
- Límite de seguridad lógica: Desacopla el acceso al almacenamiento físico del acceso a los datos con una conexión segura a recursos de Cloud. A los usuarios finales nunca se les otorga acceso físico directo de IAM a los archivos GCS sin procesar.
- Delegación de procesamiento de confianza cero: Para garantizar que ningún motor de ejecución pueda omitir las reglas de administración, todas las solicitudes de lectura de datos se enrutan estrictamente a través de la API de BigQuery Storage. Esto se aplica si la consulta se origina en BigQuery SQL nativo o en Apache Spark de código abierto.
🎯 Aplicación de políticas centralizada (derecha)
Con la base segura, Knowledge Catalog actúa como el cerebro unificado para la administración:
- Definir una vez, aplicar en todas partes: Defines tus etiquetas de política en Knowledge Catalog solo una vez, y la arquitectura aplica reglas de enmascaramiento coherentes de forma universal en todos los entornos de ejecución compatibles.
- Enmascaramiento de datos dinámico: Cuando se consultan los datos, el sistema evalúa la identidad del usuario sobre la marcha. Si bien los usuarios autorizados verán los valores sin procesar y sin enmascarar (p.ej., 100.0) en SQL y Spark, los usuarios restringidos recibirán automáticamente valores NULL enmascarados para las columnas restringidas en ambos motores.
- Linaje de datos automatizado: A medida que los datos fluyen y se transforman, Knowledge Catalog captura automáticamente los metadatos de transformación, lo que proporciona auditabilidad y trazabilidad integradas de extremo a extremo sin necesidad de código de registro personalizado.
2. Configuración y requisitos
Iniciar Cloud Shell
Si bien Google Cloud y Spanner se pueden operar de manera remota desde tu laptop, en este codelab usarás Google Cloud Shell, un entorno de línea de comandos que se ejecuta en la nube.
En la consola de Google Cloud, haz clic en el ícono de Cloud Shell en la barra de herramientas en la parte superior derecha:
El aprovisionamiento y la conexión al entorno deberían tomar solo unos minutos. Cuando termine el proceso, debería ver algo como lo siguiente:

Esta máquina virtual está cargada con todas las herramientas de desarrollo que necesitarás. Ofrece un directorio principal persistente de 5 GB y se ejecuta en Google Cloud, lo que permite mejorar considerablemente el rendimiento de la red y la autenticación. Todo tu trabajo en este codelab se puede hacer en un navegador. No es necesario que instales nada.
Inicializa el entorno
Abre Cloud Shell y configura las variables de tu proyecto para asegurarte de que todos los comandos apunten a la infraestructura correcta.
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-central1"
export ICEBERG_BUCKET="iceberg-retail-demo-${PROJECT_ID}"
export DATASET_ID="lakehouse_retail_demo"
export CONN_NAME="iceberg-bq-conn-demo"
Luego, define nuestras dos personalidades.
export USER_ANALYST="retail-analyst-demo"
export EMAIL_ANALYST="${USER_ANALYST}@${PROJECT_ID}.iam.gserviceaccount.com"
export USER_MANAGER="retail-manager-demo"
export EMAIL_MANAGER="${USER_MANAGER}@${PROJECT_ID}.iam.gserviceaccount.com"
export CURRENT_USER=$(gcloud config get-value account)
Habilita las API
Habilita los servicios de Google Cloud necesarios.
gcloud services enable \
bigquery.googleapis.com \
bigqueryconnection.googleapis.com \
datacatalog.googleapis.com \
bigquerydatapolicy.googleapis.com \
datalineage.googleapis.com \
dataplex.googleapis.com \
dataproc.googleapis.com \
storage-component.googleapis.com
Descarga el código fuente del codelab
Para evitar desordenar Cloud Shell, realizarás un checkout disperso para descargar solo las secuencias de comandos de Python necesarias para este codelab desde el repositorio de Google Cloud DevRel.
# Shallow clone without full history
git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/devrel-demos.git
cd devrel-demos
# Download only the specific folder
git sparse-checkout set data-analytics/governed-lakehouse
cd data-analytics/governed-lakehouse
Crea almacenamiento
Crea el bucket para contener los datos de Iceberg administrados y altamente seguros.
gcloud storage buckets create gs://${ICEBERG_BUCKET} --location=${REGION}
Prepara identidades y seguridad
Configura la conexión de recursos de Cloud. Esta es la única entidad que contiene las claves de IAM físicas permanentes para leer los archivos de Iceberg sin procesar.
# Create the BigQuery connection
bq mk --connection \
--connection_type=CLOUD_RESOURCE \
--location=${REGION} \
${CONN_NAME}
# Retrieve the connection's automatically generated Service Account
export BQ_CONN_SVC_ACCT=$(bq show --format=json --connection ${REGION}.${CONN_NAME} \
| jq -r '.cloudResource.serviceAccountId')
# Grant Storage Object Admin to the connection for the Iceberg bucket
gcloud storage buckets add-iam-policy-binding gs://${ICEBERG_BUCKET} \
--member="serviceAccount:${BQ_CONN_SVC_ACCT}" \
--role="roles/storage.objectAdmin" \
--quiet
A continuación, configura las personalidades de los usuarios. A los usuarios se les otorga acceso lógico, no acceso al almacenamiento físico. Para evitar errores causados por retrasos en la propagación de IAM, primero crearás las cuentas, esperarás unos segundos y, luego, asignarás sus roles.
echo "Creating Service Accounts..."
for USER in "${USER_ANALYST}" "${USER_MANAGER}"; do
gcloud iam service-accounts create ${USER} --display-name="Lakehouse ${USER}"
done
echo "⏳ Waiting 15 seconds for IAM propagation..."
sleep 15
echo "Granting IAM Roles to Service Accounts..."
for USER in "${USER_ANALYST}" "${USER_MANAGER}"; do
EMAIL="${USER}@${PROJECT_ID}.iam.gserviceaccount.com"
# Allow Cloud Shell to impersonate them for testing
gcloud iam service-accounts add-iam-policy-binding ${EMAIL} \
--member="user:${CURRENT_USER}" \
--role="roles/iam.serviceAccountTokenCreator" \
--quiet
# Allow logical viewing of the catalog, querying, and running Dataproc jobs
for ROLE in "roles/datacatalog.viewer" "roles/bigquery.dataViewer" "roles/bigquery.user" "roles/bigquery.connectionUser" "roles/serviceusage.serviceUsageConsumer" "roles/dataproc.worker"; do
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${EMAIL}" \
--role="${ROLE}" \
--quiet
done
done
# Grant the Manager data creation rights
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${EMAIL_MANAGER}" \
--role="roles/bigquery.dataEditor" \
--quiet
echo "✅ Identity and Security setup completed!"
3. Crea tablas de Iceberg nativas a través de Lakehouse
Usarás las capacidades nativas de Lakehouse para crear las tablas de Iceberg administradas.
Crea el conjunto de datos de BigQuery
Primero, crea un conjunto de datos de BigQuery para agrupar lógicamente nuestras tablas de Iceberg.
echo "Creating BigQuery Dataset..."
bq mk --location=${REGION} --dataset ${PROJECT_ID}:${DATASET_ID}
Crea las tablas de Iceberg
A continuación, ejecuta los siguientes comandos para crear las tablas. Observa el bloque OPTIONS en el que especificamos table_format = 'ICEBERG' y lo asignamos directamente a nuestro bucket de Cloud Storage y conexión.
echo "Creating Iceberg tables..."
# Inventory table
bq query --use_legacy_sql=false \
"CREATE OR REPLACE TABLE \`${PROJECT_ID}.${DATASET_ID}.inventory\` (
product_id INT64,
product_name STRING,
stock_count INT64
)
WITH CONNECTION \`${REGION}.${CONN_NAME}\`
OPTIONS (
file_format = 'PARQUET',
table_format = 'ICEBERG',
storage_uri = 'gs://${ICEBERG_BUCKET}/inventory/'
);"
# Transactions table
bq query --use_legacy_sql=false \
"CREATE OR REPLACE TABLE \`${PROJECT_ID}.${DATASET_ID}.transactions\` (
id INT64,
item STRING,
amount FLOAT64,
transaction_date DATE
)
WITH CONNECTION \`${REGION}.${CONN_NAME}\`
OPTIONS (
file_format = 'PARQUET',
table_format = 'ICEBERG',
storage_uri = 'gs://${ICEBERG_BUCKET}/transactions/'
);"
Propaga las tablas con datos
Por último, inserta datos de muestra en las tablas de Iceberg recién creadas.
echo "Inserting data into Iceberg tables..."
# Insert into Inventory table
bq query --use_legacy_sql=false \
"INSERT INTO \`${PROJECT_ID}.${DATASET_ID}.inventory\` (product_id, product_name, stock_count)
VALUES (101, 'Widget A', 500), (102, 'Widget B', 250), (103, 'Widget C', 800);"
# Insert into Transactions table
bq query --use_legacy_sql=false \
"INSERT INTO \`${PROJECT_ID}.${DATASET_ID}.transactions\` (id, item, amount, transaction_date)
VALUES
(1, 'Widget A', 100.0, DATE '2024-01-01'),
(2, 'Widget B', 150.0, DATE '2024-01-02'),
(3, 'Widget C', 50.0, DATE '2024-01-03');"
Ahora tienes dos tablas de Iceberg completamente funcionales. Lakehouse administra los metadatos, pero los archivos Parquet físicos residen de forma segura en tu bucket de GCS.
Simula una canalización de ETL
En una situación real, los datos sin procesar suelen agregarse en tablas de resumen para la generación de informes empresariales. Actuemos como ingenieros de datos y creemos una tabla de resumen de ventas diarias a partir de nuestros datos de transacciones sin procesar.
(Nota: Ejecuta este paso ahora para que Google Cloud tenga suficiente tiempo para procesar los metadatos en segundo plano. Descubrirás por qué esto es importante más adelante en el codelab).
echo "Creating transactions summary table..."
bq query --use_legacy_sql=false \
"CREATE TABLE \`${PROJECT_ID}.${DATASET_ID}.transactions_summary\` AS
SELECT transaction_date, SUM(amount) as total_sales, COUNT(id) as transaction_count
FROM \`${PROJECT_ID}.${DATASET_ID}.transactions\`
GROUP BY transaction_date;"
4. Administración centralizada: Define políticas con Python
En un entorno de producción, configurar políticas de administración a través de la IU es difícil de escalar y mantener. En cambio, se recomienda usar la infraestructura como código (IaC).
En esta sección, usarás el SDK de Python de Google Cloud para crear y aplicar de forma programática tus reglas de administración de confianza cero paso a paso.
Configura el entorno de Python
Primero, configuremos un entorno aislado de Python (venv) para evitar conflictos de bibliotecas y, luego, instalemos los SDK de Google Cloud necesarios.
Ejecute los siguientes comandos en Cloud Shell:
# Create and activate a virtual environment
python3 -m venv lakehouse_env
source lakehouse_env/bin/activate
# Install required Knowledge Catalog and BigQuery governance libraries
pip install google-cloud-datacatalog google-cloud-bigquery-datapolicies google-cloud-bigquery --quiet
echo "✅ Python environment is ready!"
Crea la taxonomía y la etiqueta de política
Una taxonomía es un contenedor lógico, y una etiqueta de política es la etiqueta específica que adjuntarás a nuestra columna sensible. Para aplicar la seguridad a nivel de columnas, primero necesitas un contenedor lógico (una taxonomía) y una etiqueta específica (una etiqueta de política).
Si observas 1_create_taxonomy.py, verás la siguiente lógica principal:
# Create Taxonomy with Fine-Grained Access Control enabled
taxonomy = datacatalog_v1.Taxonomy(
display_name="BusinessCritical",
activated_policy_types=[datacatalog_v1.Taxonomy.PolicyType.FINE_GRAINED_ACCESS_CONTROL]
)
created_taxonomy = client.create_taxonomy(parent=parent, taxonomy=taxonomy)
# Create Policy Tag inside the Taxonomy
policy_tag = datacatalog_v1.PolicyTag(display_name="RestrictedFinancial")
created_policy_tag = client.create_policy_tag(parent=created_taxonomy.name, policy_tag=policy_tag)
Si configuras de forma explícita el tipo de política FINE_GRAINED_ACCESS_CONTROL, transformas una etiqueta de metadatos estándar en un límite de seguridad estricto de confianza cero. De forma predeterminada, cualquier columna con esta etiqueta denegará el acceso a todos los usuarios.
Ejecuta la secuencia de comandos para crear los recursos:
python 1_create_taxonomy.py
Configura la regla de enmascaramiento (política de datos)
Ahora, define lo que sucede cuando alguien sin privilegios consulta la columna etiquetada. Crearás una política de datos que obliga a que el valor se muestre como NULL y adjuntarás esta regla a la personalidad del analista.
Dentro de 2_create_masking.py, la secuencia de comandos busca de forma dinámica el ID de la etiqueta de política que acabas de crear y aplica una política de datos:
# Define a Masking Policy that always returns NULL
data_policy = bigquery_datapolicies_v1.DataPolicy(
data_policy_id="mask_financial_null",
policy_tag=policy_tag_id,
data_policy_type=bigquery_datapolicies_v1.DataPolicy.DataPolicyType.DATA_MASKING_POLICY,
data_masking_policy=bigquery_datapolicies_v1.DataMaskingPolicy(
predefined_expression=bigquery_datapolicies_v1.DataMaskingPolicy.PredefinedExpression.ALWAYS_NULL
)
)
# ... (Policy creation code) ...
# Bind the Masked Reader role to the Analyst
iam_policy.bindings.add(
role="roles/bigquerydatapolicy.maskedReader",
members=[f"serviceAccount:{analyst_email}"]
)
Este código crea de forma programática una regla que obliga a que los valores subyacentes se muestren como NULL. Luego, asigna la función de IAM maskedReader específicamente a la personalidad del analista, lo que garantiza que solo vea la versión enmascarada de los datos.
Ejecuta la secuencia de comandos para configurar la regla de enmascaramiento:
python 2_create_masking.py
Otorga acceso detallado
Debido a nuestra configuración de confianza cero, nadie puede leer la columna etiquetada en este momento. Debes otorgar acceso de forma explícita al administrador y a tu cuenta personal.
Dentro de 3_grant_access.py, modificas la política de IAM de la etiqueta de política:
# Grant original data read access
iam_policy.bindings.add(
role="roles/datacatalog.categoryFineGrainedReader",
members=[f"serviceAccount:{manager_email}", f"user:{current_user}"]
)
client.set_iam_policy(request=iam_policy_pb2.SetIamPolicyRequest(resource=policy_tag_id, policy=iam_policy))
Si agregas la función categoryFineGrainedReader, estos principales específicos pueden omitir las reglas de enmascaramiento y leer los datos sin procesar y sin enmascarar.
Ejecuta la secuencia de comandos para otorgar acceso:
python 3_grant_access.py
Adjunta la etiqueta de política a la tabla de BigQuery
Por último, debes adjuntar esta etiqueta de política lógica a nuestro esquema de tabla de Iceberg físico.
Echa un vistazo a 4_attach_tag.py. La secuencia de comandos recupera el esquema de la tabla de BigQuery, itera por los campos y adjunta la etiqueta específicamente a la columna amount:
new_schema =[]
for field in table.schema:
if field.name == 'amount':
# Wrap the Policy Tag ID and attach it to the column
policy_tags_list = bigquery.PolicyTagList(names=[policy_tag_id])
new_field = bigquery.SchemaField(
name=field.name, field_type=field.field_type, mode=field.mode,
description=field.description, policy_tags=policy_tags_list
)
new_schema.append(new_field)
else:
new_schema.append(field)
# Update the table schema in BigQuery
table.schema = new_schema
client.update_table(table, ["schema"])
Cuando se aplica esta actualización del esquema, Lakehouse conecta instantáneamente nuestras etiquetas lógicas de Knowledge Catalog a los archivos Parquet físicos almacenados en tu bucket de Cloud Storage.
Ejecuta la secuencia de comandos para actualizar el esquema de la tabla:
python 4_attach_tag.py
5. Verifica las políticas de Knowledge Catalog
Es hora de probar si funciona nuestra administración centralizada. Lo probarás en dos motores diferentes para demostrar que las políticas de Knowledge Catalog se aplican de forma universal.
Verifica con SQL nativo de BigQuery
Primero, usarás Cloud Shell para asumir la identidad de nuestras dos personalidades y consultar la tabla con el motor de SQL nativo de BigQuery.
Prueba como administrador (usuario con privilegios):
# Impersonate the manager
gcloud config set auth/impersonate_service_account ${EMAIL_MANAGER}
# Query the transactions table
bq query --use_legacy_sql=false "SELECT * FROM \`${PROJECT_ID}.${DATASET_ID}.transactions\`"
Como el administrador tiene la función de lector detallado, mostrará los valores de cantidad sin procesar.
+----+----------+--------+------------------+
| id | item | amount | transaction_date |
+----+----------+--------+------------------+
| 1 | Widget A | 100.0 | 2024-01-01 |
| 3 | Widget C | 50.0 | 2024-01-03 |
| 2 | Widget B | 150.0 | 2024-01-02 |
+----+----------+--------+------------------+
Prueba como analista (usuario restringido):
gcloud config set auth/impersonate_service_account ${EMAIL_ANALYST}
bq query --use_legacy_sql=false "SELECT * FROM \`${PROJECT_ID}.${DATASET_ID}.transactions\`"
Debido a la regla de enmascaramiento de Knowledge Catalog, la columna de cantidad se muestra como NULL para cada fila.
+----+----------+--------+------------------+
| id | item | amount | transaction_date |
+----+----------+--------+------------------+
| 1 | Widget A | NULL | 2024-01-01 |
| 3 | Widget C | NULL | 2024-01-03 |
| 2 | Widget B | NULL | 2024-01-02 |
+----+----------+--------+------------------+
Restablece tu identidad
Limpia el estado de autenticación de Cloud Shell para volver a tu usuario administrador.
# Unset impersonation
gcloud config unset auth/impersonate_service_account
Verifica con Apache Spark (delegación de procesamiento)
¿Qué sucede si un científico de datos usa Apache Spark para leer esta tabla? Si Spark lee los archivos Parquet de GCS físicos directamente, las reglas de enmascaramiento de Knowledge Catalog se omiten por completo porque Cloud Storage solo comprende los permisos a nivel de buckets.
Para evitar esto, aplica la delegación de procesamiento con el conector de Spark-BigQuery. Este conector actúa como un puente seguro, ya que enruta las solicitudes de lectura de Spark a través de la API de BigQuery Storage para que las reglas de administración de Knowledge Catalog se evalúen de forma dinámica antes de que se envíen datos al clúster de Spark.
Observa la lógica principal dentro de la secuencia de comandos read_transactions.py que descargaste:
# Reading data via Compute Delegation (Knowledge Catalog policies are applied dynamically here)
df = spark.read \
.format("bigquery") \
.option("table", f"{project_id}.{dataset_id}.{table_name}") \
.load()
print("\n=== 📊 Data Preview ===")
df.show(truncate=False)
Ten en cuenta que no estamos apuntando a Spark a la ruta de acceso gs:// de los archivos de Iceberg. Si especificas .format("bigquery"), la API de BigQuery Storage intercepta la solicitud de lectura, verifica la identidad del usuario que ejecuta el trabajo de Spark, aplica las reglas de enmascaramiento de Knowledge Catalog y solo muestra los datos autorizados al DataFrame de Spark.
Sube esta secuencia de comandos de PySpark a tu bucket de Cloud Storage para que Managed Apache Spark pueda acceder a ella:
# Upload script to GCS
gsutil cp read_transactions.py gs://${ICEBERG_BUCKET}/scripts/read_transactions.py
Ejecuta Spark como administrador:
Usarás Managed Apache Spark. Este servicio administrado te permite ejecutar cargas de trabajo de Spark directamente sin necesidad de aprovisionar, configurar ni administrar clústeres dedicados.
echo "🚀 Submitting Managed Apache Spark Job as [MANAGER]..."
gcloud dataproc batches submit pyspark gs://${ICEBERG_BUCKET}/scripts/read_transactions.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--service-account=${EMAIL_MANAGER} \
--version=2.3 \
-- ${PROJECT_ID} ${DATASET_ID} \
--format="value(name)"
Observa los registros de salida del trabajo en la terminal. Como el administrador tiene la función de lector detallado, Spark recupera correctamente las cantidades sin procesar y sin enmascarar.
=== 📊 Data Preview ===
+---+--------+------+-------------------+
|id |item |amount|transaction_date |
+---+--------+------+-------------------+
|1 |Widget A|100.0 |2024-01-01 |
|2 |Widget B|150.0 |2024-01-02 |
|3 |Widget C|50.0 |2024-01-03 |
+---+--------+------+-------------------+
Ejecuta Spark como analista:
Ahora, envía el mismo trabajo de Spark, pero esta vez suplanta la personalidad del analista.
echo "🚀 Submitting Managed Apache Spark Job as [ANALYST]..."
gcloud dataproc batches submit pyspark gs://${ICEBERG_BUCKET}/scripts/read_transactions.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--service-account=${EMAIL_ANALYST} \
--version=2.3 \
-- ${PROJECT_ID} ${DATASET_ID} \
--format="value(name)"
Vuelve a verificar los registros. Aunque el analista ejecutó el mismo código de Spark, la API de BigQuery Storage interceptó la solicitud y aplicó la política de Knowledge Catalog. El DataFrame de Spark del analista muestra null para las cantidades.
=== 📊 Data Preview ===
+---+--------+------+-------------------+
|id |item |amount|transaction_date |
+---+--------+------+-------------------+
|1 |Widget A|null |2024-01-01 |
|2 |Widget B|null |2024-01-02 |
|3 |Widget C|null |2024-01-03 |
+---+--------+------+-------------------+
Compensaciones arquitectónicas: BigQuery SQL vs. Spark
Acabas de demostrar que el resultado es idéntico, independientemente del motor. La política de Knowledge Catalog se aplicó correctamente. Pero, en producción, ¿cuál deberías usar?
- BigQuery SQL: Es ideal para flujos de trabajo en los que SQL es el motor deseado y ejecuta cálculos directamente en el lugar. Es ideal para la analítica rápida y la inteligencia empresarial.
- Apache Spark: Permite cargas de trabajo más complejas gracias al uso de Python, lo que lo hace adecuado para canalizaciones avanzadas de aprendizaje automático o código heredado de Hadoop.
Conclusión clave: Sin importar qué motor se use, si se aplica la delegación de procesamiento, nunca se puede omitir la capa de administración centralizada de confianza cero.
6. Linaje de datos automatizado
En cualquier arquitectura de datos empresariales, saber exactamente de dónde provienen tus datos y cómo se modificaron es fundamental para el cumplimiento, la depuración y el establecimiento de la confianza. Este concepto se conoce como linaje de datos. Responde preguntas fundamentales como: "Si un administrador observa un informe de ventas diarias, ¿qué tablas sin procesar se usaron para calcular esos números?".
Por lo general, el seguimiento de este ciclo de vida requiere que los ingenieros de datos escriban de forma manual código de registro personalizado o usen herramientas complejas de terceros para analizar secuencias de comandos de SQL. Sin embargo, en un lakehouse de Google Cloud administrado, este seguimiento está integrado y es completamente automático.
¿Recuerdas la tabla transactions_summary que creaste a partir de la tabla de transacciones sin procesar anteriormente en el codelab? Cuando BigQuery ejecutó esa instrucción CREATE TABLE AS SELECT, el motor de procesamiento capturó automáticamente los metadatos de transformación y los envió a Knowledge Catalog. Veamos el resultado.
Visualiza el linaje
- En la consola de Google Cloud, navega a Knowledge Catalog > Search.
- Escribe
lakehouse_retail_demo.transactionsen la barra de búsqueda y haz clic en la tabla. - Haz clic en la pestaña Lineage.
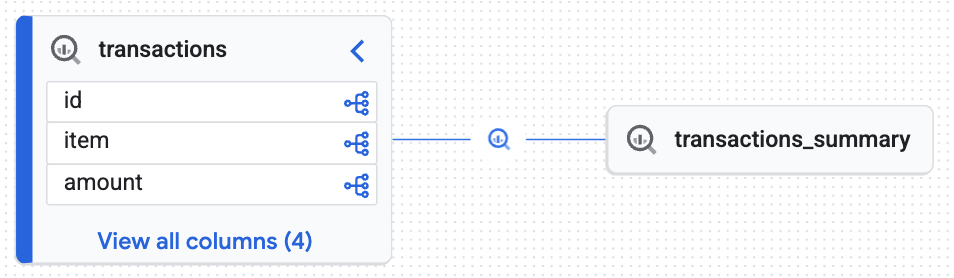
Verás un gráfico interactivo generado por Knowledge Engine que demuestra que la tabla de destino (transactions_summary) se derivó de la tabla de Iceberg administrada sin procesar (transactions). Lograste una trazabilidad de extremo a extremo esencial para la auditoría de datos.
7. Limpia
Sigue estos pasos para evitar que se apliquen cargos a tu cuenta de Google Cloud por los recursos que usaste en este codelab.
Quita los recursos de administración de Knowledge Catalog
Antes de borrar el conjunto de datos de BigQuery o el bucket de Cloud Storage, debes quitar las reglas de administración lógicas. Si observas la secuencia de comandos cleanup_governance.py del repositorio, verás la siguiente secuencia de desmantelamiento:
# 1. Delete Data Policy
data_policy_name = f"{parent_loc}/dataPolicies/mask_financial_null"
dp_client.delete_data_policy(name=data_policy_name)
# 2. Find and Delete Taxonomy (This auto-deletes child Policy Tags)
taxonomies = catalog_client.list_taxonomies(parent=parent_loc)
taxonomy_id = next((t.name for t in taxonomies if t.display_name == "BusinessCritical"), None)
catalog_client.delete_taxonomy(name=taxonomy_id)
El orden es fundamental en este caso. La secuencia de comandos primero borra la política de datos (regla de enmascaramiento) porque depende de la etiqueta de política. Una vez que se quita la política, borrar la taxonomía superior se propagará automáticamente y borrará todas las etiquetas de política subyacentes sin activar errores de dependencia de recursos.
Ejecuta la secuencia de comandos de limpieza de Python:
python cleanup_governance.py
Quita identidades, almacenamiento y recursos de procesamiento
Ahora que la capa de administración está separada, puedes borrar de forma segura las tablas de BigQuery, los buckets de Cloud Storage, las cuentas de servicio y el entorno local de Python.
Copia y ejecuta el siguiente bloque de limpieza integral en Cloud Shell:
echo "Deleting Service Accounts and Impersonation Bindings..."
export CURRENT_USER=$(gcloud config get-value account)
for USER in "${USER_ANALYST}" "${USER_MANAGER}"; do
EMAIL="${USER}@${PROJECT_ID}.iam.gserviceaccount.com"
# Remove impersonation binding
gcloud iam service-accounts remove-iam-policy-binding ${EMAIL} \
--member="user:${CURRENT_USER}" \
--role="roles/iam.serviceAccountTokenCreator" \
--quiet > /dev/null 2>&1
# Delete the Service Account
gcloud iam service-accounts delete ${EMAIL} --quiet
done
echo "Removing BigQuery Dataset and Tables..."
bq rm -f ${DATASET_ID}.transactions_summary
bq rm -f ${DATASET_ID}.transactions
bq rm -f ${DATASET_ID}.inventory
bq rm -f -d ${DATASET_ID}
echo "Removing BigQuery Cloud Resource Connection..."
bq rm --connection --location=${REGION} ${CONN_NAME}
echo "Removing Iceberg Cloud Storage Bucket..."
gcloud storage rm --recursive gs://${ICEBERG_BUCKET} --quiet
echo "Removing Auto-generated Dataproc Staging & Temp Buckets..."
for BUCKET in $(gcloud storage ls | grep -E "gs://dataproc-(staging|temp)-${REGION}"); do
gcloud storage rm --recursive $BUCKET --quiet
done
echo "Deactivating and removing the local Python environment..."
deactivate
cd ../..
rm -rf devrel-demos
echo "✅ Clean up completed successfully!"
Cuando completes estos pasos, te asegurarás de que no queden recursos huérfanos ni políticas ocultas en tu proyecto.
8. ¡Felicitaciones!
Implementaste correctamente un lakehouse de datos completamente administrado y detectable.
Aprendiste lo siguiente:
- Integración nativa de Iceberg: Lakehouse puede administrar de forma nativa las tablas de Iceberg de código abierto mientras almacena los archivos físicos de forma segura en Cloud Storage.
- Delegación de procesamiento para la seguridad: Cuando enrutas las consultas a través de la API de BigQuery Storage, aplicas un enmascaramiento dinámico detallado en archivos físicos que no pueden restringir el acceso parcial de forma nativa.
- Administración independiente del motor: Las etiquetas de política te permiten definir reglas una vez y aplicarlas de forma universal, ya sea que se consulten a través de SQL nativo o de entornos de ejecución de Apache Spark.
- Detectabilidad de datos: Knowledge Engine realizó un seguimiento automático del linaje de datos, lo que proporcionó una auditabilidad empresarial esencial.
¿Qué sigue?
- Explora el control de acceso avanzado: Para implementar situaciones de seguridad más complejas, revisa la documentación oficial sobre la personalización de Lakehouse con funciones adicionales.
- Administra datos no estructurados para GenAI: Descubre las tablas de objetos. Extiende este patrón de puente seguro exacto a archivos no estructurados (PDFs, imágenes) en Cloud Storage, lo que establece una base de datos segura y administrada para el motor de agentes de Gemini Enterprise y las canalizaciones de RAG.