
1. מבוא
בסביבת Data Cloud ארגונית מודרנית, שבה הנתונים מאוחסנים במערכות אחסון פיזיות שונות, יש אתגר ארכיטקטוני עצום של אבטחה מפוצלת.
איך מוודאים שנתונים רגישים (כמו סכומי עסקאות פיננסיות) מוגנים באופן עקבי כשהנתונים מאוחסנים פיזית בפורמטים של קוד פתוח כמו Parquet ב-Google Cloud Storage ונשלחות אליהם שאילתות על ידי מנועים שונים, כמו BigQuery SQL או Apache Spark?
בשיעור Codelab הזה תבנו ארכיטקטורת lakehouse מנוהלת שפותרת את הבעיות האלה באמצעות טבלאות Apache Iceberg, BigQuery ו-Knowledge Catalog. תשתמשו ב-Infrastructure as Code (IaC) כדי להגדיר מדיניות אבטחה של אפס אמון, וכדי להגדיר איך המדיניות הזו נאכפת באופן דינמי במנועי מחשוב שונים.
דרישות מוקדמות
- פרויקט ב-Google Cloud שהחיוב בו מופעל.
- הבנה בסיסית של מושגי SQL, IAM ו-Cloud Storage.
מה תלמדו
- איך ליצור טבלאות Google Cloud Lakehouse ל-Apache Iceberg ב-BigQuery שבהן הנתונים מאוחסנים באופן מקורי ב-Cloud Storage.
- איך לאכוף מדיניות מרכזית של נתונים באמצעות תגי מדיניות לאבטחה ברמת העמודה ולאנונימיזציה של נתונים.
- איך מפרידים בין גישה לאחסון פיזי לבין גישה לוגית לנתונים באמצעות קישור למשאבים ב-Cloud.
- איך אוכפים העברת סמכויות מחשוב לפי עקרונות Zero-Trust באמצעות Managed Service for Apache Spark כדי לוודא שמנועי קוד פתוח לא יכולים לעקוף את הממשל.
- איך ליצור ויזואליזציה של היסטוריית הנתונים.
סקירה כללית של הארכיטקטורה: ניהול אוניברסלי ב-Iceberg
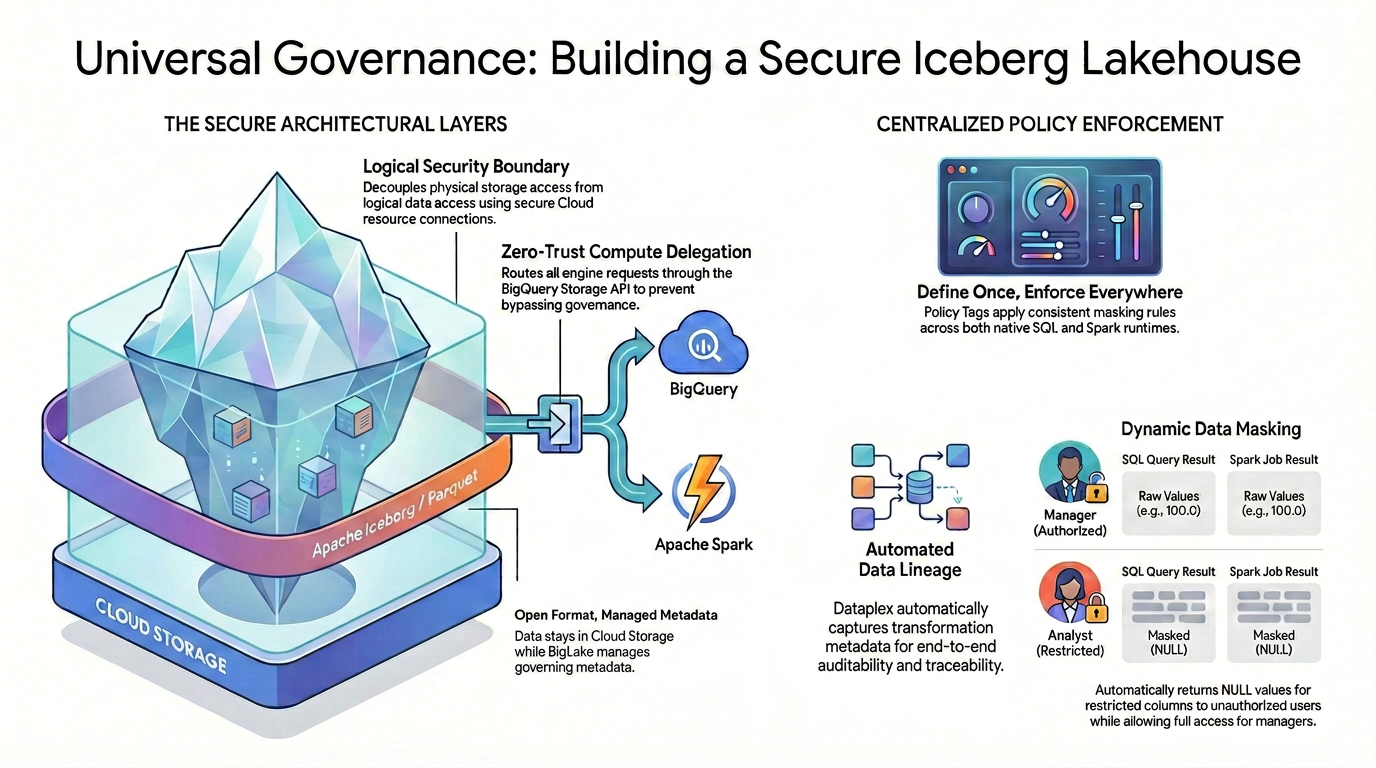
כדי להשיג בקרת גישה פרטנית (כמו אבטחה ברמת העמודה ואנונימיזציה של נתונים) בפורמטים של נתונים בקוד פתוח, צריך ליצור ארכיטקטורת אבטחה מחמירה ומאוחדת.
כפי שמוצג בתרשים, התבנית המנוהלת הזו של lakehouse מסתמכת על שני עמודים עיקריים כדי לפתור את בעיית האבטחה המפוצלת:
🛡️ השכבות הארכיטקטוניות המאובטחות (מימין)
במקום לאפשר למשתמשים או למנועים חיצוניים לגשת ישירות ל-Cloud Storage – שמאפשר רק אבטחה רחבה ברמת הקטגוריה – אתם יכולים לבנות בסיס מאובטח.
- פורמט פתוח, מטא-נתונים מנוהלים: הנתונים נשארים פיזית ב-Cloud Storage בפורמט הפתוח Apache Iceberg (Parquet), בזמן ש-Lakehouse מנהל בצורה חלקה את המטא-נתונים השולטים.
- גבול אבטחה לוגי: אתם מפרידים בין הגישה לאחסון הפיזי לבין הגישה הלוגית לנתונים באמצעות חיבור מאובטח למשאב בענן. למשתמשי קצה אף פעם לא מוענקת גישה פיזית ישירה ל-IAM לקבצי GCS גולמיים.
- העברת הרשאות מחשוב לפי עקרונות של אפס אמון: כדי לוודא שאף מנוע ביצוע לא יכול לעקוף את כללי הממשל, כל בקשות הקריאה של הנתונים מנותבות באופן קפדני דרך BigQuery Storage API. זה נכון גם אם השאילתה מגיעה מ-BigQuery SQL מקורי או מ-Apache Spark בקוד פתוח.
🎯 אכיפת מדיניות מרכזית (מימין)
אחרי שמקימים את הבסיס המאובטח, Knowledge Catalog משמש כמרכז ניהול מאוחד:
- הגדרה אחת, אכיפה בכל מקום: מגדירים את תגי המדיניות ב-Knowledge Catalog רק פעם אחת, והארכיטקטורה מחילה כללי מיסוך עקביים באופן אוניברסלי בכל סביבות זמן הריצה הנתמכות.
- טשטוש דינמי של נתונים: כשמתבצעת שאילתה על נתונים, המערכת מעריכה את זהות המשתמש תוך כדי התהליך. משתמשים מורשים יראו את הערכים הגולמיים שלא עברו טשטוש (לדוגמה, 100.0) גם ב-SQL וגם ב-Spark, אבל משתמשים עם הרשאות מוגבלות יקבלו באופן אוטומטי ערכי NULL מטושטשים עבור עמודות מוגבלות בשני המנועים.
- שקיפות אוטומטית של מקורות הנתונים: כשהנתונים זורמים ועוברים טרנספורמציה, Knowledge Catalog מתעד באופן אוטומטי את המטא-נתונים של הטרנספורמציה, ומספק יכולות מובנות של ביקורת ומעקב מקצה לקצה בלי שנדרש קוד מותאם אישית לרישום ביומן.
2. הגדרה ודרישות
מפעילים את Cloud Shell
אפשר להפעיל את Google Cloud מרחוק מהמחשב הנייד, אבל ב-Codelab הזה נשתמש ב-Google Cloud Shell, סביבת שורת פקודה שפועלת בענן.
ב-מסוף Google Cloud, לוחצים על סמל Cloud Shell בסרגל הכלים שבפינה הימנית העליונה:
יחלפו כמה רגעים עד שההקצאה והחיבור לסביבת העבודה יושלמו. בסיום התהליך, יופיע משהו כזה:

המכונה הווירטואלית הזו כוללת את כל הכלים שדרושים למפתחים. יש בה ספריית בית בנפח מתמיד של 5GB והיא פועלת ב-Google Cloud, מה שמשפר מאוד את הביצועים והאימות ברשת. אפשר לבצע את כל העבודה ב-codelab הזה בדפדפן. לא צריך להתקין שום דבר.
אתחול הסביבה
פותחים את Cloud Shell ומגדירים את משתני הפרויקט כדי לוודא שכל הפקודות מכוונות לתשתית הנכונה.
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-central1"
export ICEBERG_BUCKET="iceberg-retail-demo-${PROJECT_ID}"
export DATASET_ID="lakehouse_retail_demo"
export CONN_NAME="iceberg-bq-conn-demo"
לאחר מכן מגדירים את שתי דמויות הקונים.
export USER_ANALYST="retail-analyst-demo"
export EMAIL_ANALYST="${USER_ANALYST}@${PROJECT_ID}.iam.gserviceaccount.com"
export USER_MANAGER="retail-manager-demo"
export EMAIL_MANAGER="${USER_MANAGER}@${PROJECT_ID}.iam.gserviceaccount.com"
export CURRENT_USER=$(gcloud config get-value account)
הפעלת ממשקי API
מפעילים את שירותי Google Cloud הנדרשים.
gcloud services enable \
bigquery.googleapis.com \
bigqueryconnection.googleapis.com \
datacatalog.googleapis.com \
bigquerydatapolicy.googleapis.com \
datalineage.googleapis.com \
dataplex.googleapis.com \
dataproc.googleapis.com \
storage-component.googleapis.com
הורדת קוד המקור של ה-Codelab
כדי להימנע מבלגן ב-Cloud Shell, תבצעו שליפה דלילה כדי להוריד רק את סקריפטי Python שנדרשים ל-Codelab הזה ממאגר DevRel של Google Cloud.
# Shallow clone without full history
git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/devrel-demos.git
cd devrel-demos
# Download only the specific folder
git sparse-checkout set data-analytics/governed-lakehouse
cd data-analytics/governed-lakehouse
יצירת אחסון
יוצרים את הקטגוריה שתכיל את נתוני Iceberg המפוקחים והמאובטחים.
gcloud storage buckets create gs://${ICEBERG_BUCKET} --location=${REGION}
הכנת זהויות ואבטחה
מגדירים את הקישור למשאבים ב-Cloud. זו הישות היחידה שמחזיקה במפתחות IAM הפיזיים הקבועים לקריאת קובצי Iceberg הגולמיים.
# Create the BigQuery connection
bq mk --connection \
--connection_type=CLOUD_RESOURCE \
--location=${REGION} \
${CONN_NAME}
# Retrieve the connection's automatically generated Service Account
export BQ_CONN_SVC_ACCT=$(bq show --format=json --connection ${REGION}.${CONN_NAME} \
| jq -r '.cloudResource.serviceAccountId')
# Grant Storage Object Admin to the connection for the Iceberg bucket
gcloud storage buckets add-iam-policy-binding gs://${ICEBERG_BUCKET} \
--member="serviceAccount:${BQ_CONN_SVC_ACCT}" \
--role="roles/storage.objectAdmin" \
--quiet
לאחר מכן, מגדירים את פרסונות המשתמשים. למשתמשים ניתנת גישה לוגית, ולא גישה לאחסון פיזי. כדי למנוע שגיאות שנגרמות בגלל עיכובים בהפצת IAM, צריך ליצור את החשבונות קודם, לחכות כמה שניות ואז להקצות להם את התפקידים.
echo "Creating Service Accounts..."
for USER in "${USER_ANALYST}" "${USER_MANAGER}"; do
gcloud iam service-accounts create ${USER} --display-name="Lakehouse ${USER}"
done
echo "⏳ Waiting 15 seconds for IAM propagation..."
sleep 15
echo "Granting IAM Roles to Service Accounts..."
for USER in "${USER_ANALYST}" "${USER_MANAGER}"; do
EMAIL="${USER}@${PROJECT_ID}.iam.gserviceaccount.com"
# Allow Cloud Shell to impersonate them for testing
gcloud iam service-accounts add-iam-policy-binding ${EMAIL} \
--member="user:${CURRENT_USER}" \
--role="roles/iam.serviceAccountTokenCreator" \
--quiet
# Allow logical viewing of the catalog, querying, and running Dataproc jobs
for ROLE in "roles/datacatalog.viewer" "roles/bigquery.dataViewer" "roles/bigquery.user" "roles/bigquery.connectionUser" "roles/serviceusage.serviceUsageConsumer" "roles/dataproc.worker"; do
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${EMAIL}" \
--role="${ROLE}" \
--quiet
done
done
# Grant the Manager data creation rights
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${EMAIL_MANAGER}" \
--role="roles/bigquery.dataEditor" \
--quiet
echo "✅ Identity and Security setup completed!"
3. יצירת טבלאות Iceberg מקוריות באמצעות Lakehouse
תשתמשו ביכולות המובנות של Lakehouse כדי ליצור את טבלאות Iceberg המנוהלות.
יצירת מערך נתונים ב-BigQuery
קודם צריך ליצור מערך נתונים ב-BigQuery כדי לקבץ באופן לוגי את טבלאות Iceberg.
echo "Creating BigQuery Dataset..."
bq mk --location=${REGION} --dataset ${PROJECT_ID}:${DATASET_ID}
יצירת טבלאות Iceberg
לאחר מכן, מריצים את הפקודות הבאות כדי ליצור את הטבלאות. שימו לב לבלוק OPTIONS שבו אנחנו מציינים את table_format = 'ICEBERG' וממפים אותו ישירות לקטגוריה של Cloud Storage ולחיבור שלנו.
echo "Creating Iceberg tables..."
# Inventory table
bq query --use_legacy_sql=false \
"CREATE OR REPLACE TABLE \`${PROJECT_ID}.${DATASET_ID}.inventory\` (
product_id INT64,
product_name STRING,
stock_count INT64
)
WITH CONNECTION \`${REGION}.${CONN_NAME}\`
OPTIONS (
file_format = 'PARQUET',
table_format = 'ICEBERG',
storage_uri = 'gs://${ICEBERG_BUCKET}/inventory/'
);"
# Transactions table
bq query --use_legacy_sql=false \
"CREATE OR REPLACE TABLE \`${PROJECT_ID}.${DATASET_ID}.transactions\` (
id INT64,
item STRING,
amount FLOAT64,
transaction_date DATE
)
WITH CONNECTION \`${REGION}.${CONN_NAME}\`
OPTIONS (
file_format = 'PARQUET',
table_format = 'ICEBERG',
storage_uri = 'gs://${ICEBERG_BUCKET}/transactions/'
);"
איך מאכלסים את הטבלאות בנתונים
לבסוף, מוסיפים נתונים לדוגמה לטבלאות Iceberg החדשות שנוצרו.
echo "Inserting data into Iceberg tables..."
# Insert into Inventory table
bq query --use_legacy_sql=false \
"INSERT INTO \`${PROJECT_ID}.${DATASET_ID}.inventory\` (product_id, product_name, stock_count)
VALUES (101, 'Widget A', 500), (102, 'Widget B', 250), (103, 'Widget C', 800);"
# Insert into Transactions table
bq query --use_legacy_sql=false \
"INSERT INTO \`${PROJECT_ID}.${DATASET_ID}.transactions\` (id, item, amount, transaction_date)
VALUES
(1, 'Widget A', 100.0, DATE '2024-01-01'),
(2, 'Widget B', 150.0, DATE '2024-01-02'),
(3, 'Widget C', 50.0, DATE '2024-01-03');"
עכשיו יש לכם שתי טבלאות Iceberg שפועלות באופן מלא. Lakehouse מנהל את המטא-נתונים, אבל קובצי ה-Parquet הפיזיים נמצאים בצורה מאובטחת בדלי GCS שלכם.
סימולציה של צינור עיבוד נתונים מסוג ETL
בתרחיש מהעולם האמיתי, נתונים גולמיים נצברים לעיתים קרובות בטבלאות סיכום לצורך דיווח עסקי. בואו נתנהג כמו מהנדסי נתונים וניצור טבלת סיכום מכירות יומית מנתוני העסקאות הגולמיים שלנו.
(הערה: כדאי להריץ את השלב הזה עכשיו כדי של-Google Cloud יהיה מספיק זמן לעבד את המטא-נתונים ברקע. בהמשך ה-codelab תבינו למה זה חשוב.)
echo "Creating transactions summary table..."
bq query --use_legacy_sql=false \
"CREATE TABLE \`${PROJECT_ID}.${DATASET_ID}.transactions_summary\` AS
SELECT transaction_date, SUM(amount) as total_sales, COUNT(id) as transaction_count
FROM \`${PROJECT_ID}.${DATASET_ID}.transactions\`
GROUP BY transaction_date;"
4. ניהול מרכזי: הגדרת מדיניות באמצעות Python
בסביבת ייצור, קשה להרחיב ולתחזק את ההגדרות של מדיניות ניהול הגישה דרך ממשק המשתמש. במקום זאת, מומלץ מאוד להשתמש בתשתית כקוד (IaC).
בקטע הזה תשתמשו ב-Google Cloud Python SDK כדי ליצור ולאכוף באופן פרוגרמטי את כללי הממשל שלכם לפי גישת אפס אמון, שלב אחר שלב.
הגדרת סביבת Python
קודם כל, נגדיר סביבת Python מבודדת (venv) כדי למנוע התנגשויות בין ספריות, ונתקין את ערכות Google Cloud SDK הנדרשות.
מריצים את הפקודות הבאות ב-Cloud Shell:
# Create and activate a virtual environment
python3 -m venv lakehouse_env
source lakehouse_env/bin/activate
# Install required Knowledge Catalog and BigQuery governance libraries
pip install google-cloud-datacatalog google-cloud-bigquery-datapolicies google-cloud-bigquery --quiet
echo "✅ Python environment is ready!"
יצירת הטקסונומיה ותג המדיניות
טקסונומיה היא מאגר לוגי, ותג מדיניות הוא התווית הספציפית שתצרפו לעמודה עם מידע אישי רגיש. כדי לאכוף אבטחה ברמת העמודה, קודם צריך מאגר לוגי (טקסונומיה) ותווית ספציפית (תג מדיניות).
אם תבדקו את הקוד של 1_create_taxonomy.py, תראו את הלוגיקה הבסיסית הבאה:
# Create Taxonomy with Fine-Grained Access Control enabled
taxonomy = datacatalog_v1.Taxonomy(
display_name="BusinessCritical",
activated_policy_types=[datacatalog_v1.Taxonomy.PolicyType.FINE_GRAINED_ACCESS_CONTROL]
)
created_taxonomy = client.create_taxonomy(parent=parent, taxonomy=taxonomy)
# Create Policy Tag inside the Taxonomy
policy_tag = datacatalog_v1.PolicyTag(display_name="RestrictedFinancial")
created_policy_tag = client.create_policy_tag(parent=created_taxonomy.name, policy_tag=policy_tag)
הגדרה מפורשת של FINE_GRAINED_ACCESS_CONTROL סוג המדיניות הופכת תג מטא-נתונים רגיל לגבול אבטחה מחמיר של אפס אמון. כברירת מחדל, הגישה לכל עמודה עם התג הזה תיחסם לכל המשתמשים.
מריצים את הסקריפט כדי ליצור את המשאבים:
python 1_create_taxonomy.py
הגדרת כלל המיסוך (מדיניות נתונים)
עכשיו מגדירים מה קורה כשמישהו בלי הרשאות שולח שאילתה לעמודה עם התג. תצרו מדיניות נתונים שתחייב את החזרת הערך NULL, ותצרפו את הכלל הזה לפרסונה של אנליסט.
בתוך 2_create_masking.py, הסקריפט מחפש באופן דינמי את מזהה תג המדיניות שיצרתם ומחיל מדיניות נתונים:
# Define a Masking Policy that always returns NULL
data_policy = bigquery_datapolicies_v1.DataPolicy(
data_policy_id="mask_financial_null",
policy_tag=policy_tag_id,
data_policy_type=bigquery_datapolicies_v1.DataPolicy.DataPolicyType.DATA_MASKING_POLICY,
data_masking_policy=bigquery_datapolicies_v1.DataMaskingPolicy(
predefined_expression=bigquery_datapolicies_v1.DataMaskingPolicy.PredefinedExpression.ALWAYS_NULL
)
)
# ... (Policy creation code) ...
# Bind the Masked Reader role to the Analyst
iam_policy.bindings.add(
role="roles/bigquerydatapolicy.maskedReader",
members=[f"serviceAccount:{analyst_email}"]
)
הקוד הזה יוצר באופן פרוגרמטי כלל שמכריח את הערכים הבסיסיים לחזור כ-NULL. לאחר מכן הוא מקצה את תפקיד ה-IAM של maskedReader ספציפית לדמות האנליסט, כדי להבטיח שהיא תראה רק את הגרסה המוסתרת של הנתונים.
מריצים את הסקריפט כדי להגדיר את כלל המיסוך:
python 2_create_masking.py
הענקת גישה עם הרשאות מפורטות
בגלל הגדרת הגישה לפי עקרון אפס האמון, אף אחד לא יכול לקרוא את העמודה שתויגה כרגע. אתם צריכים להעניק גישה לחשבון הניהול ולחשבון לשימוש אישי באופן מפורש.
בתוך 3_grant_access.py, משנים את מדיניות ה-IAM של תג המדיניות עצמו:
# Grant original data read access
iam_policy.bindings.add(
role="roles/datacatalog.categoryFineGrainedReader",
members=[f"serviceAccount:{manager_email}", f"user:{current_user}"]
)
client.set_iam_policy(request=iam_policy_pb2.SetIamPolicyRequest(resource=policy_tag_id, policy=iam_policy))
הוספת התפקיד categoryFineGrainedReader מאפשרת לחשבונות המשתמשים הספציפיים האלה לעקוף את כללי ההסתרה ולקרוא את הנתונים הגולמיים שלא הוסתרו.
מריצים את הסקריפט כדי להעניק גישה:
python 3_grant_access.py
צירוף תג המדיניות לטבלת BigQuery
לבסוף, צריך לצרף את תג המדיניות הלוגי הזה לסכימת הטבלה הפיזית של Iceberg.
כדאי לעיין ב4_attach_tag.py. הסקריפט מאחזר את סכימת הטבלה ב-BigQuery, מבצע איטרציה בשדות ומצרף את התג באופן ספציפי לעמודה amount:
new_schema =[]
for field in table.schema:
if field.name == 'amount':
# Wrap the Policy Tag ID and attach it to the column
policy_tags_list = bigquery.PolicyTagList(names=[policy_tag_id])
new_field = bigquery.SchemaField(
name=field.name, field_type=field.field_type, mode=field.mode,
description=field.description, policy_tags=policy_tags_list
)
new_schema.append(new_field)
else:
new_schema.append(field)
# Update the table schema in BigQuery
table.schema = new_schema
client.update_table(table, ["schema"])
כשעדכון הסכימה הזה מוחל, Lakehouse מגשר באופן מיידי בין התגים הלוגיים של Knowledge Catalog לבין קובצי ה-Parquet הפיזיים שמאוחסנים בקטגוריה של Cloud Storage.
מריצים את הסקריפט כדי לעדכן את סכימת הטבלה:
python 4_attach_tag.py
5. אימות המדיניות של Knowledge Catalog
הגיע הזמן לבדוק אם הממשל המרכזי שלנו פועל. תבדקו את זה בשני מנועים שונים כדי להוכיח שכללי המדיניות של Knowledge Catalog נאכפים באופן אוניברסלי.
אימות באמצעות SQL מקורי של BigQuery
קודם, תשתמשו ב-Cloud Shell כדי להניח את הזהות של שתי הדמויות שלנו ולשאול שאילתה בטבלה באמצעות מנוע ה-SQL המקורי של BigQuery.
בדיקה בתור המנהל (משתמש עם הרשאות מיוחדות):
# Impersonate the manager
gcloud config set auth/impersonate_service_account ${EMAIL_MANAGER}
# Query the transactions table
bq query --use_legacy_sql=false "SELECT * FROM \`${PROJECT_ID}.${DATASET_ID}.transactions\`"
מכיוון שלחשבון הניהול יש תפקיד של קורא עם הרשאות גישה מפורטות, יוצגו בו ערכי הסכומים הגולמיים
+----+----------+--------+------------------+
| id | item | amount | transaction_date |
+----+----------+--------+------------------+
| 1 | Widget A | 100.0 | 2024-01-01 |
| 3 | Widget C | 50.0 | 2024-01-03 |
| 2 | Widget B | 150.0 | 2024-01-02 |
+----+----------+--------+------------------+
בדיקה בתור אנליסט (משתמש עם הרשאה מוגבלת):
gcloud config set auth/impersonate_service_account ${EMAIL_ANALYST}
bq query --use_legacy_sql=false "SELECT * FROM \`${PROJECT_ID}.${DATASET_ID}.transactions\`"
בגלל כלל המיסוך של Knowledge Catalog, העמודה 'סכום' מחזירה NULL לכל שורה.
+----+----------+--------+------------------+
| id | item | amount | transaction_date |
+----+----------+--------+------------------+
| 1 | Widget A | NULL | 2024-01-01 |
| 3 | Widget C | NULL | 2024-01-03 |
| 2 | Widget B | NULL | 2024-01-02 |
+----+----------+--------+------------------+
שחזור הזהות
כדי לחזור למשתמש האדמין, צריך לנקות את מצב האימות של Cloud Shell.
# Unset impersonation
gcloud config unset auth/impersonate_service_account
אימות באמצעות Apache Spark (הענקת הרשאות לחישוב)
מה קורה אם מדען נתונים משתמש ב-Apache Spark כדי לקרוא את הטבלה הזו? אם Spark קורא את קובצי ה-Parquet הפיזיים של GCS ישירות, הוא עוקף לחלוטין את כללי המיסוך של Knowledge Catalog, כי Cloud Storage מבין רק הרשאות ברמת הקטגוריה.
כדי למנוע את זה, צריך לאכוף העברת סמכויות מחשוב באמצעות מחבר Spark-BigQuery. המחבר הזה פועל כגשר מאובטח, ומנתב את בקשות הקריאה של Spark דרך BigQuery Storage API, כך שכללי השליטה של Knowledge Catalog מוערכים באופן דינמי לפני שנתונים נשלחים לאשכול Spark.
כדאי לעיין בלוגיקה המרכזית בסקריפט read_transactions.py שהורדתם:
# Reading data via Compute Delegation (Knowledge Catalog policies are applied dynamically here)
df = spark.read \
.format("bigquery") \
.option("table", f"{project_id}.{dataset_id}.{table_name}") \
.load()
print("\n=== 📊 Data Preview ===")
df.show(truncate=False)
שימו לב שלא ציינו ב-Spark את הנתיב gs:// של קובצי Iceberg. כשמציינים את הנתיב .format("bigquery"), BigQuery Storage API מיירט את בקשת הקריאה, בודק את הזהות של המשתמש שמריץ את משימת Spark, מחיל את כללי המיסוך של Knowledge Catalog ומחזיר רק את הנתונים המורשים ל-Spark DataFrame.
מעלים את סקריפט PySpark הזה לקטגוריה שלכם ב-Cloud Storage כדי ש-Managed Apache Spark יוכל לגשת אליו:
# Upload script to GCS
gsutil cp read_transactions.py gs://${ICEBERG_BUCKET}/scripts/read_transactions.py
מריצים את Spark כמנהל:
תשתמשו ב-Managed Apache Spark. השירות המנוהל הזה מאפשר להריץ עומסי עבודה של Spark ישירות, בלי צורך להקצות, להגדיר או לנהל אשכולות ייעודיים.
echo "🚀 Submitting Managed Apache Spark Job as [MANAGER]..."
gcloud dataproc batches submit pyspark gs://${ICEBERG_BUCKET}/scripts/read_transactions.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--service-account=${EMAIL_MANAGER} \
--version=2.3 \
-- ${PROJECT_ID} ${DATASET_ID} \
--format="value(name)"
בודקים את יומני הפלט של העבודה במסוף. מכיוון שלחשבון הניהול יש את התפקיד Fine-Grained Reader, Spark מאחזר בהצלחה את הסכומים הגולמיים שלא הוסתרו.
=== 📊 Data Preview ===
+---+--------+------+-------------------+
|id |item |amount|transaction_date |
+---+--------+------+-------------------+
|1 |Widget A|100.0 |2024-01-01 |
|2 |Widget B|150.0 |2024-01-02 |
|3 |Widget C|50.0 |2024-01-03 |
+---+--------+------+-------------------+
הפעלת Spark כמנתח:
עכשיו, שולחים את אותה משימת Spark בדיוק, אבל הפעם מתחזים לדמות של האנליסט.
echo "🚀 Submitting Managed Apache Spark Job as [ANALYST]..."
gcloud dataproc batches submit pyspark gs://${ICEBERG_BUCKET}/scripts/read_transactions.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--service-account=${EMAIL_ANALYST} \
--version=2.3 \
-- ${PROJECT_ID} ${DATASET_ID} \
--format="value(name)"
בודקים שוב את היומנים. למרות שהאנליסט הפעיל את אותו קוד Spark, ממשק BigQuery Storage API חסם את הבקשה ואכף את המדיניות של Knowledge Catalog. ב-DataFrame של Spark של האנליסט מוצג null בסכומי העסקאות.
=== 📊 Data Preview ===
+---+--------+------+-------------------+
|id |item |amount|transaction_date |
+---+--------+------+-------------------+
|1 |Widget A|null |2024-01-01 |
|2 |Widget B|null |2024-01-02 |
|3 |Widget C|null |2024-01-03 |
+---+--------+------+-------------------+
התפשרויות ארכיטקטוניות: BigQuery SQL לעומת Spark
הוכחת שהתוצאה זהה לא משנה באיזה מנוע משתמשים. אכיפת המדיניות של Knowledge Catalog בוצעה בהצלחה. אבל באיזו שיטה כדאי להשתמש בסביבת ייצור?
- BigQuery SQL: מתאים מאוד לתהליכי עבודה שבהם SQL הוא המנוע הרצוי, והחישובים מבוצעים ישירות במקום. הוא אידיאלי לניתוח מהיר ולבינה עסקית.
- Apache Spark: מאפשר עומסי עבודה מורכבים יותר באמצעות Python, ולכן מתאים מאוד לצינורות מתקדמים של למידת מכונה או לקוד Hadoop מדור קודם.
המסר העיקרי: לא משנה באיזה מנוע משתמשים, אי אפשר לעקוף את שכבת השליטה המרכזית של גישת אפס אמון על ידי אכיפת הקצאת הרשאות לחישוב.
6. שושלת נתונים אוטומטית
בכל ארכיטקטורת נתונים של ארגון, חשוב לדעת בדיוק מאיפה הנתונים מגיעים ואיך הם השתנו כדי לעמוד בדרישות התאימות, לבצע ניפוי באגים ולבסס אמון. הקונספט הזה נקרא מקורות נתונים. הוא עונה על שאלות בסיסיות כמו: "אם מנהל בוחן דוח מכירות יומי, באילו טבלאות גולמיות נעשה שימוש כדי לחשב את המספרים האלה?"
בדרך כלל, כדי לעקוב אחרי מחזור החיים הזה, מהנדסי נתונים צריכים לכתוב באופן ידני קוד רישום מותאם אישית או להשתמש בכלים מורכבים של צד שלישי כדי לנתח סקריפטים של SQL. עם זאת, ב-Lakehouse מנוהל ב-Google Cloud, המעקב הזה מובנה ומתבצע באופן אוטומטי לחלוטין.
זוכרים את טבלת transactions_summary שיצרתם מטבלת העסקאות הגולמיות קודם לכן ב-codelab? כש-BigQuery ביצע את ההצהרה CREATE TABLE AS SELECT, Compute Engine תיעד באופן אוטומטי את המטא-נתונים של הטרנספורמציה ושלח אותם אל Knowledge Catalog. בואו נראה את התוצאה.
הדמיה של שרשרת היוחסין
- במסוף Google Cloud, עוברים אל Knowledge Catalog > Search.
- מקלידים
lakehouse_retail_demo.transactionsבסרגל החיפוש ולוחצים על הטבלה. - לוחצים על הכרטיסייה Lineage.
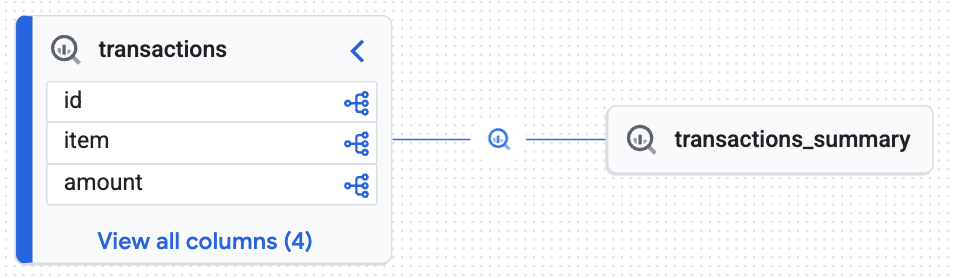
יוצג לכם גרף אינטראקטיבי שנוצר על ידי מנוע הידע, שמוכיח שהטבלה של היעד (transactions_summary) נגזרה מטבלת Iceberg הגולמית המנוהלת (transactions). השגתם יכולת מעקב מקצה לקצה, שחיונית לביקורת נתונים.
7. הסרת המשאבים
כדי לא לצבור חיובים לחשבון Google Cloud על המשאבים שבהם השתמשתם ב-Codelab הזה:
הסרת משאבי ניהול של Knowledge Catalog
לפני שמוחקים את מערך הנתונים ב-BigQuery או את הקטגוריה של Cloud Storage, צריך להסיר את כללי ניהול הנתונים הלוגיים. אם תבדקו את הסקריפט cleanup_governance.py מהמאגר, תראו את רצף הפירוק הבא:
# 1. Delete Data Policy
data_policy_name = f"{parent_loc}/dataPolicies/mask_financial_null"
dp_client.delete_data_policy(name=data_policy_name)
# 2. Find and Delete Taxonomy (This auto-deletes child Policy Tags)
taxonomies = catalog_client.list_taxonomies(parent=parent_loc)
taxonomy_id = next((t.name for t in taxonomies if t.display_name == "BusinessCritical"), None)
catalog_client.delete_taxonomy(name=taxonomy_id)
הסדר כאן הוא קריטי. הסקריפט מוחק קודם את מדיניות הנתונים (כלל המיסוך) כי הוא מסתמך על תג המדיניות. אחרי שמסירים את המדיניות, מחיקה של הטקסונומיה הראשית תגרום אוטומטית למחיקה של כל תגי המדיניות הבסיסיים, בלי להפעיל שגיאות של תלות במשאבים.
מריצים את סקריפט הניקוי של Python:
python cleanup_governance.py
הסרת נכסי זהויות, אחסון ומחשוב
עכשיו, אחרי שהשכבה של ניהול הגישה מנותקת, אפשר למחוק בבטחה את הטבלאות ב-BigQuery, את הקטגוריות ב-Cloud Storage, את חשבונות השירות ואת סביבת Python המקומית.
מעתיקים ומריצים את בלוק הניקוי המקיף הבא ב-Cloud Shell:
echo "Deleting Service Accounts and Impersonation Bindings..."
export CURRENT_USER=$(gcloud config get-value account)
for USER in "${USER_ANALYST}" "${USER_MANAGER}"; do
EMAIL="${USER}@${PROJECT_ID}.iam.gserviceaccount.com"
# Remove impersonation binding
gcloud iam service-accounts remove-iam-policy-binding ${EMAIL} \
--member="user:${CURRENT_USER}" \
--role="roles/iam.serviceAccountTokenCreator" \
--quiet > /dev/null 2>&1
# Delete the Service Account
gcloud iam service-accounts delete ${EMAIL} --quiet
done
echo "Removing BigQuery Dataset and Tables..."
bq rm -f ${DATASET_ID}.transactions_summary
bq rm -f ${DATASET_ID}.transactions
bq rm -f ${DATASET_ID}.inventory
bq rm -f -d ${DATASET_ID}
echo "Removing BigQuery Cloud Resource Connection..."
bq rm --connection --location=${REGION} ${CONN_NAME}
echo "Removing Iceberg Cloud Storage Bucket..."
gcloud storage rm --recursive gs://${ICEBERG_BUCKET} --quiet
echo "Removing Auto-generated Dataproc Staging & Temp Buckets..."
for BUCKET in $(gcloud storage ls | grep -E "gs://dataproc-(staging|temp)-${REGION}"); do
gcloud storage rm --recursive $BUCKET --quiet
done
echo "Deactivating and removing the local Python environment..."
deactivate
cd ../..
rm -rf devrel-demos
echo "✅ Clean up completed successfully!"
השלמת השלבים האלה מבטיחה שלא יישארו בפרויקט משאבים יתומים או כללי מדיניות מוסתרים.
8. מעולה!
הטמעתם בהצלחה Data Lakehouse שניתן לניהול, לגילוי ולחיפוש.
למדנו ש:
- שילוב מובנה של Iceberg: Lakehouse יכול לנהל באופן מובנה טבלאות Iceberg בקוד פתוח, תוך אחסון הקבצים הפיזיים בצורה מאובטחת ב-Cloud Storage.
- העברת חישובים לצורך אבטחה: ניתוב שאילתות דרך BigQuery Storage API מאפשר להחיל מסכות דינמיות מדויקות על קבצים פיזיים, שלא ניתן להגביל בהם גישה חלקית באופן מובנה.
- ממשל שלא תלוי במנוע: תגי מדיניות מאפשרים להגדיר כללים פעם אחת ולאכוף אותם באופן אוניברסלי, בין אם השאילתה מתבצעת באמצעות SQL מקורי או באמצעות סביבות זמן ריצה של Apache Spark.
- גילוי נתונים: מנוע הידע עקב באופן אוטומטי אחרי מקורות הנתונים, וסיפק יכולת ביקורת חיונית לארגונים.
מה השלב הבא?
- כדאי לעיין בתיעוד הרשמי בנושא התאמה אישית של Lakehouse עם תכונות נוספות כדי להטמיע תרחישי אבטחה מורכבים יותר.
- שליטה בנתונים לא מובנים עבור GenAI: הכירו את טבלאות האובייקטים. אפשר להשתמש בדפוס הגשר המאובטח הזה גם עבור קבצים לא מובנים (PDF, תמונות) ב-Cloud Storage, כדי ליצור בסיס נתונים מאובטח ומנוהל עבור Gemini Enterprise Agent Engine וצינורות RAG.