
۱. مقدمه
در یک فضای ابری داده سازمانی مدرن، که در آن دادهها در سیستمهای ذخیرهسازی فیزیکی مختلف وجود دارند، یک چالش معماری عظیم در مورد امنیت چندپاره وجود دارد.
چگونه میتوان اطمینان حاصل کرد که دادههای حساس (مانند مبالغ تراکنشهای مالی) به طور مداوم محافظت میشوند، زمانی که دادهها به صورت فیزیکی در قالبهای متنباز مانند Parquet در فضای ذخیرهسازی ابری گوگل ذخیره میشوند و توسط موتورهای مختلف مانند BigQuery SQL یا Apache Spark مورد پرسوجو قرار میگیرند؟
در این آزمایشگاه کد، شما یک معماری Governed Data Lakehouse خواهید ساخت که این مشکلات را با استفاده از جداول Apache Iceberg ، BigQuery و Knowledge Catalog حل میکند. شما از Infrastructure as Code (IaC) برای تعریف سیاستهای امنیتی zero-trust و نحوه اجرای پویای آنها در موتورهای محاسباتی مختلف استفاده خواهید کرد.
پیشنیازها
- یک پروژه گوگل کلود با قابلیت پرداخت.
- آشنایی اولیه با مفاهیم SQL، IAM و Cloud Storage
آنچه یاد خواهید گرفت
- چگونه جداول Google Cloud Lakehouse را برای Apache Iceberg در BigQuery ایجاد کنیم، جایی که Cloud Storage به صورت بومی دادهها را نگهداری میکند.
- نحوه اجرای سیاستهای داده متمرکز با استفاده از برچسبهای سیاست برای امنیت سطح ستون و پوشش دادهها.
- چگونه با استفاده از اتصال منابع ابری، دسترسی به فضای ذخیرهسازی فیزیکی را از دسترسی به دادههای منطقی جدا کنیم؟
- نحوه اعمال واگذاری محاسبات Zero-Trust با استفاده از سرویس مدیریتشده برای آپاچی اسپارک برای اطمینان از اینکه موتورهای متنباز نمیتوانند از مدیریت عبور کنند.
- چگونه تبارشناسی خودکار دادهها را تجسم کنیم.
مرور کلی معماری: حاکمیت جهانی روی کوه یخ
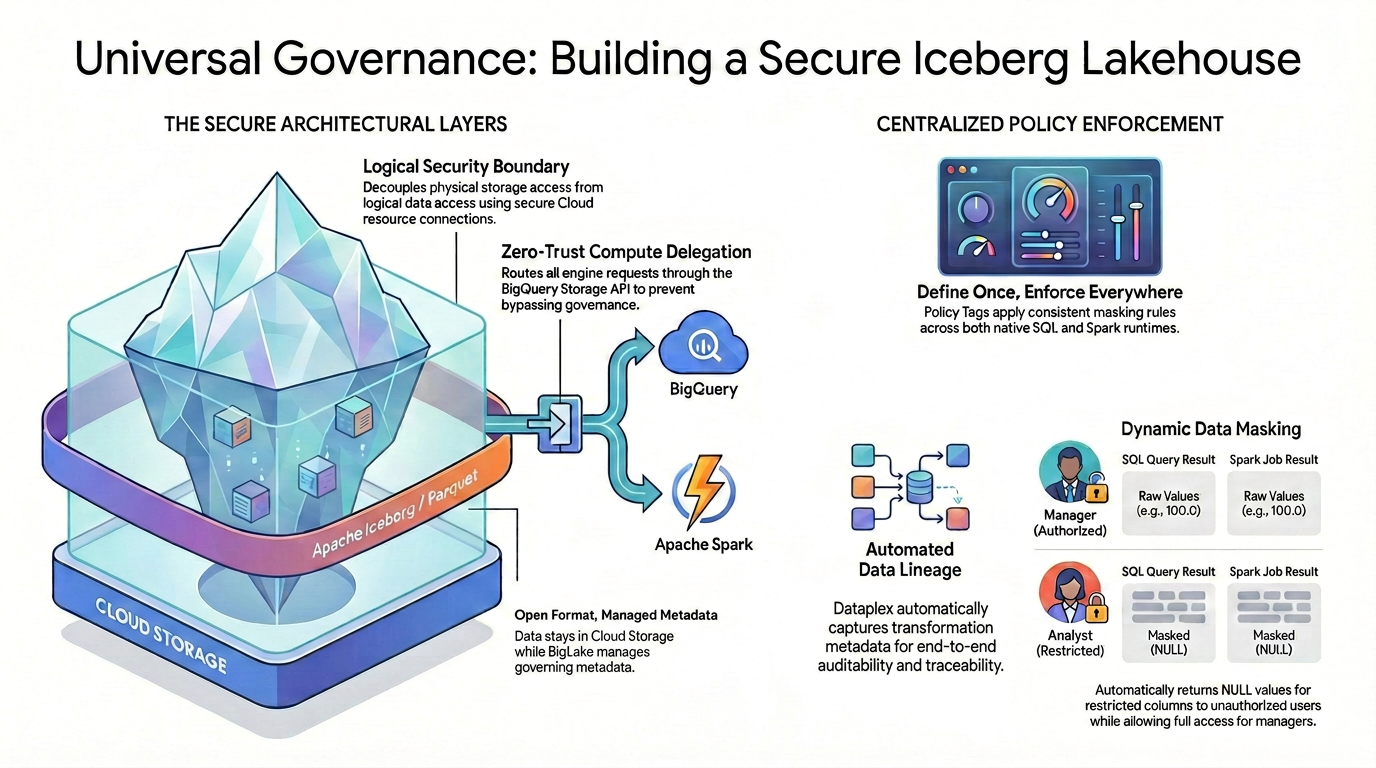
برای دستیابی به کنترل دسترسی دقیق (مانند امنیت در سطح ستون و پوشش دادهها) در قالبهای داده متنباز، باید یک معماری امنیتی دقیق و یکپارچه ایجاد کنید.
همانطور که در نمودار نشان داده شده است، این الگوی دریاچهایِ تحت کنترل، برای حل چالش امنیتیِ چندپاره، بر دو رکن اصلی متکی است:
🛡️ لایههای معماری امن (چپ)
به جای اینکه به کاربران یا موتورهای خارجی اجازه دهید مستقیماً به فضای ذخیرهسازی ابری دسترسی داشته باشند - که فقط از امنیت گسترده در سطح باکت پشتیبانی میکند: شما یک پایه امن میسازید.
- فرمت باز، فراداده مدیریتشده: دادهها به صورت فیزیکی با استفاده از فرمت باز Apache Iceberg (Parquet) در Cloud Storage باقی میمانند، در حالی که Lakehouse به طور یکپارچه فرادادههای حاکم را مدیریت میکند.
- مرز امنیتی منطقی: شما با استفاده از یک اتصال امن به منابع ابری، دسترسی به فضای ذخیرهسازی فیزیکی را از دسترسی به دادههای منطقی جدا میکنید. کاربران نهایی هرگز دسترسی فیزیکی مستقیم به فایلهای خام GCS نخواهند داشت.
- واگذاری محاسبات بدون اعتماد: برای اطمینان از اینکه هیچ موتور اجرایی نمیتواند قوانین نظارتی را دور بزند، تمام درخواستهای خواندن دادهها صرفاً از طریق API ذخیرهسازی BigQuery هدایت میشوند. این امر چه از طریق BigQuery SQL بومی و چه از طریق Apache Spark متنباز انجام شود، صدق میکند.
🎯 اجرای متمرکز سیاستها (راست)
با ایجاد پایه و اساس امن، کاتالوگ دانش به عنوان مغز یکپارچه برای مدیریت عمل میکند:
- یک بار تعریف کنید، همه جا اجرا کنید: شما برچسبهای سیاست خود را در کاتالوگ دانش فقط یک بار تعریف میکنید، و معماری، قوانین پوشش سازگار را به طور جهانی در تمام زمانهای اجرای پشتیبانی شده اعمال میکند.
- پوشش پویای دادهها: وقتی دادهها مورد پرسش قرار میگیرند، سیستم هویت کاربر را در لحظه ارزیابی میکند. در حالی که کاربران مجاز مقادیر خام و بدون پوشش (مثلاً ۱۰۰.۰) را هم در SQL و هم در Spark مشاهده میکنند، کاربران محدود شده به طور خودکار مقادیر NULL پوشش داده شده را برای ستونهای محدود شده در هر دو موتور دریافت میکنند.
- ردهبندی خودکار دادهها: همزمان با جریان و تبدیل دادهها، کاتالوگ دانش بهطور خودکار فرادادههای تبدیل را ثبت میکند و قابلیت حسابرسی و ردیابی سرتاسری داخلی را بدون نیاز به کد ثبت وقایع سفارشی فراهم میکند.
۲. تنظیمات و الزامات
شروع پوسته ابری
اگرچه میتوان از راه دور و از طریق لپتاپ، گوگل کلود را مدیریت کرد، اما در این آزمایشگاه کد، از گوگل کلود شل ، یک محیط خط فرمان که در فضای ابری اجرا میشود، استفاده خواهید کرد.
از کنسول گوگل کلود ، روی آیکون Cloud Shell در نوار ابزار بالا سمت راست کلیک کنید:
آمادهسازی و اتصال به محیط فقط چند لحظه طول میکشد. وقتی تمام شد، باید چیزی شبیه به این را ببینید:

این ماشین مجازی با تمام ابزارهای توسعهای که نیاز دارید، مجهز شده است. این ماشین مجازی یک دایرکتوری خانگی پایدار ۵ گیگابایتی ارائه میدهد و روی فضای ابری گوگل اجرا میشود که عملکرد شبکه و احراز هویت را تا حد زیادی بهبود میبخشد. تمام کارهای شما در این آزمایشگاه کد را میتوان در یک مرورگر انجام داد. نیازی به نصب چیزی ندارید.
مقداردهی اولیه محیط
Cloud Shell را باز کنید و متغیرهای پروژه خود را تنظیم کنید تا مطمئن شوید که همه دستورات زیرساخت صحیح را هدف قرار میدهند.
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-central1"
export ICEBERG_BUCKET="iceberg-retail-demo-${PROJECT_ID}"
export DATASET_ID="lakehouse_retail_demo"
export CONN_NAME="iceberg-bq-conn-demo"
سپس دو شخصیت خود را تعریف کنید.
export USER_ANALYST="retail-analyst-demo"
export EMAIL_ANALYST="${USER_ANALYST}@${PROJECT_ID}.iam.gserviceaccount.com"
export USER_MANAGER="retail-manager-demo"
export EMAIL_MANAGER="${USER_MANAGER}@${PROJECT_ID}.iam.gserviceaccount.com"
export CURRENT_USER=$(gcloud config get-value account)
فعال کردن APIها
سرویسهای ابری گوگل مورد نیاز را فعال کنید.
gcloud services enable \
bigquery.googleapis.com \
bigqueryconnection.googleapis.com \
datacatalog.googleapis.com \
bigquerydatapolicy.googleapis.com \
datalineage.googleapis.com \
dataplex.googleapis.com \
dataproc.googleapis.com \
storage-component.googleapis.com
کد منبع Codelab را دانلود کنید
برای جلوگیری از شلوغی Cloud Shell خود، یک بررسی پراکنده انجام خواهید داد تا فقط اسکریپتهای پایتون لازم برای این آزمایشگاه کد را از مخزن Google Cloud DevRel دانلود کنید.
# Shallow clone without full history
git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/devrel-demos.git
cd devrel-demos
# Download only the specific folder
git sparse-checkout set data-analytics/governed-lakehouse
cd data-analytics/governed-lakehouse
ایجاد فضای ذخیرهسازی
سطلی برای نگهداری دادههای بسیار امن و مدیریتشدهی Iceberg ایجاد کنید.
gcloud storage buckets create gs://${ICEBERG_BUCKET} --location=${REGION}
آمادهسازی هویتها و امنیت
اتصال منابع ابری را پیکربندی کنید. این تنها موجودیتی است که کلیدهای فیزیکی دائمی IAM را برای خواندن فایلهای خام Iceberg در اختیار دارد.
# Create the BigQuery connection
bq mk --connection \
--connection_type=CLOUD_RESOURCE \
--location=${REGION} \
${CONN_NAME}
# Retrieve the connection's automatically generated Service Account
export BQ_CONN_SVC_ACCT=$(bq show --format=json --connection ${REGION}.${CONN_NAME} \
| jq -r '.cloudResource.serviceAccountId')
# Grant Storage Object Admin to the connection for the Iceberg bucket
gcloud storage buckets add-iam-policy-binding gs://${ICEBERG_BUCKET} \
--member="serviceAccount:${BQ_CONN_SVC_ACCT}" \
--role="roles/storage.objectAdmin" \
--quiet
در مرحله بعد، شخصیتهای کاربری را تنظیم کنید. به کاربران دسترسی منطقی داده میشود، نه دسترسی فیزیکی به فضای ذخیرهسازی. برای جلوگیری از خطاهای ناشی از تأخیر در انتشار IAM، ابتدا حسابها را ایجاد میکنید، چند ثانیه صبر میکنید و سپس نقشهای آنها را تعیین میکنید.
echo "Creating Service Accounts..."
for USER in "${USER_ANALYST}" "${USER_MANAGER}"; do
gcloud iam service-accounts create ${USER} --display-name="Lakehouse ${USER}"
done
echo "⏳ Waiting 15 seconds for IAM propagation..."
sleep 15
echo "Granting IAM Roles to Service Accounts..."
for USER in "${USER_ANALYST}" "${USER_MANAGER}"; do
EMAIL="${USER}@${PROJECT_ID}.iam.gserviceaccount.com"
# Allow Cloud Shell to impersonate them for testing
gcloud iam service-accounts add-iam-policy-binding ${EMAIL} \
--member="user:${CURRENT_USER}" \
--role="roles/iam.serviceAccountTokenCreator" \
--quiet
# Allow logical viewing of the catalog, querying, and running Dataproc jobs
for ROLE in "roles/datacatalog.viewer" "roles/bigquery.dataViewer" "roles/bigquery.user" "roles/bigquery.connectionUser" "roles/serviceusage.serviceUsageConsumer" "roles/dataproc.worker"; do
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${EMAIL}" \
--role="${ROLE}" \
--quiet
done
done
# Grant the Manager data creation rights
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${EMAIL_MANAGER}" \
--role="roles/bigquery.dataEditor" \
--quiet
echo "✅ Identity and Security setup completed!"
۳. از طریق Lakehouse میزهای Iceberg بومی ایجاد کنید
شما از قابلیتهای بومی Lakehouse برای ایجاد جداول مدیریتشدهی Iceberg استفاده خواهید کرد.
ایجاد مجموعه داده BigQuery
ابتدا، یک مجموعه داده BigQuery ایجاد کنید تا جداول Iceberg خود را به صورت منطقی گروهبندی کنید.
echo "Creating BigQuery Dataset..."
bq mk --location=${REGION} --dataset ${PROJECT_ID}:${DATASET_ID}
جداول Iceberg را ایجاد کنید
در مرحله بعد، دستورات زیر را برای ایجاد جداول اجرا کنید. به بلوک OPTIONS توجه کنید که در آن table_format = 'ICEBERG' مشخص کردهایم و آن را مستقیماً به مخزن ذخیرهسازی ابری و اتصال خود نگاشت کردهایم.
echo "Creating Iceberg tables..."
# Inventory table
bq query --use_legacy_sql=false \
"CREATE OR REPLACE TABLE \`${PROJECT_ID}.${DATASET_ID}.inventory\` (
product_id INT64,
product_name STRING,
stock_count INT64
)
WITH CONNECTION \`${REGION}.${CONN_NAME}\`
OPTIONS (
file_format = 'PARQUET',
table_format = 'ICEBERG',
storage_uri = 'gs://${ICEBERG_BUCKET}/inventory/'
);"
# Transactions table
bq query --use_legacy_sql=false \
"CREATE OR REPLACE TABLE \`${PROJECT_ID}.${DATASET_ID}.transactions\` (
id INT64,
item STRING,
amount FLOAT64,
transaction_date DATE
)
WITH CONNECTION \`${REGION}.${CONN_NAME}\`
OPTIONS (
file_format = 'PARQUET',
table_format = 'ICEBERG',
storage_uri = 'gs://${ICEBERG_BUCKET}/transactions/'
);"
جداول را با دادهها پر کنید
در نهایت، دادههای نمونه را در جداول Iceberg که به تازگی ایجاد شدهاند، وارد کنید.
echo "Inserting data into Iceberg tables..."
# Insert into Inventory table
bq query --use_legacy_sql=false \
"INSERT INTO \`${PROJECT_ID}.${DATASET_ID}.inventory\` (product_id, product_name, stock_count)
VALUES (101, 'Widget A', 500), (102, 'Widget B', 250), (103, 'Widget C', 800);"
# Insert into Transactions table
bq query --use_legacy_sql=false \
"INSERT INTO \`${PROJECT_ID}.${DATASET_ID}.transactions\` (id, item, amount, transaction_date)
VALUES
(1, 'Widget A', 100.0, DATE '2024-01-01'),
(2, 'Widget B', 150.0, DATE '2024-01-02'),
(3, 'Widget C', 50.0, DATE '2024-01-03');"
حالا شما دو جدول Iceberg کاملاً کاربردی دارید. Lakehouse متادیتاها را مدیریت میکند، اما فایلهای فیزیکی Parquet به طور امن در سطل GCS شما قرار دارند!
شبیهسازی یک خط لوله ETL
در یک سناریوی دنیای واقعی، دادههای خام اغلب در جداول خلاصه برای گزارشهای تجاری تجمیع میشوند. بیایید به عنوان یک مهندس داده عمل کنیم و یک جدول خلاصه فروش روزانه از دادههای خام تراکنشهای خود ایجاد کنیم.
(توجه: این مرحله را اکنون اجرا کنید تا Google Cloud زمان کافی برای پردازش فرادادههای پسزمینه داشته باشد. بعداً در آزمایشگاه کد متوجه خواهید شد که چرا این موضوع مهم است!)
echo "Creating transactions summary table..."
bq query --use_legacy_sql=false \
"CREATE TABLE \`${PROJECT_ID}.${DATASET_ID}.transactions_summary\` AS
SELECT transaction_date, SUM(amount) as total_sales, COUNT(id) as transaction_count
FROM \`${PROJECT_ID}.${DATASET_ID}.transactions\`
GROUP BY transaction_date;"
۴. مدیریت متمرکز: تعریف سیاستها با استفاده از پایتون
در یک محیط عملیاتی، پیکربندی سیاستهای مدیریتی از طریق رابط کاربری، از نظر مقیاسپذیری و نگهداری دشوار است. در عوض، اکیداً توصیه میشود از زیرساخت به عنوان کد (IaC) استفاده شود.
در این بخش، شما از SDK پایتون گوگل کلود برای ایجاد و اجرای گام به گام قوانین حاکمیت Zero-Trust خود به صورت برنامهنویسی شده استفاده خواهید کرد.
محیط پایتون را تنظیم کنید
ابتدا، بیایید یک محیط پایتون ایزوله ( venv ) راهاندازی کنیم تا از تداخل کتابخانهها جلوگیری کنیم و SDK های مورد نیاز Google Cloud را نصب کنیم.
دستورات زیر را در Cloud Shell اجرا کنید:
# Create and activate a virtual environment
python3 -m venv lakehouse_env
source lakehouse_env/bin/activate
# Install required Knowledge Catalog and BigQuery governance libraries
pip install google-cloud-datacatalog google-cloud-bigquery-datapolicies google-cloud-bigquery --quiet
echo "✅ Python environment is ready!"
ایجاد برچسب طبقهبندی و سیاست
یک طبقهبندی (Taxonomy) یک ظرف منطقی است و یک برچسب سیاست (Policy Tag ) برچسب خاصی است که به ستون حساس ما الصاق خواهید کرد. برای اعمال امنیت در سطح ستون، ابتدا به یک ظرف منطقی (یک طبقهبندی) و یک برچسب خاص (یک برچسب سیاست) نیاز دارید.
اگر به داخل فایل 1_create_taxonomy.py نگاه کنید، منطق اصلی زیر را خواهید دید:
# Create Taxonomy with Fine-Grained Access Control enabled
taxonomy = datacatalog_v1.Taxonomy(
display_name="BusinessCritical",
activated_policy_types=[datacatalog_v1.Taxonomy.PolicyType.FINE_GRAINED_ACCESS_CONTROL]
)
created_taxonomy = client.create_taxonomy(parent=parent, taxonomy=taxonomy)
# Create Policy Tag inside the Taxonomy
policy_tag = datacatalog_v1.PolicyTag(display_name="RestrictedFinancial")
created_policy_tag = client.create_policy_tag(parent=created_taxonomy.name, policy_tag=policy_tag)
با تنظیم صریح نوع سیاست FINE_GRAINED_ACCESS_CONTROL ، یک برچسب فراداده استاندارد را به یک مرز امنیتی کاملاً بدون اعتماد تبدیل میکنید. هر ستونی که این برچسب را داشته باشد، به طور پیشفرض از دسترسی همه کاربران جلوگیری میکند.
اسکریپت را برای ایجاد منابع اجرا کنید:
python 1_create_taxonomy.py
پیکربندی قانون پوشش (سیاست داده)
حالا، شما تعریف میکنید که وقتی کسی بدون امتیاز، ستون برچسبگذاری شده را جستجو میکند، چه اتفاقی میافتد. شما یک Data Policy ایجاد خواهید کرد که مقدار را مجبور به برگرداندن به صورت NULL میکند و این قانون را به شخصیت Analyst متصل میکند.
درون 2_create_masking.py ، اسکریپت به صورت پویا شناسه برچسب سیاستی که اخیراً ایجاد کردهاید را جستجو میکند و یک سیاست داده اعمال میکند:
# Define a Masking Policy that always returns NULL
data_policy = bigquery_datapolicies_v1.DataPolicy(
data_policy_id="mask_financial_null",
policy_tag=policy_tag_id,
data_policy_type=bigquery_datapolicies_v1.DataPolicy.DataPolicyType.DATA_MASKING_POLICY,
data_masking_policy=bigquery_datapolicies_v1.DataMaskingPolicy(
predefined_expression=bigquery_datapolicies_v1.DataMaskingPolicy.PredefinedExpression.ALWAYS_NULL
)
)
# ... (Policy creation code) ...
# Bind the Masked Reader role to the Analyst
iam_policy.bindings.add(
role="roles/bigquerydatapolicy.maskedReader",
members=[f"serviceAccount:{analyst_email}"]
)
این کد به صورت برنامهنویسیشده قاعدهای ایجاد میکند که مقادیر اساسی را مجبور میکند به صورت NULL برگردند. سپس نقش IAM مربوط به maskedReader را بهطور خاص به شخصیت تحلیلگر (Analyst) اختصاص میدهد و تضمین میکند که آنها فقط نسخه نقابدار دادهها را میبینند.
اسکریپت را برای پیکربندی قانون پوشش اجرا کنید:
python 2_create_masking.py
اعطای دسترسی دقیق
به دلیل تنظیمات zero-trust ما، در حال حاضر هیچ کس نمیتواند ستون برچسبگذاری شده را بخواند. شما باید صریحاً به مدیر و حساب شخصی خود دسترسی بدهید.
درون 3_grant_access.py ، شما سیاست IAM مربوط به خودِ تگ Policy را تغییر میدهید:
# Grant original data read access
iam_policy.bindings.add(
role="roles/datacatalog.categoryFineGrainedReader",
members=[f"serviceAccount:{manager_email}", f"user:{current_user}"]
)
client.set_iam_policy(request=iam_policy_pb2.SetIamPolicyRequest(resource=policy_tag_id, policy=iam_policy))
اضافه کردن نقش categoryFineGrainedReader به این مدیران خاص اجازه میدهد تا قوانین پوشش را دور بزنند و دادههای خام و بدون پوشش را بخوانند.
اسکریپت را برای اعطای دسترسی اجرا کنید:
python 3_grant_access.py
برچسب سیاست را به جدول BigQuery وصل کنید
در نهایت، شما باید این برچسب سیاست منطقی را به طرح جدول فیزیکی Iceberg ما پیوست کنید.
به 4_attach_tag.py نگاهی بیندازید. این اسکریپت طرح جدول BigQuery را دریافت میکند، در فیلدها میچرخد و برچسب را به طور خاص به ستون amount متصل میکند:
new_schema =[]
for field in table.schema:
if field.name == 'amount':
# Wrap the Policy Tag ID and attach it to the column
policy_tags_list = bigquery.PolicyTagList(names=[policy_tag_id])
new_field = bigquery.SchemaField(
name=field.name, field_type=field.field_type, mode=field.mode,
description=field.description, policy_tags=policy_tags_list
)
new_schema.append(new_field)
else:
new_schema.append(field)
# Update the table schema in BigQuery
table.schema = new_schema
client.update_table(table, ["schema"])
وقتی این بهروزرسانی طرحواره اعمال میشود، Lakehouse فوراً برچسبهای منطقی کاتالوگ دانش ما را به فایلهای فیزیکی Parquet ذخیره شده در مخزن ذخیرهسازی ابری شما متصل میکند.
اسکریپت را برای بهروزرسانی طرح جدول اجرا کنید:
python 4_attach_tag.py
۵. سیاستهای فهرست دانش را تأیید کنید
وقت آن است که آزمایش کنیم آیا مدیریت متمرکز ما کار میکند یا خیر. شما این را در دو موتور مختلف آزمایش خواهید کرد تا ثابت کنید که سیاستهای کاتالوگ دانش به صورت جهانی اجرا میشوند.
با استفاده از SQL بومی BigQuery تأیید کنید
ابتدا، شما از Cloud Shell برای فرض هویت دو شخصیت ما استفاده خواهید کرد و با استفاده از موتور SQL بومی BigQuery، جدول را جستجو خواهید کرد.
به عنوان مدیر (کاربر ممتاز) تست کنید:
# Impersonate the manager
gcloud config set auth/impersonate_service_account ${EMAIL_MANAGER}
# Query the transactions table
bq query --use_legacy_sql=false "SELECT * FROM \`${PROJECT_ID}.${DATASET_ID}.transactions\`"
از آنجایی که مدیر نقش خوانندهی دقیق را دارد، مقادیر خام را نشان میدهد.
+----+----------+--------+------------------+
| id | item | amount | transaction_date |
+----+----------+--------+------------------+
| 1 | Widget A | 100.0 | 2024-01-01 |
| 3 | Widget C | 50.0 | 2024-01-03 |
| 2 | Widget B | 150.0 | 2024-01-02 |
+----+----------+--------+------------------+
تست به عنوان تحلیلگر (کاربر محدود):
gcloud config set auth/impersonate_service_account ${EMAIL_ANALYST}
bq query --use_legacy_sql=false "SELECT * FROM \`${PROJECT_ID}.${DATASET_ID}.transactions\`"
به دلیل قانون پنهانسازی کاتالوگ دانش، ستون مقدار برای هر ردیف NULL را برمیگرداند.
+----+----------+--------+------------------+
| id | item | amount | transaction_date |
+----+----------+--------+------------------+
| 1 | Widget A | NULL | 2024-01-01 |
| 3 | Widget C | NULL | 2024-01-03 |
| 2 | Widget B | NULL | 2024-01-02 |
+----+----------+--------+------------------+
هویت خود را بازیابی کنید
وضعیت احراز هویت Cloud Shell خود را پاک کنید تا به کاربر ادمین خود برگردید.
# Unset impersonation
gcloud config unset auth/impersonate_service_account
تأیید با استفاده از آپاچی اسپارک (تفویض اختیار محاسباتی)
اگر یک دانشمند داده از آپاچی اسپارک برای خواندن این جدول استفاده کند، چه میشود؟ اگر اسپارک فایلهای فیزیکی GCS Parquet را مستقیماً بخواند، قوانین پوشش کاتالوگ دانش کاملاً نادیده گرفته میشوند زیرا Cloud Storage فقط مجوزهای سطح سطل را میشناسد.
برای جلوگیری از این امر، شما با استفاده از رابط Spark-BigQuery ، واگذاری محاسبات را اعمال میکنید. این رابط به عنوان یک پل امن عمل میکند و درخواستهای خواندن Spark را از طریق BigQuery Storage API مسیریابی میکند تا قوانین مدیریت کاتالوگ دانش قبل از ارسال هرگونه داده به خوشه Spark به صورت پویا ارزیابی شوند.
به منطق اصلی درون اسکریپت read_transactions.py که دانلود کردید نگاهی بیندازید:
# Reading data via Compute Delegation (Knowledge Catalog policies are applied dynamically here)
df = spark.read \
.format("bigquery") \
.option("table", f"{project_id}.{dataset_id}.{table_name}") \
.load()
print("\n=== 📊 Data Preview ===")
df.show(truncate=False)
توجه داشته باشید که ما اسپارک را به مسیر gs:// فایلهای Iceberg هدایت نمیکنیم. با مشخص کردن .format("bigquery") ، رابط برنامهنویسی کاربردی ذخیرهسازی BigQuery درخواست خواندن را رهگیری میکند، هویت کاربری که کار اسپارک را اجرا میکند بررسی میکند، قوانین پوشش کاتالوگ دانش را اعمال میکند و فقط دادههای مجاز را به قاب داده اسپارک برمیگرداند.
این اسکریپت PySpark را در فضای ذخیرهسازی ابری خود آپلود کنید تا Managed Apache Spark بتواند به آن دسترسی داشته باشد:
# Upload script to GCS
gsutil cp read_transactions.py gs://${ICEBERG_BUCKET}/scripts/read_transactions.py
اسپارک را به عنوان مدیر اجرا کنید:
شما از Apache Spark مدیریتشده استفاده خواهید کرد. این سرویس مدیریتشده به شما امکان میدهد بارهای کاری Spark را مستقیماً و بدون نیاز به آمادهسازی، پیکربندی یا مدیریت کلاسترهای اختصاصی اجرا کنید.
echo "🚀 Submitting Managed Apache Spark Job as [MANAGER]..."
gcloud dataproc batches submit pyspark gs://${ICEBERG_BUCKET}/scripts/read_transactions.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--service-account=${EMAIL_MANAGER} \
--version=2.3 \
-- ${PROJECT_ID} ${DATASET_ID} \
--format="value(name)"
به گزارشهای خروجی کار در ترمینال نگاه کنید. از آنجا که مدیر نقش خواننده دقیق (Fine-Grained Reader) را دارد، اسپارک با موفقیت مقادیر خام و بدون نقاب را بازیابی میکند.
=== 📊 Data Preview ===
+---+--------+------+-------------------+
|id |item |amount|transaction_date |
+---+--------+------+-------------------+
|1 |Widget A|100.0 |2024-01-01 |
|2 |Widget B|150.0 |2024-01-02 |
|3 |Widget C|50.0 |2024-01-03 |
+---+--------+------+-------------------+
اسپارک را به عنوان تحلیلگر اجرا کنید:
حالا، دقیقاً همان کار اسپارک را ارسال کنید، اما این بار شخصیت تحلیلگر را جعل کنید.
echo "🚀 Submitting Managed Apache Spark Job as [ANALYST]..."
gcloud dataproc batches submit pyspark gs://${ICEBERG_BUCKET}/scripts/read_transactions.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--service-account=${EMAIL_ANALYST} \
--version=2.3 \
-- ${PROJECT_ID} ${DATASET_ID} \
--format="value(name)"
دوباره لاگها را بررسی کنید. اگرچه تحلیلگر دقیقاً همان کد اسپارک را اجرا کرده بود، اما رابط برنامهنویسی کاربردی ذخیرهسازی بیگکوئری درخواست را رهگیری و سیاست کاتالوگ دانش را اعمال کرد. قاب داده اسپارک تحلیلگر برای مقادیر، null را نمایش میدهد!
=== 📊 Data Preview ===
+---+--------+------+-------------------+
|id |item |amount|transaction_date |
+---+--------+------+-------------------+
|1 |Widget A|null |2024-01-01 |
|2 |Widget B|null |2024-01-02 |
|3 |Widget C|null |2024-01-03 |
+---+--------+------+-------------------+
بدهبستانهای معماری: BigQuery SQL در مقابل Spark
شما همین الان ثابت کردید که نتیجه صرف نظر از موتور، یکسان است! سیاست کاتالوگ دانش با موفقیت اجرا شد. اما در محیط عملیاتی، از کدام باید استفاده کنید؟
- BigQuery SQL: برای گردش کارهایی که SQL موتور مورد نظر است و محاسبات را مستقیماً در محل اجرا میکند، عالی است. این ابزار برای تجزیه و تحلیل سریع و هوش تجاری ایدهآل است.
- آپاچی اسپارک: به لطف استفاده از پایتون، امکان انجام بارهای کاری پیچیدهتر را فراهم میکند و آن را برای خطوط لوله پیشرفته یادگیری ماشین یا کد قدیمی Hadoop مناسب میکند.
نکته کلیدی: صرف نظر از اینکه از کدام موتور استفاده میشود، با اعمال واگذاری محاسبات، لایه مدیریت متمرکز مبتنی بر اعتماد صفر هرگز قابل دور زدن نخواهد بود!
۶. تبارشناسی خودکار دادهها
در هر معماری داده سازمانی، دانستن دقیق اینکه دادههای شما از کجا میآیند و چگونه تغییر کردهاند، برای انطباق، اشکالزدایی و ایجاد اعتماد بسیار مهم است. این مفهوم به عنوان تبار داده شناخته میشود. به سؤالات اساسی مانند این پاسخ میدهد: "اگر مدیری به گزارش فروش روزانه نگاه میکند، از کدام جداول خام برای محاسبه آن اعداد استفاده شده است؟"
بهطور سنتی، ردیابی این چرخه حیات مستلزم آن است که مهندسان داده بهصورت دستی کد ثبت وقایع سفارشی بنویسند یا از ابزارهای پیچیده شخص ثالث برای تجزیه اسکریپتهای SQL استفاده کنند. با این حال، در یک Google Cloud Lakehouse تحت مدیریت، این ردیابی بهصورت داخلی و کاملاً بدون دخالت دست انجام میشود.
جدول transactions_summary که قبلاً در codelab از جدول خام transactionها ایجاد کردید را به خاطر دارید؟ وقتی BigQuery دستور CREATE TABLE AS SELECT را اجرا کرد، موتور محاسبه به طور خودکار فراداده تبدیل را ضبط کرده و آن را به Knowledge Catalog ارسال کرد. بیایید نتیجه را ببینیم.
تبار را تجسم کنید
- در کنسول گوگل کلود، به مسیر Knowledge Catalog > Search بروید.
- عبارت
lakehouse_retail_demo.transactionsرا در نوار جستجو تایپ کنید و روی جدول کلیک کنید. - روی برگه دودمان (Lineage) کلیک کنید.
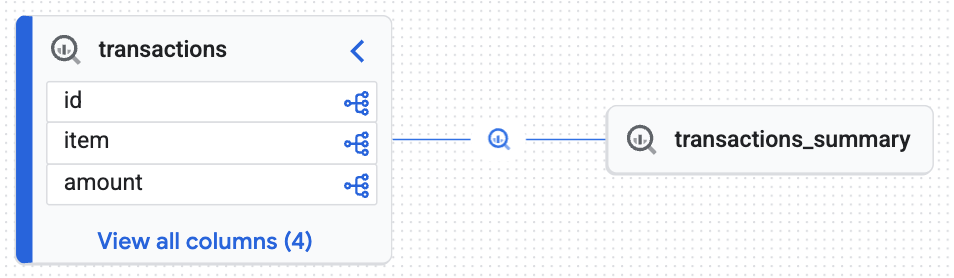
شما یک نمودار تعاملی ایجاد شده توسط موتور دانش را مشاهده خواهید کرد که ثابت میکند جدول هدف ( transactions_summary ) از جدول خام Iceberg ( transactions ) استخراج شده است. شما به قابلیت ردیابی سرتاسری که برای حسابرسی دادهها ضروری است، دست یافتهاید.
۷. تمیز کردن
برای جلوگیری از تحمیل هزینه به حساب Google Cloud خود برای منابع استفاده شده در این آزمایشگاه کد، این مراحل را دنبال کنید.
منابع مدیریت کاتالوگ دانش را حذف کنید
قبل از حذف مجموعه داده BigQuery یا مخزن ذخیرهسازی ابری، باید قوانین منطقی مدیریت را حذف کنید. اگر به داخل اسکریپت cleanup_governance.py از مخزن نگاه کنید، توالی جداسازی زیر را مشاهده خواهید کرد:
# 1. Delete Data Policy
data_policy_name = f"{parent_loc}/dataPolicies/mask_financial_null"
dp_client.delete_data_policy(name=data_policy_name)
# 2. Find and Delete Taxonomy (This auto-deletes child Policy Tags)
taxonomies = catalog_client.list_taxonomies(parent=parent_loc)
taxonomy_id = next((t.name for t in taxonomies if t.display_name == "BusinessCritical"), None)
catalog_client.delete_taxonomy(name=taxonomy_id)
ترتیب در اینجا بسیار مهم است. اسکریپت ابتدا Data Policy (قانون پوشش) را حذف میکند زیرا به Policy Tag متکی است. پس از حذف Policy، حذف Taxonomy والد به طور خودکار تمام Policy Tag های زیرین را بدون ایجاد خطاهای وابستگی به منابع، حذف میکند.
اسکریپت پاکسازی پایتون را اجرا کنید:
python cleanup_governance.py
حذف هویتها، ذخیرهسازی و داراییهای محاسباتی
اکنون که لایه مدیریت جدا شده است، میتوانید با خیال راحت جداول BigQuery، مخازن ذخیرهسازی ابری، حسابهای سرویس و محیط محلی پایتون را حذف کنید.
بلوک پاکسازی جامع زیر را در Cloud Shell خود کپی و اجرا کنید:
echo "Deleting Service Accounts and Impersonation Bindings..."
export CURRENT_USER=$(gcloud config get-value account)
for USER in "${USER_ANALYST}" "${USER_MANAGER}"; do
EMAIL="${USER}@${PROJECT_ID}.iam.gserviceaccount.com"
# Remove impersonation binding
gcloud iam service-accounts remove-iam-policy-binding ${EMAIL} \
--member="user:${CURRENT_USER}" \
--role="roles/iam.serviceAccountTokenCreator" \
--quiet > /dev/null 2>&1
# Delete the Service Account
gcloud iam service-accounts delete ${EMAIL} --quiet
done
echo "Removing BigQuery Dataset and Tables..."
bq rm -f ${DATASET_ID}.transactions_summary
bq rm -f ${DATASET_ID}.transactions
bq rm -f ${DATASET_ID}.inventory
bq rm -f -d ${DATASET_ID}
echo "Removing BigQuery Cloud Resource Connection..."
bq rm --connection --location=${REGION} ${CONN_NAME}
echo "Removing Iceberg Cloud Storage Bucket..."
gcloud storage rm --recursive gs://${ICEBERG_BUCKET} --quiet
echo "Removing Auto-generated Dataproc Staging & Temp Buckets..."
for BUCKET in $(gcloud storage ls | grep -E "gs://dataproc-(staging|temp)-${REGION}"); do
gcloud storage rm --recursive $BUCKET --quiet
done
echo "Deactivating and removing the local Python environment..."
deactivate
cd ../..
rm -rf devrel-demos
echo "✅ Clean up completed successfully!"
با انجام این مراحل، شما اطمینان حاصل کردهاید که هیچ منبع یتیم یا سیاست پنهانی در پروژه شما باقی نمانده است.
۸. تبریک میگویم!
شما با موفقیت یک Data Lakehouse کاملاً قابل مدیریت و کشف را پیادهسازی کردهاید.
یاد گرفتی که:
- یکپارچهسازی بومی با Iceberg: Lakehouse میتواند جداول متنباز Iceberg را به صورت بومی مدیریت کند و در عین حال فایلهای فیزیکی را به طور ایمن در فضای ذخیرهسازی ابری ذخیره کند.
- محاسبهی واگذاری اختیار برای امنیت: با مسیریابی کوئریها از طریق رابط برنامهنویسی کاربردی ذخیرهسازی BigQuery، شما پوشش پویای دقیقی را روی فایلهای فیزیکی اعمال کردید که به صورت بومی نمیتواند دسترسی جزئی را محدود کند.
- مدیریت مستقل از موتور: برچسبهای سیاست به شما امکان میدهند قوانین را یک بار تعریف کنید و آنها را به صورت جهانی اجرا کنید، چه از طریق SQL بومی یا زمانهای اجرای Apache Spark پرسوجو شوند.
- قابلیت کشف دادهها: موتور دانش به طور خودکار تبار دادهها را ردیابی میکرد و قابلیت حسابرسی ضروری سازمانی را فراهم میکرد.
بعدش چی؟
- بررسی کنترل دسترسی پیشرفته: برای پیادهسازی سناریوهای امنیتی پیچیدهتر، مستندات رسمی مربوط به سفارشیسازی Lakehouse با ویژگیهای اضافی را بررسی کنید.
- مدیریت دادههای بدون ساختار برای GenAI: جداول شیء را کشف کنید. این الگوی دقیق پل امن را به فایلهای بدون ساختار (PDFها، تصاویر) در فضای ذخیرهسازی ابری تعمیم دهید و یک پایه داده امن و مدیریتشده برای Gemini Enterprise Agent Engine و خطوط لوله RAG ایجاد کنید.